| БрМЭЦМі: |
| БОЮФРДздгкЪ§ОнгыЫуЗЈжЎУРЃЌЮФжаНВНтСЫЫбЫїв§ЧцЕФКЫаФФбЬтЃЌЭЌЪБЬжТлдчЦкЫбЫїв§ЧцЙигкНсЙћвГУцживЊадЦРМлЫуЗЈЕФРЇОГЃЌНшДЫв§ГіPageRankВњЩњЕФБГОАЁЃ |
|
1 ЫбЫїв§ЧцЕФФбЬт
GoogleдчвбГЩЮЊШЋЧђзюГЩЙІЕФЛЅСЊЭјЫбЫїв§ЧцЃЌЕЋетИіЕБЧАЕФЫбЫїв§ЧцОоЮоАдШДВЛЪЧзюдчЕФЛЅСЊЭјЫбЫїв§ЧцЃЌдкGoogleГіЯжжЎЧАЃЌдјГіЯжЙ§аэЖрЭЈгУЛђзЈвЕСьгђЫбЫїв§ЧцЁЃGoogleзюжеФмЛїАмЫљгаОКељЖдЪжЃЌКмДѓГЬЖШЩЯЪЧвђЮЊЫќНтОіСЫРЇШХЧАБВУЧЕФзюДѓФбЬтЃКЖдЫбЫїНсЙћАДживЊадХХађЁЃЖјНтОіетИіЮЪЬтЕФЫуЗЈОЭЪЧPageRankЁЃКСВЛПфеХЕФЫЕЃЌЪЧPageRankЫуЗЈГЩОЭСЫGoogleНёЬьЕФЕЭЮЛЁЃвЊРэНтЮЊЪВУДНтОіетИіФбЬтШчДЫживЊЃЌЮвУЧЯШРДПДвЛЯТЫбЫїв§ЧцЕФКЫаФПђМмЁЃ
2 ЫбЫїв§ЧцЕФКЫаФПђМм
ЫфШЛЫбЫїв§ЧцвбОЗЂеЙСЫКмЖрФъЃЌЕЋЪЧЦфКЫаФШДУЛгаЬЋДѓБфЛЏЁЃДгБОжЪЩЯЫЕЃЌЫбЫїв§ЧцЪЧвЛИізЪСЯМьЫїЯЕЭГЃЌЫбЫїв§ЧцгЕгавЛИізЪСЯПтЃЈОпЬхЕНетРяОЭЪЧЛЅСЊЭјвГУцЃЉЃЌгУЛЇЬсНЛвЛИіМьЫїЬѕМўЃЈР§ШчЙиМќДЪЃЉЃЌЫбЫїв§ЧцЗЕЛиЗћКЯВщбЏЬѕМўЕФзЪСЯСаБэЁЃРэТлЩЯМьЫїЬѕМўПЩвдЗЧГЃИДдгЃЌЮЊСЫМђЕЅЦ№МћЃЌЮвУЧВЛЗСЩшМьЫїЬѕМўЪЧвЛжСЖрИівдПеИёЗжИєЕФДЪЃЌЖјЦфБэДяЕФгявхЪЧЭЌЪБКЌгаетаЉДЪЕФзЪСЯЃЈЕШМлгкВМЖћДњЪ§ЕФТпМгыЃЉЁЃР§ШчЃЌЬсНЛЁАеХбѓ
ВЉПЭЁБЃЌвтЫМОЭЪЧЁАИјЮвМШКЌгаЁЎеХбѓЁЏгжКЌгаЁЎВЉПЭЁЏДЪгяЕФвГУцЁБЃЌвдЯТЪЧGoogleЖдетЬѕЙиМќДЪЕФЫбЫїНсЙћЃК

ПЩвдПДЕНЮвЕФВЉПЭГіЯждкЕкЮхЬѕЃЌЖјЕкЫФЬѕЪЧЮвжЎЧАдкВЉПЭдАЕФВЉПЭЁЃ
ЕБШЛЃЌЪЕМЪЩЯЯждкЕФЫбЫїв§ЧцЖМЪЧгаЗжДЪЛњжЦЕФЃЌР§ШчШчЙћвдЁАеХбѓЕФВЉПЭЁБЮЊЙиМќДЪЃЌЫбЫїв§ЧцЛсздЖЏНЋЦфЗжНтЮЊЁАеХбѓ
ЕФ ВЉПЭЁБШ§ИіДЪЃЌЖјЁАЕФЁБзїЮЊЭЃжЙДЪЃЈStop WordЃЉЛсБЛЙ§ТЫЕєЁЃЙигкЗжДЪМАДЪШЈЦРМлЫуЗЈЃЈШчTF-IDFЫуЗЈЃЉЪЧвЛИіКмДѓЕФЛАЬтЃЌетРяОЭВЛеЙПЊЬжТлСЫЃЌЮЊСЫМђЕЅДЫДІПЩвдНЋЫбЫїв§ЧцЯыЯѓЮЊвЛИіжЛЛсЛњаЕЦЅХфДЪгяЕФМьЫїЯЕЭГЁЃ
етбљПДРДЃЌНЈСЂвЛИіЫбЫїв§ЧцЕФКЫаФЮЪЬтОЭЪЧСНИіЃК1ЁЂНЈСЂзЪСЯПтЃЛ2ЁЂНЈСЂвЛжжЪ§ОнНсЙЙЃЌПЩвдИљОнЙиМќДЪевЕНКЌгаетИіДЪЕФвГУцЁЃ
ЕквЛИіЮЪЬтвЛАуЪЧЭЈЙ§вЛжжНаХРГцЃЈSpiderЃЉЕФЬиЪтГЬађЪЕЯжЕФЃЈЕБШЛЃЌзЈвЕСьгђЫбЫїв§ЧцР§ШчФГИібЇЪѕЛсвщЕФТлЮФМьЫїЯЕЭГПЩФмжБНгДгЪ§ОнПтНЈСЂзЪСЯПтЃЉЃЌМђЕЅРДЫЕЃЌХРГцОЭЪЧДгвЛИівГУцГіЗЂЃЈР§ШчаТРЫЪзвГЃЉЃЌЭЈЙ§HTTPавщЭЈаХЛёШЁетИівГУцЕФЫљгаФкШнЃЌАбетИівГУцurlКЭФкШнМЧТМЯТРДЃЈМЧТМЕНзЪСЯПтЃЉЃЌШЛКѓЗжЮівГУцжаЕФСДНгЃЌдйШЅЗжБ№ЛёШЁетаЉСДНгСДЯђвГУцЕФФкШнЃЌМЧТМЕНзЪСЯПтКѓдйЗжЮіетИівГУцЕФСДНгЁЁжиИДетИіЙ§ГЬЃЌОЭПЩвдНЋећИіЛЅСЊЭјЕФвГУцШЋВПЛёШЁЯТРДЃЈЕБШЛетЪЧРэЯыЧщПіЃЌвЊЧѓећИіWebЪЧвЛИіЧПСЌЭЈЃЈStrongly
ConnectedЃЉЃЌВЂЧвЫљгавГУцЕФrobotsавщдЪаэХРГцзЅШЁвГУцЃЌЮЊСЫМђЕЅЃЌЮвУЧШдШЛМйЩшWebЪЧвЛИіЧПСЌЭЈЭМЃЌЧвВЛПМТЧrobotsавщЃЉЁЃГщЯѓРДПДЃЌПЩвдНЋзЪСЯПтПДзівЛИіОоДѓЕФkey-valueНсЙЙЃЌkeyЪЧвГУцurlЃЌvalueЪЧвГУцФкШнЁЃ
ЕкЖўИіЮЪЬтЪЧЭЈЙ§вЛжжНаЕЙХХЫїв§ЃЈinverted indexЃЉЕФЪ§ОнНсЙЙЪЕЯжЕФЃЌГщЯѓРДЫЕЕЙХХЫїв§вВЪЧвЛзщkey-valueНсЙЙЃЌkeyЪЧЙиМќДЪЃЌvalueЪЧвЛИівГУцБрКХМЏКЯЃЈМйЩшзЪСЯПтжаУПИівГУцгаЮЈвЛБрКХЃЉЃЌБэЪОетаЉвГУцКЌгаетИіЙиМќДЪЁЃБОЮФВЛЯъЯИЬжТлЕЙХХЫїв§ЕФНЈСЂЗНЗЈЁЃ
гаСЫЩЯУцЕФЗжЮіЃЌОЭПЩвдМђвЊЫЕУїЫбЫїв§ЧцЕФКЫаФЖЏзїСЫЃКЫбЫїв§ЧцЛёШЁЁАеХбѓ ВЉПЭЁБВщбЏЬѕМўЃЌНЋЦфЗжЮЊЁАеХбѓЁБКЭЁАВЉПЭЁБСНИіДЪЁЃШЛКѓЗжБ№ДгЕЙХХЫїв§жаевЕНЁАеХбѓЁБЫљЖдгІЕФМЏКЯЃЌМйЩшЪЧ{1ЃЌ
3ЃЌ 6ЃЌ 8ЃЌ 11ЃЌ 15}ЃЛЁАВЉПЭЁБЖдгІЕФМЏКЯЪЧ{1ЃЌ 6ЃЌ 10ЃЌ 11ЃЌ 12ЃЌ 17ЃЌ
20ЃЌ 22}ЃЌНЋСНИіМЏКЯзіНЛдЫЫуЃЈintersectionЃЉЃЌНсЙћЪЧ{1ЃЌ 6ЃЌ 11}ЁЃзюКѓЃЌДгзЪСЯПтжаевГі1ЁЂ6ЁЂ11ЖдгІЕФвГУцЗЕЛиИјгУЛЇОЭПЩвдСЫЁЃ
3 ЫбЫїв§ЧцЕФКЫаФФбЬт
ЩЯУцВћЪіСЫвЛИіЗЧГЃМђЕЅЕФЫбЫїв§ЧцЙЄзїПђМмЃЌЫфШЛЯжДњЫбЫїв§ЧцЕФОпЬхЯИНкдРэвЊИДдгЕФЖрЃЌЕЋЦфБОжЪШДгыетИіМђЕЅЕФФЃаЭВЂЮоЖўвьЁЃЪЕМЪGoogleдкЩЯЪіСНЕуЩЯЯрБШЦфЧАБВВЂЮоИпУїжЎДІЁЃЦфзюДѓЕФГЩЙІЪЧНтОіСЫЕкШ§ИіЁЂвВЪЧзюЮЊРЇФбЕФЮЪЬтЃКШчКЮЖдВщбЏНсЙћХХађЁЃ
ЮвУЧжЊЕРWebвГУцЪ§СПЗЧГЃОоДѓЃЌЫљвдвЛИіМьЫїЕФНсЙћЬѕФПЪ§СПвВЗЧГЃЖрЃЌР§ШчЩЯУцЁАеХбѓ ВЉПЭЁБЕФМьЫїЗЕЛиСЫГЌЙ§260ЭђЬѕНсЙћЁЃгУЛЇВЛПЩФмДгШчДЫжкЖрЕФНсЙћжавЛвЛВщевЖдздМКгагУЕФаХЯЂЃЌЫљвдЃЌвЛИіКУЕФЫбЫїв§ЧцБиаыЯыАьЗЈНЋЁАжЪСПЁБНЯИпЕФвГУцХХдкЧАУцЁЃЦфЪЕжБЙлЩЯвВПЩвдИаОѕГіЃЌдкЪЙгУЫбЫїв§ЧцЪБЃЌЮвУЧВЂВЛЬЋЙиаФвГУцЪЧЗёЙЛШЋЃЈЩЯАйЭђЕФНсЙћЃЌШЋВЛШЋгаЪВУДЧјБ№ЃПЖјЧвЪЕМЪЩЯЫбЫїв§ЧцЖМЪЧШЁtopЃЌВЂВЛЛсецЕФЗЕЛиШЋВПНсЙћЁЃЃЉЃЌЖјКмЙиаФЧАвЛСНвГЪЧЗёЖМЪЧжЪСПНЯИпЕФвГУцЃЌЪЧЗёФмТњзуЮвУЧЕФЪЕМЪашЧѓЁЃ
вђДЫЃЌЖдЫбЫїНсЙћАДживЊадКЯРэЕФХХађОЭГЩЮЊЫбЫїв§ЧцЕФзюДѓКЫаФЃЌвВЪЧGoogleзюжеГЩЙІЕФЭЛЦЦЕуЁЃ
4 дчЦкЫбЫїв§ЧцЕФзіЗЈ
ВЛЦРМл
етИіПДЦ№РДПЩФмгаЕуИуаІЃЌЕЋЪЕМЪЩЯдчЦкКмЖрЫбЫїв§ЧцЃЈЩѕжСАќРЈЯждкЕФКмЖрзЈвЕСьгђЫбЫїв§ЧцЃЉИљБОВЛЦРМлНсЙћживЊадЃЌЖјЪЧжБНгАДееФГздШЛЫГађЃЈР§ШчЪБМфЫГађЛђБрКХЫГађЃЉЗЕЛиНсЙћЁЃетдкНсЙћМЏБШНЯЩйЕФЧщПіЯТЛЙЫЕЕУЙ§ШЅЃЌЕЋЪЧвЛЕЉНсЙћМЏБфДѓЃЌгУЛЇНаПрВЛЕќЃЌЪдЯыШУФуДгМИЭђЬѕжЪСПВЮВюВЛЦыЕФвГУцжабАевашвЊЕФФкШнЃЌМђжБОЭЪЧвЛГЁджФбЃЌетвВзЂЖЈетжжЗНЗЈВЛПЩФмгУгкЯжДњЕФЭЈгУЫбЫїв§ЧцЁЃ
ЛљгкМьЫїДЪЕФЦРМл
КѓРДЃЌвЛаЉЫбЫїв§Чцв§ШыСЫЛљгкМьЫїЙиМќДЪШЅЦРМлЫбЫїНсЙЙживЊадЕФЗНЗЈЃЌЪЕМЪЩЯЃЌетРрЗНЗЈШчTF-IDFЫуЗЈдкЯжДњЫбЫїв§ЧцжаШддкЪЙгУЃЌЕЋЦфвбОВЛЪЧЦРМлжЪСПЕФЮЈвЛжИБъЁЃЭъећУшЪіTF-IDFБШНЯЗБЫіЃЌБОЮФетРягУвЛжжИќМђЕЅЕФГщЯѓФЃаЭУшЪіетжжЗНЗЈЁЃ
ЛљгкМьЫїДЪЦРМлЕФЫМЯыЗЧГЃЦгЫиЃККЭМьЫїДЪЦЅХфЖШдНИпЕФвГУцживЊаддНИпЁЃЁАЦЅХфЖШЁБОЭЪЧвЊЖЈвхЕФОпЬхЖШСПЁЃвЛИізюжБНгЕФЯыЗЈЪЧЙиМќДЪГіЯжДЮЪ§дНЖрЕФвГУцЦЅХфЖШдНИпЁЃЛЙЪЧЫбЫїЁАеХбѓ
ВЉПЭЁБЕФР§згЃКМйЩшAвГУцГіЯжЁАеХбѓЁБ5ДЮЃЌЁАВЉПЭЁБ10ДЮЃЛBвГУцГіЯжЁАеХбѓЁБ2ДЮЃЌЁАВЉПЭЁБ8ДЮЁЃгкЪЧAвГУцЕФЦЅХфЖШЮЊ5
+ 10 = 15ЃЌBвГУцЮЊ2 + 8 = 10ЃЌгкЪЧШЯЮЊAвГУцЕФживЊадИпгкBвГУцЁЃКмЖрХѓгбПЩФмвтЪЖЕНетРяЕФВЛКЯРэадЃКФкШнНЯГЄЕФЭјвГЭљЭљИќПЩФмБШФкШнНЯЖЬЕФЭјвГЙиМќДЪГіЯжЕФДЮЪ§ЖрЁЃвђДЫЃЌЮвУЧПЩвдаоИФвЛЯТЫуЗЈЃЌгУЙиМќДЪГіЯжДЮЪ§Г§вдвГУцзмДЪЪ§ЃЌвВОЭЪЧЭЈЙ§ЙиМќДЪеМБШзїЮЊЦЅХфЖШЃЌетбљПЩвдПЫЗўЩЯУцЬсЕНЕФВЛКЯРэЁЃ
дчЦквЛаЉЫбЫїв§ЧцШЗЪЕЪЧЛљгкРрЫЦЕФЫуЗЈЦРМлЭјвГживЊадЕФЁЃетжжЦРМлЫуЗЈПДЫЦвРОнГфЗжЁЂЪЕЯжжБЙлМђЕЅЃЌЕЋШДЗЧГЃШнвзЪмЕНвЛжжНаЁАTerm
SpamЁБЕФЙЅЛїЁЃ
Term Spam
ЦфЪЕДгЫбЫїв§ЧцГіЯжЕФФЧЬьЦ№ЃЌspammerКЭЫбЫїв§ЧцЗДзїБзЕФЖЗЗЈОЭУЛгаЭЃжЙЙ§ЁЃSpammerЪЧетбљвЛШКШЫЁЊЁЊЪдЭМЭЈЙ§ЫбЫїв§ЧцЫуЗЈЕФТЉЖДРДЬсИпФПБъвГУцЃЈЭЈГЃЪЧвЛаЉЙуИцвГУцЛђРЌЛјвГУцЃЉЕФживЊадЃЌЪЙФПБъвГУцдкЫбЫїНсЙћжаХХУћППЧАЁЃ
ЯждкМйЩшGoogleЕЅДПЪЙгУЙиМќДЪеМБШЦРМлвГУцживЊадЃЌЖјЮвЯыШУЮвЕФВЉПЭдкЫбЫїНсЙћжаХХУћИќППЧАЃЈзюКУХХЕквЛЃЉЁЃФЧУДЮвПЩвдетУДзіЃКдквГУцжаМгШывЛИівўВиЕФhtmlдЊЫиЃЈР§ШчвЛИіdivЃЉЃЌШЛКѓЦфФкШнЪЧЁАеХбѓЁБжиИДвЛЭђДЮЁЃетбљЃЌЫбЫїв§ЧцдкМЦЫуЁАеХбѓ
ВЉПЭЁБЕФЫбЫїНсЙћЪБЃЌЮвЕФВЉПЭЙиМќДЪеМБШОЭЛсЗЧГЃДѓЃЌДгЖјзіЕНХХУћППЧАЕФаЇЙћЁЃ
ИќНјвЛВНЃЌЮвЩѕжСПЩвдИЩШХБ№ЕФЙиМќДЪЫбЫїНсЙћЃЌР§ШчЮвжЊЕРЯждкХЗжоБКмЛ№ШШЃЌЮвОЭдкЮвВЉПЭЕФвўВиdivРяМгвЛЭђИіЁАХЗжоБЁБЃЌЕБгагУЛЇЫбЫїХЗжоБЪБЃЌЮвЕФВЉПЭОЭФмГіЯждкЫбЫїНсЙћНЯППЧАЕФЮЛжУЁЃетжжааЮЊОЭНазіЁАTerm
SpamЁБЁЃ
дчЦкЫбЫїв§ЧцЩюЪметжжзїБзЗНЗЈЕФРЇШХЃЌМгжЎЛљгкЙиМќДЪЕФЦРМлЫуЗЈБОЩэвВВЛЩѕКЯРэЃЌвђДЫОГЃЪЧЫбГівЛЖбжЪСПЕЭЯТЕФНсЙћЃЌгУЛЇЬхбщДѓДѓДђСЫелПлЁЃЖјGoogleе§ЪЧдкетжжБГОАЯТЃЌЬсГіСЫPageRankЫуЗЈЃЌВЂЩъЧыСЫзЈРћБЃЛЄЁЃДЫОйГфЗжБЃЛЄСЫЕБЪБЯрЖдШѕаЁGoogleЃЌвВЪЙЕУGoogleвЛОйГЩЮЊШЋЧђЪзЧќвЛжИЕФЫбЫїв§ЧцЁЃ
5 PageRankЫуЗЈ
ЩЯЮФвбОЫЕЕНЃЌPageRankЕФзїгУЪЧЦРМлЭјвГЕФживЊадЃЌвдДЫзїЮЊЫбЫїНсЙћЕФХХађживЊвРОнжЎвЛЁЃЪЕМЪжаЃЌЮЊСЫЕжгљspamЃЌИїИіЫбЫїв§ЧцЕФОпЬхХХУћЫуЗЈЪЧБЃУмЕФЃЌPageRankЕФОпЬхМЦЫуЗНЗЈвВВЛОЁЯрЭЌЃЌБОНкНщЩмвЛжжзюМђЕЅЕФЛљгквГУцСДНгЪєадЕФPageRankЫуЗЈЁЃетИіЫуЗЈЫфШЛМђЕЅЃЌШДФмНвЪОPageRankЕФБОжЪЃЌЪЕМЪЩЯФПЧАИїДѓЫбЫїв§ЧцдкМЦЫуPageRankЪБСДНгЪєадШЗЪЕЪЧживЊЖШСПжИБъжЎвЛЁЃ
МђЕЅPageRankМЦЫу
ЪзЯШЃЌЮвУЧНЋWebзіШчЯТГщЯѓЃК1ЁЂНЋУПИіЭјвГГщЯѓГЩвЛИіНкЕуЃЛ2ЁЂШчЙћвЛИівГУцAгаСДНгжБНгСДЯђBЃЌдђДцдквЛЬѕгаЯђБпДгAЕНBЃЈЖрИіЯрЭЌСДНгВЛжиИДМЦЫуБпЃЉЁЃвђДЫЃЌећИіWebБЛГщЯѓЮЊвЛеХгаЯђЭМЁЃ
ЯждкМйЩшЪРНчЩЯжЛгаЫФеХЭјвГЃКAЁЂBЁЂCЁЂDЃЌЦфГщЯѓНсЙЙШчЯТЭМЃК

ЯдШЛетИіЭМЪЧЧПСЌЭЈЕФЃЈДгШЮвЛНкЕуГіЗЂЖМПЩвдЕНДяСэЭтШЮКЮвЛИіНкЕуЃЉЁЃ
ШЛКѓашвЊгУвЛжжКЯЪЪЕФЪ§ОнНсЙЙБэЪОвГУцМфЕФСЌНгЙиЯЕЁЃЦфЪЕЃЌPageRankЫуЗЈЪЧЛљгкетбљвЛжжБГОАЫМЯыЃКБЛгУЛЇЗУЮЪдНЖрЕФЭјвГИќПЩФмжЪСПдНИпЃЌЖјгУЛЇдкфЏРРЭјвГЪБжївЊЭЈЙ§ГЌСДНгНјаавГУцЬјзЊЃЌвђДЫЮвУЧашвЊЭЈЙ§ЗжЮіГЌСДНгзщГЩЕФЭиЦЫНсЙЙРДЭЦЫуУПИіЭјвГБЛЗУЮЪЦЕТЪЕФИпЕЭЁЃзюМђЕЅЕФЃЌЮвУЧПЩвдМйЩшЕБвЛИігУЛЇЭЃСєдкФГвГУцЪБЃЌЬјзЊЕНвГУцЩЯУПИіБЛСДвГУцЕФИХТЪЪЧЯрЭЌЕФЁЃР§ШчЃЌЩЯЭМжаAвГУцСДЯђBЁЂCЁЂDЃЌЫљвдвЛИігУЛЇДгAЬјзЊЕНBЁЂCЁЂDЕФИХТЪИїЮЊ1/3ЁЃЩшвЛЙВгаNИіЭјвГЃЌдђПЩвдзщжЏетбљвЛИіNЮЌОиеѓЃКЦфжаiааjСаЕФжЕБэЪОгУЛЇДгвГУцjзЊЕНвГУцiЕФИХТЪЁЃетбљвЛИіОиеѓНазізЊвЦОиеѓЃЈTransition
MatrixЃЉЁЃЯТУцЕФзЊвЦОиеѓMЖдгІЩЯЭМЃК

ШЛКѓЃЌЩшГѕЪМЪБУПИівГУцЕФrankжЕЮЊ1/NЃЌетРяОЭЪЧ1/4ЁЃАДA-DЫГађНЋвГУцrankЮЊЯђСПvЃК

зЂвтЃЌMЕквЛааЗжБ№ЪЧAЁЂBЁЂCКЭDзЊвЦЕНвГУцAЕФИХТЪЃЌЖјvЕФЕквЛСаЗжБ№ЪЧAЁЂBЁЂCКЭDЕБЧАЕФrankЃЌвђДЫгУMЕФЕквЛааГЫвдvЕФЕквЛСаЃЌЫљЕУНсЙћОЭЪЧвГУцAзюаТrankЕФКЯРэЙРМЦЃЌЭЌРэЃЌMvЕФНсЙћОЭЗжБ№ДњБэAЁЂBЁЂCЁЂDаТrankЃК

ШЛКѓгУMдйГЫвдетИіаТЕФrankЯђСПЃЌгжЛсВњЩњвЛИіИќаТЕФrankЯђСПЁЃЕќДњетИіЙ§ГЬЃЌПЩвджЄУїvзюжеЛсЪеСВЃЌМДvдМЕШгкMvЃЌДЫЪБМЦЫуЭЃжЙЁЃзюжеЕФvОЭЪЧИїИівГУцЕФpagerankжЕЁЃР§ШчЩЯУцЕФЯђСПОЙ§МИВНЕќДњКѓЃЌДѓдМЪеСВдкЃЈ1/4,
1/4, 1/5, 1/4ЃЉЃЌетОЭЪЧAЁЂBЁЂCЁЂDзюКѓЕФpagerankЁЃ
ДІРэDead Ends
ЩЯУцЕФPageRankМЦЫуЗНЗЈМйЩшWebЪЧЧПСЌЭЈЕФЃЌЕЋЪЕМЪЩЯЃЌWebВЂВЛЪЧЧПСЌЭЈЃЈЩѕжСВЛЪЧСЊЭЈЕФЃЉЁЃЯТУцПДПДPageRankЫуЗЈШчКЮДІРэвЛжжНазіDead
EndsЕФЧщПіЁЃ
ЫљЮНDead EndsЃЌОЭЪЧетбљвЛРрНкЕуЃКЫќУЧВЛДцдкЭтСДЁЃПДЯТУцЕФЭМЃК

зЂвтетРяDвГУцВЛДцдкЭтСДЃЌЪЧвЛИіDead EndЁЃЩЯУцЕФЫуЗЈжЎЫљвдФмГЩЙІЪеСВЕНЗЧСужЕЃЌКмДѓГЬЖШвРРЕзЊвЦОиеѓетбљвЛИіаджЪЃКУПСаЕФМгКЭЮЊ1ЁЃЖјдкетИіЭМжаЃЌMЕкЫФСаНЋШЋЮЊ0ЁЃдкУЛгаDead
EndsЕФЧщПіЯТЃЌУПДЮЕќДњКѓЯђСПvИїЯюЕФКЭЪМжеБЃГжЮЊ1ЃЌЖјгаСЫDead EndsЃЌЕќДњНсЙћНЋзюжеЙщСуЃЈвЊНтЪЭЮЊЪВУДЛсетбљЃЌашвЊвЛаЉОиеѓТлЕФжЊЪЖЃЌБШНЯПндяЃЌДЫДІТдЃЉЁЃ
ДІРэDead EndsЕФЗНЗЈШчЯТЃКЕќДњФУЕєЭМжаЕФDead EndsНкЕуМАDead EndsНкЕуЯрЙиЕФБпЃЈжЎЫљвдЕќДњФУЕєЪЧвђЮЊЕБФПЧАЕФDead
EndsБЛФУЕєКѓЃЌПЩФмЛсГіЯжвЛХњаТЕФDead EndsЃЉЃЌжБЕНЭМжаУЛгаDead EndsЁЃЖдЪЃЯТВПЗжМЦЫуrankЃЌШЛКѓвдФУЕєDead
EndsФцЯђЫГађЗДЭЦDead EndsЕФrankЁЃ
вдЩЯЭМЮЊР§ЃЌЪзЯШФУЕНDКЭDЯрЙиЕФБпЃЌDБЛФУЕНКѓЃЌCОЭБфГЩСЫвЛИіаТЕФDead EndsЃЌгкЪЧФУЕєCЃЌзюжежЛЪЃAЁЂBЁЃДЫЪБПЩКмШнвзЫуГіAЁЂBЕФPageRankОљЮЊ1/2ЁЃШЛКѓЮвУЧашвЊЗДЭЦDead
EndsЕФrankЃЌзюКѓБЛФУЕєЕФЪЧCЃЌПЩвдПДЕНCЧАжУНкЕугаAКЭBЃЌЖјAКЭBЕФГіЖШЗжБ№ЮЊ3КЭ2ЃЌвђДЫCЕФrankЮЊЃК1/2
* 1/3 + 1/2 * 1/2 = 5/12ЃЛзюКѓЃЌDЕФrankЮЊЃК1/2 * 1/3 + 5/12
* 1 = 7/12ЁЃЫљвдзюжеЕФPageRankЮЊЃЈ1/2, 1/2, 5/12, 7/12ЃЉЁЃ
Spider TrapsМАЦНЛЌДІРэ
ПЩвддЄМћЃЌШчЙћАбецЪЕЕФWebзщжЏГЩзЊвЦОиеѓЃЌФЧУДетНЋЪЧвЛИіМЋЮЊЯЁЪшЕФОиеѓЃЌДгОиеѓТлжЊЪЖПЩвдЭЦЖЯЃЌМЋЖШЯЁЪшЕФзЊвЦОиеѓЕќДњЯрГЫПЩФмЛсЪЙЕУЯђСПvБфЕУЗЧГЃВЛЦНЛЌЃЌМДвЛаЉНкЕугЕгаКмДѓЕФrankЃЌЖјДѓЖрЪ§НкЕуrankжЕНгНќ0ЁЃЖјвЛжжНазіSpider
TrapsНкЕуЕФДцдкМгОчСЫетжжВЛЦНЛЌЁЃР§ШчЯТЭМЃК

DгаЭтСДЫљвдВЛЪЧDead EndsЃЌЕЋЪЧЫќжЛСДЯђздМКЃЈзЂвтСДЯђздМКвВЫуЭтСДЃЌЕБШЛЭЌЪБвВЪЧИіФкСДЃЉЁЃетжжНкЕуНазіSpider
TrapЃЌШчЙћЖдетИіЭМНјааМЦЫуЃЌЛсЗЂЯжDЕФrankдНРДдНДѓЧїНќгк1ЃЌЖјЦфЫќНкЕуrankжЕМИКѕЙщСуЁЃ
ЮЊСЫПЫЗўетжжгЩгкОиеѓЯЁЪшадКЭSpider TrapsДјРДЕФЮЪЬтЃЌашвЊЖдPageRankМЦЫуЗНЗЈНјаавЛИіЦНЛЌДІРэЃЌОпЬхзіЗЈЪЧМгШыЁАаФСщзЊвЦЃЈteleportingЃЉЁБЁЃЫљЮНаФСщзЊвЦЃЌОЭЪЧЮвУЧШЯЮЊдкШЮКЮвЛИівГУцфЏРРЕФгУЛЇЖМгаПЩФмвдвЛИіМЋаЁЕФИХТЪЫВМфзЊвЦЕНСэЭтвЛИіЫцЛњвГУцЁЃЕБШЛЃЌетСНИівГУцПЩФмВЛДцдкГЌСДНгЃЌвђДЫВЛПЩФмецЕФжБНгзЊвЦЙ§ШЅЃЌаФСщзЊвЦжЛЪЧЮЊСЫЫуЗЈашвЊЖјЧПМгЕФвЛжжДПЪ§бЇвтвхЕФИХТЪЪ§зжЁЃ
МгШыаФСщзЊвЦКѓЃЌЯђСПЕќДњЙЋЪНБфЮЊЃК

