���ڴ����ݵ�Ƕ��ʽ������ͳ���Ѿ���Ϊ��ҵ��һ����Ҫ�����⡣�����������IJ���������������Ҫ��������ʦ�����ݷ����ṩ֧�֣��������ݽ���һЩͳ�Ƽ��㡣���ĸ�Ҫ�ؽ�����Ƕ��ʽ���ݷ�����ͳ�Ƶ���ع�����⣬���а����������������ʹ���ͳ�������ı�����ԡ����ڴ����յ���ר�����ߺ�DZ�ڵ�ר�����ߵķ��������������Ƕ����ר�����뷨���Լ�������Ҫ�˽���Щ��ؼ�������Christof
Ebert
��������Ϣ�����绹��Ƕ��ʽ�����磬�����ݶ��Ѿ�����˷dz��ؼ��ĸ��1 ����������ϵͳͨ�������ڶ���칹���ӣ���������Ӧ�ó����м���ʹ�����֮����������������ʩ��ʹ�ò������������õ�������Դ��ø��ӷḻ�ˣ����ܵ��������ܳ���������ҽҩ�������������������ӵ�����Դ������ÿ�����������ݽ���1,200���ֽڣ�������һ������������2,3
���������ķǽṹ��������ҵ���IT�������رܵľ���ս��
�����ݵĶ������ĸ�ά����ɣ�������������Դ�ĸ��Ӷȡ������ٶȣ��Լ�DZ���û�������Щ������Ҫ����֯��������������λ���ֽ�ת���ɿɲ�������Ϣ���������������������еĺ��壬���������ٷḻ��û�á�����ǰ������Ա��д����ģ���ͳ��ѧ������ͳ�Ƶġ�����Աһ����ͨ�õı�����ԣ���ͳ��ѧ��һ����ר�ŵij�������Լ����ճ�����������IBM��SPSS
(��������ѧ��ͳ��������)��ͳ��ѧ�Ұ�Ū�Ĺ���ͳ�����ݻ��г�����ͨ��ֻ��ѡ����Ⱥ���ã�������Ա�����Ĵ������ݶ��Ƿ������ݿ����־�ļ��еġ����Ƶ����������˶����õĴ����ݸı�����һ�С�

�������������������͵IJ������ӣ�Խ��Խ��Ҫ��������ʦ�����������������ͬ��ͳ�Ʒ�������������ʦ��������ǰ��δ�еĹ�ģ�ռ��ͷ������ݣ������DZ���м�ֵ����չ�µ�ҵ��ģ�͡�1
����˵������һ��������ά�������ǿ��Գ����ضԻ�����������м�⣬һ������Υ���ʧЧ���������������Ӷ������ǿ������ƻ�������ϵͳ̱��֮ǰ�������ǡ�����ԴӲ��ϳɱ��Լ��˹����������潵��ά���ɱ����������ݲ��ҳ����еĺ���ͨ��ֻ��һ������Ŀ�е�һ���ֹ���������ֻ��Ƕ��ijЩ�����У������У���Ӳ���Ż������С����˵��ǣ������������Ѿ�������������������Ӧ�����Ǵ�����һϵ�еĹ��ߣ����Խ�ͳ��ѧ�ҵ�һЩħ����������Ա��ʵ���ϣ���Щ����ͨ��Ҫ�ȴ�ͳ��ͳ�ƹ��߸�ǿ����Ϊ�����ܴ������������ڹ�ģ��Ҫ���ϵ�ͳ���������ȸ���
����Ƕ��ʽ������ͳ�Ƶļ���
����ִ��ͳ�Ʒ����������кܶࣻ��һ������һЩ�����е����������ǵ����������û�������ͳ�Ƹ��Ӷȵ�Ҫ�������ԣ��Լ������Ƕ����������������Ǵ���ͳ�������ı�����ԡ�
��һ���������ֵ������ע�⣺R��Python��D3 (���������ĵ�Data- Drives-Documents)��R��һ������ͳ�Ƶ����ԡ�Python��һ��ͨ�õı�����ԣ������Ѿ�֤ʵ�ڿ�ѧ�Һ��о���Ա�м�����У����ǻ���������ѧ��ͳ�Ƽ��㡣D3��һ��JavaScript�⣬�û����������������ӻ�ͼ�Σ���ʹ��Web�������֮����(����Ŵ���С�������չ��)
