| БрМЭЦМі: |
БОЮФжївЊНВЪіСЫеНТдВуУцЕФDDDддђЃЌЯрЖдРДЫЕНЯЮЊГщЯѓЃЌЕЋетЪЧзюПМбщФкЙІЁЂзюВЛПЩКіЪгЕФЛЗНкЁЃ
БОЮФРДздгкvivoЛЅСЊЭјММЪѕЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
СьгђЧ§ЖЏЩшМЦЃЈDomain Driven DesignЃЌDDDЃЉЦфЪЕВЂЗЧаТРэТлЃЌДѓМвПЩвдПДПД
Eric Evans БржјЕФЁЖСьгђЧ§ЖЏЩшМЦЁЗдИхЪзАцЪЧ2003ФъЃЌОрНёвбЪЎгрФъЪБМфЁЃгыЯждкЕФЗжВМЪНЁЂЮЂЗўЮёЯрБШЃЌОјЖдЪЧМДНЋВНШыжаФъЕФЁАРЯМвЛяЁБСЫЁЃ
жБЕННќаЉФъЮЂЗўЮёРэТлБЛЬсГіЁЂБЛЛЅСЊЭјаавЕЙуЗКЪЙгУЃЌШЫУЧЫЦКѕгжжиаТЗЂЯжСЫСьгђЧ§ЖЏЩшМЦЕФМлжЕЁЃЫљвдПДЦ№РДвВШЗЪЕЪЧвђЮЊЮЂЗўЮёЃЌСьгђЧ§ЖЏЩшМЦВХгРДСЫЕкЖўДКЁЃ
ВЛЙ§ЮвЗЂЯжДѓМвЖдDDDвВДцгавЛаЉЮѓЧјЃЌЪЙЦфНЅНЅГЩСЫвЛУХЁАИпЩюЕФаўбЇЁБЃЌЫцжЎгжБЛДѓМвЪјжЎИпИѓЁЃЮвБОШЫдкЙ§ШЅСНФъЖрЕФЪБМфРяЃЌбаЖСЙ§ЖрБОDDDЯрЙиЕФОЕфТлжјЁЂвВЧыНЬЙ§вЛаЉзЪЩюDDDerЃЌВЂдкЯюФПжаЪЕМљЙ§ЁЃ
ВЛЙ§дкГѕВНбЇЯАЁЂЪЕМљжЎКѓЮвгжДјзХвЩЮЪгыздМКЕФЫМПМжиаТЖССЫвЛБщЯрЙиЕФжјЪіРэТлЁЃж№НЅСьЮђЕНDDDзїЮЊвЛжжЫМЯыЃЌЦфЪЕРыЮвУЧКмНќЁЃ
ЮвАбздМКЕФбЇЯАЙ§ГЬЁЂЫМПМБраДГЩЯЕСаЮФеТЃЌгыДѓМввЛЦ№ЬНЬжбЇЯАЃЌЯЃЭћДѓМвФмЙЛгаЫљЪеЛёЃЌЕБШЛЦфжаВЛе§ШЗЕФЕиЗНвВЛЖгДѓМвХњЦРжИе§ЁЃ
ЭЌЪБЃЌдкЮФеТжаЮввВЛсв§гУЯрЙиЕФТлжјЛђепвЛаЉЮвШЯЮЊВЛДэЕФАИР§ЫиВФЃЌШЈЕБЪЧЮвУЧЖдетаЉжЊЪЖЕФЯъЯИкЙЪЭЃЌдкетРявЛВЂЖдетаЉDDDЧАБВЕФВЛОыЬНЫїБэЪОИааЛЁЃ

ЃЈDDDЯрЙиЕФОЕфТлжјЃЉ
вЛЁЂЙигкDDDЕФЮѓЧј
1ЁЂDDDЪЧНтОіДѓаЭИДдгЯюФПЕФЃЌЮвУЧЕБЧАвЕЮёБШНЯМђЕЅЃЌВЛЪЪКЯDDDЁЃ
2ЁЂDDDвЊгавЛИіЭъећЕФЁЂЗћКЯDDDддђЕФДњТыНсЙЙЃЌетПЩФмдіМгДњТыЕФИДдгЖШЃЌгаПЩФмЕМжТЯюФПНјЖШЪЇПиЁЃ
3ЁЂDDDЪЧвЛжжПђМмЃЌгІИУАќКЌОлКЯИљЁЂЪЕЬхЁЂСьгђЪТМўЁЂВжДЂЖЈвхЁЂЯоНчЩЯЯТЮФЕШвЛЧаDDDЫљГЋЕМЕФдЊЫиЃЛЗёдђФуОЭВЛЪЧDDDerЁЃ
4ЁЂDDDашвЊДѓМвбЯИёзёбИїздФЃПщЕФБпНчЃЌЧвДцдкзХЙ§ЖрвђЮЊНтёюДјРДЕФПДЫЦШпгрУЛгУЕФДњТыЃЌЛсНЕЕЭБрТыаЇТЪЃЌдьГЩЁАРрХђеЭЁБЁЃ
ЖўЁЂDDDРыЮвУЧКмНќ
DDDЪЧЪВУДЃПжкРябАЫ§ЧЇАйЖШЃЌныШЛЛиЪзЃЌЁАDDDЪЧвЛжжПЩвдНшМјЕФЫМЯыЃЌЖјЗЧбЯИёзёбЕФЗНЗЈТлЁБЁЃ
1ЁЂСьгђЧ§ЖЏЩшМЦжаЕФСьгђФЃаЭ
ЕБЮвУЧУцЯђвЕЮёПЊЗЂЕФЙ§ГЬжаЃЌгІИУЪзЯШЫМПМСьгђФЃаЭЖјВЛЪЧШчКЮНЈБэЁЃ
ЮвЬ§Й§ЬЋЖрвЕЮёПЊЗЂЕФЩљвєЃЌЁАУцЪддьКНФИЁЂЙЄзїХЁТнЫПЁБЃЌШеГЃЙЄзїОЭЪЧНЈБэаДдіЩОИФВщЁЃЮЊЪВУДЛсгаетбљЕФШЯжЊЃЌЦфИљдДдкгкБэЧ§ЖЏЩшМЦЫМЯыЖјЗЧСьгђЧ§ЖЏЩшМЦЁЃ
ЧАепжЛФмдіМгЪ§ОнПтЕФБэЪ§СПЃЌЖјКѓепВХЛсаЮГЩГЄЦкЕФЁЂОпгавЕЮёвтвхЕФФЃаЭЃЌетбљЕФЯЕЭГЩњУќСІВХИќМгГЄОУЁЃЮвУЧвВВХФмгУЙЄГЬЕФЗНЗЈРДБрТыЃЌДгБрТызЊЩэЮЊвЕЮёгђЕФПЊЗЂзЈМвЁЃ

гаКмЖрЙигкСьгђЧ§ЖЏЩшМЦЕФТлЪіжаЖМВЂЮДУїШЗЮвУЧШчКЮЕУЕНЁАСьгђЁБЃЌжЛгаКЯРэЕФСьгђФЃаЭВХФмгааЇЧ§ЖЏЩшМЦПЊЗЂЁЃЫљвдНЈКУСьгђФЃаЭЪЧЙиМќЃЌЖдгкСьгђФЃаЭЕФЫМПМгыММЪѕПђМмЩ§МЖЭЌбљживЊЁЃЮвдјОдкЛЅСЊЭјВПУХЗжЯэЙ§ШчКЮНјааСьгђНЈФЃЃЌвВЛЖгДѓМвгыЮвНЛСїЙЕЭЈЃЌгааЫШЄЕФЖСепвВПЩвджиЕудФЖСвЛЯТЁЖUMLКЭФЃЪНгІгУЁЗЯрЙиеТНкЁЃ

2ЁЂМмЙЙгыНтёю
дкЬжТлDDDжЎЧАЮвУЧЯШРДЬжТлвЛЯТЁАНтёюЁБЃЌетИіДЪЪЧЮвУЧдкШеГЃБрТыЪБКђОГЃЬсМАЕФДЪгяЁЃвЛИіОпгаЙЄНГОЋЩёЕФГЬађдБвЛЖЈЛсдкДњТыЩѓВщНзЖЮЖдвЛаЉОоЮоАдКЏЪ§ЛђепРрНјааВ№ЗжЃЌЪЙИїВПЗжЕФЙІФмИќМгОлНЙЁЂНЕЕЭёюКЯЁЃ
СэвЛЗНУцЃЌдкМмЙЙЗНУцЮвУЧвВЛсжиЪгЁАНтёюЁБЃЌвђЮЊвЛИіФЃПщжЎМфЫцвтёюКЯЕФЯЕЭГНЋЪЧЫљгаШЫЕФиЌУЮжЎдДЁЃвђДЫЃЌГ§СЫећНрЕФДњТыЮвУЧЛЙашвЊЙизЂећНрЕФМмЙЙЁЃ
МмЙЙЕФШ§вЊЫиЃКжАд№УїШЗЕФФЃПщЛђепзщМўЁЂзщМўМфУїШЗЕФЙиСЊЙиЯЕЁЂдМЪјКЭжИЕМддђЁЃФкОлЕФзщМўвЛЖЈгаУїШЗЕФБпНчЃЌЖјетИіУїШЗЕФБпНчБиШЛзїЮЊЯрЙиЕФдМЪјжИЕМНёКѓЕФЗЂеЙЁЃ

3ЁЂДгЗжВуМмЙЙЕНСљБпаЮМмЙЙ
3.1 ЗжВуМмЙЙ
ЗжВуМмЙЙЪЧдЫгУзюЮЊЙуЗКЕФМмЙЙФЃЪНЃЌМИКѕУПИіШэМўЯЕЭГЖМашвЊЭЈЙ§ВуРДИєРыВЛЭЌЕФЙизЂЕуЃЌвдДЫгІЖдВЛЭЌашЧѓЕФБфЛЏЃЌЪЙЕУетжжБфЛЏПЩвдЖРСЂНјааЃЛИїИіВуЁЂЩѕжСЭЌвЛВужаЕФИїИізщМўЖМЛсвдВЛЭЌЫйТЪЗЂЩњБфЛЏЁЃ
етРяЫљЮНЕФЁАвдВЛЭЌЫйТЪЗЂЩњБфЛЏЁБЃЌЦфЪЕОЭЪЧв§Ц№БфЛЏЕФдвђИїгаВЛЭЌЃЌете§КУЪЧЕЅвЛжАд№ддђЃЈSingle-Responsibility
PrincipleЃЌSRPЃЉЕФЬхЯжЁЃМДЁАвЛИіРргІИУжЛгавЛИів§Ц№ЫќБфЛЏЕФдвђЁБЃЌЛЛбджЎЃЌШчЙћгаСНИів§Ц№РрБфЛЏЕФдвђЃЌОЭашвЊЗжРыЁЃ
ЕЅвЛжАд№ддђПЩвдРэНтЮЊМмЙЙддђЃЌетЪБвЊПМТЧЕФОЭВЛЪЧРрЃЌЖјЪЧВуДЮЁЃР§ШчЭјТчЦпВуавщЪЧвЛИіЖЈвхЕФЗЧГЃКУЕФЁЂОЕфЕФЗжВуМмЙЙЃЌМђЕЅЁЂвзгкбЇЯАРэНтЃЌзюжеБЛЙуЗКЪЙгУНјЖјДѓДѓЭЦЖЏСЫЭјТчЭЈаХЕФЗЂеЙЁЃ

ЭЈГЃЧщПіЯТЃЌЮвУЧЛсАбШэМўЯЕЭГЗжЮЊетМИИіВуЃКUIНчУцЃЈЛђепНгШыВуЃЉЁЂгІгУЖРгаЕФвЕЮёТпМЁЂСьгђЦеЪЪЕФвЕЮёТпМЁЂЪ§ОнПтЕШЁЃ
НгЯТРДЃЌЛЙгаЪВУДВЛЭЌдвђЕФБфИќФиЃПД№АИе§ЪЧетаЉвЕЮёТпМБОЩэЃЁдкУПвЛВуФкВПЃЌВЛЭЌЕФвЕЮёГЁОАЗЂЩњБфЛЏЕФдвђЁЂЦЕДЮвВЖМВЛЭЌЃЌВЛЭЌЕФГЁОАЮвУЧЗжБ№ЖЈвхЮЊвЕЮёгУР§ЁЃгЩДЫЃЌЮвУЧПЩвдзмНсГівЛИіФЃЪНЃКдкНЋЯЕЭГЫЎЦНЧаЗжГЩЖрИіЗжВуЕФЭЌЪБЃЌАДгУР§НЋЦфЧаЗжГЩЖрИіДЙжБЧаЦЌЁЃетбљзіЕФКУДІОЭЪЧЖдЕЅИігУР§ЕФаоИФВЂВЛЛсгАЯьЦфЫћгУР§ЁЃ
ШчЙћЮвУЧЭЌЪБЖджЇГжетаЉгУР§ЕФUIКЭЪ§ОнПтвВНјааСЫЗжзщЃЌФЧУДУПИігУР§ЪЙгУИїздЕФUIБэЯжгыЪ§ОнПтЃЌетбљОЭзіЕНСЫздЩЯЖјЯТЕФНтёюЁЃСэвЛЗНУцЃЌгаВуДЮОЭгавРРЕЁЃдкOSIавщжаЃЌЩЯВуЭИУїЕФвРРЕЯТВуЁЃЕЋЪЧдкШэМўМмЙЙжаЃЌЮвУЧИќЧПЕїЁАвРРЕГщЯѓЁБЁЃМДзщМўAвРРЕBЕФЙІФмЃЌЮвУЧЕФзіЗЈЪЧдкAжаЖЈвхЦфашвЊгУЕНЕФНгПкЃЌгЩBШЅЪЕЯжЖдгІНгПкФмСІЃЌетбљОЭзіЕНСЫПЩВхАЮЃЌНЋРДЮвУЧПЩвдАбBЬцЛЛЮЊЭЌбљЪЕЯжСЫНгПкФмСІЕФзщМўCЖјЖдЯЕЭГВЛЛсдьГЩгАЯьЁЃ
3.2 ећНрМмЙЙ
ЗжВуМмЙЙжаИјШЫЕФИаОѕЪЧУПвЛВуЖМЭЌбљживЊЃЌЕЋШчЙћЮвУЧАбЙизЂЕФжиЕуЗХдкСьгђВуЃЌЭЌЪБАбвРРЕЙиЯЕАДеевЕЮёгЩжиЕНЧсаЮГЩвЛИівдСьгђВуЮЊжааФЕФЛЗЃЌМДбнБфЮЊвЛжжећНрЕФМмЙЙЗчИёЁЃетРяВЛЪЧЫЕЦфЫћВуВЛживЊЃЌНіНіЪЧЮЊСЫЭЙЯдГадиСЫвЕЮёКЫаФЕФСьгђФмСІЁЃ

ећНрМмЙЙзюжївЊддђЪЧвРРЕддђЃЌЫќЖЈвхСЫИїВуЕФвРРЕЙиЯЕЃЌдНЭљРяЃЌвРРЕдНЕЭЃЌДњТыМЖБ№дНИпЁЃЭтдВДњТывРРЕжЛФмжИЯђФкдВЃЌФкдВВЛжЊЕРЭтдВЕФШЮКЮЪТЧщЁЃвЛАуРДЫЕЃЌЭтдВЕФЩљУїЃЈАќРЈЗНЗЈЁЂРрЁЂБфСПЃЉВЛФмБЛФкдВв§гУЁЃЭЌбљЕФЃЌЭтдВЪЙгУЕФЪ§ОнИёЪНвВВЛФмБЛФкдВЪЙгУЁЃ
ећНрМмЙЙИїВужївЊжАФмШчЯТЃК
EntitiesЃКЪЕЯжСьгђФкКЫаФвЕЮёТпМЃЌЫќЗтзАСЫЦѓвЕМЖЕФвЕЮёЙцдђЁЃвЛИі Entity ПЩвдЪЧвЛИіДјЗНЗЈЕФЖдЯѓЃЌвВПЩвдЪЧвЛИіЪ§ОнНсЙЙКЭЗНЗЈМЏКЯЁЃвЛАуЮвУЧНЈвщДДНЈГфбЊФЃаЭЁЃ
Use CasesЃКЪЕЯжгыгУЛЇВйзїЯрЙиЕФЗўЮёзщКЯгыБрХХЃЌЫќАќКЌСЫгІгУЬигаЕФвЕЮёЙцдђЃЌЗтзАКЭЪЕЯжСЫЯЕЭГЕФЫљгагУР§ЁЃ
Interface AdaptersЃКЫќАбЪЪгУгк Use Cases КЭ entities ЕФЪ§ОнзЊЛЛЮЊЪЪгУгкЭтВПЗўЮёЕФИёЪНЃЌЛђАбЭтВПЕФЪ§ОнИёЪНзЊЛЛЮЊЪЪгУгк
Use Casess КЭ entities ЕФИёЪНЁЃ
Frameworks and DriversЃКетЪЧЪЕЯжЫљгаЧАЖЫвЕЮёЯИНкЕФЕиЗНЃЌUIЃЌToolsЃЌFrameworks
ЕШвдМАЪ§ОнПтЕШЛљДЁЩшЪЉЁЃ
3.3 СљБпаЮМмЙЙ
ЮвУЧАбећНрМмЙЙЕФЭтВПвРРЕАДееЦфЪфШыЪфГіЙІФмЁЂзЪдДРраЭНјааећКЯЁЃНЋДцДЂЁЂжаМфМўЁЂгыЦфЫћЯЕЭГЕФМЏГЩЁЂhttpЕїгУЗжБ№БЉТЖвЛИіЖЫПкЁЃдђЛсбнБфГЩЯТУцЕФМмЙЙЭМЁЃ

ЁАAllow an application to equally be driven by users,
programs, automated test or batch scripts, and to
be developed and tested in isolation from its eventual
run-time devices and databases.ЁБЁАЯЕЭГФмЦНЕШЕиБЛгУЛЇЁЂЦфЫћГЬађЁЂздЖЏЛЏВтЪдЛђНХБОЧ§ЖЏЃЌвВПЩвдЖРСЂгкЦфзюжеЕФдЫааЪБЩшБИКЭЪ§ОнПтНјааПЊЗЂКЭВтЪдЁБетЪЧСљБпаЮЕФОЋЫшЁЃ
ИУМмЙЙгЩЖЫПкКЭЪЪХфЦїзщГЩЃЌЫљЮНЖЫПкЪЧгІгУЕФШыПкКЭГіПкЃЌдкаэЖргябджаЃЌЫќвдНгПкЕФаЮЪНДцдкЁЃР§ШчвдШЁЯћЖЉЕЅЮЊР§ЃЌЁАЗЂЫЭЖЉЕЅШЁЯћЭЈжЊЁБПЩвдБЛШЯЮЊЪЧвЛИіГіПкЖЫПкЃЌЖЉЕЅШЁЯћЕФвЕЮёТпМОіЖЈСЫКЮЪБЕїгУИУЖЫПкЃЌЖЉЕЅаХЯЂОіЖЈСЫЖЫПкЕФЪфШыЃЌЖјЖЫПкЮЊЩЯгЮЕФЖЉЕЅЯрЙивЕЮёЦСБЮСЫЦфЪЕЯжЯИНкЁЃ
ЖјЪЪХфЦїЗжЮЊСНжжЃЌжїЪЪХфЦїЃЈБ№УћDriving AdapterЃЉДњБэгУЛЇШчКЮЪЙгУгІгУЃЌДгММЪѕЩЯРДЫЕЃЌЫќУЧНгЪегУЛЇЪфШыЃЌЕїгУЖЫПкВЂЗЕЛиЪфГіЁЃRest
APIЪЧФПЧАзюГЃМћЕФгІгУЪЙгУЗНЪНЃЌвдШЁЯћЖЉЕЅЮЊР§ЃЌИУЪЪХфЦїЪЕЯжRest APIЕФEndpointЃЌВЂЕїгУШыПкЖЫПкOrderServiceЃЌЕБШЛserviceФкВППЩФмЗЂЫЭOrderCancelledЪТМўЁЃЭЌвЛИіЖЫПкПЩФмБЛЖржжЪЪХфЦїЕїгУЃЌБОГЁОАЕФШЁЯћЖЉЕЅвВПЩФмЛсБЛЪЕЯжЯћЯЂавщЕФDriving
AdapterЕїгУвдБувьВНШЁЯћЖЉЕЅЁЃ
ДЮЪЪХфЦїЃЈБ№УћDriven AdapterЃЉЪЕЯжгІгУЕФГіПкЖЫПкЃЌЯђЭтВПЙЄОпжДааВйзїЃЌР§ШчЯђMySQLжДааSQLЃЌДцДЂЖЉЕЅЃЛЪЙгУElasticsearchЕФAPIЫбЫїВњЦЗЃЛЪЙгУгЪМў/ЖЬаХЗЂЫЭЖЉЕЅШЁЯћЭЈжЊЁЃгаБ№гкДЋЭГЕФЗжВуаЮЯѓЃЌаЮГЩвЛИіСљБпаЮЃЌвђДЫвВЛсГЦзїСљБпаЮМмЙЙЁЃ
4ЁЂDDDЪЧвЛжжЫМЯы
ЮвгоУСЕФШЯЮЊЃЌDDDМДвЕЮё+НтёюЁЃДѓЕРжСМђЁЂЖрУДЪьЯЄЕФГЁОАЃЌвђЮЊетОЭЪЧЮвУЧдкзіЕФЪТЧщЃЌжЛВЛЙ§ЮвУЧПЩФмЙ§гкЙизЂЪЙгУСЫЪВУДММЪѕПђМмЁЂгУСЫФФаЉжаМфМўЁЂаДСЫФФаЉЭЈгУЕФclassЁЃ
ЪЕМЪЩЯDDDШчЭЌБчжЄЮЈЮяжївхЫМЯывЛбљЃЌФФХТЮвУЧдкШэМўЯюФПЕФФГвЛИіЛЗНкгУЕНСЫЃЌжЛвЊетИіЫМЯыЮЊЮвУЧНтОіСЫЪЕМЪЮЪЬтОЭЙЛСЫЁЃЮвУЧУЛгаБивЊЮЊСЫDDDЖјШЅDDDЃЌЮвУЧвЛЖЈЪЧДгЮЪЬтжаРДдйЛиЕНЮЪЬтжаШЅЁЃ
Ш§ЁЂDDDгаЪВУДгУ
НшжњDDDПЩвдИФБфПЊЗЂепЖдвЕЮёСьгђЕФЫМПМЗНЪНЃЌвЊЧѓПЊЗЂепЛЈЗбДѓСПЕФЪБМфКЭОЋСІРДзаЯИЫМПМвЕЮёСьгђЃЌбаОПИХФюКЭЪѕгяЃЌВЂЧвКЭСьгђзЈМвНЛСївдЗЂЯжЃЌВЖзНКЭИФНјЭЈгУгябдЃЌЩѕжСЗЂЯжФЃаЭФЫжСЯЕЭГМмЙЙВуУцЕФВЛКЯРэжЎДІЁЃЕБШЛгаПЩФмФуЕФЭХЖгжаВЂУЛгаЯрЙивЕЮёЕФзЈМвЃЌФЧУДДЫЪБФуздМКБиаыГЩЮЊвЕЮёзЈМвЁЃ
ЭЈГЃРДЫЕЮвУЧПЩвдНЋDDDЕФвЕЮёМлжЕзмНсЮЊвдЯТМИЕуЃК
ФуЛёЕУСЫвЛИіЗЧГЃгагУЕФСьгђФЃаЭЃЛ
ФуЕФвЕЮёЕУЕНСЫИќзМШЗЕФЖЈвхКЭРэНтЃЛ
СьгђзЈМвПЩвдЮЊШэМўЩшМЦзіГіЙБЯзЃЛ
ИќКУЕФгУЛЇЬхбщЃЛ
ЧхЮњЕФФЃаЭБпНчЃЛ
ИќКУЕФЦѓвЕМмЙЙЃЛ
УєНнЁЂЕќДњЪНКЭГжајНЈФЃЃЛ
ЪЙгУеНТдКЭеНЪѕаТЙЄОпЃЛ
ЫФЁЂШчКЮDDD
ЭЈЙ§ЧАУцЕФТлЪіЃЌФуФдКЃРяУцвЛЖЈЩСЫИМИИіДЪгяЁАСьгђФЃаЭЁБЁАНтёюЁБЁАвРРЕГщЯѓЁБЁАБпНчЁБЁЃетаЉЭЈгУЕФЗжЮіЗНЗЈвЛЖЈЪЧЗХжЎЫФКЃЖјНдгааЇЕФЁЃЫљвдЮвШЯЮЊЕБФуАДееетМИИіддђНјааЫМПМЕФЪБКђОЭвбОдкDDDЕФТЗЩЯЯђЧАТѕНјСЫвЛВНЃЌНгЯТРДЮвУЧНсКЯНчЯоЩЯЯТЮФЁЂRepositoryетСНИізюШнвзБЛДѓМвЫљКіТдЕФЕиЗНРДНјвЛВНВћЪіЁЃ
дкетаЉВНжшЖМзіЭъвдКѓЃЌФудйОіЖЈНгЯТРДШчКЮШЅБрТыПЊЗЂЁЃВЛЙ§ЮвИвПЯЖЈЃЌФудкетИіЙ§ГЬжавбОЕУЕНСЫКмЖрИпвЕЮёМлжЕЕФЖЋЮїЁЃ
НгЯТРДШчКЮШЅЪЕЯжЃЌФуПЩвдИљОнЪЕМЪЧщПіЁЃЮвОѕЕУеНТдDDDБШеНЪѕDDDИќживЊЃЌЮвЯыетОЭЪЧDDDзїЮЊвЛжжЫМЯыЕФЩёЦцЫљдкЁЃШчЭЌН№гЙБЪЯТЕФЩйСжОјбЇвзНюОвЛбљЃЌвЛЬзВЂЮоУїШЗеаЪНЕФФкЙІаФЗЈШДФмДђБщЮфСжЁЃ
1ЁЂНчЯоЩЯЯТЮФ
СьгђжаЛЙЭЌЪБДцдкЮЪЬтПеМфЃЈproblem spaceЃЉКЭНтОіЗНАИПеМф(solution spaceЃЉЁЃдкЮЪЬтПеМфжаЃЌЮвУЧЫМПМЕФЪЧвЕЮёЫљУцСйЕФЬєеНЃЌЖјдкНтОіЗНАИПеМфжаЃЌЮвУЧЫМПМШчКЮЪЕЯжШэМўвдНтОіетаЉвЕЮёЬєеНЁЃ
ЮЪЬтПеМфЪЧСьгђЕФвЛВПЗжЃЌЖдЮЪЬтПеМфЕФПЊЗЂНЋВњЩњвЛИіаТЕФКЫаФгђЁЃЖдЮЪЬтПеМфЕФЦРЙРгІИУЭЌЪБПМТЧвбгазггђКЭЖюЭтЫљашзггђЁЃвђДЫЃЌЮЪЬтПеМфЪЧКЫаФгђКЭЦфЫћзггђЕФзщКЯЁЃЮЪЬтПеМфжаЕФзггђЭЈГЃЫцзХЯюФПЕФВЛЭЌЖјВЛЭЌЃЌЫћУЧИїздЙизЂгкЕБЧАЕФвЕЮёЮЪЬтЃЌетЪЙЕУзггђЖдгкЮЪЬтПеМфЕФЦРЙРЗЧГЃгагУЁЃзггђдЪаэЮвУЧПьЫйЕифЏРРСьгђжаЕФИїИіЗНУцЃЌетаЉЗНУцЖдгкНтОіЬиЖЈЕФЮЪЬтЪЧБивЊЕФЁЃ
НтОіЗНАИПеМфАќКЌвЛИіЛђЖрИіНчЯоЩЯЯТЮФЃЌМДвЛзщЬиЖЈЕФШэМўФЃаЭЁЃетЪЧвђЮЊНчЯоЩЯЯТЮФЪЧвЛИіЬиЖЈЕФНтОіЗНАИЃЌгУвдНтОіЮЪЬтЁЃ
ЭЈГЃЃЌЮвУЧЯЃЭћНЋзггђвЛЖдвЛЕиЖдгІЕНЯоНчЩЯЯТЮФЁЃетжжзіЗЈЯдЪНЕиНЋСьгђФЃаЭЗжРыЕНВЛЭЌЕФвЕЮёАхПщжаЃЌВЂНЋЮЪЬтПеМфКЭНтОіЗНАИПеМфШкКЯдквЛЦ№ЁЃ
ЕЋЪЧдкЪЕМљжаЃЌетжжзіЗЈВЂВЛзмЪЧПЩФмЕФЃЌЯыЯёвЛЯТЃЌЫУЛгаЮЌЛЄЙ§ЁАУЋЯпЭХЁБЯЕЭГЃЌЯждкЮвУЧОЭвЊНшжњНчЯоЩЯЯТЮФРДАВШЋЕФЁЂКЯРэЕФЁЂПьЫйЕФРэЫГетЖбНЛжЏВЛЧхЕФЙиЯЕЁЃ
КмЖрЪщМЎЛђепЮФеТНВНтDDDЃЌзмЪЧЫЕЭЛГігІИУдѕУДЙЙНЈДњТыАќНсЙЙЃЌЪЙгУЪВУДММЪѕПђМмЁЃЮвШЯЮЊетЪЧВЛЭъШЋЪЪгУЕФЃЌЫљвдЮвЛсЛЈНЯЖрЪБМфРДВћЪівЛЯТШчКЮНшжњНчЯоЩЯЯТЮФРДРэЫГетЖбЁАУЋЯпЭХЁБЁЃ
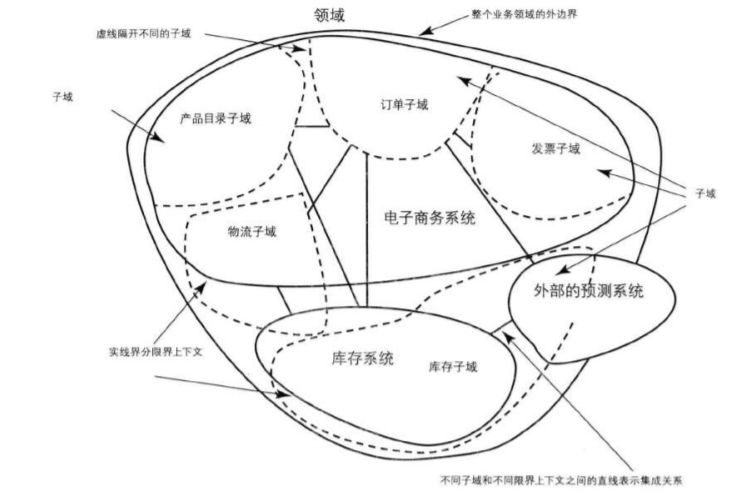
ЮвжБНгЪЙгУСЫЁЖЪЕЯжСьгђЧ§ЖЏЩшМЦЁЗЕФЯрЙиеТНкЕФХфЭМЃЌШЈЕБЪЧЮвЖдетИіЭМЕФзЂЪЭАЩЁЃ
вХСєЕФЕчзгЩЬЮёЯЕЭГЪЧИіЕфаЭЕФЁАДѓЯпЭХЁБЃЌЮвУЧАДееОбщНЋЦфдкТпМЩЯВ№НтЮЊЃКВњЦЗФПТМзггђЁЂЖЉЕЅзггђЁЂЗЂЦБзггђЃЌЕБШЛФувВПЩвдВ№НтГіИќЖрЕФзггђЃЌЩѕжСНЋВњЦЗФПТМзггђМЬајЯђЯТЗжНтЮЊРрФПзггђЁЂЩЬЦЗзггђЃЈащЯпЪЧТпМзггђЃЉЁЃСэЭтЛЙгавЛИізЈУХгУгкПтДцЙмРэЕФПтДцЯЕЭГЁЂвдМАгУгкЯњЪлдЄВтЕФдЄВтЯЕЭГЁЃ
гЩгкРњЪЗдвђЕчЩЬЯЕЭГРяУцвВДцдкЮяСїЯрЙиЕФвЕЮёТпМЃЌЭЌЪБЮяСїгжВЛПЩБмУтЕФзїгУгкПтДцТпМжЎЩЯЁЃЖјЭљЭљзюФбвдАбЮеЕФОЭЪЧетВПЗжЯрНЛЕФЕиЗНЃЌетВХЪЧЪЕМЪЕФЯюФПГЁОАЃЌЮвУЧЭЈГЃзіЗЈЪЧНЋЦфЙщВЂЮЊвЛИіаТЕФТФдМЯЕЭГЃЌзїЮЊвЛИіжЇГХзггђШЅИЈжњжївЊЕФЕчЩЬЯЕЭГЁЃ
ЕБШЛЃЌЫцзХвЕЮёВЛЖЯЗЂеЙЃЌЮвУЧЕФТФдМФЃЪНЃЈБШШчжЇГжЭЌГЧЕБШеДяЁЂЩЬМвВжДЂЗЂЛѕЁЂЕчЩЬМЏЛѕВжЗЂЛѕЁЂЭЫЛѕЕШЕШЃЉЁЂПтДцРраЭЃЈЕїВІПтДцЁЂдНПтВйзїЁЂСйЦкПтДцЁЂВаДЮПтДцЕШЕШЃЉдНРДдНИДдгЃЌЮвУЧПМТЧНЋЦфдйЯђЯТЗжНтЮЊТФдМЯЕЭГ2.0ЁЂПтДцЯЕЭГ2.0ЁЃ
КЫаФОЭЪЧЮвУЧПЩвддкИХФюЩЯЪЙгУЖрИізггђРДЗжНтНЯДѓЕФНчЯоЩЯЯТЮФЃЌвВПЩвдНЋЖрИіЗжЩЂЕФНчЯоЩЯЯТЮФАќКЌдкЭЌвЛИіаТЕФзггђЕБжаЃЌзюжезіЕНЁАзггђКЭНчЯоЩЯЯТЮФвЛвЛЖдгІЁБЁЃЮвИіШЫОѕЕУЃЌетИіЙ§ГЬЪЧзюПМбщФкЙІаФЗЈЕФЕиЗНЁЃ

ЩЯУцЮвУЧвбОЫЕСЫЛсВ№НтГіРДаТЕФзггђЃЌФПЕФЪЙЁАећНрИЩОЛЁБЕФНчЯоЩЯЯТЮФФмЙЛвЛЖдвЛЕФНтОіетИізггђЖдгІЕФЮЪЬтПеМфЃЌЕЋЪЧЫцзХВ№НтОЭБиШЛЕМжТЁАЙиСЊЙиЯЕЁБЁЃвђЮЊвЊНтОіЮЪЬтПеМфЃЌБиаыЪЙгУЖдгІЕФзггђЃЌФуПЩвдАбЫќВ№НтГіШЅЃЌЕЋЪЧЫќЪМжеДцдкгквРРЕЭјжаЁЃ
ЮвУЧЭЈгУЕФзіЗЈЪЧдкЯрНЛЕФЕиЗНЃЌЖЈвхНгПкЁЃгЩжЇГХЕФНчЯоЩЯЯТЮФШЅЪЕЯжЃЌПЩвдзіЕНжЇГХЩЯЯТЮФЕФВхАЮЪНЧаЛЛЁЃетРяШдШЛЪЧЮвУЧЧПЕїЕФЁАвРРЕГщЯѓЁБЁАНтёюЁБЁЃ
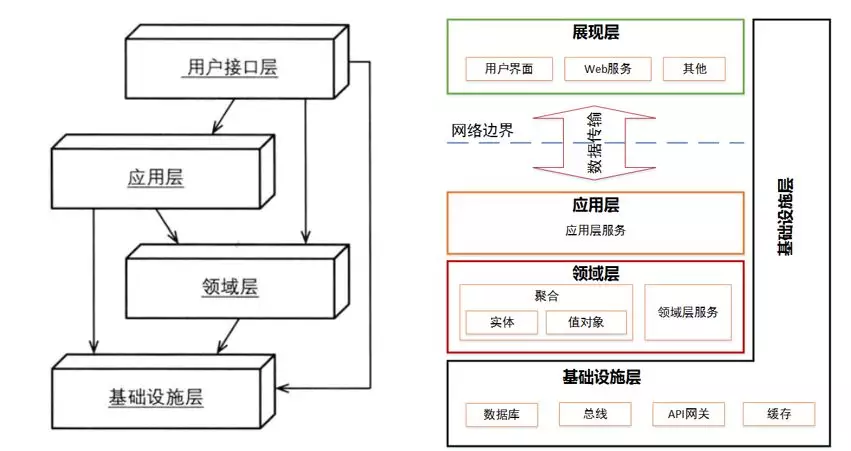
2ЁЂRepository
ЁАЖдгкУПжжашвЊНјааШЋОжЗУЮЪЕФЖдЯѓЃЌЮвУЧЖМгІИУДДНЈСэвЛИіЖдЯѓРДзїЮЊетаЉЖдЯѓЕФЬсЙЉЗНЃЌОЭЯёЪЧдкФкДцжаЗУЮЪетаЉЖдЯѓЕФМЏКЯвЛбљЁЃЮЊетаЉЖдЯѓДДНЈвЛИіШЋОжНгПквдЙЉПЭЛЇЖЫЗУЮЪЁЃЮЊетаЉЖдЯѓДДНЈЬэМгКЭЩОГ§ЗНЗЈЁЁ
ДЫЭтЃЌЮвУЧЛЙгІИУЬсЙЉФмЙЛАДееФГжжжИЖЈЬѕМўРДВщбЏетаЉЖдЯѓЕФЗНЗЈЁЁжЛЮЊОлКЯДДНЈзЪдДПтЁБв§гУздЁЖСьгђЧ§ЖЏЩшМЦЁЗЁЃДѓМвКЭЮвЕФвЩЮЪвЛбљЃЌRepositoryЪЧЪВУДЃПDAOгыRepositoryЪВУДЧјБ№ЃПЮЊЪВУДашвЊRepositoryЃП
ЪзЯШЃЌRepository ЪЧвЛИіЖРСЂЕФВуЃЌНщгкСьгђВугыЪ§ОнгГЩфВуЃЈЪ§ОнЗУЮЪВуЃЉжЎМфЁЃ
ЫќЕФДцдкШУСьгђВуИаОѕВЛЕНЪ§ОнЗУЮЪВуЕФДцдкЃЌЫќЬсЙЉвЛИіРрЫЦМЏКЯЕФНгПкЬсЙЉИјСьгђВуНјааСьгђЖдЯѓЕФЗУЮЪЁЃRepository
ЪЧВжПтЙмРэдБЃЌСьгђВуашвЊЪВУДЖЋЮїжЛашИцЫпВжПтЙмРэдБЃЌгЩВжПтЙмРэдБАбЖЋЮїФУИјЫќЃЌВЂВЛашвЊжЊЕРЖЋЮїЪЕМЪЗХдкФФЁЃЦфКЫаФЛЙЪЧЁАНтёюЁБЃЌЫљвдЮвУЧгІИУУїШЗСьгђВужЛгІИУЪЙгУRepositoryЛёШЁЖдЯѓЁЃ
НгЯТРДЃЌПДПДDAOгыRepositoryЪВУДЧјБ№ЁЃ
ЮвЕФРэНтЪЧетбљЃЌФуПЩвдНЋRepositoryЕБзї DAO РДПДД§ЃЌЕЋЪЧЧызЂвтвЛЕуЃЌдкЩшМЦRepositoryЪБЃЌЮвУЧгІИУВЩгУУцЯђМЏКЯЕФЗНЪНЃЌЖјВЛЪЧУцЯђЪ§ОнЗУЮЪЕФЗНЪНЁЃетгажњгкФуНЋздМКЕФСьгђЕБзїФЃаЭРДПДД§ЃЌЖјВЛЪЧ
CRUD ВйзїЃЛRepositoryЪЧУцЯђСьгђЕФЃЌRepositoryЖЈвхЕФФПЕФВЛЪЧDBЧ§ЖЏЕФЃЌRepositoryЙмРэЕФЪ§ОнЕФзюаЁСЃЖШЪЧОлКЯИљЃЌетСНЕуКЭDAOгаКмДѓВЛЭЌЁЃ
ЭЈГЃЮвУЧНЈвщАбRepositoryЖЈвхЮЊвЛИіМЏКЯВЂЧвжЛЬсЙЉРрЫЦМЏКЯЕФНгПкЃЌБШШчAddЃЌRemoveЃЌGetетжжВйзїЁЃвЛбдвдБЮжЎЃЌЮвУЧвЊгУМЏКЯЕФЫМЯыРДВйзїОлКЯИљЃЌЖјВЛЪЧДЋЭГЕФУцЯђDBЕФCRUDЗНЗЈЁЃ
зюКѓРДПДПДЮЊЪВУДашвЊRepositoryЃЌЮвРэНтЛЙЪЧЁАНтёюЁБЁЃЕБЮвУЧАбRepositoryЯыЯѓГЩвЛИізЪдДПтЃЌвВВЛЙиаФБГКѓЕФГжОУЛЏЃЌетаЉвВВЛЪЧDDDИУЫМПМЕФЖЋЮїЃЌЮвУЧПЩвдгУmysqlРДЪЕЯжЃЌвВПЩвдгУmongoЃЌЩѕжСredisЁЃгШЦфЪЧЕБЮвУЧдкИќЛЛЕзВуДцДЂЪБКђЃЌСьгђВувдМАЯрЙиЕФЗўЮёВЂЮоШЮКЮгАЯьЁЃ
вдЯТЪЧДњТыЪОР§ЃК

ЪЕЯжРрЃК

дкШеГЃЯюФПжаЮвУЧЪЙгУmybatisЃЌЫљвддкRepositoryжаЛсЪЙгУmybatisЕФDAOРДНјааВйзїЃЌЯТЭМЪЧвЛИіЩцМАЕНЖЉЙКЕФИДдгГЁОАЁЃ

ЮхЁЂЪЕМљЃКФГМгУЫвЕЮёЕФеНТдDDDжиЙЙ
ЮвУЧОйвЛИіМгУЫвЕЮёРДУшЪівЛЯТНчЯоЩЯЯТЮФЕФЛЎЗжЃЌШчЯТЭМвЕЮёСїГЬгІИУБШНЯЧхЮњЃЌЕЋЪЧЩцМАвЛаЉЪѕгяЃЌвђДЫЯШАбживЊЕФЪѕгяЖЈвхЧхГўЁЂНЕЕЭДѓМвЕФШЯжЊВювьЁЃ

ЭЈгУЪѕгяЃК
НјМўЃКН№ШкСьгђЪѕгяЃЌНјМўЪЧжИАбзЪСЯзМБИКУКѓЬсНЛИјДћПюЙЋЫОЛђвјааЕФЯЕЭГРяУцЃЌНазіНјМўЃЌНјМўКѓвјааЛђДћПюЙЋЫООЭЛсПЊЪМЩѓКЫетИіДћПюСЫЁЃ
ЬидМЩЬЛЇЃКН№ШкЪѕгяЃЌжИвјааЁЂЦфЫћН№ШкЛњЙЙКЭВЦЮёЙЋЫОЗЂааЕФаХгУПЈзїЮЊвЛжжжЇИЖЪжЖЮдкСїЭЈжаБЛНгЪмВЂдИвтЮЊЦфЬсЙЉЗўЮёЕФИїжжЕЅЮЛЁЃМђЖјбджЎЃЌжИгывјааЧЉЖЈЪмРэПЈвЕЮёавщВЂЭЌвтгУвјааПЈНјааЩЬЮёНсЫуЕФЩЬЛЇЁЃ

ЩЯЭМЕФ1.0АцБОЃЌвјааПЈЁЂНјМўЁЂНсЫуЙцдђЖМПчдНСЫЮЪЬтгђЃЌвђДЫЮвУЧЖдЦфГщЯѓЁАжЇИЖЁБЁАЬидМЩЬЛЇЁБЩЯЯТЮФЃЌШчЯТЭМЁЃ
етРягаШЫЛсгавЩЮЪЃЌЁАЬидМЩЬЛЇЁБЁАЩЬМвЁБЪВУДЙиЯЕЃЌЪЧЗёгІИУАбЁАЬидМЩЬЛЇЁБЙщЪєЮЊЁАЩЬМвгђЁБЃЌетжЛЪЧзжУцвтЫМЕФЯрЫЦЃЌЁАЬидМЩЬЛЇЁБЪЧНјМўЩѓХњвдКѓаЮГЩЕФжЇИЖЯрЙиЕФвЕЮёЁЃЕБШЛЁАЩЬМвгђЁБЛсЪЙгУЕНЁАЬидМЩЬЛЇЁБЕФФмСІЁЃ
вђЮЊНјМўТпМИДдгвђДЫЮвУЧвдНјМўЮЊжааФРДЛГіСЫетбљЕФЩЯЯТЮФЁЃСэвЛЗНУцДгзДЬЌСїзЊРДЫЕЃЌЁАвјааНјМўЁБЪЧвЛИіживЊНкЕуЃЌДњБэЦНЬЈЁЂЩЬМвЕФвЛаЉШЈвцМДНЋЩњаЇЃЌвђДЫвдДЫЮЊКЫаФвВЪЧгаБивЊЕФЁЃ

ЫцзХЕъЦЬЭтТєЭХЙКвЕЮёЕФЗЂеЙЃЌЮвУЧашвЊвЛИіСьгђФмСІИќЗсИЛЕФТФдМАВзАгђЃЌФмЙЛНјааЩчЧјХфЫЭЁЂЪлКѓЮЌаоЕШЁЃВЛПЩБмУтЕиНЋгыЖЉЕЅЁЂЗЂЦБЁЂПтДцЁЂЪлКѓЕШвЕЮёЖМгаЙиЯЕЃЌвђДЫвдЖЉЕЅЮЊжааФЙЙНЈСЫЯТУцЕФЩЯЯТЮФЁЃ

СљЁЂНсгя
ПМТЧЕНЦЊЗљвдМАФкШнЗБЖрЃЌСьгђВуЯрЙиЕФФкШнЯШНВНтЕНетРяЁЃ
дйДЮЧПЕївЛЕуЃЌЪЕМљDDDОјВЛЪЧВЮеевЛЬзЭјЩЯЕФДњТыНсЙЙЃЌвРКљТЋЛЦАШЅжиаДздМКЕФЯЕЭГЃЌетвЛЖЈЪЧЪЇАмЕФЁЃНЈвщДѓМвАДееБОЮФЫљНВЪіЕФддђЁЂЗНЗЈШЅЫМПМздМКЕФЯЕЭГЃЌЕБФуСьЮђЦфОЋЫшвдКѓвЛЖЈФмЙЛЁАаІАСДњТыЁБЃЌеЦЮеНтОіШэМўКЫаФИДдгадЕФФкЙІаФЗЈЁЃ |






