在这篇文章的第二章中,我们已经建立了一个供我们使用的非常简单的笑话数据库,这个库中只包括了一个名叫Jokes的数据表。这作为我们使用MySQL数据库的入门已经是足够了,但是在关系型数据库的设计中还有很多其它的东西。在这一章中,我们会对我们的例子进行扩充,学习一些有关MySQL的新知识,并试图理解并掌握关系型数据库所能提供的功能。
首先,我们得说明我们对许多问题的解决只是不正规的(也就是说非正式的)。正如你在许多计算机科学专业中了解的那样,数据库设计是一个严肃的领域,数据库设计必须包括对它的测试并会涉及到一些数学的原理。但这些可能是超过我们这篇文章的范围了。要得到更多的信息,你可以停下来到http://www.datamodel.org/去看看,在那儿你可以看到许多好的书籍,并得到一些关于这个问题的有用的资源。
给予应有的权限
在开始之前,让我们回忆一下我们的Jokes数据表的结构,这个表包含三个列:ID、JokeText和
JokeDate。这些列可以使我们标识笑话(ID),明了他们的内容(JokeText)以及他们被加入的时间(JokeDate)。
现在我们想要保存我们的笑话中的其它一些信息:提交者的姓名。这看上去很自然,我们需要在我们的Jokes数据表中添加一个新的列。SQL的ALTER命令(我们在之前没看到过这个命令)可以帮助我们完成这件事。使用mysql命令行程序登录到MySQL服务器,选择你的数据库(如果你使用我们在第二章中的命名,数据库名应该是joke),然后输入下面的命令:
|
mysql> ALTER
TABLE Jokes ADD COLUMN
-> AuthorName VARCHAR(100);
|
这将会在我们的数据表中增加一个叫AuthorName的列。其数据类型是一个可变长度的字符串,其最大长度是100个字符(这对于最复杂的名字应该也是足够了)。让我们再添加一列用来保存作者的e-mail地址:
|
mysql> ALTER
TABLE Jokes ADD COLUMN
-> AuthorEMail VARCHAR(100);
|
要得到更多的有关ALTER命令的信息,请参看MySQL参考手册。要确认我们是不是正确地添加了两列,你可以要求MySQL为我们对这个表进行描述:

看上去很不错。明显地,我们需要对我们在第四章中建立的添加新笑话的HTML以及PHP格式的代码进行调整,但是我们会把这留给你作为一个练习。使用UPDATE查询,你现在可以对表中的所有笑话添加作者的详细资料。然而,在你开始接受这个数据结构之前,我们必须考虑一下我们在这儿选择的设计是否确当。在这种情况下,我们会发现一些我们还没有做到的事情。
一个基本的规则:保持事物的分离
在你建立数据库驱动的网站的过程中,你已经觉得仅仅是有一个笑话列表是不够的。事实上,除了你自己的笑话以外,你开始接收其他人提交的笑话。你决定做一个让全世界人都可以共享笑话的网站。你有没有听说过Internet电影数据库(IMDB)?实际上你现在做的是Internet笑话数据库(IJDB)!对每一个笑话添加作者的姓名和e-mail地址肯定是最容易想到的办法,但是这种方法会导致一些潜在的问题:
如果一个经常投稿的名叫Joan Smith的人改变了她的e-mail地址将会发生什么什么情况呢?她会开始使用新地址来提交新的笑话,但是对于所有的旧笑话,你所能看到的还是旧的地址。从你的数据库来看,你也许只能认为有两人名字都叫Joan
Smith的人在向你的数据库中提交笑话。如果她是特别体贴的,她也许会通知你改变地址,你可以将所有的旧笑话改成新的地址,但是如果你遗漏了一个,那就意味着你的数据库中存储了错误的信息。数据库设计专家将这种类型的问题称之为一个“更正异常”。
很自然地你会想到从你的数据库中得到所有曾经向你的站点提交过笑话的人的列表。实际上,你可以使用下面的查询很容易地得到这样的列表:
|
mysql> SELECT
DISTINCT AuthorName, AuthorEMail -> FROM Jokes;
|
上面查询中DISTINCT是告诉MySQL不输出重复的结果行。例如,如果Joan
Smith向我们的站点提交过20个笑话,如果我们使用了DISTINCT选项,她的名字和e-mail地址将会只在列表中出现一次,否则会出现20次。
如果因为某种原因,你决定要从数据库中删除某个特定的作者所提交的所有笑话,但是,与此同时,你将不能再通过e-mail与他们联系!而你的e-mail清单可能是你的网站的收入的主要来源,所以你并不想只因为你不喜欢他们提交的笑话,就删除他们的e-mail地址。数据库设计专家将这称之为“删除异常”。
你并不能保证不会出现这样的情况:Joan Smith输入的姓名一会儿是“Joan
Smith”,一会儿是“J. Smith”,一会儿又是“Smith,
Joan”。这将使得你要确定一个特定的作者变得非常困难(特别是Joan
Smith又经常使用几个不同的email地址的时候)。
这些问题的解决其实很简单。只要你不再将作者的信息存储到Jokes数据表中,而是建立一个新的数据表来存储作者列表。因为我们在Jokes数据表中使用了一个叫ID的列来用一个数据标识每个笑话,所以我们在新的数据表中使用了同样名字的列来标识我们的作者。我们可以在我们的Jokes表中使用“author
ID's”来建立笑话和他的作者之间的关联。全部的数据库设计应该是这样的:
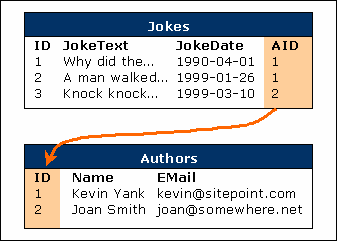
上面的两个表包含了三个笑话和两个作者。Jokes表的AID列(“Author
ID”的缩写)提供了两个表之间的关联(指出Kevin
Yank 提交了笑话1和笑话2,Joan Smith提交了笑话3)。在这里,你还需要注意到每一个作者只会在数据库中出现一次,而且他们是独立于他们提交的笑话而存在的,因此我们已经解决了我们上面提出的那些问题。
这个数据库设计的最重要的特征是,因为我们要存储两种类型的事物(笑话和作者),所以我们设计两个表。这是我们在数据库设计中要遵守的一个基本规则:对于每一个要存储其信息的实体(或事物),我们都应该给他一个自己的表。
重新生成上面的数据是非常简单的(只要使用两个CREATE
TABLE
查询就行了),但是因为我们想要在做这些变动时不会有破坏性的效果(也就是说不会丢失我们已经存入的笑话),所以我们需要再次使用ALTER命令。
首先,我们删除Jokes表中有关作者的列:
|
mysql> ALTER
TABLE Jokes DROP COLUMN AuthorName;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE Jokes DROP COLUMN AuthorEMail;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
|
现在我们建立我们的新的数据表:
|
mysql> CREATE
TABLE Authors (
-> ID INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> Name VARCHAR(100),
-> EMail VARCHAR(100)
-> );
|
最后,我们在我们的Jokes表中添加AID列:
mysql> ALTER TABLE Jokes ADD COLUMN AID INT;
现在剩下来的就是向新的表中添加一些作者,并通过填充AID列来对数据库中已经存在的笑话指定作者。
处理多个表
现在我们的数据被分布在两个表当中,要从其中获得数据看上去变得更加复杂了。例如,我们最初的目标是:显示一个笑话的列表并在每一个笑话后面显示作者的姓名和e-mail地址。在我们的单表结构中,要获得所有的信息,只需要在我们的PHP代码中使用一个SELECT语句就行了:
|
$jokelist =
mysql_query(
"SELECT JokeText, AuthorName, AuthorEMail ".
"FROM Jokes");
while ($joke = mysql_fetch_array($jokelist)) {
$joketext = $joke["JokeText"];
$name = $joke["AuthorName"];
$email = $joke["AuthorEMail"]; // Display the joke
with author information
echo( "<P>$joketext<BR>" .
"(by <HREF='mailto:$email'>$name)</P>"
);
}
|
在我们的新系统中,这样做初看起来是不可能了。因为有关每个笑话的作者的详细资料不是存储在Jokes表中,我们可能想到的一个解决方案是我们对于我们想要显示的笑话单独地获得这些资料。代码将是这样的:
|
// Get the list
of jokes
$jokelist = mysql_query(
"SELECT JokeText, AID FROM Jokes");
while ($joke = mysql_fetch_array($jokelist)) {
// Get the text and Author ID for the joke
$joketext = $joke["JokeText"];
$aid = $joke["AID"];
// Get the author details for the joke
$authordetails = mysql_query(
"SELECT Name, Email FROM Authors WHERE ID=$aid");
$author = mysql_fetch_array($authordetails);
$name = $author["Name"];
$email = $author["EMail"];
// Display the joke with author information
echo( "<P>$joketext<BR>" .
"(by <A HREF='mailto:$email'>$name)</P>"
);
}
|
很混乱,而且对于每一个显示的笑话都包含了一个对数据库的查询,这将会我们的页面的显示非常缓慢。现在看来,“老方法”可能是更好的解决方案,尽管它有其自身的弱点。
幸运的是,关系型数据库可以很容易地处理多个表中的数据!在SELECT语句中使用一个新的被称之为“join”的格式,我们可以找到两全其美的办法。连接可以使我们象对存储在单个表中的数据那样对待多个表中的关联数据。一个连接的格式应该是这样的:
|
mysql> SELECT
<columns> FROM <tables>
-> WHERE <condition(s) for data to be related>;
|
在我们目前的情况下,我们所需要的列是Jokes表中的JokeText列以及Authors表中的Name列和Email列。Jokes表和Authors表的关联条件是Jokes表中的AID列的值等于Authors表中的ID列的值。下面是一个连接的例子(前两个查询只是用来显示我们的两个表中所包含的内容):

现在明白了吗?第三个SELECT的结果就是一个连接,它将存储在两个表中的数据关联数据显示到了一个结果表中,尽管我们的数据是存储在两个表中的,我们仍然可以使用一个数据库查询就获得我们的Web页面所需要的笑话列表的全部信息。
在这里,要注意一个问题,因为在两个表中都有一个叫ID的列,所以我们在用到Authors表中的ID列时我们必须指定表名(Authors.ID)。如果我们没有指定表名,MySQL将无法知道我们指的是哪一个表中的ID,这会导致这样的一个错误:
|
mysql> SELECT
LEFT(JokeText,20), Name, Email
-> FROM Jokes, Authors WHERE AID = ID;
ERROR 1052: Column: 'ID' in where clause is ambiguous
|
现在我们知道如何有效率地从我们的两个表中获取信息了,我们可以利用连接来重新编写我们的笑话列表的程序:
|
$jokelist =
mysql_query(
"SELECT JokeText, Name, EMail " .
"FROM Jokes, Authors WHERE AID=Authors.ID");
while ($joke = mysql_fetch_array($jokelist)) {
$joketext = $joke["JokeText"];
$name = $joke["Name"];
$email = $joke["EMail"];
// Display the joke with author information
echo( "<P>$joketext<BR>" .
"(by <A HREF='mailto:$email'>$name)</P>"
);
}
|
随着你对数据库的使用,你会越来越发现连接的功能有多大的意义。例如,下面的查询用来显示所有由Joan
Smith写的笑话:
|
mysql> SELECT
JokeText FROM Jokes, Authors WHERE
-> Name="Joan Smith" AND AID=Authors.ID;
|
上面的查询的输出结果仅仅来源于Jokes表,但是我们使用了一个连接来通过存储在Authors表中的值搜索笑话。在我们的这篇文章中会有更多的这样的精巧的查询,在实际应用中,连接是经常会被使用的,而且在绝大多数的情况下,这会很大程度地简化我们的工作!
简单的数据关系
对于给定的情况的最好的数据模型往往决定于我们所工作的两种数据之间的关系类型。我这篇文章中,我们将对典型的关系类型进行研究,并学会如何在一个关系型数据中用最好的方法描述它。
对于简单的一对一的关系,只要用一个表就足够了。一对一关系的一个例子就是我们在前面已经看到的在笑话数据库中的每一个作者的e-mail地址。因为对于每一个作者只有一个e-mail地址,而且对于一个e-mail地址对应的也只有一个作者,将它们分到两个数据库中是没有道理的。
多对一的关系可能会稍微复杂一点,但是在之前其实我们也已经解决了这个问题,我们的数据库中的每一个笑话只会有一个作者,但是同一个作者可能写了很多笑话。笑话和作者之间的关系就是一个多对一的关系。我们曾经有过一个初步的解决方案,那就是将与这个笑话关联的作者的信息也促成在同一个数据库中。但是这样做,对于同一个数据会有许多拷贝,这不仅会在同步上造成困难,而且会浪费空间。将数据分开到两个数据表中并使用一个ID列来连接两个表(象上面所说的那样使用连接),所有的问题会得到很好的解决。
到目前为止,我们还没接触到一对多的关系,但是想象这样的一个关系应该是不困难的。在我们之前建立的数据库中,我们假定一个作者只有一个e-mail地址。事实上情况并不总是这样的,作出这个限制的理由只是因为我们只需要一个e-mail地址来与作者联系。我们简单地假设了作者总会输入他们常用的e-mail地址,或者至少是一个正常使用的e-mail地址。如果我们想要支持多个e-mail地址,我们将面对一个一对多的关系(一个作者会有几个e-mail地址,但是一个e-mail地址只会与一个确定的作者对应)。
一个没有经验的数据库设计者面对一个一对多的关系时,他首先会想到的是试图把多个数据存储到一个数据库域中,就象这样:

这种结构在投入使用后,要从数据库中获得一个单个的e-mail地址,将不得不通过搜索逗号(或者你所选择的用来分隔的其他符号)来分割字符串,这样做并不简单,而且会很耗时。设想一下如果要用PHP来删除某个作者的某个e-mail地址,那也将会是很困难的事。另外,对于EMail列我们需要很长的长度,这会导致磁盘空间的浪费,因为大多数的作者都只会有一个e-mail地址。
解决一对多的关系和我们上面解决多对一的关系是非常类似的。实际上两者之前只是一个简单的颠倒。我们可将Authors表分成两个表,Authors和EMails,然后在EMails表中使用作者的ID(AID)这样的一个列来实现两个表之间的连接:

使用一个连接,显示某个作者的所有E-mail地址将会是很简单的:

多对多的关系
Ok,现在你有了一个发布在你的网站上的稳定增长的笑话数据库。事实上,这种增长是非常迅速的,笑话的数量会变得难以管理!你的访问者将面对一个庞大的页面,在这个页面上杂乱地排列了数以百计的笑话。现在,我们不得不考虑作一些变动了。
你决定将你的笑话放置到不同的目录中,这些目录可能是“Knock-Knock笑话”、“Crossing
the Road笑话”、“Lawyer笑话”和“Political笑话”。记住我们之前的处理规则,因为我们的笑话目录是一个不同类型的“事物”,所以我们要为它们建立一个新的数据表:
|
mysql> CREATE
TABLE Categories (
-> ID INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> Name VARCHAR(100),
-> Description TEXT
-> );
Query OK, 0 rows affected (0.00 sec)
|
对你的笑话定义其所属目录将会是一个困难的任务。因为一个“political”笑话可能也是一个“crossing
the road”笑话,同样,一个“knock-knock”可能也是一个“lawyer”笑话。一个单个的笑话可能属于许多目录,每一个目录也会包含许多笑话。这是一个多对多的关系。
许多没有经验的设计者又会想到将几个数据存储到一个列中,最直接的解决方案是在Jokes表中增加Categories列,并在其中列举笑话所属的目录的ID。现在适用我们的第二个处理规则了:如果你需要在一个列中存储多个值,那证明你的设计可能是有缺陷的。
描述一个多对多关系的正确方法是使用一个“lookup”表。这个表不包含任何实际的数据,只是用来定义关联的事物。这儿是我们这部分的数据库设计的示意图:

JokeLookup 表将笑话的ID(JID)的目录的ID(CID)进行了关联。从上面的例子我们可以看出,以“How
many lawyers...”开头的笑话既属于“Lawyer”目录,又属于“Light
Bulb”目录。
建立lookup表的方法和建立其他表的方法基本一样。不同点在于选择主键。我们之前所建立的每一个表都有一个名为ID的列,这一列被我们定义为PRIMARY
KEY。将一个列定义为主键意味着这一列不会出现重复值。而且可以加快基于这一列的连接操作的速度。
对于我们的lookup表来说,没有一个单个的列可以保证不出现重复值。每一个笑话可以属于几个目录,所以一个joke
ID可能会出现多次;同样的,一个目录可能包含多个笑话,所以一个category
ID也可能会出现多次。我们所要求的只是相同的数据对不应重复出现。因为我们这个表的唯一作用就是用来实现连接,所以使用主键来提高连接操作的速度对我们肯定有价值。所以,我们通常会为lookup表建立一个多列的主键:
|
mysql> CREATE
TABLE JokeLookup (
-> JID INT NOT NULL,
-> CID INT NOT NULL,
-> PRIMARY KEY(JID,CID)
-> );
|
现在我们的表中的JID和CID共同组成了这个表的主键。保持lookup表中数据的唯一性是有价值的(防止重复定义某一个笑话属于某一个目录),而且这会提高这个表用来连接时的速度。
使用我们的lookup表中包含的目录分配,我们可以使用连接来建立几个有趣而且非常实用的查询。下面的查询列出了“Knock-Knock”目录下的所有笑话:
|
mysql> SELECT
JokeText
-> FROM Jokes, Categories, JokeLookup
-> WHERE Name="Knock-Knock" AND
-> CID=Categories.ID AND JID=Jokes.ID;
|
下面这个查询列举了以“How
many lawyers...”开头的笑话所属的所有目录:
|
mysql> SELECT
Categories.Name
-> FROM Jokes, Categories, JokeLookup
-> WHERE JokeText LIKE "How many lawyers%"
-> AND CID=Categories.ID AND JID=Jokes.ID;
|
下面的查询,同时使用了我们的Authors表形成了一个四个表的连接(!!!),列举了写过
Knock-Knock笑话的所有作者的名字:
|
mysql> SELECT
Authors.Name
-> FROM Jokes, Authors, Categories, JokeLookup
-> WHERE Categories.Name="Knock-Knock"
-> AND CID=Categories.ID AND JID=Jokes.ID
-> AND AID=Authors.ID;
|
结语
这一章中,我们学习了正确的数据库设计的基本原则,以及MySQL(实际上,对其他关系型数据库同样适用)如何对描述事件之间的不同类型的关系提供支持。我们不仅仅探讨了一对一的关系,还详细讨论了多对一、一对多以及多对多的关系。
在这一过程中,我们还学习了一些有关SQL命令的新的东西。特别的,我们学习了如何使用一个SELECT去连接多个表中的数据并将其反映到一个结果集中。
在第六章中,我们将使用我们已经获得的知识,并加上很少的一些新知识,去用PHP构建一个内容管理系统。我们希望这个系统可以提供一个可定制的、安全的、基于Web的界面来管理数据库的内容,而不再是在MySQL命令行中来解决问题。
|