��R��Python��D3���dz�������Ƕ��ʽͳ�ƣ��м���ԭ��
��Ϊ�����Ƕ����ı�����ԣ��������ɵ�ͨ�������Ի��Ƹ�����ϵͳ����������Ҳ����ͨ�����뼰�������ָ�ʽ�����ݡ�
Python��R�еĽű�����ֱ��Ƕ�뵽����ķ����������С�
Python��R�������ֱ����������Ӧ�ó�����ЩӦ�ó�����ԴӸ�������Դ��ȡ���ݣ��û�����ֱ��ͨ��Web����ЩӦ�ó��������ݷ��������ӻ��Ľ�����
����D3���û�����ͨ��Web���������ʽ�ز���ͳ��ͼ�Σ�����������������ˮƽ��
���DZ�רҵ��ͳ�ư�����������Ա��˼ά��ܡ�
����D3��������е����ж������ṩ�˽��и�ͳ�ƣ������Ԫ��ʱ�����з���������ʩ�����������߱�������ͨ�����ʵ�֡��������е�ÿһ�����в��ص㣬���ʺϽ���ض���Ŀ�����⡣����Python��Pandas��������֧��ʱ�����з�������Ϊ������Ϊ�˶Բ��������������ķ�����д�ġ�
Python��ͳ����̬ϵͳ
�����������ͳ�Ƶ������е�ͨ�ñ�����Ծ���Python���ڿ�ѧ���㷽���������ܵ����������м��������Python���߿���������ɸ����ӵ�ͳ������Python�еĻ�����ѧ����NumPy������Python����Ҫ������һ��ͬ���Ķ�ά���飬���������Ų������ݵķ����������Լ���C/C++��Fortran�����м���������������ִ�и�����ѧ��ͳ�Ƽ��㡣���ڲ���Ҫ�õ����Լ������ݽṹ���ñ��ش���ʵ�֣�������NumPy��ִ�еľ���������Python��ִ����ͬ�ļ����öࡣ������NumPy
֮�ϵ�SciPy���ṩ��һЩ�߲����ѧ��ͳ�ƺ�����SciPy�ٴδ�����NumPy�����飻��Щ������Ȼ���ʺ�����ѧ���㣬���������ܻ���ȱʧֵ���칹����ʱ��һ�㷱����Ϊ�˽��������⣬Pandas�ṩ�������칹���ݽṹ����������������Ƭ�������ϲ�������(������SQL��֮�������)��
����iPython�Ǹ��������˵����ã�����һ������ʽ��Python shell���������в��㡢�ܺõ���ʷ��¼���Լ��ܶ��������ԣ��ڲ�������ʱ�ر����á�Ȼ������Matplotlib�Խ�����ӻ���

����˵��
����������һ����Ϣ���⣬�������ĺܶ����ݶ�����ͨ��Web���ʡ����ڸ����ӵķ��������ڿ��Դ��������е�����Ŀ¼�������ݣ���ͨ��API�����������ܻ�ӭ�����ݼ������緢չָ��(WDI)�������������е�˵����WDI���������¡���ȷ��ȫ��չ���ݣ��������ҡ������ȫ��Ĺ��㡣��
WDI�����ֿ����صĸ�ʽ��Microsoft Excel�Ͷ��ŷָ�ֵ(CSV)�ļ��� (��Ϊ Microsoft
Excel�ļ����ʺϱ�̷������������������ﴦ������CSV�ļ���)
ͼ1.�������緢չָ������Ե�Python�����������ɼ�����ǰ��30����������ָ�꣬����˹Ƥ�������ϵ��������ͼ����ʾ�����

WDI CSV����һ��42.5M��ѹ���ĵ������ز���ѹ�����������ļ�WDI_Data.csv����ø��ļ����ݸ����ĺð취�ǽ����ؼ��������Ϊ����Ҫ��Python�����Ը�����Ҫ�õ���Щ���߽�������ð취�Ƿ���һ��iPython�Ự��Ȼ��������ݣ�
In [1]: import pandas as pd
