�������Ż�ָ��ּ�ڰ������ݿ����Ա�Ϳ�����Ա���� Microsoft® SQL Server™ 2000���Ի����ѵ����ܣ��������ҳ���ɹ�ϵ���ݿ⣨�����������ݲֿ�����ݿ⣩���ܵ��µ�ԭ��ָ�ϻ������װ�ء������ͱ�д��ѯ�Է��� SQL Server �д洢�������ṩ��ָ��ԭ��������������������˶��ֿ����ڷ������������� SQL Server ���ߡ�
Microsoft SQL Server 7.0 ��������һ���ش�Ľ���һ���ںܴ�̶��Ͽ����������á������Ż������й��������ݿ����档�� SQL Server 7.0 ����֮ǰ����������ݿ����������ķ����ݿ����Ա������ʱ��;��������DZ����ֶ��Ż������������Ի��������ܡ�ʵ���ϣ��ܶྺ�������ݿ��Ʒ������Ҫ�����Ա�ֶ����ú��Ż����ǵ����ݿ����������������ͻ����� SQL Server ����Ҫԭ��SQL Server 2000 ���� SQL Server 7.0 �춨�ļ�ʵ�����ϸ��ϲ�¥�IJ�Ʒ��SQL Server ��Ŀ���ǣ�ͨ��ʵ�����ݿ����������Ż������� DBA �Զ���ɹ�������ʹ DBA �����ֶ����úͲ����Ż����ݿ�������� ���������Կ����ֶ����ú͵���һЩ sp_configure ѡ����������ݿ����Ա������Ҫ�������������� SQL Server �Զ����ú��Ż����������ֵ���������SQL Server 7.0 �����ѱ��㷺�Ͽ��Ҿ���ʵ��֤���ijɼ���¼��SQL Server 2000 �Դ˷��������������ĸĽ��������в��ϱ仯���������ܻ�����ݿ����ܲ�������Ӱ�죬���ԣ��� SQL Server �����Ż����Ϳ���ʹ���ݿ���������ж�̬��������Ӧ��Щ�仯��
�����Բ�ȡ�����ʩ���������ݿ�����ܡ�SQL Server 2000 �ṩ�˼��ֹ����������������Щ���� ��������
���� SQL Server ���ܹ���
Ӱ�����ܵ�����ѡ������첽 IOSQL Server 7.0 �е��ֶ�����ѡ������첽 I/O �� SQL Server 2000 ���Ѿ�ʵ�����Զ�������ǰ������첽 I/O ����ָ����һ�μ�����������У�SQL Server 7.0 ������ Microsoft Windows NT® 4.0 �� Windows® 2000 ͬʱ�ύ�Ĵ��� I/O �����������Windows �������ֽ���Щ�����ύ������������ϵͳ������������ʵ���Զ�����SQL Server 2000 ���ܹ��Զ�̬��ʽ�Զ�ά����ѵ� I/O �������� ע�� Windows 98 ��֧���첽 I/O������ڸ�ƽ̨�ϲ�֧������첽 I/O ѡ� ���ݿ�ָ�ģ��SQL Server 2000 �����������ݿ⼶��������¼��ʽ�������õĹ��ܡ�ѡ����ģ�ͻ�����ܲ����ܴ��Ӱ�죬������������װ�ع����С��ָ�ģ�������֣�����ȫ��������������־��¼�ġ��͡����������ݿ�Ļָ�ģ�����������ݿⴴ��ʱ��ģ�����ݿ�̳еġ��ڴ������ݿ�֮���Ը�������ģ�͡�
����ḻ�Ĺ���Ա����ʹ������ָ�ģ���������ӿ�����װ�غʹ������������ٶȡ�������������ѡģ�Ͳ�ͬ����ʧ���ݵĿ�����Ҳ������ͬ�� ��Ҫ˵�� ��ѡ��ij�ָֻ�ģ��֮ǰ��������ϸ���ǻ������ķ��ա� ÿ�ָֻ�ģ�����������㲻ͬ����Ҫ���������ѡ��ģ��Ȩ�����ס�Ȩ��Ľ��������ܡ��ռ������ʣ����̻�Ŵ����ͷ������ݶ�ʧ�ı�����ʩ�ȷ�������ۺϿ��ǡ�����ѡ��ָ�ģ��ʱ����Ҫ������¼��������ҵ����������������
������ִ�еIJ�����ͬ��һ��ģ�Ϳ��ܻ����һ��ģ���ʺϡ���ѡ��һ�ָֻ�ģ��֮ǰ���뿼������������Ӱ�졣�±��ṩ��һЩ��������Ϣ��
�йض�ʵ����ע������SQL Server 2000 �л���������һ̨����������� SQL Server �Ķ��ʵ���Ĺ��ܡ�Ĭ������£�SQL Server ��ÿ��ʵ���ᶯ̬�ػ�ȡ���ͷ��ڴ棬�����ʵ���Ĺ������ɵı仯���е������� SQL Server 2000 �ж��ʵ������ÿ��ʵ�����������Զ������ڴ�ʹ����ʱ�������Ż����úܸ��ӡ�������߶˵�ҵ�����ܿͻ�ͨ��ֻ��ÿ̨������ϰ�װһ�� SQL Server ʵ������˶���������˵��ͨ������Ҫ��������ܡ����ǣ����ż����������Խ��Խ��Windows 2000 Datacenter Server ���֧�� 64 GB RAM �� 32 �� CPU��������Щ���������У����ܻ���ֶԶ��ʵ����������Щ������չ�ڴ�֧�ֵ�ʵ����Ҫ�ر��ע�� ��չ�ڴ�֧��һ������£�SQL Server 2000 �������Ҫ��̬�ػ�ȡ���ͷ��ڴ棬���Թ���Աͨ������Ҫָ��Ӧ��Ϊ SQL Server ��������ڴ档���ǣ�SQL Server 2000 ��ҵ��� SQL Server 2000 ������Ա�������˶�ʹ�� Microsoft Windows 2000 Address Windowing Extensions (AWE) ��֧�֡�������SQL Server 2000 �Ϳ��ԶԸ�����ڴ����Ѱַ������ Windows 2000 Advanced Server ���Լ 8 GB������ Windows 2000 Datacenter Server ���Լ 64 GB��������������չ�ڴ������£����뽫������չ�ڴ��ÿ��ʵ������Ϊ��̬��������ʹ�õ��ڴ档 ע�� ֻ�е������� Windows 2000 Advanced Server �� Windows 2000 Datacenter Server ʱ���ſ�ʹ������ܡ� ʹ�� Windows 2000 ��ע������Ҫ���� AWE �ڴ棬����ʹ���ѷ����� Windows 2000 �ġ��ڴ�������ҳ����Ȩ�� Windows 2000 �ʻ����� SQL Server 2000 ���ݿ����档SQL Server ��װ�����Զ���Ȩ MSSQLServer �����ʻ�ʹ���ڴ�������ҳѡ��������������ʾ��ʹ�� Sqlservr.exe ������ SQL Server 2000 ��ʵ��������ʹ�� Windows 2000 �ġ�����ԡ�ʵ�ù��� (Gpedit.msc) ����һȨ���ֶ�����������������û��ʻ�������Ļ������ SQL Server ����Ϊ�������оͽ���ʹ�� AWE �ڴ档 ���á��ڴ�������ҳ��ѡ��
Ҫʹ Windows 2000 Advanced Server �� Windows 2000 Datacenter Server �ܹ�֧�� 4 GB ���ϵ������ڴ棬���뽫 /pae �������ӵ� Boot.ini �ļ��С� �����ڴ治���� 16 GB �ļ�������������� Boot.ini �ļ���ʹ�� /3gb ���������ʹ Windows 2000 Advanced Server �� Windows 2000 Datacenter Server �ܹ������û�Ӧ�ó���ͨ�� 3 GB �������ڴ�������չ�ڴ����Ѱַ������Ϊ����ϵͳ�������� 1 GB �����ڴ档 ���������ϵ������ڴ泬�� 16 GB���� Windows 2000 ����ϵͳ��������Ҫ 2 GB �����ڴ��ַ�ռ�����ϵͳ��������ˣ���ֻ��֧�ֽ� 2 GB �����ַ�ռ�����Ӧ�ó����������������ڴ泬�� 16 GB ��ϵͳ��һ��Ҫ�� Boot.ini �ļ���ʹ�� /2gb ������ ע�� ���������ʹ���� /3gb ������Windows 2000 ������ 16 GB ���ϵ��κ��ڴ����Ѱַ�� ʹ�� SQL Server 2000 ��ע������Ҫʹ SQL Server 2000 ��ʵ���ܹ�ʹ�� AWE �ڴ棬��ʹ�� sp_configure ���������� awe ѡ�Ȼ���������� SQL Server �Լ��� AWE������ AWE ֧�ֻ��� SQL Server �������������ã����� SQL Server �ر�ǰһֱ��������״̬�����ԣ��� AWE ����ʹ��״̬ʱ��SQL Server ��ͨ���� SQL Server ������־���͡������� Address Windowing Extension����Ϣ��֪ͨ�û��� �������� AWE �ڴ�ʱ��SQL Server 2000 ��ʵ�����ᶯ̬������ַ�ռ�Ĵ�С����ˣ��������� AWE �ڴ沢���� SQL Server 2000 ��ʵ��ʱ���������������ڴ������÷�ʽ��ͬ��������������֮һ��
���� 32 GB ϵͳ�Ϸ��� SQL Server AWE �ڴ�ʱ��Windows 2000 ����������Ҫ 1 GB �����ڴ������� AWE����ˣ���������� SQL Server ��ʵ��ʱ�������� AWE����������Ҫʹ��Ĭ�ϵ����������ڴ����ã���Ӧ���������� 31 GB ���С�� �йع���ת��Ⱥ���Ͷ�ʵ����ע�������������ʹ�� AWE �ڴ��ͬʱʹ�� SQL Server 2000 ����ת��Ⱥ���������ж��ʵ���������ȷ���������е����� SQL Server ʵ�������������ڴ����õ�ֵ���ܺ�С�ڿ��õ����� RAM �������ڹ���ת�ƣ������뿼���κκ�ѡ���ڵ������� RAM ����С�����������ת�ƽڵ��ϵ������ڴ�ȳ�ʼ�ڵ��ϵ��٣��� SQL Server 2000 ��ʵ��������������������ʱ�õ��ڴ�����ڳ�ʼ�ڵ��ϵ��١� sp_configure ѡ�������жȵijɱ���ֵ��ѡ�� ʹ�����жȵijɱ���ֵѡ���ָ�� SQL Server ������ִ�в��мƻ����õ���ֵ��ֻ�е�Ϊͬһ����ѯִ�д��мƻ���Ԥ�Ƴɱ����������жȵijɱ���ֵ�����õ�ֵʱ��SQL Server ��Ϊ��ѯ������ִ�в��мƻ����ɱ���ָ���ض���Ӳ������ִ�д��мƻ�ʱԤ����Ҫ��ʱ�䣨����Ϊ��λ����ֻ��ԶԳƶദ���� (SMP) �������жȵijɱ���ֵ�� ͨ�������мƻ��Խϳ��IJ�ѯ�����������ϵ����ƿ��Բ�����ʼ����ͬ���Լ���ֹ�ƻ�����Ķ���ʱ�䡣�ڻ��ִ�ж̲�ѯ�ͳ���ѯʱ��ͨ����ʹ�����жȵijɱ���ֵѡ��̲�ѯִ�д��мƻ���������ѯʹ�ò��мƻ������жȵijɱ���ֵ��ֵ������Щ��ѯ����Ϊ�̲�ѯ���Ӷ�ִֻ�д��мƻ��� ����Щ����£���ʹ��ѯ�ijɱ��ƻ�С�ڵ�ǰ�����жȵijɱ���ֵֵ��Ҳ����ѡ���мƻ���������Ϊ�����жȵijɱ���ֵ���ԣ�ʹ�ò��мƻ����Ǵ��мƻ�Ҫ������ȫ�Ż����֮ǰ�ṩ��Ԥ�Ƴɱ��������� ���жȵijɱ���ֵѡ���������Ϊ�� 0 �� 32767 ���κ�ֵ��Ĭ��ֵ�� 5���Ժ���Ϊ��λ������������ֻ��һ�����������������������ϵ��������ѡ���ֵ��ʹ�� SQL Server ֻ��ʹ��һ�� CPU�������������ж�ѡ������Ϊ 1����ô��SQL Server ��������жȵijɱ���ֵ�� ������жȡ�ѡ�� ����ж�ѡ������������ִ�в��мƻ�ʱʹ�õĴ������������ 32 ������Ĭ��ֵ�� 0����ʱʹ�ÿ��õ�ʵ�������� CPU��������ж�ѡ������Ϊ 1 ��ǿ��ȡ�����ɲ��мƻ����������ֵ����Ϊ���� 1 �����֣������������ִ�е�����ѯʱʹ�õ�������������������ֵָ��Ϊ���ڿ��� CPU ���������֣���ʹ�ÿ��õ�ʵ�������� CPU�� ע�� ���δ����ϵ����ѡ�����Ĭ��ֵ�����ڶԳƶദ���� (SMP) ϵͳ�Ͽɹ� SQL Server ʹ�õ� CPU �����ܻ��ܵ����ơ� ������ SMP ����������еķ����������ٸı�����ж�����������ֻ��һ��������������������ж�ֵ�� �����ȼ�������ѡ�� ���ȼ�����ѡ������ָ�� SQL Server �Ƿ�Ӧ���Ը���ͬһ̨��������������̵ĵ������ȼ����С��������ѡ������Ϊ 1��SQL Server ���� Windows ���ȳ����а��� 13 �����ȼ��������С�Ĭ��ֵ�� 0����ʾ���ȼ����� 7�����ȼ�����ѡ��ֻӦ������ SQL Server ר���Ҿ��� SMP ���õļ�����ϡ� ע�� ��������ȼ�������̫�ߣ�����ܻ�ʹ��������ϵͳ�����繦�ܵ���Դ���㣬�Ӷ���ɹر� SQL Server ��ʹ�÷������ϵ����� Windows ��������⡣ ��ijЩ����£���������ȼ���������ΪĬ��ֵ������κ�ֵ�����ܻᵼ���� SQL Server ������־�м�¼����ͨѶ����
���� 17824 ָ���ڳ���д��ͻ���ʱ SQL Server �����������⡣����ͻ�����ֹͣ��Ӧ�����߿ͻ����Ѿ���������������ЩͨѶ�����������������������ġ����ǣ����� 17824 ��һ����ʾ�������⣬������ֻ���������ȼ�����ѡ��Ľ���� �����ù�������С��ѡ�� ���ù�������Сѡ������Ϊ SQL Server �������ڷ������ڴ����õ������ڴ�ռ䡣�������ڴ������� SQL Server ���ݹ������ɺͿ�����Դ�Զ����á���������С�������ڴ������������ڴ�֮�������仯���������ù�������С����˼�ǣ���ʹ�� SQL Server ����ʱ����һ�����̿��Ը�����ʹ�� SQL Server ҳ������ϵͳҲ�����Ի�����Щҳ�� �����Ҫ���� SQL Server ��̬ʹ���ڴ棬�벻Ҫ�������ù�������С���ڽ����ù�������С����Ϊ 1 ֮ǰ���뽫��С�������ڴ������������ڴ�����Ϊͬһ��ֵ��ϣ�� SQL Server ʹ�õ��ڴ������� ����������ϵ����ѡ��ڱ��º���ġ�Ҫ���ӵĹؼ����ܼ�������һ�����ۡ�
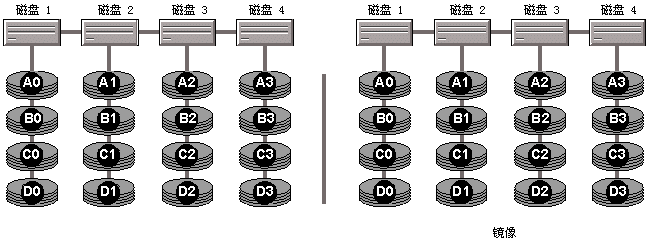
��������õ� SQL Server ��ֻ������ GB ���ݣ����Ҳ��������صĶ�д������Բ��ؿ��Ǵ��� I/O �Լ�ͨ��ƽ��Ӳ����������� SQL Server I/O ���ʵ��������ܵ�������ǣ�Ҫ�������� SQL Server ���ݿ����������� GB ���� TB �����ݣ�����/����Ҫ�ܹ��������صĶ�/д������б�Ҫ������Ӧ�����ã���ƽ����Ӳ����������ĸ��أ��Ӷ����̶ȵ���� SQL Server �Ĵ��� I/O ���ܡ� �Ż������ٶ��������ݿ������Ż���˵������Ҫ�ķ���֮һ�����Ż� I/O ���ܡ���Ȼ��SQL Server Ҳ�����⡣�������� SQL Server �ļ�������㹻�� RAM �������������ݿ⣬���� I/O ���ܽ��ɴ��� I/O ��ϵͳ���� SQL Server ��д���ݵ��ٶ���ȷ���� ��Ϊ�����ٶȡ�I/O �������Ϳ���Ӱ�� I/O ���ܵ��������ز��ϸ��ƣ��������ǽ������Ӧ���Ӵ洢ϵͳ���������������ٶȸ����������֡�Ϊ�˸��õ������������õ����ܣ�����������ѡ��Ӳ����Ӧ��Э��ȷ���������������ܡ� ���DZ���Ҫǿ������˳�� I/O ������ͨ���ֳ�Ϊ�����С�������˳�����˳�� I/O ����֮��IJ��졣���ǻ�ϣ�����ע��Ԥ�����ܶ� I/O ��������������Ӱ�졣 ˳��ͷ�˳����� I/O ���� �б�Ҫ����������Щ��������ڴ����������ĺ��塣ͨ����һ��Ӳ����������һ����������Ƭ��ɡ�ÿ����Ƭ���ṩ���ڶ�ȡ/д������ı��档һ����ж�ȡ/д���ͷ�ı���������Щ��Ƭ֮���ƶ������Ҵ���Ƭ�ı����ȡ���ݻ���������д�����ݡ��� SQL Server ���ԣ��й�Ӳ���������������������Ҫ����Ҫ��ס�� ��һ����ȡ/д���ͷ����صĴ��̱���Ҫ�ƶ����Զ�λ�� SQL Server �����Ӳ����������Ƭ�ϵ�λ�ò��������в�����������ݲ���λ��˳��ֲ���Ӳ����������Ƭ�ϣ���Ӳ����������Ҫ�������ʱ�����ƶ����̱ۣ�Ѱ��ʱ�䣩����ת��/дͷ����ת�ͺ�ʱ�䣩���ҵ����ݡ����밴λ��˳��ֲ�ʱ��������ȫ��ͬ���ڸ�����£������ȫ�����ݶ�λ��Ӳ����������Ƭ��һ���������������ϣ���˴��̱ۺͶ�ȡ/д���ͷ��ִ������Ĵ��� I/O ʱ�ƶ������١� ��˳���˳�����ε�ʱ�����ܴ�ÿ�η�˳��Ѱ����Լ���� 50 ���룬��˳��Ѱ�����Լ��Ҫ�������롣��ע�⣬��Щʱ���Ǵ��¹���ֵ�����ҽ������������ض������仯����˳�������ڴ����ϵķֲ����롢Ӳ����Ƭ������ת���ٶ� (RPM) �Լ�Ӳ���������������������ԡ���Ҫ��һ����˳�� I/O ������������ܣ�����˳�� I/O �ή�����ܡ� �ڶ���һ��Ҫ��ס����д 8 KB ���д 64 KB �����ʱ�伸��һ���ࡣ�� 8 KB ����Լ 64 KB �ķ�Χ�ڣ����̱��Լ���/дͷ���ƶ���Ѱ��ʱ�����ת�ͺ�ʱ�䣩��Ȼռһ�δ��� I/O �����������ʱ��Ĵ֡���ˣ�����ѧ�ǶȽ�������Ҫ���� 64 KB ���ϵ� SQL Server ����ʱ����Ϊ 64 KB �� 8 KB �Ĵ����ٶȻ�����һ������ÿ�δ����������� SQL Server ����ȴ�Ǻ��ߵ� 8 ����������ó��Ծ����ܶ��ִ�� 64 KB ���̴�����������ס��Ԥ���������� 64 KB ���飨���� SQL Server ��չ��������ִ�����Ĵ��̲�������־������Ҳ�Խϴ�� I/O ��Сִ��˳��д�롣Ҫ��ס����Ҫһ���ǣ�����������Ԥ������������ SQL Server ��־�ļ��벻��˳����ʵ������ļ��ֿ�������� SQL Server ���ܡ� ���ݾ��飬�����Ӳ������������˳�� I/O ����ʱ���ṩ�������Ǵ�����˳�� I/O ����ʱ�� 2 ����������Ҫ��˳�� I/O �IJ��������ѵ�ʱ����ִ��˳�� I/O ��������������ˣ�Ҫ�����ܱ�����ܵ������ݿ��г������ I/O ���������ȻӦ��������˳��ִ�� I/O ������������ҳ��ֻ��������������������λ��ǿ��ܻᵼ�³��ַ�˳�� I/O�� Ϊ�˴�ʹִ��˳�� I/O��һ��Ҫ������ֵ���ҳ��ֵ����Ρ����һ�����İ��ŵ�����װ�ز���Ҳ������������������ͨ�����ÿɷָ����ݺ������ķ�����������ʹ�ڴ����ϰ�˳��ֲ����ݡ�һ��Ҫ������ҵ�Զ��ڼ�����ݺ��������Ƿ�����Ƭ��������������Ƭ̫��ʱ��ʹ�� SQL Server �渶��ʵ�ù��������������������й�ִ����Щ�����ĸ�����Ϣ���ڱ��µ��Ժֽ��ܡ� ע�� ��Ϊ������־���������Բ����� 32 KB �Ĵ�С��˳��д����־�ļ��У�������־ͨ��������Ҫ�Ŀ������ RAIDRAID�����۴����������У���һ�ִ洢������ͨ�����ڴ��ڼ� GB �����ݿ⡣RAID �Ⱦ��������ŵ��־����ݴ��ŵ㡣��� RAID �������ʹ������û��ڳɱ������ܺ��ݴ�֮���ṩƽ�⡣����������˽� RAID �������� SQL Server ���ݿ��������������˸��������Լ�ƽ�ⷽ����
