软件测试的工作量很大(业界统计达到40% 到60%的总开发时间),而又有很大部分适于自动化,因此,测试的改进会对整个开发工作的质量、成本和周期带来非常显著的效果。
极限编程(XP)中推荐的自动化单元测试,是指在编写代码之前先写好测试代码,代码编到一定阶段就用写好的测试代码进行测试。自动化单元测试可以带来如下好处:
我们沿着“建立测试=>令测试通过=>再建立测试=>再令测试通过”的模式,一步一步地把整个程序正确地开发出来。
1.测试代码的几个关键环节
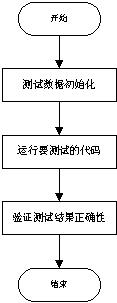
对测试代码进行概括性分析,可以发现测试代码都具有类似的结构,每一个测试用例的执行都要包括测试数据初始化、运行要测试的代码、验证测试结果正确性三部分,见图1-1。
图1-1 测试代码的一般性流程
由于测试代码一般都包含了图1-1中的三部分,我们要改善测试代码使之具有良好的结构只要从这三方面入手即可。
1)将测试数据和测试结果从测试代码中分离出来
在采用CXXUNIT系列测试工具开发测试代码时,发现一般编程人员都是测试用例和测试代码混杂在一起,同样测试结果也是和测试代码混杂在一起,这样就导致测试用例和测试结果的管理非常困难,因为要管理每个用例的数据和结果实际上就是去管理这些代码。而且对于一个函数(或功能) 每增加新测试用例,就要多出一份类似的代码,代码的逻辑实际上都是一致的,和以前测试代码的不同点就是在初始化数据、测试结果的不同,这实际上也导致了代码的重复。
我们可以将测试数据和测试结果从测试代码中分离出来,使得某一个函数(或功能)的测试代码就一份,这一份测试代码应可以进行多组测试数据的测试,可以进行多组测试结果的验证。
2)将测试数据和测试结果放入文件中,并按目录存放
将测试数据和测试结果从测试代码中分离出来是为了更好的管理代码和测试数据,将每个测试用例的数据和结果都放入到一个文件中,文件名字或文件所在目录起上能表明测试用例含义的名字,这样管理起来就方便多了,见图1-2。
图1-2 测试用例文件及目录结构图
由图1-2中可以看出此时测试用例非常直观,从目录名就可以知道该目录下的为那个功能的测试用例,从测试用例文件名就可以知道这个测试用例测的哪一个方面。当一个功能的测试用例非常多可以分成许多类别时我们还可以在下面再创建测试用例分类子目录,使得不同类型的测试用例能分隔开方便管理(详见图2-1)。
3)将测试数据和测试结果绑定在一起
当每个测试用例对应的测试结果都一样时可以将测试结果嵌入到测试代码中,当不同的测试用例要对应不同的测试结果时,根据1)中论述应该将测试结果也从测试代码中分离出来。为了不混淆测试数据和测试结果之间的关系,将它们放在同一个文件中。这里举个例子,图1-2中的“闰年2月份的测试用例.ini”文件中内容如图1-3:
由图1-3可以看到,测试数据和测试结果放在一起,增加了可读性和维护性。
4) 一份测试代码来运行多份测试用例
怎样让一份测试程序可以进行多组数据的测试和结果的比较呢?3)中已经将测试用例分门别类,并由相应的目录结构组织起来。此时测试程序只需每次从测试目录中取出一个测试用例文件,进行初始化,然后执行测试,最后比较测试结果;测试完一个用例文件,再取下一个文件进行测试,如此循环直到所有的用例文件都测了一遍,详见图1-4。
图1-4一份测试代码测试多个测试用例的流程图
2.测试用例管理方案设计
若再加上边界数据要测试的数据组数就更多了,一般CXXUNIT系列编写的测试代码是每组测试数据(其实一组数据就对应一个测试用例)都要编写初始化代码,然后调用相应功能函数测试。这样导致:
在自动测试的整个过程中,测试用例的可维护性会影响到将来测试用例增加的难易度,良好的自测程序应能很方便的扩充测试用例。
在采用CXXUNIT系列测试工具开发测试代码时,对于一些简单的测试可以测试用例就嵌在测试代码中。但当某一个功能或函数要进行很多组数据(如边界数据)的测试时使用这种方法就得重复编写测试代码,可能每增加一个测试用例就要编写大量的重复测试代码。
