| МђЕЅЕиЫЕЃЌЮвУЧДгЪТЪгЦЕЪфГіЗНУцЕФЙЄзїЁЊЁЊЮвУЧЬсЙЉЪЕЪБЕФЪгЦЕЁЃЮвУЧИКд№ЁАNTV-PlusЁБКЭЁАMatch
TVЁБЦЕЕРЕФЪгЦЕЦНЬЈЁЃИУЦНЬЈга30ЭђЕФВЂЗЂгУЛЇЃЌУПаЁЪБЪфГі300TBЕФФкШнЁЃетЪЧвЛИіКмгавтЫМЕФШЮЮёЁЃФЧУДЮвУЧЪЧШчКЮзіЕНЕФФиЃП
етБГКѓЖМгаФФаЉЙЪЪТЃПетаЉЙЪЪТЖМЪЧЙигкЯюФПЕФПЊЗЂКЭГЩГЄЃЌЙигкЮвУЧЖдЯюФПЕФЫМПМЁЃзмЖјбджЎЃЌЪЧЙигкШчКЮЬсЩ§ЯюФПЕФЩьЫѕФмСІЃЌГаЪмИќДѓЕФИКдиЃЌдкВЛхДЛњКЭВЛЖЊЪЇЙиМќЬиадЕФЧщПіЯТЮЊПЭЛЇЬсЙЉИќЖрЕФЙІФмЁЃЮвУЧзмЪЧЯЃЭћФмЙЛТњзуПЭЛЇЕФашЧѓЁЃЕБШЛЃЌетвВЩцМАЕНЮвУЧЪЧШчКЮЪЕЯжетвЛЧаЃЌвдМАетвЛЧаЪЧШчКЮПЊЪМЕФЁЃ
дкзюПЊЪМЃЌЮвУЧгаСНЬЈдЫаадкDockerМЏШКРяЕФЗўЮёЦїЃЌЪ§ОнПтдЫаадкЯрЭЌЛњЦїЕФШнЦїРяЁЃУЛгазЈгУЕФДцДЂЃЌЛљДЁЩшЪЉЗЧГЃМђЕЅЁЃ
ЮвУЧОЭЪЧетбљПЊЪМЕФЃЌжЛгаСНЬЈдЫаадкDockerМЏШКРяЕФЗўЮёЦїЁЃФЧИіЪБКђЃЌЪ§ОнПтвВдЫаадкЭЌвЛИіМЏШКРяЁЃЮвУЧЕФЛљДЁЩшЪЉРяУЛгаЪВУДзЈгУЕФзщМўЃЌЪЎЗжМђЕЅЁЃ

ЮвУЧЕФЛљДЁЩшЪЉзюжївЊЕФзщМўОЭЪЧDockerКЭTeamCityЃЌЮвУЧгУЫќУЧРДНЛИЖКЭЙЙНЈДњТыЁЃ
дкНгЯТРДЕФЪБЦкЁЊЁЊЮвГЦЦфЮЊЮвУЧЕФЗЂеЙжаЦкЁЊЁЊЪЧЮвУЧЯюФПЗЂеЙЕФЙиМќЪБЦкЁЃЮвУЧгЕгаСЫ80ЬЈЗўЮёЦїЃЌВЂдквЛзщЬиЪтЕФЛњЦїЩЯЮЊЪ§ОнПтДюНЈСЫвЛИіЕЅЖРЕФзЈгУМЏШКЁЃЮвУЧПЊЪМЪЙгУЛљгкCEPHЕФЗжВМЪНДцДЂЃЌВЂПЊЪМЫМПМЗўЮёжЎМфЕФНЛЛЅЮЪЬтЃЌЭЌЪБвЊИќаТЮвУЧЕФМрПиЯЕЭГЁЃ
ЯждкЃЌШУЮвУЧРДПДПДЮвУЧдкетвЛЪБЦкЖМзіСЫФФаЉЪТЧщЁЃDockerМЏШКРявбОгаЪ§АйЬЈЗўЮёЦїЃЌЮЂЗўЮёОЭдЫаадкЫќУЧЩЯУцЁЃетИіЪБКђЃЌЮвУЧПЊЪМИљОнЪ§ОнзмЯпКЭТпМЗжРыддђНЋЮвУЧЕФЯЕЭГВ№ЗжГЩЗўЮёзгЯЕЭГЁЃЕБЮЂЗўЮёдНРДдНЖрЪБЃЌЮвУЧОіЖЈВ№ЗжЮвУЧЕФЯЕЭГЃЌетбљЮЌЛЄЦ№РДОЭШнвзЕУЖрЃЈвВИќШнвзРэНтЃЉЁЃ
етеХЭМеЙЪОЕФЪЧЮвУЧЯЕЭГЦфжаЕФвЛаЁВПЗжЁЃетВПЗжЯЕЭГИКд№ЪгЦЕМєЧаЁЃАыФъЧАЃЌЮвдкЁАRIT++ЁБвВеЙЪОЙ§РрЫЦЕФЭМЦЌЁЃФЧИіЪБКђжЛга17ИіТЬЩЋЕФЮЂЗўЮёЃЌЖјЯждкга28ИіТЬЩЋЕФЮЂЗўЮёЁЃетаЉЗўЮёжЛеМЮвУЧећИіЯЕЭГЕФЖўЪЎЗжжЎвЛЃЌЫљвдПЩвдЯыЯѓЮвУЧЯЕЭГДѓжТЕФЙцФЃгаЖрДѓЁЃ
ЩюШыЯИНк
ЗўЮёМфЕФЭЈаХЪЧвЛМўКмгаШЄЕФЪТЧщЁЃвЛАуРДЫЕЃЌЮвУЧгІИУОЁПЩФмЬсЩ§ЗўЮёМфЭЈаХаЇТЪЁЃЮвУЧЪЙгУСЫprotobufЃЌЮвУЧШЯЮЊЫќОЭЪЧЮвУЧашвЊЕФЖЋЮїЁЃ
ЫќПДЦ№РДЪЧетбљЕФЃК

ЮЂЗўЮёЕФЧАУцгавЛИіИКдиОљКтЦїЁЃЧыЧѓЕНДяЧАЖЫЃЌЛђепжБНгЗЂЫЭИјЬсЙЉСЫJSON APIЕФЗўЮёЁЃprotobufБЛгУгкФкВПЗўЮёжЎМфЕФНЛЛЅЁЃ
protobufецЪЧвЛИіКУЖЋЮїЁЃЫќЮЊЯћЯЂЬсЙЉСЫКмКУЕФбЙЫѕТЪЁЃЯжШчНёгаКмЖрПђМмЃЌжЛвЊЪЙгУКмаЁЕФПЊЯњОЭФмЪЕЯжађСаЛЏКЭЗДађСаЛЏЁЃЮвУЧПЩвдНЋЦфЪгЮЊгаЬѕМўЕФЧыЧѓРраЭЁЃ
ЕЋШчЙћДгЮЂЗўЮёНЧЖШРДПДЃЌЮвУЧЛсЗЂЯжЃЌЮЂЗўЮёжЎМфвВДцдкФГжжЫНгаЕФавщЁЃШчЙћжЛгавЛСНИіЛђепЮхИіЮЂЗўЮёЃЌЮвУЧПЩвдЮЊУПИіЮЂЗўЮёДђПЊвЛИіПижЦЬЈЃЌЭЈЙ§ЫќУЧРДЗУЮЪЮЂЗўЮёЃЌВЂЛёЕУЯьгІНсЙћЁЃШчЙћГіЯжСЫЮЪЬтЃЌЮвУЧПЩвдЖдЦфНјааеяЖЯЁЃВЛЙ§етдквЛЖЈГЬЖШЩЯШУЮЂЗўЮёЕФжЇГжЙЄзїБфЕУИДдгЁЃ
дквЛЖЈЪБЦкФкЃЌетЕЙВЛЪЧЪВУДЮЪЬтЃЌвђЮЊВЂУЛгаЬЋЖрЕФЮЂЗўЮёЁЃСэЭтЃЌGoogleЗЂВМСЫgRPCЁЃдкФЧИіЪБКђЃЌgRPCТњзуСЫЫљгаЮвУЧЯызіЕФЪТЧщЁЃгкЪЧЮвУЧж№НЅЧЈвЦЕНgRPCЁЃгкЪЧЮвУЧЕФММЪѕеЛРяГіЯжСЫСэвЛИізщМўЁЃ

ЪЕЯжЕФЯИНквВЪЧКмгаШЄЕФЁЃgRPCФЌШЯЪЧЛљгкHTTP/2ЕФЁЃШчЙћФуЕФЛЗОГЯрЖдЮШЖЈЃЌгІгУГЬађВЛдѕУДЗЂЩњБфИќЃЌвВВЛашвЊдкЛњЦїМфЧЈвЦЃЌФЧУДgRCPЖдгкФуРДЫЕОЭЪЧИіВЛДэЕФЖЋЮїЁЃСэЭтЃЌgRPCжЇГжКмЖрПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФБрГЬгябдЁЃ
ЯждкЃЌЮвУЧДгЮЂЗўЮёНЧЖШРДПДД§етИіЮЪЬтЁЃДгвЛЗНУцРДПДЃЌgRPCЪЧвЛИіКУЖЋЮїЃЌЕЋДгСэвЛЗНУцРДПДЃЌЫќвВгаВЛзужЎДІЁЃЕБЮвУЧПЊЪМЖдШежОНјааБъзМЛЏЃЈетбљОЭПЩвдНЋЫќУЧОлКЯЕНвЛИіЖРСЂЕФЯЕЭГРяЃЉЪБЃЌЮвУЧЗЂЯжЃЌДгgRPCжаГщШЁШежОЗЧГЃТщЗГЁЃ
гкЪЧЃЌЮвУЧОіЖЈПЊЗЂздМКЕФШежОЯЕЭГЁЃЫќНтЮіЯћЯЂЃЌВЂНЋЫќУЧзЊГЩЮвУЧашвЊЕФИёЪНЁЃетбљЮвУЧВХПЩвдЛёЕУЮвУЧЯывЊЕФШежОЁЃЛЙгавЛИіЮЪЬтЃЌЬэМгаТЕФЮЂЗўЮёЛсШУЗўЮёМфЕФвРРЕБфЕУИќМгИДдгЁЃетЪЧЮЂЗўЮёвЛжБДцдкЕФЮЪЬтЃЌетвВЪЧГ§АцБОЮЪЬтжЎЭтЕФСэвЛИіОпгавЛЖЈИДдгадЕФЮЪЬтЁЃ
гкЪЧЃЌЮвУЧПЊЪМПМТЧЪЙгУJSONЁЃдкКмГЄЕФвЛЖЮЪБМфРяЃЌЮвУЧЮоЗЈЯраХЃЌдкЪЙгУСЫНєДеЕФЖўНјжЦавщжЎКѓЛсзЊЛиЪЙгУJSONЁЃгавЛЬьЃЌЮвУЧПДЕНвЛЦЊЮФеТЃЌРДздDailyMotionЕФвЛИіМвЛядкЮФеТРяЬсЕНСЫЭЌбљЕФЪТЧщЃКЁАЮвУЧжЊЕРИУШчКЮЪЙгУJSONЃЌУПИіШЫЖМПЩвдЪЙгУJSONЁЃМШШЛШчДЫЃЌЮЊЪВУДЛЙвЊздбАЗГФеФиЃПЁБ

гкЪЧЃЌЮвУЧж№НЅДгgRPCзЊЯђЮвУЧздМКЪЕЯжЕФJSONЁЃЮвУЧБЃСєСЫHTTP/2ЃЌЫќгыJSONзщКЯЦ№РДПЩвдДјРДИќПьЕФЫйЖШЁЃ
ЯждкЃЌЮвУЧОпБИСЫЫљгаБивЊЕФЬиадЁЃЮвУЧПЩвдЭЈЙ§cURLЗУЮЪЮвУЧЕФЗўЮёЁЃЮвУЧЕФQAЭХЖгЪЙгУPostmanЃЌЫљвдЫћУЧвВИаОѕКмТњвтЁЃвЛЧаЖМБфЕУМђЕЅЦ№РДЁЃетЪЧвЛИігаељвщадЕФОіЖЈЃЌЕЋШДЮЊЮвУЧДјРДСЫКмЖрКУДІЁЃ
JSONЮЈвЛЕФШБЕуОЭЪЧЫќЕФНєДеадВЛзуЁЃИљОнЮвУЧЕФВтЪдНсЙћЃЌЫќгыMessagePackжЎМфга30%ЕФВюОрЁЃВЛЙ§ЖдгквЛИіжЇГжЯЕЭГРДЫЕЃЌетВЛЫуЪЧИіДѓЮЪЬтЁЃ
ПіЧвЃЌЮвУЧдкзЊЕНJSONжЎКѓЛЙЛёЕУСЫИќЖрЕФЬиадЃЌБШШчавщАцБОЁЃгаЪБКђЃЌЕБЮвУЧдкаТАцБОЕФавщЩЯЪЙгУprotobufЪБЃЌПЭЛЇЖЫвВБиаыИФгУprotobufЁЃШчЙћФугаЪ§АйИіЗўЮёЃЌОЭЫужЛга10%ЕФЗўЮёНјааСЫЧЈвЦЃЌетвВЛсв§Ц№КмДѓЕФСЌЫјЗДгІЁЃФудквЛИіЗўЮёЩЯзіСЫвЛаЉБфИќЃЌОЭЛсгаЪЎЖрИіЗўЮёвВашвЊИњзХИФЖЏЁЃ
вђДЫЃЌЮвУЧОЭЛсУцСйетбљЕФвЛжжЧщПіЃЌвЛИіЗўЮёЕФПЊЗЂШЫдБвбОЗЂВМСЫЕкЮхИіЁЂЕкСљИіЃЌЩѕжСЕкЦпИіАцБОЃЌЕЋЩњВњЛЗОГРяШдШЛдкдЫааЕкЫФИіАцБОЃЌОЭвђЮЊЦфЫћЯрЙиЗўЮёЕФПЊЗЂШЫдБгаЫћУЧздМКЕФгХЯШМЖКЭНижЙШеЦкЁЃЫћУЧЮоЗЈГжајЕиИќаТЫћУЧЕФЗўЮёЃЌВЂЪЙгУаТАцБОЕФавщЁЃЫљвдЃЌаТАцБОЕФЗўЮёЫфШЛЗЂВМСЫЃЌЕЋЛЙХЩВЛЩЯгУГЁЁЃШЛКѓЃЌЮвУЧШДвЊвдвЛжжКмЦцЙжЕФЗНЪНРДаоИДОЩАцБОЕФbugЃЌетШУжЇГжЙЄзїБфЕУИќМгИДдгЁЃ
зюКѓЃЌЮвУЧОіЖЈЭЃжЙЗЂВМаТАцБОЕФавщЁЃЮвУЧЬсЙЉавщЕФЛљДЁАцБОЃЌПЩвдЭљРяУцЬэМгЩйСПЕФЪєадЁЃЗўЮёЕФЯћЗбепПЊЪМЪЙгУJSON
schemaЁЃ
БъзМПДЦ№РДЪЧетбљЕФЃК

ЮвУЧУЛгаЪЙгУАцБО1ЁЂ2КЭ3ЃЌЖјЪЧжЛЪЙгУАцБО1КЭжИЯђЫќЕФschemaЁЃ

етЪЧДгЮвУЧЗўЮёЗЕЛиЕФвЛИіЕфаЭЕФЯьгІНсЙћЁЃЫќЪЧвЛИіФкШнЙмРэЦїЃЌЗЕЛигаЙиЙуВЅЕФаХЯЂЁЃетРягавЛИіЯћЗбепschemaЕФР§згЁЃ

зюЕзЯТЕФзжЗћДЎзюгавтЫМЃЌвВОЭЪЧ"required"ФЧПщЁЃЮвУЧПЩвдПДЕНЃЌетИіЗўЮёжЛашвЊ4ИізжЖЮЁЊЁЊidЁЂcontentЁЂdateКЭstatusЁЃШчЙћЮвУЧЪЙгУСЫетИіschemaЃЌФЧУДЯћЗбепОЭжЛЛсЕУЕНетбљЕФЪ§ОнЁЃ

ЫќУЧПЩвдБЛгУдкУПвЛИіавщАцБОРяЃЌДгЕквЛИіАцБОЕНКѓРДЕФУПвЛИіБфИќАцБОЁЃетбљЃЌдкАцБОжЎМфЧЈвЦОЭШнвзКмЖрЁЃдкЮвУЧЗЂВМаТАцБОжЎКѓЃЌПЭЛЇЖЫЕФЧЈвЦОЭЛсМђЕЅКмЖрЁЃ
ЯТвЛИіживЊЕФвщЬтЪЧЯЕЭГЕФЮШЖЈадЮЪЬтЁЃетЪЧЮЂЗўЮёКЭЦфЫћШЮКЮвЛИіЯЕЭГЖМашвЊУцСйЕФЮЪЬтЃЈдкЮЂЗўЮёМмЙЙРяЃЌЮвУЧПЩвдИќЧПСвЕиИаОѕЕНЫќЕФживЊадЃЉЁЃЯЕЭГзмЛсдкФГИіЪБКђБфЕУВЛЮШЖЈЁЃ
ШчЙћЗўЮёМфЕФЕїгУСДжЛАќКЌСЫвЛСНИіЗўЮёЃЌФЧУДОЭУЛгаЪВУДЮЪЬтЁЃдкетжжЧщПіЯТЃЌФуПДВЛГіЕЅЬхКЭЗжВМЪНЯЕЭГжЎМфгаЖрДѓЧјБ№ЁЃЕЋЕБЕїгУСДРяАќКЌСЫ5ЕН7ИіЕїгУЃЌФЧУДЮЪЬтОЭЛсНгѕрЖјжСЁЃФуИљБОВЛжЊЕРЮЊЪВУДЛсетбљЃЌвВВЛжЊЕРФмзіаЉЪВУДЁЃдкетжжЧщПіЯТЃЌЕїЪдЛсБфЕУКмРЇФбЁЃдкЕЅЬхЯЕЭГРяЃЌФуПЩвдЭЈЙ§ж№ВНЕїЪдРДевГіДэЮѓЁЃЕЋЖдгкЮЂЗўЮёРДЫЕЃЌЭјТчВЛЮШЖЈадЛђИпИКдиЯТЕФадФмВЛЮШЖЈадвВЛсЖдЮЂЗўЮёдьГЩгАЯьЁЃЬиБ№ЪЧЖдгкгЕгаДѓСПНкЕуЕФЗжВМЪНЯЕЭГРДЫЕЃЌетаЉЧщПіОЭИќМгЯдЖјвзМћСЫЁЃ

дквЛПЊЪМЃЌЮвУЧВЩгУСЫДЋЭГЕФАьЗЈЁЃЮвУЧМрПиЫљгаЕФЖЋЮїЃЌВщПДЮЪЬтКЭЮЪЬтЕФЗЂЩњЕуЃЌШЛКѓГЂЪдОЁПьаоИДЫќУЧЁЃЮвУЧНЋЮЂЗўЮёЕФЖШСПжИБъЪеМЏЕНвЛИіЖРСЂЕФЪ§ОнПтРяЁЃЮвУЧЪЙгУDiamondРДЪеМЏЯЕЭГЖШСПжИБъЁЃЮвУЧЪЙгУcAdvisorРДЗжЮіШнЦїЕФзЪдДЪЙгУЧщПіКЭадФмЬиеїЁЃЫљгаЕФНсЙћЖМБЛБЃДцЕНInfluxDBЃЌШЛКѓЮвУЧдкGrafanaРяДДНЈвЧБэХЬЁЃ

гкЪЧЃЌЮвУЧЯждкЕФЛљДЁЩшЪЉРягжЖрСЫШ§ИізщМўЁЃ
ЮвУЧБШвдЭљИќМгЙизЂЫљЗЂЩњЕФвЛЧаЁЃЮвУЧЖдЮЪЬтЕФЗДгІЫйЖШИќПьСЫЁЃВЛЙ§ЃЌетВЂУЛгазшжЙЮЪЬтЕФГіЯжЁЃ
ЦцЙжЕФЪЧЃЌЮЂЗўЮёМмЙЙЕФжївЊЮЪЬтГідкФЧаЉВЛЮШЖЈЕФЗўЮёЩЯЁЃЫќУЧгаЕФНёЬьдЫаае§ГЃЃЌУїЬьОЭВЛааЃЌЖјЧвгаИїжжИїбљЕФдвђЁЃШчЙћЗўЮёГіЯжГЌдиЃЌЖјФуМЬајЯђЫќЗЂЫЭИКдиЃЌЫќОЭЛсхДЛњвЛЖЮЪБМфЁЃШчЙћЫќдквЛЖЮЪБМфВЛЬсЙЉЗўЮёЃЌИКдиОЭЛсЯТНЕЃЌШЛКѓЫќОЭгжЛюЙ§РДСЫЁЃетРрЯЕЭГКмФбЮЌЛЄЃЌвВКмФбжЊЕРЕНЕзГіСЫЪВУДЮЪЬтЁЃ
зюКѓЃЌЮвУЧОіЖЈАбетаЉЗўЮёЭЃЕєЃЌЖјВЛЪЧШУЫќУЧРДЛиелЬкЁЃЮвУЧвђДЫашвЊИФБфЗўЮёЕФЪЕЯжЗНЪНЁЃ
ЮвУЧзіСЫвЛМўКмживЊЕФЪТЧщЁЃЮвУЧЖдУПИіЗўЮёНгЪеЕФЧыЧѓЪ§СПЩшЖЈСЫвЛИіЩЯЯоЁЃУПИіЗўЮёжЊЕРздМКПЩвдДІРэЖрЩйИіРДздПЭЛЇЖЫЕФЧыЧѓЃЈЮвУЧЩдКѓЛсЯъЯИЫЕУїЃЉЁЃШчЙћЧыЧѓЪ§СПДяЕНЩЯЯоЃЌЗўЮёНЋХзГі503
Service UnavailableвьГЃЁЃПЭЛЇЖЫжЊЕРетИіНкЕуЮоЗЈЬсЙЉЗўЮёЃЌОЭЛсбЁдёСэвЛИіНкЕуЁЃ
ЕБЯЕЭГГіЯжЮЪЬтЪБЃЌЮвУЧОЭПЩвдЭЈЙ§етжжЗНЪНРДМѕЩйЧыЧѓЪБМфЁЃСэЭтЃЌЮвУЧвВЬсЩ§СЫЗўЮёЕФЮШЖЈадЁЃ
ЮвУЧв§ШыСЫЕкЖўжжФЃЪНЁЊЁЊЛиТЗЖЯТЗЦїЃЈCircuit BreakerЃЉЁЃЮвУЧдкПЭЛЇЖЫЪЕЯжСЫетжжФЃЪНЁЃ
МйЩшгавЛИіЗўЮёAЃЌЫќга4ИіПЩвдЗУЮЪЕФЗўЮёBЕФЪЕР§ЁЃЫќЯђзЂВсжааФЫївЊЗўЮёBЕФЕижЗЃКЁАИјЮветаЉЗўЮёЕФЕижЗЁБЁЃЫќЕУЕНСЫЗўЮёBЕФ4ИіЕижЗЁЃЗўЮёAЯђЕквЛИіЗўЮёBЕФЪЕР§ЗЂЦ№СЫЧыЧѓЁЃЕквЛИіЗўЮёBЪЕР§е§ГЃЗЕЛиЯьгІЁЃЗўЮёAНЋЦфБъМЧЮЊПЩЗУЮЪЃКЁАЪЧЕФЃЌЮвПЩвдЗУЮЪЫќЁБЁЃШЛКѓЃЌЗўЮёAЯђЕкЖўИіЗўЮёBЪЕР§ЗЂЦ№ЧыЧѓЃЌВЛЙ§ЫќУЛгадкЦкЭћЕФЪБМфФкЕУЕНЯьгІЁЃЮвУЧНћгУСЫетИіЪЕР§ЃЌШЛКѓЯђЯТвЛИіЪЕР§ЗЂЦ№ЧыЧѓЁЃЯТвЛИіЪЕР§вђЮЊФГаЉдвђЗЕЛиСЫВЛе§ШЗЕФавщАцБОЁЃгкЪЧЮвУЧвВНЋЦфНћгУЃЌШЛКѓзЊЯђЕкЫФИіЪЕР§ЁЃ
змЕУРДЫЕЃЌжЛгавЛАыЕФЗўЮёФмЙЛЮЊПЭЛЇЖЫЬсЙЉЗўЮёЁЃгкЪЧЗўЮёAНЋЛсЯђФмЙЛе§ГЃЗЕЛиЯьгІЕФСНИіЗўЮёЗЂЦ№ЧыЧѓЁЃЖјСэЭтСНИіЮоЗЈТњзувЊЧѓЕФЪЕР§БЛНћгУСЫвЛЖЮЪБМфЁЃ
ЮвУЧЭЈЙ§етжжЗНЪНРДЬсЩ§адФмЕФЮШЖЈадЁЃШчЙћЗўЮёГіЯжСЫЮЪЬтЃЌЮвУЧОЭНЋЦфЙиБеЃЌВЂЗЂГіИцОЏЃЌШЛКѓГЂЪдевГіЮЪЬтЫљдкЁЃ
вђЮЊв§ШыСЫЛиТЗЖЯТЗЦїФЃЪНЃЌЮвУЧЕФЛљДЁЩшЪЉРягжЖрСЫвЛИізщМўЁЊЁЊHystrixЁЃ

HystrixВЛНіЪЕЯжСЫЛиТЗЖЯТЗЦїФЃЪНЃЌЫќвВгажњгкЮвУЧСЫНтЯЕЭГРяГіЯжСЫФФаЉЮЪЬтЃК

дВЛЗЕФДѓаЁБэЪОЗўЮёгыЦфЫћзщМўжЎМфЕФСїСПДѓаЁЁЃбеЩЋБэЪОЯЕЭГЕФНЁПЕзДПіЁЃШчЙћдВЛЗЪЧТЬЩЋЕФЃЌФЧУДЫЕУївЛЧае§ГЃЁЃШчЙћдВЛЗЪЧКьЩЋЕФЃЌФЧУДОЭгаЮЪЬтСЫЁЃ
ШчЙћвЛИіЗўЮёгІИУБЛЭЃЕєЃЌФЧУДЫќПДЦ№РДЪЧетИібљзгЕФЁЃдВЛЗЪЧДђПЊЕФЁЃ

ЮвУЧЕФЯЕЭГБфЕУЯрЖдЮШЖЈЁЃУПИіЗўЮёжСЩйЖМгаСНИіПЩгУЕФЪЕР§ЃЌетбљЮвУЧОЭПЩвдбЁдёЭЃЕєЦфжаЕФвЛИіЁЃВЛЙ§ЃЌОЁЙмЪЧетбљЃЌЮвУЧШдШЛВЛжЊЕРЮвУЧЕФЯЕЭГОПОЙЗЂЩњСЫЪВУДЮЪЬтЁЃдкДІРэЧыЧѓЦкМфШчЙћГіЯжСЫЮЪЬтЃЌЮвУЧгІИУдѕбљВХФмжЊЕРЮЪЬтЕФИљдДЪЧЪВУДФиЃП
етЪЧвЛИіБъзМЕФЧыЧѓ

етЪЧвЛИіДІРэСДЬѕЁЃгУЛЇЗЂЫЭЧыЧѓЕНЕквЛИіЗўЮёЃЌШЛКѓЪЧЕкЖўИіЁЃДгЕкЖўИіЗўЮёПЊЪМЃЌСДЬѕНЋЧыЧѓЗЂЫЭЕНЕкШ§ИіКЭЕкЫФИіЗўЮёЁЃ

ШЛКѓвЛИіЗжжЇВЛУїдвђЕиЯћЪЇСЫЁЃдкОРњСЫетРрГЁОАжЎКѓЃЌЮвУЧГЂЪдзХЬсЩ§етжжГЁОАЕФПЩМћадЃЌгкЪЧЮвУЧевЕНСЫAppdashЁЃAppdashЪЧвЛИіИњзйЗўЮёЁЃ

ЫќПДЦ№РДЪЧетИібљзгЕФЃК
ПЩвдетУДЫЕЃЌЮвУЧжЛЪЧЯыГЂЪдвЛЯТЃЌПДПДЫќЪЧЗёЪЪКЯ ЮвУЧЁЃНЋЫќгУдкЮвУЧЕФЯЕЭГРяЪЧвЛМўКмШнвзЕФЪТЧщЃЌвђЮЊЮвУЧФЧИіЪБКђЪЙгУЕФЪЧGoгябдЁЃAppdashЬсЙЉСЫвЛИіПЊЯфМДгУЕФАќЁЃЮвУЧШЯЮЊAppdashЪЧвЛИіКУЖЋЮїЃЌжЛЪЧЫќЕФЪЕЯжВЂВЛЪЧКмЪЪКЯЮвУЧЁЃ ЮвУЧЁЃНЋЫќгУдкЮвУЧЕФЯЕЭГРяЪЧвЛМўКмШнвзЕФЪТЧщЃЌвђЮЊЮвУЧФЧИіЪБКђЪЙгУЕФЪЧGoгябдЁЃAppdashЬсЙЉСЫвЛИіПЊЯфМДгУЕФАќЁЃЮвУЧШЯЮЊAppdashЪЧвЛИіКУЖЋЮїЃЌжЛЪЧЫќЕФЪЕЯжВЂВЛЪЧКмЪЪКЯЮвУЧЁЃ

гкЪЧЃЌЮвУЧОіЖЈЪЙгУZipkinРДДњЬцAppdashЁЃZipkinЪЧгЩTwitterПЊдДЕФЁЃЫќПДЦ№РДЪЧетИібљзгЕФЃК

ЮвШЯЮЊетбљЛсИќЧхГўвЛаЉЁЃЮвУЧПЩвдДгжаПДЕНвЛаЉЗўЮёЃЌвВПЩвдПДЕНЮвУЧЕФЧыЧѓЪЧШчКЮЭЈЙ§ЧыЧѓСДЕФЃЌЛЙПЩвдПДЕНЧыЧѓдкУПИіЗўЮёРяЖМзіСЫФФаЉЪТЧщЁЃвЛЗНУцЃЌЮвУЧПЩвдПДЕНЗўЮёЕФзмЪБГЄКЭУПИіЗжЖЮЕФЪБГЄЃЌСэвЛЗНУцЃЌЮвУЧЭъШЋПЩвдЬэМгУшЪіЗўЮёФкШнЕФаХЯЂЁЃ
ЮвУЧПЩвддкетРяЬэМгвЛаЉгыЪ§ОнПтЕФЕїгУЁЂЮФМўЯЕЭГЕФЖСШЁЁЂЛКДцЕФЗУЮЪгаЙиЕФаХЯЂЃЌетбљОЭПЩвджЊЕРЧыЧѓРяФФвЛВПЗжЪЙгУСЫзюЖрЕФЪБМфЁЃTraceIDПЩвдАяжњЮвУЧзіЕНетвЛЕуЁЃЩдКѓЮвЛсНщЩмИќЖрЯИНкЁЃ

ЮвУЧОЭЪЧЭЈЙ§етжжЗНЪНжЊЕРЧыЧѓдкДІРэЙ§ГЬжаЗЂЩњСЫЪВУДЮЪЬтЃЌвдМАЮЊЪВУДгаЪБКђЮоЗЈБЛе§ГЃДІРэЁЃИеПЊЪМвЛЧаЖМе§ГЃЃЌШЛКѓЭЛШЛМфЃЌЦфжаЕФвЛИіГіЯжСЫЮЪЬтЁЃЮвУЧЩдзїХХВщЃЌОЭжЊЕРГіЮЪЬтЕФЗўЮёЗЂЩњСЫЪВУДЁЃ

ВЛОУЧАЃЌвЛаЉГЇЩЬЭЦГіСЫвЛИіИњзйЯЕЭГЕФБъзМЁЃЮЊСЫМђЛЏЯЕЭГЕФЪЕЯжЃЌжївЊЕФМИИіИњзйЯЕЭГГЇЩЬдкШчКЮЩшМЦПЭЛЇЖЫAPIКЭПЭЛЇЖЫРрПтЩЯДяГЩСЫвЛжТЁЃЯждквбОгаСЫOpenTracingЕФЪЕЯжЃЌжЇГжМИКѕЫљгаЕФжїСїПЊЗЂгябдЁЃЯждкОЭПЩвдЪЙгУЫќСЫЁЃ
ЮвУЧвбОгаАьЗЈжЊЕРФЧаЉЭЛШЛМфБРРЃЕФЗўЮёЁЃЮвУЧПЩвдПДЕНЦфжаЕФФГВПЗждкДЙЫРеѕдњЃЌЕЋЪЧВЛжЊЕРЮЊЪВУДЁЃЙтгаЛЗОГаХЯЂЪЧВЛЙЛЕФЃЌ
ЮвУЧЛЙашвЊШежОЁЃЪЧЕФЃЌетгІИУГЩЮЊБъзМЕФвЛВПЗжЃЌЫќОЭЪЧElasticsearchЁЂLogstashКЭKibanaЃЈELKЃЉЁЃВЛЙ§ЮвУЧЖдЫќУЧзіСЫвЛаЉИФЖЏЁЃ

ЮвУЧВЂУЛгаНЋДѓСПЕФШежОжБНгЭЈЙ§forwardДЋИјLogstashЃЌЖјЪЧЯШДЋИјsyslogЃЌШУЫќАбШежООлКЯЕНЙЙНЈЛњЦїЩЯЃЌШЛКѓдйЭЈЙ§forwardЕМШыЕНElasticsearchКЭKibanaЁЃетЪЧвЛИіКмБъзМЕФСїГЬЃЌФЧУДЧЩУюЕФЕиЗНдкФФРяФиЃП

ЧЩУюЕФЪЧЃЌЮвУЧПЩвддкШЮКЮПЩФмЕФЕиЗНЭљШежОРяМгШыZipkinЕФTraceIDЁЃ
етбљвЛРДЃЌЮвУЧОЭПЩвддкKibanaвЧБэХЬЩЯПДЕНЭъећЕФгУЛЇЧыЧѓжДааЧщПіЁЃвВОЭЪЧЫЕЃЌвЛЕЉЗўЮёНјШыЩњВњЛЗОГЃЌОЭЮЊдЫгЊзіКУСЫзМБИЁЃЫќвбОЭЈЙ§СЫздЖЏЛЏВтЪдЃЌШчЙћгаБивЊЃЌQAПЩвддйНјааЪжЖЏМьВщЁЃЫќгІИУУЛгаЪВУДЮЪЬтЁЃШчЙћЫќГіЯжСЫЮЪЬтЃЌФЧЫЕУїгавЛаЉЯШОіЬѕМўУЛгаЕУЕНТњзуЁЃШежОРяЯъЯИЕиМЧТМСЫетаЉЯШОіЬѕМўЃЌЭЈЙ§Й§ТЫЃЌЮвУЧПЩвдПДЕНФГИіЧыЧѓЕФИњзйаХЯЂЁЃЮвУЧвђДЫПЩвдПьЫйЕиВщГіЮЪЬтЕФИљдДЃЌЮЊЮвУЧНкЪЁСЫКмЖрЪБМфЁЃ
ЮвУЧКѓРДв§ШыСЫЖЏЬЌЕїЪдФЃЪНЁЃЯждкЕФШежОЪ§СПЛЙВЛЪЧКмДѓЃЌДѓИХжЛга100 GBЕН150 GBЃЌЮвМЧВЛЬЋЧхГўОпЬхЪ§зжСЫЁЃВЛЙ§ЃЌетаЉШежОЪЧдке§ГЃЕФШежОФЃЪНЯТЩњГЩЕФЁЃШчЙћЮвУЧЬэМгИќЖрЕФЯИНкЃЌФЧУДШежООЭПЩФмБфГЩTBМЖБ№ЕФЃЌДІРэЦ№РДОЭКмКФЗбзЪдДЁЃ
ЕБЮвУЧЗЂЯжФГаЉЗўЮёГіЯжЮЪЬтЃЌОЭДђПЊЕїЪдФЃЪНЃЈЭЈЙ§вЛИіAPIЃЉЃЌПДПДЗЂЩњСЫЪВУДЪТЧщЁЃгаЪБКђЃЌЮвУЧевЕНГіЯжЮЪЬтЕФЗўЮёЃЌдкВЛНЋЫќЙиБеЕФЧщПіЯТДђПЊЕїЪдФЃЪНЃЌГЂЪдевГіЮЪЬтЫљдкЁЃ
зюКѓЃЌЮвУЧдкELKЖЫВщевЮЪЬтЁЃЮвУЧЛЙЖдЙиМќЗўЮёЕФДэЮѓНјааОлКЯЁЃЗўЮёжЊЕРФФаЉДэЮѓЪЧЙиМќадЕФЃЌФФаЉВЛЪЧЙиМќадЕФЃЌШЛКѓНЋЫќУЧДЋИјSentryЁЃ

SentryФмЙЛжЧФмЕиЪеМЏДэЮѓШежОЃЌВЂаЮГЩЖШСПжИБъЃЌЛЙЛсНјаавЛаЉЛљБОЕФЙ§ТЫЁЃЮвУЧдкКмЖрЗўЮёЩЯЪЙгУСЫSentryЁЃЮвУЧДгЕЅЬхгІгУЪБЦкОЭПЊЪМЪЙгУЫќСЫЁЃ
ФЧУДзюгаШЄЕФЮЪЬтЪЧЃЌЮвУЧЪЧШчКЮНјааЩьЫѕЕФЃПетРяашвЊЯШНщЩмвЛаЉИХФюЁЃЮвУЧАбУПИіЛњЦїПДГЩвЛИіКкКаЁЃ

ЮвУЧгавЛИіБрХХЯЕЭГЃЌзюПЊЪМЪЙгУNomadЁЃШЗЧаЕиЫЕЃЌгІИУЪЧAnsibleЁЃЮвУЧздМКБраДНХБОЃЌЕЋЙтЪЧетаЉЛЙВЛФмТњзувЊЧѓЁЃФЧИіЪБКђЃЌNomadЕФФГаЉАцБОПЩвдМђЛЏЮвУЧЕФЙЄзїЃЌгкЪЧЮвУЧОіЖЈЧЈвЦЕНNomadЁЃ
ЭЌЪБЛЙЪЙгУСЫConsulЃЌНЋЫќзїЮЊЗўЮёЗЂЯжЕФзЂВсжааФЁЃЛЙгаVaultЃЌгУгкДцДЂУєИаЪ§ОнЃЌБШШчУмТыЁЂУидПКЭЦфЫћЫљгаВЛФмБЃДцдкGitЩЯЕФЖЋЮїЁЃ
етбљЃЌЫљгаЕФЛњЦїМИКѕЖМБфЕУвЛФЃвЛбљЁЃУПИіЛњЦїЩЯЖМАВзАСЫDockerЃЌЛЙгаConsulКЭNomadДњРэЁЃзмЕФРДЫЕЃЌУПвЛИіЛњЦїЖМДІгкБИгУзДЬЌЃЌПЩвддкШЮКЮЪБКђЭЖШыЪЙгУЁЃШчЙћВЛгУСЫЃЌЮвУЧОЭШУЫќУЧЯТЯпЁЃШчЙћФуЙЙНЈСЫдЦЦНЬЈЃЌФуОЭПЩвдЯШзМБИКУЛњЦїЃЌдкИпЗхЦкЪБНЋЫќУЧДђПЊЃЌдкИКдиЯТНЕЪБНЋЫќУЧЙиБеЁЃетЛсНкЪЁДѓСПЕФГЩБОЁЃ

КѓРДЃЌЮвУЧОіЖЈДгNomadЧЈвЦЕНKubernetesЃЌConsulвВвђДЫГЩЮЊСЫМЏжаЪНЕФХфжУЯЕЭГЁЃ
етбљвЛРДЃЌВПЗжеЛПЩвдНјааздЖЏЩьЫѕЁЃФЧУДЮвУЧЪЧдѕУДзіЕФФиЃП
ЕквЛВНЃЌЮвУЧЖдФкДцЁЂCPUКЭЭјТчНјааЯожЦЁЃ
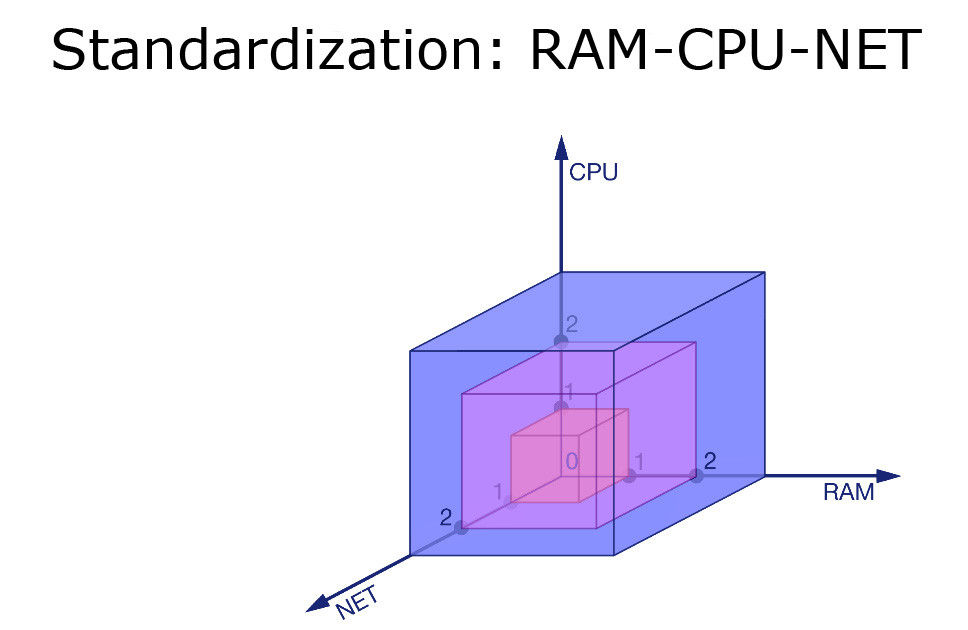
ЮвУЧЗжБ№НЋетШ§ИідЊЫиЗжГЩШ§ИіЕШМЖЃЌПГЕєЦфжаЕФвЛВПЗжЁЃР§ШчЃЌ

R3-C2-N1ЃЌЮвУЧвбОЯоЖЈжЛИјФГИіЗўЮёвЛаЁВПЗжЭјТчСїСПЁЂЖрвЛЕуЕуЕФCPUКЭИќЖрЕФФкДцЁЃетИіЗўЮёецЕФКмКФЗбзЪдДЁЃ
ЮвУЧдкетРяЪЙгУСЫжњМЧЗћЃЌЮвУЧЕФОіВпЗўЮёПЩвдЩшжУКмЖрЕФзщКЯжЕЃЌетаЉжЕПДЦ№РДЪЧетбљЕФЃК

