| UML软件工程组织 | |||
| |
|||
|
|||
第4代白盒测试方法介绍--VcTester实践篇
作者:wayne_chan 出处:.csdn
| 关键词: 白盒测试 第4代 测试方法 4GWM 在线测试 持续测试 灰盒 脚本驱动 脚本桩 摘 要: 本文是第4代白盒方法测试实践介绍,结合使用VcTester实施一次具体测试过程,描述在线测试、灰盒调测、持续测试等特性的实践特征。 缩略语: 4GWM:The 4th Generation White-box-testing Methodology,第4代白盒测试方法 XP:Extreme Programming,极限编程 SAR:Select And Run,选中执行 PCO:Points of Control and Observation,观察控制点 TDF:Test Design First,测试设计先行 LICC:Location-Independent Call Coverage,位置无关调用覆盖 LDCC:Location-Dependent Call Coverage,位置相关调用覆盖 TCC:Test Case Coverage,用例覆盖度 1从实践到理论,再到实践1.1先实践后总结 本文的上篇从理论角度描述了4GWM的九项关键特征,本文再从实践角度诠释这些特征。 4GWM方法来源于长期工程实践,强调实践性是该方法论的显著特色,现实测试中某个问题难以解决,我们先尝试各种各样方法,最后形成最佳解决方案,归结升华就成为4GWM方法论体系。 比如,当年引入测试先行,并非要赶XP时髦,而是克服一个具体问题。在推行在线测试时,许多项目组反映测试工具好用但缺少意义,因为测试针对看得见的代码,比方计算“1+1”,设计用例测试它,其结果1+1肯定是等于2的。这个问题在一次测试模式下普遍存在,其根源在于测试设计方法,若只按代码(而非按规格)设计用例,肯定会漏掉不少设计问题。尽管如此,我们后来的实践表明,这个问题并不是向大家强调要改变测试习惯就能解决的,若从根本上去解决,还得引入测试设计先行的实践。 再如,引入测试设计程度评估,也是为了解决一个长期实践中难以回避的问题,即:覆盖指标可以评估大家有没做过测试,但无法推断是否用心的做测试了。统计问题缺陷密度不足以说明问题,因为发现问题数量直接与被测代码质量相关,测试发问题多了,一定程度上能说明问题,但发现问题少了就不好说,高手会宣称自己写的代码不必测,而假装高手的人会说,“嗯,我写的代码问题本来就少嘛!”,引入用例覆盖度尝试解决这个问题。 1.2已有的4GWM实践 目前第4代白盒方法主要实践集中在C语言与CSE语言,包括在线测试、持续测试等特性,已在许多产品得到充分验证。当然,4GWM体系经历长期发展才最后形成,少量近期发展的特性(如测试用例重构)经历市场验证尚不充分。 已有VcTester工具支持C语言的4GWM方法测试,该工具分共享版与商用版两个系列,共享版可从http://www.cse-soft.org/VcTester下载,支持脚本驱动、脚本桩、在线测试等功能,商用版本则完整支持4GWM,共享版的功能弱一些,但针对简单的个人应用已基本足够。 下文并不尝试把4GWM涉及的功能彻头彻尾介绍清楚,做到这一点实际很难,也不见得必要。我们仅列举该测试方法区别于常规方法的主要特征,更细节内容,请大家参考VcTester相关参考手册。4GWM是通用方法论,对具体被测语言没有限定,既然C语言能够支持,相信多数编程语言都能支持(开发一个类似VcTester的工具即可),下面我们拿VcTester商用版为例展开介绍。 1.3从一个例子开始 下面我们以开发“冒泡排序”模块为例展开叙述。我们的任务是:使用冒泡排序算法,开发一个原型为“void BubbleSort(OBJ_DATA_PTR ObjList, int iMax)”的函数,该函数对传入参数ObjList数据排序,BubbleSort中调用ObjCompare(Obj1,Obj2)函数两两比较数据大小,比如ObjCompare(Obj1,Obj2)返回小于0的值表示Obj1小于Obj2,返回0表示两者相等,返回值大于0表示Obj1大于Obj2。 源码请参见附1:被测代码BubbleSort 2在线测试2.1在线驱动与在线桩 被测代码已定义待排序的数据结构:
