|
用户行为模拟器简称VU,VU通过运行VU脚本模拟了用户对软件的操作行为。VU是基于网络协议的。很明显,被测服务器是通过各种各样的网络协议与客户端打交道的。VU要“骗过”被测服务器,当然就要遵守这些协议,按规矩、按步骤来执行动作,否则就会吃“闭门羹”。
基于网络协议的脚本的一个好处是,我们可以使用相对少的硬件资源,来生成大量的虚拟用户负载。相比之下,WinRunner和QTP脚本时基于界面事件的,它在一台主机上同时只能运行一个虚拟用户的脚本,因为一个虚拟用户会占用整个主机的资源。
所以可以有如下结论:
1.VU不关心用户在界面发生的事情(如用户鼠标移动、填写WebForm数据)等。
2.VU中的操作关联与界面上的操作关联是不一致的。如正常用户的操作是,打开列表页,点击一行进入详细页面。而LoadRunner只记录一个请求,以及这个请求的参数直接进入,对它来说根本没有打开列表页的步骤。
一、录制脚本
VU通过录制用户在客户端软件的操作来直接生成脚本,用户的每个协议级的操作以LoadRunner的API函数方式记录在脚本里。回放脚本的时候,通过执行API函数来模拟最初用户的操作动作。
1、选择协议
协议有好多种,是用哪种协议当时你开发的时候你自然会知道。目前我一般用的都是Web(HTTP/HTML)协议。
当我们试图创建一个新的VUser的时候,就会弹出协议选择对话框。

有两种协议选择方式:单协议模式和多协议模式。
(1)、单协议模式:当用户以单协议录制时,VU只录制在既定协议上的用户操作,在VU中我们可以使用单协议模式选择任何一种协议。
(2)、多协议模式:当用户以多协议录制时,VU录制几个协议上的操作。并不是任意的协议都可以组合成多协议模式。
2、规划脚本结构
在录制时,用户可以选择哪些操作生成脚本在vuser_init、Action和vuser_end中,同时,也可以在录制时随时加入transaction的定义、注释和同步点。VU录制工具条如下所示:

3、HTTP Vuser中的URL mode和HTML mode
在录制之前,我们需要设置录制选项:


在默认情况下,选择“HTML-based script”,说明脚本中采用HTML页面的形式来表示,这种方式的Script脚本容易维护,容易理解,推荐以这种方式录制。
“URL-based script”说明脚本中的表示采用基于URL的方式,所有的HTTP的请求都会被录制下来,单独生成函数,所以URL模式生成的脚本显得有些杂乱。
Action()
{
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTML",
LAST);
} |
而以HTML模式录制,则生成如下脚本:
Action()
{
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
web_url("Default.css",
"URL=http://127.0.0.1:9090/Resources/CSS/Default.css",
"Resource=1",
"RecContentType=text/css",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t4.inf",
LAST);
web_url("gwu1.jpg",
"URL=http://127.0.0.1:9090/Resources/Images/login/gwu1.jpg",
"Resource=1",
"RecContentType=image/jpeg",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t5.inf",
LAST);
... 省略N个
} |
是选择HTML还是URL录制,有以下参考原则:
1.基于浏览器的应用程序推荐使用HTML-based script。
2.不是基于浏览器的应用程序推荐使用URL-based script。
3.如果基于浏览器的应用程序中包含了JavaScript并且该脚本向服务器产生了请求,比如DataGrid分页按钮等,也要使用URL-based
script方式录制。
4.基于浏览器的应用程序中使用了HTTPS安全协议,使用URL-based
script方式录制。
4、查看日志
在录制和回放的时候,VU会分别把发生的事件记录成日志文件,这些日志有利于我们跟踪VU和服务器的交互过程。我们可以通过VU输出窗口观察日志,也可以到脚本目录中直接查看文件。
1、执行日志(Execution Log,新版本是Replay Log)
脚本运行时的输出都记在这个Log里。
“执行日志”中使用了不同颜色的文本。
1.黑色:标准输出信息。
2.红色:标准错误信息。
3.绿色:用引号括起来的文字字符串(例如URL)。
4.蓝色:事务信息(开头、结束、状态和持续时间)。

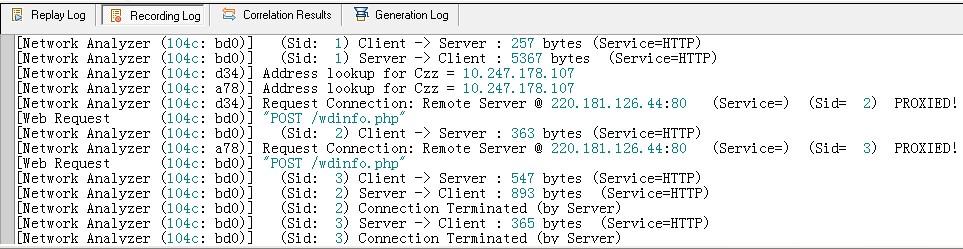
2、录制脚本(Recording Log)
当录制脚本时,Vugen会拦截Client端(浏览器)与Server端(服务器)之间的对话,并且通通记录下来,产生脚本。在Vugen的Recording
Log中,我们可以找到浏览器与服务器之间所有的对话,包含通信内容、日期、事件、浏览器的请求、服务器的响应内容等。脚本和Recording
Log最大的差别在于,脚本只记录了Client端要对Server端的请求内容,而Recording Log则是完整记录二者的对话。所以,通过录制日志,我们能够更加清楚地看到客户端与服务器的交互。
3、产生日志(Generation Log)
产生日志记录了脚本录制的设置、网络事件到脚本函数的转化过程。
提示:脚本能正常运行后应禁用日志。因为产生及写入日志需占用一定资源。
二、回放脚本
单击run按钮,或按快捷键“F5”就可以运行脚本。VU脚本运行工具条如下:

录制完成之后,最好先运行一次脚本,因为在跑测试之前必须先确保脚本没有错误。
三、关联
关联的作用是客户端每次的访问,服务器都会有动态的内容产生,如果这个动态内容跟不上,则服务器就报错的情况。如SessionId,假如每次访问,服务器都为其分配一个session号(随机的)导致报错时,此时就要对seesion做关联。
这个看起来好像很难的样子,先跳过, 用到再学。
四、脚本视图和树视图
VU提供两种视图来查看脚本的内容,一个是脚本视图,另一个是基于图标的树视图。
所有类型的Vuser都有文本脚本视图,但是只有特定的Vuser才会有树视图。
1、树视图(Tree View)
Tree View也叫做基于icon的View,也就是说,脚本的每个函数在Tree
View中都以一个带有icon的节点来代替。可以点击工具栏=>"Tree"按钮或者在“View”=>“Tree
View”,显示VU树视图。

Tree View的好处是使用户更方便地修改脚本,Tree View支持拖拽,用户可以把任意一个节点拖拽到他想要的地方,从而达到修改脚本的目的。用户可以右键单击节点,进行修改/删除当前函数参数属性,增加函数等操作,通过Tree
View能够增加LoadRunner提供的部分常用通用函数和协议相关函数。比如Web Service Vuser就不能通过Tree
View参数化一些复杂的数据类型,在这种情况下,就需要Script View了。
2、脚本视图(Script View)
在Script View中能够看到一行行的API函数,Script View适合一些高级用户,通过Script
View向脚本中增加一些其他的API函数。可以单击工具栏上的"Script"按钮或者在"View"菜单下选择"Script
View",显示VU脚本视图。
当用户在Script View中对脚本做了修改之后,Tree View也会做相应的变化。如果脚本有语法错误,Script
View将不能转化为Tree View或缩略图。

3、理解Snapshot
napshot,顾名思义,就是快照,代表当前的step,Snapshot显示了客户端执行完当前step后的样子,在Tree
View右侧的frame中可以查看Snapshot,在LoadRunner 8.0中,Snapshot包含Page
View、Client Request和Server Response。
Snapshot有两种生成方式,一种是在record的时候生成,另一种是在replay的时候生成。可以对比两种方式生成的Snapshot,以发现哪些是动态值,需要参数化。
五、事务、同步点和思考时间
1、Transaction(事务)
在LoadRunner里,我们定义事务主要是为了度量服务器的性能。每个事务度量服务器响应指定的Vuser请求所有的时间,这些请求可以是简单任务,也可以是复杂任务。
要度量事务,需要插入Vuser函数以标记任务的开始和结束。在脚本内,可以标识的事务不受数量限制,每个事务的名称都不同。
在场景执行期间,Controller将度量执行每个事务所用的时间。场景运行后,可使用LoadRunner的图和报告来分析各个事务的服务器性能。
设置Transaction的方法如下:
1.选择新Transaction开始点,在被度量脚本段之前插入lr_start_transaction。
2.选择新Transaction结束点,在被度量脚本段之后插入lr_end_transaction。
下面的脚本例子中将登陆操作设为一个名为"login"的事务:
lr_start_transaction("login_start");
web_submit_data("login",
"Action=http://127.0.0.1:9090/account/login",
"Method=POST",
"RecContentType=text/html",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t19.inf",
"Mode=HTTP",
ITEMDATA,
"Name=userName", "Value=xpj", ENDITEM,
"Name=submitBtn", "Value= ", ENDITEM,
"Name=password", "Value=123", ENDITEM,
LAST);
lr_end_transaction("login_end",LR_AUTO); |
如果手工插入的Transaction如果称为“显式事务”的话,那么LoadRunner还提供了一种“隐式事务”的机制,在VU的Run-time
Settings中又称为“自动事务”。
在Run-time Settings中,在Miscellaneous选项卡的Automatic Transactions中定义自动事务。
Vuser => Run-time Setting => Miscellaneous
可以设置LoadRunner直接按事务处理Vuser中的每个Action或step。这里,Action指的是vuser_init、Action和vuser_end三大函数,而step指的是LoadRunner执行的每个函数。LoadRunner将Action名或step指定为事务名。默认情况下,将启用按Action使用自动事务的功能。
1.要禁用按操作使用自动事务的功能,清除"Define each
action as a transaction"复选框(默认情况下启用)。
2.要启用按步骤使用自动事务的功能,选中"Define each
step as a transaction"复选框。
Transaction的开始点和结束点必须在一个Action中,跨越多个Action是不允许的。Transaction的名字在脚本中必须是唯一的,当然也包括在多个Action的脚本中唯一。你也可以在一个Transaction中创建另外一个Transaction,叫做Nested
Transaction。
2、Rendezvous Point同步点
在系统上模拟较重的用户负载,需要同步各个Vuser以便在同一时刻执行任务。通过创建集合点,可以确保多个Vuser同时执行操作。当某个Vuser到达该集合点时,Controller会将其保留,直到参与该集合的全部Vuser到达。Controller才允许Vuser执行。
可通过将集合点插入到Vuser脚本中来指定回合位置。在Vuser执行脚本并遇到集合点时,脚本将暂停执行,Vuser将等待Controller的允许才继续执行。Vuser被从集合释放后,将执行脚本中的下一个任务。
lr_rendezvous("the begin port"); //集合点
web_submit_data("login",
"Action=http://127.0.0.1:9090/account/login",
"Method=POST",
"RecContentType=text/html",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t19.inf",
"Mode=HTTP",
ITEMDATA,
"Name=userName", "Value=xpj", ENDITEM,
"Name=submitBtn", "Value= ", ENDITEM,
"Name=password", "Value=4297F44B13955235245B2497399D7A93", ENDITEM,
LAST); |
注意:
1.只能在Action中添加集合点(不能在vuser_init或vuser_end中添加)。
2.同步点只有多用户并发的场景,同步点的意义才表现出来。
3、注释
LoadRunner支持C语言的注释方法:
多行注释:
单行注释:
4、Think Time(思考时间)
用户在执行两个连续操作期间等待的时间成为“思考时间”。Vuser使用lr_think_time函数模拟用户思考时间。录制Vuser脚本时,Vugen将录制实际的思考时间并将相应的lr_think_time脚本插入到Vuser脚本。此功能通过lr_think_time实现。
lr_think_time参数的单位是秒,比如lr_think_time(5)意味着LoadRunner执行到此条语句时,停留5秒,然后再继续执行后面的语句。
如果不想在脚本中执行Think Time语句,需要逐条语句删除,这是非常麻烦,LoadRunner提供了再Run-time
Settings中可以设置直接忽略Think Time,而不用修改脚本。
有Think Time比没有Think Time的脚本对服务器造成的压力更小,但是有Think Time才是更符合用户的实际工作场景的。
Vuser => Run-time Settings =>
General => Think Time

六、数据驱动-参数化(Parameters)
数据驱动就是把测试脚本和测试数据分离开来的一种思想,脚本体现测试流程,数据体现测试案例。数据不写死在脚本里面,这样大大提高了脚本的可复用性。
1、为什么需要参数化
在录制程序运行的过程中,Vugen(脚本生成器)自动生成了脚本以及录制过程中实际用到的数据。在这个时候,脚本和数据是混在一起的。
如登录操作:
web_submit_data("login",
"Action=http://127.0.0.1:9090/account/login",
"Method=POST",
"RecContentType=text/html",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t19.inf",
"Mode=HTTP",
ITEMDATA,
"Name=userName", "Value=xpj", ENDITEM,
"Name=password", "Value=123123", ENDITEM,
LAST); |
在登录操作中,很明显xpj与123123是填入的数据,如果Controller里以多用户方式运行这个脚本的时候,每个虚拟用户都会以同样的用户名"robin"、密码"123123"去登录系统。这样做性能测试,不太眼睛,服务器大多会采用缓存功能提高系统性能,以同样的用户名/密码登录系统的缓存命中率会很高,也要快得多。
因此,LoadRunner支持参数变量。
web_submit_data("login",
"Action=http://127.0.0.1:9090/account/login",
"Method=POST",
"RecContentType=text/html",
"Referer=http://127.0.0.1:9090/Account/Login",
"Snapshot=t19.inf",
"Mode=HTTP",
ITEMDATA,
"Name=userName", "Value={username}", ENDITEM,
"Name=password", "Value={password}", ENDITEM,
LAST);
|
参数化后,用户名xpj被一个参数{username}替换,密码被另外一个参数{password}替换。其中{username}和{password}分别和参数文件关联,在脚本运行时,用户名和密码的值从参数{username}和{password}中获得。而我们会在后面介绍LoadRunner有一套机制来保证参数的使用和变化,这样就实现了脚本与数据的分离。
参数化是我们学习LoadRunner中经常用到的功能。除了实现数据驱动之外,参数化脚本还有以下两个优点:
1.可以使脚本的长度变短;
2.可以增强脚本的可读性和可维护性;
实际上,参数化的过程如下:
1.在脚本中用参数取代常量值;
2.设置参数的属性以及数据源;
2、参数的创建
LoadRunner对脚本中参数个数没有限制,我们可以在一个脚本中创建任意多个参数。

选择参数类型:
Parameter name:输入参数名称;
Parameter type:选择参数类型;
参数类型说明
1.Data Files:这是我们最长使用的一种参数类型,它的数据存在于文件中。该文件的内容可以手工添加,也可以利用LoadRunner的Data
Wizard从数据库中导出。
2.User-Defined Functions:调用外部DLL函数生成的数据
3.Internal Data:虚拟用户内部产生的数据。Internal
Data包括以下几种类型:
Date/Time:用当前的日期/事件替换参数。要指定一个Date/Time的格式,菜单中可以选择格式。格式要与脚本中录制的格式保持一致。
Group Name:用虚拟用户组名称替换参数。在创建scenario的时候,你可以指定虚拟用户组的名称。
Load Generator Name:用脚本负载生成器的名称替换参数。负载生成器是虚拟用户在运行的计算机。
Iteration Number:用当前的迭代数目替换参数。
Random Number:用一个随机数替换参数。通过指定最大值和最小值来设置随机数的范围。
Unique Number:用一个唯一的数字来替换参数。你可以指定一个起始数字和一个块的大小。
VuserID:用分配给虚拟用户的ID替换参数,ID是由LoadRunner的控制器在scenario运行时生成的。如果从脚本生成器运行脚本的话,虚拟用户的ID总是-1.

然后为该参数设置不同的值。


如果想用以前定义过的参数来代替常量字符串的话,选中该字符串,单击右键,然后选择“Use
existing parameters”,从弹出的子菜单中选择参数,或者用"Select from
Parameter List"来打开参数列表对话框。

对于已经用参数替换过的地方,如果想取回原来的值,那么就在参数上单击右键,然后选择"Restore
Original value"。
不是所有的数据都可以参数化
在LoadRunner中,只有函数的参数才能参数化,不能参数化非函数参数的数据。
如lr_eval_string,我们可以在Vuser脚本中的任何地方使用它来参数化数据,lr_eval_string用来得到一个参数的值,而参数可以预先在LoadRunner的Parameter
List里定义好,也可以是之前通过其他函数创建的。
//通过lr_save_datetime把七天后的时间保存在date参数中
lr_save_datetime("%d %m %y", DATE_NOW + (ONE_DAY * 7),"date");
//通过lr_eval_string把date参数中的值取出来,lr_output_message的输出值为七天后的时间
lr_output_message("Date is s%",lr_eval_string("{date}")); |
更多的函数可以翻查LoadRunner函数手册。lr_eval_string函数的返回值是一个指向参数值的指针,如果这个指针向的内存是LoadRunner内部分配的,每次Iteration后自动释放。如果在Iteration中还有多层循环进行参数化,那么最好不要使用lr_eval_string了,这会导致内存迟迟不能释放。在这种情况下,应该使用lr_eval_string_ext,同时配对使用lr_eval_string_ext_free来及时释放内存。
3、定义参数的属性
1、数据文件
数据文件包含着脚本执行过程中虚拟用户访问的数据。局部和全局文件中都可以存储数据。可以指定现有的ASCII文件、用脚本生成器创建一个新的文件或者引入一个数据库。数据文件中的数据是以表的形式存储的。一个文件中可以包含很多参数值。每一列包含一个参数的数据,列之间用分隔符隔开,比如用逗号。
如果使用文件作为参数的数据源,必须指定以下内容:文件的名称和位置、包含数据的列、文件格式、包括列的分隔符、更新方法。
如果参数的类型是"File",打开参数属性(Parameter Properties)对话框,设置文件属性如下:
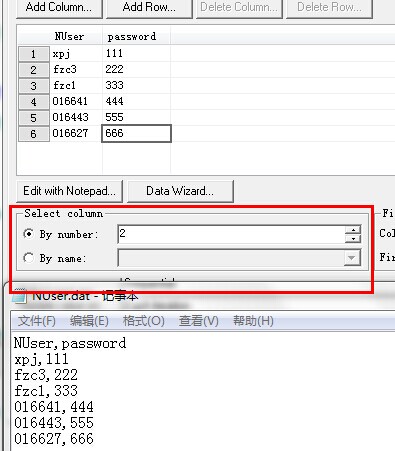
(1)、在"File path"中输入文件的位置,或者单击"Browse"按钮指定一个已有文件的位置,如图:

在默认情况下,所有新的数据文件名都是"parameter_name.dat",注意,已有的数据文件的后缀必须是.dat。
(2)、单击"Edit With Notepad"按钮,打开记事本,里面第一行是参数的名称,第二行是参数的初始值。使用诸如逗号之类的分隔符将列隔开。对于每一个新的表行开始一行新的数据。

在没有启动记事本的情况下如果想添加咧,就在参数属性对话框中单击"Add Column"按钮,打开"Add
new column"对话框。输入新列的名称,单击"OK"按钮,脚本生成器就会将该列添加到表中,并显示该列的初始值。
(3)、在"Select column"部分,致命选择参数数据的列。可以指定列名或列号。列号是包含你所需要数据的列的索引;列名显示在每列的第一行。
(4)、在"Column delimiter"中输入列分隔符,可以指定逗号、空格符等。
(5)、在"First data line"中,在脚本执行的时候选择第一行数据使用。列标题是第0行,若从列标题后面的第一行开始的话,那么就在"First
data line"中输入1;如果没有列标题,就输入0;
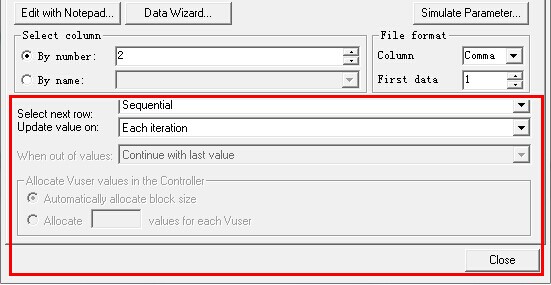
(6)、在"Select next row"中输入更新方法,以说明虚拟用户在获取第一行数据后,下一行数据按照什么规则来取。方法可以是:顺序的(Sequential)、随机的(Random)、唯一的(Unique),或者与其他参数表相同的行(Same
Line as..)。
顺序(Sequential):该方法顺序地给虚拟用户分配参数值。取的时候会逐次取下一行数据,到最后一条又循环回取第一行。
随机(Random):该方法在每次迭代的时候会从数据表中随机取一行数据。
唯一(Unique):该方法分配一个唯一有顺序的值给每个虚拟用户。10行数据,能分10次。第11个虚拟用户来取LoadRunner会报错,提示数据不够用。
与以前定义的参数取同一行(Same Line As <parameter>):该方法从以前定义过的参数中同样的一行分配数据,但必须指定包含有该数据的列。在下拉列表中会出现定义过的所有参数列表。注意:至少其中的一个参数必须是Sequential、Random或Unique。
NUser,password
xpj,111 //前面定义了xpj,则后面是111(同一行)
fzc3,222
fzc1,333 |
(7)、Update value on,数据的更新方法
我们做事主要考虑3个因素:什么时候做,什么地点做,还有怎么做。对应参数表的读取规则来说,上面的Select
next row指的是怎么取新值,是顺序还是随机等。而这里Update value on指的是什么时候取新值。
LoadRunner并不是每次取值都是要取新值的。所以就有了以下几种取新值的策略:
Each iteration:每次迭代就要取新值(在同一个迭代中,无论读几次参数,获得的都是同一个参数值)。
Each occurrence:只要取一次,就要新的(同一个迭代中,读一次参数,就要取其新值,而新值从哪里来,有Select
next row来规定)。
Once:在所有的循环中都使用同一个值(只取一次,也就是说,这个参数只有一个值)。
(8)、When out of values,超出范围:(选择数据位Unique时才可用到)
Abort Vuser:中止。
Continue in cyclic manner:继续循环取值。
Continue with last value:取最后一个值。
(9)、Allocate Vuser values in the Controller在控制器中分配值:(选择数据为unique时才可用到)
Automatically allocate block size:自动分配。
Allocate()calues for each Vuser:指定一个值。
4、高级-从已存在的数据库中导入参数数据
LoadRunner允许你利用参数化从已经存在的数据库中导入数据。可以使用下列两种方式之一:
(1)、使用Microsoft Query(要求在系统上先安装MS Query)。
(2)、指定数据库连接字符串和SQL语句。
用户脚本生成器在从数据库中导入数据的过程中提供了一个向导。在向导中,指明如何导入数据。通过MS
Query创建查询语句或者直接书写SQL语句。在导入数据以后,以.dat为后缀并作为正规的参数文件保存。要开始导入数据库中数据的过程,在参数属性对话框中单击"Data
Wizard"按钮,则打开数据库查询向导。

由于第一种要安装MS Query,下面介绍第二种方式。
指定数据库连接或SQL语句
1.选择"Specify SQL statement manually",下一步;
2.打击"Create"按钮,指定一个新的连接字符串。
3.选择已有的数据源,或者单击"新建"按钮创建一个新的数据源。向导将提示你完成创建ODBC数据源的过程。在完成后,连接字符串就会在连接字符串框中显示出来。
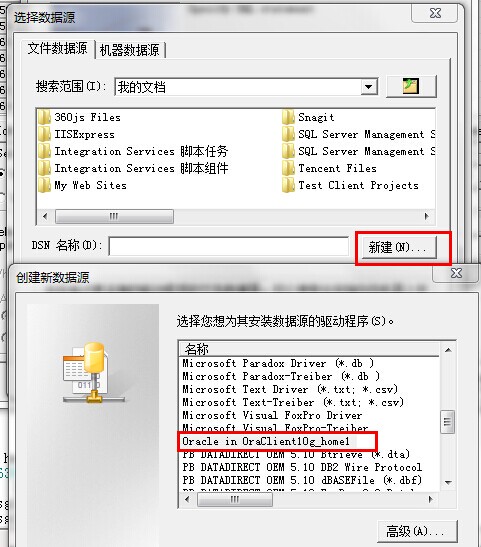
点击下一步,在选择一个路径用于保存文件数据源。注意后缀是.dsn。
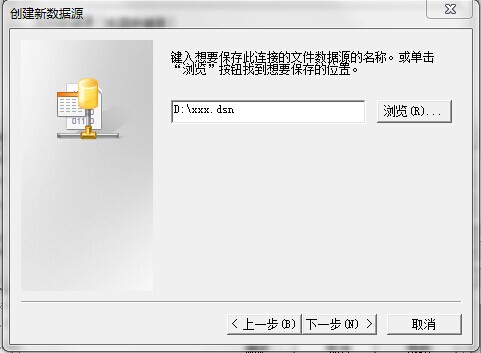
下一步后,点击完成。

此时,在D盘会生成一个D:xxx.dsn文件。
在弹出的对话框中输入数据库连接的信息

4.在SQL statement框中,输入或粘贴SQL语句。

5.输入SQL语句后,单击"Finish"按钮。数据库记录将以data文件的形式显示在参数列表对话框中。

6.在"Select column"部分中,指定包含当前参数数据的列。你可以指定列号或者列名。
7.从"Select next row"列表中选择一个更新方法来告诉虚拟用户在脚本指定的过程中如何选择表中的数据。可选项是:Sequential、Random、Unique或者Same
Line as。
8.如果从Update value on中选择"Each iteration",虚拟用户在每次迭代的时候都会使用新的一行数据而不是重复同样的数据。
4、检查点(Check point)
1、为什么需要检查点
LoadRunner的很多API函数的返回值会改变脚本的运行结果。比如web_find函数,如果它查找匹配的结果为空,它的返回值就是LR_FAIL,整个脚本的运行结果也将置为FAIL;反之,查找匹配成功,则web_find返回值是LR_PASS,整个脚本的运行结果置为PASS。而脚本的结果则反应在Controller的状态面板上和Analysis统计结果中。
但是仅仅通过脚本函数执行结果来决定整个脚本的成功/失败,这并不严谨。因为脚本往往是在执行一个业务流程,VU脚本函数本身是协议级的,它执行的失败会引起整个业务的失败,但它运行成功却未必意味着业务会成功。比如,要测100人登录一个Web邮件系统,此邮件系统限制不允许同一个IP登录两个用户。这时,如果LoadRunner没有开启多IP欺骗功能的话,第一个虚拟用户登录成功后,第二个虚拟用户试图登录,系统将返回一个页面,提示用户"你已经登录本系统,请不要重复登录!"。在这种场景下,如果没有设检查点来判断这个页面,那么VU认为它已经成功地发送了请求,并接到了页面结果(http状态码200,虽然是个错误页面)。这样VU就认为这个请求时成功的,但事实这次请求用于性能测试结果是不准确的。这个时候,我们就要采用检查点来判断结果。
检查点(Check Point)并不是一个LoadRunner里专有的概念。在WinRunner和QTP中就有检查点。对于自动化测试来讲,检查点是一个很重要的功能,它的作用是验证程序的运行结果是否与预期结果相符。
2、检查点实施1:ContentCheck定义
在"导航条Vuser => Run-time settings
=> ContentCheck"中,这里的设置是为了让Vugen检测何种页面为错误页面。如果被测的Web应用没有使用自定义错误页面,那么这里不用更改;如果被测的Web系统使用了自定义错误页面,那么这里需要定义,以便让Vugen在运行中检测,服务器返回的页面是否包含预定义的字符串,从而判断该页面是否为错误页面,如果是,Vugen就停止运行,指示运行失败。
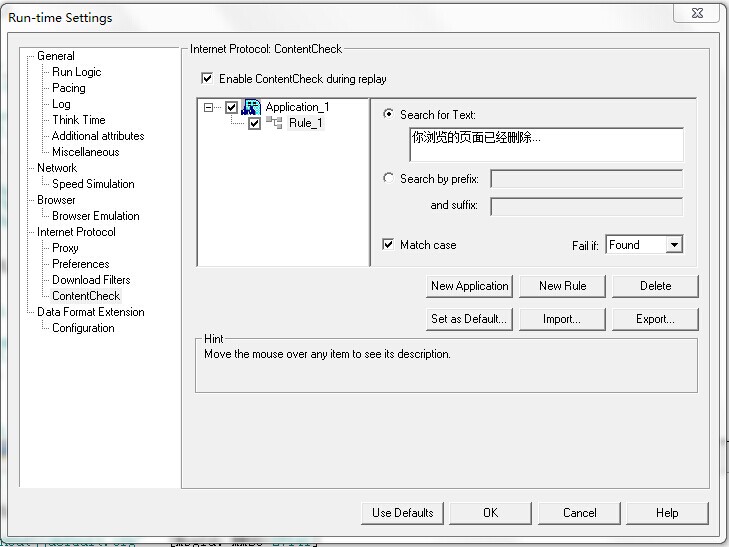
3、检查点实施二:检查函数
另外一种设置方法是在Web Vuser里,通过检查函数来完成检查点功能。Web Vuser提供Image
Check和Text Check两种方式,其原理就是在上一个请求页面的函数完成后,运行检查函数,在结果页面中搜索指定的图片或关键文字等。
检查关键字示例:
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
web_find("login Check",
"expect=notfound",
"matchcase=yes",
"onfailure=abort",
"report=failure",
"repeat=no",
"what=页面已删除",
LAST
) |
在这个例子中,web_find函数在login页面中搜索"页面已删除"关键字。有关web_find函数的各个参数的含义以及使用方法。
检查图片示例:
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
web_image_check("NotFount",
new String[]{"Alt = NotFound",
web.LAST}); |
web_image_check在login页面中查找alt属性为NotFount的图片。
VU的Web Vuser还提供了和web_find十分类似的另外一个检查点函数:web_reg_find。
web_reg_find里的reg意为注册(register)。因此web_reg_find和web_find的不同之处是web_reg_find是先注册,后查找;而web_find是查找前面的请求结果。因此,我们再使用web_reg_find函数的时候,将它放在请求语句的前面。
web_reg_find("Text=ABC","SaveCount=abc_count",LAST);
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
if(strcmp(lr_eval_string("{abc_count}"),"0") == 0)
Action A
else
Action B |
上面脚本运行的过程是:如果web_reg_find在login页面中没有找到"ABC"字符串,则执行Action
A;如果找到了一次或一次以上,则执行Action B。
web_find和web_reg_find函数两者是有一些区别的:
web_reg_find("Text=ABC","SaveCount=abc_count",LAST);
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
if(strcmp(lr_eval_string("{abc_count}"),"0") == 0)
Action A
else
Action B |
1.web_reg_find先注册的优势是脚本能够一边接收Server的数据缓冲,一边进行查找,提高了查找的效率。
2.web_reg_find的参数与web_find并不完全一样,其中有个参数叫做SaveCount,它能够记录查找匹配的次数,而web_find的机制是一旦查找匹配成功就立即返回,并不继续查找和记录匹配次数。
3.VU run time设置中的"enable image
and text check"对web_find有效,而对web_reg_find无效。
4、检查点设置技巧
如何加入检查点,才能检查出正确的结果。与事实相符,有如下技巧:
它必须满足是验证事务通过与与否的充分必要条件。检查点通过,我们就能够确信系统是一个正常的状态。
检查点可以是常量,也可以是变量。
检查点可以是文本、图像文件,也可以是数据库记录等。
5、高级-脚本错误处理机制
VU提供了一套在出错情况下的脚本处理机制。VU的错误处理机制可设定Vuser在执行脚本时遇到错误怎样处理。当Vuser遇到错误时,可以由两种处理策略:
一是停止执行脚本,这适用于严重的问题。
二是忽略这个错误,继续执行下去。
默认情况下,当检测到错误时,Vuser将停止执行脚本,在Run-time Settings中我们就可以看到它的默认设置。
如不想VU在出错后结束,而是继续执行。那么在运行设置中,可以勾选"Continue
on error"(出现错误时仍继续)。这个设置适用于整个Vuser脚本,它是一个全局开关。

这种方法有一个问题,不够灵活。对于所有的错误,都是跳过或停止执行。不能对于不同函数应用不同的错误处理机制。对于这种问题,我们只能在脚本使用lr_continue_error函数来自定义实现。
1.使用lr_continue_on_error函数。通过lr_continue_on_error(1)和lr_continue_on_error(0)语句将其括起来。
2.使用lr_continue_on_error函数的脚本段将会覆盖"出现错误时仍继续"的Run-time
Settings运行时设置。
例如,下面的脚本,其运行时设置没有勾选"Continue on error",VU如果访问xxx错误,将会结束执行脚本。
lr_continue_on_error(1);
web_url("Login",
"URL=http://127.0.0.1:9090/Account/Login",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);
lr_continue_on_error(0);
lr_output_message("finished linking"); |
在上面的脚本中,几时web_url函数执行失败,li_output_message("finished
linking")也会被继续执行。第一个lr_continue_error(1)是将"Continue
on error"设为true,其后面的语句的错误处理机制都被应用为"Continue
on error",直到VU遇见lr_continue_error(0),再将"Continue
on error"恢复成false。
| 




