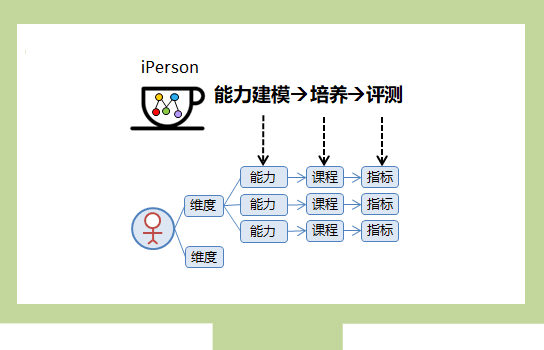
| ЮЂЗўЮёМмЙЙЕФгХЪЦгыВЛзу
гХЪЦ
1.ИќМђЕЅЃКЭЈЙ§ЗжНтОоДѓЕЅЬхЪНгІгУЮЊЖрИіЗўЮёЗНЗЈНтОіСЫИДдгадЮЪЬтЁЃдкЙІФмВЛБфЕФЧщПіЯТЃЌгІгУБЛЗжНтЮЊЖрИіПЩЙмРэЕФЗжжЇЛђЗўЮёЁЃ
2.здгЩбЁаЭЃКетжжМмЙЙЪЙЕУУПИіЗўЮёЖМПЩвдгазЈУХПЊЗЂЭХЖгРДПЊЗЂЁЃПЊЗЂепПЩвдздгЩбЁдёПЊЗЂММЪѕЃЌЬсЙЉAPIЗўЮё
3.ВПЪ№ЖРСЂЃКЮЂЗўЮёМмЙЙФЃЪНЪЧУПИіЮЂЗўЮёЖРСЂЕФВПЪ№ЁЃПЊЗЂепВЛдйашвЊаЕїЦфЫќЗўЮёВПЪ№ЖдБОЗўЮёЕФгАЯь
4.ЗўЮёЖРСЂРЉеЙ:ФуПЩвдИљОнУПИіЗўЮёЕФЙцФЃРДВПЪ№ТњзуашЧѓЕФЙцФЃЁЃЩѕжСгкЃЌФуПЩвдЪЙгУИќЪЪКЯгкЗўЮёзЪдДашЧѓЕФгВМўЁЃ
СгЪЦ
1.ЮЂЗўЮёЧПЕїСЫЗўЮёДѓаЁЃКВ№ЬЋаЁЃП
2.ЮЂЗўЮёгІгУЪЧЗжВМЪНЯЕЭГЃЌгЩДЫЛсДјРДЙЬгаЕФИДдгадЃКПЊЗЂепашвЊдкRPCЛђепЯћЯЂДЋЕнжЎМфбЁдёВЂЭъГЩНјГЬМфЭЈбЖЛњжЦЁЃИќЩѕгкЃЌЫћУЧБиаыаДДњТыРДДІРэЯћЯЂДЋЕнжаЫйЖШЙ§Т§ЛђепВЛПЩгУЕШОжВПЪЇаЇЮЪЬтЁЃЕБШЛетВЂВЛЪЧЪВУДФбЪТЃЌЕЋЯрЖдгкЕЅЬхЪНгІгУжаЭЈЙ§гябдВуМЖЕФЗНЗЈЛђепНјГЬЕїгУЃЌЮЂЗўЮёЯТетжжММЪѕЯдЕУИќИДдгвЛаЉЁЃ
3.ЗжВМЪННЛвз/ЪТЮёЮЪЬт
4.ВтЪдИДдгЃКЭЌбљЕФЗўЮёВтЪдашвЊЦєЖЏКЭЫќгаЙиЕФЫљгаЗўЮё
5.ЮЂЗўЮёМмЙЙФЃЪНгІгУЕФИФБфНЋЛсВЈМАЖрИіЗўЮёЃКБШШчЃЌМйЩшФудкЭъГЩвЛИіАИР§ЃЌашвЊаоИФЗўЮёAЁЂBЁЂCЃЌЖјAвРРЕBЃЌBвРРЕC
6.ВПЪ№вЛИіЮЂЗўЮёгІгУвВКмИДдгЃКвЛИіЗжВМЪНгІгУжЛашвЊМђЕЅдкИДдгОљКтЦїКѓУцВПЪ№ИїздЕФЗўЮёЦїОЭКУСЫЁЃУПИігІгУЪЕР§ЪЧашвЊХфжУжюШчЪ§ОнПтКЭЯћЯЂжаМфМўЕШЛљДЁЗўЮёЁЃЯрЖдБШЃЌвЛИіЮЂЗўЮёгІгУвЛАугЩДѓХњЗўЮёЙЙГЩЁЃ
ЪЙгУAPI Gateway

ПЭЛЇЖЫЕНЮЂЗўЮёжБНгЭЈаХ
ВЛавЕФЪЧЃЌетИіЗНАИгаКмЖрРЇФбКЭЯожЦЁЃЦфжавЛИіЮЪЬтЪЧПЭЛЇЖЫЕФашЧѓСПгыУПИіЮЂЗўЮёБЉТЖЕФЯИСЃЖШAPIЪ§СПЕФВЛЦЅХфЁЃШчЭМжаЃЌПЭЛЇЖЫашвЊ7ДЮЕЅЖРЧыЧѓЁЃдкИќИДдгЕФГЁОАжаЃЌПЩФмЛсашвЊИќЖрДЮЧыЧѓЁЃР§ШчЃЌбЧТэбЗЕФВњЦЗзюжевГвЊЧыЧѓЪ§АйИіЮЂЗўЮёЁЃЫфШЛвЛИіПЭЛЇЖЫПЩвдЭЈЙ§LANЗЂЦ№КмЖрИіЧыЧѓЃЌЕЋЪЧдкЙЋЭјЩЯетбљЛсКмУЛгааЇТЪЃЌетИіЮЪЬтдквЦЖЏЛЅСЊЭјЩЯгШЮЊЭЛГіЁЃетИіЗНАИЭЌЪБЛсЕМжТПЭЛЇЖЫДњТыЗЧГЃИДдгЁЃ
СэвЛИіДцдкЕФЮЪЬтЪЧПЭЛЇЖЫжБНгЧыЧѓЮЂЗўЮёЕФавщПЩФмВЂВЛЪЧwebгбКУаЭЁЃвЛИіЗўЮёПЩФмЪЧгУThriftЕФRPCавщЃЌЖјСэвЛИіЗўЮёПЩФмЪЧгУAMQPЯћЯЂавщЁЃЫќУЧЖМВЛЪЧфЏРРЛђЗРЛ№ЧНгбКУЕФЃЌВЂЧвзюКУЪЧФкВПЪЙгУЁЃгІгУгІИУдкЗРЛ№ЧНЭтВЩгУРрЫЦHTTPЛђепWEBSocketавщЁЃ
етИіЗНАИЕФСэвЛИіШБЕуЪЧЫќКмФбжиЙЙЮЂЗўЮёЁЃЫцзХЪБМфЕФЭЦвЦЃЌЮвУЧПЩФмашвЊИФБфЯЕЭГЮЂЗўЮёФПЧАЕФЧаЗжЗНАИЁЃР§ШчЃЌЮвУЧПЩФмашвЊНЋСНИіЗўЮёКЯВЂЛђепНЋвЛИіЗўЮёВ№ЗжЮЊЖрИіЁЃЕЋЪЧЃЌШчЙћПЭЛЇЖЫжБНггыЮЂЗўЮёНЛЛЅЃЌФЧУДетжжжиЙЙОЭКмФбЪЕЪЉЁЃ
ВЩгУвЛИіAPI Gateway
ЭЈГЃРДЫЕЃЌвЛИіИќКУЕФНтОіАьЗЈЪЧВЩгУAPI GatewayЕФЗНЪНЁЃAPI GatewayЪЧвЛИіЗўЮёЦїЃЌвВПЩвдЫЕЪЧНјШыЯЕЭГЕФЮЈвЛНкЕуЁЃетИњУцЯђЖдЯѓЩшМЦФЃЪНжаЕФFacadeФЃЪНКмЯёЁЃAPI
GatewayЗтзАФкВПЯЕЭГЕФМмЙЙЃЌВЂЧвЬсЙЉAPIИјИїИіПЭЛЇЖЫЁЃЫќЛЙПЩФмгаЦфЫћЙІФмЃЌШчЪкШЈЁЂМрПиЁЂИКдиОљКтЁЂЛКДцЁЂЧыЧѓЗжЦЌКЭЙмРэЁЂОВЬЌЯьгІДІРэЕШЁЃЯТЭМеЙЪОСЫвЛИіЪЪгІЕБЧАМмЙЙЕФAPI
GatewayЁЃ
API GatewayИКд№ЧыЧѓзЊЗЂЁЂКЯГЩКЭавщзЊЛЛЁЃЫљгаРДздПЭЛЇЖЫЕФЧыЧѓЖМвЊЯШОЙ§API GatewayЃЌШЛКѓТЗгЩетаЉЧыЧѓЕНЖдгІЕФЮЂЗўЮёЁЃAPI
GatewayНЋОГЃЭЈЙ§ЕїгУЖрИіЮЂЗўЮёРДДІРэвЛИіЧыЧѓвдМАОлКЯЖрИіЗўЮёЕФНсЙћЁЃЫќПЩвддкwebавщгыФкВПЪЙгУЕФЗЧWebгбКУаЭавщМфНјаазЊЛЛЃЌШчHTTPавщЁЂWebSocketавщЁЃ
API GatewayПЩвдЬсЙЉИјПЭЛЇЖЫвЛИіЖЈжЦЛЏЕФAPIЁЃЫќБЉТЖвЛИіДжСЃЖШAPIИјвЦЖЏПЭЛЇЖЫЁЃвдВњЦЗзюжевГетИіЪЙгУГЁОАЮЊР§ЁЃAPI
GatewayЬсЙЉвЛИіЗўЮёЬсЙЉЕуЃЈ/productdetails?productid=xxxЃЉЪЙЕУвЦЖЏПЭЛЇЖЫПЩвддквЛИіЧыЧѓжаМьЫїЕНВњЦЗзюжевГЕФШЋВПЪ§ОнЁЃAPI
GatewayЭЈЙ§ЕїгУЖрИіЗўЮёРДДІРэетвЛИіЧыЧѓВЂЗЕЛиНсЙћЃЌЩцМАВњЦЗаХЯЂЁЂЭЦМіЁЂЦРТлЕШЁЃ
вЛИіКмКУЕФAPI GatewayР§згЪЧNetfix API GatewayЁЃNetflixСїЗўЮёЬсЙЉЪ§АйИіВЛЭЌЕФЮЂЗўЮёЃЌАќРЈЕчЪгЁЂЛњЖЅКаЁЂжЧФмЪжЛњЁЂгЮЯЗЯЕЭГЁЂЦНАхЕчФдЕШЁЃЦ№ГѕЃЌNetflixЪгЭМЬсЙЉвЛИіЪЪгУШЋГЁОАЕФAPIЁЃЕЋЪЧЃЌЫћУЧЗЂЯжетжжаЮЪНВЛКУгУЃЌвђЮЊЩцМАЕНИїЪНИїбљЕФЩшБИвдМАЫќУЧЖРЬиЕФашЧѓЁЃЯждкЃЌЫћУЧВЩгУвЛИіAPI
GatewayРДЬсЙЉШнДэадИпЕФAPIЃЌеыЖдВЛЭЌРраЭЩшБИгаЯргІДњТыЁЃЪТЪЕЩЯЃЌвЛИіЪЪХфЦїДІРэвЛИіЧыЧѓЦНОљвЊЕїгУ6ЕН8ИіКѓЖЫЗўЮёЁЃNetflix
API GatewayУПЬьДІРэЪ§ЪЎвкЕФЧыЧѓЁЃ
API GatewayЕФгХЕуКЭШБЕу
API GatewayЕФвЛИізюДѓКУДІЪЧЗтзАгІгУФкВПНсЙЙЁЃЯрБШЦ№РДЕїгУжИЖЈЕФЗўЮёЃЌПЭЛЇЖЫжБНгИњgatwayНЛЛЅИќМђЕЅЕуЁЃAPI
GatewayЬсЙЉИјУПвЛИіПЭЛЇЖЫвЛИіЬиЖЈAPIЃЌетбљМѕЩйСЫПЭЛЇЖЫгыЗўЮёЦїЖЫЕФЭЈаХДЮЪ§ЃЌвВМђЛЏСЫПЭЛЇЖЫДњТыЁЃ
API GatewayвВгавЛаЉШБЕуЁЃЫќЪЧвЛИіИпПЩгУЕФзщМўЃЌБиаывЊПЊЗЂЁЂВПЪ№КЭЙмРэЁЃЛЙгавЛИіЮЪЬтЃЌЫќПЩФмГЩЮЊПЊЗЂЕФвЛИіЦПОБЁЃПЊЗЂепБиаыИќаТAPI
GatewayРДЬсЙЉаТЗўЮёЬсЙЉЕуРДжЇГжаТБЉТЖЕФЮЂЗўЮёЁЃИќаТAPI GatewayЪББиаыдНЧсСПМЖдНКУЁЃЗёдђЃЌПЊЗЂепНЋвђЮЊИќаТGatewayЖјХХЖгСаЁЃЕЋЪЧЃЌГ§СЫетаЉШБЕуЃЌЖдгкДѓВПЗжЕФгІгУЃЌВЩгУAPI
GatewayЕФЗНЪНЖМЪЧгааЇЕФЁЃ
ЪЕЯжвЛИіAPI Gateway
адФмКЭПЩРЉеЙад
ДДНЈвЛИіжЇГжЭЌВНЁЂЗЧзшШћI/OЕФAPI GatewayЪЧгавтвхЕФЁЃвбОгаВЛЭЌЕФММЪѕПЩвдгУРДЪЕЯжвЛИіПЩРЉеЙЕФAPI
Gateway
1.JVM:ВЩгУЛљгкNIOММЪѕЕФПђМмЃЌШчNettyЃЌVertxЃЌSpring
ReactorЛђепJBoss Undertow
2.Node.js
3.nginx_plus
ВЩгУЗДгІадБрГЬФЃаЭ
ЖдгкгааЉЧыЧѓЃЌAPI GatewayПЩвдЭЈЙ§жБНгТЗгЩЧыЧѓЕНЖдгІЕФКѓЖЫЗўЮёЩЯЕФЗНЪНРДДІРэЁЃЖдгкСэЭтвЛаЉЧыЧѓЃЌЫќашвЊЕїгУЖрИіКѓЖЫЗўЮёВЂКЯВЂНсЙћРДДІРэ
ЖдгквЛаЉЧыЧѓЃЌР§ШчВњЦЗзюжевГУцЧыЧѓЃЌЗЂИјКѓЖЫЗўЮёЕФЧыЧѓЪЧЯрЛЅЖРСЂЕФЁЃЮЊСЫзюаЁЛЏЯьгІЪБМфЃЌAPI GatewayгІИУВЂЗЂЕФДІРэЯрЛЅЖРСЂЕФЧыЧѓЁЃЕЋЪЧЃЌгаЪБКђЧыЧѓжЎМфЪЧгавРРЕЕФЁЃAPI
