| БрМЭЦМі: |
БОЮФжївЊНщЩмЛЊЮЊКшУЩOSгаЪВУДДДаТЃЌЪЧЗёзджїбаЗЂЭъШЋПЊдДЃЌБОЮФДјФуЩюШыКшУЩЕФЪРНчЃЌЯЃЭћБОЮФЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЬкбЖММЪѕЙЄГЬЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЙигкЪ§ВжЕФвЛаЉИХФю
1ЁЂЪ§ВжЖЈвх
Bill Inmon -- Ъ§ОнВжПтжЎИИЃЌЪ§ОнВжПтИХФюЕФДДЪМШЫЁЃ
Ъ§ОнВжПтЪЧвЛИіжЇГжЙмРэОіВпЕФ Ъ§ОнМЏКЯ ЃЌ ЪЧУцЯђжїЬтЕФЁЂМЏГЩЕФЁЂЮШЖЈЕФЁЂЗДгІРњЪЗБфЛЏ ЕФЁЃ
ЦфжаЃЌжїЬтЪЧвЛИіГщЯѓЕФИХФюЃЌУПвЛИіжїЬтЖдгІвЛИіКъЙлЕФЗжЮіСьгђЁЃ
Ъ§ОнВжПтЪЧЫљга ВйзїЛЗОГ КЭ ЭтВПЪ§ОндД ЕФ ПьееМЏКЯ ЁЃ
2ЁЂЪ§ВжЗЂеЙЪЗ
1ЃЉЪ§ОнПтНзЖЮ
OLTPЃЈСЊЛњЪТЮёДІРэЃЉ -- ЪЧДЋЭГЕФЙиЯЕаЭЪ§ОнПтЕФжївЊгІгУЁЃ
жївЊЪЧЛљБОЕФЁЂШеГЃЕФЪТЮёДІРэЃЌМЧТМ МДЪБЕФдіЁЂЩОЁЂИФЁЂВщЁЃ
2ЃЉЪ§ВжНзЖЮ
OLAPЃЈСЊЛњЗжЮіДІРэЃЉ --жЇГжИДдгЕФЗжЮіВйзїЃЌВржиОіВпжЇГж ВЂЧвЬсЙЉжБЙлЕФЗжЮіНсЙћЁЃ
3ЃЉЪ§ОнЦНЬЈ
ЗжВМЪНЕФЪЕЪБЛђепРыЯпЕФМЦЫуПђМм ЁЃНЈСЂМЦЫуМЏШКЃЌВЂдкЩЯУцдЫааИїжжМЦЫуШЮЮёЃЌ
ОпгаЪ§ОнЛЅСЊЛЅЭЈЁЂжЇГжЖрЪ§ОнМЏЪЕЪБЭЌВНЁЂжЇГжЪ§ОнзЪдДЙмРэЁЂЪЕЯжЖрдДвьЙЙЪ§ОнЕФећКЯЙмПиЁЃ
ЃЈЦНЬЈИќЯёЪЧвЛИіНтОіЗНАИЃЉ
4ЃЉЪ§ОнжаЬЈ
ДгвЕЮёМмЙЙЕНФЃаЭЩшМЦЃЌДгЪ§ОнбаЗЂЕНЪ§ОнЗўЮё ЃЌзіЕНЪ§ОнПЩЙмРэЁЂПЩзЗЫнЁЂПЩЙцБмжиИДНЈЩшЁЃ
ЧПЕїЕФЪЧЪ§ОнвЕЮёЛЏЕФФмСІЁЃЃЈИќЯёЪЧгавЛжжЬхЯЕЃЉ
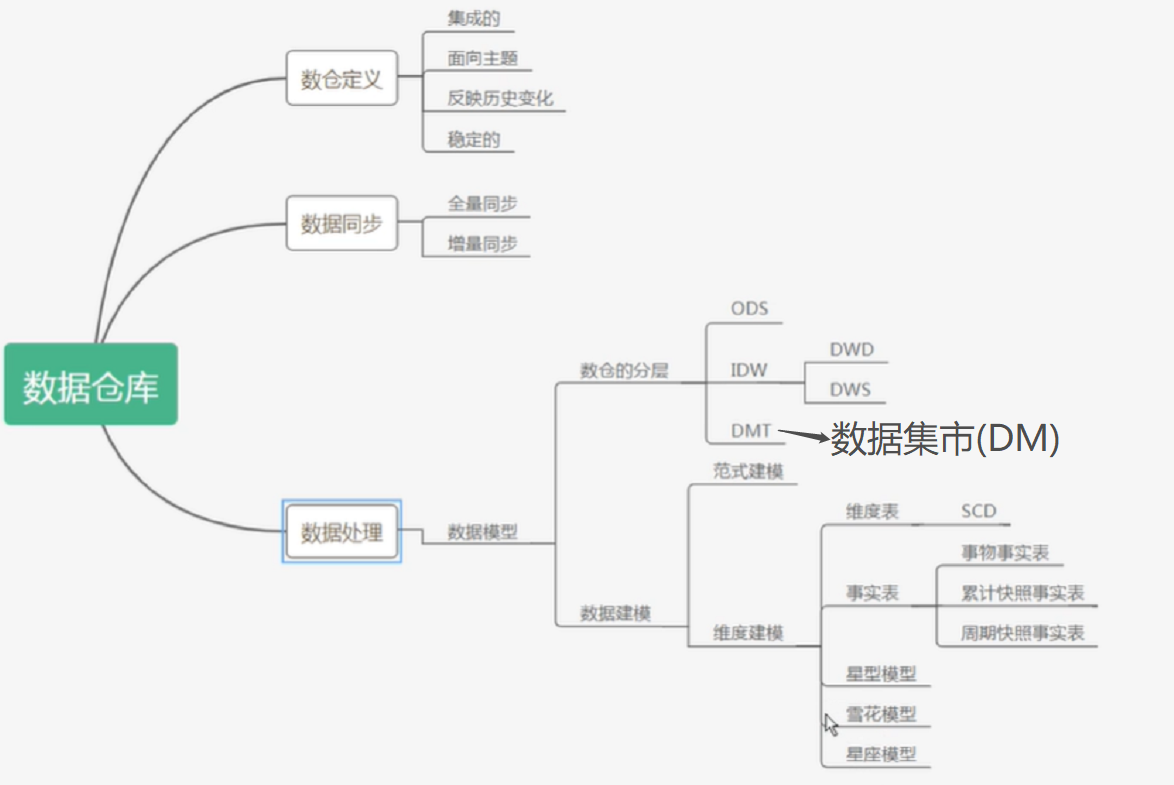
3ЁЂODS гы DWЕФМђНщКЭБШНЯ
ЃБЃЉODS
ODSЃЈOperational Data StoreЃЉ ВйзїаЭЪ§ОнВжПт ЃЌдчЦкЕФЪ§ОнВжПтФЃаЭЁЃОпгаЕФЬиадЃКУцЯђжїЬтадЁЂЖЏЬЌадЁЂМЏГЩадЁЂМДЪБадЁЂУїЯИадЕШЁЃ
ЃВЃЉDW
DW (Data Warehouse) Ъ§ОнВжПт, ЪЧЮЊЦѓвЕЫљгаМЖБ№ЕФОіВпжЦЖЈЙ§ГЬ ЬсЙЉЫљгаРраЭЪ§ОнжЇГжЕФеНТдМЏКЯЁЃ
3 ЃЉODSКЭDWЧјБ№
(1) Ъ§ОнЕФЕБЧАад
ODS АќРЈЕФЪЧ ЕБЧАЛђНгЕБЧАЕФЪ§Он ЃЌODSЗДгГЕФЪЧЕБЧАвГЮёЬѕМўЕФзДЬЌЃЌODSЕФЩшМЦгыгУЛЇЛђвЕЮёЕФашвЊЪЧгаЙиСЊЕФЃЛ
DWдђИќЖрЕФЗДгГвЕЮёЬѕМўЕФ РњЪЗЪ§Он ЁЃ
(2) Ъ§ОнЕФИќаТЛђМгди
ODSжаЕФЪ§ОнЪЧ ПЩвдНјаааоИФ ЕФЃЌЖјDWжаЕФЪ§ОнвЛАуЪЧ ВЛПЩНјааИќаТ ЕФЁЃ
ODSЕФИќаТЪЧИљОнвЕЮёЕФашвЊНјааВйзїЕФЃЌЖјУЛгаБивЊСЂМДИќаТЃЌвђДЫЫќашвЊвЛжж ЪЕЪБЛђНќЪЕЪБЕФИќаТЛњжЦ ЁЃ
DWжаЕФЪ§ОнЪЧАДее е§ГЃЕФЛђдЄЯШжИЖЈЕФЪБМф НјааЪ§ОнЕФЪеМЏКЭМгдиЕФЁЃ
(3) Ъ§ОнЕФЛузмад
ODSжаЕФЛузмЪ§ОнЩњУќжмЦкБШНЯЖЬЃЌЫљвдПЩГЦзїЮЊ ЖЏЬЌЛузмЪ§Он ЃЌШчЙћЯИНкЪ§ОнОЙ§СЫаоИФЃЌдђЛузмЪ§ОнЭЌбљашвЊаоИФЁЃЖјDWжаЕФЪ§ОнПЩГЦЮЊ ОВЬЌЕФЛузмЪ§Он ЁЃ
ODSжївЊЪЧАќРЈвЛаЉЯИНкЪ§ОнЃЌЕЋЪЧгЩгкадФмЕФашвЊЃЌПЩФмЛЙАќРЈвЛаЉЛузмЪ§ОнЃЌШчЙћАќРЈЛузмЪ§ОнЃЌПЩФмКмФбБЃжЄЪ§ОнЕФЕБЧАадКЭзМШЗадЁЃ
(4) Ъ§ОнСП
ODSжЛАќРЈ ЕБЧАЕФЪ§Он ЃЌDWДцДЂЕФЪЧУПвЛИіжїЬтЕФ РњЪЗПьее ЁЃ
(5) Ъ§ОнНЈФЃ
ODSЪЧеОдк МЧТМВуУцЗУЮЪЕФНЧЖШ ЖјЩшМЦЕФЃЌDWЛђDMЃЈЪ§ОнМЏЪаData MartЃЉдђЪЧеОдк НсЙћМЏВуУцЗУЮЪЕФНЧЖШ ЖјЩшМЦЕФЁЃODSжЇГж ПьЫйЕФЪ§ОнИќаТ ЃЌDWзїЮЊвЛИіећЬхЪЧ УцЯђВщбЏЕФ ЁЃ
(6) гУЛЇ
ODSжївЊгУгк ВпТдаЭЕФгУЛЇ ЃЌБШШчБЃЯеЙЋЫОУПЬьгыПЭЛЇНЛСїЕФПЭЗўЃЛ
DWжївЊгУгк еНТдаЭЕФгУЛЇ ЃЌБШШчЙЋЫОЕФИпВуЙмРэШЫдБЁЃ
(7) гУЭО
ODSгУгкУПвЛЬьЕФВйзїаЭОіВпЃЌЪЧ вЛжжЖЬЦкЕФ ЃЛ
DWПЩвдЛёШЁ вЛжжГЄЦкЕФ КЯзїЙуЗКЕФОіВпЁЃ
ODSЪЧ ВпТдаЭ ЕФЃЌDWЪЧ еНТдаЭ ЕФЁЃ
(8) ВщбЏЕФЪТЮё
ODSжаЕФ ЪТЮёВйзїБШНЯЖр ЃЌПЩФмвЛЬьжаЛсВЛЖЯЕФжДааЯрЭЌЕФЪТЮёЃЛ
DWжаЪТЮёЕФЕНДяЪЧ ПЩвддЄВтЕФ ЁЃ
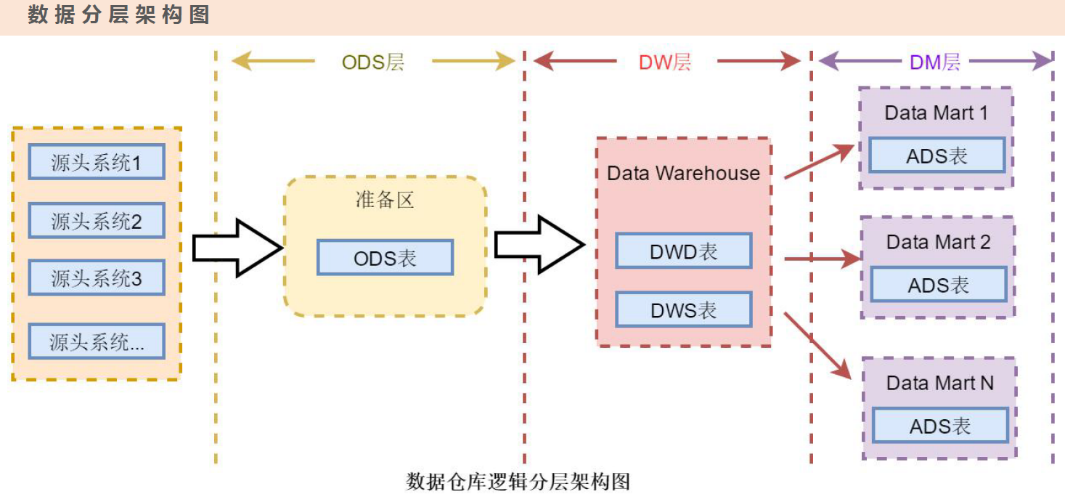
4ЁЂЪ§ОнМЏЪа Data Mart
DM-Ъ§ОнМЏЪаЪЧ ЭъећЕФЪ§ОнВжПтЕФвЛИіТпМзгМЏ ЃЌПЩГЦЮЊЪ§ОнВжПтжаЖРСЂГіРДЕФвЛВПЗжЪ§ОнЃЌвВПЩвдГЦЮЊ ВПУХЪ§ОнЛђжїЬтЪ§Он ЁЃ
Ъ§ОнВжПтЪЧгЩЫљгаЕФЪ§ОнМЏЪагаЛњзщГЩЖјГЩЕФЁЃ
дДЯЕЭГ-->ODS-->DW-->DM
5ЁЂETL
ETLЃЈExtract-Transform-LoadЃЉ ГщШЁЁЂзЊЛЛЁЂМгдиЁЃ
ГщШЁЃКНЋЪ§ОнДгИїжждЪМЕФвЕЮёЯЕЭГжа ЖСШЁ ГіРДЁЃ
зЊЛЛЃКАДеедЄЯШЩшМЦКУЕФЙцдђНЋГщШЁЕФЪ§ОнНјаа зЊЛЛЁЂЧхЯДвдМАДІРэ вЛаЉШпгрЁЂЦчвхЕФЪ§ОнЃЌЪЙБОРДвьЙЙЕФЪ§Он ИёЪНФмЙЛЭГвЛ Ц№РДЁЃ
зАдиЃКНЋзЊЛЛЭъЕФЪ§Он ЕМШы ЕНЪ§ОнВжПтжаЁЃ
6ЁЂOLAP-СЊЛњЗжЮіДІРэ
1ЃЉROLAP
Relational OLAP
РћгУ ЙиЯЕЪ§ОнПт РДДцДЂКЭЙмРэЛљБОЪ§ОнКЭОлКЯЪ§ОнЃЌВЂРћгУвЛаЉжаМфМўРДжЇГжШБЪЇЪ§ОнЕФДІРэЃЛ
ОпгаСМКУЕФПЩРЉеЙадЁЃ
2ЃЉMOLAP
Multidimensional OLAP
РћгУ ЖрЮЌЪ§ОнПт РДДцДЂКЭЙмРэЛљБОЪ§ОнКЭОлКЯЪ§ОнЃЌЦфжаашвЊЖдЯЁЪшОиеѓЕФДІРэММЪѕЃЛ
ЖддЄзлКЯЕФЪ§ОнНјааПьЫйЫїв§ЁЃ
3ЃЉHOLAP
Hybrid OLAP
РћгУ ЙиЯЕЪ§ОнПт РДДцДЂКЭЙмРэ ЛљБОЪ§Он ЃЌРћгУ ЖрЮЌЪ§ОнПт РДДцДЂКЭЙмРэ ОлКЯЪ§ОнЁЃ
ЖўЁЂЪ§ВжМмЙЙ
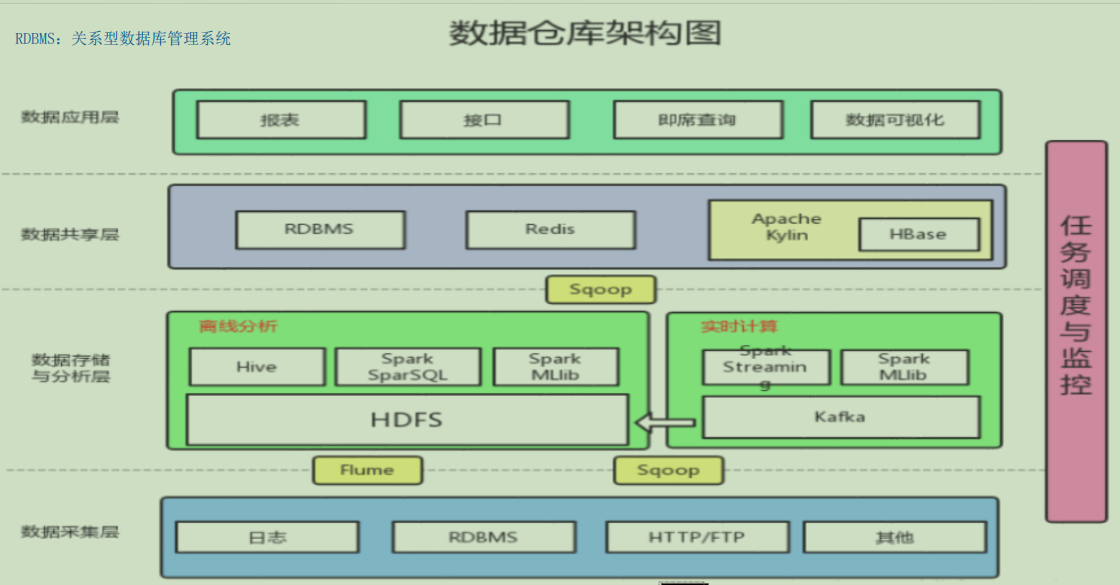
1ЁЂЪ§ВжМмЙЙЭМ
2ЁЂЪ§ВжЗжВу
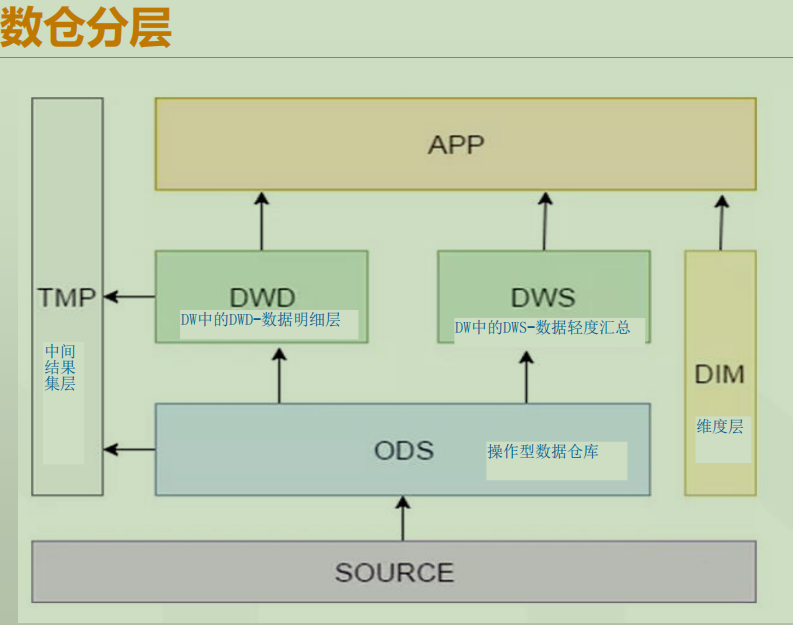
1ЃЉODS-ВйзїЪ§ОнВу
ODS ШЋГЦЪЧ Operational Data StoreЃЌЪЧзюНгНќЪ§ОндДжаЪ§ОнЕФвЛВуЁЃ ОЭЪЧдЪМЪ§ОнВуЃЌЪ§ОндДЭЗБэЭЈГЃЛсдЗтВЛЖЏЕФДцДЂвЛЗнЁЃ ЪЕЯжЖдЪ§ОндДжаЪ§ОнЕФ ГщШЁЁЂЧхЯДЁЂДЋЪфЁЃ
2ЃЉDWD-УїЯИЪ§ОнВуЁЂ DWS-ЛузмЪ§ОнВу
Ъ§ОнВжПтВу(DW)ЃЌЪЧЪ§ОнВжПтЕФжїЬхЁЃдкетРяЃЌДг ODS ВужаЛёЕУЕФЪ§ОнАДеежїЬт НЈСЂИїжжЪ§ОнФЃаЭ ЁЃ
Ъ§ОнВжПт УїЯИВу DWD КЭЪ§ОнВжПтЛу змВуDWS ЪЧЪ§ОнЦНЬЈЕФжївЊФкШнЁЃ ЫќУЧЪЧЭЈЙ§ODSВуОЙ§ETL- ЧхЯДЁЂзЊЛЛЁЂМгди ЩњГЩЕФЁЃ
ЛљгкЮЌЖШНЈФЃРэТлРДЙЙНЈЃЌЭЈЙ§вЛжТадЮЌЖШКЭЪ§ОнзмЯпРД БЃжЄИїИізгжїЬтЕФЮЌЖШвЛжТад ЁЃЃЈОЭЫуЪ§ОнБэБЛЩОСЫвВПЩвджиаТХм ДгODSЛжИДЙ§РДЃЉ
3ЃЉADS-гІгУЪ§ОнВу
Ъ§ОнВњЦЗВу(APP)ЃЌетвЛВуЪЧЬсЙЉЮЊ Ъ§ОнВњЦЗ ЪЙгУЕФ НсЙћЪ§Он ЁЃ
ADSЃЈМЏЪаЪ§ОнВуЃЌвВГЦгІгУВуЃЉЃКжївЊЪЧИїИівЕЮёЗНЛђепВПУХЛљгкDWDКЭDWSНЈСЂЕФ Ъ§ОнМЏЪаЃЈDMЃЉ ЃЌЪ§ОнМЏЪаЪЧЯрЖдгкЪ§ОнВжПтРДЫЕЕФЁЃ
вЛАугІгУВуЕФЪ§ОнЪЧРДдДгкDWВуЃЌддђЩЯЪЧВЛФмЗУЮЪODSВуЕФЁЃ
ЖдБШгкDWВуЃЌ гІгУВужЛАќКЌВПУХ ЛђвЕЮёЗНздМКЙиаФЕФУїЯИВуКЭЛузмВуЕФЪ§ОнЁЃ ЃЈвЛАуЪЧНЋИїИівЊгУЕФБэjoinЦ№РДаЮГЩПэБэЃЌЙЉЯТгЮвЕЮёЗжЮіШЫдБ select * ЃЉ
Ш§ЁЂЪ§ВжНЈФЃ
1ЁЂERФЃаЭ
Bill Inmon -- Ъ§ОнВжПтжЎИИЃЌЪ§ОнВжПтИХФюЕФДДЪМШЫ
1ЃЉЕквЛЗЖЪН
Ъ§ОнПтБэжаВЛФмГіЯжжиИДМЧТМЃЌУПИізжЖЮЪЧдзгадЕФВЛФмдйЗжЁЃ
EGЃК

2ЃЉЕкЖўЗЖЪН
