| 编辑推荐: |
本文主要介绍什么是测试基础架构,测试执行和测试执行环境服务的设计,测试数据服务的设计,最后介绍测试结果自动化分析服务的设计,希望对您的学习有所收获。
本文来自于博客园,由Alice编辑、推荐。 |
|
概述:
今天我主要讲四个内容,我做内容规划的时候其实内容偏多,对于一些通用的内容可以讲得快一点,干货部分会讲得仔细一点。
第一部分,DevOps 中高效测试基础架构设计概览。
第二部分,测试执行服务和测试执行环境服务的设计。涉及 Jenkins 和容器,帮助我们非常短的时间内完成成千上万测试用例的执行。
第三部分,做 DevOps 的过程当中发起测试。其实有时候测试是不稳定的,有些测试的不稳定很多是来自于测试数据。怎么建立一套测试数据体系来帮助测试跑得流畅和顺利?这里会介绍行业内的一些最佳实践。
第四部分,测试结果自动化分析服务的设计与应用。全回归测试的用例数量往往很多,很多大型企业全回归测试用例数量会达到好几万这样的量级。在这种情况下哪怕有1%的失败率,失败的绝对数量还是很大的。
大量的失败用例如果用传统人工方式对其做分析,你会发现CI流水线跑得再快,测试本身会成为过程中的瓶颈。我们怎样通过构建自动化的测试结果分析,运用一些AI的理念快速做失败用例的分类?这就成了我们讨论的重点。
一、DevOps中高效测试基础架构设计概览
首先讲一下什么是测试基础架构?我们可以从一个非常简单的方式去理解一下,当我们的CI/CD的Job要跑测试的时候,需要通过测试执行环境测试执行用例,测试执行环境本身需要人维护,测试用例代码需要管理,测试代码版本也需要人管理。
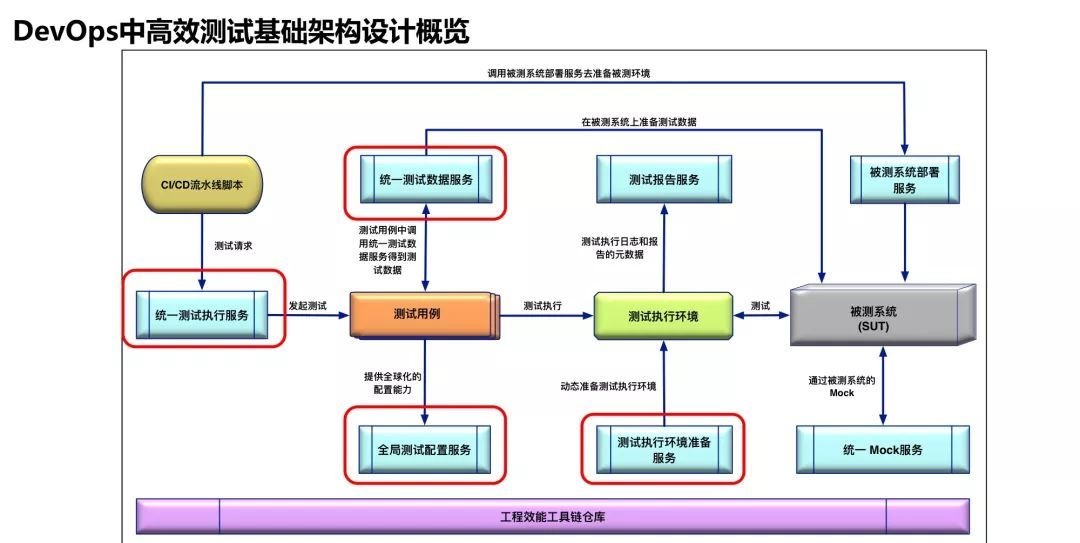
看一下整体架构。这个架构看上去有点复杂,但是其实也是很容易理解的。
CI在不同阶段会去执行不同测试,在早期或者在传统的CI的脚本里,对于发起测试的命令行是在Jenkins的脚本里,所以测试脚本是强绑定的。我们希望CI可以和测试发起的命令行不是这种强绑定的关系。
在这种情况下,我们提出了统一测试执行服务概念,这个统一测试执行服务可以发起各种类型的测试,但接口统一,在这种情况下CI脚本里可以直接调用统一的API的service达到解耦。
统一测试执行服务会作为发起测试的唯一入口,统一测试执行服务会先调用测试环境准备服务建立测试执行环境,然后实际发起测试,测试用例中还会调用测试数据准备服务来生成测试数据,同时将测试结果发送到测试报告服务。其中的全局配置服务用来实现测试脚本和测试配置的解耦。
这里有一个测试执行环境的概念,早年测试执行环境比较容易理解,就是本地机器装了浏览器发起测试执行的机器。但在互联网背景下,测试执行环境变得非常复杂,主要体现在几方面。第一方面,要兼容不同浏览器还要兼容不同手机终端上不同的浏览器。以前比如100个case,一个一个跑,没问题,有时间。
但在互联网模式下,迭代周期可能是以天为单位的,你希望在很短的时间内把测试用例跑完,一定要采用并发,我们会让很多的case并发去跑,意味着如果有100个case想最短的时间跑完,意味着要100个机器同时跑,这样时间最短,100个case里面最长的执行时间就是整体的执行时间。
这时候希望整个测试环境和机器数量可以根据测试用例的多少,以及需要完成的时间来动态计算或准备,这个服务叫测试执行环境准备服务。
还有一些测试报告服务,可以提供统一报告。还有一些微服务测试的Mock服务,这些不是今天的重点。
二、测试执行服务和测试执行环境服务的设计
整个过程我们会讲一下测试执行和测试执行环境服务的设计。讲这个之前我们先想一下,测试执行环境有哪些诉求,或者说有哪些问题?

如果你是开发,或者是需要发起测试执行的人,当你发起测试的时候,最理想的情况是要跑一个测试的时候不需要自己去准备测试执行环境,希望执行环境是按需得到的,只需要说我要什么,不关心我怎么得到,这就是所谓的测试执行环境的透明性,所有的测试环境要准备好,这个是透明的,你要他就给你,至于他是怎么准备的?你不用管。
对维护者来讲问题就来了,要啥给你啥,意味着后台要维护大量不同操作系统中的不同浏览器,甚至是不同的手机终端,这里面有大量的维护工作,怎么在两边做平衡?这是测试执行环境的痛点。