举例:要测试周期会议预约功能的代码,要测试以下几组数据:
1)每日召开的周期会议
1.1)按召开次数预约的周期会议
1.2)按开始时间、终止时间预约的周期会议
2)每周召开的周期会议
……(内容和1.1、1.2一致)
3)每月召开的周期会议
4)每年召开的周期会议
2.1测试用例目录结构
为此很有必要设计一套能良好管理和添加测试用例的体系结构。
当一个功能有很多组测试数据时,我们可以将测试用例数据全部存放在文件中,使测试用例和测试代码分离开。由于测试用例脱离测试代码而存在,可以很方便的进行管理和维护。我们可以为每个要测试的函数(或功能)建个目录,每个测试用例放在一个单独的文本文件中,将所有对应于该函数的测试数据文件全部放入该目录下,当测试数据量很大时还可以在目录下再创建相应的子目录,分类进行管理。这样可以方便测试用例的管理,而测试程序也只用专注于测试逻辑。还以测试周期会议预约功能的例子为基础进行讨论。
图2-1 测试用例目录结构图
由图2-1上可以看到,当某个函数(或功能)的测试用例很多时,还可以在“某功能测试用例总目录”下再使用子目录来划分,若觉得划分不够细还可以继续加深目录层次,直到分类比较清晰为止。
由于测试用例数据和测试代码进行了分离,以后对于某个函数(或功能)有了新的测试用例时不用再去修改测试代码,只需在该功能的测试数据目录下添加新的测试用例文件即可。该功能的测试程序每次运行时对于相应测试数据目录下的每个测试用例文件(包括各级子目录下的用例文件)都要执行一遍。
使用了目录结构对它们进行了分门别类方便了以后的管理,正如良好的程序应具有好的可读性和维护性一样,良好的测试数据也应具有好的可读性和维护性。
2.2测试用例文件结构
测试用例文件中存放测试用例初始化数据和测试完毕后的验证数据。数据的结构采用一般配置文件的格式,详见图2-2。
图2-2 测试用例文件结构图
1)段名
配置文件中使用了段的概念,段相当于C++中的NameSpace,每个段内的关键字(Key)与其它段内的关键字互不影响,Section即为段名。
2)关键字
关键字用来标志不同元素的值,Key即为关键字的名字,关键字的名字不区分大小。
3)值
每个关键字都对应一个值,Value 即为值,值要区分大小。
4)注释
支持单行注释,字符“#”后面的内容为注释。
5)行结构
一行的结构只能是以下几种:
2.3测试程序通用库
测试数据从测试代码中分离出来后,增加了管理测试数据文件和解析测试数据文件的代码,这部分代码是通用的,可以将它们组织成库供开发测试程序时使用。
图2-3 测试程序和测试通用库关系图
2.3.1管理测试数据文件的库
管理测试数据文件的库的功能如下:
1)获取目录下所有测试文件路径的接口
能找出某个目录下 (包括该目录下所有子目录)所有的测试文件(如“*.ini”文件)的路径并存起来。
2)获取下一个测试文件的接口
向用户提供下一个测试文件的路径,若已没有下一测试文件则返回空。
2.3.2解析测试文件的库
解析测试文件的库的功能如下:
1)文件解析接口
按照 2.2测试用例文件结构 中的文件结构解析出一个测试文件。
2)获取值的接口
向用户提供测试文件中某个段内某个关键字对应的值。
由于测试文件的结构和一般配置文件结构一致,可以使用已有的库来实现(如PWLIB中配置文件解析类)。
3.总结
一个完整的测试用例包含测试数据和测试代码,当测试数据和代码混在一起时给测试用例的维护带来了很大困难,而且给测试代码带来许多冗余。本文提出了将测试数据和测试代码分离的想法,并对怎样进行分离进行了阐述。测试数据从测试代码中分离出来后,使得测试数据维护简单、方便。
4.参考资料
CppUnit 主页 : http://cppunit.sourceforge.net/
xprogramming 主页 :http://www.xprogramming.com
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号
京公海网安备110108001071号