ժҪ:
���Ľ�������ν��û��Զ���Ĺ���ģ���� IBM SPSS Statistics ���м��ɣ� ������� Statistics
�ṩ��ͳ�Ʒ��������Թ���ģ����������ݽ���Ԥ���������Լ��ɽ�����з�������ʾ��
��������
����������ҵ������Business Analytics��BA��������Ϊ��ҵ��ǿ�����������������У�IBM
SPSS Statistics ��ͳ�Ʒ��������о���ʢ����Ӧ����������ҵ��ʵ����Ӫ�У��Ѹ��ݲ�ͬ��ҵ�����������������������������ҵ�������Ϸ��������ڴ���
Statistics ���м��ɣ��Ա����Ч��ȷ�ķ������ݣ���ȡ��������������Ϣ��
Statistics ����Ϊ�û��ṩ�˷ḻ��ͳ���㷨�������û��������ݣ�����Ҳ�ṩ�˷dz����ı�̽ӿڣ����ⲿ�û����Զ���Ĺ���ģ����
Statistics ���ɡ��û�����ͨ���Զ���ģ��� Statistics ���й�����չ������ Statistics���û��Զ���ģ����Ի�ø�����������������������ݡ�
Statistics 16.0�������ϣ�Ϊ�û��ṩ�˵Ŀɱ�̲����Programmability
plug-ins������ Python plug-in��R plug-in �� Microsoft .NET
plug-in�����У�Python ��������������зḻǿ�����⣬�������ܹ������ɵ�����������ʵ�ֵ�ģ�鼯����һ�����ԣ����Ľ�ʹ��
Python ����ģ����Ϊ��ʾ��
Customer Dialog ���
Statistics �ڱ�̲���Ļ������ṩ�� Extension Command
����ʹ�û��ܹ��� Statistics �ڲ�����syntax command�� ����ʽ����װʹ�ñ�̲�����������Ĺ���ģ�顣Customer
Dialog Ϊ Extension Command �ṩ����Ӧ���û����档
Customer Dialog �����û��������� Statistics
������ĶԻ����ڣ��Լ������Զ���� Statistics ����ͳ�Ƴ��Ի�������Ϊ��ͳ�Ƴ�����û����棬�ɽ��ܲ����ݻ����û�����IJ�������������Ӧ������ͳ�Ƴ���ͨ��
Customer Dialog Builder���û�����
�����Զ���ĶԻ����̣���������ͳ�Ƴ���
Ϊһ����չ��������û����档��չ������ָ���û��Զ���ġ��� Python
�� R ʵ�ֵ� SPSS Statistics ���
���洴����ɵ� Customer Dialog�������䰲װ�� Statistics
�С�
Statistics Syntax �� Python plug-in
���
SPSS Statistics �߱�ǿ������ݴ����ͷ������ܣ������ṩ�Ѻá�����
UI ���������⣬Statistics Ϊ�����еĹ����������Ӧ������� Statistics ���
