| ±ајНЖјц: |
ЦШµг·ЦПнБЛ»щУЪ
AI µДЧФ¶Ї»ЇІвКФїтјЬЎЈТФј°ФЪКµјщ№эіМЦРБмОтµЅµДЙо¶ИС§П°µДУЕКЖУлМфХЅЎЈ
±ѕОДАґЧФУЪОўРЕ№«ЦЪєЕЗ°¶ЛЦ®бЫЈ¬УЙ»рБъ№ыИнјюAnna±ајЎўНЖјцЎЈ |
|
АнПлЦРµД UI ІвКФїтјЬ
ґУІвКФїтјЬµДЅЗ¶ИАґЅІЈ¬їП¶Ё»бУРТ»Р©ЧФјєПлТЄµД№¦ДЬ»тРиЗ󣬶ФХвёцІвКФїтјЬµДЖЪНыТІ»бєЬёЯЎЈ

КЧПИЈ¬ФЪєвБїТ»ёцІвКФїтјЬµД№эіМЦРЈ¬»бХТТ»Р©Цё±кАґєвБїХвёцІвКФїтјЬµДєГ»µЈ¬±ИИзЛµОТГЗ»бТЄЗуХвёцІвКФїтјЬТЧУЪО¬»¤єНїЄ·ўЈ¬РЮёДєуµДґъВлОИ¶ЁРФ±дµГёьєГЈ¬»бТЄЗуЛьµДЦґРРР§ВКДЬ№»ВъЧгРиЗуЎЈФЪХвР©»щґЎТЄЗуЦ®ЙПЈ¬їЙДЬ»№»бТЄЗуЛьДЬ№»УРР©їзЖЅМЁµДДЬБ¦Ј¬їзУ¦УГµДДЬБ¦Ј¬»тХЯЦ§іЦ
Hybrid µДДЬБ¦ЎЈ

ПЦФЪЦчБчµДІвКФїтјЬФЪХвР©Цё±кЙПµД±нПЦЖдКµІ»М«Т»ЦВЈ¬ТтОЄУРІ»Н¬µДІаЦШµгЎЈѕЩёцјтµҐµДАэЧУЈ¬Пс UIAutomatorЈ¬ЛьЖдКµ±ѕЙнІаЦШУЪєНПµНіµДЅ»»ҐДЬБ¦Ј¬ЛщТФЛьФЪїзУ¦УГµДДЬБ¦ЙП»б±нПЦµДёьЗїТ»µгЈ¬µ«КЗПа¶ФАґЛµЛь¶Ф
Hybrid ХвЦЦіЎѕ°µДЦ§іЦ»бПа¶ФАґЛµИхТ»µгЎЈПс Espresso ХвЦЦїтјЬЈ¬ЛьµДДЬБ¦єЬЗїЈ¬їЙТФЧцєЬ¶аКВЗйЈ¬±ИИзїЙТФДГµЅµ±З°У¦УГµДФЛРРЧґМ¬Ј¬ДГµЅµ±З°ґъВлАпГжДЪґжµДКэѕЭЈ¬ХвР©№¦ДЬЖдЛыІвКФїтјЬ¶јКЗІ»ДЬЧцµЅµДЈ¬µ«КЗХвёцІвКФїтјЬЈ¬Жд±Ч¶ЛѕНКЗїЙДЬ¶ФДгґъВлµДТЄЗу±ИЅПёЯЈ¬ТЄЗуДгАнЅвТ»Р©ґъВлµДФЛРРВЯјЈ¬Ль±ѕЙнёьЗгПтУЪГжПтїЄ·ўХЯµДІвКФїтјЬЎЈ
ХыМеАґЛµЈ¬ГїёцЖЅМЁЛьЧФјєМṩµДІвКФїтјЬЈ¬ЖдКµ¶јІ»ѕЯУРїзЖЅМЁµДДЬБ¦Ј¬ПЦФЪ±ИЅПЦчБчµДѕЯ±ёїзЖЅМЁДЬБ¦КЗµЪИэ·ЅµД
Appium ХвСщТ»ёцїтјЬЈ¬ХвёцїтјЬЛь±ѕЙнКЗ°СёчёцЖЅМЁµДІвКФїтјЬЅшРРБЛХыєПЈ¬И»єуФЩЅшРР·вЧ°Ј¬ЛщТФХвЦЦїзЖЅМЁДЬБ¦ІўГ»УРКµПЦјјКхЙПХжХэµДїзЖЅМЁЎЈ¶шЗТУЙУЪЛьЧцХвР©·вЧ°Ј¬Ц§іЦєЬ¶аУпСФЈ¬Ц§іЦёчЦЦЖЅМЁЈ¬ЛьКЗТ»ЦЦ»щУЪРТйµДїтјЬЈ¬ХвёцїтјЬѕН»бµјЦВґъВлµДїЙО¬»¤РФЈ¬Па¶ФАґЛµ±ИЖдЛыїтјЬ¶јТЄµНЎЈ

ЧЬЅбТ»ПВґ«НіїтјЬ¶ј»бґжФЪµДТ»Р©И±µгЎЈµЪТ»ёцѕНКЗїзЖЅМЁДЬБ¦±ИЅПІоЈ»µЪ¶юёцКЗїзУ¦УГДЬБ¦ТІВъЧгІ»БЛОТГЗµДРиЗуЎЈґЛНвПЦФЪЛщУРµДІвКФїтјЬ¶ј»бУРТ»ёцОКМвЈ¬ѕНКЗПµНі¶ФУЪ
ID µДТААµРФ±ИЅПЗїЈ¬ХвёцФЪЦ®З°ОКМвІ»ґуЈ¬µ«КЗЛжЧЕЅьЖЪТЖ¶Ї¶ЛјјКхµД·ўХ№Ј¬ТЖ¶Ї¶ЛУ¦УГФЪ·ўІјµДК±єтЈ¬»бЧцТ»Р©ЧКФґ
ID »мПэµДКВЗйЈ¬ЛщТФФЪГїёц°ж±ѕАпГж Android µДЧКФґ ID ¶ј»б·ўЙъ±д»ЇЈ¬ХвёцК±єтДг»б·ўПЦДгµДІвКФµД
ID І»¶ПµШ±дёьЈ¬Гїёц°ж±ѕµДІвКФґъВл¶јТЄЅшРРО¬»¤ЎЈµЪЛДёцКЗЈ¬УЙУЪТЄИҐІ¶ЧЅїШјюЈ¬ОТГЗРиТЄДГµЅїШјю¶ФУ¦µДКфРФЈ¬ХвР©КфРФєЬДСЦ±№ЫИҐДГµЅЈ¬РиТЄПИ
Dump ПµНіКУНјКчіцАґЈ¬ХТµЅЛьµД¶ФУ¦№ШПµЈ¬ІЕДЬ№»ХТµЅХвР©КфРФЎЈПа¶ФАґЛµЈ¬їШјюµДІ¶»сДЬБ¦ФЪОТїґАґЈ¬КЗТ»ёцПа¶Ф±ИЅПёЯµДіЙ±ѕЎЈ»№УРТ»ёцОКМвѕНКЗЈ¬ДїЗ°ФЪЛщУРµДїтјЬАпГжЈ¬ФЪ
Dump ПµНіКчµД№эіМЦРЈ¬¶ј»бґжФЪТ»¶Ёј¶±рµДК§°ЬЎЈ
»щУЪХвР©И±µгЈ¬ОТГЗПлТЄТ»ёцКІГґСщµДїтјЬЈ¬ІЕКЗАнПлµДїтјЬЈїОТПлПуХвЦЦїтјЬКЗТ»ёцЦ§іЦЛщјыјґЛщµГµДЧФ¶Ї»ЇїтјЬЈ¬КІГґКЗЛщјыјґЛщµГЈїТтОЄОТГЗЖЅК±єЬ¶аЧц
UI ІвКФµД№эіМЦРЈ¬ЖдКµѕНКЗФЪДЈДвУГ»§µДІЩЧчЎЈ¶шУГ»§ФЪЅшРРК№УГµДК±єтЈ¬КЗІ»РиТЄХвР©їШјю ID РЕПўµДЈ¬ЛьКЗТ»ЦЦЛщјыјґЛщµГµДІЩЧчЈ¬ЛщТФИз№ыОТГЗµДЧФ¶Ї»ЇІвКФїтјЬАпТІДЬ№»ЧцµЅХвµгЈ¬¶ФІвКФґъВлµДїЙО¬»¤РФѕН»бУРёцПФЦшµДМбЙэЈ¬°ьАЁЛьµДАнЅвЙПТІ»б±дµГЗбЛЙУдїмЎЈ
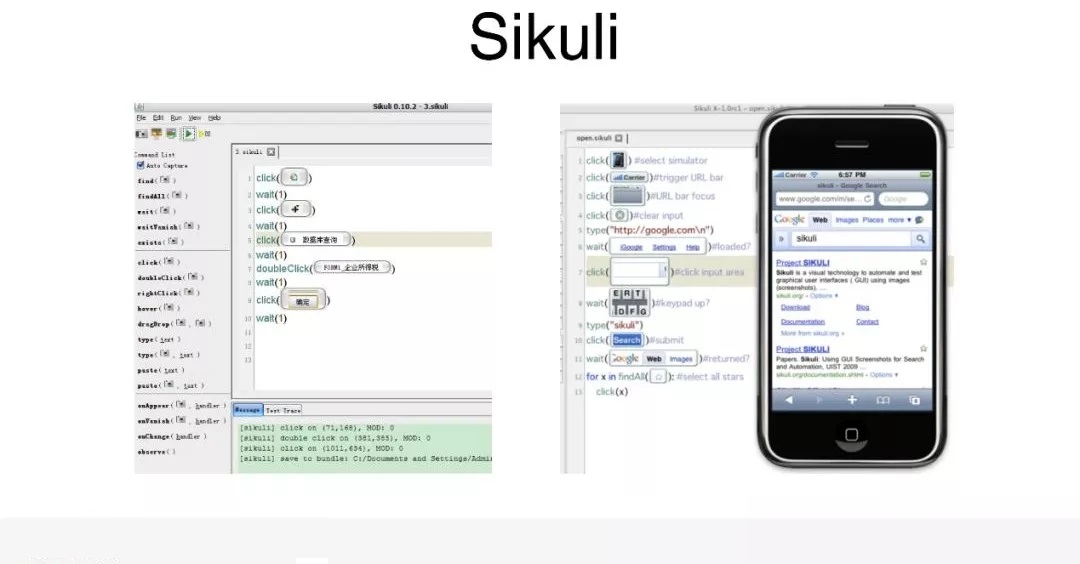
ЖдКµРРТµАпУРТ»Р©ИЛЈ¬Ц®З°ТІІ»¶ПµШЧц№эТ»Р©ХвСщµДіўКФЈ¬ХвёцКЗФзЖЪµДЈ¬ФЪ PC ¶ЛµДІвКФїтјЬЈ¬ЅР SikuliЎЈїЙДЬІвКФЧцµГ±ИЅПѕГµДИЛ»бУРТ»Р©ЙжБФЈ¬ПЦФЪХвёцїтјЬТСѕІ»О¬»¤БЛЈ¬ЛьµДМШµгЈ¬КЗ°С¶ФУ¦µДЅзГжЅшРРЅШНјЈ¬Из№ыПлТЄЖҐЕдДіёцФЄЛШµД»°Ј¬°СДіёцІї·ЦЅшРРЅШИЎЈ¬ЖҐЕд¶ФУ¦µДДЈїйЈ¬НкИ«НЁ№эНјЖ¬ЖҐЕдµД·ЅКЅЈ¬Чц¶ФУ¦ЗшУтµДСЎИЎєНСйЦ¤ЎЈХвёцїтјЬКЗ
PC К±ґъµДЈ¬ПЦФЪТСѕІ»ФхГґО¬»¤БЛЎЈ

ЖдКµЅьЖЪТІУРТ»Р©№«ЛѕЧц№эХвСщµДіўКФЈ¬АэИзЈ¬НшТЧНЖіцБЛТ»ёц±ИЅП»рµДїтјЬ AirTestЈ¬ХвёцїтјЬ±ѕЙнДЬБ¦±ИЅПЗїЈ¬Т»ёцєЬН»іцµДМШµгТІКЗ»щУЪНјЖ¬ЅШНјЖҐЕдµД·ЅКЅЎЈ

ХвЦЦНкИ«»щУЪНјЖ¬ЖҐЕдµД·ЅКЅґжФЪєЬ¶аІ»ЧгЎЈµЪТ»КЗЧјИ·ВКІ»ЧгЈ¬І»Н¬КЦ»ъ·Ц±жВКЗйїцПВЈ¬»тХЯКЦ»ъґжФЪТ»Р©Й«ІоµДЗйїцПВЈ¬Дг»б·ўПЦЈ¬ДгіўКФЅШµДДЗХЕНјУГАґЧцІвКФУГАэЈ¬ФЩИҐЖҐЕдРВКЦ»ъЙПµДЅШНјЈ¬ѕіЈЖҐЕдІ»ЙПЈ¬ѕНКЗЧјИ·ВКµДОКМвЎЈµЪ¶юЈ¬ЅШНјµДІЩЧч·ЅКЅЈ¬їП¶ЁКЗ№№ЅЁІ»іцІгґОЅб№№µДЈ¬ЛьЛщУРРґµДґъВл¶јКЗТ»ІгЖЅј¶µДёЕДоЎЈ»№УРѕНКЗЈ¬УЙУЪОТГЗКЗНкИ«»щУЪТ»ХЕЅШНјµД·ЅКЅЈ¬±ИИзНјЖ¬У¦УГЙФОў·ўЙъТ»Р©ЅзГжЙПµД±д»ЇЈ¬±іѕ°ЙФОў·ўЙъТ»µг±д»ЇЈ¬Дг»б·ўПЦДг¶јТЄЦШРВЅШНјЈ¬ХвёцК±єтОИ¶ЁРФ»б±дµГєЬІоЎЈїЙТФПлПуЈ¬ХвСщµДґъВлО¬»¤іЙ±ѕ»б±дµГ±ИЅПёЯЎЈ
.jpg)
їЙТФїґТ»ПВЖЅК±Ѕ»Бч№эіМЦРЈ¬Дг»бКЗТ»ёцКІГґСщµДЧґїцЎЈОТГЗФЪГиКцТ»ёціЎѕ°µДК±єтЈ¬±ИИзЛµµгТ»ПВ tap
ПВГж VIP °ґЕ¦Ј¬»тХЯµгТ»ПВ»бФ±°ґЕ¦Ј¬Па¶ФАґЛµЈ¬ФЪ№µНЁ№эіМЦРКЗТ»ёц±ИЅПЦ±°ЧµДІЩЧчЎЈµ±ОТГЗПлТЄ°СХвСщµДГиКц·ТліЙґъВлµДК±єтЈ¬ПЈНыЛьКЗ±діЙКІГґСщµДґъВлЎЈОТГЗЅшРРТ»ёцјтµҐµД·ТлЈ¬±ИИзЛµЗ°Гжµг»ч»бФ±°ґЕ¦Ј¬ѕН±діЙ
find('tab').find('»бФ±')Ј¬Из№ыДгТЄКЗРґХвСщµДґъВлЈ¬»б·ўПЦґъВлО¬»¤РФѕН»б±дµГ·ЗіЈєГЎЈ

