| ±ајНЖјц: |
±ѕОДАґЧФ51ctoЈ¬ОДХВЦчТЄЅйЙЬБЛІЯВФДЈКЅЎў№ЫІмХЯДЈКЅЎў
Ч°КОДЈКЅЎўµҐАэДЈКЅТФј°¶цєєДЈКЅµИµДПа№ШДЪИЭЎЈ
|
|
. »щґЎС§П°ЈєUMLЛДЦЦ№ШПµ
соєП¶ИґуРЎ№ШПµ
·є»Ї = КµПЦ > ЧйєП > ѕЫєП > №ШБЄ > ТААµ
ТААµ(Dependency)

Т»ёцИЛ(Person)їЙТФВтіµ(car)єН·їЧУ(House)Ј¬ДЗГґѕНїЙТФіЖЈєPersonАаТААµУЪCarАаєНHouseАа
ХвАпЧўТвУлПВГжµД№ШБЄ№ШПµЗш·ЦЈєPersonАаАпІўГ»УРК№УГCarєНHouseАаРНµДКфРФЈ¬CarєНHouseµДКµАэКЗТФІОБїµД·ЅКЅґ«ИлµЅbuy()·Ѕ·ЁЦРЎЈ
ТААµ№ШПµФЪJavaУпСФЦРМеПЦОЄѕЦУт±дБїЎў·Ѕ·ЁµДРОІОЈ¬»тХЯ¶ФѕІМ¬·Ѕ·ЁµДµчУГЎЈ
№ШБЄ(AssociationЈ© 
ЛьК№Т»ёцАаЦЄµАБнТ»ёцАаµДКфРФєН·Ѕ·ЁЎЈ
№ШБЄїЙТФКЗЛ«ПтµДЈ¬ТІїЙТФКЗµҐПтµДЎЈ
ФЪJavaУпСФЦРЈ¬№ШБЄ№ШПµТ»°гК№УГіЙФ±±дБїАґКµПЦЎЈ
ѕЫєП(Aggregation) 
ѕЫєПКЗ№ШБЄ№ШПµµДТ»ЦЦЈ¬КЗЗїµД№ШБЄ№ШПµЎЈ
ѕЫєПКЗХыМеєНёцМеЦ®јдµД№ШПµЈ¬µ«ёцМеїЙТФНСАлХыМе¶шґжФЪЎЈ
АэИзЈ¬ЖыіµАаУлТэЗжАаЎўВЦМҐАаЈ¬ТФј°ЖдЛьµДБгјюАаЦ®јдµД№ШПµ±гХыМеєНёцМеµД№ШПµЎЈ
Ул№ШБЄ№ШПµТ»СщЈ¬ѕЫєП№ШПµТІКЗНЁ№эіЙФ±±дБїКµПЦµДЎЈµ«КЗ№ШБЄ№ШПµЛщЙжј°µДБЅёцАаКЗґ¦ФЪН¬Т»ІгґОЙПµДЈ¬¶шФЪѕЫєП№ШПµЦРЈ¬БЅёцАаКЗґ¦ФЪІ»ЖЅµИІгґОЙПµДЈ¬Т»ёцґъ±нХыМеЈ¬БнТ»ёцґъ±нІї·ЦЎЈ
ЧйєП(Composition) 
ЧйєПКЗ№ШБЄ№ШПµµДТ»ЦЦЈ¬КЗ±ИѕЫєП№ШПµЗїµД№ШПµЈ¬ТІТФіЙФ±±дБїµДРОКЅіцПЦЎЈ
ФЪДіТ»ёцК±їМЈ¬Ії·Ц¶ФПуЦ»ДЬєНТ»ёцХыМе¶ФПу·ўЙъЧйєП№ШПµЈ¬УЙєуХЯЕЕЛыµШёєФрЙъГьЦЬЖЪЎЈ
Ії·ЦєНХыМеµДЙъГьЦЬЖЪТ»СщЎЈ
ХыМеїЙТФЅ«Ії·Цґ«µЭёшБнТ»ёц¶ФПуЈ¬ХвК±єтёГІї·ЦµДЙъГьЦЬЖЪУЙРВХыМеїШЦЖЈ¬И»єуѕЙХыМеїЙТФЛАНцЎЈ
. ІЯВФДЈКЅ
КІГґКЗІЯВФДЈКЅ
Т»ёцАаЦРµДТ»Р©РРОЄЈ¬їЙДЬ»бЛжЧЕПµНіµДµьґъ¶ш·ўЙъ±д»ЇЎЈОЄБЛК№µГёГАаВъЧгїЄ·Е-·в±ХФФтЈЁјґЈєѕЯ±ёїЙА©Х№РФ
»т µЇРФЈ©Ј¬ОТГЗРиТЄЅ«ХвР©ОґАґ»б·ўЙъ¶ЇМ¬±д»ЇµДРРОЄґУёГАаЦР°юАліцАґЈ¬ІўНЁ№эФ¤ІвОґАґТµОс·ўХ№µД·ЅКЅЈ¬ОЄХвР©РРОЄійПуіц№ІУРµДМШХчЈ¬·вЧ°ФЪійПуАа»тЅУїЪЦРЈ¬ІўНЁ№эЛьГЗµДКµПЦАаМṩѕЯМеµДРРОЄЎЈФ±ѕАаЦРРиТЄіЦУРёГійПуАа/ЅУїЪµДТэУГЎЈФЪК№УГК±Ј¬Ѕ«ДіТ»ёцѕЯМеµДКµПЦАа¶ФПуЧўИлёшёГАаЛщіЦУРµДЅУїЪ/ійПуАаµДТэУГЎЈ
АаНјГиКц 
Из№ыАаAЦРУРБЅёцРРОЄXєНY»бЛжЧЕТµОсµД·ўХ№¶ш±д»ЇЈ¬ДЗГґЈ¬ОТГЗРиТЄЅ«ХвБЅёцРРОЄґУАаAЦР°юАліцАґЈ¬ІўРОіЙёчЧФµДјМіРМеПµ(ІЯВФМеПµ)ЎЈГїёцјМіРМеПµ(ІЯВФМеПµ)µД¶ҐІгёёАа/ЅУїЪЦР¶ЁТе№ІУРРРОЄµДійПуєЇКэЈ¬ГїёцЧУАа/КµПЦАаЦР¶ЁТеёГІЯВФМеПµѕЯМеµДКµПЦЎЈ
ЖдЦРЈ¬ГїТ»ёц±»ійПуіцАґµДјМіРМеПµ±»іЖОЄТ»ёцІЯВФМеПµЈ¬ГїёцѕЯМеµДКµПЦАа±»іЖОЄІЯВФЎЈ
ґЛК±Ј¬ІЯВФМеПµТСѕ№№ЅЁНкіЙЈ¬ЅУПВАґРиТЄёДФмАаAЎЈ
ФЪАаAЦРФцјУЛщРиІЯВФМеПµµД¶ҐІгёёАа/ЅУїЪЈ¬ІўПтНⱩ¶һёц№ІУРµДєЇКэactionёшµчУГХЯК№УГЎЈ
ФЪSpringПоДїЦРЈ¬ІЯВФАаєНАаAЦ®јдµДТААµ№ШПµїЙТФНЁ№эТААµЧўИлАґНкіЙЎЈ
µЅґЛОЄЦ№Ј¬ІЯВФДЈКЅТСѕ№№ЅЁНкіЙЈ¬ПВГжОТГЗАґїґУЕИ±µг·ЦОцЎЈ
ІЯВФДЈКЅµДУЕµг
1. ВъЧгїЄ·Е·в±ХФФт
Из№ыАаAРиТЄёь»»Т»ЦЦІЯВФµДК±єтЈ¬Ц»РиРЮёДSpringµДXMLЕдЦГОДјюјґїЙЈ¬ЖдУаЛщУРµДґъВлѕщІ»РиТЄРЮёДЎЈ
±ИИзЈ¬Ѕ«АаAµДІЯВФX_1ёь»»іЙX_2µД·Ѕ·ЁИзПВЈє
<bean id="a"
class="АаA">
<!-- Ѕ«Ф±ѕІЯВФКµПЦАаX_1РЮёДОЄІЯВФКµПЦАаX_2јґїЙ
-->
<property name="ІЯВФЅУїЪX"
class="ІЯВФКµПЦАаX_2" />
</bean> |
ґЛНвЈ¬Из№ыРиТЄРВФцТ»ЦЦІЯВФЈ¬Ц»РиТЄОЄІЯВФЅУїЪXМнјУТ»ёцРВµДКµПЦАајґїЙЈ¬ІўёІёЗЖдЦРµДcommonActionєЇКэЎЈИ»єу°ґХХЙПГжµД·ЅКЅРЮёДXMLОДјюјґїЙЎЈ
ФЪХвёц№эіМЦРЈ¬ФЪ±ЈіЦФУРJavaґъВлІ»·ўЙъ±д»ЇµДЗ°МбПВЈ¬А©Х№РФБЛРВµД№¦ДЬЈ¬ґУ¶шВъЧгїЄ·Е·в±ХФФтЎЈ
2. їЙ·Ѕ±гµШґґЅЁѕЯУРІ»Н¬ІЯВФµД¶ФПу
Из№ыОТГЗРиТЄёщѕЭІ»Н¬µДІЯВФґґЅЁ¶аЦЦАаAµД¶ФПуЈ¬ДЗГґК№УГІЯВФДЈКЅѕНДЬєЬИЭТЧµШКµПЦХвТ»µгЎЈ
±ИИзЈ¬ОТГЗТЄґґЅЁИэёцAАаµД¶ФПуЈ¬aЎўbЎўcЎЈЖдЦРЈ¬aК№УГІЯВФX_1єНY_1Ј¬bК№УГІЯВФX_2єНY_2Ј¬cК№УГІЯВФX_3єНY_3ЎЈ
ТЄґґЅЁХвИэёц¶ФПуЈ¬ОТГЗЦ»РиФЪXMLЦРЧчИзПВЕдЦГјґїЙЈє
<bean id="a"
class="АаA">
<property name="ІЯВФЅУїЪX"
class="ІЯВФКµПЦАаX_1" />
<property
name="ІЯВФЅУїЪY" class="ІЯВФКµПЦАаY_1"
/>
</bean>
<bean id="b" class="АаA">
<property name="ІЯВФЅУїЪX" class="ІЯВФКµПЦАаX_2"
/>
<property name="ІЯВФЅУїЪY"
class="ІЯВФКµПЦАаY_2" />
</bean>
<bean id="c" class="АаA">
<property name="ІЯВФЅУїЪX" class="ІЯВФКµПЦАаX_3"
/>
<property name="ІЯВФЅУїЪY"
class="ІЯВФКµПЦАаY_3" />
</bean> |
ґрТЙ
ОКЈєИзєОКµПЦІї·ЦјМіРЈїТІѕНКЗАаSon1Ц»јМіРFatherµДТ»Ії·Ц№¦ДЬЈ¬Son2јМіРFatherµДБнТ»Ії·Ц№¦ДЬЎЈ
ХвКЗЙијЖЙПµДИ±ПЭЈ¬µ±іцПЦХвЦЦЗйїцК±Ј¬У¦µ±Ѕ«ёёАаФЩґОІр·ЦіЙ2ёцЧУАаЈ¬±ЈЦ¤ИОєОТ»ёцёёАаµДРРОЄєНМШХчѕщКЗёГјМіРМеПµЦР№ІУРµДЈЎ

ОКЈєЛжЧЕРиЗуµД±д»ЇЈ¬ёёАаЦРРиТЄФцјУ№ІУРРРОЄК±ФхГґ°мЈїХвѕНЖЖ»µБЛЎ°їЄ·Е·в±ХФФтЎ±ЎЈ
ХвІўОґЖЖ»µЎ°їЄ·Е·в±ХФФтЎ±ЈЎФЪПµНіµьґъёьРВµД№эіМЦРЈ¬РЮёДФУРµДґъВлКЗФЪЛщДСГвµДЈ¬ХвІўІ»ОҐ±іЎ°їЄ·Е·в±ХФФтЎ±ЎЈ
Ў°їЄ·Е·в±ХФФтЎ±ТЄЗуОТГЗЈєµ±ПµНіФЪµьґъ№эіМЦРЈ¬µЪТ»ґОіцПЦДіТ»АаРНµДРиЗуК±Ј¬КЗФКРнРЮёДµДЈ»ФЪґЛК±Ј¬У¦ёГ¶ФПµНіЅшРРРЮёДЈ¬ІўЅшРРєПАнµШЙијЖЈ¬ТФ±ЈЦ¤¶ФёГАаРНРиЗуµДФЩґОРЮёДѕЯ±ёїЙА©Х№РФЎЈµ±ФЩТ»ґОіцПЦёГАаРНµДРиЗуК±Ј¬ѕНІ»У¦ёГРЮёДФУРґъВлЈ¬Ц»ФКРнНЁ№эА©Х№АґВъЧгРиЗуЎЈ
. №ЫІмХЯДЈКЅ
№ЫІмХЯДЈКЅКЗКІГґ
Из№ыіцПЦИзПВіЎѕ°РиЗуК±Ј¬ѕНРиТЄК№УГ№ЫІмХЯДЈКЅЎЈ
Из№ыґжФЪТ»ПµБРАаЈ¬ЛыГЗ¶јРиТЄПтЦё¶ЁАа»сИЎЦё¶ЁµДКэѕЭЈ¬µ±»сИЎµЅКэѕЭєуРиТЄґҐ·ўПаУ¦µДТµОсВЯјЎЈХвЦЦіЎѕ°ѕНїЙТФУГ№ЫІмХЯДЈКЅАґКµПЦЎЈ
ФЪ№ЫІмХЯДЈКЅЦРЈ¬ґжФЪБЅЦЦЅЗЙ«Ј¬·Ц±рКЗЈє№ЫІмХЯєН±»№ЫІмХЯЎЈ±»№ЫІмХЯјґОЄКэѕЭМṩХЯЎЈЛыГЗіК¶а¶ФТ»µД№ШПµЎЈ
АаНјГиКц
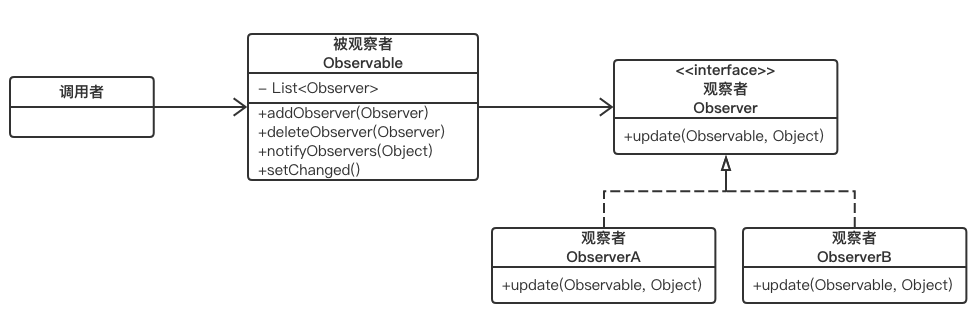
±»№ЫІмХЯКЗКэѕЭМṩ·ЅЈ¬№ЫІмХЯКЗКэѕЭ»сИЎ·Ѕ
Т»ёцЖХНЁµДАаЈ¬Из№ыТЄіЙОЄ№ЫІмХЯЈ¬»сИЎЦё¶ЁµДКэѕЭЈ¬Т»№ІРиТЄИзПВјёІЅЈє
КЧПИЈ¬РиТЄКµПЦObserverЅУїЪЈ¬ІўКµПЦupdateєЇКэЈ»
И»єуЈ¬ФЪёГєЇКэЦР¶ЁТе»сИЎКэѕЭєуµДТµОсВЯјЈ»
update(Observable, Object)Т»№ІУРБЅёцІОКэЈє
ObservableЈє±»№ЫІмХЯ¶ФПуЈЁКэѕЭМṩ·ЅЈ©
ObjectЈєКэѕЭ±ѕЙн
ЧоєуЈ¬НЁ№эµчУГ ±»№ЫІмХЯ µДaddObservable()»тХЯНЁ№эSpringµДXMLЕдЦГОДјюНкіЙ№ЫІмХЯПт±»№ЫІмХЯµДЧўИлЎЈґЛК±Ј¬ёГ№ЫІмХЯ¶ФПуѕН»б±»МнјУЅш
±»№ЫІмХЯ µДListЦРЎЈ
µчУГХЯІЕКЗХжХэµДКэѕЭМṩ·ЅЎЈµ±µчУГХЯРиТЄ№гІҐЧоРВКэѕЭК±Ј¬Ц»РиµчУГ ±»№ЫІмХЯ µДnotidyObservers()єЇКэЈ¬ёГєЇКэ»б±йАъListјЇєПЈ¬ІўТАґОµчУГГїёцObserverµДupdateєЇКэЈ¬ґУ¶шНкіЙКэѕЭµД·ўЛНЈ¬ІўґҐ·ўГїёцObserverКХµЅКэѕЭєуµДТµОсВЯјЎЈ
БЅЦЦЧўІб№ЫІмХЯµД·ЅКЅ
Ѕ«ObserverЧўІбЅшObservableЦРУРИзПВБЅЦЦ·ЅКЅЈє
1. ФЛРРЗ°Ј¬НЁ№эSpring XML
ФЪПµНіФЛРРЗ°Ј¬Из№ы№ЫІмХЯКэБїїЙТФИ·¶ЁЈ¬ІўФЪФЛРР№эіМЦРІ»»б·ўЙъ±д»ЇЈ¬ДЗГґѕНїЙТФФЪXMLЦРНкіЙList¶ФПуµДЧўИлЈ¬ХвЦЦ·ЅКЅґъВлЅ«»б±ИЅПјтЅаЎЈ
1ЎўЕдЦГєГЛщУР №ЫІмХЯ bean
<!-- ґґЅЁobserverA
-->
<bean name="observerA" class="ObservserA">
</bean>
<!-- ґґЅЁobserverB-->
<bean name="observerB" class="ObservserB">
</bean> |
2Ўў ЕдЦГєГ ±»№ЫІмХЯ beanЈ¬ІўЅ«ЛщУР№ЫІмХЯbeanЧўИлёш±»№ЫІмХЯbean
<!-- ґґЅЁobservable
-->
<bean name="observable" class="Observable">
<property name="observerList">
<list>
<ref bean="observerA"
/>
<ref bean="observerB" />
</list>
</property>
</bean> |
2. ФЛРРЦРЈ¬НЁ№эaddObserver()єЇКэ
ФЪSpringіхКј»ЇµДК±єтЈ¬НЁ№эaddObserver()єЇКэЅ«ЛщУРObserver¶ФПуЧўИлObservableµДobserverListЦРЎЈ
@Component
