���
�������Ҫ�Ĺ�ϵ�����ݿ����ϵͳ������ DB2 for Linux, UNIX,
and Windows��������һ�ֻ��ڳɱ����Ż�����ơ����Ż�������һЩ�����������ɱ������� CPU �����Ժ��ٶȡ�I/O
�洢������ͨ�Ŵ������ⲿ�������Լ� DB2 ע���������DB2 �Ż�����ͳ����Ϣ���ڲ����������ң���ϵͳ����ʱ�ڼ䣬��Щ����������ڲ��ϱ仯������ѡ�����ִ�мƻ��Ĺ��̶��κ����ݿ�ϵͳ���Զ���һ���dz����ӵĹ��̡�DB2
�Ż������ļ��Ƕ��Ż�������Ҫ���䡣������ʵ������������ʵ��֮��������������� SQL ��䣬����ʹ�ô˹�����Ĭ��ִ�мƻ�������Ӧ�ó�����Ժ�
SQL ��������Ż������á�
�洢���������ݿ�ϵͳ����һ�����õĹ��ܡ�ʹ�ô洢���̣����ݿ��ʵ�ִ����ڸ���������еĹ��ܣ�����������塢�����������������ȡ�DB2
�еĴ洢������ʹ�� DB2 SQL �������� (SQL PL) ��д�ġ�SQL PL �� SQL �־ô洢ģ�����Ա���һ���Ӽ����������ͨ��
SQL �������ݵķ������������Ե������ƹ������ϡ�
�洢�����е� SQL ��䳣�����и����ӵ������ҷdz����Ե��Ի���ڣ���һЩ����£�DB2
ѡ��ķ��ʼƻ�����������Ҫ�ģ���������Ӧ�ó�����������¡���ʹ���������ʵ�����������Ȼ���Ӵ洢���̻����Ҫ�����ܣ�����ʹ���Ż������ļ����ṩ�������洢�����е�
SQL �������������ط��� SQL �������ͬ����Ϊ���dz�������һЩ���루���������������ϣ������Щ���͵����ʹ���Ż������ļ�ʱ������Ҫ��ȡһЩ����IJ�����ܵõ���Ҫ�Ľ�������Ľ�ͨ��һ��ʾ�����������ʹ���Ż������ļ��Ĵ洢�����е�
SQL ����ִ�мƻ���
�Ż������ļ����
�Ż������ļ���һ�� XML �ĵ������а������һ���������ݲ������� (DML)
�����Ż�ָ�ϡ��Ż������ļ��ɰ���ȫ��ָ�ϣ������������������ļ���Чʱִ�е����� DML ��䣬�Ż������ļ����ɰ���������һ�����и���
DML �����ض�ָ�ϡ��Ż������ļ��������� SQL ���ķ��ʼƻ������Ⲣ����ζ������������Ϊһ�����ָ�����ʼƻ���
��Ӧ���ر��ע�����������⡣
�Ż����������Ż������ļ���Ҳ����˵���Ż���ֻ����ָ�Ϸ��ϵ�ǰ�Ż���Ĺ���ʱ����ʹ����Щָ�ϡ����磬���������Ż�����
0 ��ʹ�úϲ����� (merge join) ���ϣ���� (Hash-Join)��
ֻ�����Ż�ָ�����Ż���������һ��ƻ�ʱ���Ż���ѡ�����������ij��ԭ���Ż���û�������Ż������ļ���ָ���ļƻ�����������ʹ�øüƻ���
�Ż������ļ��Ļ�����ʽ���嵥 1 ��ʾ��
�嵥 1. �Ż������ļ���ʾ��
<?xml version="1.0" encoding="UTF-8"?>
<OPTPROFILE VERSION="9.1.0.0">
<!-- Global optimization guidelines section. Optional but at most one. -->
<OPTGUIDELINES>
Here is for the global guidelines
</OPTGUIDELINES>
<!-- Statement profile section. Zero or more.
-->
<STMTPROFILE ID="profile id">
<STMTKEY>
Here is for the statement that we want to apply
this statement level
optimization guidelines to
</STMTKEY>
<OPTGUIDELINES>
Here is for the optimization guidelines for the
statement defined in the
<STMTKEY> element
</OPTGUIDELINES>
</STMTPROFILE>
</OPTPROFILE> |
OPTPROFILE
�Ż������ļ��� OPTPROFILE Ԫ�ؿ�ʼ����Ԫ�ذ���һ����Ϊ VERSION �����ԣ���ָ�����ļ�Ҫ���ص�
XML ģʽ�汾��һ���Ż������ļ���������ҽ��ܰ���һ�� OPTPROFILE Ԫ�ء�
ȫ���Ż�ָ��
һ���Ż������ļ���ӵ����� 1 ��ȫ���Ż�ָ�Ͻڡ����Ż������ļ���Чʱ������Ӧ������ִ�е�������䡣ȫ���Ż�ָ����
OPTGUIDELINES Ԫ���ж��塣���磬������ָ��ʹ���ĸ� MQT���Ż����𡢲�ѯ�IJ����̶ȣ��ȵȡ�
��������ļ���
һ���Ż������ļ��ɰ��� 0 ��������������ļ��ڡ����Ż��ļ���Чʱ��������Ӧ�õ�ȷƥ��� SQL
��䡣����Ż�ָ���� STMTPROFILE Ԫ���ж��塣������һ�� STMTKEY Ԫ�غ�һ�� OPTGUIDELINES
Ԫ�ء�
STMTKEY Ԫ�ض�������Ż�ָ�Ͻ�Ӧ�õ��� SQL ��䡣DB2 ʹ�� STMTKEY Ԫ���ж����������ƥ��
SQL ��䡣���ƥ��ɹ������ STMTKEY ��ص��Ż�ָ�Ͻ�Ӧ�õ��� SQL ��䡣�� STMTKEY
Ԫ���ڶ������������ҪӰ�쵽����ʼƻ������ȷƥ�䣬����ƥ�������ִ�Сд�ġ�����������Ŀո�Ϳ����ַ������绻���ַ������ǣ���������ʹ��ͨ�����ƥ������顣ÿ����Ҫ�ܵ�Ӱ������ֻӦ��һ��������
STMTPROFILE �ڡ�����ж���һ����ִ�����ƥ��� STMTPROFILE�����ǽ���ѡ��Ӧ�õ�һ����
�� OPTGUIDELINES Ԫ���ڣ�������ָ�� DB2 ��ij�����ķ��ʷ�������ɨ�������ɨ�裩����Ҫʹ�õ����Ӳ��������ӷ�����˳��ָ����ѯ��д���ȵȡ���ִ�е�
SQL ����� STMTKEY Ԫ���е�����ȷƥ��ʱ����� OPTGUIDELINES Ԫ���е������Ż�ָ�Ͻ�Ӧ���ڴ�
SQL ���ķ��ʼƻ��Ĵ�����
�Ĵ洢�����е� SQL �����ʼƻ�
��һ���洢������ʹ�õ� SQL �����ܾ����������ʽ�����磬���dz�������һЩ���루���������������
SQL ����ֱ�ӹ� STMTKEY Ԫ��ʹ�á��� DB2 ������Щ���ʱ��������Щ�����滻Ϊ�ڲ���ʽ��Ȼ��ʹ�ô��ڲ���ʽ��Ϊ���հ汾�����ʹ�������
SQL �����Ϊ STMTKEY���� DB2 ʹ���ڲ���ʽ����ƥ��ʱ������ɹ������ԣ�����Ҫ�����ҵ���Щ
SQL �����ڲ���ʽ��Ȼ��ʹ��������Ϊ STMTKEY �������Ż������ļ������¸��ڽ���������IJ��衣
���Ի���
����Ϊ�����еIJ��Ժ�ʾ��ʹ�����»�����
����ϵͳ��AIX 6.1
DB2 for Linux, UNIX, and Windows Version 9.7
���ݿ⣺SAMPLE ���ݿ�
�����е�����ʾ���������� AIX 6.1 ����ϵͳ�����е� DB2 V9.7��������������ϵͳ��ʵ��Ӧ����ͬ��
���������ݿ�
��ͼ 1 ��ʾ��SAMPLE ���ݿ��� DB2 �ṩ��һ��С�����ݿ⡣����ڰ�װ�ڼ�δ��װ�����������ҵ���ǰʵ����
sqllib/bin Ŀ¼������ db2sampl �������Զ���������

ͼ 1. �����������ݿ�
����˵���� (Explain table)
����Ҫʹ�� DB2 Explain ���߲鿴�Ż�ָ���Ƿ���ѡ��SQL ���ķ��ʼƻ��Ƿ����ġ�Explain
���ߵ��������ʾ�Ż������ļ������ƺ�ʹ�õ���Чָ�ϡ���ˣ�����Ҫ���� Explain ��������ı�����Ĭ������£�DB2
���ᴴ����Щ����
���嵥 2 ��ʾ���ӵ�ǰʵ�������ߵ� sqllib/misc Ŀ¼��ִ���ļ� EXPLAIN.DDL
��������� Explain ���Ĵ���������
�嵥 2. ���� Explain ���Ľű�
db2 connect sample
db2 -tvf EXPLAIN.DDL
db2 connect reset |
����ǰ�������������������ݿⲢ���� db2 list tables����������ϵͳĿ¼�п������о���
EXPLAIN ǰ���´����ı�����ͼ 2 ��ʾ��������Щ���� Explain �������ڴ洢��Ϣ��
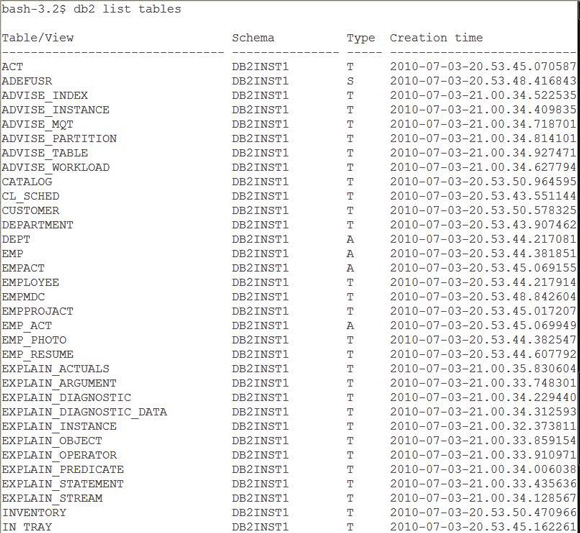
ͼ 2. �´����� Explain ��
���� SYSTOOLS.OPT_PROFILE ��
���嵥 3 ��ʾ��������������Ż������ļ����洢��ģʽ SYSTOOLS �µ� OPT_PROFILE
���С�Ĭ������£�DB2 ���ᴴ���˱��������ϣ��ʹ���Ż������ļ����� SQL ���ķ��ʼƻ�������Ҫ���д�������
�嵥 3. ���� SYSTOOLS.OPT_PROFILE ���� SQL
CREATE TABLE SYSTOOLS.OPT_PROFILE (
SCHEMA VARCHAR(128) NOT NULL,
NAME VARCHAR(128) NOT NULL,
PROFILE BLOB (2M) NOT NULL,
PRIMARY KEY ( SCHEMA, NAME ) ); |
�˱��а������� 3 �С�
�� SCHEMA ָ�Ż������ļ���ģʽ���ơ�
�� NAME ָ�Ż������ļ������ơ�
�� PROFILE �洢�Ż������ļ������ݡ�
SCHEMA.NAME ������Ωһ��ʶ���ݿ��е�һ���Ż������ļ������嵥 4 ����ʾ����֮ǰ�Ľű����浽�ļ�
SYSTOOLS.OPT_PROFILE.DDL �в������������ݿ⡣
�嵥 4. ���� SYSTOOLS.OPT_PROFILE ���Ľű�
db2 connect to sample
db2 -tvf SYSTOOLS.OPT_PROFILE.DDL
db2 connect reset |
���нű���������ɴ˱��Ĵ�����������ͼ 3 ��ʾ��
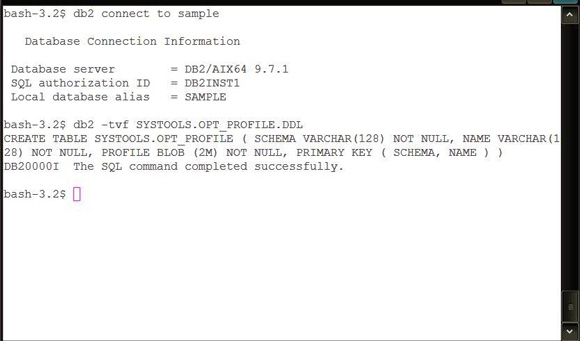
ͼ 3. ���� SYSTOOLS.OPT_PROFILE ��
�����洢����
���ڴ洢���̵���ϸ��������Բ��� IBM DB2 9.7 ��Ϣ�����е� ���洢���̡� һ�ڣ������
�ο����� һ�ڡ����嵥 5 ��ʾ����������һ����Ϊ GET_EMP_NUM �ļ洢�������������ʾ�����˴洢����ʹ���������ݿ��е�
DEPARTMENT ���� EMPLOYEE ������������������һ����Ϊ DEPT_NO������ ID�������������һ����Ϊ
EMP_NUM���˲����е�Ա������������������˴洢���̵Ĺ����ǻ����û�����IJ��� ID������һ�������е�Ա������
�嵥 5. ����洢���̵Ľű�
CONNECT TO SAMPLE%
CALL SYSPROC.SET_ROUTINE_OPTS('EXPLAIN ALL')%
CREATE PROCEDURE GET_EMP_NUM(
IN DEPT_NO CHAR(50),
OUT EMP_NUM INTEGER)
LANGUAGE SQL
BEGIN
SELECT COUNT(*) INTO EMP_NUM
FROM DEPARTMENT, EMPLOYEE
WHERE DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT
AND DEPARTMENT.DEPTNAME = DEPT_NO;
END%
CONNECT RESET% |
���� SYSPROC.SET_ROUTINE_OPTS �洢����������Ԥ����Ͱ�ѡ�Ȼ���ٶ��� GET_EMP_NUM
�洢���̡���Ҳ������ DB2_SQLROUTINE_PREPOPTS ע���������ʵ����ͬ���ܡ��������
SYSPROC.SET_ROUTINE_OPTS �洢���̣��������Ǵ�ע���������ֵ�������ォ���� EXPLAIN
ALL ��ֵ���ݸ� SYSPROC.SET_ROUTINE_OPT �洢���̡��������ڴ����洢�����ڼ䣬���е�����
SQL ���ķ��ʼƻ��������� Explain ���С�
��֮ǰ�Ľű����浽�ļ� create_procedure.ddl �У����嵥 6 ��ʾ��Ȼ������ͼ 4
����ʾ����������ɴ洢���̵Ĵ�����������ע�⣬��Ӧ������������������ִ�� RUNSTATS��Ȼ���ٴ����洢���̣��Ա�
DB2 ��ʹ�����µ�ͳ����Ϣ�����ɸ���Ч�ķ��ʼƻ���
�嵥 6. �����洢���̵Ľű�
db2 connect to sample
db2 'runstats on table db2inst1.department and indexes all'
db2 'runstats on table db2inst1.employee and indexes all'
db2 connect to reset
db2 -td% -vf create_procedure.ddl |
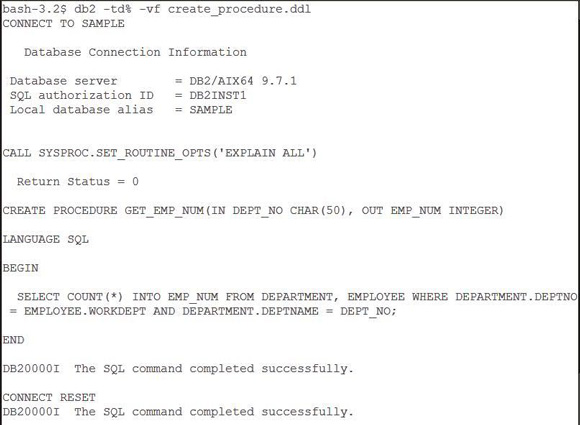
ͼ 4. ���� GET_EMP_NUM �洢����
�鿴�ڴ洢�����ж��� SQL �����ڲ���ʽ
�����ڴ洢�����ж������Щ SQL ��䣬DB2 �����루����������滻Ϊ�����ڲ���ʽ������ʹ���嵥
7 ����ʾ�� SQL ���鿴��Щ�����ڲ���ʽ��
�嵥 7. �鿴�ڴ洢�����ж���� SQL �����ڲ���ʽ�� SQL
SELECT PKGNAME, S.TEXT
FROM SYSCAT.STATEMENTS AS S,
SYSCAT.ROUTINEDEP AS D,
SYSCAT.ROUTINES AS R
WHERE PKGSCHEMA = BSCHEMA
AND PKGNAME = BNAME
AND BTYPE = 'K'
AND R.SPECIFICNAME = D.SPECIFICNAME
AND R.ROUTINESCHEMA = D.ROUTINESCHEMA
AND R.ROUTINENAME = 'GET_EMP_NUM'
AND R.ROUTINESCHEMA = 'DB2INST1'
ORDER BY STMTNO; |
��Ӧ�ý� R.ROUTINESCHEMA ��ֵ�滻Ϊ��ʹ�õĴ洢���̵�ģʽ�����ڱ�����Ϊ DB2INST1��������
R.ROUTINENAME ��ֵ�滻Ϊ�洢���̵����ƣ��ڱ�����Ϊ GET_EMP_NUM��������֮���ű����浽�ļ�
get_routine_sqls.sql �У��������ݿ���ִ�иýű������嵥 8 ��ʾ��
�嵥 8. �鿴�洢�����ж���� SQL �����ڲ���ʽ�Ľű�
db2 connect to sample
db2 -tvf get_routine_sqls.sql
db2 connect reset |
���� SQL ��������������С�һ������洢������صİ����ƣ���һ���� SQL �����ڲ���ʽ�����иýű�֮�������ͼ
5 ��ʾ��
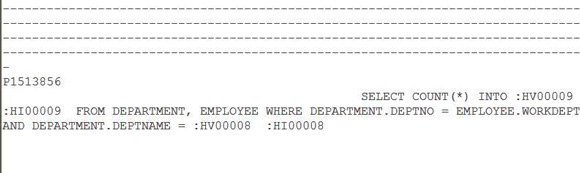
ͼ 5. ��ѯ�洢�����ж���� SQL �����ڲ���ʽ
�����Կ������������ EMP_NUM ���滻Ϊ :HV00009 :HI00009��������� DEPT_NO
���滻Ϊ :HV00008 :HI00008������֮ǰ�ڴ洢�����ж���� SQL ����кܴ�ͬ����Ϊ�������ʽ��
DB2 �ڱ���ʱ��ִ��ʱ��ִ�е���ʽ���������������� STMTKEY Ԫ����ʹ�õ���ʽ�����⣬�ý���ĵ�һ������˴洢������صİ����ƣ��ڱ����У���Ϊ
P1513856��������Ҫ���Ժ�IJ�ѯ��ʹ�ô���Ϣ�����˴洢���̵ķ��ʼƻ���
�鿴Ĭ�Ϸ��ʼƻ�
Ҫȷ�ϸ��Ż������ļ����� DB2 ��Ĭ�Ϸ��ʼƻ�������Ҫ���Ȼ�� SQL ��䵱ǰ�ķ��ʼƻ���ʹ��
db2exfmt ���ߣ��Cn ѡ�����������ء����ڴ˹��ߵ�ÿ��ѡ�����ϸ��Ϣ�������Բ��� IBM DB2
9.7 ��Ϣ�����е���ز��֣������ �ο����� һ�ڡ����嵥 9 ��ͼ 6 ��ʾ������ԭʼ���ʼƻ��������ļ�
orig_plan.out �С�
�嵥 9. �鿴 SQL ����ԭʼ���ʼƻ��Ľű�
db2exfmt -d sample -e db2inst1 -g -l -n 'P1513856' -s db2inst1
-o orig_plan.out -w -1 -# 0 -v % |

ͼ 6. ԭʼ���ʼƻ�
����ǰ�ķ��ʼƻ��������Կ��� DB2 Ĭ��ѡ����һ��Ƕ��ѭ��������ִ�д���䡣��ѡ�� DEPARTMENT
��Ϊ�ⲿ����ʹ�ñ�ɨ�跽��������ѡ EMPLOYEE ��Ϊ�ڲ�����ʹ������ɨ�跽����XEMP2 �DZ� EMPLOYEE
��һ����������������ʾ���У�����ʹ���Ż������ļ�������������У��� EMPLOYEE ��Ϊ�ⲿ������
DEPARTMENT ��Ϊ�ڲ���������������Ŀ�IJ���ʵ�ָ��ߵ����ܣ�ֻ��Ϊ�˱����Ż������ļ���Ӧ���� SQL
��䡣
�����Ż������ļ�
���嵥 10 ��ʾ��ʹ�ô洢�����ж���� SQL �����ڲ���ʽ�����Ż������ļ���
�嵥 10. �Ż������ļ��Ľű�
<?xml version='1.0' encoding='UTF-8'?>
<OPTPROFILE VERSION='9.1.0.0'>
<STMTPROFILE ID='example profile'>
<STMTKEY>
<![CDATA[SELECT COUNT(*) INTO :HV00009 :HI00009
FROM DEPARTMENT, EMPLOYEE
WHERE DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT AND DEPARTMENT.DEPTNAME =
:HV00008 :HI00008]]>
</STMTKEY>
<OPTGUIDELINES>
<NLJOIN>
<ACCESS TABLE='EMPLOYEE'/>
<ACCESS TABLE='DEPARTMENT'/>
</NLJOIN>
</OPTGUIDELINES>
</STMTPROFILE>
</OPTPROFILE> |
����һ���ű��У�һ��Ҫ�ر�ע�����¼��㡣
STMTPROFILE Ԫ�ص� ID ���ԣ�ID ���Ե�ֵ�Ǵ��Ż������ļ��������伶�Ż�ָ�ϵ�Ωһ��ʶ������������Ż�ָ��Ӧ����ij��
SQL ��䣬�����Դ����ķ��ʼƻ��п����˱�ʶ����
STMTKEY Ԫ�أ�������ʹ�� SQL �����ڲ���ʽ��Ϊ STMTKEY�����������ɹ�ƥ�䡣ͨ������ʼ��ʹ��
<![CDATA[]]> ��װ��䡣
NLJOIN Ԫ�أ���Ԫ��ָ�����ӵ�˳�������ʹ�� EMPLOYEE ��Ϊ�ⲿ����ʹ�� DEPARTMENT
��Ϊ�ڲ�����
���Ż������ļ��������ݿ���
�����Ż������ļ�֮�������浽�ļ� test_profile.prof �С�Ȼ�����ݼ��ص��� SYSTOOLS.OPT_PROFILE
�У�������ʹ�õ���������ɴ˲�����
���ȣ�ʹ������ profile_file.load ���嵼�������Դ�ļ������嵥 11 ��ʾ�����ļ�ָ���Ż������ļ���ģʽ����Ϊ
Test���Ż������ļ�������Ϊ OPTPROF���Ż������ļ�����ϸ���ݰ����� test_profile.prof
�ļ��С�
�嵥 11. ���������Դ�ļ�
"TEST","OPTPROF","test_profile.prof" |
Ȼ�����е���������嵥 12 ��ͼ 7 ��ʾ�������ݼ��ص����ݿ��С�
�嵥 12. ��������Ľű�
db2 "IMPORT FROM profile_file.load OF DEL MODIFIED BY LOBSINFILE
INSERT_UPDATE INTO SYSTOOLS.OPT_PROFILE" |

ͼ 7. ��������
�Ĵ洢���̵Ķ����ļ���ʹ�ô��Ż������ļ�
�����ϣ���ڴ洢������ʹ���Ż������ļ�����������ǰ���ע������������ô˹��ܣ�������Ҫ���� SYSPROC.SET_ROUTINE_OPTS
ϵͳ�洢����������ģʽ���ƣ�Ȼ�����ý���Ԥ����Ͱ�ʱʹ�õ��Ż������ļ������ƣ����嵥 13 ��ʾ������Ҫ��
SYSPROC.SET_ROUTINE_OPTS ������ָ�� OPTPROFILE ѡ�����ֵΪ TEST.OPTPROF����������ǰ������Ż������ļ�����Ϊ�˴洢�����е�
SQL ��䴴�����ʼƻ�ʱʹ�á���Ȼ������������ DB2_SQLROUTINE_PREPOPTS ע������������ͬ�Ľ����
�嵥 13. �ĵĴ洢����
CONNECT TO SAMPLE%
CALL SYSPROC.SET_ROUTINE_OPTS('EXPLAIN ALL OPTPROFILE
TEST.OPTPROF')%
CREATE PROCEDURE GET_EMP_NUM(
IN DEPT_NO CHAR(50),
OUT EMP_NUM INTEGER)
LANGUAGE SQL
BEGIN
SELECT COUNT(*) INTO EMP_NUM
FROM DEPARTMENT, EMPLOYEE
WHERE DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT
AND DEPARTMENT.DEPTNAME = DEPT_NO;
END%
CONNECT RESET% |
���嵥 14 ��ʾ�������Ѵ����Ĵ洢���̣�Ȼ�����´�������
�嵥 14. ���´����洢����
db2 connect to sample
db2 drop procedure GET_EMP_NUM
db2 -td% -vf create_procedure.ddl |
�鿴�·��ʼƻ��Լ����ʹ�����Ż������ļ�
Ҫ����Ż������ļ��Ƿ��ѳɹ�ʹ�ã�����Ҫ�Ա�ԭʼ���ʼƻ����·��ʼƻ���
���ȣ���Ϊ�洢���������´�����DB2 ��Ϊ������һ���°��������嵥 15 ��ͼ 8 ����ʾ�������ô˴洢���̵���صİ����ơ�
�嵥 15. ��ô洢���̵İ�����
db2 connect to sample
db2 -tvf get_routine_sqls.sql |

ͼ 8. ���´����Ĵ洢���̵��°�����
Ȼ��ʹ��ǰ��İ����Ʋ鿴�洢���̵��·��ʼƻ���������������ļ� curr_plan.out �У����嵥
16 ��ʾ��
�嵥 16. ����·��ʼƻ�
db2exfmt -d sample -e db2inst1 -g -l -n 'P2270199' -s db2inst1
-o curr_plan.out -w -1 -# 0 -v % |
���·��ʼƻ��������Կ�����һ�����ӵ� Profile Information ���֣���ͼ 9 ��ʾ��������ģʽ���ƣ��������ɴ�
SQL ���ķ��ʼƻ����Ż������ļ����ڱ�����Ϊ TEST.OPTPROF�����Լ�������ƥ�����伶�Ż�ָ�ϵ�
ID����� ID �ڶ����Ż������ļ�ʱָ����
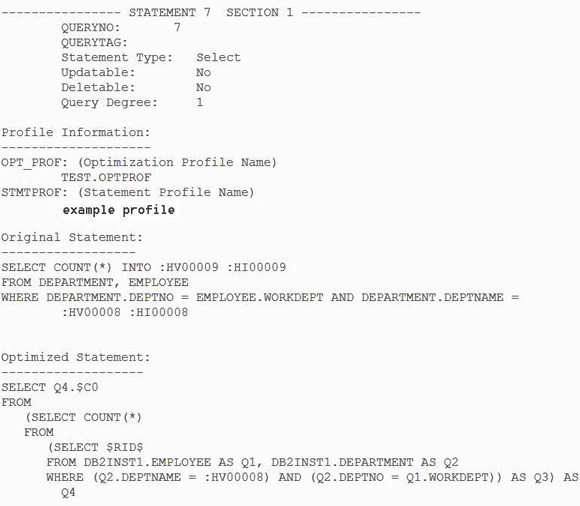
ͼ 9. stored procedure_1 ���·��ʼƻ�
���ͬʱ�����·��ʼƻ��У������Կ������ӵ�˳���Ѹı䣬��ͼ 10 ��ʾ�����ڣ��ⲿ��Ϊ EMPLOYEE
�����ڲ���Ϊ DEPARTMENT ��������������֤�����Ż������ļ��������ɹ������˴洢�����е� SQL
���ķ��ʼƻ���

ͼ 10. stored procedure_2 ���·��ʼƻ�
������
�洢������ DB2 ��һ��dz����õĹ��ܡ�һ���洢�����ж���� SQL ���ͨ���dz����ӣ��������Ե��Ժ͵��ڡ���һЩ�����£�DB2
ѡ��ķ��ʼƻ����ܲ�������Ҫʹ�õģ������ǵ�������������ʱ��ͨ��ʹ���Ż������ļ���������Ӱ�� SQL ���ķ��ʼƻ������������Ӧ�ó�������ݿ����á�����һ������Ӧ�ó�����Ż�
SQL �ķdz���Ч�Ĺ��ߡ�
|





