ժҪ:
������Ҫ���������ͨ�� ISW 10.5 �Ľ�ģ�� Flow Solution ���������ھ�ģ�͡�
InfoSphere Warehouse ��ģ���
�ڱ�ϵ�����µĵ�һƪ�����ǽ��ܵ������ݵ�Ԥ�����������ھ�ģ�͵Ľ����������ھ���������е���Ҫ���ڣ������������������临�����Լ��������ھ����Ա�ĸ�Ҫ��Ϊ�����ھ���Ŀ����Ϊ��ʱ�������Ρ�
���������ھ�ģ�͵Ĺ��̣�Ҫ�������ھ����Ա���˶�ҵ����������̵����⣬����Ҫ�߱����ּ��ܣ�����������ھߵ�ʹ�á�SQL
���Ժʹ����д�ȡ�
��ǰҵ���и�������ͼ�λ��Ĺ��߰������������ھ�ģ�ͣ� �� InfoSphere
Warehouse �� Design Studio ���������������У�����ͨ����һϵ�в��������պ����ķ�ʽ��ϳ��ھ�����Mining
Flow����ִ���ھ������ɵõ�����������ھ�ģ�͡�
��Ȼ�ھ�����ʹ�������Ǵ����б�д���������ھ�ģ�͵ĸ��ӹ����н�ų���������������Ȼ���ټ������⣺
���ѡ����ʵ��ھ�ʽ�����ʵ��ھ��㷨ȥ���һ����ҵ���⣻
��κ���ʹ�úͰ������ڽ����ҵ������ھ����������ȷ���á�Ҫ��ȷ�����ھ�����������������һ��������Ҫ��Ƹ��ӵ��ھ���ʱ����ʹ���о���������ھ����ԱҲ��Ҫ���ѽϳ���ʱ��
Ϊ�˽�����������⣬ISW V10.5 �ṩ�������������Flow Solution�����ߡ�����������ṩ������ض�ҵ�������һϵ��ģ�����ͨ���ش�������⣬���ո������ǵ����õõ�����������һ����Ч�ġ������ġ���ִ�е�����Ŀǰ��������������������ھ�������������
�����������ʹ�ÿ��Դ���ȼ������ڽ��ҵ�������ʱ��;�����ͨ��ʹ���������������ʹ�Ƕ��ھ������û��ʹ�þ���������ھ����Ա��Ҳ������������ھ��������ҵ�����⣻���о���������ھ����Ա����ɸ����ٵĴ����ھ�ģ�͡�
������鼰������
�ڽ��������½��У����ǽ�����ͨ������ĵ��Ź�˾�����ӽ������ʹ�� ISW
10.5 �ṩ���������������ʵ�������ھ�Ľ�ģ���̣�ͨ������ʷ�����û��ķ���������������������û����Ӷ���ȡ��ʩ�����м�ֵ���û���
����ձ�ϵ�����µĵ�һƪ��ʹ�� Data Preparation ���������ھ�Ԥ�������̡�һ���еİ�����鼰������һ�ڰ�װ�����û�����
ʹ�� Flow Solution �����ھ���
��ģǰ�ķ���
���ſͻ�����ʧ�ɷ�Ϊ�����ࣺ��Ը��ʧ�ͷ���Ը��ʧ��ǰ����ָ�ͻ����ڸ������������жϺ�Լ��������ָ���ڿͻ������������ԭ����ɵ��Ź�˾��ֹ�������Ƿ����Ķ�����Ҫ����Ը��ʧ�Ŀͻ���
Ҫ�����ͻ�����Ϊ����Ԥ�⽫����ʧ�Ŀͻ���������Ҫ����һ��Ԥ��ģ�͡�
�û��ĸ�����Ϣ�����䡢�Ա�ְҵ���Լ��û���ͬ��Ϣ��ʹ�õ��ʷ��ײ͡�����ʱ����Ŀǰ��״̬�������û���ʷʹ��״������Щ����������Ҫ�����ġ�����Щ�������ǿ��Դ�ÿ���û����µ�ͨ��������ܣ�DW_USER_COLLECT���л�á�
�ڴ������������ǰ�����ǻ���Ҫ�������¼������棺
�Ƿ�ʹ�ÿ��ӻ�����ʾ���յ��ھ�ģ��
�Ƿ��ȡģ���е���Ϣ���洢������
�Ƿ��ģ�ͽ���Ӧ�����֣��Լ��Ƿ�����ֽ�����н�һ���ķ���
���Ҫ��������Ԥ��ģ�ͣ��Ƿ������ɵ�Ԥ��ģ�͵�����
�������������
���������ķ���������Ҫͨ���������������Ԥ��ģ�ͣ�����ϣ����ֱ�۵Ŀ����ھ����������ھ�ģ�͵���������ʹ��ģ����Ϣ����һ���ķ�����Ӧ�á�
���岽��Ϊ��
1.�½���������� CHURN_PREDICT_FW
��������Ŀ��Դ�������У�չ����Ŀ������������������Ҽ������ѡ���½�
-> �����������
�ڡ��½���������������У�ѡ��ǰ���̲�ָ������ģ���� CHURN_PREDICT_FW�����
[ ��� ] ����Ӧ�������������
2.ѡ���������ƻ�
��������ƻ������˽��ijһ��������Ҫ�IJ��輰��Ϣ��Ϊ��ʹ�������������ԣ����ǻ���Ҫѡ���ý�����������������������������͡�Ŀǰ������������ṩ��
�� 1 �������
��������Ҫ������������ģ�ͣ����ѡ�����������������Ϊ������ѡ��Ԥ�⡱��Ϊ���⣬ѡ����Ԥ�⡱��Ϊ��������ƻ������
[ ��һ�� ]��
3.�ڡ�ѡ�����ӡ��У�Ϊ����Ҫ�������ھ���ָ������Դ��������Դ�洢���ھ�����Ҫ��Դ�������ǵ�ʾ����ʹ�õ����ݿ��ǡ�TELE����
4.ѡ��Դ��
������Σ�����Ҫָ�����ڷ������������ڵı�����ͼ��
���ݷ�����������Ҫ��ÿ���û����µ�ͨ��������ܣ�DW_USER_COLLECT�����֡�����Ϊ�˵õ�����ȷ�ķ��������ǽ������н������ݽ��з��������ʹ��Դ���������ܴ���ͨ��ָ���������ʡ�������������
���б���ѡ�б� TELE.DW_USER_COLLECT������� [ ѡ��Դ��
] �ӵ���ѡ���Դ�����У����ֲ�����Ϊ 100%��
5.���߲���
���߲����а����˶�����⣬����ȷ����������༭���������ɵ����Ľṹ�����Ƕ���Щ����Ļش𣬾������ھ������������ĸ����ԡ����ڲ�ͬ�Ľ�������ƻ������߲��貢����ͬ��
���ߣ����к��н��й���
����Ҫѡȡ 2006 �� 1 �µ� 4 ���û����ݽ��з��������ѡ���Դ���й��˵�����Ҫ���С��ڡ�ѡ���С��У����
[ �������� ] ���ڡ�SQL ����������ָ���� �� 2 �Ĺ�����������ѡ�������������ٷ�������һ����������
���ߣ����ھ�ģ�ͽ��к���
�������ǵ�������ѡ����ʾ�ھ�ģ�͡���ģ���г�ȡ��������Ԥ��ģ�͡���Ϊÿ����¼Ԥ���Ŀ��ֵ�洢��һ�����У����֣���
���ߣ��ָ������Ա���в��Ժ�ѵ��
Ϊ�˲���Ԥ��ģ�ͣ���Ҫ��Դ�������ݷ�Ϊ�����֣�һ�������ڲ���ģ�͵�������һ��������ģ�͵Ĺ��������ǿ���ѡ��ͨ��ָ��һ���ٷֱ�ֵ���������ݵķֲ���Ҳ�������ж������ݷָ�������
���������ѡ������ָ��������ݣ����趨�������ݺ�ѵ�����ݵı���Ϊ 30��70��
���ߣ�ѡ������Ԥ��Ļ��
����Դ�������е������Ƕ�ϣ������ģ�͵Ĺ�������ѡ����һҳ�У����ǿ���ָ��Ҫ���ڹ���ģ�͵��С�����Ҳ���Խ���������ھ�ģ���㷨�����㷨������Щ������ģ�͵ļ��㡣
���⣬����ѡ���Լ�������Щ������Ԥ����̣����ڡ�ѡ������Ԥ��Ļ�С�һҳ��ȡ����
MONTH��USER_ID��SVC_NUM ��ѡ�У�Ȼ�������һ��
6.Ԥ��������
��Ԥ���������У�������Ҫָ������Ԥ���Ŀ���ֶκ��㷨��ϵͳ�����Ŀ���ֶ�ѡ���Ƽ����㷨�����ǿ���������Ҫ���㷨�б���ѡ��������Ҫʹ�õ��㷨��
����ҪԤ����ǿͻ��Ƿ��������������ѡ���ʾ�ͻ�״̬�ı�ʶ���ֶ� IS_LOGOUT��������ϵͳ�Ƽ����㷨
�C ������
7.��ȡ������
���ߣ�����������й���
���ǿ��Զ�������ij�ȡ������й��ˣ��趨����ֻ�������������IJ��ֽ�������磬ѡ��ֻ������Ŷȣ�CONFIDENCE������ij������Ĺ���
����ϣ���������е����������ȡ������������й���һ���ѡ�С�������һ��
������ѡ����
ͬ������ȡ����в������е���Ϣ����������Ҫ�ģ����ڲ���Ҫ�������ǿ���ȡ�����ǵ�ѡ�С�
����������
��� [ ������ ]����ָ���½�����ģʽ�����֣��� TELE.CHURN_TREERULES��ȷ����ϵͳ�ͻ���ݡ�������ѡ���С���ѡ���������ָ���ı�����������Ŀ����б���ѡ�б�
TELE.CHURN_TREERULES����ѡ�С�ɾ��Ŀ�������ǰ���ݡ������ [ ��һ�� ]
8.����Ԥ��ģ��
����Ԥ��ģ����ָ��ģ��Ӧ���ڰ���ģ��Ԥ��Ŀ��������ݣ�����Ԥ���Ŀ��ֵ��ʵ��Ŀ��ֵ���бȽϣ����ݱȽϽ����������ģ�͵�������Ч�档
����������
��������������ָ��������������Ԥ��ģ���ֶ�֮���ӳ���ϵ��
�������Dz���������ָʽ�ָ�Դ���ݣ���˲�����������Ԥ��ģ���ֶ���ȫƥ�䣬ϵͳ���Զ�������ƥ����ֶ�ӳ��������ֱ�ӽ�����һ��
���ߣ��Բ��Խ�����к���
���ǿ��Խ���ģ�͵IJ��Խ����ʾ�ڿ��ӻ����У�Ҳ���Գ�ȡ��������浽���С�
ʹ�ÿ��ӻ������Ը�ֱ�ӵز鿴�����ѡ���ڿ��ӻ�������ʾ���Խ����
9.Ԥ��ģ������
������ָ���ھ�ģ��Ӧ���������ݼ�¼��ȷ��ÿ����¼�ʺ���ģ�͵ij̶ȵĹ��̡�
���ߣ���ԭʼ���ݻ��������ݽ�������
����ʹ����Щ���ݽ������֣��Լ��Ƿ�������ǰ�����ݽ��й��ˡ�
����ѡȡ��Դ���� 1 �µ� 4 �µ���������ģ�͵Ľ�������������Ҫʹ��Դ����
5 �º� 6 �µ�����Ӧ����ģ�͡�ѡ����һ�����е����ݽ������֡������ڡ�ѡ���µ����ֱ���һҳ��ѡ�б�
TELE.DW_USER_COLLECT
���ߣ������ֱ����к��н��й���
����Ҫѡȡ 5 �º� 6 �µ����ݣ�����ѡ����˲���Ҫ���У����ڡ�ѡ�����ֱ����С�һҳ��������
�� 3 �Ĺ�����������ѡ�������������ٷ�������һ����������
����������
��������������ָ����������Ԥ��ģ���ֶ�֮���ӳ���ϵ���������Ѿ��Զ�������������ģ���ֶ�֮��ij�ʼӳ�䣬���ǿ��Ը�����Ҫ�����ʵ��ĵ�����
��ǰ��������ȫ�������ǵ�����ֱ�ӽ�����һ��
���ߣ������ֽ�����кͼ�¼���й���
����ֻ�Կ��Ŷȴ��� 0.3 �ļ�¼����Ȥ��ѡ�����ֽ���й��˳�ijЩ��¼����Ȼ���ڡ�ѡ�����ֽ����¼��һҳ��������
�� 4 �Ĺ�����������ѡ�������������ٷ�������һ����������
���ֽ����ѡ����
ѡ��Ҫ�洢�����е��С����������ֽ���в���Ҫ��ʾ���У�ȡ�����ǵ�ѡ��״̬��
ֱ�ӽ�����һ������Ϊ����ϣ�������ж��洢��������С�
�������ֽ��
��� [ ������ ]����ָ���½�����ģʽ�����֣��� TELE.CHURN_SCORE
ȷ����ϵͳ�ͻ���ݡ����ֽ����ѡ���С���ѡ���������ָ���ı��������ּ�¼Ŀ����б���ѡ�б� TELE.CHURN_SCORE����ѡ�С�ɾ��Ŀ�������ǰ���ݡ������
[ ��һ�� ]
10.���������ժҪ
ժҪ���г���ǰ�沽���е���ҪԪ�أ������������������͡���������ƻ������ڽ�ģԴ�����������ֵ�Դ������ģ�IJ������õȡ�
ָ��Ŀ���ھ���������Ϊ MF_CHURN_PREDICT��ѡ�������е����������
[ ������ ] �����ھ���
���ɵ��ھ�����ͼ 1��ִ�и��ھ�����������������Ԥ��ģ�Ͳ��õ���ģ�͵IJ��������Լ������ݵ����ֽ����
���������������:
������:����
�������������:���ڴ����ھ����Է������ݼ�Ĺ�ϵ����������Ĺ�������Ⱥ��Ԥ�������
��ҵ�������:Ϊ�ض���ҵҵ�����ⴴ�����̡���ǰ�����ڽ���ͻ�ϸ������
�ֿ�任:���������������ݱ任��֧�ֵı任���������ӡ�ȥ���ظ�����ݹ��˲��������������������ݸ��Ƶ��ļ�
���߹�������
MONTH = '200601' OR MONTH = '200602'
OR MONTH = '200603' OR MONTH = '200604'
���ֱ���������
MONTH = '200605' OR MONTH = '200606'
���ֽ����������
CLASS_CONFIDENCE > 0.3
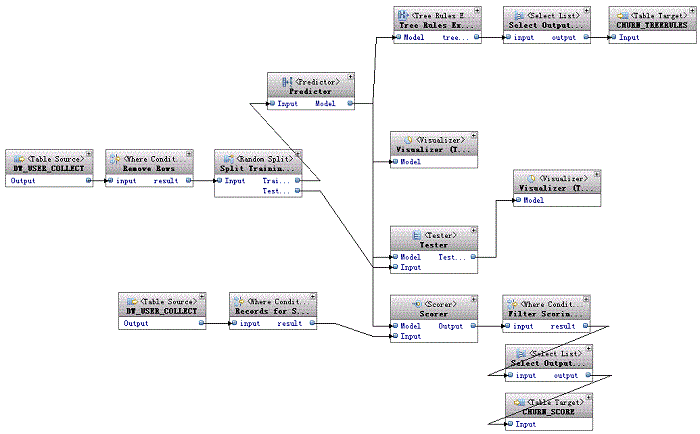
ͼ 1. �ھ��� MF_CHURN_PREDICT
|





