|
客户端自动化特点
客户端的自动化,通常做过的人都不是很愿意深入讨论。因为除了功能和逻辑之外,不得不面对各种界面变化,各种和环境交互,各种兼容问题以及想不到灰色地带,就算这样,也找不到太多有效的bug。然而即便如此,客户端的自动化必须去做,尤其是GUI的。它的自动化特点是:
复杂
成本高
不容易发现问题
技术要求高
架构很难通用
下面,从一些基本的东西开始一点点的讨论客户端GUI测试的一些问题和处理办法,以及自动化架构设计的一些思路。事实上就像上面说的,GUI的测试并不是为了发现bug,而是回归的一种方式,作为保证而已――它过了不能说明质量多么好,但是不过,质量肯定不达标。即使在微软内部,客户端的GUI一样不是个受欢迎的家伙,通常用来做BVT的测试(或一些重要性回归,冒烟等)。
客户端自动化简述
这里并不花过多的笔墨介绍什么是客户端,或者如何分类的种种――这些东西教材和网上的东西一坨一坨很多很多,这里可能“漫谈”的,是实际工作中,客户端和GUI自动化中可能遇到的一些底层技术,基本上原理,架构设计方法以及一些项目存在困惑,这些方面的一些处理的方法。
最早的自动化
我个人认为所谓的计算机行业的自动化,是一直跟着这个行业的发展在走,比如下面的这些:
老式计算机――CPU计算: 最早自动解决手工分配穿孔的卡片问题

内存分配任务调度:操作系统的核心就是内存和任务的自动管理
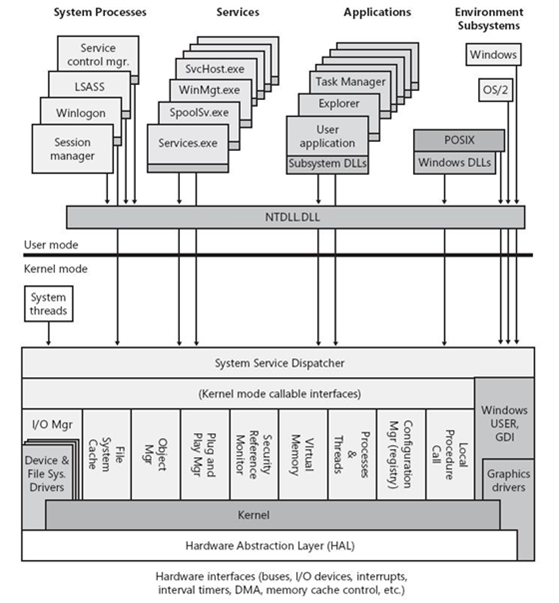
系统配置Loader:操作系统启动的引导
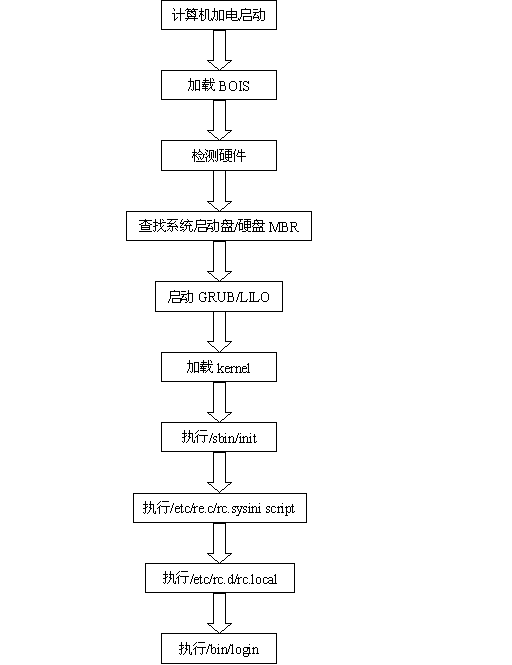
自启动程序注册表:windows系统中自启动程序的配置
什么是自动化测试
我个人认为自动化测试,就是用技术和自动化去服务测试,保证质量,提高产品生产率(不是测试生产力)。无论如何这个行业需求是关键,脱离需求和具体环境,一切都是玩笑。
传统客户端
客户端的特点是基于操作系统之上,它的GUI一般寄生于操作系统的接口。传统客户端一般采用系统提供的默认GUI来完成主要逻辑功能。特点是技术相对简单,系统兼容性好,但是相对没有那么炫。对于自动化来说,尽管完成起来“冗余”,但是不存在技术的难点。也就是通道都已经铺平了,大部分流行的GUI工具都是服务于这样的客户端。
互联网常用客户端
互联网常用的客户端,由于为了提供用户体验度,大都采用directUI,无论哪种自绘方法,都不是系统直接提供的。另外,由于互联网客户端的功能很杂,对注册表的各种注入,操作系统的各种更改等,都会导致一些兼容性和安全性问题出现。这是互联网客户端的特点。
特殊客户端(浏览器)
浏览器作为特殊的客户端出现是因为它是b/s和c/s的一个界限,它本身是一个客户端,但是却是web的依赖着,PC上Web的主要入口。对于其他客户端,它的特点如下:
寄生js
Cookies等安全
各种插件
W3c标准
其他
不同浏览器页面GUI识别不同
客户端自动化特点
一开始已经提到过客户端GUI自动化测试的特点,由于这些特点,导致很多没有预算和积累的公司,会放弃客户端GUI的自动化测试。
客户端自动化通用模型
一般来说,客户端GUI的自动化测试,大体可以分为5个部分,底层GUI技术,用例组织和开发,调度和执行,日志以及用户操作接口。事实上,除了底层GUI实现是客户端GUI的专属,其他的部分都属于一般的自动化测试架构部分,不过对客户端测试,这些部分可以适当调整。所以这里的重点,是GUI测试的底层。
底层实现
底层实现中包括GUI控件识别操作,信息hook,进程检测,文件管理等各种底层,其中GUI控件识别是难点,其他的都可以比较轻松的完成,任何工具和编程语言都有相关部分。关于控件识别部分,包含以下内容:
基本原理
控件识别是GUI的测试最核心部分,它是客户端GUI可测与否的关键――底层如果走不通,其他的都是噱头。
IPC
基本上操作系统标准控件默认使用的都是IPC的方式,实际上这个也是大多数GUI的底层技术,即进程间通信。被测程序和测试程序之间采取这种方式,达到GUI的识别和操作。
内存共享
内存共享是IPC的一种方法,这里提到只是说出了操作系统提供的IPC方法,一些项目和产品也可以自己采用内存共享的方法进行GUI的数据共享,比如测试输入法的时候,共享的数据可以使用windows接口hook到,但是中文输入的分音符”’”,是私有数据,不可能搞到。通常的做法就是在测试程序中给一个带有私有数据定义和传出的.h文件。
通信
这里的通信不只是IPC中的管道通信,而是真正的通信,它的特点是安全性高,但是效率低一些。某些情况下,底层处理好,易用性很高。比如web测试中流行的webdriver,其中chrome浏览器对应的是chromedriver.exe,这个驱动就是采用代理和通信的方式完成的。Chrome内置一个服务,chormedriver.exe会开启一个socket和chrome连接驱动浏览器执行,selenium使用http和chromedriver通信,达到和其他driver使用封装的一致。
Chromedriver

后门
后门的方法,其实上面提到的输入法私有数据就算一种,开发提供.h文件到测试系统中,只给测试程序开后面。
当然还有其他的方法,比如编译出测试版本,进行测试,发布版本关掉这些支持;还可以开发直接提供一些hook工具,开启的时候提供相关支持等。
自绘控件
自绘控件,是GUI测试的最核心问题。这个问题是这样的――即使开发人员帮着写自绘控件的支持,也不会每个控件都写,每个方法都写,如果这样的话,用一些流行的工具,还是会错误百出。
IAcessible实现
最根本的自绘控件实现,可以参考Chrome的源代码,windows的chrome,在UI上,都实现了这个东东。总的来说,需要三个步骤:
继承IAccessible相关类,然后通过LresultFromObject把IAccessible
接口返回给测试程序
注册系统VM_GETOBJECT事件,使对外proxy可以获取实例的变量
分别实现IAccessible中的各个接口
Chrome中原生的界面库采用这种方式实现,这样的事例在chrome中看到很多,比如:
初始化:

注册:
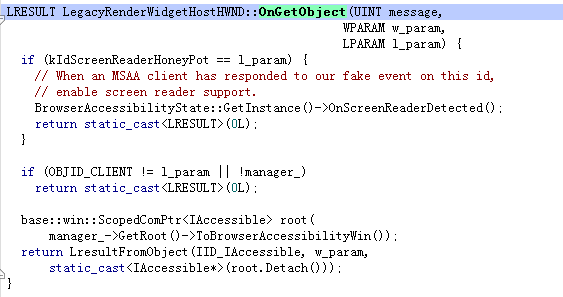
接口实现:

hook实现
hook的方法前面提到过一些,有些情况并不适合做控件的这些接口支持,还是用前面的输入法为例,及时是操作系统自带输入法,在微软内部也没有实现――最早的微软输入法是有IAccessbie的支持,后来的就没有了。微软内部也是采用hook的方法去进行测试的。一些互联网公司的输入法,同样也是hook去解决。
坐标计算
坐标去判断是一种无奈之举,但是有时候确实有用。之前我做过的一个特殊需求,就是完全的模拟用户乱点浏览器页面的链接,不能用任何接口和通信支持。最终打开页面的时候,用鼠标在整个页面扫一下,记录下鼠标指针变化的位置。
Win32 handle
Win32handle是基于句柄和消息的windows sdk中的一个工具,是windows系统中,GUI最基础的支持。通常能获取窗口句柄信息,类名消息等,使用相关windows
api操作。当然根本技术还是IPC,被测和测试之间通信完成。如下:

获取采取windows api的方式
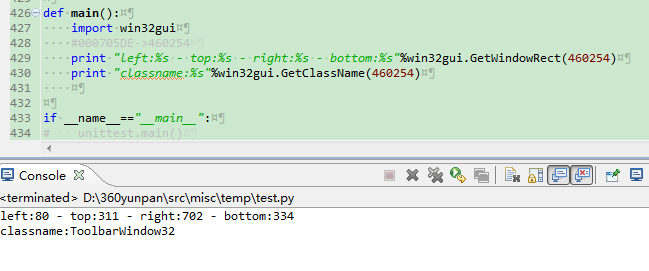
这种技术能处理起来比较简单,也是很多流行工具的根本原理。但是使用的范围极其有限。
Msaa
Msaa是在windows api的基础上,专门应对IAccessible接口而设计的,msdn上有各种相关的资料。它还是基于IPC技术的,原理如下:
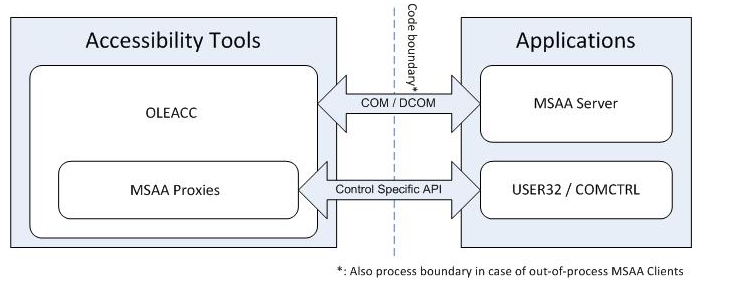
Msaa的核心和ole,com这些是一样的,因为msaa的实现依赖于oleacc。事实上这些技术的核心,就是边界值检测和引用计数,但是由于不是这里的重点,所以这里不详细讨论。可以参考各种教程,比如wiki。
Msaa可以获取更多hwnd的隐藏信息和一些自定义控件的信息,如下图所示:
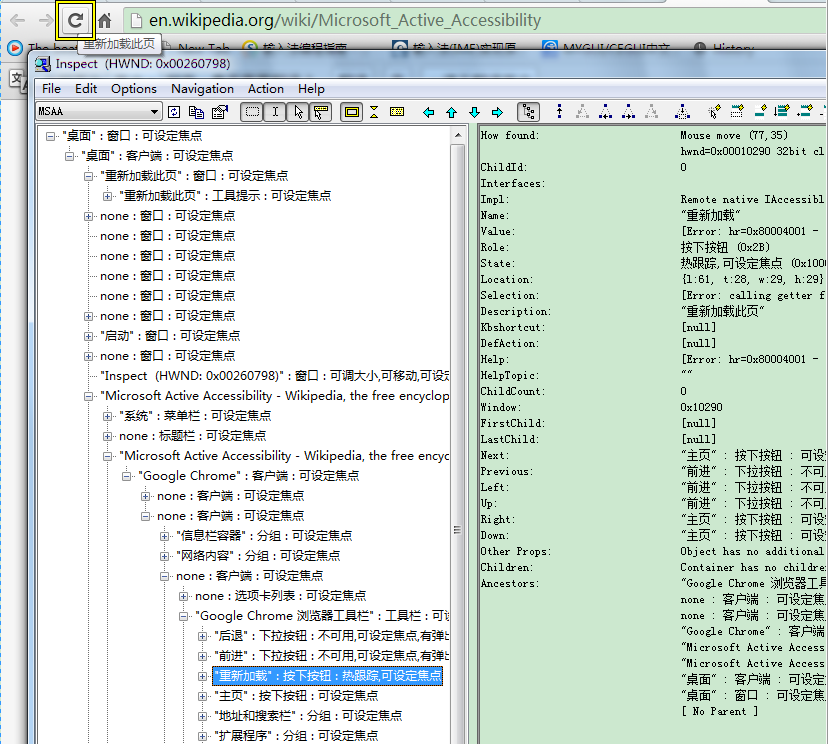
Msaa的信息获取,可以通过oleacc实现。比如在一下的python代码(更多请参考python的msaa封装,在之前的相关博客):
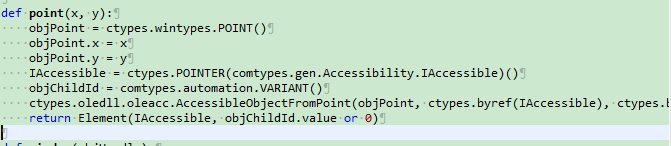
最终结果如下:
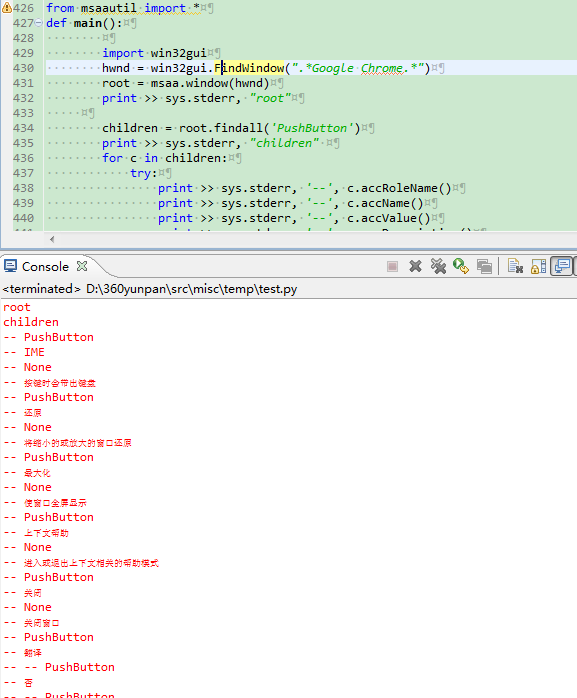
Msaa的方式能够满足大多数需要,但是还有其局限性。
UIA
UIA是在.net framework之上,所以针对msaa,提供了更多有效的功能。然后由于结构的复杂,需要更强的编程能力。UIA的原理如下:

类似的,UIA可以获取到如下信息:
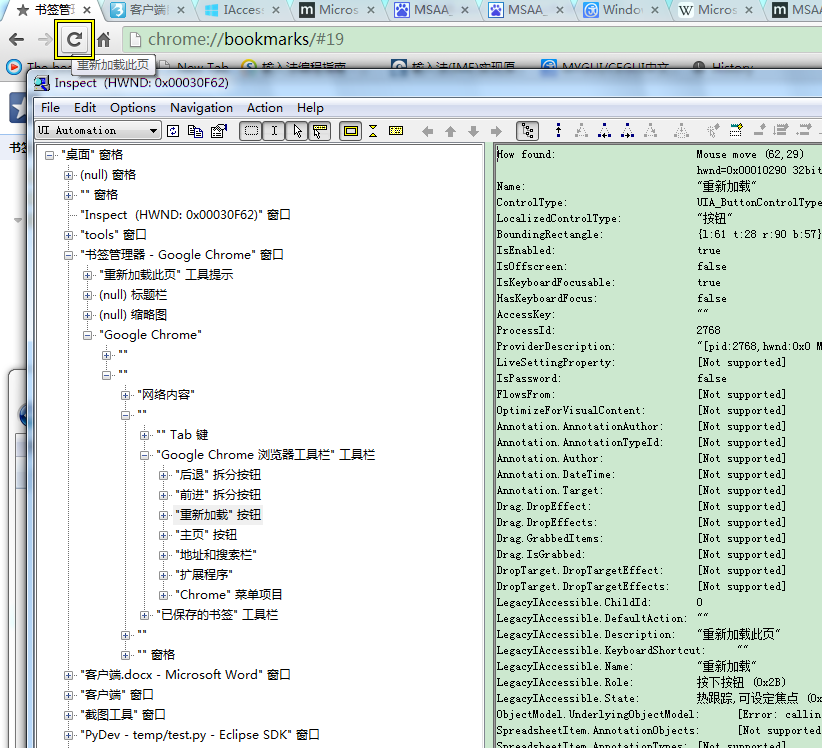
由于UIA的部分需要.net framework的支持,暂时没有示例。但是毕竟是在framework之上的东西,网上相关的教程也是一把一把的。
UIA的特点是提供了更为丰富的实现和功能,IPC结构更加完善,使用便利,支持vista以上系统和WPF的测试。。缺点是太过于繁琐,开发复杂。微软内部的GUI测试架构Mita,也是完全重新封装UIA的架构,不进行二次封装,很难快速的使用。比如msaa整个的封装可能几K而已,但是UIA相比之下,就是巨无霸级别了。当然各种基于UIA的工具,性能可想而知――很多情况下我们需要测试XP和一些老式的低配机,这种情况下它并不适合。
基于图像技术
严格来讲,我本人并不推荐这种技术,一方面不稳定,另一方面性能消耗较大。
大的方面说,有一些整体都基于图像的如ikuli,可以通过图像去识别驱动一些程序,并且不依赖被测程序开发。但是我个人认为这东西用在自动化测试上,并不实用。
小的方面说,一些用例的检查点,和图像有关,这时候需要做一些基于图像的处理,比如对比图片MD5呀,分析图像色度之类的功能。
所以基于图像的技术,可以用在一些边角的实现上,不太适合作为底层的主角――当然这是我个人的体会。
WebGUI
Web的GUI之所以放到最后,是因为它的特殊性――常用的浏览器中,原理是不同的。在IE上,由于有com的支持,页面的GUI和控件是一样的,selenium中IE的driver部分也是这样的原理,甚至一些基于IE内核的浏览器,只要内嵌IE_frame结构,都是一样的,如下:
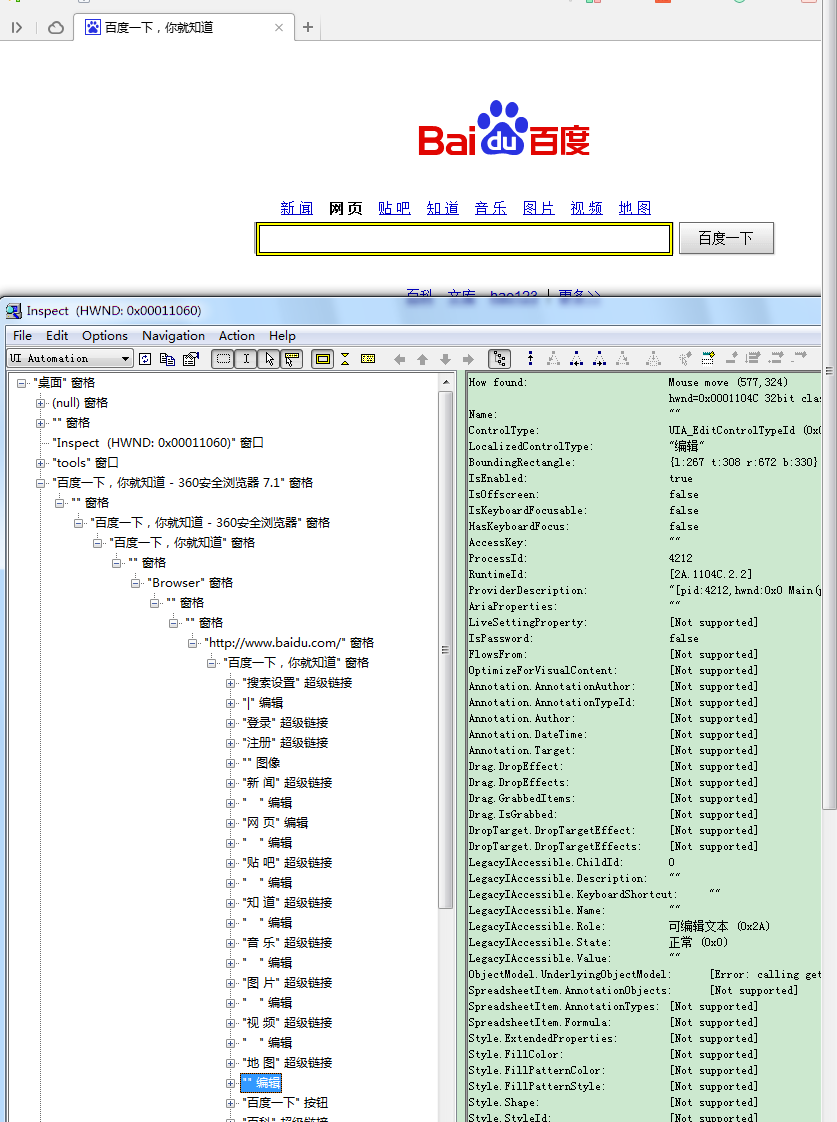
对于Chrome的页面GUI,之前已经提到过chromedriver.exe了,它是采取了通信的手段实现,而不是com或Ole这种基于IPC的方式。
辅助工具
辅助工具,指一些辅助开发使用的GUI查看工具,这些工具比较多,包括上面使用过的spy++,inspect,当然还包括各种UIASpy等等。当然也可以自己开发,或者使用网上其他的工具,这部分工具还是很多的。
Web页面的自动化工具,如果单独的IE情况下,可以像上面那样按照客户端GUI的方式完成,但是如果使用selenium这样的架构,最好还是像chrome一样使用自带的开发者工具完成web结构定位等。好在IE也有相应的开发者工具,而且相比真正客户端的层级关系,web的更加规范,也稳定。
简单示例
msaa接口:如上示例
UIA接口:如上示例
QTP等:自行查阅
用例组织和开发
Unittest
Unittest是两个聪明的家伙创作的(名字忘了),最早在smalltalk的单元测试中,后来到JUnit和pyunit。
用Pyunit举例,大概包含如下部分:
TestResult:用例结果实例,架构自动调用
TestCase:测试用例基类
TestSuite:测试套件实例,用来管理测试用例
TestLoader:加载测试用例,返回一个测试套件
TextTestRunner:执行实例
TestProgram:执行核心
对于这个优秀的小测试架构,当然不能浪费了。有些测试用例的执行和管理,直接使用这个架构。
另外,很多大型的测试驱动架构,和这个小架构核心非常类似,比如微软的MTM,用例管理的套件,思路上很像。
直接使用这个框架,大部分是三种情况:
第一种在uniitest框架上编写用例,和一般的单元测试相似;
第二种动态将测试用例在执行时转化为uniitest结构,并且执行;
第三种借用测试套件管理测试用例;
基于unittest的用例组织和管理直接,灵活,但是对于场景复杂并且测试人员 编程功底不够的情况,是不适合的。
更多内容可以参考:http://pyunit.sourceforge.net/pyunit_cn.html
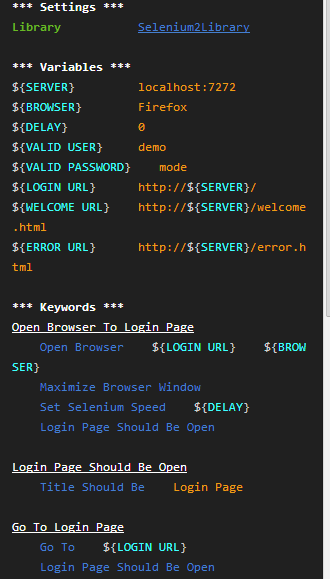
用例格式
unittest中提供的,只是一种格式,事实上用例的格式千变万化,没有所谓的最好,只有最适合。
文本
文本类的用例比较适合编写,而且不存在太多复杂的东西,定义好用例结构,可以直接解析。
Xml
扩充容易,复用度高――编辑容易出错
比如网上的一个示例:

Txt
编写容易――结构不严谨,难扩展
比如IBM的robot中的测试用例结构:
表格
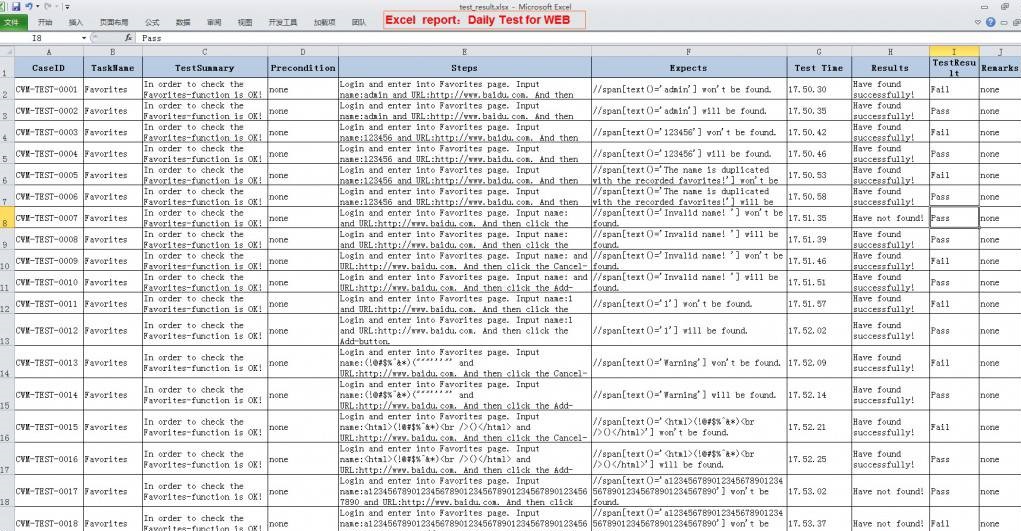
excel等
excel格式的自动化用例一般都用在数据驱动的架构中,一般底层封装层次比较多,只留下外部数据接口,这种测试用例适合简单但是数量多的测试情况。如下;
脚本
脚本的测试用例一般测试开发人员比较提倡,无缝调用,适用性强,并且重用度高。但是这种用例需要一定编程功底。
Lua
类似的用例如下:

Java&C#
Java&C#的测试用例类似于下面的情况:
Python
Python的测试用例使用比较多,chrome和互联网的发展,让Python的地位越来越高,典型的用例如下:
嵌套用例
调用形式
一些场景类的用例,需要很多重用的逻辑,也就意味着需要有很多公用的用例或者模块,一些最终用例也很可能某一天,会成为公共用例。这样的情况下,需要实现嵌套的结构。
一般来说,这样的情况分为两种方法。一种是脚本或者编程语言写的测试用例,这种用例可以打包为模块或者测试套件实现公用;另一种是文本类用例,这种情况下必须采取文本嵌套的模式进行调用,比如xml的:
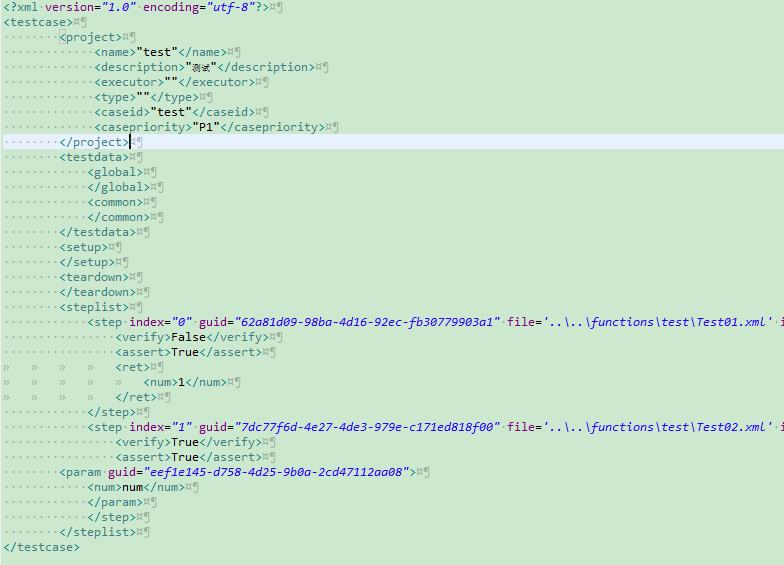
将每一个step都统一成一个文件,这样就实现了用例的递归调用。
管理方式
无论包方式还是文件方式,都是都是以模板和功能为核心进行文件夹的管理。一般会统一到svn或者其他源代码管理工具,因为测试用例也需要维护,某种程度上,这就是代码。
用例驱动
用例驱动方面,我个人并不提议各种驱动什么的,这些是个名词而已,而且大都是针对使用工具的人来介绍而已。对于架构设计和开发人员来说,更关注的是名字后面代表的各种含义和解决方案。
我个人对这些驱动的解释是,他们没有本质性的差别,只是在封装、重用和特殊需求下的粒度不同,有些极端,有些折中。
关键字驱动
这种方式是大多数流行的测试工具所提倡的,因为这些测试工具并不是为工具开发者使用,而是商业的,所以这种方式最适合,也有推广性。
这种解决方案适用在业务复杂,重复度一般的情况下。除了底层的封装外,外层封装和测试用例都是和业务逻辑对应的,管理和封装方法也取决于业务逻辑特点。一般来说将业务的最小粒度分层封装,一直到业务顶层。执行的时候只需要判断关键字的结构和分层顺序执行。
方法驱动
这种解决方案完全为由测试开发人员决定,一般来说,底层封装完全,提供了共有的接口之后,业务很乱或者对业务不理解,都会直接保留接口封装而不是业务逻辑,这样的情况下,以后业务梳理完一部分,用方法顺序执行一部分。当然,测试开发负责接口开发,手工测试进行逻辑业务用例编写一般也是这种情况。
数据驱动
所谓数据驱动,是自动化测试的一个极端情况――这种情况业务逻辑相对单一,但是需要反复测试不同的数据。这种情况下,外部接口相对简单,用例更多的是数据的编写和组织。比如之前提到的输入法的测试,比如我新开发一款输入法,需要测试a开头到z开头的100万个字母串输入的首个匹配中文,并且和搜狗的输入法做对比,这就是典型的所谓数据驱动模式。功能逻辑的接口很少,但是需要不断重复执行,去测试不同的数据。
场景驱动
场景驱动,噱头的成分更大一些。纯面向对象的业务开发都没有什么成功的案例,面向业务和服务的开发模式,更是不实际。个人觉得所谓的场景驱动,是建立在一定粒度的关键字驱动封装之上。一些稳定回归的,逻辑固定的场景抽象出来,作为独立的部分,所以纯面向场景的驱动不是没有,而已意义没有宣传的那么大,它更多是结构上的,但是实际工作上很少完全场景化。
录制回放
录制回放的方式,比场景驱动噱头还要大,尤其在一些控件点击和web元素执行的情况下。录制回放并不能算作一个驱动方式,只是一种辅助的手段,好处是一些技术基础差的测试人员能够参与测试用例的开发中,提高开发速度。不好的地方,是录制后的脚本和用例一样需要修改和调试才能实际工作,而且在自动化架构开发的过程中,需要配套的使用hook和消息机制,做出相关的录制功能。实际工作并不是商业软件开发,需要合理的折中预算和人力投入,所以做不做是要看收益。
但是事实上,录制回放可以和后续的日志部分结合一起――执行步骤,日志和录像都可以通过索引整合到一起,定位到出错部分,并且重现。这是它的另一个好处。
调度和执行
前面所有的东西,包括底层和测试用例管理驱动的部分,能够保证自动化可测,即这两方面都完成的话,放到测试机上,就可以正常执行和测试了。但是如果用例集很大,执行环境复杂,人力执行显然不是好办法。成熟的自动化架构,必须考虑到测试机的执行和调度。
测试机管理
测试机管理中,一般可以分为测试机执行接口和代理――这两个词并不准确,我临时拿来用。
命令发送
命令发送这个词同样不准确,因为在实体机的服务端和代理端,确实是以命令作为最小单元,但是如果是虚拟机,就不存在命令发送,而是虚拟机接口。
虚拟机
调度虚拟机,需要使用vmware提供的接口,流行语言都已经提供,或者可以自行调用dll完成。接口在WM安装路径的32bit\vix.dll中。官网有相关信息。
实体机
实体机的命令发送,是我说的真正的命令发送,无论服务和代理之间采用任何形式通信,执行一条命令是最基本的颗粒。最小颗粒之上,是定义各种需要的命令。
代理通信
代理是调度驱动的核心,一般情况下,实体机想要驱动,必须保持双向联通。一起单项的命令模式也能驱动,但是这是不完善的,没有回执和状态查询,就不能叫做调度和代理。
虚拟测试机一样需要代理通信――一个服务器资源有限,即便虚拟30多台测试机,有时候同样不够用。这时候可能有很多台服务器提供虚拟机,那么每台服务上必须有自己的代理,服务和服务器通信,并且管理它的所有虚拟机。
Socket
通常,代理会选用socket进行通信,服务端管理多个代理,这是通信的最常用技术。
但是一些时候也会选择直接使用http通信,每个client端管理一个web服务,这种情况比较少。
反ping
对于有些特殊情况,比如需要重启或者重装系统的情况,需要代理的client端失去联系后反Ping服务端,重新恢复session。
ICE
一个比较久远的面相对象的中间件平台,可以借助ICE定义自己的接口,最终完成代理通信和调用。
GoogleProtoBuf
简单的说,googleprotoBuf是谷歌的一种数据交换格式,更确切的说,是一种可扩展的序列化结构数据格式,可以用来存储,RPC或者等数据通信。对于通信调用,可以借助这种格式进行传输和临时存储。
Mina
Mina在这里,是一个重量级的东西。因为上面ICE和googleprotobug的内容它都包含。它的根本是一个通信应用框架,提供了协议的封装,流和管道机制,同步和异步等。和ICE一样也提供了server和client的封装。在考虑写代理的时候,可以优先选择。缺点是只能用java来写。

WTT&MTM
WTT是微软内部一直使用的一个测试机任务派发调度系统,它是基于命令的,同时采取了反ping技术,所以一些断网和删除驱动的测试,一样可以胜任。这是我觉得任务派发的调度的一个比较好的系统,并且支持定时任务和派发模板的创建,通过配置几乎可以完成任何测试调度的任务。只可惜是个内部的东东,而且太大了,一般的测试团队很难开发和维护。
相对来说,微软的另一个主推的测试生态平台MTM和Auto Lib,并不是很好,很难和流行的QC等系统比较。主要愿意是它勉强和VS的搞到了一起,而且很多设计在根本上没有考虑到扩展和模板的概念。另外,作为一个平台,它寄生在VS的生态环境,使得性能无法提高。
其他
调度分配
调度分配在执行调度中,是一个可大可小的东西。一般在自动化架构开发初期不怎么去考虑。但是如果自动化架构稳定之后,可能会有一些分配上的需求,包括平均,动态以及一些特殊的需求。通常分配策略使用插合的方式,可以一种策略对应一个对象,也可以所有策略对应工厂类,或者使用纯算法的方式完成。
平均
平均模式一般将M个用例分到N台机器上执行,即使能够监控测试机状态,也没办法对已经分法出去的任务进行异常处理
动态
动态分配是一种相对较优的办法,它通常会轮询测试机,有空闲则分配测试任务。它不会因为某个任务异常或者测试机异常而卡住。但是由于轮询都需要计算,所以分发计算上效率差一些。
队列和池
无论任何任务队列也好,调度池也好,各种说法等等,在分配策略中,事实上只有任务集合和测试机集合。再没有其他约束条件的情况下,即所有任务级别一样,所以测试机级别一样,它的调度会有一个折中的动态方法,在动态分配的基础上,定义每次分发的最小单元。在动态的同时保证了计算效率。
特殊需求
这里的特殊需求,指的特殊的任务级别和特定测试机环境。这里一些有效的方法就是聚成,重排和过滤。无论是任务和测试机,都可以分成各种集合和子集合,在执行的时候,可以才去节点为参数进行任务的下发,满足特殊需求;如果用例和测试机的命令有约束,也可以采取过滤的方法,制定好过滤规则。另外在任务队列里,会涉及到一些局部排序方法,这些可能要具体
情况具体考虑。
日志
日志是一个测试架构必须的部分,可以几乎任何部分都要涉及到日志。当然除了通常的一般日志,还有一些特定的日志,他们可以用来定位测试用例失败点等等。
调试日志
调试日志通常放在执行目录下,无论调度服务还是测试用例在测试机上的执行。一般来说,调度服务的日志只需要记录具体关注的问题即可,但是在测试机中执行的测试用例,其日志需要和用例执行步骤一一对应。这部分
建议是,如果用例顺序执行,则顺序记录日志,如果递归执行,则递归格式记录日志。日志的内容可以包括和用例一一对应的信息,以及执行的具体山下文环境,和运行时状态。
本地&数据库
通常,测试日志分为两部分,一部分测试结果在运行时存入数据库,这也是最终查看测试执行结果的数据源。当时一些调试信息日志,没必要放在数据库,而且也不便于调试,一般来说这部分日志在用例执行结束后,会按照具体执行ID放入到固定的共享文件夹。测试人员调研和调试测试用例的时候,这些都是重要的东西。另外,放到共享文件夹的调试日志,最好也包含用例执行步骤和结果,因为一些断网的情况下,无法保证数据库的连通,但是却希望得到执行的正常结果。
结果
执行结果
执行结果一般是以步骤为最小粒度,存放在数据库。当然本地日志中也最好有一份,如上面所提到的。
失败截图
失败截图是日志的重要组成部分,对于将截图放在日志的共享文件夹目录下,是没有太多异议的,一般来说,这部分的异议是是否应该将失败截图保存到数据库中。个人建议这个看情况,但是一般保存到数据库中也没有什么不好,如果不需要在数据库读取的话,是个备份,如果读取的话,可以整合到一些前台页面中。这里唯一需要注意的是,如果将失败截图存放到数据库,那么,那么千万别使用select
* from XXX的这种方式进行读取,不然你的数据库服务器内存再大也承受不住。
录像
录像没有太多争议的放在了文件共享系统中进行保存,毕竟它太大了,也没有太多页面显示的必要,反而不如在文件系统查看方便。
录像这部分需要注意的是,很多时候录像可以和失败日志集成到一起,通过失败日志进行索引的定位,然后点击录像查看。一些流行的测试框架也提供了这类的日志和录像的查看工具。
存储
存储主要是用来查看的,之前也提到了主要分为数据库存储和文件系统存储,他们适合存不同的东西。数据库一般存数据性较强的东西,比如执行结果,任务参数等,结构化并且永远存储;文件系统适合放大容量并且经常读取的日志。
数据库
大需求的前提下,这种逻辑很少有人使用nosql来存储数据,毕竟一个整体的自动化架构逻辑和业务很清晰,而且关系型数据库也能够胜任。
关系型
一般推荐这种情况下使用关系型数据库,第一是选择比较多,适合存放大量的结构化数据,而且关系型数据库比较容易,真的出现什么问题,很方便的找到解决方案。
非关系型
非关系型数据库的优点是快,比较适合一些小项目和互联网传输等,而且数据的对象化更加容易。但是非关系型数据库我并不建议――可能会有更多的成本,比如自己去写事务,写同步异步和处理锁等,而且性能如何也都是
问题,nosql的数据库相对来说,对内存的依赖更多一些,这种情况不适合一些测试数据的存储。
文件
文件系统存放日志一般没有太深技术性的东西,只有一些小技巧的东西,比如尽可能使用文件拷贝的方式而不是网络通信的方式传输,也可以做一些盘符映射直接使用远程文件,而不是拷贝。等等这样的小技巧。
用户控制接口
这部分主要是用户如何查看,制定和执行相关的自动化测试。之前提到过一些架构环境,可以通过web或者客户端进行任务下发,或者通过定时任务进行。另一方面,具体的结果的数据如何查看等等,也都是提供给使用者的外部接口。
中控
无论client还是web,最终都需要核心的控制服务,它的功能主要是两大部分,一个是任务下发,另一个结果查询,当然还有其他一些数据配置等等的功能。总体来说,就是将之前的这些调度和数据库服务器形成有机的一个环境的过程。
前端
前端无论是从操作还是查看的角度,至少都需要涉及到如下的部分
任务
可以下发测试任务,也可以查看任务历史记录和详细结果;
用例
可以编辑和创建测试用例,查询并且管理用例套件,能产看用例测试历史记录和结果;
过程
能够编写用例过程,能够统计出具体过程的执行状态和数据等等;
报告
报告一般是通过数据库中的数据,整合最终报告逻辑,按照报告的模板生成的具体测试执行结果信息汇总。一般情况下,会以文件形式存在。格式中,采用最多的是html和word,有些是直接生成的,有些是预览后导出的。
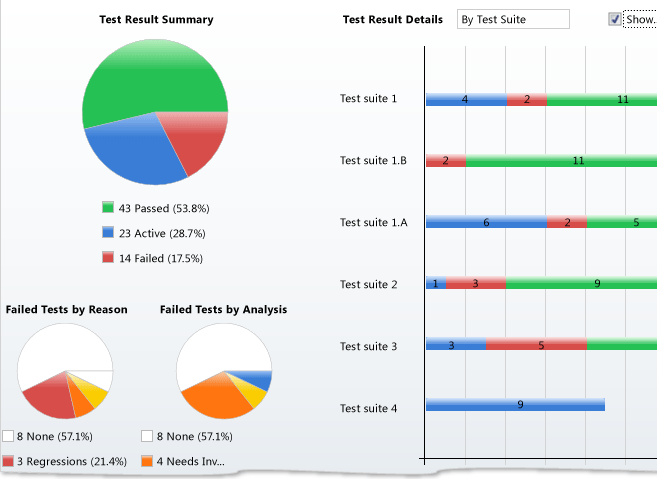
消息通知
消息通知,一般都是报告完成后配合报告将测试结果发送到负责人邮箱的,通常这种时候会带着一些汇总的数据信息作为邮箱的主要内容,将其制成html格式的报表,然后发送邮件,详细的模板可以作为附件使用。
当然,消息通知机制不限于邮件,也不限于执行的结果汇报,决定关键的任何事件都可以触发通知,短信甚至以后的电话提示都是可以的。
| 