ЪТЪЕЩЯЃЌЮвУЧЛЙгаC4КЭR4ЃЌВЛЙ§ЫќУЧвбОГЌГіСЫетаЉБъзМЕФЯожЦЁЃБъзМПДЦ№РДЪЧетбљЕФЃК

ЯТвЛВНПЊЪМзівЛаЉдЄБИЙЄзїЁЃЮвУЧЯШШЗЖЈЗўЮёЕФЩьЫѕРраЭЁЃ
ЖРСЂЕФЗўЮёзюШнвзЩьЫѕЃЌЫќПЩвдНјааЯпадЕиЩьЫѕЁЃШчЙћгУЛЇдіГЄСЫСНБЖЃЌЮвУЧОЭдЫааСНБЖЕФЗўЮёЪЕР§ЁЃетОЭЭђЪТДѓМЊСЫЁЃ
ЕкЖўжжЩьЫѕРраЭЃКЗўЮёвРРЕСЫЭтВПЕФзЪдДЃЌБШШчФЧаЉЪЙгУСЫЪ§ОнПтЕФЗўЮёЁЃЪ§ОнПтгаЫќздМКЕФШнСПЩЯЯоЃЌетИівЛЖЈвЊзЂвтЁЃФуЛЙвЊжЊЕРЃЌШчЙћЯЕЭГадФмГіЯжЫЅЭЫЃЌОЭВЛгІИУдйдіМгИќЖрЕФЪЕР§ЃЌЖјЧвФувЊжЊЕРетжжЧщПіЛсдкЪВУДЪБКђЗЂЩњЁЃ
ЕкШ§жжЧщПіЪЧЃЌЗўЮёЪмЕНЭтВПЯЕЭГЕФЧЃжЦЁЃР§ШчЃЌЭтВПЕФеЫЕЅЯЕЭГЁЃОЭЫудЫааСЫ100ИіЗўЮёЪЕР§ЃЌЫќвВУЛАьЗЈДІРэГЌЙ§500ИіЧыЧѓЁЃЮвУЧвЊПМТЧЕНетаЉЯожЦЁЃдкШЗЖЈСЫЗўЮёРраЭВЂЩшжУСЫЯргІЕФБъМЧжЎКѓЃЌЪЧЪБКђПДПДЫќУЧЪЧШчКЮЭЈЙ§ЮвУЧЕФЙЙНЈЙмЕРЕФЁЃ

ЮвУЧдкCIЗўЮёЦїЩЯдЫааСЫвЛаЉЕЅдЊВтЪдЃЌШЛКѓдкВтЪдЛЗОГдЫааМЏГЩВтЪдЃЌЮвУЧЕФQAЭХЖгЛсЖдЫќУЧзівЛаЉМьВщЁЃдкетжЎКѓЃЌЮвУЧОЭНјШыСЫдЄЩњВњЛЗОГЕФИКдиВтЪдЁЃ

ШчЙћЪЧЕквЛжжРраЭЕФЗўЮёЃЌЮвУЧЪЙгУвЛИіЪЕР§ЃЌВЂдкетИіЛЗОГРядЫааЫќЃЌИјЫќзюДѓЕФИКдиЁЃдкдЫааСЫМИТжжЎКѓЃЌЮвУЧШЁЦфжаЕФзюаЁжЕЃЌНЋЫќДцШыInfluxDBЃЌНЋЫќзїЮЊИУЗўЮёЕФИКдиЩЯЯоЁЃ
ШчЙћЪЧЕкЖўжжРраЭЕФЗўЮёЃЌЮвУЧж№НЅМгДѓИКдиЃЌжБЕНГіЯжСЫадФмЫЅЭЫЁЃЮвУЧЖдетИіЙ§ГЬНјааЦРЙРЃЌШчЙћЮвУЧжЊЕРИУЯЕЭГЕФИКдиЃЌФЧУДОЭБШНЯЕБЧАИКдиЪЧЗёвбОзуЙЛЃЌЗёдђЃЌЮвУЧОЭЛсЩшжУИцОЏЃЌВЛЛсАбетИіЗўЮёЗЂВМЕНЩњВњЛЗОГЁЃЮвУЧЛсИцЫпПЊЗЂШЫдБЃКЁАФуУЧашвЊЗжРыГівЛаЉЖЋЮїЃЌЛђепМгНјШЅСэвЛИіЙЄОпЃЌШУетИіЗўЮёПЩвдИќКУЕиЩьЫѕЁЃЁБ

вђЮЊЮвУЧжЊЕРЕкШ§жжРраЭЗўЮёЕФЩЯЯоЃЌЫљвдЮвУЧжЛдЫаавЛИіЪЕР§ЁЃЮвУЧвВЛсИјЫќвЛаЉИКдиЃЌПДПДЫќПЩвдЗўЮёЖрЩйИігУЛЇЁЃШчЙћЮвУЧжЊЕРеЫЕЅЯЕЭГЕФЩЯЯоЪЧ1000ИіЧыЧѓЃЌВЂЧвУПИіЗўЮёЪЕР§ПЩвдДІРэ200ИіЧыЧѓЃЌФЧУДОЭашвЊ5ИіЪЕР§ЁЃ
ЮвУЧАбетаЉаХЯЂЖМБЃДцЕНСЫInfluxDBЁЃЮвУЧЕФОіВпЗўЮёПЊЪМХЩЩЯгУГЁСЫЁЃЫќЛсМьВщСНИіБпНчЃКЩЯЯоКЭЯТЯоЁЃШчЙћГЌГіСЫЩЯЯоЃЌФЧУДОЭгІИУдіМгЗўЮёЪЕР§ЁЃШчЙћГЌГіЯТЯоЃЌФЧУДОЭМѕЩйЪЕР§ЁЃШчЙћИКдиЯТНЕЃЈБШШчЭэЩЯЕФЪБКђЃЉЃЌЮвУЧОЭВЛашвЊетУДЖрЛњЦїЃЌПЩвдМѕЩйЫќУЧЕФЪ§СПЃЌВЂЙиЕєвЛВПЗжЛњЦїЃЌЪЁЯТвЛаЉЗбгУЁЃ
ећЬхПДЦ№РДЪЧетбљЕФ

УПИіЗўЮёЕФЖШСПжИБъБэУїСЫЫќУЧЕБЧАЕФИКдиЁЃИКдиаХЯЂБЛБЃДцЕНInfluxDBЃЌШчЙћОіВпЗўЮёЗЂЯжЗўЮёЪЕР§ДяЕНСЫЩЯЯоЃЌЫќЛсЯђNomadКЭKubernetesЗЂЫЭУќСюЃЌвЊЧѓдіМгЗўЮёЪЕР§ЁЃгаПЩФмдкдЦЖЫвбОгаПЩгУЕФЪЕР§ЃЌЛђепПЊЪМзівЛаЉзМБИЙЄзїЁЃВЛЙмдѕбљЃЌЗЂГівЊЧѓдіМгаТЗўЮёЪЕР§ЕФИцОЏВХЪЧЙиМќЫљдкЁЃ
вЛаЉЪмЯоЕФЗўЮёШчЙћДяЕНЩЯЯоЃЌвВЛсЗЂГіЯрЙиЕФИцОЏЁЃЖдгкетРрЧщПіЃЌЮвУЧГ§СЫМгДѓЕШД§ЖгСаЃЌвВзіВЛСЫЦфЫћЪВУДЪТЧщЁЃВЛЙ§зюЦ№ТыЮвУЧжЊЕРЮвУЧКмПьОЭЛсУцСйетбљЕФЮЪЬтЃЌВЂПЊЪМзіКУгІЖдДыЪЉЁЃ
етОЭЪЧЮвЯыИцЫпДѓМвгаЙиЩьЫѕадЗНУцЕФЪТЧщЁЃГ§СЫетаЉЃЌЛЙгаСэЭтвЛИіЖЋЮїЁЊЁЊGitlab
CIЁЃ

ЮвУЧвЛАуЪЧЭЈЙ§TeamCityРДПЊЗЂЗўЮёЕФЁЃКѓРДЃЌЮвУЧвтЪЖЕНЃЌЫљгаЕФЗўЮёЖМгавЛИіЙВадЃЌетаЉЗўЮёЖМЪЧВЛвЛбљЕФЃЌВЂЧвжЊЕРздМКИУШчКЮВПЪ№ЕНШнЦїРяЁЃвЊЩњГЩетУДЕФЯюФПецЕФКмРЇФбЃЌВЛЙ§ШчЙћЪЙгУymlЮФМўРДУшЪіЫќУЧЃЌВЂАбетИіЮФМўгыЗўЮёЗХдквЛЦ№ЃЌОЭЛсЗНБуКмЖрЁЃЫфШЛЮвУЧжЛзіСЫвЛаЉаЁЕФИФБфЃЌВЛЙ§ШДЮЊЮвУЧДјРДСЫЗЧГЃЖрЕФПЩФмадЁЃ
ЯждкЃЌЮвЯыЫЕвЛаЉвЛжБЯыЖдздМКЫЕЕФЛАЁЃ
ЙигкЮЂЗўЮёПЊЗЂЃЌЮвНЈвщдквЛПЊЪМОЭЪЙгУБрХХЯЕЭГЁЃПЩвдЪЙгУзюМђЕЅЕФБрХХЯЕЭГЃЌБШШчNomadЃЌЭЈЙ§nomad
agent -devУќСюЦєЖЏвЛИіБрХХЯЕЭГЃЌАќРЈConsulКЭЦфЫћЖЋЮїЁЃ
ЮвУЧЗТЗ№ЪЧдквЛИіКкКазгЙЄзїЁЃФуЪдЭМБмУтБЛАѓЖЈЕНФГЬЈЬиЖЈЕФЛњЦїЩЯЃЌЛђепБЛИНМгЕНФГЬЈЬиЖЈЛњЦїЕФЮФМўЯЕЭГЩЯЁЃетаЉЪТЧщЛсШУФуПЊЪМжиаТЫМПМЁЃ
дкПЊЗЂНзЖЮЃЌУПИіЗўЮёжСЩйашвЊСНИіЪЕР§ЃЌШчЙћЦфжавЛИіГіЯжЮЪЬтЃЌОЭПЩвдЙиЕєЫќЃЌгЩСэвЛИіНгЙмМЬајЗўЮёЁЃ
ЛЙгавЛаЉгаЙиМмЙЙЕФЮЪЬтЁЃдкЮЂЗўЮёМмЙЙРяЃЌЯћЯЂзмЯпЪЧвЛИіЗЧГЃживЊЕФзщМўЁЃ
МйЩшФугавЛИігУЛЇзЂВсЯЕЭГЃЌФЧУДШчКЮвдзюМђЕЅЕФЗНЪНЪЕЯжЫќФиЃПЖдгкзЂВсЯЕЭГРДЫЕЃЌашвЊДДНЈеЫЛЇЃЌШЛКѓдкеЫЕЅЯЕЭГРяДДНЈвЛИігУЛЇЃЌВЂЮЊЫћДДНЈЭЗЯёКЭЦфЫћЖЋЮїЁЃФугавЛзщЗўЮёЃЌЦфжаЕФГЌМЖЗўЮёЪеЕНСЫвЛИіЧыЧѓЃЌЫќНЋЧыЧѓЗжЗЂИјЦфЫћЗўЮёЁЃОЙ§МИДЮжЎКѓЃЌЫќОЭжЊЕРИУДЅЗЂФФаЉЗўЮёРДЭъГЩзЂВсЁЃ
ВЛЙ§ЃЌЮвУЧПЩвдЪЙгУвЛжжИќМђЕЅЁЂИќПЩППЁЂИќИпаЇЕФЗНЪНРДЪЕЯжЁЃЮвУЧЪЙгУвЛИіЗўЮёРДДІРэзЂВсЃЌЫќзЂВсСЫвЛИігУЛЇЃЌШЛКѓЗЂЫЭвЛИіЪТМўЕНЯћЯЂзмЯпЃЌБШШчЁАЮввбОзЂВсСЫвЛИіyoghurtЃЌIDЪЧЁЁЁБЁЃЯрЙиЕФЗўЮёЛсЪеЕНетИіЪТМўЃЌЦфжаЕФвЛИіЗўЮёЛсдкеЫЕЅЯЕЭГРяДДНЈвЛИіеЫЛЇЃЌСэвЛИіЗўЮёЛсЗЂЫЭвЛЗтЛЖггЪМўЁЃ
ВЛЙ§ЃЌЯЕЭГЛсвђДЫЪЇШЅЧПвЛжТадЁЃетИіЪБКђФуУЛгаГЌМЖЗўЮёЃЌвВВЛжЊЕРУПИіЗўЮёЕФзДЬЌЁЃВЛЙ§ЃЌетбљЕФЯЕЭГКмШнвзЮЌЛЄЁЃ
ЯждкЃЌЮвдйЫЕвЛаЉжЎЧАЬсЕНЙ§ЕФЮЪЬтЁЃВЛвЊЪдЭМаоИДГіЮЪЬтЕФЗўЮёЁЃШчЙћФГаЉЗўЮёЪЕЧóЯжСЫЮЪЬтЃЌНЋЫќевГіРДЃЌШЛКѓАбСїСПЖЈЯђЕНЦфЫћЗўЮёЪЕР§ЃЈПЩФмЪЧаТдіЕФЪЕР§ЃЉЩЯЃЌШЛКѓдйеяЖЯЮЪЬтЁЃетбљПЩвдЯджјЬсЩ§ЯЕЭГЕФПЩгУадЁЃ
ЭЈЙ§ЪеМЏЖШСПжИБъРДСЫНтЯЕЭГЕФзДЬЌздШЛВЛдкЛАЯТЁЃ
ВЛЙ§вЊзЂвтЃЌШчЙћФуЖдФГИіЖШСПжИБъВЛСЫНтЃЌВЛжЊЕРдѕУДЪЙгУЫќЃЌЛђепЫќЖдФуРДЫЕУЛгаЪВУДвтвхЃЌОЭВЛвЊЪеМЏЫќЁЃвђЮЊгаЪБКђЃЌетбљЕФЖШСПжИБъЛсгаЪ§АйЭђИіЁЃФудкетаЉЮогУЕФЖШСПжИБъЩЯУцРЫЗбСЫКмЖрзЪдДКЭЪБМфЁЃетаЉЪЧЮоаЇЕФИКдиЁЃ
ШчЙћФуШЯЮЊФуашвЊФГаЉЖШСПжИБъЃЌФЧУДОЭЪеМЏЫќУЧЁЃШчЙћВЛашвЊЃЌОЭВЛвЊЪеМЏЁЃ
ШчЙћФуЗЂЯжСЫвЛИіЮЪЬтЃЌВЛвЊМБзХШЅаоИДЁЃдкКмЖрЧщПіЯТЃЌЯЕЭГЛсЖдДЫзїГіЗДгІЁЃЕБЯЕЭГашвЊФуВЩШЁааЖЏЕФЪБКђЃЌЫќЛсИјФуЗЂГіИцОЏЁЃШчЙћЫќВЛвЊЧѓФудкАывЙХмШЅаоИДЮЪЬтЃЌФЧУДЫќОЭВЛЫуЪЧвЛИіИцОЏЁЃЫќжЛВЛЙ§ЪЧвЛжжОЏИцЃЌФуПЩвддкАбЫќЕБГЩвЛАуЕФЮЪЬтРДДІРэЁЃ |