Syntax������֮�⣬Syntax ���и���̵Ĺ��ܣ�������ɱ� UI ���ṩ�Ĺ��ܸ�Ϊ���ӵ����ݷ���������SPSS
Statistics �ں��ǻ������������ģ�Syntax ������ꡣ�û��� UI ��������в��������ᱻת����
Syntax ��������ں�ִ�С������ͼ��
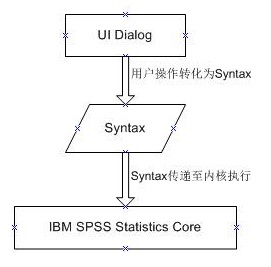
ͼ 1. Statistics ִ�й���
Python plug-in �� Statistics ��Ʒ�Ľ�����ʽ�����û��ȿ������Զ����
Python ���������� SPSS ģ�飬���� Statistics ������ݵĶ�ȡ���������������������Ҳ������
Syntax ��ֱ�Ӽ��� Python ����飨BEGIN PROGRAM PYTHON-END PROGRAM��������
Syntax �����������IJ����˺�һ�ַ�ʽ���磺

ͼ 2. Python Plug-in �����
1
ʹ�� Python Plug-in �ĺô��ǣ����Զ�̬�Ĵ��� string
�ַ����Լ� Syntax ���
���ɷ�������
���Ͻ����ۿ�֪�����ǿ������� Statistics �е� Python
Plug-in ���Զ��� Python ģ����м��ɣ����������� Customer Dialog ��������û�ϰ�ߵ�
UI �������棻��д����ͳ�Ƴ����� Statistics ���м��ɡ�
������Ƶ� Python ����ģ��ʵ����һ�ֿͻ���Ⱥ�����������ݴ����Ŀͻ��������ݺ��������ݣ����ͻ����飬����ͬһ��Ŀͻ����м���������ԣ����Բ�����ͬ����ҵ���ԣ���ͬ��Ŀͻ����м���IJ����ԣ���֤������֮��IJ������Ա��ȡ��ͬ����ҵ���ԣ����������ҵ����
UI ������Ƽ���������
���ڽ����� UI ����IJ����Լ� UI �������ݡ������ UI ����ǰ����������Ӧ����ȷ��Python
����ģ������������������Щ������������ UI �����ϡ�ͬʱ����ģ�鹦�ܽ�Ϊ���ӣ����������ӶԻ�����ʵ���ض��Ĺ��ܡ��ù���ģ�����������������ļ��������ļ��Լ��������������Ϊ�ͻ���Ⱥ����ļ��������û��Ļ�����Ϣ�Լ�������Ⱥ��š��ӶԻ��Ĺ���Ϊ�ͻ���Ⱥ����ϴ������ݿ⡣
���� Utilities -> Customer Dialog Builder������
Customer Dialog �༭���档ͨ����ק�ؼ��ķ�ʽ���û����Կ�ݵضԽ�����б༭������ָ����Ӧ�ؼ������ԡ������Ժ���μ�
Statistics �̡̳�
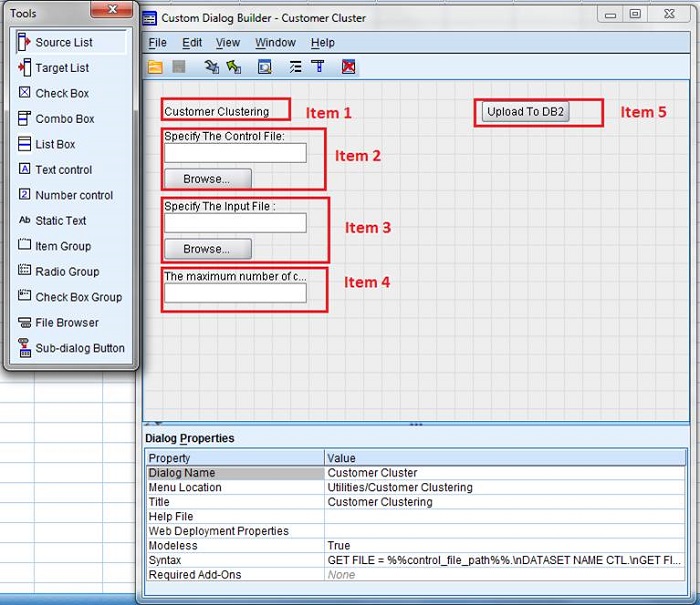
ͼ 3. Customer Dialog
1- ���Ի������
ͼ�У��� dialog �� 5 ���ؼ���Item 1 Ϊ�öԻ����ڵı��⣬����ʾ�ڸô��ڵı������У�Item
