| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЮЊЪВУДвЊЖдЪ§ОнВжПтНјааЗжВуЃЌЪ§ОнВжПтЕФЫФжжКЫаФЗжВуЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздInfoQЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЮЊЪВУДвЊЖдЪ§ОнВжПтНјааЗжВу
здДгДѓЪ§ОнЦНЬЈhadoopМАЦфММЪѕЛ№Ц№РДжЎКѓЃЌЮоТлЪЧеўЦѓЁЂУёЦѓЛЙЪЧИїРрН№ШкЛњЙЙЃЌЖМЯЦЦ№СЫвЛЙЩДѓЪ§ОнММЪѕзЊаЭЁЂЪ§ОнВжПтжиЙЙЁЂжЧФмЪ§ОнЗжЮіЁЂAI
ЕШвЛЯЕСаКкПЦММЧвИпДѓЩЯЕФШШГБЁЃЦфЪЕЃЌЪЧЗёзЊаЭДѓЪ§ОнММЪѕвдКѓЃЌВњЦЗгЊЯњЁЂЗчЯеЙмПиЁЂЪ§ОнЗжЮіЁЂЙмРэОіВпЕШЦѓвЕКЫаФЫпЧѓЖМПЩвдгІгаОЁгаФиЃПЦѓвЕЕФЪ§ОнЙмРэКЫаФЁЊЁЊЪ§ОнВжПтгжгІИУвдКЮжжаЮЬЌРДНЈЩшЃПвЊЛиД№ЩЯЪіЮЪЬтЃЌБиаывЊДгРэНтЪ§ОнВжПтЕФБОжЪгыМмЙЙПЊЪМЁЃ
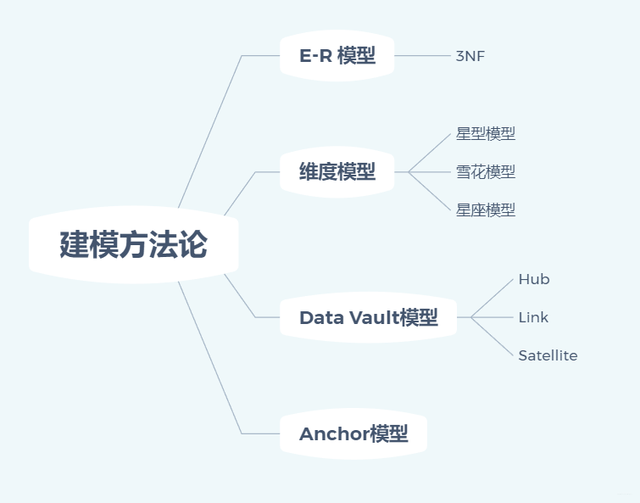
Ъ§ОнВжПтЃЌгЩЪ§ОнВжПтжЎИИ Bill Inmon дк 1991 ФъГіАцЕФЁАBuilding
the Data WarehouseЁБЖЈвхЧвБЛЙуЗКНгЪмЕФЁЊЁЊУцЯђжїЬтЕФЁЂМЏГЩЕФЁЂЯрЖдЮШЖЈЕФЁЂЗДгГРњЪЗБфЛЏЕФЪ§ОнМЏКЯЃЌгУгкжЇГжЙмРэОіВпЁЃДгЖЈвхЩЯРДПДЃЌЪ§ОнВжПтЕФЙиМќДЪЮЊУцЯђжїЬтЁЂМЏГЩЁЂЮШЖЈЁЂЗДгГРњЪЗБфЛЏЁЂжЇГжЙмРэОіВпЃЌЖјетаЉЙиМќДЪЕФЪЕЯжОЭЬхЯждкЗжВуМмЙЙФкЁЃ
ЪЕЯжКУЗжВуМмЙЙЃЌгавдЯТКУДІЃК
1ЃЉЧхЮњЪ§ОнНсЙЙЃКУПвЛИіЪ§ОнЗжВуЖМгаЖдгІЕФзїгУгђЃЌдкЪЙгУЪ§ОнЕФЪБКђФмИќЗНБуЕФЖЈЮЛКЭРэНтЁЃ
2ЃЉЪ§ОнбЊдЕзЗзйЃКЬсЙЉИјвЕЮёШЫдБЛђЯТгЮЯЕЭГЕФЪ§ОнЗўЮёЪБЖМЪЧФПБъЪ§ОнЃЌФПБъЪ§ОнЕФЪ§ОнРДдДвЛАуЖМРДздгкЖреХБэЪ§ОнЁЃШєГіЯжФПБъЪ§ОнвьГЃЪБЃЌЧхЮњЕФбЊдЕЙиЯЕПЩвдПьЫйЖЈЮЛЮЪЬтЫљдкЁЃЖјЧвЃЌбЊдЕЙмРэвВЪЧдЊЪ§ОнЙмРэживЊЕФвЛВПЗжЁЃ
