| ұајӯНЖјц: |
ұҫОДАҙЧФcsdnЈ¬ұҫОДЦчТӘјтөҘҪйЙЬБЛТ»ёцНкХыөДSeleniumЧФ¶Ҝ»ҜҝтјЬөДЛјҝј№эіМәНҝтјЬөДСЭҪш№эіМЈ¬ПЈНы¶ФДъөДС§П°УРЛщ°пЦъЎЈ
|
|
УЙУЪ№«ЛҫөДҝӘ·ўНЕ¶УЖ«ПтУЪК№УГJavaјјКхЈ¬¶шЗТ№«Лҫі«өјС§П°ҝӘФҙјјКхЈ¬ЛщТФОТСЎФсУГJavaУпСФАҙҪшРРSelenium
WebDriverөДЧФ¶Ҝ»ҜҝтјЬҝӘ·ўЎЈУЙУЪұҫИЛГ»УРJavaҝӘ·ўҫӯСйЈ¬ТФЗ°ЛдИ»С§№эQTPө«ҙУГ»УРҪУҙҘ№эSeleniumЈ¬ХэәГНЁ№эХвёц»ъ»бДЬС§П°Т»ПВЧФ¶Ҝ»ҜІвКФЈ¬Н¬КұТІС§П°Т»ПВ»щұҫөДJavaҝӘ·ў№эіМЎЈ
Т»ЎўКЧПИКЗҙоҪЁҝтјЬҝӘ·ў»·ҫі
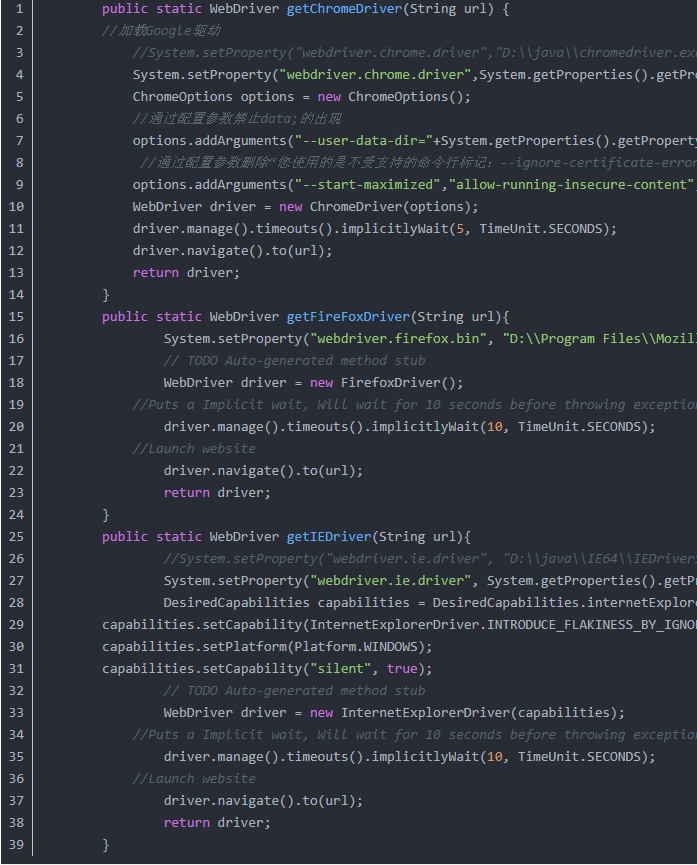
°ҙХХНшЙПөД·Ҫ·ЁІҝКрeclipseЈ¬ҪЁБўTestAction№ӨіМЈ¬ІўImportТэУГJDKәНSelenium-2.44НкХы°ь

¶юЎўјМРшТэУГәН°ІЧ°Па№Шjar°ь
1ЎўКЧПИКЗТӘВъЧгКэҫЭЗэ¶ҜЈЁіЎҫ°УГАэәН¶ҜЧчУГАэЎўКэҫЭУГАэ¶јРиТӘ·ЕөҪexcelұнЙПЈ©Ј¬ҫНРиТӘТэУГjxl.rar°ьЈЁКөПЦөчУГәНІЩЧчexcelЈ©Ј»
2ЎўРиТӘКөПЦЧФ¶Ҝ»ҜҝтјЬЈЁУРІвКФМЧјюЎўІвКФІгЈ©ҫНРиТӘНЁ№эeclipse°ІЧ°TestNgЈЁНшЙПУРПа№ШҪМіМЈ©Ј»
ИэЎў№№ҪЁҝтјЬөДСщАэҙъВл
1ЎўКөПЦДЬ№»¶ФexcelУГАэКэҫЭөДөчУГЈЁНЁ№эjxlөДТэУГЈ©Ј¬ҙҙҪЁExcelData.javaАаОДјюЈЁЧЁГЕУГУЪ¶ФexcelөДөчУГЈ©Ј¬ТФПВҪШИЎІҝ·ЦҙъВлСщАэЈә
/**
* @param fileName excelОДјюГы
* @param caseName sheetГы
*/
public ExcelData(String fileName, String caseName)
{
super();
this.fileName = fileName;
this.caseName = caseName;
}
/**
* »сөГexcelұнЦРөДКэҫЭ
*/
public Object[][] getExcelData() throws BiffException,
IOException {
workbook = Workbook.getWorkbook(new File(getPath()));
sheet = workbook.getSheet(caseName);
rows = sheet.getRows();
columns = sheet.getColumns();
// ОӘБЛ·ө»ШЦөКЗObject[][],¶ЁТеТ»ёц¶аРРөҘБРөД¶юО¬КэЧй
@SuppressWarnings("unchecked")
HashMap<String, String>[][] arrmap = new
HashMap[rows - 1][1];
// ¶ФКэЧйЦРЛщУРФӘЛШhashmapҪшРРіхКј»Ҝ
if (rows > 1) {
for (int i = 0; i < rows - 1; i++) {
arrmap[i][0] = new HashMap<String, String>();
}
} else {
System.out.println("excelЦРГ»УРКэҫЭ");
}
// »сөГКЧРРөДБРГыЈ¬ЧчОӘhashmapөДkeyЦө
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, 0).getContents();
arrkey.add(cellvalue);
}
// ұйАъЛщУРөДөҘФӘёсөДЦөМнјУөҪhashmapЦР
for (int r = 1; r < rows; r++) {
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, r).getContents();
arrmap[r - 1][0].put(arrkey.get(c), cellvalue);
}
}
return arrmap;
}
/**
* »сөГexcelОДјюөДВ·ҫ¶
* @return
* @throws IOException
*/
public String getPath() throws IOException {
File directory = new File(".");
sourceFile = directory.getCanonicalPath() + "\\src\\source\\"
+ fileName + ".xls";
return sourceFile;
}
|
2ЎўКөПЦ¶ФдҜААЖчөДөчУГЈ¬ҝјВЗөҪјжИЭРФЈ¬РиТӘН¬КұВъЧг¶ФChromeЎўFireFoxЎўIEИэҙудҜААЖчөДөчУГЈ¬ОТГЗРиТӘЧјұёПа№ШЗэ¶Ҝchromedriver.exeЎўIEDriverServer.exeЈ¬ХвБҪЗэ¶Ҝ¶јКЗ№ИёиәНIE№Щ·ҪМṩөДЈ¬ҝЙТФҙУНшЙППВФШөҪЈ»¶шFireFoxІ»РиТӘПВФШЗэ¶ҜЈ¬Ц»ТӘ°ІЧ°дҜААЖчҫНҝЙөчУГЈЁSeleniumәНFireFoxКфУЪТ»ёцНЕ¶УҝӘ·ўіцАҙөДЈ¬ҙэУцҫНКЗІ»Т»СщЈ©ЎЈ
УРБЛдҜААЖчЗэ¶ҜәуЈЁОТГЗ°СЗэ¶Ҝ·ЕөҪ№ӨіМДҝВјөДWebDriverОДјюјРПВЈ¬·Ҫұг°ҙПа¶ФВ·ҫ¶НіТ»өчУГЈ©Ј¬ОТГЗҫНРиТӘТ»ёцДЬөчУГдҜААЖчөДАаЈ¬ТФПВМṩәЛРДҙъВлСщАэЈә
3ЎўРҙТ»ёцТФКэҫЭЗэ¶ҜөДіЎҫ°АаЈ¬АҙҪшРРөҘёцКВОсөДУГАэЕЬІв
ЈЁ1Ј©КЧРРОТГЗРиТӘУГTesgNgМṩөДКэҫЭЗэ¶Ҝ·Ҫ·ЁЈЁ@DataProviderЈ©Ј¬Аҙ»сИЎТ»ёціЎҫ°өДУГАэұнКэҫЭЈ¬ХвёціЎҫ°ҙУexcelөДөЪТ»ёцёҪұн»сИЎ

НЁ№эactionГыЈ¬өчИЎУГАэұнЈЁУГАэұнКЗТФactionГыГьГыөДёҪұнЈ©Ј¬УГАэұнИзПВЛщКҫЈЁExpectedObjectұнКҫУГАэРЈСй¶ФПуөДТіГжElementұкЗ©Ј¬УГЈ»·ЦёфЈ¬·ЦәЕЗ°ГжөДұнКҫIDЈ¬·ЦәЕәуГжөДұнКҫxpathЈ©Јә
ТФПВОӘУГАэұнКэҫЭ»сИЎөДҙъВлЈә
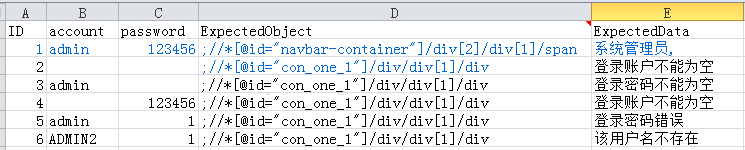
ТФПВОӘУГАэұнКэҫЭ»сИЎөДҙъВлЈә

И»әуНЁ№эJavaөД·ҙЙд»ъЦЖЈ¬КөПЦ¶ҜМ¬өД»сИЎҫЯМеКВОсАаәНЦҙРРПа№ШІЩЧчЈЁГҝёцКВОсөДАаГыәН·Ҫ·ЁГы¶јУлactionіЎҫ°ГыТ»ЦВЈ©Ј¬ТФПВҪШСЎПа№ШіЎҫ°өДІҝ·ЦөчУГҙъВлЈә

БнНвЛөГчөДКЗЈ¬өчУГдҜААЖчөД·Ҫ·ЁЈ¬РиТӘГчИ·КЗ·ЕФЪ@BeforeMethodЦРЈ¬»№КЗФЪ@BeforeClassЦРЈ¬Из№ыКЗөЗВјРЈСйІвКФЈ¬ҫНТӘұЈЦӨГҝҙОЦҙРРІвКФ·Ҫ·Ё¶јТӘҙтҝӘТ»ҙОдҜААЖчәН№ШұХТ»ҙОдҜААЖчЈ¬ДЗГҙОТГЗҫНТӘ°СөчУГдҜААЖчЈ¬әН№ШұХдҜААЖчөД·Ҫ·Ё·ЕөҪ@BeforeMethodЦРәН@AfterMethodЦРЎЈЖдЛыТөОсІвКФЈ¬Ц»ТӘФЪТ»ёцМЧјюАаЦРҙтҝӘТ»ҙОдҜААЖчәН№ШұХТ»ҙОдҜААЖчҫНҝЙТФЈ¬ЛщТФУГөҪөДКЗ@BeforeClassәН@AfterClassЎЈ
