| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФЯъЯИНщЩмСЫKimballКЭInmonЪЧСНжжжїСїЕФЪ§ОнВжПтЗНЗЈЃЌвдМАСНепЕФВювьЖдБШЕШЯрЙижЊЪЖЁЃ |
|
ИХЪі
KimballКЭInmonЪЧСНжжжїСїЕФЪ§ОнВжПтЗНЗЈТлЃЌЗжБ№гЩ Ralph KimbalДѓЩё КЭ Bill
InmonДѓЩёЬсГіЃЌдкЪЕМЪЪ§ОнВжПтНЈЩшжаЃЌвЕНчЭљЭљЛсЯрЛЅНшМјЪЙгУСНжжПЊЗЂФЃЪНЁЃБОЮФНЋЯъЯИНщЩм Kimball
КЭ Inmon РэТлдкЪЕМЪЪ§ОнВжПтНЈЩшжаЕФгІгУгыЖдБШ,ЭЈЙ§Ъ§ОнВжПтРэТлЮфзАЪ§ОнВжПтЪЕМљЁЃ
ЪВУДЪЧKimball
ИХФю
Kimball ФЃЪНДгСїГЬЩЯПДЪЧЪЧздЕзЯђЩЯЕФЃЌМДДгЪ§ОнМЏЪаЕНЪ§ОнВжПтдйЕНЪ§ОндД(ЯШгаЪ§ОнМЏЪадйгаЪ§ОнВжПт)ЕФвЛжжУєНнПЊЗЂЗНЗЈЁЃЖдгкKimballФЃЪНЃЌЪ§ОндДЭљЭљЪЧИјЖЈЕФШєИЩИіЪ§ОнПтБэЃЌЪ§ОнНЯЮЊЮШЖЈЕЋЪЧЪ§ОнжЎМфЕФЙиСЊЙиЯЕБШНЯИДдгЃЌашвЊДгетаЉOLTPжаВњЩњЕФЪТЮёаЭЪ§ОнНсЙЙГщШЁГіЗжЮіаЭЪ§ОнНсЙЙЃЌдйЗХШыЪ§ОнМЏЪажаЗНБуЯТвЛВНЕФBIгыОіВпжЇГжЁЃ
СїГЬ
ЭЈГЃЃЌKimballЖМЪЧвдзюжеШЮЮёЮЊЕМЯђЁЃЪзЯШЃЌдкЕУЕНЪ§ОнКѓашвЊЯШзіЪ§ОнЕФЬНЫїЃЌГЂЪдНЋЪ§ОнАДееФПБъЯШВ№ЗжГіВЛЭЌЕФБэашЧѓЁЃЦфДЮЃЌдкУїШЗЪ§ОнвРРЕКѓНЋИїИіШЮЮёдйЭЈЙ§ETLгЩStageВузЊЛЏЕНDMВуЁЃетРяDMВуЪ§ОндђгЩШєИЩИіЪТЪЕБэКЭЮЌЖШБэзщГЩЁЃНгзХЃЌдкЭъГЩDMВуЕФЪТЪЕБэЮЌЖШБэВ№ЗжКѓЃЌЪ§ОнМЏЪавЛЗНУцПЩвджБНгЯђBIЛЗНкЪфГіЪ§ОнСЫЃЌСэвЛЗНУцПЩвдЯШDWВуЪфГіЪ§ОнЃЌЗНБуКѓајЕФЖрЮЌЗжЮіЁЃ
