| 编辑推荐: |
|
本文介绍了数据库索引的概念和各种索引结构,如哈希表、B+树、InnoDB引擎的索引运作原理等。还分享了覆盖索引、联合索引、最左前缀原则等优化技巧,以及如何避免索引误用,提高数据库性能。希望对你的学习有帮助。
本文来自于阿里云开发者,由火龙果软件Linda编辑、推荐。 |
|
阿里妹导读
本文介绍了数据库索引的概念和各种索引结构,如哈希表、B+树、InnoDB引擎的索引运作原理等。还分享了覆盖索引、联合索引、最左前缀原则等优化技巧,以及如何避免索引误用,提高数据库性能。
一、几个前提认知
1.1 硬盘&内存
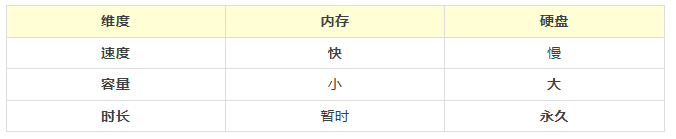
作为大批量的结构化数据,MySQL 选择讲数据存储在硬盘上,这就要求必须要想办法解决读写速度问题。
1.2 快慢
快慢,我们一般说的是 I/O。关于 I/O,同样的存储介质,我们一般认为:
一次 I/O 的时间是差不多的;
I/O 的时间远大于其他的计算时间;
二、索引(index)
回到我们最初的目标,解决 MySQL 作为硬盘存储技术,要解决读写速度的问题。再简化一下,就是尽量减少
I/O 次数。
选择的手段,就是通过索引,来帮我们快速找到特定值,提高查找效率。
索引的本质,就是像目录一样的,一种排好序的数据结构。
三、索引结构
3.1 哈希表
我们最为熟悉的一种数据结构,面试的时候被问的最多的一种数据结构。
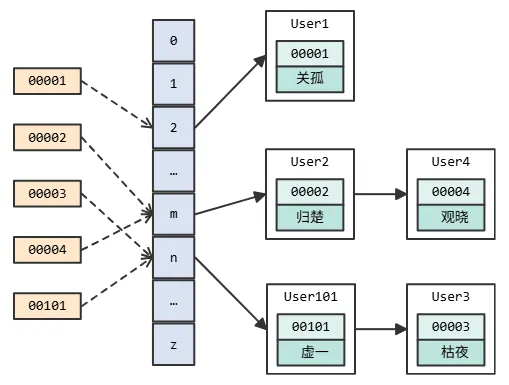
哈希表是一种以键 - 值(key-value)存储数据的结构,输入要查找的 key,通过哈希运算,得到在数组中的位置,然后再遍历链表,找到要查询的具体值。
所以这个查询效率极高,一个哈希运算加上一个遍历链表的时间,基本上是 O(1),是单条记录查询效率最高的存储结构。
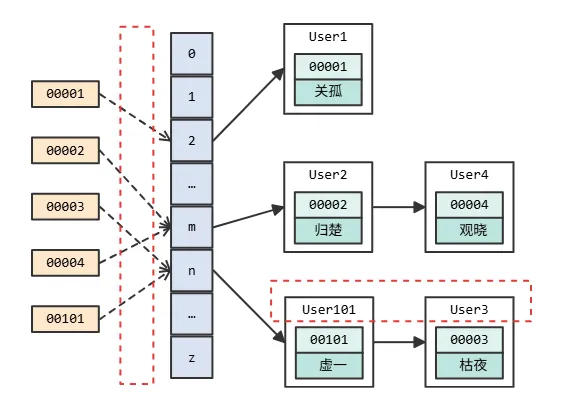
但是,无论是哈希运算对应的数组下标,还是后面的链表,都是乱序的,这就意味着你没有办法做范围查找。如果你的查询条件是一个
[a, b] 区间或者 >c 的查询,就必须要扫描全表。
所以,哈希表只能支持等值查询的场景,在 Memcached、Redis 等 NoSQL 数据库中使用比较多。
3.2 有序数组
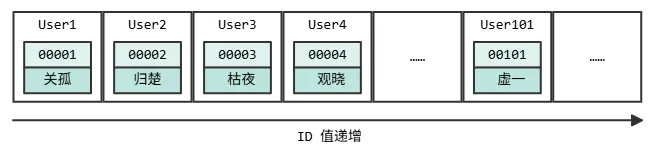
