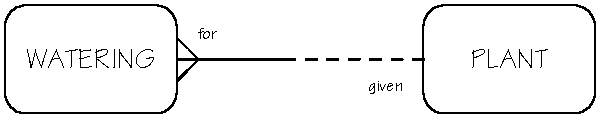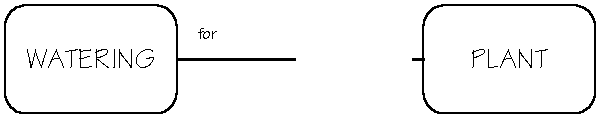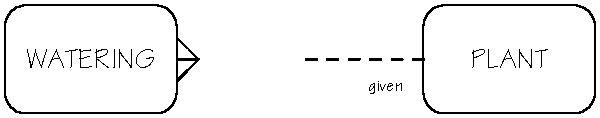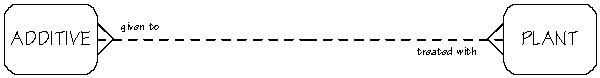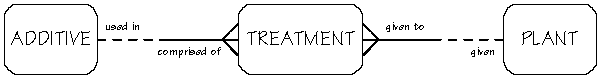If you ask an application developer what the most important task is in developing new or enhanced applications for institutional data and processes, almost every time they will tell you it is the initial analysis of client requirements. Before purchasing any software, before storing a single byte of data in a database, analysis of the client's requirements is paramount to developing the appropriate solution. More time spent in analysis directly increases the effectiveness of the resulting application. Since the early 1960s, and despite the waves of change since then, one thing has remained constant -- the initial analysis is still the most important activity that an application designer undertakes. It gives the developer the chance to design an effective, spectacular application, no holds barred. This analysis takes on various forms. Usually the application developer has a feeling about what form the analysis should take. It may simply require a phone call to the client asking them "Do you want to add or subtract 5 percent from all the employees' salaries?" Or, it may require the organization of week-long meetings with clients to collectively analyze their requirements. Overkill is rarely a problem in the analysis stage as it guarantees the involvement of all the relevant people. The worst thing a developer can do is to not include a key person in the requirements analysis. Everyone's knowledge and experience is needed during this analysis. Their presence or absence makes or breaks the success of the analysis. The participants in the analysis bring their much-needed knowledge and experience into the meeting, but it is also important to ask them to "leave their baggage at the door." Excess baggage such as idealization of the features or constraints of the current application can impede the design of a new and improved application, one without those same "time-honored" constraints. While the developer recognizes that there are always rules, regulations, and constraints, they must also examine these constraints for their continuing validity within the new application. Data ModelingMost people involved in application development follow some kind of methodology. A methodology is a prescribed set of processes through which the developer analyzes the client's requirements and develops an application. Major database vendors and computer gurus all practice and promote their own methodology. Some database vendors even make their analysis, design, and development tools conform to a particular methodology. If you are using the tools of a particular vendor, it may be easier to follow their methodology as well. For example, when CNS develops and supports Oracle database applications it uses the Oracle toolset. Accordingly, CNS follows Oracle's CASE*Method application development methodology (or a reasonable facsimile thereof). One technique commonly used in analyzing the client's requirements is data modeling. The purpose of data modeling is to develop an accurate model, or graphical representation, of the client's information needs and business processes. The data model acts as a framework for the development of the new or enhanced application. There are almost as many methods of data modeling as there are application development methodologies. CNS uses the Oracle CASE*Method for its data modeling. As time goes by, applications tend to accrue new layers, just like an onion. We develop more paper pushing and report printing, adding new layers of functions and features. Soon it gets to the point where we can only see with difficulty the core of the application where its essence lies. Around the core of the application we see layer upon layer, protecting, nurturing, but ultimately obscuring the core. Our systems and applications often fall victim to these protective or hiding processes. The essence of an application is lost in the shuffle of paper and the accretion of day-to-day changes. Data modeling encourages both the developer and the client to tear off these excess layers, to explore and revisit the essence or purpose of the application once more. The new analysis determines what needs to feed into and what feeds from the core purpose. Application Audience and ServicesAfter participants at CNS-sponsored application analysis meetings agree on a scope and objectives statement, we find it helpful to identify the audience of the application. To whom do you offer the services we are modeling? Who is affected by the application? Answers to these and similar questions help the participants stay in focus with the desired application results. After assembling an audience list, we then develop a list of services provided by the application. This list includes the services of the existing application and any desired future services in the new application. From this list, we model the information requirements of each service. To do this, it is useful to first identify the three most important services of the application, and then of those three, the single most important service. Eventually all of the services will be modeled. Focusing our data modeling on one service just gives us a starting point. EntitiesThe next step in modeling a service or process, is to identify the entities involved in that process. An entity is a thing or object of significance to the business, whether real or imagined, about which the business must collect and maintain data, or about which information needs to be known or held. An entity may be a tangible or real object like a person or a building; it may be an activity like an appointment or an operation; it may be conceptual as in a cost center or an organizational unit. Whatever is chosen as an entity must be described in real terms. It must be uniquely identifiable. That is, each instance or occurrence of an entity must be separate and distinctly identifiable from all other instances of that type of entity. For example, if we were designing a computerized application for the care of plants in a greenhouse, one of its processes might be tracking plant waterings. Within that process, there are two entities: the Plant entity and the Watering entity. A Plant has significance as a living flora of beauty. Each Plant is uniquely identified by its biological name, or some other unique reference to it. A Watering has significance as an application of water to a plant. Each Watering is uniquely identified by the date and time of its application. AttributesAfter you identify an entity, then you describe it in real terms, or through its attributes. An attribute is any detail that serves to identify, qualify, classify, quantify, or otherwise express the state of an entity occurrence or a relationship. Attributes are specific pieces of information which need to be known or held. An attribute is either required or optional. When it's required, we must have a value for it, a value must be known for each entity occurrence. When it's optional, we could have a value for it, a value may be known for each entity occurrence. For example, some attributes for Plant are: description, date of acquisition, flowering or non-flowering, and pot size. The description is required for every Plant. The pot size is optional since some plants do not come in pots. Again, some of Watering's attributes are: date and time of application, amount of water, and water temperature. The date and time are required for every Watering. The water temperature is optional since we do not always check it before watering some plants. The attributes reflect the need for the information they provide. In the analysis meeting, the participants should list as many attributes as possible. Later they can weed out those that are not applicable to the application, or those the client is not prepared to spend the resources on to collect and maintain. The participants come to an agreement on which attributes belong with an entity, as well as which attributes are required or optional. The attributes which uniquely define an occurrence of an entity are called primary keys. If such an attribute doesn't exist naturally, a new attribute is defined for that purpose, for example an ID number or code. RelationshipsAfter two or more entities are identified and defined with attributes, the participants determine if a relationship exists between the entities. A relationship is any association, linkage, or connection between the entities of interest to the business; it is a two-directional, significant association between two entities, or between an entity and itself. Each relationship has a name, an optionality (optional or mandatory), and a degree (how many). A relationship is described in real terms. Rarely will there be a relationship between every entity and every other entity in an application. If there are only two or three entities, then perhaps there will be relationships between them all. In a larger application, there are not always relationships between one entity and all of the others. Assigning a name, an optionality, and a degree to a relationship helps confirm the validity of that relationship. If you cannot give a relationship all these things, then perhaps there really is no relationship at all. For example, there is a relationship between Plant and Watering. Each Plant may be given one or more Waterings. Each Watering must be for one and only one specific Plant. Entity Relationship DiagramsTo visually record the entities and the relationships between them, an entity relationship diagram, or ERD, is drawn. An ERD is a pictorial representation of the entities and the relationships between them. It allows the participants in the meeting to easily see the information structure of the application. Later, the project team uses the ERD to design the database and tables. Knowing how to read an ERD is very important. If there are any mistakes or relationships missing, the application will fail in that respect. Although somewhat cryptic, learning to read an ERD comes quickly. Each entity is drawn in a box. Each relationship is drawn as a line between entities. The relationship between Plant and Watering is drawn on the ERD as follows:
Since a relationship is between two entities, an ERD shows how one entity relates to the other, and vice versa. Reading an ERD relationship means you have to read it from one entity to the other, and then from the other to the first. Each style and mark on the relationship line has some significance to the relationship and its reading. Half the relationship line belongs to the entity on that side of the line. The other half belongs to the other entity on the other side of the line. When you read a relationship, start with one entity and note the line style starting at that entity. Ignore the latter half of the line's style, since it's there for you to come back the other way. A solid line at an entity represents a mandatory relationship. In the example above, each Watering must be for one and only one Plant. A dotted line at an entity represents an optional relationship. Each Plant may be given one or more Waterings. The way in which the relationship line connects to an entity is significant. If it connects with a single line, it represents one and only one occurrence of that entity. In the example, each Watering must be for one and only one Plant. If the relationship line connects with three prongs, i.e., a crowsfoot, it represents one or more of the entities. Each Plant may be given one or more Waterings. As long as both statements are true, then you know you have modeled the relationship properly. In the relationship between Plant and Watering, there are two relationship statements. One is: each Watering must be for one and only one Plant. These are the parts of the ERD which that statement uses:
The second statement is: each Plant may be given one or more Waterings. The parts of the ERD which that statement uses are:
After some experience, you learn to ask the appropriate questions to determine if two entities are related to each other, and the degree of that relationship. After agreeing on the entities and their relationships, the process of identifying more entities, describing them, and determining their relationships continues until all of the services of the application have been examined. The data model remains software and hardware independent. Many-to-Many RelationshipsThere are different types of relationships. The greenhouse plant application example showed a one-to-many and a many-to-one relationship, both between Plant and Watering. Two other relationships commonly found in data models are one-to-one and many-to-many. One-to-one relationships are between two entities where both are related to each other, once and only once for each instance of either. In a many-to-many relationship, multiple occurrences of one entity are related to one occurrence of another, and vice versa. An example of a many-to-many relationship in the greenhouse plant application is between the Plant and Additive entities. Each plant may be treated with one or more Additives. Each Additive may be given to one or more Plants. The ERD for this relationship is shown below.
Many-to-many relationships cannot be directly converted into database tables and relationships. This is a restriction of the database systems, not of the application. The development team has to resolve the many-to-many relationship before it can continue with the database development. If you identify a many-to-many relationship in your analysis meeting, you should try to resolve it in the meeting. The participants can usually find a fitting entity to provide the resolution. To resolve a many-to-many relationship means to convert it into two one-to-many, many-to-one relationships. A new entity comes between the two original entities, and this new entity is referred to as an intersection entity. It allows for every possible matched occurrence of the two entities. Sometimes the intersection entity represents a point or passage in time. The Plant-Additive many-to-many relationship above is resolved in the following ERD diagram:
With these new relationships, Plant is now related to Treatment. Each Plant may be given one or more Treatments. Each Treatment must be given to one and only one Plant. Additive is also related to Treatment. Each Additive may be used in one or more Treatments. Each Treatment must be comprised of one and only one Additive. With these two new relationships, Treatment cannot exist without Plant and Additive. Treatment can occur multiple times, once for each treatment of a plant additive. To keep each Treatment unique, a new attribute is defined. Treatment now has application date and time attributes. They are the unique identifiers or the primary key of Treatment. Other attributes of Treatment are quantity and potency of the additive. Will Data Modeling Look Good on You?There are other processes and marks to enhance a data model besides the ones shown in this article. Many of them are used in the actual development of the database tables. The techniques shown here only provide a basic foundation for undertaking your own data modeling analysis. Data modeling gives you the opportunity to shed the layers of processes covering up the fundamental essence of your business. Remember to leave your baggage at the door of a data modeling session. Come to the meeting with enthusiasm and a positive outlook for a new and improved application. |