| 编辑推荐: |
本文主要介绍了JMeter压力测试:下载安装及使用、性能测试常用指数简介、JMeter的重要参数简介、JMeter工具常用界面设置、JMeter压力测试时遇到的常见问题及Linux查看程序运行情况,希望对您的学习有所帮助。
本文来自于CSDN,由Linda编辑、推荐。 |
|
一、下载安装及使用
下载地址:jmeter-plugins.org
安装:下载后文件为plugins-manager.jar格式,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。
启动jemter,点击选项,最下面的一栏,如下图所示: 
打开后界面如下:
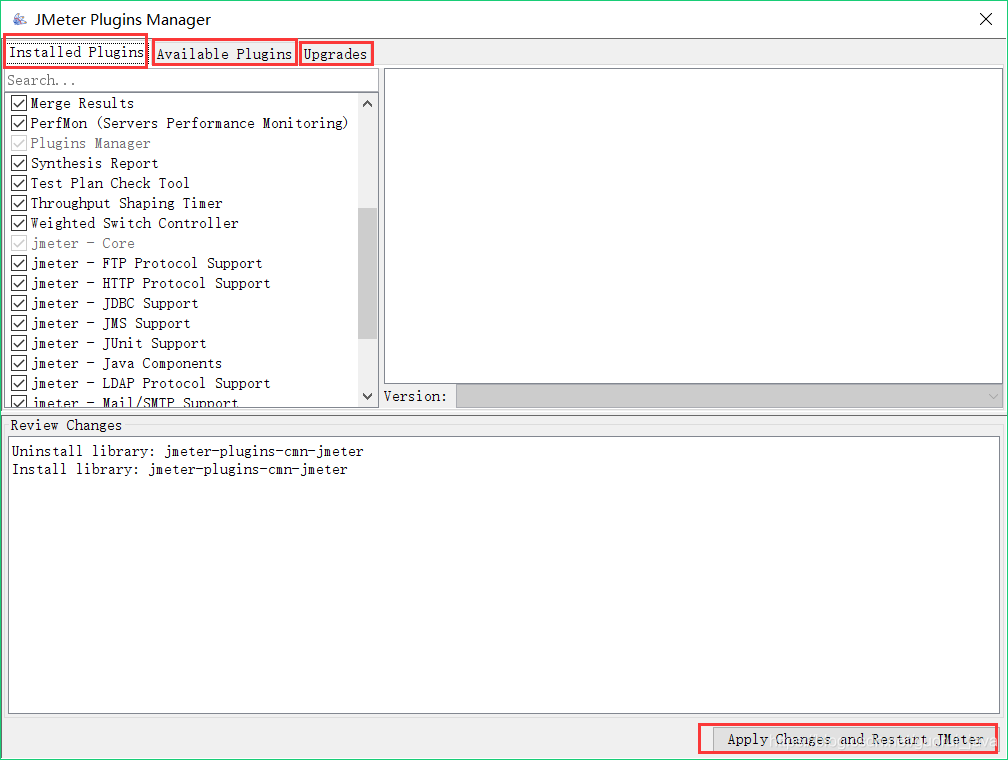
Installed Plugins(已安装的插件):即插件jar包中已经包含的插件,可以通过选中勾选框,来使用这些插件;
Available Plugins(可下载的插件):即该插件扩展的一些插件,可以通过选中勾选框,来下载你所需要的插件;
Upgrades(可更新的插件):即可以更新到最新版本的一些插件,一般显示为加粗斜体,可以通过点击截图右下角的Apply
Changes and Restart Jmeter按钮来下载更新;
PS:一般不建议进行更新操作,因为最新的插件都有一些兼容问题,而且很可能导致jmeter无法使用(经常报加载类异常)!!!