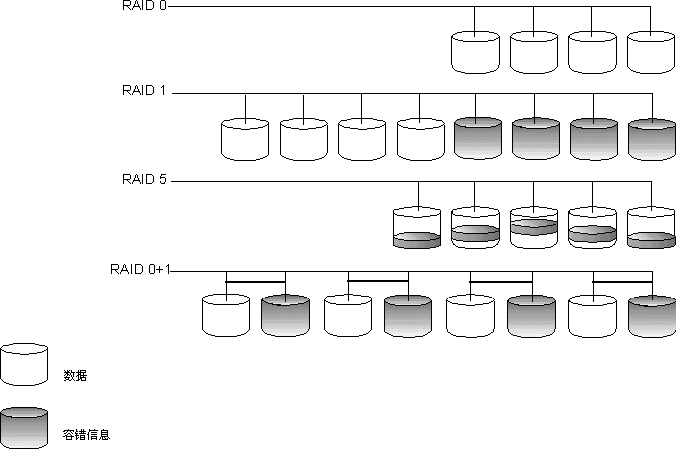
����ͨ������Ϣд����һ�飨��������������ʵ�֡�������о���ʱ��ʧ���������������ͨ�������й��ϵ����������ؽ��������ؽ���ʧ�������ϵ����ݡ������ RAID �����������ṩ�� Windows NT 4.0 �� Windows 2000 �Լ� SQL Server ����������¸������������������¾���Ĺ��ܡ������� RAID ϵͳͨ���������ܹ����Ȳ�Ρ����������� ������һ���ŵ㣺�����Ҫ�ݴ�������ʵ�ֵ������� RAID ѡ������ѵġ����мǣ�SQL Server ÿ��д�뾵��ʱ������ִ���������� I/O ���������ھ���ÿһ���ִ��һ�������IJ�������һ���ŵ��ǣ����о����ʵ����żУ�� RAID �ṩ���ݴ����ࡣ�����ܹ�ʹϵͳ������һ���������������Ϻ�������У����ң��ھ����ж����������������й��ϵ�����£�Ҳ�����ܹ�֧��ϵͳ��������ǿ��ϵͳ����Ա�رշ����������ļ������лָ��� �����ȱ���dzɱ��ߡ�����Ĵ��̳ɱ��ǣ�ÿ����Ҫ����������ݵ���������������Ҫһ������������ʵ���Ͼͻ�ʹ�洢�ɱ�����һ�����������ݲֿ���˵���洢��ͨ����������������֮һ��RAID 1 ������ RAID 0+1����ʱ���� RAID 10 �� 0/1������ͨ������ʵ�ֵġ� ��żУ��������ʵ�ֵģ������й�д����̵����ݵĻָ���Ϣ��Ȼ����żУ����Ϣд�빹�� RAID ���е����������������ij���������������ϣ�һ�����������ͻ���� RAID ���У���ͨ����ȡд�������������ϵĻָ���Ϣ����żУ�飩��ʹ����Щ��Ϣ�������ɹ����������ϵ����ݣ��Ӷ��ָ������������ϵ����ݡ�RAID 5 ������ͨ����żУ��ʵ�֡� ��żУ����ŵ��dzɱ��͡�Ҫ�� RAID 5 ����������������������ֻ��Ҫ��������һ������������żУ����Ϣ����ȷֲ��ڲ��� RAID 5 ���е������������ϡ���żУ���ȱ�������ܺ��ݴ������������ڼ����д����żУ��ʱ���������ɱ������ RAID 5 ����ÿ��д�붼��Ҫ�ĸ����� I/O ������������ֻ���������� I/O �������������żУ��Ķ�ȡ I/O �����ɱ�����ͬ�ġ����ǣ���ȡ����ͨ���ᷢ�����й��ϵ��������ϣ��˺��뽫�����ѻ������ұ���ӱ��ݽ�����ִ�лָ����Իָ����ݡ� һ�㾭�飺һ��Ҫ������������������Ͻ�������������ʵ�ֿɿ��Ĵ��� I/O ���ܡ�ϵͳ����������ָ�����ض��� RAID �������Ƿ���ڴ��� I/O ƿ��������������Ҫ���Ӵ��̣������������·ֲ��� RAID ���к�/��С�ͼ����ϵͳ�ӿ� (SCSI) ͨ���У���ƽ����� I/O ������ȵ�������ܡ� Ӳ�� RAID ���������ػ����Ч�� ����Ӳ�� RAID ����������ij����ʽ�Ķ�ȡ��/��д�뻺�档�� SQL Server ��˵�����ֿ��õĻ��湦�ܿ���������ǿ������ϵͳ��Ч���� I/O ����������Щ���ڿ������Ļ�����Ƶ�ԭ���ǣ��ռ��������������� (SQL Server) �Ľ�С�IJ����п����Ƿ�˳��� I/O ����Ȼ�����ڼ������ڽ����������� I/O ����ϳ�һ���������������� I/O �Ϳ����γɽϴ� (32�C128 KB) �����п�����˳�� I/O �����Ա㷢�͵�Ӳ���������� ��˳��ĺͽϴ�� I/O ����������������ܣ�����ѭ��һԭ����Ϊ��Ӳ���������ܹ��� RAID �������ṩ�̶����� I/O ������£����������ڲ�������Ĵ��� I/O ��������Ӳ��ÿ���ܹ���������� I/O�������� RAID �������Ļ��湦���ж�ô���棬������Ϊ RAID ����������ʹ����ij����֯��ʽ�����д���� I/O ���Ӷ��ܹ������ܳ�ֵ����úû���Ӳ�̶̹��� I/O ���������� ��Щ RAID ������ͨ����ij����ʽ�ĺ�Դ���������ǵĻ�����ơ����ֺ�Դ�������ڶϵ�ʱ����д�뻺���е����ݱ���һ��ʱ�䣨�����Ǽ��죩��������ݿ������Ҳ�ɲ���ϵ�Դ (UPS) ֧�֣��ڶϵ�ʱ��RAID ���������и����ʱ��ͻ��Ὣ����ˢ�µ������С���Ȼ�������� UPS ��ֱ��Ӱ�����ܣ�������ȷ����Ϊ RAID �������������ṩ�����ܸĽ��ṩ������ RAID ���� ������������ RAID �ĸ��������У�RAID 1 �� RAID 0+1 �ṩ��ѵ����ݱ�����������ܣ����Ǿ�����Ĵ��̶��Ի���Ҫ����ijɱ�����Ӳ�̳ɱ�������������ʱ���ͼ�����ܺ��ݴ����ԣ�RAID 1 �� RAID 0+1 �����ѡ�� RAID 5 �ijɱ��� RAID 1 �� RAID 0+1 �ͣ��������ṩ���ݴ���д�����ܽϲRAID 5 ��д�����ܴ�Լֻ�� RAID 1 �� RAID 0+1 ��һ�룬������Ϊ RAID 5 ��ȡ��д����żУ����Ϣ��Ҫ����� I/O�� ʹ�� RAID 0 ��ʵ����Ѵ��� I/O ���ܣ�����������û���ݴ�����������Ϊ RAID 0 ���ṩ�ݴ����������Ծ���Ӧ�������������������У�Ҳ�����齫�����ڿ��������С�RAID 0 ͨ��ֻ���ڻ��������ԡ� ���� RAID ���п�������ͨ������Ӳ���������ṩ RAID 0+1���ֳ��� RAID 1/0 �� RAID 10��ѡ�RAID 0+1 ��һ�ֻ�� RAID ����������ڽϵͼ��𣬸ÿ���������ͨ�� RAID 1 �����������е����ݡ��ڽϸ��������� RAID 0 һ���������������������е��������ϡ���ˣ�RAID 0+1 �ṩ���ı������������ܣ�������������Ϊ��Щ�������;�������� RAID ���������й������������Ƕ��� Windows �� SQL Server �����ġ�RAID 1 �� RAID 0+1 ֮���������Ӳ�������������ϡ����ڸ����Ĵ洢����RAID 1 �� RAID 0+1 ��Ҫ��ͬ���������������й��� RAID 0+1 ��ʽʵ���ض� RAID �������ĸ�����Ϣ�����������ÿ�������Ӳ����Ӧ����ϵ�� ����IJ�ͼ��ʾ�� RAID 0��RAID 1��RAID 5 �� RAID 0+1 ֮�������
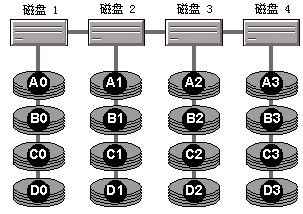
ע�� ������IJ�ͼ�У�Ϊ�������൱���ĸ����̵����ݣ�RAID 1���� RAID 0+1����Ҫ�˸����̣��� Raid 5 ֻ��Ҫ������̡�һ��Ҫ��ѯ���Ĵ洢����Ӧ�̣����˽��й������ض��� RAID ʵ�ֵĸ�����Ϣ�� 0 �� ��Ϊ�ü���ʹ����Ϊ�������Ĵ����ļ�ϵͳ�������ֽ��������������������ݱ����ֳɶ���鲢���̶�˳��ֲ��������е����д����ϡ�RAID 0 ����������ֲ�����������ϣ��Ա����ͬʱ������ִ����Щ�������Ӷ������˶�ȡ/д�����ܡ�RAID 0 ������ RAID 5������ RAID 5 ���ṩ�ݴ����ܡ� ����IJ�ͼ��ʾ���� RAID 0��
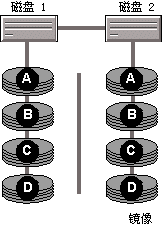
1 �� ��Ϊ�ü���ʹ����Ϊ���Ĵ����ļ�ϵͳ�������ֽ����������̾����̾�����ṩһ������ѡ������ȫ��ͬ�����ั����д�������̵��������ݶ���д�뾵����̡�RAID 1 �ṩ���ݴ����ܣ�����ͨ�����ԸĽ���ȡ���ܣ����ǿ��ܻή��д�����ܣ�������IJ�ͼ��ʾ���� RAID 1��
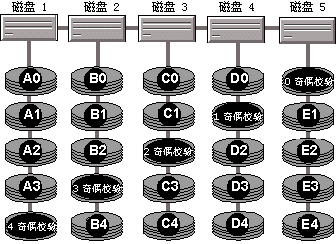
2 �� �ü���ͨ��ʹ�ý���żУ��ֲ������д����ϵľ����������������ࡣ�������ô����������Խ�һ���ļ��ֳɶ���ֽڲ������ļ��ֲ�����������ϡ��뾵�� (RAID 1) ��ȣ��ò����ڴ��������ʺͶ�ȡ/д�����ܷ���ֻ�����˺�С�ĸĽ���RAID 2 �������� RAID ����Ч�ʸߣ�ͨ����ʹ������ 3 �� �ü���ʹ���� RAID 2 ��ͬ�����������������Ǿ�������ֻ��һ������������żУ�����ݡ����̿ռ��ʹ����������ݴ��̵��������졣RAID 3 �ڶ�ȡ/д�����ܷ����ṩһЩ�Ľ���RAID 3 Ҳ����ʹ�á� 4 �� �ü���ʹ�õ��������ݿ��α� RAID 2 �� RAID 3 ��öࡣ�� RAID 3 һ������������ֻ��һ������������żУ�����ݡ������û�������������ݷֿ���RAID 4 �������� RAID ����Ч�ʸߣ�ͨ����ʹ�á� 5 �� �ü����ֳ���������żУ������������������������õIJ��ԡ��� RAID 4 ���ƣ����������Դ����ʽ�������������еĴ����ϡ���֮ͬ�������������д���֮��д����żУ��ķ�ʽ����������ͨ����żУ����Ϣ�ṩ�����ݺ���żУ����Ϣ���ڴ������������У�������������Ϣ����λ�ڲ�ͬ�Ĵ����ϡ�����̾��� (RAID 1) ��ȣ�������żУ������������ṩ���õ����ܡ����ǣ���������Ա��ʧʱ�����磬�����̷�������ʱ������ȡ���ܻ��½���RAID 5 ����õ� RAID ����֮һ������IJ�ͼ��ʾ���� RAID 5��
Level 10 (1+0) �ü����ֳ��������������ľ��ü���ʹ���������Ĵ������У����������־�����һ����ͬ�����������̡����磬��ʹ���ĸ����̴���һ�������������С�Ȼ���������Ĵ�������ʹ����һ�飨�ĸ����������Ĵ��̽��о���RAID 10 �ṩ���������������������洦�Լ���������Ĵ������ࡣ�����е� RAID �����У�RAID 10 �ṩ�Ķ�ȡ/д��������ߣ�������ʹ�õĴ����������������������������IJ�ͼ��ʾ���� RAID 10��
���� RAID ��չ ʹ�øù��ܿ����� SQL Server ��������������¶�̬�ظ����� RAID �������Ӵ��̡����ӵĴ������������Զ����ɵ� RAID �洢���С����Ӵ����������ķ����ǣ������ǰ�װ������Ϊ�Ȳ����������ۻ��Ȳ�β�۵�����λ�á�����Ӳ����Ӧ�̶��ṩ���ܹ�ʵ�ָù��ܵ�Ӳ�� RAID �����������ݻ���ȵ������������������������ӵ���������֮����ȵ����½��������������Ҳ���Ҫ�ر� SQL Server �� Windows�� ������ͨ���ڴ������к��е��Ȳ�β���б�����λ�����øù��ܡ���� SQL Server ������ I/O �����ʹ RAID ���и������أ����������� RAID ����������� Windows ���������̷��Ĵ��̶��г�����ָʾ�����������Ҫ�� SQL Server ��������ʱ����һ�������µ�Ӳ����������װ���Ȳ�β���С�RAID �������ὫһЩ���е� SQL Server �����Ƶ���Щ���������ϣ��Ա����ݾ��ȵطֲ��� RAID �����е������������ϡ�Ȼ������������ I/O ����������ÿ��������ÿ�� 75 ����˳��/150 ��˳�� I/O�������ӵ� RAID ���е����� I/O ���������С� ϵͳ�������� RAID ��ϵͳ���������� Microsoft Windows NT® 4.0 ��Ϊ���ܼ��������У����Ի�ȡ��������������������������������Ϣ�������̺��������̵��������ڣ���ϵͳ�������У��������� Windows �������������̷������������������������ Windows ����һ������Ӳ�̵������������ �� Windows NT 4.0 �У�Ĭ������£����ܼ����������д��̼��������Ǵ��ڹر�״̬�ģ���Ϊ���ǿ��ܻ����������Ӱ�졣�� Windows 2000 �У�Ĭ������£��������̼��������ڴ�״̬�������̼��������ڹر�״̬��Diskperf.exe ��һ�� Windows ��������ƿ���ϵͳ�������в鿴�ļ����������͡� �� Windows 2000 �У�Ҫ��ȡ����������洢�������ܼ��������ݣ���������������ʾ���¼��� diskperf -yv��Ȼ�� Enter ������ᵼ�������ռ������������ݵĴ�������ͳ��������������������洢�������ݡ���Ĭ������£�����ϵͳʹ�� diskperf -yd ��������ȡ���������������ݡ� �� Windows 2000 �У�Diskperf.exe ���������ʾ�� diskperf [-y[d|v] | -n[d|v]] [\\computername] ���� (none) ����������ܼ������Ƿ�������״̬����ʶ���õļ������� -y ��ϵͳ����Ϊ�ڼ������������ʱ�������еĴ������ܼ������� -yd �ڼ������������ʱ���������������Ĵ������ܼ������� -yv �ڼ������������ʱ��������������洢���Ĵ������ܼ������� -n ��ϵͳ����Ϊ�ڼ������������ʱ�������еĴ������ܼ������� -nd ���������������Ĵ������ܼ������� -nv �������������Ĵ������ܼ������� \\computername ָ��Ҫ�鿴������Ҫʹ�õĴ������ܼ������ļ������ �� Windows NT 4.0 ���Ͱ汾�У�diskperf �Cy ���ڼ��Ӳ�ʹ�� Windows NT ���� RAID ��Ӳ������������Ӳ���������� RAID �������ļ��͡���ʹ�� Windows ���� RAID ʱ����ʹ�� diskperf �Cye���Ա�ϵͳ���������� Windows NT ������֮����ȷ�ر��������������������ʹ�� diskperf �Cye �� Windows NT ������ʱ�������������������Ϣ������ȷ����Ӧ�������ԡ�������뽫�����̼�������Ϣ�� Windows NT ���������ʹ�ã���ʹ�� diskperf �Cy�� ��ʹ�� diskperf �Cy ʱ�������̼������ᱻ��ȷ�ر���� Windows NT �������������������̼��������������Ϣ������ȷ����Ӧ�������ԡ� ע�� diskperf ����Ҫ������������ Windows ֮��Ż������ã�Windows 2000 �� Windows NT 4.0 �����Ͱ汾������ˣ��� �йؼ���Ӳ�� RAID ��ע������ ��Ϊ RAID ���������������Ӳ����������Ϊһ�� RAID �����������ṩ�� Windows������ Windows �ͻ����ȡһ����������������ȡ�÷��顣ʵ�ʵײ�Ӳ��������������ճ�����ͼ�ᵼ�����ܼ�����������ܻ��������õ���Ϣ�� ���Ż����ܵĽǶȿ���֪��һ�� RAID ���й����˶�������Ӳ���������Ǻ���Ҫ�ġ���ȷ�� Windows �� SQL Server ����ÿ������Ӳ���������Ĵ��� I/O ������ʱ������Ҫ����Ϣ����ϵͳ����������Ϊ��ij��Ӳ��������������Ĵ��� I/O ���������Ը� RAID ��������֪��ʵ������Ӳ������������ Ҫ���Թ��� RAID ������ÿ��Ӳ���������� I/O ���һ����Ҫ��ϵͳ����������Ĵ���д�� I/O ������ 2��RAID 1 �� 0+1���� 4 (RAID 5)���⽫����ȷ�ظ������͵�����Ӳ����������ʵ�� I/O ����������Ϊ�����������������Ӧ��Ӳ���������� I/O ���������ǣ���Ӳ�� RAID ������ʹ�û��湦��ʱ���˷�������ȷ����Ӳ�������� I/O����Ϊ���湦�ܻἫ���Ӱ���Ӳ�����������е�ֱ�� I/O�� �ڼ��Ӵ��̻ʱ����ý��ص��ע���̶��У�������ÿ�����̵�ʵ�� I/O������ I/O ���ٶ�ȡ�����������Ĵ������ʣ��������������������ġ����˹������������������⣬��û��ʲô������ʩ�����ԣ�����ʵ�ʷ����� I/O ��û��ʲô���塣���ǣ�����ϣ��������ֹ���Ĵ��̶��С������Ĵ��̶��б������� I/O �����⡣��Ϊ Windows ���ܶ�ȡ RAID ���������������������������Ժ��Ѿ�ȷ����ÿ���������̵Ĵ��̶��С�ͨ�������̶��г��ȳ��Բ������۲������������Ӳ�� RAID �������е�������������������ȷ�����µĽ���ֵ������ SQL Server �ļ����ڵ�Ӳ����������Ŭ��ʹ���̶�����������������������ġ� ���� RAID Windows 2000 ֧������ RAID���ڲ�ʹ��Ӳ�� RAID ������ʱ������ RAID ͨ������ϵͳ���ṩ���������������л����ݴ����ܣ����Ӷ��ṩ�ݴ����ܡ�������ʹ�ò���ϵͳ���������� RAID 0��RAID 1 �� RAID 5 ���ܡ������������ݲֿⶼʹ��Ӳ�� RAID�����ǣ�������İ�װ��ģ��Խ�С��������ѡ��ʵ��Ӳ�� RAID����ô������ RAID ���Դ���һЩ���ݷ��ʺ��ݴ�������ŵ㡣 ���� RAID ȷʵ��ռ��һЩ CPU ��Դ����Ϊ Windows �������ͨ����Ӳ�� RAID ������Ϊ�������� RAID ��������ˣ��ڴ�������������ͬ������£�Windows ���� RAID �ṩ�����ܻ��Ӳ�� RAID �ͼ����ٷֵ㣬�����ǵ�ϵͳ��������ʹ����������Ŀ�Ķ��ӽ� 100% ʱ��ͨ������ I/O ƿ���Ŀ����ԣ���û������ RAID ʱ��ȣ�Windows ���� RAID ͨ��������һ��������Ϊ SQL Server I/O �ṩ���õķ������ʹ������ RAID��SQL Server Ӧ���ܹ����õ����� CPU����Ϊ������ͨ���ȴ� I/O ������ɵ�ʱ�����١� ���� I/O ���ж� Ϊ�˸��ƴ洢�ڶ�������������ϵĴ��� SQL Server ���ݿ�����ܣ�һ����Ч�ķ����Ǵ������� I/O ���л��ƣ��û���ͬʱ�Զ���������������ж�д������RAID ͨ��Ӳ��������ʵ�ִ��� I/O ���жȡ���һ����������ʹ�÷�������֯ SQL Server �����Խ�һ�����Ӵ��� I/O ���жȡ�
���ڴ洢�ڶ�������������ϵ� SQL Server ���ݿ⣬��ͨ�������ݽ��з��������Ӵ��� I/O ���ж����������ܡ� ��ʹ�ö��ַ��������з����������Ĵ������������������ô洢��ϵͳ�����̡�RAID ���������� SQL Server ��Ӧ�ø����������û��ƣ����磬�ļ����ļ��顢������ͼ������Ȼ�����ص����һЩ��������صķ������ܣ����ǵ� 18 �¡��� SQL Server 2000 ���ݲֿ���ʹ�÷�����Ҳ�ر�����˷������⡣ �������� I/O ���жȵ�������ǣ�ʹ��Ӳ������������һ��Ϊ���е� SQL Server ���ݿ��ļ���������־�ļ����⣬��������Ӧ���洢�ڴ������Ϸֿ��ҽ�ר������־�ļ��Ĵ����������ϣ��ṩ������������ء��������ؿ�����һ�� RAID ���У����� Windows �г���Ϊһ������������������ʹ�ö�� RAID ���к� SQL Server �ļ�/�ļ��������ýϴ�ijء����Խ�һ�� SQL Server �ļ���ÿ�� RAID �����������������Щ�ļ���ϳ�һ�� SQL Server �ļ��顣Ȼ�ɻ��ڸ��ļ��鹹��һ�����ݿ⣬�Ա㽫���ݾ��ȵطֲ������е��������� RAID �������ϡ��������ط������� RAID �����е�����������֮�仮�����ݣ�����������ȷ�������ݿ���������������жԸ����ݽ��в��з��ʡ� ���������ط������� SQL Server I/O �������Ż�����Ϊ���ݿ����Ա֪��ֻ��һ������λ�ÿɹ��������ݿ���ɼ��ӵ����������صĴ��̶����������Ҫʱ����ó������Ӹ����Ӳ���������Է����ִ����Ŷ�����һ������£���ȷ�����ݿ���Щ���ֵ���������ߣ���ʱʹ�ø÷����������Ż����ܡ���ò�Ҫֻ����Ϊ SQL Server ����Ҫ�� 5% ��ʱ��������һ���̷������� I/O ����������� I/O ������һ���ָ��뵽�ô��̷����ϡ��������������ء�����������ʹ���п��õ� I/O �������� SQL Server ������ʼ�ա����á��������� I/O �����ֲ�����������Ŀ��ô����ϡ� SQL Server ��־�ļ�ʼ�� ��Ӧ�ô������Ϸ�ɢ����ͬ��Ӳ�������������������� SQL Server ���ݿ��ļ��ֿ������ڹ��������æ���ݿ�ļ��䷱æ�� SQL Server ��˵��ÿ�����ݿ��������־�ļ�Ӧ���������ϻ�����룬�Լ����������� ����������־��¼��Ҫ��˳��д�� I/O�����Խ���־�ļ��ֿ�������������� I/O ���ܡ�������־�ļ��Ĵ������������Էdz���Ч��ִ����Щ˳��д���������ǰ������Щ������������ I/O �����жϡ���ʱ������Ҫ�� SQL Server ���������磬���ơ��ع����ӳٸ��£������ж�ȡ������־����Щʵ��ͨ���������ݼ���ʵʱ��װ�ص����ݲֿ��У�����������������ת��ʵ�ù��ߵ�ǰ�ˡ����븴�Ƶ� SQL Server �Ĺ���Ա��Ҫȷ����������������־�ļ��Ĵ��̶����㹻�� I/O �����������Ա㴦����������־����д��֮����Ҫ�����Ķ�ȡ������ �����Ϸָ���ļ����ļ�����Ҫ����Ĺ�����������ʵ֤����Ϊ�˸�����ƶԷdz���ı��������ķ��ʶ����зָ�ʱ����Щ����Ĺ�����ֵ�õġ������г���һЩ�洦��
�йض��������ע�����������ڲ�ͬ��Ӳ����������RAID �������� PCI ͨ�����������ߵ���ϣ�֮��ָ����·���� SQL Server ���
ע�� �� SQL Server 2000 �У�Microsoft ��ǿ�˷ֲ�ʽ������ͼ��ʹ��������ͼ���Դ����������ݿ⣨ͨ��������չ�����������ݿ�Ὣ��Դ���ɺ� I/O ��ֲ�������������ϡ��������ݿ�����ijЩ�߶������������� (OLTP) Ӧ�ó����ǽ��鲻Ҫʹ�ø÷�����������ݲֿ������ ʹ��Ӳ�� RAID ��������RAID �Ȳ�������������� RAID ��չ���ܿ�������ʵ�ֶ� SQL Server I/O ��������ָ�����ķ��������� RAID ���������õ����� RAID ͨ����������ͬ������������ͬ����Ӧ����ÿ�� RAID ͨ�����ӵ�һ�������� RAID �Ȳ�λ����Ա����������� RAID ��չ���ܣ������ͨ�� RAID ������ʹ�øù��ܣ������Windows ���������̷�������ÿ�� RAID ��������������� SQL Server �ļ��������֪�� I/O ʹ��ģʽ�ڲ�ͬ�� RAID ����֮�䱻�ָ����� ʹ���������ã��п��ܽ���ÿ���������Ĵ��̶���������һ����ͬ�� RAID ͨ��������������������������ij�� RAID �������������������л����֧������ RAID ��չ���ܣ����һ��������Ȳ��Ӳ���������IJ�ۣ���ֻ���� RAID ���������Ӹ������������ֱ��ϵͳ����������� RAID ���еĴ��̶����Ѿ��ﵽ�ɽ��ܵij̶ȣ����� SQL Server �ļ�������������������ɽ���� RAID ���еĴ��̶������⡣������� SQL Server ����ʱ��ɡ� ����������־ ά��������־�ļ��Ĵ洢�豸Ӧ�����������������ļ����ڵ��豸�ֿ��������������ݿ�ָ�ģ�����ò�ͬ����������»�Ȳ��������豸��ֲ�����־�������������������Ϊ����ͬһ���豸����Ҫִ�еIJ���������ͬһ��������Դ���������װ�������ڽ���Щ���� I/O ��ֿ��� ���� tempdb SQL Server ����ÿ��������ʵ���ϴ���һ����Ϊ tempdb �����ݿ⣬�Թ��������������ֲ�ͬ��Ĺ�������������Щ���������ʱ�����������Ӳ�ѯ�����ɾۺ���֧�� GROUP BY �� ORDER BY �Ӿ䡢ʹ�� DISTINCT �IJ�ѯ�����봴����ʱ����������ɾ���ظ��У����α꣬�Լ���ϣ���ӡ�ͨ���� tempdb �ָ���Լ��� RAID ͨ���ϣ�����ʹ tempdb I/O �����ܹ������ǵ��������� I/O �������з��������� tempdb ʵ������һ���ݸ������Ҹ���Ƶ�������� RAID 5 ���� tempdb �����Ǻõ�ѡ�� RAID 1 �� 0+1 �ṩ�����ܸ��á���Ȼ Raid 0 ���ṩ�ݴ����ܣ������Կ��ǽ������� tempdb����Ϊÿ�������������ݿ������ʱ������������ tempdb��RAID 0 ʹ�����ٵ�����������Ϊ tempdb ��������ѵ� RAID ���ܣ��������������н� RAID 0 ���� tempdb ʱ��Ҫ�Ĺ����ǣ�������������������������� tempdb �������������ֹ��ϣ��Ϳ���Ӱ�쵽 SQL Server �Ŀ����ԡ������ tempdb ���ھ߱��ݴ������� RAID �����ϣ��Ϳ��Ա�����һ�㡣 Ҫ�ƶ� tempdb ���ݿ⣬��ʹ�� ALTER DATABASE ��������� tempdb ������� SQL Server ���ļ����������ļ�λ�á����磬Ҫ�� tempdb �Լ���֮���������־�Ƶ����ļ�λ�� E:\mssql7 �� C:\temp����ʹ���������
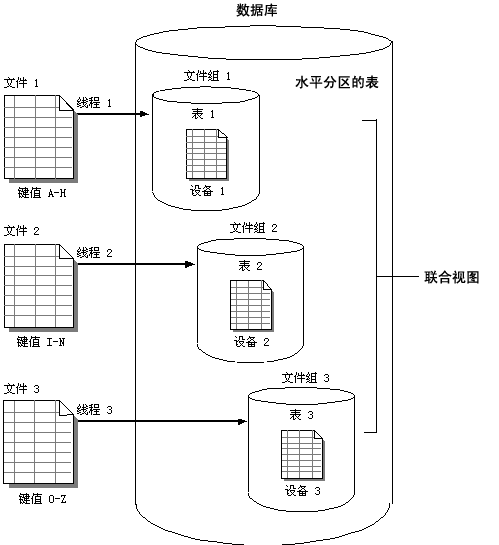
���û����ݿ���ȣ�master ���ݿ� msdb ��model ���ݿ������������к���ʹ�ã���ˣ��ڿ����Ż� I/O ����ʱ��ͨ�����ؿ������ǡ�master ���ݿ�ͨ��ֻ���������µ�¼�����ݿ⡢�豸������ϵͳ���� ���ݿ���� ����ʹ���ļ���/���ļ�������ݿ���з������ļ���ֻ��Ϊ����Ŀ�Ķ�������������ļ������һ����������ϡ�һ���ļ������Ƕ���ļ���ij�Ա������������text��ntext �� image ���ݶ�������һ���ض����ļ���������������˵���������е�ҳ���ǴӸ��ļ����е��ļ��з�������ġ���������������͵��ļ��顣 ���ļ��� ���ļ�������������ļ��Լ�δ�ŵ���һ���ļ����е����������ļ���ϵͳ��������ҳ���Ǵ����ļ������ġ� �û�������ļ��� ���ļ�����ʹ�� CREATE DATABASE �� ALTER DATABASEfilegroup ����е� FILEGROUP �ؼ��ֻ����� SQL Server ��ҵ�������е������Ի�����ָ�����κ��ļ��顣 Ĭ���ļ��� Ĭ���ļ�������ڴ���ʱδָ���ļ�������б���������ҳ����ÿ�����ݿ��У�ÿ��ֻ����һ���ļ�����Ĭ���ļ��顣���δָ��Ĭ���ļ��飬�����ļ������Ĭ���ļ��顣 �ļ����ļ�����ڿ������ݺ�������λ���Լ������豸������������á����൱һ���ְ�װ�����ļ����ļ�������һ�ֱ����ݿ����ȸ�ϸ�Ļ��ƣ��Ա�����ǵ����ݿⱸ��/�ָ����Խ��и���Ŀ��ơ� ˮƽ���������� ˮƽ������һ�����ָ�ɶ������ÿ������������ͬ��������������������١������Ա�����ˮƽ����Ҫ���ݷ������ݵķ�ʽ����������һ�㾭�飬�ڶԱ����з���ʱ��Ӧ��ʹ��ѯ���õı��������١����������ڲ�ѯʱ�����ϲ����� UNION ��ѯ�ͻ���࣬�Ӷ���Ӱ�����ܡ� ���磬�ٶ���ҵҪ��涨������Ҫ��ʮ�������Ϲ������������ݴ洢���������ݲֿ��������ʵ���С����ǹ�˾ʮ����������������ζ�����ݻᳬ��ʮ���С������ﵽʮ�ڵ��κ����ݹ���������������ѡ����ڣ��뿼��ÿ�����Ƕ������ȥ��ʮ������ݣ�Ȼ��װ������һ������ݡ� ����Աͨ�����õķ����ǣ�����ʮ���������ṹ��ͬ�ı���ÿ�����д��һ������ݡ�Ȼ����Ա����ʮ�����Ļ����϶���һ��������ͼ���Ա��������û������������ݶ�����һ�����С�ʵ���ϲ�����ˡ���Ը���ͼִ�е��κβ�ѯ�����Ż���ֻ����ָ������ݣ�����Ӧ�ı���������������Աȷʵ����˹������������ڣ�����Ա�ܹ������ȷ�ʽ��������ÿ������ݡ�ÿ������ݶ����Ե���װ�ء�������ά������������ݾ�����������ȥ����ͼ����ȥ������ʮ�����ݵı���װ�غ���������ݵ����ݣ�Ȼ�����¶�������ͼ��������ݵ����ݡ� �����ڶ��������������֮������ݽ��з���ʱ��ֻ���ʲ������ݵIJ�ѯ���еø��죬��ΪҪɨ������ݱȽ��١������Щ��λ�ڲ�ͬ�ķ������ϣ�������һ̨���ж���������ļ�����ϣ������Բ���ɨ���ѯ���漰��ÿ�������Ӷ����Ʋ�ѯ���ܡ����⣬ά���������磬�ؽ������ݱ�����ִ���ٶȻ���졣 ͨ��ʹ�÷�����ͼ����������ʾΪһ�����������ڲ�ѯ����ʱ���Բ����ֶ�������Ӧ�Ļ��������������������һ������������ͼ�Ϳ��Խ��и��¡��йط�����ͼ�������Ƶ���ϸ��Ϣ������ġ�SQL Server �������顱��
����Ǿۼ����� ����פ���� B �����ṹ�У�ͨ��ʹ�� ALTER DATABASE ����������һ����ͬ���ļ��飬��Щ�������������ǵ�������ݿ���ֿ����ۼ��������⣩���������ʾ���У���һ�� ALTER DATABASE ����һ���ļ��顣�ڶ��� ALTER DATABASE ���´������ļ���������һ���ļ���
�ڴ������ļ��鼰��������ļ�֮�����ڴ�������ʱָ�����ļ��飬�Ӷ�ʹ�ø��ļ������洢������
SP_HELPFILE �Ὣ�йظ������ݿ����ļ����ļ������Ϣ����������SP_HELP <����> ������������һ�ڣ��ý��ṩ�йر������������ļ����ϵ����Ϣ��
�������ݼ���SQL Server �ھ��ж���������ļ����������ʱ���Բ���ɨ�����ݡ����һ�����ڰ�������ļ����ļ����У�����ԶԸñ�ִ�ж������ɨ�衣ֻҪ��˳�����ij�������ͻᴴ��һ�������߳������ж�ȡÿ���ļ������磬�����ȫɨ���ڰ����ĸ��ļ����ļ����ϴ����ı�������ʹ���ĸ������߳������ж�ȡ���ݡ���ˣ�Ϊÿ���ļ��鴴������ļ���������������ܣ���Ϊ������ʹ�ö������߳�������ɨ��ÿ���ļ���ͬ������ij����ѯ�����Ų�ͬ�ļ����ϵı�ʱ�����Բ��ж�ȡÿ�������Ӷ��Ľ���ѯ���ܡ� ���⣬���е��κ� text��ntext �� image �ж������ڳ����������ļ���������ļ����ϴ����� ���գ��ļ�����ᵼ�²����̹߳��࣬�������´��� I/O ��ϵͳ�г���ƿ������ʱ�ͻ�ﵽ���͵㡣ͨ��ʹ��ϵͳ������������ PhysicalDisk ��������̶��г���������������ȷ����Щƿ����������̶��г������������� 3���뿼�Ǽ����ļ������� Ϊ��ͨ��ʹ�ö���ļ����з���������������������������ܶ�����ݷֲ��������ܶ���������������Ǻ����洦�ġ�Ҫ�����ݾ��ȵطֲ������д����ϣ����������û���Ӳ���Ĵ�����������Ȼ�������Ҫʹ���ļ��齫���ݷֲ������Ӳ���������ϡ� ���в�ѯ����SQL Server ���Զ��Բ��з�ʽִ�в�ѯ�������ͻ���ڶദ�����������ִ�в�ѯ�����Ż���������ϸ��Ϊ����̣߳����̺߳��ڴ�Ŀ�����Ӱ�죩��������һ����ѯ��һ������ϵͳ�߳�ִ�У���������ɸ��Ӳ�ѯʱ�ͻ��ٶȸ��죬Ч�ʸ��ߡ� SQL Server �е��Ż�����Ϊ��ѯ���ɼƻ���ȷ�����ں�ʱ����ִ�в�ѯ��ȷ��ʱ����������������
������� SQL Server �Բ��з�ʽ���в��в��������� DBCC �ʹ������������Է�������Դ��ѹ���ͻ���أ�������ִ�з��صIJ��в�������ʱ�������ܻῴ��������Ϣ�����������������־�о��������й���Դ����ľ�����Ϣ���뿼��ʹ��ϵͳ��������������Щ��Դ�����磬�ڴ桢CPU ʹ���ʺ� I/O ʹ���ʣ����á� �����������л�û�ʱ���벻Ҫ�������д�����ѯ���볢����û�и��ص�ʱ�����ִ��ά����ҵ�����磬DBCC �ʹ�������������Щ��ҵ���Բ���ִ�С����Ӵ��� I/O ���ܡ��۲�ϵͳ���������� Windows NT 4.0 ��Ϊ���ܼ��������еĴ��̶��г��ȣ�ȷ��������Ӳ�̻��ǽ����ݿ����·ֲ�����ͬ�Ĵ����ϡ���� CPU ��ʹ���ʷdz��ߣ������������Ӹ���Ĵ������� ���з���������ѡ����ܻ�Ӱ���ѯ�IJ���ִ�У�
�Ż����ݸ����ڼ�������װ�ػʱ��һ��Ҫ��ס������ʾ�ͷ�����������ִ�е��dz�ʼ����װ�ػ�����������װ�أ���Щ�������ܻ�������ͬ��һ����˵������װ�ظ������������Ը�ǿ����ѡ��ķ������ܻ������������Ƶ����ء���������Ҫ����ѡ�洢���á�������Ӳ�������Ƶȶ���Ӱ��ɹ���ʹ�õ�ѡ� ��ִ�г�ʼ����װ�غ���������װ��ʱ����һЩ��ͬ��Ҫ����Ҫ��ס�����潫��ϸ�����������⣺
ѡ���ʵ������ݿ�ָ�ģ���������ڡ�Ӱ�����ܵ�����ѡ�һ�������������ݿ�ָ�ģ�͡�һ��Ҫ��ס��ѡ�ָ�ģ�Ͷ�ִ������װ�������ʱ����ܻ��кܴ��Ӱ�졣��Щ�ָ�ģ����Ҫ���ƽ�д����������־�е�����������Ϊ��������־ִ��д����������ϻ�ʹ�������ɼӱ���������dz���Ҫ�� ��־��¼����С��־��¼���������Ʋ��� ��ʹ����ȫ�ָ�ģ��ʱ����ij������������װ�ػ��ƣ������������ۣ�ִ�е����в����в�������¼��������־�С����ڴ�������װ�أ�����ܻᵼ�¿������������־��Ϊ�˰�����ֹ������־�Ŀռ䲻�㣬��ִ����С��־��¼���������Ʋ�����������־��¼����������־��¼��ʽִ�д��������Ʋ���Ϊ���������Ʋ�����һ������ָ������ȡ���ڴ������������漰�������ݿ�ͱ���״̬����������������е�����������������־��¼�Ĵ��������ƣ�
�κβ����������������� SQL Server ʵ���н��еĴ��������ƽ���ȫ��¼������ ��ִ�г�ʼ����װ��ʱ��Ӧ�������ڡ���������־��¼�ġ����ָ�ģ�������С�������������װ�أ�ֻҪ���ݶ�ʧ�Ŀ����Ժܵͣ��Ϳ���ʹ�á���������־��¼�ġ�ģ�͡���Ϊ�������ݲֿ�����϶���ֻ���Ļ����������������٣����Խ����ݿ�ָ�ģ������Ϊ����������־��¼�ġ���������κ����⡣ ʹ�� bcp��BULK INSERT ����������� APISQL Server �ڲ������������ƣ���������������ƶ����ݵ�����һ�������� bcp ʵ�ù��ߡ��ڶ��������� BULK INSERT ��䡣bcp ��һ��������ʾ��ʵ�ù��ߣ����Ƚ����ݸ��Ƶ� SQL Server ���ִ����и������ݡ��� SQL Server 2000 �У�bcp ʵ�ù������� ODBC ����������Ӧ�ó����̽ӿ� (API) ���±�д�ġ�bcp ʵ�ù��ߵ����ڰ汾��ʹ�� DB-Library ���������� API ��д�ġ� BULK INSERT �� SQL Server ������ Transact-SQL ��䣬�����ɴ����ݿ����ִ�С��� bcp ��ͬ���ǣ�BULK INSERT ֻ�ܽ��������� SQL Server �С������ܽ������Ƴ���ʹ�� BULK INSERT ��һ���ô����ڣ�������ʹ�� Transact-SQL ��佫���ݸ��Ƶ� SQL Server ��ʵ���У��������˳�������ת��������ʾ���С� ������ѡ���Ǵ��������� API������Աͨ���Ը�ѡ��ܸ���Ȥ��������Щ API������Ա���ܹ�ʹ�� ODBC��OLE DB��SQL-DMO ������������ DB ���Ӧ�ó�������������Ƴ� SQL Server�� ������Щѡ�ʹ���ܹ�����������С���п��ơ�������ʹ�õ���С�������ݣ��������ϰ����ָ����������С�Խ��лָ������δָ����������С���� SQL Server ������Ҫװ�ص�����Ϊһ���ύ�����磬�����Խ� 1,000,000 ��������װ�ص�ij�����С��������ڴ������ 999,999 �к�ͻȻ�ϵ硣���������ָ�ʱ������Ҫ�����ݿ��лع�������� 999,999 �У�Ȼ���ٳ�������װ�����ݡ�������ͨ������������Сָ��Ϊ 10,000 ������ʡ�Լ��Ļָ�ʱ�䣬�����������Ѿ��� 1 �� 990,000 ���ύ�����ݿ��У���˽�ֻ��ع� 9,999 �У������� 999,999 �У���ͬ�������δָ����������С������ӵ� 1 ����������װ�ش�����������װ�����ݡ��������������Сָ��Ϊ 10,000 �У���ֻ��ӵ� 990,001 ����������װ�ش�����������Ч���ƹ����Ѿ��ύ�� 990,000 �С� ����������Ϊbcp ʵ�ù��ߺ� BULK INSERT ������ TABLOCK ��ʾ������ʾ�����û�ָ��Ҫʹ�õ�������Ϊ��TABLOCK ָ���ڴ��������Ʋ��������н����ô��������±�������ʹ�� TABLOCK ���Լ��ٱ��϶��������ã��Ӷ��Ľ����������Ʋ��������ܡ�����Ե�������������װ��ʱ���������зdz���Ҫ�ĺ��壨������һ�����ۣ��� ���磬Ҫ�� Authors.txt �����ļ��е����ݴ��������Ƶ� pubs ���ݿ��е� authors2 ���У���ָ��������������������������ʾ��ִ�У�
���ߣ������ԴӲ�ѯ���ߣ��� SQL ��ѯ����������ʹ�� BULK INSERT ������������������ݣ���������ʾ��
���δָ�� TABLOCK�����Ƕ��ڱ��� table lock on bulk load ѡ������Ϊ on������Ĭ��������ʹ���м������� table lock on bulk load ѡ���� sp_tableoption ����һ��ʹ�ã�Ҳ�������ô�����װ�ز��������б���������Ϊ��
ע�� ���ָ���� TABLOCK ��ʾ�����ڴ�����װ�ع����У��������ʹ�� sp_tableoption ���������á� ����װ����������װ�� �� �Ƿ����� ʹ�� SQL Server �е���һ����������װ�ػ��ƣ������Խ����ݲ���װ�ص�һ���Ƿ������С�����ͨ��ͬʱ���ж������װ������ɵġ��ڿ�ʼװ��֮ǰ����Ҫ��Ҫ����װ�ص����ݲ�ֳɶ�������ļ������������� API ������Դ����Ȼ��ͬʱ�������еĶ���װ�ز������Ա㲢��װ�����ݡ� ���磬��������ҪΪ��ȫ���ĸ����������ķ���˾װ�غϲ������ݿ⣬ÿ������ÿ���¶�����ĸ��ͻ����ʵ��ϵı���ʱ�䣨Сʱ�������ڴ��ͷ�����֯������ܱ�ʾ��Ҫ�ϲ������������ݡ�������ĸ�����������ֱ��ṩ�����ļ��������ʹ��������ܵķ��������ĸ��ļ�ͬʱװ�ص�һ�����С� ע�� ���д����IJ����̣߳�װ�أ���������Ӧ���� SQL Server �Ŀ��ô��������� ����IJ�ͼ˵���˶ԷǷ��������еIJ���װ�ء�
����װ�أ�ˮƽ���������� �����ص�������ʹ��ˮƽ���������������װ�ص��ٶȡ�����һ���У����������˽����ݴӶ���ļ�װ�ص�һ�����Ƿ��������С�����Ա�����ˮƽ����������Լ����豸�������Ӷ��л���������ݵ������Բ�����װ�ع��̡���Ȼ��ͼ��ʾ��������װ�ص��˱��IJ�ͬ�����У��������ı������ܲ�ȷ���������װ���е����������߳���ͬʱ�����ģ�Ϊ�ñ���ȡ����չ�������Ϳ��ܻ��ǻ��״̬�������ݻ�Ϻ��ܵ����ڼ�������ʱ��ʵ��������ܡ������������ݲ��ǰ�������������˳��洢�ģ��Ӷ����ܵ���ϵͳʹ�ò������� I/O �������� �ڸñ����������ɾۼ�����������������⣬��Ϊ���ݻᰴ����˳���롢����˳����������д�����ǣ���ȡ������ɾ���������Լ�������������ݻ�д������һ��dz���ʱ����������������װ��Ԥ����������ݣ���Ϊ����������ֻ�ϵ����Σ��뿼��ʹ���ļ����ڿ��Դ洢�����λ�ñ�����������ռ䡣���లװ��ʹ���ļ��齫��������������ݷֿ��� Ϊ���ڲ������ٶ���һ�����ݲֿ������һ���������������ϡ��κζԸ����ݿⲢ��ִ�е�װ�ز������п��ܵ����Է���������ϣ�״̬�洢��Ӱ�������/����ҳ����ִ�����ֲ������κζ����ݽ����ĵIJ��������������ݱ�ò�������Ϊ�����㴦�����ڵ�Ҫ���û����᳢ܻ�Բ���ִ�г�ʼ����װ�ء���������װ�ء���������������ά�������롢���¡�ɾ���Ȼ�� ����IJ�ͼ��ʾ���ǿ����ļ���Ա�������
װ��Ԥ�����������SQL Server �����ڰ汾�ṩ��һ��ѡ��������ڴ�������ʱ������ָ�� SORTED_DATA ѡ�SQL Server 2000 ȡ�������ѡ������ڰ汾�У�����ѡ��ָ��Ϊ CREATE INDEX ����һ�����ǣ����ܹ��������������������б�������IJ��衣Ĭ������£��� SQL Server �д����ۼ�����ʱ���������ݻ��ڴ�������������Ҫ�� SQL Server 2000 �л��ͬ����Ч�����뿼���ڴ�����װ������֮ǰ�����ۼ�������SQL Server 2000 �еĴ���������ʹ������ǿ������ά�����ԣ������������Ѿ��оۼ������ı������ԸĽ����ݵ������ܣ������ڵ���֮����Ҫ�������������� FILLFACTOR �� PAD_INDEX ������װ�ص�Ӱ��FILLFACTOR �� PAD_INDEX ������Ϊ������������ά������һ���и������ؽ��ܡ����� FILLFACTOR �� PAD_INDEX������Ҫ��ס�ؼ���һ�㣺��������ʱ����������DZ���ΪĬ��ֵ���ã����ܻᵼ�� SQL Server Ϊ�洢���ݶ�ִ�бȱ����������д��Ͷ�ȡ I/O ������������ݲֿ���û�з�������д���������˴�����ȡ����������ˡ�Ҫ�� SQL Server ��һҳ����ҳ������ҳ��д���������ݣ��������ڴ�������ʱָ���ض��� FILLFACTOR��������ṩ���� FILLFACTOR ֵʱָ�� PAD_INDEX�� ��ʼ����װ�ص�һ������װ������ʱ
��װ������֮��
��������װ�ص�һ����
����������ά��ǰ���Ѿ������˷�����Ӳ���豸�� I/O ���������ڣ����ǽ����� SQL Server ���ݺ������ṹ������������η����ڴ����������ϵġ����Ҫ��������֮��������ܣ�������λ���п�����Ӱ�����ݲֿ��һ��������ء� SQL Server �е�����������Ȼ SQL Server 2000 �����˼������������ͣ�������ȫ���������������Ĵ��塣���������Ĵ���ĸ�ʽ�Ǿۼ�������Ǿۼ��������� SQL Server �У����ݿ������Ա����ʹ������������Ҫ���͵�������
��������Ҫ���͵��������������
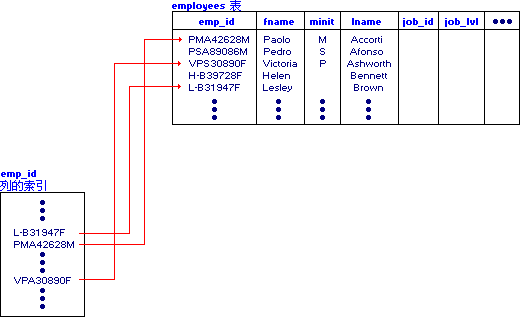
���¸��ڽ���ϸ���������ᵽ��ÿ��������ȫ���������⣩��ȫ��������һ����������������������ݿ�������ͬ�����²��������н��ܡ�������ͼ�� SQL Server 2000 ���������һ����������Ӧ�û��������ݲֿ��û����ر��ע��SQL Server 2000 ���������һ���¹����ǰ�������������� �����Ĺ���ԭ�����ݿ��е�����������ͼ���е���������һ�����У���ʹ����������Ѹ���ҵ���Ϣ�������ض���ȫ�顣��һ�����ݿ��У����ݿ����ʹ�����������ҵ����е����ݣ�������ɨ�������������е�������һ���ִ��Լ����ִ�����ҳ����б������ݿ��е������DZ��е�ֵ�Լ���ֵ�洢λ�ã��ڱ������ڵ��У����б��� ����������Ա��е�һ�л�һ���д��������� B ������ʽʵ�֡���������һ����Ŀ�Լ�һ��������Ӧ�ڱ���ÿһ�е��У�����������B ���������������������������߽����Ӵ�������ʱ��ѡѡ��������洢�����ø����������κ�ǰ���Ӽ������Ը�Ч�������� B �������磬����������ϣ����Ը�Ч������ A��B��C �е�������A��A �� B��A��B �� C�� �����������ݿⲢ�Ż�������ʱ��Ӧ��Ϊ��ѯ��ʹ�õ��д��������������ݵ��������� SQL Server ������ pubs ʾ�����ݿ��У��� employee ���� emp_id ����һ�����������û�ִ�е�������ָ���� emp_id ֵ�� employee ���в�������ʱ��SQL Server ��ѯ������ʶ�� emp_id �е�������ʹ�ø��������������ݡ�����IJ�ͼ˵���˸�������δ洢ÿ�� emp_id ֵ��ָ����о�����Ӧֵ���������ڵ��С�
���ǣ��������ı���Ҫ�����ݿ���ռ�ø���Ĵ洢�ռ䡣ͬ�����������롢���»�ɾ�����ݵ����������ʱ���Լ�ά����������Ĵ���ʱ��������������ƺʹ�������ʱ��һ��Ҫע�⣺�����洦�ȴ洢�ռ�ʹ�����Դ�����µĶ���ɱ�������Ҫ�� ��������SQL Server ��ѯ����������һ����صĹ��ܣ�ִ����������������һ��������ʽ���������ǣ����ǽ����Ժ�������������������������ԭ�����Ҫ�ἰ������������һ������һ�ֿ��ܻ�Ӱ������������Ʋ��Եļ����� �ڶ����ü������ܻ��������Ҫ�����������Ӷ����Դ���ʡ�������ݿ�ռ�õĴ��̿ռ䡣 ��������������ѯ������ʹ�ö�������������ѯ����������ݿ��ѯ�������ڳ��Խ����ѯʱ��ֻʹ��һ��������SQL Server ������ϸ���������ͼ�еĶ��������������Щ�������ɹ�ϣ�������ù�ϣ�������ٸ�����ѯ�� I/O �������ͱ��ʶ��ԣ����������������ɵĹ�ϣ������˸������������ң����ṩ�� I/O �����븲�������ṩ����ͬ�������ݿ��û������У�����Ԥ��ȷ������Ը����ݿ����е����в�ѯ������������Ϊ���ֻ����ṩ�˸��������ԡ�����������£��ϺõIJ�����������о����ᱻ��ѯ���ж��嵥�еķ�Ⱥ����������������������������Ҫ�������������Ρ� �����ʾ��ʹ��������������
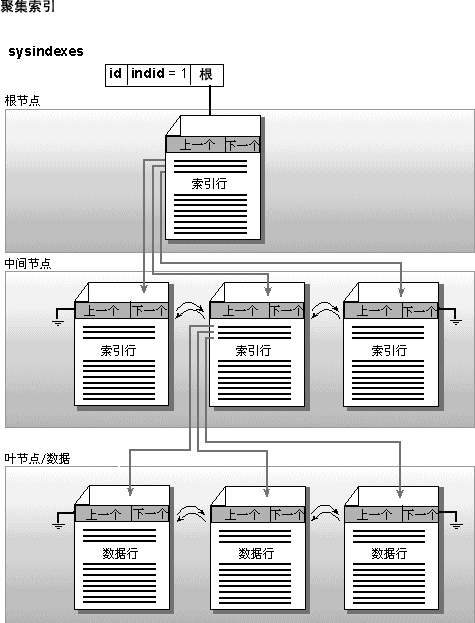
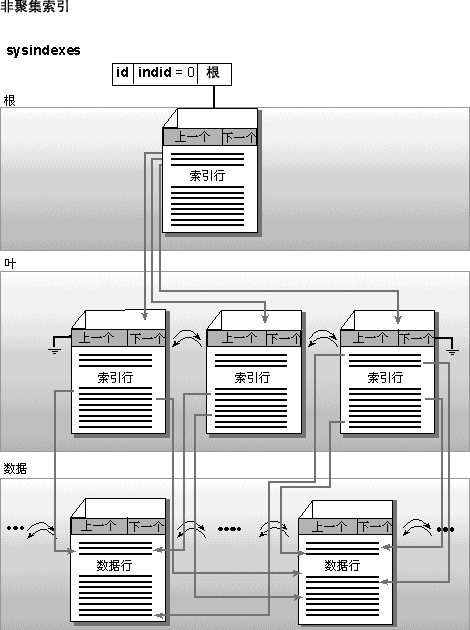
��ִ������IJ�ѯʱ������ͨ�������Щ���������ٸ�Ч�ؽ���ò�ѯ�� SQL Server �е������ṹSQL Server �����е������������϶��ǻ��ڴ洢�� 8 KB ����ҳ�ϵ� B �������ṹ�����ġ�ÿ������ҳ����һ��ҳͷ��ҳͷ�����������С�ÿ�������ж�����һ����ֵ��һ��ָ���м�����ҳ��ʵ�������е�ָ�롣�����е�ÿһҳ�ֱ�����һ�������ڵ㡣B ���Ķ���ڵ㱻�������ڵ㡣�����еĵײ�ڵ㱻����Ҷ�ڵ㡣����Ҷ֮����κ������㶼ͳ��Ϊ�м����ڵ㡣ÿ�������е�ҳ����˫�������б���������һ�� SQL Server ����ҳ������ҳ�Ĵ�С��Ϊ 8 KB��SQL Server ����ҳ�������������ij�й��������ݣ��ı���ͼ�����ݿ��ܳ��⣩�����ı���ͼ�����ݶ��ԣ���Ĭ������£���������ı���ͼ���й������е� SQL Server ����ҳ������һ��ָ�룬��ָ��ָ��һ�������������ı���ͼ�����ݵ� 8 KB ҳ�Ķ����������� B �����ṹ��SQL Server 2000 �е�һ���¹������ܹ���С���ı���ͼ��ֵ�洢�����У�����ζ��С���ı���ͼ���н��洢������ҳ�ϡ���Ϊ���Ա�����ȡ��Ӧ��ͼ����ı�����������Ķ��� I/O�����Ըù��ܿ��Լ��� I/O �������й���ν�������Ϊ�����д洢�ı���ͼ�����Ϣ������ġ�SQL Server �������顱�� �ۼ������ۼ��������ڴӱ��м���һ����Χ������ֵ�dz����á��Ǿۼ����������ڼ����ض��У����ۼ����������ڼ���һ����Χ���С����ǣ�����ÿ����ֻ����ʹ��һ���ۼ���������˰������������ȷ��Ҫ�����������͵������������ܳɹ������ڸ�������һ��������ԭ���ھۼ����� B ���ṹ���ϲ�����Ҷ�㣩�����������ǵķǾۼ���������������֯����ۼ������ĵײ��ɱ���ʵ�� 8 KB ����ҳ��ɡ������������һ�����⣬�Ǿ�������ͼ�Ļ����ϴ����ۼ�����ʱ����Ϊ�����������������ͼ���������ǽ��������ʵ�ʱ������ľۼ�����������Ա������ۼ�����ʱ���ᰴ��������������ͬ��˳���ȡ��ñ����������ݡ�����Щ���ݽ����������������Ͻ����Ǵ�����ݿ⡣��Ϊ�ñ�������ֻ�ܰ���һ��˳�浽�洢���У����ᵼ���ظ������Է���һ���ۼ������ơ� ��ͼ�����˾ۼ������Ĵ洢����
�ۼ����������� �ۼ�������һЩ��Ӱ�����ܵĹ��������� ��ʹ�þۼ��������������������� SQL Server ����ʱ������Ҫָ����ת���ᵼ��Ӳ���ϵ�λ�ÿ��ܲ���˳����ģ�����������������ҳ���������ھۼ�������Ҷ��ʵ���Ͼ��ǹ���������ҳ�� ��ǰ������Ҷ�㣨��ȻҲ��������������ͼ�����ݣ��������ϻᰴ������������ͬ��˳���������ʹ洢����Ϊ�ۼ�������Ҷ���������ʵ�� 8 KB ����ҳ�������������������ݻᰴ���ɾۼ�����ȷ����˳����������ʽ�����ڴ����������ϡ���ͻ��ڸ��ݾۼ�������ֵ�Ӹñ�����ȡ�����У����ٴ��� 64 KB��ʱ����DZ�ڵ� I/O �������ƣ���Ϊʹ�õ���˳����� I/O�����Ǹñ��Ϸ�����ҳ��֣��������������Ϊ��FILLFACTOR �� PAD_INDEX����һ�������ۣ�������Ϊ��ˣ������ڼ���������ʱ��һ��Ҫ���ݽ�����ִ�з�Χɨ��������Ա�ѡȡ�ۼ������� ������ۼ�������������б��밴����������������ͬ��˳������ʹ洢����һ������������壺
ע�� ��Դ��������������ѡ�����ǣ������ɾۼ�������Ȼ�����ɷǾۼ��������������Ͳ�����Ϊ�����ƶ�����Ҫ�������ɷǾۼ��������ڳ�ȥ��������ʱ�����Ȼ��ȥ�Ǿۼ�����������ȥ�ۼ��������������Ͳ���Ҫ�������������� �Ǿۼ������Ǿۼ����������ڸ����ض��ļ�ֵ���Ӵ��� SQL Server ������ȡ����������������ѡ���Ե��С���ǰ�������Ǿۼ��������� 8 KB ����ҳ�γɵĶ�������������ҳ���������ĵײ��Ҷ�������ɸ����������е��������ݡ���ʹ�÷Ǿۼ��������ݼ�ֵ��ƥ����ӱ��м�����Ϣʱ������������� B ����ֱ����������Ҷ���ҵ�����ƥ��������Ҫ���в������������У�ָ��ͻ���ת������ָ����ת���п�����Ҫ��Դ���ִ�з�˳�� I/O ������������������Ҫ����һ�����ж�ȡ���ݣ��������ڱ������������� B ���ܴ�ʱ��������ָ��ָ��ͬһ�� 8 KB ����ҳ���� I/O ���ܵ�Ӱ��ͻ�Ƚ�С����Ϊֻ�轫��ҳ�������ݻ���һ�Ρ���� SQL ��ѯ�漰���÷Ǿۼ�������������������ڶԸò�ѯ���ص�ÿһ�У�������Ҫһ��ָ����ת�� ע�� ����ָ��ÿ����ת���������֮��صĿ�������˷Ǿۼ����������ڴ����ӱ���ֻ����һ�л��еIJ�ѯ���ۼ����������ڴ�����Ҫһϵ���еIJ�ѯ�� ��ͼ˵���˷Ǿۼ������Ĵ洢����ע�⣬���ӵ�Ҷ��ָ���Ӧ������ҳ����ʹ�÷Ǿۼ����������Ǿۼ����������ʱ�����ʱ�����ӵ�ָ����ת�ͻ������������á��йطǾۼ������ĸ�����Ϣ������ġ�SQL Server �������顱��
Ψһ�����ۼ������ͷǾۼ�������������ǿ�Ʊ��ڵ�Ψһ�ԣ������������б��ϴ�������ʱָ�� UNIQUE �ؼ��֡�ȷ������Ψһ�Ե���һ�ַ�����ʹ�� UNIQUE Լ������ͬΨһ������UNIQUE Լ��ǿ��һ�����и�ֵ��Ψһ�ԡ�ʵ���ϣ�UNIQUE Լ���ĸ�ֵ�Զ���������Ψһ������������ǿ�Ƹ�Լ��������Ψһ�Կ�����Ϊ CREATE TABLE ����һ���������Զ���ͼ�¼����ˣ�UNIQUE Լ��ͨ�������ڵ���Ψһ�����Ĵ����� �������ϵ�����SQL Server 2000 �������ڼ������ϴ��������Ĺ��ܡ������ѯ����һ�㷽ʽ�ύ�ģ����һ������ṩ�����У�������Ա��Ը��ֻ��Ϊ������������������ʵ�ʵı����г���������ݣ�������������£�ʹ������ܾͻ�ܷ��㡣�ڴ�����£�ֻҪ�������������������ȫ���������Ϳ���ͨ�����ü������������������������ư����������б���ʽ������ȷ���ԡ���ȷ�����Ҳ���ȡֵΪ text��ntext �� image �������͡� ȷ���� ���Ҫ����ͼ��������ϴ�����������ͼ�ͼ����о������ѵ���û��ȷ���Ե��û����庯�������к���Ҫô��ȷ���ԣ�Ҫôû��ȷ���ԣ�
���磬DATEADD ���ú�����ȷ���ԣ���Ϊ����ͨ���ú���������������������һ���������ֵ����ʼ�շ��ؿ�Ԥ��Ľ����GETDATE û��ȷ���ԡ���Ȼʼ������ͬ�IJ���ֵ���ѵ��� GETDATE ��������ÿ��ִ�е��÷��ص�ֵ������ͬ�� ��ȷ �����������������˵�������б���ʽ�Ǿ�ȷ�ģ�
COLUMNPROPERTY ������ IsPrecise ���Ա��� computed_column_expression �Ƿ�ȷ�� ע�� �κ� float ����ʽ������Ϊ����ȷ��������Ϊ�����ļ���float ����ʽ������������ͼ��ʹ�ã�����������������һ����ͬ�������ڼ����С��κκ���������ʽ���û����庯������ͼ���壬ֻҪ�����κ� float ����ʽ������������ʽ���Ƚϣ���������Ϊû��ȷ���ԡ� ����ڼ����л���ͼ�ϴ�����������ǰ�ܹ���ȷִ�е� INSERT �� UPDATE �������ڿ�����ִ�С��ڼ����е�����������ʱ�����ܻᷢ��������ִ�е���������磬��Ȼ�±��еļ����� c ������������ INSERT ���������ã�
�����Ϊ�ڴ����ñ�֮���ڼ����� c �ϴ�����������ͬ�� INSERT ��佫��ʧ�ܡ�
������ͼ������ͼ��Ϊ��ʵ�ֿ��ٷ��ʶ�������������������ݿ��ڲ�������������ͼ�����κ�������ͼһ����������ͼҲ�����������ṩ��ͼ���ݡ������������ζ�ţ��������Ϊ������ͼ�ṩ���ݵĻ�����������ͼ���ܱ����Ч�����磬������Ϊ��ͼ�ṩ���ݵ��л�ʹ����ͼ��Ч��Ϊ�˱���������⣬SQL Server ֧�ִ������мܹ�����ͼ���ܹ���ֹ�Ա����н����κλ�ʹ��ͼ��Ч���ġ�ʹ����ͼ�����������������ͼ�Զ���üܹ�����Ϊ SQL Server Ҫ���������ͼ���мܹ����ܹ�������˵����������ͼ��������˼�������ܰ�������ͼ������ķ�ʽ���Ļ���������ͼ�����⣬����������ϵ�����һ����������ͼҲ������ȷ���ԡ���ȷ���Ҳ��ð��� text��ntext �� image ���С� ������ͼ�ڻ������ݲ��������µ������Ч����ѡ�ά��������ͼ�ijɱ����ܸ���ά���������ijɱ�������������ݸ���Ƶ����������ͼ���ݵ�ά���ɱ��Ϳ��ܳ���ʹ��������ͼ�������������档 ������ͼ�Ľ������¼����ѯ�����ܣ�
������ͼͨ������Ľ����¼����ѯ�����ܣ�
����Ƶ�������ͼӦ����������������Ϊ����ʹδ�� FROM �Ӿ���ָ��������ͼ���Ż�����Ҳ��ʹ��������ͼ�����������õ�������ͼ���Լӿ������ѯ�Ĵ����ٶȡ����磬������������ͼ�ϴ���������
����ͼ��������ֱ��������ͼ�еIJ�ѯ�����ҿ������������ѯ�����������Ұ��� SUM(Colx)��COUNT_BIG(Colx)��COUNT(Colx) �� AVG(Colx) �ȱ���ʽ�IJ�ѯ�����д����ѯ���ٶȶ�����죬��Ϊ����ֻ�������ͼ�е��������У������ض�ȡ�����е������С� ����ͼ�ϴ����ĵ�һ������������Ψһ�ľۼ�������������Ψһ�ľۼ�����֮�������Դ��������Ǿۼ���������ͼ�ϵ�����������������ϵ���������������ͬ��Ψһ��ͬ���DZ������滻Ϊ��ͼ���� �����ȥ��ͼ����ͼ�ϵ���������Ҳ������ȥ�������ȥ�ۼ���������ͼ�ϵ����зǾۼ�����Ҳ������ȥ���Ǿۼ������ɱ�������ȥ����ȥ��ͼ�ϵľۼ�������ɾ���洢�Ľ�������Ż������ָ��Ա���ͼ�Ĵ�����ʽ����������ͼ�� ��Ȼ�� CREATE UNIQUE CLUSTERED INDEX ����н�ָ�����ɾۼ����������У�����ͼ������������洢�����ݿ��С������ڻ����ľۼ�������һ�����ۼ������� B ���ṹֻ�������У��������а�����ͼ������е������С� ע�� SQL Server 2000 ���κΰ汾���ɴ���������ͼ���� SQL Server 2000 ��ҵ���У�������ͼ���ɲ�ѯ�Ż������Զ����ǡ�Ҫ�����������汾��ʹ��������ͼ������ʹ�� NOEXPAND ��ʾ�� �����������������Ǹ������� SQL ��ѯ����ѡ�������� WHERE ν�����������㣩����������н����ķǾۼ������������������Խ�ʡ���� I/O���Ӷ�����������˲�ѯ�����ܡ����ǣ�����Ҫƽ�⿼���������Ĵ����ɱ���������ص� B �������ṹά���ɱ����븲������������ I/O �������档��������������Ἣ�������ij����ѯ��ij���ѯ�����ܣ�����Щ��ѯ������ SQL Server �����У���ô��ֵ�ô������������� �����ʾ��˵�����ʹ�ø�������������
ִ��������ѯʱ��ֻ���ȡ���ٵ�����ҳ�������ܹ�Ѹ�ٴӻ������м����������ֵ���Ӷ��dz���Ч�ؽ����ò�ѯ��ͨ�����������������С���������������е��ֽ�����ñ��ĵ����ڵ��ֽ�����Ƚ϶��ԣ�������ʹ�ø��������IJ�ѯȷʵ�ᾭ��ִ�У���ô�ʺ�ʹ�ø��������� ����ѡ����������ѡ��Ἣ���Ӱ�����ɵĴ��� I/O ���������������Ӱ�����ܡ��Ǿۼ������ʺ��ڼ����������У����ۼ������ʺ�������ɨ�衣����ԭ��������ѡ��Ҫʹ�õ��������ͣ�
�����Ĵ����Ͳ��в����� SQL Server 2000 ��ҵ��� Developer Edition �У���Դ��������������IJ�ѯ�ƻ����������ж���������ļ�����Ͻ��в��С����̵߳��������������� SQL Server ��Ϊ������������ȷ�����жȣ�ͬʱ���еĵ����̵߳�������ʱʹ�õ��㷨��Ϊ���� Transact-SQL ���ȷ�����ж�ʱʹ�õ��㷨��ͬ��Ψһ��ͬ�Ǵ��������� CREATE INDEX��CREATE TABLE �� ALTER TABLE ��䲻֧�� MAXDOP ��ѯ��ʾ����������������ж�ȡ��������ж�����������ѡ���������Ϊ�����������������ò�ͬ�� MAXDOP ֵ�� �� SQL Server ��������������ѯ�ƻ�ʱ�����в������������������СֵΪ��
���磬ij̨��������а˸� CPU��������ж�ѡ������Ϊ 6����ôΪ�����������ɵIJ����̲߳��ᳬ������������ڽ�����������ִ�мƻ�ʱ��������е���� CPU ���� SQL Server ��������ֵ��ִ�мƻ���ָֻ�����������̡߳� ����������������Ҫ�ΰ�����
�����в����߳���ɹ�����Э���߳̽���������ӵ�Ԫ���ӵ����������С������� CREATE TABLE �� ALTER TABLE �����Ծ��ж����Ҫ����������Լ������Ȼ���������ж�� CPU �ļ�����ϲ���ִ��ÿ�������������������˴������Ķ����������������Ȼ����ִ�С� ����ά�������ݿ��д�������ʱ����ѯʹ�õ�������Ϣ�洢������ҳ�С���������ҳ֮��ͨ��ָ��һҳһҳ�������һ�𡣶�Ӱ�����������ݽ��и���ʱ�����ݿ��е�������Ϣ�ᱻ��ɢ���ؽ�������������֯�������ݵĴ洢�����Ϊ�ۼ�����������������֯�����ݵĴ洢�����Ա�ɾ����Ƭ���������Լ���Ϊ����������������ҳ��ȡ����Ŀ���Ӷ��Ľ��������ܡ� ��������»��ľۼ�������������ֵ����ִ�д����IJ��������ʱ�����������Ƭ����ˣ�Ϊ�˷�ֹ�������ҳ������ҳ����Ӧ�ó���������ҳ������ҳ�ϱ���һ���Ŀ��ſռ䣬��һ�����Ҫ���������ҳ������ҳ�����ٴ���κ����У��������ڸ�ҳ�ж�������ݵ���������Ҫ��ijһ�в����ҳ������ָ�ҳ�����ִ����ʱ��SQL Server ��Ҫ��һ��ҳ�����ݽ��зָ����Լһ��������Ƶ���ҳ�ϣ��������¾���ҳ���ܱ���һ���Ŀ��ſռ䡣��Ϊ���������ϵͳ��Դ��ʱ�䣬���Խ��鲻Ҫ������������ �����������ʱ��SQL Server ���Խ������� B ���ṹ����������������ҳ�ϣ�����������ʹ������ I/O ɨ������ҳʱ�Ż� I/O ���ܡ��ڷ������ҳ����Ҫ����ҳ������������ B ���ṹʱ��SQL Server ��������µ� 8 KB ����ҳ�������Ӳ�̵�����λ�÷���������������ƻ�����ҳ�������������ԡ������ᵼ�� I/O ������ִ�д������л�Ϊ�����������һ��Ἣ��ؽ������ܡ�ͨ���ؽ��������ָ�����ҳ����������˳��Ӧ���ܽ��ҳ��ֹ�������⡣ͬ������Ϊ�������ھۼ�������Ҷ�����Ϸ������Ӷ�Ӱ���������ҳ�� ��ϵͳ�������У�����Ҫע�⡰SQL Server�����ʷ��� �C ҳ���/�������ü������ķ���ֵ��ʾ���ڽ���ҳ��֣�Ӧʹ�� DBCC SHOWCONTIG ����һ�������� DBCC SHOWCONTIG ����Ҳ��������ʾ�����Ƿ��ѽ����˹����ҳ��֡�ɨ���ܶ��� DBCC SHOWCONTIG �ṩ�Ĺؼ�ָ�ꡣ��ֵӦ�����ӽ� 100%��Խ�ӽ�Խ�á������ֵ������ 100%���뿼�ǶԳ����������������ά���� DBCC INDEXDEFRAG һ������ά��ѡ��Ҫʹ�� SQL Server 2000 ������������ (DBCC INDEXDEFRAG)��DBCC INDEXDEFRAG ����Ϊ������ͼ�ϵľۼ������ͷǾۼ�����������Ƭ��DBCC INDEXDEFRAG ��������Ҷ����������Ƭ����˸�ҳ������˳����Ҷ�ڵ�������ҵ���˳��һ�£��Ӷ��Ľ�������ɨ�����ܡ� DBCC INDEXDEFRAG ��ѹ�������ĸ�ҳ�����ῼ���ڴ�������ʱָ���� FILLFACTOR����ѹ�������Ŀ�ҳ����ɾ���� ���������Խ����ļ���DBCC INDEXDEFRAG һ��Ϊһ���ļ�������Ƭ������ҳ�������ļ�֮��Ǩ�ơ�DBCC INDEXDEFRAG ÿ����������û�����һ��Ԥ������ɵİٷֱȡ���ִ�й����У�����ʱ��������ֹ DBCC INDEXDEFRAG������ɵ����й����ᱻ������ �� DBCC DBREINDEX����һ�������������������ͬ��DBCC INDEXDEFRAG �����������������᳤�ڱ������������������ֹ���в�ѯ����¡�Ϊ��Զ���û����Ƭ������������Ƭ���ԱȽ����������죬��Ϊ������Ƭ�����ʱ������Ƭ����ء�Ϊ�dz����������������Ƭ��ʱ����ܱ��ؽ�������ʱ��Ҫ���öࡣ���⣬�������ݿ�ָ�ģ��������Σ�ʼ����ȫ��¼��Ƭ�������������� ALTER DATABASE����Ϊ�dz����������������Ƭ�����ɵ���־�������ܱȼ�¼���������������������ɵ���־���ࡣ������������Ƭ��������Ϊһϵ��С����ִ�еģ���ˣ��������������־���ݣ����ָ�ģ������Ϊ SIMPLE������Ҫ����־�� ���⣬������������ڴ����Ͻ�����ţ����ʺ�ʹ�� DBCC INDEXDEFRAG����Ϊ INDEXDEFRAG ���������ҳ��λ�á�Ҫ�Ľ�����ҳ�ľۼ������ؽ�������������ͬ��ԭ��DBCC INDEXDEFRAG ������ҳ��֡������Ѱ���ӳ������������˳����������ҳ����ʵ���ϻ����������������ҳ�Ĵ�����������ԭ�����ò���ȷ����Щԭ���������������װ�ء�����IJ��롢���¡�ɾ������ȵȡ� ��SQL Server �������顱���ṩ��һ��ʾ�����룬��ֻ��Ըô����Լ��ģ�����ʹ�������Զ�ִ�и�������ά������ʾ��˵�������һ�ּķ����������ݿ�����Ƭ������������ֵ����������������Ƭ�������йظ�����Ϣ������ġ�SQL Server �������顱�е����⡰DBCC SHOWCONTIG���� DBCC DBREINDEX �����������ͬ��DBCC DBREINDEX ����ֻ�ؽ�����ijһ��ָ������������Ҳ�����ؽ������������������ȥ�����´�����������ʱ���õķ������ƣ�DBCC DBREINDEX ���Ҳ�߱��ܹ���һ��������ؽ���������������һ�ŵ㡣�����ȱ�д������ DROP INDEX �� CREATE INDEX �������㣬���ң����ؽ�����һ����������ʱ������֪�����ṹ���κ�ָ����Լ�����������⣬DBCC REINDEX ������ԭ���ԡ����Ҫ�ڱ�д������ DROP INDEX �� CREATE INDEX ���ʱ�����ͬ��ԭ���ԣ����뽫������������������һ�������ڡ� �뵥���� DROP INDEX �� CREATE INDEX �����ȣ�DBCC DBREINDEX ���Զ����ø����Ż��������ڶ���Ǿۼ��������þ��оۼ������ı�ʱ������ˡ�DBCC DBREINDEX Ҳ�������ؽ�ǿ�� PRIMARY KEY �� UNIQUE Լ����������������ɾ�������´���Լ������Ϊ���������ɾ��Լ��������ɾ��Ϊ��ǿ�� PRIMARY KEY �� UNIQUE Լ���������������������磬������ϣ��ͨ���� PRIMARY KEY Լ�����ؽ�������Ϊ�������½���������������ӡ� DROP_EXISTING �ؽ�����������������Ƭ����һ�ַ����ǣ���ȥ�����������´���������ͨ��ɾ����������Ȼ�������´�����ͬ���������ؽ��ۼ����������ַ����ܰ�����Ϊ���ж�������������ָ�������еľۼ��������ֻɾ���ۼ�������Ȼ�������´��������������ܻ�������������÷Ǿۼ�������ɾ�������´������Ρ��ڳ�ȥ�ۼ�����ʱ���е�һ�γ�ȥ/���´����������´����ۼ�����ʱ���еڶ��γ�ȥ/���´����� Ϊ�˱�����һ������ʹ�� CREATE_INDEX �� DROP_EXISTING �Ӿ�Ϳ���һ�������һ���´����Ĺ��̡�����һ���������´������������ SQL Server ��Ҫ������֯����������������ɾ�������½���طǾۼ������Ȳ���Ҫ�Ĺ��������ַ�������һ�����Եĺô�������ʹ��������������Ԥ����������ݣ��������Ҫִ���������������Ϳ������Լ������´����ۼ�������ʱ��ͳɱ��� DROP INDEX / CREATE INDEX ά�����������һ�ַ����ǣ�ֱ�ӳ�ȥ������Ȼ�������´�����������ѡ�����ڹ㷺ʹ�ã����ҿ�����������Ա����ѡ����Ϥ��ѡ�����Ա���䴦�������ܹ����ɱ��������������������´�������Ա��ʹ�ô˷�����ȱ���DZ����ֶ������¼�����ʹ�¼������ʵ���˳���������ֶ���ȥ�����´�������ʱ��һ��Ҫ�ڳ�ȥ�����´����ۼ�����֮ǰ����ȥ���зǾۼ������������ڴ����ۼ�����ʱ�����Զ��������зǾۼ������� �ֶ������Ǿۼ�������һ���ŵ㣺�����Ǿۼ���������ͬʱ���´��������������ķ������Կ��ܻ�Ӱ�������ɵ��������������֡����ͬʱ��ͬһ���ļ����ļ��飩���ؽ������Ǿۼ�����������������������ҳ�����ڴ����Ͻ�����һ������ܻ�������ݵĴ洢˳���������ļ����ļ��飩λ�ڲ�ͬ�Ĵ����ϣ�������ָ���������ļ����ļ��飩�ڴ�������֮���������Ӷ�����������ҳ��˳�������ԡ� ǰ���ἰ���й���Ԥ������������Ͻ��������������ڴ˴�ͬ�����á���������������Ͻ����ľۼ���������ִ�ж���������裬�Ӷ����Լ���ؼ��ٽ������������ʱ��ʹ�����Դ�� FILLFACTOR �� PAD_INDEX FILLFACTOR ѡ���ṩ��һ�ַ���������ָ��������ҳ������ҳ�ϱ����Ŀ��ſռ�İٷֱȡ�CREATE INDEX �� PAD_INDEX ѡ����ڷ�Ҷ���������ҳ��Ӧ�� FILLFACTOR �����á����û�� PAD_INDEX ѡ�FILLFACTOR ��ҪӰ��ۼ�������Ҷ��������ҳ�����ͬʱʹ�� PAD_INDEX ѡ��� FILLFACTOR ѡ� PAD_INDEX �� FILLFACTOR ���ڿ���ҳ��֡�Ϊ FILLFACTOR ָ�������ֵȡ�����ڸ���ʱ����ڲ��� 8 KB ����ҳ������ҳ���������������ס��ͨ����SQL Server ����ҳ����������ԶԶ��������ҳ��������������Ϊ����ҳֻ�������������ص������ݣ�������ҳ�������е����ݣ���һ�����Ҫ�� ���⣬���סά�����ڵij���Ƶ�ʣ�ά�����������ؽ��������Ա��������������ҳ��֡��볢��ֻ�ڴ��������ҳ������ҳ����������ʱ���ؽ�������������ľۼ�����ѡ��õ����ᾭ����Ҫ�ؽ�����������ۼ��������ȵطֲ����ݣ��Ӷ����������ص�����ҳ�϶����ڸñ��в������У���ô������ҳ���������䡣����˵�����⽫�ڿ�ʼ����ҳ������б�Ҫ�ؽ��ۼ�����֮ǰ�ṩ�����ʱ�䡣 Ϊ��ȷ������ PAD_INDEX �� FILLFACTOR ���ʵ���ֵ������Ҫ�����ж�������������֮ǰ����Ӧ�ÿ��������棺һ����ҳ�ϱ����������ſռ䣬���ǿ��ܷ����IJ��ҳ����������������Ҫ���������ϵ�ƽ�⡣���Ϊ FILLFACTOR ָ���İٷֱȺ�С������������ҳ������ҳ�ϱ����������ſռ䣬������Ϊ�˻ش��ѯ��SQL Server ����Ҫ��ȡ������������ҳ�����ڴ�����ȡ�������ԣ��������ҳ������ҳ�ϵ�ѹ������Խ�࣬SQL Server �Ĵ����ٶȻ����Լӿ졣ָ�����ߵ� FILLFACTOR ��ʹ��ҳ�ϱ����Ŀ��ſռ���٣���������ҳ�ܿ�ͻ�������Ӷ�����ҳ��֡� ��ȷ�� FILLFACTOR �� PAD_INDEX ֵ֮ǰ�����ס�����������ݲֿ���У���ȡ����������������д�������������öࡣ�������������װ�����ݣ����ܾͲ�����������ˡ��������ݲֿ����Ա���ԶԱ�/�������з�������֯���Ա�����Ԥ�ƻ���ֵĶ�������װ�ء� ����һ�㾭�飬���Ԥ�Ƶ�д�����൱�ڶ�ȡ����һ�֣���ѷ����ǰ�����������ߵ�ָ�� FILLFACTOR��ͬʱ��ÿ�� 8 KB ҳ�ϱ����㹻�Ŀ��ÿռ䣬�Ա��⾭������ҳ��֣�����Ҫ�� SQL Server �ܹ��������´��������������һ������ʱ�䴰���ò��Ծ����� I/O ���ܣ�����������ҳ�������ұ�����ҳ��֣����ø�ҳ������������д�� SQL Server ���ݿ⣬FILLFACTOR Ӧ����Ϊ 100%���Ա�������������ҳ������ҳ�������� I/O ���ܡ� ���ڷ������Ż��� SQL Server ���������ṩ�ڱ���װ�����ݵ�ʾ�����룬�Ժ����øöδ���˵�����ʹ�� SQL �¼�̽������ SQL ��ѯ�������������Ż����ܡ� �������ݺ������������ʾ��˵�����ʹ�� SQL Server ���ܹ��ߡ����ȹ����±���
Ȼ���ڸñ���װ�� 20,000 �в������ݡ�װ�ص� nkey1 �е����������ڷǾۼ�������ckey1 ���е����������ھۼ�������col2 �е�����ֻ��Ϊ�˽�ÿ�еĴ�С���� 300 ���ֽڶ���������ݡ�
���в�ѯ���������ݿ�������������ɣ�
SQL �¼�̽�����Ż����ܵij��÷���ͨ����Ϊ��ǺͶ�����Ҫ��֤Ϊ�Ľ����������ĸ����Ƿ�ȷʵ�Ľ������ܣ�������Ҫ�������в�����������Ļ������������ ָ����һЩ�������ķ���������֤���������ڵõ��Ľ��� SQL �¼�̽�������������б�ǺͶ����Ĺ��ߡ����������Բ���������ڷ����Ļ�������������ܷ��������ҿ����Ժ��ٻطŸû��SQL Server �еĻطŹ����ṩ��һ�����õĻع���Թ��ߡ�ʹ�ûطŹ��ܣ������Է����ȷ��ĿǰΪ�˸Ľ����ܶ���ȡ�IJ����Ƿ��ܴﵽԤ��Ч���� �طŹ��ܻ�����ģ�⸺�ػ�ѹ�����ԡ����������ö���¼�̽�����ͻ��˻Ự��������ͬʱ�طš����磬������һ���ܣ�����Ա�������ɵز�����������û��Ļ��Ȼ��ͬʱ����ʮ���طţ�ģ���� 50 �������û�ʱ��ϵͳ���ܡ��������Ը������ݿ���Ȼ�����������ĵ����ݿ��лطŸû�����������в��Ե���Ӳ�������лطŸû�� ���ס������������ SQL �¼�̽������¼ SQL Server ���ݿ��з����Ļ�����Զ� SQL �¼�̽�����������ã��������Ӻͼ�¼�� SQL Server ִ�в�ѯ��һ�������û������� SQL ����⣬ʹ�øù����ܲ�����ָ�����������Ϣ��ʹ�� SQL �¼�̽������¼��ijЩ������Ϣ������I/O ͳ����Ϣ��CPU ͳ����Ϣ����������Transact-SQL �� RPC ͳ����Ϣ�������ͱ�ɨ�衢�����ľ���ʹ������ݿ����Ĵ���/��ȥ����������/�Ͽ����ӡ��洢���̲������α�������ȵȡ� ���������Ż���ʹ�õ��¼�̽������Ϣ SQL �¼�̽�����������Ż��Ľ��ʹ�ã��γ���һ�����ܷdz�ǿ��Ĺ�����ϣ������������ݿ����Աȷ���ڱ�����ͼ�Ϸ�����ȷ��������SQL �¼�̽�������Խ���ѯ����Դ���������¼������λ���ϡ����Խ�������� .trc �ļ���SQL Server �����������֮�������Ż��� .trc �ļ��� SQL Server ����ȡ��������ݡ������Ż��Բ���Ĺ��������е���Ϣ���йر��ṹ����Ϣ���з�����Ȼ����ԸĽ��������Ӧ�ô�����Щ�����Ľ��顣���������Ż��� �������Զ������������Ϊ���ݿⴴ����ȷ�������������Ժ���е��������������ɿ����ֶ�����ִ�е� Transact-SQL �ű��� ������ѯ������Ҫ������²��裺 ���� SQL �¼�̽����
������������� (3-4) ��
ֹͣ SQL �¼�̽����
�������ļ����װ�ص������Ż�����
�����Ż�������������ݿ�����������ɵ� Transact-SQL
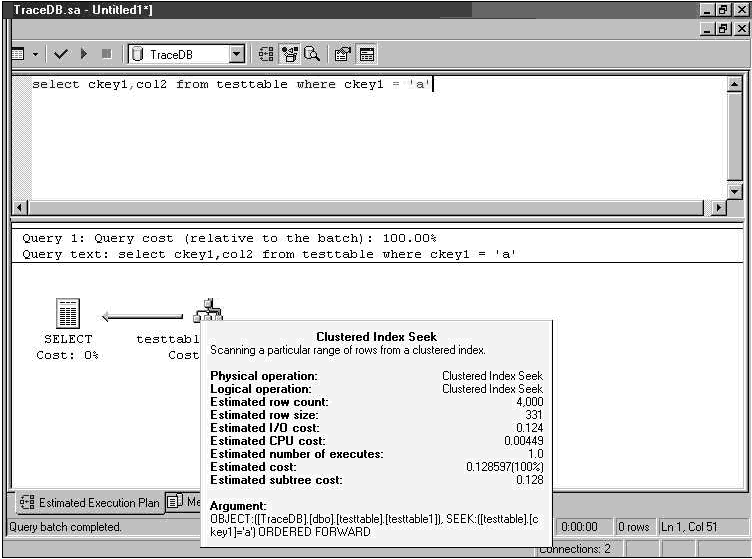
�����Ż���Ϊ�����������ݽ��������������������Ҫ�ģ��� ckey1 �ϴ����ۼ��������� nkey1 �ϴ����Ǿۼ�������ckey1 ֻ�����Ψһֵ��ÿ��ֵ�� 4000 �С��ٶ�����һ��������ѯ (select ckey1, col2 from testtable where ckey1 = 'a') ��Ҫ���� ckey1 �е�ij��ֵ�������������ʺ��� ckey1 ���ϴ����ۼ��������ڶ�����ѯ (select nkey1, col2 from testtable where nkey1 = 5000) ���� nkey1 �е�ֵ��ȡһ�С���Ϊ nkey1 ��Ψһ�ģ������� 20,000 �У������ʺ��ڸ����ϴ����Ǿۼ������� ��ʹ���˺ܶ������Ҫ�����ܶ��ѯ��ʵ�����ݿ�����������У��� SQL �¼�̽�����������Ż������ʹ�ã����ܻ�dz�ǿ�������ݿ�������������͵�һ���ѯʱ��ʹ�� SQL �¼�̽������¼ .trc �ļ�����ٱ����������װ�ص������Ż����У���ȷ��Ҫ��������ȷ���������������Ż����е���ʾִ�в��������Զ�������������������������ҵ�ڷǸ߷�ʱ�����С�������ϣ���������� SQL �¼�̽�����������Ż�����ϣ�Ҳ��ÿ��һ�λ�ÿ��һ�Σ����Բ鿴Ŀǰ�����ݿ��������ִ�еIJ�ѯ�Ƿ������ش�仯���������п��ܻ���Ҫ��ͬ���������������ʹ�� SQL �¼�̽�����������Ż������������ݿ����Ա�ڲ�ѯ�������ɲ��ϱ仯�����ݿ��ս����������£��Ա��� SQL Server �����������״̬�� ʹ�� SQL ��ѯ�����������¼�̽�����м�¼����Ϣ ����Ϣ��¼�� SQL Server ����֮����ʹ�� SQL ��ѯ��������ȷ��ϵͳ����Щ��ѯ������Դ��ࡣ���������ݿ����Ա���ܼ��о����Ľ���Щ����Ҫ�����IJ�ѯ��������������ݴ洢�ڱ��У������ܷ���ضԸ������ݵ��Ӽ�����ѡ���ɸѡ���Ӷ�Ϊ�Ż����ܱ�ʶ���������IJ�ѯ�����磬�������ʾ���У�Duration ������ʹ�� SQLProfiler Tuning ģ���Զ�������У�������������ʶ��Ҫ�ִ��ʱ�䣨�Ժ���ƣ��IJ�ѯ��Ҫ����ǰ 10% ������ʱ����IJ�ѯ���������������������IJ�ѯ��
Ҫ��������ʱ�����ǰ�����ѯ��������������������IJ�ѯ��
Ҫֻ��ϣ�������Ż����з��ڵ����ı��У��뿼��ʹ������� SELECT/INTO ��䣺
ǰ���ᵽ�� SQLProfiler Tuning ģ��ֻ������Ż������һ��Ԥѡ�к�ɸѡ�����á������ܻᷢ�֣�����Ҫ����������Ϣ����Ȼ������ȫ���Դ����Լ����Զ����Ż�ģ�壬�����ǣ�ֻ���Ԥ���ṩ��һ��ģ�壬Ȼ���ò�ͬ�����Ʊ��漴�ɡ������¼����ɱ������� I/O ͳ����Ϣ��������Ϣ���ȵȡ� SQL ��ѯ������SQL ��ѯ�����������Ż���ѯ���ù����ṩ�˶������ơ�ͳ����Ϣ I/O���Ļ��ƺ����������ѯ�����ִ�мƻ��� ͳ����Ϣ I/O SQL ��ѯ�������ṩ��һ��ѡ����ø�ѡ����ܹ������ SQL ��ѯ��������ִ�еIJ�ѯ�� I/O ���ķ���������Ϣ��Ҫ���ø�ѡ����� SQL ��ѯ����������ѯ�˵��ϣ�ѡ����ǰ��������������ʾ��ǰ���������Ի���ѡ������ statistics I/O ��ѡ��Ȼ��رոöԻ���Ȼ��ִ�в�ѯ���ڽ��������ѡ����Ϣѡ����鿴 I/O ͳ����Ϣ�� ���磬��ѡ������ statistics IO ѡ��ʱ����ǰ��ġ�SQL �¼�̽������һ���д������������ݽ������²�ѯ��������Ϣѡ��Ϸ������� I/O ��Ϣ��
ʹ��ͳ����Ϣ I/O �Ǽ��Ӳ�ѯ�Ż�Ч����һ�ֺ÷��������磬���������Ż���Ϊ�������ݽ����������Ȼ���ٴ����иò�ѯ��
��ע�⣬�ڿ���ʹ������ʱ������ȡ��������ȡ�����������Խ��͡� ִ�мƻ� ʹ��ͼ�λ�ִ�мƻ�������ʾ�йز�ѯ�Ż�����������������ϸ��Ϣ���Ӷ��������ع�ע������� SQL ��ѯ�� ��ѯ��Ԥ��ִ�мƻ�������ʾ�� SQL ��ѯ�������ġ�����������У������ǣ��� CTRL+L ��ִ�� SQL ��ѯ��������ѯ�˵���ѡ����ʾԤ�Ƶ�ִ�мƻ�����ͼ������˲�ѯ�Ż��������ִ���˲�ѯ���ִ����Щ����������ͷ��ʾ��ѯ���������������ָ����ͣ�ڲ���ͼ���Ϸ���������ʾ�й�ÿ����������ϸ��Ϣ����������ͼ���·���ע����ÿ����������Ĵ��³ɱ���ͨ���˱�ǩ��������Ѹ���жϳ���ѯ��������������ġ� ��Ҳ���Բ鿴��ѯ��ʵ��ִ�мƻ�������������ѯ�˵���ѡ����ʾִ�мƻ���Ȼ��ִ�в�ѯ������ʾԤ�Ƶ�ִ�мƻ�ѡ����ȣ���ʾִ�мƻ���ִ�в�ѯ��Ȼ�����ʾ���ڸò�ѯ��ʵ��ִ�мƻ��� �����Դ���ִ�мƻ����ı��汾������������ѯ�˵���ѡ����ǰ����������Ȼ���ڸöԻ�����ѡ������ showplan_text ѡ�ִ�в�ѯʱ��ִ�мƻ����ڽ��ѡ�����ʾΪ�ı��� ���������ڲ�ѯ������ִ�мƻ�ѡ�������ִ��������һ���
SET SHOWPLAN_ALL ����ȡ�������Ӧ�ó���ʹ�á�ʹ�� SET SHOWPLAN_TEXT ���� Microsoft MS-DOS® Ӧ�ó����� osql ʵ�ù��ߣ��ɶ�ȡ������� SET SHOWPLAN_TEXT �� SET SHOWPLAN_ALL ��һ���ı��е���ʽ������Ϣ����Щ�ı������γɵķֲ�����ʾ SQL Server ��ѯ��������ִ��ÿ�����ʱ����ȡ�IJ��衣����з�ӳ��ÿ��������һ������ı��У�������������зֱ�����ִ�в������ϸ��Ϣ�� ִ�мƻ����ʾ�� ��Щ�����ʹ��ǰ�涨��IJ�ѯʾ������ SQL ��ѯ��������ִ�еġ�set showplan_text on���ó��ġ� ��ѯ 1
�����ı���ִ�мƻ����
ͬ�ȵ�ͼ�λ�ִ�мƻ���� ��ͼ��ʾ��ѯ 1 ��ͼ�λ�ִ�мƻ���
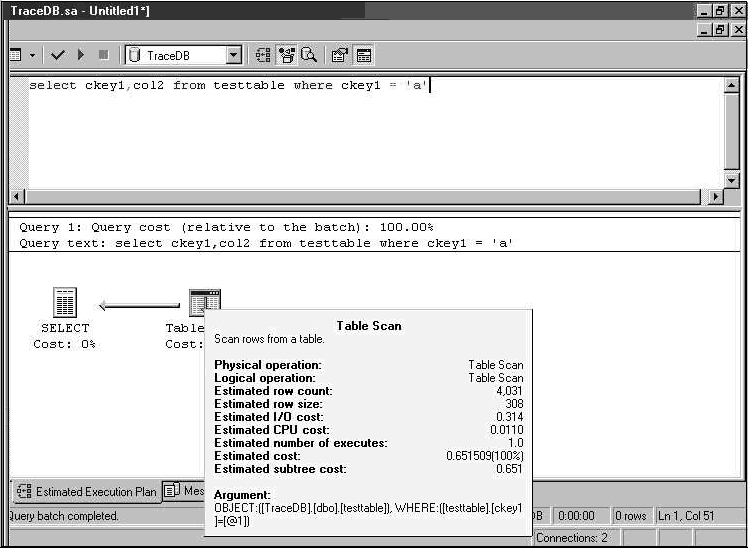
ִ�мƻ����� ckey1 ���ϵľۼ�������������ѯ�������ۼ�����������ʾ�� ����ӱ���ɾ���˾ۼ������������ٴ�ִ����ͬ�IJ�ѯ����ѯ���ָ�ʹ�ñ�ɨ�衣�����ͼ�λ�ִ�мƻ���������Ϊ�仯�� �����ı���ִ�мƻ����
ͬ�ȵ�ͼ�λ�ִ�мƻ���� ��ͼ��ʾ��ѯ 1 ��ͼ�λ�ִ�мƻ���
��ִ�мƻ�ʹ�ñ�ɨ����������ѯ 1��Ҫ��С��������Ϣ������Ч�ķ�����ʹ�ñ�ɨ�衣���ڴ���ϣ���ִ�мƻ�ָ���ı�ɨ��ʵ����һ�־��棬��˵������Ҫ��õ���������������������ͳ����Ϣ��Ҫ���¡�������ʹ�� UPDATE STATISTICS �����ڱ��������ϸ���ͳ����Ϣ���������ʽҳ���������ֵ��ͬ���������SQL Server ���Զ��������������磬������� testtable ��ɾ�������а��� ckey1 ֵ���ڡ�b�����У�Ȼ��û���ȸ���ͳ����Ϣ�����в�ѯ������� SQL Server �Զ�ά������ͳ����Ϣ����Ϊ��������ȷ����ѯʼ���ܹ�ʹ����õ�����ͳ����Ϣ�����ʹ�� ALTER DATABASE ��佫 AUTO_UPDATE_STATISTICS ���ݿ�ѡ����Ϊ OFF���� SQL Server �����Զ�����ͳ����Ϣ�� ��ѯ 2
�����ı���ִ�мƻ����
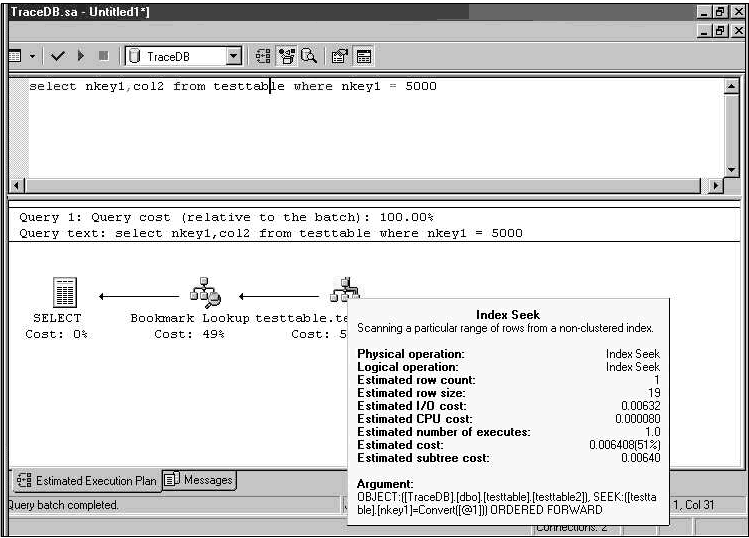
ͬ�ȵ�ͼ�λ�ִ�мƻ���� ������ͼ��ʾ��ѯ 2 ��ͼ�λ�ִ�мƻ���
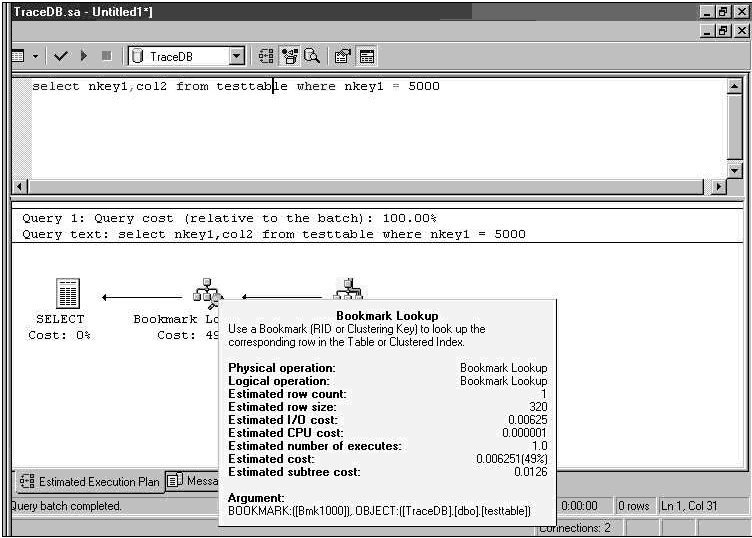
��ѯ 2 ��ִ�мƻ��� nkey1 ����ʹ�÷Ǿۼ������������� nkey1 ���ϵ� Index Seek ����ָ���ġ�Bookmark Lookup ����ָ�� SQL Server ��Ҫִ��ָ����ת���ӱ�������ҳ��ת������ҳ���Լ�����������ݡ���Ҫִ��ָ����ת��ԭ���Dz�ѯҪ����� col2 �У����Ǿۼ������ڲ��������С� ��ѯ 3
�����ı���ִ�мƻ����
ͬ�ȵ�ͼ�λ�ִ�мƻ���� ��ͼ��ʾ��ѯ 3 ��ͼ�λ�ִ�мƻ���
��ѯ 3 ��ִ�мƻ�ʹ�� nkey1 �ϵķǾۼ�������Ϊ������������ע�⣬�ò�ѯ����Ҫִ�� Bookmark Lookup ������ԭ���Ǹò�ѯ��SELECT �� WHERE �Ӿ䣩�����ȫ����Ϣ���ɷǾۼ������ṩ�������˵���Ǿۼ�����ҳ�в���Ҫ��ָ������ҳ��ָ����ת������Ҫ��ǩ���ҵ������ȣ�I/O �������١� ϵͳ����ϵͳ�������ṩ�������й����ݿ������ִ���ڼ��������� Windows �� SQL Server ��������Ϣ�� ��ϵͳ��������ͼ��ģʽ�£���ע���������Сֵ����Ϊ�����С�����ݵ㶼��ʹƽ��ֵʧ�棬���ԶԹ���ǿ��ƽ��ֵ�����һ��ҪС�ġ��о�ͼ�ε���״������С�����ֵ�Ƚϣ��Ա�ȷ��������Ϊ��ʹ�� BACKSPACE ������һ������ͻ����ʾ�������� ������ʹ��ϵͳ����������־�ļ��м�¼���п��õ� Windows �� SQL Server ϵͳ����������/����������ͬʱ�Խ�����ʽ�鿴ϵͳ��������ͼ��ģʽ����������������þ�������־�ļ�������ٶȡ���־�ļ����ܺܿ������磬��������м����������������Ϊ 15 �룬��־�ļ��� 1 Сʱ�ھ��ܴﵽ 100 ���ֽڣ������Է�������������㹻�Ŀ���ǧ���ֽ����洢��Щ���͵��ļ�����������������ռ��������Ҫ���볢�Բ��ýϳ�����־���������ϵͳ����������Ƶ���ض�ϵͳ�������볢�� 30 �� 60 �롣������ϵͳ���������Ժ�����Ƶ�ʶ����м��������²�����ͬʱ���ܱ��ֽ�С����־�ļ���С�� ϵͳ������Ҳ��������� CPU ��Դ�ʹ��� I/O ��Դ�����ϵͳû�ж���ı��ô��� I/O ��/�� CPU���뿼�Ǵ���һ̨���������ϵͳ��������Ȼ��ͨ��������� SQL Server����ͨ���������ʱ����ֻʹ��ͼ��ģʽ����ͨ��������������Ϣ��ȣ��� SQL Server ���ؼ�¼���ܼ�����Ϣ��Ч����������ߡ����������ͨ�������¼��־��Ϣ������ֻ��¼����Ҫ�ļ�������Ϣ�� �����ܲ��������ڼ䣬�����п��ü���������Ϣ��¼��ij���ļ��й��Ժ�������ⲻʧΪһ���������������������κμ��������Ժ���������һ����顣����������ϵͳ�����������м�������¼����־�ļ��У����ͬʱ��������ij��ģʽ����ͼ��ģʽ���¼��������Ȥ�ļ������������������������ڼ䣬������Ϣ���ᱻ��¼�������������ע�ļ������������������ϵͳ������ͼ����ʾ������ ����Ҫ��¼��ϵͳ�������Ự
ע�� Ҫ������־�ļ��ļ��������ã������Ҽ�������ϸ��Ϣ�����е��ļ���Ȼ������������Ϊ��Ȼ��ָ������������Щ���õ� .htm �ļ���Ҫ������־�������ѱ�������ã������Ҽ�������ϸ��Ϣ����Ȼ������־���������� �����Ѽ�¼�ļ��ӻỰ
ֹͣ�Ѽ�¼�ļ��ӻỰ
���Ѽ�¼�ļ��ӻỰ��ϵͳ������װ�����ݹ�����ʹ��
���ʹϵͳ��������¼���¼����ȥ��ij��ʱ�����
��Ҫ���ӵĹؼ����ܼ������м������ܼ������ṩ���й�������Ҫ�������Ϣ���ڴ桢��ҳ����������I/O �ʹ��̻�� �����ڴ� Ĭ������£�SQL Server ����ݿ���ϵͳ��Դ��̬�������ڴ�������� SQL Server ��Ҫ�����ڴ棬�����ѯ����ϵͳ����ȷ���Ƿ��п��õĿ��������ڴ棬��ʹ�ÿ����ڴ档��� SQL Server ��ǰ����Ҫ����������ڴ棬���������ϵͳ�ͷ��ڴ档��������̬ʹ���ڴ��ѡ��ᱻ����������ѡ���������Щѡ������С�������ڴ������������ڴ������ù�������С���йظ�����Ϣ������ġ�SQL Server �������顱�� Ҫ������ SQL Server ʹ�õ��ڴ����������������ܼ�������
��������������ʾ�ɽ���ʹ�õ��ڴ��������������һֱ���� SQL Server ����ʹ�õ��ڴ������ɷ�����ѡ����С�������ڴ������������ڴ����ã���˵��Ϊ SQL Server ���õ��ڴ����ʵ����Ҫ���ڴ�ࡣ����ʹ�����ù�������С������ѡ������������Ĵ�С�� �������������������ض���Ӧ�ó���ģ��������ñ��ʴﵽ�� 90% �Ƚ����롣�������ڴ棬ֱ����ֵ�ȶ��شﵽ 90% ���ϣ������ͱ������ݻ��������� 90% ���ϵ��������� ����������е������ڴ�����ȣ��ܵķ������ڴ� (KB) ������ֵһֱ�ϸߣ�˵����Ҫ�����ڴ档 ǿ�Ʒ�ҳ ����ڴ棺ҳ/����������ڴ棺ҳ��ȡ/�������壬˵�� Windows ����ʹ�ô���������ڴ����ã�ǿ�Ʒ�ҳ���������ô��� I/O + CPU ��Դ���ڴ棺ҳ/�������ָ���� Windows ����ִ�еķ�ҳ�����Լ����ݿ��������ǰ�� RAM �����Ƿ��á�ϵͳ�������е�ǿ�Ʒ�ҳ��Ϣ��һ���Ӽ���¼���� Windows Ϊ�˽���ڴ����ö������ȡ��ҳ�ļ��Ĵ���/�룬�����ڴ棺ҳ��ȡ/����ʾ������ڴ棺ҳ��ȡ/������ 5��������ܲ����� Ϊ�˱����ҳ��SQL Server �Զ��ڴ��Ż������Զ�̬���� SQL Server ���ڴ��ʹ�á�ÿ���ȡ����ҳ�������ģ��������ҳ���࣬�����ȡ������ʩ�� ��� SQL Server �Զ��Ż��ڴ棬������ѡ�����Ӹ��� RAM ������ݿ��������ɾ������Ӧ�ó��������ڴ棺ҳ/���ﵽ����ˮƽ�� ��� SQL Server �ڴ��������ݿ���������ֶ����õģ�����Ҫ����ָ���� SQL Server ���ڴ棬�����ݿ��������ɾ������Ӧ�ó��������ݿ���������Ӹ��� RAM�� �����ڴ棺ҳ/��Ϊ���ӽ��㣬�����ݿ���������������������˵��Windows ��������Ӧ�ó����� SQL Server������Ϊ�����ڴ������е��κ����ݶ�ת����ҳ�ļ������Է������ϵ� RAM �dz���ġ�ҳ/���Դ������пɽ��ܣ������ס��ÿ�δӷ�ҳ�ļ������� RAM����������ʱ������������Խϸߵ����ܳͷ������� I/O���� ���� Windows ��ҳ�ļ���ص���������������ڴ棺ҳ����/���������̣����̶�ȡ/���Լ��ڴ棺ҳ���/���������̣�����д��/�����бȽ��Ǻ����õģ���Ϊͨ�����ǿ���֪���������ҳ��������Ӧ�ó��� SQL Server����صĴ��� I/O ���������ҳ�ļ� I/O �����һ�ֱ�ݷ�ʽ��ȷ����ҳ�ļ����������� SQL Server �ļ�����ͬһ���������ϡ�����ҳ�ļ��� SQL Server �ļ�����Ҳ�Դ��� I/O ������������Ϊ���������ҳ��صĴ��� I/O ���� SQL Server ��صĴ��� I/O ����ִ�С� ����ҳ ����ڴ棺��ҳ����/�������㣬˵�� Windows ���ڷ�ҳ�����������м���ǿ�Ʒ�ҳ��Ҳ������ҳ������������һ�����۹�ǿ�Ʒ�ҳ������ҳ��ʾ���ݿ�������ϵ�Ӧ�ó�������������ڴ�ҳ��Ȼλ�� RAM ���ڣ�����λ�� Windows ������֮�⡣�ڴ棺��ҳ����/�������ڻ�����ڷ���������ҳ����ϵͳ��û�г�Ϊ������ҳ����/�롱�ļ�������������ʹ�ô˹�ʽ����ÿ���ӷ���������ҳ���������ڴ棺��ҳ����/�� - �ڴ棺ҳ����/�� = ����ҳ����/�� Ҫȷ�����¹����ҳ���Ƿ��� SQL Server �������������̣������ SQL Server ���̵����̣���ҳ����/������������ע����� Sqlservr.exe ʵ���ķ�ҳ������/���Ƿ�ӽ��ڴ棺ҳ/������ֵ�� ��Ӳ��ҳ������ȣ�����ҳ��������ܵIJ���Ӱ��ͨ��ҪСһЩ����Ϊ���Ǻ��� CPU ��Դ��Ӳ��ҳ������ô��� I/O ��Դ������������ܵ���ѻ����Ƕž��κ����͵Ĵ��� ע�� �� SQL Server ��һ�η��������е����ݻ���ҳʱ����ÿһҳ�ĵ�һ�η��ʾ��ᵼ������ҳ������ SQL Server ��һ�������͵�һ��ʹ�����ݻ���ʱ�����ص������������ҳ���� ���Ӵ����� ����Ŀ��Ӧ���ǣ������ܳ�ֵ��������з�����������Ĵ��������Ի��������ܣ���ͬʱ�ֱ�������ڷ�æ�����ִ�����ƿ���������Ż������ٵ���ս�ǣ���� CPU ����ƿ������������������ƿ�����ܿ����Ǵ�����ϵͳ��������˷��� CPU ������ͨ����CPU ��������չ����Դ��ijЩ�����ض��ļ�����⣬���磬��������ϵͳ�ϵ� 4 CPU �� 8 CPU������ˣ������æϵͳ�ϵ� CPU ʹ���ʳ��� 95%��˵��ϵͳ�������á�ͬʱ����Ӧ�ü����������Ӧʱ�䣬ȷ����Ӧʱ������������Ӧʱ�䲻�������� CPU ʹ���ʳ��� 95%�������˵������ CPU ��Դ�е��Ĺ������ɹ��࣬��Ҫô���� CPU ��Դ��Ҫô���ٻ��Ż��������ɡ� ��鿴ϵͳ��������������������% ������ʱ����ȷ��ÿ�� CPU �ϵĴ�����ʹ����һֱ���� 95%��ϵͳ�����������г����� Windows ϵͳ������ CPU �Ĵ��������С����ÿ�� CPU ��ϵͳ�����������г������ڶ�����˵�������� CPU ƿ�����ڼ� CPU ƿ��ʱ������Ҫ����������Ӵ������������ϵͳ�ϵĹ������ɡ����ٹ������ɵķ����ǣ�ͨ���Ż���ѯ��Ľ����������� I/O���Ӷ����� CPU ʹ���ʡ� �ڻ��ɳ��� CPU ƿ��ʱ��Ҫ���ӵ���һ��ϵͳ��������������ϵͳ���������л�/������Ϊ��ָ���� Windows �� SQL Server �������һ���߳���ִ���л�������һ���߳����϶���Ƶ�ʣ�����/�룩�������� CPU ��Դ���������л��Ƕ��̡߳��ദ���������������������������������л��ή��ϵͳ���ܡ�Ӧ�Է��������д���������ʱ��ֻ��ע�������л��� ����۲촦�������У����������л��������� SQL Server �����Ż��ij߶ȡ�������������������л����³���ƿ���������Կ������ַ�����ʹ����ϵ����ѡ�ʹ�û����˳̵ĵ��ȡ� ʹ����ϵ����ѡ���������ظ��������еĶԳƶദ���� (SMP) ϵͳ�����������������ĸ��������ܡ�������ʹ�߳����ض���������أ���ָ�� SQL Server ��ʹ�õĴ���������������ʹ����ϵ����ѡ����������ֹ SQL Server �ʹ��ijЩ���������ڸ�����ϵ����������֮ǰ�����ס��Windows �Ὣ�� NIC ������ӳٽ��̵��� (DPC) ������ϵͳ�б����ߵĴ��������ڰ�װ�������˶�� NIC ��ϵͳ�У�����ÿ����һ�����Ļ���ͻ�������һ�������ߵĴ����������磬��װ������ NIC �İ˴�����ϵͳ��ÿ�� NIC �� DPC ����������� 7 �ʹ����� 6���� 0 ��ʼ����������ʹ��������ѡ��ʱ��SQL Server �л��������˳̵ĵ���ģʽ��������Ĭ�ϵĻ����̵߳ĵ���ģʽ���˳̱������������̡߳�ʹ������ sp_configure 'lightweight pooling',1 �����û����˳̵ĵ��ȡ� ͨ�����Ӵ��������к��������л��������Լ���������ϵ��������������ֵ֮�������Ч����ijЩ����£���Щ���÷ǵ�����Ľ����ܣ�������ʹ�����½������⣬����ϵͳ�����ĸ�����������������������һ�㲻������ܴ�����档DBCC SQLPERF (THREADS) �ṩ��ӳ��� SPID ���й� I/O���ڴ��Լ� CPU ʹ���ʵĸ�����Ϣ��ִ������� SQL ��ѯ�ɵ��鵱ǰ����� CPU ʱ���ʹ���ߣ�
���Ӵ��������г��� ���ϵͳ�����������г������ڶ���˵���������Ĵ������յ��Ĺ���������������ܹ���һ����ķ�ʽ���崦����������ˣ�Windows ��Ҫ����Щ������ڶ����С� ijЩ����������˵�� SQL Server ������ I/O �������á����û�д��������У����� CPU ʹ���ʵͣ�˵��ϵͳij�����ܳ���������ƿ�������п��ܵĵط����Ǵ�����ϵͳ�����������������к����Ĺ�������������˵�� CPU �������У�ϵͳ�����ಿ��Ҳ�� CPU ����ͬ���� ����һ�㾭�飬����Ĵ����������������ݿ�������е� CPU �����Զ��� ������������������Ը��ڸ�ֵ�����ܱ��������������� CPU ƿ��������Ҫ���е��顣����Ĵ��������л���ò�ѯִ��ʱ�䡣�����ͬ����ܵ��³��ִ��������С�����ǿ�Ʒ�ҳ������ҳ�����ڽ�ʡ CPU ��Դ�����������ڼ��ٴ��������еķ����������Ż� SQL ��ѯ����ѡ���õ������Լ��ٴ��� I/O���Ӷ����� CPU ʹ����������ϵͳ�����Ӹ��� CPU������������ ���� I/O ����д���ֽ�/�������̶�ȡ�ֽ�/���������������̵���������������ÿ����������������������ÿ����ֽ����ơ�����ϸ�ؽ���Щ���������̶�ȡ/��������д��/������Ƚϡ���Ҫ�����ϵ͵��ֽ���/�룬�����Ŵ��� I/O ��ϵͳ��æ�� ������ SQL Server �ļ���ص����������������̶��г�����Ȼ��ȷ����Щ�ļ������Ĵ��̶�����ء� ���ϵͳ����������ijЩ����������������������æ����ɽ� SQL Server �ļ��ӳ���ƿ�����������Ƶ���̫��æ�������������������ڽ����� I/O ������ȵطֲ�������Ӳ�̡������һ������������������ SQL Server �ļ������̶��еĽ���������ڳ������Ӹ�����������������Ӷ������������ص� I/O ������ ���ִ��̶��п��ܱ���ij�� SCSI ͨ���е� I/O ���������Ѵﵽ���͡�ϵͳ��������ֱ��ȷ��������Ƿ���ʵ���洢����Ӧ��ͨ���������ṩ���ߣ��������� RAID ������������� I/O �������Լ��������Ƿ��ڶ� I/O ��������Ŷӡ���� SCSI ͨ�������������������������ʮ������������������������������ȫ��ִ�� I/O������п��ܷ����������Ӧ�Դ�����Ľ�������ǣ���һ��������������ӵ���һ�� SCSI ͨ���� RAID ����������ƽ��� I/O��ͨ������ SCSI ͨ��֮������ƽ����������Ҫ�ؽ� RAID �����Լ���ȫ����/��ԭ SQL Server ���ݿ��ļ��� ����ʱ��ٷֱ� ��ϵͳ�������У��������̣�% ����ʱ���������̣�% ����ʱ�����������Ӵ������ȡ/д�������ڷ�æ״̬��ʱ��ٷֱȡ���� % ����ʱ���������ܸߣ����� 90%����������ǰ���̶��г������������Բ鿴�ж���ϵͳ�������ڵȴ����̷��ʡ��ȴ� I/O ����������Ӧ��ʼ�ղ����������������̵��������� 1.5 �� 2 �������������ֻ��һ���ᣬȻ��������Ĵ����������� (RAID) �豸ͨ���ж���ᡣӲ�� RAID �豸��ϵͳ����������ʾΪһ���������̣�ͨ������������ RAID �豸��ʾΪ���ʵ���� ���̶��г��� ���ӹ����Ĵ��̶�����һ����Ҫ���� Ҫ���Ӵ��̶��г��ȣ�����Ҫ�۲���ϵͳ���������̼�������Ҫ������Щ����������� Windows 2000 �� Windows NT ��������� diskperf �Cy ���Ȼ����������������� ���ִ��̶��е�����Ӳ�������������ֲ� I/O ������ͬʱ��ֹ���� I/O ������Щ�������ϵ� SQL Server ��Ӧʱ��Ҳ�����ǰ���˲�������ò�ѯִ��ʱ�䡣 ���ʹ�� RAID��Ϊ�˼���ÿ�������������Ĵ��̶��У�����Ҫ�˽��ж��ٸ�����Ӳ����������ÿ�� Windows ��Ϊ����������������������������ء�Ϊ���˽�ÿ���������������� SQL Server ���ݵľ��巽ʽ���Լ�ÿ�� SCSI ͨ���Ϸַ��� SQL Server ������������Ӳ��ר����ѯ�������������� SCSI ͨ���������������ַ��� ͨ��ϵͳ�������鿴���̶��е�ѡ���ж��֡������̼�������ͨ�����̹�������������������̷���أ����������̼���������̹�������Ϊһ�����������豸��������ء���ע�⣬���̹�������Ϊһ�������豸��������������һ��Ӳ����������Ҳ������һ���������Ӳ���������� RAID ���С���ǰ���̶��г����ǶԴ��̶��еļ�ʱ��������ƽ�����̶��г����Dz����ڼ���̶��ж�����ƽ��ֵ�����ָ������������һ����������ע�⣺
��Щ����Ķ�������ÿ������Ӳ������������� RAID ��������̶��ж�����أ�����Ҫ�øö������� RAID �����е�����Ӳ������������������ȷ��ÿ������Ӳ���������Ĵ��̶��С� ע�� �ڱ��� SQL Server ��־�ļ�������Ӳ���������� RAID �����ϣ����̶��в������õĶ�����������Ϊ��־����������Զ����� SQL Server ��־�ļ��� I/O ��������Ŷӡ� �˽� SQL Server ������Ļ�˽� SQL Server 2000 ��һЩ������Ļ���������������ݿ�����ܡ� �����߳�SQL Server ά����һ�� Windows �̳߳أ���Щ�̵߳�������Ϊ�����ύ�����ݿ�������� SQL Server �����ṩ����sp_configure ѡ��������߳������ù涨�˿���Ϊ���д�����������ṩ������̣߳��� SQL Server �����г�Ϊ�����̣߳�����������������ύ������������������ָ����������߳��������������ύ������������֮�乲�������̡߳����లװ���ʺ�ʹ��Ĭ��ֵ 255����ע�⣬�����Ӵ������ʱ�䶼�ڵȴ��ӿͻ��˽����������� �� SQL Server ������������д�� 8 KB ��ҳ��������Ҫ�ɹ����߳�����ɡ�Ϊ�˻��������ܣ������̻߳��첽�������ǵ� I/O ������ ����д��������д�������ڻ�������������е� SQL Server ϵͳ���̡�����д����ˢ����ľɻ��壨�����Ƚ���Щ�����������ĸ���д����̣������ܽ�������������������ͬ��ҳ������Ȼ�������ṩ���û����̡��û���������ɺ�ά�����õĿ��л��壬�����Ǵ�СΪ 8 KB�������κ����ݣ���������ʹ�õ����ݻ���ҳ���ڶ���д������ÿ�� 8 KB ���滺����ˢ�µ�������ʱ������ҳ�ı�ʶ�ᱻ��ʼ�����������������ݾͿ���д����еĻ�����������д�����ڴ��� I/O ����ʱ�������Ӷ����û������ SQL Server ������Ӱ�������С�� SQL Server �Զ����ú������л���ˮƽ�����ܼ����� SQL Server�����������������д��/��ָ��������д�������̵� 8 KB ҳ������������� SQL Server�����������������ҳ���鿴��ֵ�Ƿ��½������״̬�ǣ�����д����ʹ�ü����������� SQL Server ����֮�䱣��ˮƽ������ζ�Ŷ���д�������û��Կ��л��������ͬ�������ϵͳ���������� SQL Server�����������������ҳ��ֵ�ﵽ�㣬˵���û�������ʱ��Ҫ�ϸ�ˮƽ�Ŀ��л��壬������д�������ṩ��һˮƽ�Ŀ��л��塣 �������д��������ʹ���л��屣���ȶ������ٱ����������ϣ�˵��������ϵͳ�������ṩ�㹻�Ĵ��� I/O ���ܡ�Ҫ֤���Ƿ�ȷʵ��ˣ��뽫���л���ˮƽ���½�����̶������Ƚϡ�����취�������ݿ������������ϵͳ���Ӹ�����������������������ߴ��� I/O ���������� ��ϵͳ�������м��ӵ�ǰ�Ĵ��̶���ˮƽ�������Dz鿴�����̻��������̵����ܼ�����ƽ�����̶��г�������ǰ���̶��г�����ȷ�����κ� SQL Server ���ص�ÿ�������������Ĵ��̶���С�� 2������ʹ��Ӳ�� RAID �������ʹ������е����ݿ����������ס�á���/�������̡���������������ֳ���������������̷�������Ӳ���������̷������ݴ��̹������ı��棩��ص�ʵ��Ӳ����������Ϊ Windows �� SQL Server ��֪���� RAID ����������������Ӳ����������ʵ��������Ϊ����ȷ�ؽ���ϵͳ����������Ĵ��̶���������һ��Ҫ֪���� RAID ���п�������ص������������� �йظ�����Ϣ������ġ�SQL Server �������顱�� ����SQL Server ��ÿ��ʵ����Ҫ����ȷ������������־������ҳˢ�µ����̡����Ϊ���㡣���������� SQL Server ��ʵ��ʱ��ʹ�ü�����Լ��ٴӹ����лָ������ʱ�����Դ���ڼ����ڼ䣬��ҳ�����뻺����������Ѿ����ĵĻ���������ҳ���ᱻд�� SQL Server �����ļ����ڼ��㴦д����̵Ļ�����Ȼ��������ҳ���û����Զ�ȡ����¸�ҳ�������شӴ������¶�ȡ����һ�������д���������Ŀ��л��岻ͬ�� �����������ù����̺߳Ͷ���д��������ֵ���ҳд��������Ϊ�ˣ����п��ܣ���������д����ҳ֮ǰ�����Զ����ȴ�һ�����㡣�����������̺߳Ͷ���д�������и����ʱ����д����ҳ��ijЩ����£���������д����ҳ֮ǰ��Ҫ������һ��ʱ�䣬�й���Щ�������ϸ��Ϣ������ġ�SQL Server �������顱�е����⡰�������־�Ļ���֡���Ҫ��ס���ص��ǣ��������᳢��ͨ���ȴ�����ļ����ڸ�����ʱ����ھ��� SQL Server ���� I/O ��� ���д���������ҳ��Ҫ�ӻ���ˢ�µ�������ʱ��Ϊ��ʹ�����������Ч��SQL Server ��Ҫˢ�µ�����ҳ���������ڴ����ϳ��ֵ�˳����������������ھ������ٴ����ڻ���ˢ�¹����е������ƶ������ڿ��ܵ������ʹ���������� I/O���������Ҳ�������ϵͳ�첽�ύ 8 KB ���� I/O ����������SQL Server ���ܸ������ɶ�������� I/O ������ύ����Ϊ������̲��صȴ�������ϵͳ����ָ���ѽ�����ʵ��д����̵ı��档 ��Ҫ��һ����Ҫ������ SQL Server �����ļ���ص�Ӳ���������ϵĴ��̶��У�ȷ�� SQL Server Ŀǰ���͵� I/O �����Ƿ����̵�ʵ�ʴ�����������������ʵ��������ߴ�����ϵͳ�Ĵ��� I/O ������ʹ���ܹ��������ء� ��־�������������������� RDBMS ��Ʒһ����SQL Server Ҳ����ȷ���ڷ����ж� SQL Server ����״̬���¼������磬�ϵ硢�����������й��ϡ�����������𣬵ȵȣ�ʱ�����ݿ���ִ�е�����д�������롢���º�ɾ�������ᶪʧ��SQL Server ��־��¼����������ȷ���ɻָ��ԡ�������κ���ʽ������ SQL ��ѯ������ʽ����������ķ��� BEGIN TRAN/COMMIT �� ROLLBACK �������е�����֮ǰ����־����������Ӵ�����ϵͳ�յ��źţ��������������ص��������ݸ��ľ��ѳɹ�д����ص���־�ļ�����һ�������ȷ������� SQL Server ��ij��ԭ���ͻȻ�ػ���������Ͷ���д������δ��д�����ݻ��������ˢ�µ������ļ�����ô��SQL Server �������������ȡ������Ӧ��������־���ָ���ָ������ͣ��֮���ȡ������־�Լ��� SQL Server ����Ӧ������ ������ÿ���������ʱ��SQL Server ����ȴ�������ϵͳ��ɶ� SQL Server ��־�ļ��� I/O�������� SQL Server ��־�ļ��Ĵ���Ҫ���㹻�Ĵ��� I/O ��������������Ԥ�ڵ������أ���һ�����Ҫ�� SQL Server ��־�ļ�����ش��̶��еļ��ӷ����� SQL Server ���ݿ��ļ�����ش��̶��еļ��ӷ�����ͬ����ʹ��ϵͳ������������ SQL Server�����ݿ� <���ݿ�ʵ��>����־ˢ�µȴ�ʱ���� SQL Server�����ݿ� <���ݿ�ʵ��>����־ˢ�µȴ�/�����鿴������ϵͳ���Ƿ��д��ڵȴ����״̬����־д�������� �߱����湦�ܵĿ�����������ߣ������Ǹÿ������ܹ�ȷ�������������������д����̣������ڵ�Դ����ʱҲ������д����̣����ý������ڰ�����־�ļ��Ĵ��̡��йؾ߱����湦�ܵĿ������ĸ�����Ϣ������ı��µġ�Ӳ�� RAID ���������ػ����Ч����һ�ڡ� Ԥ������SQL Server 2000 Ϊ���ģ������ȡ��ɨ��Ȼ�ṩ���Զ��������ܡ�Ԥ��������ȫ�������ú������Ż��������� SQL Server ��ѯ�������IJ������ܵؽ����һ��Ԥ���������ڴ��ɨ�衢����������ɨ�衢̽��ۼ������ͷǾۼ����������������Լ����������ԭ����Ԥ�����õ��� 64 KB I/O���� 8 KB I/O ��ȣ�64 KB I/O ��ʹ������ϵͳ�ﵽ����Ĵ����������������Ҫ�����������ݣ�SQL Server ��ʹ��Ԥ������������������� SQL Server ʹ�ü���Ч����������ӳ��� (IAM) �洢�ṹ���ýṹ֧��Ԥ��������IAM �� SQL Server ���ڼ�¼��չ����λ�õĻ��ƣ���ÿ 64 KB ��չ����������ҳ���ݻ�������Ϣ��ÿ�� IAM ҳ�ǰ������ܴ����λӳ�䣩��Ϣ�� 8 KB ҳ����Щ��Ϣָ����Щ��չ����������������ݡ�IAM ҳ��ѹ�����Լӿ������ǵĶ�ȡ�ٶȣ�����ʹ�õ� IAM ҳ�����Ա����ڻ����������С� Ԥ���������Խ����Բ�ѯ�������IJ�ѯ��Ϣ����Ҫ�� IAM ҳ��ȡ��������չ������λ����Ϣ�����һ�𣬴Ӷ����ɶ�������Ķ�ȡ���������� 64 KB ���̶�ȡ�ṩ����Ĵ��� I/O ���ܡ�SQL Server�������������Ԥ��ҳ/�����ܼ������ṩ�й�Ԥ����������Ч�Լ�Ч�ʵ���Ϣ�� SQL Server 2000 ��ҵ����������ڴ�����̬����Ԥ��ҳ������������� SQL Server 2000 �����������汾�У���ֵ�̶����䡣SQL Server 2000 ��ҵ�����һ�Ľ�֮����ͨ����˵�ġ���תľ��ʽɨ�衱�����������������������ɨ�衣��� SQL ����ִ�мƻ�Ҫ��ɨ����е�����ҳ�����ҹ�ϵ���ݿ�������Ѿ�Ϊ��һ��ִ�мƻ�ɨ����ñ�����ô���ݿ������ڵڶ���ɨ��ĵ�ǰλ�ý��ڶ���ɨ����뵽��һ��ɨ���С����ݿ�����ÿ�ζ�ȡһҳ������ÿһҳ��������ͬʱ���ݵ�������ִ�мƻ����˲�����һֱ���У�ֱ��������Ľ�β����ʱ����һ��ִ�мƻ�����������ɨ���������ڶ���ִ�мƻ��Ա�����������������ڽ��е�ɨ��֮ǰ������������ҳ��Ȼ��Ϊ�ڶ���ִ�мƻ�ִ�е�ɨ����۷��ر��ĵ�һ������ҳ��������ǰɨ�����������һ��ɨ���λ�á������ַ�ʽ�����������������ɨ�裻���ݿ����潫һֱ����������ҳ֮��ѭ����ֱ���������ɨ�衣 �й�Ԥ��������Ҫע��һ�㣬�Ǿ��ǹ����Ԥ������������ܲ�������Ϊ���ڻ��������벻��Ҫ������ҳ��ռ�ñ�Ӧ����������;�� I/O �� CPU��������һ�㣬ֻ��ͨ��һ��������Ż���������Ż����� SQL ��ѯ���������ٽ��뻺���������ҳ������������ȷ���߱���ȷ����������ʹ����Щ������ʹ�þۼ��������Ի����Ч������ɨ�裬����Ǿۼ����������ڿ��ٶ�λ���л��С���м������磬��������ڱ���ֻ����һ�����������Ҹ�������������ȡ���л��С���м���������ӦΪ�ۼ��������ӱ����Ͽ����ۼ������ȷǾۼ��������ٶȿ졣 ������������ʹ�����ͼܹ���ѩ���μܹ������ݿ�������ݲֿ�ʹ��ά�Ƚ�ģ����֯���ݣ��Ա���з�����ά�Ƚ�ģ���������ͼܹ���ѩ���ܹ�������Ҳ��Ϊ���ݲֿ��о���ִ�еĴ������ݶ�ȡ��������������Ч�ʡ����������ݣ�ͨ����ǧ�����У��洢����ʵ���ݱ��У����ڸ��ж��̣ܶ����ʹ�洢����Ͳ�ѯʱ��������١�ҵ����ʵ���ݵ����Ի��������Ϊά�ȱ��������̶ȵؼ��ټ�������ʱ�ı����������� �й����ݲֿ�����ݿ���Ƶ����ۣ�����ĵ� 17 �¡����ݲֿ����ע������� �� Transact-SQL ��ѯ��ʹ�õȼ�������� SQL ��ѯ��ʹ�÷ǵȼ��������ǿ�����ݿ�ʹ�ñ�ɨ�����Էǵȼ۶���ȡֵ����������Էdz���ı�������Щ��ѯ���������ɸ� I/O��������NOT���������!=��<>��!<��!>���� WHERE �Ӿ䣨�� WHERE <column_name> != some_value�������ɸ� I/O�� �����Ҫ���д����ѯ���볢�Ը��IJ�ѯ�Ľṹ������������ NOT �ؼ��֡����磺 ��ʹ�ã�
����ʹ�ã�
�����м���С��ͨѶ����ʹ�� Microsoft ActiveX® ���ݶ��� (ADO)��Զ�����ݶ��� (RDO) �����ݷ��ʶ��� (DAO) ���ݿ� API �����ý���� SQL ���ݿ����Ա��Ҫ�����������ɵĽ������ ADO��RDO �� DAO Ϊ����Ա�ṩ�˼��õ����ݿ�����棬����Ա��ʹû��̫��� SQL ��̾���Ҳ��ʵ�ַḻ�� SQL �м����ܡ��������Ա��ϸ�������ǵ�Ӧ�ó��ص��ͻ��˵������������Ҹ��� SQL Server ������λ���Լ� SQL Server ���ݵİ��ŷ�ʽ�����ܱ����������⡣SQL �¼�̽�����������Ż���ͼ�λ���ִ�мƻ����Ƿdz����õĹ��ߣ����ǿ���������Ա��ȷ��λ������������IJ�ѯ�� ��ʹ���α���ʱ����ѡ�����ʺ����Ĵ������͵��αꡣ��ͬ���͵��α꿪��Ҳ��ͬ����Ӧ���˽���Ҫִ�е��Ǻ������͵IJ�����ֻ����ֻ��ǰ�������ȵȣ���Ȼ��ѡ����Ӧ���α����͡� Ѱ�Ҹ��ֻ��������ٷ��صĽ�����Ĵ�С������������ѡ���б�����������Ҫ���ص��С�ֻ����������С��������ڼ��� I/O �� CPU ���ġ� ʹ�ö����� ͨ�������ݿ���ִ�д����������Լ��ٽ�����Ĵ�С���������ڿͻ��˺����ݿ������֮����в���Ҫ������ͨѶ��Ϊ��ִ�����õ��� Transact-SQL ���ִ�еĴ�����SQL Server ����������� Transact-SQL ��������з�ʽ�����һ��
����� SQL Server ����ʹ�����Զ�ͬʱʹ�ö�� Transact-SQL ����������п��ơ�
����ִ�мƻ���� SQL Server �ܹ�������ǰ��ѯ������ִ�мƻ��������������ܡ�Ҫ��ʹ SQL Server ����ִ�мƻ���������Ա�������Ĺ����кܶࡣTransact-SQL ���Ӧ��������ԭ���д��
�Զ������������ִ�мƻ� ����������Ӧ�ó�����һ����֪����ִ��ͬһ�����������뽫��������ʵ��Ϊ������ЩӦ�ó�����õĴ洢���̡� �� ADO��OLE DB �� ODBC Ӧ�ó�����ִ��ͬһ��������ʱ����ʹ��ִ�и��������� PREPARE/EXECUTE ģ�͡�ʹ�ð���������IJ���������ṩ�����ȫ������ֵ�����磬�� UPDATE VALUES �Ӿ����������ν����ʹ�õı���ʽ�� ά�����е�ͳ����ϢSQL Server ����������ij������ֵ�ķֲ��йص�ͳ����Ϣ����ʹ���в���������һ����Ҳ�������⡣��ѯ����������ʹ�ø�ͳ����Ϣ��ȷ��������ѯ����Ѳ��ԡ�������������ʱ��SQL Server ���Զ��洢���������е�ֵ�ķֲ��йص�ͳ����Ϣ�����������⣬��� AUTO_CREATE_STATISTICS ���ݿ�ѡ������Ϊ ON��Ĭ�����ã���ֻҪ��ν����ʹ����ij���У���ʹ���в��������У�SQL Server Ҳ���Զ��������е�ͳ����Ϣ�� �����������ݵĸ��ģ��������е�ͳ����Ϣ�����ʱ���Ӷ����²�ѯ�Ż������������й���δ�����ѯ�ľ���Ҳ������ǰ���롣���ű������ݵĸ��ģ�SQL Server �ᶨ�ڵ��Զ����´�ͳ����Ϣ��������������ҳ��������еģ������Ǵ�ͳ����Ϣ����ı��л�������С�ķǾۼ������в������ڴӴ��̶�ȡ������ҳ֮������ҳ�ϵ������ж�����������ͳ����Ϣ������ͳ����Ϣ��Ƶ�����л������е��������Լ��������ĵ������������� ���磬ij�����а��� 10,000 �У�������е� 1,000 ������ֵ�����˸��ģ���ʱ�Ϳ�����Ҫ���¸ñ���ͳ����Ϣ����Ϊ�� 1,000 ��ֵ���ܴ����˱��кܴ�һ�������ݡ����ǣ����ڰ��� 1000 ���������Ŀ�ı����ԣ����� 1000 ������ֵ�����˸��ľ�û��̫���ϵ����˿��ܲ����Զ�����ͳ����Ϣ��������SQL Server ʼ�ջ�ȷ������С�������н��в�����ʼ�ջ��С�� 8 MB �ı�ͨ����ȫɨ�����ռ�ͳ����Ϣ�� ע�� ʹ�� SQL ��ѯ��������ͼ�η�ʽ��ʾ��ѯ��ִ�мƻ�ʱ������ʾ������ʽ�������ú�ɫ������ʾ��ָ��ͳ����Ϣ��ʱ��ȱ��ͳ����Ϣ�����⣬ʹ�� SQL �¼�̽��������ȱ�ٵ���ͳ����Ϣ�¼��࣬���Է���ʲôʱ��ȱ��ͳ����Ϣ�� ͨ��ʹ�� sp_createstats ϵͳ�洢���̣�������ʹ�õ�����䣬�ڵ�ǰ���ݿ��ڵ������û����е������ʺϵ����Ϻ����ɵش���ͳ����Ϣ�������ڴ���ͳ����Ϣ���а�������ȷ���Ļ�ȷ�ļ����У�������������Ϊ image��text �� ntext ���С� ����ֶ�����ͳ����Ϣ���������Դ�������������ܶȣ�������ظ���ƽ��������ͳ����Ϣ�����磬ij����ѯ���������Ӿ䣺
ͬʱ�����У�a �� b���ϴ����ֶ�ͳ����Ϣ����ʹ SQL Server ���õ�Ԥ����ѯ����Ϊͳ����ϢҲ���� a �� b ����ϵķ��ظ�ֵ��ƽ������������SQL Server �Ϳ������� col1 �Ͻ���������������������Ϊ�ۼ��������������ؽ��б�ɨ�衣�й���δ�����ͳ����Ϣ����Ϣ������ġ�SQL Server �������顱�е����⡰����ͳ����Ϣ����
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


{kind=link}
{kind=link}