| БрМЭЦМі: |
БОЮФжївЊДгЯжзДЁЂЪЕЪБЪ§ВжЕїбаЁЂММЪѕЗНАИЁЂНзЖЮадГЩЙћЁЂеЙЭћетЮхЗНУцНщЩмЯагуДѓЙцФЃЪЕЪБЪ§ВжДюНЈЪЕМљЕШЯрЙиФкШнЁЃ
БОЮФРДзд ЯагуММЪѕЭХЖгЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1.ЯжзД
ЯагузїЮЊвЛПюЯажУНЛвз APPЃЌдкЖўЪжНЛвзЪаГЁжаЪЧЕБжЎЮоРЂЕФйЎйЎепЁЃЯагуДг 2014 ФъЕЎЩњЕНЯждкЦпећФъМфГжајдіГЄЃЌдкетИпЫйдіГЄЕФБГКѓДјРДЕФЪЧУПЬьНќАйвкЕФЦиЙтЕуЛїфЏРРЕШЪ§ОнЃЌдкетаЉЪ§ОнЙцФЃШчДЫХгДѓЕФБГКѓвВЛсДјРДжюЖрЙигкЪЕЪБадЕФЮЪЬтЃК
гУЛЇЗДРЁЩЬЦЗЦиЙтвьГЃЃЌШчКЮПьЫйЖЈЮЛЃП
ВњЦЗЭЌбЇШІСЫвЛХњЩЬЦЗЃЌШчКЮВщПДИУбљБОЕФЪЕЪББЈБэЃП
ЗЂЯжЮЪЬтзмЪЧЭэвЛВНЃЌШчКЮдкЕквЛЪБМфЛёШЁздЖЈвхЕФдЄОЏаХЯЂЃП
ЮЊСЫНтОіЩЯЪіЕФетаЉЮЪЬтЃЌЮвУЧПЊЪМСЫДђдьЯагуЪЕЪБЪ§ВжЕФЬНЫїжЎТЗЁЃ
2.ЪЕЪБЪ§ВжЕїба
Ъ§ВжЕїба
дкПЊЪМЩшМЦЯагуЕФЪЕЪБЪ§ОнВжПтжЎЧАЃЌЮвУЧвВЕїбаСЫМЏЭХФкЭтЕФИїжжЪ§ОнВжПтЕФЩшМЦгыМмЙЙЃЌвЛаЉЪЧБШНЯРЯЕФМмЙЙЩшМЦЃЌСэЭтвЛаЉЪЧгЩгкММЪѕЭЛЦЦКѓНјЖјДјРДЕФДДаТадЕФНтОіЗНАИЁЃБОЮФВЛЗСНЋетаЉЪЕЪБЪ§ОнВжПтЕФаТРЯЩшМЦзівЛЯТЗжРрЃК
ЕквЛРрЃКДгЮоЕНга
ЕБ Apache Storm(ПЊдДЕФЗжВМЪНЪЕЪБМЦЫуЯЕЭГ)ЮЪЪРКѓЃЌДѓЪ§ОнВЛдквРПП MapReduce
етжжЕЅвЛЕФМЦЫуЗНЪНЃЌгЕгаСЫЕБШеЪ§ОнЕБШеДІРэЕФФмСІЁЃ
ЕкЖўРрЃКДггаЕНШЋ
вд Lambda КЭ Kappa ЮЊДњБэЕФМмЙЙЃЌФмЙЛНЋЪЕЪБгыРыЯпМмЙЙНсКЯдквЛЦ№ЃЌвЛЬзВњЦЗПЩвдЪЕЯжЖржжЪ§ОнИќаТВпТдЁЃ
ЕкШ§РрЃКДгШЋЕНМђ
вд Flink ЮЊДњБэЕФжЇГжДАПкМЦЫуЕФСїЪНПђМмГіЯжЃЌЪЙРыЯпКЭЪЕЪБЕФТпМФмЙЛЭГвЛЦ№РДЃЌвЛЬзДњТыЪЕЯжСНжжИќаТВпТдЃЌБмУтСЫвђЮЊПЊЗЂЗНЪНВЛЭГвЛЕМжТЕФЪ§ОнВЛвЛжТЮЪЬтЁЃ
ЕкЫФРрЃКМмЙЙзпЯђЙЄОп
вд Hologres ЮЊДњБэЕФ HSAP(Hybrid Serving/Analytical Processing)в§ЧцЃЌгУЗўЮёЗжЮівЛЬхЛЏЕФЩшМЦРэФюЃЌЭГвЛЗжЮіаЭЪ§ОнПтКЭвЕЮёЪ§ОнПтЃЌдйХфКЯ
FlinkЃЌеце§ЪЕЯжЪ§ВжЕФГЙЕзЪЕЪБЛЏЁЃ
ЪзЯШЮвУЧо№ЦњСЫБШНЯЙХРЯЕФЗНАИЃЌгЩгкЯждкЕФММЪѕДДаТЗЧГЃПьЃЌгПЯжГіКмЖргХауЕФВњЦЗПЩЙЉЮвУЧШЅЪЙгУЃЌСэЭтЛљгкЯагуздЩэЕФвЕЮёашЧѓЃЌзюжебЁдёСЫ
Hologres[1]+Blink[2]РДЙЙНЈЪЕЪБЪ§ОнВжПтЁЃ
Ъ§ОнФЃаЭ
ВЛЙмЪЧДгМЦЫуГЩБОЃЌвзгУадЃЌИДгУадЃЌЛЙЪЧвЛжТадЕШЗНУцЃЌЮвУЧЖМБиаыБмУтбЬДбЪНЕФПЊЗЂФЃЪНЃЌЖјЪЧвджаМфВуЕФЗНЪНШЅНЈЩшЪЕЪБЪ§ВжЃЌбЬДбЪНМмЙЙгаКмДѓБзЖЫЃЌЫќЮоЗЈгыЦфЫћЯЕЭГНјаагааЇаЕїЙЄзїЃЌВЛРћгквЕЮёГСЕэЃЌЖјЧвКѓЦкЮЌЛЄГЩБОЗЧГЃДѓЁЃЯТЭМеЙЪОСЫЯагуЪЕЪБЪ§ВжЕФЪ§ОнФЃаЭЩшМЦМмЙЙЭМЁЃ

ДгЩЯЭМПЩвдПДГіЮвУЧНЋЪЕЪБЪ§ВжЕФЪ§ОнФЃаЭЗжЮЊ 4 ВуЃЌздЕзЯђЩЯвРДЮЮЊ ODSЁЂDWDЁЂDWS КЭ ADSЁЃЭЈЙ§ЖрВуЩшМЦПЩвдНЋДІРэЪ§ОнЕФСїГЬГСЕэдкИїВуЭъГЩЁЃБШШчдкЪ§ОнУїЯИВуЭГвЛЭъГЩЪ§ОнЕФЙ§ТЫЁЂЧхЯДЁЂЙцЗЖЁЂЭбУєСїГЬЃЛдкЪ§ОнЛузмВуМгЙЄЙВадЕФЖрЮЌжИБъЛузмЪ§ОнЃЌЬсИпСЫДњТыЕФИДгУТЪКЭећЬхЩњВњаЇТЪЁЃЭЌЪБИїВуМЖДІРэЕФШЮЮёРраЭЯрЫЦЃЌПЩвдВЩгУЭГвЛЕФММЪѕЗНАИгХЛЏадФмЃЌЪЙЪ§ВжММЪѕМмЙЙИќМђНрЁЃЯТУцЖдетЫФВуНјааМђЕЅЕФНщЩмЃК
