| БрМЭЦМі: |
ЮФеТЮЇШЦН№ШкаавЕЛљгкK8SЕФШнЦїдЦЕФЮЂЗўЮёНтОіЗНАИЁЂН№ШкаавЕЮЂЗўЮёМмЙЙЩшМЦЁЂШнЦїдЦећЬхЩшМЦМмЙЙЕШЗНУцЕФЮЪЬтНјаазмНсЕШЁЃ
БОЮФРДздгкelecfansЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
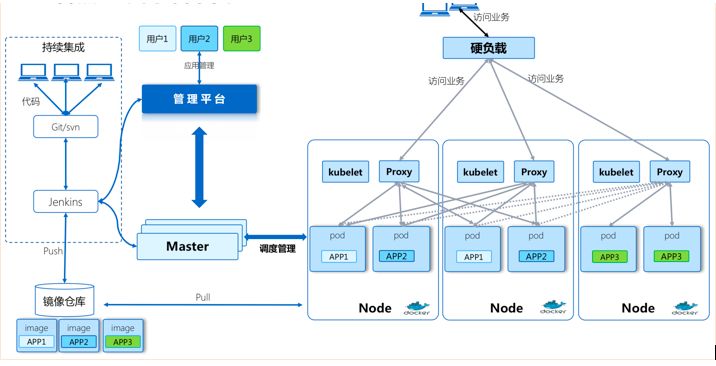
K8SЪЧЕквЛИіНЋЁАвЛЧавдЗўЮёЮЊжааФЃЌвЛЧаЮЇШЦЗўЮёдЫзЊЁБзїЮЊжИЕМЫМЯыЕФДДаТаЭВњЦЗЃЌЫќЕФЙІФмКЭМмЙЙЩшМЦздЪМжСжеЖМзёбСЫетвЛжИЕМЫМЯыЃЌЙЙНЈдкK8SЩЯЕФЯЕЭГВЛНіПЩвдЖРСЂдЫаадкЮяРэЛњЁЂащФтЛњМЏШКЛђепЦѓвЕЫНгадЦЩЯЃЌвВПЩвдБЛЭаЙмдкЙЋгадЦжаЁЃ
ЮЂЗўЮёМмЙЙЕФКЫаФЪЧНЋвЛИіОоДѓЕФЕЅЬхгІгУВ№ЗжЮЊКмЖраЁЕФЛЅЯрСЌНгЕФЮЂЗўЮёЃЌвЛИіЮЂЗўЮёБГКѓПЩФмгаЖрИіЪЕР§ИББОдкжЇГХЁЃЕЅЬхгІгУЮЂЗўЮёЛЏвдКѓЃЌЗўЮёжЎМфБиШЛЛсгавРРЕЙиЯЕЃЌдкЗЂВМЪБЃЌШєУПИіЗўЮёЖМЕЅЖРЦєЖЏЛсЗЧГЃЭДПрЃЌМђЕЅЕиЫЕАќРЈвЛаЉЕЧТМЗўЮёЁЂжЇИЖЗўЮёЃЌШєЯывЛДЮШЋВПЦєЖЏЃЌДЫЪББиВЛПЩЩйвЊгУЕНБрХХЕФЖЏзїЁЃ
K8SЭъУРЕиНтОіСЫЕїЖШЃЌИКдиОљКтЃЌМЏШКЙмРэЁЂгазДЬЌЪ§ОнЕФЙмРэЕШЮЂЗўЮёУцСйЕФЮЪЬтЃЌГЩЮЊЦѓвЕЮЂЗўЮёШнЦїЛЏЕФЪзбЁНтОіЗНАИЁЃЪЙгУK8SОЭЪЧдкШЋУцгЕБЇЮЂЗўЮёМмЙЙЁЃ
дкВЛОУЧАЕФНЛСїжаЃЌЮЇШЦН№ШкаавЕЛљгкK8SЕФШнЦїдЦЕФЮЂЗўЮёНтОіЗНАИЁЂН№ШкаавЕЮЂЗўЮёМмЙЙЩшМЦЁЂШнЦїдЦећЬхЩшМЦМмЙЙЕШЗНУцЕФЮЪЬтНјааСЫГфЗжЕФЬжТлЃЌЕУЕНСЫЖрЮЛЩчЧјзЈМвЕФжЇГжЁЃДѓМвеыЖдK8SШнЦїдЦКЭЮЂЗўЮёНсКЯЯрЙиЕФЮЪЬтЃЌЬхЯжГіСЫИпЖШЕФВЮгыШШЧщЁЃдкДЫЃЌЖдДѓМвЙизЂЕФЮЪЬтвдМАеыЖдетаЉЮЪЬтИїЮЛзЈМвЕФЙлЕузмНсШчЯТЃК
вЛЁЂK8SШнЦїдЦВПЪ№ЪЕМљЦЊ
Q1:ЯжНзЖЮШнЦїдЦВПЪ№ПђМмЪЧЪВУДЃП
A1:
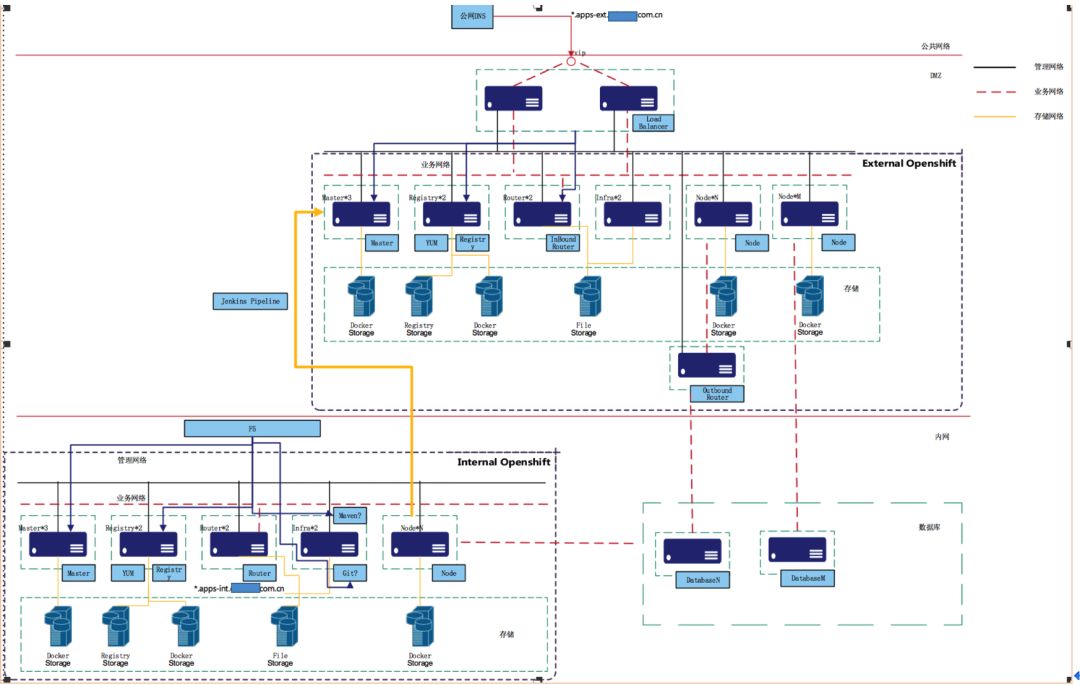
дкDMZКЭФкЭјЗжБ№ВПЪ№БЫДЫЖРСЂЕФ2ЬзOpenshiftЃЌЗжБ№ЮЊФкЭјКЭDMZЧјСНИіЭјЖЮЃЌСНЬзЛЗОГБЫДЫИєРыЁЃ
DMZЧјЕФOpenshiftВПЪ№ЖдЭтЗЂВМЕФгІгУЃЌИКд№ДІРэЭтЭјЕФЗУЮЪ
ФкЭјЕФOpenshiftВПЪ№еыЖдФкЭјЕФгІгУЃЌНіИКд№ДІРэФкЭјЕФЗУЮЪ
-ШЈЯоЙмРэ
