| БрМЭЦМі: |
БОЮФжївЊДгФПЧАЛЅСЊЭјаавЕЪ§ОнЕФВЩМЏЃЌДцДЂЃЌЭЌВНвдМАШЮЮёЕїЖШгыМрПиЗНУцВћЪіСЫДѓЪ§ОнЪ§ОнВжПтНЈЩшЕФЯрЙиММЪѕЃЌЛЙзЈУХеыЖдЪ§ОнВжПтЕФЮЌЖШНЈФЃММЪѕзіСЫЯъЯИЕФНщЩмЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХМмЙЙЪІЩчЧјЃЌгЩLindaБрМЁЂЭЦМіЁЃ |
|
01 ЧАбд
ЛЅСЊЭјаавЕЃЌГ§СЫЪ§ОнСПДѓжЎЭтЃЌвЕЮёЪБаЇадвЊЧѓвВКмИпЃЌЩѕжСКмЖрЪЧвЊЧѓЪЕЪБЕФЁЃСэЭтЃЌЛЅСЊЭјаавЕЕФвЕЮёБфЛЏЗЧГЃПьЃЌВЛПЩФмЯёДЋЭГаавЕвЛбљЃЌПЩвдЪЙгУздЖЅЯђЯТЕФЗНЗЈНЈСЂЪ§ОнВжПтЃЌвЛРЭгРвнЃЌЫќвЊЧѓаТЕФвЕЮёКмПьФмШкШыЪ§ОнВжПтжаРДЃЌРЯЕФЯТЯпЕФвЕЮёЃЌФмКмЗНБуЕФДгЯжгаЕФЪ§ОнВжПтжаЯТЯпЁЃ
БОЮФжївЊДгФПЧАЛЅСЊЭјаавЕЪ§ОнЕФВЩМЏЃЌДцДЂЃЌЭЌВНвдМАШЮЮёЕїЖШгыМрПиЗНУцВћЪіСЫДѓЪ§ОнЪ§ОнВжПтНЈЩшЕФЯрЙиММЪѕЃЌЛЙзЈУХеыЖдЪ§ОнВжПтЕФЮЌЖШНЈФЃММЪѕзіСЫЯъЯИЕФНщЩмЁЃ
02 ећЬхМмЙЙ
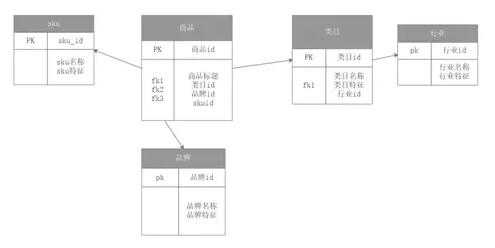
ШчЯТЭМОЭЪЧЪ§ОнВжПтЕФТпМЗжВуМмЙЙЃК

1. Ъ§ОндД
Ъ§ОндДЃЌЙЫУћЫМвхОЭЪЧЪ§ОнЕФРДдДЃЌЛЅСЊЭјЙЋЫОЕФЪ§ОнРДдДЫцзХЙЋЫОЕФЙцФЃРЉеХЖјГЪЕндіЧїЪЦЃЌЭЌЪБздВЛЭЌЕФвЕЮёдДЃЌБШШчТёЕуВЩМЏЃЌПЭЛЇЩЯБЈЕШЁЃ
2. ODSВу
Ъ§ОнВжПтдДЭЗЯЕЭГЕФЪ§ОнБэЭЈГЃЛсдЗтВЛЖЏЕиДцДЂвЛЗнЃЌетГЦЮЊODSЃЈOperation Data StoreЃЉВу,
ODSВувВОГЃЛсБЛГЦЮЊзМБИЧјЃЈStaging areaЃЉ,ЫќУЧЪЧКѓајЪ§ОнВжПтВуЃЈМДЛљгкKimballЮЌЖШНЈФЃЩњГЩЕФЪТЪЕБэКЭЮЌЖШБэВуЃЌвдМАЛљгкетаЉЪТЪЕБэКЭУїЯИБэМгЙЄЕФЛузмВуЪ§ОнЃЉМгЙЄЪ§ОнЕФРДдДЃЌЭЌЪБODSВувВДцДЂзХРњЪЗЕФдіСПЪ§ОнЛђШЋСПЪ§ОнЁЃ
3. DWВу
ОнВжПтУїЯИВуЃЈData Warehouse Detail ЃЌ DWDЃЉКЭЪ§ОнВжПтЛузмВуЃЈData Warehouse
Summary, DWSЃЉЪЧЪ§ОнВжПтЕФжїЬтФкШнЁЃDWDКЭDWSВуЕФЪ§ОнЪЧODSВуОЙ§ETLЧхЯДЁЂзЊЛЛЁЂМгдиЩњГЩЕФЃЌЖјЧвЫќУЧЭЈГЃЖМЪЧЛљгкKimballЕФЮЌЖШНЈФЃРэТлРДЙЙНЈЕФЃЌВЂЭЈЙ§вЛжТадЮЌЖШКЭЪ§ОнзмЯпРДБЃжЄИїИізгжїЬтЕФЮЌЖШвЛжТадЁЃ
4. DWSВу
гІгУВуЛузмВужївЊЪЧНЋDWDКЭDWSЕФУїЯИЪ§ОндкhadoopЦНЬЈНјааЛузмЃЌШЛКѓНЋВњЩњЕФНсЙћЭЌВНЕНDWSЪ§ОнПтЃЌЬсЙЉИјИїИігІгУЁЃ
03 Ъ§ОнВЩМЏ
Ъ§ОнВЩМЏЕФШЮЮёОЭЪЧАбЪ§ОнДгИїжжЪ§ОндДжаВЩМЏКЭДцДЂЕНЪ§ОнДцДЂЩЯЃЌЦкМфгаПЩФмЛсзівЛаЉМђЕЅЕФЧхЯДЁЃ
