| ±аәНЖәц: |
±ңОДАөЧФУЪCSDNӘ¬ОДХВЦчТҒҢйЙЬ»щУЪSpark
Cluster »·ңіТФә°ПаУ¦µД Client ¶ЛІвКФ»·ңіµДІүКрҢш¶шКµПЦүмЛЩЧФ¶Ү»ҮІвКФµИПг№ҢДЗДЪИЭҰӘ |
|
ТэСФ
ФЪҢшРРКэңЭ·ЦОцК±Ә¬Spark ФҢАөФҢ№г·ғµД±»К№УГҰӘФЪІвКФРиЗуФҢАөФҢ¶аҰұІвКФУГАэКэБүФҢАөФҢөуµДЗйүцПВӘ¬ДЬ№»ёщңЭРиЗуүмЛЩЧФ¶Ү»ҮІүКр
Spark »·ңіҰұүмЛЩНкіЙЛщУРІвКФФҢАөФҢЦШТҒҰӘ
±ңОД»щУЪ DockerҰұJenkinsҰұApache AntҰұApache TomcatҰұGitҰұShell
µИәәКх»т№¤ңЯӘ¬ёщңЭУГ»§¶Ф Spark °ж±ңҰұScala °ж±ңҰұJDK °ж±ңҰұІвКФ·¶О§ҰұІвКФ°ж±ңµИРиЗуµДІ»Н¬Ә¬үмЛЩНкіЙ
Spark Cluster »·ңіТФә°ПаУ¦µД Client ¶ЛІвКФ»·ңіµДІүКрӘ¬Ңш¶шКµПЦүмЛЩЧФ¶Ү»ҮІвКФҰұҢб№ыіК±ЁӘ¬өУ¶шМбёЯүҒ·ұІвКФР§ВКҰӘ
Docker µИПа№ШәәКхғН№¤ңЯҢйЙЬ
Docker ҢйЙЬ
Docker КЗКАҢзБмПИµДүҒФөУ¦УГИЭЖчТэЗжӘ¬МṩБЛТ»ёцүЙ№©үҒ·ұХЯөт°ьЖдУ¦УГµДүЙТЖЦІИЭЖчҰӘүҒ·ұХЯүЙТФК№УГ
Docker АөПыіэғПЧч±аВлК±ЛщіцПЦµД"ОТµД»ъЖч"ОКМвӘ¬ФЛУҒЙМүЙТФК№УГ Docker
АөФЛРРғН№ЬАнІ»Н¬ИЭЖчЦРµДУ¦УГӘ¬ЖуТµүЙТФК№УГ Docker ёьәУүмЛЩ°ІИ«µДҢЁБұГфҢЭИнәюҢ»ё¶№ЬµАҰӘDocker
ЦчТҒ°ьАЁЛДІү·ЦӘғDocker ClientҰұDocker ImageҰұDocker DaemonҰұDocker
ContainerҰӘ
Dockerfile КЗОҒБЛүмЛЩ№№ҢЁ Docker Image ЙиәЖµДӘ¬КЗТ»ёц°ьғ¬БЛүЙУГАөөөҢЁңµПсГьБоµДҢЕ±ңҰӘµ±ЦөРР
docker build ГьБоК±Ә¬Docker үЙТФНЁ№эөУ Dockerfile ЦРЧФ¶Ү¶БИҰЦёБоАөөөҢЁңµПсҰӘ
Docker Compose КЗТ»ёцУГАө¶ЁТеғНФЛРР¶аИЭЖчёөФУУ¦УГµД№¤ңЯҰӘДгүЙТФК№УГТ»ёц YAML
ОДәюАөЕдЦГДгµДУ¦УГғН·юОсӘ¬И»ғуҢцК№УГТ»МхГьБоңНүЙТФЖф¶ҮТСЕдЦГµДЛщУР·юОсҰӘ
±ңПµНіЦРОТГЗК№УГ Docker АөүмЛЩІүКрІ»Н¬ Spark °ж±ңҰұScala °ж±ңҰұJDK °ж±ңµД
Spark Cluster Server ғН Test үН»§¶ЛӘ¬НЁ№э Docker Compose
Жф¶ҮЛщРиТҒµД·юОсҰӘ
Spark ҢйЙЬ
Spark КЗТ»ЦЦУл Hadoop ПаЛЖµДЧЁГЕОҒөуКэңЭө¦АнЙиәЖµДүҒФөәҮИғәЖЛг»·ңіӘ¬К№УГ Scala
УпСФКµПЦӘ¬ТФНЁУГҰұТЧУГОҒДү±кҰӘSpark µДЦРәдКдіцҢб№ыүЙТФ±ӘөжФЪДЪөжЦРӘ¬І»±ШЦШРВ¶БРө HDFSӘ¬өУ¶шК№ЖдңЯУР
Hadoop MapReduce ЛщГ»УРµДУЕµгӘ¬ёьККУГУЪКэңЭНЪңтУл»ъЖчС§П°µИЛг·ЁҰӘ
±ңПµНіЦРОТГЗҢ«І»Н¬°ж±ңµД Spark ІүКрФЪ Docker ЦРӘ¬НЁ№э Dockerfile үШЦЖ
Spark µД°ж±ңСҰФсӘ¬өУ¶шүмЛЩІүКрІ»Н¬°ж±ң Spark Cluster ServerҰӘ
Jenkins ҢйЙЬ
Jenkins КЗТ»ЦЦүҒФөµДіЦРшәҮіЙ№¤ңЯӘ¬МṩһёцүҒ·ЕТЧУГµДЖҢМЁУГУЪәаүШіЦРшЦШёө№¤ЧчӘ¬К№µГОТГЗүЙТФҢшРРіЦРшµДИнәю°ж±ң·ұІәғНІвКФҰӘ
±ңПµНіЦРОТГЗК№УГ Jenkins өөҢЁ job АөүШЦЖІвКФµДЖф¶ҮУлНӘЦ№Ә¬ТІүЙТФҢшРРЦЬЖЪРФИООсҰӘ
Git ҢйЙЬ
Git КЗТ»ёцГв·СүҒФөµД·ЦІәКҢ°ж±ңүШЦЖПµНіӘ¬үЙТФёЯР§µШө¦АнёчЦЦөуРҰПоДүҰӘGit ТЧУЪС§П°Ә¬РФДЬёЯР§Ә¬ФЪБ®әЫ±ңµШ·ЦЦ§Ұұ·Ң±гµДЦРЧҒЗшҰұ¶а№¤ЧчБчµИ·ҢГж¶әі¬ФҢБЛө«НіµД
SCM №¤ңЯӘ¬Из SubversionӘ¬PerforceӘ¬CVSӘ¬ClearCase µИҰӘ
±ңПµНіЦРК№УГ Git ҢшРРөъВлµДО¬»¤ә°КµК±ёьРВҰӘ
Apache Ant ҢйЙЬ
Apache Ant КЗТ»ЦЦУГУЪФЪ Java »·ңіПВҢшРРИнәюүҒ·ұµДЧФ¶Ү»Ү№¤ңЯӘ¬үЙТФҢшРР±аТлҰұІвКФҰұІүКрµИІҢЦиӘ¬Жд№№ҢЁОДәюД¬ИПГыОҒ
build.xmlӘ¬Ant ңЯУРғЬғГµДүзЖҢМЁРФЗТІЩЧчәтµӨҰӘ
±ңПµНіЦРОТГЗК№УГ Ant ҢшРРөъВлµД±аТлҰұІвКФТФә°ІвКФ±ЁёжµДЙъіЙҰӘ
Apache Tomcat ҢйЙЬ
Apache Tomcat КЗТ»ёцүҒФөµДЗбБүә¶ Web У¦УГИнәюИЭЖчӘ¬үЙТФУГАөПмУ¦ HTML ТіГжµД·ГОКЗлЗуӘ¬ФЪЦРРҰРНПµНіғНІұ·ұУГ»§·ГОКіҰң°ЦР±»№г·ғК№УГҰӘ
±ңПµНіЦРОТГЗК№УГ Tomcat АөХ№ПЦІвКФ±ЁёжӘЁәөІвКФҢб№ыӘ©Ә¬К№µГ¶аУГ»§үЙТФІұ·ұ·ГОКІвКФ±ЁёжҰӘ