ЦфжаІТЭљЭљБЛЩшжУЮЊвЛИіБШНЯаЁЕФВЮЪ§ЃЈ0.2ЛђИќаЁЃЉЃЌeЮЊNЮЌЕЅЮЛЯђСПЃЌМгШыeЕФдвђЪЧетИіЙЋЪНЕФЧААыВПЗжЪЧЯђСПЃЌвђДЫБиаыНЋІТ/NзЊЮЊЯђСПВХФмЯрМгЁЃетбљЃЌећИіМЦЫуОЭБфЕУЦНЛЌЃЌвђЮЊУПДЮЕќДњЕФНсЙћГ§СЫвРРЕзЊвЦОиеѓЭтЃЌЛЙвРРЕвЛИіаЁИХТЪЕФаФСщзЊвЦЁЃ
вдЩЯЭМЮЊР§ЃЌзЊвЦОиеѓMЮЊЃК

ЩшІТЮЊ0.2ЃЌдђМгШЈКѓЕФMЮЊЃК

вђДЫЃК

ШчЙћАДетИіЙЋЪНЕќДњЫуЯТШЅЃЌЛсЗЂЯжSpider TrapsЕФаЇгІБЛвжжЦСЫЃЌДгЖјУПИівГУцЖМгЕгавЛИіКЯРэЕФpagerankЁЃ
6 Topic-Sensitive PageRank
ЦфЪЕЩЯУцЕФЬжТлЮвУЧЛиБмСЫвЛИіЪТЪЕЃЌФЧОЭЪЧЁАЭјвГживЊадЁБЦфЪЕУЛвЛИіБъзМД№АИЃЌЖдгкВЛЭЌЕФгУЛЇЃЌЩѕжСгаКмДѓЕФВюБ№ЁЃР§ШчЃЌЕБЫбЫїЁАЦЛЙћЁБЪБЃЌвЛИіЪ§ТыАЎКУепПЩФмЪЧЯывЊПДiphoneЕФаХЯЂЃЌвЛИіЙћХЉПЩФмЪЧЯыПДЦЛЙћЕФМлИёзпЪЦКЭжжжВММЧЩЃЌЖјвЛИіаЁХѓгбПЩФмдкевЦЛЙћЕФМђБЪЛЁЃРэЯыЧщПіЯТЃЌгІИУЮЊУПИігУЛЇЮЌЛЄвЛЬззЈгУЯђСПЃЌЕЋУцЖдКЃСПгУЛЇетжжЗНЗЈЯдШЛВЛПЩааЁЃЫљвдЫбЫїв§ЧцвЛАуЛсбЁдёвЛжжГЦЮЊTopic-SensitiveЕФелжаЗНАИЁЃTopic-Sensitive
PageRankЕФзіЗЈЪЧдЄЖЈвхМИИіЛАЬтРрБ№ЃЌР§ШчЬхг§ЁЂгщРжЁЂПЦММЕШЕШЃЌЮЊУПИіЛАЬтЕЅЖРЮЌЛЄвЛИіЯђСПЃЌШЛКѓЯыАьЗЈЙиСЊгУЛЇЕФЛАЬтЧуЯђЃЌИљОнгУЛЇЕФЛАЬтЧуЯђХХађНсЙћЁЃ
Topic-Sensitive PageRankЗжЮЊвдЯТМИВНЃК
1ЁЂШЗЖЈЛАЬтЗжРрЁЃ
вЛАуРДЫЕЃЌПЩвдВЮПМOpen DirectoryЃЈDMOZЃЉЕФвЛМЖЛАЬтРрБ№зїЮЊtopicЁЃФПЧАDMOZЕФвЛМЖtopicгаЃКArtsЃЈвеЪѕЃЉЁЂBusinessЃЈЩЬЮёЃЉЁЂComputersЃЈМЦЫуЛњЃЉЁЂGamesЃЈгЮЯЗЃЉЁЂHealthЃЈвНСЦНЁПЕЃЉЁЂHomeЃЈОгМвЃЉЁЂKids
and TeensЃЈЖљЭЏЃЉЁЂNewsЃЈаТЮХЃЉЁЂRecreationЃЈгщРжаобјЃЉЁЂReferenceЃЈВЮПМЃЉЁЂRegionalЃЈЕигђЃЉЁЂScienceЃЈПЦММЃЉЁЂShoppingЃЈЙКЮяЃЉЁЂSocietyЃЈШЫЮФЩчЛсЃЉЁЂSportsЃЈЬхг§ЃЉЁЃ
2ЁЂЭјвГtopicЙщЪєЁЃ
етвЛВНашвЊНЋУПИівГУцЙщШызюКЯЪЪЕФЗжРрЃЌОпЬхЙщРргаКмЖрЫуЗЈЃЌР§ШчПЩвдЪЙгУTF-IDFЛљгкДЪЫиЙщРрЃЌвВПЩвдОлРрКѓШЫЙЄЙщРрЃЌОпЬхВЛдйеЙПЊЁЃетвЛВНзюжеЕФНсЙћЪЧУПИіЭјвГБЛЙщЕНЦфжавЛИіtopicЁЃ
3ЁЂЗжtopicЯђСПМЦЫуЁЃ
дкTopic-Sensitive PageRankжаЃЌЯђСПЕќДњЙЋЪНЮЊ

ЪзЯШЪЧЕЅЮЛЯђСПeБфЮЊСЫsЁЃsЪЧетбљвЛИіЯђСПЃКЖдгкФГtopicЕФsЃЌШчЙћЭјвГkдкДЫtopicжаЃЌдђsжаЕкkИідЊЫиЮЊ1ЃЌЗёдђЮЊ0ЁЃзЂвтЖдгкУПвЛИіtopicЖМгавЛИіВЛЭЌЕФsЁЃЖј|s|БэЪОsжа1ЕФЪ§СПЁЃ
ЛЙЪЧвдЩЯУцЕФЫФеХвГУцЮЊР§ЃЌМйЩшвГУцAЙщЮЊArtsЃЌBЙщЮЊComputersЃЌCЙщЮЊComputersЃЌDЙщЮЊSportsЁЃФЧУДЖдгкComputersетИіtopicЃЌsОЭЪЧЃК
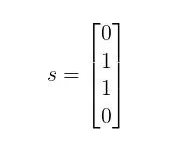
Жј|s|=2ЁЃвђДЫЃЌЕќДњЙЋЪНЮЊЃК

зюКѓЫуГіЕФЯђСПОЭЪЧComputersетИіtopicЕФrankЁЃШчЙћЪЕМЪМЦЫувЛЯТЃЌЛсЗЂЯжBЁЂCвГдкетИіtopicЯТЕФШЈжиЯрБШЩЯУцЗЧTopic-SensitiveЕФrankЛсЩ§ИпЃЌетЫЕУїШчЙћгУЛЇЪЧвЛИіЧуЯђгкComputers
topicЕФШЫЃЈР§ШчГЬађдБЃЉЃЌФЧУДдкИјЫћГЪЯжЕФНсЙћжаBЁЂCЛсИќживЊЃЌвђДЫПЩФмХХУћИќППЧАЁЃ
4ЁЂШЗЖЈгУЛЇtopicЧуЯђЁЃ
зюКѓвЛВНОЭЪЧдкгУЛЇЬсНЛЫбЫїЪБЃЌШЗЖЈгУЛЇЕФtopicЧуЯђЃЌвдбЁдёКЯЪЪЕФrankЯђСПЁЃжївЊЗНЗЈгаСНжжЃЌвЛжжЪЧСаГіЫљгаtopicШУгУЛЇздМКбЁдёИааЫШЄЕФЯюФПЃЌетжжЗНЗЈдквЛаЉЩчНЛЮЪД№ЭјеОзЂВсЪБОГЃЪЙгУЃЛСэЭтвЛжжЗНЗЈОЭЪЧЭЈЙ§ФГжжЪжЖЮЃЈШчcookieИњзйЃЉИњзйгУЛЇЕФааЮЊЃЌНјааЪ§ОнЗжЮіХаЖЯгУЛЇЕФЧуЯђЃЌетБОЩэвВЪЧвЛИіКмгавтЫМЕФЛАЬтЃЌАДЪБетИіЛАЬтГЌГіБОЮФЕФЗЖГыЃЌВЛдйеЙПЊЯИЫЕЁЃ
7 еыЖдPageRankЕФSpamЙЅЛїгыЗДзїБз
ЩЯЮФЫЕЙ§ЃЌSpammerКЭЫбЫїв§ЧцЗДзїБзЙЄГЬЪІЕФЖЗЗЈДгРДОЭУЛЭЃжЙЙ§ЁЃЪЕМЪЩЯЃЌжЛвЊЪЧЫуЗЈЃЌОЭвЛЖЈгаspamЗНЗЈЃЌВЛДцдкЮоаИПЩЛїЕФХХУћЫуЗЈЁЃЯТУцПДвЛЯТеыЖдPageRankЕФspamЁЃ
Link Spam
ЛиЕНЮФеТПЊЭЗЕФР§згЃЌШчЙћЮвЯыШУЮвЕФВЉПЭдкЫбЫїЁАеХбѓ ВЉПЭЁБЪБХХУћППЧАЃЌЯдШЛдкPageRankЫуЗЈЯТППTerm
SpamЪЧЮоЗЈЪЕЯжЕФЁЃВЛЙ§МШШЛЮвУїАзСЫPageRankжївЊППФкСДЪ§МЦЫувГУцШЈжиЃЌФЧУДЮвЪЧВЛЪЧПЩвдПМТЧНЈСЂКмЖрПеМмзгЭјеОЃЌШУетаЉЭјеОЖМСДНгЕНЮвВЉПЭЪзвГЃЌетбљЪЧВЛЪЧПЩвдЬсИпЮвВЉПЭЪзвГЕФPageRankЃПКмВЛавЃЌетжжЗНЗЈааВЛЭЈЁЃдйПДЯТPageRankЫуЗЈЃЌвЛИівГУцЛсНЋШЈжиОљдШЩЂВЅИјБЛСДНгЭјеОЃЌЫљвдГ§СЫФкСДЪ§ЭтЃЌЩЯгЮвГУцЕФШЈживВКмживЊЁЃЖјЮвФЧаЉПеМмзгЭјеОБОЩэОЭУЛЩЖШЈжиЃЌЫљвдРДздЫќУЧЕФФкСДВЂВЛФмЦ№ЕНЬсИпЮвВЉПЭЪзвГPageRankЕФзїгУЃЌетбљжЛЪЧздгщздРжЖјвбЁЃ
ЫљвдЃЌSpam PageRankЕФЙиМќОЭдкгкЯыАьЗЈдіМгвЛаЉИпШЈживГУцЕФФкСДЁЃЯТУцОпЬхПДвЛЯТLink
SpamдѕУДзіЁЃ
ЪзЯШУїШЗНЋвГУцЗжЮЊМИИіРраЭЃК
1ЁЂФПБъвГ
ФПБъвГЪЧspammerвЊЬсИпrankЕФвГУцЃЌетРяОЭЪЧЮвЕФВЉПЭЪзвГЁЃ
2ЁЂжЇГжвГ
жЇГжвГЪЧspammerФмЭъШЋПижЦЕФвГУцЃЌР§ШчspammerздМКНЈСЂЕФеОЕужавГУцЃЌетРяОЭЪЧЮвЩЯЮФЫљЮНЕФПеМмзгвГУцЁЃ
3ЁЂПЩДявГ
ПЩДявГЪЧspammerЮоЗЈЭъШЋПижЦЃЌЕЋЪЧПЩвдгаНгПкЙЉspammerЗЂВМСДНгЕФвГУцЃЌР§ШчЬьбФЩчЧјЁЂаТРЫВЉПЭЕШЕШетжжгУЛЇПЩЗЂЬћЕФЩчЧјЛђВЉПЭеОЁЃ
4ЁЂВЛПЩДявГ
етЪЧФЧаЉspammerЭъШЋЮоЗЈЗЂВМСДНгЕФЭјеОЃЌР§ШчеўИЎЭјеОЁЂАйЖШЪзвГЕШЕШЁЃ
зїЮЊвЛИіspammerЃЌЮвФмРћгУЕФзЪдДОЭЪЧжЇГжвГКЭПЩДявГЁЃЩЯУцЫЕЙ§ЃЌЕЅДПЭЈЙ§жЇГжвГЪЧУЛгаАьЗЈspamЕФЃЌвђДЫЮввЊзіЕФЕквЛМўЪТЧщОЭЪЧОЁСПеввЛаЉrankНЯИпЕФПЩДявГШЅМгЩЯЖдЮвВЉПЭЪзвГЕФСДНгЁЃР§ШчЮвПЩвдШЅЬьбФЁЂУЈЦЫЕШЕиЗНЛиИіетбљЕФЬљЃКЁАТЅжїЕФЬћзгКмВЛДэЃЁОЋВЪФкШнЃКhttp://codinglabs.orgЁБЁЃЮвЯыДѓМввЛЖЈдкИїДѓЩчЧјУЛЩйМћетжжЬћзгЃЌетОЭЪЧгаШЫдкзіspamЁЃ
ШЛКѓЃЌдйЭЈЙ§ДѓСПЕФжЇГжвГЗХДѓrankЃЌОпЬхзіЗЈЪЧШУУПИіжЇГжвГКЭФПБъвГЛЅСДЃЌЧвУПИіжЇГжвГжЛгавЛЬѕСДНгЁЃ
етбљвЛИіНсЙЙНазіSpam FarmЃЌЦфЭиЦЫЭМШчЯТЃК 
ЦфжаTЪЧФПБъвГЃЌAЪЧПЩДявГЃЌSЪЧжЇГжвГЁЃЯТУцМЦЫувЛЯТlink spamЕФаЇЙћЁЃ
ЩшTЕФзмrankЮЊyЃЌдђyгЩШ§ВПЗжзщГЩЃК
1ЁЂПЩДявГЕФrankЙБЯзЃЌЩшЮЊxЁЃ
2ЁЂаФСщзЊвЦЕФЙБЯзЃЌЮЊІТ/nЁЃЦфжаnЮЊШЋВПЭјвГЕФЪ§СПЃЌІТЮЊзЊвЦВЮЪ§ЁЃ
3ЁЂжЇГжвГЕФЙБЯзЃК
ЩшгаmИіжЇГжвГЃЌвђЮЊУПИіжЇГжвГжЛКЭTгаСДНгЃЌЫљвдПЩвдЫуГіУПИіжЇГжвГЕФrankЮЊЃК

дђжЇГжвГЙБЯзЕФШЋВПrankЮЊЃК

вђДЫПЩвдЕУЕНЃК

гЩгкЯрЖдІТЃЌnЗЧГЃОоДѓЃЌЫљвдПЩвдШЯЮЊІТ/nНќЫЦгк0ЁЃ МђЛЏКѓЕФЗНГЬЮЊЃК

НтЗНГЬЕУЃК

МйЩшІТЮЊ0.2ЃЌдђ1/(2ІТ-ІТ^2) = 2.77дђетИіspam farmПЩвдНЋxдМЗХДѓ2.7БЖЁЃвђДЫШчЙћЦ№ЕНВЛДэЕФspamаЇЙћЁЃ
Link SpamЗДзїБз
еыЖдspammerЕФlink spamааЮЊЃЌЫбЫїв§ЧцЕФЗДзїБзЙЄГЬЪІашвЊЯыАьЗЈМьВтетжжааЮЊЃЌвЛАуРДЫЕгаСНРрЗНЗЈМьВтlink
spamЁЃ
ЭјТчЭиЦЫЗжЮі
вЛжжЗНЗЈЪЧЭЈЙ§ЖдЭјвГЕФЭМЭиЦЫНсЙЙЗжЮіевГіПЩФмДцдкЕФspam farmЁЃЕЋЪЧЫцзХWebЙцФЃдНРДдНДѓЃЌетжжЗНЗЈЗЧГЃРЇФбЃЌвђЮЊЭМЕФЬиЖЈНсЙЙВщевЪЧЪБМфИДдгЖШЗЧГЃИпЕФвЛИіЫуЗЈЃЌВЛПЩФмЭъШЋППетжжЗНЗЈЗДзїБзЁЃ
TrustRank
ИќПЩФмЕФвЛжжЗДзїБзЗНЗЈЪЧНазівЛжжTrustRankЕФЗНЗЈЁЃ
ЫЕЦ№РДTrustRankЦфЪЕЪ§бЇБОжЪЩЯОЭЪЧTopic-Sensitive RankЃЌжЛВЛЙ§етРяЖЈвхСЫвЛИіЁАПЩаХЭјвГЁБЕФащФтtopicЁЃЫљЮНПЩаХЭјвГОЭЪЧЩЯЮФЫЕЕНЕФВЛПЩДявГЃЌЛђепЫЕУЛЗЈspamЕФвГУцЁЃР§ШчеўИЎЭјеОЃЈБЛКкСЫЕФВЛЫуЃЉЁЂаТРЫЁЂЭјвзУХЛЇЪзвГЕШЕШЁЃвЛАуЪЧЭЈЙ§ШЫСІЛђепЦфЫќЪВУДЗНЪНбЁдёГівЛИіЁАПЩаХЭјвГЁБМЏКЯЃЌзщГЩвЛИіtopicЃЌШЛКѓЭЈЙ§ЩЯЮФЕФTopic-SensitiveЫуЗЈЖдетИіtopicНјааrankМЦЫуЃЌНсЙћНазіTrustRankЁЃ
TrustRankЕФЫМЯыКмжБЙлЃКШчЙћвЛИівГУцЕФЦеЭЈrankдЖИпгкПЩаХЭјвГЕФtopic rankЃЌдђКмПЩФметИівГУцБЛspamСЫЁЃ
ЩшвЛИівГУцЦеЭЈrankЮЊPЃЌTrustRankЮЊTЃЌдђЖЈвхЭјвГЕФSpam MassЮЊЃК(P ЈC T)/PЁЃ
Spam MassдНДѓЃЌЫЕУїДЫвГУцЮЊspamФПБъвГЕФПЩФмаддНДѓЁЃ
8 змНс
етЦЊЮФеТЪЧЮвЖдвЛаЉзЪСЯЕФЙщФЩЛузмЃЌМђЕЅНщЩмСЫPageRankЕФБГОАЁЂзїгУЁЂМЦЫуЗНЗЈЁЂБфжжЁЂSpamМАЗДзїБзЕШФкШнЁЃЮЊСЫЭЛГіжиЕуЮвМђЛЏСЫЫбЫїв§ЧцЕФФЃаЭЃЌЕБШЛдкЪЕМЪжаЫбЫїв§ЧцдЖУЛгаетУДМђЕЅЃЌецЪЕЫуЗЈвВвЛЖЈЗЧГЃИДдгЁЃВЛЙ§ФПЧАМИКѕЫљгаЯжДњЫбЫїв§ЧцвГУцШЈжиЕФМЦЫуЗНЗЈЖМЛљгкPageRankМАЦфБфжжЁЃвђЮЊЮвУЛзіЙ§ЫбЫїв§ЧцЯрЙиЕФПЊЗЂЃЌвђДЫБОЮФФкШнжївЊЪЧЛљгкЯжгаЮФЯзЕФПЭЙлзмНсЃЌЩдМгвЛЕуЮвЕФРэНтЁЃ
|