ЖдгкЦѓвЕМЖЕФгІгУЦНЬЈРДЫЕЃЌЛсгаРДздЦѓвЕФкЭтВЛЭЌНЧЩЋЕФгУЛЇЃЌЫљвдСщЛюЕФЁЂЯИСЃЖШЕФЁЂПЩРЉеЙЕФШЈЯоЙмРэЪЧБиВЛПЩЩйЕФЁЃOCPДгЩшМЦГѕЦкОЭПМТЧЕНЦѓвЕМЖгУЛЇЕФашЧѓЃЌЫљвддкЦНЬЈФкВПМЏГЩСЫБъзМЛЏЕФШЯжЄЗўЮёЦїЃЌВЂЧвЖЈвхСЫЯъЯИЕФШЈЯоВпТдКЭНЧЩЋЁЃ
1. ШЯжЄЃК
OCPЦНЬЈЕФгУЛЇЪЧЛљгкЖдOCP APIЕФЕїгУШЈЯоРДЖЈвхЕФЃЌгЩгкOCPЫљгаЕФВйзїЖМЪЧЛљгкAPIЕФЃЌвВОЭЫЕгУЛЇПЩвдЪЧвЛИіПЊЗЂШЫдБЛђепЙмРэдБЃЌПЩвдКЭOCPНјааНЛЛЅЁЃOCPФкжУСЫвЛИіЛљгкOAuthЕФЭЈгУЩэЗнШЯжЄЙцЗЖЕФЗўЮёЦїЁЃетИіOAuthЗўЮёЦїПЩвдЭЈЙ§ЖржжВЛЭЌРраЭЕФШЯжЄдДЖдгУЛЇНјааШЯжЄЁЃ
2. МјШЈЃК
ШЈВпТдОіЖЈСЫвЛИігУЛЇЪЧЗёОпгаЖдФГИіЖдЯѓЕФВйзїШЈЯоЁЃЙмРэдБПЩвдЩшжУВЛЭЌЙцдђКЭНЧЩЋЃЌПЩвдЖдгУЛЇЛђепгУЛЇзщИГгшвЛЖЈЕФНЧЩЋЃЌНЧЩЋАќКЌСЫвЛЯЕСаЕФВйзїЙцдђЁЃ
Г§СЫДЋЭГЕФШЯжЄКЭМјШЈЙІФмЃЌOCPЛЙЬсЙЉСЫеыЖдpodЕФЯИСЃЖШШЈЯоПиSCCЃЈsecurity context
constraintsЃЉЃЌПЩвдЯожЦpodОпБИКЮжжРраЭЕФШЈЯоЃЌБШШчШнЦїЪЧЗёПЩвддЫаадкЬиШЈФЃЪНЯТЁЂЪЧЗёПЩвдЙвдкЫожїЛњЕФФПТМЁЂЪЧЗёПЩвдЪЙгУЫожїЛњЕФЖЫПкЁЂЪЧЗёПЩвдвдrootгУЛЇдЫааЕШЁЃ
-ЖрзтЛЇЙмРэ
зтЛЇЪЧжИЖрзщВЛЭЌЕФгІгУЛђепгУЛЇЭЌЪБдЫаадквЛИіЛљДЁзЪдДГижЎЩЯЃЌЪЕЯжШэМўЁЂгВМўзЪдДЕФЙВЯэЃЌЮЊСЫАВШЋашЧѓЃЌЦНЬЈашвЊЬсЙЉзЪдДИєРыЕФФмСІЁЃ
дкOCPжаЃЌprojectЪЧвЛИіНјаазтЛЇИєРыЕФИХФюЃЌЫќРДдДгкkubernetesЕФnamespaceЃЌВЂЖдЦфНјааСЫЙІФмЕФРЉеЙЁЃРћгУProjectЃЌOCPЦНЬЈДгЖрИіВуУцЬсЙЉСЫЖрзтЛЇЕФжЇГжЁЃ
1. ШЈЯоПижЦЁЃЭЈЙ§OCPЦНЬЈЯИСЃЖШЕФШЈЯоЙмРэЛњжЦЃЌЙмРэдБПЩвдЖдВЛЭЌЕФгУЛЇКЭзщЩшжУВЛЭЌprojectЕФШЈЯоЃЌВЛЭЌгУЛЇЕЧТМвдКѓжЛФмВйзїКЭЙмРэЬиЖЈЕФproject
2. ЭјТчИєРыЁЃOCPЦНЬЈЪЙгУopenvswitchРДЙмРэФкВПЕФШнЦїЭјТчЃЌЬсЙЉСНжжРраЭЕФЭјТчФЃЪНЃЌвЛжжЪЧМЏШКЗЖЮЇФкЛЅЭЈЕФЦНУцЭјТчЃЌСэвЛжжЪЧprojectМЖБ№ИєРыЕФЭјТчЁЃУПИіprojectЖМгавЛИіащФтЭјТчIDЃЈVNIDЃЉЃЌВЛЭЌVNIDЕФСїСПБЛopenvswitchздЖЏИєРыЁЃЫљвдВЛЭЌЯюФПжЎМфЕФЗўЮёдкЭјТчВуВЛФмЛЅЭЈЁЃ