public class InitConfiguration implements ApplicationListener<ContextRefreshedEvent>{
@Override
public void onApplicationEvent(ContextRefreshedEvent
arg0) {
if(event.getApplicationContext().getParent() ==
null){
Observable observable = (Observable)event.getApplicationContext().getBean
("observable");
ObserverA observerA = (ObserverA)event.getApplicationContext().getBean
("observerA");
ObserverB observerB = (ObserverB)event.getApplicationContext().getBean
("observerB");
observable.setObserverList(Arrays.asList(observerA,
observerB));
}
}
} |
ЅЁТйК№УГµЪТ»ЦЦ·ЅКЅіхКј»ЇЛщУРµД№ЫІмХЯЈ¬ґЛНвЈ¬±»№ЫІмХЯИФИ»РиТЄМṩaddObserver()єЇКэ№©ПµНіФЪФЛРРЖЪјд¶ЇМ¬µШМнјУЎўЙѕіэ№ЫІмХЯ¶ФПуЎЈ
JDKМṩµД№ЫІмХЯДЈКЅ№¤ѕЯ°ь
JDKТСѕМṩБЛ№ЫІмХЯДЈКЅµД№¤ѕЯ°ьЈ¬°ьАЁObservableАаєНObserverЅУїЪЎЈИфТЄКµПЦ№ЫІмХЯДЈКЅЈ¬Ц±ЅУК№УГХвБЅёц№¤ѕЯ°ьјґїЙЎЈ
. Ч°КОДЈКЅ
єОК±К№УГ
РиТЄФцЗїТ»ёц¶ФПуЦРДіР©єЇКэµД№¦ДЬЎЈ
РиТЄ¶ЇМ¬µШёшТ»ёц¶ФПуФцјУ№¦ДЬЈ¬ХвР©№¦ДЬїЙТФФЩ¶ЇМ¬µШі·ПъЎЈ
РиТЄФцјУ УЙТ»Р©»щ±ѕ№¦ДЬЕЕБРЧйєП ¶шІъЙъµДґуБї№¦ДЬЈ¬ґУ¶шК№јМіРМеПµґу±¬ХЁЎЈ
АаНјГиКц 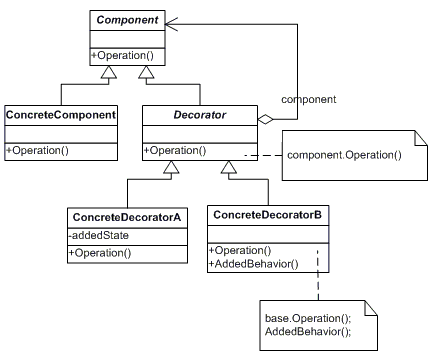
ФЪЧ°КОДЈКЅЦРµДёчёцЅЗЙ«УРЈє
ійПу№№јюЈЁComponentЈ©ЅЗЙ«ЈєёшіцТ»ёційПуЅУїЪЈ¬ТФ№ж·¶Чј±ёЅУКХёЅјУФрИОµД¶ФПуЎЈ
ѕЯМе№№јюЈЁConcrete ComponentЈ©ЅЗЙ«Јє¶ЁТеТ»ёцЅ«ТЄЅУКХёЅјУФрИОµДАаЎЈ
Ч°КОЈЁDecoratorЈ©ЅЗЙ«ЈєіЦУРТ»ёц№№јюЈЁComponentЈ©¶ФПуµДКµАэЈ¬Іў¶ЁТеТ»ёцУлійПу№№јюЅУїЪТ»ЦВµДЅУїЪЎЈ
ѕЯМеЧ°КОЈЁConcrete DecoratorЈ©ЅЗЙ«ЈєёєФрёш№№јю¶ФПуЎ±МщЙПЎ±ёЅјУµДФрИОЎЈ
DecoratorЦР°ьє¬ComponentµДіЙФ±±дБїЈ¬ГїёцConcrete
DecoratorКµПЦАаѕщРиТЄКµПЦoperation()єЇКэЈ¬ёГєЇКэґуЦВ№эіМИзПВЈє
class ConcreteDecorator
{
private Component component;
·µ»ШАаРН operation(){
// ЦґРРЙПТ»ІгµДoperation()Ј¬Іў»сИЎ·µ»ШЅб№ы
·µ»ШЅб№ы = component.operation();
// ДГµЅ·µ»ШЅб№ыєуЈ¬ФЩЧц¶оНвµДґ¦Ан
ґ¦Ан·µ»ШЅб№ы
return ·µ»ШЅб№ы; |
К№УГЧ°КОАаµД№эіМИзПВЈє
// Чј±ёєГЛщУРЧ°КОАа
DecoratorA decoratorA = new DecoratorA();
DecoratorB decoratorB = new DecoratorB();
DecoratorC decoratorC = new DecoratorC();
// Чј±ёєГ ±»Ч°КОµДАа
Component component = new Component();
// ЧйЧ°Ч°КОАа
decoratorC.setComponent(decoratorB);
decoratorB.setComponent(decoratorA);
decoratorA.setComponent(component);
// ЦґРР
decoratorC.operation(); |
ЦґРР№эіМИзПВЈє

УЕµг
1ЎўDecoratorДЈКЅУлјМіР№ШПµµДДїµД¶јКЗТЄА©Х№¶ФПуµД№¦ДЬЈ¬µ«КЗDecoratorїЙТФМṩ±ИјМіРёь¶аµДБй»оРФЎЈјМіРНЁ№эёІёЗµД·ЅКЅЦШРґРиТЄА©Х№µДєЇКэЈ¬µ±И»ТІїЙТФНЁ№эsuper.xxx()»сИЎФ±ѕµД№¦ДЬЈ¬И»єуФЪёГ№¦ДЬ»щґЎЙПА©Х№РВ№¦ДЬЈ¬µ«ЛьЦ»ДЬФцјУДіТ»ПДЬЈ»Из№ыТЄНЁ№эјМіРКµПЦФцјУ¶аЦЦ№¦ДЬЈ¬ДЗГґРиТЄ¶аІгјМіР¶аёцАаАґКµПЦЈ»¶шDecoratorДЈКЅїЙТФФЪФУР№¦ДЬµД»щґЎЙПНЁ№эЧйєПАґФцјУРВ№¦ДЬЈ¬ХвР©РВ№¦ДЬТСѕ±»·вЧ°іЙТ»ёцёц¶АБўµДЧ°КОАаЈ¬ФЪФЛРРЖЪјдНЁ№эґо»эДѕµД·ЅКЅСЎФсЧ°КОАаЖґґХјґїЙЎЈ
2ЎўНЁ№эК№УГІ»Н¬µДѕЯМеЧ°КОАаТФј°ХвР©Ч°КОАаµДЕЕБРЧйєПЈ¬ЙијЖК¦їЙТФґґФміцєЬ¶аІ»Н¬РРОЄµДЧйєПЎЈ
И±µг
1ЎўХвЦЦ±ИјМіРёьјУБй»о»ъ¶ЇµДМШРФЈ¬ТІН¬К±ТвО¶ЧЕёьјУ¶аµДёґФУРФЎЈ
2ЎўЧ°КОДЈКЅ»бµјЦВЙијЖЦРіцПЦРн¶аРЎАаЈ¬Из№ы№э¶ИК№УГЈ¬»бК№іМРт±дµГєЬёґФУЎЈ
3ЎўЧ°КОДЈКЅКЗХл¶ФійПуЧйјюЈЁComponentЈ©АаРН±аіМЎЈµ«КЗЈ¬Из№ыДгТЄХл¶ФѕЯМеЧйјю±аіМК±Ј¬ѕНУ¦ёГЦШРВЛјїјДгµДУ¦УГјЬ№№Ј¬ТФј°Ч°КОХЯКЗ·сєПККЎЈµ±И»ТІїЙТФёД±дComponentЅУїЪЈ¬ФцјУРВµД№«їЄµДРРОЄЈ¬КµПЦЎ°°лНёГчЎ±µДЧ°КОХЯДЈКЅЎЈФЪКµјКПоДїЦРТЄЧціцЧојССЎФсЎЈ
