|
适用于: 摘要:了解常见的服务器功能合并方案,其中一个系统上承载了多个数据库,而每个数据库中只有较少的几个用户。这些参数的效果可以通过一个称为“PACE”的实际应用程序来了解,这是一个来自 Microsoft bCentral 的财务应用程序。 目录
概述本文是 Microsoft 和 Dell 公司共同合作的成果,用来说明 Microsoft® SQL Server™ 2000 和 Dell 硬件的可缩放性。在 Dell 企业版八路服务器上运行的 SQL Server 2000 可以支持上千个数据库及为数众多的用户,同时还可以提供进行集中管理所需的性能。SQL Server 2000 使用户能够在对称多重处理 (SMP) 系统方面获得最大的投资回报;用户可以增加处理器、内存和磁盘,以建立集中管理的大型企业服务器。 更多公司愿意从应用服务提供商 (ASP) 那里获取数据库服务。内部信息技术 (IT) 组织正在根据其总拥有成本 (TCO) 和可管理收益合并数据库服务。本文重点介绍常见的 ASP 方案,其中一个系统上承载了多个数据库,而每个数据库中只有较少的几个用户。此方案同样适用于希望将跨企业服务器的多个数据库合并到一个集中管理的服务器上的公司。因此,本文的目的也就是要说明如何使用多个实例成功地调整单个服务器上增加的工作负荷。我们将使用 Microsoft bCentral™ 的应用程序来研究不同的配置对工作负荷性能的影响,测量依据是每分钟的事务处理数 (TPM)。 下表列出了在一台服务器上使用多个实例的优点:
此案例研究的结果表明:
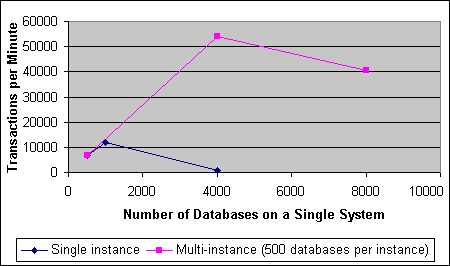
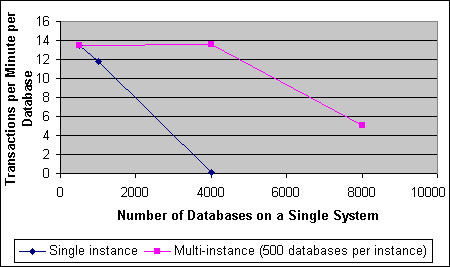
本文提供了一些一般的原则,以帮助用户理解成功配置多个实例以获取最佳吞吐量过程中所涉及的标准。 简介鉴于越来越多的客户开始关注服务器功能合并,我们期望 ASP 和企业 IT 部署多个 SQL Server 2000 实例,以承载更多的数据库。 分离数据库的能力使得 ASP 或企业 IT 能够更灵活地向客户提供不同层次的服务,而无需使用单独的计算机。要使用这种方法,需要确定何时使用多个实例,以及如何配置这些实例以获得最佳性能。 最佳配置是在研究过若干个参数(包括多个实例、内存配置、CPU 关系、磁盘布局和 TPM 中的恢复模式)的影响之后确定的。 本文重点介绍一个常见的方案,其中一个系统上承载了多个数据库,而每个数据库只有较少的几个用户。上述参数的影响可以从称为“PACE”的实际应用程序中看出。PACE 来自 Microsoft bCentral 的一个财务应用程序,它运行在一组服务器上。这些服务器包括:Microsoft SQL Server 2000 Enterprise Edition、Microsoft Windows® 2000 Datacenter™ Server 和 Dell PowerEdge 8450 servers。 PACE 应用程序所部署的 PACE 应用程序是一个会计和财务管理产品,是 Microsoft bCentral 为客户提供的众多服务之一。PACE 用来帮助小型企业更有效地完成日常工作,它包括处理财务问题、银行业务、生成工资单、记录销售、采购信息以及快速方便地生成报告的功能。 为了向每位客户提供实体安全的会计控制和可靠的多用户访问,该应用程序在一台服务器上提供了许多小型财务数据库,为每位客户建立一个数据库。它还使用户能够对安全性、备份和恢复、变化控制和维护操作进行更精确的控制。此应用程序为每个数据库提供了 200 多个存储过程,以支持 Web 服务。 这种反传统的设计为系统管理和 SQL Server 的性能优化带来了新的问题。最大的问题是,随着数据库的增多,支持大量存储过程所需要的内存也在成倍地增加。对于 SQL Server 来说,需要具有虚拟内存空间,以便为每个数据库上的每个过程编译执行计划,然后将该计划保存在过程高速缓存中。对于 PACE 应用程序来说,为 500 个数据库高速缓存的执行计划数量为 200*500,即 100000 个高速缓存条目。PACE 数据库的数量越多,所需的服务器过程高速缓存大小就越大。如果执行计划的数量超出了过程高速缓存能够存储的数量,将对执行重新进行编译,这将减少处理查询的吞吐量。利用传统的方法(例如使存储过程参数化)不能解决此问题。 进行有效的调整需要完成特定的配置,以增加用于过程高速缓存的有效内存空间。其他问题还包括如何有效地利用 CPU,以处理由于数据库和用户数量增加而导致频繁发生并发活动的情况,以及如何有效地利用最佳磁盘布局和最佳恢复模式。 使用多个实例使用多个实例可以增加每台服务器上的数据库数量和工作负荷当数据库的数量和相应的工作负荷达到一定水平后,将多个 SQL Server 实例中的数据库分组是一个好办法,因为这样可以缓解内存压力。为每个实例的服务器过程高速缓存分配更多内存可以获得良好的性能,并能够提供更好的操作和安全隔离。 测试表明,使用多个实例可以增加数据库的总数以及系统上产生的相应工作负荷,同时还能维护每个数据库的吞吐量。 图 1 表明,当 PACE 数据库的数量从 500 增加至 4000 时,单个实例的性能将降低。但是如果分散到 8 个实例上,每个实例上运行 500 个数据库,那么每分钟的事务处理数量是在一个实例上运行 500 个数据库时的 8 倍。在 8 个实例中的每个实例上运行高工作负荷的 500 个数据库几乎利用了此硬件配置中的全部 CPU 容量,所以通过在 16 个实例中的每个实例上运行 500 个数据库来增加数据库的总数不能增加总吞吐量(但是,系统仍然显示了一个可接受的吞吐量)。 图 2 表明,当单个 SQL Server 上的数据库数量(或客户端连接数量)增加时,每个数据库的工作负荷吞吐量将减少。如果每个实例的数据库保持在 500 个,则每个数据库的吞吐量在单个实例和在 8 个实例上是一样的,但是当增加至 16 个实例后,吞吐量会因为 CPU 的限制而减少。
图 1:系统上的总工作负荷吞吐量与系统上的 PACE 数据库总数
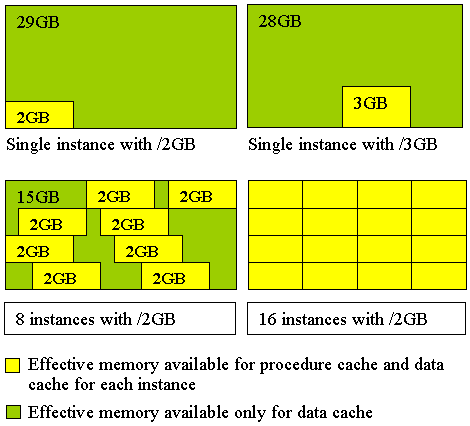
图 2:每个数据库上的工作负荷吞吐量与系统上的 PACE 数据库数量 为什么要在此方案中使用多个实例在一个实例上使用上千个 PACE 数据库会造成性能下降 SQL Server 2000 最多可以为该过程高速缓存使用 2 GB 的虚拟内存(如果在 boot.ini 中设置了 /3 GB 开关,则为 3 GB)。当单个实例上的数据库数量从 500 增加至 1000 时,过程高速缓存中将没有足够的虚拟内存来保存内存中增加的所有查询执行计划。为了释放内存,以便为其他存储过程的计划腾出空间,系统会丢弃过程高速缓存中的某些执行计划,但是此操作要求在需要时重新编译这些被丢弃的存储过程计划。请注意,这样所造成的频繁的重新编译工作会影响工作负荷性能。 使用多个实例缓解内存压力 如图 3 所示,在具有 4 GB 以上物理内存的情况下,在多个实例上运行数据库可以留出更多的内存供过程高速缓存使用(每个实例具有自己的虚拟地址空间和过程高速缓存)。 当单个实例的 PACE 数据库数量增至数千后,这些数据库对象会占用太多供过程高速缓存使用的内存空间,从而导致性能下降。过程高速缓存将被丢弃,然后进行重新编译。综上所述,我们建议使用多个实例。
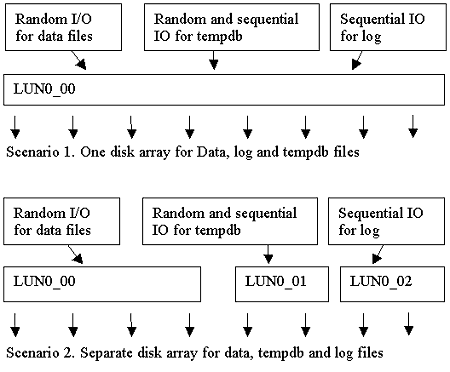
图 3:不同配置中过程高速缓存的有效内存 其他类似的设计也面临同样的问题 决定多个实例是否能够提高性能的关键因素是所有执行计划所需的内存空间总量。所需的内存空间总量是由执行计划的平均大小、每个数据库的存储过程数量和数据库数量决定的。如果每个数据库中有较多的过程,那么即使使用较少的数据库也会产生同样的问题。此外,如果较少的数据库中存在非常复杂的过程,即使每个数据库的存储过程较少,也会产生同样的问题。 多个实例的内存配置要使多个实例发挥最佳性能,只需指定合理的最小服务器内存,而无需额外调整内存配置。我们注意到,如果为每个实例预留 1 GB 的最小服务器内存并保持开放最大的服务器内存,在性能方面要比使用默认的动态内存分配提高 25%。这样获得的性能与使用最佳静态内存分配一样,无需进行高成本的反复重新校准。使用此方法的客户应注意,此方法可能会影响同一服务器上其他应用程序的内存分配。争用内存的其他应用程序会影响动态内存分配。因此,Microsoft 建议您将此系统专用于 SQL Server。 将此系统专用于 SQL Server 的另外一个优点是使配置能够支持不同实例上的不同工作负荷,无需为了确定最合适的内存配置而进行特别的测试和调整。这种方法(将系统专用于 SQL Server)能够减少为了在工作负荷不同的情况下获得最佳性能而重新配置内存的工作。 简化内存配置可以提高系统性能为每个实例使用最小内存配置可以获得与使用最佳静态分配时一样的性能。可以减少为确定每个实例的最佳静态分配所进行的测试工作。 为了确定某种方法是否可以提供更好的性能,我们分别使用静态和动态内存分配设置在 8 实例和 16 实例配置上进行了测试。因为每个数据库具有相同的工作负荷而且每个实例具有相同数量的数据库,所以工作负荷在各个实例中是相等的。 但是运行 16 个实例时,使用静态内存分配提供的性能比使用动态分配提供的性能高 25%。 对于 16 个实例的配置,通过为每个实例预留 1 GB 的最小服务器内存并保持开放最大的服务器内存,可以获得与使用最佳静态内存分配一样的性能。 为什么需要内存配置当一台计算机上运行多个 SQL Server 实例时,各实例分别使用标准算法进行动态内存管理。分配给每个特定 SQL Server 实例的内存量是根据每个实例的相对工作负荷而定的。这样可以确保处理较多工作负荷的实例可以获得较多的内存,而处理较少工作负荷的实例获得较少的内存。 运行 16 个实例时,系统中没有足够的物理内存来满足所有实例的需求。SQL Server 的实例开始争用有限的可用内存,要在各实例之间获得平衡会花费很长的时间。在本方案中,使用静态内存分配可以确保实例的最佳初始内存容量分配提供更好的性能。 请注意,每个实际的方案会有所不同。需要对它们进行测试,以确定分配给每个实例的最佳内存量。同样,不同实例上的工作负荷水平发生变化时,也需要进行测试,以重新确定各个实例间的最佳内存分配。这种测试在大多数实际应用中是不适用的。 要在多个实例间分配内存,较可行的方法是结合静态内存分配和动态内存分配。为每个实例合理地预留最小的服务器内存可以减少为了达到平衡所需的系统开销。保持开放最大服务器内存可以使实例根据自身的工作负荷动态地调整内存分配。 处理器关系测试表明,使用关系掩码手动为 SQL Server 的特定实例分配处理器可以使性能提高 80%(假设工作负荷是一样的,ASP 工作负荷通常如此)。如果 SQL Server 的实例不需要与其他服务器应用程序进程共享处理器,这时可以获得最佳效果。 使用 CPU 关系可以提高性能 测试是在最佳内存配置下,在 8 个实例,每个实例上 500 个数据库上进行的。各实例上的工作负荷是相同的。相对于默认处理器关系设置,将 8 个实例分别分配给 8 个 CPU 时,吞吐量将增加 80%。 为什么使用 CPU 关系可以提高性能 默认情况下,SQL Server 实例的每个线程都被安排给了下一个可用的处理器。CPU 关系掩码设置可以用来将实例限制在 CPU 的某个子集中,并且可以确保每个线程在各个中断间隔之间使用相同的处理器,而不用在多个处理器之间切换同一个线程,同时提高了二级高速缓存上的高速缓存命中率。但是,使用 CPU 关系设置时要小心,因为如果每个实例上的工作负荷不相等,那么不同 CPU 上的工作负荷就无法动态取得平衡。 在一台具有多个处理器的服务器上运行多个实例时,通过设置 CPU 关系为特定实例分配派处理器,可以减少每个处理器的活动线程数,还可以减少上下文切换次数,因此最好使用二级高速缓存。 磁盘布局基于可恢复性的考虑,请勿将日志和数据放在同一设备上。此外,分隔日志文件使用的物理磁盘可以提高性能。 本测试方案表明,相对于将日志文件和数据文件放在同一个(较大)卷中,分隔物理磁盘上的日志文件和数据文件可以使性能提高 10%。 测试是使用具有最佳内存配置、最佳 CPU 配置的 8 个实例(每个实例上 500 个数据库)上进行的,具有两个不同的磁盘布局,如图 4 所示。
分隔物理磁盘上的日志文件和数据文件可以使性能提高 10%。
图 4:磁盘布局 为什么分隔物理磁盘上的日志文件可以提高性能 通常会将日志文件与数据文件放在不同的物理磁盘上,以便分开日志文件上的顺序磁盘 I/O 和数据文件上的随机磁盘 I/O。这也适用于本测试方案中的数百个日志文件。在较大卷中具有更多轴的好处大于将随机数据 I/O 和顺序日志 I/O 分开的好处。 恢复模式测试表明,在完全恢复模式 (full recovery model) 下运行工作负荷可以获得在批量记录恢复模式 (bulk-logged recovery model) 下运行性能的 90%。在特定的方案中,使用完全恢复模式可以最灵活地进行恢复,同时还能维护良好的性能。 完全恢复模式可以提供良好的性能 为了确定不同恢复模式对工作负荷性能的影响,我们在 8 个实例中每个实例上的 500 个数据库中进行测试,使用最佳内存配置、磁盘配置和具有两种恢复模式的 CPU 关系,这两种恢复模式为:完全恢复和批量记录恢复。相对于使用完全恢复模式,使用批量记录模式运行工作负荷使性能提高 10%。 其他注意事项 Microsoft 建议所有的生产联机事务处理 (OLTP) 系统使用完全恢复模式及其提供的数据保护。进行工作量较大的操作(例如创建索引或装载大量数据)时,可以暂时使用批量记录恢复模式。工作量较大的操作能够提高性能,但也增加了丢失数据的风险。有关详细信息,请参阅 SQL Server 联机图书。 小结结合使用 Microsoft SQL Server 2000、Microsoft Windows 2000 Datacenter Server 和 Dell PowerEdge 8450 Server 时,如果有数千个数据库分布在单台服务器上的多个 SQL Server 实例中,则可以获得较好的可缩放性能。最佳配置是在研究过若干参数(包括多个实例、内存配置、CPU 关系、磁盘布局和恢复模式)的影响后确定的。 通常,在单台服务器上为大量数据库成功分配工作负荷以及提供数据保护的步骤为:
附录 A:适用于可缩放企业计算的 Dell 解决方案Dell PowerEdge 8450 是适用于可缩放企业计算 (SEC) 环境的理想解决方案,因为它可以在 Microsoft Windows 2000 Datacenter Server 和 2000 Advanced Server 上运行解决方案来提供高水平的可缩放性能。PowerEdge 8450 可用来支持企业应用程序和合并数据中心环境中的服务器资源。 PowerEdge 8450最多可提供 8 个 700 MHz 或 900 MHz 的 Intel Pentium III Xeon 处理器(具有 1 MB 和 2 MB 可用高速缓存),以获得最大的可缩放性。
PowerVault 650FPowerVault 650F 提供了高可用的、可缩放的光纤通道 RAID 存储系统,该系统:
PowerVault 630FPowerVault 630F 是 PowerVault 650F 的扩充口, 它提供:
附录 B:硬件/软件配置测试是在以下环境中进行的: 服务器 1 个 Dell PowerEdge 8450 8 个 Intel® Pentium® III Xeon™ 处理器 (700 MHz) 32 GB 的 RAM 8 个 Qlogic QLA2200 PCI 主机总线适配器 4 个 Dell|EMC2 FC4700 DPE,每个具有 10 个 32.9 GB、10000 RPM 磁盘和 512 KB 的读-写高速缓存 12 个 Dell|EMC2 FC4700 DAE,每个具有 10 个 32.9 GB、10000 RPM 磁盘 总磁盘空间 = 5 TB-(160) 32.9 GB,10000 RPM 磁盘 操作系统 Microsoft Windows 2000 Datacenter Server,Build 5.00.2195,Service Pack 1 数据库服务器 Microsoft SQL Server 2000 Enterprise Edition,Build 2000.80.194.0 SP1 附录 C:PACE 工作负荷模拟配置
附录 D:测试配置
附录 E:磁盘配置针对于单个实例的磁盘配置 1:
LUN 00、LUN 01 和 LUN 02 通过两个主机总线适配器 (HBA) 连接至服务器。 针对 8 个实例中每个实例的磁盘配置 2(每个实例的相同 LUN 上的所有数据文件和日志文件):
每个实例具有一个 LUN,并且每个 LUN 都通过一个 HBA 连接至服务器。 针对 8 个实例中每个实例的磁盘配置 3(每个实例的相同 LUN 上的所有数据文件和日志文件):
每个实例都具有一个 LUN 组(三个 LUN),都通过一个 HBA 连接至服务器。 针对 16 个实例中每两个实例的磁盘配置 4(每个实例的相同 LUN 上的所有数据文件和日志文件):
每两个实例共享一个 LUN 组(三个 LUN),都通过一个 HBA 连接至服务器。 附录 F:针对 8 个实例中每个实例上的 500 个数据库的最佳系统配置
|