2��Item 3 �Լ� Item 4 �����û����� Python ����ģ����� , �ֱ�Ϊ�����ļ�·���������ļ�·���Լ�����������Item
5 Ϊ�öԻ����ڵ��ӶԻ����ڣ�����ʵ���ض��ӹ��ܡ���������Ƶ��ӹ����ǽ� Python ģ���ִ�н���ϴ������ݿ��С�Item
5 �� UI ��������ͼ��
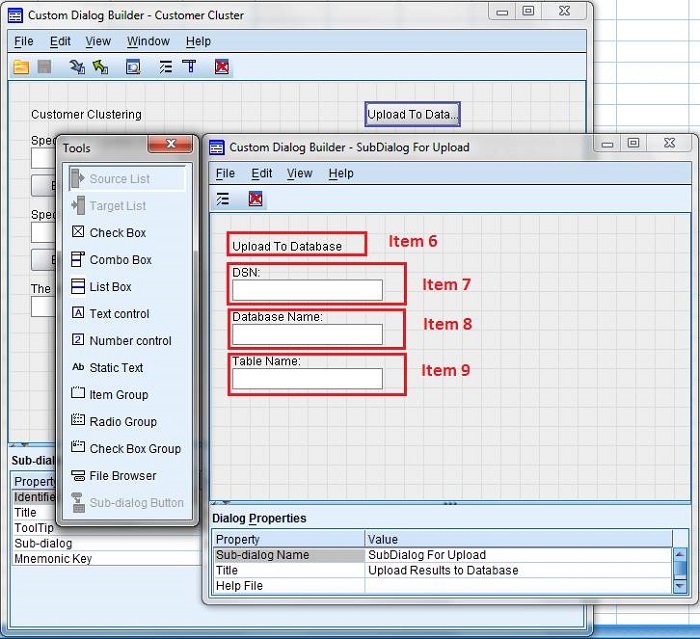
ͼ 4. Customer Dialog
2 �C �ӶԻ������
ͼ 4 �� Item 6 Ϊ�ӶԻ���ı��⣬Item 7��Item8 �Լ�
Item9 ���������ϴ����ݿ�����������ֱ�Ϊ DSN ���ơ����ݿ����ƣ��Լ����������ݱ�����
�� Item 2 Ϊ����������ʾ��δ��ݲ�������ͼΪ Item 2 �����ԡ�
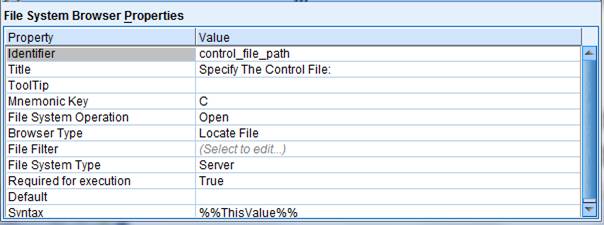
ͼ 5. Customer Dialog
3 �C �ؼ�����
���У����ԡ�Identifier�����ڴ��ݲ�������ͼ�еġ�control_file_path��������¼�û�������ֵ����
Python �����У��ԡ�%%����ǶԶ���������ֵ�����ݸ� Syntax �� Python �����ݹ�������ͼ��ʾ��

ͼ 6. Python Plug-in �����
2 �C Python Plug-in ��������
�༭�� UI ������䱣��Ϊ customer dialog package
file(.spd) �ļ���������Ϊ CustomerClustering.spd��ʹ�á�Preview�����ܣ��Խ������Ԥ����
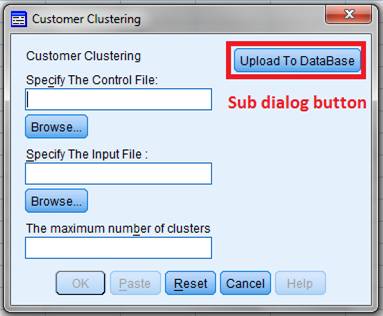
ͼ 7. Customer Dialog
4 - Preview 1
ͼ 7 ������ӶԻ����ڰ�ť���û�����ð�ť�������ӶԻ�������ͼ��ʾ��
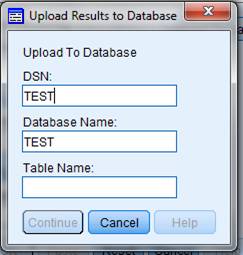
ͼ 8. Customer Dialog
5 - Preview 2
������ӶԻ����ڿؼ�����ʱ������Ϊ��DSN���Լ���Database Name��������Ĭ��ֵ��TEST����
���� Python ����ģ��
�����漰�����Զ��� Python ģ����Ҫʵ������ܡ�һ���ǿͻ���Ⱥ������Ƕ����
Python ����� Syntax ʵ�� (CustomerClustering.sps) ����һ���Ƿ�Ⱥ����ϴ������ݿ⣬����
Python �ű�ʵ�� (UploadtoDatabase.py)���������� Customer Dialog
��� Syntax Template �� UI ������ Python ����������
���ɿͻ���Ⱥ����
�ڼ��ɸù���ʱ������ѡ���� Statistics �ṩ�ġ�INSERT������������÷����
Statistics �̡̳�����ͨ���û��� UI ��������� control_file_path��input_file_path
��ô����������ݼ���ͨ�� max_clusters_ui ��ȡ�������ļ�������������������ò�����ֵ������
max_clusters��max_clusters Ϊ�����ļ��ж����ȫ�ֱ��� , ��ʵ�ֲ������ݡ������������
spss.Submit( ) ����ִ�и�������ˣ�����ͳ�Ƴ���������ʱ�����Ե���ָ���������ļ�����������ʱ�������ݸ��������ļ�������ʵ������ͼ��ʾ��
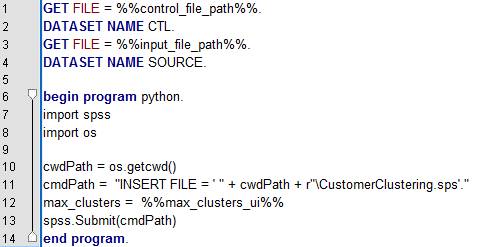
ͼ 9. ���ɿͻ���Ⱥ����
�������ݿ��ϴ�����
���ڰ�ȫ�Կ��ǣ����ǽ� UploadtoDatabase.py �ļ��༭Ϊ�����Ƶ�
UploadtoDatabase.pyc �ļ��Ա��Ⱪ¶Դ���룬����ͼ�С�import UploadtoDatabase���������ʵ��Ϊ
.pyc �ļ������������ .pyc �ļ�ʱ����Ҫָ���������ļ���·��������sys.path.append('C:\\Integration\\PythonScript\\')����ʾ��dsn��db_name
�� db_tablename Ϊ�û�ͨ�� UI ���洫�ݵ����ݿ���Ϣ�����÷������¡�
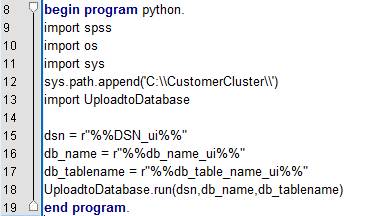
ͼ 10. �������ݿ��ϴ�����
ͼ�� UploadtoDatabase �� run ������������ʵ�ַ�ʽ���£�
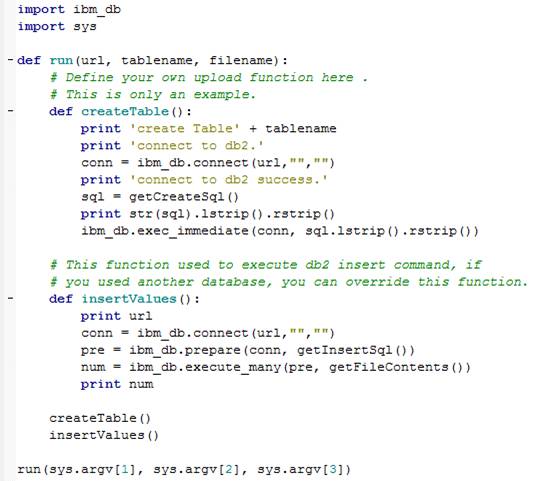
ͼ 11. Python Script ����������
���� Python ����ģ�����н��
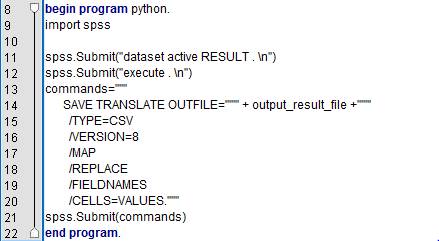
���ǿ��Խ� Python ����ģ������н������Ϊָ����ʽ�ļ������ϴ������ݿ⡣ʹ��
Syntax ��SAVE TRANSLATE OUTFILE������ɽ����н������Ϊָ����ʽ���ļ������У����ݼ�
RESULT Ϊ Python ����ģ���������ݼ���output_result_file Ϊ�������ļ����ļ����������������ò����������ݼ���
RESULT��Ȼ��ʹ�� spss.Submit( ) ����ִ�б�������������Ϳ��Խ� RESULT
���ݼ�����Ϊָ����ʽ���ļ��������������¡�
ͼ 12. �ļ���������
�����У����ǽ� RESULT ���ݼ��ֱ𱣴�Ϊ .csv �ļ��Լ� .sav
�ļ�������֮�⣬���ǻ��������� ODBC ���ӽ�������ݼ� RESULT �ϴ������ݿ⣬Ϊ�ˣ�������Ҫ��ϵͳ���趨
DSN��Data Source Name����DSN Ϊ ODBC ָ����ijһ����Դ�����Ӧ�� ODBC
���������ţ�ʹ�� Syntax ��SAVE TRANSLATE ������ʵ���ϴ����ݿ�ܣ������������¡�
�嵥 1. ���ݿ��ϴ������
begin program python.
import spss
import spssaux
DSN = r"%%DSN%%"
db_name=r"%%DBName%%"
table_name=r"%%TableName%%"
spss.Submit("dataset active RESULTS . \n")
spss.Submit("execute . \n")
varcount=spss.GetVariableCount()
data_str = spss.GetVariableName(0)
if spss.GetVariableType(0) > 0:
data_type_str=spss.GetVariableName(0)+' '+'varchar'
else:
data_type_str=spss.GetVariableName(0)+' '+ 'double'
for i in range(1,varcount):
data_str = data_str +', '+ spss.GetVariableName(i)
data_type_str = data_type_str +',
'+spss.GetVariableName(i)
if spss.GetVariableType(i) > 0:
data_type_str = ' '+data_type_str+' ' +'varchar'
else:
data_type_str = ' '+data_type_str+' ' + 'double'
print DSN,db_name,table_name
commands="""
SAVE TRANSLATE /TYPE=ODBC
/CONNECT='DSN="""+DSN+""";UID=
;PWD=,3;DBALIAS="""+db_name+
""";'
/ENCRYPTED
/MISSING=IGNORE
/SQL='CREATE TABLE """+table_name+"""
("""+data_type_str+"""
)'
/REPLACE
/TABLE='SPSS_TEMP'
/KEEP=All
/SQL='INSERT INTO """+table_name+"""
("""+data_str+""")
SELECT """+data_str+"""
FROM SPSS_TEMP'
/SQL='DROP TABLE SPSS_TEMP'."""
print commands
spss.Submit(commands)
end program. |
��������ȡ�����ݼ� RESULT �и�����ֵ�������ͣ�������Щ������Ϣ��
SQL ���������ݿ��д������ݱ����ñ��ı��������û�ͨ�� UI ����ָ���ġ�
�� Statistics �����
�� Customer Dialog ������� UI ���棬�� UI ������������
Python ������й�����������Ҫ�� Statistics �а�װ�� Customer Dialog�������û�ͨ��
UI ��ʹ�������Զ���� Python ����ģ�顣��װ��ʽ��ͼ��
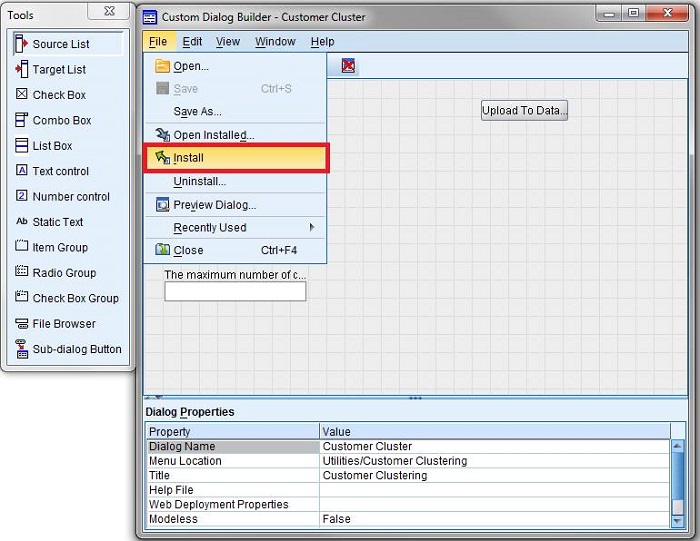
ͼ 13. ��װ Customer Dialog
1
��ͼ��ʾ���� Customer Dialog Builder ����ѡ��
File -> Install��ѡ��õĶԻ����ļ���CustomerClustering.spd����ָ����װλ�ñ��������ǰѴ�������Ϊ
Customer Clustering �Ĺ��ܰ�װ �� Utilities �˵��¡���װ��ɽ��������ʾ��
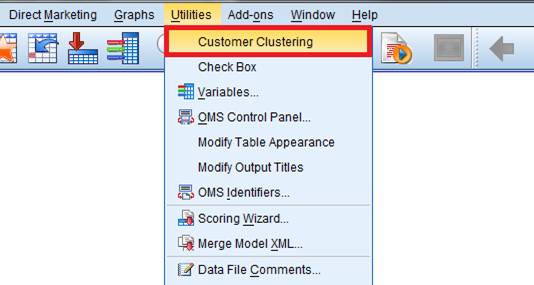
ͼ 14. ��װ Customer Dialog
2
��ͼ��ʾ��Statistics �IJ˵��� Utilities �£������������Զ���Ĺ���ģ��
Customer Clustering��
�Զ��� Python ģ��������ʾ���������
���ڷ�Ϊ�����֣������������ Statistics ���Զ��� Python
����ģ���������Ԥ�����Լ��Ըù���ģ���ִ�н�����з�����
����Ԥ����
�ڴ�������ݷ����У�ԭʼ���ݲ��ʺ�ֱ��ʹ�ã�����Ҫ����Ԥ�����������������磬�����С����ֵ���Ϊһ�������ֵ����һ����������ת���ɷ�������������ʹ�÷�������������⡣������Ҫ�������ͱ��������۶����Ϊһ�����������磺�ߡ��С��ͣ��Ӷ���������ݵ������ԡ�ͬʱ��ʹ��
Statistics �� Visual Binning �Թ���ģ���������ݽ���Ԥ������
�����Ǵ������̡����������ļ�������ʾ��
ͼ 15. �����ļ���ʾ
��ͼ��ʾ��������Ҫ���������۶���з��࣬�ֱ�Ϊ��SALES_RETAIL������SALES_ONLINE���Լ���SALES_TOTAL���������ԡ�SLAES_RETAIL��Ϊ�������������������������������ơ�
�� Statistics �������У�ѡ�� Transform ->
Visual Binning������ Visual Binning �Ի���ѡ�С�SALES_RETAIL��������ͼ��ʾ��
ͼ 16. Visual Binning
1
ѡ��Continue����ָ���±����� B_SALES_RETAIL���ڡ�Grid�������÷���㣨bin
cut point���������������ҵ���壬ѡ���� 9 ������㣬����� Make Lable ��ť��Statistics
���Զ�Ϊ����������ɱ�ǩ��
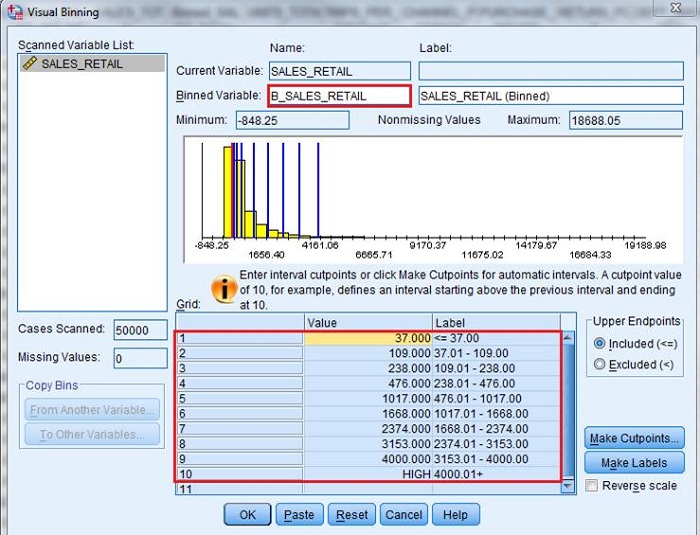
ͼ 17. Visual Binning
2
��ͼ��ʾ�����ǰ�ԭʼ�ġ�SALES_RETAIL��������Ϊ�� 10 �࣬��ͼʾ��֪�������ͱ�����SALES_RETAIL����ֵ������ֱ������������"B_SALES_RETAIL"��
10 ������ֵ�С����н������չʾ����ͼ��ʾ��
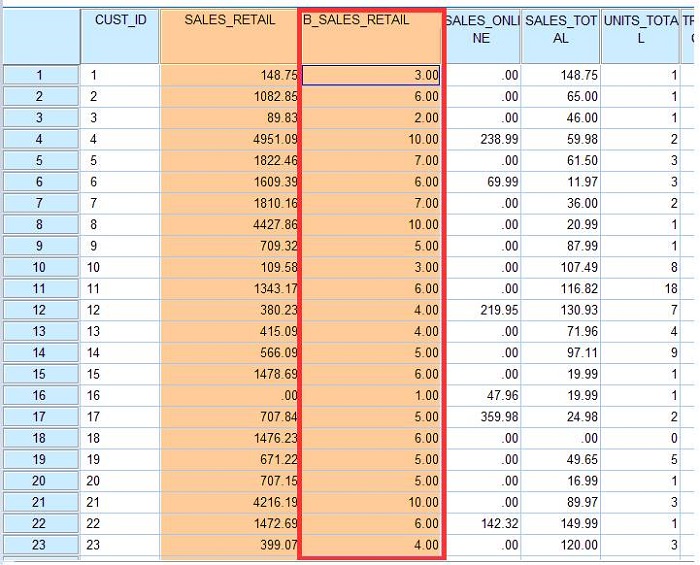
ͼ 18. Visual Binning
3
ʾ�� Python ģ�鼯�ɽ����ʾ
ԭʼ���ݵľ���Ԥ�������Ѿ������˱����û��Զ��幦��ģ�������Ҫ�����ڣ��û�����ֱ�ӽ���
Utilities->Customer Clustering���������Զ���ķ�������ý����
���� Statistics ������ Utilities -> Customer
Clustering �������Զ���Ի���
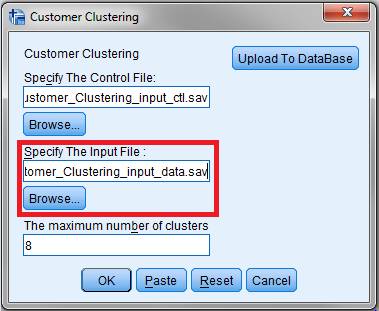
ͼ 19. ���ɽ����ʾ 1
��ͼ��ʾ������������������Ϊ��������Ԥ���� Visual Binning
��������ļ����û��涨������Ϊ 8������ 9 ���ͻ���Ⱥ���ֱ�Ϊ 0 �� 8�������OK�����У����н������Ϊ
.csv �ļ��� .sav �ļ�������֮�⣬���ǻ����Խ�ִ�н���ϴ������ݿ⡣�����Upload to
Database�������������ӶԻ���
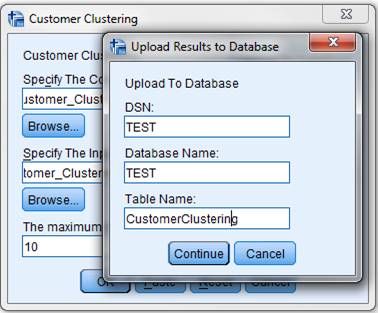
ͼ 20. ���ɽ����ʾ 2
��ͼ��ʾ�������ϴ����ݿ��������������CustomerClustering�����ڴ洢�ͻ���Ⱥ�����
�������ļ�����ͼ��ʾ��
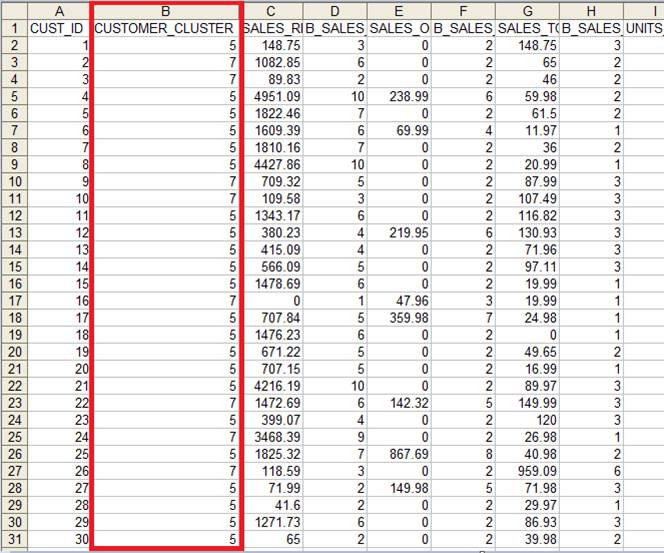
ͼ 21. ���ɽ����ʾ 3
���У���CUSTOMER_CLUSTER��Ϊ�ͻ��ķ�����Ϣ���� Customer
ID �ֱ�Ϊ 1 �Ŀͻ������ڷ��� 5�����ݿ��ϴ����������ʾ��
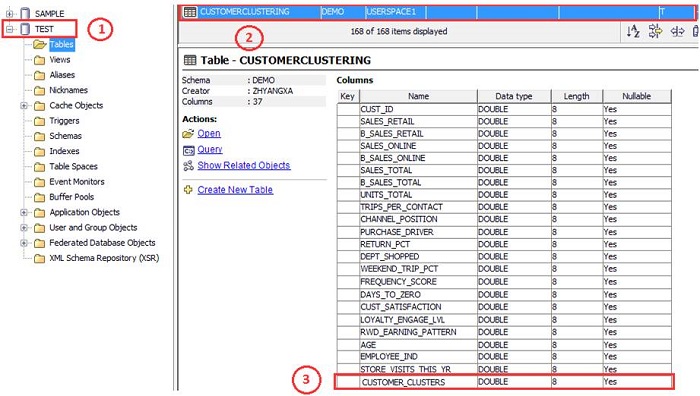
ͼ 22. ���ɽ����ʾ 4
��ͼ��֪��������ָ�����ݿ� TEST �У������˱� CUSTOMERCLUSTERING�����
3 ��Ϊ CUSTOMERCLUSTER ���ԣ�������˿ͻ�����������Ϣ��
ʾ�� Python ģ�鼯�ɽ������
Ϊ�˸���������˽�ͻ���Ⱥ��������ǿ������� Statistics �е�
Frequencies ����������з���������������¡�
�� 1. ͳ�ƽ��
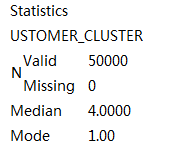
�ɱ� 1 ��֪���������У���Կͻ����顰CUSTOMER_CLUSTER������
50000 ����Ч�Ŀͻ���¼��������λ��Ϊ���� 4��˵���ֵĿͻ���������ǰ�벿�ֵķ��鵱�У����� 1
������ 4�������� 1 ӵ�����Ŀͻ����� 1 ֻ���ṩ�����Ǵ�ŵ�ͳ�ƽ����ҵ������٣���ϸͳ����Ϣ���¡�
�� 2. ͳ�ƽ����ϸ
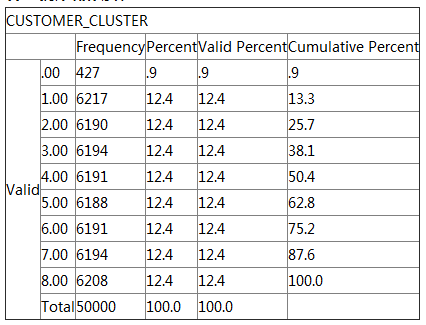
�ɱ� 2 ��֪������ 0 ӵ�����ٵĿͻ��� 427������ 1 ӵ�����Ŀͻ���
6217�����ҿͻ���Ϊ���ȵķֲ��ڷ��� 1 ������ 8���ͻ��ֲ����ͼ���¡�
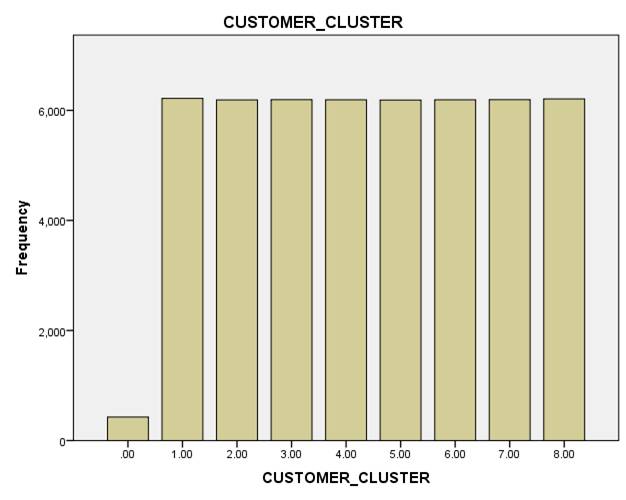
ͼ 23. �ͻ�����ͼʾ
��ͼ�ǶԿͻ���Ⱥ�����Ϊֱ�۵�չʾ������ 1 ������ 8 ӵ�н϶�Ŀͻ����ҷֲ��Ͼ��ȡ���Է��� 0���������������٣�ҵ�����ȼ��ϵͣ����ǿ��ԶԸ���ͻ�����һ������۲��ԡ������ڷ���
1 ������ 8�������������϶࣬ҵ�����ȼ��ϸߣ�������Ҫ�Ը���ͻ����н�һ���ķ������Ա��ȡ����ȷ�����۲��ԣ������ͻ����ҳ϶ȣ����ٿͻ���ʧ�� |