建议使用jmeter最新的3.2版本来尝试更新这些插件。
二、性能测试常用指数简介
1、TPS,每秒事务数
Transactions per Second
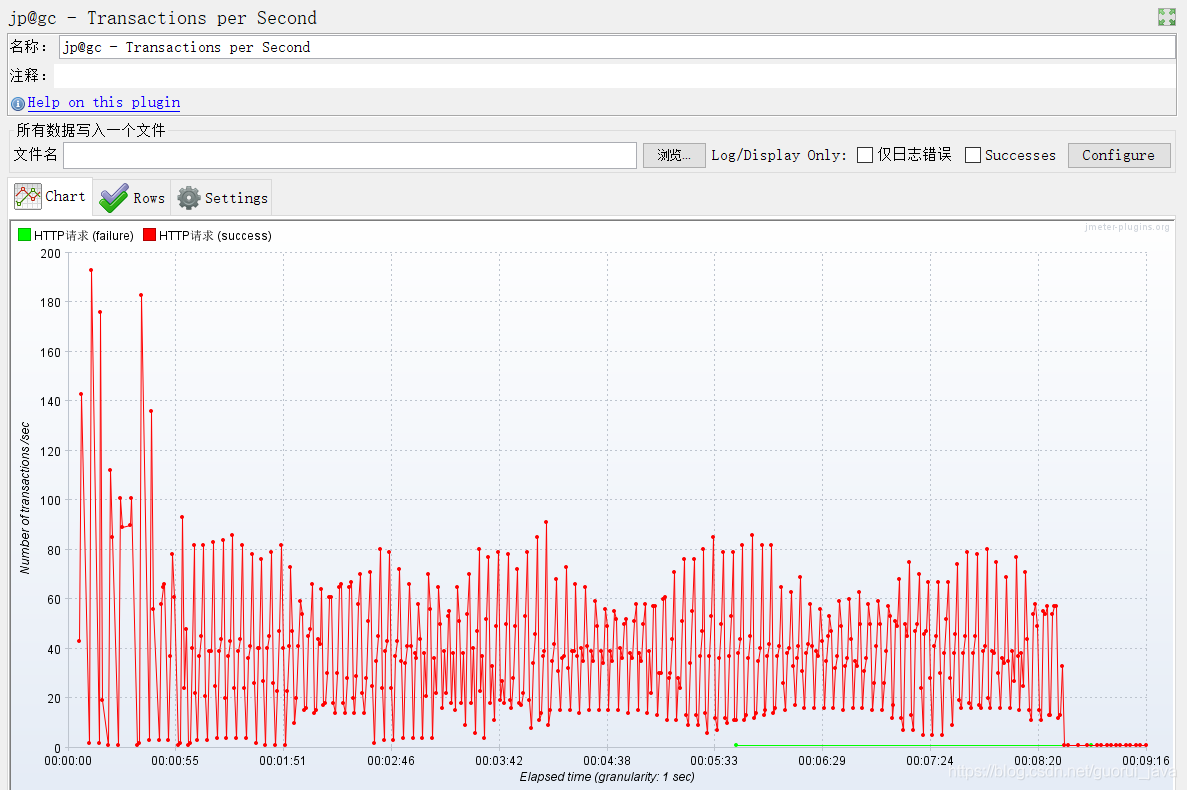
即TPS:每秒事务数,性能测试中,最重要的2个指标之一。该插件的作用是在测试脚本执行过程中,监控查看服务器的TPS表现————比如整体趋势、实时平均值走向、稳定性等。
jmeter本身的安装包中,监视器虽然提供了比如聚合报告这种元件,也能提供一些实时的数据,但相比于要求更高的性能测试需求,就稍显乏力。
某次压力测试TPS变化展示图:
2、系统吞吐量 QPS(TPS)
系统吞吐量 = 每秒处理的事务数
QPS(TPS)= 并发数/平均响应时间
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
3、TRT,事务响应时间
Response Times Over Time
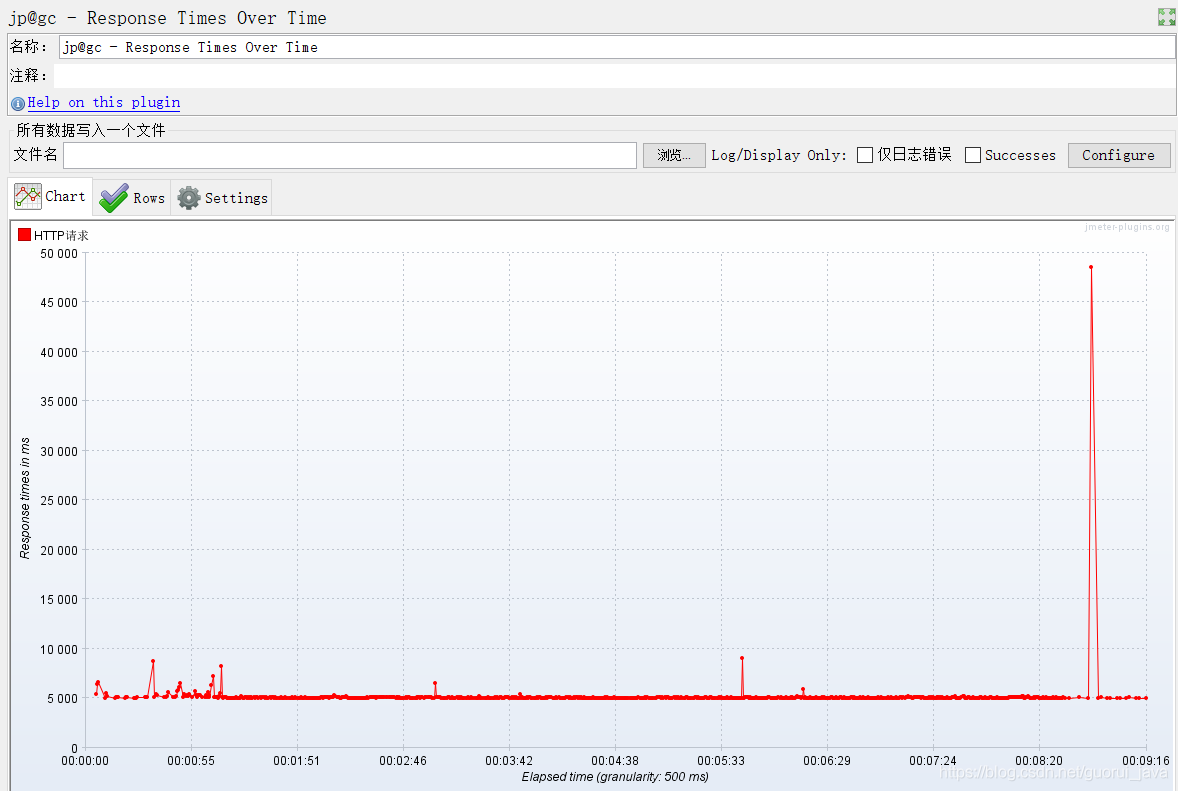
即TRT:事务响应时间,性能测试中,最重要的两个指标的另外一个。该插件的主要作用是在测试脚本执行过程中,监控查看响应时间的实时平均值、整体响应时间走向等。
使用方法如上,下载安装配置好插件之后,重启jmeter,添加该监视器,即可实时看到实时的TRT数值及整体表现。
某次压力测试TRT变化展示图:
4、PerfMon Metrics Collector
即服务器性能监控数据采集器。在性能测试过程中,除了监控TPS和TRT,还需要监控服务器的资源使用情况,比如CPU、memory、I/O等。该插件可以在性能测试中实时监控服务器的各项资源使用。
下载地址:http://jmeter-plugins.org/downloads/all/或链接:http://pan.baidu.com/s/1skZS0Zb
密码:isu5
下载界面如下:
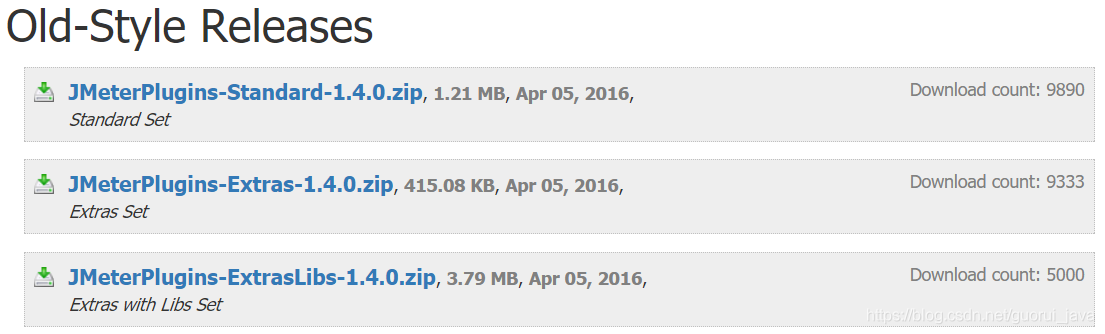
其中JMeterPlugins-Standard和JMeterPlugins-Extras是客户端的插件,ServerAgent是服务端的插件。
下载成功后,复制JmeterPlugins-Extras.jar和JmeterPlugins-Standard.jar两个文件,放到jmeter安装文件中的lib/ext中,重启jmeter,即可看到该监视器插件。
将ServerAgent-2.2.1.jar上传到被测服务器,解压,进入目录,Windows环境,双击ServerAgent.bat启动;linux环境执ServerAgent.sh启动,默认使用4444端口。
如出现如下图所示情况,即表明服务端配置成功:

(1)服务端启动校验
CMD进入命令框,观察是否有接收到消息,如果有,即表明ServerAgent成功启动。
(2)客户端监听测试
给测试脚本中添加jp@gc - PerfMon Metrics Collector监听器,然后添加需要监控的服务器资源选项,启动脚本,即可在该监听器界面看到资源使用的曲线变化。如下图所示:
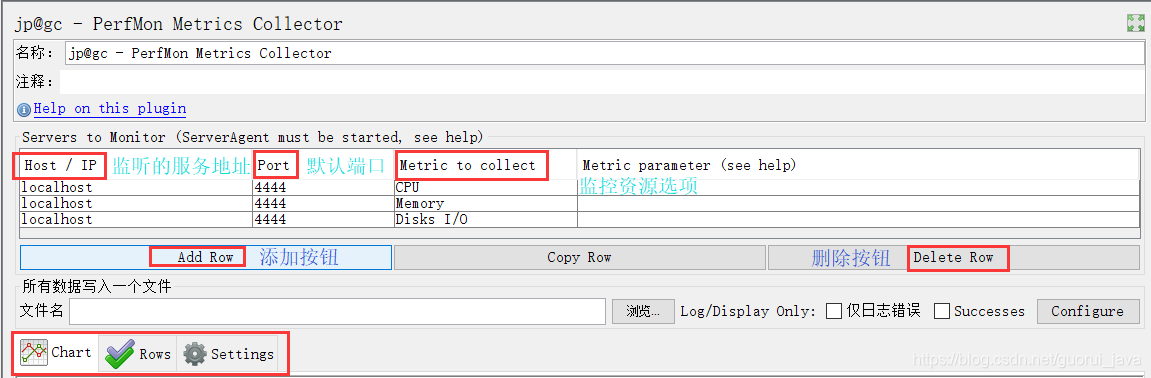
在脚本启动后,即可从界面看到服务器资源使用的曲线变化,Chart表示主界面显示,Rows表示小界面以及不同资源曲线所代表的颜色,Settings表示设置,可选择自己需要的配置。
PS:注意测试脚本需要持续运行一段时间,才可以看到具体的曲线变化,否则ServerAgent端会断开连接!
三、JMeter的重要参数简介
1、JMeter客户端实现方式简介
1、Java:选择压测时,链接是复用的(代码中的http调用都加了连接池)
2、httpclient4:压测时,每请求一次都创建一个新的链接,(jmeter5.0以前默认关闭了连接复用,5.0上是打开的:即每请求一次都会创建一个新的链接)。
从JMeter 5.0开始,当使用默认的HC4实现时,JMeter将在每个线程组迭代时重置HTTP状态(SSL状态+连接)。如果您不想要此行为,请设置httpclient.reset_state_on_thread_group_iteration
= false
所以httpclient4 在连接复用设置打开的情况下,压测结果与java的是不一样的,因为java复用链接,httpclient4每次连接都会重新建立tcp连接,如果httpclient4吞吐量过低,需要考虑网络带宽的限制
java实现适合压榨性测试,httpclient4适合真实场景的模拟,
连接池的作用于原理:
正常访问数据库的过程中,每次访问都需要创建新的连接,这会消耗大量的资源;连接池的就是为数据库连接建立一个“缓冲区”,预先在缓冲池中放入一定数量的连接对象,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去;且连接池允许多个客户端使用缓存起来的连接对象,这些对象可以连接数据库,它们是共享的、可被重复使用的;使用连接池可以节省大量资源,提高程序运行速度。
连接池的基本原理是:先初始化一定的数据库连接对象,并且把这些连接保存在连接池中。这些数据库连接的数量是由最小数据库连接数来设定的。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。当程序需要访问数据库的时候,如果连接池中有空闲的连接,可直接得到一个连接;如果连接池对象中没有空闲的连接,且连接数没有达到最大,会创建一个新的连接从连接池中取出一个连接,数据库操作结束后,再把这个用完的连接重新放回连接池。
2、Keep-Alive模式
我们知道Http协议采用“请求-应答”模式,当使用普通模式,即非Keep-Alive模式时,每个请求/应答,客户端和服务器都要新建一个连接,完成之后立即断开连接;当使用Keep-Alive模式时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
http1.0中默认是关闭的,需要在http头加入”Connection: Keep-Alive”,才能启用Keep-Alive;
http 1.1中默认启用Keep-Alive,如果加入”Connection: close “才关闭。目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep-
Alive连接就看服务器设置情况。
开启Keep-Alive的优缺点:
优点:Keep-Alive模式更加高效,因为避免了连接建立和释放的开销。
缺点:长时间的Tcp连接容易导致系统资源无效占用,浪费系统资源。
3、自动重定向与跟随重定向
Redirect Automatically(自动重定向):只针对Get和Head请求,勾选此项则“跟随重定向”失效;自动重定向可以自动转向到最终目标页面,但是Jmeter是不记录重定向的过程内容,比如在察看结果树中是无法找到重定向过程内容的(A重定向到B,此时只记录B的内容不去记录A的内容)
Follow Redirects(跟随重定向):Http Request取样器的默认选项,当响应code是3xx时(301永久性转移,302暂时性转移),自动跳转到目标地址。与自动重定向不同,Jmeter会记录重定向过程中的所有请求响应,在查看结果树时可以看到服务器返回的内容,所以此时可以对响应的内容做关联。
四、JMeter工具常用界面设置
1、线程组 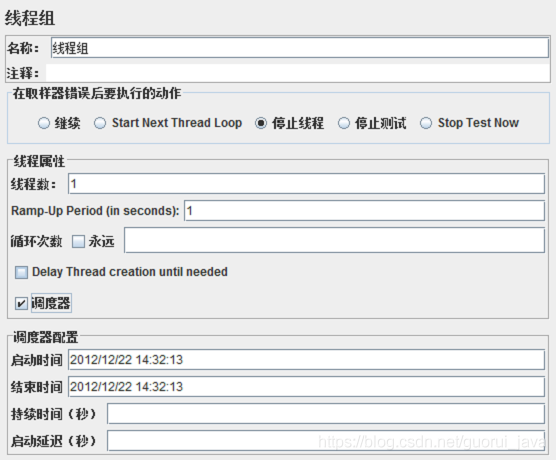
1、线程数:表示启动的线程数,也就是并发的数量。
2、Ramp-Up Period:表示1秒内启动1个线程,默认为0,表示程序启动后,立即开启1个线程,设置太大或太小都不是很好,设置的最佳值,Ramp-Up
Period = 线程数/吞吐量。
3、循环次数:表示每个线程要发送多少次请求。
4、调度器:顾名思义,持续时间如果设置为60,表示持续1分钟,通常循环次数和调度器设置一个即可。
2、添加HTTP请求 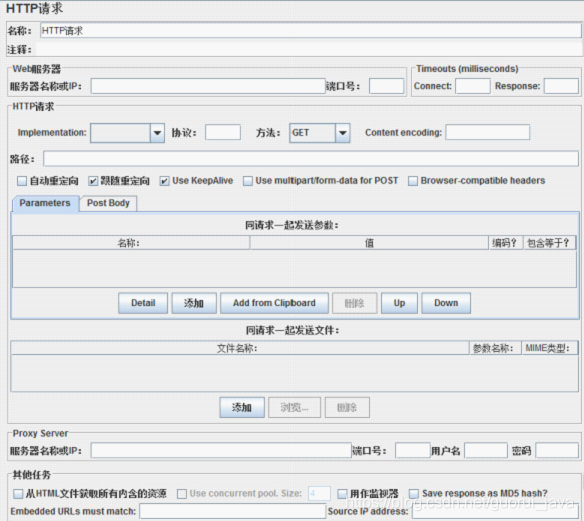
一个HTTP请求有着许多的配置参数,下面将详细介绍:
1、名称:本属性用于标识一个取样器,建议使用一个有意义的名称。
2、注释:对于测试没有任何作用,仅用户记录用户可读的注释信息。
3、服务器名称或IP :HTTP请求发送的目标服务器名称或IP地址。
4、端口号:目标服务器的端口号,默认值为80 。
5、协议:向目标服务器发送HTTP请求时的协议,可以是http或者是https ,默认值为http
。
6、方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE等。
7、Content encoding :内容的编码方式,默认值为iso8859
8、路径:目标URL路径(不包括服务器地址和端口)
9、自动重定向:如果选中该选项,当发送HTTP请求后得到的响应是302/301时,JMeter 自动重定向到新的页面。
10、Use keep Alive : 当该选项被选中时,jmeter 和目标服务器之间使用 Keep-Alive方式进行HTTP通信,默认选中。
11、Use multipart/from-data for HTTP POST :当发送HTTP
POST 请求时,使用Use multipart/from-data方法发送,默认不选中。
12、同请求一起发送参数 : 在请求中发送URL参数,对于带参数的URL ,jmeter提供了一个简单的对参数化的方法。用户可以将URL中所有参数设置在本表中,表中的每一行是一个参数值对(对应RUL中的
名称1=值1)。
13、同请求一起发送文件:在请求中发送文件,通常,HTTP文件上传行为可以通过这种方式模拟。/14、从HTML文件获取所有有内含的资源:当该选项被选中时,jmeter在发出HTTP请求并获得响应的HTML文件内容后,还对该HTML进行Parse
并获取HTML中包含的所有资源(图片、flash等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的Embedded
URLs must match 文本框中填入需要下载的特定资源表达式,这样,只有能匹配指定正则表达式的URL指向资源会被下载。
15、用作监视器:此取样器被当成监视器,在Monitor Results Listener 中可以直接看到基于该取样器的图形化统计信息。默认为不选中。
16、Save response as MD5 hash:选中该项,在执行时仅记录服务端响应数据的MD5值,而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减少取样器记录响应数据的开销。
3、聚合报告简介
我认为聚合报告应该是JMeter压力测试软件中最重要的报告。
1. #Samples:样本数,如果你看过上一篇,这个就是前面我们那个公式算出来的结果
(Loop Count(Loop Controler)*Number of Threads*Loop
Count(group))
2. Average:平均响应时间。
3. Median:中位数,50%用户响应时间。
4. Line:90%用户响应时间。
5. Min:最小响应时间。
6. Max:最大响应时间。
