| ժҪ: R ��һ�����ı�����ԣ�רΪ�ٽ�̽�������ݷ���������ͳ��ѧ���Ժ�ͼ��ѧ����ơ�R
ӵ�зḻ�ġ����ڲ�����������ݰ��⣬����ͳ��ѧ�����ݷ����������ھ�չ��ǰ�ء�
Ϊʲôѡ�� R��
R ����ִ��ͳ�ơ������Խ�����Ϊ SAS Analytics �ȷ���ϵͳ�ľ������֣��������� StatSoft
STATISTICA �� Minitab �ȸ��İ�����������ҵ����ҩ��ҵ������רҵͳ��ѧ�Һͷ���ѧ�Ҷ�����ȫ��ְҵ���Ķ�Ͷ�뵽��
IBM SPSS �� SAS �У���ȴû�б�д��һ�� R ���롣���Դ�ij�̶ֳ��Ͻ���ѧϰ��ʹ�� R �ľ����¹���ҵ�Ļ�����ϣ����ι���������ͳ����ѯʵ����ʹ���˶��ֹ��ߣ����ҵĴֹ���������
R ����ɵġ�������Щʾ����������ʹ�� R ��ԭ��
R ��һ��ǿ��Ľű����ԡ��������Ҫ�����һ����Χ�о��Ľ�����о���Ա����� 1,600 ƪ�о����ģ������ݶ�����������ǵ����ݽ��б��룬��ʵ�ϣ���Щ�����Ǵ������ж��ѡ��ͷֲ�����������ǵ����ݣ�������ƽ����һ��
Microsoft? Excel? ���ӱ����ϣ����� 8,000 ���У����дֶ��ǿյġ��о���Աϣ��ͳ�Ʋ�ͬ���ͱ����µ�������R
��һ��ǿ��Ľű����ԣ��ܹ��������� Perl ���������ʽ�������ı������ҵ�������Ҫһ�ֱ��������Դ�����Ҿ���
SAS �� SPSS �ṩ�˽ű�������ִ�������˵���������� R ����Ϊһ�ֱ�����Ա�д�ģ�������һ�ָ��ʺϸ���;�Ĺ��ߡ�
R ����ʱ����ǰ�ء�ͳ��ѧ�е������·�չ��������� R ������ʽ���ֵģ�Ȼ��ű����뵽��ҵƽ̨�С�����������һ��Ի������ҽ���о������ݡ�����ÿλ���ߣ�����ӵ��ҽ�������������Ŀ�������Լ�����ʵ�ʼ�ס����Ŀ��������Ȼģ���DZ���������ֲ������������
50 �������֪����������ģ�������Ȥ�ı���������Ĺ������������ų��ֵġ�������������ͨ���ɹ�����Ʒ���ʽ
(general estimating equations, GEE) �������� GEE �����ǽ����ģ����Ҽ��������Χ�ܹ㡣����Ҫһ�־��б���������
R �Ĺ�������ģ�͡�һ�����µ� R ����������һģ�ͣ�Ben Bolker ��д�� betabinom����
SPSS û�С�
�����ĵ������� R �����ؼ����� LaTeX �ĵ�����ϵͳ������ζ������ R ��ͳ�������ͼ�ο�Ƕ�뵽�ɹ��������ĵ��С��ⲻ�������˶��õ��ϣ��������ϣ����Я�첽�������ݷ������鼮������ֻ�Dz�ϣ����������Ƶ����ִ����ĵ�������������ŵ�·������ͨ��
R �� LaTeX��
û�гɱ�����Ϊһ��С����ҵ�������ߣ��Һ�ϲ�� R ������ض�����ʹ���ڸ������ҵ��֪�����ܹ���ʱ����ij���˲��������������ڹ���վ��ʹ��һ���ķ���������Ҳ�ܲ��������赣��Ԥ�㡣
R ��ʲô�����к���;��
��Ϊһ�ֱ�����ԣ�R �������������Զ������ơ��κα�д��������˶����� R ���ҵ��ܶ���Ϥ�Ķ�����R ��������������֧�ֵ�ͳ����ѧ��
һ��ͳ��ѧ������S ��̽�������ݷ���
����������ó����� �� ������д��������һ��������ִ������Ҫ���㷨���������� 60 �� 70 ���������������ó���Ϣ����ʾ��������ͼ�Ρ���Щ���������ڽ��ͳ�������е����ƣ���ζ��ͳ��ʵ����ͳ��ѧ�ҵ���ѵרע��ģ�����ͼ�����ԡ�һ���˼ٶ�����һ�����磬�о���Ա�������趨���裨������ũҵ����ģ�������������Ƶ�ʵ�飨��һ��ũҵվ��������ģ�ͣ�Ȼ�����в��ԡ�һ�����ڵ��ӱ��˵������ij�����
SPSS ��ӳ����һ����������ʵ�ϣ�SPSS �� SAS Analytics �ĵ�һ���汾����һЩ�����̣���Щ�����̿ɴ�һ����Fortran
���������������������Ͳ���һ��ģ�������е�һ��ģ�͡�
������淶���������۵Ŀ���У�John Tukey ������̽�������ݷ���
(EDA) �ĸ�������һ������ʯ�����˲����ݶ������������û��ʹ������ͼ��box plot�� �����ƫ�Ⱥ��쳣ֵ�Ϳ�ʼ����һ�����ݼ������Σ�����û�����һ����λ��ͼ���ij������ģ�Ͳв�ij�̬�����Ρ���Щ�뷨��
Tukey ����������κν����Ե�ͳ�ƿγ̶���������ǡ�������������ˡ�
����˵ EDA ��һ�����ۣ�����˵����һ�ַ������÷����벻�����¾������
1��ֻҪ�п��ܣ���Ӧʹ��ͼ����ʶ�����Ȥ�Ĺ��ܡ�
2�������ǵ����ġ�������������ģ�ͣ����ݽ���������һ��ģ�͡�
3��ʹ��ͼ�μ��ģ�ͼ��衣��Ǵ����쳣ֵ��
4��ʹ�ý�ȫ�ķ�������ֹΥ���ֲ����衣
Tukey �ķ���������һ���µ�ͼ�η������Ƚ����Ƶķ�չ�˳�������������һ�����ʺ�̽���Է�������������ܵĿ�����
S �������ڱ���ʵ������ John Chambers ��ͬ�¿����ģ�������һ��ͳ�Ʒ���ƽ̨�������� Tukey
����һ���汾��������ʵ�����ڲ�ʹ�ã��� 1976 �꿪������ֱ�� 1988 �꣬�����γ��������䵱ǰ��ʽ�İ汾������ʱ��������Ҳ�ɹ�����ʵ�����ⲿ���û�ʹ�á������Ե�ÿ�����涼�������ݷ�����
����ģ�͡���
1��S ��һ���ڱ�̻��������Ľ������ԡ�S ��� C ��������ƣ���ʡȥ�����ѵIJ��֡�S
����ִ���ڴ�����ͱ����������������ԣ������û��������д�������Щ�����ˡ����͵ı�̿���ʹ���û�������ͬһ�����ݼ��Ͽ���ִ�д���������
2����һ��ʼ��S �Ϳ��ǵ��˸�ͼ�εĴ������������κδ�ͼ�δ������ӹ��ܡ����ɺ�����ͻ����Ȥ�㣬��ѯ���ǵ�ֵ��ʹɢ��ͼ��ø�ƽ�����ȵȡ�
3������������� 1992 �����ӵ� S �еġ���һ����������У����������ݺͺ����������û���ֱ���������˼άʼ�����������ģ�ͳ������������ˡ�ͳ��ѧ�Ҵ���Ƶ�ʱ���ʱ�����С������и����������͵ĵ��ӱ���ģ�ͣ��ȵȡ���ÿ������£�ԭʼ���ݶ�ӵ�����Ժ�����ֵ���������ԣ�һ��ʱ�����а����۲�ֵ��ʱ��㡣���Ҷ���ÿ���������ͣ���Ӧ�õ���ͳ�����ݺ�ƽ��ͼ������ʱ�����У��ҿ��ܻ���һ��ʱ������ƽ��ͼ��һ�����ͼ���������ģ�ͣ��ҿ��ܻ������ֵ�ͲвS
֧��Ϊ������Щ��������������Ը�����Ҫ��������Ķ����ࡣ����ʹ�ô�����ĸ����������ʵ�ֱ�÷dz���
һ�־���̬�ȵ����ԣ�S��S-Plus �ͼ������
����� S ���Էdz����� Tukey �� EDA���Ѵﵽֻ�� �� S ��ִ��
EDA ������ִ�������κβ����ij̶ȡ�����һ�־���̬
�����ԡ��������ԣ����� S ������һЩ���õ��ڲ����ܣ�����ȱ����ϣ��ͳ������ӵ�е�һЩ�����ԵĹ��ܡ�û�к�����ִ��˫�������Ի��κ����͵���ʵ������ԡ���
Tukey ��Ϊ�����������ʱ�����ʡ�
1988 �꣬λ������ͼ�� Statistical Science
��� S ����Ȩ�����������Ե�һ����ǿ�汾����Ϊ S-Plus����ֲ�� DOS �Լ��Ժ�� Windows?
�С�ʵ����ʶ���ͻ���Ҫʲô��Statistical Science �� S-Plus �����˾���ͳ��ѧ���ܡ�����ִ�з������
(ANOVA)�����Ժ�����ģ�͵Ĺ��ܡ��� S ����������Զ��ԣ��κ��������ģ�͵Ľ����������һ�� S
�����ʵĺ������ö����ṩ������Ե����ֵ���в�� p-ֵ��ģ�Ͷ��������������������м���㲽�裬����һ����ƾ����
QR �ֽ⣨���� Q �ǶԽ��ߣ�R �����Ͻǣ���
��һ�� R ������ɸ�������һ����Դ����
��Լ���뷢�� S-Plus ��ͬ��ʱ�䣬�������¿�����ѧ�� Ross Ihaka
�� Robert Gentleman �������Ա�дһ��������������ѡ���� S ������Ϊ��ģ�͡�����Ŀ���β������֧�֡����ǽ�������Ϊ
R��
R �� S ��һ��ʵ�֣����� S-Plus �����ĸ���ģ�͡���ʱ�������õ���ͬһЩ�ˡ�R
�� GNU �����µ�һ����Դ��Ŀ���ڴ˻����ϣ�R ���Ϸ�չ����Ҫͨ�����Ӱ���R �� ��һ���������ݼ���R
�������ĵ��� C �� Fortran ��̬������ļ��ϣ�����һ��װ���� R �Ự���ʡ�R ���� R �����¹��ܣ�ͨ����Щ�����о���Ա����ͬ��֮�����ɵع������㷽����һЩ���ķ�Χ���ޣ���һЩ������������ͳ��ѧ������һЩ�������µļ�����չ����ʵ�ϣ�ͳ��ѧ�е����չ���������
R ����ʽ���ֵģ�Ȼ���Ӧ�õ����������С�
��д����ʱ��R ����վ�� CRAN ������ 4,701
�� R �������У�������һ��������� 6 �� R ���������ﶼ��һ����Ӧ�� R �������ٿ�������������
����ʹ�� R ʱ�ᷢ��ʲô��
��ע�����IJ���һ�� R �̡̳������ʾ������ͼ�����˽� R �Ự��������ʲô���ġ�
R �������ļ������� Windows��Mac OS X �Ͷ�� Linux?
���а档Դ����Ҳ�ɹ��������б��롣
��WindowsR�У���װ���� R ���ӵ���ʼ�˵��С�Ҫ�� Linux
������ R���ɴ�һ���ն˴��ڲ�����ʾ���¼��� R����Ӧ��������ͼ 1 �Ļ��档
ͼ 1. R ������
����ʾ���¼���һ�����R �ͻ���Ӧ��
��ʱ������ʵ�Ļ����У������ܻ��һ���ⲿ�����ļ������ݶ���
R �����С�R �ɴӸ��ֲ�ͬ��ʽ���ļ���ȡ���ݣ������ڱ�ʾ������ʹ�õ������� MASS ���� michelson
���ݡ������������ Venables and Ripley �ı�־���ı� Modern Applied
Statistics with S-Plus���μ� �ο����ϣ���michelson �������Բ������ٵ����е�
Michelson and Morley ʵ��Ľ����
�嵥 1 ���ṩ��������Լ��� MASS
������ȡ���鿴 michelson ���ݡ�ͼ 2 ��ʾ����Щ��������� R ����Ӧ��ÿһ�а���һ�� R
���������IJ������ڷ����� ([]) �ڡ�
�嵥 1. ����һ�� R �Ự
2+2 # R can be a calculator. R responds, correctly, with 4.
library("MASS")# Loads into memory the functions and data sets from
# package MASS, that accompanies Modern Applied Statistics in S
data(michelson) # Copies the michelson data
set into the workspace.
ls() # Lists the contents of the workspace.
The michelson data is there.
head(michelson) # Displays the first few lines
of this data set.
# Column Speed contains Michelson and Morleys
estimates of the
# speed of light, less 299,000, in km/s.
# Michelson and Morley ran five experiments with
20 runs each.
# The data set contains indicator variables for
experiment and run.
help(michelson) # Calls a help screen, which describes
the data set. |
ͼ 2. �Ự������ R ����Ӧ
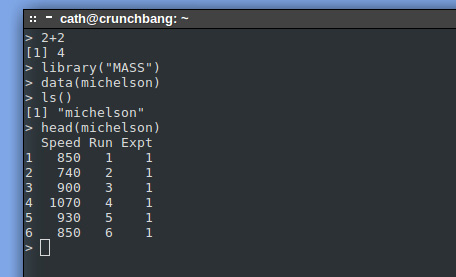
���������ǿ��������ݣ��μ� �嵥 2���������
ͼ 3 ����ʾ��
�嵥 2. R �е�һ������ͼ
# Basic boxplot
with(michelson, boxplot(Speed ~ Expt))
# I can add colour and labels. I can also save
the results to an object.
michelson.bp = with(michelson, boxplot(Speed
~ Expt, xlab="Experiment", las=1,
ylab="Speed of Light - 299,000 m/s",
main="Michelson-Morley Experiments",
col="slateblue1"))
# The current estimate of the speed of light,
on this scale, is 734.5
# Add a horizontal line to highlight this value.
abline(h=734.5, lwd=2,col="purple")
#Add modern speed of light |
Michelson and Morley �ƺ��мƻ��ظ߹��˹��١�����ʵ��֮���ƺ�Ҳ����һ���IJ������ԡ�
ͼ 3. ����һ������ͼ
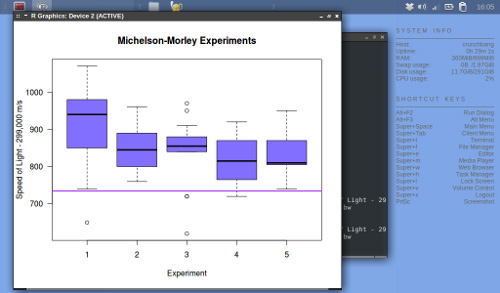
�ڶԷ����е�������ҿ��Խ���������浽һ��
R �����С��μ��嵥 3��
�嵥 3. R �е�һ������
MyExample = function(){
library(MASS)
data(michelson)
michelson.bw = with(michelson, boxplot(Speed ~ Expt, xlab="Experiment", las=1,
ylab="Speed of Light - 299,000 m/s", main="Michelsen-Morley Experiments",
col="slateblue1"))
abline(h=734.5, lwd=2,col="purple")
} |
�����ʾ����ʾ�� R �Ķ����Ҫ���ܣ�
1����������boxplot()
��������һЩ���õ�ͳ�����ݺ�һ��ͼ����������ͨ������michelson.bp = ... �ĸ�ֵ��佫��Щ������浽һ��
R �����У�������Ҫʱ��ȡ���ǡ��κθ�ֵ���Ľ�������� R �Ự�����������л�ã����ҿ�����Ϊ��һ�����������⡣boxplot
��������һ�����ڻ�������ͼ��ͳ�����ݣ���λ�����ķ�λ�ȣ�����ÿ������ͼ�е��������Լ��쳣ֵ���� ͼ 3
�е�ͼ������ʾΪ����Բ����
2����ʽ���ԡ�
R���� S����һ�ֽ��յ�����������ͳ��ģ�͡������еĴ��� Speed ~ Expt ���ߺ�����ÿ�� Expt
��ʵ�����֣������ϻ��� Speed ������ͼ�����ϣ��ִ�з�����������Ը���ʵ���е��ٶ��Ƿ�����������죬��ô����ʹ����ͬ�Ĺ�ʽ��lm(Speed
~ Expt)����ʽ���Կɱ���ḻ������ͳ��ģ�ͣ����������Ƕ��ЧӦ���Լ��̶���������ء�
3���û������R������
����һ�ֱ�����ԡ�
R �ѽ��� 21 ����
Tukey ��̽�������ݷ��������ѳ�Ϊ����γ̡������ڽ������ַ�������ͳ��ѧ��Ҳ��ʹ�ø÷�����R
֧�����ַ��������������Ϊʲô��Ȼ������е�ԭ����������Ի����� R �������£���Ϊ�µ�������Դ��Ҫ�µ����ݽṹ��ִ�з�����InfoSphere?
Streams ����֧�ֶ��� John Chambers ������IJ�ͬ������ִ�� R ������
ע��
140 �ַ��Ľ���
R �� S ��һ�ֿ�Դʵ�֣���һ���������ݷ�����ͼ�εı�̻�����
���� ��ͼ�λ������ݷ���������
�����κ������Ӧ���У���Ӧ��ͨ�����ַ�ʽ�������ݣ�����һЩƽ��ͼ����ִ�ж�η�������ÿ������Ľ��Ϊ��һ�������ṩ���顣��Ч�����ݷ����ǵ���ʽ�ġ�����John
Chambers���μ� �ο����ϣ���
R ��Ҫ����Ӳ����
����һ̨���� Crunchbang Linux �ĺ곞�����������������ʾ����R
����Ҫ���صĻ�����ִ����С��ģ�ķ�����20 ����������һֱ��Ϊ R ֮���Ի�������Ϊ����һ�ֽ��������ԣ����������Է��������ݴ�С�ܼ�����ڴ�����ơ�������ģ�����ͨ�����ִ���������ϵ������Ӧ�ó���dz������ݣ���
|