GatewayПЩФмашвЊЯШЭЈЙ§ЪкШЈЗўЮёРДбщжЄЧыЧѓЃЌШЛКѓдкТЗгЩЕНКѓЖЫЗўЮёЁЃ
РћгУДЋЭГЕФЭЌВНЛиЕїЗНЗЈРДЪЕЯжAPIКЯВЂЕФДњТыЛсЪЙЕУФуНјШыЛиЕїКЏЪ§ЕФиЌУЮжаЁЃетжжДњТыНЋЗЧГЃФбЖШЧвФбвдЮЌЛЄЁЃвЛИігХбХЕФНтОіЗНАИЪЧВЩгУЗДгІадБрГЬФЃЪНРДЪЕЯжЁЃ
РрЫЦЕФЗДгІГщЯѓЪЕЯжга:
ЗДгІГщЯѓ
1.ScalaЕФFuture
2.Java8ЕФCompletableFuture
3.JavaScriptЕФPromise
4.ЛљгкЮЂШэ.NetЦНЬЈЕФгаReactive Extensions(Rx)ЁЃ
NetflixЮЊJVMЛЗОГДДНЈСЫRxJavaРДЪЙгУЫћУЧЕФAPI GatewayЁЃЭЌбљЕиЃЌJavaScriptЦНЬЈгаRxJS
ЃЌПЩвддкфЏРРЦїКЭNode.jsЦНЬЈЩЯдЫааЁЃВЩгУЗДгІБрГЬЗНЗЈПЩвдАяжњПьЫйЪЕЯжвЛИіИпаЇЕФAPI GatewayДњТыЁЃ
ЦфЫћЮЪЬт
ЗўЮёЗЂЯж: API GatewayашвЊВЩгУЯЕЭГЕФЗўЮёЗЂЯжЛњжЦЃЌвЊУДВЩгУЗўЮёЖЫЗЂЯжЃЌвЊУДЪЧПЭЛЇЖЫЗЂЯж.
ДІРэВПЗжЪЇАм: етИіЮЪЬтЗЂЩњдкЗжВМЪНЯЕЭГжаЕБвЛИіЗўЮёЕїгУСэЭтвЛИіЗўЮёГЌЪБЛђепВЛПЩгУЕФЧщПіЁЃAPI GatewayВЛгІИУБЛзшЖЯВЂДІгкЮоЯоЦкЕШД§ЯТгЮЗўЮёЕФзДЬЌ
ЩюШыЮЂЗўЮёМмЙЙЕФНјГЬМфЭЈаХ
НЛЛЅФЃЪН
ПЭЛЇЖЫКЭЗўЮёЦїжЎМфгаКмЖрЕФНЛЛЅФЃЪНЃЌЮвУЧПЩвдДгСНИіЮЌЖШНјааЙщРрЁЃЕквЛИіЮЌЖШЪЧвЛЖдвЛЛЙЪЧвЛЖдЖрЃК
1. вЛЖдвЛЃКУПИіПЭЛЇЖЫЧыЧѓгавЛИіЗўЮёЪЕР§РДЯьгІЁЃ
2. вЛЖдЖрЃКУПИіПЭЛЇЖЫЧыЧѓгаЖрИіЗўЮёЪЕР§РДЯьгІ
ЕкЖўИіЮЌЖШЪЧетаЉНЛЛЅЪНЭЌВНЛЙЪЧвьВНЃК
1. ЭЌВНФЃЪНЃКПЭЛЇЖЫЧыЧѓашвЊЗўЮёЖЫМДЪБЯьгІЃЌЩѕжСПЩФмгЩгкЕШД§ЖјзшШћЁЃ
2. вьВНФЃЪНЃКПЭЛЇЖЫЧыЧѓВЛЛсзшШћНјГЬЃЌЗўЮёЖЫЕФЯьгІПЩвдЪЧЗЧМДЪБЕФЁЃ
вЛЖдвЛЕФНЛЛЅФЃЪНгавдЯТМИжжЗНЪН
1. ЧыЧѓ/ЯьгІЃКвЛИіПЭЛЇЖЫЯђЗўЮёЦїЖЫЗЂЦ№ЧыЧѓЃЌЕШД§ЯьгІЁЃПЭЛЇЖЫЦкЭћДЫЯьгІМДЪБЕНДяЁЃдквЛИіЛљгкЯпГЬЕФгІгУжаЃЌЕШД§Й§ГЬПЩФмдьГЩЯпГЬзшШћЁЃ
2. ЭЈжЊЃЈвВОЭЪЧГЃЫЕЕФЕЅЯђЧыЧѓЃЉЃКвЛИіПЭЛЇЖЫЧыЧѓЗЂЫЭЕНЗўЮёЖЫЃЌЕЋЪЧВЂВЛЦкЭћЗўЮёЖЫЯьгІЁЃ
3. ЧыЧѓ/вьВНЯьгІЃКПЭЛЇЖЫЗЂЫЭЧыЧѓЕНЗўЮёЖЫЃЌЗўЮёЖЫвьВНЯьгІЧыЧѓЁЃПЭЛЇЖЫВЛЛсзшШћЃЌЖјЧвБЛЩшМЦГЩФЌШЯЯьгІВЛЛсСЂПЬЕНДяЁЃ
вЛЖдЖрЕФНЛЛЅФЃЪНгавдЯТМИжжЗНЪНЃК
1. ЗЂВМ/ ЖЉдФФЃЪНЃКПЭЛЇЖЫЗЂВМЭЈжЊЯћЯЂЃЌБЛСуИіЛђепЖрИіИааЫШЄЕФЗўЮёЯћЗбЁЃ
2. ЗЂВМ/вьВНЯьгІФЃЪНЃКПЭЛЇЖЫЗЂВМЧыЧѓЯћЯЂЃЌШЛКѓЕШД§ДгИааЫШЄЗўЮёЗЂЛиЕФЯьгІЁЃ
APIЕФбнЛЏ
ШчЙћФуе§дкЪЙгУЛљгкЛљгкHTTPЛњжЦЕФIPCЃЌР§ШчRESTЃЌвЛжжНтОіЗНАИЪЧАбАцБОКХЧЖШыЕНURLжаЁЃУПИіЗўЮёЖМПЩФмЭЌЪБДІРэЖрИіАцБОЕФAPIЁЃ
ВПЗжЪЇАм
ЗжВМЪНЯЕЭГжаВПЗжЪЇАмЪЧЦеБщДцдкЕФЮЪЬтЁЃвђЮЊПЭЛЇЖЫКЭЗўЮёЖЫЪЧЖМЪЧЖРСЂЕФНјГЬЃЌвЛИіЗўЮёЖЫгаПЩФмвђЮЊЙЪеЯЛђепЮЌЛЄЖјЭЃжЙЗўЮёЃЌЛђепДЫЗўЮёвђЮЊЙ§диЭЃжЙЛђепЗДгІКмТ§ЁЃ
NetfilixЗНАИ:
1. ЭјТчГЌЪБЃКЕБЕШД§ЯьгІЪБЃЌВЛвЊЮоЯоЦкЕФзшШћЃЌЖјЪЧВЩгУГЌЪБВпТдЁЃЪЙгУГЌЪБВпТдПЩвдШЗБЃзЪдДВЛЛсЮоЯоЦкЕФеМгУЁЃ
2. ЯожЦЧыЧѓЕФДЮЪ§ЃКПЩвдЮЊПЭЛЇЖЫЖдФГЬиЖЈЗўЮёЕФЧыЧѓЩшжУвЛИіЗУЮЪЩЯЯоЁЃШчЙћЧыЧѓвбДяЩЯЯоЃЌОЭвЊСЂПЬжежЙЧыЧѓЗўЮёЁЃ
3. ЖЯТЗЦїФЃЪНЃЈCircuit Breaker PatternЃЉЃКМЧТМГЩЙІКЭЪЇАмЧыЧѓЕФЪ§СПЁЃШчЙћЪЇаЇТЪГЌЙ§вЛИіуажЕЃЌДЅЗЂЖЯТЗЦїЪЙЕУКѓајЕФЧыЧѓСЂПЬЪЇАмЁЃШчЙћДѓСПЕФЧыЧѓЪЇАмЃЌОЭПЩФмЪЧетИіЗўЮёВЛПЩгУЃЌдйЗЂЧыЧѓвВЮовтвхЁЃдквЛИіЪЇаЇЦкКѓЃЌПЭЛЇЖЫПЩвддйЪдЃЌШчЙћГЩЙІЃЌЙиБеДЫЖЯТЗЦїЁЃ
4. ЬсЙЉЛиЙіЃКЕБвЛИіЧыЧѓЪЇАмКѓПЩвдНјааЛиЙіТпМЁЃР§ШчЃЌЗЕЛиЛКДцЪ§ОнЛђепвЛИіЯЕЭГФЌШЯжЕЁЃ
Netflix Hystrix ЪЧвЛИіЪЕЯжЯрЙиФЃЪНЕФПЊдДПтЁЃШчЙћЪЙгУJVMЃЌЭЦМіПМТЧЪЙгУHystrixЁЃЖјШчЙћЪЙгУЗЧJVMЛЗОГЃЌФуПЩвдЪЙгУРрЫЦЙІФмЕФПт
ЗўЮёЗЂЯжЕФПЩааЗНАИвдМАЪЕМљАИР§
ПЭЛЇЖЫЗЂЯжФЃЪН
ЕБЪЙгУПЭЛЇЖЫЗЂЯжФЃЪНЪБЃЌПЭЛЇЖЫИКд№ОіЖЈЯргІЗўЮёЪЕР§ЕФЭјТчЮЛжУЃЌВЂЧвЖдЧыЧѓЪЕЯжИКдиОљКтЁЃПЭЛЇЖЫДгвЛИіЗўЮёзЂВсЗўЮёжаВщбЏЃЌЦфжаЪЧЫљгаПЩгУЗўЮёЪЕР§ЕФПтЁЃПЭЛЇЖЫЪЙгУИКдиОљКтЫуЗЈДгЖрИіЗўЮёЪЕР§жабЁдёГівЛИіЃЌШЛКѓЗЂГіЧыЧѓЁЃ
Netflix OSSЬсЙЉСЫвЛжжЗЧГЃАєЕФПЭЛЇЖЫЗЂЯжФЃЪНЁЃ
Netflix Eureka ЁЃNetflix Eureka] ЪЧвЛИіЗўЮёзЂВсБэЃЌЮЊЗўЮёЪЕР§зЂВсЙмРэКЭВщбЏПЩгУЪЕР§ЬсЙЉСЫREST
APIНгПкЁЃ Netflix RibbonЪЧвЛжжIPCПЭЛЇЖЫЃЌгыEurekaКЯЭЌЙЄзїЪЕЯжЖдЧыЧѓЕФИКдиОљКтЁЃЮвУЧЛсдкКѓУцЯъЯИЬжТлEurekaЁЃ
ПЭЛЇЖЫЗЂЯжФЃЪНвВЪЧгХШБЕуЗжУїЁЃетжжФЃЪНЯрЖдБШНЯжБНгЃЌЖјЧвГ§СЫЗўЮёзЂВсБэЃЌУЛгаЦфЫќИФБфЕФвђЫиЁЃГ§ДЫжЎЭтЃЌвђЮЊПЭЛЇЖЫжЊЕРПЩгУЗўЮёзЂВсБэаХЯЂЃЌвђДЫПЭЛЇЖЫПЩвдЭЈЙ§ЪЙгУЙўЯЃвЛжТадЃЈhashing
consistentlyЃЉБфЕУИќМгДЯУїЃЌИќМггааЇЕФИКдиОљКтЁЃ
ЖјетжжФЃЪНвЛИізюДѓЕФШБЕуЪЧашвЊеыЖдВЛЭЌЕФБрГЬгябдзЂВсВЛЭЌЕФЗўЮёЃЌдкПЭЛЇЖЫашвЊЮЊУПжжгябдПЊЗЂВЛЭЌЕФЗўЮёЗЂЯжТпМЁЃ
ЗўЮёЖЫЗЂЯжФЃЪН
AWS Elastic Load BalancerЃЈELBЃЉЪЧвЛжжЗўЮёЖЫЗЂЯжТЗгЩЕФР§згЃЌELBвЛАугУгкОљКтДгЭјТчРДЕФЗУЮЪСїСПЃЌвВПЩвдЪЙгУELBРДОљКтVPCФкВПЕФСїСПЁЃПЭЛЇЖЫЪЙгУDNSЃЌЭЈЙ§ELBЗЂГіЧыЧѓЃЈHTTPЛђепTCPЃЉЁЃELBИКдиОљКтЦїИКд№дкзЂВсЕФEC2ЪЕР§ЛђепECSШнЦїжЎМфОљКтИКдиЃЌВЂВЛДцдквЛИіЗжРыЕФЗўЮёзЂВсБэЃЌЖјEC2ЪЕР§КЭECSЪЕР§вВЯђELBзЂВсЁЃ
HTTPЗўЮёКЭРрЫЦNGINXКЭNGINX PlusЕФИКдиОљКтЦїЖМПЩвдзїЮЊЗўЮёЖЫЗЂЯжОљКтЦїЁЃР§ШчЃЌетЦЊВЉЮФОЭУшЪіШчКЮЪЙгУConsul
TemplateРДЖЏЬЌХфжУNGINXЗДЯђДњРэЁЃConsul TemplateЪЧжмЦкадДгДцЗХдкConsul
TemplateзЂВсБэжаХфжУЪ§ОнжиНЈХфжУЮФМўЕФЙЄОпЁЃЕБЮФМўЗЂЩњБфЛЏЪБЃЌЛсдЫаавЛИіУќСюЁЃдкШчЩЯВЉПЭжаЃЌConsul
TemplateВњЩњСЫвЛИіnginx.confЮФМўЃЌгУгкХфжУЗДЯђДњРэЃЌШЛКѓдЫаавЛИіУќСюЃЌИцЫпNGINXжиаТЕїШыХфжУЮФМўЁЃИќИДдгЕФР§згПЩвдгУHTTP
APIЛђепDNSЖЏЬЌжиаТХфжУNGINX PlusЁЃ
ЗўЮёЖЫЗЂЯжФЃЪНвВгагХШБЕуЁЃзюДѓЕФгХЕуЪЧПЭЛЇЖЫЮоашЙизЂЗЂЯжЕФЯИНкЃЌПЭЛЇЖЫжЛашвЊМђЕЅЕФЯђИКдиОљКтЦїЗЂЫЭЧыЧѓЃЌЪЕМЪЩЯМѕЩйСЫБрГЬгябдПђМмашвЊЭъГЩЕФЗЂЯжТпМЁЃЖјЧвЃЌШчЩЯЫЕЫљЃЌФГаЉВПЪ№ЛЗОГУтЗбЬсЙЉвдЩЯЙІФмЁЃ
етжжФЃЪНвВгаШБЯнЃЌГ§ЗЧВПЪ№ЛЗОГЬсЙЉИКдиОљКтЦїЃЌЗёдђИКдиОљКтЦїЪЧСэЭтвЛИіашвЊХфжУЙмРэЕФИпПЩгУЯЕЭГЙІФмЁЃ
ЗўЮёзЂВсБэ
ШчЧАЫљЪіЃЌNetflix EurekaЪЧвЛИіЗўЮёзЂВсБэКмКУЕиР§згЃЌЬсЙЉСЫREST APIзЂВсКЭЧыЧѓЗўЮёЪЕР§ЁЃ
ЗўЮёЪЕР§ЪЙгУPOSTЧыЧѓзЂВсЭјТчЕижЗЃЌУП30УыБиаыЪЙгУPUTЗНЗЈИќаТзЂВсБэЃЌЪЙгУHTTP DELETEЧыЧѓЛђепЪЕЧÍЪБРДзЂЯњЁЃПЩвдЯыМћЃЌПЭЛЇЖЫПЩвдЪЙгУHTTP
GETЧыЧѓНгЪмзЂВсЗўЮёЪЕР§аХЯЂЁЃ
NetflixЭЈЙ§дкУПИіAWS EC2гђдЫаавЛИіЛђепЖрИіEurekaЗўЮёЪЕЯжИпПЩгУадЃЌУПИіEurekaЗўЮёЦїЖМдЫаадкгЕгаЕЏадIPЕижЗЕФEC2ЪЕР§ЩЯЁЃDNS
TEXTМЧТМгУгкДцДЂEurekaМЏШКХфжУЃЌЦфжаДцЗХДгПЩгУгђЕНвЛЯЕСаEurekaЗўЮёЦїЭјТчЕижЗЕФСаБэЁЃЕБEurekaЗўЮёЦє
etcd ЈC ЪЧвЛИіИпПЩгУЃЌЗжВМЪНЕФЃЌвЛжТадЕФЃЌМќжЕБэЃЌгУгкЙВЯэХфжУКЭЗўЮёЗЂЯжЁЃСНИіжјУћАИР§АќРЈKubernetesКЭCloud
FoundryЁЃ
consul ЈC ЪЧвЛИігУгкЗЂЯжКЭХфжУЕФЗўЮёЁЃЬсЙЉСЫвЛИіAPIдЪаэПЭЛЇЖЫзЂВсКЭЗЂЯжЗўЮёЁЃConsulПЩвдгУгкНЁПЕМьВщРДХаЖЯЗўЮёПЩгУадЁЃ
Apache ZooKeeper ЈC ЪЧвЛИіЙуЗКЪЙгУЃЌЮЊЗжВМЪНгІгУЬсЙЉИпадФмећКЯЕФЗўЮёЁЃApache
ZooKeeperзюГѕЪЧHadoopЕФзгЯюФПЃЌЯждквбОБфГЩЖЅМЖЯюФПЁЃ
ЗўЮёзЂВсФЃЪН
здзЂВсЗНЪН ->
ЕБЪЙгУздзЂВсФЃЪНЪБЃЌЗўЮёЪЕР§ИКд№дкЗўЮёзЂВсБэжазЂВсКЭзЂЯњЁЃСэЭтЃЌШчЙћашвЊЕФЛАЃЌвЛИіЗўЮёЪЕР§вВвЊЗЂЫЭаФЬјРДБЃжЄзЂВсаХЯЂВЛЛсЙ§ЪБЁЃЯТЭМУшЪіСЫетжжМмЙЙЁЃ
здзЂВсФЃЪНвВгагХШБЕуЁЃвЛИігХЕуЪЧЃЌЯрЖдМђЕЅЃЌВЛашвЊЦфЫћЯЕЭГЙІФмЁЃЖјвЛИіжївЊШБЕудђЪЧЃЌАбЗўЮёЪЕР§ИњЗўЮёзЂВсБэСЊЯЕЦ№РДЁЃБиаыдкУПжжБрГЬгябдКЭПђМмФкВПЪЕЯжзЂВсДњТыЁЃ
ЕкШ§ЗНзЂВсФЃЪН ->
ЗўЮёЪЕЧ€ВЛИКд№ЯђЗўЮёзЂВсБэзЂВсЃЌЖјЪЧгЩСэЭтвЛИіЯЕЭГФЃПщЃЌНазіЗўЮёЙмРэЦїЃЌИКд№зЂВсЁЃЗўЮёЙмРэЦїЭЈЙ§ВщбЏВПЪ№ЛЗОГЛђЖЉдФЪТМўРДИњзйдЫааЗўЮёЕФИФБфЁЃЕБЙмРэЦїЗЂЯжвЛИіаТПЩгУЗўЮёЃЌЛсЯђзЂВсБэзЂВсДЫЗўЮёЁЃЗўЮёЙмРэЦївВИКд№зЂЯњжежЙЕФЗўЮёЪЕР§ЁЃЯТЭМЪЧетжжФЃЪНЕФМмЙЙЭМ
вЛИіЗўЮёЙмРэЦїЕФР§згЪЧПЊдДЯюФПRegistratorЃЌИКд№здЖЏзЂВсКЭзЂЯњБЛВПЪ№ЮЊDockerШнЦїЕФЗўЮёЪЕР§ЁЃReistratorжЇГжЖржжЗўЮёЙмРэЦїЃЌАќРЈetcdКЭConsulЁЃ
ЮЂЗўЮёЕФЪТМўЧ§ЖЏЪ§ОнЙмРэ
ЕЅЬхЪНгІгУвЛАуЖМЛсгавЛИіЙиЯЕаЭЪ§ОнПтЃЌгЩДЫДјРДЕФКУДІЪЧгІгУПЩвдЪЙгУ ACID transactionsЁЃ
ШЛЖјЃЌЖдгкЮЂЗўЮёМмЙЙРДЫЕЃЌЪ§ОнЗУЮЪБфЕУЗЧГЃИДдгЃЌетЪЧвђЮЊЪ§ОнЖМЪЧЮЂЗўЮёЫНгаЕФЃЌЮЈвЛПЩЗУЮЪЕФЗНЪНОЭЪЧЭЈЙ§APIЁЃетжжДђАќЪ§ОнЗУЮЪЗНЪНЪЙЕУЮЂЗўЮёжЎМфЫЩёюКЯЃЌВЂЧвБЫДЫжЎМфЖРСЂЁЃШчЙћЖрИіЗўЮёЗУЮЪЭЌвЛИіЪ§ОнЃЌschemaЛсИќаТЗУЮЪЪБМфЃЌВЂдкЫљгаЗўЮёжЎМфНјаааЕїЁЃ
Ъ§ОнЯрЙиЕФСНИіЬєеН
1.ЕквЛИіЬєеНдкгкШчКЮЭъГЩвЛБЪНЛвзЕФЭЌЪББЃГжЖрИіЗўЮёжЎМфЪ§ОнвЛжТад.
2.ЕкЖўИіЬєеНЪЧШчКЮЭъГЩДгЖрИіЗўЮёжаЫбЫїЪ§Он.
ЪТМўЧ§ЖЏМмЙЙ
ЖдаэЖргІгУРДЫЕЃЌетИіНтОіЗНАИОЭЪЧЪЙгУЪТМўЧ§ЖЏМмЙЙЃЈevent-driven architectureЃЉЁЃдкетжжМмЙЙжаЃЌЕБФГМўживЊЪТЧщЗЂЩњЪБЃЌЮЂЗўЮёЛсЗЂВМвЛИіЪТМўЃЌР§ШчИќаТвЛИівЕЮёЪЕЬхЁЃЕБЖЉдФетаЉЪТМўЕФЮЂЗўЮёНгЪеДЫЪТМўЪБЃЌОЭПЩвдИќаТздМКЕФвЕЮёЪЕЬхЃЌвВПЩФмЛсв§ЗЂИќЖрЕФЪТМўЗЂВМ.
ЪТМўЧ§ЖЏМмЙЙвВЪЧМШгагХЕувВгаШБЕуЃЌДЫМмЙЙПЩвдЪЙЕУНЛвзПчЖрИіЗўЮёЧвЬсЙЉзюжевЛжТадЃЌВЂЧвПЩвдЪЙгІгУЮЌЛЄзюжеЪгЭМЃЛЖјШБЕудкгкБрГЬФЃЪНБШACIDНЛвзФЃЪНИќМгИДдгЃКЮЊСЫДггІгУВуМЖЪЇаЇжаЛжИДЃЌЛЙашвЊЭъГЩВЙГЅадНЛвзЃЌР§ШчЃЌШчЙћаХгУМьВщВЛГЩЙІдђБиаыШЁЯћЖЉЕЅЃЛСэЭтЃЌгІгУБиаыгІЖдВЛвЛжТЕФЪ§ОнЃЌетЪЧвђЮЊСйЪБЃЈin-flightЃЉНЛвздьГЩЕФИФБфЪЧПЩМћЕФЃЌСэЭтЕБгІгУЖСШЁЮДИќаТЕФзюжеЪгЭМЪБвВЛсгіМћЪ§ОнВЛвЛжТЮЪЬтЁЃСэЭтвЛИіШБЕудкгкЖЉдФепБиаыМьВтКЭКіТдШпгрЪТМў.
дзгВйзїAchieving Atomicity
ЪТМўЧ§ЖЏМмЙЙЛЙЛсХіЕНЪ§ОнПтИќаТКЭЗЂВМЪТМўдзгадЮЪЬтЁЃР§ШчЃЌЖЉЕЅЗўЮёБиаыЯђORDERБэВхШывЛааЃЌШЛКѓЗЂВМOrder
Created eventЃЌетСНИіВйзїашвЊдзгадЁЃШчЙћИќаТЪ§ОнПтКѓЃЌЗўЮёЬБСЫЃЈcrashesЃЉдьГЩЪТМўЮДФмЗЂВМЃЌЯЕЭГБфГЩВЛвЛжТзДЬЌЁЃ
2pc
ЖЉЕЅЗўЮёвВПЩвдЪЙгУ distributed transactions, вВОЭЪЧжмжЊЕФСННзЖЮЬсНЛ (2PC)ЁЃ2PCдкЯждкгІгУжаВЛЪЧПЩбЁадЁЃИљОнCAPРэТлЃЌБиаыдкПЩгУадЃЈavailabilityЃЉКЭACIDвЛжТадЃЈconsistencyЃЉжЎМфзіГібЁдёЃЌavailabilityвЛАуЪЧИќКУЕФбЁдёЁЃЕЋЪЧЃЌаэЖрЯжДњПЦММЃЌР§ШчаэЖрNoSQLЪ§ОнПтЃЌВЂВЛжЇГж2PCЁЃдкЗўЮёКЭЪ§ОнПтжЎМфЮЌЛЄЪ§ОнвЛжТадЪЧЗЧГЃИљБОЕФашЧѓЃЌвђДЫЮвУЧашвЊевЦфЫћЕФЗНАИЁЃ
ЪЙгУБОЕиНЛвзЗЂВМЪТМў
ЕУдзгадЕФвЛИіЗНЗЈЪЧЖдЗЂВМЪТМўгІгУВЩгУmulti-step process involving only
local transactionsЃЌММЧЩдкгквЛИіEVENTБэЃЌДЫБэдкДцДЂвЕЮёЪЕЬхЪ§ОнПтжаЦ№ЕНЯћЯЂСаБэЙІФмЁЃгІгУЗЂЦ№вЛИіЃЈБОЕиЃЉЪ§ОнПтНЛвзЃЌИќаТвЕЮёЪЕЬхзДЬЌЃЌЯђEVENTБэжаВхШывЛИіЪТМўЃЌШЛКѓЬсНЛДЫДЮНЛвзЁЃСэЭтвЛИіЖРСЂгІгУНјГЬЛђепЯпГЬВщбЏДЫEVENTБэЃЌЯђЯћЯЂДњРэЗЂВМЪТМўЃЌШЛКѓЪЙгУБОЕиНЛвзБъжОДЫЪТМўЮЊвбЗЂВМ.
ЖЉЕЅЗўЮёЯђORDERБэВхШывЛааЃЌШЛКѓЯђEVENTБэжаВхШыOrder Created eventЃЌЪТМўЗЂВМЯпГЬЛђепНјГЬВщбЏEVENTБэЃЌЧыЧѓЮДЗЂВМЪТМўЃЌЗЂВМЫћУЧЃЌШЛКѓИќаТEVENTБэБъжОДЫЪТМўЮЊвбЗЂВМЁЃ
ДЫЗНЗЈвВЪЧгХШБЕуЖМгаЁЃгХЕуЪЧПЩвдШЗБЃЪТМўЗЂВМВЛвРРЕгк2PCЃЌгІгУЗЂВМвЕЮёВуМЖЪТМўЖјВЛашвЊЭЦЖЯЫћУЧЗЂЩњСЫЪВУДЃЛЖјШБЕудкгкДЫЗНЗЈгЩгкПЊЗЂШЫдББиаыРЮМЧЗЂВМЪТМўЃЌвђДЫгаПЩФмГіЯжДэЮѓЁЃСэЭтДЫЗНЗЈЖдгкФГаЉЪЙгУNoSQLЪ§ОнПтЕФгІгУЪЧИіЬєеНЃЌвђЮЊNoSQLБОЩэНЛвзКЭВщбЏФмСІгаЯоЁЃ
ЭкОђЪ§ОнПтНЛвзШежО
СэЭтвЛжжВЛашвЊ2PCЖјЛёЕУЯпГЬЛђепНјГЬЗЂВМЪТМўдзгадЕФЗНЪНОЭЪЧЭкОђЪ§ОнПтНЛвзЛђепЬсНЛШежОЁЃгІгУИќаТЪ§ОнПтЃЌдкЪ§ОнПтНЛвзШежОжаВњЩњБфЛЏЃЌНЛвзШежОЭкОђНјГЬЛђепЯпГЬЖСетаЉНЛвзШежОЃЌНЋШежОЗЂВМИјЯћЯЂДњРэЁЃ
ДЫЗНЗЈЕФР§згШчLinkedIn Databus ЯюФПЃЌDatabus ЭкОђOracleНЛвзШежОЃЌИљОнБфЛЏЗЂВМЪТМўЃЌLinkedInЪЙгУDatabusРДБЃжЄЯЕЭГФкИїМЧТМжЎМфЕФвЛжТадЁЃ
СэЭтЕФР§згШчЃКAWSЕФ streams mechanism in AWS DynamoDBЃЌЪЧвЛИіПЩЙмРэЕФNoSQLЪ§ОнПтЃЌвЛИіDynamoDBСїЪЧгЩЙ§ШЅ24аЁЪБЖдЪ§ОнПтБэЛљгкЪБађЕФБфЛЏЃЈДДНЈЃЌИќаТКЭЩОГ§ВйзїЃЉЃЌгІгУПЩвдДгСїжаЖСШЁетаЉБфЛЏЃЌШЛКѓвдЪТМўЗНЪНЗЂВМетаЉБфЛЏЁЃ
НЛвзШежОЭкОђвВЪЧгХШБЕуВЂДцЁЃгХЕуЪЧШЗБЃУПДЮИќаТЗЂВМЪТМўВЛвРРЕгк2PCЁЃНЛвзШежОЭкОђПЩвдЭЈЙ§НЋЗЂВМЪТМўКЭгІгУвЕЮёТпМЗжРыПЊЕУЕНМђЛЏЃЛЖјжївЊШБЕудкгкНЛвзШежОЖдВЛЭЌЪ§ОнПтгаВЛЭЌИёЪНЃЌЩѕжСВЛЭЌЪ§ОнПтАцБОвВгаВЛЭЌИёЪНЃЛЖјЧвКмФбДгЕзВуНЛвзШежОИќаТМЧТМзЊЛЛЮЊИпВувЕЮёЪТМўЁЃ
ЪЙгУЪТМўдД
Event sourcing ЃЈЪТМўдДЃЉЭЈЙ§ЪЙгУИљБОВЛЭЌЕФЪТМўжааФЗНЪНРДЛёЕУВЛаш2PCЕФдзгадЃЌБЃжЄвЕЮёЪЕЬхЕФвЛжТадЁЃ
етжжгІгУБЃДцвЕЮёЪЕЬхвЛЯЕСазДЬЌИФБфЪТМўЃЌЖјВЛЪЧДцДЂЪЕЬхЯждкЕФзДЬЌЁЃгІгУПЩвдЭЈЙ§жиЗХЪТМўРДжиНЈЪЕЬхЯждкзДЬЌЁЃжЛвЊвЕЮёЪЕЬхЗЂЩњБфЛЏЃЌаТЪТМўОЭЛсЬэМгЕНЪБМфБэжаЁЃвђЮЊБЃДцЪТМўЪЧЕЅвЛВйзїЃЌвђДЫПЯЖЈЪЧдзгадЕФЁЃ
ЮЊСЫРэНтЪТМўдДЙЄзїЗНЪНЃЌПМТЧЪТМўЪЕЬхзїЮЊвЛИіР§згЁЃДЋЭГЗНЪНжаЃЌУПИіЖЉЕЅгГЩфЮЊORDERБэжавЛааЃЌР§ШчдкORDER_LINE_ITEMБэжаЁЃЕЋЪЧЖдгкЪТМўдДЗНЪНЃЌЖЉЕЅЗўЮёвдЪТМўзДЬЌИФБфЗНЪНДцДЂвЛИіЖЉЕЅЃКДДНЈЕФЃЌвбХњзМЕФЃЌвбЗЂЛѕЕФЃЌШЁЯћЕФЃЛУПИіЪТМўАќРЈзуЙЛЪ§ОнРДжиНЈЖЉЕЅзДЬЌЁЃ
Ъ§ОндДЗНЗЈЬсЙЉСЫ100%ПЩППЕФвЕЮёЪЕЬхБфЛЏМрПиШежОЃЌЪЙЕУЛёШЁШЮКЮЪБЕуЪЕЬхзДЬЌГЩЮЊПЩФмЁЃСэЭтЃЌЪТМўдДЗНЗЈПЩвдЪЙЕУвЕЮёТпМПЩвдгЩЪТМўНЛЛЛЕФЫЩёюКЯвЕЮёЪЕЬхЙЙГЩЁЃетаЉгХЪЦЪЙЕУЕЅЬхгІгУвЦжВЕНЮЂЗўЮёМмЙЙБфЕФЯрЖдШнвзЁЃ
ЪТМўдДЗНЗЈвВгаВЛЩйШБЕуЃЌвђЮЊВЩгУВЛЭЌЛђепВЛЬЋЪьЯЄЕФБфГЩФЃЪНЃЌЪЙЕУжиаТбЇЯАВЛЬЋШнвзЃЛЪТМўДцДЂжЛжЇГжжїМќВщбЏвЕЮёЪЕЬхЃЌБиаыЪЙгУ
Command Query Responsibility Segregation (CQRS) РДЭъГЩВщбЏвЕЮёЃЌвђДЫЃЌгІгУБиаыДІРэзюжевЛжТЪ§ОнЁЃ
бЁдёЮЂЗўЮёВПЪ№ВпТд
ЕЅжїЛњЖрЗўЮёЪЕР§ФЃЪН
ВПЪ№ЮЂЗўЮёЕФвЛжжЗНЗЈОЭЪЧЕЅжїЛњЖрЗўЮёЪЕР§ФЃЪНЃЌЪЙгУетжжФЃЪНЃЌашвЊЬсЙЉШєИЩЬЈЮяРэЛђепащФтЛњЃЌУПЬЈЛњЦїЩЯдЫааЖрИіЗўЮёЪЕР§ЁЃКмЖрЧщПіЯТЃЌетЪЧДЋЭГЕФгІгУВПЪ№ЗНЗЈЁЃУПИіЗўЮёЪЕР§дЫаавЛИіЛђепЖрИіжїЛњЕФwell-knownЖЫПкЃЌжїЛњПЩвдПДзіГшЮяЁЃ
ЕЅжїЛњЖрЗўЮёЪЕР§ФЃЪНвВЪЧгХШБЕуВЂДцЁЃжївЊгХЕудкгкзЪдДРћгУгааЇадЁЃЖрЗўЮёЪЕР§ЙВЯэЗўЮёЦїКЭВйзїЯЕЭГЃЌШчЙћНјГЬзщдЫааЖрИіЗўЮёЪЕР§аЇТЪЛсИќИпЃЌР§ШчЃЌЖрИіwebгІгУЙВЯэЭЌвЛИіApache
Tomcat ServerКЭJVMЁЃ
СэвЛИігХЕудкгкВПЪ№ЗўЮёЪЕР§КмПьЁЃжЛашНЋЗўЮёПНБДЕНжїЛњВЂЦєЖЏЫќЁЃШчЙћЗўЮёгУJavaаДЕФЃЌжЛашвЊПНБДJARЛђепWARЮФМўМДПЩЁЃЖдгкЦфЫќгябдЃЌР§ШчNode.jsЛђепRubyЃЌашвЊПНБДдДТыЁЃвВОЭЪЧЫЕЭјТчИКдиКмЕЭЁЃ
вђЮЊУЛгаЬЋЖрИКдиЃЌЦєЖЏЗўЮёКмПьЁЃШчЙћЗўЮёЪЧздАќКЌЕФНјГЬЃЌжЛашвЊЦєЖЏОЭПЩвдЃЛЗёдђЃЌШчЙћЪЧдЫаадкШнЦїНјГЬзщжаЕФФГИіЗўЮёЪЕР§ЃЌдђашвЊЖЏЬЌВПЪ№НјШнЦїжаЃЌЛђепжиЦєШнЦї
Г§СЫЩЯЪігХЕуЭтЃЌЕЅжїЛњЖрЗўЮёЪЕР§вВгаШБЯнЁЃЦфжавЛИіжївЊШБЕуЪЧЗўЮёЪЕР§МфКмЩйЛђепУЛгаИєРыЃЌГ§ЗЧУПИіЗўЮёЪЕР§ЪЧЖРСЂНјГЬЁЃШчЙћЯыОЋШЗМрПиУПИіЗўЮёЪЕР§зЪдДЪЙгУЃЌОЭВЛФмЯожЦУПИіЪЕР§зЪдДЪЙгУЁЃвђДЫгаПЩФмдьГЩФГИідуИтЕФЗўЮёЪЕР§еМгУСЫжїЛњЕФЫљгаФкДцЛђепCPUЁЃ
СэвЛИібЯжиЮЪЬтдкгкдЫЮЌЭХЖгБиаыжЊЕРШчКЮВПЪ№ЕФЯъЯИВНжшЁЃЗўЮёПЩвдгУВЛЭЌгябдКЭПђМмаДГЩЃЌвђДЫПЊЗЂЭХЖгПЯЖЈгаКмЖрашвЊИњдЫЮЌЭХЖгЙЕЭЈЪТЯюЁЃЦфжаИДдгаддіМгСЫВПЪ№Й§ГЬжаГіДэЕФПЩФмад
ЕЅШнЦїЕЅЗўЮёЪЕР§ФЃЪН
?ЪЙгУетжжФЃЪНашвЊНЋЗўЮёДђАќГЩШнЦїгГЯёЁЃвЛИіШнЦїгГЯёЪЧвЛИідЫааАќКЌЗўЮёЫљашПтКЭгІгУЕФЮФМўЯЕЭГ?ЁЃФГаЉШнЦїгГЯёгЩЭъећЕФlinuxИљЮФМўЯЕЭГзщГЩЃЌЦфЫќдђЪЧЧсСПМЖЕФЁЃР§ШчЃЌЮЊСЫВПЪ№JavaЗўЮёЃЌашвЊДДНЈАќКЌJavaдЫааПтЕФШнЦїгГЯёЃЌвВаэЛЙвЊАќКЌApache
Tomcat serverЃЌвдМАБрвыЙ§ЕФJavaгІгУЁЃ
вЛЕЉНЋЗўЮёДђАќГЩШнЦїгГЯёЃЌОЭашвЊЦєЖЏШєИЩШнЦїЁЃвЛАудквЛИіЮяРэЛњЛђепащФтЛњЩЯдЫааЖрИіШнЦїЃЌПЩФмашвЊМЏШКЙмРэЯЕЭГЃЌР§Шчk8sЛђепMarathonЃЌРДЙмРэШнЦїЁЃМЏШКЙмРэЯЕЭГНЋжїЛњзїЮЊзЪдДГиЃЌИљОнУПИіШнЦїЖдзЪдДЕФашЧѓЃЌОіЖЈНЋШнЦїЕїЖШЕНФЧИіжїЛњЩЯЁЃ
Serverless ВПЪ№
AWS LambdaЪЧserverlessВПЪ№ММЪѕЕФР§згЃЌжЇГжJavaЃЌNode.jsКЭPythonЗўЮёЃЛашвЊНЋЗўЮёДђАќГЩZIPЮФМўЩЯдиЕНAWS
LambdaОЭПЩвдВПЪ№ЁЃПЩвдЬсЙЉдЊЪ§ОнЃЌЬсЙЉДІРэЗўЮёЧыЧѓКЏЪ§ЕФУћзжЃЈвЛИіЪТМўЃЉЁЃAWS LambdaздЖЏдЫааДІРэЧыЧѓзуЙЛЖрЕФЮЂЗўЮёЃЌШЛЖјжЛИљОндЫааЪБМфКЭЯћКФФкДцСПРДМЦЗбЁЃЕБШЛЯИНкОіЖЈГЩАмЃЌAWS
LambdaвВгаЯожЦЁЃЕЋЪЧДѓМвЖМВЛашвЊЕЃаФЗўЮёЦїЃЌащФтЛњЛђепШнЦїФкЕФШЮКЮЗНУцОјЖдЮќв§ШЫЁЃ
Lambda КЏЪ§ ЪЧЮозДЬЌЗўЮёЁЃвЛАуЭЈЙ§МЄЛюAWSЗўЮёДІРэЧыЧѓЁЃР§ШчЃЌЕБгГЯёЩЯдиЕНS3 bucketМЄЛюLambdaКЏЪ§КѓЃЌОЭПЩвддкDynamoDBгГЯёБэжаВхШывЛИіЬѕФПЃЌИјKinesisСїЗЂВМвЛЬѕЯћЯЂЃЌДЅЗЂгГЯёДІРэЖЏзїЁЃLambdaКЏЪ§вВПЩвдЭЈЙ§ЕкШ§ЗНwebЗўЮёМЄЛюЁЃ
гаЫФжжЗНЗЈМЄЛюLambdaКЏЪ§ЃК
жБНгЗНЪНЃЌЪЙгУwebЗўЮёЧыЧѓ
здЖЏЗНЪНЃЌЛигІР§ШчAWS S3ЃЌDynamoDBЃЌKinesisЛђепSimple Email ServiceЕШВњЩњЕФЪТМў
здЖЏЗНЪНЃЌЭЈЙ§AWS APIЭјЙиРДДІРэгІгУПЭЛЇЖЫЗЂГіЕФHTTPЧыЧѓ?
ЖЈЪБЗНЪНЃЌЭЈЙ§cronЯьгІ?--КмЯёЖЈЪБЦїЗНЪН
ПЩвдПДГіЃЌAWS LambdaЪЧвЛжжКмЗНБуВПЪ№ЮЂЗўЮёЕФЗНЪНЁЃЛљгкЧыЧѓМЦЗбЗНЪНвтЮЖзХгУЛЇжЛашвЊГаЕЃДІРэздМКвЕЮёФЧВПЗжЕФИКдиЃЛСэЭтЃЌвђЮЊВЛашвЊСЫНтЛљДЁМмЙЙЃЌгУЛЇжЛашвЊПЊЗЂздМКЕФгІгУЁЃ
ШЛЖјЛЙЪЧгаВЛЩйЯожЦЁЃВЛашвЊгУРДВПЪ№ГЄЦкЗўЮёЃЌР§ШчгУРДЯћЗбДгЕкШ§ЗНДњРэзЊЗЂРДЕФЯћЯЂЃЌЧыЧѓБиаыдк300УыФкЭъГЩЃЌЗўЮёБиаыЪЧЮозДЬЌЃЌвђЮЊРэТлЩЯAWS
LambdaЛсЮЊУПИіЧыЧѓЩњГЩвЛИіЖРСЂЕФЪЕР§ЃЛБиаыгУФГжжжЇГжЕФгябдЭъГЩЃЌЗўЮёБиаыЦєЖЏКмПьЃЌЗёдђЃЌЛсвђЮЊГЌЪББЛЭЃжЙЁЃ |