有序数组就解决了哈希表的这个问题,在等值查询和范围查询场景中的性能就都非常优秀。同样是范围查找 [a,
b] ,通过二分查找定位到 a,然后往后遍历到 b,就能够完成,时间复杂度 O(log(N))。
如果只考虑查询效率,那么有序数组基本上就是最好的数据结构了。但是,如果你想插入一条数据可就麻烦了,必须要挪动后面所有的记录,成本极高。
所以,有序数组索引只适合用于静态存储引擎,比如一个班级的学生信息,通过学号排序。
3.3 二叉树
二叉树也是很经典的数据结构,我们学习树的时候,第一个学的就是这个。
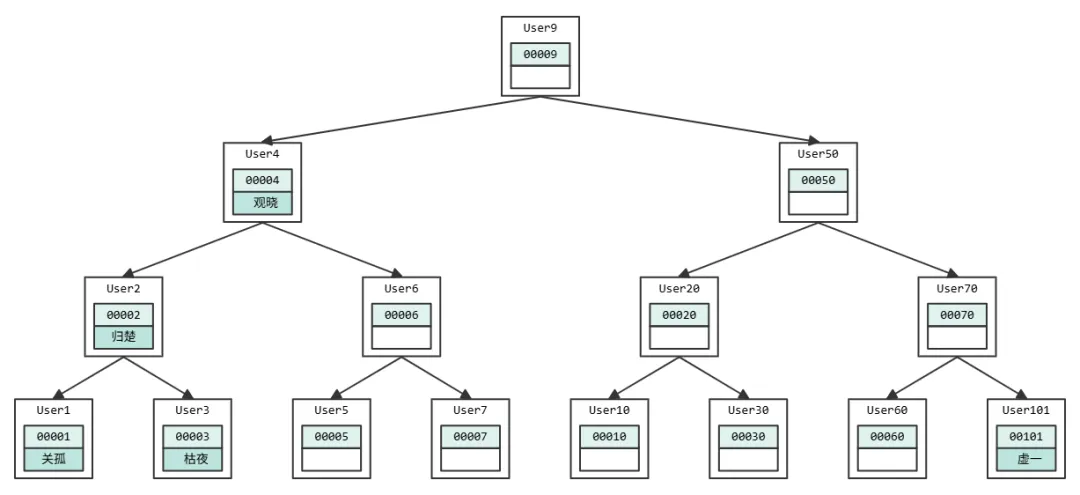
二叉树的特点:
一个节点只能有两个子节点,即度不超过 2;
左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值;
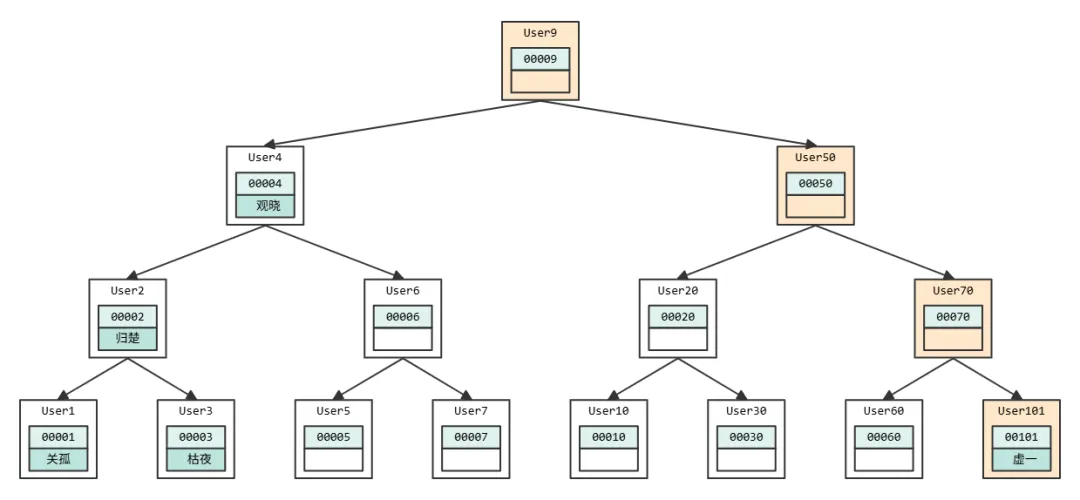
如果要查 User101 这个用户的话,按照图中的顺序就是 User9 → User50 → User70
→ User101这个路径得到。时间复杂度是 O(log(N))。
但是这个并不是稳定的,二叉树如果发生链化,也就是节点一直在某一边增加。那么时间复杂度就会降低到 O(N)。
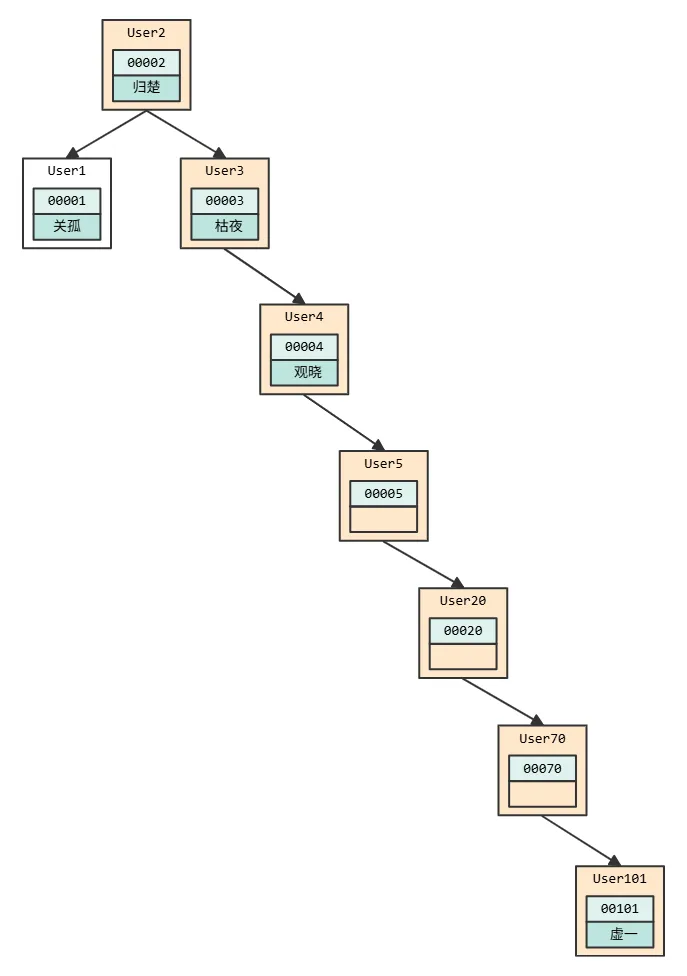
为了维持 O(log(N)) 的查询复杂度,避免链化,就需要保持这棵树是平衡二叉树。我们常听到的树好多都是这种,包括平衡二叉搜索树、红黑树、数堆、伸展树等。为了达到这个目的,就要在每次写入的时候做调整,那么更新的时间复杂度就也是
O(log(N))。
平衡二叉树的查询效率稳定了,但是,它是一个好选择吗?
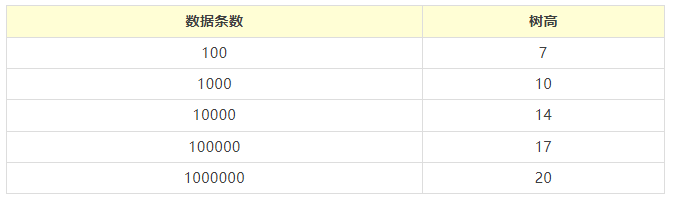
当我们有100万条数据,树高20,那么一次查询需要访问20个数据块,假设读取一个数据块需要10ms的寻址时间,那么查询一次数据需要需要200ms。相对比的,我们的
dwork_park 数据库,95% 以上的查询中 10ms 以内。
所以,继续优化……既然树的高度影响了效率,那就降低树的高度。
3.4 B树
针对同样的数据,如果我们把二叉树改成 M 叉树(M>2)呢?
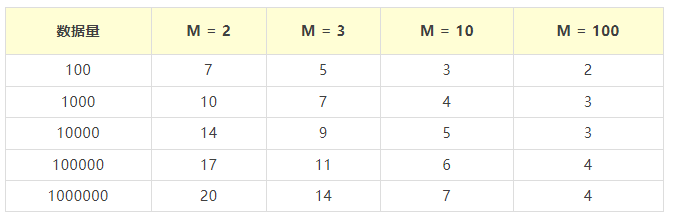