7. Error%:本次测试中出现错误的请求的数量/请求的总数
8. Throughput:吞吐量,表示每秒完成的请求数。
9. KB/Sec:每秒从服务器端接收到的数据量(只是接收)。
五、JMeter压力测试时遇到的常见问题
1、Response Times Over Time中的峰值和聚合报告中的最大值为何不一致?
因为Response Times Over Time中的点是一个时间的概念,表示的是一段时间内的请求的平均响应时间,而聚合报告中的最大值表示的是一个请求的最大响应时间,因此Response
Times Over Time的峰值和聚合报告中的最大值不一致。
2、Response Times Over Time图中有多少个点,和请求数有什么关系?
Response Times Over Time中的点是一个时间的概念,在setting中可以设置,每隔500ms记录一个点,这个点就表示这段时间内的请求的平均响应时间。
3、压测接口时,并发一段时间后,会报java.net.BindException: Address
already in use: connect
原因:
Jmeter里的http sample勾选了keep alive,导致会话一直保持,而windows本身的端口有限,导致端口被占用完后,无法分配新的端口,因此会产生java.net.BindException:
Address already in use: connect 报错。
解决方案:
HTTP SAMPLE 不勾选keep alive
4、internal server error是什么意思?
internal server error错误通常发生在用户访问网页的时候发生,该错误的意思是因特网服务错误。能够引起internal
server error报错的原因有多个,如果你是网站主的话,可以对下列情形进行一一排查。
(1)服务器资源超载
如果网站文件没有做过修改,最有可能的是同服务器的资源超载:即同一时间内处理器有太多的进程需要处理的时候,会出现500错误。借助SSH,可以在命令行中输入以下命令查看:ps
faux ps faux |grep username 如果你查到某个进程消耗过多资源,可以用kill命令强制关闭这个进程,只需输入该进程的进程号(Pid):kill
-9 pid。
(2)文件权限设置错误
500错误还有可能是对文件设置了不正确的权限:后台目录和文件的权限默认应该是755,而图片,文字等html文件应该是644,所以如果在刚刚上传文件后出现500错误,应该主要检查文件权限设置。可以使用FTP软件选中所有文件,然后批量修改文件权限。
(3)htaccess文件写入错误的代码
在使用某些wordpress SEO插件的时候,插件会改写.htacess文件,如果语法错误的话就有可能造成500错误!
5、Internal server error 500 问题解决思路
(1)明确错误含义
500 Internal Server Error
通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。
根据这个描述,基本可以排除客户端以及网络因素,需要重点关注服务端的状态。
我们系统服务端的架构如下图:
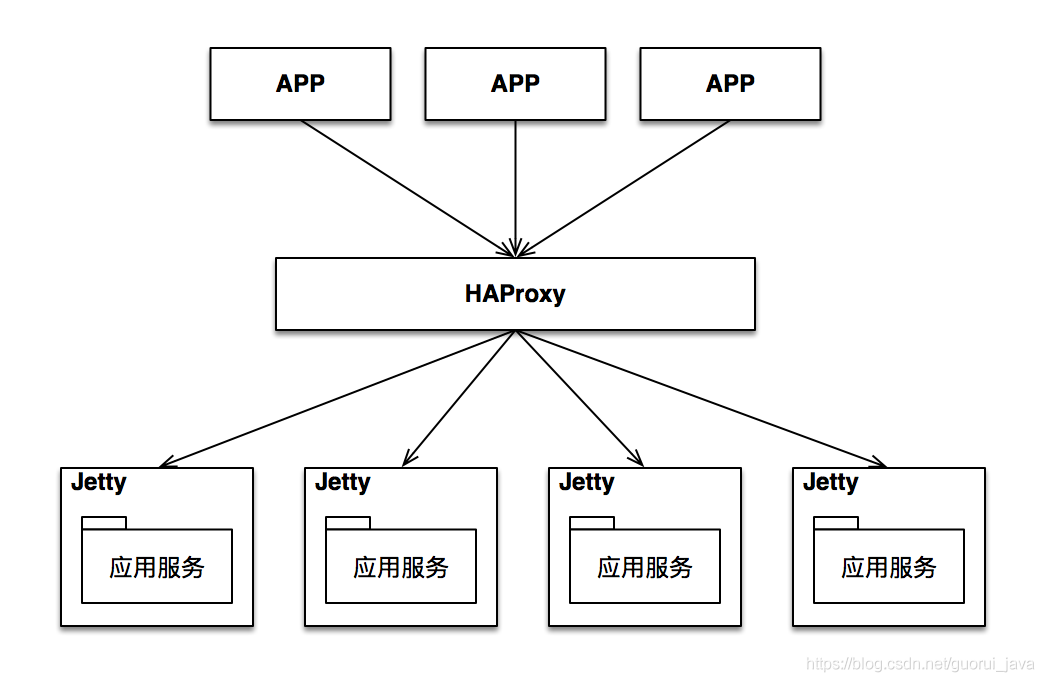
接下来就要根据这个架构由前往后一层一层排查。
(2)检查HAProxy
重点排查HAProxy当前是否可用,负荷是否超标,包括下面的一些指标。
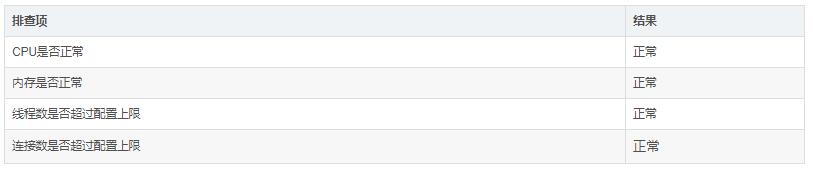
排查之后发现一切正常,与版本更新前的数据作比较,也没有出现大幅度波动。
而在查看请求日志时,发现大量500错误信息,说明HAProxy出异常的可能性较小,错误更可能来自HAProxy之后的环节。
(3)检查Jetty
重点排查jetty的配置信息。

虽然jetty配置信息检查正常,但是在access.log中存在大量500错误,定位到这里,有两种可能的原因:
应用代码逻辑问题。部分异常信息没有被拦截住,直接抛给Jetty,导致500错误。
Jetty逻辑问题。请求没有到达应用,而是由于Jetty自身的某些逻辑导致请求被直接返回了。
(4)检查应用
为了验证是否第一个原因,我们继续走查了应用代码,发现所有的异常都被正确处理了,不存在继续往上抛的情况。另外,也检查了图片保存的代码,确认文件连接都正确释放了。
因此,由于应用逻辑问题导致错误的可能性很小,那么第二个原因的嫌疑最大,就是Jetty逻辑问题。
如果直接排查Jetty的源码,太费时费力,这个时候最好的办法是实时抓包,看看Jetty和应用服务之间到底发生了什么。
(5)使用tcpdump抓包
使用tcpdump命令抓取从jetty到应用服务之间所有的数据包,将结果输出到临时文件中。
tcpdump -i eth0:0 -s0 host 1X.XXX.XXX.XX -w /tmp/out1.cap
使用wireshark打开out1.cap文件,查找出现500错误的数据包,然后很意外的看到了下面的逻辑。

通过这段代码我们发现,jetty对于请求数据的大小做了限制,超过200000 byte的时候就会报错,返回错误码500。
App这次更新后,上传了很多大于200000 byte的图片,于是便出现了大量的500错误。
找到问题根源,修正起来就很简单了,在WEB-INF目录下添加jetty-web.xml 文件解决,文件内容如下:
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-//MortBay
Consulting//DTD Configure//EN"
"http://jetty.mortbay.org/configure.dtd">
<Configure id="WebAppContext"class="org.eclipse.jetty.webapp.WebAppContext">
<Set name="maxFormContentSize"type="int">
0 </Set>
</Configure> |
6、JMeter问题总结
出现Internal server error 500错误,往往意味着服务端出现一些未知异常,但是在排查的时候我们不能仅仅只是关注应用服务,而是要关注从服务端接收请求开始,一直到应用服务的整条链路。
以本文中的情景为例,就是从HAProxy 到 Jetty 再到 应用服务,中间的任何一个环节都有可能导致500错误。
另外,其实在一开始我们就可以采用抓包的方式去排查,因为在包数据中包含了完整请求/响应消息,比查看CPU、线程、配置信息要更加快捷,直接。
六、Linux查看程序运行情况
1、Top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
top显示系统当前的进程和其他状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户
终止该程序为止. 比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间
对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
在linux系统中,top命令可谓是分析系统性能最方便的工具,而且top还是个交互式工具;通过top命令可以清楚地了解到正在执行的进程信息包括进程ID,内存占用率,CPU占用率等。其实就跟window的任务管理器类似。
2、查看CPU使用率
sar -u 1 5
表示每1秒采集一次,共采集5次。
这个命令可根据实际线程组中的设置,进行CPU使用率方面的查看。
[root@sss ~]#
sar -u 1 5
Linux 3.10.0-957.10.1.el7.x86_64 (izuf633l0ge76tv5mzalpmz)
04/16/2019 _x86_64_ (1 CPU)
04:56:03 PM CPU %user %nice %system %iowait %steal
%idle
04:56:04 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:05 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:06 PM all 0.99 0.00 0.99 0.00 0.00 98.02
04:56:07 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:08 PM all 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.20 0.00 0.20 0.00 0.00 99.60 |
3、查看内存占用情况
free -m

1352/1838即为内存占用。
4、Linux如何统计进程的CPU利用率
Linux的/proc文件系统,可以看到自启动时候开始,所有CPU消耗的时间片;对于个进程,也可以看到进程消耗的时间片。这是一个累计值,可以"非阻塞"的输出。获得一定时间间隔的两次统计就可以计算出这段时间内的进程CPU利用率。
所以,是否存在一种简单的,非阻塞的方式获得进程的CPU利用率? 答案是:“没有”。这里给出一个很恰当的比喻:"这就像有人给你一张照片,要你回答照片中车子的速度一样"。
1、/proc/stat 统计总CPU消耗
计算CPU总消耗可以使用如下shell命令:
cat /proc/stat|grep "cpu "|awk '{for(i=2;i<=NF;i++)j+=$i;print
"cpu_total_slice " j;}'
cpu_total_slice 19208187744
2、进程消耗的CPU时间片
在proc文件系统中,可以通过/proc/[pid]/stat获得进程消耗的时间片,输出的第14、15、16、17列分别对应进程用户态CPU消耗、内核态的消耗、用户态等待子进程的消耗、内核态等待子进程的消耗(man
proc)。所以进程的CPU消耗可以使用如下命令:
cat /proc/9583/stat|awk '{print "cpu_process_total_slice
" $14+$15+$16+$17}'
cpu_process_total_slice 1068099
3、"非阻塞"的计算进程CPU利用率
从这里也看到,是没有某个时刻CPU利用率的说法的,也就没法获得某个时刻的CPU利用率。这就像物理中的"速度"的概念,没有某一时刻速度的概念,速度一定是一个时间段之内的。那么要"非阻塞"计算某个进程CPU利用率,则需要取两次事件间隔进行计算,这两次事件间隔的操作可以是非阻塞的。计算办法如下:
时刻A,计算操作系统总CPU时间片消耗total_cpu_slice_A;计算进程总CPU时间片消耗;total_process_slice_A
;
时刻B,计算操作系统总CPU时间片消耗total_cpu_slice_B;计算进程总CPU时间片消耗;total_process_slice_B。
B时刻就可以"非阻塞"的计算这段时间进程的CPU利用率了:
100%*(total_process_slice_B-total_process_slice_A)/(total_cpu_slice_B-total_cpu_slice_A)
5、CPU使用率与CPU空闲时间的关系?
多任务操作对CPU都是分时间片使用的,比如A进程占用10ms,B进程占用30ms,然后空闲60ms,再又是A进程占用10ms,B进程占用30ms,空闲60ms;如果一段时间内都是如此,那么这段时间内的CPU占用率就是40%。
CPU对线程的响应并不是连续的,通常会在一段时间后自动中断线程。未响应的线程增加,就会不断加大CPU的占用。
|