该数据定义映射到CSE脚本就是vt.struct.OBJ_DATA,比较两个OBJ-DATA数据,先比较Level子成员,Level相同再比较Data成员,BubbleSort按此规则将数组从小到大排序。开发功能代码之前,我们先编写如下调测脚本:
接着设计功能代码:
上面代码编译通过后,我们启动测试系统,在CseWin界面选中上面CSE脚本,按快捷键Ctrl+E,该段代码立即运行,这样的过程是选中执行(Select And Run,SAR),SAR是CSE脚本调测的主要模式,因为实时交互、所见即所得,用起来很直观,很便捷。 由于ObjCompare函数尚未定义,运行报错如下: 我们得给ObjCompare定义脚本桩,让当前BubbleSort排序函数能正常调起来,如下:
然后再运行测试脚本,发现测试通不过,我们选中上面脚本中局部代码“vc.buff[0].Data”,按快捷键Ctrl+E,可查看该变量值为4.0,再分别选中“vc.buff[1].Data”与“vc.buff[2].Data”查看变量值,都是4.0。到这里,我们立刻猜出,肯定是冒泡排序的两两数据交换出问题了,对照一下原码,果不出所料,相关代码修改如下:
顺便提一句,越是高手就越应该通过看代码找问题,而不是架调试环境费时费力的去定位。之后我们重起修改后的被测程序,重新执行前面调试脚本,可发现脚本跑通过了。 调试通过的脚本,我们可随时转换成正式测试用例,如下:
当然,我们也可以先创建测试用例框架,在框架内编写测试脚本,通过SAR选中执行方式调试脚本,必要时配合在线单步跟踪进行问题定位。 从上面操作步骤可以看出,VcTester提供了脚本测试驱动与脚本桩,这两者都是在线定义、再线运行的,使用起来非常方便。另外脚本桩可替代眼前尚未实现函数(如上面举例的ObjCompare),能有效隔离函数之间的耦合关系,使“写一点、测一点”的操作模式能顺利展开。 2.2在线测试改进 一次测试完成后,我们想看看当前BubbleSort函数还有哪些语句还没跑到。打开Inspector导航页,将编辑焦点移到bubbleSort函数,导航页即显示当前函数的抽象语法树。 如图1所示,抽象语法树下红色图标节点表示该节点尚未运行,灰色节点表示已运行。由图1我们立即看出,判断数据两两是否要交换的条件,其不成立分支(即不必交换的分支)还没跑到,因为前面设计用例是对4.0、3.0、1.0排序,每次都要交换,现在我们增加一个用例,排序4.0、1.0、3.0,就会有一次(即1.0与3.0比较)不交换的分支能跑到。
图1:快速查看未被覆盖语句 从前面用例TTest_BubbleSort1拷贝代码生成新用例,TTest_BubbleSort2,调换vc.buff[1]与vc.buff[2]的顺序,即生成一个新用例。许多同志不愿写测试用例,觉得麻烦,像前面第一个用例,除掉自动生成的框架代码,仍有20多行,以前如此投入不值。其实不然,VcTester提供的操作模式使用例设计尽可能重用,这里简单拷贝修改,立即设计出第2个用例,后面还有第3个、第4个用例都是这样的拷贝修改,所以整体效率不低。另外,VcTester测试脚本还被调试重用,边写代码边写用例,有个很大的好处就是让尚在编码中的系统随时可调测。 运行TTest_BubbleSort2后再看代码覆盖情况,发现最后一个if分支仍未覆盖,即“if ( !exchanged ) return;”的TRUE分支没跑到,据此我们再增加用例TTest_BubbleSort3,仍从前面用例拷贝代码再作修改,用例参见附2:本文用到的测试用例,本处不赘述。 在CSE集成环境中编辑源码、调试与测试、评估测试结果,到再次完善源码或增加用例,所有操作都是在线进行的,每一步都实时交互进行。这里,我们演示了一种快速改进设计的方法,后面章节还将介绍测试覆盖率与用例覆盖度评估,评估结果也用于改进测试设计。 3测试设计先行3.1测试设计先行 前面举例已经按测试先行的模式进行操作了,实施测试先行的基本步骤是:
测试设计先行的开发模式具备三个基本特征,一是系统始终处于可运行状态,不可运行是临时状态,如每次功能迭代的编码过程,一次功能迭代一般只新增几个函数,所以系统不可运行的状态非常短暂。 二是调试与测试混为一体,这是4GWM具备的特征,我们编写脚本驱动与脚本桩,首先要让系统运转起来,然后在调试或测试中发现问题、解决问题。当编写的脚本较为随意,它是调试用脚本,稍经整理,规范一点就是测试用例了。 三是产品趋于完善是测试所驱动的,我们经常先不具体实现某项新功能,而只用语句“RaiseExpt("ENotImplement",NULL)”让它报错,调测通不过了就要解决问题,通过问题依次解决逐步推进产品功能实现,及优化、稳定。这种测试先行的思路有别于常规软件过程,它使开发过程变为“不断解决问题”的过程,测试用例不停增加,当前用例多少直接反映待开发功能完成多少。 上面BubbleSort功能实现是一次迭代,我们接着下一次迭代,完成ObjCompare定义,首先设计调测脚本,如下:
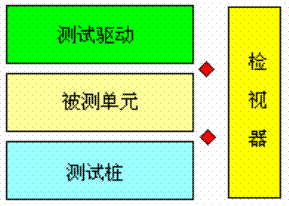
然后实现ObjCompare函数定义,进行测试,发现尚有分支未被覆盖,增加用例使之覆盖完全。完整的用例及源码参见附1与附2。 3.2 增量开发 测试先行必然伴随增量开发,我们遵循的思路是“写一点测一点,再写一点,再测一点”,这个模式被XP实践称为持续集成。但请注意,4GWM提倡的测试先行是测试设计先行,而非测试实施先行,本方法论对测试实施的要求相对宽松,只要不过于滞后就行。所以,4GWM并不强求用例一定要先于功能代码写出来,如果测试设计针对规格,是有必要先行的,但测试操作只针对现成代码,只要不影响调测连续性,滞后是允许的。 比如前面举例的几个步骤,先关注冒泡排序的逻辑,ObjCompare如何实现先放一边,即使是打脚本桩需要,也只比较其Data成员,而不综合Level与Data一起比较。等调通冒泡逻辑后,再专项关注ObjCompare实现。这样的迭代过程中测试与功能开发交替推进的,但我们不强求一次功能实现就彻底测试它,许多情况下,先设计用例把基本功能调通,就可以继续往下编码,等功能累积到一定程度,才细致的去分析代码覆盖情况,一次性增加用例使测试质量评估达标。 这里,我们不难看出,4GWM奉行一种实用至上的现实主义理念,它并不为了增量开发而开发,也不为了测试先行而先行。尤其是多个功能之间耦合很紧时,每写一点代码就彻底测试可能会很低效,因为前后功能相互影响,在后面功能没还调通前,前面的功能代码不够稳定,会经常变化。 4检视器VcTester的检视器一种提供脚本化控制的调试器,它在被测单元的上下层之间插入观察控制点(Points of Control and Observation,PCO),PCO依附于检视断点,VcTester规定一个被测函数只能设置一个检视断点,当断点条件满足,定义于PCO的PreCheck脚本与PostCheck脚本即自动执行。如图2所示:
图2:检视器结构 PreCheck脚本在被检视函数刚进入时运行,PostCheck在函数退出前运行,被测函数中的PreCheck脚本常用于修改传入参数,或修改全局变量构造出特定的测试环境,而PostCheck脚本常用来检查测试结果是否预期。此外,测试桩函数的PostCheck还常用于修改调用返回值,实现的功能相当于前面提到的脚本桩,让桩函数返回特定值便于被测函数中特定代码分支能被覆盖。 前面我们以自顶向下方式进行功能开发,下面我们换一个方式,采用自底向上方式来集成,先调测ObjCompare函数,然后调测BubbleSort函数,自底向上方式下,代码与测试脚本都容易重用。 PreCheck脚本在被检视函数刚进入时运行,PostCheck在函数退出前运行,被测函数中的PreCheck脚本常用于修改传入参数,或修改全局变量构造出特定的测试环境,而PostCheck脚本常用来检查测试结果是否预期。此外,测试桩函数的PostCheck还常用于修改调用返回值,实现的功能相当于前面提到的脚本桩,让桩函数返回特定值便于被测函数中特定代码分支能被覆盖。 前面我们以自顶向下方式进行功能开发,下面我们换一个方式,采用自底向上方式来集成,先调测ObjCompare函数,然后调测BubbleSort函数,自底向上方式下,代码与测试脚本都容易重用。 4.1选择检视变量 编写如下脚本测试ObjCompare:
这几行脚本用于发起测试,修改Obj1与Obj2的值可形成各式各样的用例,接下来我们演示怎么样把它快速的转化为正式用例。 先在ObjCompare函数设置检视断点,运行上面脚本发起测试,当程序在断点函数的头部停住时,我们在watch列表添加vc.Obj1->Data与vc.Obj2->Data这两个变量,再按住Ctrl键,用鼠标双击这两个变量使之选中,如图3,选中的变量有“*”标记,标记这些变量是为了将相关检查语句添加到自动生成列表。
图3:在函数首部添加检视变量 然后点击step out按纽(或按快捷键F6),当前程序随即运行到断点函数的尾部停住,如图4所示,同样,我们按住Ctrl键双击鼠标,选中vc.ret_,这个变量表示当前函数调用的返回值。
图4:在函数尾部添加检视变量 由图4可见当前ObjCompare返回值是1,正果是正确的。然后我们点continue按纽(或按F9快捷键)消调试断点,让程序一直跑结束。 最后,我们希望把刚才的调试操作转化为测试脚本,用Ctrl+P热捷粘贴自动生成的代码,这个代码加上刚才的测试驱动就形成一个完整用例。如下(方框内代码是自动生成的):
vd.ObjCompare(vc.Obj1.addr(),vc.Obj2.addr()); 自动生成的脚本用于设置检视断点,setBp的原型为: func setBp(vFunc,sCond='',ignoreNum=0,sPreCheck='',sPostCheck='') 其中,vFunc用来指定断点函数,sCond是断点条件,取空字串值表示它是无条件断点,ignoreNum是断点的忽略次数(取值N表次N次条件满足后才在断点停下来),sPreCheck与sPostCheck分别是断点函数运行前的检查语句与运行后的检查语句。用户可以手工修改自动生成代码,比方修改断点条件,设置断点忽略次数使断点函数在调用N次后才触发PreCheck等。 4.2添加检视操作 上面我们测试OBJ_DATA.Data值为5.0与4.0的两个数据比较,接下来,我们重用这个问例设计,修改OBJ_DATA.Data为其它值再做测试。 在同样函数设断点,同样调用“vd.ObjCompare(vc.Obj1.addr(),vc.Obj2.addr())”发起调试。当执行在函数头部停住时,我们把Obj1->Data从“5.0”改成“3.0”,如图5所示:
图5:添加检视操作 键入表达式“vc.Obj1->Data = 3.0”,然后按住Ctrl键再击回车,系统运行该表达式同时,还自动将它添加到检查列表,接着如前面用例,在函数末尾时再标记vc.ret_变量。结束调试后,按Ctrl+P热键粘贴自动脚本,整理用例如下:
vd.ObjCompare(vc.Obj1.addr(),vc.Obj2.addr()); 其中方框内代码是自动生成的,这个例子中,我们在检视函数的PreCheck修改传入参数,而在PostCheck检查测试结果。 5测试设计模式5.1三种测试设计模式 在白盒测试中,被测单元(Unit Under Test,UUT)是我们的观察对象,UUT上层是测试驱动,发起测试的脚本处于这一层,UUT的下层是支撑被测单元提供正常功能的桩函数。为保证被测单元中各个分支都被覆盖到,我们通常要仿真桩函数,同样要使被测单元各项功能都遍历到,测试驱动层也通常是模拟的。 根据测试驱动与测试桩的构造方式不同,形成三种主要测试模式。其一,仿真模式,测试驱动与测试桩都在测试用例中模拟。其二,点控制模式,测试驱动与测试桩都使用真实的产品代码,但在被测单元的上下层之间插入观察控制点(Points of Control and Observation ,PCO)。这一模式下,检视器控制PCO的行为,比如在被测单元调用前,修改某些变量的值,包括修改传入参数的值,另外也可以在桩函数调用结束时,篡改返回值,PCO的行为可以模拟测试驱动与测试桩。其三,混合模式,仿真与点控制同时存在,测试驱动与测试桩其中一个是模拟的,另一个通过点控制实现。 前面列举了几个例子,大家回头看看,它们都属于哪种设计模式?不妨自行分析一下它们的应用特点。 本文一开始的例子中,因这ObjCompare函数尚未定义,我们通过打脚本桩让BubbleSort函数测起来的,现在我们把桩改成检视断点:
我们为了测试bubbleSort,先给桩函数compFunc设置检视断点,由检视断点控制compFunc直接返回指定值。如下:
打桩与设置检视断点效果等同,实际上这两者是按同一机制实现的,打脚本桩等同于在检视断点的PreCheck中直接返回结果值。检视断点比脚本桩提供更强大的调测能力,可以设置断点条件、忽略次数等。 5.2如何选择测试设计模式 上述三种测试设计模式各有优劣,仿真模式要手工编写脚本驱动与脚本桩,工作效率低下,但测试代码与被测代码有隔离,用例可维护性较好。点控制模式能自动生成脚本,开发用例的效率较高,但测试脚本与被测代码耦合紧,对用例可维护性有影响。 应该根据实际情况选择哪种模式,如果被测系统的功能比较内聚,少量用例即驱动大量测试时,可以多用点控制模式。如果被测系统功能分散,或者函数接口简单容易模拟的,不妨多采用仿真模式。还有,越是低层代码或是库函数代码,较少依赖其它函数,就能越多采用仿真模式,反之,越是高层应用,应更多采用点控制模式。 6测试效果评估6.1基于函数调用的评估体系 VcTester的测试质量评估体系由两部分组成,一是测试覆盖程度评估,二是测试设计程度评估。前者主要针对用例有效性,后者主要针对用例完整性,都是基于函数调用分析来构造的。 支持两类测试覆盖率评估,一是位置无关调用覆盖率(Location-independent call coverage,LICC),二是位置相关调用覆盖率(Location-dependent call coverage,LDCC),定义如下:
比如某函数中调用了3个子函数,其中第1个子函数在该函数定义的两个地方出现,其余2个子函数都只在一处调用。如果这个3个子函数都被调用过,其中第1个子函数只在一个位置调用了,另一个位置尚未调用到。这时,我们计算LICC是“3/3 = 100%”,而LDCC是“3/4 = 75%”。 LICC指标主要用于粗测,确保某模块具备一定的初始稳定度,适合于与其它模块集成,LICC指标尝试说明新定义的函数是否跑到过,而不关心是否每个地方都跑到。LDCC则在正式测试中使用,比较完整的评估测试程度。 测试设计程度也称用例覆盖度(Test Case Coverage,TCC),以被测函数在正式测试中使用频度与其函数定义中分支总数之间关系作为依据,定义如下:
其中,某函数的分支总数的定义如下:
if语句有TRUE与FALS两个分支,原理上说应该设计两次测试才是完整的,while与for也类似,循环至少进入一次应设计一个用例,一次都不进入也应设计一个用例,所以计算出if、while与for语句总数后要乘以2,但如果一个函数没使用这3个控制语句,也应至少设计一个用例测试它,这是上面公式额外加上1的含义。 用例覆盖度通常不作为测试结果的硬性评价指标,而只设置一个下限值,未达标时测试结果应该是一票否决的。设置这个指标可监控不经意测试,即,非测试目调用被测函数而导致代码覆盖率上升,使得覆盖指标虚高。 6.2测试效果评估 最后我们进入正式测试,先检查一遍前面调通的用例,为让它们能连续执行,前后用例不应产生藕合,比方前面用例修改全局变量了,而后面用例是假定全局变量未被修改,冲突就产生了。前面举例的用例经整理,放在附2:本文用到的测试用例。 定义所有用例后,我们双击快捷面板“Run All Case”运行测试工程,由打印信息可知,当前测试通过了,再查看主界面右上角三个提示灯,如图6所示:
图6:测试结果评估 左边的指示灯表示测试是否通过,中间指示灯表示覆盖率是否达标,右边的指示灯表示测试设计是否达标。把鼠标移到中间指示灯上,系统将显示详细的覆盖率信息,如上图提示信息表明当前测试已通过,LICC覆盖率为92%,LDCC覆盖率为87%,用鼠标双击覆盖率指示灯可在Coverage导航树查看详细信息。如上图,覆盖率导航树下灰色图标节点表示已覆盖,红色图标是目前尚未调用的函数,用鼠标双击某节点,编辑光标将跳转到该语句行,可以看出ObjCompare的第二个if语句条件为TRUE的分支尚未被覆盖。 我们当前设定的测试通过标准是:LICC值为0.8,LDCC为0.8,用例覆盖度为0.5,所以本次测试,覆盖率已满足要求,右边指示灯亮黄灯,表示测试设计程度未达标(当前用例覆盖度才0.43),同样双击这个指示灯,可在导航树查看各个函数的用例覆盖度的值。 6.3红灯停,绿灯行 如果当前有用例没跑通过,左边指示灯将亮红灯,如果覆盖率未达标,中间指示灯将亮黄灯,如果用例覆盖度未达标,右边指示灯将亮黄灯,只有当前测试通过、代码覆盖率与用例覆盖度都达标3个指示灯才都亮绿灯,使用VcTester的开发过程,就是让这3个绿灯常常亮起的编码与测试过程。 红绿灯机制规定了简单的研发准则,亮红灯必须先解决问题,亮黄灯要改善测试设计,只有3个指示灯都是绿灯,才能进入下一步开发。如果所有团队成员都遵守“交通规则”,形成职业习惯,项目整体研发就能高质量、有节奏的平稳推进。 有了红绿灯机制,我们还得提供配套措施,保证它规范的执行起来。首先,要解决测试标准的定制问题。不同产品、不同模块有不同的质量要求,我们要求LICC、LDCC及TCC的达标值可定制,另外,当前评估范围可调整,某些关注范围之外的函数定义不必纳入统计,再有,函数内特定语句可定义到例外列表,不纳入覆盖率统计,比如错误处理,或者某些当前不必关心的语句,如处理跨平台的语句等。 其次,还得有系列配套措施,使研发过程的代码质量、用例质量能集中监控,能自动生成报告、配合QA审计等。限于篇幅我们不对上述配套功能展开论述,感兴趣者请参阅VcTester使用手册。 基于调用分析的评估体系,是我们经过多年实践,最后沉淀下来的操作模式,优于其它常见评估手段。比如,如何选择覆盖标准存在一个误区,大家通常认为覆盖率评估得越细越好,标准越高越好,其实未必,作为一项可持续的软件过程,首先要求适度,保障操作可持续性应该摆第一位,其次才是拔高要求,能够锦上添花是最好。 另外,维持测试评估体系的一致性与稳定性也很重要,商用工具经常采用的分支覆盖、MCDC覆盖等评估标准,在适应不同场合或不同风格的代码时,都存在一定“噪声”。比方分支覆盖中,条件判断的AND与OR具有短路功能,只取条件结果分析哪条路径覆盖或未覆盖是有失偏颇的,尽管不必考虑条件组合情况,但该对等看待的分支确实漏统计了。再如C语言中的switch语句,统计各case分支实际只分析可见代码,漏写一处case是统计不到的,但在if与else分支统计时,漏写else却可以统计,显然不怎么协调。 再有,常见商用工具将特殊语句(如错误处理、不可达或难到达代码),不作区分的纳入评价标准,这些都会给项目持续平稳的运作带来伤害。 7总结4GWM集中了我们认为比较优秀的白盒测试实践,是经提炼的通用方法论,VcTester工具作为该方法论的载体,又是通用方法的具体语言下具体实践。 工具与方法论是互为依赖并共同促进的,这好比是茶道与茶具,茶道总结了良好的喝茶体验,而茶具固化并传承这种体验,比如,茶壶要多大,多少茶只能加多少水,要泡多长时间等都有讲究,茶杯必小,且分三口徐徐下咽(三口才成品,否则是牛饮),这种具体化、规格化的器具,加上形式化的操作规则,必能有效传承经验。 VcTester就是这种规格化的器具,承载了良好的测试习惯,我们在详细介绍第4代白盒方法同时,也希望广大同道中人积极参与,尽快将4GWM扩展到其它语言,如Java、C#等。 |





组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |