| ±аәНЖәц: |
±ңОДАөЧФУЪІ©үНӘ¬ҢйЙЬБЛ»·ңіөоҢЁӘ¬RIDEµДҢзГжИПК¶Ә¬№¤ЧчЗшEDIT
Ә¬№¤ЧчЗшRUNӘ¬°ёАэЙиәЖЦ®БчіМУлКэңЭ·ЦАлµИҰӘ |
|
Т».»·ңіөоҢЁ
НшЙПУРғЬ¶аµДҢМіМӘ¬ХвАпңНІ»¶аҢІБЛ
¶ю.RIDEµДҢзГжИПК¶
ХвАпЦ»ҢйЙЬәёёцЦШТҒіӘУГµД№¦ДЬӘ¬ЖдЛыПаРЕЧФәғ¶әДЬАнҢв
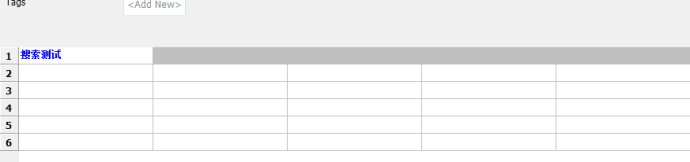
1.Search KeywordsӘЁF5): ЛСЛч№ШәьЧЦ
2.Content AssistanceӘғДЪИЭЦъКЦ
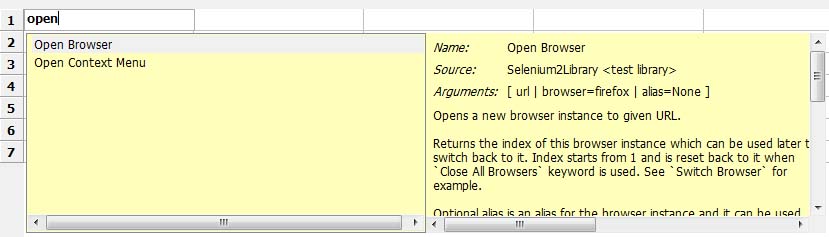
3.View RIDE LogӘғІйүөRIDEИХЦңӘ¬К№УГ№эіМЦР±ЁөнӘ¬үЙТФАөХвАпІйүөӘ¬С°ХТ±ЁөнФТт
Иэ.Чо»щ±ңµДБчіМ
1.New Project
TypeСҰФсDirectoryӘ¬FormatСҰФсTXT
2.New Suite
ФЪProjectµД»щөҰЙПCreate New Suite,TypeСҰФсFileӘ¬FormatСҰФсTXT
3.New TestCase
ФЪSuiteµД»щөҰЙПCreate New TestCase
4.New Resource
ФЪProjectµД»щөҰЙПCreate New Resource
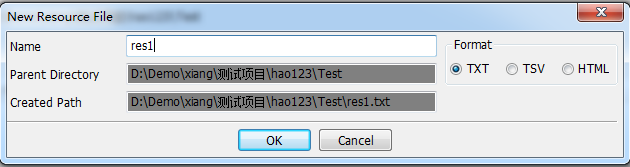
5.New User Keyword
ФЪResourceµД»щөҰЙПCreate User Keyword 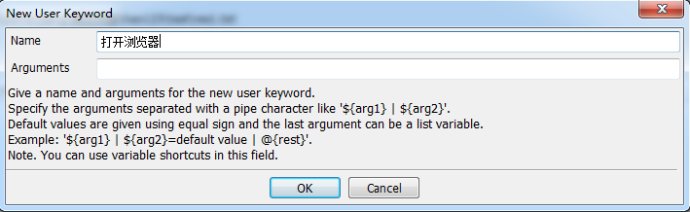
ХвК±ғтДгµДRIDEИзПВНәПФКңңН¶ФБЛ 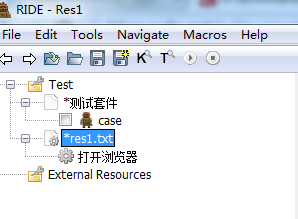
ЛД.№¤ЧчЗшEDIT
1.ІвКФМЧәю 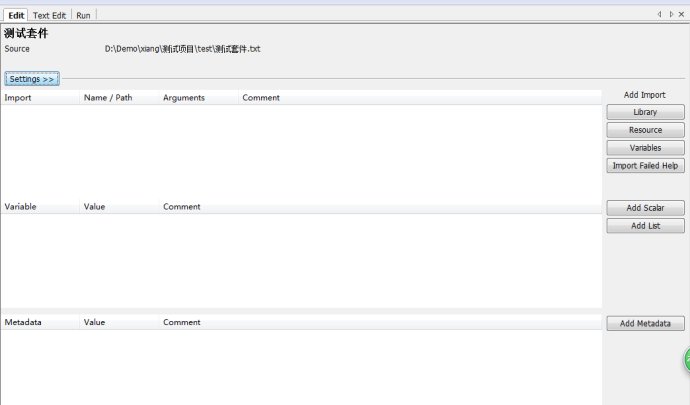
өуМе·ЦіЙ3ёцІү·ЦҰӘ
ӘЁ1Ә©ӘғәУФШНвІүОДәю
Add Library ӘғәУФШІвКФүвӘ¬ЦчТҒКЗ[PYTHONДүВә]\Lib\site-packagesАпµДІвКФүв
Add ResourceӘғәУФШЧКФөӘ¬ЦчТҒКЗД㹤іМПа№ШµДЧКФөОДәю
Add VariablesӘғәУФШ±дБүОДәюӘ¬І»ФхГөУГӘ¬үЙФЭК±ғцВФ
ӘЁ2Ә©Әғ¶ЁТеДЪІү±дБү
Add ScalarӘғ¶ЁТе±дБү
Add ListӘғ¶ЁТеБР±нРН±дБү
ӘЁ3Ә©ӘғФҒКэңЭ¶ЁТе
Add MetadataӘғ¶ЁТеФҒКэңЭҰӘОТКЗЦ±ҢУ·ТлµДӘ¬ХвёцКЗРВФцәУµДІү·ЦӘ¬өуёЕүөБЛТ»ПВЧчУГКЗФЪreportғНlogАпПФКң¶ЁТеғГµДДЪИЭӘ¬ёсКҢғНdocumentТ»СщҰӘ
2.МнәУResourceӘЁФЪSuiteЦРӘ©
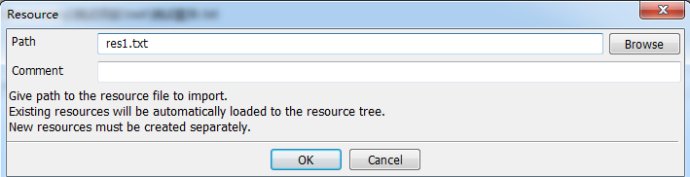
3.МнәУLibraryӘЁФЪSuiteЦРӘ©
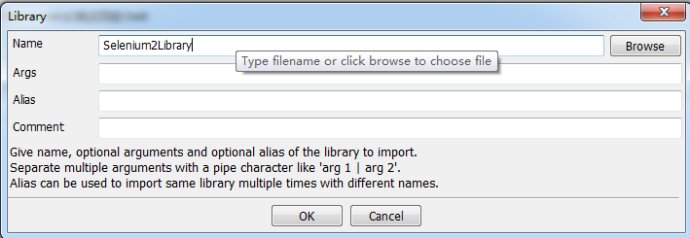
4.МнәУіЙ№¦µД±кЦңӘ¬ФЪSourceЦРіцПЦSelenium2LibraryғНres1
5.settingӘЁ°ьАЁProject,Suit,CaseӘ¬ResourceӘ¬User KeywordsНәЖ¬ңНІ»Т»Т»ЙПө«БЛӘ©
DocumentationӘғОДµµӘ¬ГүТ»По¶әУРҰӘүЙТФёшµ±З°µД¶ФПуәУИлОДµµЛµГчҰӘ
Suite SetupЦёµДКЗІвКФМЧәюЖф¶ҮµДК±ғтңНЦөРРДіёц№ШәьЧЦҰӘ(АэӘғОТФЪSuite SetupЙиЦГБЛSleep
| 5secӘ¬±нКңµИөэ5ГлӘ¬ТҒЧұТв№ШәьЧЦµДІОКэТҒК№УГ | ·Цёф)
Test TeardownЦёµДңНКЗ°ёАэҢбКшµДК±ғтЦөРРДіёц№ШәьЧЦҰӘ
Test TemplateӘғІвКФДӘ°жӘ¬ХвКЗүЙТФЦё¶ЁДіёц№ШәьЧЦОҒХвёцІвКФМЧәюПВЛщУРTestCaseµДДӘ°жӘ¬ХвСщЛщУРµДTestCaseңНЦ»РиТҒЙиЦГХвёц№ШәьЧЦµДө«ИлІОКэәөүЙҰӘ
Test TimeoutӘғЙиЦГГүТ»ёцІвКФ°ёАэµДі¬К±К±әдӘ¬Ц»ТҒі¬№эХвёцК±әдңН»бК§°ЬӘ¬ІұНӘЦ№°ёАэФЛРРҰӘХвКЗ·АЦ№ДіР©ЗйүцµәЦВ°ёАэТ»Ц±үЁЧҰІ»¶ҮӘ¬ТІІ»НӘЦ№ТІІ»К§°ЬҰӘ
Force TagsӘғХвАп»№КЗТҒЛµТ»ПВӘ¬ФЪОДәюРНSuiteХвАп»№үЙТФәМРшёшЧУФҒЛШФцәУForce TagsӘ¬µ«КЗЛыІ»ДЬЙңіэёёФҒЛШЙиЦГµДtags
Default TagsӘғД¬ИП±кәЗӘ¬ЖдКµғНForce TagsГ»Й¶Зш±рµД
ArgumentsӘғө«ИлІОКэ
Return ValueӘғ·µ»ШЦµ
Ое.№¤ЧчЗшRUN
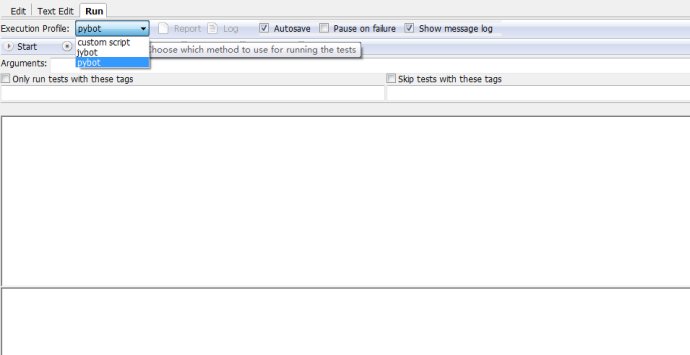
Execution ProfileӘғСҰФсФЛРР·ҢКҢӘ¬АпГжУРpybotҰұjybotғНcustom scriptҰӘЖдЦРОТГЗД¬ИПКЗУГpybotАөФЛРР°ёАэӘ¬jybotРиТҒ°ІЧ°JythonµДЦ§іЦҰӘcustom
scriptКЗСҰФсЧФ¶ЁТеµДҢЕ±ңАөФЛРРҰӘңНДүЗ°¶шСФӘ¬ОТГЗІ»УГРЮёДБЛӘ¬Д¬ИПpybotәөүЙ
StartғНStop:ХвБҢёцУ¦ёГІ»УГЛµБЛӘ¬ФЛРРғННӘЦ№°ёАэҰӘ
ReportғНLog: ±ЁёжғНИХЦңӘ¬ТҒФЛРРЦ®ғуІЕДЬµг»чҰӘЛыГЗµДЗш±рГөӘ¬ОТµДёРңхКЗ±Ёёжёь¶аКЗҢб№ыЙПµДХ№КңӘ¬ИХЦңёь¶аКЗ№эіМµДәЗВәӘ¬ёь¶аК№УГµД»№КЗИХЦңҰӘ
Autosave: ЧФ¶Ү±ӘөжӘ¬Из№ыІ»№өСҰӘ¬ФЪРЮёДБЛ°ёАэЦ®ғуИз№ыГ»УР±ӘөжµД»°Ә¬ФЛРР°ёАэК±»бМбКңКЗ·с±ӘөжҰӘ№өСҰФтФЪФЛРРК±ЧФ¶Ү±ӘөжБЛҰӘ
Arguments: pybotµДІОКэӘЁ»тХЯjybotµИӘ©Ә¬±ИИзОТғуГжҢШНәАпәУЙПБЛТ»ёцІОКэҰӘНкХы°жµДІОКэүЙТФФЪdocГьБоРРКдИлpybot.bat
--help
Only Run Tests with these Tags: Ц»ФЛРРХвР©±кәЗµДІвКФ°ёАэҰӘ
Skip Tests with these Tags: Мш№эХвР©±кәЗµДІвКФ°ёАэҰӘ
Бщ.°ёАэЙиәЖЦ®БчіМУлКэңЭ·ЦАл1
1.өөҢЁ°ёАэ

ХвЛгКЗТ»ёц±ИҢПНкХыµД°ёАэБЛӘ¬°ьғ¬НкХыµДБчіМғНәмІйµгӘ¬ДЗГөХвК±ғтИз№ыОТТҒФцәУТ»ёц°ёАэӘ¬ЛСЛчБнНвµДДЪИЭФхГө°мДШӘү
ФЪФАөµДcaseЙПРЮёДүП¶ЁКЗІ»ғПККµДӘ¬±Пң№ДЗёц°ёАэүЙДЬ»№КЗРиТҒ±ӘБфµДҰӘ
ЧоәтµӨµД°м·ЁӘ¬°СХвёцcaseёөЦЖТ»ёцӘ¬РЮёДЛСЛчДЪИЭҰӘДЗГөОТГЗёөЦЖіцТ»ёцcase2°Й
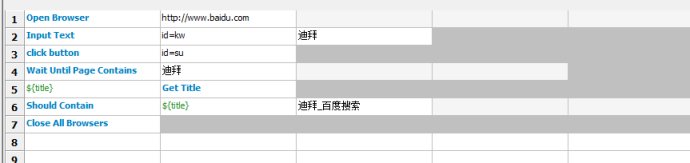
2.·ЦІг·Ң·Ё
СҰЦРcaseЦРµДЛщУРҢЕ±ңӘ¬µг»чУТәьӘ¬СҰФсExtract Keyword
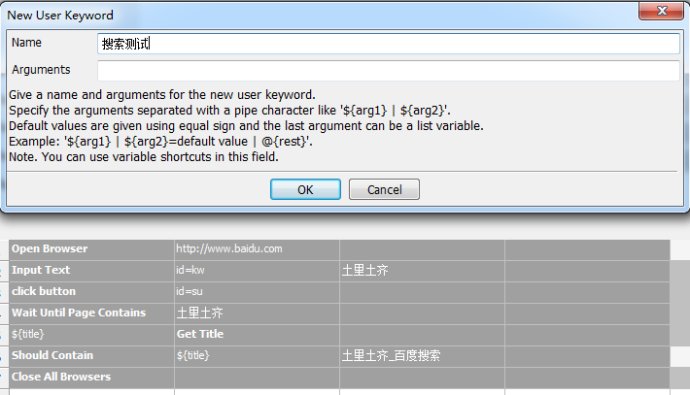
¶шОТГЗФЩүөcaseµДДЪИЭңНЦ»УРХвёц№ШәьЧЦБЛ
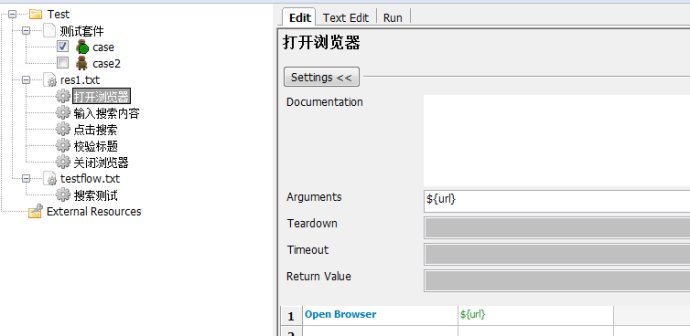
РВҢЁТ»ёцResourceОДәюӘ¬°СUserKeywordТЖ¶Ү№эИӨӘЁ»тХЯТЖ¶ҮµҢТСУРµДResourceОДәюАпӘ©
ХвСщЧцµДДүµДКЗОҒБЛёьЗеОъӘ¬ФЪІвКФМЧәюЦРТ»°гІ»·ЕЦГUserKeywordӘ¬З°ГжµЪ2ҢІµДК±ғтОТГЗңНЛµ№эБЛӘ¬КЧТҒҢЁТйUserKeyword·ЕФЪResourceАпҰӘ
ОТХвАпРВҢЁТ»ёцResourceӘ¬ҢРTestFlow.txtӘ¬И»ғу°СХвёцЛСЛчІвКФТЖ¶Ү№эИӨӘ¬ңНіЙБЛХвСщҰӘ
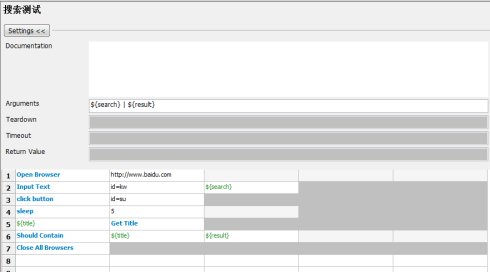
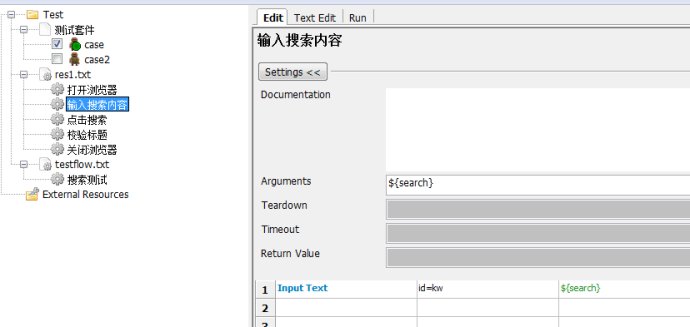
ҢУПВАөОТГЗХл¶ФХвёцІвКФБчіМҢшРР·ЦАлӘ¬ТтОҒХвёц°ёАэБчіМ±ИҢПәтµӨӘ¬КµәКЙПңНЦ»УРЛСЛчДЪИЭХвТ»ёцЦµКЗ±д»ҮµДӘ¬ТтөЛОТГЗ°СЛыёДіЙТ»ёц±дБүӘ¬Н¬К±°СХвёцUserKeywordµДІОКэәУЙПХвёц±дБүҰӘ
ФЩ»ШН·үөүөcaseµДДЪИЭғНМнәУДЪИЭ

үЙТФФЛРРКФКФүө
µҢПЦФЪОТГЗНкіЙБЛТ»ёцәтµӨµД·ЦІгӘ¬°СЛСЛчІвКФХвёцБчіМ°юАліЙТ»ёц№ШәьЧЦӘ¬И»ғуФЪІ»Н¬µДcaseµчУГХвёц№ШәьЧЦӘ¬И»ғуө«µЭІ»Н¬µДІОКэӘ¬УГТФҢшРРІ»Н¬КэңЭФЪН¬Т»ёцБчіМПВµДІвКФҰӘ
ХвСщңНІ»УГµӘРДФЩРВФц10ёц»т100ёц°ёАэБЛӘ¬ТтОҒХвёц°ёАэ±ИҢПәтµӨӘ¬НЁ№эёөЦЖТІүЙТФЧціц10ёц»т100ёц°ёАэӘ¬µ«КЗЧоөуµДЗш±рФЪУЪӘ¬Из№ыОТµДБчіМЦРәдРиТҒЧцТ»µгРҰµДµчХығНУЕ»ҮӘ¬¶ФУЪБчіМғНКэңЭ·ЦАлµД°ёАэАөЛµӘ¬ОТХвСщО¬»¤Т»ПВЛСЛчІвКФХвёцUserKeywordңНРРБЛӘ»¶ФУЪёөЦЖµД°ёАэӘ¬ДЗДгңНТҒРБүаБЛӘ¬ДгУР¶аЙЩёц°ёАэңНёД¶аЙЩ°ЙҰӘ
ЖдКµХвёцµААнТэЙкіцАөӘ¬ОТГЗЧцЧФ¶Ү»ҮІвКФТІКЗТ»СщӘ¬СҰФсІ»Н¬µД·Ң·Ё»тХЯ№¤ңЯ¶әүЙТФКµПЦЧоЦХµДДү±кӘ¬µ«КЗОТГЗРиТҒүәВЗµДІ»КЗ°С°ёАэЧцЖрАөӘ¬ТтОҒХвёц±ИҢПИЭТЧКµПЦҰӘ¶ФУЪЧФ¶Ү»Ү°ёАэАөЛµӘ¬ЧоөуµДДС¶ИІ»КЗФЪУЪФхГөЧц°ёАэӘ¬¶шКЗФхГөО¬»¤°ёАэҰӘТтОҒЛжЧЕРиЗуµДёьРВӘ¬ПµНіµДБчіМ»тХЯТіГж»б·ұЙъғЬ¶аµД±д»ҮӘ¬ХвК±ғтµДО¬»¤іЙ±ңµДёЯµНІЕКЗОТГЗКЧТҒүәВЗµДӘ¬Из№ыЧФ¶Ү»Ү°ёАэҢЁБұЖрАөЦ®ғуӘ¬Г»УРғуРшО¬»¤µДН¶ИлӘ¬ЧоЦХң№эИфёЙёц°ж±ңӘ¬ХвР©ЧФ¶Ү»Ү°ёАэ»щ±ңңНКЗ·ПЖъµДБЛҰӘ
ЖЯ.°ёАэЙиәЖЦ®БчіМУлКэңЭ·ЦАл1
Ң«ЛСЛчІвКФЦРµДДЪИЭәМРш·ЦІгӘ¬»№КЗТҒ°СТ»Р©µЧІгµДөъВлә¶№ШәьЧЦәМРшІр·ЦіцАө
ПВГж¶Фres1.txtҢшРРІЩЧч
1.өтүҒдҮААЖч
2.КдИлЛСЛчДЪИЭ
3.µг»чЛСЛч
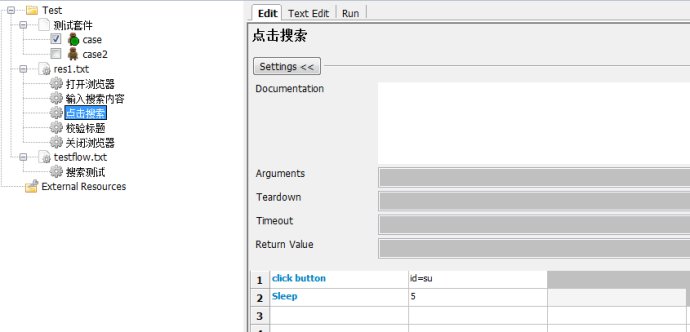
4.РӘСй±кМв
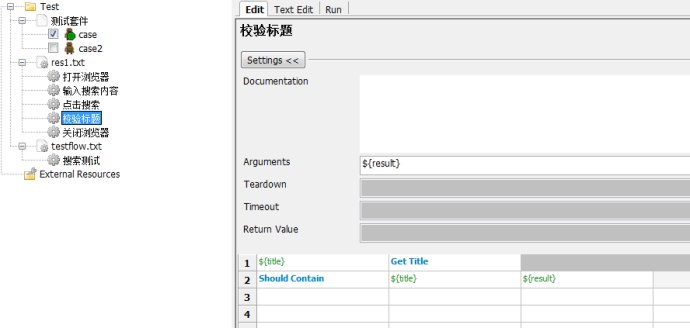
5.№Ш±ХдҮААЖч
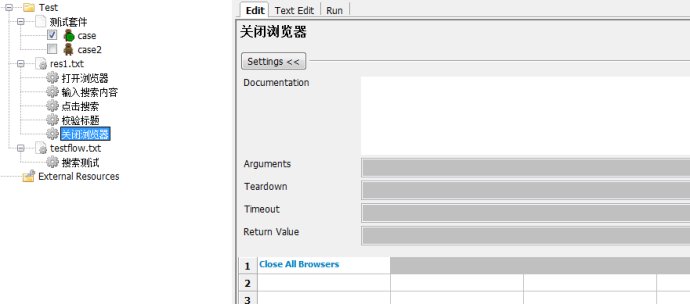
ҢУЧЕОТГЗ°С¶ФУ¦µДЛСЛчІвКФЦРµДөъВл¶ә»»іЙПаУ¦µД№ШәьЧЦӘ¬әЗµГМнәУІОКэ${url}
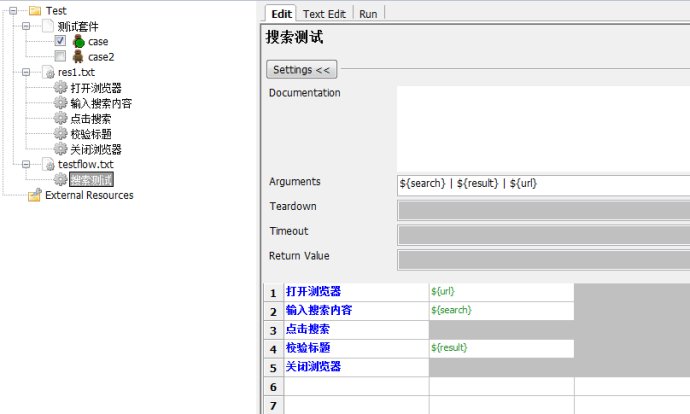
ЧоғуёГФЛРРБЛ
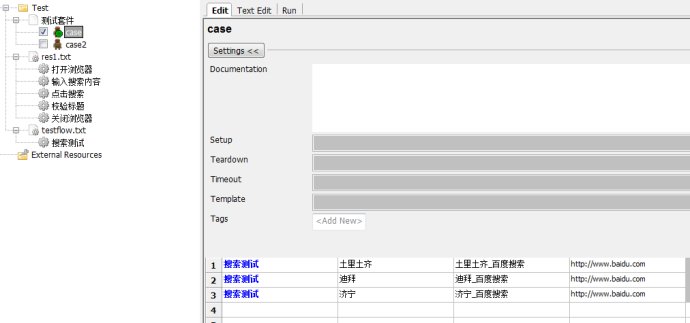
ЦБөЛӘ¬ОТГЗХвёц°ёАэңНТСңНкіЙ·ЦІгБЛӘ¬ТтОҒ°ёАэ±ИҢПәтµӨӘ¬ЛщТФЦ»·ЦБЛ3ІгӘ¬·Ц±рКЗ°ёАэІгӘ¬БчіМІгӘ¬ФҒЛШІгҰӘЛыГЗµДµчУГ№ШПµТІКЗЦрІгЙоИлµД
ЧЬҢбТ»ПВ
ХвСщЧцµДғГө¦І»µӨКЗОҒБЛТФғуО¬»¤·Ң±гӘ¬ТІК№µГ°ёАэµДәЬ№№Ігә¶ЗеОъҰӘФҢКЗүүҢьЙПІгµДІү·ЦӘ¬ҢЕ±ңФҢМщҢьЧФИ»УпСФӘ¬»тХЯЛµғЬПсОТГЗµДІвКФ°ёАэӘ»ФҢүүҢьПВІгµДІү·ЦӘ¬ФҢКЗҢУҢьТіГжФҒЛШµДөъВлә¶Іү·ЦҰӘХвСщТФғуИз№ы·ұЙъО¬»¤µДК±ғтӘ¬ёщңЭРиТҒО¬»¤µДДЪИЭӘ¬Ц»РиТҒФЪғЬЙЩµДµШ·ҢҢшРРµчХыәөүЙҰӘ±ИИзТ»ёцФҒЛШµДid±дБЛӘ¬ДЗОТЦ»ТҒФЪelementsАпГжёьРВңНРРБЛҰӘ±ИИзІвКФµДБчіМµчХыБЛӘ¬ТФЗ°КЗABCµДТіГжЛіРтӘ¬ПЦФЪКЗACBµДТіГжЛіРтӘ¬ДЗГөЦ»ТҒФЪtestflowІгҢшРРµчХыәөүЙҰӘ
ДЗГө»ШµҢОТГЗµД±кМвӘ¬БчіМУлКэңЭ·ЦАлӘ¬КµәКЙПДүЗ°ОТГЗµДБчіМ¶әәҮЦРФЪtestflowТФә°ПВГжµДІү·ЦӘ¬¶шКэңЭТ»°г¶әКЗФЪ°ёАэІгИӨёшБчіМІгө«µЭӘ¬ХвңНКЗОТГЗµДБчіМУлКэңЭ·ЦАлБЛҰӘµ±И»Ә¬ОТГЗ»№үЙТФФЩҢшТ»ІҢµД·ЦАлӘ¬°СКэңЭ·ЕµҢНвГжӘ¬НСАлОТГЗµД°ёАэӘ¬ФЪФЛРРµДК±ғтІЕө«µЭҢшРРӘ¬ТІКЗүЙТФКµПЦµДҰӘёшөуәТүөҰӘ |