НЈСЂдкЕквЛЗЖЪНЛљДЁЩЯЃЌвЊЧѓЗЧжїМќзжЖЮЭъШЋвРРЕжїМќзжЖЮЃЌ ВЛФмВњЩњВПЗнвРРЕЁЃОЁСПВЛЪЙгУСЊКЯжїМќЁЃ
EGЃК
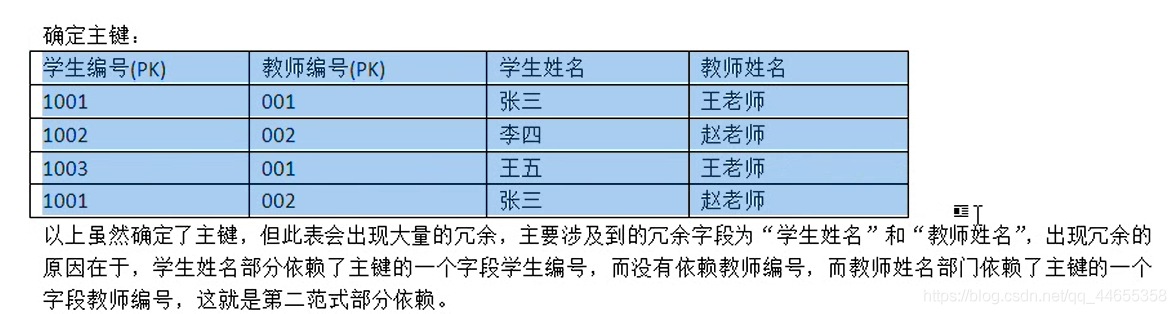
3ЃЉЕкШ§ЗЖЪН
НЈСЂдкЕкЖўЗЖЪНЛљДЁЩЯЃЌЗЧжїМќзжЖЮВЛФмДЋЕнвРРЕгкжїМќзжЖЮЁЃ ЃЈВЛвЊВњЩњДЋЕнвРРЕЃЉ
EGЃК
2ЁЂЮЌЖШНЈФЃ
Ralph Kimball -- Ъ§ОнВжПтЗНУцЕФжЊУћбЇеп
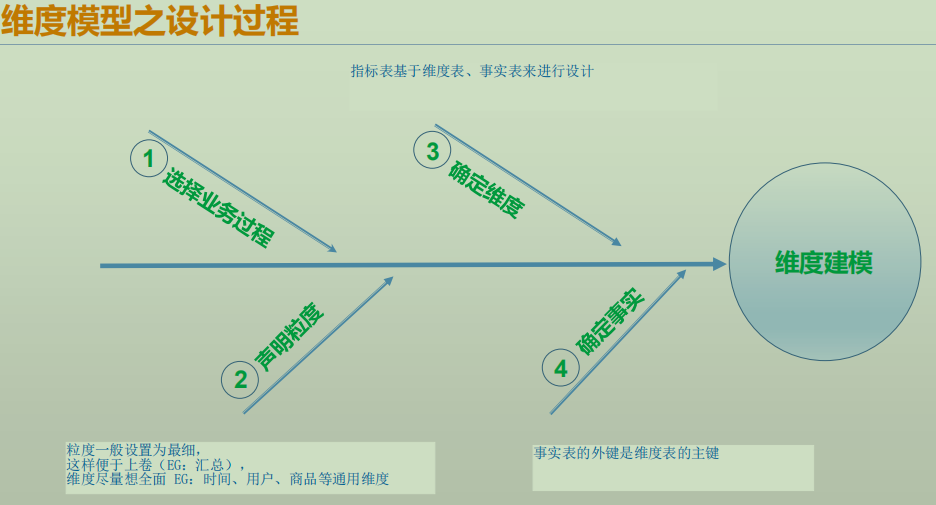
ЮЌЖШНЈФЃжиЕуНтОі гУЛЇШчКЮИќПьЫйЭъГЩЗжЮіашЧѓ,ЭЌЪБЛЙНЯКУЕФДѓЙцФЃИДдгВщбЏЕФЯргІадФм .
ЮЌЖШФЃаЭЪЧгЩвЛИі ЙцЗЖЛЏЕФЪТЪЕБэ КЭ ЗДЙцЗЖЛЏЕФвЛаЉЮЌЖШБэ зщГЩЕФ.
1ЃЉЮЌЖШБэ
УПвЛеХЮЌЖШБэЖдгІЯжЪЕЪРНчжаЕФ вЛИіЖдЯѓЛђепИХФю . EG: ПЭЛЇ, ВњЦЗ, ШеЦк, ЕиЧј, ЩЬГЁ.
(1) ЮЌЖШБэЕФЬиеї:
- АќКЌжкЖрУшЪіадЕФСа (ОпгаЖрИіЪєад)
- ааЪ§ЯрЖдНЯЩй (ЭЈГЃ < 10ЭђЬѕ)
- ФкШнЯрЖдЙЬЖЈ (МИКѕОЭЪЧвЛРрВщевБэ Лђ БрТыБэ)
(2) ЛКТ§БфЛЏЮЌ (SCD)
ЛКТ§БфЛЏЮЌжИЕФЪЧ: ЮЌЖШБэРяУцЕФЪ§ОнВЂЗЧЪЧЪМжеВЛБфЕФ, змЛсЫцзХЪБМфЗЂЩњБфЛЏ.
Ш§жжжївЊЕФЩшМЦЗНЪН:
- гывЕЮёЪ§ОнБЃГжвЛжТ,ЮЊжБНгЕФupdate
- БЃСєРњЪЗБфЛЏ,діМгвЛЬѕаТЕФЮЌЖШЪ§Он
- діМгвЛИізжЖЮРДДцДЂОЩЕФЮЌЖШЪ§Он
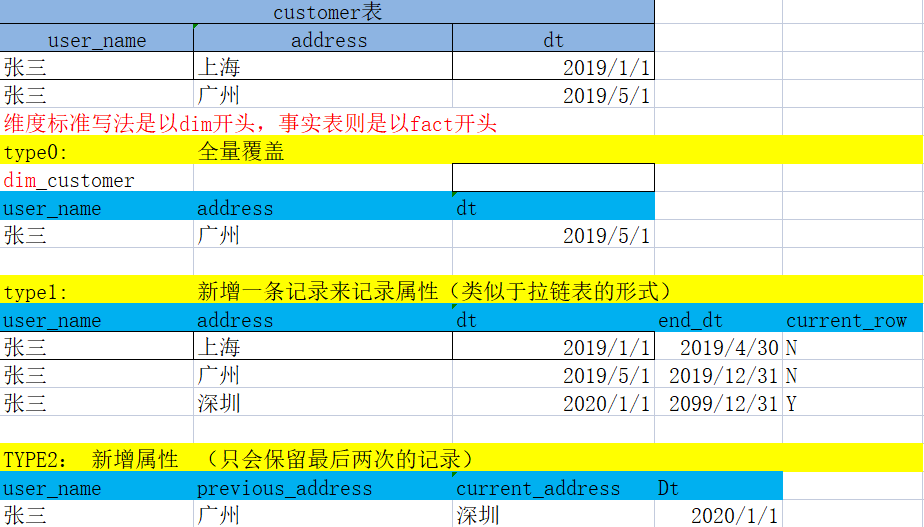
ЭЫЛЏЮЌЖШЭЈГЃБЛБЃСєзїЮЊ ВйзїаЭЪТЮёЕФБъЪЖЗћ .