3. RouterИєРыЁЃRouterЪЧOCPЦНЬЈвЛИіживЊШэМўзЪдДЃЌЫќЬсЙЉСЫЭтВПЧыЧѓЕМШыOCPМЏШКФкВПЕФФмСІЁЃOCPЬсЙЉСЫRouterЗжзщЕФЙІФмЃЌВЛЭЌЕФprojectПЩвдЪЙгУЖРСЂЕФRouterЃЌВЛЛЅЯрИЩШХЃЌетбљОЭБмУтСЫгЩгкФГаЉгІгУСїСПЙ§ДѓЪБЖдЦфЫћгІгУдьГЩИЩШХЁЃ
ЮяРэзЪдДГиИєРыЁЃдкЖрзтЛЇЕФЛЗОГжаЃЌЮЊСЫЬсИпзЪдДЕФРћгУТЪвЛАуЧщПіЯТЮяРэзЪдДГиЪЧЙВЯэЕФЃЌЕЋЪЧгааЉгУЛЇвВЛсЬсЙЉЖРеМзЪдДГиЕФашЧѓЁЃеыЖдетжжРраЭЕФашЧѓЃЌOCPЦНЬЈРћгУnodeSelectorЕФЙІФмПЩвдНЋЛљДЁЩшЪЉзЪдДГиЛЎЗжИјЬиЖЈЕФprojectЖРЯэЃЌЪЕЯжДгЮяРэВуУцЕФИєРыЁЃ
-ШежОКЭМрПи
ЃЈ1ЃЉДЋЭГгІгУШежО
гаБ№гкЕБЧАСїааЕФШнЦїгІгУЃЌЕФДЋЭГгІгУЭЌЪБвЛИіжаМфМўЛсдЫааЖрИігІгУЃЌЧвгІгУЭЈЙ§log4jЕШЛњжЦБЃДцдкЮФМўжаЗНБуВщПДКЭХХДэЁЃвђЮЊШнЦїдЫааЕФЬиадЃЌЖдгкетВПЗжЕФШежОЮвУЧашвЊГжОУЛЏЕНЭтжУДцДЂжаЁЃ
ШежОЕФЗжРрШчЯТЃК
жаМфМўШежО
dumpЮФМў
гІгУШежО
ШежОБЃДцдкМЦЫуНкЕуЩЯЙвдиЕФNFSДцДЂЁЃЮЊСЫЙцЗЖКЭЗНБуВщевЁЃШежОНЋЛсАДOCPЦНЬЈжаЕФnamespaceНЈСЂФПТМЃЌНјааЛЎЗжЁЃ
ЃЈ2ЃЉаТгІгУШежО
гІЖдЗжВМЪНЛЗОГЯТШежОЗжЩЂЕФНтОіАьЗЈЪЧЪеМЏШежОЃЌНЋЦфМЏжаЕНвЛИіЕиЗНЁЃЪеМЏЕНЕФКЃСПШежОашвЊОЙ§НсЙЙЛЏДІРэЃЌНјЖјНЛИјашвЊЕФШЫдБЗжЮіЃЌЭкОђШежОЕФМлжЕаХЯЂЁЃЭЌЪБВЛЭЌЕФШЫдБЖдШежОЕФашЧѓЪЧВЛвЛбљЕФЃЌдЫгЊШЫдБЙизЂЗУЮЪШежОЃЌдЫЮЌШЫдБЙизЂЯЕЭГШежОЃЌПЊЗЂШЫдБЙизЂгІгУШежОЁЃетбљОЭашвЊгавЛжжзуЙЛПЊЗХЁЂСщЛюЕФЗНЗЈШУЫљгаЙиаФШежОЕФШЫдкШежОЪеМЏЙ§ГЬжаЖдЦфЖЈвхЁЂЗжИюЁЂЙ§ТЫЁЂЫїв§ЁЂВщбЏЁЃ
OpenShiftЪЙгУEFKРДЪЕЯжШежОЙмРэЦНЬЈЁЃИУЙмРэЦНЬЈОпБИвдЯТФмСІЃК
ШежОВЩМЏЃЌНЋШежОМЏжадквЛЦ№
Ыїв§ШежОФкШнЃЌПьЫйЗЕЛиВщбЏНсЙћ
ОпгаЩьЫѕадЃЌдкИїИіЛЗНкЖМФмЙЛРЉШн
ЧПДѓЕФЭМаЮВщбЏЙЄОпЁЂБЈБэВњГіЙЄОп
EFKЪЧElasticsearch(вдЯТМђаДЮЊES)+ Fluentd+KibanaЕФМђГЦЁЃESИКд№Ъ§ОнЕФДцДЂКЭЫїв§ЃЌFluentdИКд№Ъ§ОнЕФЕїећЁЂЙ§ТЫЁЂДЋЪфЃЌKibanaИКд№Ъ§ОнЕФеЙЪОЁЃ
FluentdЮоТлдкадФмЩЯЃЌЛЙЪЧдкЙІФмЩЯЖМБэЯжЭЛГіЃЌгШЦфдкЪеМЏШнЦїШежОСьгђИќЪЧЖРЪївЛжФЃЌГЩЮЊжкЖрPAASЦНЬЈШежОЪеМЏЕФБъзМЗНАИЁЃ
ЃЈ3ЃЉМрПи
PaaSЦНЬЈЕФМрПиАќРЈЯЕЭГМрПиЁЂШнЦїМрПиЕШЁЃМрПиСїГЬгЩаХЯЂЪеМЏЁЂаХЯЂЛузмКЭаХЯЂеЙЪОЕШМИИіВПЗжзщГЩЁЃ
дкOpenshiftжаФЌШЯЪЙгУkubenetesЕФМрПиаХЯЂЪеМЏЛњжЦЃЌдкУПИіНкЕуЩЯВПЪ№cadvisorЕФДњРэЃЌИКд№ЪеМЏШнЦїМЖБ№ЕФМрПиаХЯЂЁЃШЛКѓНЋЫљгааХЯЂЛузмЕНheapsterЃЌheapsterКѓЬЈЕФЪ§ОнГжОУЛЏЦНЬЈЪЧCassandraЁЃзюКѓгЩhawkularДгCassandraЛёШЁаХЯЂНјааЭГвЛЕФеЙЪОЁЃ
1. зщМўЫЕУї
OpenshiftЕФМрПизщМўЃЌгУгкЖдpodдЫаазДЬЌЕФCPUЁЂФкДцЁЂЭјТчНјааЪЕЪБМрПиЃЌКЭKubernetesЪЙгУЕФМрПиММЪѕеЛвЛбљЃЌАќРЈШ§ИіВПЗжЃК
HEAPSTER
гУгкМрПиЪ§ОнЕФВЩМЏ
https://github.com/kubernetes/heapster
HAWKULAR METRICS
ЪєгкПЊдДМрПиНтОіЗНАИHawkularЃЌЛљгкJSONИёЪНЙмРэЁЂеЙЪОМрПиЪ§Он
http://www.hawkular.org/
CASSANDRA
Apache CassandraЪЧвЛИіПЊдДЕФЗжВМЪНЪ§ОнПтЃЌзЈУХгУгкДІРэДѓЪ§ОнСПвЕЮё
http://cassandra.apache.org/
-DMZЧјМЦЫуНкЕу
дкDMZЧјгІгУВПЪ№зёбвдЯТВпТдЃК
вбгагІгУЧЈвЦжСШнЦїдЦЦНЬЈЪБЕФзЪдДЩъЧыАДЯжгаХфжУЩшжУЃЌЩъЧыЕФЗўЮёЦїНЋНіЙЉИУЪЙгУ
ШчЙћашвЊКсЯђРЉеЙЃЌвВНідквбЗжХфЕФМЦЫуНкЕуЩЯЃЌШчЙћзЪдДВЛзуЃЌгІгУЯюФПзщПЩдйЩъЧыаТЕФМЦЫузЪдД
БОЦкЯюФПжаЃЌXXXВПЪ№дкDMZЧјЦНЬЈЩЯЃЌЪЙгУ2ИіМЦЫуНкЕуЃЛXXXВПЪ№дкФкЭјЦНЬЈЩЯЃЌЪЙгУ2ИіМЦЫуНкЕу
дкЪЕЪЉЪБашвЊЮЊЯргІЕФМЦЫуНкЕуБъМЧБъЧЉЃЌЪЙгІгУВПЪ№ЪБВПЪ№ЕНжИЖЈЕФМЦЫуНкЕуЩЯЁЃ
Р§ШчдкDMZЭјЖЮЖдXXXгІгУЫљЪЙгУЕФ2ЬЈМЦЫуНкЕуДђЩЯБъЧЉ
дкВПЪ№XXXгІгУЪЙЃЌnodeSelectorашвЊжИУїЪЙгУЕФНкЕуЕФБъЧЉЮЊXXX=XXXЁЃ
-ДЋЭГгІгУЗУЮЪВпТд
OpenshiftВњЦЗЭЦМіЭЈЙ§NodePortРраЭЕФServiceЮЊФГИігІгУЖдЭтБЉТЖвЛИіЗўЮёЖЫПкЁЃNodePortРраЭЕФServiceЛсдкМЏШКжаЕФЫљгаНкЕуЩЯМрЬ§вЛИіЬиЖЈЕФЖЫПкЃЌЗУЮЪШЮвтвЛИіМЦЫуЛњНкЕуЕФЖЫПкЃЌМДПЩЗУЮЪФкВПШнЦїжаЕФЗўЮёЁЃдкМЏШКЕФЫљгаНкЕуЕФетИіЖЫПкЖМЛсдЄСєИјИУгІгУЫљгУЁЃ
дкF5 VSЕФPool MemberжаХфжУЫљгаНкЕуЃЌЭЈЙ§KeepalivedРДЪЕЯжHA
гІгУЯЕЭГКЭгУЛЇВЛгУИФБфЯжгаЕФЗУЮЪЗНЪН
-гІгУЗУЮЪМАЗРЛ№ЧН
ФкЭјМЦЫуНкЕуПЩвджБНгЗУЮЪЪ§ОнПт
DMZЧјМЦЫуНкЕуЗУЮЪЪ§ОнПтга2жжЗНАИЃК
МЦЫуНкЕужБНгЭЈЙ§ФкЭјЗРЛ№ЧНЗУЮЪИУгІгУЪ§ОнПт
ФкЭјЗРЛ№ЧННіПЊЭЈгІгУЫљдкНкЕуЗУЮЪФкВПЪ§ОнПтЕФЖЫПкЃЌР§ШчБОЦкЯюФПЃЌxxxгІгУНіЪЙгУ2ИіНкЕуЃЌдђЗРЛ№ЧННіПЊЭЈет2ИіНкЕуЗУЮЪxxxЪ§ОнПтЕФШЈЯо
МЦЫуНкЕуОOutbound ТЗгЩЭЈЙ§ФкЭјЗРЛ№ЧНЗУЮЪФкЭјЪ§Онo
етoOutboundТЗгЩдкOpenshiftжаГЦжЎЮЊEgress Routero
вђДЫЃЌФкЭјЗРЛ№ЧННіПЊЭЈгІгУЫљдкНкЕуЗУЮЪФкВПЪ§ОнПтЕФЖЫПкЃЌР§ШчЃЌгІгУAНіЭЈЙ§ТЗгЩНкЕуAКЭBЗУЮЪФкВПЪ§ОнПтЃЌдђЗРЛ№ЧННіПЊЭЈет2ИіНкЕуЗУЮЪAЪ§ОнПтЕФШЈЯо
Q2: ШнЦїЦНЬЈНЈЩшЙ§ГЬжаЃЌШчКЮРћгУКУвбгадЦЦНЬЈЃЌДгММЪѕЁЂМмЙЙЕШВуДЮЃЌашвЊзЂвтФФаЉЪТЯюЃП
A2:
ШнЦїХмдкЮяРэЛњЩЯЃЌЛЙЪЧХмдкдЦЦНЬЈащЛњЩЯЃЌетЪЧИіжЕЕУЬжТлЕФЛАЬтЁЃ
ЖдгкЙЋгадЦЖјбдЃЌКСЮовЩЮЪЃЌПЯЖЈЪЧХмдкдЦжїЛњЩЯЕФЁЃФЧУДЃЌгаЕФПЭЛЇдкЩЯЯпШнЦїЮЂЗўЮёжЎЧАЃЌвбОгаСЫздМКЕФЫНгадЦЦНЬЈЃЌФЧУДетИіЪБКђЪЧЙКТђвЛЖбЮяРэЛњРДСэЦ№ТЏдюЃЌЛЙЪЧЛљгквбгадЦЦНЬЈПьЫйВПЪ№ЃЌетОЭжЕЕУехзУСЫЁЃ
ЦфЪЕвВУЛЪВУДКУОРНсЕФЃЌЮоЗЧОЭЪЧвЛИіЮЪЬт:адФмЃЁ
ХмдкЮяРэЛњЩЯЃЌадФмПЯЖЈЪЧзюМбЕФЃЌЕЋЪЧФуецЕФашвЊЫљЮНЕФадФмТ№ЃПВтЙ§УЛгаЃЌЪЧЗёецЕФжЛгаЮяРэЛњВХФмТњзуФуЕФШнЦїЮЂЗўЮёгІгУЃЌИљОнЮвЕФОбщЃЌвдН№ШкаавЕРДЫЕЃЌДѓВПЗжгУЛЇЮяРэЛњзЪдДГЃФъДІгкЕЭИККЩзДЬЌЃЁвдадФмЮЊНшПкЃЌЖёвтРЖЏGDPЃЌОЭЪЧЫЃСїУЅАЁЃЁ
ШчЙћФуОіЖЈХмдквбгадЦЦНЬЈЩЯЃЌФЧУДЃЌФувЊПМТЧЕФЮЪЬтШчЯТЃК
1ЁЂГфЗжРћгУLaCЃЈInfrastructure as CodeЃЉЪЕЯжздЖЏЛЏБрХХВПЪ№ЃЌетЪЧдЦЦНЬЈзюДѓЕФгХЪЦЃЈБШШчopenstackжаЕФheatЃЉЃЌвВЪЧТуЛњМЏШКзюДѓЕФСгЪЦЃЛ
2ЁЂЭјТчадФмЁЃдкIaaSВуЩЯУцХмШнЦїЃЌЭјТчЪЧИіашвЊШЯецПМТЧЕФЮЪЬтЃЌcalicoзюМбЃЌЕЋЪЧЛљДЁЩшЪЉИФЖЏДѓЃЌВЛЪЧЫљгаПЭЛЇЖМФмНгЪеЃЌflannel+hostgwЪЧИіВЛзібЁдёЃЌддђОЭЪЧОЁСПЗРжЙЖўДЮЗтзАЕўМгЃЌжТЪЙЭјТчадФмЯТНЕЙ§ЖрЁЃ
3ЁЂМмЙЙЩЯОпБИКѓајРЉеЙадЃЌетРяжИЕФВЛНіНіЪЧscale-outРЉеЙЃЌИќЪЧЙІФмЩЯЕФЯђКѓРЉеЙЃЌБШШчЫцзХЮЂЗўЮёВЛЖрРЉДѓЃЌЭјТчИКдиВЛЖЯдіМгЃЌКѓајФуПЩФмЛсДђЫуЪЙгУservice
meshЃЌФЧУДЧАЦкОЭПППМТЧЧхГўМцШнадЮЪЬт
4ЁЂзюКѓЃЌвВЪЧзюЦгЫиЕФвЛЕуЃЌМђЕЅЁЂКУгУЁЂИпПЩгУддђЃЌВЛвЊЮЊСЫИпДѓЩЯЖјЁАИпДѓЩЯЁБЃЌИуЕУздМКЭъШЋholdВЛзЁЃЌЕУВЛГЅЪЇЃЌвЛИіКУЕФЦНЬЈбЁаЭОЭЪЧГЩЙІЕФ80%
Г§ДЫжЎЭт
1.ашвЊПДвбгадЦЦНЬЈЬсЙЉСЫФФаЉЙІФмЛђНгПкПЩвдЙЉ ШнЦїЦНЬЈЪЙгУЃЌБШШчCMDBЁЂБШШчШЈЯоЙмРэЁЂБШШчгІгУЛђепжаМфМўХфжУЕШ
2.гІгУ вд ШнЦїЗНЪНКЭДЋЭГЗНЪН ЕФВПЪ№ЗНЪНКЭСїГЬ ПДЪЧЗёПЩвдГщЯѓЭГвЛЛЏЃЌВЛЙмЪЧЩ§МЖЛиЙіРЉШнЕШЃЌдкдЫЮЌВуУцааЮЊвЛжТОЭФмРћгУвбгаЦНЬЈЕЋЪЧздМКвЊЪЕЯжЕзВугыБрХХЯЕЭГЕФЖдНг
Q3: K8SМЏШКШчКЮЪЕЯжМЏШКАВШЋЃПЫЋЯђШЯжЄorМђЕЅШЯжЄЃП
A3:
KubernetsЯЕЭГЬсЙЉСЫШ§жжШЯжЄЗНЪНЃКCAШЯжЄЁЂTokenШЯжЄКЭBaseШЯжЄЁЃАВШЋЙІФмЪЧвЛАбЫЋШаНЃЃЌЫќБЃЛЄЯЕЭГВЛБЛЙЅЛїЃЌЕЋЪЧвВДјРДЖюЭтЕФадФмЫ№КФЁЃМЏШКФкЕФИїзщМўЗУЮЪAPI
ServerЪБЃЌгЩгкЫќУЧгыAPI ServerЭЌЪБДІгкЭЌвЛОжгђЭјФкЃЌЫљвдНЈвщгУЗЧАВШЋЕФЗНЪНЗУЮЪAPI
ServerЃЌаЇТЪИќИпЁЃ
-ЫЋЯђШЯжЄХфжУ
ЫЋЯђШЯжЄЗНЪНЪЧзюЮЊбЯИёКЭАВШЋЕФМЏШКАВШЋХфжУЗНЪНЃЌжївЊХфжУСїГЬШчЯТЃК
1ЃЉЩњГЩИљжЄЪщЁЂAPI ServerЗўЮёЖЫжЄЪщЁЂЗўЮёЖЫЫНдПЁЂИїИізщМўЫљгУЕФПЭЛЇЖЫжЄЪщКЭПЭЛЇЖЫЫНдПЁЃ
2ЃЉаоИФKubernettsИїИіЗўЮёНјГЬЕФЦєЖЏВЮЪ§ЃЌЦєгУЫЋЯђШЯжЄФЃЪНЁЃ
-МђЕЅШЯжЄХфжУ
Г§СЫЫЋЯђШЯжЄЗНЪНЃЌKubernetsвВЬсЙЉСЫЛљгкTokenКЭHTTP BaseЕФМђЕЅШЯжЄЗНЪНЁЃЭЈаХЗНШдШЛВЩгУHTTPSЃЌЕЋВЛЪЙгУЪ§зжжЄЪщЁЃ
ВЩгУЛљгкTokenКЭHTTP BaseЕФМђЕЅШЯжЄЗНЪНЪБЃЌAPI ServerЖдЭтБЉТЖHTTPSЖЫПкЃЌПЭЛЇЖЫЬсЙЉTokenЛђгУЛЇУћЁЂУмТыРДЭъГЩШЯжЄЙ§ГЬЁЃ
ВЛНіНіЪЧAPIВуУцЃЌЛЙгаУПИіНкЕуkubeletКЭгІгУдЫааЪБЕФАВШЋЃЌПЩвдПДЯТетРя
https://kubernetes.io/docs/tasks/
administer-cluster/securing-a-cluster/
K8SЕФШЯжЄЯрЖдРДЫЕЛЙЪЧИіБШНЯИДдгЕФЙ§ГЬЃЌШчЯТетЦЊЮФеТЃЌЯъЯИНщЩмСЫK8SжаЕФШЯжЄМАЦфдРэЃК
https://www.kubernetes.org.cn/4061.html
Q4: K8SдкШнЦїдЦЩЯЕФИКдиОљКтВпТдКЭзмЬхЫМЯыЪЧЪВУДЃП
A4:
ИпПЩгУжївЊЗжЮЊШчЯТМИИіЃК
-ЭтВПОЕЯёВжПтИпПЩгУ
ЭтВПОЕЯёВжПтЖРСЂгкOCPЦНЬЈжЎЭтЃЌгУгкДцДЂЦНЬЈЙЙНЈЙ§ГЬжаЫљЪЙгУЕФЯЕЭГзщМўОЕЯёЁЃвђЮЊЭтВПЮоЗЈжБНгЗУЮЪOCPЦНЬЈЕФФкВПОЕЯёВжПтЃЌЫљвдгЩQAЛЗОГCDЭЦЫЭЕНЩњВњЛЗОГЕФОЕЯёвВЪЧЯШИДжЦЕНЭтВПОЕЯёВжПтЃЌдйгЩЦНЬЈЕМШыжСФкВПОЕЯёВжПтЁЃ
ЮЊСЫБЃжЄЭтВПОЕЯёВжПтЕФИпПЩгУЃЌ ЪЙгУСЫ2ЬЈЗўЮёЦїЃЌЧАЖЫЪЙгУF5НјааИКдиОљКтЃЌЫљгаЕФЧыЧѓОљЗЂжСF5ЕФащФтЕижЗЃЌгЩF5НјаазЊЗЂЁЃКѓЖЫОЕЯёВжПтЭЈЙ§ЙвдиNFSЙВЯэДцДЂЁЃ
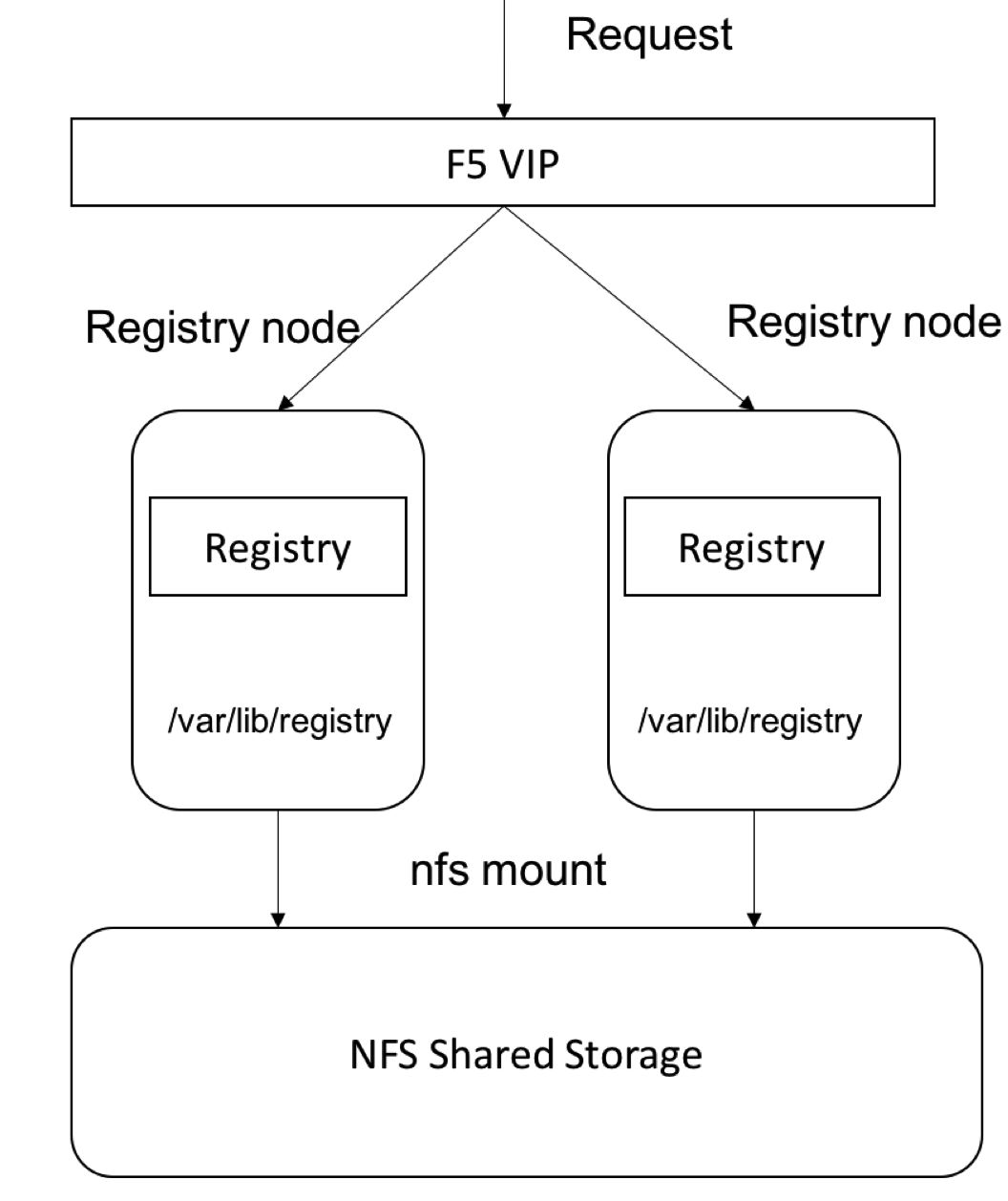
-masterжїПиНкЕуИпПЩгУ
OpenshiftЕФMasterжїПиНкЕуГаЕЃСЫМЏШКЕФЙмРэЙЄзї
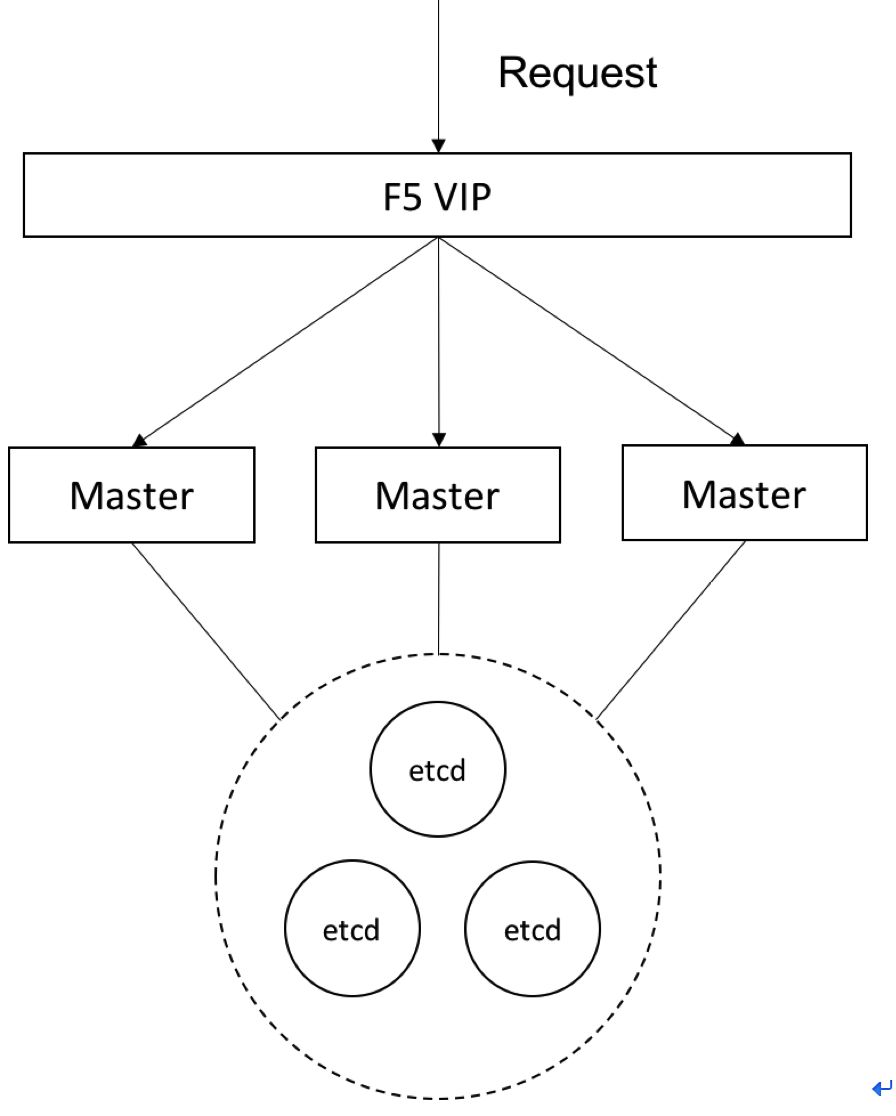
-МЦЫуНкЕуЃЈШнЦїгІгУЃЉИпПЩгУ
МЦЫуНкЕуИпПЩгУжИМЦЫуНкЕуЩЯдЫааЕФШнЦїгІгУЕФИпПЩгУЁЃвЛИіМЦЫуНкЕувьГЃЭЃЛњКѓЃЌЦфЩЯЕФШнЦїНЋЛсБЛж№ВНЧЈвЦЕНЦфЫћНкЕуЩЯЃЌДгЖјБЃжЄСЫИпПЩгУЁЃ
ЭЌЪБПЩвдЭЈЙ§БъЧЉЕФЗНЪНРДЙмРэМЦЫуНкЕуЃЌдкВЛЭЌЕФМЦЫуНкЕуЛЎЗжЮЊВЛЭЌЕФПЩгУЧјЛђзщЁЃдкВПЪ№гІгУЪБЃЌЪЙгУНкЕубЁдёЦїНЋгІгУВПЪ№жСДјгажИЖЈБъЧЉЕФФПБъМЦЫуНкЕуЩЯЁЃЮЊСЫБЃжЄИпПЩгУЃЌБъЧЉзщКЯЕФФПБъМЦЫуНкЕуЪ§вЊДѓгк1ЁЃетбљПЩвдБмУтвЛЬЈФПБъНкЕухДЛњКѓЃЌЕїЖШЦїЛЙФмевЕНТњзуЬѕМўЕФМЦЫуНкЕуНјааШнЦїВПЪ№ЁЃ
-гІгУИпПЩгУ
ЛљгкШэМўЃЈHAproxyЃЉИКдиОљКтЗўЮёЃЌШнЦїЗўЮёЕЏадЩьЫѕЪБЮоашШЫЙЄЖдИКдиОљКтЩшБИНјааХфжУИЩдЄЃЌМДПЩБЃжЄШнЦїЛЏгІгУЕФГжајЁЂе§ГЃЗУЮЪЃЛПЩЭЈЙ§ЭМаЮНчУцздЖЈвхИКдиОљКтЛсЛАБЃГжВпТдЁЃ
гЩгкЦНЬЈФкВПЭЈЙ§ШэМўЖЈвхЭјТчЮЊУПИігІгУШнЦїЗжХфСЫIPЕижЗЃЌЖјДЫЕижЗЪЧФкЭјЕижЗЃЌвђДЫЭтВППЭЛЇЮоЗЈжБНгЗУЮЪЕНИУЕижЗЃЌЫљвдЦНЬЈЪЙгУТЗгЩЦїзЊЗЂЭтВПЕФСїСПЕНМЏШКФкВПОпЬхЕФгІгУШнЦїЩЯЃЌШчЙћгІгУгаЖрИіШнЦїЪЕР§ЃЌТЗгЩЦївВПЩЪЕЯжИКдиОљКтЕФЙІФмЁЃТЗгЩЦїЛсЖЏЬЌЕФМьВтЦНЬЈЕФдЊЪ§ОнВжПтЃЌЕБгааТЕФгІгУВПЪ№ЛђепгІгУЪЕР§ЗЂЩњБфЛЏЪБЃЌТЗгЩЦїЛсздЖЏИљОнБфЛЏИќаТТЗгЩаХЯЂЃЌДгЖјЪЕЯжЖЏЬЌИКдиОљКтЕФФмСІЁЃ
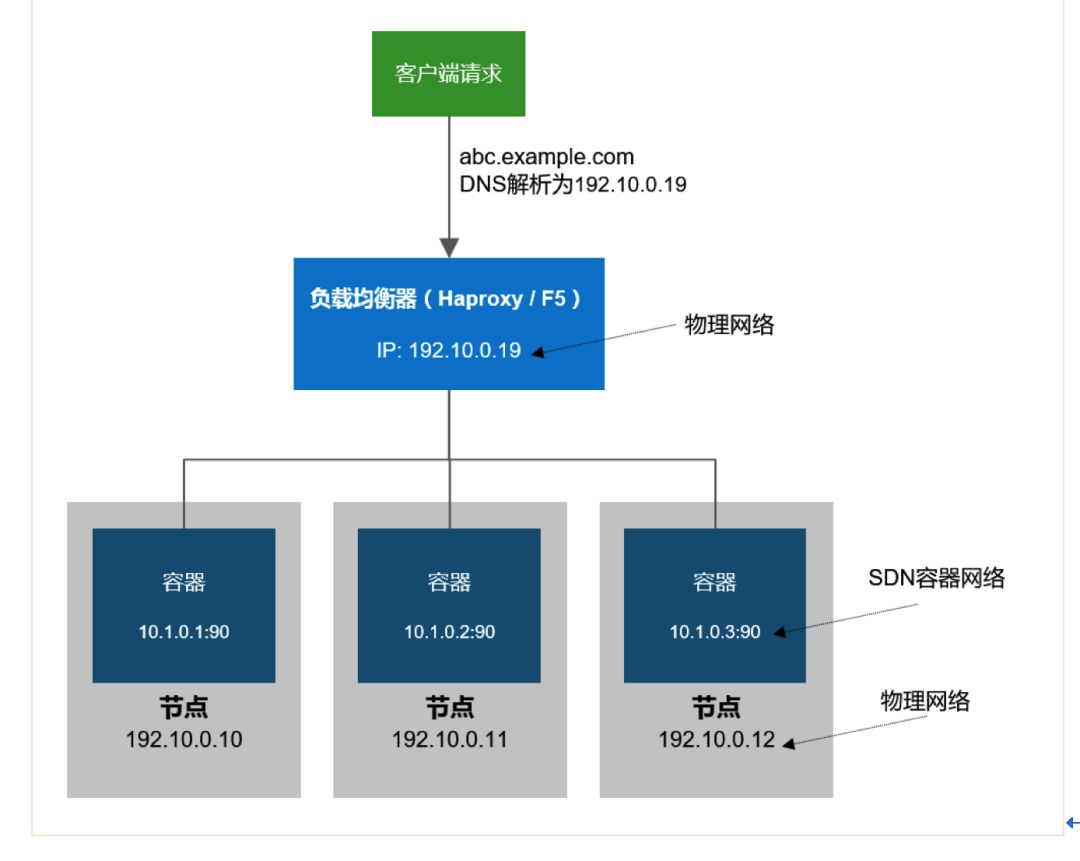
МђЕЅвЛЕуРДЫЕЃЌОЭЪЧФкВПЗўЮёЕФЖЏЬЌЗЂЯжЁЂИКдиОљКтЁЂИпПЩгУКЭЭтВПЗУЮЪЕФТЗгЩЃЛ
ЭЈЙ§serviceЃЌНтёюЖЏЬЌБфЛЏЕФIPЕижЗЃЌPODПЩвдЫцвтЙиЭЃЃЌIPПЩвдШЮвтБфЃЌжЛвЊDNSе§ГЃЃЌЗўЮёЗУЮЪВЛЪмгАЯьЃЌЕЋЪЧетРяУцФуЕФЫцЪББЃжЄгаИіПЩгУЕФPOD,етИіЪБКђФуОЭЕУашвЊLBСЫЃЌЛђепЫЕLBИЩЕФОЭЪЧетИіЪТЧщЁЃ
ФкВПЗўЮёжЎМфЗУЮЪЭЈЙ§serviceНтОіСЫЃЌФЧУДЭтВПЗУЮЪМЏШКФкЗўЮёЃЌдђЭЈЙ§routerМДЪЧНтОіЃЌЭтЭјЗУЮЪвЊВЛвЊИКдиОљКтЃЌДѓЙцФЃИпВЂЗЂЧщПіЯТЪЧПЯЖЈЕФЃЌЕБШЛЃЌЭтВПИКдиОљКтЭЈГЃашвЊгУЛЇздМКИуЖЈСЫЃЌF5ЛђепПЊдДЕФHAproxyЖМааЃЁ
Q5: ЖрзтЛЇдкkubernets/openshiftЕФЪЕЯжКЭЙмРэЃП
A5:
зтЛЇЪЧжИЖрзщВЛЭЌЕФгІгУЛђепгУЛЇЭЌЪБдЫаадквЛИіЛљДЁзЪдДГижЎЩЯЃЌЪЕЯжШэМўЁЂгВМўзЪдДЕФЙВЯэЃЌЮЊСЫАВШЋашЧѓЃЌЦНЬЈашвЊЬсЙЉзЪдДИєРыЕФФмСІЁЃ
дкOCPжаЃЌprojectЪЧвЛИіНјаазтЛЇИєРыЕФИХФюЃЌЫќРДдДгкkubernetesЕФnamespaceЃЌВЂЖдЦфНјааСЫЙІФмЕФРЉеЙЁЃРћгУProjectЃЌOCPЦНЬЈДгЖрИіВуУцЬсЙЉСЫЖрзтЛЇЕФжЇГжЁЃ
1. ШЈЯоПижЦЁЃЭЈЙ§OCPЦНЬЈЯИСЃЖШЕФШЈЯоЙмРэЛњжЦЃЌЙмРэдБПЩвдЖдВЛЭЌЕФгУЛЇКЭзщЩшжУВЛЭЌprojectЕФШЈЯоЃЌВЛЭЌгУЛЇЕЧТМвдКѓжЛФмВйзїКЭЙмРэЬиЖЈЕФproject
2. ЭјТчИєРыЁЃOCPЦНЬЈЪЙгУopenvswitchРДЙмРэФкВПЕФШнЦїЭјТчЃЌЬсЙЉСНжжРраЭЕФЭјТчФЃЪНЃЌвЛжжЪЧМЏШКЗЖЮЇФкЛЅЭЈЕФЦНУцЭјТчЃЌСэвЛжжЪЧprojectМЖБ№ИєРыЕФЭјТчЁЃУПИіprojectЖМгавЛИіащФтЭјТчIDