| 编辑推荐: |
本文作者结合在团队的实践过程,分享了自己对领域驱动设计的一些思考。希望对您的学习有所帮助。
本文来自于微信公众号阿里云开发者,由火龙果软件Linda编辑、推荐。 |
|
了解过领域驱动设计的同学都知道,人们常常把领域驱动设计分为两部分:战术设计和战略设计。这两个概念本身都是抽象的,有人把战术设计看作是领域内的设计过程,而战略设计看作是领域间关系的设计过程。也有一种认知是把战术设计看作是编码的设计,把战略设计看作是架构的设计。实际上领域驱动设计的作者Eric
Evans本无意将这两者进行割裂,相反两者之间相辅相成,缺一不可。我将在本文中结合团队的实践过程,分享我对领域驱动设计的一些思考。
转变思维
被忽视的面向对象
我们在刚开始学习面向对象的时候,知道面向对象的三个特性:继承、封装、多肽,也知道面向对象的SOLID原则,但很不幸的是,当我们在实际工作以后,这些特性和原则好像并无用武之地。目前我在公司看到过的大部分代码中的对象只有两种类型:服务类(Service
Object)和数据类(Data Object),所有的数据对象,被无脑的开放了所有的Getter和Setter方法,加之lombok等语法糖的推波助澜,对象的封装变得更加困难了。而所有的业务逻辑都被堆在了各种Service中,当然好的团队依然会对这些Service类做很好的分层设计,使代码的演进还能够正常的进行。
实际上我并不是要说这种开发方式不好,相反它能够在程序员中被广泛认可,其优势不言而喻,它能够让一个只要掌握编程语言的新手,快速的承接需求并交付,无需在代码设计和怎么写的问题上花费更多的精力和学习成本。
大部分情况下,团队内的架构师只需要做好接口设计和数据库的设计,这个需求就可以完全交给一个新人去实现了。
我把这种方式看作是一种通过确定【输入】和【输出】来控制软件开发确定性的方式,
输入即程序对外提供的可以执行程序的入口,我们常见的像RPC接口、HTTP接口、消息监听、定时任务等。
输出是程序对外部环境或者状态的影响,可以是数据库的写入、消息的广播推送、外部系统的调用等等。
在一个系统刚开始的阶段,这种方式能够以非常高的效率完成交付,这个阶段业务的本质复杂性低,技术的复杂性也低,程序的输入和输出链路比较单一。更重要的是在人的方面,每个人都能够很好的理解这种开发方式,只要从输入到输出的转换没有问题,程序员们不会去关注其中潜在的设计问题,无论是新人还是老手,开发这样的软件都能得心应手。相比于使用领域驱动设计的思维进行开发,面向过程的这种开发方式更简单直接,对人和团队的要求更低,在人员变动频繁的现状中,它能带来更快速的交付。
复杂度的膨胀
然而随着系统逐渐的演进,业务的核心复杂性变高,系统之间的联系逐渐变多,面向过程的这种开发方式就显得捉襟见肘了。不知道大家能否在自己团队中找到这样的代码:
上千行的方法
上百个属性的类
循环依赖的Service
无法控制的数据一致性
越来越多的分支逻辑
...
这些问题本质上并不是我们采用哪种开发方式就能解决的,但它们一定能说明我们当前的代码设计是存在问题的,这就像埋在我们系统中的一个个定时炸弹,如果你足够小心,团队的质量保障足够充足,这颗炸弹在你工作的期间可能并不会引爆,但根据墨菲定律,它们早晚是会引爆的。潜在的风险是一方面,另一方面是我们的交付速度,理解成本,沟通成本,知识的传递,都会因为这些混乱的代码而变得缓慢和困难。
但是程序员们总是会有办法的,用战术上的勤奋来弥补战略上的懒惰,花更多的时间去讨论,去梳理,写更多的文档,做更多的测试,掉更多的头发。当系统最终无法应对业务的变化时,要么一走了之,要么从头再来搞个2.0。
应对软件复杂度的方法有很多,即使是使用面向过程的开发方式,也有很多设计模式和方法论能够去解决这些问题。如果你还没有找到一个特别好的方式,不妨尝试一下领域驱动设计。
基于面向对象
在进行领域驱动设计落地的过程中,我感觉到最大的一个困难点是面向对象思维的转变,领域驱动设计实际上是基于面向对象设计的一种更高维度的设计模式,但我们之中大部分的开发者,已经习惯于按照面向过程的方式来进行开发,即使我们在很多场合都在强调我们在使用面向对象,但实际上却事与愿违。
经验越丰富,越资深的工程师,越无法跳出之前长期积累的认知,这种先入为主的思维定式改变起来尤为困难。
还有源源不断的新人逐渐开始进入这个行业,成为一个软件工程师,他们被要求能够尽快的开始交付和产出,他们也只能去模仿团队现在的代码,逐渐熟练以后,也只会把这种开发方式奉为圣经,再次传承下去。
随着实践领域驱动设计逐渐进入到深海区,我越来越感受到,面向对象至关重要,长期面向接口编程、面向数据库编程、面向中间件编程,已经让大家的思维很难去转变。即使我们有再好的领域设计,边界划分,如果无法将其在代码中表现出来,那也只会是空中楼阁,无法发挥领域驱动设计的真正作用。
领域模型
之前提到,我们现在的开发现状是通过【输入】和【输出】来进行设计,而领域驱动设计则是在其基础上增加了一层:【领域模型】。即所有的输入都要转换为领域模型,所有的输出也都要通过领域模型去完成。领域驱动设计的所有模块、模式、方法都是基于领域对象,为领域对象服务的。
领域模型本身作为对现实世界中我们所解决问题空间的抽象,它的演进与问题空间的演进原则上是一致的,之所以使用面向对象来作为领域模型的承载,主要原因还是面向对象更加符合当下人们对现实世界的认知,理解和使用都更加简单。现实世界中大部分的“系统”,都是可以用对象,以及对象之间的关系来描述,认识、理解、描述现实世界中的客观事物是人类哲学最早开始思考的问题,先秦时期的名家,古希腊的形而上学,都是基于此目的建立的。今天我们的工作又何尝不是在混乱复杂的世界中,寻找规律,将其通过有限的模型表达出来,再转换为机器可以理解的语言,形成软件或者系统,简化人与人,人与物,物与物之间的交互过程。
每次想到这些我就会热血沸腾,虽然生活限制了你人身的自由,但并没有限制你思维的自由,去认识世界、抽象现实,软件工程不光只有埋头敲代码的吗喽,也可以有像苏格拉底一样探索世界本质的思考者。
当然如何建模以我现在掌握的技巧和经验,实在有点拿不出手,还需再沉淀一下,本文还是主要关注于如何把领域模型在代码中进行落地。
领域对象
1. 实体(Entities)
Many objects are not fundamentally defined by their
attributes, but rather by a thread of continuity and
identity.
领域模型中最核心的是领域对象,而领域对象中最核心的是实体,《领域驱动设计》里对实体的定义如上,意思是,实体从根本上不由其属性来定义,而是由连续性和唯一性来定义。
类似于“白马非马”的哲学问题,“白马”是名(Defination),“马”也是名,只有你看得见摸得着实际存在的那匹白马才是实(Instance),假设这个世界是一个巨大的Java虚拟机,唯一能代表那匹白马的,只有它在内存里的地址。即使这匹马之后染了黄毛,起了个名字叫“小黑”,它还是它,不因其属性或者特征的变化而成为另外一匹马。直到这匹马死去,尸骨化为养分,它的存在不再有任何意义,系统收回它所占用的内存,这个实也就彻底不存在了。在领域模型中,需要通过一个唯一标识而不是其属性来区分,且在其生命周期中具有连续性的对象,我们将它定义为一个实体。概念的解释过于抽象,我们来通过我们最熟悉的订单Order为例:
class Order{
private String id;
private Date createTime;
private Status status;
void complete(){
this.status = Status.COMPLETED;
}
}
// 实体的一生
void lifeOfOrder{
// 创建:对象的首次创建,需要通过一个符号来唯一标识它
Order order = new Order("ID", new
Date(), Status.INIT);
// 存储:存储到数据库或者文件中
new OrderRepository().save(order);
// 重建:冲数据库或文件中读取
Order orderRef = new OrderRepository().get("ID");
// 修改:对象在修改其属性并重新持久化
orderRef.complete();
new OrderRepository().save(orderRef);
// 删除:从数据库或文件系统中存档或永久删除,系统将无法再次重建该对象
new OrderRepository().delete(orderRef);
}
|
我们在实际应用的过程中,实体往往是需要持久化到数据库的,因此大部分情况下,我们都以数据库中的主键作为实体的唯一标识,虽然这种方式并不完全符合领域对象应独立于数据库存在,但在实际使用的过程中,并不会产生太大的影响。以一个订单实体Order的创建为例,我们来看几种不同的唯一标识落地策略:
使用数据库主键作为实体唯一标识
注:使用这种策略,实体只有经过持久化以后,才能产生唯一标识,实际使用的过程中很容易出错,不建议使用。
//领域对象
class Order{
private Long id;
}
//ORM框架数据库表对象
class OrderDO{
//数据库主键
private Long id;
}
class OrderFactory {
public Order buildOrder(){
return new Order();
}
}
class OrderRepository {
@Autowired
private OrderDao orderDao;
public void insert(Order order){
OrderDO orderDO = new OrderDO()
orderDao.insert(orderDO);
//从ORM对象中获取表自增ID回填领域对象
order.setId(orderDO.getId());
}
}
|
使用随机UUID作为实体唯一标识
//领域对象
class Order{
private String id;
public Order(String id){
this.id = id;
}
}
//ORM框架数据库表对象
class OrderDO{
//数据库主键
private Long id;
//Order唯一标识
private String orderId;
}
class OrderFactory {
public Order buildOrder(){
return new Order(UUID.randomUUID().toString());
}
}
class OrderRepository {
@Autowired
private OrderDao orderDao;
public void insert(Order order){
OrderDO orderDO = new OrderDO()
orderDO.setOrderId(order.getId());
orderDao.insert(orderDO);
}
}
|
使用Sequence生成实体唯一标识
//领域对象
class Order{
private String id;
public Order(String id){
this.id = id;
}
}
//ORM框架数据库表对象
class OrderDO{
//数据库主键
private Long id;
//Order唯一标识
private String orderId;
}
class OrderFactory {
//序列生成器,可以参考TDDL Seq:https://mw.alibaba-inc.com/tddl/DeveloperReference/sequence
@Autowired
private SeqGenerator seqGenerator;
public Order buildOrder(){
return
new Order("PREFIX_" + seqGenerator.nextInt());
}
}
class OrderRepository {
@Autowired
private OrderDao orderDao;
public void insert(Order order){
OrderDO orderDO = new OrderDO()
orderDO.setOrderId(order.getId());
orderDao.insert(orderDO);
}
}
|
2. 关联(Association)
一个实体往往会关联另外一个实体,这种关联关系主要包含一对一、一对多、多对多这三种类型,这个相信大家在数据库设计的过程中已经很熟悉了。在领域模型里,一对多,多对多的关联,往往会让代码复杂度急剧上升。
以订单为例,一个订单(Order)可以包含多个产品(Product),一个产品也可以属于多个订单。
class Order{
private String id;
private List<Product> products;
}
class Product{
private String id;
private List<Order> orders;
}
|
表面看起来领域对象如此设计没有任何问题,符合现实中两者之间的关系,但是在对象使用的过程中却很麻烦,尤其是这种对象互相引用的场景。解决这个问题有几种思路:
规定一个遍历的方向:仅允许通过订单遍历该订单下所有的产品,这样订单和货品之间多对多的关系就简化为一对多。
添加限定:限定订单只允许包含一个产品,这种限定可能作用于某种特殊类型的订单,这样订单和产品的关系就会简化为一对一。
消除不必要的关联:产品对订单的引用,往往并没有实际作用的场景,这种情况我们可以消除产品对订单的关联关系。
简化后的领域对象:
class SingleProductOrder{
private String id;
private Product product;
}
class Product{
private String id;
}
|
3. 领域对象的持久化(Persistence)
这个章节本来想放到最后去说,但是想想又不得不把这部分提到前面来讲,因为这部分可能是我们在设计领域模型过程中最容易出现问题的。我们大部分应用使用的ORM框架,基本上都是用Mybatis,因此我们往往都需要有一个对象来映射数据库表结构,这里我将它命名为数据库对象,我们在代码中一般会通过DO、BO等后缀来进行区分。也正因为这个原因,我们很多时候都会直接将数据库模型作为代码设计的目标,代码逻辑也是为了操作数据库对象来写,导致代码中缺失真实业务场景的还原。
所以首先要强调的是一定要将领域模型和数据库模型分离开,这样我们的业务代码仅需要关注领域模型,到需要持久化的时候再去关心如何将领域模型转换为数据库模型。如此,即使之后数据库的选型发生变化,对代码的改动也仅限于对象转换的那部分逻辑;领域模型的迭代演进也可以更加自由,不受数据库设计的约束。
领域模型到数据库模型转换的过程中需要注意几个细节:
不要将数据库关注的属性,无脑添加到领域对象中去,比如id、gmt_created、gmt_modified等。
实体间的关联,在数据库中经常会通过关系表来表达,但在领域对象中,完全可以通过类的引用关系来表示,不需要将关系抽象为实体(除非这个关系有特殊的业务意义)。
将领域对象转换为数据库对象:
class Order{
private String id;
private List<Product> products;
}
class Product{
private String id;
}
class OrderDO{
private Long id;
private String orderId;
private Date gmtCreated;
private Date gmtModified;
}
class OrderProductRelationDO{
private Long id;
private String orderId;
private String productId;
private Date gmtCreated;
private Date gmtModified;
}
class OrderRepository{
void save(Order order){
orderDao.insert(new OrderDO(order.getId()));
order.getProducts().forEach(orderProduct ->
{
orderProductRelationDao.insert(new OrderProductRelationDO(order.getId(),
orderProduct.getId()));
});
}
}
|
扩展阅读:
来阿里之前在一个项目中,使用Spring JPA做了领域对象持久化的解决方案,用起来很爽,但是也有很多的问题,这里不做展开的介绍,仅通过JPA的一些注解来让大家浅尝一下,如果感兴趣可以自己尝试一下:Getting
Started :: Spring Data JPA
@Entity:标识实体类是JPA实体,告诉JPA在程序运行时生成实体类对应表
@Table:设置实体类在数据库所对应的表名
@Id:标识类里所在变量为主键
@GeneratedValue:设置主键生成策略,此方式依赖于具体的数据库
@Column:表示属性所对应字段名进行个性化设置
@Transient:表示属性并非数据库表字段的映射,ORM框架将忽略该属性
@Temporal:当我们使用到java.util包中的时间日期类型,则需要此注释来说明转化成java.util包中的类型。
@Enumerated:使用此注解映射枚举字段,以String类型存入数据库
@Embedded、@Embeddable:当一个实体类要在多个不同的实体类中进行使用,而其不需要生成数据库表
@Embeddable:注解在类上,表示此类是可以被其他类嵌套
@Embedded:注解在属性上,表示嵌套被@Embeddable注解的同类型类
@ElementCollection:集合映射
@CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy:
表示字段为创建时间字段(insert自动设置)、创建用户字段(insert自动设置)、最后修改时间字段(update自定设置)、最后修改用户字段(update自动设置)
4. 值对象(Value Object)
Many objects have no conceptual identity. These objects
describe some characteristic of a thing.
当一个实体内的部分属性,我们发现它们具有较强的相关性,这些属性单独抽象成一个对象可以更好的描述事物,且这个对象并不具备唯一性,我们就将它归类为值对象,值对象具备以下特征:
不需要唯一标识来代表其唯一性
一些有关系的属性的聚合
有自己的特征
对模型有重要的意义
是用来描述事物的对象
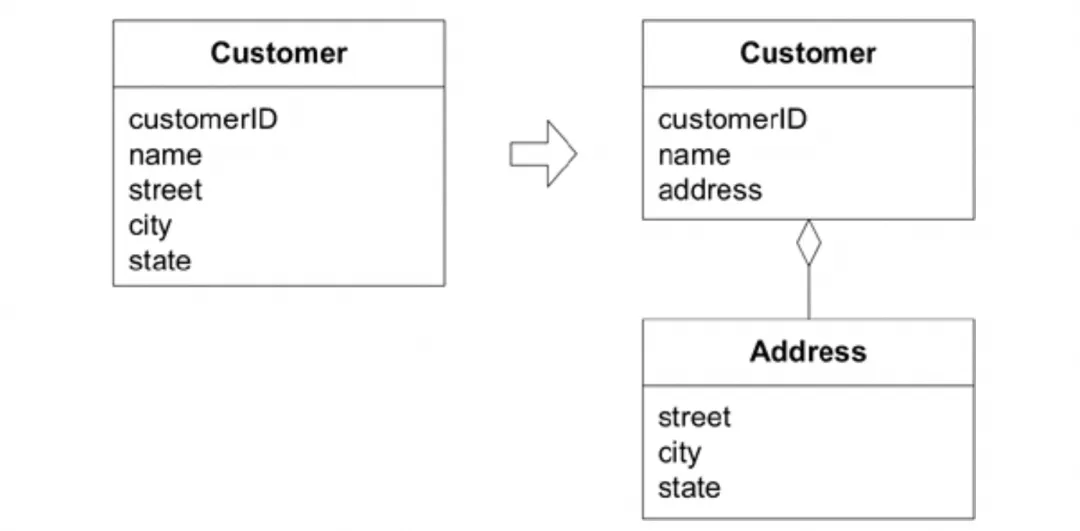
如图所示,客户(Customer)这个对象中,描述客户地址的三个属性,可以将其抽象为一个地址对象(Address),在我们实际的代码中,这样做的好处主要包括:
关注点分离:通过值对象的提取,可以简化实体,突出实体核心属性,开发者只需要把注意力放在实体本身关键的属性上;
控制复杂度:使实体在持续演进的过程中,不会逐渐膨胀;
不变性:值对象可以复制,并在对象间传递;
class Customer{
private String id;
private Address address;
public Customer(String id, Address address){
this.id = id;
this.address = address;
}
}
class Order{
private String id;
private Address customerAddress;
}
class Address {
private String street;
private String city;
private String stateOrProvince;
private String postalCode;
private String country;
private String unitNumber;
private String latitude;
private String longitude;
private String additionalInfo;
}
void buildOrder(Customer customer){
new Order("id", customer.getAddress());
}
|
5. 聚合(Aggregate)
实体关联的极简设计能够帮助我们描述现实世界事物之间的关系,并且能在一定程度上限制关系的复杂度增长,但随着业务发展,实体间的关系会越来越复杂,我们依然需要将这种关系表达在模型里,但是如果还是将这种关联表达在实体中,实体就会因各种关系带来的复杂性而膨胀,开发者也无法关注到模型的核心。当多个实体之间在某些场景下需要保持更改的一致性时,除了使用对象关联外,还可以建立一个对象组,将有着紧密关系的实体和值对象封装在一起,这个对象组就是领域模型中的聚合。
继续之前的例子,我们丰富一下订单模型:客户购买产品会产生交易订单,一个交易订单下会关联多个订单项,一个订单项包含购买的产品及数量,交易订单完成支付后会创建一个物流单。
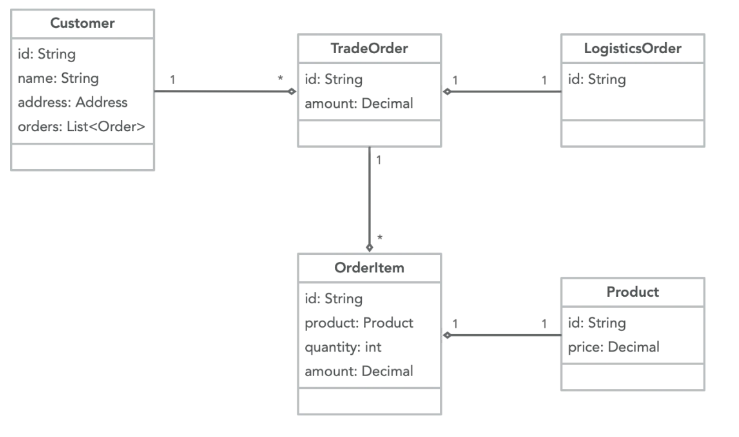
class TradeOrder {
private String id;
private Customer customer;
private List<OrderItem> orderItems;
private LogisticsOrder logisticsOrder;
}
|
如此我们建立的实体就会变成这样,从交易单视角来看似乎没有什么问题,但这个模型在其他的场景下就会变得臃肿难以使用。假设以下几种用例(本故事纯属虚构,如有雷同,纯属巧合,实际情况可能更离谱):
用户注销账号,需要立即终止所有订单;
物流单完成签收后,需要更新交易单状态;
某个产品紧急下架,需要删除所有该产品的订单项,并更新交易单价格;
为了保证在不同场景下,各个实体间更改的一致性,我们需要将以上的实体按照不同场景做个分组:
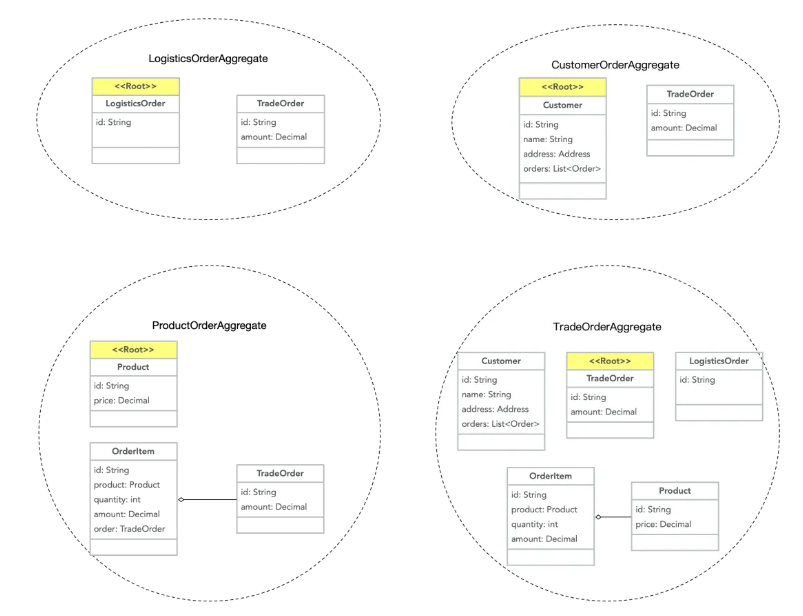
如此,几个实体间复杂的关联关系被我们以聚合的方式做了分离,聚合拥有两个重要特征:
边界:定义聚合内有什么,与其他聚合区分。
聚合根:聚合中的一个特定实体
选择聚合中的一个Entity作为聚合根;
通过根来控制对边界内其他对象的访问;
只允许外部对象保持对根的访问;
对边界内的其他对象通过根来遍历关联来发现;
在实际将聚合在代码中落地的过程中,我曾经历过两种不同的写法:
一个对象,即是实体,也是聚合,同时是该聚合中的聚合根。
@Entity
@Aggregate
@AggregateRoot
class TradeOrder {
private String id;
private Customer customer;
private List<OrderItem> orderItems;
private LogisticsOrder logisticsOrder;
}
|
在实体之上单独定义一个聚合对象,在其中选择一个实体作为聚合根。
@Aggregate
class TradeOrderAggreagte{
@AggregateRoot
private TradeOrder tradeOrder;
private Customer customer;
private List<OrderItem> orderItems;
}
|
两种方式都实践过后,我暂时倾向于第二种写法,第一种方式实体和聚合的概念经常容易搅在一起,只需要关注实体本身时,又不得不去考虑这个对象中关联的其他实体。第二种方式虽然命名会很冗长,但能够保证实体间的关联最大程度的减少,所有基于业务场景建立起来的关联都集中在聚合内。两种方式各有利弊,如果团队在实践的过程中能够结合起来使用是最好的,还是那句话,软件工程没有“银弹”,模型需要在实践中不断的演进和迭代,从简单到复杂,只要我们时刻关注模型是否能够反映业务实际情况。(各位看官如果有更好的方式也欢迎一起讨论)下面我们来看一下完整的领域模型:
package entity;
@Entity
class TradeOrder {
private String id;
private String customerId;
private Address address;
private BigDecimal ammount;
private Status status;
}
@Entity
class OrderItem {
private String id;
private Order order;
private Status status;
private Product product;
private int quantity;
private BigDecimal amount;
}
@Entity
class Customer {
private String id;
private Address address;
}
@Entity
class LogisticsOrder {
private String id;
private Address address;
private LogisticsStatus status;
}
@Entity
class Product {
private String id;
private String name;
private BigDecimal price;
}
|
package aggregate;
@Aggregate
class TraderOrderAggregate{
@Root
private TradeOrder tradeOrder;
private Customer customer;
private LogisticsOrder logisticsOrder;
private List<OrderItem> orderItems;
}
@Aggregate
class LogisticsOrderAggregate{
@Root
private LogisticsOrder logisticsOrder;
private TradeOrder tradeOrder;
}
@Aggregate
class CustomerOrderAggregate{
@Root
private Customer customer;
private List<TradeOrder> order;
}
@Aggregate
class ProductOrderAggregate{
@Root
private Product product;
private List<OrderItem> orderItems;
}
|
6. 查询不是领域模型
需要强调的是,不要因为对数据的查询需求而改变领域模型,领域模型是为了映射业务活动,以及业务活动的影响,这个影响可能是领域内的数据,也可能是对领域外的改变。在我们的开发过程中,页面的展示,对外提供查询接口往往是高频变更的地方,查询的逻辑也经常是无花八门,很难控制用户想要把哪些数据聚合在一起展示。因此对于这种纯查询的场景,我们不要用领域模型去承载,最简单直接的方式就是直接从数据层去查询、拼装数据。这也是命令查询的责任分离(Command
Query Responsibility Segregation,CQRS)这种设计模式一种体现。

在数据查询中也会遇到一些数据库对象有密切的联系,在多个场景中需要一起查出来,这个时候则可以通过构建一些读模型来封装查询逻辑。原则上只要对象间都通过组合的方式来进行组装,避免耦合,读模型可以随时按需来创建,不要吝啬于创建一个对象。
为了避免误解,这里还是要讲清楚的一点是,以上所说的查询,和我们在写链路里需要从数据库中重建领域对象,是两种不同的场景。重建领域对象一般是通过repository来提供查询接口,返回的结果一定是领域对象,重建出来的领域对象也一定是在写入链路使用的。团队以前也有过一个应用,无论是查询还是写入都要通过领域模型,导致各种复杂的查询的逻辑是Repository逐渐膨胀,同时领域对象中也多了很多预期以外的属性,模型从数据库对象(DO)转成领域对象(DomainObject)再转成数据传输对象(DTO),对开发十分不友好。
领域对象的生命周期
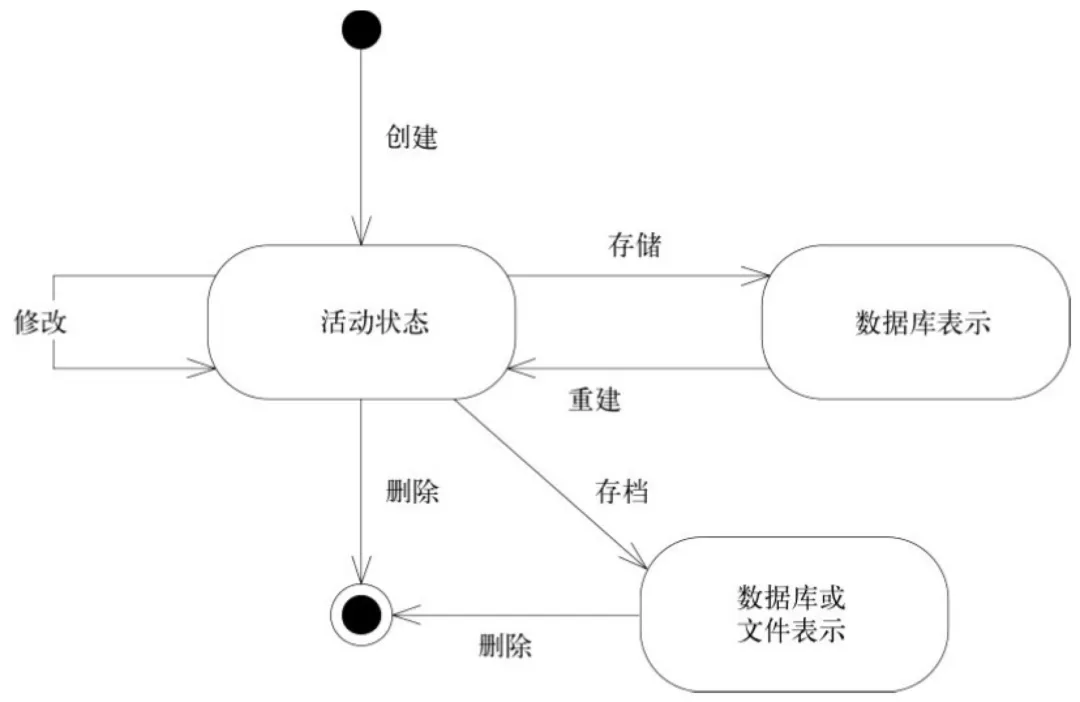
前文我们在讲实体的时候,简单介绍了一个实体的生命周期,领域驱动设计为我们提供了一系列可选的构造块,帮助我们将领域对象生命周期的各个环节需要关注的问题做进一步的分离。
1. 工厂(Factory)
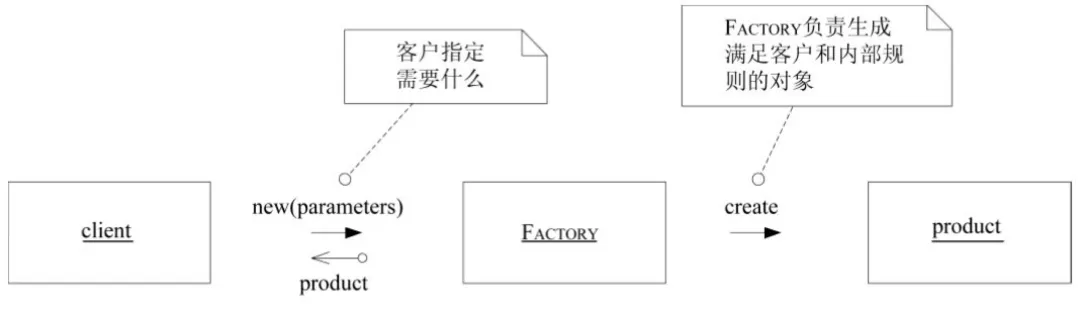
不同于设计模式中的工厂模式,这里的Factory仅仅是为了将领域对象创建的过程通过一种单独的模式独立出来。我们的一个系统,可能会对外提供多种类型、多种模式的入口,比如消息监听、端面、接口、定时任务等,不同的入口我们对外的契约不同,用户能提供的入参也不相同。我们使用领域驱动设计来作为代码设计的基本诉求是所有的核心业务代码都基于领域对象,因此领域对象的创建是一切业务代码的开始。简单点来说,Factory是承载将系统对外提供的请求模型转换为领域模型功能的一系列对象,它包含两个核心约束:
满足客户约束
满足内部规则
@HsfProvider
class OrderServiceImpl{
@Autowired
private OrderApplicationService applicationService;
public createOrder(OrderCreateRequestDTO request){
TradeOrderAggregate order = new TradeOrderAggregateFactory().buildOrder(request);
applicationService.createOrder(orderAggregate);
}
}
@RestController
class OrderController{
public createOrder(OrderCreateRequestVO request){
TradeOrderAggregate order = new TradeOrderAggregateFactory().buildOrder(request);
applicationService.createOrder(orderAggregate);
}
}
class TradeOrderAggregateFactory{
public TradeOrderAggregate buildOrder(OrderCreateRequestDTO
request){
Assert.notNull(request);
return TradeOrderAggregate.builder()
.tradeOrder(new OrderFactory().build(request))
.orderItems(new OrderItemFactory().build(request))
.build();
}
public TradeOrderAggregate buildOrder(OrderCreateRequestDTO
request){
Assert.notNull(request);
return TradeOrderAggregate.builder()
.tradeOrder(new OrderFactory().build(request))
.orderItems(new OrderItemFactory().build(request))
.build();
}
}
|
构建领域对象的Factory和领域对象的代码分层可以保持一致,聚合引用多个实体,聚合的Factory也可以饮用其他实体的Factory。只要领域对象之间的耦合度足够低,基于领域对象的其他代码构造块也可以保持低耦合高内聚。
2. 仓库(Repository)
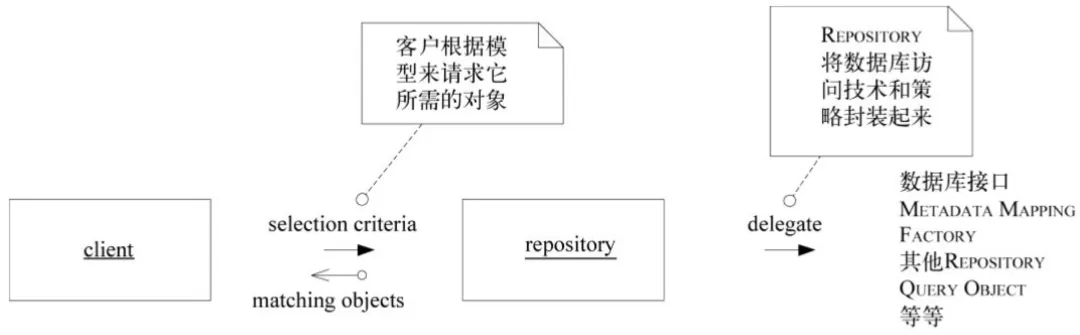
Repository提供了领域对象重建和持久化的功能,它隔离了领域模型与数据库系统的复杂性,使开发人员可以将关注点分离开,在处理业务逻辑的时候,不需要考虑数据库实现的问题;而当需要关注数据库时,则关注于数据库、ORM框架就可以。团队在实践的过程中将领域层(Domain)与数据接收层(DAL)做了依赖倒置,领域层仅依赖Repository的接口,具体实现在DAL层中实现,这样即使未来换了数据库实现或其他的基础设施,对领域层的代码都是无需修改的。
public class TradeOrderAggregateReposiotry{
void save(TradeOrderAggregate tradeOrderAggregate);
}
public class TradeOrderAggregateReposiotryTddlImpl
implements TradeOrderAggregateReposiotry{
@Autowired
private TradeOrderRepository tradeOrderRepository;
@Autowired
private OrderItemRepository orderItemRepository;
@Transactional
void save(TradeOrderAggregate tradeOrderAggregate){
tradeOrderRepository.save(tradeOrderAggregate.getTradeOrder());
tradeOrderAggregate.getOrderItems().forEach(orderItem->
orderItemRepository.save(orderItem);
);
}
void get(String tradeOrderId){
TradeOrder order = tradeOrderRepository.get(tradeOrderId);
List<OrderItem> orderItems = orderItemRepository.queryByOrderId(tradeOrderId);
return TradeOrderAggregate.builder()
.traderOrder(order)
.orderItems(orderItems)
.build();
}
}
|
3. 领域服务(Service)
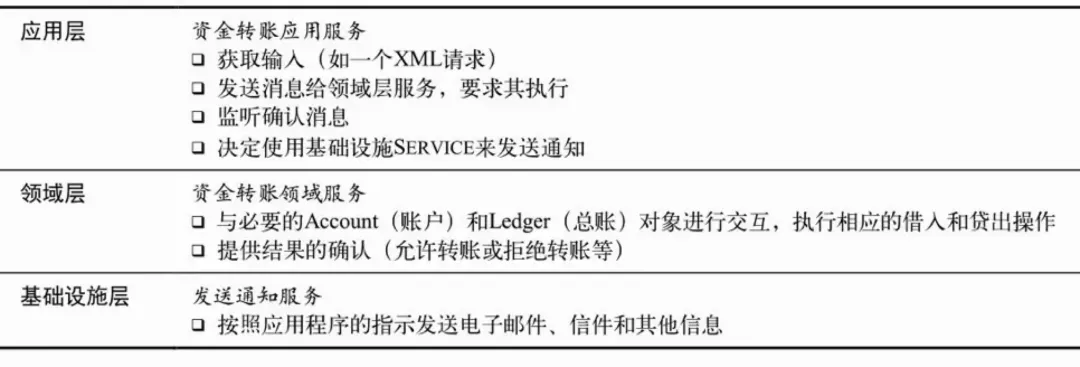
相信我们工作的代码库中最多类名后缀就是Service了,我们也应该被各种Service的调用层级、循环依赖教训过很多遍了,出现这种问题实际上还是我们对代码缺少设计,一股脑的把业务逻辑、系统逻辑、应用逻辑、基础设施等等随意组装到一起使用,本来每一个部分的复杂度就已经非常高了,我们还要将这些复杂度揉到一起。领域驱动设计给我们提供了一种分层治理的思路,将系统内的服务类分为几个大类:应用层服务、领域层服务、基础设施层服务。应用层服务用于处理输入输出、与领域模型和领域服务之间的调度、连接基础设施层服务。
当领域模型中某个动作或者操作不能看作某个领域对象自身的职责时,可以将其托管到一个单独的服务类中,这种服务类,我们把它叫做领域服务。对于领域服务的使用,经常很难去定义哪些行为或逻辑是应该托管到服务类中还是由领域对象自己来负责。全部托管到领域服务中,领域对象则会变成贫血模型,如果不托管,又容易因职责过多而导致领域对象过于膨胀。对于这个问题我们也没有太好的解决办法,软件工程的问题永远都是在Balance的过程中,当代码复杂度可控的范围内,我们尽量减少对领域服务的使用,如果领域对象开始出现膨胀的现象,那就将其托管到领域服务中。
对于领域服务,一定要把守住一条底线,领域服务一定不要有状态,也就是我们所说的“纯函数”,这样做能够让领域服务保持单纯,仅关注于领域对象之间的关系和其状态的变化,而不会引入领域逻辑以外的复杂性。
领域模型嵌入工程
呼~领域驱动设计里基本的构造单元已经介绍完了,接下来看看怎么将这些单元融合在一起,使其成为一个可工作的软件。这部分在《领域驱动设计》里作者Eric
Evans将其称为分离领域,对它的介绍放在最开始的部分,我换了一个思路将它放在了最后,并换了个方向从分离的视角换成嵌入的视角。如果我们不做工程,只是简单的写一个程序,我们都可以很熟练的使用面向对象,但就是因为工程的复杂性,导致我们没有办法随心所欲去用面向对象里的各种优秀设计。
假设你现在有一个完整领域模型的二方包,里面完全由上述所有的代码构造块组成,不依赖数据库、环境、框架外部系统等等,接下来只需要把这个核引入到我们的工程代码中,完成它与实际应用的关联。Eric
Evans为领域驱动设计提供了一个分层架构,用户界面层 - 应用层 - 领域层 - 基础设施层,后来也有人提出了洋葱架构和六边形架构等,它们都有一个共同特征:独立且处于核心的领域层。对于这几种架构的介绍,网上有很详细的资料,我这里不展开进行介绍,搜罗几张图供大家了解:
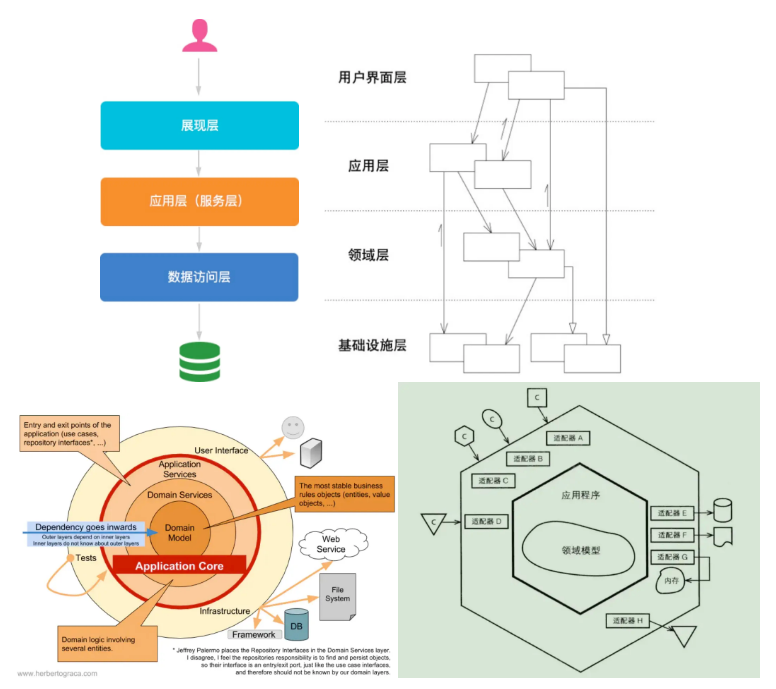
可以看到,在将领域模型与工程结合的过程中,应用服务(ApplicationService)扮演了十分重要的角色,它对入口、领域模型、外部依赖、基础设施等部分进行编排和调度,最终使领域模型能够在实际应用中正常工作。
class TradeOrderApplicationService{
void createTradeOrder(TradeOrderAggregate tradeOrderAggregate){
// 从领域外获取客户信息,映射到当前上下文
Customer customer = customerFacade.getCustomer(tradeOrderAggregate.getCustomerId());
// 声明式设计,显性表达领域对象在特定场景中的规约
new TradeOrderSpecification(tradeOrderAggregate).isSatisfiedCreate(customer);
// 调用领域对象方法完成领域对象状态的改变,如果逻辑逐渐复杂超出领域对象职责范围,可以托管到领域服务中
tradeOrderAggregate.created();
// 使用repository持久化对象
tradeOrderAggregateRepository.save(tradeOrderAggregate);
// 调度其他系统、基础设施中间件等
msgService.send(tradeOrderAggregate);
}
}
|
以下是我们团队当前正在使用的一种分层模式,基本上前面也都介绍的差不多了,贴一下我们一个工程的代码分层目录吧:
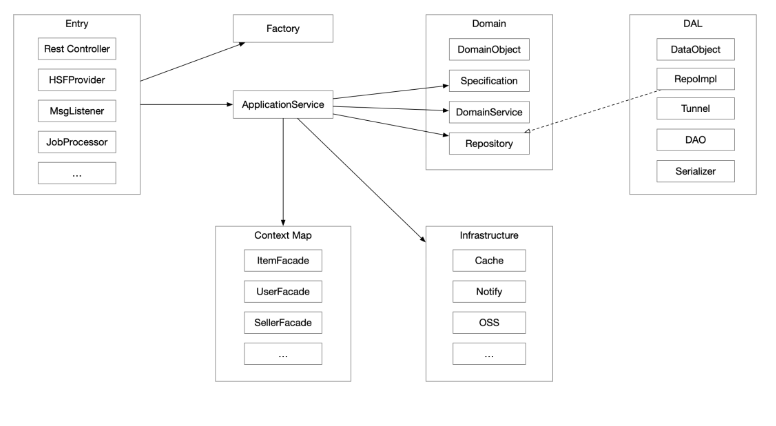
在现在微服务泛滥的现状下,为了每个领域能够自治,往往领域会拆分的很细,领域间为了防止耦合过深,一般会选择建立起高高的边界,导致领域间上下文映射会越来越复杂,领域内也会有越来越多的防腐层建设。深度自治过后带来的理解成本和维护成本都呈指数级上升。
有没有可能在一定范围内的团队能够共同维护一套领域模型,这个模型通过二方包版本升级来更新,各个团队基于领域模型来完成应用层和基础设施层的建设,通过这种方式减少因人而产生的认知成本以及协同成本,同时它也不违背微服务的理念。我刚来阿里时是在供应链中台,当时我所在团队的前身是盒马供应链,我从代码中看到之前的架构师辉子老师似乎做过这种尝试,将业务的变化表现在领域模型中,架构师只需要关注核心领域模型的变化,而不用过于关注团队的技术架构和系统架构建设。但当时也只是局限于统一了领域模型的属性,没有定义行为,而且我加入团队的时候,辉子老师已经离开了,这种约束也不复存在,加上业务和组织的变化,最后还是把模型分散到各个团队自治了。 |







 订阅
订阅