4ЎўОТГЗРиТӘФЩРҙТ»ёцТФ¶ҜЧчЈЁ№ШјьҙКЈ©Зэ¶ҜөДіЎҫ°Аа
Н¬СщЈ¬өчУГөЪ¶юёціЎҫ°өДУГАэұнЈ¬СщАэҙъВлИзПВЈә

И»әуФЪІвКФ·Ҫ·ЁЦРЈ¬¶ҜМ¬өДөчУГҫЯМеІЩЧч¶ҜЧчЈ¬»сИЎWebElementұкЗ©өД·Ҫ·ЁЈ¬°ьАЁНЁ№эBy ID»тХЯBy?xpathЈ¬ІЩЧч¶ҜЧчТФЧоіЈјыөДБҪёцОӘАэЈЁsendKeysЎўclickЈ©Ј¬ТФПВОӘСщАэҙъВлҪЪСЎЈә

Хв¶О·Ҫ·ЁЛщөчУГөДУГАэұнИзПВЛщКҫЈЁТФөЗВјОӘАэЈ©Јә

5ЎўКЈПВҫНКЗТөОсА©Х№АаБЛЈ¬ЛщУРёҙФУөДКВОс¶јҝЙТФөҘ¶АҪЁБўІвКФАаәН·Ҫ·ЁЈЁ·ҪұгА©Х№О¬»ӨЈ¬Ц»РиТӘФЪexcelіЎҫ°ұнЦР¶ЁТеәуҫНДЬөчУГЈ¬АыУГөДКЗJava·ҙЙд»ъЦЖЈ©Ј¬ФЪХвАпҫНІ»ҫЩАэБЛЎЈ
ЛДЎўКөПЦІвКФМЧјюөчУГәНұЁёжКдіц
УРБЛТФЙПІҪЦиЈ¬Т»ёцҝЙА©Х№өДЧФ¶Ҝ»ҜҝтјЬТСҫӯ»щұҫРОіЙЈ¬ө«КЗ»№ҙпІ»өҪҙу№жДЈУҰУГІвКФәНҪЕұҫ·ҪұгҝЙТЖЦІЈ¬ХвКұәтОТГЗТэИлAntЈЁҝЙТФФЪEclipseЦР°ІЧ°ІејюЈ¬ҝЙТФЦұҪУЙПНшПВФШәуТэУГЈ©Ј¬ОӘБЛДЬКдіцЖҜББТ»өгөДұЁёжёсКҪЈ¬ОТГЗ»№ТэИлТ»ёцsaxon-8.7.jarЎЈ
УРБЛAntәуЈ¬ОТГЗҫНҝЙТФҪЁТйbuild.xmlОДјюЈ¬ҫНДЬТ»јьbulidОТГЗТФЙПөДЧФ¶Ҝ»ҜҙъВлЈ¬ІўҪ«ЦҙРРІвКФәуөДҪб№ыКдіціЙұЁёжЎЈ
1ЎўКЧПИОТГЗРиТӘұајӯәГІвКФМЧјюөчУГөДtestng.xmlЈ¬јтөҘҫЩАэИзПВЈә
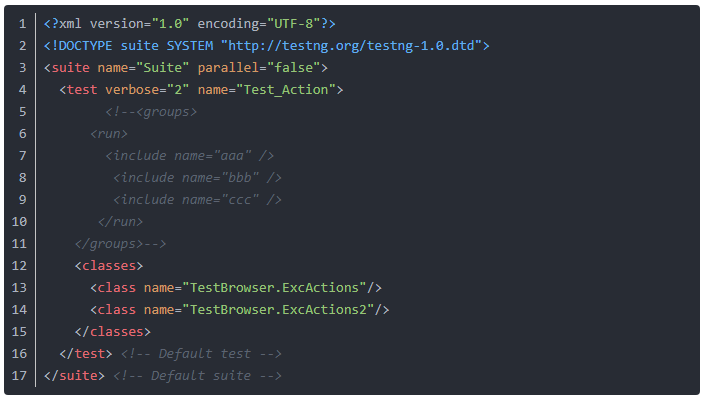
2ЎўИ»әуОТГЗРиТӘұајӯәГТ»ёцДЬТэУГ»щҙЎjar°ьЎўbuildІвКФҙъВлЎўөчУГtestngЎўКдіцЖҜББұЁёжөДbuild.xmlОДјю
<?xml version="1.0" encoding="UTF-8"?>
<project name= "TestAction" basedir=
"." default="testoutput"><!--defaultЙиЦГОӘrunұнКҫЦ»ЦҙРРҪЕұҫЈ¬ЙиОӘtestoutputұнКҫЦҙРРНкҪЕұҫІўКдіцКУНјұЁёж-->
<echo message="import libs" />
<property name= "lib.dir" value=
"lib" /> <!--<property name="libdir"
location="${basedir}/lib" />-->
<!--<property name="testng.output.dir"
location="${basedir}/test-output" />-->
<path id= "test.classpath" >
<!-- adding the saxon jar to your classpath
-->
<fileset dir= "${lib.dir}" includes=
"*.jar" />
<fileset dir="${basedir}/selenium-2.44.0">
<include name="selenium-java-2.44.0.jar"
/>
<include name="libs/*.jar"
/>
</fileset>
</path>
<taskdef name="testng" classname="org.testng.TestNGAntTask"
classpathref="test.classpath" />
<target name="clean">
<delete
dir="build"/>
</target>
<target name="compile" depends="clean">
<echo message="mkdir"/>
<mkdir
dir="build/classes"/>
<javac
srcdir="src" destdir="build/classes"
debug="on" encoding="UTF-8"
includeAntRuntime="false">
<classpath
refid="test.classpath"/>
</javac>
</target>
<path id="runpath">
<path
refid="test.classpath"/>
<pathelement
location="build/classes"/>
</path>
<target name="run" depends="compile">
<testng classpathref="runpath" outputDir="test-output">
<xmlfileset dir="${basedir}" includes="testng.xml"/>
<jvmarg value="-ea" />
</testng>
</target>
<target name= "testoutput" depends="run">
<xslt in= "test-output/testng-results.xml"
style= "test-output/testng-results.xsl"
out= "test-output/index1.html" >
<!-- you need to specify the directory here
again -->
<param name= "testNgXslt.outputDir"
expression= "${basedir}/test-output/"
/>
<param name="testNgXslt.showRuntimeTotals"
expression="true" />
<classpath refid= "test.classpath"
/>
</xslt>
</target>
</project>
|
3ЎўНкіЙХвР©әуЈ¬ОТГЗҫНҝЙТФНЁ№эEclipseЦұҪУRun As Ant
BuildОТГЗөДЧФ¶Ҝ»ҜҪЕұҫБЛЈ¬КдіцТ»·Э»№ЛгЖҜББөДұЁёжЈә
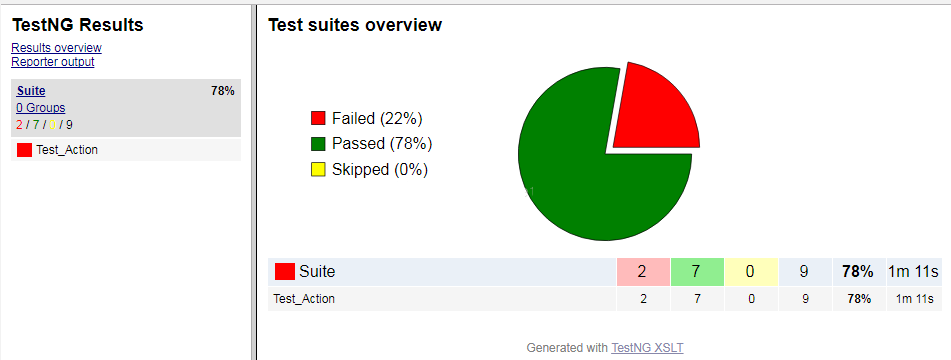
Н¬КұЈ¬РиТӘФЪКВОсІЩЧчАаЦРЈ¬¶ФКөјКҪб№ыәНФӨЖЪҪб№ыҪшРРұИҪПЈ¬ІўҪ«ІвКФҪб№ыРҙИлexcelөДУГАэұнЦРЈ¬ИзПВЈә
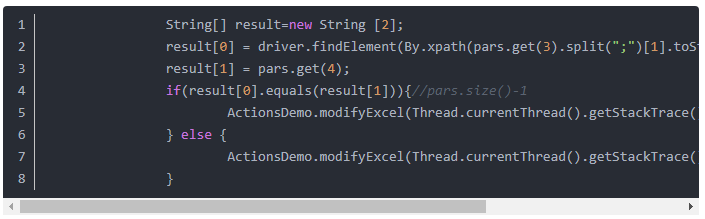

ОеЎўКөПЦЧФ¶Ҝ»ҜҝтјЬҪЕұҫөДЗЁТЖөчУГ
ТФЙПөДҪЕұҫКјЦХКЗФЪEclipseПВұаТләНөчУГөДЈ¬Из№ыТӘКөПЦБй»оЗЁТЖЈ¬Лжұг»»ИОәОТ»МЁЦ»Ч°БЛJDKөДөзДФ¶јДЬФЛРРЈ¬ДЗГҙОТГЗҫНТӘАҙөгёДФм
1ЎўКЧРРКЗұЈЦӨОТГЗРҙөДҙъВлЦРЈ¬ЛщТФРиТӘТэУГОДјюөДөШ·ҪЈ¬¶јУГПа¶ФВ·ҫ¶өД·ҪКҪЈ¬ұЬГвҙъВл°ьЗЁТЖәуРиТӘёДВ·ҫ¶ЎЈ
2ЎўНЁ№эЕъҙҰАнөчУГbuildОДјюј°УГАэОДјюЈ¬өчУГКұТІКЗНЁ№эЕъҙҰАнЧФ¶ҜХТөҪПа№ШВ·ҫ¶Ј¬ұЬГвУГҫш¶ФВ·ҫ¶ЎЈ
3ЎўРиТӘУГ»·ҫіұдБҝөДөШ·ҪЈ¬ҫЎБҝУГЕъҙҰАнөД·ҪКҪКөПЦЈ¬ЙхЦБЧоәГКЗІ»УГЕдЦГ»·ҫіұдБҝЈ¬ЦұҪУөчУГПаТэУГПа¶ФГьБоОДјюөДВ·ҫ¶өчУГ
ТФПВҫЩёцНЁ№эbatЕъҙҰАнөчУГAntАҙЦҙРРХыёцҝтјЬҙъВлөДbuildЈә
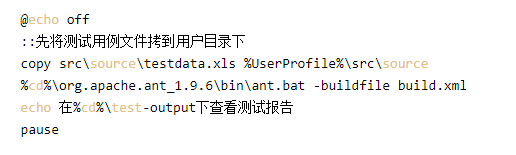
БщЎўҪшТ»ІҪКөПЦЧФ¶Ҝ»ҜөДіЦРшјҜіЙ
ФЪТФЙП»щҙЎЙПЈ¬ОТГЗ»№ҝЙТФНЁ№эjenkinsКөПЦ¶ФЧФ¶Ҝ»ҜҪЕұҫөДөчУГЈ¬ТФј°ҙпөҪГҝИХ№№ҪЁЈ¬іЦРшјҜіЙҝӘ·ўөДТӘЗуЎЈ
1ЎўКЧПИІҝКрjenkinsЈЁНшЙПУРПа№Ш·Ҫ·ЁЈ©Ј¬УЙУЪұҫИЛ№«ЛҫТ»ЦұФЪУГjenkinsЈ¬ОТҫНКЎБЛҙоҪЁІҝКрХвТ»ІҪЈ¬ЦұҪУҪ«ТФЙПөДЧФ¶Ҝ»ҜҝтјЬҪЕұҫЙПҙ«
2ЎўЧФ¶Ҝ»ҜҪЕұҫНкХыДҝВјЈЁ°ьАЁҙъВлЎўУГАэЎўlibЎўТэУГөДjarЎўbuild.xmlОДјюөИЈ©ЙПҙ«өҪSVNЈЁФЩЧФ¶ҜҙУSVNПВөҪjenkinsЛщФЪ·юОсЖчЈ©
3ЎўФЪjenkinsЦРРВҪЁТ»ёцІвКФПоДҝTestActionЈ¬ЦчТӘЕдЦГИзПВЈә
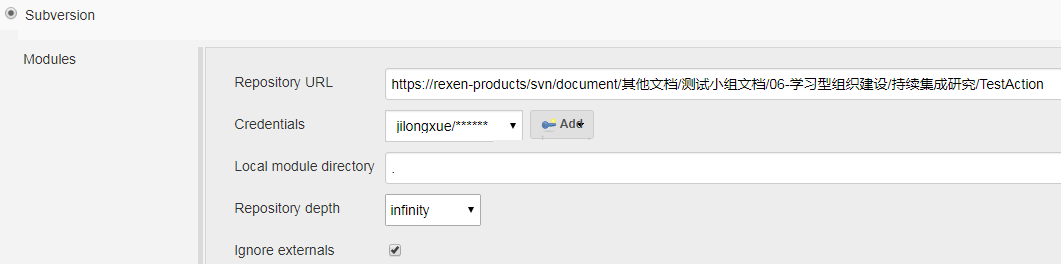
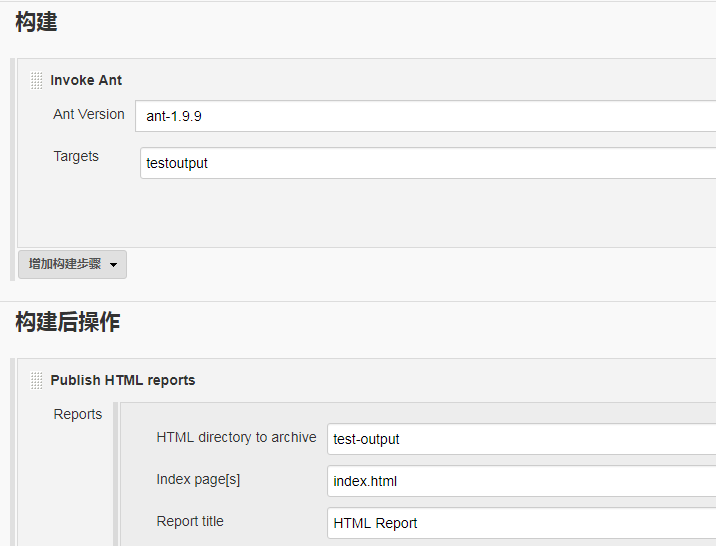
4ЎўЕдЦГНкәуЈ¬ҫНҝЙТФБўјҙ№№ҪЁЈЁИз№ыЕцөҪПа№ШұЁҙнОКМвЈ¬ҫН°ҙКдіцөДМбКҫҪшРРҙҰАнЈ©Ј¬№№ҪЁіЙ№ҰәуЈ¬ҫНҝЙТФФЪHTML_ReportЦРҝҙөҪІвКФҪб№ыЈә

ЖЯЎўәуРшҙҰАн
өҪҙЛОӘЦ№Ј¬Т»ёцНкХыөДSeleniumЧФ¶Ҝ»ҜҝтјЬҫНіцАҙБЛЈ¬ТӘЛөәГУГІ»Ј¬І»әГЛөЈ¬»№өГҫӯ№эКөјщөДјмСйЈ¬ө«КЗТФЙПХвёцЛјҝј№эіМәНҝтјЬөДСЭҪш№эіМЈ¬УҰёГТІКЗЦөөГҪијшөДЈ¬ұПҫ№ХвКЗОТХвјёМмГюЛчәНС§П°өД№эіМЈ¬¶ФУЪТ»ёцГ»УРҙУКВ№эЧФ¶Ҝ»ҜІвКФЈ¬¶шЗТГ»УРЧц№эJavaҝӘ·ўөДІвКФИЛФұАҙЛөЈ¬ХвЦ»КЗёцҝӘКјЎЈ
ДҝЗ°АҙҝҙЈ¬ХвёцҝтјЬФЪјЬ№№·ЦІгЙПЈ¬»№КЗІ»№»ЗеОъЈ¬УРәЬ¶аТӘёДҪшөД¶«ОчЈ¬ҙУјјКхЙПАҙЛөЈ¬ОТТСҫӯКөПЦБЛОТөДДҝұкЈЁС§П°ЧФ¶Ҝ»ҜІвКФЈ©Ј¬ө«КЗФЪХыМејЬ№№әНҙъВлЦШ№№ЙПЈ¬»№УРәЬ¶а№ӨЧчГ»ЧцЈ¬ТФПВМщіцТ»·ЭSeleniumЧФ¶Ҝ»ҜҝтјЬөД·ЦІгҪб№№Ј¬ТФұгәуЖЪ°ҙХХХвёцұкЧјҪшРРёДҪшЈә

ІвКФКэҫЭІгЈә¶АБў·вЧ°КэҫЭЈ»
ТіГж¶ФПуІгЈә·вЧ°ТіГж¶ФП󣬹ІТіГжИООсІгЧцөчУГЈ»
ТіГжИООсІгЈәКөПЦёчёц¶АБўТіГжөДІЩЧчЈ»
ІвКФІгЈәКөПЦТіГжІвКФЈ»
ІвКФМЧјюІгЈәКөПЦІвКФІгөД№ЬАнөчУГЈ»
|





