|
Spark 1.2在MLlib中引入了随机森林和梯度提升树(GBTs).这两种机器学习方法适用于分类和回归,且是在机器学习算法中应用得最多和最成功的算法。随机森林和GBTs都是集成学习算法,它们通过集成多棵决策树来实现强分类器。这篇博文中,我们会阐述这些模型及其他们在MLlib中的分布式实现。我们也给出一些简单例子和要点以便你知道如何上手。
集成学习方法
简单来说,集成学习方法就是基于其他的机器学习算法,并把它们有效的组合起来的一种机器学习算法。组合产生的算法相比其中任何一种算法模型更强大、准确。
在MLlib 1.2中,我们使用决策树作为基础模型。我们提供两种集成算法:随机森林和梯度提升树(GBTs)。两者之间主要差别在于每棵树训练的顺序。
随机森林通过对数据随机采样来单独训练每一棵树。这种随机性也使得模型相对于单决策树更健壮,且不易在训练集上产生过拟合。
GBTs则一次只训练一棵树,后面每一棵新的决策树逐步矫正前面决策树产生的误差。随着树的添加,模型的表达力也愈强。
最后,两种方法都生成了一个决策树的权重集合。该集成模型通过组合每棵独立树的结果来进行预测。下图显示一个由3棵决策树集成的简单实例。
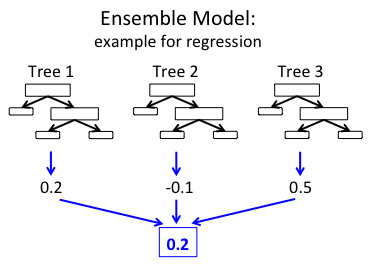
在上述例子的回归集合中,每棵树都预测出一个实值。这些预测值被组合起来产生最终集成的预测结果。这里,我们通过取均值的方法来取得最终的预测结果(当然不同的预测任务需要用到不同的组合算法)。
集成学习的分布式学习算法
在MLlib中,随机森林和GBTs的数据都是按实例(行)存储的。算法的实现以原始的决策树代码为基础,每棵决策树采用分布式学习(早前的博客中有提到)。我们的许多算法优化都是参考Google’s
PLANET project,特别是其中一篇关于分布式环境下的集成学习的文章。
随机森林:随机森林中的每棵树都是单独训练,多棵树可以并行训练(除此之外,单独的每棵树的训练也可以并行化)。MLlib也确实是这么做的:根据当前迭代内存的限制条件,动态调整可并行训练的子树的数量。
GBTs:因为GBTs只能一次训练一棵树,因此并行训练的粒度也只能到单棵树。
我们在这里强调一下MLlib中用到的两项重要的优化技术
1.内存:随机森林使用一个不同的样本数据训练每一棵树。我们利用TreePoint这种数据结构来存储每个子采样的数据,替代直接复制每份子采样数据的方法,进而节省了内存。
2.通信:尽管决策树经常通过选择树中每个决策点的所有功能进行训练,但随机森林则往往在每一个节点限制选择一个随机子集。MLlib的实现中就充分利用了这个子采样特点来减少通信:例如,若每个节点值用到1/3的特征,那么我们就会减少1/3的通信。
详细部分请见MLlib编程指南的集成章节。
使用MLlib集成学习
我们将演示如何使用MLlib进行学习集成模型。下面的Scala例子说明了怎么读取数据集,将数据集分割为训练集和测试集,学习一个模型以及打印出模型及其测试精度。Java和Pyton的例子请参阅MLlib编程指南。需要注意的是GBTs暂时还没有Python接口,但是我们期望Spark1.3发布版中会包含。(via
Github PR 3951)
随机森林例子
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.configuration.Strategy
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data =
MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training/test sets
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a RandomForest model.
val treeStrategy = Strategy.defaultStrategy("Classification")
val numTrees = 3 // Use more in practice.
val featureSubsetStrategy = "auto" // Let the algorithm choose.
val model = RandomForest.trainClassifier(trainingData,
treeStrategy, numTrees, featureSubsetStrategy, seed = 12345)
// Evaluate model on test instances and compute test error
val testErr = testData.map { point =>
val prediction = model.predict(point.features)
if (point.label == prediction) 1.0 else 0.0
}.mean()
println("Test Error = " + testErr)
println("Learned Random Forest:n" + model.toDebugString) |
GBTs例子
import org.apache.spark.mllib.tree.GradientBoostedTrees
import org.apache.spark.mllib.tree.configuration.BoostingStrategy
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data =
MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training/test sets
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a GradientBoostedTrees model.
val boostingStrategy =
BoostingStrategy.defaultParams("Classification")
boostingStrategy.numIterations = 3 // Note: Use more in practice
val model =
GradientBoostedTrees.train(trainingData, boostingStrategy)
// Evaluate model on test instances and compute test error
val testErr = testData.map { point =>
val prediction = model.predict(point.features)
if (point.label == prediction) 1.0 else 0.0
}.mean()
println("Test Error = " + testErr)
println("Learned GBT model:n" + model.toDebugString) |
Scalability 扩展性
通过二分类问题的实证结果,我们证明了MLlib的扩展性。以下的各张图表分别对GBTs和随机森林的特性进行比较,其中每棵树都有不同的最大深度。
这些测试是一个回归的任务,即从音频特征从预测出歌曲的发布日期(YearPredictionMSD数据集来自UCI
ML repository)。我们使用EC2 r3.2xlarge机器,算法的参数除非特别说明都使用默认值。
模型大小的伸缩:训练时间和测试误差
下面的两张图表显示了增加树的数量对集成效果的影响。对于GBTs和随机森林这两者而言,增加树的数量都会增加训练的时间(第一张图所示),同时树的数量增加也提高了预测精度(以测试的平均均方误差为衡量标准,图二所示)。
两者相比,随机森林训练的时间更短,但是要达到和GBTs同样的预测精度则需要更深的树。GBTs则能在每次迭代时显著地减少误差,但是经过过多的迭代,它又太容易过拟合(增加了测试误差)。随机森林则不太容易过拟合,测试误差也趋于稳定。
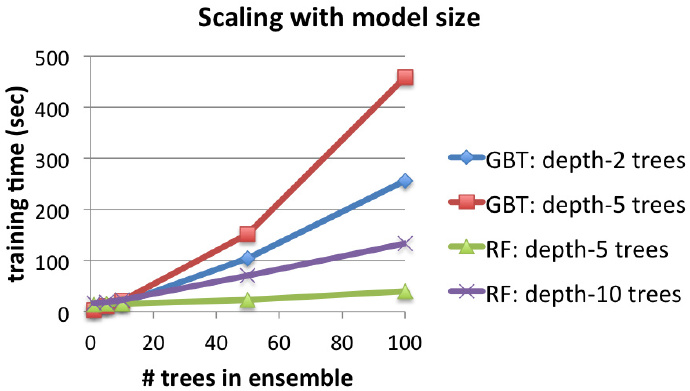
下面为均方误差随单棵决策树深度(深度分别为2,5,10)变化曲线图。
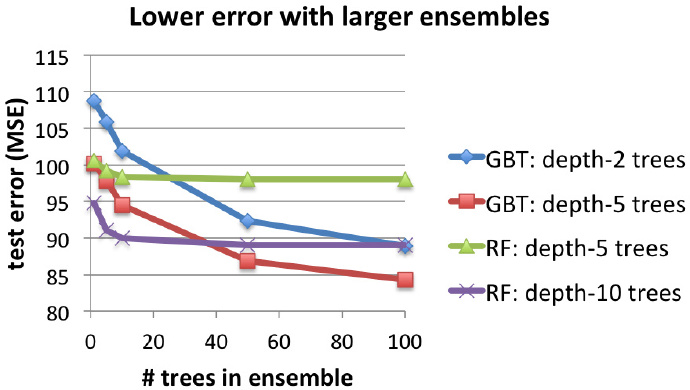
说明:463,715 个训练实例. 16个节点。
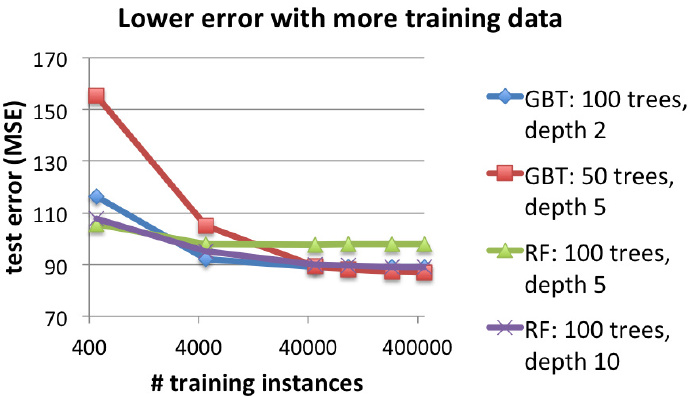
训练集的伸缩:训练时间和测试误差
下面两张图表显示了使用不同的训练集对算法结果产生的影响。图表表明,虽然数据集越大,两种方法的训练时间更长,但是却能产生更好的测试结果。
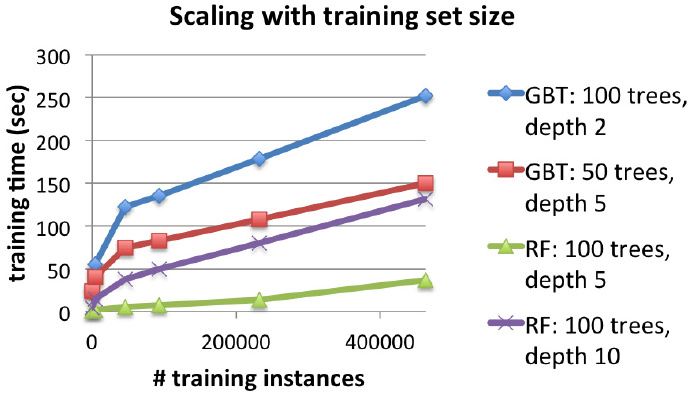
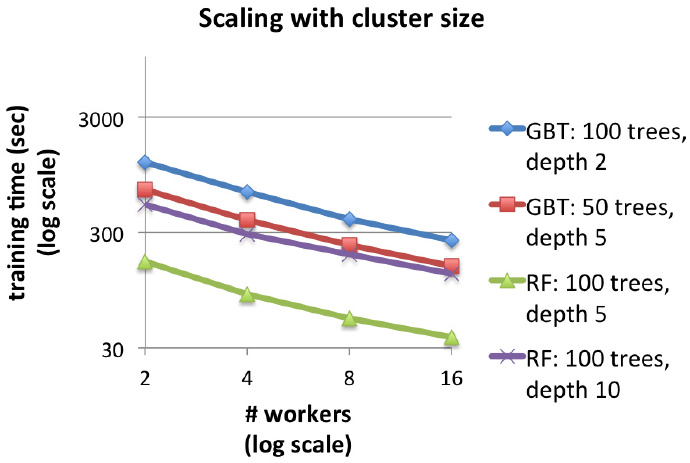
进一步伸缩:更多的节点,更快的训练速度
最后一张图表展示了使用更大的计算机集群来解决上述问题的效果,结论是GBTs和随机森林在大集群上速度得到显著提升。例如说,单树深度为2的GBTs在16个节点上的训练速度大约是在2个节点上的4.7倍。数据集越大则效果提升的越明显。
展望
GBTs不久就会提供Python的API。未来的另一个开发议题就是可插入性:集成方法不仅仅可以集成决策树,它可以集成几乎所有的分类和回归算法。在Spark
1.2中,处于实验中的spark.ml包中引入的Pipelines API将使得集成方法通用化,并做到真正的可插入。
进一步了解
API和相关例子详见MLlib集成学习文档。
要想了解更多用于构建集合的决策树相关背景知识,详见之前的博客。
致谢 MLlib集成算法由本博客的作者们合作开发完成,他们是Qiping Li (Alibaba),
Sung Chung (Alpine Data Labs), and Davies Liu (Databricks).我们也感谢Lee
Yang, Andrew Feng, and Hirakendu Das (Yahoo) ,他们帮助设计与测试。我们也欢迎你来贡献一份力量!
| 




