| БрМЭЦМі: |
БОЮФЭЈЙ§ вЛИіЯюФПНщЩмСЫTiDB ДгЛљДЁдкЪЕЪБЪ§ВжжаЕФгІгУЃЌЯЃЭћБОЮФЖдДѓМвгаАяжњЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЯюФПБГОА
ФПЧАЦѓвЕДѓЖрЪ§ЕФЪ§ОнЗжЮіГЁОАЕФНтОіЗНАИЕзВуЖМЪЧЮЇШЦ Hadoop ДѓЪ§ОнЩњЬЌеЙПЊЕФЃЌГЃМћЕФШч HDFS
+ Hive + Spark + Presto + KylinЃЌдквзЙћМЏЭХЃЌЮвУЧГѕЦквВЪЧВЩШЁетжжЫМТЗЃЌЕЋЪЧЫцзХвЕЮёЙцФЃЕФПьЫйдіГЄКЭашЧѓЕФВЛЖЯБфЛЏЃЌвЛаЉЪЕЪБЛђепзМЪЕЪБЕФашЧѓБфЕУдНРДдНЖрЃЌетРрвЕЮёГ§СЫгаЪЕЪБЕФ
OLTP ашЧѓЃЌЛЙАщЫцзХвЛаЉгавЛЖЈИДдгЖШЕФ OLAP ЕФашЧѓЃЌЕЅДПЕиЪЙгУ Hadoop вбОЮоЗЈТњзуашЧѓЁЃ
ЯжгаЕФзМЪЕЪБЯЕЭГдЫаадк SQL Server жЎЩЯЃЌЭЈЙ§ПЊЗЂШЫдББраДКЭЮЌЛЄЯргІЕФДцДЂЙ§ГЬРДЪЕЯжЁЃгЩгкЪ§ОнСПВЛДѓЃЌSQL
Server ФмЙЛТњзуашЧѓЃЌЕЋЪЧЫцзХвЕЮёЕФЗЂеЙЃЌЪ§ОнСПЫцжЎдіГЄЃЌSQL Server дНРДдНВЛФмТњзуашЧѓЃЌЕБЪ§ОнСПЕНДявЛЖЈЕФНзЖЮЃЌадФмБуЛсГіЯжЙеЕуЁЃетИіЪБКђЃЌетЬзЗНАИвбЭъШЋЮоЗЈжЇГХвЕЮёЃЌВЛЕУВЛжиаТЩшМЦаТЕФЗНАИЁЃ
бЁаЭЦРЙР
дкЦРЙРГѕЦкЃЌGreenplumЁЂKuduЁЂTiDB ЖМНјШыСЫЮвУЧЕФЪгвАЃЌЖдгкаТЕФЪЕЪБЯЕЭГЃЌЮвУЧгажївЊПМТЧЕуЃК
ЪзЯШЃЌЯЕЭГМШвЊТњзу OLAP ЛЙвЊТњзу OLTP ЕФЛљБОашЧѓЃЛ
ЦфДЮЃЌаТЯЕЭГвЊОЁСПНЕЕЭвЕЮёЕФЪЙгУвЊЧѓЃЛ
зюКѓЃЌаТЯЕЭГзюКУФмЙЛгыЯжгаЕФ Hadoop ЬхЯЕЯрНсКЯЁЃ
Greenplum ЪЧвЛЬзЛљгк PostgreSQL ЗжЮіЮЊжїЕФ MPP в§ЧцЃЌДѓЖргУдкВЂЗЂЖШВЛИпЕФРыЯпЗжЮіГЁОАЃЌЕЋдк
OLTP ЗНУцЃЌЮвУЧЕФГѕВНВтЪдЗЂЯжЦфЖдБШ TiDB ЕФадФмВюКмЖрЁЃ
дйЫЕЫЕ KuduЁЃKudu ЪЧ CDH 2015ФъЗЂВМЕФвЛЬзНщгк Hbase КЭ HDFS жаМфЕФвЛЬзДцДЂЯЕЭГЃЌФПЧАдкЙњФкжївЊЪЧаЁУзЙЋЫОгІгУЕФНЯЖрЃЌдкВтЪджаЃЌЮвУЧЗЂЯжЦфдк
OLTP БэЯжДѓжТгы TiDB ЯрЕБЃЌЕЋЪЧвЛаЉжаЕШЪ§ОнСПЯТЃЌЦфЗжЮіадФмЯрБШ TiDB гавЛЖЈВюОрЁЃСэЭтЮвУЧЕФВщбЏФПЧАжївЊвд
Presto ЮЊжїЃЌPresto ЖдНг Kudu КЭ PostgreSQL ЖМЪЧашвЊПМТЧМцШнадЕФЮЪЬтЃЌЖј