当 M 增大,树的高度会快速降低。这个时候,B树就出现了。
B树的英文是 Balance Tree,也就是平衡的多路搜索树,它的高度远小于平衡二叉树的高度。在文件系统和数据库系统中的索引结构经常采用B树来实现。
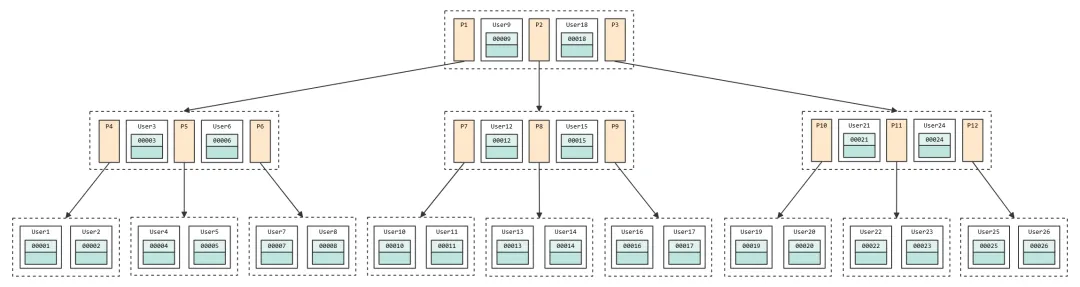
B树的每一个节点最多可以包括M(图中 M=3)个子节点,M称为B树的阶。同时每个磁盘块中可以又多个关键字,还另外多了子节点的指针。如果一个磁盘块中包括了
x 个关键字,那么指针数就是 x+1。对于一个100阶的B树来说,4层最多可以存储约100万的索引数据。对于大量的索引数据来说,采用B树的结构是非常适合的。
一个M阶的B树(M>2)有以下的特性:
根节点的儿子数的范围是[2,M]
每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为[ceil(M/2),
M]
叶子节点包括 k-1 个关键字,k 的取值范围为[ceil(M/2), M]
所有叶子节点位于同一层
对于B树,如果是等值查询,效率是很高的;但是对于范围查找,效率有所下降,因为要找到左右两个区间值,并且要遍历中间的所有子树。为了解决这个问题,B+树登场了。
3.5 B+树

B+树,是基于B树进行的改造,主要变化点有:
父节点的关键字在子节点也有,最终叶子节点有所有的关键字
非叶子节点只用作索引,不记录数据,所有跟记录有关的信息都存放在叶子节点中
叶子节点构成了一个有序链表,叶子节点本身也是按照从小到大排序
这带来了两个好处:
非叶子节点每个索引信息占的空间非常小(只有关键字信息),这样一个数据块就可以存放更多的数据,也就是M(树的阶)可以更大,进而让树的高度更低
所有的叶子节点都是排序的,那么对于范围查找只需要定位起始点,然后往后遍历即可,极大减少了读不同节点的I/O次数
MySQL的InnoDB引擎,使用的就是B+树这种索引模型,也就是说,我们平时在数据库中创建的索引,都是存储在B+树中的,每一个索引对应了一棵树。
四、InnoDB 的索引
4.1 主键索引
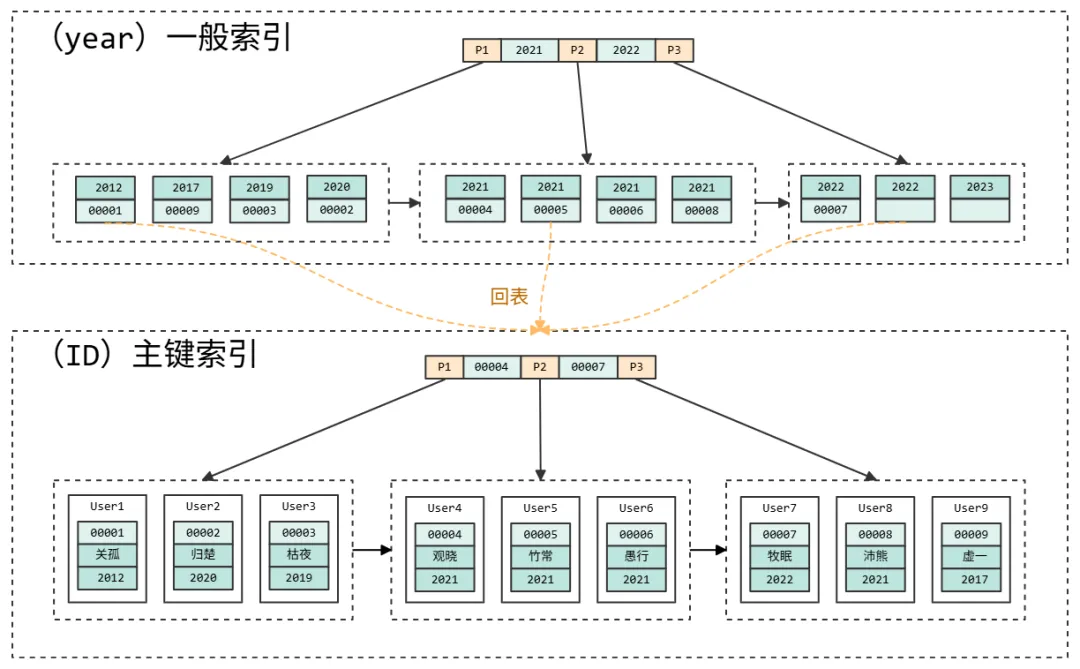
● 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered
index)。