ЙијЖФФт
¶аУГЧйєПЈ¬ЙЩУГјМіРЎЈ
АыУГјМіРЙијЖЧУАаµДРРОЄЈ¬КЗФЪ±аТлК±ѕІМ¬ѕц¶ЁµДЈ¬¶шЗТЛщУРµДЧУАа¶ј»бјМіРµЅПаН¬µДРРОЄЎЈИ»¶шЈ¬Из№ыДЬ№»АыУГЧйєПµДЧц·ЁА©Х№¶ФПуµДРРОЄЈ¬ѕНїЙТФФЪФЛРРК±¶ЇМ¬µШЅшРРА©Х№ЎЈ
. µҐАэДЈКЅ
JavaЦРµҐАэ(Singleton)ДЈКЅКЗТ»ЦЦ№г·єК№УГµДЙијЖДЈКЅЎЈµҐАэДЈКЅµДЦчТЄЧчУГКЗ±ЈЦ¤ФЪJavaіМРтЦРЈ¬ДіёцАаЦ»УРТ»ёцКµАэґжФЪЎЈТ»Р©№ЬАнЖчєНїШЦЖЖчіЈ±»ЙијЖіЙµҐАэДЈКЅЎЈ
µҐАэДЈКЅУРєЬ¶аєГґ¦Ј¬ЛьДЬ№»±ЬГвКµАэ¶ФПуµДЦШёґґґЅЁЈ¬І»ЅцїЙТФјхЙЩГїґОґґЅЁ¶ФПуµДК±јдїЄПъЈ¬»№їЙТФЅЪФјДЪґжїХјдЈ»ДЬ№»±ЬГвУЙУЪІЩЧч¶аёцКµАэµјЦВµДВЯјґнОуЎЈИз№ыТ»ёц¶ФПуУРїЙДЬ№бґ©ХыёцУ¦УГіМРтЈ¬¶шЗТЖрµЅБЛИ«ѕЦНіТ»№ЬАнїШЦЖµДЧчУГЈ¬ДЗГґµҐАэДЈКЅТІРнКЗТ»ёцЦµµГїјВЗµДСЎФсЎЈ
µҐАэДЈКЅУРєЬ¶аЦЦРґ·ЁЈ¬ґуІї·ЦРґ·Ё¶ј»т¶а»тЙЩУРТ»Р©І»ЧгЎЈПВГжЅ«·Ц±р¶ФХвјёЦЦРґ·ЁЅшРРЅйЙЬЎЈ
. ¶цєєДЈКЅ
public class
Singleton{
private static Singleton instance = new Singleton();
private Singleton(){}
public static Singleton newInstance(){
return instance;
}
} |
АаµД№№ФмєЇКэ¶ЁТеОЄprivateЈ¬±ЈЦ¤ЖдЛыАаІ»ДЬКµАэ»ЇґЛАаЈ»
И»єуМṩБЛТ»ёцѕІМ¬КµАэІў·µ»ШёшµчУГХЯЈ»
¶цєєДЈКЅФЪАајУФШµДК±єтѕН¶ФКµАэЅшРРґґЅЁЈ¬КµАэФЪХыёціМРтЦЬЖЪ¶јґжФЪ
УЕµгЈєЦ»ФЪАајУФШµДК±єтґґЅЁТ»ґОКµАэЈ¬І»»бґжФЪ¶аёцПЯіМґґЅЁ¶аёцКµАэµДЗйїцЈ¬±ЬГвБЛ¶аПЯіМН¬ІЅµДОКМвЎЈ
И±µгЈєјґК№ХвёцµҐАэГ»УРУГµЅТІ»б±»ґґЅЁЈ¬¶шЗТФЪАајУФШЦ®єуѕН±»ґґЅЁЈ¬ДЪґжѕН±»АЛ·СБЛЎЈ
ККУГіЎѕ°ЈєХвЦЦКµПЦ·ЅКЅККєПµҐАэХјУГДЪґж±ИЅПРЎЈ¬ФЪіхКј»ЇК±ѕН»б±»УГµЅµДЗйїцЎЈµ«КЗЈ¬Из№ыµҐАэХјУГµДДЪґж±ИЅПґуЈ¬»тµҐАэЦ»КЗФЪДіёцМШ¶ЁіЎѕ°ПВІЕ»бУГµЅЈ¬К№УГ¶цєєДЈКЅѕНІ»єПККБЛЈ¬ХвК±єтѕНРиТЄУГµЅАБєєДЈКЅЅшРРСУіЩјУФШЎЈ
. АБєєДЈКЅ(ґжФЪПЯіМ°ІИ«РФОКМв)
public class
Singleton{
private static Singleton instance = null;
private Singleton(){}
public static Singleton newInstance(){
if(null == instance){
instance = new Singleton();
}
return instance;
}
} |
АБєєДЈКЅЦРµҐАэКЗФЪРиТЄµДК±єтІЕИҐґґЅЁµДЈ¬Из№ыµҐАэТСѕґґЅЁЈ¬ФЩґОµчУГ»сИЎЅУїЪЅ«І»»бЦШРВґґЅЁРВµД¶ФП󣬶шКЗЦ±ЅУ·µ»ШЦ®З°ґґЅЁµД¶ФПуЎЈ
Из№ыДіёцµҐАэК№УГµДґОКэЙЩЈ¬ІўЗТґґЅЁµҐАэПыєДµДЧКФґЅП¶аЈ¬ДЗГґѕНРиТЄКµПЦµҐАэµД°ґРиґґЅЁЈ¬ХвёцК±єтК№УГАБєєДЈКЅѕНКЗТ»ёцІ»ґнµДСЎФсЎЈ
µ«КЗХвАпµДАБєєДЈКЅІўГ»УРїјВЗПЯіМ°ІИ«ОКМвЈ¬ФЪ¶аёцПЯіМїЙДЬ»бІў·ўµчУГЛьµДgetInstance()·Ѕ·ЁЈ¬µјЦВґґЅЁ¶аёцКµАэЈ¬ТтґЛРиТЄјУЛшЅвѕцПЯіМН¬ІЅОКМвЈ¬КµПЦИзПВЎЈ
. АБєєДЈКЅ(ПЯіМ°ІИ«Ј¬µ«Р§ВКµН)
public class
Singleton{
private static Singleton instance = null;
private Singleton(){}
public static synchronized Singleton newInstance(){
if(null == instance){
instance = new Singleton();
}
return instance;
}
} |
јУЛшµДАБєєДЈКЅїґЖрАґјґЅвѕцБЛПЯіМІў·ўОКМвЈ¬УЦКµПЦБЛСУіЩјУФШЈ¬И»¶шЛьґжФЪЧЕРФДЬОКМвЈ¬ТАИ»І»№»НкГАЎЈsynchronizedРЮКОµДН¬ІЅ·Ѕ·Ё±ИТ»°г·Ѕ·ЁТЄВэєЬ¶аЈ¬Из№ы¶аґОµчУГgetInstance()Ј¬АЫ»эµДРФДЬЛрєДѕН±ИЅПґуБЛЎЈ
. АБєєДЈКЅ(ПЯіМ°ІИ«Ј¬Р§ВКёЯ)
public class
Singleton {
private static Singleton instance = null;
private Singleton(){}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
} |
ХвЦЦ·ЅКЅ±ИЙПТ»ЦЦ·ЅКЅЦ»¶ајУБЛТ»РРґъВлЈ¬ДЗѕНКЗФЪsynchronizedЦ®ЙПУЦјУБЛТ»ІгЕР¶Пif (instance
== null)ЎЈХвСщµ±µҐАэґґЅЁНк±ПєуЈ¬І»УГГїґО¶јЅшИлН¬ІЅґъВлїйЈ¬ґУ¶шДЬМбЙэР§ВКЎЈµ±И»Ј¬іэБЛіхКј»ЇµҐАэ¶ФПуµДПЯіМThreadAНвЈ¬їЙДЬ»№ґжФЪЙЩКэПЯіМЈ¬ФЪThreadAґґЅЁН굥АэєуЈ¬ёХКН·ЕЛшµДК±єтЅшИлН¬ІЅґъВлїйЈ¬µ«ґЛК±УРµЪ¶юµАif
(instance == null)ЕР¶ПЈ¬ТтґЛТІѕН±ЬГвБЛґґЅЁ¶аёц¶ФПуЎЈ¶шЗТЅшИлН¬ІЅґъВлїйµДПЯіМПа¶ФЅПЙЩЎЈ
. ѕІМ¬ДЪІїАа(АБєє+ОЮЛш)
public class
Singleton{
private static class SingletonHolder{
public static Singleton instance = new Singleton();
}
private Singleton(){}
public static Singleton newInstance(){
return SingletonHolder.instance;
}
} |
ХвЦЦ·ЅКЅН¬СщАыУГБЛАајУФШ»ъЦЖАґ±ЈЦ¤Ц»ґґЅЁТ»ёцinstanceКµАэЎЈЛьУл¶цєєДЈКЅТ»СщЈ¬ТІКЗАыУГБЛАајУФШ»ъЦЖЈ¬ТтґЛІ»ґжФЪ¶аПЯіМІў·ўµДОКМвЎЈІ»Т»СщµДКЗЈ¬ЛьКЗФЪДЪІїАаАпГжИҐґґЅЁ¶ФПуКµАэЎЈХвСщµД»°Ј¬Ц»ТЄУ¦УГЦРІ»К№УГДЪІїАаЈ¬JVMѕНІ»»бИҐјУФШХвёцµҐАэАаЈ¬ТІѕНІ»»бґґЅЁµҐАэ¶ФП󣬴ӶшКµПЦАБєєКЅµДСУіЩјУФШЎЈТІѕНКЗЛµХвЦЦ·ЅКЅїЙТФН¬К±±ЈЦ¤СУіЩјУФШєНПЯіМ°ІИ«ЎЈ
. Г¶ѕЩ
public enum
Singleton{
instance;
public void whateverMethod(){}
} |
ЙПГжМбµЅµДЛДЦЦКµПЦµҐАэµД·ЅКЅ¶јУР№ІН¬µДИ±µгЈє
1ЎўРиТЄ¶оНвµД№¤ЧчАґКµПЦРтБР»ЇЈ¬·сФтГїґО·ґРтБР»ЇТ»ёцРтБР»ЇµД¶ФПуК±¶ј»бґґЅЁТ»ёцРВµДКµАэЎЈ
2ЎўїЙТФК№УГ·ґЙдЗїРРµчУГЛЅУР№№ФмЖчЈЁИз№ыТЄ±ЬГвХвЦЦЗйїцЈ¬їЙТФРЮёД№№ФмЖчЈ¬ИГЛьФЪґґЅЁµЪ¶юёцКµАэµДК±єтЕЧТміЈЈ©ЎЈ
¶шГ¶ѕЩАаєЬєГµДЅвѕцБЛХвБЅёцОКМвЈ¬К№УГГ¶ѕЩіэБЛПЯіМ°ІИ«єН·АЦ№·ґЙдµчУГ№№ФмЖчЦ®НвЈ¬»№МṩБЛЧФ¶ЇРтБР»Ї»ъЦЖЈ¬·АЦ№·ґРтБР»ЇµДК±єтґґЅЁРВµД¶ФПуЎЈТтґЛЈ¬Ў¶Effective
JavaЎ·ЧчХЯНЖјцК№УГµД·Ѕ·ЁЎЈІ»№эЈ¬ФЪКµјК№¤ЧчЦРЈ¬єЬЙЩїґјыУРИЛХвГґРґЎЈ
. ДЈ°е·Ѕ·ЁДЈКЅ
¶ЁТе
ФЪёёАаЦР¶ЁТеЛг·ЁµДБчіМЈ¬¶шЛг·ЁµДДіР©ОЮ·ЁИ·¶ЁµДПёЅЪЈ¬НЁ№эійПуєЇКэµДРОКЅЈ¬ФЪЧУАаЦРИҐКµПЦЎЈ
ТІїЙТФАнЅвОЄЈ¬Т»МЧЛг·ЁµДДіР©ІЅЦиїЙДЬЛжЧЕТµОсµД·ўХ№¶шёД±дЈ¬ДЗГґОТГЗїЙТФЅ«И·¶ЁµДІЅЦиФЪёёАаЦРКµПЦЈ¬¶шїЙ±дµДІЅЦиЧчОЄійПуєЇКэИГЖдФЪЧУАаЦРКµПЦЎЈ
ФЪДЈ°е·Ѕ·ЁДЈКЅЦРЈ¬ёёАаКЗТ»ёційПуАаЈ¬Лг·ЁµДГїТ»ІЅ¶ј±»·вЧ°іЙТ»ёцєЇКэЈ¬templateMethodєЇКэЅ«ЛщУРЛг·ЁІЅЦиґ®БЄЖрАґЎЈ
¶ФУЪІ»±дµДІЅЦиЈ¬УГprivateРЮКОЈ¬·АЦ№ЧУАаЦШРґЈ»
¶ФУЪїЙ±дµДІЅЦиЈ¬УГabstract protectedРЮКОЈ¬±ШРлТЄЗуЧУАаЦШРґЈ»
ЧУАаЦШРґНкЛщУРійПуєЇКэєуЈ¬µчУГtemplateMethodјґїЙЦґРРЛг·ЁЎЈ
. Нв№ЫДЈКЅ
Нв№ЫДЈКЅХвЦЦЛјПлФЪПоДїЦРЖХ±йґжФЪЈ¬ТІј«ЖдИЭТЧАнЅвЈ¬ґујТТ»¶ЁУГ№эЈ¬Ц»КЗГ»УРЙПЙэµЅАнВЫµДІгГжЎЈХвАп¶ФХвЦЦЛјПлЅшРРЅйЙЬЎЈ
Нв№ЫДЈКЅЛыЖБ±ОБЛПµНі№¦ДЬКµПЦµДёґФУРФЈ¬ПтїН»§¶ЛМṩһМЧј«ЖдјтµҐµДЅУїЪЎЈїН»§¶ЛЦ»РиТЄЦЄµАЅУїЪМṩʲô№¦ДЬЈ¬ИзєОµчУГѕНРРБЛЈ¬І»РиТЄ№ЬХвР©ЅУїЪ±ієуКЗИзєОКµПЦµДЎЈґУ¶шК№µГїН»§¶ЛєНПµНіЦ®јдµДсоєП¶ИґуґуЅµµНЈ¬їН»§¶ЛЦ»РиёъТ»МЧјтµҐµДFacadeЅУїЪґтЅ»µАјґїЙЎЈ
. ККЕдЖчДЈКЅ
¶ЁТе
ЧчОЄТ»ёц»щЅрЅ»ТЧЖЅМЁЈ¬РиТЄМṩһМЧЅУїЪ№ж·¶Ј¬№©ёчёц»щЅр№«ЛѕЅУИлЎЈИ»¶шЈ¬ёчёц»щЅр№«ЛѕµДЅУїЪёчІ»ПаН¬Ј¬Г»УР°м·ЁЦ±ЅУєНЖЅМЁЅУїЪ¶ФЅУЎЈґЛК±Ј¬ёчёц»щЅр№«ЛѕРиТЄЧФРРКµПЦТ»ёцККЕдЖчЈ¬ККЕдЖчНкіЙІ»Н¬ЅУїЪµДЧЄ»»№¤ЧчЈ¬К№µГ»щЅр№«ЛѕµДЅУїЪєНЖЅМЁМṩµДЅУїЪ¶ФЅУЙПЎЈ
. ИэЦЦККЕдЖч
ККЕдЖчДЈКЅУРИэЦЦКµПЦ·ЅКЅЈ¬ПВГж¶јТФ»щЅрЅ»ТЧЖЅМЁµДАэЧУАґЅвКНЎЈ
»щЅр№«ЛѕµДЅ»ТЧЅУїЪЈє
/**
* »щЅр№«ЛѕµДЅ»ТЧЅУїЪ
*/
class FundCompanyTrade{
/**
* ВтИлєЇКэ
*/
public void mairu() {
// ЎЎ
}
/**
* ВфіцєЇКэ
*/
public void maichu() {
// ЎЎ
}
} |
»щЅрЅ»ТЧЖЅМЁµДЅ»ТЧЅУїЪ
/**
* »щЅрЅ»ТЧЖЅМЁµДЅ»ТЧЅУїЪ
*/
interface FundPlatformTrade {
// ВтИлЅУїЪ
void buy();
// ВфіцЅУїЪ
void sell();
} |
»щЅрЅ»ТЧЖЅМЁѕщНЁ№эИзПВґъВлµчУГёчёц»щЅр№«ЛѕµДЅ»ТЧЅУїЪЈє
class Client
{
@Autowired
private FundPlatformTrade fundPlatformTrade;
/**
* ВтИл»щЅр
*/
public void buy() {
fundPlatformTrade.buy();
}
/**
* Вфіц»щЅр
*/
public void sell() {
fundPlatformTrade.sell();
}
} |
·ЅКЅ1ЈєАаККЕдЖч
НЁ№эјМіРАґКµПЦЅУїЪµДЧЄ»»ЎЈ
»щЅрЅ»ТЧККЕдЖчЈє
class Adapter
extends FundCompanyTrade implements FundPlatformTrade
{
void buy() {
mairu();
}
void sell(){
maichu();
}
} |
ККЕдЖчAdapterјМіРБЛFundCompanyTradeЈ¬ТтґЛУµУРБЛFundCompanyTradeВтИлєНВфіцµДДЬБ¦Ј»ККЕдЖчAdapterУЦКµПЦБЛFundPlatformTradeЈ¬ТтґЛРиТЄКµПЦЖдЦРµДВтИлєНВфіцЅУїЪЈ¬Хвёц№эіМ±гНкіЙБЛ»щЅр№«ЛѕЅ»ТЧЅУїЪПт»щЅрЖЅМЁЅ»ТЧЅУїЪµДЧЄ»»ЎЈ
К№УГК±Ј¬Ц»РиЅ«AdapterНЁ№эSpringЧўИлёшClientАаµДfundPlatformTradeіЙФ±±дБїјґїЙЈє
<!-- ЙщГчAdapter¶ФПу
-->
<bean name="adapter" class="Adapter">
</bean>
<!-- Ѕ«adapterЧўИлёшClient -->
<bean class="Client">
<property
name="fundPlatformTrade" ref="adapter"
/>
</bean> |
·ЅКЅ2Јє¶ФПуККЕдЖч
НЁ№эЧйєПАґКµПЦЅУїЪµДЧЄ»»ЎЈ
»щЅрЅ»ТЧККЕдЖчЈє
class Adapter
implements FundPlatformTrade {
@Autowired
private FundCompanyTrade fundCompanyTrade;
void buy() {
fundCompanyTrade.mairu();
}
void sell(){
fundCompanyTrade.maichu();
}
} |
ХвЦЦ·ЅКЅЦРЈ¬ККЕдЖчAdapterІўОґјМіРFundCompanyTradeЈ¬¶шКЗЅ«ёГ¶ФПуЧчОЄіЙФ±±дБїЧўИлЅшАґЈ¬Т»СщїЙТФґпµЅН¬СщµДР§№ыЎЈ
·ЅКЅ3ЈєЅУїЪККЕдЖч
µ±ґжФЪХвСщТ»ёцЅУїЪЈ¬ЖдЦР¶ЁТеБЛN¶аµД·Ѕ·ЁЈ¬¶шОТГЗПЦФЪИґЦ»ПлК№УГЖдЦРµДТ»ёцµЅјёёц·Ѕ·ЁЈ¬Из№ыОТГЗЦ±ЅУКµПЦЅУїЪЈ¬ДЗГґОТГЗТЄ¶ФЛщУРµД·Ѕ·ЁЅшРРКµПЦЈ¬ДДЕВОТГЗЅцЅцКЗ¶ФІ»РиТЄµД·Ѕ·ЁЅшРРЦГїХЈЁЦ»РґТ»¶ФґуАЁєЕЈ¬І»ЧцѕЯМе·Ѕ·ЁКµПЦЈ©ТІ»бµјЦВХвёцАа±дµГУ·ЦЧЈ¬µчУГТІІ»·Ѕ±гЈ¬ХвК±ОТГЗїЙТФК№УГТ»ёційПуАаЧчОЄЦРјдјюЈ¬јґККЕдЖчЈ¬УГХвёційПуАаКµПЦЅУїЪЈ¬¶шФЪійПуАаЦРЛщУРµД·Ѕ·Ё¶јЅшРРЦГїХЈ¬ДЗГґОТГЗФЪґґЅЁійПуАаµДјМіРАаЈ¬¶шЗТЦШРґОТГЗРиТЄК№УГµДДЗјёёц·Ѕ·ЁјґїЙЎЈ
Дї±кЅУїЪЈєA
public interface
A {
void a();
void b();
void c();
void d();
void e();
void f();
} |
ККЕдЖчЈєAdapter
КµПЦЛщУРєЇКэЈ¬Ѕ«ЛщУРєЇКэПИЦГїХЎЈ
public abstract
class Adapter implements A {
public void a(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
public void b(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
public void c(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
public void d(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
public void e(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
public void f(){
throw new UnsupportedOperationException("¶ФПуІ»Ц§іЦХвёц№¦ДЬ");
}
} |
КµПЦАаЈєAshili
јМіРККЕдЖчАаЈ¬СЎФсРФµШЦШРґПаУ¦єЇКэЎЈ
public class Ashili extends Adapter {
public void a(){
System.out.println("КµПЦA·Ѕ·Ё±»µчУГ");
}
public void d(){
System.out.println("КµПЦd·Ѕ·Ё±»µчУГ");
}
}
. µьґъЖчДЈКЅ
¶ЁТе
µьґъЖчДЈКЅУГУЪФЪОЮРиБЛЅвИЭЖчДЪІїПёЅЪµДЗйїцПВЈ¬КµПЦИЭЖчµДµьґъЎЈ
ИЭЖчУГУЪґжґўКэѕЭЈ¬¶шИЭЖчµДґжґўЅб№№ЦЦАа·±¶аЎЈФЪІ»К№УГККЕдЖчДЈКЅµДЗйїцПВЈ¬Из№ыТЄµьґъИЭЖчЦРµДФЄЛШЈ¬ѕНРиТЄід·ЦАнЅвИЭЖчµДґжґўЅб№№ЎЈґжґўЅб№№І»Н¬Ј¬µјЦВБЛІ»Н¬ИЭЖчµДµьґъ·ЅКЅ¶јІ»Т»СщЎЈХвОЮТЙФцјУБЛОТГЗК№УГИЭЖчµДіЙ±ѕЎЈ
¶шµьґъЖчДЈКЅМбіцБЛТ»ЦЦµьґъИЭЖчФЄЛШµДРВЛјВ·Ј¬µьґъЖч№ж¶ЁБЛТ»ЧйµьґъИЭЖчµДЅУїЪЈ¬ЧчОЄИЭЖчК№УГХЯЈ¬Ц»Ри»бУГХвМЧµьґъЖчјґїЙЎЈИЭЖч±ѕЙнРиТЄКµПЦХвМЧµьґъЖчЅУїЪЈ¬ІўКµПЦЖдЦРµДµьґъєЇКэЎЈТІѕНКЗИЭЖчМṩ·ЅФЪМṩИЭЖчµДН¬К±Ј¬»№РиТЄМṩµьґъЖчµДКµПЦЎЈТтОЄИЭЖч±ѕЙнКЗБЛЅвЧФјєµДґжґўЅб№№µДЈ¬УЙЛьАґКµПЦµьґъєЇКэ·ЗіЈєПККЎЈ¶шОТГЗЧчОЄИЭЖчµДК№УГХЯЈ¬Ц»РиЦЄµАФхГґУГµьґъЖчјґїЙЈ¬ОЮРиБЛЅвИЭЖчДЪІїµДґжґўЅб№№ЎЈ
АаНјГиКц 
ФЪµьґъЖчДЈКЅЦРЈ¬Т»№ІУРБЅЦЦЅЗЙ«ЈєµьґъЖч єН ИЭЖч
µьґъЖч IteratorЈє·вЧ°БЛµьґъИЭЖчµДЅУїЪ
ИЭЖч ContainerЈєґжґўФЄЛШµД¶«Оч
ИЭЖчИфТЄѕЯ±ёµьґъµДДЬБ¦Ј¬ѕН±ШРлУµУРgetIterator()єЇКэЈ¬ёГєЇКэЅ«»б·µ»ШТ»ёцµьґъЖч¶ФПу
ГїёцИЭЖч¶јУРКфУЪЧФјєµДµьґъЖчДЪІїАаЈ¬ёГДЪІїАаКµПЦБЛIteratorЅУїЪЈ¬ІўКµПЦБЛЖдЦРУГУЪµьґъµДБЅёцєЇКэhasNext()єНnext()
boolean hasNext()ЈєУГУЪЕР¶Пµ±З°ИЭЖчКЗ·с»№УРЙРОґµьґъНкµДФЄЛШ
Object next()ЈєУГУЪ»сИЎПВТ»ёцФЄЛШ
ґъВлКµПЦ
µьґъЖчЅУїЪЈє
public interface
Iterator {
public boolean hasNext();
public Object next();
} |
ИЭЖчЅУїЪЈє
public interface
Iterator {
public boolean hasNext();
public Object next();
} |
ѕЯМеµДИЭЖчЈЁ±ШРлКµПЦContainerЅУїЪЈ©Јє
public class
NameRepository implements Container {
public String names[] = {"Robert" ,
"John" ,"Julie" , "Lora"};
@Override
public Iterator getIterator() {
return new NameIterator();
}
private class NameIterator implements Iterator
{
int index;
@Override
public boolean hasNext() {
if(index < names.length){
return true;
}
return false;
}
@Override
public Object next() {
if(this.hasNext()){
return names[index++];
}
return null;
}
}
} |
ѕЯМеµДИЭЖчКµПЦБЛContainerЅУїЪЈ¬ІўКµПЦБЛЖдЦРµДgetIterator()єЇКэЈ¬ёГєЇКэУГУЪ·µ»ШёГИЭЖчµДµьґъЖч¶ФПуЎЈ
ИЭЖчДЪІїРиТЄКµПЦЧФјєµДµьґъЖчДЪІїАаЈ¬ёГДЪІїАаКµПЦIteratorЅУїЪЈ¬ІўКµПЦБЛЖдЦРµДhasNext()єНnext()єЇКэЎЈ
µ±ИЭЖчєНИЭЖчµДµьґъЖчґґЅЁНк±ПєуЈ¬ЅУПВАґѕНВЦµЅУГ»§К№УГБЛЈ¬К№УГѕН·ЗіЈјтµҐБЛЈє
public class
IteratorPatternDemo {
public static void main(String[] args) {
NameRepository namesRepository = new NameRepository();
for(Iterator iter = namesRepository.getIterator();
iter.hasNext();){
String name = (String)iter.next();
System.out.println("Name : " + name);
}
}
} |
¶ФУЪК№УГХЯ¶шСФЈ¬Ц»ТЄЦЄµАIteratorЅУїЪЈ¬ѕНДЬ№»µьґъЛщУРІ»Н¬ЦЦАаµДИЭЖчБЛЎЈ
. ЧйєПДЈКЅ
¶ЁТе
ЧйєПДЈКЅ¶ЁТеБЛКчРОЅб№№µДОпАнґжґў·ЅКЅЎЈ
ПЦКµКАЅзЦРКчРОЅб№№µД¶«ОчЈ¬ФЪґъВлКµПЦЦРЈ¬¶јїЙТФУГЧйєПДЈКЅАґ±нКѕЎЈ
±ИИзЈє¶ај¶ІЛµҐЎў№«ЛѕµДЧйЦЇЅб№№µИµИЎЈ
ПВГжѕНТФ¶ај¶ІЛµҐОЄАэЈ¬ЅйЙЬЧйєПДЈКЅЎЈ
АэЧУ
јЩЙиОТГЗТЄКµПЦТ»ёц¶ај¶ІЛµҐЈ¬ІўКµПЦ¶ај¶ІЛµҐµДФцЙѕёДІйІЩЧчЎЈІЛµҐИзПВЈє
Т»ј¶ІЛµҐA
¶юј¶ІЛµҐA_1
Иэј¶ІЛµҐA_1_1
Иэј¶ІЛµҐA_1_2
Иэј¶ІЛµҐA_1_3
¶юј¶ІЛµҐA_2
Т»ј¶ІЛµҐB
¶юј¶ІЛµҐB_1
¶юј¶ІЛµҐB_2
¶юј¶ІЛµҐB_3
¶юј¶ІЛµҐB_4
Иэј¶ІЛµҐB_4_1
Иэј¶ІЛµҐB_4_2
Иэј¶ІЛµҐB_4_3
Т»ј¶ІЛµҐC
¶юј¶ІЛµҐC_1
¶юј¶ІЛµҐC_2
¶юј¶ІЛµҐC_3 |
ІЛµҐµДМШµгИзПВЈє
Йо¶ИІ»ПЮЈ¬їЙТФУРОЮПЮј¶ІЛµҐ
ГїІгІЛµҐКэБїІ»ПЮ
АаНјГиКц
Item±нКѕКчЦРµДЅЪµгЈ»
ItemЦР°ьє¬БЅёціЙФ±±дБїЈє
parentЈєЦёПтµ±З°ЅЪµгµДёёЅЪµг
childListЈєµ±З°ЅЪµгµДЧУЅЪµгБР±н
ХвЦЦItemЦРУЦ°ьє¬ItemµД№ШПµѕН№№іЙБЛЧйєПДЈКЅЎЈ
ЧўТвЈєС»·ТэУГ
ФЪ№№ЅЁКчµД№эіМЦРЈ¬їЙДЬ»біцПЦС»·ТэУГЈ¬ґУ¶шФЪ±йАъКчµДК±єтїЙДЬѕН»біцПЦЛАС»·ЎЈТтґЛЈ¬ОТГЗРиТЄФЪМнјУЅЪµгµДК±єт±ЬГвС»·ТэУГµДіцПЦЎЈ
ОТГЗїЙТФФЪItemЦРФЩМнјУТ»ёцListіЙФ±±дБїЈ¬УГУЪјЗВјёщЅЪµгµЅµ±З°ЅЪµгµДВ·ѕ¶ЎЈёГВ·ѕ¶їЙТФУГГїёцЅЪµгµДID±нКѕЎЈТ»µ©РВјУИлµДЅЪµгIDТСѕіцПЦФЪµ±З°В·ѕ¶ЦРµДК±єтЈ¬ѕНЛµГчіцПЦБЛС»·ТэУГЈ¬ґЛК±У¦ёГёшіцМбКѕЎЈ
. ЧґМ¬ДЈКЅ
К№УГіЎѕ°
Из№ыТ»ёцєЇКэЦРіцПЦґуБїµДЎўёґФУµДif-elseЕР¶ПЈ¬ХвК±єтѕНТЄїјВЗК№УГЧґМ¬ДЈКЅБЛЎЈ
ТтОЄґуБїµДif-elseЦРНщНщ°ьє¬БЛґуБїµДТµОсВЯјЈ¬єЬУРїЙДЬ»бЛжЧЕТµОсµД·ўХ№¶ш±д»ЇЎЈИз№ыЅ«ХвР©ТµОсВЯј¶јРґЛАФЪТ»ёцАаЦРЈ¬ДЗГґµ±ТµОсВЯј·ўЙъ±д»ЇµДК±єтѕНРиТЄРЮёДХвёцАаЈ¬ґУ¶шОҐ·ґБЛїЄ·Е·в±ХФФтЎЈ¶шЧґМ¬ДЈКЅѕНДЬєЬєГµШЅвѕцХвТ»ОКМвЎЈ
ЧґМ¬ДЈКЅЅ«ГїТ»ёцЕР¶П·ЦЦ§¶ј·вЧ°іЙТ»ёц¶АБўµДАаЈ¬ГїТ»ёцЕР¶П·ЦЦ§іЙОЄТ»ЦЦЎ°ЧґМ¬Ў±Ј¬ТтґЛГїТ»ёц¶АБўµДАаѕНіЙОЄТ»ёцЎ°ЧґМ¬АаЎ±ЎЈІўЗТУЙТ»ёцИ«ѕЦЧґМ¬№ЬАнХЯContextАґО¬»¤µ±З°µДЧґМ¬ЎЈ
АаНјГиКц
ФЪЧґМ¬ДЈКЅЦРЈ¬ГїТ»ёцЕР¶П·ЦЦ§±»іЙОЄТ»ЦЦЧґМ¬Ј¬ГїТ»ЦЦЧґМ¬Ј¬¶ј»б±»·вЧ°іЙТ»ёцµҐ¶АµДЧґМ¬АаЈ»
ЛщУРµДЧґМ¬Аа¶јУРТ»ёц№ІН¬µДЅУїЪЎЄЎЄState
StateЅУїЪЦРУРТ»ёцdoActionєЇКэЈ¬ГїёцЧґМ¬АаµДЧґМ¬ґ¦АнВЯјѕщФЪёГєЇКэЦРНкіЙЈ»±ШРлЅ«Context¶ФПуЧчОЄdoActionєЇКэµДІОКэґ«ИлЎЈёГєЇКэµДЅб№№ИзПВЈє
class StateA
implements State{
public void doAction(Context context){
if (ВъЧгМхјю) {
// ЦґРРПаУ¦µДТµОсВЯј
}
else {
// ЙиЦГПВТ»МшЧґМ¬
context.setState(new StateB());
// ЦґРРПВТ»МшЧґМ¬
context.doCurState();
}
}
} |
ГїёцЧґМ¬АаµДdoActionєЇКэЦР¶јУРЗТЅцУРТ»¶Фif-elseЈ¬ifЦРМоРґВъЧгМхјюК±µДТµОсВЯјЈ¬¶шelseЦРМоРґІ»ВъЧгМхјюК±µДТµОсВЯјЎЈ
elseЦРµДґъВл¶јТ»СщЈ¬УРЗТЅцУРХвБЅІЅЈє
КЧПИЅ«contextµДstateЙиОЄПВТ»ёцЧґМ¬¶ФПуЈ»
И»єуµчУГcontextµДdoCurState()ЦґРРЈ»
ContextАаЖдКµѕНКЗФ±ѕ°ьє¬ДЗёцѕЮґуЎўёґФУµДif-elseµДАаЎЈёГАаЦРіЦУРБЛState¶ФП󣬱нКѕµ±З°ТЄЦґРРµДЧґМ¬¶ФПуЎЈ
ContextАа±ШРлТЄУРТ»ёцdoCurStateєЇКэЈ¬ёГєЇКэµДґъВл¶јТ»СщЈєstate.doAction()
їЄЖфЧґМ¬ЕР¶П№эіМµДґъВлИзПВЈє
// Чј±ёєГµЪТ»ёцЧґМ¬
StateA stateA = new StateA();
// ЙиЦГµЪТ»ёцЧґМ¬
context.setState(stateA);
// їЄКјЦґРР
context.doCurState(); |
УЕµг
ЧґМ¬ДЈКЅЅ«Ф±ѕФЪТ»ёцАаЦРµДЕУґуµДif-elseІр·ЦіЙТ»ёцёц¶АБўµДЧґМ¬АаЎЈФ±ѕХвёц°ьє¬ЕУґуif-elseµДАаіЙОЄContextЈ¬°ьє¬БЛµ±З°µДЧґМ¬ЎЈContextЦ»РиТЄЦЄµАЖрКјЧґМ¬АајґїЙЈ¬І»РиТЄЦЄµАЖдЛыЧґМ¬АаµДґжФЪЎЈТІѕНКЗContextЦ»УлµЪТ»ёцЧґМ¬Аа·ўЙъсоєПЎЈ¶шГїТ»ёцЧґМ¬АаЦ»єНПВТ»ёцЧґМ¬Аа·ўЙъсоєПЈ¬ґУ¶шРОіЙТ»МхЧґМ¬ЕР¶ПБґЎЈЧґМ¬АаЦ®јдµДсоєПНЁ№эSpring
XMLОДјюЕдЦГЎЈХвСщЈ¬µ±ЕР¶ПВЯј·ўЙъ±д»ЇµДК±єтЈ¬Ц»РиТЄРВФцЧґМ¬АаЈ¬ІўНЁ№эРЮёДXMLµД·ЅКЅЅ«РВµДЧґМ¬АаІеИлµЅЕР¶ПВЯјЦРЎЈґУ¶шВъЧгБЛїЄ·Е·в±ХФФтЎЈ
ґъАнДЈКЅ
. ґъАнДЈКЅ
ґъАнДЈКЅКЗФЪІ»ёД±дДї±кАаєНК№УГХЯµДЗ°МбПВЈ¬А©Х№ёГАаµД№¦ДЬЎЈ
ґъАнДЈКЅЦРґжФЪЎєДї±к¶ФПуЎ»єНЎєґъАн¶ФПуЎ»Ј¬ЛьГЗ±ШРлКµПЦПаН¬µДЅУїЪЎЈУГ»§Ц±ЅУК№УГґъАн¶ФП󣬶шґъАн¶ФПу»бЅ«УГ»§µДЗлЗуЅ»ёшДї±к¶ФПуґ¦АнЎЈґъАн¶ФПуїЙТФ¶ФУГ»§µДЗлЗуФцјУ¶оНвµДґ¦АнЎЈ
Java¶ЇМ¬ґъАнµДК№УГ
КЧПИДгµГУµУРТ»ёцДї±к¶ФПуЈ¬ёГ¶ФПу±ШРлТЄКµПЦТ»ёцЅУїЪЈє
public interface
Subject
{
public void doSomething();
}
public class RealSubject implements Subject
{
public void doSomething()
{
System.out.println( "call doSomething()"
);
}
} |
ЖдґОЈ¬ОЄДї±к¶ФПуФцјУ¶оНвµДВЯјЈє
ЧФ¶ЁТеТ»ёцАаЈ¬ІўКµПЦInvocationHandlerЅУїЪЈ»
КµПЦinvokeєЇКэЈ¬ІўЅ«РиТЄФцјУµДВЯјРґФЪёГєЇКэЦРЈ»
public class
ProxyHandler implements InvocationHandler
{
private Object proxied;
public ProxyHandler( Object proxied )
{
this.proxied = proxied;
}
public Object invoke( Object proxy, Method method,
Object[] args ) throws Throwable
{
//ФЪЧЄµчѕЯМеДї±к¶ФПуЦ®З°Ј¬їЙТФЦґРРТ»Р©№¦ДЬґ¦Ан
//ЧЄµчѕЯМеДї±к¶ФПуµД·Ѕ·Ё
return method.invoke( proxied, args);
//ФЪЧЄµчѕЯМеДї±к¶ФПуЦ®єуЈ¬їЙТФЦґРРТ»Р©№¦ДЬґ¦Ан
}
} |
ґґЅЁґъАн¶ФП󣬵чУГХЯЦ±ЅУК№УГёГ¶ФПујґїЙЈє
RealSubject
real = new RealSubject();
Subject proxySubject = (Subject)Proxy.newProxyInstance
(Subject.class.getClassLoader(),
new Class[]{Subject.class},
new ProxyHandler(real));
proxySubject.doSomething(); |
|