3ЃЉМѕЩйжиИДПЊЗЂЃКЪ§ОнЕФж№ВуМгЙЄддђЃЌЯТВуАќКЌСЫЩЯВуЪ§ОнМгЙЄЫљашвЊЕФШЋСПЪ§ОнЃЌетбљЕФМгЙЄЗНЪНБмУтСЫУПИіЪ§ОнПЊЗЂШЫдБЖМжиаТДгдДЯЕЭГГщШЁЪ§ОнНјааМгЙЄЁЃ
4ЃЉЪ§ОнЙиЯЕЬѕРэЛЏЃКдДЯЕЭГМфДцдкИДдгЕФЪ§ОнЙиЯЕЃЌБШШчПЭЛЇаХЯЂЭЌЪБДцдкгкКЫаФЯЕЭГЁЂаХДћЯЕЭГЁЂРэВЦЯЕЭГЁЂзЪН№ЯЕЭГЃЌШЁЪ§ЪБИУШчКЮОіВпФиЃПЪ§ОнВжПтЛсЖдЯрЭЌжїЬтЕФЪ§ОнНјааЭГвЛНЈФЃЃЌАбИДдгЕФЪ§ОнЙиЯЕЪсРэГЩЬѕРэЧхЮњЕФЪ§ОнФЃаЭЃЌЪЙгУЪБОЭПЩБмУтЩЯЪіЮЪЬтСЫЁЃ
5ЃЉЦСБЮдЪМЪ§ОнЕФгАЯьЃКЪ§ОнЕФж№ВуМгЙЄддђЃЌЩЯВуЕФЪ§ОнЖМгЩЯТвЛВуЕФЪ§ОнМгЙЄЛёШЁЃЌВЛдЪаэЬјМЖШЁЪ§ЁЃЖјдЪМЪ§ОнЮЛгкЪ§ВжЕФзюЕзВуЃЌРыгІгУВуЪ§ОнЛЙгаЖрВуЕФЪ§ОнМгЙЄЃЌЫљвдМгЙЄгІгУВуЪ§ОнЕФЙ§ГЬжаОЭЛсАбдЪМЪ§ОнЕФБфИќЯћГ§ЕєЃЌБЃГжгІгУВуЕФЮШЖЈадЁЃ
СЫНтСЫЗжВуМмЙЙЕФКУДІЃЌЙиМќЪЧИУШчКЮНјааЙцЛЎгыНЈЩшЁЃ
Ъ§ОнВжПтКЫаФЗжВу
ФПЧАЪаГЁЩЯжїСїЕФЗжВуЗНЪНблЛЈчдТвЃЌВЛЙ§ПДЪТЧщВЛФмжЛПДБэУцЃЌЛЙвЊПДЕНФкдкЕФЙцТЩЁЃДгЗБЖрЕФЗжВуЗНЪНжаЃЌПЩвдЬсСЖГівдЯТЙВадЃК
1ЃЉОпБИдДЯЕЭГЪ§ОнЙщМЏЕНЪ§ВжЕФЛКГхВуЃЌЛђГЦЮЊЬљдДВуЁЃ
2ЃЉОпБИЪ§ОнБъзМЛЏМАКЯВЂШЋСПЪ§ОнЕФБъзМВуЁЃ
3ЃЉОпБИжїЬтЛЎЗжМАУїЯИЪ§ОнећКЯЕФжїЬтВуЁЃ
4ЃЉОпБИЬсЙЉЪ§ОнЗўЮёИјЯТгЮЯЕЭГЪЙгУЕФМЏЪаВуЃЌЛђГЦЮЊгІгУВуЁЃ
5ЃЉГ§ЩЯЪіКЫаФЗжВуЃЌЦфЫћЗжВуЪЧДгКЫаФЗжВуЩЯЯИЗжЕУЕНЕФЁЃ
ЫљвдЃЌЪ§ОнВжПтЕФКЫаФЗжВуЮЊ ODM ЬљдДВуЁЂSDM БъзМВуЁЂFDM жїЬтВуЁЂADM гІгУВуЃЌШчЯТЭМЫљЪОЃК