● 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary
index)。
面试的时候经典问题又来了:
● select * from Table where id = 00001,即主键查询方式
● select * from Table where year = 2012,即普通索引查询方式
这两条查询语句在性能上有什么不同?我们通过上图可以知道,基于主键查询,只需要检索 ID 这棵 B+树,就可以直接得到结果数据;而普通索引查询,需要先搜索
year 这棵 B+树,得到 ID 的值为 00001,再到 ID 索引树搜索一次,这个过程也被称为回表。也就是说,基于非主键索引的查询需要多扫描一次索引树。所以,我们在应用中应该尽量使用主键查询。
4.2 覆盖索引
我们说,尽量使用主键索引,而不是一般索引,是为了避免回表,减少一次 B+ 树的扫描。那么,是不是有另外一种可能的方式,就是只扫描一般索引树,不扫描主键索引树呢?这就是覆盖索引。
如果执行的语句是 select ID, year from T able where year =
2012,这时只需要查 ID 的值,而 ID 的值已经在 year 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引
year 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
覆盖索引,是一个非常常用的性能优化方式。但是,我们并不总是只返回 ID 就够了,我们可能还需要其他字段,比如
name。
这个时候,就出现了另外一个技术:联合索引。
4.3 联合索引
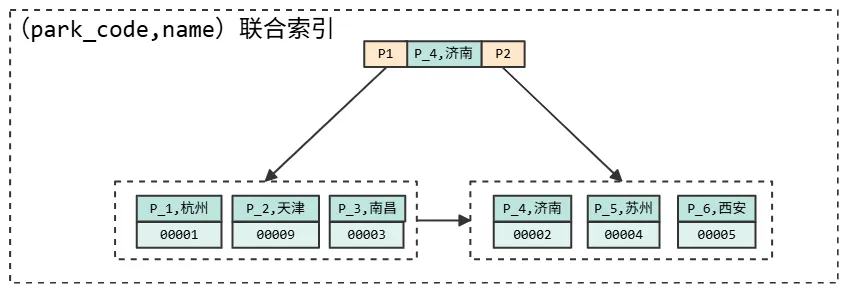
在我们的业务场景中,parkCode 是园区的唯一标识。也就是说,如果通过 parkCode 查询园区信息,只需要建立
parkCode 索引就可以了。这个时候建立(parkCode_name) 联合索引,是不是在浪费空间呢?
这个时候还是要分析具体业务,看查询园区名是不是高频请求,如果需要根据parkCode 查询园区名称,那么这个索引就非常必要,因为可以用到覆盖索引,不需要回表就可以获得查询结果。但是如果查询园区名称并不高频,或者说更多的时候需要和其他字段一起查询,那么就没有必要建立联合索引。
因为索引字段的维护是要付出代价的:
时间代价:因为联合索引意味着索引的值会变得更细更多,那么每增加一条数据进行的索引调整就会更加频繁
空间代价:因为每一个数据块的大小是固定的,每一条索引占用的空间越大,每个数据块可容纳的索引条数就更小,带来的结果就是
M 变小,B+ 树的高度就会变大,进一步降低查询效率
4.4 最左前缀原则
B+树的索引,遵循最左前缀原则。也就是说,并不需要匹配索引的全部关键字信息,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。这个“最左”包含了两层意思:
字符串索引的最左侧 M 个字符:比如使用 where name like ' 南%'就可以在字符串中进行匹配,而'%京'就无法进行匹配。
联合索引的最左 N 个字段:比如对一个(area,name,year) 索引,如果查询条件是where
area = '中区' and name = '武汉江夏' 就可以匹配到 area 与 name;而如果查询条件是
where area = '中区' and year = '2014',由于跳过了 name,就无法匹配
year,只能匹配到 area。
这里面又引申出来一个原则,要充分发挥索引的复用能力,如果建立了(area,name,year) 联合索引,就没有必要单独建立(area)索引了,因为前一个联合索引可以兼容后面的独立索引。
但是要注意,(a,b)索引可以覆盖(a) 索引,但是不能覆盖(b)索引,如果有比较高频的 b 的筛选条件,就需要建立(a,b)(b)
两个索引。
再次强调,索引是要付出代价的,所以:
索引不是越多越好
联合索引不是字段越多越好
小思考:假设一个表有两个字段:name、age,在查询的时候可能筛选 name、可能筛选 age、也可能筛选
name和 age 两个字段,如何设计索引?
参考答案:(name,age)和(age)两个索引,因为 age 所占的空间比 name 小。
4.5 给字符串加索引
不知道大家在创建索引的时候,有没有注意到后面这个字段,就是前缀长度。比如我们对用户的 email
创建索引,一种方式是不设置长度 idx_email_1(email),一种是设置长度为5, idx_email_2(email(5)),这两种在存储和查询的时候,会有什么区别呢?
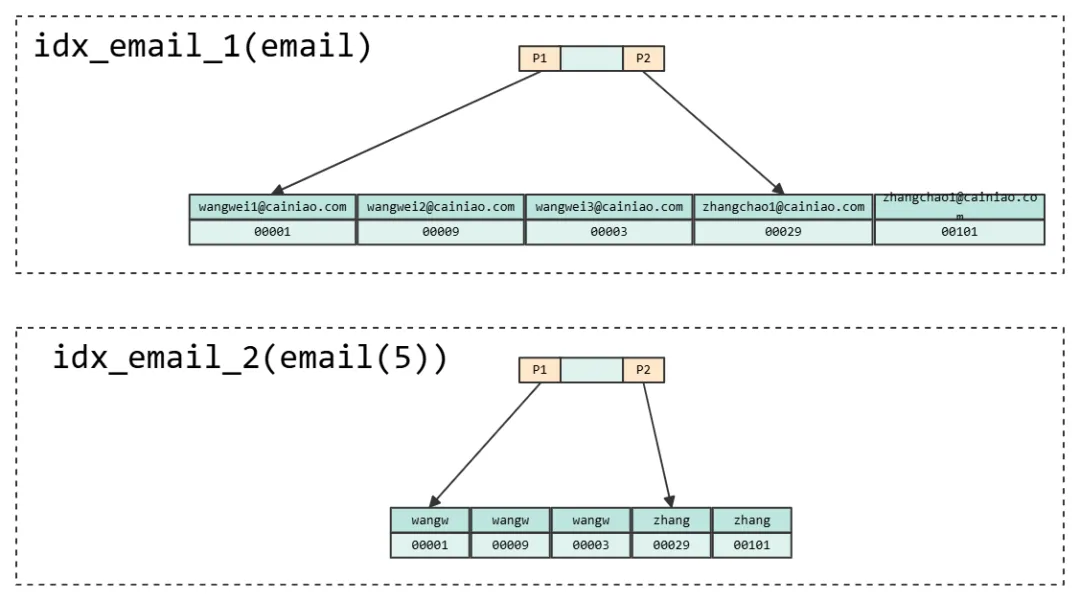
我们查询语句 select * from table where email = 'wangwei3@cainiao.com'
会发生什么?
在 index_email_1(email) 下比较简单,就是直接匹配索引,得到 id 00003,回表查询全部信息;而在
idx_email_2(email(5))下呢,你会发现可以匹配到的索引非常多,先是得到 00001
回表匹配 email,发现不是,再继续得到 00002,回表匹配还不是,继续得到 00003 回表匹配成功,这个时候才最终返回,比前面的要多两次回表。也就是说,使用前缀索引,可能导致查询次数增加,效率降低。
那为什么还有这么个配置可以选择呢?因为全量字符串会浪费空间,前面讲到过,空间也很带来时间的浪费。所以,怎么选择是个艺术活。
还是这个例子,对于我们公司的员工而言,邮箱的后缀基本都是@cainiao.com,而前缀是两到三个字的人名,那么如果我设置
idx_email_3(email(8)) 呢? 那么索引就会变成'wangwei3',也是可以唯一定位到查询数据的。
所以,使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
前缀索引可能带来多次回表,而我们接触到“回表”这个概念是在讲覆盖索引的时候。那么我们看这样一个查询:
select id, email from table where email = 'wangwei3@cainiao.com',分别使用index_email_1(email)
和 idx_email_3(email(8)) 会有什么差别?
对于 index_email_1(email),由于可以使用覆盖索引,所以不需要回表就可以返回结果了;而对于idx_email_3(email(8))
虽然也是可以唯一匹配,但是数据库并不知道前缀是否被截断了,所以还是需要回表查询确认。
也就是说,使用了前缀索引就无法使用覆盖索引做性能优化了。
此外,对于字符串类型的索引,还可以考虑:
● 倒序存储,再前缀索引,比如身份证这种前面几位是区域信息,如果说本地出生的数据库,大家都一样
● 使用 hash 字段,对于较长的字符串做 hash 运算,转成较短的字符串,可以节省存储空间,缺点是需要额外存储一个字段
4.6 order by
SELECT
id, park_code, park_name, biz_type, biz_id,
approve_type, approve_status, assignee, assignee_name,
creator_name, data_before, data_after, data_update,
attachment, reason, opinion, process_order,
assignee_code_list, assignee_code_user_list,
deleted, creator, operator, extra, gmt_create,