In [2]: data = pd.read_csv(��WDI_Data.csv��)
�����data�У�һ���������ݵ�DataFrame�������DataFrame����һ����ά���飬��һЩ���ڲ����Ķ���ܡ���һ��DataFrame�У����ݱ���֯Ϊ���к�һ������
(���ж�Ӧ)�������������
In [3]: data.columns
���ǻ�õ���ʾ����������������������Ҵ��롢ָ������ָ����롣��Щ���涼���Ŵ�1960��2012��ÿ��������С����Ƶģ������������
In [4]: data.index
���ǻῴ��������317,094�С�ÿһ�ж���Ӧһ������һ���ض�ָ���1960��2012���ֵ��һ����û��ֵ����ݱ�����һ�����Ǹ�������û�в�����һָ�ꡣ�����ȿ�һ���ж���ָ��
In [5]: len(data[��Indicator Name��].unique())
Out[5]: 1289
Ȼ��һ���ж��ٹ���
In [6]: len(data[��Country Name��].unique())
Out[6]: 246
����������һ��Ҫ��������⣺��Щָ���DZ˴˶����ģ�����������Щ�������
��Ϊ�����ǰ���ݺ��Ҳ�����ָ�꣬�������DZ���ȷ�����ĸ��������ֺ㶨���Ӷ�����ȷ�ض���������⡣һ����ԣ�����������ʱ�����ǻ�õ����õ�ͳ�ƽ����Ȼ�����±����������ͱ���������ˣ���һ��IJ��������࣬��������ָ���Ƕ����ģ���������һЩ�˴���أ���ν����������ָ�ꡱ����ָ��Щ�ڸ�������в�����ָ�ꡣ��ʵ֤�������ǿ����ڴ�Լ50��LOC���ҵ�����Ĵ𰸡�ͼһ���������ij���
����1�C10�е��������ǽ�Ҫ�õ��Ŀ⡣��11�ж�ȡ���ݡ��ڵ�13���У����Ǹ�����һ����ֵ����������Ҫ���IJ�������ָ��ĸ������ڵ�15�У������ҵ��˴�0��ʼ�Ĵ�����Ȳ���ֵ�ĵ�һ�С�����֮�����ǿ����ڵ�17���ҵ���������ֵ����һ�У�2005�꣩��Ȼ������ȥ����û����Щ����������������ݡ��ڵ�20��26�У����ǻ�ȡ�˲�������ָ�ꡣ
������ͳ�Ƽ���ӵ�28�п�ʼ����������һ�������������ÿ��ָ������ԵĽ��ֵ���ڽ�������ѭ���У����Ǽ���ÿ��ָ�������ԣ�����������֮ǰ���õı��С�����ڵ�41��52�У����ǰ���Щ�����ʾ����Ļ�ϣ�������Ϊһ��PDF�ļ�����ͼ���������ǻ�����ؾ���Ĵ�ֱ˳�����˷��������Ա�������Ҫ��ָ������ھ���Ķ���������41��49�У���
�Խ�����������������ԡ���Ӧ��ˣ���Ϊ�����������ͬ��ָ�ꡣ����֮�⣬���ǵ�ȷ��������Щָ��֮��������ԡ���Щ������صģ�������ǿ��Ҳ��Щ�Ǹ���ػ��߷dz��ĸ���ء�
ͼ2. ͼһ�е�Python�������������緢չָ����ؾ���
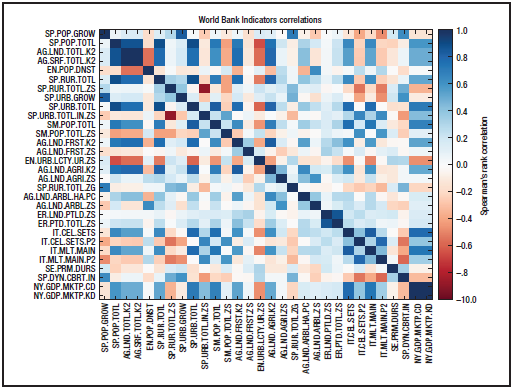
Python��̬ϵͳ�и��������
��ΪPython�ܵ��˿��н��������һЩרҵ���Ĺ���Ҳ��֮���֡������й�����NumPy��SciPy��matplotlib֮�ϵ�Scikit-learn�����ṩ���걸�Ļ���ѧϰ���߰������ڷ��ϲ㼶�ṹ�ij��������ݼ���Python�ṩ��PyTables������HDF5
��Ϊ����������һ����ҵ�ȵ㣬 DARPA ��2013���XDATA��Ŀ�������ó�300����Ԫ��Continuum
