|
����
����ĵ���Ҫ��������������Ҫ��֪ʶ��
webӦ�ó���
ϵͳ����������ifconfig��
$ ifconfig eth0
eth0 Link encap:Ethernet HWaddr 52:54:00:12:34:56
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fe12:3456/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:88 errors:0 dropped:0 overruns:0 frame:0
TX packets:77 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:10300 (10.0 KiB) TX bytes:10243 (10.0 KiB)
Interrupt:11 Base address:0x8000 |
���ȡ��ǰ��ip��ַ:
���������,ip��ַ����10.0.2.15.
������ѵ���У���������ģ���ܺ���������������vulneralble.�������ip��ַ�������������������������host�ļ��������������Ͷ�Ӧ��ip��ַ.
windows�£�host�ļ�λ��C:\Windows\System32\Drivers\etc\hosts
Unix/Linux��Mac OS X��,host�ļ�λ��/etc/hosts ��ʾ:ip����������,ip��ַ��ı䣬Ҳ������Ҫ��host�ļ�����һЩ��Ӧ�ĸ���.
����web������Կ��������ҳ��

Web
�ܶ˾���ܶ��п�����web����,���ң��ܶ�Ӧ�ó������ڶ�����web�汾.�ɴˣ�web��ȫ����Ҫ�Բ��Զ���.
web��ȫģ��
web��ȫģ�͵ľ���ܼ�:��Ҫ���ſͻ��ύ������.����˵õ��Ĵ���Ϣ���ǿͻ����ύ��.������ù��˺�ת���û��ύ������.
web��ȫ����
webӦ�ó�������ķ��պ��������͵ij����������һ����:
��Ϣй©
������ʧ
��Ϣ��ʧ
������ʧ
web����
����
�������web���������������:
1.�ͻ���:��������������
2.�������ܿͻ��������web������.
һ��Ӧ�ó���������ᴦ������������������,web��������ֻ�ǰ����ݸ���Ӧ�ó��������.
3.���������Ϣ�Ĵ洢���:ͨ�������ݿ�.
��Щ����IJ�ͬ��Ϊ���ܱ�¶������Ͱ�ȫ����.
�ͻ��˼���
ÿ�챻�õ��Ŀͻ��˼����־���HTML,JavaScript,Flash��ͨ�������(�ȸ裬���IE��)���ӷ����.������web����Ŀͻ���Ҳ������һ������web����Ľű�����.
����˼���
�ڷ���˾��кܶ�ļ����ᱻ�õ�,��ʹ��Щ�����������յ�����.
��Щ��������ϸ��Ϊ���漸��
1.web������
��Apache,lighttpd,Nginx,IIS��
2.Ӧ�ó��������
��Tomcat,Jboss,Oracle Application server
3.�������
��PHP, Java, Ruby, Python, ASP,C#, ���������Ҳ���Ա��õ�һЩ����У���Ruby-on-Rails,.Net
MVC,Django.
�洢���
�洢��˿��Ժ�web������λ��ͬһ�����ϣ�Ҳ����λ�ڲ�ͬ������.
һЩ�洢��˵�����:
�ļ��洢
��ϵ���ݿ�
����Mysql,Oracle, SQL Server, PostgreSQL.
���������ݿ�
����MongoDB, CouchDB.
Ŀ¼
����openLDAP���Ŀ¼ .
һ��Ӧ�ó������ʹ�ö��ִ洢�ķ���.����˵��һЩ������LDAP�����û��������룬ͬʱ��Oracle�����û���������Ϣ.
HTTP��
HTTP������web�Ļ���,��Ҫweb���ԣ��Ƕ����Э����һ��������˽��Ǻ���Ҫ��.��ϤHTTP�淶�������ھ�©��.
һ�οͻ��˺ͷ���˵ĻỰ
HTTP��һ���ͻ��˺�һ�������֮��ĻỰ.�ͻ��ˣ���������������ͻᷢ�����������ˣ�Ȼ�����˶��������һ����Ӧ.HTTP���ı�Э�飬���Զ�������������˵��������.һ�������,web��������Ķ˿ڶ���TCP/80.�������������ַ��������http://pentesterlab.com/���س�ʱ��ʵ�����������ӵ�pentesterlab.com��Ӧ��ip��80�˿�.��������������������ҳ��ʱ��.���������һ��������Ԫ����ɵ�����:
HTTP����
����÷�����������������е���ʲô����
��Դ
˵���ͻ�������ʷ������ϵ���ʲô
�汾��Ϣ
˵��������ʹ�õ����ĸ��汾��HTTPЭ��
���ָ�����ͷ����Ϣ
��Щ��Ϣ�����˷���������������ֺͰ汾���û�ƫ��������(��Ӣ�������)..
��������
����HTTP������ͬ���в�ͬ�Ľ���
һ�����ӣ���http://vulnerable/index.php����������HTTP����
GET /index.php HTTP/1.1
Host: vulnerable
User-Agent: Mozilla Firefox |
����
����
�кܶ��HTTP����:
GET����
�õ���ҳ���ݣ��������õķ���
POST����
POST�������������������ݽ϶�����ݣ��������ںܶ�������ļ��ϴ���.
HEAD����
HEAD������GET���������ƣ�Ψһ���������server���ص���Ӧ.HEAD�����õ�����Ӧֻ����ͷ������û��ʵ��.web֩����һ��ҳ����û�и��ĵ�ʱ���õ��������������֩��Ͳ���Ҫ��������ҳ���������.
��������������HTTP����:PUT,DELETE,PATCH,TRACE,OPTIONS,CONNECT��
����
������һ������Ҫ�IJ��־��Dz���.���ͻ��˷��������ҳ��http://vulnerable/article.php?id=1&name=2
ʱ�����������ᱻ���͵�web������:
POST����dz����ƣ�����ʵ�ʵIJ����ǰ���������ʵ���е�.������ı���:
<html>
[...]
<body>
<form action="/login.php" method="POST">
Username: <input type="text" name="username"/> <br/>
Password: <input type="password" name="password"/> <br/>
<input type="submit" value="Submit">
</form>
</body>
</html> |
���HTML�����Ӧ����ĵ�¼����:

���������ֵ������������
username�ǡ�admin��
password�ǡ�Password123��.
�DZ����ύ�����������ͻᱻ���͵�������:
POST /login.php HTTP/1.1
Host: vulnerable
User-Agent: Mozilla Firefox
Content-Length: 35
username=admin&password=Password123 |
���<form��ǩ���õ���GET�������Ƿ��͵������������������:
GET /login.php?username=admin&password=Password123 HTTP/1.1
Host: vulnerable
User-Agent: Mozilla Firefox |
���form��ǩ��������enctype=��multipart/form-data��,���͵�����������������.
POST /upload/example1.php HTTP/1.1
Host: vulnerable
Content-Length: 305
User-Agent: Mozilla/5.0 [...] AppleWebKit
Content-Type: multipart/form-data; boundary=��-
WebKitFormBoundaryfLW6oGspQZKVxZjA
����WebKitFormBoundaryfLW6oGspQZKVxZjA
Content-Disposition: form-data; name=��image��; filename=��myfile.html��
Content-Type: text/html
My file
����WebKitFormBoundaryfLW6oGspQZKVxZjA
Content-Disposition: form-data; name=��send��
Send file
����WebKitFormBoundaryfLW6oGspQZKVxZjA�C |
���ǿ��Կ���������ͷ����Content-type������:Content-Type:
multipart/form-data; boundary=��-WebKitFormBoundaryfLW6oGspQZKVxZjA.
��WebKit�������ڻ���webkit�ں˵��������,�����ں˵����������һ��������ַ������.����ַ����ںü����ط���������.���һ�����Ǹ��ַ������滹���˸��C�ַ���.�����ϴ�һ���ļ�ʱ,������ᷢ������Ķ���.
�ļ���:myfile.html
������:image
�ļ�����:text/html
�ļ�����:my file
Ҳ�������鵱����������ȥ(����hash���ܲ�����ֻҪ������ܹ���������).��Ҳ������/index.php?id[1]=0���������ֵ0������.
���ֱ��뾭����һЩ�齨�����Զ���ӳ����Զ�����.����˵�����������:user[name]=louis&user[group]=1�ᱻӳ�䵽һ��User�������User������һ������nameֵΪlouis������һ��group����ֵΪ1.�Զ�ӳ����ʱ��ᱻ����.ͨ�����ͱ������ֵ���������û�б���������ԣ�Ҳ������Ըı��Ǹ����������.��������ǰ�������У����������һ��user[admin]=1�������У��������ܷ�õ�adminȨ��.
from:91ri.org
HTTPͷ��
HTTP�����а����ܶ��ͷ����Ϣ.�����ԣ�����Կ������е�ͷ����Ϣ,����������ͷ��ֵ���ô���ʲô�ģ����п����������ͷ��ˣ�����˸����Ͳ�����ĵ�����.���������ֻ�õ��������õ�ͷ����
Referer
���壺ȷ�Ͽͻ����Ǵ���һ�����������������
Cookie
���壺���ܿͻ��˷�������cookies
User-Agent
���壺����ȷ�Ͽͻ����õ���ʲô�����
X-Forwarded-For
���壺�õ��ͻ��˵�ip��ַ(������ǵõ�ip��ַ��õķ�������Ϊ���ǿ��Ա�α���)
������HTTPͷ����������õ��ܶ�,����˴�����Щͷ����ʱ����ܴ��ڰ�ȫ����.���ǣ���web����˷���bug����web�����з���bugҪ�ѵĶ�.
��һ���dz���Ҫ��ͷ���ǡ�Host��.Hostͷ����Ҫ��web����������ȷ��������ʵ����ĸ���վ.����˵����һ���������ϴ�˺ü�����վ���ṩ������������,������վ�Ķ���ip����һ����.����������е�һ����վʱ,��Ȼ������վ��ip����һ���ģ����Ƿ������ῴhost����ֶ�ֵ����������֪������Ҫ�����ĸ���վ�ˣ��ͻ᷵�������վ�����ݸ���.������Host�ֶε�ֵ�ij�ip��ַ����һ����Ч��������,���п��ܻ�õ������վ���ص�����.
���㷢��һ������ʱ������˻᷵��http��Ӧ.�����������Ӧ:
Date: Sun, 03 Mar 2013 10:56:20 GMT
Server: Apache/2.2.16 (Debian)
X-Powered-By: PHP/5.3.3-7+squeeze14
Content-Length: 6988
Content-Type: text/html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>PentesterLab » Web for Pentester</title>
<meta name="viewport" content="width=device-width, initialscale=1.0">
<meta name="description" content="Web For Pentester">
<meta name="author" content="Louis Nyffeneggerlouis@pentesterlab.com"> |
��Ӧ���Ǹ�״̬��dz���Ҫ.���ص�״̬��λ����Ӧ�ĵ�һ��.�ͻ��˻������Ӧ����������Ӧ.
�����״̬���Ǻܳ�����.
200 OK:�������ɹ�����������
302 Found:�ض���
401 Unauthorized:����������
404 Not Found:�������Դû�ҵ�
500 Internal Server Error:���������������ʱ�������
��һЩ״̬��ͺ���Ƨ�ˣ�����418:I��m a teapot.
��״̬��������HTTPͷ��.���ص�HTTPͷ��Ӱ���������ʾ��ҳ�ķ�ʽ.������ʾ������Ӧ��,ͷ���������������Ϣ:
Date
���壺����
Sever
���壺ͷ��¶��һЩ���ڷ���������Ϣ���������apache������,�汾2.2.16
X-Powered-By
���壺ͷ��¶�˸������Ϣ.
Content-Length
���壺ͷ��˵������Ӧ�Ĵ�С.
Content-type
���壺ͷ��������������ص���ʲô����.������ֵ��text/html,���������Ⱦ��Ӧ.�����text/plain,�����������Ⱦ.
content
���壺���־��Ƿ��ص���Ϣ��������HTML��ҳ,һЩͼƬ.����������յ�һ��HTML��ҳʱ����������������Զ�����һЩ�������ļ���:
Javascript�ļ�
CSS�ļ�
ͼƬ
��
HTTPs
HTTPsֻ�ǻ���SSL��HTTP.SSL��ȷ���ͻ���:
������ȷ�ķ������ڽ���:��֤�����ǰ�ȫ��:����.
SSL���ںܶ�汾,����һЩ�汾����Ϊ������SSLv1��SSLv2��.
SSLҲ��������ȷ�Ͽͻ��˵�����.�ͻ����и�֤�飬���֤��ȷ����ֻ��ӵ����Ч֤��Ŀͻ��˲��ܺͷ�����ͨ��.
���ַ����������ڰ�ȫ��Ҫ��ϸߵ�ϵͳ��.Ȼ��������֤��ȷʵһ������ͷʹ������.
����HTTP����
��3�ַ���������HTTP����:
��Wireshark����tcpdump�����ֱ�Ӽ�������
��������ϲ鿴.�������������п��������û��鿴���ͺͽ������ݰ��IJ��.
��������ͷ�����������һ������
���ַ��������б�.ʹ����һ����Ҫȡ���������Ƿ�����SSL���û��Ƿ���������.
����HTTP����
�кü��ַ�����������
����HTTP��һ�������ı���Э�飬�����ʹ��telnet����netcat��Щ��������������
Ҳ���Ա��ʵ�ַ���HTTP����.��socket������ʵ���������϶�д����.��������ǣ��ܶ�
���Զ���HTTP�⣬����Щ�����ǻ��������ͷ�������Ҳ�����ɾ��ܻ����Ӧ.
��Ȼ����ľ����������������������.
���������������.���ǣ������ķ�����������������HTTP�����ϸ��.
��telnet��������
$ telnet vulnerable 80GET / HTTP/1.1 Host: vulnerable |
Ҳ������netcat
$ echo "GET / HTTP/1.1\r\nHost: vulnerable\r\n\r\n" | nc vulnerable 80 |
���ݱ���
����vs����
������İ�ȫ���ⷢ���ڹ����߿��Բ����ϴ������ݣ�����Ӧ�ó�������Щ���ݵ�������ִ��.
����xss��SQLע��.
URL����
��һЩ�ַ���HTTP����Ҫ����Դ�:
����˵url�е�?,&,=�Ŷ������Լ�����˼.�������ڴ����������˵����Щ�ַ��DZ����.Ϊ�˱�֤��Щ�ַ��ܱ��������ֵ����������ķָ�����;����Ӧ�ö���Щ�ַ����б���.��ı��뷽ʽ����%��������ַ���ʮ������ֵ.Ϊ�˵õ�һ���ַ���ʮ������ֵ������Ӧ���˽���ascii���.�±����Կ����ַ��Ͷ�ӦURL�б����ֵ:
Character URL encoded value
\r %0d
\n %0a
%20 or `+`
? %3f
& %26
= %3d
; %3b
# %23
% %25 |
��Ҫ�õ�������ASCII������ڴ������linuxϵͳ�Ͽ���ʹ��man
ascii����õ�������google��.
�����
��ʱ������ϵͳ���������.���磬����˽����Ӧ�ó������ڶ���.�����Ļ�������Ӧ�ñ�������������Ҫ���͵��ַ�.
����,�����Ҫ�ԵȺ�=�������Σ���һ�����������%3d,�ڶ������ͱ������%253d��.����˽��յ�%253d�Ժ���������%3d��Ȼ��Ӧ�ó�����%3d�����=��.���α�����ʱҲ��������bypassһЩ����.
HTML����
��URL����һ��,һЩHTML�����е��ַ�Ҳ������ĺ��壬�������Ҫ�����ǵ�����ͨ��ֵ�ã�ҲҪ�����DZ���.
Character HTML encoded value
\r %0d
\n %0a
%20 or `+`
? %3f
& %26
= %3d
; %3b
# %23
% %25 |
�κ��ַ���������ʮ���ƻ���ʮ�����Ʊ���.
����=���Ա����=,Ҳ���Ա����=.(ע����;�ֺ�)
Cookies��sessions
����˻���һ��HTTPͷ:Set-Cookie����ʼ��Cookie.��������ܵ����ͷ���ͻ��Զ��ذ�cookie
���ͻط���ˣ������Ժ��ÿ�������ж�����cookieͷ���������cookie.
Set-Cookieͷ����������ѡ��:
expiration date
����ʱ��:���������ʲôʱ���ɾ�����cookie.
Domain��:
���������cookieӦ�ñ����͵��ĸ�����������������,������Զ�ȡ�����cookie.
Path·��:
���������cookieӦ�÷��͵��ĸ�·����,ֻ��Ŀ��·���µ�js������ܶ������cookie.
��ȫ��־
Path��Domain�ֶζ����������Ϊ�˰�ȫ��.Cookie��������ȫ��صı�־
httpOnly
������ֹjs�����дcookie.�����ڿ�վ�ű���document.cookie��û�����ˣ�������cookie.
secure
���������־��cookieֻ����HTTPS���氲ȫ����.���������HTTP�ģ����cookie�Ͳ��ᱻ����.session���Ʋ��õ����ڷ������˱���״̬�ķ�������cookie���Ʋ��õ����ڿͻ��˱���״̬�ķ�����
���ͻ��˷��ʵ�һ������ʱ������ҪΪ�ͻ�����һ��session���ڴ������session��ʱ���������ȼ������ͻ��˵��������Ƿ��Ѱ�����һ��session��ʶ��session
id��������Ѱ���һ��session id��˵��֮ǰ�Ѿ�Ϊ�˿ͻ��˴�����session���������Ͱ���session
id�����session��������ʹ�ã�����������������ܻ��½�һ����������ͻ���������session
id����Ϊ�˿ͻ��˴���һ��session��������һ�����session�������session id��session
id��ֵӦ����һ���Ȳ����ظ����ֲ����ױ��ҵ������Է�����ַ��������session id�����ڱ�����Ӧ�з��ظ��ͻ��˱��档�������session
id�ķ�ʽ���Բ���cookie�������ڽ�������������������Զ��İ��չ���������ʶ������������
Rack::Session::Cookie
�ڻ���Rack��������Ĭ��ʹ�õ�(�������Ruby�����õ�Rack).���ṩ��һ�ֲ�ͬ�ĻỰ����.�û���Ȼ�ܽ��յ�session����Ϣ,������Щ��Ϣ�Ǽ����˵�.�����Ļ����û��Ͳ�����session�е���Ϣ��(����һ��������������ܷ�����).
��PHP�У�Ĭ�������ÿһ��sessions������һ���ļ��У�����û�м���.(��Debianϵͳ��λ����/var/lib/php5).�������Ȩ������Щ�ļ�����Ϳ��Զ�ȡ
�����˵�session��Ϣ��.�ٸ����ӣ��������session id��o8d7lr4p16d9gec7ofkdbnhm93����ῴ��һ������sess_o8d7lr4p16d9gec7ofkdbnhm93���ļ�������ļ��Ͱ�����session�е���Ϣ.
# cat /var/lib/php5/sess_o8d7lr4p16d9gec7ofkdbnhm93pentesterlab|s:12:"pentesterlab";HTTP��֤
HTTPҲ�ṩ��������֤�û�.Э���������ֿ��õķ���:
Basic Authencation
�û�����������base64�����ˣ���������Authencationͷ��:
Authorization: basic YWRtaW46YWRtaW4K. Digest Authencation
����˷���һ���C(��һ������Ϣ),�ͻ��˷���һ���C(hash������Ϣ�����а����û�������).���ַ���ȷ���˷����������������Ǽ��ܵ�.
NTLM authencation
���ַ�����Ҫ������ϵͳ�У����Һ�Digest��������.
Web����
�����Զ�̷�������HTTP�����������Ǹ������ķ���,�����Ͼ��Ƿ�����������Ȼ��õ�һ�����ص���Ӧ.���͵Ķ���������:
HTTP����
XML��Ϣ
����JSON����Ϣ
Զ�̵�������Ա�����˽���:
����URL
����HTTPͷ��(����SOAPActionͷ��)
����web����Ͳ���һ���webӦ�ó����ֻ࣬������������ܸ�����˽�������.�������һ�������������������ù������Լ��ýű��������������������fuzz��������˵Ĵ���.
webӦ�ó���ȫ
�ͻ��˰�ȫ
һ���ձ����������dz���Ա�ڿͻ��˽��а�ȫ��飬����javascript�У���֤һ���ֻ������Ƿ���Ч.
һ��ʼ���û�������һ���ֻ�����

JS����������ֵ

����ֻ�����ֵò������Ч��
���ֵ�ͻᱻ���͵������


������ֵ��Ч��������Ͳ��ᷢ������������

js����������ֵ

����˵�������ֵ�Ǵ���

�������͵���������
���ַ�ʽ�ļ���ǵ��ܵģ������ͱ��ƹ����Բ��ܱ���Ϊ��ȫ�����ơ����ǣ�ͨ�����Ʒ�����������������������ּ�鷽ʽ�ܼ���������ĸ��������ÿ����������������������ȷ�ģ���������ᱻ���͵����������������൱�ڼ����˷������ĸ�����
�ƹ��ͻ��˷���ļ��
Ҫ�ƹ��ͻ�����һ���飬����Ҫ����һ����Burp Suite�����Ĵ��������������������˴���������֮���㻹Ҫ��������������������������ת��������������������������������Ͳ���ϵͳ��������
����������û�������������֮����Ϳ��Կ���������������������������������غ����������ݡ�
����������������������Ժ�����������������������������
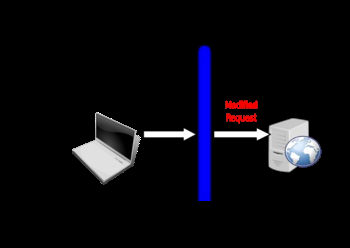
Ȼ�������������

����������Ӧ���Ĺ�������

���������д��ȷ��ֵ���Ϳ��Գɹ��ύ���������ǣ��������������ص���һ������ͨ���������ֵ���ﵽ����webӦ�ó����Ŀ�ġ�

��������
Ӧ�ó���İ�ȫ���ڷ�������һ�����еġ����е��յ�����Ϣ����Ӧ�����Σ����ݱ��������ݸ�ʽ��Ӧ�ñ�����Ϊ���ж�������롣��Ҫָ������IJ�����һ�����ģ�
�������ǻ��ӻ��������еġ���Ҫָ������IJ��������ͣ����������ַ�������������ǰ������������������hostͷ�ṩ��Ҳ���Ƕ������롣��Ҫ�����κ��������ݣ���ȷ�����Ѿ��ٴμ�������е��������ݡ�������д��һ����ȫ�Դ�����Ӧ�ó����Ǻ��п��ܱ�һЩ���ҵ�һЩ���⡣��Ҫ��ϣ���ڱ����Ҳ������⣬��
�����д��һ����ȫ�Դ����Ķ����ܻ������ҵ�©�����ڡ�
Web�����Թ���(��)
Web�����Թ���(��)
| 




