| БрМЭЦМі: |
БОЮФжївЊДгвјааЪ§ОнВжПтЛЯёЁЂЧГЬИЪ§ОнВжПтНЈЩшЁЂЪ§ОнВжПтЯюФПЙмРэетШ§ЗНУцНщЩмвјааЪ§ОнВжПтЕФНЈЩшФПБъгыНЈЩшТЗОЖЕШЯрЙиФкШнЁЃ
БОЮФРДзд AIЧАЯпЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧА бд
Ъ§ОнВжПтЃЌЖдДгЪТ IT аавЕЕФДгвЕепРДЫЕВЂВЛЪЧИіФАЩњЕФУћДЪЃЌетИіИХФюгЩЪ§ОнВжПтжЎИИ Bill Inmon
дк 1991 ФъГіАцЕФЁАBuilding the Data WarehouseЁБжаЖЈвхЕФЁЊЁЊУцЯђжїЬтЕФЁЂМЏГЩЕФЁЂЯрЖдЮШЖЈЕФЁЂЗДгГРњЪЗБфЛЏЕФЪ§ОнМЏКЯЃЌгУгкжЇГжОіВпЙмРэЁЃДгЖЈвхПЩвдСЫНтЕНЃЌЪ§ОнВжПтОпгавдЯТЙиМќЬиадЃК
УцЯђжїЬт
Ъ§ОнВжПтЙщМЏШЋааЪ§ОнВЂАДЬиЖЈжїЬтЪсРэЃЌЗНБуЪЙгУепАДжїЬтБрФППьЫйВщевЕНЫљашЪ§ОнВЂЪЙгУЃЛ
Ъ§ОнМЏГЩ
Ъ§ОнВжПтЙщМЏШЋааЪ§ОнЃЌДђЦЦЯЕЭГМфЪ§ОнЙТЕКЕФОжУцЃЌДгЖјЮЊКѓајЕФОіВпЙмРэгыЪ§ОнЗўЮёЬсЙЉЧПДѓЕФЪ§ОнжЇГХЃЛ
ЯрЖдЮШЖЈ
НЈЩшЪ§ОнгІгУЪБЃЌзюЕЃгЧЪЧдДЯЕЭГЕФЪ§ОнФЃаЭБфИќЕМжТЁАЧЃвЛЗЂЖјЖЏШЋЩэЁБЁЃУПДЮФЃаЭБфИќЖМАщЫцзХЪ§ОнгІгУЕФгАЯьЗжЮіКЭБфИќПЊЗЂЃЌМШЖдПЊЗЂЭХЖгдьГЩМЋДѓЕФЙЄзїИКЕЃЃЌгжгАЯьЪ§ОнгІгУЕФЮШЖЈадЁЃЪ§ОнВжПтПЩЭЈЙ§ЗжВуМмЙЙЁАФкВПЯћЛЏЁБдДЯЕЭГФЃаЭБфИќДјРДЕФгАЯьЃЌЧвЮоашБфИќЪ§ОнЗўЮёНгПкЃЌБЃжЄЪ§ОнгІгУЕФЮШЖЈадЃЛ
ЗДгГРњЪЗБфЛЏ
Ъ§ОнВжПтЛсМЧТМЪ§ОнЕФРњЪЗЙьМЃЃЌгУгкВщбЏШЮвтЪБЕуЕФЪ§ОнПьееДгЖјЗжЮіЬиЖЈЪБМфЗЖЮЇЕФЪ§ОнЧїЪЦЃЌЮЊОіВпЙмРэЬсЙЉЪ§ОнжЇГжЁЃ
РэНтСЫЪ§ОнВжПтЕФЙиМќЬиадЃЌЯрЕБгкСЫНтСЫНЈЩшЪ§ОнВжПтЕФе§ШЗЗНЯђЃЌЕЋЪЧЃЌВЂВЛДњБэОЭЧхГўЪ§ОнВжПтЕФНЈЩшФПБъКЭНЈЩшТЗОЖЁЃЬиБ№ЖдгквјааЛњЙЙЃЌЖдЪ§ОнЕФЮШЖЈадЁЂзМШЗадгыЪБаЇадвЊЧѓЖМБШвЛАуЦѓвЕвЊИпЁЃФЧУДЃЌвјааЪ§ОнВжПтЕФНЈЩшФПБъгыНЈЩшТЗОЖЗжБ№ЪЧЪВУДЃЌНгЯТРДНЋЗжЮЊШ§ИіеТНкШЅВћЪіЁЃ

вјааЪ§ОнВжПтЛЯё

ЛЅСЊЭјЖдгкДЋЭГаавЕЕФГхЛїЪЧШЋЗНЮЛЕФЃЌЮоТлЪЧАйЛѕЁЂЩЬГЁЁЂВЫЪаГЁЕШСуЪлаавЕЃЌЛЙЪЧвјааЁЂВЦЮёЙЋЫОЕШН№ШкаавЕЃЌЖМЖдЦфОгЊФЃЪННјааЁАНЕЮЌДђЛїЁБЃЌЦШЪЙДЋЭГаавЕвЕЮёНјааЯпЩЯЛЏзЊаЭЁЃгШЦфЪЧвјааЃЌдкЛЅСЊЭјЗЂеЙЧАЃЌЛљБОЖМЪЧЬЩзХзЌЧЎЃЌЪЧДѓМвблжаЕФН№ЗЙЭыЃЌНсЙћдкЛЅСЊЭјЗЂеЙКѓЃЌгШЦфЪЧЛЅСЊЭјН№Шкж№НЅЕФзГДѓЃЌЖМБЛЦШКАГіЁАвјааЪЧШѕЪЦШКЬхЁБЕФЛАгяЃЌЦфГЬЖШПЩЯыЖјжЊЁЃЛЅСЊЭјОгЊФЃЪНЖдБШвјааДЋЭГЕФОгЊФЃЪНСьЯШЪЧЖрЗНУцЕФЃЌвдЯТСаБэНіДгЪ§ОнЕФНЧЖШНјааЗжЮіЁЃ

ЩЯЪіЖдБШЕФНсЙћЃЌНвЪОСЫЛЅСЊЭјОгЊФЃЪНСьЯШЕФвЊЕужЎвЛЪЧЪ§зжЛЏЕФвЕЮёдЫгЊЃЌЫљвдвјааОгЊФЃЪНЯывЊИњЩЯЪБДњЕФВНЗЅЃЌЙиМќЕуЪЧ
Ъ§зжЛЏзЊаЭЁЃ
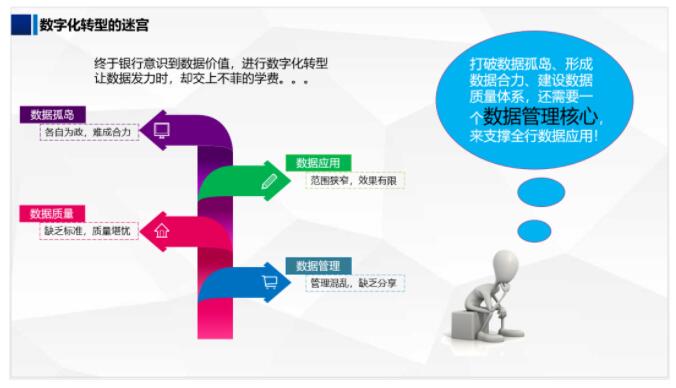
дквјааж№НЅШЯЪЖЕНЪ§ОнМлжЕКѓЃЌвВПЊеЙСЫздЩэЕФЪ§зжЛЏзЊаЭжЎТЗЁЃШЛЖјдкТѕЯђЕФЙ§ГЬжаЃЌШДЗЂЯжгЬШчНјШыУдЙЌвЛбљЃЌзЪдДЪЧДѓСІЭЖШыСЫЃЌГЩаЇШДдЖдЖЮДДяЕНдЄЦкЯыЯѓЃЌЩѕжСЛЙгАЯьЕНдгавЕЮёПЊеЙЁЃ
вЕЮёЪ§ОнШдвд Ъ§ОнЙТЕК ЕФЗНЪНДцдкЃЌДѓСПЕФЪ§ОнШдЮДаЮГЩКЯСІЃЌФбвдВњЩњОоДѓЕФМлжЕЃЛ
гЩгкЪ§ОнЙТЕКЕФДцдкЃЌЪ§ОнгІгУ жЛФмОжЯогкЯЕЭГФкЃЌПЩЗЂЛгЕФПеМфВЛДѓЃЛ
Ъ§ОнЙТЕКЕФИїздЮЊеўЃЌдьГЩИїИіЯЕЭГЕФЪ§ОнЖМгЕгавЛЬзЖРСЂЕФБъзМЃЌЪЙЕУЯЕЭГМфЕФЪ§ОнСЊЯЕИќМгИДдггыРЇФбЁЃЧвБъзМИївьЕФЪ§ОнФбвдВтСПЪ§ОнжЪСПЃЌЪ§ОнжЮРэ
ЪЦБиГЩЮЊЯТвЛНзЖЮЕФЙЄзїжиаФЃЛ
ШБЗІЭГвЛЕФ Ъ§ОнЙмРэЃЌЮоЗЈгааЇЗЂЛгЪ§ОнЕФЪЙгУМлжЕЃЌвВЮоЗЈЛЅЯрЗжЯэЪ§ОнГЩЙћЃЌДгЖјЕМжТСэвЛИіЮЪЬтЁЊЁЊбЬДбЪННЈЩшЁЃ
НтОіЩЯЪіЪ§зжЛЏзЊаЭгіЕНЕФЭДЕуЃЌашвЊДђЦЦЪ§ОнЙТЕКЁЂаЮГЩЪ§ОнКЯСІЁЂНЈЩшЪ§ОнжЪСПЬхЯЕЃЌетЪБОЭашвЊвЛИіЪ§ОнЙмРэКЫаФЃЌРДжЇГХШЋааЪ§ОнгІгУЁЃетИіЪ§ОнЙмРэКЫаФОЭЪЧЪ§ОнВжПтЁЃ

ЯИЛЏЪ§ОнВжПтФПБъЃЌУшЛцГіЪ§ОнВжПтЕФЛЯёЁЃ
ШЋааЪ§ОнЙщМЏ
НЋШЋааЪ§ОнЙщМЏЕНЪ§ОнВжПтжаЃЌДгЖјДђЦЦЪ§ОнЙТЕКЃЌЪЕЯжЪ§ОнМЏжаЙмРэМАЙиСЊЗжЮіЃЌВњЩњ 1+1>2
ЕФМлжЕЃЛ
Ъ§ОнжЪСПЬхЯЕ
жївЊЗжЮЊСНИіЗНУцЃЌЦфвЛЪЧНЈЩшЪ§ОнЭГвЛБъзМЁЃБъзМИївьЕФЪ§ОнЛсЖдЪ§ОнЪсРэећКЯдьГЩОоДѓЕФзшАЃЌЪ§ОнЭГвЛБъзМгІДгвЕЮёЪєадЁЂММЪѕЪєадМАВйзїЪєадШ§ЗНУцНјааЁЃЦфЖўЪЧзіКУдЊЪ§ОнЙмРэЃЌдЊЪ§ОнЪЧЯЕЭГНЈЩшЙ§ГЬВњЩњЕФУшЪіЪ§ОнЃЌАќКЌЯЕЭГЩшМЦЁЂЪ§ОнФЃаЭЁЂЪ§ОнзжЕфЁЂдЫааШежОЕШЃЌЙмРэКУдЊЪ§ОнгажњгкЯЕЭГЮЌЛЄМАПЩГжајЗЂеЙЃЛ
Ъ§ОнМлжЕЭкОђ
ЛљгкШЋааЪ§ОнЕФЙиСЊгыЗжЮіЃЌЭкОђЪ§ОнМфЕФСЊЯЕгыМлжЕЃЌЪЕЯжжЧФмгЊЯњгыЗчПиЃЛ
ЩЬвЕжЧФмОіВп
ЪЙгУПЩЪгЛЏЕФЪ§ОнЗжЮіЙЄОпАбЪ§ОнЭМаЮЛЏЁЂжБЙлЛЏГЪЯжЃЌАяжњвЕЮёШЫдБСЫНтЪ§ОнЕФБфЛЏгыЧїЪЦЃЌДгЖјПьЫйИпаЇаЮГЩОіВпЃЛ
Ъ§ОнЗўЮёжЇГХ
ЬсЙЉЭГвЛЁЂЙВЯэЕФЪ§ОнНгПкТњзуШЋаагІгУЯЕЭГЕФЪ§ОнЗўЮёашЧѓЃЛ
Ъ§ОнзЪВњЙмРэ
Ъ§ОнВжПтМШЪєгкЪ§ОнЙмРэКЫаФЃЌвВЪєгкЪ§ОнзЪВњКЫаФЁЃЖдФкЖјбдЃЌЪ§ОнВжПтНЋШЋааЪ§ОнНјааЙщМЏВЂећКЯЃЌЮЊШЋаавЕЮёгІгУЬсЙЉЪ§ОнЗўЮёЃЛЖдЭтЖјбдЃЌЩцМАгЊЯњгыЗчПиЕФМлжЕЪ§ОнЃЌБШШчПЭЛЇЛЯёЁЂЦлеЉУћЕЅЁЂРЯРЕУћЕЅЃЌЖдЦфЫћвјааОпгаЧПДѓЕФЮќв§СІЃЌПЩЭЈЙ§гаГЅВщбЏЕФЗНЪНаЮГЩДДаТвЕЮёЁЃ