ТЄЧцХвСщµДКВЗйЈ¬РиТЄѕЯ±ёКІГґСщµДДЬБ¦ЎЈµЪТ»ёцѕНКЗОТГЗТЄѕЯ±ёНјПсЗРёоµДДЬБ¦Ј¬ДЬЗРёо¶ФУ¦µДїйіцАґЎЈµЪ¶юѕНКЗРиТЄНјПс·ЦАаµДДЬБ¦Ј¬ДЬ№»ЦЄµАХвїйКЗКІГґ¶«ОчЎЈµЪИэёцРиТЄ
OCR µДОДЧЦК¶±рДЬБ¦Ј¬ХвёцКЗУЙУЪОТГЗГ»УРИҐ Dump Т»ёцПµНіКчЈ¬ЛщТФІ»ЦЄµА¶ФУ¦µДКУНјАпГжУРКІГґ¶«ОчЈ¬ТЄНкИ«ТААµНјПс
OCR µДК¶±рДЬБ¦Ј¬ЦЄµА¶ФУ¦µДКУНјАпГжУРДДР©ОДЧЦЎЈ»№УРѕНКЗґ«НіµДНјПсПаЛЖ¶ИЖҐЕдДЬБ¦ЎЈЧоєуТ»ёцКЗПсЛШµгµДІЩЧчЈ¬їЙТФТААµґ«НіµДїтјЬЈ¬±ИИзёшТ»ёцО»ЦГИҐЧцТ»Р©ІЩЧчЈ¬ТІїЙТФТААµТ»Р©»ъРµ±ЫАґ°пОТГЗАґНкіЙПсЛШµгµДІЩЧчЎЈ
Йо¶ИС§П°ґшАґµД»ъ»б
ФЪґ«НіµДјјКхїтјЬАпГжЈ¬УРТ»Р©ДЬБ¦µГµЅВъЧгЈ¬»№УРТ»Р©ДЬБ¦ОЮ·ЁµГµЅВъЧгЎЈХвёцК±єтЈ¬ОТГЗ·ўПЦЖдКµФЪЙо¶ИС§П°јјКх·ўХ№№эіМЦРЈ¬ЛьёХєГДЬ№»°пНкіЙТ»Р©Ц®З°µДјјКхІ»ДЬНкіЙµДИООсЎЈ

Хв»бёшОТГЗґшАґКІГґСщµД»ъ»бДШЈїµЪТ»ёцѕНКЗЛьµДНјПс·ЦАаДЬБ¦Ј¬їЙТФїґµЅХвКЗАо·Й·Й·ўЖрµД ImageNet
ґуРНКУѕх·ЦАаМфХЅИьµДЅб№ыЎЈДг»б·ўПЦФЪ 2012 ДкТФЗ°Ј¬ТІѕНКЗЛµФЪЙо¶ИС§П°±»ТэИлµЅНјПс·ЦАа±ИИьЦ®З°Ј¬ЛьµДЧјИ·ВКТ»Ц±ФЪ
75% ТФПВГ»УРН»ЖЖЈ¬µ«КЗФЪ 2012 ДкЈ¬Йо¶ИС§П°±»ТэИлµЅНјПс·ЦАаБмУтТФєуЈ¬ЛьµДЧјИ·ВКГїТ»Дк¶јФЪМбЙэЈ¬¶шЗТµЅЧоЅьТ»ДкЈ¬ТСѕґпµЅ
98%Ўў99% µДЧјИ·ВКЈ¬ХвёцЧјИ·ВКТвО¶ЧЕКІГґЈїТтОЄЦ®З°їґµЅ№эТ»Р©ОДХВЛµЈ¬Из№ыЛьµДЧјИ·ВКМбёЯµЅ 95%
ТФЙПЈ¬ѕНТСѕі¬№эИЛАа·Ц±жНјПсµДЛ®ЖЅБЛЈ¬ХвКЗТ»ёцПаµ±ёЯµДЛ®ЖЅЎЈ

µЪ¶юёцКЗ OCR µДДЬБ¦Ј¬ОТГ»УРУГТ»Р©РРТµµДКэѕЭЈ¬¶шКЗєНОТГЗ OCR НЕ¶УЧцБЛТ»Р©іўКФЈ¬ЛыГЗёшµЅТ»Р©КэѕЭЎЈХвАпУРБЅёцЦё±кЈ¬Т»ёцКЗЛьµДНкХыЧјИ·ВКЈ¬Т»ёцКЗОДЧЦµДЧјИ·ВКЎЈНкХыµДЧјИ·ВККЗЦёЈ¬ФЪТ»ёцЅШНјАпГжЈ¬»бУРТ»Р©
titleЈ¬»бУРТ»Р©ґКЧйЈ¬ФЪТ»ёц title АпГжУРТ»ёцЧЦіцПЦБЛґнОуЈ¬ѕНИПОЄХвёц title µДК¶±рКЗґнОуµДЈ¬ХвѕНЧчОЄТ»МхґнОуЈ¬ХвСщµДЧјИ·ВКДЬ№»ґпµЅ
93%ЎЈОД±ѕµДЧјИ·ВКЈ¬ДЬ№»ґпµЅ 98%ЎЈOCR АпГжУРТ»ёц±ИЅПЦШТЄµДКЗХЩ»ШВКЈ¬ХыМеµДХЩ»ШВКФЪІвКФ№эіМЦРКЗІ»М«АнПлµДЈ¬Ц»УР
70%-80% ХвСщµДЧґМ¬Ј¬µ«КЗФЪОТГЗµДУ¦УГіЎѕ°АпГжЈ¬УЙУЪ»бЧцМбЗ°µДФ¤ЗРёоІЩЧчЈ¬ёш OCR µДДЪИЭПаµ±РЎµДТ»ёцДЈїйЈ¬ХыМеАґЛµ¶ФУЪЛьµДХЩ»ШВКТЄЗу»бёьµНТ»µгЎЈЧоєуІвКФПВАґЈ¬ЛьµДИ·ДЬ№»ВъЧгРиЗуЎЈ
AIon µДµ®Йъ
УРБЛХвР©јјКх»щґЎТФєуЈ¬ОТГЗѕНИҐіўКФ AIon µДїтјЬЎЈ