БШНЯГЃМћЕФОЭЪЧгУЛЇааЮЊЪ§ОнЕФВЩМЏЁЃЯШзіsdkТёЕуЃЌЭЈЙ§kafkaЪЕЪБВЩМЏЕНгУЛЇЕФЗУЮЪЪ§ОнЃЌдйгУsparkзіМђЕЅЕФЧхЯДЃЌДцШыhdfsзїЮЊЪ§ОнВжПтЕФЪ§ОндДжЎвЛЁЃ
04 Ъ§ОнДцДЂ
ЫцзХЙЋЫОЕФЙцФЃВЛЖЯРЉеХЃЌВњЩњЕФЪ§ОнвВдНРДдНЕНЃЌЯёвЛаЉДѓЙЋЫОУПЬьВњЩњЕФЪ§ОнСПЖМдкPBМЖБ№ЃЌДЋЭГЕФЪ§ОнПтвбОВЛФмТњзуДцДЂвЊЧѓЃЌФПЧАhdfsЪЧДѓЪ§ОнЛЗОГЯТЪ§ОнВжПт/Ъ§ОнЦНЬЈзюЭъУРЕФЪ§ОнДцДЂНтОіЗНАИЁЃ
дкРыЯпМЦЫуЗНУцЃЌвВОЭЪЧЖдЪЕЪБадвЊЧѓВЛИпЕФВПЗжЃЌHiveЛЙЪЧЪзЕБЦфГхЕФбЁдёЃЌЗсИЛЕФЪ§ОнРраЭЁЂФкжУКЏЪ§ЃЛбЙЫѕБШЗЧГЃИпЕФORC/PARQUETЮФМўДцДЂИёЪНЃЛЗЧГЃЗНБуЕФSQLжЇГжЃЌЪЙЕУHiveдкЛљгкНсЙЙЛЏЪ§ОнЩЯЕФЭГМЦЗжЮідЖдЖБШMapReduceвЊИпаЇЕФЖрЃЌвЛОфSQLПЩвдЭъГЩЕФашЧѓЃЌПЊЗЂMRПЩФмашвЊЩЯАйааДњТыЃЛЖјдкЪЕЪБМЦЫуЗНУцЃЌflinkЪЧзюгХЕФбЁдёЃЌВЛЙ§ФПЧАНіжЇГжjavaИњscalaПЊЗЂЁЃ
05 Ъ§ОнЭЌВН
Ъ§ОнЭЌВНЪЧжИВЛЭЌЪ§ОнДцДЂЯЕЭГжЎМфвЊНјааЪ§ОнЧЈвЦЃЌБШШчдкhdfsЩЯЃЌДѓЖрвЕЮёКЭгІгУвђЮЊаЇТЪЕФдвђВЛПЩвджБНгДгHDFSЩЯЛёШЁЪ§ОнЃЌвђДЫашвЊНЋhdfsЩЯЛузмКѓЕФЪ§ОнЭЌВНжСЦфЫћЕФДцДЂЯЕЭГЃЌБШШчmysqlЁЃ
SqoopПЩвдзіЕНетвЛЕуЃЌЕЋЪЧSqoopЬЋЙ§ЗБжиЃЌЖјЧвВЛЙмЪ§ОнСПДѓаЁЃЌЖМашвЊЦєЖЏMapReduceРДжДааЃЌЖјЧвашвЊHadoopМЏШКЕФУПЬЈЛњЦїЖМФмЗУЮЪвЕЮёЪ§ОнПтЁЃАЂРяПЊдДЕФdataXЪЧвЛИіКмКУЕФНтОіЗНАИЁЃ
06 ЮЌЖШНЈФЃ
ЮЌЖШНЈФЃ(dimensional modeling)ЪЧзЈУХгУгкЗжЮіаЭЪ§ОнПтЁЂЪ§ОнВжПтЁЂЪ§ОнМЏЪаНЈФЃЕФЗНЗЈЁЃетРяЧЃГЖЕНСНИіЛљБОЕФУћДЪЃКЮЌЖШЃЌЪТЪЕЁЃ
1ЁЂЮЌЖШ
ЮЌЖШЪЧЮЌЖШНЈФЃЕФЛљДЁКЭСщЛъЃЌдкЮЌЖШНЈФЃжаЃЌНЋЖШСПГЩЮЊЪТЪЕЃЌНЋЛЗОГУшЪіЮЊЮЌЖШЃЌЮЌЖШЪЧгУгкЗжЮіЪТЪЕЫљашЕФЖрбљЛЗОГЁЃ
Р§ШчЃЌдкЗжЮіНЛвзЙ§ГЬжаЃЌПЩвдЭЈЙ§ТђМвЁЂТєМвЁЂЩЬЦЗКЭЪБМфЕШЮЌЖШУшЪіНЛвзЗЂЩњЕФЛЗОГЁЃ
2ЁЂЪТЪЕ
ЪТЪЕБэзїЮЊЪ§ОнВжПтЮЌЖШНЈФЃЕФКЫаФЃЌНєНєЮЇШЦзХвЕЮёЙ§ГЬРДЩшМЦЃЌЭЈЙ§ЛёШЁУшЪівЕЮёЙ§ГЬЕФЖШСПРДБэДявЕЮёЙ§ГЬЃЌАќКЌСЫв§гУЕФЮЌЖШКЭгывЕЮёЙ§ГЬгаЙиЕФЖШСПЁЃ
ЪТЪЕБэжавЛЬѕМЧТМЫљБэДяЕФвЕЮёЯИНкБЛГЦжЎЮЊСЃЖШЁЃЭЈГЃСЃЖШПЩвдЭЈЙ§СНжжЗНЪНРДБэЪіЃКвЛжжЪЧЮЌЖШЪєадзщКЯЫљБэЪОЕФЯИНкГЬЖШЃЛвЛжжЪЧЫљБэЪОЕФОпЬхвЕЮёКЌвхЁЃ
ЮЌЖШНЈФЃЩцМАЕНЕФзЈвЕЪѕгяжївЊгавдЯТМИИіЃК
1ЁЂ Ъ§Онгђ
жИУцЯђвЕЮёЗжЮіЃЌНЋвЕЮёЙ§ГЬЛюЖЏЮЌЖШНјааГщЯѓЕФМЏКЯЁЃЦфжаЃЌвЕЮёЙ§ГЬПЩвдИХРЈЮЊвЛИіИіВЛПЩЗжИюЕФааЮЊЪТМўЃЌдквЕЮёЙ§ГЬРяПЩвдЖЈвхжИБъЃЛЮЌЖШЪЧжИЖШСПЕФЛЗОГЃЌШчТђМвЯТЕЅЪТМўЃЌТђМўЪЧЮЌЖШЁЃ
ЮЊБЃеЯећИіЬхЯЕЕФЩњУќСІЃЌЪ§ОнгђЪЧашвЊГщЯѓЬсСЖВЂЧвГЄЦкЮЌЛЄИќаТЕФЃЌЕЋВЛЧсвзБфЖЏЁЃдкЛЎЗжЪ§ОнгђЪБЃЌМШвЊФмКИЧЫљгавЕЮёашЧѓЃЌгжФмдкаТвЕЮёНјШыЪБЮогАЯьЕФАќКЌвбгаЕФЪ§ОнЛЙвЊРЉеЙаТЕФЪ§ОнгђЁЃ
2ЁЂ вЕЮёЙ§ГЬ
жИЦѓвЕЛюЖЏЪТМўЃЌШчЯТЕЅЁЂжЇИЖЁЂЭЫПюЖМЪЧвЕЮёЙ§ГЬЁЃвЕЮёЙ§ГЬЪЧвЛИіВЛПЩЗжИюЕФааЮЊЪТМўЁЃ
3ЁЂ ЪБМфжмЦк
гУРДУїШЗЪ§ОнЭГМЦЕФЪБМфжмЦкЛђепЪБМфЕуЃЌШчздШЛдТЁЂзюНќ30ЬьЃЌздШЛжмЕШЁЃ
4ЁЂ аоЪЮРраЭ
ЪЧЖдГщЯѓДЪЕФвЛжжГщЯѓЛЎЗжЁЃаоЪЮРраЭДгЪєФГИіЪ§ОнгђЃЌШчШежОгђЕФЗУЮЪжеЖЫКИЧЮоЯпЖЫЃЌPCЖЫЕШаоЪЮДЪЁЃ
5ЁЂ аоЪЮДЪ
жИГ§СЫЭГМЦЮЌЖШвдЭтжИБъЕФвЕЮёГЁОАЯоЖЈГщЯѓЁЃаоЪЮДЪСЅЪєгкФГвЛИіаоЪЮРраЭЁЃ
6ЁЂ ЖШСП/дзгжИБъ
ЛљгкФГвЛвЕЮёЪТМўааЮЊЯТЕФЖШСПЃЌЪЧвЕЮёЖЈвхжаВЛПЩдйЗжИюЕФжИБъЃЌОпгаУїШЗЕФвЕЮёКЌвхУћДЪЃЌШчжЇИЖН№ЖюЁЃ
7ЁЂЮЌЖШ
ЩЯЪівбОзіСЫНщЩмЃЌВЛБижиЪіЁЃ
8ЁЂ ЮЌЖШЪєад
ЮЌЖШЪєадСЅЪєгкФГвЛИіЮЌЖШЃЌШчЕиРэЮЌЖШРяУцЕФЙњМвУћГЦЃЌЙњМвidЃЌЪЁЗнУћГЦЕШЁЃ
9ЁЂ ЪТЪЕ
ЩЯЪівбОзіСЫНщЩмЃЌВЛБижиЪіЁЃ
10ЁЂХЩЩњжИБъ
ХЩЩњжИБъ=вЛИідзгжИБъ+ЖрИіаоЪЮДЪ+ЪБМфжмЦкЃЌПЩвдРэНтЮЊЖддзгжИБъвЕЮёЭГМЦЗЖЮЇЕФШІЖЈЁЃ
ШчдзгжИБъЃКжЇИЖН№ЖюЃЌзюНќвЛЬьКЃЭтТђМвжЇИЖН№ЖюЮЊХЩЩњжИБъЃЈзюНќвЛЬьЮЊЪБМфжмЦкЃЌКЃЭтЮЊаоЪЮДЪЃЌТђМвЮЊЮЌЖШЃЉЁЃ
11ЁЂзъШЁ
зъШЁЪЧИФБфЮЌЕФВуДЮЃЌБфЛЛЗжЮіЕФСЃЖШЁЃЫќАќРЈЯђЩЯзъШЁЃЈroll upЃЉКЭЯђЯТзъШЁЃЈdrill downЃЉЁЃЯђЩЯзъШЁЪЧдкФГвЛЮЌЩЯНЋЕЭВуДЮЕФЯИНкЪ§ОнИХРЈЕНИпВуДЮЕФЛузмЪ§ОнЃЌЛђепМѕЩйЮЌЪ§ЃЛЪЧжИздЖЏЩњГЩЛузмааЕФЗжЮіЗНЗЈЁЃЭЈЙ§ЯђЕМЕФЗНЪНЃЌгУЛЇПЩвдЖЈвхЗжЮівђЫиЕФЛузмааЃЌР§ШчЖдгкИїЕиЧјИїФъЖШЕФЯњЪлЧщПіЃЌПЩвдЩњГЩЕиЧјгыФъЖШЕФКЯМЦааЃЌвВПЩвдЩњГЩЕиЧјЛђепФъЖШЕФКЯМЦааЁЃ
ЖјЯђЯТзъШЁдђЯрЗДЃЌЫќДгЛузмЪ§ОнЩюШыЕНЯИНкЪ§ОнНјааЙлВьЛђдіМгаТЮЌЁЃР§ШчЃЌгУЛЇЗжЮіЁАИїЕиЧјЁЂГЧЪаЕФЯњЪлЧщПіЁБЪБЃЌПЩвдЖдФГвЛИіГЧЪаЕФЯњЪлЖюЯИЗжЮЊИїИіФъЖШЕФЯњЪлЖюЃЌЖдФГвЛФъЖШЕФЯњЪлЖюЃЌПЩвдМЬајЯИЗжЮЊИїИіМОЖШЕФЯњЪлЖюЁЃЭЈЙ§зъШЁЕФЙІФмЃЌЪЙгУЛЇЖдЪ§ОнФмИќЩюШыСЫНтЃЌИќШнвзЗЂЯжЮЪЬтЃЌзіГіе§ШЗЕФОіВпЁЃ
ШЛКѓНщЩмЯТЮЌЖШНЈФЃЕФШ§жжФЃЪНЃЌШчЯТЃК
1ЁЂ аЧаЮФЃЪН
аЧаЮФЃЪН(Star Schema)ЪЧзюГЃгУЕФЮЌЖШНЈФЃЗНЪНЃЌЯТЭМеЙЪОСЫЪЙгУаЧаЮФЃЪННјааЮЌЖШНЈФЃЕФЙиЯЕНсЙЙЃК

ПЩвдПДГіЃЌаЧаЮФЃЪНЕФЮЌЖШНЈФЃгЩвЛИіЪТЪЕБэКЭвЛзщЮЌБэГЩЃЌЧвОпгавдЯТЬиЕуЃК
a. ЮЌБэжЛКЭЪТЪЕБэЙиСЊЃЌЮЌБэжЎМфУЛгаЙиСЊ
b. УПИіЮЌБэЕФжїТыЮЊЕЅСаЃЌЧвИУжїТыЗХжУдкЪТЪЕБэжаЃЌзїЮЊСНБпСЌНгЕФЭтТы
c. вдЪТЪЕБэЮЊКЫаФЃЌЮЌБэЮЇШЦКЫаФГЪаЧаЮЗжВМ
2ЁЂбЉЛЈФЃЪН
бЉЛЈФЃЪН(Snowflake Schema)ЪЧЖдаЧаЮФЃЪНЕФРЉеЙЃЌУПИіЮЌБэПЩМЬајЯђЭтСЌНгЖрИізгЮЌБэЁЃЯТЭМЮЊЪЙгУбЉЛЈФЃЪННјааЮЌЖШНЈФЃЕФЙиЯЕНсЙЙЃК

аЧаЮФЃЪНжаЕФЮЌБэЯрЖдбЉЛЈФЃЪНРДЫЕвЊДѓЃЌЖјЧвВЛТњзуЙцЗЖЛЏЩшМЦЁЃбЉЛЈФЃаЭЯрЕБгкНЋаЧаЮФЃЪНЕФДѓЮЌБэВ№ЗжГЩаЁЮЌБэЃЌТњзуСЫЙцЗЖЛЏЩшМЦЁЃШЛЖјетжжФЃЪНдкЪЕМЪгІгУжаКмЩйМћЃЌвђЮЊетбљзіЛсЕМжТПЊЗЂФбЖШдіДѓЃЌЖјЪ§ОнШпгрЮЪЬтдкЪ§ОнВжПтРяВЂВЛбЯжиЁЃ
3ЁЂаЧзљФЃЪН
аЧзљФЃЪН(Fact Constellations Schema)вВЪЧаЧаЮФЃЪНЕФРЉеЙЁЃЛљгкетжжЫМЯыОЭгаСЫаЧзљФЃЪНЃК

ЧАУцНщЩмЕФСНжжЮЌЖШНЈФЃЗНЗЈЖМЪЧЖрЮЌБэЖдгІЕЅЪТЪЕБэЃЌЕЋдкКмЖрЪБКђЮЌЖШПеМфФкЕФЪТЪЕБэВЛжЙвЛИіЃЌЖјвЛИіЮЌБэвВПЩФмБЛЖрИіЪТЪЕБэгУЕНЁЃдквЕЮёЗЂеЙКѓЦкЃЌОјДѓВПЗжЮЌЖШНЈФЃЖМВЩгУЕФЪЧаЧзљФЃЪНЁЃ
4ЁЂШ§жжФЃЪНЖдБШ
ЙщФЩвЛЯТЃЌаЧаЮФЃЪН/бЉЛЈФЃЪН/аЧзљФЃЪНЕФЙиЯЕШчЯТЭМЫљЪОЃК

бЉЛЈФЃЪНЪЧНЋаЧаЭФЃЪНЕФЮЌБэНјвЛВНЛЎЗжЃЌЪЙИїЮЌБэОљТњзуЙцЗЖЛЏЩшМЦЁЃЖјаЧзљФЃЪНдђЪЧдЪаэаЧаЮФЃЪНжаГіЯжЖрИіЪТЪЕБэЁЃ
ЮЌЖШБэЩшМЦ
ЮЌЖШЕФЩшМЦЙ§ГЬОЭЪЧШЗЖЈЮЌЖШЪєадЕФЙ§ГЬЃЌШчКЮЩњГЩЮЌЖШЪєадЃЌвдМАЫљЩњГЩЮЌЖШЪєадЕФгХСгЃЌОіЖЈСЫЮЌЖШЪЙгУЕФЗНБуадЃЌГЩЮЊЪ§ОнВжПтвзгУадЕФЙиМќЁЃЪ§ОнВжПтЕФФмСІжБНггыЮЌЖШЪєадЕФжЪСПКЭЩюЖШГЩе§БШЁЃ
ЮЌЖШБэЛљБОЩшМЦЗНЗЈ
ЯТУцвдЩЬЦЗЮЌЖШЮЊР§ЖдЮЌЖШЩшМЦЗХЗЂНјааЯъЯИЫЕУїЃК
ЕквЛВНЃКбЁдёЮЌЖШЛђепаТНЈЮЌЖШЁЃзїЮЊЮЌЖШНЈФЃЕФКЫаФЃЌдкЦѓвЕМЖЪ§ОнВжПтжаЃЌБиаыБЃжЄЮЌЖШЕФЮЈвЛадЁЃвдЩЬЦЗЮЌЖШЮЊР§ЃЌгаЧвжЛгавЛИіЮЌЖШЖЈвхЁЃ
ЕкЖўВНЃКШЗЖЈжїЮЌБэЁЃДЫДІЕФжїЮЌБэвЛАуЪЧODSБэЃЌжБНггывЕЮёЯЕЭГЭЌВНЁЃ
ЕкШ§ВНЃКШЗЖЈЯрЙиЮЌБэЁЃЪ§ОнВжПтЪЧвЕЮёдДЯЕЭГЕФЪ§ОнећКЯЃЌВЛЭЌвЕЮёЯЕЭГЛђепЭЌвЛвЕЮёЯЕЭГжаЕФБэжЎМфДцдкЙиСЊадЃЌИљОнвЕЮёЯЕЭГЕФЪсРэЃЌШЗЖЈФФаЉБэКЭжїЮЌБэДцдкЙиСЊЙиЯЕЃЌВЂбЁдёЦфжаЕФФГаЉБэгУгкЩњГЩЮЌЖШЪєадЁЃвдЩЬЦЗЮЌЖШЮЊР§ЃЌИљОнвЕЮёТпМЕФЪсРэЃЌПЩвдЕУЕНЩЬЦЗгыРрФПЁЂskuЁЂТђМвЁЂТєМвЁЂЕъЦЬЕШЮЌЖШДцдкЕФЙиСЊЙиЯЕЁЃ
ЕкЫФВНЃКШЗЖЈЮЌЖШЪєадЁЃБОВНжшжївЊАќРЈСНИіНзЖЮЃЌЦфжавЛИіНзЖЮЪЧДгжїЮЌБэжабЁдёЮЌЖШЪєадЛђЩњГЩаТЕФЮЌЖШЪєадЃЛЕкЖўИіНзЖЮЪЧДгЯрЙиЮЌБэжабЁдёЮЌЖШЪєадЛђепЩњГЩаТЕФЮЌЖШЪєадЁЃвдЩЬЦЗЮЌЖШЮЊР§ЃЌДгжїЮЌБэКЭРрФПЁЂskuЁЂТєМвЁЂЕъЦЬЕШЯрЙиЮЌБэжабЁдёЮЌЖШЪєадЛђепЩњГЩаТЕФЮЌЖШЪєадЁЃ
ШЗЖЈЮЌЖШЪєадЕФМИЕуЬсЪОЃК
aЁЂ ОЁПЩФмЩњГЩЗсИЛЕФЮЌЖШЪєад
bЁЂ ОЁПЩФмЖрЕФИјГіАќРЈвЛаЉИЛгавтвхЕФЮФзжУшЪі
cЁЂ ЧјЗжЪ§жЕаЭЪєадКЭЪТЪЕ
dЁЂ ОЁПЩФмГСЕэГіЭЈгУЕФЮЌЖШЪєад
ШчЯТЭМЪЧЙцЗЖЛЏЕФЩЬЦЗЮЌЖШБэЯжаЮЪНЃК
ИУФЃЪНЪєгкбЉЛЈФЃЪНЁЃ
зЂвтЃКВЩгУбЉЛЈФЃЪНЃЌгУЛЇдкЭГМЦЗжЮіЕФЙ§ГЬжаашвЊДѓСПЕФЙиСЊВйзїЃЌЪЙгУИДдгЖШИпЃЌЭЌЪБВщбЏадФмКмВюЃЌШчЙћЪ§ОнСПОоДѓЃЌФЧОЭИќВюСЫЃЛвђДЫашвЊНЋЮЌЖШЕФЪєадВуДЮКЯВЂЕНЕЅИіЮЌЖШжаЃЌИУВйзїГЦжЎЮЊЗДЙцЗЖЛЏЃЌВЩгУЗДЙцЗЖЛЏДІРэЃЌЗНБуЃЌвзгУЧвадФмКУЁЃ
ЖдгкЩЬЦЗЮЌЖШЃЌШчЙћВЩгУЗДЙцЗЖЛЏЃЌНЋБэЯжЮЊЯТЭМЫљЪОЕФаЮЪНЃК 
ВЩгУбЉЛЈФЃЪНЃЌГ§СЫПЩвдНкдМвЛВПЗжДцДЂжЎЭтЃЌЖдгкOLAPЯЕЭГРДЫЕУЛгаЦфЫћЕФаЇгУЁЃЖјЯжНзЖЮДцДЂЕФГЩБОЗЧГЃЕЭЁЃГігквзгУадКЭадФмЕФПМТЧЃЌЮЌБэвЛАуЩшМЦГЩВЛЙцЗЖЛЏЕФЁЃдкЪЕМЪгІгУжаЃЌМИКѕзмЪЧЪЙгУЮЌБэЕФПеМфРДЛЛШЁМђУїадКЭВщбЏадФмЁЃ
ЛКТ§БфЛЏЮЌ
Ъ§ОнВжПтЕФЬиеїжЎвЛОЭЪЧЗДгІРњЪЗБфЛЏЃЌЫљвдШчКЮДІРэЮЌЖШЕФБфЛЏЪЧЩшМЦЕФЙЄзїжЎвЛЁЃЛКТ§БфЛЏЮЌЕФЬсГіЪЧвђЮЊдкЯжЪЕЪРНчжаЃЌЮЌЖШЕФЪєадВЛЪЧОВЬЌЕФЃЌЫќЛсЫцзХЪБМфЕФСїЪХЛКТ§ЕФБфЛЏЃЌгыЪ§ОндіГЄНЯПьЕФЪТЪЕБэЯрБШЃЌЮЌЖШБфЛЏЯрЖдЛКТ§ЁЃ
вдЯТНщЩмМИжжДІРэетжжЧщПіЕФШ§жжЗНЪНЃК
ЃЈ1ЃЉЕквЛжжЗНЪНЃКжиаДЮЌЖШжЕЁЃВЩгУДЫжжЗНЪНЃЌВЛБЃСєРњЪЗЪ§ОнЃЈМђЕЅРДЫЕОЭЪЧИќаТЯрЙиЕФЮЌЖШзжЖЮЃЉЁЃБШШчЩЬЦЗЫљЪєРрФПгы2019Фъ5дТ20ШегЩРрФП1БфГЩРрФП2ЃЌВЩгУЕквЛжжДІРэЗНЪНЃЌБфЛЏМЧТМЕФЧАКѓШчЯТЭМЫљЪОЃК
БфЛЏЧАЩЬЦЗБэКЭЖЉЕЅБэ 
БфЛЏКѓЩЬЦЗБэКЭЖЉЕЅБэ 
ЃЈ2ЃЉЕкЖўжжЗНЪНЃКВхШыаТЕФЮЌЖШааЁЃВЩгУДЫжжЗНЪНЃЌБЃСєРњЪЗЪ§ОнЃЌЮЌЖШжЕБфЛЏЧАКѓЕФЪТЪЕКЭЙ§ШЅЕФЮЌЖШЙиСЊЃЌЮГЖШжЕБфЛЏЧАКѓЕФЪТЪЕКЭЕБЧАЕФЮЌЖШжЕЙиСЊЁЃЭЌЩЯУцЕФР§згВЩгУЕкЖўжжЗНЪНЃЌБфЛЏКѓЕФМЧТМШчЯТЭМЫљЪОЃК 
ЃЈ3ЃЉЕкШ§жжЗНЪНЃКЬэМгЮЌЖШСаЁЃВЩгУЕкЖўжжЗНЪНВЛФмНЋБфЛЏЧАКѓМЧТМЕФЪТЪЕЙщвЛЮЊБфЛЏЧАЕФЮЌЖШЛђепЙщвЛЮЊБфЛЏКѓЕФЮЌЖШЁЃБШШчИљОнвЕЮёашЧѓЃЌашвЊНЋ5дТЗнЕФНЛвзН№ЖюШЋВПЭГМЦЕНРрФП2ЩЯЃЌВЩгУЕкЖўжжЗНЪНЮоЗЈЪЕЯжЁЃеыЖдДЫЮЪЬтЃЌВЩгУЕкШ§жжДІРэЗНЪНЃЌБЃСєРњЪЗЪ§ОнЃЌПЩвдЪЙгУШЮКЮвЛИіЪєадСаЁЃЭЌЩЯУцЕФР§згЃЌВЩгУЕкШ§жжЗНЪНЃЌБфЛЏЧАКѓЕФЪ§ОнМЧТМШчЯТЃК
БфЛЏЧАЩЬЦЗБэКЭЖЉЕЅБэЃК 
БфЛЏКѓЕФЩЬЦЗБэКЭЖЉЕЅБэЃК 
ЖдгкВЩгУФФжжЗНЪННтОіЛКТ§БфЛЏЮЌЃЌжЛФмИљОнвЕЮёашЧѓШЅбЁдёЁЃ
ЪТЪЕБэЩшМЦ
ЪТЪЕБэзїЮЊЪ§ОнВжПтЮЌЖШНЈФЃЕФКЫаФЃЌНєНєЮЇШЦзХвЕЮёЙ§ГЬРДЩшМЦЃЌЭЈЙ§ЛёШЁУшЪівЕЮёЙ§ГЬЕФЖШСПРДБэДявЕЮёЙ§ГЬЃЌАќКЌСЫв§гУЕФЮЌЖШКЭвЕЮёЙ§ГЬгаЙиЕФЖШСПЁЃЯрЖдЮЌБэРДЫЕЃЌЪТЪЕБэвЊЯИГЄЕФЖрЃЌааЕФдіМгЫйЖШвВБШЮЌБэПьКмЖрЁЃЪТЪЕБэЗжЮЊШ§жжРраЭЃКЪТЮёЪТЪЕБэЃЌжмЦкПьееЪТЪЕБэЃЌРлМЦПьееЪТЪЕБэЁЃ
1ЁЂ ЪТЮёЪТЪЕБэ
гУРДУшЪівЕЮёЙ§ГЬЃЌИњзйЪБМфЛђепПеМфЩЯФГЕуЕФЖШСПЪТМўЃЌБЃДцЕФЪЧзюдзгЕФЪ§ОнЃЌвВГЩЮЊЁАдзгЪТЪЕБэЁБЁЃ
2ЁЂ жмЦкПьееЪТЪЕБэ
вдОпгаЙцТЩЕФЃЌПЩдЄМћЕФЪБМфМфИєМЧТМЪТЪЕШчУПЬьЁЂУПдТЁЂУПФъЕШЁЃ
3ЁЂ РлМЦПьееЪТЪЕБэ
гУРДБэЪіПЊЪМКЭНсЪјжЎМфЕФЙиМќВНжшЪТМўЃЌИВИЧећИіЩњУќжмЦкЃЌЭЈГЃОпгаЖрИіЪБМфзжЖЮРДМЧТМЙиМќЪБМфЕуЃЌЕБЙ§ГЬЫцзХЪБМфБфЛЏЪБЃЌМЧТМвВЛсИњзХаоИФЁЃ
БОЮФжївЊЬжТлЪТЮёЪТЪЕБэЃЌвдЯТНщЩмЪТЪЕБэЕФЩшМЦддђКЭЩшМЦЗНЗЈЃК
ЪТЪЕБэЩшМЦддђ
aЁЂ ОЁПЩФмАќРЈЫљгавЕЮёЙ§ГЬЯрЙиЕФЪТЪЕ
bЁЂ жЛбЁдёгывЕЮёЙ§ГЬЯрЙиЕФЪТЪЕ
cЁЂ ЗжНтВЛПЩМгЪТЪЕЮЊПЩМгЕФзщМў
dЁЂ бЁдёЮЌЖШКЭЪТЪЕжЎЧАБиаыЯШЩљУїСЃЖШ
eЁЂ дкЭЌвЛИіЪТЪЕБэжаВЛПЩвдгаЖржиВЛЭЌСЃЖШЕФЪТЪЕ
fЁЂ ЪТЪЕЕФЕЅЮЛвЊБЃГжвЛжТ
gЁЂ ЖдЪТЪЕЕФnullжЕвЊДІРэ
hЁЂ ЪЙгУЭЫЛЏЮЌЬсИпЪТЪЕБэЕФвзгУад
ЪТЮёЪТЪЕБэЕФЛљБОЩшМЦЗНЗЈ
ШЮКЮРраЭЕФЪТМўЖМПЩвдБЛРэНтГЩвЛжжЪТЮёЁЃБШШчНЛвзЙ§ГЬжаЕФДДНЈЖЉЕЅЃЌТђМвИЖПюЃЌЮяСїжаЕФЗЂЛѕЃЌЧЉЪеЃЌИЖПюЕШЁЃЪТЮёЪТЪЕБэеыЖдетаЉЙ§ГЬДДНЈЕФвЛжжЪТЪЕБэЁЃЯТУцЕъЦЬНЛвзЪТЮёЮЊР§ЃЌВћЪіЪТЮёЪТЪЕБэЕФвЛАуЩшМЦЙ§ГЬЁЃ
1ЁЂ бЁдёвЕЮёЙ§ГЬ
НЛвзЕФЙ§ГЬЗжЮЊЃКДДНЈЖЉЕЅЁЂТђМвИЖПюЁЂТєМвЗЂЛѕЁЂТђМвШЗШЯЪеЛѕЃЌМДЯТЕЅЁЂжЇИЖЁЂЗЂЛѕКЭГЩЙІЭъНсЫФИівЕЮёЙ§ГЬЁЃ
KimballЮЌЖШНЈФЃРэТлШЯЮЊЃЌЮЊСЫБугкНјааЖРСЂЕФЗжЮібаОПЃЌгІИУЮЊУПвЛИівЕЮёЙ§ГЬНЈСЂвЛИіЪТЪЕБэЁЃ
2ЁЂ ШЗЖЈСЃЖШ
вЕЮёЙ§ГЬбЁЖЈжЎКѓЃЌОЭвЊЖдУПИівЕЮёЙ§ГЬШЗЖЈвЛИіСЃЖШЃЌМДШЗЖЈЪТЪЕБэУПвЛааЫљБэДяЕФЯИНкВуДЮЁЃашвЊЮЊЫФИівЕЮёЙ§ГЬШЗЖЈСЃЖШЃЌЦфжаЯТЕЅЁЂжЇИЖКЭГЩЙІЭъНсбЁдёНЛвззгЖЉЕЅСЃЖШЃЌМДУПИізгЖЉЕЅЮЊЪТЪЕБэЕФвЛааЃЌТђМвЪеЛѕЕФСЃЖШЮЊЮяСїЕЅЁЃ
3ЁЂ ШЗЖЈЮЌЖШ
бЁЖЈКУвЕЮёЙ§ГЬВЂЧвШЗЖЈСЃЖШКѓЃЌОЭПЩвдШЗЖЈЮЌЖШаХЯЂСЫЁЃдкЕъЦЬНЛвзЪТЪЕБэЩшМЦЙ§ГЬжаЃЌАДееОГЃгУгкЭГМЦЗжЮіЕФГЁОАЃЌШЗЖЈЮЌЖШАќКЌЃКТђМвЁЂТєМвЁЂЩЬЦЗЁЂЩЬЦЗРрФПЁЂЗЂЛѕЕиЧјЁЂЪеЛѕЕижЗЁЂИИЖЉЕЅЮЌЖШвдМАдгЯюЮЌЖШЁЃ
4ЁЂ ШЗЖЈЪТЪЕ
зїЮЊЙ§ГЬЖШСПЕФКЫаФЃЌЪТЪЕБэгІИУАќКЌгыЦфУшЪіЙ§ГЬгаЙиЕФЫљгаЪТЪЕЁЃвдЕъЦЬНЛвзЪТЪЕБэЮЊР§ЃЌбЁЖЈШ§ИівЕЮёЙ§ГЬ:ЯТЕЅЁЂжЇИЖЁЂГЩЙІЭъНсЃЌВЛЭЌЕФвЕЮёЙ§ГЬгаВЛЭЌЕФЪТЪЕЁЃБШШчдкЯТЕЅвЕЮёЙ§ГЬжаЃЌашвЊАќКЌЯТЕЅН№ЖюЁЂЯТЕЅЪ§СПЁЂЯТЕЅЗжЬЏН№ЖюЃЛ
ОЙ§вдЩЯЫФВНЕъЦЬНЛвзЪТЮёЪТЪЕБэвбГЩаЭЃЌШчЯТЭМЫљЪОЃК

дкШЗЖЈЮЌЖШЪБЃЌАќКЌСЫТђТєМвЮЌЖШЃЌЩЬЦЗЮЌЖШЃЌРрФПЮЌЖШЃЌЪеЗЂЛѕЕШЁЃKimballЮЌЖШНЈФЃРэТлНЈвщдкЪТЪЕБэжажЛБЃСєетИіЮЌЖШБэЕФЭтМќЃЌЕЋЪЧдкЪЕМЪЕФгІгУжаЃЌПЩвдНЋЕъЦЬУћГЦЁЂЩЬЦЗРраЭЁЂЩЬЦЗЪєадЁЂРрФПЪєадШпгрЕНЪТЪЕБэжаЃЌЬсИпЖдЪТЪЕБэЕФЙ§ТЫВщбЏЃЌМѕЩйБэжЎМфЕФЙиСЊДЮЪ§ЃЌМгПьВщбЏЫйЖШЃЌИУВйзїГЦжЎЮЊЭЫЛЏЮЌЁЃ
ОЙ§вдЩЯЕФВйзїЃЌЛљБОЭъГЩСЫЕъЦЬНЛвзЪТЮёЪТЪЕБэЕФЩшМЦЙЄзїЁЃ
07 дЊЪ§ОнЙмРэ
дЊЪ§ОнЭЈГЃЖЈвхЮЊЁАУшЪіЪ§ОнЕФЪ§ОнЁБ,дкЪ§ОнВжПтжаЪЧЖЈвхКЭУшЪіDW/BIЯЕЭГЕФНсЙЙЃЌВйзїКЭФкШнЕФЫљгааХЯЂЁЃдЊЪ§ОнЙсДЉСЫЪ§ОнВжПтЕФећИіЩњУќжмЦкЃЌЪЙгУдЊЪ§ОнЧ§ЖЏЪ§ОнВжПтЕФПЊЗЂЃЌЪЙЪ§ОнВжПтздЖЏЛЏЃЌПЩЪгЛЏЁЃАДееВЛЭЌЕФгУЭОНЋдЊЪ§ОнЗжЮЊСНРрЃКММЪѕдЊЪ§ОнКЭвЕЮёдЊЪ§ОнЁЃ
ММЪѕдЊЪ§ОнжИУшЪіЯЕЭГжаММЪѕЯИНкЯрЙиЕФИХФюЁЂЙиЯЕКЭЙцдђЕФЪ§ОнЃЌАќРЈЖдЪ§ОнНсЙЙЁЂЪ§ОнДІРэЗНУцЕФУшЪіЃЌвдМАЪ§ОнВжПтЁЂETLЁЂЧАЖЫеЙЯжЕШММЪѕЯИНкЗНУцЕФаХЯЂЁЃГЃМћЕФММЪѕдЊЪ§ОнгаЃК
1ЁЂЗжВМЪНМЦЫуДцДЂдЊЪ§ОнЃЌШчБэЁЂСаЁЂЗжЧјЕШаХЯЂЁЃМЧТМБэЕФБэУћЁЂЗжЧјаХЯЂЁЂд№ШЮШЫаХЯЂЁЂЮФМўДѓаЁЁЂБэРраЭЁЂЩњУќжмЦкЁЂСаЕФзжЖЮЁЂзжЖЮРраЭЁЂзжЖЮБИзЂЕШЁЃ
2ЁЂЗжВМЪНМЦЫуЯЕЭГдЫаадЊЪ§ОнЃЌМЏШКЩЯЫљгаШЮЮёЕФдЫаааХЯЂЃЛРрЫЦhiveЕФдЫааШежОЃЌАќРЈзївЕРраЭЁЂЪЕР§УћГЦЁЂЪфШыЪфГіЁЂдЫааВЮЪ§ЁЂдЫааЪБМфЕШЁЃ
3ЁЂЕїЖШШЮЮёжаЕФЕїЖШаХЯЂЃЌАќРЈЪфШыЪфГізжЖЮЁЂвРРЕРраЭЁЂвРРЕЙиЯЕЕШЁЃ
4ЁЂЪ§ОнжЪСПИњдЫЮЌЯрЙидЊЪ§ОнЃЌШчШЮЮёМрПиЁЂдЫЮЌБЈОЏЁЂЪ§ОнжЪСПЁЂЙЪеЯЕШЁЃ
вЕЮёдЊЪ§ОнжИДгвЕЮёНЧЖШУшЪівЕЮёСьгђЯрЙиЕФИХФюЁЂЙиЯЕКЭЙцдђЕФЪ§ОнЃЌАќРЈвЕЮёЪѕгяКЭвЕЮёЙцдђЕШаХЯЂЁЃГЃгУЕФММЪѕдЊЪ§ОнгаЃК
ШчЮЌЖШКЭЪєадЁЂвЕЮёЙ§ГЬЁЂжИБъЕШЙцЗЖЛЏЖЈвхЃЌгУгкИќКУЕФЙмРэКЭЪЙгУЪ§ОнЁЃ
Ъ§ОнгІгУдЊЪ§ОнЃЌЪ§ОнБЈБэЁЂЪ§ОнВњЦЗЕШХфжУКЭдЫаадЊЪ§ОнЁЃ
08 ШЮЮёЕїЖШгыМрПи
дкЪ§ОнВжПтНЈЩшжаЃЌгаИїжжИїбљЗЧГЃЖрЕФГЬађКЭШЮЮёЃЌБШШчЃКЪ§ОнВЩМЏШЮЮёЁЂЪ§ОнЭЌВНШЮЮёЁЂЪ§ОнЧхЯДШЮЮёЁЂЪ§ОнЗжЮіШЮЮёЕШЁЃетаЉШЮЮёГ§СЫЖЈЪБЕїЖШЃЌЛЙДцдкЗЧГЃИДдгЕФШЮЮёвРРЕЙиЯЕЁЃ
БШШчЃКЪ§ОнЗжЮіШЮЮёБиаыЕШЯргІЕФЪ§ОнВЩМЏШЮЮёЭъГЩКѓВХФмПЊЪМЃЛЪ§ОнЭЌВНШЮЮёашвЊЕШЪ§ОнЗжЮіШЮЮёЭъГЩКѓВХФмПЊЪМЃЛетОЭашвЊвЛИіЗЧГЃЭъЩЦЕФШЮЮёЕїЖШгыМрПиЯЕЭГЃЌЫќзїЮЊЪ§ОнВжПтЕФжаЪрЃЌИКд№ЕїЖШКЭМрПиЫљгаШЮЮёЕФЗжХфгыдЫааЁЃ
ФПЧАгаФмСІЕФЙЋЫОЖМЪЧздМКПЊЗЂЕїЖШЙЄОпЃЌШчжаЙњЦНАВЃЈlinkduЃЉЃЌвјаааавЕгУЕФНЯЖрЪЧControl-MЃЌвЛаЉЛЅСЊЭјЙЋЫОПЩФмЛсбЁдёairflowзїЮЊздМКЕФЕїЖШЙЄОпЁЃОпЬхВЩгУФФжжЙЄОпЃЌЧыИљОнздМКЙЋЫОЕФБОЩэЯжзДШЅзіЖЈЖсЁЃ
09 змНс
Ъ§ОнВжПтНЈЩшЪЧвЛИізлКЯадММЪѕЃЌЖјЧвЕБЦѓвЕвЕЮёИДдгЕФЪБКђЃЌетВПЗжЙЄзїИќЪЧашвЊзЈУХЭХЖггывЕЮёЗНЙВЭЌКЯзїРДЭъГЩЁЃвђДЫвЛИігХауЕФЪ§ОнВжПтНЈФЃЭХЖгМШвЊгаМсЪЕЕФЪ§ОнВжПтНЈФЃММЪѕЃЌЛЙвЊгаЖдЯжЪЕвЕЮёЧхЮњЁЂЭИГЙЕФРэНтЁЃСэЭтЃЌМмЙЙВЂВЛЪЧММЪѕдНЖрдНаТдНКУЃЌЖјЪЧдкПЩвдТњзуашЧѓЕФЧщПіЯТЃЌдНМђЕЅдНЮШЖЈдНКУЁЃ
|