вјааЪ§ОнВжПтЕФЛЯёЧхЮњСЫЃЌНЈЩшФПБъвВУїШЗСЫЃЌЕЋЃЌИУШчКЮЙЙНЈЪ§ОнВжПтЃП
ЧГЬИЪ§ОнВжПтНЈЩш
КъЙлРэНтвјааЪ§ОнВжПтЕФећЬхМмЙЙЃЌгаРћгкЯТвЛВНРэНтЪ§ОнВжПтЕФНЈЩшТЗОЖЁЃДгећЬхМмЙЙЃЌжїЬхФЃПщЕФЙІФмЫЕУїгыжАд№ЗжЙЄШчЯТЫљЪОЃК
Ъ§ОнзмЯп
Ъ§ОнВжПтзїЮЊЪ§ОнЙмРэКЫаФЃЌБиаыгЕгаЭГвЛБъзМЕФЪ§ОнЪфШыНгПкгыЪ§ОнЪфГіЭЈЕРЃЌВХФмБЃжЄЪ§ОнЪфШыЪфГіЕФЮШЖЈадЁЃЕЋЪЧЪ§ОнЪфШыЪфГіЛсдьГЩЪ§ОнВжПтЕФзЪдДЫ№КФЃЌгШЦфЪЧ
IO гыЭјТчЃЌЫљвдНЈЩшЪ§ОнзмЯпЯЕЭГПЩАбЪ§ОнЪфШыЪфГіЙІФмгыЪ§ОнВжПтНтёюЃЌШУЪ§ОнВжПтзЈзЂгкЪ§ОнЕФећКЯгыМЦЫуШЮЮёЁЃ
Ъ§ОнВжПтЗжВу
Ъ§ОнВжПтЗжВуМмЙЙЮЊ ODM ВуЁЂSDM ВуЁЂFDM ВуМА ADM ВуЁЃЖдЩЯЪіЗжВуЗНЪНПЩФмгаЭЏаЌЛсгаетбљЕФвЩЮЪЃКЮЊЪВУДУЛгаЙВадФЃаЭВуЃПУПИіЪ§ОнВуЕФЖЈвхгыжАд№ЃЌвдМАЙВадФЃаЭВуЕФвЩЮЪНЋдкЯТЮФж№ВННщЩмЃЌгааЫШЄЕФЭЏаЌвВПЩвдВщдФзїепЕФЮФеТЁЖЧГЬИвјааЕФЪ§ОнВжПтЃКЗжВуМмЙЙЦЊЁЗЃЛ
Ъ§ОнЗўЮё
ЗжЮЊ SOA НгПкгыЮФМўНгПкСНжжЗНЪНЃЌЗжБ№ЬсЙЉЪЕЪБгыРыЯпЕФЪ§ОнЗўЮёЁЃгЩгкгІгУЯЕЭГЕїгУЪ§ОнЗўЮёНгПкЭЌбљЛсдьГЩЪ§ОнВжПтЕФ
IO гыЭјТчзЪдДЫ№КФЃЌЫљвдНЈЩшЪ§ОнЗўЮёЯЕЭГПЩАбЕїгУЪ§ОнЗўЮёЙІФмгыЪ§ОнВжПтНтёюЃЌЭЌЪБвВБмУтгІгУЯЕЭГжБНгЗУЮЪЪ§ОнВжПтЫљдьГЩЕФЪ§ОнАВШЋЗчЯеЃЛ
ЕїЖШЙмРэ
ИКд№Ъ§ОнВжПтЫљгазївЕЃЈКЌЪ§ОнзмЯпЕФ ETL зївЕЃЉЕФЕїЖШХфжУЁЂвРРЕХфжУЁЂШеЧаЛњжЦМАжДааМрПиЃЛ
дЊЪ§ОнЙмРэ
ИКд№ЖддЊЪ§ОнЕФТМШыгыВщбЏЁЃЖдЪ§ОнВжПтЖјбдЃЌБШНЯживЊЕФдЊЪ§ОнгаЪ§ОнзжЕфЁЂбЊдЕЙиЯЕЁЂжИБъПкОЖЁЂЪ§ОнгГЩфЃЈmappingЃЉМАВЮПМЪ§ОнЃЈТыБэгыЯЕЭГВЮЪ§ЃЉЃЛ
жЪСПЙмРэ
ИКд№СНДѓЙІФмЁЊЁЊЪ§ОнКЫМьМАжЪСПЦРЗжЁЃ
Ъ§ОнКЫМьЗжЮЊБэФкКЫМьгыБэМфКЫМьСНжжЗНЪНЁЃБэФкКЫМьжївЊЪЧЪ§ОнИёЪНКЫМьЃЌвРОнЪ§ОнБъзМЖдЪ§ОнЕФГЄЖШЁЂИёЪНЁЂЗЖЮЇЁЂЗЧПеЕШЮЌЖШНјааМьВщЁЃГ§СЫЪ§ОнИёЪНКЫМьЭтЃЌЛЙгаБэФкЪ§ОнЙДЛќЙиЯЕКЫМьЃЌБЃжЄБэФкЭГМЦНсЙћЕФвЛжТадЁЃБэМфКЫМьжївЊЪЧМьВщПчЯЕЭГЕФЪ§ОнЙДЛќЙиЯЕЃЌБШШчзмеЫПЦФПгыНЛвзУїЯИЕФзмЗжКЫЖдЁЃЫљгаЕФКЫМьНсЙћОљвдШежОЕФЗНЪНЪфГіЃЌБугкЪ§ОнжЮРэЭХЖгЭЦНјЪ§ОнжЪСПЬсЩ§ЕФЙЄзїЁЃ
жЪСПЦРЗжвРРЕЪ§ОнКЫМьНсЙћЃЌЖдИїИідДЯЕЭГЕФЪ§ОнжЪСПНјаазлКЯЦРЗжЃЌжївЊгУгкПМКЫдДЯЕЭГЕФЪ§ОнжЪСПЭъЩЦГЬЖШЃЌВЂЖдПЊЗЂЭХЖгЪЕЪЉНБГЭЛњжЦЃЌЭЦНјЪ§ОнжЪСПЬсЩ§ЕФЙЄзїЁЃ
АВШЋЙмРэ
ИКд№СНДѓЙІФмЁЊЁЊЪ§ОнЩњУќжмЦкЙмРэМАЪ§ОнАВШЋВпТдЁЃ
Ъ§ОнЩњУќжмЦкЙмРэжївЊЪЧЩшЖЈЪ§ОнЕФгааЇЦкМАздЖЏДІРэВпТдЁЃЕБЪ§ОнДяЕНгааЇЦкЪБЃЌЛсздЖЏАбЙ§ЦкЪ§ОнНјааЮФБОЕМГіЁЂЗжБэЁЂЧхРэЕШВйзїЃЌБмУтЪ§ОнДцДЂЙ§ДѓдьГЩЕФвЛЯЕСаЯЕЭГЮЪЬтЁЃ
Ъ§ОнАВШЋВпТджївЊЩшЖЈЪ§ОнЕФШЈЯоЃЌАќРЈВщбЏЁЂЯТдиЁЂЗжЯэЁЂВЙТМЕШШЈЯоЃЌБмУтУєИаЪ§ОнаЙТЖЁЃ
Ъ§ОнзмЯп

дкећЬхМмЙЙЕФЗжЯэжаЃЌвбЫЕУїЪ§ОнзмЯпЛсзїЮЊЪ§ОнВжПтЭГвЛБъзМЕФЪ§ОнЪфШыгыЪ§ОнЪфГіЕФЭЈЕРЃЛ
Ъ§ОнНЛЛЅНЈвщЪЙгУЮФБОЗНЪННјааЃЌНтГ§Ъ§ОнВжПтгыЩЯЯТгЮЯЕЭГЖЫЖдЖЫЕФЧПёюКЯЃЌЪЙЪ§ОнНЛЛЅзЈзЂдкНгПкБъзМКЭЪ§ОнНсЙЙЃЌЭЌЪБвВБмУтЩЯЯТгЮЯЕЭГжБСЌДјРДЕФЦцЦцЙжЙжЮЪЬтЃЛ
ЮоТлЪЧЪ§ОнМгдиЛЙЪЧЪ§ОнГщШЁЃЌЦфжДааСїГЬЛљБОЪЧЙЬЖЈЕФЁЃБШШчЪ§ОнМгдиЕФжДааСїГЬЮЊЃК

ЫљвдПЩвдЩшМЦЭЈгУГЬађЪЕЯжБъзМЛЏЕФЪ§ОнМгдигыЪ§ОнГщШЁЃЌМШПЩДѓДѓМѕЧсПЊЗЂЭХЖгЕФЙЄзїСПЃЌвВПЩвддіЧПЪ§ОнзмЯпЕФЮШЖЈадЁЃ
Ъ§ОнВжПт ODM Ву 
ODM ЕФгЂЮФШЋГЦЪЧ Origin Data ManagerЃЌМДЪ§ОнВжПтЕФЬљдДВуЃЌЙЫУћЫМвхЃЌЪ§ОнВуЕФЪ§ОнНсЙЙИњдДЯЕЭГЕФЪ§ОнНсЙЙвЛжТЁЃЪ§ОнзмЯпАбУПШеВЩМЏЕФдДЯЕЭГдіСПЪ§ОнЮФБОМгдиЕН
ODM ВужаЃЛ
ODM ВугЩгкНіБЃСєдДЯЕЭГЕБШедіСПЪ§ОнЃЌЧвЪ§ОнНсЙЙгыдДЯЕЭГвЛжТЃЌЙЪЪ§ОнМгдиЫйЖШЪЧМЋПьЕФЃЌЮоашЕЃаФЬљдДВуЕФЪ§ОнМгдиЖдЪ§ОнВжПтадФмдьГЩгАЯьЃЛ
гЩгк ODM ВуЕФЪ§ОнНсЙЙгыдДЯЕЭГвЛжТЃЌЫљвдХХВщЪ§ОнжЪСПЮЪЬтЪБПЩЭЈЙ§ ODM ВуЫндДХХВщЁЃЕБШЛЃЌODM
ВуНіБЃСєЕБШедіСПЪ§ОнЕФЩшМЦЛсЯожЦЫндДЕФЗЖЮЇЃЌетЪЧЪЙгУЙиЯЕаЭЪ§ОнПтДюНЈЪ§ОнВжПтдьГЩДцДЂГЩБОМЋИпЕФдЕЙЪЁЃЕБЧАЪЙгУДѓЪ§ОнММЪѕПђМмДюНЈЪ§ОнВжПтЃЌПЩЪЙгУЦеЭЈДХХЬДцДЂЪ§ОнЃЌЪЙЕУДцДЂГЩБОДѓЗљНЕЕЭЃЌЫљвдвВБЃСє
ODM ВуЬљдДЪ§ОнЕФРњЪЗЙьМЃЁЃДгКмЖрвјааДюНЈРњЪЗЪ§ОнВщбЏЦНЬЈРДПДвВФмЫЕУїетвЛЕуЃЛ
ЫфШЛ ODM ВужЛЪЧМгдидДЯЕЭГЕФУПШедіСПЪ§ОнЃЌЧвЪ§ОнНсЙЙгыдДЯЕЭГвЛжТЃЌЮоШЮКЮИДдгМгЙЄЃЌЕЋКмЖрПЊЗЂЭХЖгЛсвђВЛжиЪгЕМжТЕзВуЪ§ОнМгдиГіДэЃЌв§ЗЂСЌЫјЕФЪ§ОнЮЪЬтЁЃНтОіЗНАИПЩВЮПМЪ§ОнзмЯпЃЌЙиМќЪЧзіКУМрПиБЃжЄЪ§ОнМгдиЕФзМШЗадгыЮШЖЈадЁЃ
Ъ§ОнВжПт SDM Ву

SDM ЕФгЂЮФШЋГЦЪЧ Standard Data ManagerЃЌМДЪ§ОнВжПтЕФБъзМЪ§ОнВуЃЌЙЫУћЫМвхЃЌИУЪ§ОнВужївЊгУгкЪ§ОнБъзМТфЕиЁЃГ§СЫЪ§ОнЙсБъЕФжАд№ЭтЃЌЛЙвЊИКд№МЧТМЪ§ОнРњЪЗЙьМЃЃЌКЯГЩРњЪЗПьееЃЛ
дкКЯГЩРњЪЗПьеежЎЧАЃЌЪзЯШЖд ODM ВуЕФдіСПЪ§ОнАДееЪ§ОнБъзМНјааЧхЯДгыЙсБъЃЌБЃжЄЪ§ОнБъзМЕФвЛжТадЃЛ
КЯГЩРњЪЗПьееашвЊЖдгІдДЯЕЭГЕФЙЉЪ§ВпТдЃЌЗжБ№ЮЊЃК
1ЁЂдДЯЕЭГШЋСПЙЉЪ§ЪБЃЌЪ§ОнБэжЛашАбШЋБэЪ§ОнЧхПеВЂМгдиМДПЩЃЌЕЋетбљжЛФмВщбЏЕНзюаТЕФЪ§ОнПьееЁЃЮЊСЫМЧТМЪ§ОнРњЪЗЙьМЃЃЌЧвНкдМЪ§ОнПтЪЙгУПеМфЃЌвЛАужЛБЃСєЬиЪтЪБЕуЕФРњЪЗЪ§ОнПьееЃЌБШШчУПдТФЉЁЂДцПюЦ№ЯЂЁЂаХгУПЈеЫЕЅШеЕШЁЃ
2ЁЂдДЯЕЭГдіСПСїЫЎЙЉЪ§ЪБЃЌгЩгкдіСПЪ§ОнВЛЛсгАЯьЕНРњЪЗЪ§ОнЃЌЙЪжЛашАбдіСПЪ§ОнМгдиЕНРњЪЗЪ§ОнПьееаЮГЩзюаТЪ§ОнПьееМДПЩЁЃ
3ЁЂдДЯЕЭГдіСПРњЪЗЙЉЪ§ЪБЃЌгЩгкдіСПЪ§ОнПЩФмЛсгАЯьЕНРњЪЗЪ§ОнЃЌЙЪашвЊЪЙгУРСДЫуЗЈМШВхШыаТдіЪ§ОнгжБЃСєРњЪЗЪ§ОнЁЃ
4ЁЂЪЙгУРСДЫуЗЈМЧТМЪ§ОнРњЪЗЙьМЃЪБЃЌЫцзХЪБМфЕФдіГЄЪ§ОнСПКмПЩФмЛсжИЪ§МЖдіГЄЃЌБШШчеЫЛЇБэетРрБфЛЏМЋЦфЦЕЗБЕФдДЪ§ОнЁЃЕБРСДЪ§ОнГЩГЄЕНвЛИіЪ§ОнМЖЪБЃЌРСДЫуЗЈЗДЖјЛсГЩЮЊРлзИЃЌМШЕМжТКЯГЩРњЪЗПьееЕФЪБМфдНРДдНГЄЃЌгжЕМжТЪ§ОнВщбЏЕФаЇТЪдНРДдНТ§ЁЃИљОнАЫЖўддђЃЌДѓВПЗжЪ§ОнМгЙЄНівРРЕЕБЧАЪ§ОнЃЌЫљвдЃЌНЈвщАбРСДБэЕФРњЪЗЪ§ОнгыЕБЧАЪ§ОнЗжБэДцДЂЁЃгЩгкЕБЧАЪ§ОнЕФСПМЖаЁЃЌЫљвдЮоТлЪЧЪЙгУРСДЫуЗЈКЯГЩРњЪЗПьееЃЌЛЙЪЧВщбЏЪ§ОнЃЌЩЯЪіЮЪЬтЖМЛёЕУНтОіЁЃ
Ъ§ОнВжПт FDM Ву

FDM ЕФгЂЮФШЋГЦЪЧ Finance Data ManagerЃЌМДЪ§ОнВжПтЕФН№ШкжїЬтВуЁЃЕБШЛЃЌН№ШкжїЬтВуЪЧеыЖдвјааЖјбдЃЌЖдвЛАуЦѓвЕЃЌГЦЮЊжїЬтФЃаЭВуЛсИќМгКЯЪЪЁЃгЩгквјаавЕЮёЯЕЭГЪЧЗБЖрЧвИДдгЕФЃЌЛљгкдДЯЕЭГЪ§ОнФЃаЭМгЙЄЪ§ОнгІгУЪБЃЌБиаывЊЖдЦфЪьЯЄВХааЃЌЖјЧвдДЯЕЭГЪ§СПЛЙВЛЩйЃЈжСЩй
80 ИівдЩЯЃЉЃЌвЊЪьСЗеЦЮеЫљгадДЯЕЭГЪ§ОнФЃаЭВЂСщЛюдЫгУЕФбЇЯАГЩБОМЋИпЁЃЖддДЯЕЭГЪ§ОнФЃаЭАДеевЛЖЈЕФжїЬтНјааЪсРэгыећКЯКѓЃЌЪ§ОнгІгУПЊЗЂжЛашбЇЯАжїЬтФЃаЭМДПЩЃЌДѓДѓНЕЕЭПЊЗЂУХМїгыбЇЯАГЩБОЃЛ
жїЬтЛЎЗжЪЧвЛУХвеЪѕЁЃЛЎЗжжїЬтЩйСЫЃЌЪ§ОнЙ§ЖШећКЯЗДЖјЪЙЪ§ОнФЃаЭИќМгВЛКУРэНтЃЌЧвЧПгВећКЯВЛЭЌвЕЮёжжРрЕФдДЪ§ОнЛсГіЯжИїжжЦцЦцЙжЙжЕФЪ§ОнЮЪЬтЁЃЛЎЗжжїЬтЖрСЫЃЌЪ§ОнФЃаЭМђЛЏДяВЛЕНаЇЙћЃЌЪЙгУЪБИњдДЯЕЭГЕФЪ§ОнФЃаЭВювьВЛДѓЁЃЫљвдЛЎЗжжїЬтНЈвщеввЕЮёжЊЪЖЩюКёЁЂЪЕЪЉОбщЗсИЛЕФНЈФЃзЈМвжїЕМЩшМЦЃЌШУ
FDM ВуНЈЩшЩйВШЕуПгЃЛ
FDM ВуЮЛгкдЪМЪ§ОнЃЈODM ВуЃЌSDM ВуЪ§ОнНсЙЙЛљБОгыдДЯЕЭГвЛжТЃЌЫљвдПЩЭГГЦЮЊдЪМЪ§ОнЃЉгыгІгУЪ§ОнжЎМфЃЌЦ№ЕНЛКГхЕиДјЕФзїгУЁЃвЛЕЉдДЯЕЭГЪ§ОнФЃаЭЗЂЩњБфИќЃЌЪ§ОнВжПтжЛашЕїећ
SDM Вугы FDM ВуЕФЪ§ОнгГЩфМДПЩЃЌЖј FDM Вугы ADM ВуЕФЪ§ОнгГЩфЪЧЛљБОВЛБфЕФЃЌБЃжЄСЫ
ADM ВуЕФЮШЖЈадЁЃ

Ъ§ОнВжПт ADM Ву