ODS(Operational Data Store): ЬљдДВу
етвЛВугжНазіЬљдДВуЃЌзюЮЊНгНќЪ§ОндДЕФвЛВуЃЌашвЊДцДЂЕФЪ§ОнСПЪЧзюДѓЕФЃЌДцДЂЕФЪ§ОнвВЪЧзюдЪМЁЃЖджкЖрЪ§ОндДЖјбдЃЌЫћУЧЕФЪ§ОнИёЪНЛљБОВЛвЛжТЃЌОЙ§ЭГвЛЙцИёЛЏКѓПЩвдЕУЕНЙцећЕФЪ§ОнЃЌНЋЪ§ОндДжаЕФЪ§ОнОЙ§ГщШЁЁЂЧхЯДЁЂДЋЪфКѓзАШы
ODS ВуЁЃ
DWD(Data Warehouse Detail)ЃКЪ§ОнУїЯИВу
вЕЮёВугыЪ§ОнВжПтЕФИєРыВуЃЌжївЊЖд ODS ВузівЛаЉЪ§ОнЧхЯДКЭЙцЗЖЛЏЕФВйзїЃЌВЂЧвПЩвдАДееВЛЭЌЕФааЮЊЮЌЖШЖдЪ§ОнНјааЛЎЗжЃЌР§ШчБОЮФЖдЪ§ОндДОЭНјааСЫЛЎЗжЃЌжївЊЗжЮЊфЏРРЁЂЦиЙтЁЂЕуЛїЁЂНЛвзЕШВЛЭЌЕФЮЌЖШЃЌетаЉВЛЭЌЕФЮЌЖШФмЙЛЖдЩЯВуЕїгУЗНЬсЙЉИќЯИСЃЖШЕФЪ§ОнЗўЮёЁЃ
DWS(Data WareHouse Servce)ЃКЪ§ОнЗўЮёВу
ЖдИїИігђНјааСЫЪЪЖШЛузмЃЌжївЊвдЪ§Онгђ + вЕЮёгђЕФРэФюНЈЩшЙЋЙВЛузмВуЃЌгыРыЯпЪ§ВжВЛЭЌЕФЪЧЃЌЪЕЪБЪ§ВжЕФЛузмВуЗжЮЊЧсЖШЛузмВуКЭИпЖШЛузмВуЃЌР§ШчНЋЧсЖШЛузмВуЪ§ОнаДШы
ADSЃЌгУгкЧАЖЫВњЦЗИДдгЕФ OLAP ВщбЏГЁОАЃЌТњзузджњЗжЮіКЭВњГіБЈБэЕФашЧѓЁЃ
ADS(Application Data Store)ЃКгІгУЪ§ОнЗўЮёВу
жївЊЪЧЮЊСЫОпЬхашЧѓЖјЙЙНЈЕФгІгУВуЃЌЭЈЙ§ RPC ПђМмЖдЭтЬсЙЉЗўЮёЃЌР§ШчБОЮФжаЬсЕНЕФЪ§ОнБЈБэЗжЮігыеЙЪОЁЂМрПиИцОЏЁЂСїСПЕїПиЁЂПЊЗХЦНЬЈЕШгІгУЁЃ
DIM(Dimension)ЃКЮЌБэ
дкЪЕЪБМЦЫужаЗЧГЃживЊЃЌвВЪЧжиЕуЮЌЛЄЕФВПЗжЃЌЮЌБэашвЊЪЕЪБИќаТЃЌЧвЯТгЮЛљгкзюаТЕФЮЌБэНјааМЦЫуЃЌР§ШчЯагуЕФЪЕЪБЪ§ВжЮЌБэЛсгУЕНЯагуЩЬЦЗБэЁЂЯагугУЛЇБэЁЂШЫШКБэЁЂГЁОАБэЁЂЗжЭАБэЕШЁЃ
3.ММЪѕЗНАИ
ећЬхМмЙЙ
ЩЯУцЖдЯагуЪЕЪБЪ§ВжЕФЪ§ОнФЃаЭНјааСЫНтЦЪВЂЯъЯИЕиНщЩмСЫФЃаЭЕФИїВуДЮЩшМЦЫМЯыКЭЪЕМЪдЫгУЁЃЯТУцЪЧИљОнЪ§ОнФЃаЭЙЙНЈЕФММЪѕМмЙЙЭМЃЌЙВЗжЮЊЮхИіВуДЮЃЌздЕзЯђЩЯЗжБ№ЮЊЪ§ОндДЁЂЪ§ОнНгШыВуЁЂЪ§ОнМЦЫуВуЁЂЪ§ОнЗўЮёВуКЭгІгУВуЁЃ
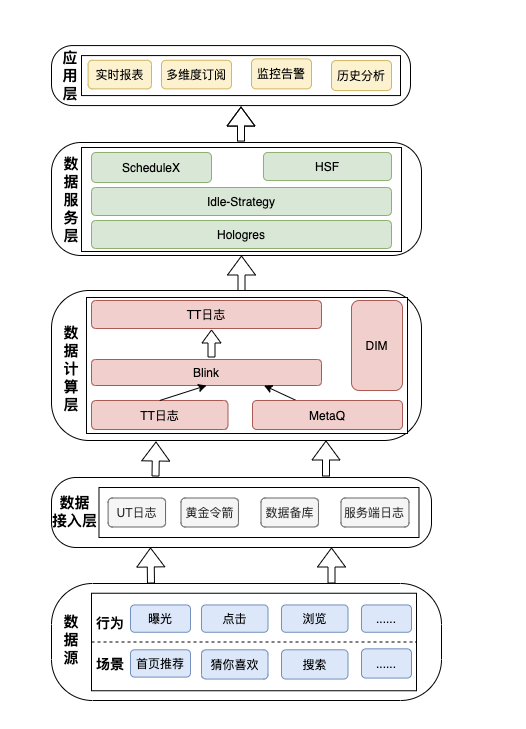
Ъ§ОндДЪЧећИіЪЕЪБЪ§ВжЕФЕззљЃЌЯагугЕгажкЖрГЁОАЃЌР§ШчЪзвГЭЦМіЁЂВТФуЯВЛЖЁЂЫбЫїЕШЃЌдкетаЉГЁОАжаЛсгаВЛЭЌЕФгУЛЇааЮЊЃЌгУЛЇВњЩњЕФЦиЙтЁЂЕуЛїЁЂфЏРРЕШааЮЊШежОЛсБЛЩЯВуДцДЂЙЄОпЪеМЏЁЃШчЩЯЭМжаЕФЪ§ОнНгШыВуЃЌПЩвдНЋЪ§ОндДНгШыЕН
UT[3]ШежОЁЂЛЦН№СюМ§ЁЂЪ§ОнБИПтЛђЗўЮёЖЫШежОжаДцДЂЁЃ
Ъ§ОнЧхЯДгыЙцећЪЧЙЙНЈЪЕЪБЪ§ВжЕФКЫаФЙ§ГЬЃЌЪ§ОнМЦЫуВуРћгУ Blink ЕФЪЕЪБДІРэФмСІНЋВЛЭЌИёЪНЕФЪ§ОнЭГвЛЧхЯДЁЂВЙГфКЭЙцећКѓДцШы
TT[4]жаЁЃЪ§ОнЗўЮёВуЪЧЪЕЪБЪ§ВжЕФЭјЙиВуЃЌНЋЪЕЪБЪ§ОнНјааТпМДІРэКѓЖдЭтЬсЙЉЪ§ОнЗўЮёКЭ API ЭјЙиФмСІЁЃ
гІгУВуЪЧзюЬљНќгУЛЇЕФВуДЮЃЌетвЛВуЪЧЮЊСЫОпЬхашЧѓЖјЙЙНЈЕФЃЌПЩвдЖдИїИіЮЌЖШЪ§ОнНјааЪЕЪББЈБэеЙЪОЃЌЖдЯпЩЯвьГЃСїСПМрПиИцОЏЃЌЖдЩЬЦЗгђНјааСїСПЕїПиЃЌЛЙПЩЙЉЦфЫћгІгУПЊЗХЯрЙиНгПкЕШЁЃ
ММЪѕФбЕу
МмЙЙШчЩЯЭМЫљЪОЃЌЙЙНЈЪЕЪБЪ§ВжЕФЙиМќЪЧЪЕЪБЪ§ОнДІРэвдМАЪЕЪБНЛЛЅЕФФмСІЃЌЯагуУПШеВњЩњНќАйвкЕФТёЕуЪ§ОнвдМАЗўЮёЦїШежОЃЌдкЙЙНЈЪЕЪБЪ§ВжгавдЯТЙиМќФбЕуЃК
ЁЄЪ§ОнСПДѓЃЌашвЊДІРэЕФТёЕуЪ§ОнвдМАЗўЮёЦїШежОДяАйвкЁЃ
ЁЄЪЕЪБадФмвЊЧѓИпЃЌМрПиИцОЏашвЊНЯИпЕФЪЕЪБадЁЃ
ЁЄЗжЮіНЛЛЅашЧѓЧПЃЌЪ§ОнЗжЮіГЁОАИДдгЧвНЛЛЅЦЕЗБЁЃ
ЁЄвьЙЙЪ§ОндДЖрЃЌЯагуИїИіЯЕЭГФЃПщВњЩњИїРрИёЪНЕФЪ§ОнЁЃ
ЪзЯШШчКЮФмЙЛМДЮШЖЈгжИпаЇЕиДІРэЪ§ОнЪЧЮвУЧиНД§НтОіЕФЮЪЬтЃЌдкУцСйКЃСПЪ§ОнМЦЫуДІРэЪБЃЌЮвУЧбЁгУСЫМЏЭХФкВПЕФСїЪНМЦЫуПђМм
BlinkЃЌЫќЪЧЛљгкПЊдДПђМм Flink ЕФдйЗтзАЕФаТвЛДњСїЪНМЦЫув§ЧцЃЌОЙ§ЖрФъЫЋ 11 ЕФПМбщЃЌЦфЪЕЪБМЦЫуФмСІЖдЮвУЧЯЕЭГРДЫЕЪЧЮугЙжУвЩЕФЁЃ
ЮвУЧдкзіЪЕЪББЈБэеЙЪОЪБНсКЯадФмКЭЪЕМЪЧщПіЃЌЛсЖдЪЕЪБЪ§ОнНјааЗжжгМЖБ№ЕФЪ§ОнОлКЯЃЌЭЈЙ§ Blink ЬсЙЉЕФЙіЖЏДАПкОлКЯОЭФмЙЛИпаЇЕиНтОіИУЮЪЬтЁЃЙіЖЏДАПкНЋУПИідЊЫиЗжХфЕНвЛИіжИЖЈДАПкДѓаЁЕФДАПкжаЃЌЙіЖЏДАПкгавЛИіЙЬЖЈЕФДѓаЁЃЌВЂЧвВЛЛсГіЯжжиЕўЁЃР§ШчЃКШчЙћжИЖЈСЫвЛИі
1 ЗжжгДѓаЁЕФЙіЖЏДАПкЃЌФЧУДЮоЯоСїЕФЪ§ОнЛсИљОнЪБМфЛЎЗжГЩ[0:00 - 0:01), [0:01,
0:02), [0:02, 0:03)... ЕШДАПкЃЌЙіЖЏДАПкЛЎЗжаЮЪНШчЯТЭМЫљЪОЁЃ

ЮвУЧдкБраДЗжжгМЖБ№ЕФ Blink ШЮЮёЪБЃЌжЛашвЊдк GROUP BY згОфжаЖЈвхЙіЖЏДАПкМДПЩЃЌЮБДњТыШчЯТЃК
| GROUP BY TUMBLE(<time-attr>, <size-interval>) |
ЩЯЪі SQL жаЕФВЮЪ§БиаыЪЧСїжаЕФвЛИіКЯЗЈЕФЪБМфЪєадзжЖЮЃЌгаСНжжРраЭЃКprocessing time
ЛђЪЧ event timeЁЃ
Event TimeЃКгУЛЇЬсЙЉЕФЪТМўЪБМф(ЭЈГЃЪЧЪ§ОнЕФзюдЪМЕФДДНЈЪБМф)ЃЌevent time вЛЖЈЪЧгУЛЇЬсЙЉдкБэЕФ
schema РяЕФЪ§ОнЁЃ
Processing TimeЃКБэЪОЯЕЭГЖдЪТМўНјааДІРэЕФБОЕиЯЕЭГЪБМфЃЌЕЅЮЛЮЊКСУыЁЃ
ИљОнЯюФПЪЕМЪЧщПіЃЌвђЮЊЮвУЧОлКЯЕФЪЧТёЕуЪТМўЕБЪБЕФЪ§ОнЃЌЫљвдбЁдёЪЙгУ Event TimeЃЌбЁдёИУРраЭЪБМфЕФСэвЛКУДІЪЧдкжиХмФГИіЪБМфЖЮЕФШЮЮёЪБвВФмЙЛБЃГжНсЙћЕФвЛжТадЁЃ
ЭЈЙ§ Blink ЕФетИіЗЈБІЮвУЧФмЙЛИпаЇЪЕЪБЕиДІРэКЃСПЪ§ОнЃЌФЧдкУцСйЪ§ОнЗжЮіГЁОАИДдгВЂЧвНЛЛЅЗЧГЃЦЕЗБЕФетжжЧщПіЯТЃЌЮвУЧгжШчКЮШЅБмУтДЋЭГ
OLAP ЕФДцДЂМЦЫуБзЖЫФиЃПдкбАевЪЕЪБЕФВЂЧвМцВЂЗўЮё/ЗжЮівЛЬхЛЏЕФЯЕЭГЙЄОпЪБЮвУЧЗЂЯжСЫвЛПюРћЦїЃЌЫќОЭЪЧ
Hologres(Holographic+Postgres)ЃЌЫќжЇГжЖдЭђвкМЖЪ§ОнНјааИпВЂЗЂЕЭбгЪБЖрЮЌЗжЮіЭИЪгКЭвЕЮёЬНЫїЃЌПЩвдЧсЫЩЖјЧвОМУЕФЪЙгУЯжга
BI ЙЄОпЗжЮіЫљгаЪ§ОнЃЌдкУцСй PB МЖЪ§ОнЪБвРШЛФмЙЛБЃГжУыМЖЯьгІЕФФмСІЃЌВЂЧвМђЕЅвзгУЃЌФмЙЛПьЫйЩЯЪжЁЃ
Hologres ЪЧЛљгкДцДЂМЦЫуЗжРыЕФЩшМЦФЃЪНЖјЙЙНЈЕФЃЌЪ§ОнШЋВПДцдквЛИіЗжВМЪНЮФМўЯЕЭГжаЃЌДцДЂв§ЧцЕФзмЬхМмЙЙШчЯТЭМЫљЪОЃК

УПИіЗжЦЌ(shard)ЙЙГЩСЫвЛИіДцДЂЙмРэКЭЛжИДЕФЕЅдЊ(recovery unit)ЃЌЩЯЭМеЙЪОСЫвЛИіЗжЦЌЕФЛљБОМмЙЙЃЌвЛИіЗжЦЌгЩЖрИі
tablet зщГЩЃЌетаЉ tablet ЛсЙВЯэвЛИіШежОЃЈWrite-Ahead LogЃЌМђГЦ WALЃЌЫљгаЕФаТЪ§ОнЖМЪЧвд
