| “我们公司主要的业务是软件开发和系统集成,而这两个方面都会涉及到数据库软件,公司大多数的产品和工作都和ORACLE数据库有关;因此,可以说我们宏智科技在ORACLE数据库应用方面是高手云集、藏龙卧虎!下面,我本着“鲁班门前弄大斧”的动机和“成功就是把犯错误的速度提高一倍”的精神,战战兢兢地写下了一些个人认为重要的观点和一点点个人的体会,希望大家不要吝啬给我成长的机会,多提意见。 摘要:基于数据库的业务系统的核心是数据库和数据。理解ORACLE数据的体系框架有助于我们成功开发基于数据库的业务系统。通过增加一个索引、改变SQL语句的连接方法可以极大的改变系统的性能;80%的性能问题都是由不良的SQL语句引起的。 关键词:数据库、ORACLE、体系框架、SQL性能调整 应用系统最重要的部分:数据库 一个基于数据库的业务系统的成功开发,除了要求项目组对客户的需求有深刻的理解、对开发工具有熟练的掌握并有卓越管理之外,还要求项组能明确知道应用程序如何使用数据库。正如开发一个成功的业务系统对操作系统的理解非常重要一样,开发一个成功的基于ORACLE数据库应用的业务系统要求我们能全面的理解ORACLE。对于一个基于数据库的应用系统来说,系统中最重要的部分是数据库。记得我们公司CEO王栋在2000年时,在三明市地方税务局对前来福建考察的国家税务总局信息官员讲述《地方税收征管信息系统》时说:“三分技术、七分管理、十二分的数据”,这不仅强调了数据的重要性,同时也体现了数据库在一个基于数据库的业务系统中的核心地位。一个成功的开发团队必定是深刻认识这点并让相关人员都认识这一点的团队。 下面,首先介绍一下ORACLE数据库体系结构,以便开发人员对ORACLE体系结构有一个基本的、整体的映像;其次是围绕ORACLE数据库的性能对ORACLE开发中SQL语句的使用进行一些探讨。 理解ORACLE数据库体系框架 数据库软件就是处理数据文件的一批程序。关系数据库自上世纪70年代I B M 圣约瑟研究实验室的高级研究员埃德加・考特(E F Codd)的《大型共享数据库数据的关系模型》一文发表世以来,就逐步成为了数据库的主流。1977年,ORACLE公司成立第一个以关系数据库为核心的软件公司,现在已经推出ORACLE 9i。下面的探讨主要以ORACLE8i版本为基础。 虽然大家在很多介绍ORACLE的书籍中都可以看到类似下面的图,但是我认为下面的这张图是对ORACLE的体系结构展现的最清晰和简明扼要的。也许你在看介绍ORACLE的书籍时对这些枯燥的理论介绍没有太多的关心,而直接进入你关心的、可操作的内容。现在就让我们一起对这个图进行简单的了解。 大家可以看到,如果从简单的角度来描述,可以说一个ORACLE实例(Instance)是由一定的内存与后台进程组成,而数据库(Database)指物理文件。下面就SGA、五个必须的ORACLE后台进程进行简单的介绍: SGA(System Global Area 也称 Shared Global Area) 主要由以下三部分组成: 共享池(Shared Pool) 主要用来存储最近执行过的SQL语句和最近使用过的数据字典的数据;它主要通过INIT.ORA文件中的shared_pool_size和shared_pool_reserved_size两个参数来设置。 数据高速缓存区(Data Buffer Cache) 主要用来存储最近使用过的数据,可能是要写到数据文件的,也可能是从数据文件读取的;它主要通过INIT.ORA文件中db_block_buffers参数来设置;Data Buffer的大小=db_block_buffers* db_block_size; 重做日志缓存区(Redo Log Buffer) 主要存储服务进程和后台进程的变化信息;它主要通过INIT.ORA文件中的log_buffer参数来设置; Redo Log Buffer的大小=log_buffer* db_block_size; 当然,SGA不仅仅只是上面的三部分,还包括如Java pool(用来存储java代码)、Large pool(供不是和SQL直接相关的进程使用,如:当数据备份或恢复操作时,RMAN backup 用作磁盘I/O缓存器;Parallel时用作消息缓存器;MTS回话内存)等部分,我们可以通过v$sysstat、v$rowcache、v$librarycache等系统视图来监控SGA。 五个必须的ORACLE后台进程SMON、PMON、DBWn、CKPT、LGWR 系统监控进程(System Monitor SMON) 在数据库系统启动时执行恢复工作的强制性进程 进程监控进程(Process Monitor PMON) 用于恢复失败的数据库用户的强制性进程,它先获取失败用户的标识,释放该用户占有的所有数据库资源。 数据库写入进程(Database Writer, DBWR) 它将修改后的数据块写回数据库文件。日志写入进程(Log Writer , LGWR) 一个专门用于将重做项写入重做日志的进程。 校验点进程(Checkpoint Process CKPT ) ORACLE把内存中脏数据块中的信息写回磁盘的判断进程。 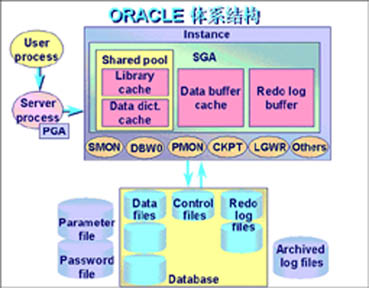 (注:本图引自ORACLE8i的OCP考试培训官方资料) SQL性能调整 我们考虑一个基于ORACLE数据库的应用系统的性能时,优先要考虑什么呢?主机操作系统?磁盘的I/O还是内存的使用?不,都不是!是系统的业务规则。从这个意义上说,我们对各个行业的业务专家的渴求不仅基于市场方面的,更是基于技术方面的。如果我们能够优化客户的业务规则,我们的系统将在起点上超越竞争对手! 在无法改变客户的业务规则的情况下,我们考虑影响应用系统性能的先后顺序应该是: 首先,考虑SQL语句的性能; 其次,考虑内存的分配; 第三,CPU的使用分配和磁盘I/O瓶颈; 第四,考虑网络因素; 第五,考虑操作系统因素; 等等…… 由此可以说,一个基于数据库的应用系统性能的好坏,首先是应用系统设计人员、应用系统开发人员的责任,而数据库管理员(DBA)是在其基础上进行的性能调整。80%的性能问题都是由不良的SQL语句引起的。设计和建立最佳的SQL对于系统的可扩展性和响应时间是基本工作。下面,我主要就SQL语句的性能进行一些粗浅的探讨,希望能起到抛砖引玉的效果。 SQL语句性能调整的目标是: 去掉不必要的大表全表扫描 不必要的大表全表扫描会造成不必要的输入输出,而且还会拖垮整个数据库; 检查优化索引的使用 这对于提高查询速度来说非常重要 检查子查询 考虑SQL子查询是否可以用简单连接的方式进行重新书写; 调整PCTFREE和PCTUSED等存储参数优化插入、更新或者删除等操作; 考虑数据库的优化器; 考虑数据表的全表扫描和在多个CPU的情况下考虑并行查询; 一、 索引(INDEX)使用的问题 1. 索引(INDEX),用还是不用?这是个的问题。 是全表扫描还是索引范围扫描主要考虑SQL的查询速度问题。这里主要关心读取的记录的数目。根据DONALD K .BURLESON的说法,使用索引范围扫描的原则是: 对于数据有原始排序的表,读取少于表记录数40%的查询应该使用索引范围扫描。对读取多于表记录数40%的查询应全表扫描。 对于未排序的表,读取少于表记录数7%的查询应该使用索引范围扫描,反之,对读取多于表记录数7%的查询应全表扫描。 注:在不同的书中,对是否使用索引的读取记录的百分比值不太一致,基本上是一个经验值,但是读取记录的百分比越低,使用索引越有效。 2. 如果列上有建索引,什么SQL查询是有用索引(INDEX)的?什么SQL查询是没有用索引(INDEX)的? 存在下面情况的SQL,不会用到索引: 存在数据类型隐形转换的,如: select * from staff_member where staff_id=’123’; 列上有数学运算的,如: select * from staff_member where salary*2<10000; 使用不等于(<>)运算的,如: select * from staff_member where dept_no<>2001; 使用substr字符串函数的,如: select * from staff_member where substr(last_name,1,4)=’FRED’; ‘%’通配符在第一个字符的,如: select * from staff_member where first_name like ‘%DON’; 字符串连接(||)的,如: select * from staff_member where first_name||’’=’DONALD’ 3. 函数的索引 日期类型也是很容易用到的,而且在SQL语句中会使用to_char函数以查询具体的的范围日期。如:select * from staff_member where TO_CHAR(birth_day,’YYYY’)=’2003’; 我们可以建立基于函数的索引如:CREATE INDEX Ind_emp_birth ON staff_member (to_char((birth_day,’YYYY’)); 二、 SQL语句排序优化 1. 排序发生的情况: SQL中包含group by 子句 SQL 中包含order by 子句 SQL 中包含 distinct 子句 SQL 中包含 minus 或 union操作 创建索引时 2. 排序在内存还是在磁盘中进行? 在内存执行的排序速度要比在磁盘执行的排序速度快14000倍。如果是专用连接,排序内存根据INIT.ORA的sort_area_size进行分配,如果是多线程服务连接,排序内存根据large_pool_size进行分配。 sort_area_size的增大可以减少磁盘排序,但是过大将使ORACLE性能降低,因为所用的连接回话都会分配到一个sort_area_size大小的内存,所以,为了提高有限的查询速度,可能会浪费大量的内存。 增加sort_multiblock_read_count的值使每次读取更多的内容,减少运行次数,提高性能。 三、SQL子查询的调整 1、理解关联子查询和非关联子查询。 下面是一个非关联子查询: select staff_name from staff_member where staff_id in (select staff_id from staff_func); 而下面是一个关联子查询: select staff_name from staff_member where staff_id in (select staff_id from staff_func where staff_member.staff_id=staff_func.staff_id); 以上返回的结果集是相同的,可是它们的执行开销是不同的: 非关联查询的开销――非关联查询时子查询只会执行一次,而且结果是排序好的,并保存在一个ORACLE的临时段中,其中的每一个记录在返回时都会被父查询所引用。在子查询返回大量的记录的情况下,将这些结果集排序,以及将临时数据段进行排序会增加大量的系统开销。 关联查询的开销――对返回到父查询的的记录来说,子查询会每行执行一次。因此,我们必须保证任何可能的时候子查询用到索引。 2、XISTS子句和IN子句 带IN的关联子查询是多余的,因为IN子句和子查询中相关的操作的功能是一样的。如: select staff_name from staff_member where staff_id in (select staff_id from staff_func where staff_member.staff_id=staff_func.staff_id); 为非关联子查询指定EXISTS子句是不适当的,因为这样会产生笛卡乘积。如: select staff_name from staff_member where staff_id Exists (select staff_id from staff_func); 尽量不要使用NOT IN子句。使用MINUS 子句都比NOT IN 子句快,虽然使用MINUS子句要进行两次查询: select staff_name from staff_member where staff_id in (select staff_id from staff_member MINUS select staff_id from staff_func where func_id like ‘81%’); 3、 任何可能的时候,用标准连接或内嵌视图改写子查询。 四、更新、插入、以及删除等DML语句的调整 1、DML语句是指用来执行更新、插入、以及删除等操作类型的语句。这些语句在结构上是很简单的,可调整的余地较小。性能低下的情况有: 插入缓慢并占有过多的I/O资源――这种情况主要是空闲列表(free list)中的数据块的空间过小,仅容的下较少的记录。 更新缓慢――这种情况主要是UPDATE操作扩展了一个VARCHAR2类型的列,而ORACLE被强制将内容迁移到其他数据块时。 删除缓慢――这种情况主要是记录被删除,ORACLE必须将数据块重新放置到空闲列表(free list)时。 因此,对DML进行调整,主要时利用对象存储参数和SQL之间的关系进行调整。 2、 CTFREE存储参数 PCTFREE存储参数告诉ORACLE什么时候应该将数据块从对象的空闲列表中移出。ORACLE的默认参数是PCTFREE=10;也就是说,一旦一个INSERT操作使得数据块的90%被使用,这个数据块就从空闲列表(free list)中移出。 PCTUSED存储参数 PCTUSED存储参数告诉ORACLE什么时候将以前满的数据块加到空闲列表中。当记录从数据表中删除时,数据库的数据块就有空间接受新的记录,但只有当填充的空间降到PCTUSED值以下时,该数据块才被连接到空闲列表中,才可以往其中插入数据。PCTUSED的默认值是PCTUSED=40。 存储参数规则小结 (1)PCTUSED较高意味着相对较满的数据块会被放置到空闲列表中,从而有效的重复使用数据块的空间,但会导致I/O消耗。PCTUSED低意味着在一个数据块快空的时候才被放置到空闲列表中,数据块一次能接受很多的记录,因此可以减少I/O消耗,提高性能。 (2)PCTFREE的值较大意味着数据块没有被利用多少就从空闲列表中断开连接,不利于数据块的充分使用。PCTFREE过小的结果是,在更新时可能会出现数据记录迁移(Migration)的情况。(注:数据记录迁移(Migration)是指记录在是UPDATE操作扩展了一个VARCHAR2类型的列或BLOB列后,PCTFREE参数所指定的空间不够扩展,从而记录被ORACLE强制迁移到新的数据块,发生这种情况将较严重的影响ORACLE的性能,出现更新缓慢)。 (3)在批量的插入、删除或者更新操作之前,先删除该表上的索引,在操作完毕之后在重新建立,这样有助于提高批量操作的整体速度,并且保证B树索引在操作之后有良好的性能。 3、 同优化器下的调整; 基于成本优化器(CBO): (1)ORACLE 8i 以上版本更多地使用成本优化器,因为它更加智能; (2)通过optimizer_mode=all_rows 或 first_rows来选择CBO;通过alter session set optimizer_goal=all_rows 或 first_rows来选择CBO;通过添加hint来选择CBO; (3)使用基于成本优化的一个关键是:存在表和索引的统计资料。通过analyze table 获得表的统计资料;通过analyze index获得索引的统计资料。 (4)对于超过5个表的连接的查询,建议不要使用成本优化器,而是在SQL语句中通过添加/* + rule */提示或者通过指定的执行计划来避免可能会在20分钟以上的SQL解析时间。 基于规则优化器(RBO): (1)ORACLE 8i以及ORACLE的以前版本主要用(RBO),并且比较有效; (2)通过optimizer_mode=rule来选择RBO;通过alter session set optimizer_goal=rule来选择RBO; 通过添加/* + rule */来选择RBO; (3)在RBO中,from 子句的表的顺序决定表的连接顺序。From 子句的最后一个表是驱动表,这个表应该是最小的表。 (4)限定性最强的布尔表达式放在最底层。 4、跟踪、优化SQL语句的方法 保证在实例级将TIMED_STATISTICS设置为TRUE(在 INIT.ORA中永久的设置它或执行 ALTER SYSTEM 命令临时设置它); 保证将MAX_DUMP_FILE_SIZE设置的较高。此参数控制跟踪文件的大小。 决定USER_DUMP_DEST所指向的位置,并保证有足够的磁盘空间。这是放置跟踪文件的位置。 在应用系统运行时,打开所怀疑的回话的SQL_TRACE.(在 INIT.ORA中通过SQL_TRACE=TRUE永久的设置对所有的回话进行跟踪或通过使用系统包DBMS_SYSTEM.set_sql_trace_in_session(sid,serial,true);命令临时设置它) 执行业务相关操作; 设置跟踪结束(DBMS_SYSTEM.set_sql_trace_in_session(sid,serial,false),如果没有该步骤,可能跟踪文件中的信息不全,因为可能有一部分还在缓存中); 定位跟踪文件; 对步骤6的跟踪文件进行TKPROF,生成报告文件; 研究此报告文件,可以看到CPU、DISK、 QUERY、 COUNT等参数和execution plan(执行计划),优化开销最大的SQL; 重复执行步骤4)~9)直到达到所需的性能目标; SQL_TRACE、TKPROF、EXPLAIN PLAN和AUTOTRACE为与ORACLE数据库软件一起发行的核心工具。掌握这些工具对应用程序的优化取得成功有非常大的帮助,具体的使用我就不多说了,大家可以到网上查到使用操作,也可以参考一些有关ORACLE性能调整的书籍。 通过上面的探讨,我们认识到:基于数据库的应用系统的核心是数据库和业务数据;在理解ORACLE数据库体系框架部分,我们重点在于建立一个对ORACLE的体系架构的基本的、整体的映像;在SQL性能调整部分,我们讨论了有关索引(INDEX)、子查询、DML性能等问题。请相信:通过增加一个索引、改变SQL语句的连接方法可以极大的改变系统的性能。同时需要说明的是,SQL性能调整远不止上面的这些,如: ORACLE何时进行并行查询?表的不同的连接方法(如:NESTED LOOPS JOIN、HASH JOIN等)对SQL有何影响?如何使用提示(hint)进行SQL的优化?等等。愿大家在工作中逐步积累经验,从而让SQL语句有更好的性能。 参考文献: 《ORACLE 专家高级编程 expert one-on-one ORACLE》 清华大学出版社 Thomas Kyte 著。 《ORACLE 性能优化技术内幕 ORACLE Performance Tuning 101》机械工业出版社 Gaja Krishna Vaidyanatha,kirtikumar Deshpande,John Kostelac 著。 《ORACLE高性能SQL调整 Oracle-High-Performance SQL Tuning》机械工业出版社 DONALD K.Burleson著。 《ORACLE8 完全参考手册 Oracle 8: The Complete Reference》机械工业出版社 Geoge Koch,Kevin Loney 著。 |