ADM ЕФгЂЮФШЋГЦЮЊ Application Data ManagerЃЌМДЪ§ОнВжПтЕФЪ§ОнгІгУВуЃЌжївЊЮЊЪ§ОнЗўЮёЖјВњЩњЕФЁЃгЩгкЪ§ОнЗўЮёвЛАуОпБИЬиЖЈвЕЮёГЁОАЃЌЫљвд
ADM ВувдЗўЮёЬиЖЈвЕЮёГЁОАЕФЪ§ОнМЏЪааЮЬЌДцдкЁЃШЛЖјЃЌгаСНРрЪ§ОнМЏЪаЖдгк ADM ВуРДЫЕЯрЖдвьРрЃЌвЛИіЪЧЙВадПэБэЃЌСэвЛИіЪЧжИБъЬхЯЕЃЌвђЮЊетСНРрЪ§ОнМЏЪаВЂЗЧеыЖдЬиЖЈвЕЮёГЁОАЃЌЖјЪЧеыЖдЙВадвЕЮёГЁОАЃЛ
ЙВадПэБэгЩШеГЃЪ§ОнЗжЮіЪЙгУЦЕЗБЕФЃЌЙВадЕФдЊЫиЃЌАДвЕЮёжїМќЙиСЊВЂећКЯЕФУїЯИЪ§ОнЁЃЙВадПэБэжївЊЮЊСЫвЕЮёШЫдБНјаазджњЪ§ОнЗжЮіЃЌвЕЮёШЫдБПЩИљОнЙВадПэБэЕФЮЌЖШздгЩзщКЯЩИбЁМАЖдБэФкдЊЫиБрММЦЫуТпМДгЖјПьЫйЩшМЦБЈБэЃЛ
жИБъЬхЯЕгЩШеГЃЪ§ОнЗжЮіЪЙгУЦЕЗБЕФЃЌЙВадЕФЭГМЦжИБъЃЌАДЯрЭЌЕФЭГМЦЮЌЖШЙиСЊВЂећКЯЕФЛузмЪ§ОнЁЃжИБъЬхЯЕжївЊЮЊСЫШУвЕЮёШЫдБПьЫйВщбЏЭГМЦЪ§ОнМАздгЩБрМжИБъМЦЫуТпМРДбмЩњаТжИБъЃЌДгЖјПьЫйСЫНтвЕЮёЕФОгЊЧщПіЁЃЖдБШЙВадПэБэЃЌжИБъЬхЯЕЩйСЫСщЛюадЃЈвђжИБъЭГМЦПкОЖЪЧЙЬЛЏдкДњТыжаЃЌжЛФмППММЪѕШЫдБЮЌЛЄЃЉЃЌЕЋФмМЋДѓЬсЩ§ВщбЏаЇТЪЁЃ
ЙВадПэБэгыжИБъЬхЯЕПЩНсКЯГЩЮЊвЕЮёШЫдБЕФзджњЭГМЦЙЄОпЃЌМШАяжњвЕЮёШЫдБПьЫйЛёШЁЯывЊЕФЪ§ОнЃЌгжФмДѓДѓНтЗХПЊЗЂЭХЖгЕФЙЄзїСПЁЃ
КмЖрЭЏаЌПЩФмЖдЙВадПэБэгыжИБъЬхЯЕБЇгавЩЮЪЃКЮЊЪВУДВЛАбетСНРрЕФЪ§ОнФЃаЭзіГЩЪ§ОнВжПтЕФЙВадФЃаЭВуЃПетРяЗжЯэвЛЯТзїепЕФЙлЕуЃК
1ЁЂЙВадПэБэгыжИБъЬхЯЕЖМЪЧеыЖдШеГЃЪ§ОнЗжЮіЪЙгУЦЕЗБЕФЃЌЙВадЕФФкШнНјааећКЯЃЌДяЕНЪ§ОнЙВЯэЕФаЇЙћЁЃЪЕМЪЩЯЃЌЪ§ОнгІгУЕФЭГМЦжИБъЖМОпБИЬиЖЈвЕЮёГЁОАЬиЩЋЃЌЖјЗЧЙВадЭГМЦжИБъПЩвдТњзуЃЌБШШчгааЇеЫЛЇЪ§ЭГМЦЃЌЙВадЭГМЦжИБъПкОЖЪЧвЊЧѓЗЧзЂЯњЕФеЫЛЇЃЌЖј
A ВПУХЕФПкОЖЪЧвЊЧѓеЫЛЇЗЧзЂЯњЃЌЧвеЫЛЇгрЖюВЛЮЊ 0ЃЌетбљЪЕМЪЙВадЭГМЦжИБъЕФЙВЯэадЛсДѓДђелПлЁЃ
2ЁЂЙВадПэБэгыжИБъЬхЯЕЮоЗЈИВИЧЫљгаЕФдДЪ§ОнЃЌвВОЭЪЧЫЕЪ§ОнгІгУЛсДгН№ШкжїЬтВугыЙВадФЃаЭВуШЁЪ§МгЙЄЃЌЛсЕМжТбЊдЕЙиЯЕЕФаѕТвЁЃ
3ЁЂвЛаЉЛљДЁЕФЙВадЭГМЦжИБъвВПЩвдТфЕиЕНН№ШкжїЬтВуЃЌетбљМШТњзуЪ§ОнЙВЯэЃЌвВТњзуЧхЮњЕФбЊдЕЙиЯЕЁЃ

вјааМШЪЧгЊЯњН№ШкВњЦЗЕФЛњЙЙЃЌвВЪЧЗчЯедЫгЊЕФЛњЙЙЃЌЫљвдгЊЯњМЏЪагыЗчЯеМЏЪаЖдвЕЮёжЇГХзїгУМЋДѓЃЛ
гЊЯњМЏЪаКЫаФЪЧНЈЩшПЭЛЇБъЧЉЬхЯЕЃЌгЩПЭЛЇБъЧЉЙЙГЩПЭЛЇЛЯёжњСІгЊЯњЃЛ
ЗчЯеМЏЪаКЫаФЪЧНЈЩшЗчЯеЦРЗжЬхЯЕМАЗчЯедЄОЏЬхЯЕЁЃЗчЯеЦРЗжЬхЯЕЙсДЉећИіаХДћвЕЮёЕФЩњУќжмЦкЃЌЮЊПьЫйвЕЮёОіВпЬсЙЉЪ§ОнжЇГжЁЃЗчЯедЄОЏЬхЯЕЭЈЙ§ЭГМЦгыеЙЪОШЋааЛњЙЙЕФЗчЯедЫгЊЕФЪ§ОнЃЌШУСьЕМВуМАЪБЪЖБ№ОгЊЗчЯеМАВЩШЁЯргІДыЪЉЃЛ
ЮоТлЪЧгЊЯњМЏЪаЕФПЭЛЇЛЯёЬхЯЕЛЙЪЧЗчЯеМЏЪаЕФЗчЯеЦРЗжЬхЯЕЃЌЖМашвЊаЮГЩвЕЮёЪ§ОнБеЛЗРДВЛЖЯЕќДњгыгХЛЏЁЃ
Ъ§ОнЗўЮё

Ъ§ОнЗўЮёгІНЈЩшЖРСЂЯЕЭГНјаадЫгЊЁЃРэЯызДЬЌЯТЃЌЫљгаЕФЪ§ОнЗўЮёЖМеЙЯждкЯЕЭГНчУцЩЯЃЌШчГЌЪавЛбљЃЌгІгУЯЕЭГдкЯЕЭГНчУцзджњзЂВсЫљашЕФЪ§ОнЗўЮёМДПЩЪЙгУЁЃ
Ъ§ОнЗўЮёжївЊЗжЮФМўНгПкгы SOA НгПкЁЃЮФМўНгПкеыЖдЪ§ОнСПДѓЁЂЙЬЖЈЪБМфМфИєЁЂдЪаэРыЯпИќаТЕФЪ§ОнНЛЛЅЃЛSOA
НгПкеыЖдЪ§ОнСПаЁЁЂЦЕЗБЧвВЛЖЈЪБЁЂБиаыЪЕЪБЖСШЁЕФЪ§ОнНЛЛЅЁЃ
гЩгк SOA НгПкашвЊЪЕЪБВщбЏЪ§ОнЃЌНЈвщЕЅЖРВПЪ№ЙиЯЕаЭЪ§ОнПтзїЮЊ SOA НгПкЕФЪ§ОнДцДЂЃЌМШЬсЩ§ВщбЏаЇТЪЃЌгжБмУтгІгУЯЕЭГжБНгЗУЮЪЪ§ОнВжПтЁЃ
БОеТНкжївЊВћЪіСЫЪ§ОнВжПтЕФећЬхМмЙЙгыНЈЩшТЗОЖЕФЙиМќЕуЃЌДгММЪѕВуУцЩЯвбОЛљБОСЫНтЪ§ОнВжПтШчКЮЪЕЪЉЁЃШЛЖјЃЌНЈЩшЪ§ОнВжПтЃЌВЛНіЪЧЯЕЭГЕФНЈЩшЃЌЛЙЪЧЯюФПЕФдЫгЊЁЃВЛЖЎЕУЯюФПдЫгЊЃЌЯЕЭГНЈЩшБиЖЈРЇФбжижиЁЃ
Ъ§ОнВжПтЯюФПЙмРэ

Ъ§ОнВжПтЪєгкВЛЖЯЕќДњИќаТЯЕЭГЃЌЪ§ОнЗўЮёФмСІгІЫцзХЕќДњЙ§ГЬБфЕУдНРДдНЧПЁЃЕЋЃЌЮЊЪВУДКмЖрЦѓвЕЕФЪ§ОнВжПтЯВЛЖУПИєМИФъОЭЭЦЕНжиНЈФиЃПБОеТНкДгЯюФПЙмРэЕФНЧЖШВћЪіЪ§ОнВжПтЕФНЈЩшЃЌВЛЙ§ЯогкЦЊЗљЃЌНіЗжЯэЯюФПЙмРэЕФжївЊЭДЕуЃЌЮДРДгаЛњЛсЛсБраДЯюФПЙмРэЕФЪЕЪЉСїГЬгыЙцЗЖЕФЮФеТИњДѓМвзїЗжЯэЁЃ
ДгзїепЕФОбщРДЫЕЃЌЪ§ОнВжПтЯюФПЭДЕужївЊгаЫФИіЃК
ШБЗІЙцЗЖЙмРэЃКЯюФПЙмРэЕФжиЕужЎвЛЪЧЙцЗЖЛЏЁЃЖдФкЖјбдЃЌЙцЗЖЛЏгажњгкЬсЩ§ПЊЗЂЭХЖгЕФЙЄзїаЇТЪЃЌЯЕЭГНЈЩшЙ§ГЬжаММЪѕЮФЕЕЕФГСЕэвВгажњгкЯЕЭГЕФПЩГжајЗЂеЙЃЛЖдЭтЖјбдЃЌЙцЗЖЛЏгажњгкЯЕЭГМфЕФНЛЛЅЃЌВЂЧвгааЇЕиНЕЕЭЙЕЭЈГЩБОЁЃШБЗІЙцЗЖЙмРэЃЌШнвзЕМжТЪ§ОнВжПтФЃаЭгњМгЛьТвЃЌзюжеЪ§ОнВжПтБфГЩЪ§ОнегдѓЃЌБЛЦШвЊЭЦЕЙжизіЃЛ
ШБЗІЮШЖЈЭХЖгЃКЪ§ОнВжПтЖдШЋааЕФЪ§ОнНјааЙщМЏВЂЪсРэећКЯГЩжїЬтФЃаЭЃЌзюжеМгЙЄГЩЪ§ОнМЏЪаЮЊИїРргІгУЯЕЭГЬсЙЉЪ§ОнЗўЮёЃЌЫљвдЪ§ОнВжПтЪЧвЛИіЪ§ОнЙиЯЕЪЎЗжИДдгЕФЯЕЭГЃЌФФХТвбОФЃаЭМђЛЏЁЃетбљЕФЯЕЭГвРРЕПЊЗЂЭХЖгВЛЖЯЕиГСЕэгыЕќДњВХФмЭкОђгыЗЂЛгИќДѓЕФадФмЁЃВЛЮШЖЈЕФПЊЗЂЭХЖгЛсЕМжТММЪѕГСЕэГіЯжЖЯВуЃЌЫцзХЯЕЭГЕФИДдгГЬЖШЩЯЩ§ЛсШУаТГЩдБдНРДдНФбРэНтЪ§ОнЙиЯЕЕФТпММАБГОАЃЛ
ШБЗІИпЙмжЇГжЃКЪ§ОнВжПтЯюФПНЈЩшЪЧвЛИіЛКТ§ЕФЙ§ГЬЧвМлжЕЬхЯжВЛУїЯдЃЌетРрЯюФПдкИпЙмЕФблжаОЭЪЧдДдДВЛЖЯЭЖШызЪдДЕФЮоЕзЖДЁЃМйШчИпЙмВЂВЛСЫНтЪ§ОнВжПтЕФБОжЪгыМлжЕЃЌКмПЩФмЛсТ§Т§АбзЪдДЭЖШыЕНЦфЫћШнвзВњЩњМлжЕЕФЯюФПШЅЁЃвЛЕЉЪ§ОнВжПтШБЗІзЪдДЕФжЇГХЃЌТ§Т§ЫйЖШОЭИњВЛЩЯЪ§ОнЗўЮёЕФЦШЧаашЧѓЃЌзюжеБфЕУБпдЕЛЏЃЛ
ШБЗІгааЇДђЗЈЃКЪ§ОнВжПтЕФЕќДњгХЛЏжївЊЬхЯждкжїЬтФЃаЭгыЪ§ОнМЏЪаЃЌМйШчПЊЗЂЭХЖгВЛЖЎЛђепВЛИвВйзїЃЌРЯОЩЕФЪ§ОнФЃаЭЛсГЩЮЊЪ§ОнЗўЮёФмСІЕФбЯжизшАЁЃ

ЯюФПЙмРэЖМЪЧгаЬзТЗЕФЃЌЫљвдЩЯЪіЕФЭДЕувВЪЧгаЗНЗЈШЅНтОіЁЃ
ЛёШЁИпЙмЕФжЇГжГаХЕ
1ЁЂдкЯюФПНЈЩшЧАЃЌБиаыИњИпЙмЗжЮіЪ§ОнВжПтНЈЩшЕФРћгыБзЃЌУїШЗИцжЊНЈЩшТЗОЖЪЧвЛИіЛКТ§ЕФЙ§ГЬЃЌШУИпЙмаЮГЩаФРэдЄЦкгыОпБИвЛЖЈЕФШЯжЊЁЃЭЌЪБвЊаћбяЭЌвЕЪ§ОнВжПтНЈЩшЕФГЩЙІАИР§ЃЌЬиБ№ЪЧУПИіРяГЬБЎЕФГЩаЇЃЌШУИпЙмУїШЗСЫНтЯюФПДјРДЕФКУДІЃЌздШЛОЭШнвзЛёЕУжЇГжСЫЁЃ
2ЁЂдкЯюФПНЈЩшЙ§ГЬжаЃЌвЊЖЎЕУЯђИпЙмЁАбћЙІЁБЃЌетбљВХФмЛёЕУИќЖрЕФаХШЮгыжЇГжЁЃ
НјааЙцЗЖЛЏЙмРэ
1ЁЂНЈСЂашЧѓЪЕЪЉСїГЬЃЌЙмРэашЧѓЩњУќжмЦкЃЌШУећИіашЧѓЪЕЪЉЙ§ГЬЖМЪЧгаМЃПЩбЁЃ
2ЁЂзіКУдЊЪ§ОнЙмРэЃЌФФХТШБЗІдЊЪ§ОнЙмРэЯЕЭГЃЌвВвЊгУЮФЕЕГСЕэЯТживЊЕФдЊЪ§ОнЃЌБШШчМмЙЙЮФЕЕЁЂФЃаЭЮФЕЕЁЂЪ§ОнгГЩфЮФЕЕЁЂжИБъПкОЖЮФЕЕЁЃ
3ЁЂ ЮЌЛЄКУММЪѕЮФЕЕЃЌФўПЩЮўЩќвЛЖЈЕФПЊЗЂЪБМфЃЌвВБиаыЮЌЛЄКУЯюФПЙ§ГЬЕФзЪСЯЁЃетбљЯЕЭГГіЯжвьГЃЛђепашвЊНЛНгЯюФПЪБЃЌОЭФмЗЂЛгжиДѓЕФзїгУЁЃ
ДђдьНзЬнаЭПЊЗЂЭХЖг
1ЁЂПЊЗЂЭХЖгФФХТЙцФЃаЁЃЌвВвЊзіЕНТщШИЫфаЁЮхдрОуШЋЃЌжСЩйвЊОпБИЯюФПОРэЁЂМмЙЙЪІ / ФЃаЭЪІЁЂашЧѓЗжЮіЪІЁЂбаЗЂЙЧИЩЁЂбаЗЂЙЄГЬЪІЁЂВтЪдЙЄГЬЪІЕФНЧЩЋЁЃ
2ЁЂживЊНЧЩЋБиаывЊга AB НЧЃЌБмУтживЊНЧЩЋЭЛШЛСїЪЇдьГЩЕФЯюФПЗчЯегыММЪѕЖЯВуЁЃ
3ЁЂзюКУФмжїЖЏХрбјШЫВХЖјЗЧвЛЮЖвРРЕЭЈЙ§ЩчеаРДеаФМШЫВХЁЃЫфШЛжїЖЏХрбјШЫВХЛЈЗбГЩБОБШНЯИпЃЌЖјЧвДцдкСїЪЇЕФЗчЯеЃЌЕЋвЛЕЉФмСєЯТРДЃЌЛљБОЖМЪЧЙЧИЩНЧЩЋЖјЧвЖдЭХЖггаМЋИпЕФЙщЪєИаЃЌИќВЛгУЫЕЩчеаРДЕФШЫВХвЛбљДцдкСїЪЇЕФЗчЯеЁЃ
ЖрЁЂКУЁЂаТЕФДђЗЈ
1ЁЂдЪаэЪдДэВЂЙФРјГЂЪдЃЌдкКЯЪЪЗЖЮЇФкЖдФЃаЭНјаадіЩОИФЃЌЩѕжСЭЦЕНжиЙЙЃЌХрбјФмНЈФЃЕФФмСІЁЃ
2ЁЂдкНЈФЃФмСІХрбјЙ§ГЬжаЃЌЫљЩцМАЕФФЃаЭПЯЖЈЛсГіЯжаЇЙћЬиБ№КУЕФЛњЛсЁЃвдДЫЛњЛсзїЮЊБъИЫЃЌИДХЬЩшМЦЫМТЗВЂаЮГЩЗНЗЈТлГСЕэЁЃ
3ЁЂД§ЕНФЃаЭНЈЩшЛљБОГЩЪьКѓЃЌдйДгКъЙлЕФНЧЖШЙлВьФЃаЭЃЌНсКЯвЕЮёГЁОАГжајЫМПМПЩгХЛЏЕиЗНВЂТфЕиЁЃетбљОЭЛсЛиЕНЁАЖрЁБНзЖЮЃЌВЛЖЯЪдДэДгЖјВњЩњаТЕФНЈФЃФмСІМАЗНЗЈТлЁЃ
|