ODMЃЈOrigin Data ManagerЃЉЬљдДВу
жївЊгУгкдДЯЕЭГЬсЙЉЕФ T-1 діСПЮФБОЪ§ОнАДдДЯЕЭГвЛжТЕФЪ§ОнНсЙЙШыПтЕНЪ§ОнПтЁЃЮЊЪВУДвЊАбдДЯЕЭГЪ§ОнЃЈМђГЦдДЪ§ОнЃЉШыПтЕНЪ§ОнПтЃЌЖјВЛЪЧжБНгКЯВЂЕНШЋСПЪ§ОнФиЃПДцдквдЯТдвђЃК
1ЃЉжБНгДІРэЮФБОЪ§ОнЕФЛАЃЌвЊЯШАбЮФБОЪ§ОнМгдиЕНФкДцЩЯЃЌвЊЪЧЪ§ОнДѓаЁГЌЙ§
GB МЖБ№ЃЌЖдЗўЮёЦїФкДцбЙСІПЩВЛаЁЁЃЫљвдИУДІРэЗНЪНЖдЗўЮёЦїгВМўвЊЧѓИпЃЌМйШчАбЮФБОЪ§ОнЯШЭЈЙ§Ъ§ОнПтТфЕиЕНДХХЬЩЯЃЌПЩвдМѕЧсКѓајДІРэЕФгВМўбЙСІЁЃСэЭтЃЌЮФБОЪ§ОнБОЩэЪЧУЛгаНсЙЙЕФЃЌжБНгДІРэЪБЛЙЕУащФтГЩЖўЮЌБэВХШнвзДІРэЃЌЕЋЪЧЮФБОЪ§ОнМгдиЕНЪ§ОнПтКѓздЖЏаЮГЩЖўЮЌБэЃЌБугкКѓајДІРэЁЃ
ФПЧАгаВПЗжЙиЯЕаЭЪ§ОнПтЃЌжЇГжНЈСЂЭтВПБэЃЌЪЙгУЖўЮЌБэЕФЗНЪНЖСШЁЮФБОЪ§ОнЃЌБШШч
greenplumЃЌЕЋЪЧИУЗНЪНЕФЖСШЁаЇТЪЛЙЪЧБШВЛЩЯАбЪ§ОнДцЗХдкЪ§ОнПтФкЁЃ
2ЃЉгЩгк ODM ЮЛгкЪ§ВжЕФзюЕзВуЃЌвЛЕЉдДЪ§ОнШыПтГіДэЃЌПЩДгзюЕзВуИєЖЯКѓајЕФЪ§ОнМгЙЄСїГЬЃЌБмУтАбДэЮѓЕФдДЪ§ОнШыПтЕНБъзМВув§ЗЂСЌЛЗЩњВњЮЪЬтЁЃ
3ЃЉЕБЗЂЯжЩЯВуЪ§ОнвьГЃЪБЃЌПЩЭЈЙ§ ODM ХХВщИљвђЪЧЗёГіЯждкдДЪ§ОнЩЯЁЃ
ODM ЕФНЈЩшЗжЮЊдДЪ§ОнГщШЁМАдДЪ§ОнШыПтСНВПЗжЁЃдДЪ§ОнГщШЁЕФДІРэЗНЪНгаСНжжЃЌвЛжжЪЧгЩдДЯЕЭГЕФММЪѕЭХЖгАДееЪ§ВжвЊЧѓЕФНгПкИёЪНЃЌГщШЁЪ§ОнЭЦЫЭЕНЪ§ВжРДЪЕЯжЃЌСэвЛжжЪЧгЩзЈУХЕФ
ETL ЭХЖгИКд№дДЪ§ОнГщШЁМАдДЪ§ОнШыПтЕФЪЕЯжЁЃВПЗжЦѓвЕЛсбЁдёЕквЛжжЪЕЯжЗНЪНЃЌетЪЧвђЮЊШБЗІзЈУХЕФ ETL
ЭХЖгГаЕЃЃЌЛђепВЛЯЃЭћ ETL ЭХЖгЖрНгЛюЃЈНгЙјЃЉЁЃЪТЪЕЩЯЃЌЮЊСЫДгИљБОЩЯБЃжЄЪ§ВжЕФЪ§ОнжЪСПЃЌЛЙЪЧгУЕкЖўжжЗНЪНЪЕЯжВХЪЧзюКУЕФЃЌетвВЪЧЦѓвЕНЈЩшЪ§ВжЪБЛсКіТдЕФвЛЕуЁЃ
ODM ПДЫЦЪЧЪ§ВжРяЕФзюЕзВуЃЌвВЪЧзюШнвзЪЕЯжЕФВуМЖЃЌвђЮЊЪ§ОнНсЙЙгыдДЯЕЭГвЛжТЃЌБЃжЄЪ§Оне§ГЃШыПтМДПЩЁЃЕЋЪЧБЃжЄЪ§Оне§ГЃШыПтЃЌецЕФЪЧФЧУДШнвзЪЕЯжТ№ЃПДѓМвЪЧЗёгіЕНЙ§вдЯТЮЪЬтЃК
дДЪ§ОнГщШЁЕНЪ§ВжЃЌУЛгаШЮКЮБЃжЄЪ§ОнЭъећадЕФДыЪЉЃЌЙ§ЖЮЪБМфКѓВХЗЂЯжЪ§ВжТЉЪ§СЫЃЌгжЕУДгдДЯЕЭГНјааЪ§ОнГѕЪМЛЏЃЛ
вЛЕЉдДЪ§ОнГщШЁГіЯжвьГЃЃЌШБЗІдЄОЏЭЈжЊЛњжЦЃЌжЛгадкЪ§ВжМгдиЪ§ОнЪБВХЗЂЯжЪ§ОнЩаЮДЭЦЫЭЙ§РДЃЌгАЯьКѓајЪ§ОнМгЙЄЃЛ
дДЯЕЭГГіЯжЪ§ОнФЃаЭЕФаТдіЛђБфИќКѓЃЌУЛгаМАЪБЭЈжЊЪ§ВжЃЌЕНЪ§ВжМгдиЪ§ОнГіЯжБЈДэЪБВХЗЂЯжЃЌБЦзХЪ§ВжНјааНєМББфИќЁЃ
ЩЯЪіЮЪЬтЕФГіЯжЃЌОЭЪЧвђЮЊУЛгаАбЮеЕН ODM НЈЩшЕФКЫаФЃЌЙЙНЈвЛЬѕЭъЩЦЕФЪ§ОнГщШЁЁЊЁЊЪ§ОнШыПтЕФ
ETL ТЗЯпЁЃODM НЈЩшЕФКЫаФгавдЯТЗНУцЃК
1ЃЉНЈСЂЪ§ОнГщШЁЁЊЁЊЪ§ОнШыПтЕФШЋСїГЬаЃбщЛњжЦЁЃНјааЪ§ОнГщШЁЪБЃЌАбТфЕиЕФЮФБОЪ§ОнМЧТМЪ§гыдДЯЕЭГГщШЁМЧТМЪ§НјааЦЅЖдЃЌМДПЩЭъГЩЪ§ОнГщШЁЕФЭъећадаЃбщЁЃНјааЪ§ОнШыПтЪБЃЌАбШыПтЕФМЧТМЪ§гыЮФБОЪ§ОнЕФМЧТМЪ§НјааЦЅЖдЃЌМДПЩЭъГЩЪ§ОнШыПтЕФЭъећадаЃбщЁЃ
2ЃЉЪЙгУдЊЪ§ОнЙмРэЙЄОпЃЌЖЈЪБЭЌВНдДЯЕЭГЕФЪ§ОнНсЙЙЕНЪ§ВжНјааБШЖдЃЌЕБЗЂЯжВювьЪБМАЪБдЄОЏЁЃ
3ЃЉгЩгкЪ§ОнГщШЁМАЪ§ОнШыПтЕФДІРэСїГЬЖМЪЧЙЬЖЈЕФЃЌПЩЙЬЛЏЮЊвЛЬзГЬађЃЌЮДРДдДЯЕЭГГіЯжаТдіЛђепБфИќашЧѓЪБЃЌжЛашДІРэКУгГЩфЙиЯЕМДПЩЃЌЮоаыжиИДПЊЗЂДІРэСїГЬЁЃ
4ЃЉНЈЩшдЄОЏЛњжЦЃЌБЪепБШНЯЭЦМіЪЙгУЖЬаХдЄОЏЭЈжЊЃЌетбљЮоТлЪЧЗёдкЙЋЫОЃЌЖМПЩвдЪЕЪБСЫНтЕН
ETL зївЕЕФжДааЧщПіЃЌМАЪБЖдвьГЃНјааДІРэЁЃЕБШЛЃЌгЩгкЩњВњЛЗОГЕФВйзїШЈЯодкдЫЮЌЭХЖгЪжЩЯЃЌдЄОЏЛњжЦЛЙашвЊдЫЮЌЭХЖгХфКЯвЛЦ№ЪЕЯжЁЃ
SDMЃЈStandard Data ManagerЃЉБъзМВу
SDM ЕФЪ§ОнДІРэжївЊЗжЮЊСНВПЗжЃЌвЛВПЗжЪЧдДЪ§ОнЧхЯДМАБъзМЛЏЃЌСэвЛВПЗжЪЧКЯВЂШЋСПЪ§ОнЁЃ
гЩгкдДЪ§ОнЕФжЪСПВЮВюВЛЦыЃЌЮЊСЫЪЙЪ§ВжФкЕФЪ§ОнЪЧБъзМЙцЗЖЕФЃЌЫљвдЖддДЪ§ОнвЊАДееЪ§ОнБъзМЃЌНјааЪ§ОнЧхЯДКЭБъзМЛЏзЊЛЛЃЈPSЃКгЩгкдДЪ§ОнвбШыПтЕН
ODMЃЌЫљвдЪ§ОнЧхЯДМАБъзМЛЏзЊЛЛЖМЪЧдкЪ§ОнПтВуУцНјааЃЌдйДЮЬхЯж ODM НЈЩшЕФБивЊадЃЉЁЃЪ§ОнБъзМгЩЪ§ОнЙмРэЭХЖгИКд№жЦЖЈЕФЃЌЫљвдЪ§ВжНЈЩшЭХЖгвВвЊгыЪ§ОнЙмРэЭХЖгЩюЖШКЯзїВХФмзіКУЪ§ОнБъзМЛЏЕФЖЏзїЁЃ
етРяПЩФмгаИівЩЮЪЃЌЪ§ОнЧхЯДгыБъзМЛЏЕФЖЏзїФмЗёЗХдк ODM ЭъГЩФиЃПД№АИЪЧВЛФмЃЌвђЮЊ
ODM ФПБъЪЧвЊЧѓШыВжЪ§ОнгыдДЪ§ОнЭъШЋвЛжТЁЃШє ODM вбЖддДЪ§ОнНјааСЫЧхЯДгыБъзМЛЏЖЏзїЃЌЮДРДХХВщЪ§ОнвьГЃЪБОЭВЛФмИљОн
ODM РДХХВщИљвђЪЧЗёГігкдДЪ§ОнСЫЁЃ
КЯВЂШЋСПЪ§ОнЕФЗНЪНгаШ§жжЃЌЗжБ№ЮЊШЋСПИќаТЁЂдіСПБфИќМАдіСПСїЫЎЁЃ
ШЋСПИќаТЃЌЪ§ОнГщШЁЪБАбдДЯЕЭГБэЕФЪ§ОнШЋСПГщШЁЙ§РДЃЌИУИќаТЗНЪНжЛашАб SDM ЖдгІБэЕФЪ§ОнЯШЧхПеЃЌдкШыПтБъзМЛЏКѓЕФЪ§ОнМДПЩЁЃ

діСПБфИќМАдіСПСїЫЎЃЌЪ§ОнГщШЁЪБАбдДЯЕЭГБэФкБфЛЏЕФЪ§ОнГщШЁЙ§РДЁЃСНепЧјБ№ЪЧЃЌдіСПБфИќЕФЪ§ОнГ§СЫАќКЌаТдіЪ§ОнЭтЃЌЛЙАќКЌЖдРњЪЗЪ§ОнгаБфИќЕФЪ§ОнЃЌЖјдіСПСїЫЎЕФЪ§ОнжЛАќКЌаТдіЪ§ОнЁЃ
діСПСїЫЎЕФЪ§ОнДІРэЗНЗЈЯрЖдМђЕЅЃЌжБНгАбдіСПЪ§ОнШыПтЕНБэФкМДПЩЁЃдіСПБфИќЕФЪ§ОнвЛАуВЩгУРСДФЃаЭРДДІРэЃЌетбљМШБЃжЄПЩвдВщбЏЕНШЮвтЪБПЬЕФРњЪЗШЋСППьееЃЌвВПЩвдМѕЩйЪ§ВжЕФДцДЂПеМфЁЃРСДФЃаЭЃЌЙЫУћЫМвхЃЌОЭЪЧАбРњЪЗБфЛЏЕФЪ§ОнвЛЛЗПлвЛЛЗЃЌОЭЯёСДзгвЛбљДЎСЊЦ№РДЁЃЕБВщбЏЪ§ОнЪБЃЌАДееПлЛЗЩЯЕФЪБМфБъЪЖНјааВщбЏМДПЩЁЃОпЬхЪЕЯжЗНЪНЮЊЕквЛДЮШыПтЕФШЋСПЪ§ОнЃЌАбПЊЪМЪБМфМЧТМЮЊШыПтШеЦкЃЌНсЪјЪБМфМЧТМЮЊгРОУШеЦкЃЈБШШч
2999-12-31ЃЉЁЃКѓајШыПтдіСПЕФЪ§ОнЩцМАРњЪЗЪ§ОнБфИќЪБЃЌАбГіЯжБфИќЕФОЩЪ§ОнЕФНсЪјЪБМфМЧТМЮЊЕБЧАШыПтЕФШеЦкЃЌдйАбаТЪ§ОнЕФПЊЪМЪБМфМЧТМЮЊЕБЧАШыПтЕФШеЦкЃЌНсЪјЪБМфМЧТМЮЊгРОУШеЦкЃЌВЂаДШыЕНБэРяЁЃетбљЃЌвЊВщбЏРњЪЗЪБЕуЪ§ОнЃЌИљОнПЊЪМШеЦкКЭНсЪјШеЦкЕФЗЖЮЇВщбЏМДПЩЁЃ
ШЛЖјЃЌРСДФЃаЭгаСНИіУїЯдЕФШБЯнЃЌвЛИіЪЧЕБЗЂЯжРСДБэФкФГвЛПлЛЗЕФЪ§ОнвьГЃЪБЃЌРСДБэгІШчКЮЛжИДзМШЗадгыЭъећадЃЌСэвЛИіЪЧЫцзХЪ§ОнВЛЖЯдіМгЃЌРСДБэЛсдНРДдНДѓЃЌУПШеРСДВйзїЕФаЇТЪЛсдНРДдНЕЭЃЌИУШчКЮгХЛЏЪ§ОнДцДЂЗНЪНРДБмУтИУЮЪЬтЃЌЮДРДЛсеЙПЊаТЕФЮФеТЫЕУїЁЃ
FDMЃЈFinance Data ManagerЃЉН№ШкжїЬтВу
ЮЊСЫШУИДдгЕФдДЪ§ОнБфЕУШнвзРэНтМАЪЙгУЃЌБиаыАДееЯрЭЌЕФН№ШкжїЬтАбЪ§ОнећКЯЕНЭЌвЛЬзФЃаЭжаЃЌЖд
SDM Ъ§ОнНјааУїЯИМЖЕФЪ§ОнећКЯЛузмЁЃжїЬтЩшМЦЕФЪ§СПВЛвЫЬЋЖрЃЌЗёдђећИі FDM ОЭДяВЛЕНМђЛЏЕФзїгУЁЃFDM
ЪЧЪ§ВжФЃаЭЩшМЦЕФЙиМќЃЌODM гы SDM ЕФЪ§ОнНсЙЙЖМгыдДЯЕЭГЪ§ОнНсЙЙвЛжТЃЈSDM ЕФЪ§ОнНсЙЙЛсЖрвЛВуБъзМЛЏЃЉЃЌФЃаЭЩшМЦФбЖШВЛДѓЃЌЕЋЪЧ
FDM вЊЛЏЗБЮЊМђЃЌЗЧГЃПМбщНЈФЃЪІЖдвЕЮёЕФРэНтМАНЈФЃОбщЁЃFDM ЪЧКѓајЪ§ОнЗжЮіМАЪ§ОнМЏЪаМгЙЄЕФЛљДЁЃЌКЫаФЪЧЪ§ОнЙиЯЕЕФМђЛЏМАИДгУЃЌЩшМЦВЛКУЗДЖјЛсГЩЮЊећИіЪ§ВжЕФРлзИЃЌЪГжЎЮоЮЖЦњжЎПЩЯЇЁЃгЩгкЮФеТЦЊЗљЙиЯЕЃЌFDM
ЕФН№ШкжїЬтЛЎЗжгыНЈФЃЫМТЗЮДРДЛсеЙПЊаТЕФЮФеТНјааЬжТлЁЃ
ПЩФмЛсгавЩЮЪЃЌФмЗёВЛНЈЩш FDMЃЌМЏЪаЪ§ОнМАЪ§ОнЗжЮіжБНгДг SDM
НјааФиЃПД№АИЪЧФмЃЌЕЋЪЧКѓајЮЌЛЄЕФДњМлЗЧГЃДѓЃЌжївЊгавдЯТдвђЃК
1ЃЉFDM ЕФКЫаФжЎвЛЪЧЪ§ОнИДгУЃЌШБЗІ FDM ЕФЛАЃЌЯрЭЌЪ§ОнМгЙЄЖМБиаыБраДжиИДЕФДІРэТпМЪЕЯжЃЌММЪѕЭХЖгЕФПЊЗЂСПЛсДѓДѓдіМгЃЛ
2ЃЉFDM ЕФКЫаФжЎЖўЪЧЪ§ОнЙиЯЕМђЛЏЃЌШБЗІ FDM ЕФЛАЃЌУПИіЪ§ОнПЊЗЂЙЄГЬЪІЖМвЊРэНтИїИідДЯЕЭГжЎМфЕФЪ§ОнЙиЯЕЃЌПЊЗЂУХМїМЋИпЃЌзюжеЕМжТММЪѕЭХЖгЪЕЪЉГЩБОЙ§ИпЃЛ
3ЃЉМйШч ADM ЪЧДг SDM МгЙЄЛёЕУЃЌдДЯЕЭГЗЂЩњШЮвтБфИќЃЌЖМЛсгАЯьЕН
ADMЃЌетЪБ ADM ЕФЮШЖЈадОЭЮоДгЬИЦ№ЁЃБЪепЕФЙЋЫОдјОЪдЙ§аХЩѓЯЕЭГжиЙЙДгЖјаТаХЩѓЯЕЭГЕФЪ§ОнФЃаЭБфЛЏМЋДѓЃЌЖјЕБЪБЪ§ВжШБЗІЙВадећКЯЕФ
FDMЃЌЕМжТБОДЮБфИќЖдвРРЕЪ§ВжЕФЪ§ОнгІгУдьГЩФбвдЙРСПЕФгАЯьЁЃЖјЧвгЩгкашЧѓЗжЮіНзЖЮУЛгаЪЖБ№ЕНетИіЗчЯеЕуЃЌзюжеЕМжТаХЩѓЯЕЭГжиЙЙЯюФПБЛЦШбгГй
2 ИідТВХФмЩЯЯпЃЌЖјЪ§ВжЮЊСЫМѕЩйЖдЪ§ОнгІгУЕФгАЯьЃЌАбдДЯЕЭГЕФБфИќЗХдк SDM ФкЪЕЯжЃЌетОЭЪЧ FDM
ЕФживЊадЁЃга FDM ЕФЛАЃЌЫљгадДЯЕЭГЕФБфИќЖМПЩвддк SDM МгЙЄЕН FDM ЕФЙ§ГЬНјааЦСБЮЃЌетбљЪ§ВжЛсИќМгЪЪгІдДЯЕЭГв§ЗЂЕФБфИќЁЃ