KimballЭљЭљвтЮЖзХПьЫйНЛИЖЁЂУєНнЕќДњЃЌВЛЛсЖдЪ§ОнВжПтМмЙЙзіЙ§ЖрИДдгЕФЩшМЦЃЌдкБфЛЛФЊВтЕФЛЅСЊЭјаавЕЃЌетжжМмЙЙЗНЪНж№НЅГЩЮЊвЛжжжїСїЗЖЪНЁЃ
ЪВУДЪЧInmon
ИХФю
Inmon ФЃЪНДгСїГЬЩЯПДЪЧздЖЅЯђЯТЕФЃЌМДДгЪ§ОндДЕНЪ§ОнВжПтдйЕНЪ§ОнМЏЪаЕФЃЈЯШгаЪ§ОнВжПтдйгаЪ§ОнЪаГЁЃЉвЛжжЦйВМСїПЊЗЂЗНЗЈЁЃЖдгкInmonФЃЪНЃЌЪ§ОндДЭљЭљЪЧвьЙЙЕФЃЌБШШчДгздааЖЈвхЕФХРГцЪ§ОнОЭЪЧНЯЮЊЕфаЭЕФвЛжжЃЌЪ§ОндДЪЧИљОнзюжеФПБъздааЖЈжЦЕФЁЃетРяжївЊЕФЪ§ОнДІРэЙЄзїМЏжадкЖдвьЙЙЪ§ОнЕФЧхЯДЃЌАќРЈЪ§ОнРраЭМьбщЃЌЪ§ОнжЕЗЖЮЇМьбщвдМАЦфЫћвЛаЉИДдгЙцдђЁЃдкетжжГЁОАЯТЃЌЪ§ОнЮоЗЈДгstageВужБНгЪфГіЕНdmВуЃЌБиаыЯШЭЈЙ§ETLНЋЪ§ОнЕФИёЪНЧхЯДКѓЗХШыdwВуЃЌдйДгdwВубЁдёашвЊЕФЪ§ОнзщКЯЪфГіЕНdmВуЁЃдкInmonФЃЪНжаЃЌВЂВЛЧПЕїЪТЪЕБэКЭЮЌЖШБэЕФИХФюЃЌвђЮЊЪ§ОндДБфЛЏЕФПЩФмадНЯДѓЃЌашвЊИќМгЧПЕїЪ§ОнЕФЧхЯДЙЄзїЃЌДгжаГщШЁЪЕЬх-ЙиЯЕЁЃ
СїГЬ
ЭЈГЃЃЌInmonЖМЪЧвдЪ§ОндДЭЗЮЊЕМЯђЁЃЪзЯШЃЌашвЊЬНЫїадЕиШЅЛёШЁОЁСПЗћКЯдЄЦкЕФЪ§ОнЃЌГЂЪдНЋЪ§ОнАДеедЄЦкЛЎЗжЮЊВЛЭЌЕФБэашЧѓЁЃЦфДЮЃЌУїШЗЪ§ОнЕФЧхЯДЙцдђКѓНЋИїИіШЮЮёЭЈЙ§ETLгЩStageВузЊЛЏЕНDWВуЃЌетРяDWВуЭЈГЃЩцМАЕННЯЖрЕФUDFПЊЗЂЃЌНЋЪ§ОнГщЯѓЮЊЪЕЬх-ЙиЯЕФЃаЭЁЃНгзХЃЌдкЭъГЩDWЕФЪ§ОнжЮРэжЎКѓЃЌПЩвдНЋЪ§ОнЪфГіЕНЪ§ОнМЏЪажазіЛљБОЕФЪ§ОнзщКЯЁЃзюКѓЃЌНЋЪ§ОнМЏЪажаЕФЪ§ОнЪфГіЕНBIЯЕЭГжаШЅИЈжњОпЬхвЕЮёЁЃ
ЬиеїЖдБШ
Ьиад 
гХСгБШНЯ