append-only ЕФаЮЪНВхШыЕФЁЃЕБаДВйзїВЛЖЯНјРДЃЌУПИі tablet РяЛсЛ§РлГіКмЖрЮФМўЁЃЕБвЛИі
tablet РяаЁЮФМўЛ§РлЕНвЛЖЈЪ§СПЪБЃЌДцДЂв§ЧцЛсдкКѓЬЈАбаЁЮФМўКЯВЂЦ№РДЃЌФмМѕЩйЪЙгУЯЕЭГзЪдДЧвКЯВЂКѓЕФЮФМўМѕЩйСЫЃЌЬсИпСЫЖСЕФадФмЃЌЮЊЪЕЪБИпаЇЗжЮіЬсЙЉСЫПЩФмадЁЃ
ЩЯУцЯъЯИУшЪіСЫКЃСПЪ§ОнЕФЪЕЪБДІРэЁЂЪ§ОнДцДЂвдМАЗжЮіЕФНтОіЗНАИЃЌФЧдкУцЖдвьЙЙЪ§ОндДНгШыгжЪЧШчКЮДІРэЕФФиЃПЯагугЩгкГЁОАжкЖрЃЌвЕЮёИДдгЃЌдкДІРэвьЙЙЪ§ОндДЪБЮвУЧВЩгУСьгђЮЌЖШЭГМЦЕФЗНЪНЃЌНЋВЛЭЌСьгђЕФИїРрЪ§ОндДзжЖЮЭГвЛЛЏЃЌдк
Blink ЧхЯДЪ§ОнЪБЛсНсКЯГЁОАЁЂШЫШКЁЂЗжЭАЕШЮЌЖШаХЯЂРДНтОівьЙЙЪ§ОндДЕФЮЪЬтЁЃ

гЩЩЯЭМПЩжЊЃЌСьгђФЃПщжївЊЗжЮЊСїСПгђЁЂгУЛЇгђЁЂНЛвзгђЁЂЛЅЖЏгђЕШЃЌУПИіСьгђжаЖМЛсГщЯѓГіЯргІЕФЖдЯѓЃЌР§ШчСїСПгђжагаЩЬЦЗЁЂЙуИцКЭдЫгЊЭЖЗХЃЛгУЛЇгђжагагУЛЇЁЂЩшБИЁЂТєМвКЭТђМвЃЛНЛвзгђжагабЏЕЅЁЂГЩНЛЁЂGMVЃЛЛЅЖЏгђжагаЪеВиЁЂГЌдоКЭЦРТлЁЃ
дкЩшМЦвьЙЙЪ§ОндДЕФНтОіЗНАИЪБвВПМТЧЕНКѓУцДђдьПЊЗХЦНЬЈЕФашЧѓЃЌЫљвдНЋЪ§ОнНгШыВуГщЯѓГЩВЛЭЌСьгђЕФНгПкЖдЭтЬсЙЉНгШыЗўЮёВЂЧвдкгІгУВувВПЊЗХСЫИїИіЮЌЖШЕФЭГМЦНгПкЁЃетбљЖдгаНгШыЪЕЪБЪ§ВжЕФвЕЮёашЧѓЪБПЩвдЭЈЙ§Ъ§ОнВуКЭгІгУВуПЊЗХЕФГщЯѓНгПкПьЫйНгШыЃЌВЛгУПМТЧећИіСДТЗжаМфЕФЯИНкЃЌФмЙЛМЋДѓЕиМѕЩйПЊЗЂжмЦкЁЃ
4.НзЖЮадГЩЙћ
БОЮФжаЫљЙЙНЈЕФЪЕЪБЪ§ВждкЪЕЪББЈБэЃЌЦиЙтвьГЃЗДРЁЕШЗНУцгаЫљгІгУЃЌЭЈЙ§ЦНЬЈПЩвдЪЕЪБЕифЏРРЯЕЭГДѓХЬЁЂЪзвГЁЂВТФуЯВЛЖЁЂЫбЫїЕШГЁОАЕФИїИіЮЌЖШЪ§ОнЃЌЬсЩ§СЫЯагуИїИіГЁОАЕФЪЕЪБЪ§ОнЕФЗсИЛЖШЁЃФПЧАЭЈЙ§ЪЕЪБЪ§ВжЕФгІгУЃЌвВШЁЕУСЫвЛаЉГЩЙћЃК
ЁЄФмЙЛЪЕЪБЦРЙРЯпЩЯВпТдЕФзюжеаЇЙћЃЛ
ЁЄФмЙЛПьЫйХХВщЖЈЮЛгУЛЇЗДРЁЕФЦиЙтвьГЃЮЪЬтЃЛ
ЁЄФмЙЛИјВњЦЗЭЌбЇЬсЙЉШІЦЗКѓЕФЪЕЪББЈБэаХЯЂЕШЕШЁЃ


5.еЙЭћ
ФПЧАЮвУЧЖдЪЕЪБЪ§ВжЕФПЊЗЂЛЙДІгкГѕЦкНзЖЮЃЌКѓајЮвУЧЛсМгДѓСІЖШЭЖШыбаЗЂЃЌЪЙЪЕЪБЪ§ВждкИќЖрЕФГЁОАгІгУЦ№РДЃЌДђдьвЛИіЪЕЪБЁЂШЋУцЁЂЮШЖЈЕФСїСПгІгУЦНЬЈЁЃКѓЦкЮвУЧНЋЛсдквдЯТМИИіЗНУцЩюЭкКЭгХЛЏЃК
гыМЏЭХФкЕФЦфЫћМрПиИцОЏЦНЬЈЖдНгЃЌЪЙЕУдкБОЦНЬЈФкВЛНіФмЙЛИќЯИСЃЖШЕиМрПиИїИіГЁОАЕФЩЬЦЗСїСПвьГЃЧщПіЃЌЖјЧвФмЙЛЪеЛёвЛИігЕгаМрПиЁЂдЄОЏЁЂЖЈЮЛЁЂздаоИДвЛеОЪНЕФАВБЃЦНЬЈЁЃ
ДђдьЪЕЪБЪ§ВжЕФПЊЗХЦНЬЈЬсЙЉИјЦфЫћЭХЖгЪЙгУЃЌФмЙЛНкдМИќЖрЕФШЫСІзЪдДКЭПЊЗЂжмЦкЁЃ
зЂЪЭЃК
[1] Hologres: Hologres ЪЧАЂРяАЭАЭзджїбаЗЂЕФвЛПюНЛЛЅЪНЗжЮіВњЦЗЃЌМцШн PostgreSQL 11 авщЃЌгыДѓЪ§ОнЩњЬЌЮоЗьСЌНгЃЌжЇГжИпВЂЗЂКЭЕЭбгЪБЕиЗжЮіДІРэ PB МЖЪ§ОнЁЃ
[2] Blink:Blink ЪЧАЂРяАЭАЭЪЕЪБМЦЫуВПЭЈЙ§ИФНјПЊдД Apache Flink ЯюФПЖјДДНЈЕФАЂРяФкВПВњЦЗЁЃ
[3] UT:UserTrack жївЊжИЮоЯпЖЫ APP ЕФИїжжгУЛЇааЮЊВйзїШежОЃЌЪЧЫљгаЛљгкгУЛЇааЮЊЗжЮіЕФдЫгЊБЈБэЕФЛљДЁЁЃ
[4] TT:TimeTunnel ЪЧвЛИіИпаЇЕФЁЂПЩППЕФЁЂПЩРЉеЙЕФЯћЯЂЭЈаХЦНЬЈЁЃ
|