最关键的一点,对大量的测试用例执行而言的执行能力可扩展性。刚才讲过,为了要在有限时间内,在CI过程中跑完很多case,会用并发来跑,但这个机器数量到底是放多少台机器?如果放固定的,比如测试执行机里面放了800台机器,空闲的时候全部是闲在那里的,但是到了发布的高峰阶段,这800台机器明显不够用,每台机器都在排队,所以我们希望机器可以随着测试用例数量的变化来动态扩容或者缩容,我们会用Docker技术来做,这是主要的诉求。
我们也不是一开始就做得很好,一开始是用很简单的环境,然后一点一点做成相对比较完善的方案,接下来我会通过这个过程,讲解一下整个过程是怎么发生变化的,以及在这个过程中我们遇到了什么问题,用什么方案进行的解决。
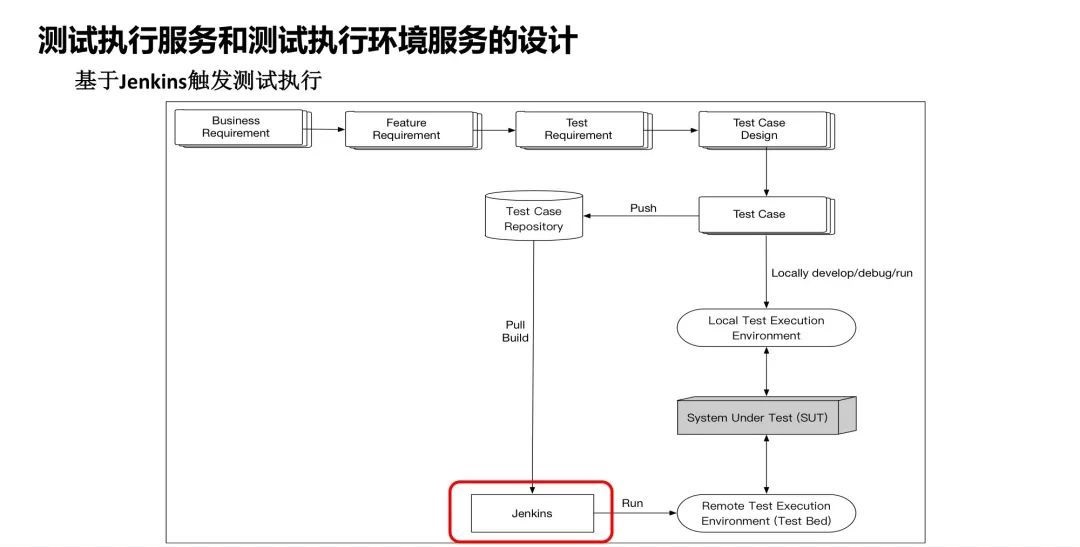
最早期的版本,相信大家都非常熟悉,Test case 放在代码仓库里管理,然后会有一个Jenkins的Job,Jenkins会把仓库里面的Test
case给push下来,在一台或一批固定的机器上打开相应的浏览器,对被测系统进行发起测试,这是最原始的方案。我相信很多公司都在按这个方式用,随着这个方式越用越多,我们会发现有一个地方出了问题。
在Jenkins里面的Job数量越来越多,而且这些Jenkins的Job命名和规范,某某项目、某某版本、某某类型的测试会越来越多和越来越复杂,测试执行完成后的测试报告管理,都是依赖于Jenkins做的,这时候我们觉得这个东西不够灵活,也不够方便。
为此,我们在Jenkins的上层放了一个新组件,叫统一测试执行服务。这是什么系统?说白了这个很简单,就是在Jenkins的基础上放了UI,这个UI是一个壳,对测试用例的Jenkins
Job进行界面化管理或者说版本化管理。在这里面我们可以统一基于项目、时间和不同类型的测试分类,对这些Jenkins的Job进行管理。同时,我们会对Jenkins执行完成后的Test
report进行统一化管理,这是我们做的第一件事情。
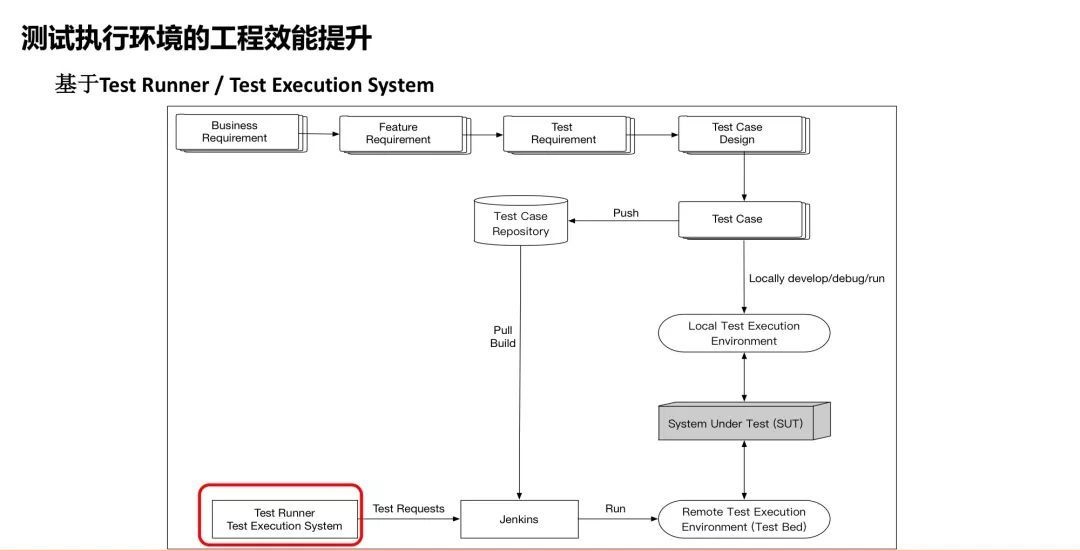
同时,这个系统除了有UI界面外,我们把这个系统对外暴露出了Restful API接口,这个接口用于和CI的Jenkins打交道。
到了这个阶段之后我们发现,测试执行的管理虽然方便了很多,但问题还有。问题来自于哪里?大家有没有注意到,这里的测试执行机器,通常是固定放在那里的,这里面放的是不同操作系统装了不同浏览器组合的机器。
当Jenkins要跑测试的时候,假定这个测试跑在Linux的Chrome上面,这时候就需要到这个库里找到安转了Chrome的Linux机器的IP地址,然后把这个IP地址作为Jenkins
Job的参数,然后Jenkins Job才能找到这台机器做测试。这样一来,你是不是觉得这个东西非常不方便?还要人工维护一张列表来记录所有测试执行机器的列表。
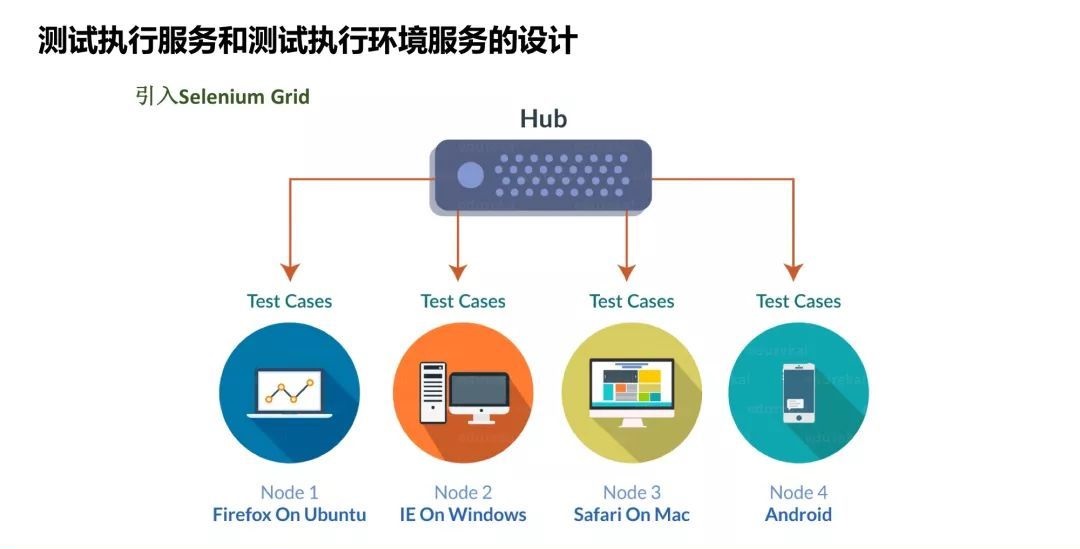
有什么好的方法来解决?我们引入了Selenium Grid。大家不要把Selenium Grid想象得很复杂,如果时间充裕我们可以在现场机器搭建Grid环境,不超过五分钟就可以把这个环境搭建起来。它是类似于一个二层的树状结构,根接点我们称为Hub,下面的叶子节点我们称为Node,节点可以挂不同浏览器和操作系统的组合。

当我们需要跑不同浏览器或者不同手机测试的时候,把请求发给Hub,由Hub统一分发。发给Hub的时候告诉Hub测试需要在什么操作系统的什么浏览器上执行,然后Hub会到下面的节点去寻找,如果有满足要求的Node就会在该Node上执行测试。
于是我们就把架构变成了这样,把固定的机器变成了Selenium Grid,这时候Jenkins还需要知道每个具体执行机的IP地址吗?不需要,它只需要知道Hub的地址,所有后面的分发全部由Hub完成,这是我们第一次做的比较大的更新。有了这个环境之后,我们觉得测试用例越跑越顺了,但这时候我们发现还有新的问题。
由于Hub下Node的容量可以扩展,一个Hub下面可以放的Node数量很多,可以挂成百上千个Node,这个时候,在实际工程环境中Jenkins就成为了瓶颈。
我们会发现,Hub下面大量的Node其实有很多处于空闲状态,但Jenkins却在排队,因为Jenkins只有单节点,不能及时把测试分发下去,相当于这个Jenkins节点变成了整个系统的瓶颈点,那我们怎么解决?最简单的方式就是把Jenkins做成Cluster,于是就有了Master/Slave部署的Jenkins集群,这样就把Jenkins的排队的问题解决了。
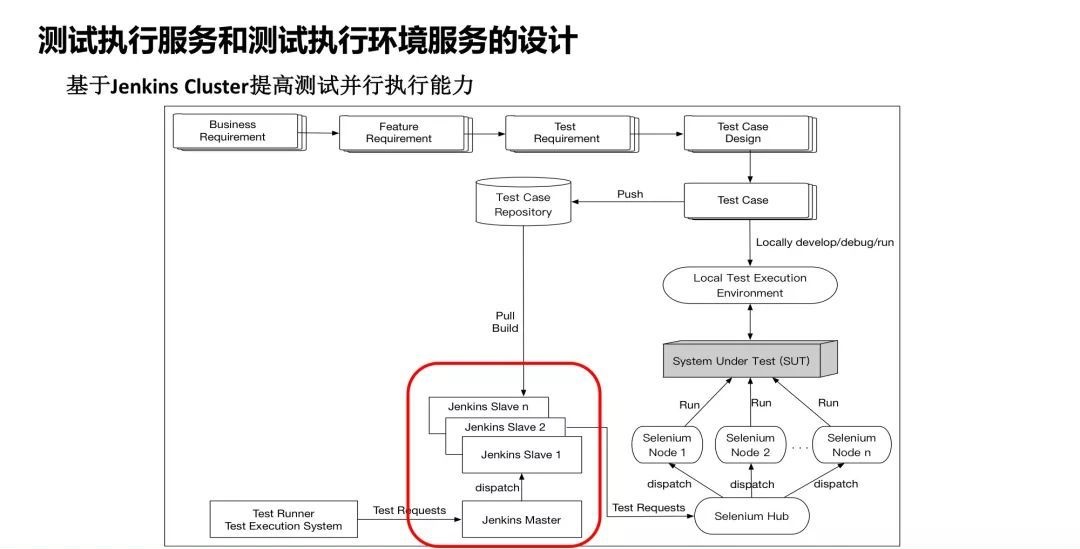
之后又引来了一个新的问题,到底应该在这个环境里放几个Node?就像我说的,如果你放的Node数量比较少,那就省钱了,但是在高峰的时候不够用。但如果放的很多,浪费钱浪费电。我们有什么好的方法解决这个问题?现在大家可以想到,我们完全可以用容器做这个事情,不需要用虚拟机挂Node。
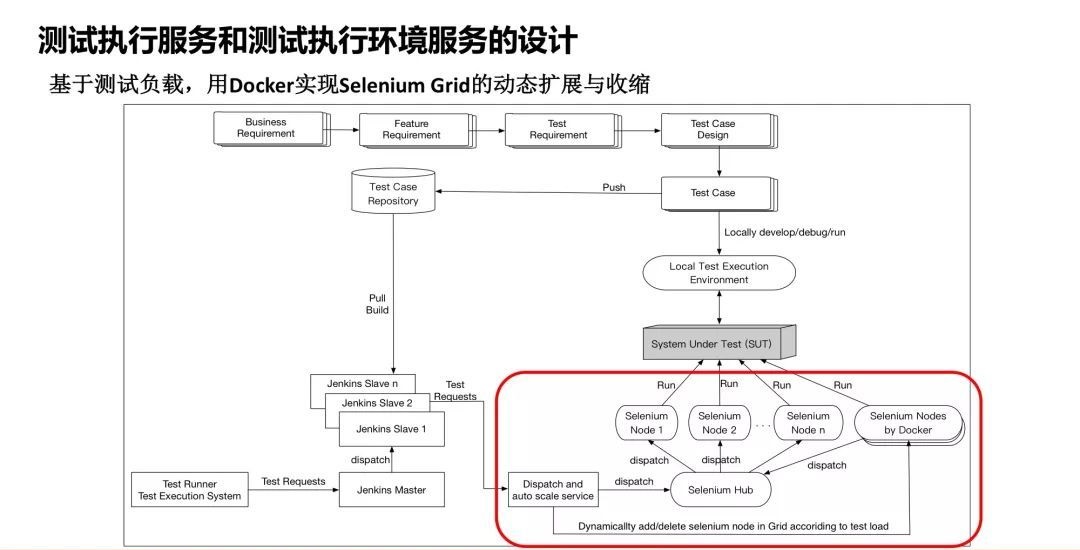
一旦用了容器挂Node,下面的节点就变成了Docker容器,同时引入了容量自动伸缩的模块,这个模块会根据Jenkins这边送过来的测试用例的排队数量以及需要在多少时间内完成,然后动态计算一个最佳的Node数量,以此快速来产生这个Node集群。
Jenkins来的时候,明确知道需要哪个操作系统和浏览器,所以在准备这个集群的Node的时候针对性很强,没有任何的浪费。这个事情是我们好多年前做的,当时我们做这个的时候,Selenium
Grid的这套系统还没有Docker版本,后来我们还发现了很多bug,跟Selenium Grid和Docker团队做了沟通,他们意识到这是很好的方向。
所以后来,Selenium Grid官方开始提供Docker版本的交付,所有的Docker Image都是现成的,你可以直接拿下来用,如果我们现场搭的话,几分钟就搭起来。
这样一来,我们就可以做到在一分钟以内甚至是秒级,可以从平时的几百个Node,在很短的时间内扩展成几千个Node,跑完后测试执行环境会自动回收,这样我们就省了很多钱,测试执行环境的执行能力明显上去了。
这是刚才讲的测试执行服务的截图,从界面来看,可以在这上面选择要跑什么测试,以及跑在哪些设备上,通过点击就可以跑。跑的时候可以选择测试环境、国家。红框里的内容很关键,这个选择的是测试用例的版本号。这个怎么选择?我们这个系统会动态侦测被测环境上的开发部署包是什么版本,自动找寻跟它一比一的测试用例版本。
三、测试数据服务的最佳实践
刚才讲的是测试执行服务以及测试执行环境服务,接下来讲一下测试数据服务。
说白了,这个就是为你的CI过程中所执行的测试准备相应的测试数据。

测试数据准备有很多的复杂性,时间原因不一条一条展开讲了。我们最终做了一个非常棒的解决方案,把它变成了一个统一测试数据服务,只要你告诉该服务需要什么数据,该服务就会就帮你生成想要的测试数据。怎么生成的?你什么都不用管,由这个服务全权负责。但统一测试数据服务也不是一蹴而就做出来的,我们也经过了很长时间的发展,我会讲一下这个发展历程,可能对大家开阔思路还是很有帮助的。

我们一开始的时候做了1.0版本,你不是要测试数据吗?比如要一个用户数据,我会把创建user所需要的API或数据操作封装成数据工具函数。当你需要创建user的时候,可以直接调用数据工具函数就能拿到user。当时我在设计这个方案的时候,我自认为肯定受欢迎,因为原来的数据是乱七八糟各搞各的,有些用脚本,有些自己复制,我觉得做完这个一定会受欢迎。但实际情况很悲惨,做完这个之后他们一点都不喜欢,你们知道为什么吗?
很多时候测试要一个user,其实绝大多数场景是能用就行了,不关注user的具体属性。更多的场景或者有一些场景只关心一个属性,要一个美国的用户,或者要一个绑定了支付宝的用户,只关心这一个属性,其他以外的不关心。
如果封装成这种函数,你需要知道数据的每个属性,那就很不方便了,而且更坑的是什么?数据工具函数的参数还有复杂类型,调用之前要构建复杂类型,所以这个东西肯定不好用。

为了解决这个问题,我们做了2.0。这个我们做出来大家就很受欢迎了,我们会把最顶部这部分五个参数的组合作为底层函数实现,把其中A,B,C,D,E五个参数默认初始化,然后调用底层函数。如果你只关心一个参数,就把这一个参数暴露出来。除了暴露出来以外的余下参数,帮你做默认初始化,这样一来用的人就爽了,只需要用一行。如果要改一个参数,那就调这个,使用的人就会很方便。
这个就像讲测试执行环境是一个道理,用的人爽了,维护的人很就苦了。如果有五个参数、六个参数、十五个参数怎么办?单个可以暴露,两两可以组合,三个也可以组合,那就无休止了。
为此,我们在此基础上又做了改良。当我需要一个user,我们引入了Builder模式,当需要指定一个属性而其他属性可以采用默认值的时候,with这个参数值就可以了。如果需要两个参数修改,就是with两个参数就可以了。其他没有被制定的参数就会直接使用默认值。这样,不管测试数据多复杂,都可以用一行代码调用来生成测试数据。这就是2.0时代。
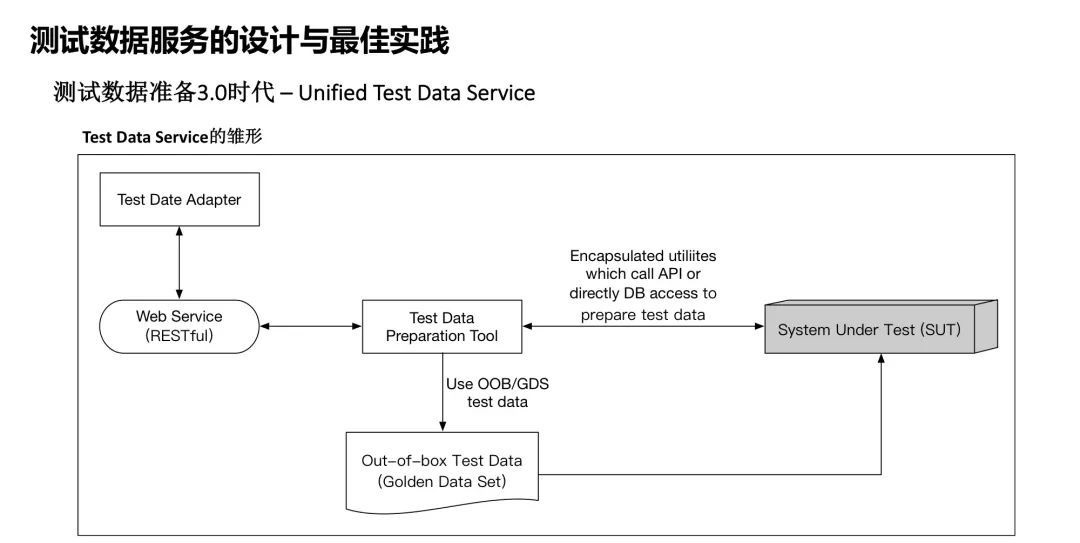
接下来,再看一下3.0时代,上述的测试数据工具和相应的Builder模式都是基于Java语言实现的,但是实际工程实践中,往往基于不同开发语言的测试开发框架可能同时存在,这就要求上述的测试数据生成分案需要支持不同的开发语言,为此,我们把上述测试数据工具用Spring
Boot和Swagger转化成了测试数据服务,对外提供Restful接口。
四、测试结果自动化分析服务的设计与应用
看一下测试结果分析,这部分比较有意思。大公司的回归测试用例数量往往都很大,百分之一的失败就是几十个乃至百个用例。我们第一步分析的目的是什么?仅仅把这个bug分配给正确的team,靠人做效率很差,我们能不能让机器来做?于是我们就引入了一个系统,该系统会根据Test
report和test log,结合kNN算法来对失败用例进行分类,判断这个bug应该分配给哪个团队去继续跟进。

KNN算法的核心思想相当于在三种豆子里面分豆子。比如这颗画圈的豆子,到底是黄色橙色还是绿色?会先计算距离,然后拉一个框看这些距离哪个最近,看哪个多,它属于最多的这一类的可能性就最高,以这种方式进行分类。
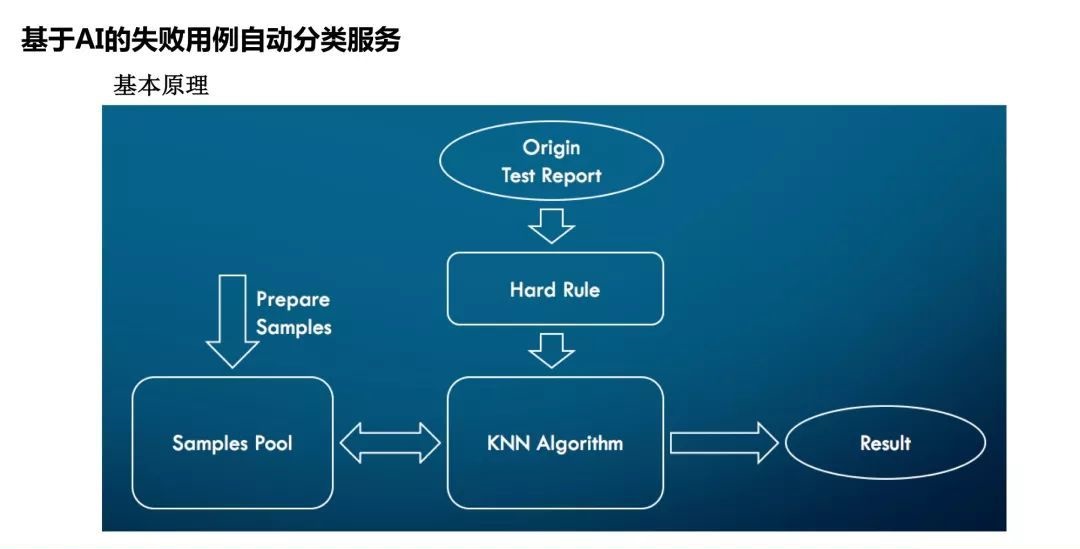
做分类的时候有特征值选取的问题,通常会用这些值来做。
|