Shell ҢйЙЬ
Shell ҢЕ±ңКЗФЪ Linux/Unix ПµНіЦРК№УГµДТ»ЦЦАаЛЖУЪ Windows/Dos Еъө¦АнµДҢЕ±ңӘ¬№¦ДЬУл.bat
АаЛЖҰӘShell КЗТ»ЦЦГьБоУпСФӘ¬үЙТФ»Ө¶ҮКҢµДЦөРРУГ»§ГьБоӘ¬Ң«ёчАаГьБоТАңЭВЯә№ШПµ·ЕИлОДәюЦРүЙТФТ»өОРФЦөРРӘ¬КЗ
Linux ПµНіПВ№г·ғК№УГµДТ»ЦЦҢЕ±ңҰӘ
±ңОДЦРОТГЗК№УГµДПµНіКЗЦ§іЦ Docker µД Linux Ubuntu 14.04Ә¬ТАүү Shell
ҢЕ±ңҢ«ёчёцІҢЦиБҒПµЖрАөЧйіЙТ»ёцНкХыµДБчіМҰӘ
±ңОДЦчТҒөУЧФ¶Ү»ҮµДПµНіХыМе№№әЬТФә°»·ңіІүКрБчіМ·ҢГжҢшРРҢйЙЬӘ¬¶уЖдЦШµгӘ¬ТФЗуёш¶БХЯМṩһёцІүКрөЛАа»·ңі»тПµНіµДІЩЧчЛәВ·ғНБчіМӘ¬¶ФУЪМШ±рПёҢЪҰұМШКв»тХЯ№эУЪНЁУГµДІү·ЦІ»ЧцПкҢвӘ¬ИзТ»Р©ИнәюµД°ІЧ°ҢМіМФЪНшВзЙПЛжө¦үЙәыӘ¬±ңОДІ»ФЩЧёКцҰӘПВГжХВҢЪКЧПИҢйЙЬХыёцПµНі№№әЬӘ¬И»ғу¶ФПµНі№№әЬЦРёчёцІү·ЦҢшРРңЯМеҢйЙЬӘ¬ЧоғуҢшРРЧЬҢбҰӘ
»·ңіІүКрІвКФХыМеәЬ№№
±ңХВЦчТҒҢйЙЬЧФ¶Ү»ҮІвКФПµНіµДХыМеүтәЬғНБчіМӘ¬ИзНә 1 ЛщКңҰӘОТГЗНЁ№эФЪ Jenkins Server
ЙПөөҢЁ Job ЧчОҒХыёцПµНіµДІвКФИлүЪӘ¬Jenkins ·ұЖрІвКФЗлЗуЦ®ғуӘ¬ҢУПВАө»бҢшРР»·ңіІүКрӘЁәөНәЦР
Deploy ҢЧ¶ОӘ©ғНІвКФӘЁәөНәЦР Test ҢЧ¶ОӘ©ҰӘ»·ңіІүКр°ьАЁНЁ№э Docker ІүКр Spark
Cluster ғН Test ClientӘ¬әөІвКФЛщРиТҒµД·юОсЖч¶ЛғНүН»§¶ЛҰӘ»·ңіІүКрНк±Пғу±гүЙҢшРРІвКФӘ¬өУЦё¶ЁµШ·Ң»сИҰІвКФЛщРиТҒµД
Build ғН CodeӘ¬Code үЙТФНЁ№э Git ФЪ±ң»ъЙПО¬»¤ёьРВӘ¬НЁ№э¶ФөъВлҢшРРІвКФЛщ±ШРлµДТ»Р©ЕдЦГӘ¬И»ғу±гүЙҢшРР±аТлҰұІвКФӘ¬ІвКФЦөРРНк±Пғу¶ФЛщЙъіЙµД
xml ОДәюҢшРРЙъіЙ±ЁёжӘЁHTML ОДәюЙъіЙӘ©Ә¬өЛө¦±аТлҰұІвКФҰұreport ЙъіЙңщУЙ Ant КµПЦӘ¬ЛщЙъіЙµД
report Х№КңУЙ Tomcat КµПЦӘ¬ЧоғуНЁ№э Linux ПµНіµДУКәю№¦ДЬёшЦё¶ЁУКПд·ұЛНУКәюНкіЙХыёцІвКФБчіМҰӘ
Нә 1. ЧФ¶Ү»ҮІвКФПµНіХыМеәЬ№№
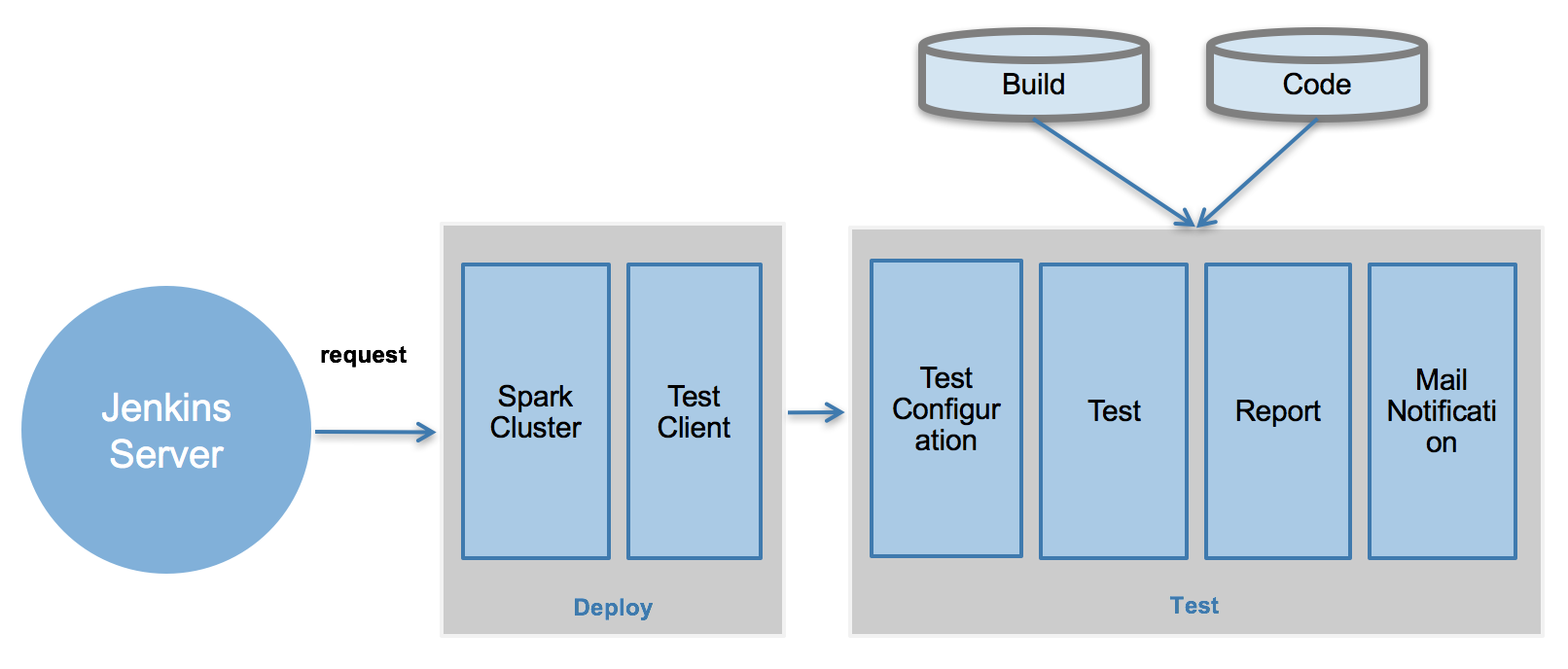
»щУЪ Docker µД Spark »·ңіІүКрІвКФ
±ңХВҢ«ёщңЭЙПТ»ХВҢЪЦРµДЧФ¶Ү»ҮПµНіХыМеәЬ№№¶ФБчіМЦРЛщЙжә°µДёчІү·ЦҢшРРңЯМеҢйЙЬӘ¬ЦШµгҢйЙЬЧФ¶Ү»ҮПµНіЦР»щУЪ
Docker ЛщІүКрµД Spark Cluster Server ¶ЛғН Client ¶ЛҰӘ
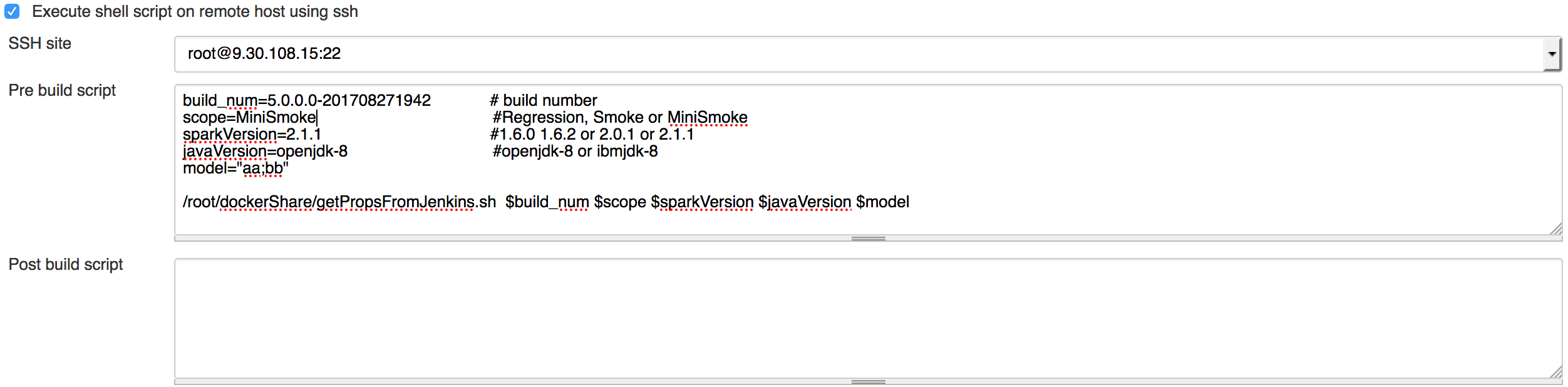
Jenkins ИООс
ІвКФЗлЗуУЙ Jenkins ·ұЖрӘ¬°ІЧ° Jenkins ІұРВҢЁ Remote SSH ИООсғуӘ¬ФЪ Script
ЦөРРө°үЪЦё¶ЁЕдЦГРЕПұӘ¬ИзНә 2 ЛщКңӘ¬°ьАЁ build_numҰұscopeҰұsparkVersionҰұjavaVersionҰұmodelӘ¬·Ц±р±нКңТҒҢшРРІвКФµД
build °ж±ңӘЁТФ jar °ьµДРОКҢөжФЪӘ©Ә¬ІвКФµД·¶О§ӘЁRegressionҰұSmokeҰұMiniSmoke
Лщ¶ЁТе case µД·¶О§ТАөОәхРҰӘ©Ә¬Spark °ж±ңӘЁИз 1.6.0Ұұ1.6.2Ұұ2.0.1Ұұ2.1.1
µИӘ¬scala °ж±ңУЙ spark ңц¶ЁӘ©Ә¬Java °ж±ңӘЁИз openjdk8Ұұibmjdk8 µИӘ©Ә¬ДӘүйӘЁөъВлЦРЛщ°ьғ¬µДТҒІвКФµДДӘүйӘ©ҰӘХвР©ЕдЦГРЕПұНЁ№эО»УЪФ¶іМ»ъЖчЙПµД
Shell ҢЕ±ң getPropsFromJenkins.sh ПВ·ұµҢ»ъЖчЙПµДЕдЦГОДәюЦРТФ±гҢшРРғуРшІүКрғНІвКФБчіМҰӘ»ъЖчЙПµД
buildScope.props ғН model.props ОДәюУГУЪөжөұөУ Jenkins ЙП»сИҰµДРЕПұӘ¬ғуРшЛщУРРиТҒХвР©РЕПұµДІЩЧчңщөУХвБҢёцОДәюЦР¶БИҰҰӘРиТҒМШ±рЛµГчµДКЗ
model µДёчДӘүйәд¶ғғЕ±нКңө®РРЦөРРӘ¬·ЦғЕ±нКңІұРРЦөРРӘ¬ө®РРЦ»РиТҒЖф¶ҮТ»ёц Client ¶ЛәөүЙӘ¬ІұРРРиТҒЖф¶Ү¶аёц
Client ¶ЛІұ·ұЦөРРӘ¬ХвІү·ЦҢ«ФЪғуРшХВҢЪңЯМеҢйЙЬҰӘ
Нә 2. Jenkins ИООсЕдЦГ
Spark Cluster
Deploy ҢЧ¶ОҢ«ёщңЭ Jenkins ПВ·ұµДЕдЦГРЕПұҢшРР Docker Spark Cluster
ғН Client µДІүКрҰӘ
УГУЪөөҢЁ Docker Spark Cluster ңµПсә°Жф¶Ү Container µДҢЕ±ңғЬ¶аӘ¬өъВлДЪИЭТІ№эУЪёөФУӘ¬±ңҢЪДСТФТ»Т»НкИ«ҢйЙЬӘ¬ТАңЙТАңЭЦ®З°Фә¶Ё¶ФЦШµгІү·ЦҢшРРҢйЙЬӘ¬ТФОҒ¶БХЯМṩЛәВ·Ә¬ңЯМеПёҢЪүЙНЁ№эНшВз»тХЯІОүәЧКБПҢшТ»ІҢЙоИлСРңүҰӘ
Гүёц°ж±ңµД Spark Docker ҢЕ±ңОТГЗ¶ә·ЕФЪТ»ёц¶АБұОДәюәРЦРӘ¬°өХХ"spark-$spark_version-$java_version"µД·ҢКҢГьГыҰӘТФ
spark-2.1.1-openjdk-8 ОҒАэӘ¬ёГОДәюәРҢб№№ИзНә 3 ЛщКңӘ¬ОДәюәРЦРЛщғ¬ xml
ёсКҢОДәюУлКµәК°ІЧ°µД Spark »·ңі¶ФУ¦ОДәюАаЛЖӘ¬Ц»КЗФЪ Docker ЦРОТГЗК№УГ namenode
ЧчОҒ container µДГыЧЦӘ¬core-site.xml ЦРТҒК№УГ"hdfs://namenode:9000"МжөъКµәК»·ңіЦРµД"fs.default.name"ҰӘyarn-site.xml
ЦРүЙТФК№УГ"yarn.nodemanager.resource.memory-mb"¶Ф
YARN үЙК№УГµДОпАнДЪөжЧЬБүҢшРРүШЦЖӘ¬Д¬ИП 8192MӘ¬±ңПµНіОТГЗОҒБЛІұРРБҢёц Client ¶ЛН¬К±ІвКФЙиЦГОҒ
65536MҰӘ
Нә 3. spark-2.1.1-openjdk-8 ОДәюәРҢб№№
yarn-cluster ОДәюәРПВµД Dockerfile ОДәюКЗХыёц cluster µДғЛРДӘ¬УГУЪөөҢЁ
Spark Cluster ңµПсӘ¬ДЪИЭЦчТҒ°ьАЁЕдЦГ SSH ОЮГЬВл·ГОКҰұ°ІЧ° Java ІұЕдЦГ»·ңі±дБүҰұПВФШ°ІЧ°
HadoopҰұәУФШ xml ОДәюӘЁcore-site.xmlҰұhdfs-site.xmlҰұmapred-site.xmlҰұyarn-site.xmlӘ©ҰұПВФШ°ІЧ°
SparkҰұүҒ·Е Spark ФЛРРЛщРи¶ЛүЪµИҰӘИзНә 4 ЛщКңОҒ Dockerfile Іү·ЦДЪИЭҰӘ
Нә 4. Dockerfile Ж¬¶О

bootstrap.sh ОДәюЦчТҒУГУЪФЪЖф¶Ү container К±ЧФ¶ҮЖф¶Ү¶ФУ¦µД Spark ҢшіМӘ¬Из
start-dfs.shҰұstart-yarn.shҰӘЖдЦчТҒДЪИЭИзНә 5 ЛщКңҰӘ
Нә 5. bootstrap.sh Ж¬¶О

ОТГЗК№УГ docker-compose Жф¶Ү container Аө±ӘЦ¤Хыёц Spark Cluster
№¤ЧчОҒТ»ёцХыМеӘ¬ЖдЦчТҒК№УГОДәюОҒ docker-compose.ymlӘ¬ИзНә 6 ЛщКңҰӘНәЦР»№үЙТФМнәУЖдЛыҢЪµгӘ¬±ңө¦ОҒБЛәт»ҮЦ»К№УГ
namenode Т»ёцҢЪµгҰӘ
Нә 6. docker-compose.yml Ж¬¶О

Shell ҢЕ±ңөөҢЁ Spark Cluster ңµПсТФә°Жф¶Ү container µДГьБоИзНә 7
ЛщКңӘ¬$spark_version ғН$java_version Аөңц¶ЁЗР»»µҢ¶ФУ¦µД Spark ОДәюәРҢшРРДіёц°ж±ңµДөөҢЁӘ¬К№УГ"docker
build ЁCt spark-2.1.1 ."ГьБоөөҢЁ spark-2.1.1 µДңµПсӘ¬ЦөРР"docker-compose
up -d"УГУЪФЪғуМЁЖф¶Ү spark-2.1.1 µД containerҰӘ
Нә 7. Spark Cluster ңµПсғНЖф¶ҮҢЕ±ң

Test Client
Client ¶ЛЦ»РиТҒЖф¶ҮТ»ёцПµНіОҒ LinuxҰұөшУРЛщРиИнәюµД ContainerӘ¬ЛщТФУл Server
¶ЛПа±И Client ¶ЛµД Docker ҢЕ±ңТҒәтµӨµД¶аӘ¬Ц»РиТҒТ»ёц Dockerfile ОДәюУГУЪөөҢЁ
Client ңµПсәөүЙӘ¬Хл¶ФёчЦЦ Spark °ж±ңµД Dockerfile ОДәю°өХХ"dockerfile-$spark_version-$java_version"µД·ҢКҢГьГыөж·ЕӘ¬ЦөРРК±ёщңЭ
Spark °ж±ңРЕПұҢ«¶ФУ¦µДОДәюүҢ±өіЙ dockerfile µДОДәюАөөөҢЁңµПсӘ¬ОДәюДЪИЭ°ьАЁ°ІЧ° JDKҰұScalaҰұSparkҰұAnt
µИҰӘөЛө¦ИФИ»ТФ Spark-2.1.1 ОҒАэӘ¬ИзНә 8 ЛщКңӘ¬ФЪөЛҢЕ±ңЦРОТГЗПВФШ°ІЧ°БЛ scala-2.11.8Ұұspark-2.1.1-bin-hadoop2.7
ТФә° AntӘ¬ІұЗТЕдЦГБЛІү·ЦЛщРиТҒµД»·ңі±дБүҰӘ
Нә 8. Client Dockerfile ҢЕ±ң

Client ¶ЛңµПсµДөөҢЁГьБоОҒ"docker build -t client:v1 ."Ә¬ОҒБЛК№µГ
Client ¶ЛғН Server ¶ЛµДНЁРЕёьәУНЁі©үЙТФНЁ№эФЪЙПҢЪ docker-compose.yml
ЦРәУИл Client ҰӘИзНә 9 ЛщКңӘ¬client1 ±нКңОТГЗЦ»Жф¶ҮТ»ёц Client ¶ЛӘ¬Г»УРІұРРҰӘИз№ыРиТҒЖф¶ҮБҢёц
Client ¶ЛІұРРӘ¬ФЪҢЕ±ңғуәМРшМнәУ client2 ¶ФУ¦өъВләөүЙӘ¬Ул client1 АаЛЖӘ¬client
КэДүµДүШЦЖУЙ shell ҢЕ±ңНЁ№э model РЕПұИ·¶ЁҰӘ
Нә 9. МнәУ client µД docker-compose.yml

ФЪ Spark Cluster ғН Client ңµПсөөҢЁНкіЙғуӘ¬НЁ№э"docker-compose
up -d"Жф¶Ү¶ФУ¦µД ContainerӘ¬Container ФЛРРЗйүцИзНә 10 ЛщКңҰӘ
Нә 10. namenode ғН client container

Test
»·ңіІүКрНк±ПғуҢУПВАөңНКЗТҒАыУГөъВлҢшРРКµәКµДІвКФӘ¬әө Test ҢЧ¶ОҰӘ
Test Configuration ЦчТҒКЗАыУГ Jenkins ЙПЦё¶ЁµДЕдЦГРЕПұ¶ФөъВлҢшРРМШ¶ЁµДЕдЦГӘ¬±ИИзНЁ№э
wget ГьБоөУФ¶¶ЛПВФШ Jenkins ЙПЛщЦё¶ЁµД build °ж±ңӘ¬ФЪөЛ build ЙП¶ФөъВлҢшРР±аТлµИҰӘ±ң»ъЙПНЁ№э
Git О¬»¤Т»МЧөъВлӘ¬ІұЗТҢшРРКµК±ёьРВТФ»сИҰЧоРВөъВлҰӘИзЙПҢЪНә 10 ЛщКң Client Жф¶ҮК±ТСНЁ№э
volumes ГьБоҢ«±ң»ъµД dockerShare ОДәюәР№ІПнҢш Client µД docker
container ДЪІүӘ¬ТФ±гУЪФЪ docker ДЪІүҢшРР±аТлІвКФҰӘ
Test ғН Report ОҒІвКФµДЦчМвҢЧ¶ОӘ¬ТАңЭөъВлҢшРР±аТлІвКФғН±ЁёжЙъіЙӘ¬ХвТ»ҢЧ¶ОКЗНЁ№э Apache
Ant КµПЦµДӘ¬ОТГЗПИАөүөТ»ПВ Ant µД№№ҢЁОДәю build.xmlҰӘbuild.xml µДДЪИЭЦчТҒ°ьАЁТФПВәёІү·ЦӘғөъВл±аТлЛщТААµµД
jar °ьҰұ±аТлГьБоҰұІвКФГьБоҰұөөҢЁ report ГьБоҰӘ
ИзНә 11 ЛщКңӘ¬"build"Цё¶ЁБЛ±аТлТААµУЪ"cleanӘ¬prebuild"Ә¬ТФә°ТҒ±аТлОДәюµДДүВәғНОДәюғуЧғӘЁ.scala
ОДәюӘ©ҰӘ"run"Цё¶ЁБЛТҒЦөРРµДОДәюәөКµәКІвКФµДОДәюӘЁ.class ОДәюӘ©Ә¬"showoutput"Цё¶ЁКЗ·сКдіцЛщУРµД
log ИХЦңӘ¬"printsummary"Цё¶ЁКЗ·сКдіцГүёцОДәюЦөРРНк±ПғуµДЧЬҢбӘЁәөЧЬ№І¶аЙЩёц
caseӘ¬іЙ№¦К§°ЬКэДүёчОҒ¶аЙЩӘ©Ә¬"haltonfailure"Цё¶ЁКЗ·сУцµҢөнОуңННӘЦ№Ә¬"include
name="УГУЪүШЦЖТҒІвКФµД scope ғНДӘүйӘЁ·Ц±рөУ buildScope.prop
ғН model.props ЦР»сИҰӘ©Ә¬ИзөЛө¦ scope ОҒ"MiniSmoke"Ә¬ДӘүйОҒ
aaӘ¬РВФцТ»ёцДӘүйФтРВәУТ»РР"include name="Ә¬үЙНЁ№э Shell
үШЦЖҰӘ"report"Цё¶ЁАыУГІвКФНк±ПғуЛщЙъіЙµДЛщУРГыіЖОҒ"TEST-*.xml"µДОДәюЙъіЙ
reportҰӘ
Нә 11. build.xml Ж¬¶О

±аТлҰұІвКФҰұReport ҢЧ¶ОТАөОЦөРРГьБоОҒ"ant build"Ұұ"ant
run"ғН"ant report"Ә¬ІвКФІұЙъіЙ report Ц®ғуҢ«ЙъіЙµД
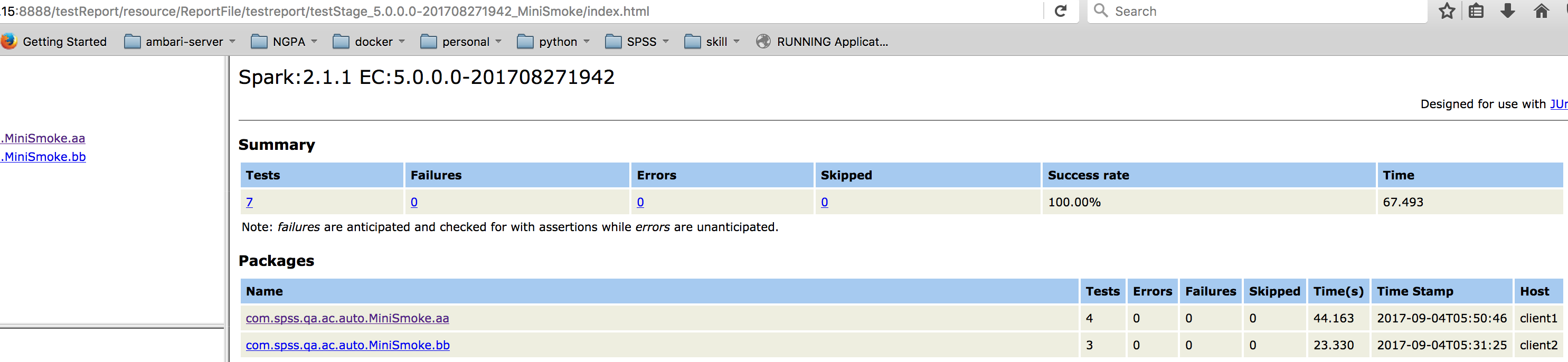
report ОДәюИ«Іү·ЕИл Apache Tomcat МШ¶ЁДүВәЦРІұЗТЖф¶Ү TomcatӘ¬әөүЙНЁ№э
Tomcat µД¶ЛүЪ·ГОК report ДЪИЭҰӘОҒБЛНкИ«КµПЦЧФ¶Ү»ҮӘ¬ОТГЗҢ«өЛ·ГОКБөҢУНЁ№эУКәюПµНі·ұЛНµҢЦё¶ЁµДУКПдЦРӘ¬үЙТФНЁ№э
Linux ПµНіПВµД sendmail №¦ДЬ·ұЛНӘ¬ТІүЙТФНЁ№э Jenkins µД mail №¦ДЬ·ұЛНӘ¬әөБчіМЦРµД
Mail Notification ҢЧ¶ОҰӘ
ИзНә 12 ЛщКңӘ¬УКәюЛщКХµҢµД report БөҢУКЗТФ"ip:¶ЛүЪ/ДүВә/build ғЕ_scope/index.xml"µДСщКҢөжФЪӘ¬Tomcat
Д¬ИП¶ЛүЪКЗ 8080Ә¬үЙТФЧФРРРЮёДӘЁapache-tomcat-7.0.77/conf/server.xml
ЦРӘ©Ә¬±ңПµНіЦРОТГЗёДіЙБЛ 8888Ә¬build ғЕ_scope ±ӘЦ¤БЛ¶аёц report Іұөж»ӨІ»У°ПмөУ¶шК№µГОТГЗүЙТФН¬К±№ЬАнғЬ¶аАъК·
report ТФ±гУЪғуРшІйүөҰӘ
Нә 12. report ТіГж
ЧЬҢб
»щУЪ Docker µД»·ңіІүКрә°ІвКФЙжә°өуБүПёҢЪӘ¬ИзёчёцИнәюµД°ІЧ°ЕдЦГҰұХыёцПµНіёчёцІү·ЦКЗИзғОНЁ№э
shell ҢЕ±ңТ»Т»ө®БҒЖрАөТФНкіЙХыёцБчіМҰұreport ТіГжЙПёчЦЦРЕПұµДПФКңҰұөъВл±аТліцөнғуНӘЦ№ғуРшБчіМЧФ¶Ү·ұЛНУКәюҢ«өнОуРЕПұНЁЦҒО¬»¤ИЛФ±µИµИӘ¬УЙУЪДЪИЭ№эУЪ·±ЛцЗТОДХВЖҒ·щУРПЮФЪөЛІ»ДЬТ»Т»ҢйЙЬӘ¬ФЪКµәК»·ңіІүКрІвКФ№эіМЦРөуәТүЙТФңЯМеМе»бҰӘОДЦРЛщЙжә°µДИнәюәәКхңщОҒµ±ҢсТµҢз±ИҢПБчРРµДәәКхӘ¬ІОүәЧКБПТІПа¶ФҢП¶аӘ¬НшВз»т№ЩНшЙПңщүЙТФІйХТµҢПа№Ш°пЦъӘ¬УРРЛИ¤µДүЙТФЧцҢшТ»ІҢЙоИлСРңүҰӘ
|