ЪЕМЪЩЯПЩвдНЋЖЉЕЅКХзїЮЊвЛИіЪєадМгШыЕНЪТЪЕБэжаЁЃ
БШШч ЖЉЕЅБэжаЕФЖЉЕЅУїЯИIDЃЌЫћУЛгаШЮКЮЕФвтвхЃЌжЛЪЧзїЮЊЖЉЕЅУїЯИБэЕФБъЪЖЗћЖјвбЁЃ
ЫфШЛУЛгаШЮКЮЗжЮіЕФзїгУЃЌЕЋЪЧЛЙЪЧвЊгаЕФЁЃ
зїгУОЭЪЧПЩвдЗНБуЕиВщбЏЖЉЕЅУїЯИIDЁЃ
(4)СЃЖШ
Ъ§ОнСЃЖШжИЪ§ОнВжПтЕФЪ§ОнжаБЃДцЪ§ОнЕФЯИЛЏГЬЖШЛђзлКЯГЬЖШЕФМЖБ№ЁЃ Ъ§ОнСЃЖШгАЯьДцЗХдкЪ§ОнВжПтжаЕФЪ§ОнСПЕФДѓаЁЃЌЭЌЪБгАЯьЪ§ОнВжПтЫљФмЛиД№ЕФВщбЏРраЭЁЃ
2ЃЉЪТЪЕБэ
УПвЛИіЪТЪЕБэЭЈГЃАќКЌСЫДІРэЫљЙиаФЕФ ЖШСПжЕ
(1) УПвЛИіЪТЪЕБэЕФааАќРЈ :
- ОпгаПЩМгадЕФЪ§жЕаЭЕФ ЖШСПжЕ
- гыЮЌБэЯрСЌЕФЭтМќ (ЭЈГЃгаСНИіЛђСНИівдЩЯЕФЭтМќ , ЭтМќжЎМфБэЪОЮЌБэжЎМфЖрЖдЖрЕФЙиЯЕ)
(2) ЪТЪЕБэЕФЬиеї:
- ЗЧГЃЕФДѓ (АќКЌОоЭђ , МИЪЎЭђ, ЩѕжСМИАйМИЧЇЭђЬѕЕФЪ§Он)
- СаЪ§НЯЩй
- ОГЃЗЂЩњБфЛЏ
(3) ЪТЮёЪТЪЕБэ
ЪТЮёЪТЪЕБэ МЧТМЪТЮёВуУцЕФЪТЪЕ,БЃДцЕФЪЧзюдзгЕФЪ§Он, вВГЦ"дзгЪТЪЕБэ".
РяУцЕФЪ§ОнЛсдкЪТЮёЪТМўЗЂЩњКѓВњЩњ,Ъ§ОнСЃЖШЭЈГЃЪЧУПИіЪТЮёЕФвЛЬѕМЧТМ.
ЪТЮёвЛЕЉБЛЬсНЛ,ЪТЪЕБэЪ§ОнБЛВхШы,Ъ§ОнОЭВЛЛсдйНјааИќИФ, ЦфИќаТЗНЪНЮЊ діСПИќаТ.
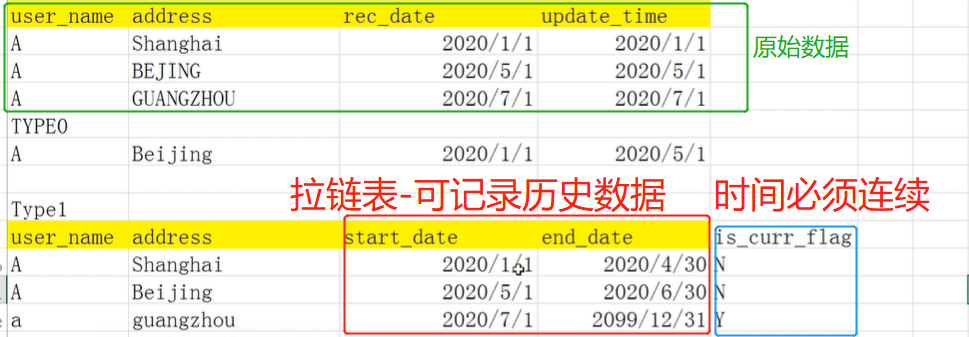
(4) РлМЦПьееЪТЪЕБэ
РлМЦПьееЪТЪЕБэДњБэЕФЪЧ ЭъШЋИВИЧвЛИіЪТЮёЛђВњЦЗЕФЩњУќжмЦкЕФЪБМфПчЖШ ,
ЫќЭЈГЃОпгаЖрИіШеЦкзжЖЮ, гУРДМЧТМећИіЩњУќжмЦкжаЕФЙиМќЪБМфЕу.
СэЭт, ЫќЛЙЛсга вЛИігУгкжИЪОзюКѓИќаТШеЦкЕФИНМгШеЦкзжЖЮ .
EG: РСДБэ
(5) жмЦкадПьееЪТЪЕБэ
жмЦкадПьееЪТЪЕБэ вдОпгаЙцТЩадЕФ ПЩдЄМћЕФЪБМфМфИєРДМЧТМЪТЪЕ.
3ЃЉСЃЖШ
Ъ§ОнСЃЖШжИ Ъ§ВжЕФЪ§Онжа БЃДцЪ§ОнЯИЛЏГЬЖШЛђзлКЯГЬЖШЕФМЖБ№ .
Ъ§ОнСЃЖШжИЪ§ОнВжПтЕФЪ§ОнжаБЃДцЪ§ОнЕФЯИЛЏГЬЖШЛђзлКЯГЬЖШЕФМЖБ№ЁЃ Ъ§ОнСЃЖШгАЯьДцЗХдкЪ§ОнВжПтжаЕФЪ§ОнСПЕФДѓаЁЃЌЭЌЪБгАЯьЪ§ОнВжПтЫљФмЛиД№ЕФВщбЏРраЭЁЃ
4ЃЉНЈФЃРраЭ
ЃЈ1ЃЉаЧаЭФЃаЭ
ЮЌЖШБэжБНгИњЪТЪЕБэСЌНг, ЪТЪЕБэБЛЮЌЖШБэАќЮЇ, ЧвЮЌЖШБэУЛгаБЛаТЕФБэСЌНг.
ЃЈ2ЃЉбЉЛЈФЃаЭ
УПвЛИіЮЌЖШЖМПЩвдЯђЭтСЌНгЖрИіЯъЯИРрБ№Бэ.
ЃЈ3ЃЉаЧзљФЃаЭ
ЪТЪЕаЧзљФЃаЭашвЊЖрИіЪТЪЕБэЙВЯэЮЌЖШБэ ,вВГЦЮЊаЧЯЕФЃаЭ.
ЮЌЖШБэЙВгУзюДѓЕФзїгУОЭЪЧПЩвдБЃжЄЪ§ОнЕФвЛжТадЁЃ
5) ЮЌЖШНЈФЃЕФЩшМЦЙ§ГЬ
СьгђЧ§ЖЏНЈФЃЩшМЦЃЌОЭЪЧЯШвЊРэНтећИівЕЮёСїГЬЃЌШЛКѓИљОнвЕЮёЕФЯъЯИГЬЖШЩљУїСЃЖШЁЃ
3ЁЂзмНс
1) змНс
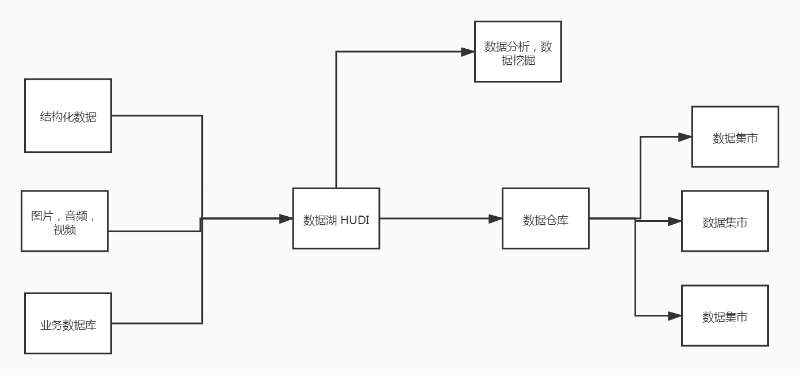
Ъ§ОнКўашвЊЯШгавЛИіШыКўЕФБъзМЃЌЗёдђЛсГіЯжЪ§ОнегдѓЁЃЪЙгУЕФЪБКђвВЪЧашвЊЩшжУвЛИіБъзМЁЃ
ЪЕЯжЕФОЭЪЧДцДЂКЭМЦЫуЗжРыЁЃБШШчCDH7ЛђЪЧИќИпАцБОЕФЛАЃЌЛљБОЩЯОЭЪЧРрЫЦЕФдРэЁЃ
Ъ§ОнКўЕФШнСПЛсБШЪ§ОнВжПтИќДѓЃЌ Ъ§ОнКўИќзЂжиЪ§ОнЕФДцДЂЃЌЪ§ОнЕФБъзМЕФЩшжУЃЌЪ§ОнКўФПЧАУЛгаНЈФЃЕФБъзМЃЌ
ЕЋЪЧЪ§ВжЪЧвЊзёбвЛИібЯИёЕФНЈФЃБъзМЕФЁЃ
|