СэЭтЃЌЮЊЪВУД FDM ЪЧУїЯИМЖЪ§ОнЕФМгЙЄФиЃПетЪЧЮЊСЫНЈЩшЪ§ОнзджњЗжЮіЦНЬЈзізМБИЕФЁЃМйШчЪЧИпЖШЛузмЕФжИБъЪ§ОнЃЌвЕЮёШЫдБвЛЕЉЖджИБъПкОЖЗЂЩњБфИќЃЌММЪѕШЫдБОЭЛсЦЃгкБМУќЕФБфИќжИБъЕФТпМДњТыРДТњзувЕЮёШЫдБЕФашЧѓЁЃЖјУїЯИМЖЪ§ОнПЩвдЮЊвЕЮёШЫдБЬсЙЉздгЩзщКЯЕФвЕЮёТпМЃЌММЪѕШЫдБжЛашвЊВЛЖЯРЉеЙ
FDM ОЭПЩвдТњзувЕЮёШЫдБЦЕЗББфЖЏЕФашЧѓСЫЁЃ
ADMЃЈApplication Data ManagerЃЉгІгУВу
гІгУВуОЭЪЧвдЬиЖЈвЕЮёГЁОАЮЊФПБъЖјИпЖШЛузмЕФЪ§ОнЃЌвЛАувдЪ§ОнМЏЪаЕФаЮЬЌГЪЯжЃЌБШШчДѓМвГЃЫЕЕФгЊЯњМЏЪаЁЂЗчЯеМЏЪаЁЂМЈаЇМЏЪаЁЃгЩгкЪ§ОнМЏЪаЕФНЈЩшЖдгІЕФЪЧЬиЖЈЧвЖРСЂЕФвЕЮёГЁОАЃЌМИЮоЙВадПЩбдЃЌЫљвдБиаыЖдУПРрМЏЪаНјааЕЅЖРЫЕУїЁЃ
аЁНс
ЯывЊСЫНтЪ§ОнВжПтЕФНЈЩшЃЌБиаывЊСЫНтЪ§ОнВжПтЕФЗжВуМмЙЙЁЃШЛЖјНіСЫНтЗжВуМмЙЙЕФФкШнЃЌЖдЪ§ВжЕФНЈЩшШджЛЭЃСєдкаЮЖјЩЯбЇЕФНзЖЮЁЃжЊЦфШЛвВжЊЦфЫљвдШЛЃЌеце§СЫНтЗжВуМмЙЙЛЎЗждРэМАНЈЩшЫМТЗЃЌВХЛсЖдЗжВуМмЙЙШкЛсЙсЭЈЃЌЮДРДУцЖдЧЇБфЭђЛЏЕФвЕЮёаЮЬЌМАЪ§ОнаЮЬЌЃЌШдгаЙВадЕФЪжЖЮРДДІРэЁЃ
НЈЩшЪ§ОнВжПтгЬШчДДдьвЛЬѕаТЕФЩњУќЃЌЗжВуМмЙЙжЛЪЧетЬѕЩњУќЕФТпМЙЧМмЖјвбЁЃЯывЊдкЙЧМмЩЯГЄГібЊШтЃЌОЭБиаыНјааКЯЪЪЕФЪ§ОнНЈФЃЃЌЪ§ОнВжПтЕФЧПзГЛЙЪЧхюШѕЃЌНЁУРЛЙЪЧГѓТЊЃЌОЭШЁОігкНЈФЃЕФНсЙћЁЃ
ШчЙћЯывЊетЬѕЩњУќе§ГЃЗЂЛгСІСПЃЌЛЙашвЊДюХфКЯЪЪЕФММЪѕЦНЬЈЃЌВХФмАбСІСПЗЂЛгЕНЕуЩЯЃЌЖјВЛЪЧгаСІЪЙВЛГіЁЃзюКѓЃЌвЊЯыетЬѕЩњУќзТзГЩњГЄЕФЛАЃЌЛЙБиаызїЯЂЙцТЩЃЈСїГЬЙцЗЖЃЉЁЂСЫНтздМКЃЈдЊЪ§ОнЙмРэЃЉЁЂзіКУЩэЬхМьВщЃЈЪ§ОнжЪСПЙмРэЃЉМАбЇЛсЗРЩэЪѕЃЈЪ§ОнАВШЋЙмРэЃЉЁЃ |








