| UML软件工程组织 | |||
| |
|||
|
|||
《LoadRunner 没有告诉你的》之一
作者: 陈雷 来源: cnblogs
| 描述性统计与性能结果分析 LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。 为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求? 假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想? 假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信? 为了解答上面的疑问,我们先来看一张表:
CmdID 测试时被请求的页面 NUM 响应成功的请求数量 MEAN 所有成功的请求的响应时间的平均值 STD DEV 标准差(这个值的作用将在下一篇文章中重点介绍) MIN 响应时间的最小值 50 th(60/70/80/90/95 th) 如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义 MAX 响应时间的最大值 我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下: 1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%; 2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况; 3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的; 4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的; 5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况; 6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的; 7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。 数据统计分析的思路与分析结果的展示方式是同样重要的,有了好的分析思路,但是却不懂得如何更好的展示分析结果和数据来印证自己的分析,就像一个人满腹经纶却不知该如何一展雄才 一图胜千言,所以这次我会用两张图表来说明“描述性统计”在性能测试结果分析中的其他应用。
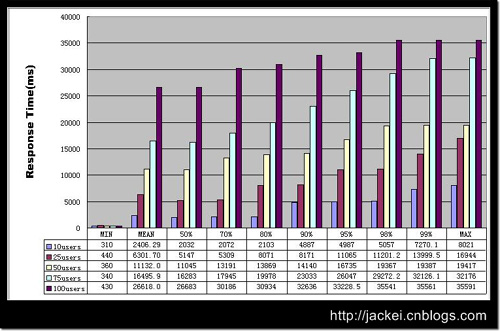
在这张图中,我们继续使用了上一篇文章――《描述性统计与结果分析》一文中的方法,对响应时间的分布情况来进行分析。上面这张图所使用的数据是通过对 Google.com 首页进行测试得来的,在测试中分别使用10/25/50/75/100 几个不同级别的并发用户数量。通过这张图表,我们可以通过横向比较和纵向比较,更清晰的了解到被测应用在不同级别的负载下的响应能力。
这张图所使用的数据与第一张图一样,但是我们使用了另外一个视角来对数据进行展示。表中最左侧的2000/5000/10000/50000的单位是毫秒,分别表示了在整个测试过程中,响应时间在0-2000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在2001-5000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在5001-10000毫秒范围内的事务数量占成功的事务总数的百分比,以及响应时间在10001-50000毫秒范围内的事务数量占成功的事务总数的百分比。 这几个时间范围的确定是参考了业内比较通行的“2-5-10原则”――当然你也可以为自己的测试制定其他标准,只要得到企业内的承认就可以。所谓的“2-5-10原则”,简单说,就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-10秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过10秒后仍然无法得到响应时,会感觉系统糟透了,或者认为系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。 那么从上面的图表中可以看到,当并发用户数量为10时,超过95%的用户都可以在5秒内得到响应;当并发用户数量达到25时,已经有80%的事务的响应时间处在危险的临界值,而且有相当数量的事务的响应时间超过了用户可以容忍的限度;随着并发用户数量的进一步增加,超过用户容忍限度的事务越来越多,当并发用户数到达75时,系统几乎已经无法为任何用户提供响应了。 这张图表也同样可以用于对不同负载下事务的成功、失败比例的比较分析。 Note:上面两个图表中的数据,主要通过Excel 中提供的FREQUENCY,AVERAGE,MAX,MIN和PERCENTILE几个统计函数获得,具体的使用方法请参考Excel帮助手册。 理发店模型 大概在一年前的一次讨论中,我的好友陈华第一次提到了这个模型的最初版本,经过几次讨论后,我们发现经过完善和扩展的“理发店模型”可以用来帮助我们理解很多性能测试的概念和理论,以及一些测试中遇到的问题。在最近的一次讨论后,我决定撰写一篇文章来专门讲述一下这个模型,希望可以帮助大家更好的理解性能测试有关的知识。 不过,在这篇文章中,我将会尽量的只描述模型本身以及相关的一些扩展,而具体如何将这个模型完全同性能测试关联起来,我不会全部说破,留下足够的空间让大家继续思考和总结,最好也一起来对这个模型做进一步的完善和扩展^_^ 我相信,当大家在思考的过程中有所收获并有所突破时,那种快感和收获的喜悦才真的是让人倍感振奋而且终生难忘的 ^_^ 当然,我要说明的是,这个模型仅仅是1个模型,它与大家实际工作中遇到的各式各样的情况未必都可以一一对应,但是大的方向和趋势应该是一致的。 相信大家都进过或见过理发店,一间或大或小的铺面,1个或几个理发师,几张理发用的椅子和供顾客等待的长条板凳。
在我们的这个理发店中,我们事先做了如下的假设: 1. 理发店共有3名理发师; 2. 每位理发师剪一个发的时间都是1小时; 3. 我们顾客们都是很有时间观念的人而且非常挑剔,他们对于每次光顾理发店时所能容忍的等待时间+剪发时间是3小时,而且等待时间越长,顾客的满意度越低。如果3个小时还不能剪完头发,我们的顾客会立马生气的走人。 通过上面的假设我们不难想象出下面的场景: 1. 当理发店内只有1位顾客时,只需要有1名理发师为他提供服务,其他两名理发师可能继续等着,也可能会帮忙打打杂。1小时后,这位顾客剪完头发出门走了。那么在这1个小时里,整个理发店只服务了1位顾客,这位顾客花费在这次剪发的时间是1小时; 2. 当理发店内同时有两位顾客时,就会同时有两名理发师在为顾客服务,另外1位发呆或者打杂帮忙。仍然是1小时后,两位顾客剪完头发出门。在这1小时里,理发店服务了两位顾客,这两位顾客花费在剪发的时间均为1小时; 3. 很容易理解,当理发店内同时有三位顾客时,理发店可以在1小时内同时服务三位顾客,每位顾客花费在这次剪发的时间仍然是均为1小时; 从上面几个场景中我们可以发现,在理发店同时服务的顾客数量从1位增加到3位的过程中,随着顾客数量的增多,理发店的整体工作效率在提高,但是每位顾客在理发店内所呆的时间并未延长。 当然,我们可以假设当只有1位顾客和2位顾客时,空闲的理发师可以帮忙打杂,使得其他理发师的工作效率提高,并使每位顾客的剪发时间小于1小时。不过即使根据这个假设,虽然随着顾客数量的增多,每位顾客的服务时间有所延长,但是这个时间始终还被控制在顾客可接受的范围之内,并且顾客是不需要等待的。 不过随着理发店的生意越来越好,顾客也越来越多,新的场景出现了。假设有一次顾客A、B、C刚进理发店准备剪发,外面一推门又进来了顾客D、E、F。因为A、B、C三位顾客先到,所以D、E、F三位只好坐在长板凳上等着。1小时后,A、B、C三位剪完头发走了,他们每个人这次剪发所花费的时间均为1小时。可是D、E、F三位就没有这么好运,因为他们要先等A、B、C三位剪完才能剪,所以他们每个人这次剪发所花费的时间均为2小时――包括等待1小时和剪发1小时。 通过上面这个场景我们可以发现,对于理发店来说,都是每小时服务三位顾客――第1个小时是A、B、C,第二个小时是D、E、F;但是对于顾客D、E、F来说,“响应时间”延长了。如果你可以理解上面的这些场景,就可以继续往下看了。 在新的场景中,我们假设这次理发店里一次来了9位顾客,根据我们上面的场景,相信你不难推断,这9位顾客中有3位的“响应时间”为1小时,有3位的“响应时间”为2小时(等待1小时+剪发1小时),还有3位的“响应时间”为3小时(等待2小时+剪发1小时)――已经到达用户所能忍受的极限。假如在把这个场景中的顾客数量改为10,那么我们已经可以断定,一定会有1位顾客因为“响应时间”过长而无法忍受,最终离开理发店走了。 我想并不需要特别说明,大家也一定可以把上面的这些场景跟性能测试挂上钩了。如果你还是觉得比较抽象,继续看下面的这张图
这张图中展示的是1个标准的软件性能模型。在图中有三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。 在这张图中我们可以看到,最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大;不过当并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。如果并发用户数继续增长,你会发现软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。 根据这种性能表现,图中划分了三个区域,分别是Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。 当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。 对应到我们上面理发店的例子,每小时3个顾客就是这个理发店的最佳并发用户数,而每小时9个顾客则是它的最大并发用户数。当每小时都有3个顾客到来时,理发店的整体工作效率最高;而当每小时都有9个顾客到来时,前几个小时来的顾客还可以忍受,但是随着等待的顾客人数越来越多,等待时间越来越长,最终还是会有顾客无法忍受而离开。同时,随着理发店里顾客人数的增多和理发师工作时间的延长,理发师会逐渐产生疲劳,还要多花一些时间来清理环境和维持秩序,这些因素将最终导致理发师的工作效率随着顾客人数的增多和工作的延长而逐渐的下降,到最后可能要1.5小时甚至2个小时才能剪完1个发了。 当然,如果一开始就有10个顾客到来,则注定有1位顾客剪不到头发了。 进一步理解“最佳并发用户数”和“最大并发用户数” 在上一节中,我们详细的描述了并发用户数同资源占用情况、吞吐量以及响应时间的关系,并且提到了两个新的概念――“最佳并发用户数(The Optimum Number of Concurrent Users)”和“最大并发用户数(The Maximum Number of Concurrent Users)”。在这一节中,我们将对“最佳并发用户数”和“最大并发用户数”的定义做更加清晰和明确的说明。 对于一个确定的被测系统来说,在某个具体的软硬件环境下,它的“最佳并发用户数”和“最大并发用户数”都是客观存在。以“最佳并发用户数”为例,假如一个系统的最佳并发用户数是50,那么一旦并发量超过这个值,系统的吞吐量和响应时间必然会 “此消彼长”;如果系统负载长期大于这个数,必然会导致用户的满意度降低并最终达到一种无法忍受的地步。所以我们应该 保证最佳并发用户数要大于系统的平均负载。 要补充的一点是,当我们需要对一个系统长时间施加压力――例如连续加压3-5天,来验证系统的可靠性或者说稳定性时,我们所使用的并发用户数应该等于或小于“最佳并发用户数”――大家也可以结合上面的讨论想想这是为什么 ^_^ 而对于最大并发用户数的识别,需要考虑和鉴别一下以下两种情况: 1. 当系统的负载达到最大并发用户数后,响应时间超过了用户可以忍受的最大限度――这个限度应该来源于性能需求,例如:在某个级别的负载下,系统的响应时间应该小于5秒。这里容易疏忽的一点是,不要把顾客因为无法忍受而离开时店内的顾客数量作为理发店的“最大并发用户数”,因为这位顾客是在3小时前到达的,也就是说3小时前理发店内的顾客数量才是我们要找的“最大并发用户数”。而且,这位顾客的离开只是一个开始,可能有会更多的顾客随后也因为无法忍受超长的等待时间而离开; 2. 在响应时间还没有到达用户可忍受的最大限度前,有可能已经出现了用户请求的失败。以理发店模型为例,如果理发店只能容纳6位顾客,那么当7位顾客同时来到理发店时,虽然我们可以知道所有顾客都能在可容忍的时间内剪完头发,但是因为理发店容量有限,最终只好有一位顾客打道回府,改天再来。 对于一个系统来说,我们应该 确保系统的最大并发用户数要大于系统需要承受的峰值负载。 如果你已经理解了上面提到的全部的概念,我想你可以展开进一步的思考,回头看一下自己以往做过的性能测试,看看是否可以对以往的工作产生新的理解。也欢迎大家在这里提出自己的心得或疑惑,继续讨论下去。 理发店模型的进一步扩展 这一节中我会提到一些对理发店模型的扩展,当然,我依然是只讲述现实中的理发店的故事,至于如何将这些扩展同性能测试以及性能解决方案等方面关联起来,就留给大家继续思考了 ^_^ 扩展场景1:有些顾客已经是理发店的老顾客,他们和理发师已经非常熟悉,理发师可以不用花费太多时间沟通就知道这位顾客的想法。并且理发师对这位顾客的脑袋的形状也很熟悉,所以可以更快的完成一次理发的工作。 扩展场景2:理发店并不是只有剪发一种业务,还提供了烫发染发之类的业务,那么当顾客提出新的要求时,理发师服务一位顾客的时间可能会超过标准的1小时。而且这时如果要计算每位顾客的等待时间就变得复杂了很多,有些顾客的排队时间会比原来预计的延长,并最终导致他们因为无法忍受而离开。 扩展场景3:随着烫发和染发业务的增加,理发师们决定分工,两位专门剪发,一位专门负责烫发和染发。 扩展场景4:理发店的生意越来越好,理发师的数量和理发店的门面已经无法满足顾客的要求,于是理发店的老板决定在旁边再开一家店,并招聘一些工作能力更强的理发师。 扩展场景5:理发店的生意变得极为火爆了,两家店都无法满足顾客数量增长的需求,并且有些顾客开始反映到理发店的路途太远,到了以后又因为烫发和染发的人太多而等太久。可是理发店的老板也明白烫发和染发的收入要远远高于剪发阿,于是他脑筋一转,决定继续改变策略,在附近的几个大型小区租用小的铺面开设分店,专职剪发业务;再在市区的繁华路段开设旗舰店,专门为烫发、染发的顾客,以及VIP顾客服务。并增设800电话,当顾客想要剪发时,可以拨打这个电话,并由服务人员根据顾客的居住地点,将其指引到距离最近的一家分店去。 这篇文章就先写到这里了,希望大家在看完之后可以继续思考一下,也写出自己的心得体会或者新的想法,记下自己的不解和疑惑,让我们在不断的交流和讨论中走的更远 ^_^ 性能测试相关术语的英文书写方法(不断更新ing)――知道了这些术语在英文中的正确书写方法之后,可以通过 Google 更加高效的获取到更多有用的资料。 |




组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |