|
1.简介
数据挖掘、机器学习这些字眼,在一些人看来,是门槛很高的东西。诚然,如果做算法实现甚至算法优化,确实需要很多背景知识。但事实是,绝大多数数据挖掘工程师,不需要去做算法层面的东西。他们的精力,集中在特征提取,算法选择和参数调优上。那么,一个可以方便地提供这些功能的工具,便是十分必要的了。而weka,便是数据挖掘工具中的佼佼者。
Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化的,基于JAVA环境下开源的机器学习以及数据挖掘软件。它和它的源代码可在其官方网站下载。有趣的是,该软件的缩写WEKA也是New Zealand独有的一种鸟名,而Weka的主要开发者同时恰好来自新西兰的the University of Waikato。(本段摘自百度百科)。
Weka提供的功能有数据处理,特征选择、分类、回归、聚类、关联规则、可视化等。本文将对Weka的使用做一个简单的介绍,并通过简单的示例,使大家了解使用weka的流程。本文将仅对图形界面的操作做介绍,不涉及命令行和代码层面的东西。
2.安装
Weka的官方地址是http://www.cs.waikato.ac.nz/ml/weka/。点开左侧download栏,可以进入下载页面,里面有windows,mac os,linux等平台下的版本,我们以windows系统作为示例。目前稳定的版本是3.6。
如果本机没有安装java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。
安装完毕,打开启动weka的快捷方式,如果可以看到下面的界面,那么恭喜,安装成功了。
图2.1 weka启动界面
窗口右侧共有4个应用,分别是
Explorer
用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。(An environment for exploring data with WEKA)
2)Experimentor
用来进行实验,对不同学习方案进行数据测试的环境。(An environment for performing experiments and conducting statistical tests between learning schemes.)
3)KnowledgeFlow
功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)
4)SimpleCLI
简单的命令行界面。(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)
3.数据格式
Weka支持很多种文件格式,包括arff、xrff、csv,甚至有libsvm的格式。其中,arff是最常用的格式,我们在这里仅介绍这一种
Arff全称是Attribute-Relation File Format,以下是一个arff格式的文件的例子。
%
% Arff file example
%
@relation ‘labor-neg-data’
@attribute ‘duration’ real
@attribute ‘wage-increase-first-year’ real
@attribute ‘wage-increase-second-year’ real
@attribute ‘wage-increase-third-year’ real
@attribute ‘cost-of-living-adjustment’ {‘none’,'tcf’,'tc’}
@attribute ‘working-hours’ real
@attribute ‘pension’ {‘none’,'ret_allw’,'empl_contr’}
@attribute ’standby-pay’ real
@attribute ’shift-differential’ real
@attribute ‘education-allowance’ {‘yes’,'no’}
@attribute ’statutory-holidays’ real
@attribute ‘vacation’ {‘below_average’,'average’,'generous’}
@attribute ‘longterm-disability-assistance’ {‘yes’,'no’}
@attribute ‘contribution-to-dental-plan’ {‘none’,'half’,'full’}
@attribute ‘bereavement-assistance’ {‘yes’,'no’}
@attribute ‘contribution-to-health-plan’ {‘none’,'half’,'full’}
@attribute ‘class’ {‘bad’,'good’}
@data
1,5,?,?,?,40,?,?,2,?,11,’average’,?,?,’yes’,?,’good’
2,4.5,5.8,?,?,35,’ret_allw’,?,?,’yes’,11,’below_average’,?,’full’,?,’full’,'good’
?,?,?,?,?,38,’empl_contr’,?,5,?,11,’generous’,'yes’,'half’,'yes’,'half’,'good’
3,3.7,4,5,’tc’,?,?,?,?,’yes’,?,?,?,?,’yes’,?,’good’
3,4.5,4.5,5,?,40,?,?,?,?,12,’average’,?,’half’,'yes’,'half’,'good’
2,2,2.5,?,?,35,?,?,6,’yes’,12,’average’,?,?,?,?,’good’
3,4,5,5,’tc’,?,’empl_contr’,?,?,?,12,’generous’,'yes’,'none’,'yes’,'half’,'good’
3,6.9,4.8,2.3,?,40,?,?,3,?,12,’below_average’,?,?,?,?,’good’
2,3,7,?,?,38,?,12,25,’yes’,11,’below_average’,'yes’,'half’,'yes’,?,’good’
1,5.7,?,?,’none’,40,’empl_contr’,?,4,?,11,’generous’,'yes’,'full’,?,?,’good’
3,3.5,4,4.6,’none’,36,?,?,3,?,13,’generous’,?,?,’yes’,'full’,'good’
2,6.4,6.4,?,?,38,?,?,4,?,15,?,?,’full’,?,?,’good’
2,3.5,4,?,’none’,40,?,?,2,’no’,10,’below_average’,'no’,'half’,?,’half’,'bad’
这个例子来自于weka安装目录data文件下的labor.arff文件,来源于加拿大劳资谈判的案例,它根据工人的个人信息,来预测劳资谈判的最终结果。
文件中,“%”开头的是注释。剩余的可以分为两大部分,头信息(header information)和数据信息(data information)。
头信息中,“@relation”开头的行代表关系名称,在整个文件的第一行(除去注释)。格式是
@relation <relation-name>
“@attribute”开头的代表特征,格式是
@attribute <attribute-name> <datatype>
attribute-name是特征的名称,后面是数据类型,常用数据类型有以下几种
1)numeric,数字类型,包括integer(整数)和real(实数)
2)nominal,可以认为是枚举类型,即特征值是有限的集合,可以是字符串或数字。
3)string,字符串类型,值可以是任意的字符串。
从“@data”开始,是实际的数据部分。每一行代表一个实例,可以认为是一个特征向量。各个特征的顺序与头信息中的attribute逐个对应,特征值之间用逗号分割。在有监督分类中,最后一列是标注的结果。
某些特征的数值如果是缺失的,可以用“?”代替。
数据挖掘流程
使用weka进行数据挖掘的流程如下图

图4.1 数据挖掘流程图
其中,在weka内进行的是数据预处理,训练,验证这三个步骤。
1)数据预处理
数据预处理包括特征选择,特征值处理(比如归一化),样本选择等操作。
2)训练
训练包括算法选择,参数调整,模型训练。
3)验证
对模型结果进行验证。
本文剩余部分将以这个流程为主线,以分类为示例,介绍使用weka进行数据挖掘的步骤。
5. 数据预处理
打开Explorer界面,点“open file”,在weka安装目录下,选择data目录里的“labor.arff”文件,将会看到如下界面。我们将整个区域分为7部分,下面将分别介绍每部分的功能。
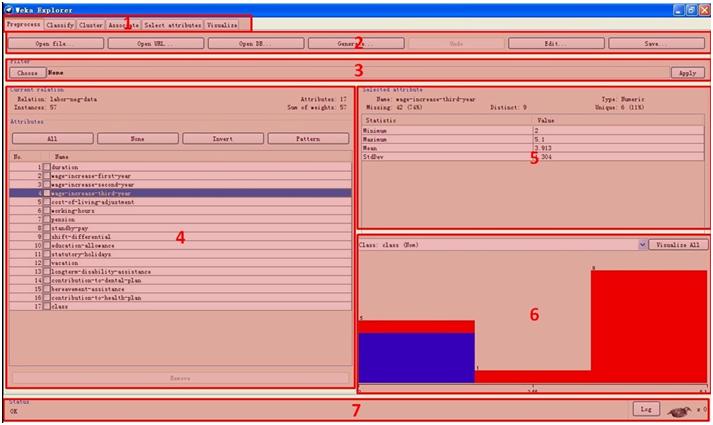
图5.1 Explorer界面
1)区域1共6个选项卡,用来选择不同的数据挖掘功能面板,从左到右依次是Preprocess(预处理)、Classify(分类)、Cluster(聚类)、Associate(关联规则)、Select attribute(特征选择)和Visualize(可视化)。
2)区域2提供了打开、保存,编辑文件的功能。打开文件不仅仅可以直接从本地选择,还可以使用url和db来做数据源。Generate按钮提供了数据生成的功能,weka提供了几种生成数据的方法。点开Edit,将看到如下界面

图5.2 arff viewer
在这个界面,可以看到各行各列对应的值,右键每一列的名字,可以看到一些编辑数据的功能,这些功能还是比较实用的。
3)区域3名为Filter,有些人可能会联想到特征选择里面的Filter方法,事实上,Filter针对特征(attribute)和样本(instance)提供了大量的操作方法,功能十分强大。
4)在区域4,可以看到当前的特征、样本信息,并提供了特征选择和删除的功能。
5)在区域4用鼠标选择单个特征后,区域5将显示该特征的信息。包括最小值、最大值、期望和标准差。
6)区域6提供了可视化功能,选择特征后,该区域将显示特征值在各个区间的分布情况,不同的类别标签以不同的颜色显示。
7)区域7是状态栏,没有任务时,小鸟是坐着的,任务运行时,小鸟会站起来左右摇摆。如果小鸟站着但不转动,表示任务出了问题。
下面将通过实例介绍Filters的各项功能。
点开Filter下面的choose按钮,可以看到如下界面
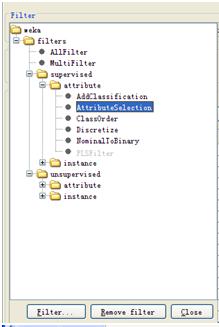
图5.3 filter方法选择界面
Filters可分为两大类,supervised和unsupervised。supervised下的方法需要类别标签,而unsupervised则不需要。attribute类别表示对特征做筛选,instance表示对样本做选择。
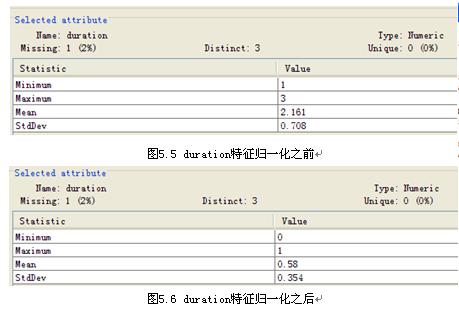
1)case 1:特征值归一化
该项功能与类别无关,且是针对attribute的,我们选择unsupervised -> attribute下面的Normalize。点开Normalize所在的区域,将看到如下界面。左边的窗口,有几个参数可以选择。点击more,将出现右边的窗口,该窗口详细介绍了此功能。
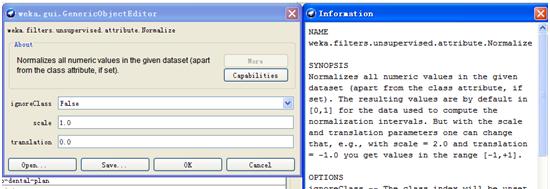
图5.4 归一化参数设置界面
使用默认参数,点击ok,回到主窗口。在区域4选好将要归一化的特征,可以是一个或多个,然后点击apply。在可视化区域中,我们可以看到特征值从1到3被归一到了0到1之间。
2)case 2: 分类器特征筛选
该功能与类别相关,选择supervised -> attribute下面的AttributeSelection。该界面有两个选项,evaluator是评价特征集合有效性的方法,search是特征集合搜索的方法。在这里,我们使用InformationGainAttributeEval作为evaluator,使用Ranker作为search,表示我们将根据特征的信息增益值对特征做排序。Ranker中可以设置阈值,低于这个阈值的特征将被扔掉。
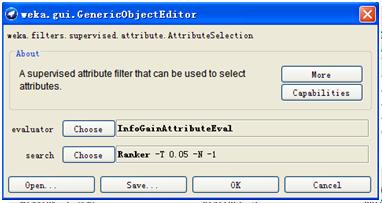
图5.7 特征选择参数
点击apply,可以看到在区域4里特征被重新排序,低于阈值的已被删掉
3)case 3:选择分类器错分的样本
选择unsupervised -> instance下面的RemoveMisclassified,可以看到6个参数,classIndex用来设置类别标签,classifier用来选择分类器,这里我们选择J48决策树,invert我们选择true,这样保留的是错分样本,numFolds用来设置交叉验证的参数。设置好参数之后,点击apply,可以看到样本的数量从57减少到了7。
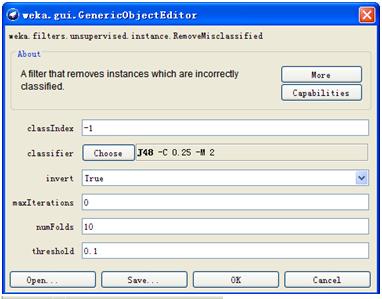
图5.10 参数设置
6. 分类
在Explorer中,打开classifer选项卡,整个界面被分成几个区域。分别是
1)Classifier
点击choose按钮,可以选择weka提供的分类器。常用的分类器有
a)bayes下的Na?ve Bayes(朴素贝叶斯)和BayesNet(贝叶斯信念网络)。
b)functions下的LibLinear、LibSVM(这两个需要安装扩展包)、Logistic Regression、Linear Regression。
c)lazy下的IB1(1-NN)和IBK(KNN)。
d)meta下的很多boosting和bagging分类器,比如AdaBoostM1。
e)trees下的J48(weka版的C4.5)、RandomForest。
2)Test options
评价模型效果的方法,有四个选项。
a)Use training set:使用训练集,即训练集和测试集使用同一份数据,一般不使用这种方法。
b)Supplied test set:设置测试集,可以使用本地文件或者url,测试文件的格式需要跟训练文件格式一致。
c)Cross-validation:交叉验证,很常见的验证方法。N-folds cross-validation是指,将训练集分为N份,使用N-1份做训练,使用1份做测试,如此循环N次,最后整体计算结果。
d)Percentage split:按照一定比例,将训练集分为两份,一份做训练,一份做测试。
在这些验证方法的下面,有一个More options选项,可以设置一些模型输出,模型验证的参数。
3)Result list
这个区域保存分类实验的历史,右键点击记录,可以看到很多选项。常用的有保存或加载模型以及可视化的一些选项。
4)Classifier output
分类器的输出结果,默认的输出选项有Run information,该项给出了特征、样本及模型验证的一些概要信息;Classifier model,给出的是模型的一些参数,不同的分类器给出的信息不同。最下面是模型验证的结果,给出了 一些常用的一些验证标准的结果,比如准确率(Precision),召回率(Recall),真阳性率(True positive rate),假阳性率(False positive rate),F值(F-Measure),Roc面积(Roc Area)等。Confusion Matrix给出了测试样本的分类情况,通过它,可以很方便地看出正确分类或错误分类的某一类样本的数量。
Case 1:使用J48对labor文件做分类
1)打开labor.arff文件,切换到classify面板。
2)选择trees->J48分类器,使用默认参数。
3)Test options选择默认的十折交叉验证,点开More options,勾选Output predictions。
4)点击start按钮,启动实验。
5)在右侧的Classifier output里面,我们看到了实验的结果。

图6.1 Run information
上图给出了实验用的分类器以及具体参数,实验名称,样本数量,特征数量以及所用特征,测试模式。

图6.2 模型信息
上图给出了生成的决策树,以及叶子节点数、树的节点数、模型训练时间。如果觉得这样不直观,可以在Result list里面右键点击刚刚进行的实验,点击Visualize Tree,可以看到图形界面的决策树,十分直观。
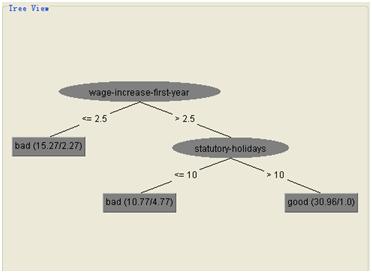
图6.3 决策树
再往下是预测结果,可以看到每个样本的实际分类,预测分类,是否错分,预测概率这些信息。
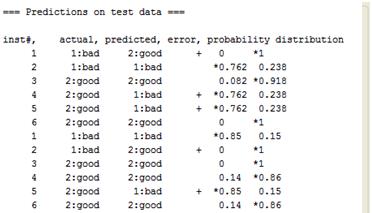
图6.4 预测结果
最下面是验证结果,整体的accuracy是73.68%,bad类准确率是60.9%,召回率70.0%,good类准确率是82.4%,召回率75.7%。
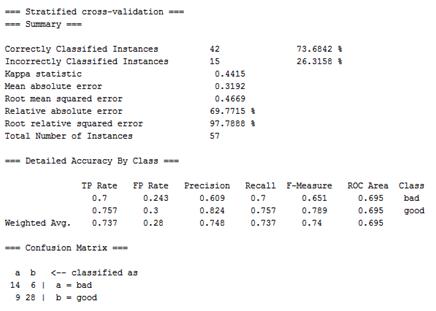
图6.5 模型效果评估结果
7. 可视化
打开Explorer的Visualize面板,可以看到最上面是一个二维的图形矩阵,该矩阵的行和列均为所有的特征(包括类别标签),第i行第j列表示特征i和特征j在二维平面上的分布情况。图形上的每个点表示一个样本,不同的类别使用不同的颜色标识。
下面有几个选项,PlotSize可以调整图形的大小,PointSize可以调整样本点的大小,Jitter可以调整点之间的距离,有些时候点过于集中,可以通过调整Jitter将它们分散开。
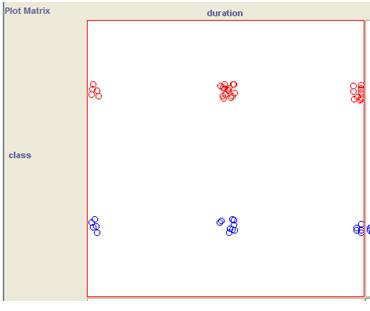
图7.1 plot matrix二维图
上图是duration和class两个特征的图形,可以看出,duration并不是一个好特征,在各个特征值区间,good和bad的分布差不多。
单击某个区域的图形,会弹出另外一个窗口,这个窗口给出的也是某两个特征之间分布的图形,不同的是,在这里,通过点击样本点,可以弹出样本的详细信息。
可视化还可以用来查看误分的样本,这是非常实用的一个功能。分类结束后,在Result list里右键点击分类的记录,选择Visualize classify errors,会弹出如下窗口。
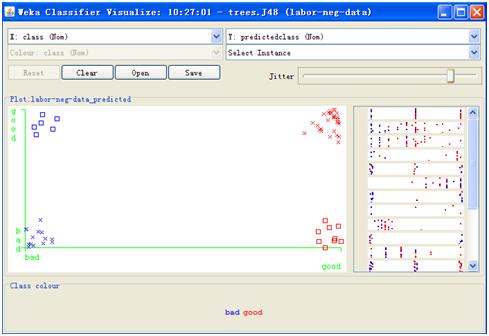
图7.2 误分样本可视化
这个窗口里面,十字表示分类正确的样本,方块表示分类错误的样本,X轴为实际类别,Y轴为预测类别,蓝色为实际的bad,红色为实际的good。这样,蓝色方块就表示实际为bad,但为误分为good的样本,红色方块表示实际为good,被误分为bad的样本。单击这些点,便可以看到该样本的各个特征值,分析为什么这个样本被误分了。
再介绍一个比较实用的功能,右键点击Result list里的记录,选择Visualize threshold curve,然后选好类别,可以看到如下图形
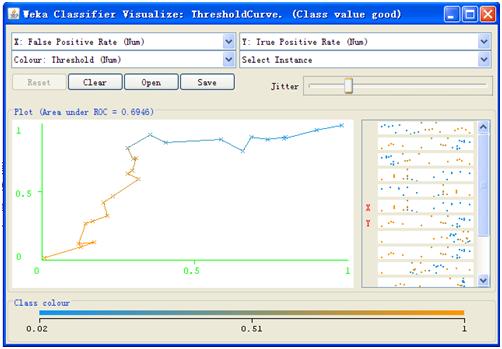
图7.3 阈值曲线
该图给出的是分类置信度在不同阈值下,分类效果评价标准的对比情况。上图给出的是假阳性比率和真阳性比率在不同阈值下的对比,其实给出的就是ROC曲线。我们可以通过选择颜色,方便地观察不同评价标准的分布情况。如果X轴和Y轴选择的是准确率和召回率,那我们可以通过这个图,在这两个值之间做trade-off,选择一个合适的阈值。
其它的一些可视化功能,不再一一介绍。
8. 小结
本文仅仅针对weka的Explorer界面的某些功能做了介绍,Explorer其它的功能,比如聚类、关联规则、特征选择,以及Experimentor和KnowledgeFlow界面使用,可以参考weka的官方文档。
另外,weka支持扩展包,可以很方便地把liblinear、libsvm这样的开源工具放进来。
在Linux下面,可以使用weka的命令行进行实验,具体的使用方法,也请参考weka官方文档。
有这样一款开源、免费、强大的数据挖掘工具,你还在等什么呢?没有用过weka的数据挖掘工程师们,赶紧行动吧。
| 