ЧцХвёцїтјЬЦ®З°Ј¬їП¶Ё»бИҐ¶Ф±ИТ»ПВЈ¬РРТµУРГ»УРИЛЧц№эАаЛЖХвСщµДКВЗйЈ¬УРГ»УРїЙІОїјµДµШ·ЅЎЈЖдКµ·ўПЦЈ¬ФЪЧц
UI ЧФ¶Ї»ЇІвКФїтјЬµДК±єтЈ¬ЛьєНОТГЗПЦУРµДТ»ёцБмУт±ИЅППсЈ¬UI2Code ХвСщТ»ёцУ¦УГіЎѕ°Ј¬°СТ»ёцУ¦УГЅШНјЈ¬»тХЯ°СТ»ёц
UI µДЙијЖНјЈ¬НЁ№эНјПсК¶±рµД·ЅКЅЙъіЙіц¶ФУ¦µДґъВлЈ¬ХвСщµДУ¦УГіЎѕ°єННЁ№эНјПсК¶±рЈ¬ХТµЅЛьµДКдИлФЄЛШЅшРРµг»чКЗєЬПсµДЎЈФЪХвёц·ЅГжµДіўКФЈ¬ѕНУРєЬ¶аµДАэЧУЈ¬±ИИзЛµПс
PixelToAppЈ¬КЗ№ъНвµДТ»ёцґуС§Ј¬ЛыГЗФЪ 2012 ДкµЅ 2014 ДкµДК±єт·ўІјБЛХвСщТ»ёцПоДїЈ¬ХвКЗТ»ёцУГґ«НіµДНјПсґ¦АнјјКхНкіЙµДПоДїЎЈЛьµДЦчТЄБчіМКЗЈ¬ПИ°СНјЖ¬ДжПтЙъіЙКУНјКчЈ¬И»єуМбИЎіц¶ФУ¦µДЧКФґЈ¬ёщѕЭЗ°ГжµДКУНјКчєНЧКФґѕНДЬЙъіЙєЛРДµДУ¦УГґъВлЎЈ
ХвАпЧоєЛРДµДІї·ЦЈ¬ѕНКЗНЁ№эТ»ёцЅШНјЈ¬ДжПтЙъіЙіцАґОТГЗПлТЄµДКУНјКчЈ¬ТтОЄХвёцКУНјКчЙъіЙіцАґТФєуУГАґЙъіЙІјѕЦНјЈ¬»№КЗУГАґЙъіЙ
APPЈ¬»тХЯУГАґЧцІвКФµг»чЈ¬ЖдКµКЗТ»СщµДЎЈ

їґПВХвАпЛьКЗФхГґЧцµДЈ¬OCR ИҐК¶±ріцОД±ѕЗшУтµДО»ЦГЈ¬ЅшРРТ»ёц±кјЗЈ¬ФЩУГНјПсК¶±рјјКхЈ¬К¶±ріц¶ФУ¦ФЄЛШµДО»ЦГЈ¬Н¬СщТІ»бЙъіЙІјѕЦНјЈ¬ФЩ°СХвБЅёцІјѕЦНјЅшРРИЪєПЈ¬ЦчТЄДїµДКЗМбЙэЧоєуІјѕЦµДЧјИ·ВКЈ¬ФЩ¶ФРВµДІјѕЦЅшРР·ЦОцЈ¬±ИИзЛµОТГЗїЙТФ·ЦОціцЛьУРГ»УРБР±нЈ¬ЧоєуѕН»бЙъіЙЧоЦХµДІјѕЦОДјюЈ¬И»єуЙъіЙ¶ФУ¦µД
APPЎЈ
ґжФЪЅП¶аµДОКМвЈє
µЪТ»ёцКЗЛьФЪёґФУЅзГжЙПµДґ¦Ан»б±ИЅПДСЈ¬ОДХВАпГжУГµДНјЖ¬Па¶ФАґЛµ»б±ИЅПјтµҐТ»µгЈ¬µ«КЗКµјКУ¦УГЦРєЬ¶аёґФУіЎѕ°Ј¬Льёщ±ѕґ¦АнІ»БЛЎЈ
µЪ¶юКЗЛьУ¦УГґ«НіµДНјПсґ¦АнЛг·ЁЈ¬Т»ёц±ИЅПґуµДОКМвКЗЈ¬ЛьµДгРЦµФЪІ»Н¬µДіЎѕ°ПВРиТЄІ»¶ПµчХыЈ¬єЬДСЧцµЅЧФ¶Ї»ЇЎЈ
µЪИэКЗЈ¬єЬ¶аЛг·ЁФЪЕцµЅТ»Р©ОКМвµДК±єтЈ¬ЛьµДЖїѕ±КЗєЬДСН»ЖЖµДЈ¬ёъОТГЗЗ°ГжНјПс·ЦАаµДЖїѕ±КЗТ»СщµДЈ¬±ИЅПДСН»ЖЖЎЈ
µЪЛДКЗЈ¬УЙУЪЛьµҐёцЛг·ЁµДЖїѕ±єЬДСН»ЖЖЈ¬їЙДЬ»бУГєЬ¶аЛг·ЁЈ¬НЁ№эТ»ЦЦ filter БчµД·ЅКЅЈ¬ИГЧйєПµД·ЅКЅґпµЅёьєГµДР§№ыЈ¬ХвёцК±єт»б·ўПЦЈ¬Дг»бµюјУєЬ¶аЛг·ЁЈ¬ЧоєуХыёцґъВлµДО¬»¤РФ»б±дµГёьІоЎЈ
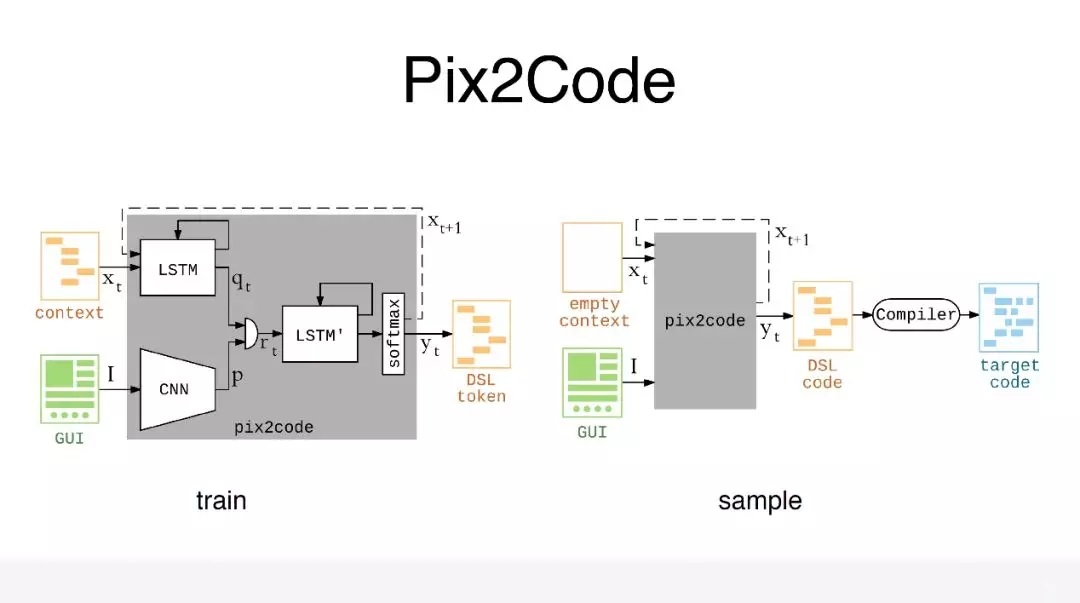
іэБЛХвЦЦ»щУЪґ«НіµДНјПсґ¦АнјјКхЦ®НвЈ¬ФЪЙо¶ИС§П°ТФєуЈ¬ТІУРИЛЧц№эХвСщµДіўКФЈ¬ЅР Pix2CodeЈ¬КЗТ»ёц±ИЅПЦЄГыµДїЄФґПоДїЈ¬ёъОТГЗПЦФЪНјПсК¶±рАпГжНјПсАнЅвµДУ¦УГіЎѕ°єЬПсЎЈёшДгТ»ХЕНјЖ¬Ј¬ДгёжЛЯОТЈ¬ХвёцИЛКЗФЪґтµз»°Ј¬»№КЗФЪЖпЧФРРіµЎЈОТГЗїЙТФїґјыЛь№№ЅЁБЛЙо¶ИС§П°¶Л¶Ф¶ЛµДДЈРНЈ¬ХвёцДЈРНПа¶ФАґЛµ»б±ИЅПјтµҐЈ¬ЛьУРБЅёцКдИлЈ¬Т»ёцКдИлКЗНјЖ¬µДЅШНјЈ¬БнНвТ»ёцКдИлКЗНјЖ¬ЅШНј¶ФУ¦µДІјѕЦГиКцОДјюЈ¬ХвёцІјѕЦГиКцОДјюЦ»КЗГиКцБЛІјѕЦАпГжµД№ШјьµДКУНјЅЪµгЈ¬±ИОТГЗХжХэµДІјѕЦТЄјтµҐєЬ¶аЎЈ
µЪТ»ІЅКЗПИ°С¶ФУ¦µДЅШНјНЁ№э CNN НшВзЙъіЙМШХчПтБїЈ¬И»єу»б°С¶ФУ¦µДІјѕЦГиКцОДјюЗРёоіЙТ»ёцРтБРЈ¬РтБРµДГїТ»ПоПИНЁ№э
LSTM ДЈїйЈ¬ТІ»бН¬СщЙъіЙМШХчПтБїЈ¬ХвёцМШХчПтБїєНЦ®З°µД CNN µДМШХчПтБї»бЅшРРј¶БЄЈ¬ј¶БЄНкіЙТФєуЈ¬ФЩНЁ№э
LSTM ДЈїйЈ¬ФЩНЁ№э softmax ЅшРРТ»ёц·ЦАаЈ¬¶Фµ±З°µДПоЅшРРФ¤ІвЎЈФ¤ІвНкБЛТФєуЈ¬ЛьН¬К±»б°СХвёцКдіцЧчОЄПВТ»ПоµДКдИлЈ¬ХвёцДЈРНПа¶ФАґЛµ»б±ИЅПјтµҐЎЈЗТІ»ЛµХвёцДЈРНµДєГ»µЈ¬µ«ЦБЙЩґУЧјИ·ВКЙПАґЅІЈ¬ЛьїП¶ЁКЗВъЧгІ»БЛРиЗуµДЈ¬ТтОЄЛьµДЧјИ·ВКЦ»УР
70% ЧуУТЎЈЖдКµПЦФЪТІУРТ»Р©ИЛФЪХвёц»щґЎЙПЈ¬Чц№эТ»Р©УЕ»ЇЈ¬±ИИзОч°ІЅ»НЁґуС§Ц®З°ѕН·ў№эТ»ЖЄВЫОДЈ¬ТІКЗАаЛЖµДХвСщЈ¬ФЪЛьЙПГжЧцБЛТ»Р©УЕ»ЇЈ¬ХвАпѕНІ»ЧцХ№їЄЎЈ