Analytics��Ϊ������������һ���ƽ�Python���ݷ������ߵĿ���������Ԥ�ϵ����ǽ������ļ��������̬ϵͳ�Խ��Ȳ���չ��
����ͳ�Ƽ����R��Ŀ
R����ͳ�Ƶ����ԡ�������ô˵��Python����ͳ�Ʊ���˳���Ա�Ļ��R��д��������ͳ����Ա�������������Ե���������Ч������ʾͳ�����ݼ��Ķ�����Щ����ͨ�����������б����ͱ�ʾ���к�����֯�����ݼ�������֡��R�г��õ����̿��ƽṹ�������õ�����������̵�˼�루���������������ʵ�ָ������ڸ���ͳ��������������еĸ����кܴ��𣩡�R��Խ֮�����������ṩ�ĸ���ͳ����⡣R������м���ʵ�������е�ͳ�Ʋ��Ի���Ȼ����Python�У���ʱ����ܻᷢ��������Ƴ��Լ���ʵ�֣���Ϊ��������������������ʲô���ģ�ͼ��������һ����ͼһһ���ij�����ͬ��������ʵ���õ���R������Python��ͼ���ǽ����
ͼ3. ��Rʵ��ͼһ���Ǹ��������緢չָ������Եij���

��ϡ����ϡ�����Ƕ��ʽ��������
�����ڱ����и����������Dz�ͬӦ�ó���ϲ���һ���������ݵĵ��Ͱ취�����ݴ�Դͷ����ij��ԭʼ��ʽ���������ǵ�ͳ�ư��ɽ��ܵĸ�ʽ��ͳ�ư�������һЩ�ܹ������Ͳ�ѯ���ݵİ취���Ա�������ȡ����Ҫ���������Ӽ�����Щ����ͳ�Ʒ��������еġ�ͳ�Ʒ����Ľ���������ı���ʽ��ͼ����Ⱦ���������ǿ����ڱ��ؼ������ִ����һ������Ҳ����ͨ��Web��ɣ���ʱ���ݵ�����ʹ������ɷ�����ִ�еģ������������ͼ��Ҫͨ��Web�������������һ����ǿ��ĸ����Ϊ���ͬ���趨����ERP��ܵ�������������������Խ����ݵ���ΪCSV�����ĸ�ʽ��ʵ���ϣ�����������һ�������������κζ�������ղ�����ר�����ݸ�ʽ������ʱ��Ӧ��������һ�־��档
Ҫ�밴����Ҫ�ķ�ʽ�������ݣ�����������ܹ����ʵ�����������Ӧ��ͨ�������ֶ�ѡ����Щ���Դٽ����ݽ����ļ���������ͨ���ĵ������ƣ�����ͨ���ʵ��ĵ��ã�����ͨ��һ��REST��������״̬ת�ƣ�API��
����һֱ�ڱ�������������е��У��������ڿ��ǵĹ����ܷ�ʤ��������ݴ�����������û��Ҫ�������д����������ݡ�����˵��R��һ��
���ڴ� �⣬�������ù����ڴ���ڴ�ӳ���ļ������������ݼ������У�Ҫȷ�������������ܴ����������룬��Ҫ�ܴ����������ݽṹ������˵��������Ĵ�С������32λ����֮�ڣ���Ͳ��ܴ�����5��������¼�ı���
������������У������Ķ��߿����Ѿ�ע��ˣ����ǽ����ݱ������ͳ�Ʒ����ĸ�ʽ���õĴ��룬Ҫ��ͳ�Ʒ��������Ĵ��뻹�࣬������ô˵���������Ѿ�д�õĺ������ġ����ǵ������е��С������Ԥ�����������Ĵ������ߵı������������Ե�ͷ�ؽ��ᣬ���������Ҳ��������һ��ʵ�������ݲ���ͨ�������ݷ���ͬ����Ҫ���Ϳ��̣���ʵ���ϣ�R��NumPy/SciPy
������ʵ��������������������ͳ���㷨��������������֪�������Ч�ش��������ṩ�����ݽṹ��������������dz���Ա�Ĺ���������ͳ��ѧ�ҵġ����и��������Դ�ɹ��Ķ���4-7
ͼ 4. ��R�����������緢չָ����ؾ���
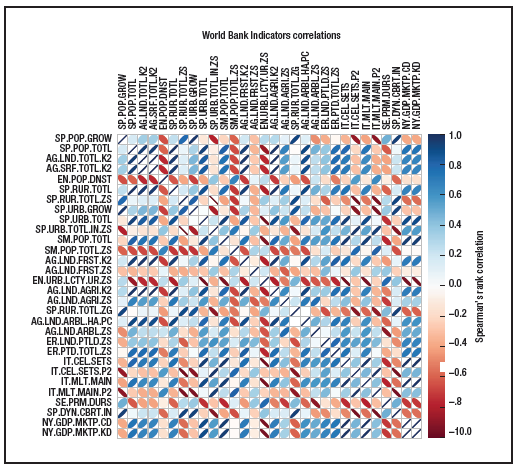
|


