一、持续集成基础
在典型的软件项目中,集成阶段一般都是在最后,因此也是出现问题最多,而且最有可能导致不能按时交付。而持续集成(XP十二实践之一)可以用来解决这个问题。既然大家都认为“频繁地使软件在某一代码基线构建并通过测试”是个不错的做法,那么让代码每次变化时都能够成功构建并通过测试不是更好吗?
通过持续集成,所有的工作都会尽可能地集成到单一的代码基线上。而每次代码的提交都会触发一次构建以及一系列的测试。因此开发人员可以得到及时的反馈,并可以随时构建和测试。同时,还可以减少在软件发布之前的集成过程中可能出现问题。
二、大规模项目团队中可能遇到的问题
对于小规模、短周期的项目来说,团队与持续集成会相处地非常融洽。同时,对于大规模、长周期项目的初期,也不会有太多的问题。此时常见的也是基本的持续集成模式就是:Build->test->package。然而,只要时间稍长一点儿,持续集成就会发出坏味道了。此时的症状包括:
1. 做为开发人员
A 要等很长时间才能知道是否可以提交代码了
如果你遵守“频繁提交”的原则,那么百人团队不间断的提交,会使集成服务器一直处于繁忙状态,而你不得不等待他人的build过了以后,才能看到自己提交的结果。
B 要等很长时间才能知道我的提交是否通过了
C 如果build失败了,要花很长时间才能知道是否和自己的修改相关
D 即使提交了fix,也不知道自己的提交是否真的fix了build.
E build常常处于失败状态。
2. 做为测试人员
F 测试人员不知道在哪里拿build来进行测试.
G 发布管理者不知道当前各种各样的测试部署环境中,到底部署了哪个版本,包括哪些新功能或修改的bug.
H 不确定同一个build中,是否所有组件的版本都是正确的
3. 做为项目经理
I 不确定各个测试部署环境中的配置是否都与其上运行的build相一致
J 不确定测试人员测试的是否在正确的运行环境上运行了正确的版本。
4. 其他方面的问题
所有的安装都是手工操作.
以上这些问题会给你的发布管理带来无限的问题和风险。那么,是否因为这种“持续闹心”就放弃持续集成呢?回答当然是否定的。Do
it more if it hurts you. 不要因问题的暴露而放弃,相反,应该欢呼。因为这反映了发布过程中的问题与风险,是时候解决它们了。
三、如何解决大规模项目中的持续集成问题
由于大项目本身的复杂性,其解决方案也不能一概而论。下面以某大型项目为例,介绍其中的几个解决方法。
1、项目基本信息描述
该项目最初就试图建立一个好的持续集成环境和基础。虽然能够得到工作的软件,但是由于队伍不断壮大,而且环境也在不断变化,持续集成达不到预期目标。
项目背景:
项目是一个具有可配置性的Web 门户产品,面向不同行业的市场,可自己定制门户。该项目有一个遗留的代码库,而且可以肯定的说,在今后的一年半之内是无法摆脱这个遗留代码库的。而且,很多紧耦合的、不必要的臃肿代码,同时根本不存在有价值的测试代码。现在我们在逐步地重写代码,但还是不能删除它们,因为某些网站还要依赖于旧代码。事实上,这是一个.NET平台上基于SOA的网站。
开发团队情况:
团队是一个敏捷分布开发团队(三地协作,均有开发人员,且有时差)。整个团队有150多人,分成十几个团队,每个团队都有一个完成的结构(BA/DEV/QA),其中有一个是项目持续集成团队(最初大约有五六个人,工作负荷很大),最后只要两个人就足够了。使用SVN做版本管理工具,在Windows2003上使用NAT,
MSbuild和batch脚本进行构建管理,最初使用CC.NET做为持续集成服务器。
持续集成环境:
上面所述的持续集成问题在项目一开始就出现了,因为该项目有一个庞大的遗留代码库,而且使用的基本持续集成方式(build->test->package)而且测试人员手工部署进行各类测试。
其初始的持续集成环境如下所示:

第一步目标:尽量减少团队之间影响
方法:先化整为零,再化零为整 ――――根据团队划分代码(或者根据代码划分团队)。
手段:DVCS+私有持续集成服务器+全局持续集成服务器
每个团队都使用GIT做为中间源代码管理工具。这样,团队人员可以先提交到GIT。每个团队有自己的持续集成环境。一但构建成功,触发将代码提交到中心的源代码库,并触发中心源代码的持续集成。有一个专职团队负责全局持续集成的结果跟踪。
益处:
1. 每个团队都可以天天提交代码 (如果这些代码没有让自己的构建失败,就说明至少能够通过初步检验)。
2. 任何一个团队的构建坏了,并不影响整个项目,而只是一个团队。
3. 有一个专职团队负责全局,不用每个团队都停下来。
4. 如果全局持续集成失败了,不用所有的团队停下。
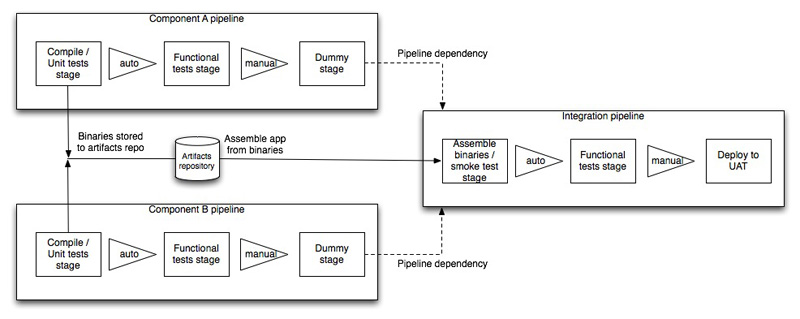
第二步目标:提高反馈速度
方法:化整为零,再化零为整――――测试分组运行。
手段:并行化与中心仓库(Cruise的并行化与中心仓库)
由于功能多且复杂,测试较多,运行很长。利用Cruise的并行化特点,每个团队将测试分成28组。一旦提交后,Cruise会将其放在28台机器上并行运行。运行后,将所有测试输出和结果上传到同一处(Cruise
Server的中心仓库)。
益处:
1. 反馈时间大幅度缩短(原来30分钟以上,现在20分钟之内)。
2. 易扩展:如果因测试增多而导致反馈周期长,可通过增加更多的机器解决。
3. 易维护:对于测试分组和构建机器的增减来说,在Cruise中都非常容易,只要在同一处修改配置即可。
4. 易追踪和Debug:所有的信息(包括artifacts)都放在同一处,能过Web访问。
5. Single view (在同一个Web管理页面上,可以监控所有团队的构建状态)。
第三步目标:减少手工操作
方法:一键发布――――自动化部署
手段:Cruise (Cruise的dependency + Story Tracker plugin
+ audit)
由于有很多个团队,每个团队都有多个测试环境。如果全部使用手工部署分花费很多时间。所以,每个团队建立三个构建管道,其目标分别为:(1)得到测试过的
installer;(2)部署到测试环境中;(3)将通过测试的installer部署到演示环境中。前一个构建成功后,就可以触发下一个(自动或手动)。
益处:
1. QA可以清晰识别需要测试哪个安装包,该安装包中含有哪些功能
2. QA自己可能很容易地部署测试环境。
3. 易于追踪功能的历史版本(在同一个pipeline中,所有的stage同一版本.而且在使用Pipeline
dependency时,版本信息会向下游传递)。
4. 易于掌握对各种部署环境的管理。
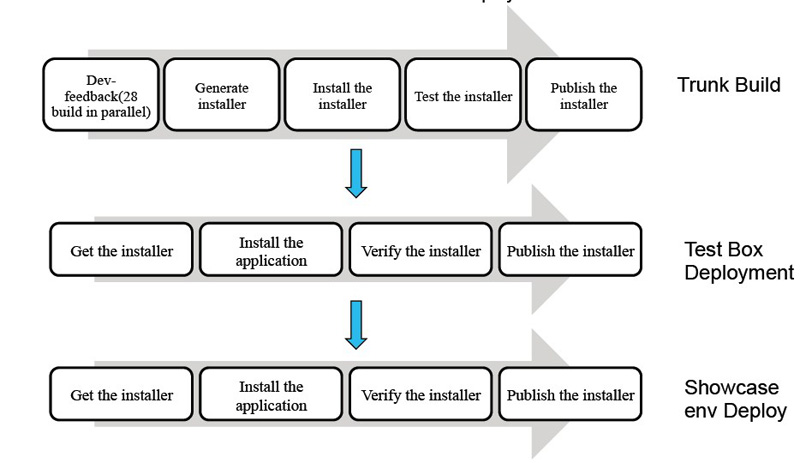
使用上述手段后,该项目的持续集成已入佳境。目前可以做到:
所有的构建和部署都是自动化的;
开发人员最多在20分钟内就会得到反馈。
对于每个环境来说,可以做到每天部署四次。
部署无差错:因为是自动化过程,每次的执行步骤都一样。
机器资源复用:Cruise自动向165台机器上分发工作进行构建和部署。
Single dashboard view of everything!
开发人员非常高兴:他们可以多次提交而不影响他人。
测试人员非常高兴:他们可以很快地得到好的installer,通过自己点一下按钮就完成部署工作。
管理人员非常高兴:他们可以马上了解当前的项目状态(哪些版本在测试中,那些版本已经演示了)。
很容易了解每个版本里包括哪些功能和修复了哪些缺陷。
最终的持续集成环境中共计有260个构建和部署机器,每六周一个release,每个release需要生成15个独立的安装包.
| 