ХвСщТ»ёц¶Л¶Ф¶ЛµДДЈРНЈ¬ЛьЖдКµґжФЪТ»Р©ОКМвЎЈµЪТ»ёцКЗґУХвёцДЈРНЙПАґЅІЈ¬ЛьµДЧјИ·¶ИКЗІ»№»µДЎЈµЪ¶юИз№ыХвёцДЈРНµДЧјИ·ВКґпІ»µЅТЄЗуЈ¬ѕН±ШРлТЄЦШРВ№№ЅЁТ»ёцДЈРНЈ¬»б·ўПЦЛьµДіЙ±ѕПа¶Ф±ИЅПёЯЎЈµЪИэЈ¬ПЦФЪЛщУРµДЙо¶ИС§П°АпГж¶ј»бЕцµЅТ»ёцОКМвЈ¬ѕНКЗЛьµДСµБ·ЛШІД±кЧўіЙ±ѕёЯЎЈБнНвЈ¬»щУЪЙо¶ИС§П°НјПсґ¦АнµДјјКхЈ¬ЛьФЪНјПсЗРёоµДЧјИ·¶ИЙПКЗєЬДСґпµЅПсЛШј¶µДѕ«И·¶ИЈ¬ЛьµДѕ«И·¶ИТІІ»ДЬВъЧгОТГЗµДРиЗуЎЈЛщТФґїґ«НіЛг·Ёґ¦АнµДєНґї¶Л¶Ф¶ЛЙо¶ИС§П°µДјјКхЈ¬¶ј»бґжФЪТ»Р©ОКМвЎЈ
AIon КЗФхГґЧцµДЈїєЬјтµҐЈ¬ѕНКЗЧцБЛТ»ёцИЪєПЎЈ

ЅУПВАґїґТ»ПВ AIon КЗФхГґЧцµДЎЈAIon »б°СХвСщТ»ёцЅШНј·ЦЗРЈ¬ЗРіЙјёїйТФєу»б·ўПЦЈ¬TABЎўµјєЅЎўЧґМ¬Аё¶ј»б±»ЗРёоіцАґЈ¬ОТГЗ»бУГЙо¶ИС§П°НјПс·ЦАаЈ¬¶ФГїТ»їйЅшРР·ЦАаК¶±рЈ¬К¶±рНкБЛТФєуЈ¬ѕН»б°С¶ФУ¦їйАпµДЧУФЄЛШМбИЎіцАґЈ¬ФЩУГТ»Р©
AI µДјјКхЈ¬МбИЎАпГжµДДЪИЭЈ¬°СЛьМоідµЅЧУФЄЛШµДКфРФАпГжИҐЈ¬ЧоєуѕН»бµГµЅ¶юј¶КУНјКчµДЅб№№Ј¬И»єуѕНїЙТФИҐЧц¶ФУ¦µДµг»чІЩЧчЎЈ

ХвКЗТ»ёцјтµҐµДКѕАэґъВлЈ¬їЙТФґУТ»ёц TAB АпГжХТµЅТ»ёцЅРИИµгµД¶«ОчЈ¬ЛьѕНїЙТФКµПЦОТГЗЗ°ГжЛµµДІЩЧчЎЈ

ХыёцІвКФїтјЬЛьµДєЛРДБчіМКЗКІГґСщµДДШЈї
±ИИзРґБЛТ»ёцХвСщµДІвКФУГАэЈ¬µЪТ»јюКВЗйКЗЅШЖБЈ¬ОТГЗ»б¶ФЛьЅшРРіЎѕ°ЕР¶ПЈ¬іЎѕ°ЕР¶П»бУ¦УГµЅТ»Р© AI
·ЦАаК¶±рЈ¬ѕНКЗ»бК¶±ріцµ±З°ЅзГжУРГ»УРµЇіц¶Ф»°Ј¬»тХЯЛьКЗ·сКЗµЗВЅТіµДіЎѕ°К¶±рЎЈіЎѕ°К¶±рНкБЛТФєуЈ¬ѕН»бЅшРРґ«НіµДНјПсЗРёоЈ¬НјПсЗРёоНкБЛТФєуЈ¬ЅшРРІјѕЦ·ЦАаЈ¬ІјѕЦ·ЦАаТІ»бУ¦УГµЅТ»Р©
AI µДјјКхЈ¬·ЦАаНкБЛТФєуЈ¬ЅшРРЧУФЄЛШµДМбИЎЈ¬¶ФХвёцЧУФЄЛШЅшРРМоідЈ¬Моід»бУ¦УГµЅТ»Р© AI µДјјКхЎЈ
ЧоєуѕНКЗµ±КУНјКч№№ЅЁНкБЛЦ®єуЈ¬ОТГЗѕН»бЖҐЕдЦ®З°РґµДІвКФУГАэАпГжµДМхјюЈ¬ЅшРРТ»Р©МхјюЖҐЕдЈ¬ЖҐЕдНкБЛТФєуЈ¬ХвёцІвКФУГАэѕНїЙТФИҐЦґРРБЛЈ¬ХвѕНКЗОТГЗХыёц
AIon µДєЛРДБчіМЎЈУЙУЪїјВЗµЅЦ®З°µДТ»Р©ІвКФУГАэЈ¬»№УРТ»Р©ґ«НіµДІвКФїтјЬРґµДІвКФУГАэЈ¬ОТГЗ±ѕЙн»№ЧцБЛ¶Фґ«НіІвКФїтјЬµДИЪєПЎЈ
ХыёцБчіМТФєуЈ¬ЅУПВАґЅйЙЬТ»ПВЙжј°µЅµДТ»Р©јјКхРФµДОКМвЎЈµЪТ»ёцѕНКЗФЪНјПсЗРёоАпГжУГµЅµДТ»Р©Лг·ЁЈ¬ТтОЄУРТ»Р©ґ«НіµДНјПсґ¦АнїЙДЬ»бУ¦УГµЅєЬ¶аЛг·ЁЈ¬І»їЙДЬ°СЛщУРµДЛг·Ё¶јёшґујТЦрТ»ЅйЙЬЈ¬ХвАпёшґујТјтµҐЅйЙЬЖдЦРТ»ёцЛг·ЁЎЈѕНКЗАыУГЧУФЄЛШІјѕЦµДПаЛЖ¶ИАґЗРёоЅзГжЎЈ

їЙТФїґµЅФЪХвХЕНјАпГжЈ¬ТЄМбИЎЗ°ГжµДН·КЗ±ИЅПјтµҐµДЈ¬µ«КЗИз№ыОТГЗТЄ°СХвёцН·ФЩЅшТ»ІЅЗРёоіЙПВГжИэїйЈ¬КЗУРТ»¶ЁµДДС¶ИµДЈ¬ХвёцК±єтУ¦ёГФхГґЧцЈї

КЧПИ°СЛьЗРіЙЛДїйЈ¬ГїТ»їйЦ®јд¶ј»бУРёц±ИЅПЗеОъµД·ЦёоЈ¬И»єу°С¶ФГїТ»їйЧУФЄЛШµД·ЦІјЅшРРФЄЛШМбИЎЈ¬МбИЎНкБЛТФєуЈ¬ФЩ¶ФМбИЎНкµДМШХчЅшРРТ»ёцґ¦АнЈ¬ґ¦АнНкБЛТФєуЈ¬УГХвёцґ¦АнНкµДМШХчЈ¬јЖЛгЛьµ±З°µДЙПГжБЅёцїйєНПВГжБЅёцїйµДПаЛЖ¶ИЈ¬јЖЛгПаЛЖ¶ИµД№эіМЦРЈ¬»бУ¦УГµЅТ»Р©ЧУФЄЛШµДКэБїЎў·ЦІјЈ¬»№УРТ»Р©µ±З°ЅзГжµДїн¶ИРЕПўЈ¬ЧЫєПЖрАґѕНУРХвСщТ»ёцПаЛЖ¶ИЎЈїЙТФїґµЅЈ¬ХвАпЛьµГіцАґµДПаЛЖ¶ИКЗ
85.6%Ј¬Х§їґЖрАґЈ¬ЛьµДПаЛЖ¶И»№КЗєЬёЯµДЎЈ

ФЩїґТ»ПВХыМеµДИэёцПаЛЖ¶И·Ц±рКЗ¶аЙЩЈ¬ХвХЕНјЗРёоіцАґ»бµГµЅИэёцПаЛЖ¶ИЈ¬85.6%Ўў99.4% єН 94.8%Ј¬ФЪОТГЗµД¶ЁТеАпГжЈ¬µНУЪ
99% µД¶ј»бІ»ВъЧгРиЗуЈ¬ЛщТФ»бЦ±ЅУ°СЦРјдХвёцВъЧгРиЗуµДёшИҐµфЈ¬ЖдЛыІ»ВъЧгРиЗуµДѕНЦ±ЅУЗРёоїЄАґЈ¬ХвСщѕННкіЙБЛХвТ»їйµДЗРёоЎЈХвКЗОТГЗФЪґ«НіЛг·ЁАпГжµДТ»Р©іўКФЎЈ

ОТГЗФЪ AI ЙПТІ»бУРТ»Р© AI јјКхЙПµДУ¦УГЎЈ
µЪТ»ёцѕНКЗФЪ AI ДЈРНµДСЎФсЈ¬УРТ»ёцЧоґуµДОКМвКЗДЈРНµДЦґРРР§ВКЈ¬єНЦґРРµДРФДЬЙПГж»бЧцѕщєвЎЈФзЖЪТ»їЄКјКЗСЎФс
Google µД Inception V3 ХвСщТ»ёцНшВзЈ¬ЛьµДНшВзЧјИ·ВКПа¶ФАґЛµ»№КЗ±ИЅПёЯµДЈ¬µ«КЗЛьПЦФЪУРёцОКМвЈ¬ЛьµДЦґРРР§ВК»б±ИЅПВэЈ¬ТтОЄДЈРН±ИЅПґуТІ±ИЅПЙоЎЈєуГжОТГЗѕ№эєвБїЈ¬ІЙУГБЛ
MobileNetV2 ХвСщТ»ёцДЈРНЈ¬Па¶ФАґЛµЛьµДЦґРРР§ВК»бёьёЯЈ¬µ«КЗЛьµДЧјИ·ВК»бЙФОўЖ«Т»µгµгЈ¬ТІКЗВъЧгРиЗуµДЎЈ
іэБЛ·ЦАаДЈРНµДСЎФсЈ¬ОТГЗФЪЖдЛы AI У¦УГЦРТІ»бЕцµЅТ»Р©ОКМвЈ¬ТІЧц№эТ»Р©УЕ»ЇЎЈ
µЪТ»ёцѕНКЗХвёцЛШІД·ЦІјІ»ѕщµДОКМвЈ¬ТтОЄУРР©ФЄЛШПа¶ФАґЛµКЗ±ИЅПєГЅШИЎЈ¬µ«УРР©ЛШІДТтОЄЛьµДіЎѕ°±ИЅПЙЩЈ¬ХвСщµДЛШІДїЙДЬЕЬНкБЛХыёцУ¦УГЦ»УРТ»БЅёцЈ¬ЕЬНкЛДОеёцУ¦УГЈ¬·ўПЦЦ»УРК®ёцЈ¬ХвСщµДіЎѕ°¶ФОТГЗАґЛµ±ИЅПЮПЮОЈ¬ХвСщµДЛШІДДГАґСµБ·їП¶ЁКЗУРОКМвµДЎЈ¶шОТГЗѕН»бНЁ№эТ»Р©·Ѕ·ЁИҐЅвѕцЈ¬µЪТ»ёцКЗНЁ№эЅЕ±ѕЙъіЙµД·ЅКЅЈ¬°пОТГЗА©ідєЬ¶аЛШІДЎЈ
µЪ¶юёцЈ¬ОТГЗ»бХТёь¶аµДУ¦УГИҐЅШИЎНјЖ¬Ј¬ТФА©ідЛШІДївЎЈОЄКІГґУГБЛЅЕ±ѕЙъіЙєуЈ¬»№»бФЩИҐХТёь¶аУ¦УГДШЈїТтОЄЅЕ±ѕЙъіЙКЗ»щУЪТ»Р©јЩЙиЈ¬¶шОТГЗµДјЩЙиКЗУРТ»Р©ѕЦПЮРФµДЈ¬ЛщТФЖдКµ»№КЗТЄ»щУЪёь¶аµДіЎѕ°ИҐЅШИЎёь¶аµДНјЖ¬Ј¬ЛщТФ»бХТёь¶аµДУ¦УГЎЈНЁ№эХвБЅЦЦ·ЅКЅѕНДЬ№»ХТµЅ±ИЅПѕщєвµДСµБ·ЛШІДµДЧґМ¬Ј¬И»єуѕНїЙТФЅшРР·ЦАаСµБ·ЎЈ

УЙУЪУГµДКЗЗЁТЖС§П°µД·ЅКЅЈ¬ФЪЗЁТЖС§П°АпГж±ИЅПїмЛЩЙПКЦµД·ЅКЅѕНКЗ Top-layer µД·ЅКЅЈ¬ФЪ Top-layer
ХвСщЗЁТЖС§П°µД¶ЁТеАпГжЈ¬ОТГЗ»б°СНшВзДЈРНЦРјдµДЛщУРІг¶ј¶іЅбЈ¬ѕНКЗФЪСµБ·µДК±єтЈ¬ХвТ»¶ОКЗІ»ІОУлСµБ·µДЈ¬И»єу»б°СЧоєуµД·ЦАаІгЈ¬Мж»»іЙОТГЗЧФјєµД·ЦАаІгЈ¬Ц»¶ФЧоєу·ЦАаІгЅшРРСµБ·ЎЈХвСщµД»°Ј¬ХвЦЦ»щУЪ
Top-layer µДСµБ·Ј¬ТСѕДЬ№»ґпµЅ±ИЅПєГµДР§№ыЎЈµ«КЗµ±ОТГЗПлТЄ°Сѕн»эВКЅшТ»ІЅМбЙэµДК±єтЈ¬ѕНРиТЄ°ССµБ·µДІгґО±дµГёь¶аЎЈ±ИИзОТГЗЦ®З°И«Ії¶іЅбБЛЈ¬ПЦФЪОТГЗФЩ·ЕіцБЅИэІгіцАґТІІОУлСµБ·Ј¬¶шХвёцК±єтСµБ·ІгѕН»бёь¶аЈ¬ХвСщЧјИ·ВКѕН»бУРТ»ёцёьґуµДМбЙэЈ¬ХвёцПаµ±УЪ
Fine-tune µДСµБ·ДЈКЅЎЈХвСщТ»ёцДЈКЅЛьЕцµЅµДОКМвКЗДгРиТЄёь¶аµДЛШІДЈ¬ХвёцФЪµ±З°µД№эіМЦРЈ¬ТІКЗРиТЄѕщєвµДОКМвЈ¬ФЪЛШІДУРПЮµДЗйїцПВЈ¬Дг»б·ўПЦТЄЧцХвёціўКФЈ¬ТІКЗІ»М«ДЬВъЧгРиЗуЈ¬ОТГЗПЦФЪТІ»№ФЪА©ідЛШІДµД№эіМЦРЎЈ

µЪИэёцКЗ¶аЅб№ыІўУГЈ¬ТІКЗПЦФЪіЈУГµДТ»ЦЦ·ЅКЅЈ¬ёшТ»ёцФНјЈ¬НЁ№эТ»ёцДЈРНЈ¬ѕН»бµГіцПлТЄµДЅб№ыЎЈ»№УРГ»УРЖдЛыµД·ЅКЅМбЙэѕн»эВКЈї»№УРТ»Р©±ИЅПєГµД·Ѕ·ЁЈ¬±ИИзЛµїЙТФ°СХвХЕНјЈ¬ЙъіЙТ»ХЕ»Т¶ИНјЈ¬ФЩЙъіЙТ»ХЕВЦАЄНјЈ¬УГ»Т¶ИНјЎўФНјЎўВЦАЄНј·Ц±рСµБ·ХвёцДЈРНЈ¬ДЈРНФЪІ»Н¬µДНјЧчОЄКдИлµДК±єтЈ¬УЙУЪЛьµДМШХчМбИЎІ»М«Т»ЦВЈ¬УРР©НјЛьµД·ЦАаФЪ»Т¶ИНјµД±нПЦ»б±дµГёьєГЈ¬УРР©НјФЪВЦАЄНјАпГжµД±нПЦ»бёьєГЈ¬¶шХвёцЗйїцПВЛь»бРОіЙТ»ёц»ҐІ№µД№ШПµЈ¬ЧјИ·ВКТІ»бµГµЅТ»ёц±ИЅПєГµДМбЙэЎЈ
ЖдКµіэБЛФЪФНјµДКдИлЛШІДЙПЅшРРТ»Р©ґ¦АнЈ¬»№їЙТФУГёь¶аµДНшВзДЈРНЈ¬ОТГЗСЎИЎБЛ ShuffleNet
ЗбБїј¶µДХвСщТ»ёцДЈРНЈ¬ХвёцК±єтѕН»бІъЙъґуёЕБщЦЦКдіцЅб№ыЈ¬¶ФЅб№ыЅшРРЧоґуёЕВКµДМбИЎЎЈЧоєуµДЅб№ыѕН»бУРТ»ёц±ИЅППФЦшµДМбЙэЎЈ
AIon µДУЕКЖУлМфХЅ
їЙТФїґТ»ПВХыёцІвКФїтјЬЈ¬Ль±ѕЙнґжФЪДДР©УЕКЖТФј°Ль»бГжБЩµЅДДР©МфХЅЎЈ

µЪТ»ёцЈ¬ОТГЗФЩїґТ»ПВµЪТ»ХЕНјЈ¬ХвѕНКЗёХїЄКјїґµДХвХЕНјЈ¬AIon ХвёцїтјЬФЪёчёцЦё±кЙПµД±нПЦЈ¬¶ј»б±ИЖдЛыїтјЬТЄєГЈ¬±ИИзЛµЛьµДїШјюІ¶»сїП¶ЁКЗµНµДЈ¬ТтОЄЛьНкИ«КЗ»щУЪНјПсК¶±рЈ¬ЛьµДїзЖЅМЁДЬБ¦КЗЦ§іЦµДЈ¬УЙУЪЛьІ»ТААµ
IDЈ¬ЛьµДОИ¶ЁРФТІКЗ±ИЅПёЯµДЎЈ

ЧЬЅбТ»ПВЈ¬їЙТФїґµЅЈ¬ЛьКЗТ»ёцїЙјыЗТїЙµГµДДЈРНЈ¬±ИЅПТЧУЪАнЅвєНїЄ·ўЎЈУЙУЪЛь¶ФПµНіїтјЬТААµ»б±ИЅПИхЈ¬µЅПЦФЪАґЛµЈ¬ЛьЦ»ТААµУЪОТГЗ¶ФПсЛШµгµДІЩЧчЈ¬їзЖЅМЁДЬБ¦ѕН»б±ИЅПЗїЎЈУЙУЪЛьІ»ТААµУЪ
IDЈ¬ЛщТФІ»УГµЈРДУЙУЪ ID »мПэµДОКМвЈ¬µјЦВґъВлТЄІ»¶ПёьРВЎЈ
µЪЛДёцЈ¬УЙУЪЦ»УРБЅІгКУНјКчЈ¬¶шЗТ±ИЅПЦ±№ЫЈ¬Па¶ФАґЛµЈ¬ЛьµДїХјдІ¶»с»б±ИЅПјтµҐЎЈ»№УРёцєГґ¦КЗЈ¬ЛьТІїЙТФЧцµЅОЮ·мЦ§іЦґ«НіїтјЬЈ¬ХвКЗЛьПа¶ФУЪПЦФЪїтјЬґжФЪµДУЕКЖЎЈ

µ±И»ЛьТІ»бУРР©І»ЧгµДµШ·ЅЈ¬ТІѕНКЗОТГЗЛщТЄГжБЩµДМфХЅЎЈµЪТ»ёцЈ¬УЙУЪјјКхСЎРНµДОКМвЈ¬ЛьТ»¶Ё»бГжБЩЧјИ·ВКµДОКМвЈ¬ЗЁТЖіцАґµДОКМвКЗСщ±ѕКэБїІ»№»µДОКМвЈ¬¶шЗТХвБЅёцОКМвКЗ±ИЅПУРМфХЅµДЎЈіэґЛЦ®НвЈ¬»№УРѕНКЗЦґРРР§ВКµДОКМвЈ¬ТтОЄ»бЕЬєЬ¶аДЈРНЈ¬ЧцНјПсЗРёоЈ¬ЧцНјПс·ЦАаЈ¬»№УР
OCR ХвСщµДКВЗйЈ¬Дг»б·ўПЦЛьЙжј°µДІЅЦиєЬ¶аЈ¬ТтОЄОТГЗЦґРРТ»ёцІвКФУГАэЈ¬К±јдїП¶ЁФЪТ»БЅГлЈ¬Чо¶аБЅИэГлЎЈТЄФЪТ»БЅГлЦ®ДЪЈ¬НкіЙХвГґ¶аІЩЧчЈ¬ФЪЦґРРР§ВКЙПТІКЗУРТ»Р©МфХЅµДЎЈУЙУЪКЗФЄЛШМбИЎµД·ЅКЅЈ¬µ±ЕцµЅєН±іѕ°µДИЪєП¶И±ИЅПёЯµДіЎѕ°Ј¬Дг»б·ўПЦЛьµДЗ°ѕ°µДМбИЎПа¶ФАґЛµ±ИЅПА§ДСЎЈ
»№УРѕНКЗПсМШХчЦµ·ЗіЈЙЩµДФЄЛШЈ¬ЧоµдРНµДѕНКЗОД±ѕКдИлїтЈ¬єЬ¶аОД±ѕКдИлїтЙијЖЦ»УРПВГжТ»МхПЯЈ¬ФЩєГµДЗйїцЈ¬ФЪѕЫЅ№µДЗйїцПВ»бУР№в±кЈ¬ТЄ»щУЪХвСщµДМШХчЦµЈ¬°СЛьК¶±ріцАґКЗКдИлїтЈ¬ДС¶ИПа¶ФАґЛµ±ИЅПґуЎЈ»№УРТ»Р©РьёЎФЄЛШµДМбИЎЈ¬РьёЎФЄЛШєНµЪЛДёцЕцµЅµДОКМвКЗТ»СщµДЈ¬ЛьФЪТ»Р©єН±іѕ°ФЄЛШИЪєП¶ИІ»КЗєЬёЯµДЗйїцПВЈ¬ТІГ»УРМ«ґуµДОКМвЈ¬µ«КЗИз№ыЕцµЅТ»Р©іЎѕ°єН±іѕ°µДФЄЛШИЪєП·ЗіЈЙоЈ¬ХвёцК±єтЛьТІ»бУРТ»Р©ОКМвЎЈ
AI ОґАґ
ЅсМмЦчТЄЅІБЛТ»ПВїЙТФУГ AI °пОТГЗЅвѕцЦ®З°Т»Р©ґ«НіїтјЬїЙДЬ»бЕцµЅµДОКМвЈ¬јґК№ґ«НіµДЛг·ЁТІ»бЕцµЅТ»Р©Лг·ЁЈ¬УГБЛ
AI јјКхТІ»б·ўПЦЈ¬ХвР©ОКМв¶ј»бµГµЅ±ИЅПєГµДЅвѕцЎЈіэґЛЦ®НвЈ¬ОТГЗФЪ AIЈ¬»№УРёь¶аµДі©ПлЈ¬іэБЛХвёцКВЗйТФНвЈ¬»№ДЬУГ
AI Чцёь¶аµДКВЗйЎЈ

µЪТ»Ј¬ґнОуЅзГжµДК¶±рЈ¬ФЪЛщУРµДЧФ¶Ї»ЇІвКФ№эіМЦРЈ¬¶ј»бЕцµЅТ»ёцОКМвЈ¬±ИИзДіТ»ёцЅзГжЈ¬ДіТ»ёцОДЧЦ±»ХЪёЗЧЎБЛЈ¬»тХЯЛµХвБЅёцОД±ѕіцПЦБЛЦШµюЈ¬»тХЯіцПЦТ»ёцґуµДїХ°ЧЈ¬¶шХвСщµДіЎѕ°Из№ыУГґ«НіµДІвКФїтјЬЈ¬ИҐЧцСйЦ¤Па¶ФАґЛµКЗ±ИЅПА§ДСµДЈ¬µ«КЗИз№ыУГОТГЗµДІвКФїтјЬЈ¬ѕН»б·ўПЦДгТЄЧцХвёцКВЗй·ЗіЈјтµҐЎЈїЙТФєЬ·Ѕ±гµШ°пДгјмІвіцТ»ґу¶ОїХ°ЧЈ¬ОД±ѕЦШµюЈ¬ОДЧЦёІёЗХвСщµДіЎѕ°Ј¬ЙхЦБУРР©±іѕ°Й«І»ВъЧгРиЗуТІїЙТФ°пДгјмІвіцАґЎЈ
µЪ¶юЈ¬ЧУФЄЛШµД AI К¶±рЈ¬ХвКЗ¶ФОТГЗїтјЬµДТ»ёцУЕ»ЇЈ¬¶Фґ«НіНјПсЖҐЕдјјКхµДТААµРФ»бёьИхЈ¬ОТГЗТЄХТЛСЛч°ґЕ¦µДК±єтЈ¬ѕНІ»УГЛСЛч°ґЕ¦ИҐЖҐЕдЈ¬Ц»ТЄёшЛьТ»ёцЛСЛчОДЧЦЈ¬ХвјюКВ
APM їтјЬ№«ЛѕТІФЪЧцЎЈ
µЪИэЈ¬ФЪУ¦УГµДРФДЬУЕ»ЇіЎѕ°ЙПТІДЬЧцБЛТ»Р©КВЗйЈ¬Из№ыФЪїН»§¶ЛДЬ№»Ф¤ІвіцУГ»§ПВТ»ёц»бЅшИлДіёцТіГжЈ¬ХвёцКЗНЁ№эУГ»§РРОЄ·ЦОцЈ¬»тХЯ»щУЪС§П°µД»°Ј¬КЗїЙТФФ¤ІвУР¶аґуёЕВК»бЅшИлµЅДЗёцЅзГжµДЎЈИз№ыДгДЬФ¤ІвіцЈ¬ЛьПВГж»бЅшИлДДТ»ёцЅзГжЈ¬Дг»б·ўПЦЈ¬¶ФЛьЅшРРФ¤јУФШµД»°Ј¬ХыёцУ¦УГµДМеСйѕН»б±дµГёьєГЎЈ
µЪЛДёцЈ¬ПЦФЪТІКЗ·ЗіЈ»рµДУ¦УГіЎѕ°БЛЈ¬ДЗѕНКЗ UI2CodeЈ¬°ьАЁОўИнЎў°ўАпЈ¬»№Уж๫˾¶јФЪЧцХвСщµДіўКФЈ¬°ьАЁОТГЗТІФЪЧцХвСщµДіўКФЈ¬ѕНКЗЛьїЙТФ°СТ»ХЕНјЖ¬Ј¬ДжПтЙъіЙІјѕЦНјіцАґЎЈОТГЗФЪЧФ¶Ї»ЇІвКФ№эіМЦР»№»бВјИЎТ»Р©КУЖµРЕПўЈ¬ВјИЎНкКУЖµРЕПўТФєуЈ¬ОТГЗ»бФЪєуГж¶ФКУЖµРЕПўЅшРР·ЦЦЎК¶±р»тХЯТ»Р©·ЦОцЈ¬¶шХвёцК±єтИз№ыФЩТэИл
AI јјКхЈ¬Дг»б·ўПЦЛьДЬґуґуМбЙэ·ЦОцК±єтµДЧјИ·ВКєНИЛ№¤ІОУл¶ИЎЈ
|





