| 编辑推荐: |
本文将继续对客户订单数据进行处理,将包括客户细分和客户行为分析与预测
,希望能够给大家带来些许帮助,欢迎交流学习!
本文来自
数据STUDIO
,由火龙果软件Alice编辑、推荐。 |
|
本文主要内容
本次实战项目共分为上下两部分,上篇 《 一个企业级数据挖掘实战项目|客户细分模型(上) 》 包括数据探索性数据分析,缺失值等处理,各个关键变量的分析。最后通过聚类方法,将产品进行聚类分类,并通过词云图和主成分分析各个类别聚类分离效果。
下篇(本篇)将继续对客户订单数据进行处理,将包括客户细分和客户行为分析与预测。本篇主要结构与内容思维导图如下图所示。
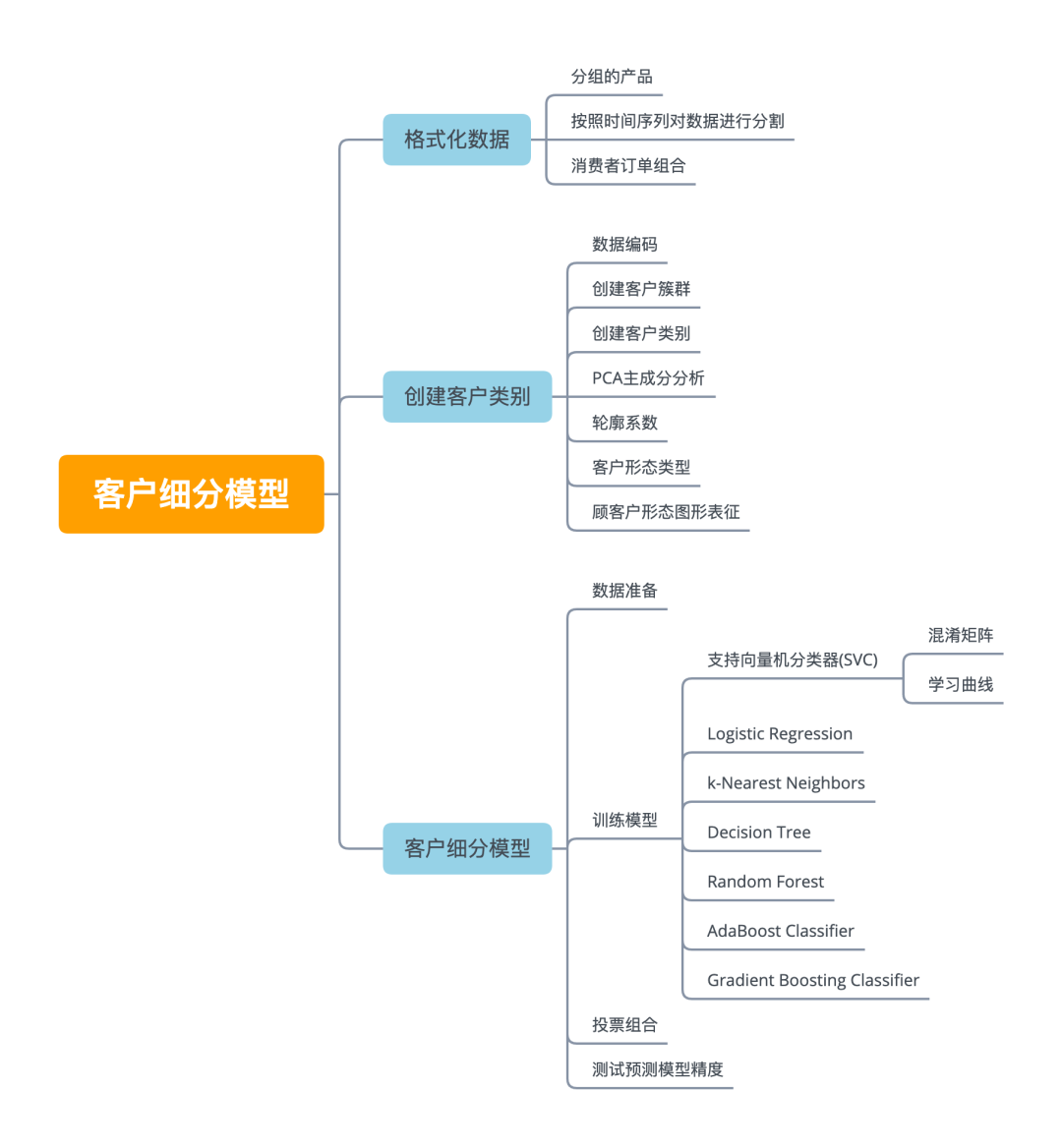
数据预处理
在上篇中,将不同的产品分组为五个簇群。接下来主要分析客户分类,接下来的第一步是将产品分组信息引入数据集。此处创建了分类变量 categ_product 来表示每个产品的集群。

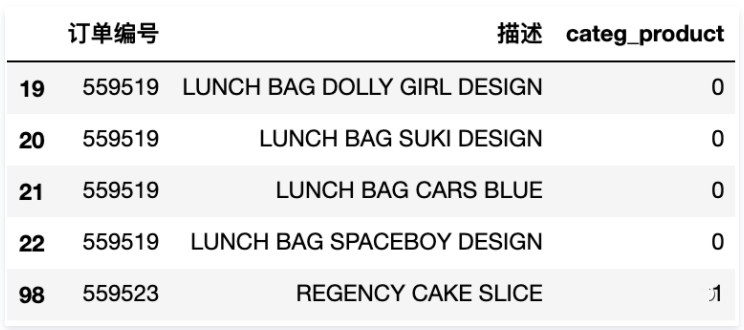
产品分组处理
接下来创建 categ_N 变量(
N ∈ [ 0 : 4 ]
),它包含在每个产品类别中花费的金额。这一步相当于一维数据转二维数据,将五个簇群扩展为五个分类变量,每个变量下存储的是该条记录的价格数据。
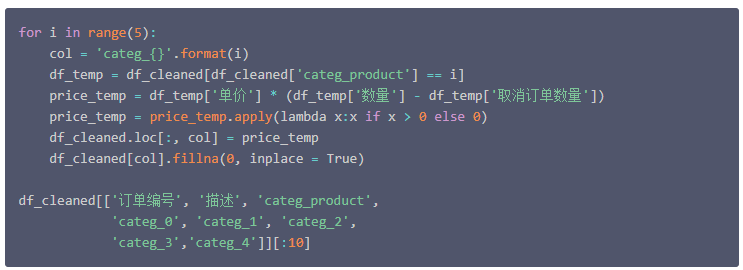
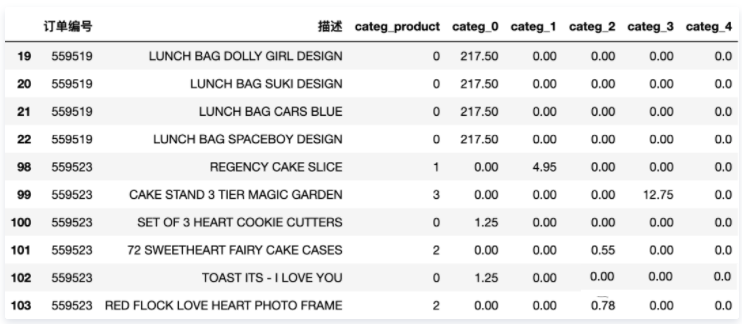
到目前为止,与单个订单相关的信息被划分到数据集的几行中(每个产品一行)。
接下来按照单个订单聚合,将一个订单中所有产品聚合到一条记录中,并记为 购物车价格 ,代表某个特定订单中所有产品的总价。因此,创建了一个新的数据表,其中包含每个订单的购物车价格,以及它在5类产品中分布的方式。

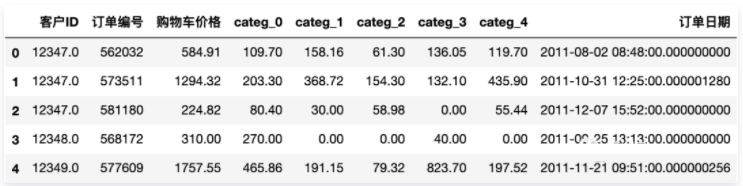
按照时间序列对数据进行分割
数据集中 购物篮价格 包含为期12个月的信息。接下来的目标之一将是开发一个模型,能够描述和预测客户访问网站的习惯,并且是从他们第一次访问网站就开始记录。
为了能够获得训练和测试模型的数据,选择使用前10个月的数据开发模型和接下来的2个月的数据来测试模型,这样的策略来分割数据集。
注意,这里的分割指保留 订单日期 中的日期,不包含具体的时间。

消费者订单组合
接下来,将对应于同一用户的不同订单分组聚合在一起。由此确定了用户的购买次数,以及在所有访问期间的最小、最大、平均金额和总金额。

最后,定义了两个额外的变量,它们给出了自第一次购买以来经过的天数( 第一次购买 )和自最后一次购买以来的天数( 最后一次购买 )。
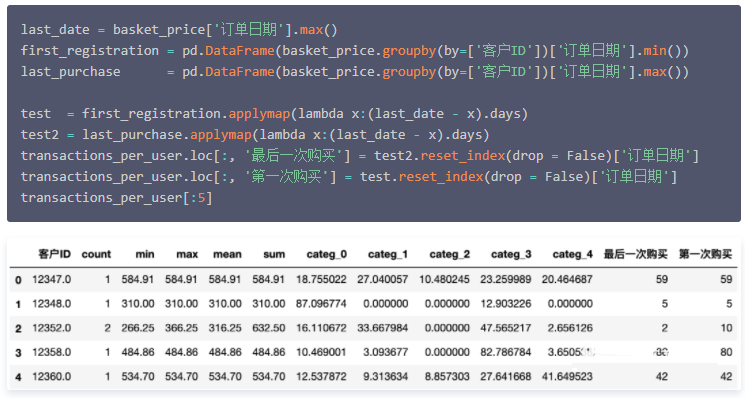
这里我们注意到,有许多客户只购买过一次产品,而细分客户的目标之一,就是针对这些客户做一些特定的营销策略以留住他们,促使得他们做二次或更多次购买行为。
并且通过下面的计算结果得知,此类客户(仅发生一次购买行为的客户),接近所有客户的60%,还是非常庞大的一个客户群体。
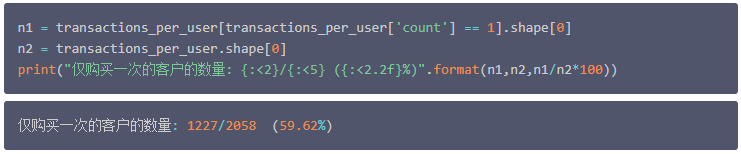
创建客户类别
数据编码
数据集 'transactions_per_user' 中包含的信息比较丰富。该表中的每个记录对应于一个特定的客户,可以使用这些信息来描述不同类型的客户。

这里值得注意的是,选择的不同变量的数据具有不同的尺度范围,在继续接下来的分析之前,需要对当前数据进行一个标准化的处理。

创建客户簇群
接下来将创建客户集群。在创建这些集群之前,按照之前产品分类的思路,将用来描述用户特征的数据集进行降维度,在一个较小的维度上建立客户簇群。降维方法同样选用PCA主成分分析。

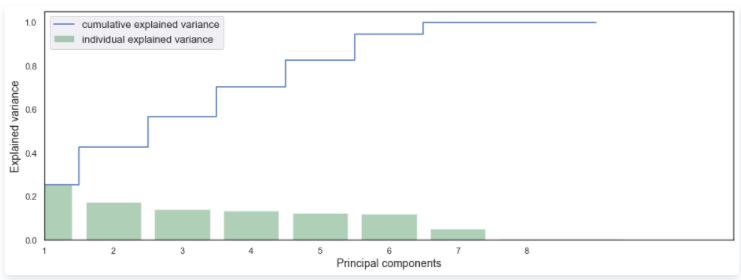
并绘制出累积可解释性方差图看确定需要降到某个维度。
创建客户类别
接下来,我们需要从之前定义的标准化矩阵中定义客户集群,这里使用了scikit-learn中的 “k-means”聚类算法 。根据轮廓系数选择最佳聚类的簇群数量,最后发现有11个聚类得到了最好的效果。
首先定义簇群数量为11个,并使用降维之前的数据进行聚类。

得到平均轮廓系数为 0.224。然后查看每个集群中的客户数量。
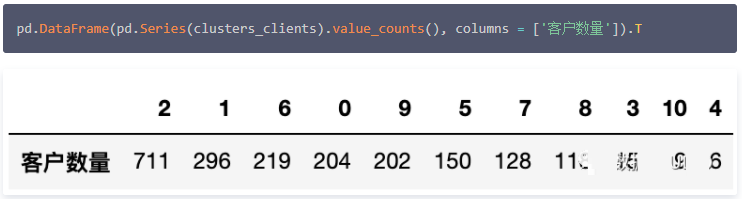
PCA主成分分析
从可解释性方差图中可以看出,当维度在6维时,已经能够代表总体方差的80%以上的信息了,因此此处我们选择 维度数为6 。

由上面可以看出,已经创建的不同簇的大小存在一定的差异。因此,此处通过可视化尝试理解这些簇群的内容,以便验证(或不验证)这种特殊的聚类。
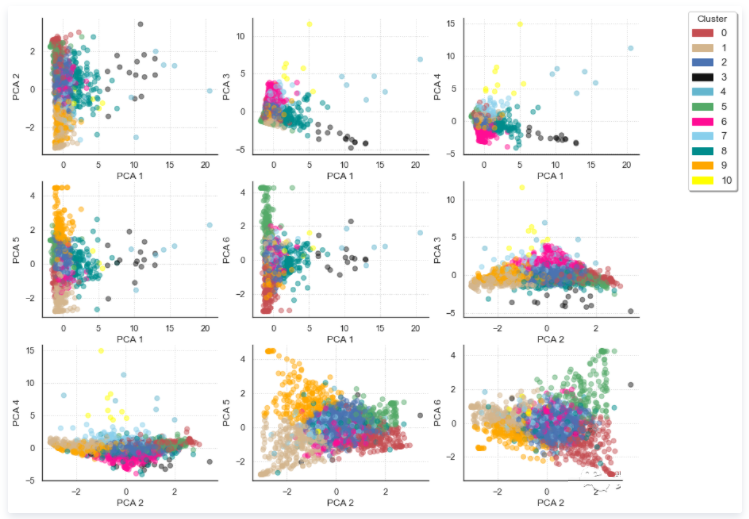
从这个图中可以看出一些有用的信息,例如,第一个主成分可以将最小的簇群从其他簇群中分离出来 (簇3,4,10) 。
轮廓系数
这里同之前产品类别一样,另一种查看聚类质量的方法是查看不同簇群内的轮廓系数。
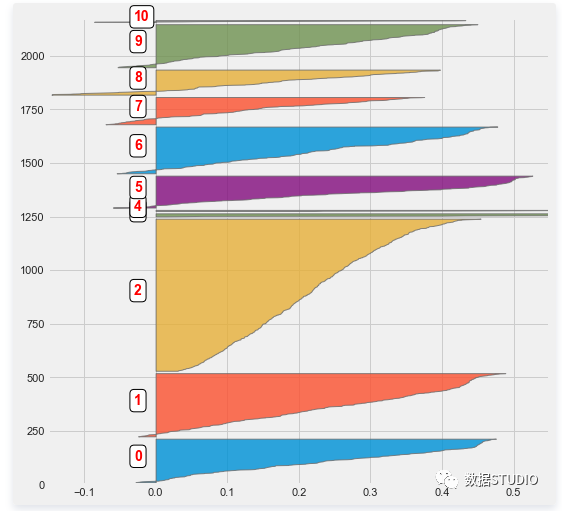
客户形态类型
到目前为止,我们已经验证了不同的集群确实是不相交的(至少在全局方面)。
为了进一步细分客户,了解每个集群中客户的习惯。因此在表 'selected_customers' 中添加一个变量来定义每个客户端所属的集群。

然后,在每个不同的客户集群中平均各客户信息。这样就可以获得一些信息,例如不同集群的客户的平均购物车价格、访问次数或消费总额等等。并且还确定了每组的客户数量。
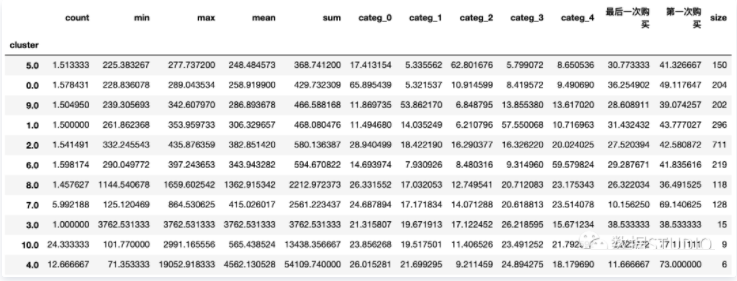
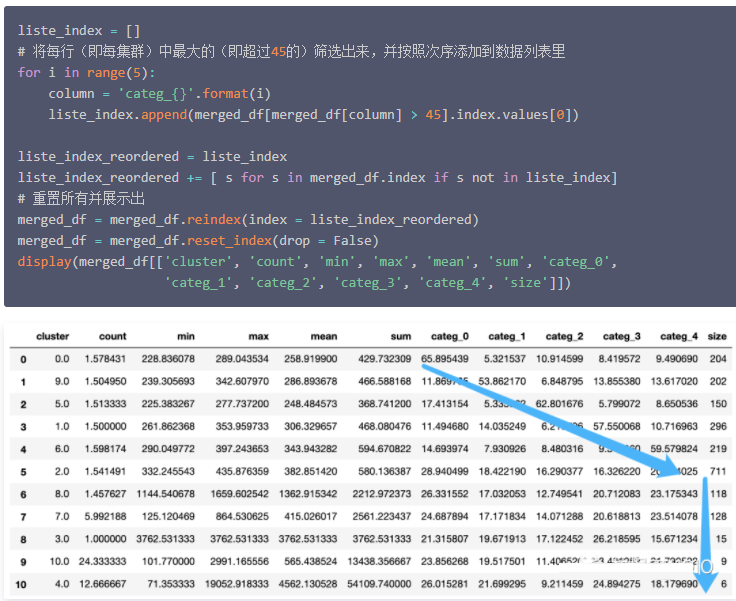
最后,重新组织数据表中的内容,通过以下方法排序不同的集群:首先,根据每个产品类别中花费的金额排序,然后再根据总花费进行排序。
顾客户形态图形表征
最后,创建了不同形态的表现。这里定义了一个类来创建 "雷达图" 。
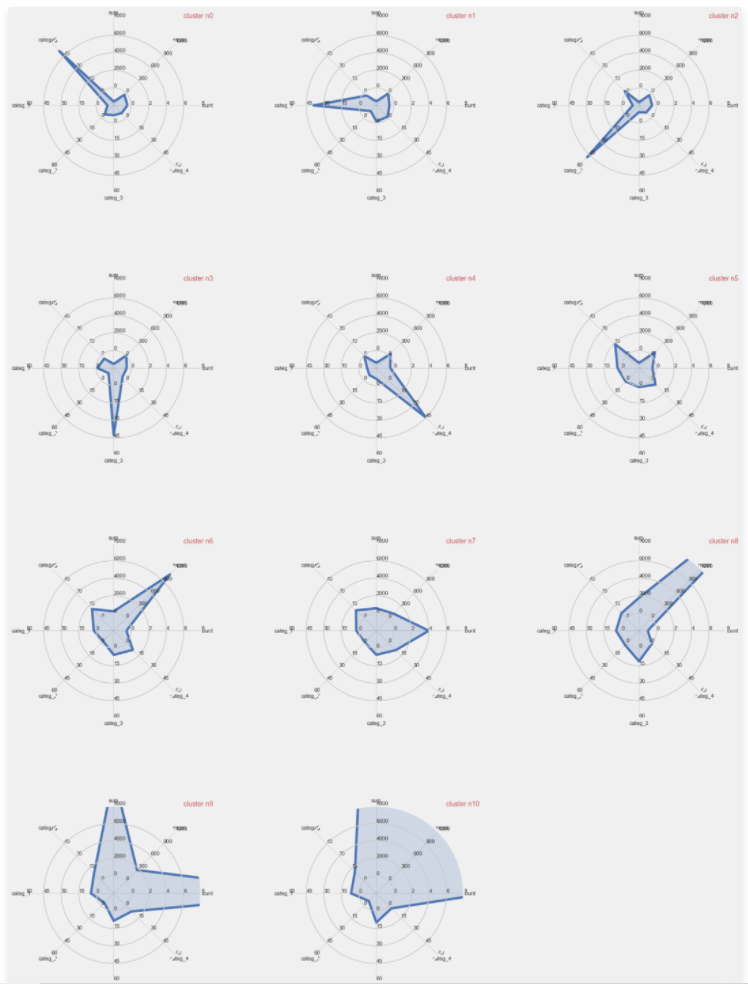
从这个图形中可以获得不少信息。例如,可以看出前5个集群对应的是购买某一特定类别产品的强烈优势。其他集群将不同于一购物车平均数( sum )、客户的总花费( sum )或访问总次数( count )。
客户的分类
在这一部分中,目标是训练一个分类器,该分类器在上一节中建立的不同客户群的类别中将消费者分类。
为了实现这个目标,我将测试"scikit-learn"中的几个分类器。为了简化它们的使用,我定义了一个类,它允许接口这些不同的分类器常见的几个功能。
本次目标是定义客户类别所属,一旦客户第一次访问,就只保留描述购物车里的内容的变量,并且不考虑访问的频率或购物车价格随时间的变化等相关的变量。
数据准备

将数据集分成训练集和测试集。

支持向量机分类器(SVC)
使用的第一个分类器是 支持向量机SVC分类器 。云朵君也总结了 支持向量机中非线性核函数原理 ,以及 一文掌握sklearn中的支持向量机 。
创建了一个 'Class_Fit' 类的实例,然后调用 'grid_search()' 。当调用这个方法时,需要提供参数:

注意,每一次运行精度值可能会改变。
混淆矩阵
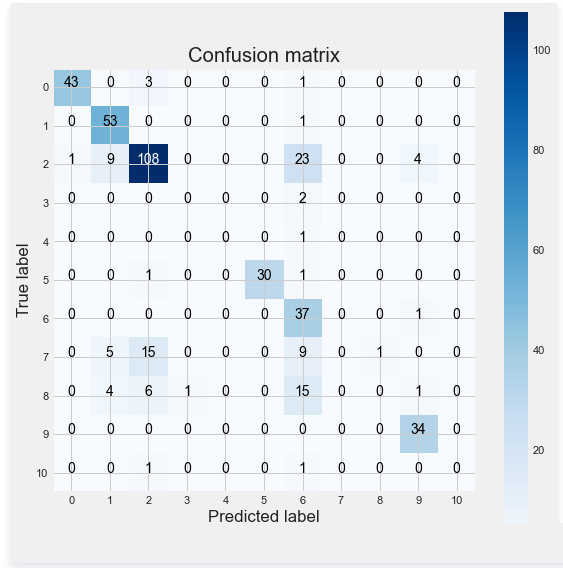
支持向量机的结果的准确性看起来似乎是正确的。但之前定义的类不一定都是平衡的。特别当一个类包含大约40%的客户时。因此这里需要用到评价不平衡数据集所用到的评价指标,即混淆矩阵。
如有不太熟悉的朋友们可以参考云朵君之前介绍的 机器学习中样本不平衡处理方法 。文中介绍样本不平衡处理一般方法,以及不平衡时使用的评价指标。
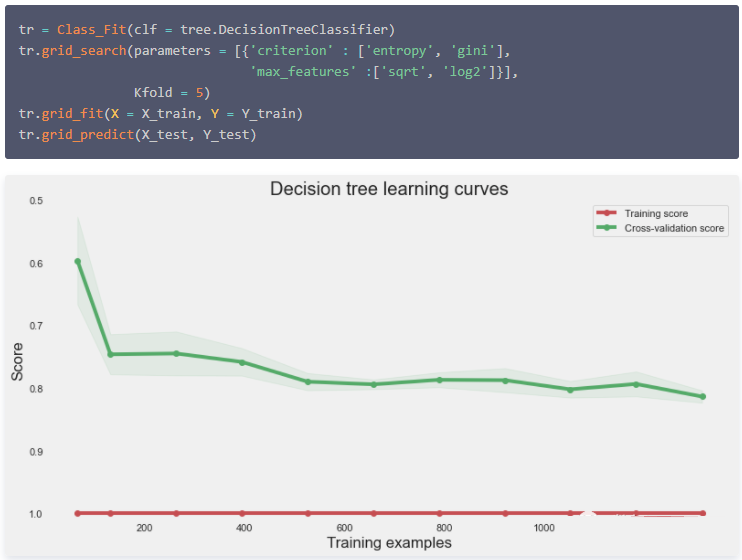
学习曲线
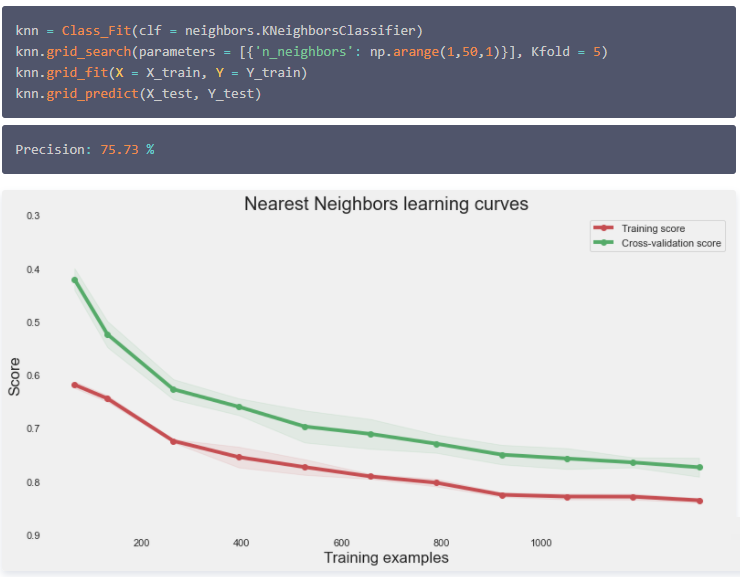
评价模型拟合质量的一种典型方法是绘制学习曲线。特别是这种类型的学习曲线可以检测模型中可能的不足,例如,检测到模型的过拟合或欠拟合。并且还能看出,模型在较 大数据 集中得到更好模型效果的可能性。下面绘制这条曲线。
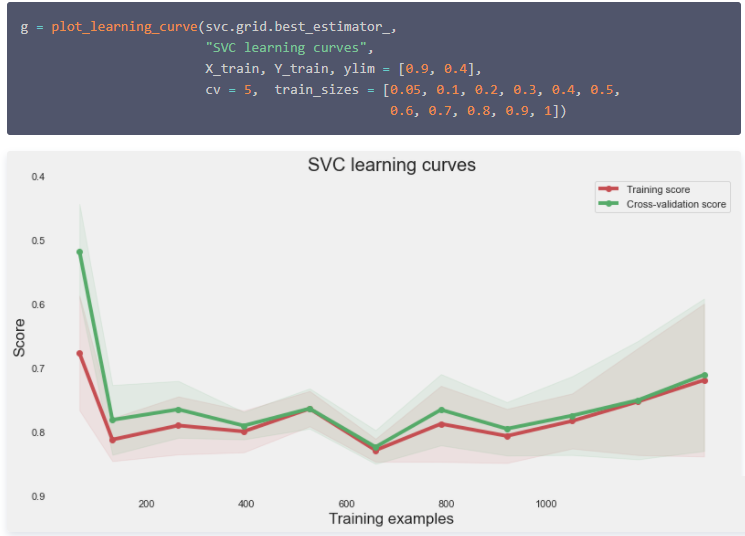
从这条曲线上可以看出,随着样本量的增加,列车和交叉验证曲线趋于相同的极限。这是典型的低方差建模,并证明了模型不会遭受过拟合。此外,我们可以看到,训练曲线的准确性是正确的。因此,该模型没有欠拟合数据。
Logistic Regression
现在考虑使用逻辑回归分类器。仍然使用之前创建的一个 'Class_Fit' 类的实例,并在训练数据上调整模型,并查看预测与实际值的比较。
这里有两篇文章可以参考: 逻辑回归算法理论 和 逻辑回归算法案例 。
同样绘制学习曲线。
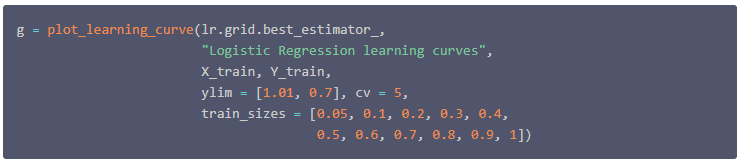
k-Nearest Neighbors
K近邻算法模型,具体可以参考: 机器学习|KNN,k近临算法 。文中包括算法模型理论和实操案例介绍。
Decision Tree
决策树分类器,具体可以参见: 机器学习|决策树模型理论 和 决策树模型实例 。
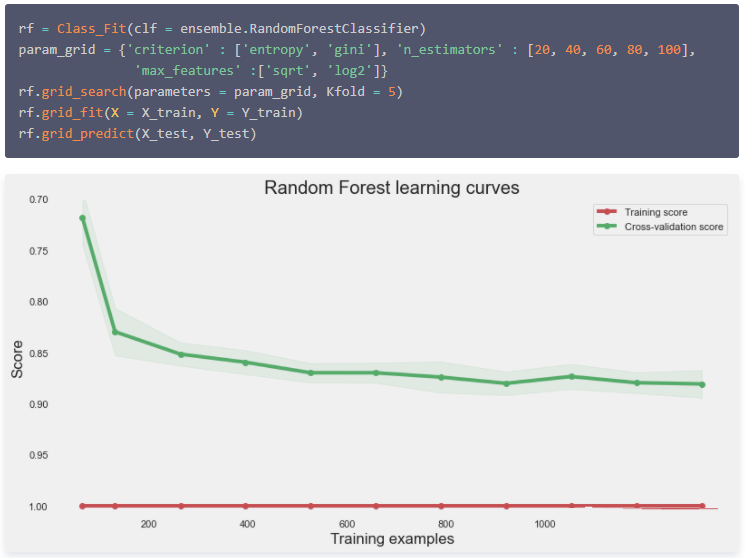
Random Forest
随机森林分类器,可以参见: 集成算法|随机森林分类模型 。
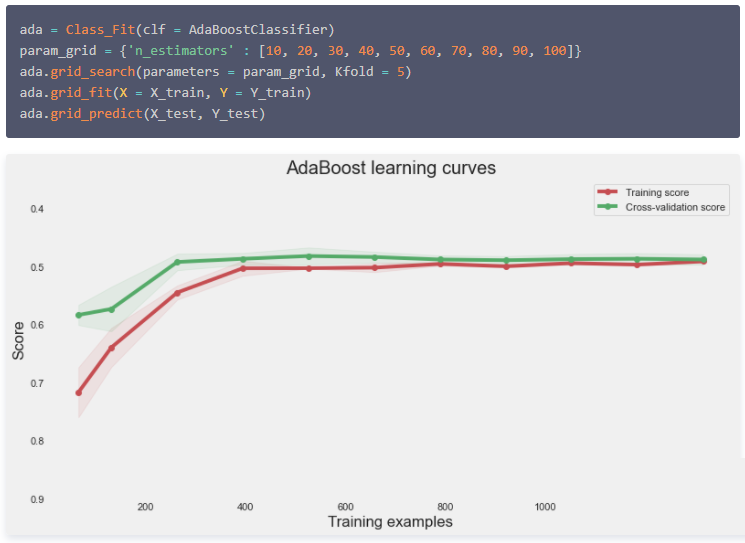
AdaBoost Classifier
AdaBoost分类器,可以参见: 集成算法|AdaBoost模型 。
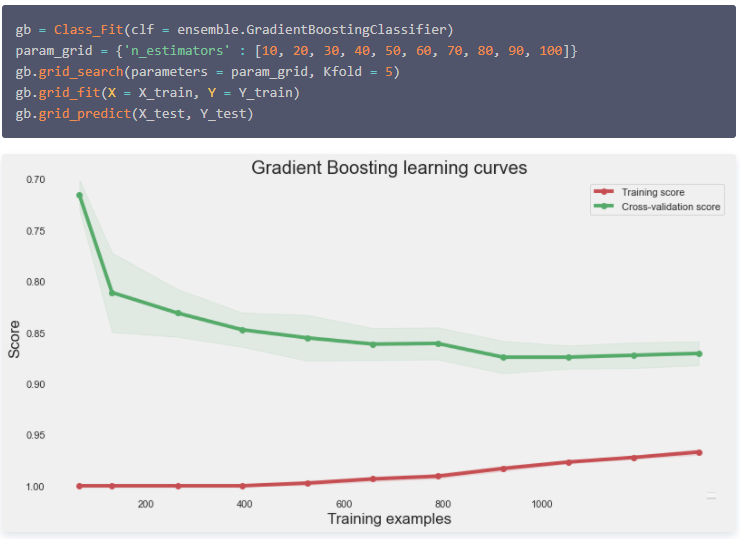
Gradient Boosting Classifier
投票组合
最后,可以将前面中给出的不同分类器的结果进行组合,以改进分类模型。这可以通过选择大多数分类器所指示的客户类别来实现。这里使用了"sklearn"包的 "VotingClassifier" 方法。
首先在使用之前找到的每个分类器通过网格搜索得到的最佳参数来调整各种分类器的参数。

然后,定义一个分类器来合并各种分类器的结果,并且训练该分类器。
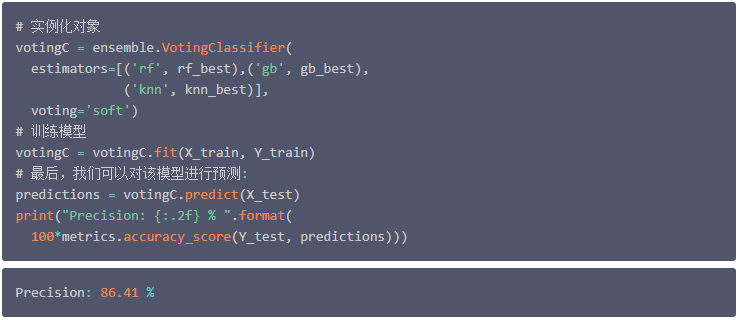
注意,在实例化 'votingC' 分类器时,只使用了上述定义的整个分类器集的一个子样本,并且只保留了 Random Forest, nearest Neighbors 和 Gradient Boosting 三个分类器。而这一选择与下一节中进行的分类的性能有关。
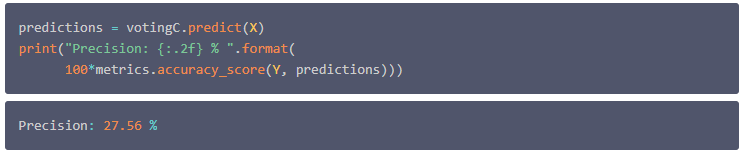
测试预测精度
在上一节中,我们训练了几个分类器来对客户进行分类。并且整个分析都是基于前10个月的数据。在本节中,将用存储在 'set_test' 数据表中的数据集的最后两个月来测试模型效果。