gmt_modified FROM approval_list WHERE (park_code
IN ('P_1', 'P_2', 'P_3', 'P_4', 'P_5', 'P_6',
'P_7', 'P_8', 'P_9', 'P_10', 'P_11', 'P_12',
'P_13', 'P_14', 'P_15', 'P_16', 'P_17', 'P_18',
'P_19', 'P_20', 'P_21', 'P_22', 'P_23', 'P_24',
'P_25', 'P_26', 'P_27', 'P_28', 'P_29', 'P_30',
'P_31', 'P_32', 'P_33', 'P_34', 'P_35', 'P_36',
'P_37', 'P_38', 'P_39', 'P_40') AND deleted
= 0) ORDER BY approve_status ASC, id DESC LIMIT
10 |
平均查询耗时:22.1s
平均扫描行数:3,544,023
上面这个语句我优化了一天,修改索引、修改查询逻辑,都没啥用。观晓说:“你把approve_status的排序删掉吧”,然后降到了6ms。
发生了啥?就算 park_code 的 in 查询几乎包含了所有的值,limit10 也不至于扫描全表吧。
我们使用 explain 看一下,发现了这么一个信息:“Using filesort”,
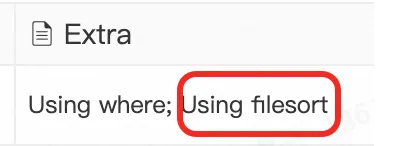
也就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
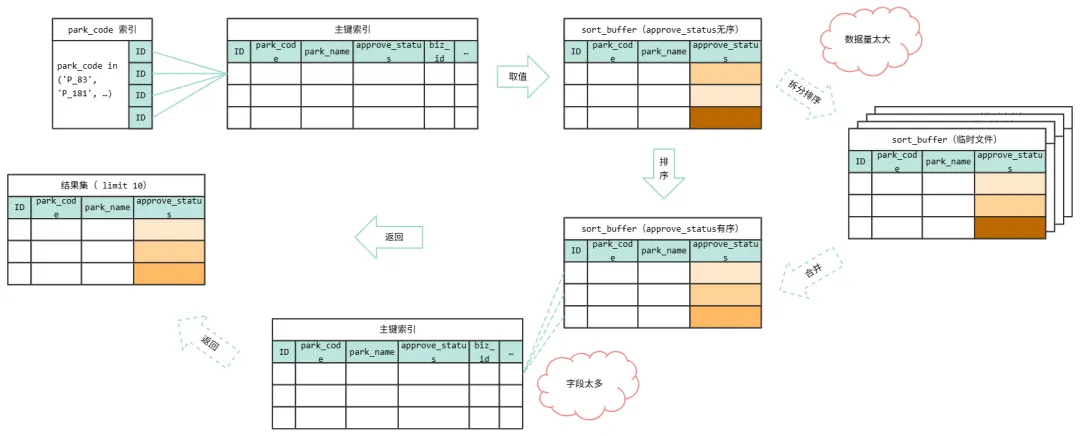
我们按照这个图来分析一下上面这条语句:
1)先是通过 park_code 索引,查询符合条件的数据,由于几乎所有的 parcCode 都包含了,所以这里需要扫描全表
2)回表查询各个字段,由于字段太多,丢弃一些,把需要排序的字段放到 sort_buffer
3)由于数据量太大,无法在内存中完成,需要拆分临时文件排序,再合并
4)limit10,截取个 id
5)由于前面丢弃了一些字段,所以需要回表查询补充所需字段
6)返回结果集
当我把 ORDER BY approve_status ASC, id DESC 去掉 approve_status
排序,只剩下 ORDER BY id DESC 后呢?
我们使用 explain 再看一下,发现了已经没有了:“Using filesort”,
也就是说,没有经过 sort_buffer 排序!
为什么会这样呢?我们还是有 order by,为何不需要排序了呢?
因为数据库判断需要全表扫描,没有走索引;而order by id,只需要走主键索引排序取10个值即可。
还有一种情况,如果我们的索引是 (a,b) 联合索引,如果 order by b 或者是唯一索引也是排序字段,那么在读取索引的时候就也可以直接获得排序结果,并不需要排序过程。
所以,我们回到前面的覆盖索引,索引上的信息不仅可以满足查询需求,还可以满足排序需求。
在此产生一个建议,排序字段尽量放到索引里(且大部分情况放在后面)。
4.7 选错索引
我们建立了索引就万事大吉了吗?No,还有很多时候 MySQL“很傻”,会选错索引。
MySQL 优化器在选择索引的时候,需要找到一个“最优解”,用最小的代价去执行语句。而寻找这个“最优解”的目标,就是更快,更少的
I/O,更少的扫描行数。但是,优化期并不知道真实的扫描行数,那样就执行完了,它只能根据统计数据来获取这个信息,而这个统计数据还是抽样统计。
算基数
一个索引上不同的值越多,这个索引的区分度就越好,也就是我们要寻找的索引。一个索引上不同的值的个数,称之为“基数”(cardinality),也就是说,这个基数越大,索引的区分度越好。
这个基数的计算,InnoDB 会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。也就是
(count(1) + count(2) + ... + count(N)) / N * page。选取的这
N 页并不均匀,所以导致最后的结果存在偏差。
算行数
索引统计只是一个输入,对于一个具体的语句来说,优化器还要判断,执行这个语句本身要扫描多少行。
而这个数据,也是统计数据。
需要额外注意的一点是,数据库不仅会计算所有的扫描行数,还会计算回表的行数。如果发现加一起和全量数据差不多,就会直接全表扫描。
优化手段
执行analyze table t,重新统计索引信息
使用 force index 强行选择一个索引
修改语句,引导 MySQL 使用我们期望的索引,比如我们order by b limit 1,会大概率采用
b 的索引,但是也许 a 更合适,这个时候可以改成 order by b, a limit 1,逻辑上一致,但是可能就会选择
a 索引
新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引
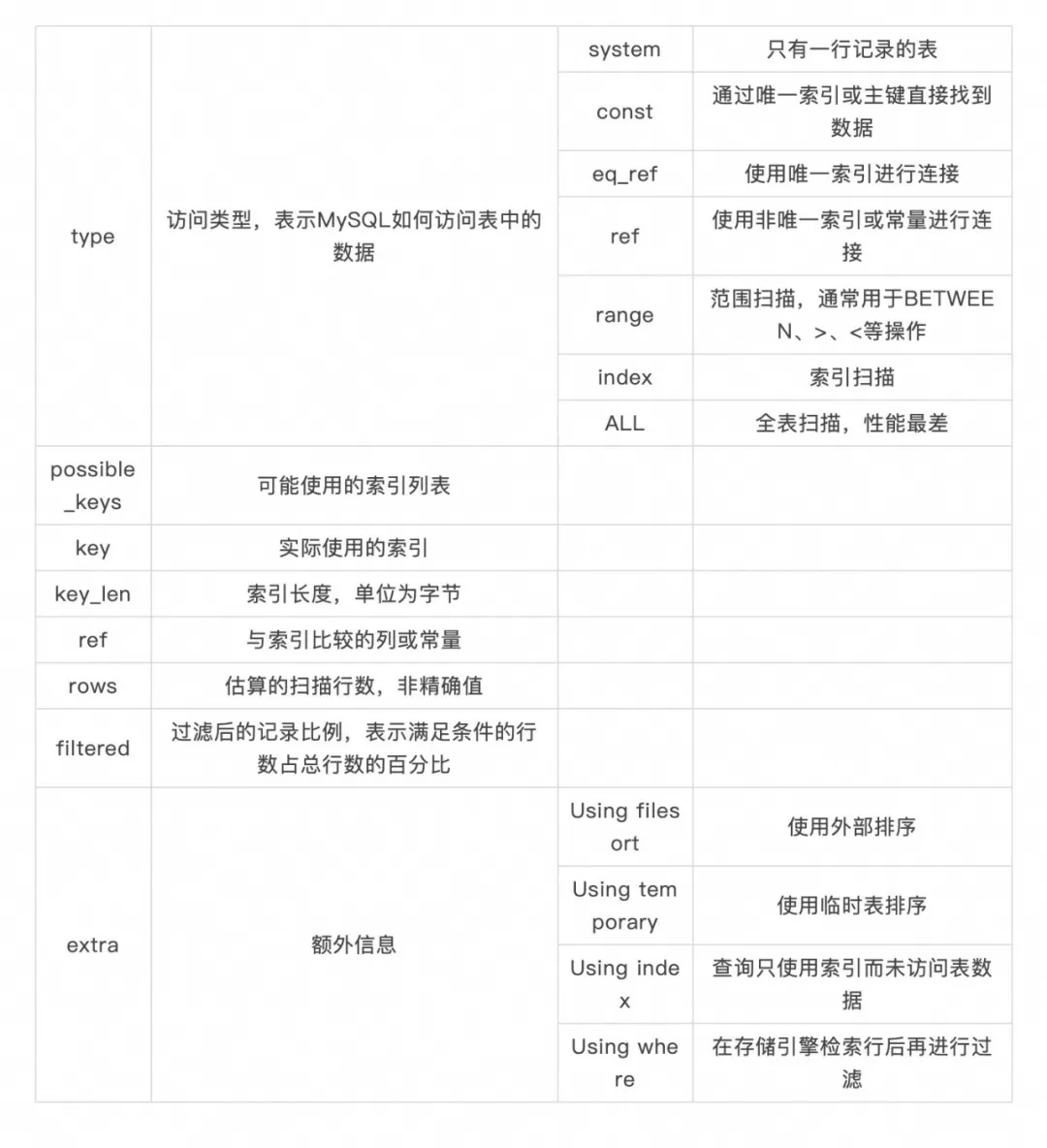
4.8 多用 explain
五、几点建议和忠告
在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的。
数据量很少的情况下(比如少于 1000 条),是没必要使用索引的。
数据重复度大(区分度小)的,也没必要使用索引。几千万条数据,deleted = 1 的一共没几条,并且几乎不会查(代码里面大部分默认
deleted = 0),所以创建(deleted) 索引出了让引擎误会,选错索引导致全表扫描外,起不到任何作用。
order by 不要乱用,尤其是对于分页表格,已经有了筛选项,就没必要按照分类排序了。
不要给每个字段都创建一个单独索引,好多是被联合索引覆盖了,另外一些可能没有区分度。
没有任何一条优化规则是可以解决所有问题的(否则就被引擎内置了),你能做的是了解原理,根据实际业务场景做出更优的选择。
六、巨人的肩膀
做这次分享主要是因为最近团队内部出现了很多慢sql,发现部分同学对于索引不是很理解,就整理了一下。在这个过程中,参考了很多前辈技术大牛的分享,在此表示感谢!
| 