TiDB МцШн MySQL авщЃЌдкгІгУГѕЦкПЩвджБНгЪЙгУ Presto-MySQL НјааЭГвЛВщбЏЃЌЯТвЛВНдйПМТЧзЈУХПЊЗЂ
Presto-TiDBЁЃ
СэЭтЃЌЮвУЧЯЃЭћЮДРДЕФЪЕЪБЯЕЭГКЭРыЯпЯЕЭГФмЙЛЭЈгУЃЌвЛЬзДњТыдкСНИіЯЕЭГжаЖМФмЙЛЭъШЋМцШнЃЌФПЧА Tispark
КЭ SparkSQL вбОКмДѓГЬЖШЩЯЪЕЯжСЫетЕуЃЌетжЇГжЮвУЧдквдКѓРыЯпЩЯЕФаЁЪБМЖШЮЮёПЩвджБНгЧаЛЛЕН TiDBЩЯЃЌдк
TiDB ЩЯЪЕЯжЪЕЪБвЕЮёЕФЭЌЪБЃЌШчЙћга T+1 ЕФашЧѓвВФмЙЛжБНгжИ HDFS МДПЩЃЌВЛгУЖўДЮПЊЗЂЃЌетЪЧ
Kudu КЭ GP днЪБЪЕЯжВЛСЫЕФЁЃ
зюКѓЃЌTiSpark ЪЧНЈСЂдк Spark в§ЧцжЎЩЯЃЌSpark дкЛњЦїбЇЯАСьгђРягажюШч Mllib
ЕШжюЖрГЩЪьЕФЯюФПЃЌЖдБШ GP КЭ KuduЃЌЫуЗЈЙЄГЬЪІУЧЪЙгУ TiSpark ШЅВйзї TiDB ЕФУХМїЗЧГЃЕЭЃЌЭЌЪБвВЛсДѓДѓЬсЩ§ЫуЗЈЙЄГЬЪІУЧЕФаЇТЪЁЃ
ОЙ§злКЯЕФПМТЧЃЌЮвУЧзюжеОіЖЈЪЙгУ TiDB зїЮЊаТЕФЪЕЪБЯЕЭГЁЃЭЌЪБЃЌФПЧА TiDB ЕФЩчЧјЛюдОЖШЗЧГЃКУЃЌетвВЪЧЮвУЧПМТЧЕФвЛИіКмживЊЕФЗНУцЁЃ
TiDB МђНщ
дкетРяНщЩмвЛЯТ TiDB ЕФЯрЙиЬиадЃКTiDB ЪЧЛљгк Google Spanner/F1 ТлЮФЦєЗЂПЊдДЕФвЛЬз
NewSQL Ъ§ОнПтЃЌЫќОпБИШчЯТ
NewSQL КЫаФЬиадЃК
SQLжЇГж ЃЈTiDB ЪЧ MySQL МцШнЕФЃЉ
ЫЎЦНЯпадЕЏадРЉеЙ
ЗжВМЪНЪТЮё
Ъ§ОнЧПвЛжТадБЃжЄ
ЙЪеЯздЛжИДЕФИпПЩгУ
ЭЌЪБЃЌTiDB ЛЙгавЛЬзЗсИЛЕФЩњЬЌЙЄОпЃЌР§ШчЃКПьЫйВПЪ№ЕФ TiDB-AnsibleЁЂЮоЗьЧЈвЦ MySQL
ЕФ SyncerЁЂвьЙЙЪ§ОнЧЈвЦЙЄОп WormholeЁЂвдМА TiDB-BinlogЁЂBackup &
Recovery ЕШЁЃ
SQL Server ЧЈвЦЕН TiDB
гЩгкЮвУЧЙЋЫОЕФМмЙЙЪЧ .NET + SQL Server МмЙЙЃЌЫљвдЮвУЧЮоЗЈЯёДѓЖрЪ§ЙЋЫОвЛбљШЅЪЙгУ
MySQL Binlog ШЅзіЪ§ОнЭЌВНЃЌЕБШЛвВОЭЮоЗЈЪЙгУ TiDB ЙйЗНЬсЙЉЕФ Syncer ЙЄОпСЫЁЃвђДЫЮвУЧВЩгУСЫ
Flume + Kafka ЕФМмЙЙЃЌЮвУЧздМКПЊЗЂСЫЛљгк Flume ЕФ SQL Server Source
ШЅЪЕЪБМрПи SQL Server Ъ§ОнБфЛЏЃЌНјааВЖзНВЂаДШы Kafka жаЃЌЭЌЪБЃЌЮвУЧЪЙгУ Spark
Streaming ШЅЖСШЁ Kafka жаЕФЪ§ОнВЂаДШы TiDBЃЌЭЌЪБЮвУЧНЋжЎЧА SQL Server
ЕФДцДЂЙ§ГЬИФдьГЩЖЈЪБЕїЖШЕФ MySQL НХБОЁЃ

ЭМЃКSQL Server Ъ§ОнЧЈвЦЕН TiDB
TiDB ЧАЦкВтЪд
дкВтЪдГѕЦкЃЌЮвУЧВЩгУ TiDB ЕФАцБОЮЊ RC4ЃЌдкВтЪдЙ§ГЬжадјОдкЭЌЪБЖдвЛеХБэНјааЖСаДЪБЃЌГіЯж Region
is stale ЕФДэЮѓЃЌдк GitHub ЩЯЬсГі Issue КѓЃЌTiDB ЙйЗНКмПьдк Pre-GA
АцБОжаНјааСЫаоИДЁЃдкВтЪдЛЗОГЃЌЮвУЧЪЧЪжЖЏЭЈЙ§ЖўНјжЦАќЕФаЮЪНРДВПЪ№ TiDB ЃЌЫфШЛБШНЯМђЕЅЃЌЕЋЪЧЕБ
TiDB ЗЂВМ GA АцБОжЎКѓЃЌАцБОЩ§МЖШДЪЧвЛИіБШНЯДѓЕФЮЪЬтЃЌгЩгкдчЦкУЛгаЪЙгУ TiDB-ansible
АВзАЃЌЙйЗНжЦзїЕФЩ§МЖНХБОЮоЗЈЪЙгУЃЌЖјЪжЖЏНјааЙіЖЏЩ§МЖЕШВйзїЗЧГЃТщЗГЁЃгЩгкЕБЪБЪЧВтЪдЛЗОГЃЌдкЬ§ШЁСЫ TiDB
ЙйЗНЕФНЈвщжЎКѓЃЌЮвУЧжиаТРћгУ TiDB ЙйЗНЬсЙЉЕФ TiDB-ansible ВПЪ№СЫ TiDB ЕФ
GA АцБОЁЃжЛашвЊЯТдиЙйЗНЬсЙЉЕФАќЃЌаоИФЯргІЕФХфжУЃЌОЭФмЭъГЩАВзАКЭВПЪ№ЁЃЙйЗНвВЬсЙЉСЫЩ§МЖНХБОЃЌФмЙЛдкЯрСкЕФ
TiDB АцБОжЎЧАЭъГЩЮоЗьЙіЖЏЩ§МЖЁЃЭЌЪБ TiDB-ansible ФЌШЯЛсЬсЙЉ Prometheus
+ Grafana ЕФМрПиАВзАЃЌЙйЗНЬсЙЉСЫЗЧГЃЗсИЛЭъЩЦЕФ Grafana ФЃАхЃЌЪЁШЅСЫдЫЮЌКмЖрМрПиХфжУЕФЙЄзїСПЃЌНшзХ
TiDB ВПЪ№МрПиЕФЦѕЛњЃЌЮвУЧвВЭъГЩСЫжюШч RedisЃЌRabbitMQЃЌElasticsearch
ЕШКмЖргІгУГЬађЕФМрПигЩ Zabbix Эљ Prometheus ЕФЧЈвЦЁЃетРяашвЊзЂвтЕФЪЧЃЌШчЙћЪЧгУЙйЗНЬсЙЉЕФВПЪ№ЙЄОпВПЪ№
Prometheus КЭ GrafanaЃЌдкжДааЙйЗНЕФЭЃжЙНХБОЪБЧаМЧЬјЙ§ЯргІЕФзщМўЃЌвдУтИЩШХЦфЫћГЬађЕФМрПиЁЃ
TiDB ЩЯЯпЙ§ГЬ
дк10дТжабЎЃЌЫцзХаТЛњЦїЕФВЩЙКЕНЮЛЃЌЮвУЧе§ЪННЋ TiDB ВПЪ№ЕНЩњВњЛЗОГНјааВтЪдЃЌећИіМмЙЙЮЊ 3 ЬЈЛњЦїЃЌ3TiKVЃЋ3PDЃЋ2TiDB
ЕФМмЙЙЁЃдкЩњВњЛЗОГжаЕФДѓЪ§ОнСПГЁОАЯТЃЌгіЕНСЫвЛаЉаТЕФЮЪЬтЁЃ
ЪзЯШгіЕНЕФЮЪЬтЪЧ OLTP ЗНУцЃЌSpark Streaming ГЬађЩшжУЕФ 5 УывЛИіДАПкЃЌЕБ
5 УыжЎФкВЛФмДІРэЭъЕБЧАХњДЮЕФЪ§ОнЃЌОЭЛсВњЩњбгГйЃЌЭЌЪБ Streaming дкетИіХњДЮНсЪјКѓЛсТэЩЯЦєЖЏЯТвЛИіХњДЮЃЌЕЋЪЧЫцзХЪБМфЕФЛ§РлЃЌбгГйЕФЪ§ОнОЭЛсдНРДдНЖрЃЌзюКѓЩѕжСбгГйСЫ
8 аЁЪБжЎОУЃЛСэвЛЗНУцЃЌгЩгкЮвУЧЪЙгУЕФЪЧЛњаЕгВХЬЃЌвђДЫаДШыЕФаЇТЪЪЎЗжВЛЮШЖЈЃЌетвВЪЧдьГЩаДШыбгГйЕФвЛИіКмжївЊЕФвђЫиЁЃ
ГіЯжЮЪЬтжЎКѓЮвУЧСЂМДгы TiDB ЙйЗНШЁЕУСЊЯЕЃЌШЗШЯ TiDB ећЬхМмЙЙжївЊЛљгк SSD ДцДЂадФмжЎЩЯНјааЩшМЦЕФЁЃЮвУЧНЋ
3 ЬЈЛњЦїЕФгВХЬЖМЛЛГЩСЫ SSDЃЛгыДЫЭЌЪБЃЌЮвУЧЕФЙЄГЬЪІвВПЊЗЂСЫЯргІЕФЭЌВНГЬађРДЬцДњ Spark StreamingЃЌЫцзХгВМўЕФИќаТвдМАГЬађЕФЬцЛЛЃЌаДШыЗНУцж№НЅЮШЖЈЃЌГЬађдЫааЕФЗНЪНвВКЭ
Streaming ГЬађРрЫЦЃЌЖрГЬађЭЌЪБжИЖЈвЛИі Kafka ЕФ Group IDЃЌЭЌЪБСЌНгВЛЭЌЛњЦїЕФ
TiDB вдДяЕНаДШыаЇТЪзюДѓЛЏЃЌЭЌЪБвВЪЕЯжСЫ HAЃЌБЃжЄСЫМДЪЙвЛИіНјГЬЙвЕєвВВЛгАЯьећЬхЪ§ОнЕФаДШыЁЃ
дк OLTP гХЛЏНсЪјжЎКѓЃЌЫцжЎЖјРДЕФЪЧЗжЮіЗНУцЕФашЧѓЁЃгЩгкЮвУЧЖд TiDB ЕФЖЈЮЛЪЧЪЕЪБЪ§ОнВжПтЃЌетбљОЭЛсЯё
Hadoop вЛбљДцдкКмЖр ETL ЕФСїГЬЃЌдк Hadoop ЕФСїГЬжаЃЌвд T+1 ЮЊжїЕФШЮЮёеМОнСЫОјДѓЖрЪ§ЃЌЖјетаЉШЮЮёЦеБщдкСшГПЦєЖЏжДааЃЌвђДЫжЛФмгУгкЖдЪБМфбгГйБШНЯДѓЕФГЁОАЃЌЖдЪЕЪБадвЊЧѓБШНЯИпЕФГЁОАдђВЛЪЪКЯЃЌЖј
TiDB дђФмКмКУЕФТњзуЪЕЪБЛђепзМЪЕЪБЕФашЧѓЃЌдкЮвУЧЕФвЕЮёГЁОАЯТЃЌКмЖрШЮЮёвд 5-10 ЗжжгЮЊжДаажмЦкЃЌвђДЫЃЌБиаыШЗБЃШЮЮёЕФжДааЪБГЄдкМфИєжмЦкФкЭъГЩЁЃ
ЮвУЧШЁСЫСНИідк SQL Server ЩЯХмЕФБШНЯТ§ЕФживЊНХБОзіСЫЧЈвЦЃЌЯрБШгк SQL ServerЃЏMySQL
ЧЈвЦжС HadoopЃЌДг SQL Server ЧЈвЦжС TiDB ЕФИФЖЏЗЧГЃаЁЃЌSQL Server
ЕФ Merge Вйзїдк TiDB РявВЭЈЙ§ replace into ФмЙЛЭъГЩЃЌЦфгрвЛаЉ SQL Server
ЕФЬиадЃЌвВФмЙЛЭЈЙ§ TiDB ЕФЖрааЪТЮёЕУвдЪЕЯжЃЌдкетвЛЗНУцЃЌTiDB ЕФ GA АцБОвбОзіЕФЗЧГЃЭъЩЦЃЌИпЖШМцШн
MySQLЃЌвђДЫЧЈвЦЕФГЩБОЗЧГЃаЁЃЌДгЖјЪЙЮвУЧФмЙЛНЋДѓВПЗжОЋСІЗХдкСЫЕїгХЗНУцЁЃ
дкНХБОЧЈвЦЭъБЯжЎКѓЃЌвЛаЉМђЕЅЕФНХБОФмЙЛдкУыМЖЭъГЩДяЕНСЫЮвУЧЕФдЄЦкЁЃЕЋЪЧвЛаЉИДдгЕФНХБОЕФБэЯждкГѕЦкВЂУЛБэЯжГігХЪЦЃЌвЛаЉНХБОгы
SQL Server ГжЦНЩѕжСИќТ§ЃЌЦфжазюДѓЕФНХБО SQL ДњТыСПвЛЙВ 1000 ЖрааЃЌЩцМАНЋНќ 20
еХжаМфБэЁЃдкжЎЧАЕФ SQL Server ЩЯЃЌЫцзХЪ§ОнСПТ§Т§діДѓЃЌУПЬьЕФжДааЪБГЄж№НЅгЩ 1-2 ЗжжгдіГЄЕН
5-6 ЗжжгЩѕжСИќОУЃЌдкЫЋ11ЕБЬьСшГПЃЌЫцзХЕЅСПЕФгПШыКЭЦфЫћШЮЮёЕФИЩШХбгГйЕН 20 ЗжжгЩѕжСвдЩЯЁЃдкЧЈвЦжС
TiDB ГѕЦкЃЌдкАыЬьЕФЪ§ОнСПЯТ TiDB ЕФжДааЪБГЄДѓжТЮЊ 15 ЗжжгзѓгвЃЌгы SQL Server
ДѓжТЯрЭЌЃЌЕЋЪЧВЂВЛФмТњзуЮвУЧЕФдЄЦкЁЃЮвУЧВЮПМСЫ TiDB ЕФЯрЙиЮФЕЕЖдВщбЏВЮЪ§зіСЫвЛаЉЕїгХЃЌМИИіживЊВЮЪ§ЮЊЃКtidb_distsql_scan_concurrencyЃЌtidb_index_serial_scan_concurrencyЃЌtidb_index_join_batch_sizeЃЈTiDB
ЬсЙЉСЫКмКУЕФВЂааМЦЫуФмСІЃЉЁЃОЙ§бщжЄЃЌЕїећВЮЪ§КѓЃЌвЛаЉ SQL ФмЙЛЫѕЖЬвЛБЖЕФжДааЪБМфЃЌЕЋетРявРОЩВЛФмЭъШЋТњзуЮвУЧЕФашЧѓЁЃ
в§Шы TiSpark
ЫцКѓЃЌЮвУЧАбФПЙтзЊЯђСЫ TiDB ЕФвЛИізгЯюФП TiSparkЃЈhttps://github.com/pingcap/tisparkЃЉЃЌгУЙйЭјЕФНщЩмРДНВ
TiSpark ОЭЪЧНшжњ Spark ЦНЬЈЃЌЭЌЪБШкКЯ TiKV ЗжВМЪНМЏШКЕФгХЪЦЃЌКЭ TiDB вЛЦ№НтОі
HTAP ЕФашЧѓЁЃTiDB-ansible жавВДјга TiSpark ЕФХфжУЃЌгЩгкЮвУЧвбОгЕгаСЫ Spark
МЏШКЃЌЫљвджБНгдкЯжгаЕФ Spark МЏШКжаМЏГЩСЫ TiSparkЁЃЫфШЛИУЯюФППЊЗЂВЛОУЃЌЕЋЪЧОЙ§ВтЪдЃЌЪевцЗЧГЃУїЯдЁЃ
TiSpark ЕФХфжУЗЧГЃМђЕЅЃЌжЛашвЊАб TiSprak ЯрЙиЕФ jar АќЗХШы Spark МЏШКжаЕФ
jars ЮФМўМажаОЭФмв§Шы TiSparkЃЌЭЌЪБЙйЗНвВЬсЙЉСЫ 3 ИіНХБОЃЌЦфжаСНИіЪЧЦєЖЏКЭЭЃжЙ TiSpark
ЕФ Thrift ServerЃЌСэвЛИіЪЧЬсЙЉЕФ TiSpark ЕФ cli ПЭЛЇЖЫЃЌетбљЮвУЧОЭФмЯёЪЙгУ
Hive вЛбљЪЙгУ TiSpark ШЅзіВщбЏЁЃ
дкГѕВНЪЙгУжЎКѓЃЌЮвУЧЗЂЯжвЛаЉжюШч select count(*) from table ЕШ SQL
ЯрБШгк TiDB гаЗЧГЃУїЯдЕФЬсЩ§ЃЌвЛаЉМђЕЅЕФ OLAP ЕФВщбЏЛљБОЩЯЖМФмЙЛдк 5 УыжЎФкЗЕЛиНсЙћЁЃОЙ§ГѕВНВтЪдЃЌДѓжТдк
OLAP ЕФНсТлШчЯТЃКвЛаЉМђЕЅЕФВщбЏ SQLЃЌдкЪ§ОнСПАйЭђМЖзѓгвЃЌTiDB ЕФжДаааЇТЪПЩФмЛсБШ TiSpark
ИќКУЃЌдкЪ§ОнСПдіЖржЎКѓ TiSpark ЕФжДаааЇТЪЛсГЌЙ§ TiDBЃЌЕБШЛетвВПД TiKV ЕФХфжУЁЂБэНсЙЙЕШЁЃдк
TiSpark ЕФЪЙгУЙ§ГЬжаЃЌЮвУЧЗЂЯж TiSpark ЕФВщбЏНсЙћдкАйЭђМЖЪБЃЌжДааЪБМфЖМЗЧГЃЮШЖЈЃЌЖј
TiDB ЕФВщбЏЪБМфдђЛсЫцзХЪ§ОнСПЕФдіГЄЖјдіГЄЃЈОЙ§гы TiDB ЙйЗНЙЕЭЈЃЌетИіЧщПіжївЊЪЧвђЮЊУЛгаБШНЯКУЕФЫїв§НјааЪ§ОнЩИбЁЃЉЁЃеыЖдЮвУЧЕФЖЉЕЅБэзіВтЪдЃЌдкЪ§ОнСПЮЊНќАйЭђМЖЪБЃЌTiDB
ЕФжДааЪБМфЮЊ 2 УызѓгвЃЌTiSpark ЕФжДааЪБМфЮЊ 7 УыЃЛЕБЪ§ОнСПдіГЄЮЊНќЧЇЭђМЖЪБЃЌTiDB
ЕФжДааЪБМфДѓжТЮЊ 12 УыЃЈВЛПМТЧЛКДцЃЉЃЌTiSpark вРОЩЮЊ 7 УыЃЌЗЧГЃЮШЖЈЁЃ
вђДЫЃЌЮвУЧОіЖЈНЋвЛаЉИДдгЕФ ETL НХБОгУ TiSpark РДЪЕЯжЃЌЖдЩЯЪіЕФИДдгНХБОНјааЗжЮіКѓЃЌЮвУЧЗЂЯжЃЌДѓЖрЪ§НХБОжаМфБэКмЖрЃЌдк
SQL Server жаЪЧЭЈЙ§ SQL Server ФкДцБэЪЕЯжЃЌЖјЧЈвЦжС TiDBЃЌУПеХжаМфБэЖМвЊЩОГ§КЭВхШыТфЕиЃЌетаЉПЊЯњДѓДѓдіМгСЫжДааЪБГЄЃЈОнЙйЗНД№ИД
TiDB КмПьвВЛсжЇГж ViewЁЂФкДцБэЃЉЁЃдкгаСЫ TiSpark жЎКѓЃЌЮвУЧБуРћгУ TiSpark
НЋжаМфБэЛКДцЮЊ Spark ЕФФкДцБэЃЌжЛашвЊНЋзюКѓЕФЪ§ОнТфЕиЛи TiDBЃЌдйжДаа Merge ВйзїМДПЩЃЌетбљЪЁЕєСЫКмЖржаМфЪ§ОнЕФТфЕиЃЌДѓДѓНкЪЁСЫКмЖрНХБОжДааЕФЪБМфЁЃ
дкВщбЏЫйЖШНтОіжЎКѓЃЌЮвУЧЗЂЯжНХБОжаЛсгаКмЖреыЖджаМфБэ update КЭ delete ЕФгяОфЁЃФПЧА
TiSpark днЪБВЛжЇГж update КЭ delete ЕФВйзїЃЈКЭ TiSpark зїепЙЕЭЈЃЌКѓајЛсПМТЧжЇГжетСНИіВйзїЃЉЃЌЮвУЧБуГЂЪдСЫСНжжЗНАИЃЌвЛВПЗжжДааРрЫЦгк
HiveЃЌВЩгУ insert into вЛеХаТБэЕФЗНЪНРДНтОіЃЛСэЭтвЛВПЗжЃЌЮвУЧв§ШыСЫ Spark жаЕФ
Snappydata зїЮЊвЛВПЗжФкДцБэДцДЂЃЌдк Snappydata жаНјаа update КЭ deleteЃЌвдДяЕНЯывЊЕФФПЕФЁЃвђЮЊЖМЪЧ
Spark ЕФЯюФПЃЌвђДЫдкШкКЯСНИіЯюФПЕФЪБКђЛЙЪЧБШНЯЧсЫЩЕФЁЃ
зюКѓЃЌЙигкЪЕЪБЕФЕїЖШЙЄОпЃЌФПЧАЮвУЧЪЧКЭРыЯпЕїЖШвЛЦ№НјааЕїЖШЃЌетвВДјРДСЫвЛаЉЮЪЬтЃЌУПДЮНХБОЖМЛсГѕЪМЛЏвЛаЉ
Spark ВЮЪ§ЕШЃЌетвВЯрЕБКФЪБЁЃдкЮДРДЃЌЮвУЧДђЫуВЩгУ Spark Streaming зїЮЊЕїЖШЙЄОпЃЌУПДЮжДааЭъГЩжЎКѓМЧТМЪБМфДСЃЌSpark
Streaming жЛашМрПиЪБМфДСБфЛЏМДПЩЃЌФмЙЛБмУтЖрДЮГѕЪМЛЏЕФКФЪБЃЌЭЈЙ§ Spark МрПиЃЌЮвУЧвВФмЙЛЧхГўЕФПДЕНШЮЮёЕФбгГйКЭвЛаЉзДЬЌЃЌетвЛВПЗжНЋдкЮДРДНјааВтЪдЁЃ
TiDB ЙйЗНжЇГж
дкЧЈвЦЙ§ГЬжаЃЌЮвУЧЕУЕНСЫ TiDB ЙйЗНКмКУЕФжЇГжЃЌЦфжавВАќРЈ TiSpark ЯрЙиЕФММЪѕИКд№ШЫЃЌвЛаЉ
TiSpark ЕФ Corner Case МАЪЙгУЮЪЬтЃЌЮвУЧЖМЛсдкШКРяХзГіЃЌTiDB ЕФЙйЗНШЫдБЛсЗЧГЃМАЪБЕФАяжњЮвУЧНтОіЮЪЬтЃЌдкЙйЗНжЇГжЯТЃЌЮвУЧЧЈвЦжС
TiSpark ЕФЙ§ГЬКмЫГРћЃЌУЛгаЪмЕНЪВУДЬЋДѓЕФММЪѕзшАЁЃ
ЪЕЪБЪ§Вж TiDB / TiSpark
дкЧЈвЦЭъГЩжЎКѓЃЌЦфжавЛЬѕИДдгЕФ SQLЃЌвЛЙВ Join СЫ 12 еХБэЃЈзюДѓБэЪ§СПвкМЖЃЌВПЗжБэАйЭђМЖЃЉЃЌдкЦНЪБаЁХњСПЕФЧщПіЯТЃЌжДааЪБМфЛсдк
5 ЗжжгзѓгвЃЌЮвУЧвВФУСЫЫЋ11ШЋСПЕФЪ§ОнНјааСЫВтЪдЃЌжДааЪБМфдк 9 ЗжжгвдЩЯЃЌЖјВЩгУСЫ TiSpark
ЕФЗНЪНШЅжДааЃЌЫЋ11ШЋСПЕФЪ§ОнвВНіНіЛЈСЫ 1 ЗжжгЃЌадФмЬсЩ§СЫ 9 БЖЁЃећИіДѓНХБОдк SQL Server
ЩЯдЫааЫЋ11ЕФШЋСПЪ§ОнвдЧАжСЩйвЊЯћКФ 30 ЗжжгЃЌРћгУ TiDB ШЅжДааДѓжТашвЊ 20 ЗжжгзѓгвЃЌРћгУ
TiSpark жЛашвЊ 8 ЗжжгзѓгвЃЌЯрЖд SQL Server адФмЬсЩ§ 4 БЖЃЌвВОЭЪЧЫЕЃЌУПФъЪ§ОнСПзюИпЗхЕФДІРэФмСІДяЕНСЫЗжжгМЖЃЌКмКУЕФТњзуСЫЮвУЧЕФашЧѓЁЃ
зюКѓЃЌВЛЙмЪЧгУ TiDB ЛЙЪЧгУ TiSpark ЖМЛсгавЛВПЗжжаМфБэвдМАгыдБэНјаа Merge ЕФВйзїЃЌетРягЩгк
TiDB ЖдЪТЮёНјааЕФЯожЦЃЌЮвУЧвВВЩгУвдЭђЬѕЮЊЕЅХњДЮНјааХњСПЕФВхШыКЭ MergeЃЌМШБмУтСЫГЌЙ§ЪТЮёЕФБЈДэгжЗћКЯ
TiDB ЕФЩшМЦРэФюЃЌФмЙЛДяЕНзюМбЪЕМљЁЃ
гаСЫ TiSpark етИіЯюФПЃЌTiDB гы Hadoop ЕФЩњЬЌЬхЯЕЕУЕННјвЛВНЕФШкКЯЃЌдкУЛга TiSpark
жЎЧАЃЌЮвУЧЕФЯЕЭГЩшМЦШчЯТЃК
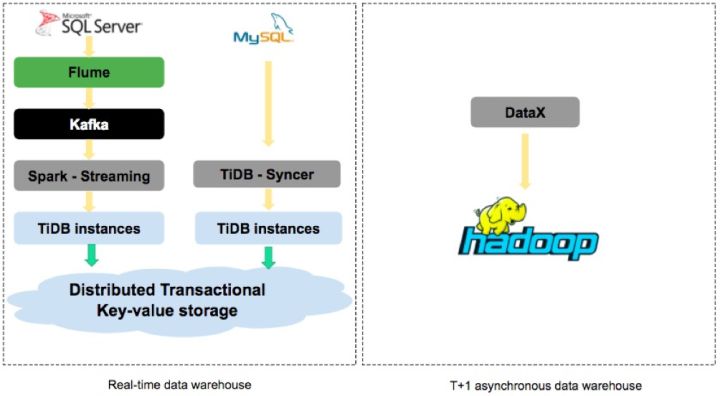
ЭМЃКЖрЬзЪ§ВжВЂДц
ПЩвдЗЂЯжЃЌЪЕЪБЪ§Вжгы T+1 вьВНЪ§ВжЪЧСНИіЯрЖдЖРСЂЕФЯЕЭГЃЌВЂУЛгаШЮКЮНЛМЏЃЌЮвУЧашвЊНјааЪ§ОнЪЕЪБЕФЭЌВНЃЌЭЌЪБвВЛсдквЙЭэзівЛДЮвьВНЭЌВНЃЌВЛЙмЪЧ
Datax ЛЙЪЧ Sqoop ЖСШЁЙиЯЕаЭЪ§ОнПтЕФаЇТЪЖМдЖдЖДяВЛЕН TiSpark ЕФЫйЖШЃЌЖјдкгаСЫ
TiSpark жЎКѓЃЌЮвУЧПЩвдЖд T+1 вьВНЪ§ВжНјааећКЯЃЌгкЪЧЮвУЧЕФМмЙЙНјЛЏЮЊШчЯТЃК
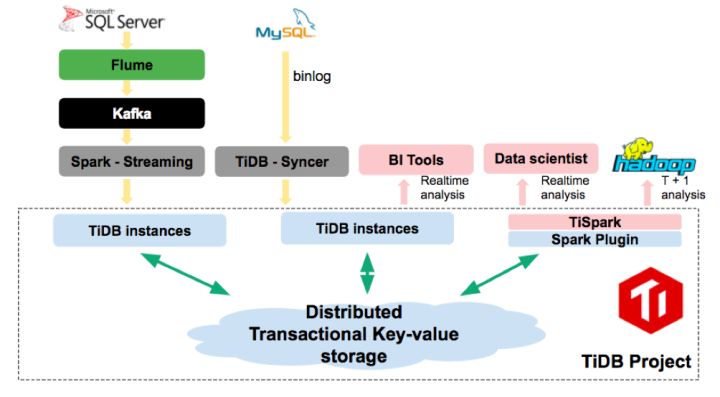
ЭМЃКTiDB / TiSpark ЪЕЪБЪ§ВжЦНЬЈ
етбљОЭФмЙЛРћгУ TiSpark НЋ TiDB КЭ Hadoop КмКУЕФДЎСЊЦ№РДЃЌЛЅЮЊВЙГфЃЌTiDB
ЕФЙІФмвВгЩЕЅДПЕФЪЕЪБЪ§ВжБфГЩФмЙЛЬсЙЉШчЯТМИИіЙІФмЛьКЯЪ§ОнПтЃК
1. ЪЕЪБЪ§ВжЃЌЩЯгЮ OLTP ЕФЪ§ОнЭЈЙ§ TiDB ЪЕЪБаДШыЃЌЯТгЮ OLAP ЕФвЕЮёЭЈЙ§ TiDB
/ TiSpark ЪЕЪБЗжЮіЁЃ
2. T+1 ЕФГщШЁФмЙЛДг TiDB жаРћгУ TiSpark НјааГщШЁЁЃ
TiSpark ЫйЖШдЖдЖГЌЙ§ Datax КЭ Sqoop ЖСШЁЙиЯЕаЭЪ§ОнПтЕФЫйЖШЃЛ
ГщШЁЙЄОпвВВЛгУЮЌЛЄЖрИіЯЕЭГПтЃЌжЛашвЊЮЌЛЄвЛИі TiDB МДПЩЃЌДѓДѓЗНБуСЫвЕЮёЕФЭГвЛЪЙгУЃЌЛЙНкЪЁСЫЖрДЮЮЌЛЄГЩБОЁЃ
TiDB ЬьШЛЗжВМЪНЕФЩшМЦвВБЃжЄСЫЯЕЭГЕФЮШЖЈЁЂИпПЩгУЁЃ
3. TiDB ЗжВМЪНЬиадПЩвдКмКУЕФЦНКтШШЕуЪ§ОнЃЌПЩвдгУЫќзїЮЊвЕЮёПтШШЕуЪ§ОнЕФвЛИіБИЗнПтЃЌЛђепжБНгЧЈШы
TiDB ЁЃ
ЩЯУцетШ§ЕувВЪЧЮвУЧНёКѓШЅХЌСІЕФЗНЯђЃЌгЩДЫПЩМћЃЌTiSpark ВЛНіЖдгк ETL НХБОЦ№ЕНСЫКмживЊЕФзїгУЃЌдкЮвУЧНёКѓЕФМмЙЙжавВЦ№ЕНСЫОйзуЧсжиЕФзїгУЃЌЮЊЮвУЧДДНЈвЛИіЪЕЪБЕФЭГвЛЕФЛьКЯЪ§ОнПтЬсЙЉСЫПЩФмЁЃ
гыДЫЭЌЪБЃЌЮвУЧвВЕУЕН TiDB ЙйЗНШЫдБЕФШЗШЯЃЌTiDB НЋгкНќЦкжЇГжЪгЭМЁЂЗжЧјБэЃЌВЂЛсГжајдіЧП
SQL гХЛЏЦїЃЌЭЌЪБвВЛсЬсЙЉвЛПюУћЮЊ TiDB Wormhole ЕФвьЙЙЦНЬЈЪ§ОнЪЕЪБЧЈвЦЙЄОпРДБуНнЕФжЇГжгУЛЇЕФЖрдЊЛЏЧЈвЦашЧѓЁЃЮвУЧвВМЦЛЎНЋИќЖрЕФВњЦЗЯпж№ВНЧЈШы
TiDBЁЃ
змНс
ЭЌЪБНтОі OLAP КЭ OLTP ЪЧвЛМўЯрЕБРЇФбЕФЪТЧщЃЌTiDB КЭ TiSpark ЫфШЛЭЦГіВЛОУЃЌЕЋЪЧвбОТњзуКмЖргІгУГЁОАЃЌЭЌЪБдквзгУадКЭММЪѕжЇГжЩЯвВЗЧГЃжЕЕУГЦдоЃЌЯраХ
TiDB вЛЖЈФмЙЛдкдНРДдНЖрЕФЦѓвЕжаЕУЕНЙуЗКгІгУЁЃ |