首先根据在训练集上使用的相同过程重新组合这些数据。但在校正数据,考虑到两个数据集之间的时间差异,需要增加变量 count 和 sum 的权重以获得与训练集的更佳的等价性。
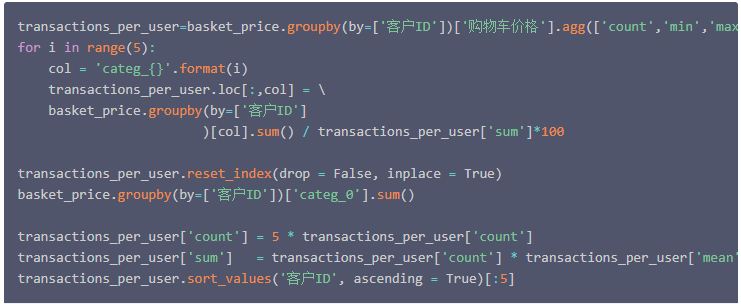
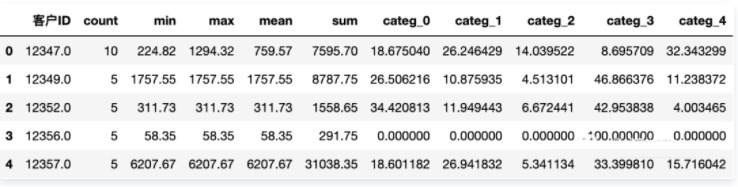
然后将数据表转换为一个矩阵,并只保留定义客户所属类别的变量。这里的数据标准化处理方法仍然使用在训练集上使用的标准化方法。

这个矩阵中的每一行都包含一个客户的购买习惯。到目前为止的问题是,如何使用这些习惯来定义消费者所属的类别。而这些类别已在前面章节中确定,这里需要注意的是,该类别定义并不对应于测试时的分类本身。
因此在这个阶段,我们通过定义客户所属的类别来准备测试数据,这个定义是使用了2个月期间获得的数据(通过变量 count , min , max 和 sum )。而在之前的定义的分类器使用了一组限制更严格的变量,这些变量将在客户第一次购买时定义。
这里使用的是两个月内可用数据,并使用这些数据定义客户所属的类别。分类器可以通过比较其预测值与这些原油类别来测试模型效果。
为了定义客户端所属的类别,我们回忆下前面使用的 'kmeans' 方法的实例。这个实例的 'predict' 方法计算所有客户与11个客户类的质心之间的距离,通过与衡量哪个质心的距离最小,而将其归属于哪个类别。

接下来只需要检查之前训练过的不同分类器的预测效果即可。
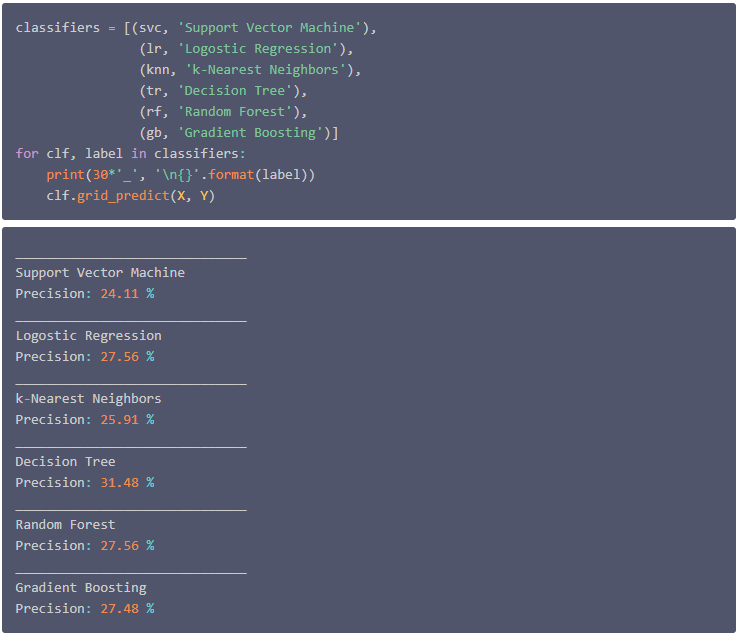
最后,训练模型时预测的那样,通过结合各自的预测来提高分类器的效果是可行的。这里选择混合 Random Forest, nearest Neighbors和Gradient Boosting ,因为这将导致预测略有改进。
写在最后
至此,本次Python业务分析实战项目已经告一段落。从开始数据预处理,缺失值分析,各个特征变量分析,产品类别划分,客户群体聚类,客户行为分析,到最终客户行为预测模型建立与评价。
|