ОпЬхР§зг
ЯраХвЛЭЈРэТлжЎКѓПЩФмЛЙЪЧФмРЇЛѓЃЌЯждкОйвЛИіОпЬхЕФР§згЁЃ
Ъ§Он
ЙЩЦБНЛвзЮЊР§ЃК
ЃЈOLTPЃЉдЪМЪ§ОнАќКЌСЫШчЯТМИеХЪТЮёБэЃК(ецЪЕГЁОАзжЖЮЩшМЦИќЮЊИДдгЃЌДЫДІвбОМђЛЏ)
НЛвзМЧТМБэЃКМЧТМгУЛЇЯТЕЅЧщПі

ГЩНЛШежОБэЃКМЧТМгУЛЇЯТЕЅЧвГЩНЛЕФЧщПі

гУЛЇаХЯЂБэ

ЖдБШ
ШчЙћЪЧ Inmon ФЃЪНЃЌЮвУЧашвЊНЋЪ§ОнПтВ№ЗжГЩ гУЛЇЪЕЬхБэЁЂГЩНЛШежОЪЕЬхБэЁЂгУЛЇгыГЩНЛШежОЙиЯЕБэЕШЖрИізгФЃПщЁЃШчЙћЪЧ
Kimball ФЃЪНЃЌЮвУЧдђашвЊНЋЪ§ОнПтВ№ЗжГЩ гУЛЇЮЌЖШБэЁЂгУЛЇзЪВњЪТЪЕБэЁЂГЩНЛЪТЪЕБэЁЃдкKimballФЃЪНжаЃЌЮвУЧВЛашвЊЕЅЖРЮЌЛЄЙиЯЕБэЃЌвђЮЊЙиЯЕвбОШпгрдкЮЌЖШБэКЭЪТЪЕБэжаЁЃ
Inmon ФЃЪНЃК
гУЛЇЪЕЬхБэ
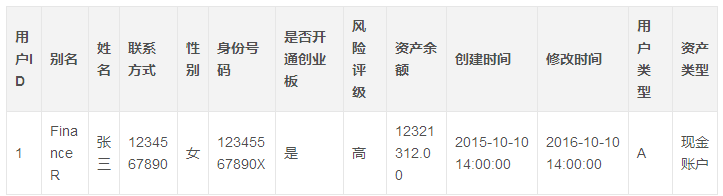
ГЩНЛЙиЯЕБэ

гУЛЇзЪВњЙиЯЕБэ

Kimball ФЃЪН
гУЛЇЮЌЖШБэ

ПЩвдПДЕНетРяЕФгУЛЇЮЌЖШБэВЛАќКЌвЕЮёНЛвзаХЯЂЃЌБфЛЏЯрЖдЛКТ§ЃЈОВЬЌЃЉЖјЗчЯеЦРМЖЁЂгУЛЇРраЭвВашвЊгЩЗчЯеЦРМЖЮЌЖШБэЁЂгУЛЇРраЭЮЌЖШБэРДЮЌЛЄ
гУЛЇзЪВњЪТЪЕБэ

етРяЕФгУЛЇзЪВњЪТЪЕБэЭЈГЃЪ§ОнЪЧгЩгУЛЇзЪВњНЛвзШежОВњЩњЕФЃЌвђЮЊШежОДцдкжЛВхШыЃЌВЛИќаТЕФЬиЕуЃЈПьЫйдіМгЁЂзюЯИСЃЖШЃЉ
змНс
ЖдгкДѓЖрЪ§ЛЅСЊЭјЙЋЫОгЩгкашЧѓЕФПьЫйБфЛЏЃЌДІаФЛ§ТЧЩшМЦЃЈInmonЃЉЪЕЬх-ЙиЯЕЕФЩшМЦембЇЫЦКѕВЂВЛФмТњзуПьЫйЕќДњЕФвЕЮёашвЊЁЃЫљвдЃЌИќЖрГЁОАЯТЧїЯђгкЪЙгУЃЈKimballЃЉЮЌЖШ-ЪТЪЕЕФЩшМЦембЇЗДЖјПЩвдИќПьЕиЭъГЩШЮЮёЁЃ
Ъ§ОнВжПтНЈЩшЭЈГЃвдШеЮЊСЃЖШЃЌНЋOLTPЪ§ОнБфЛЏЕФВЛЧщПідіСПЭЌВНЕНЪ§ОнВжПтжаЁЃ
дкЪ§ОнВжПтЕФЪЕМЪЙЄзїжаЃЌ80%ЕФЪБМфЛсЛЈЗбдкШЮЮёЕїЖШЁЂЪ§ОнЧхЯДКЭвЕЮёЪсРэЩЯЃЌжЛга20%ЕФЪБМфЛсЭЖШыЕНЪ§ОнЭкОђЩЯЁЃ |








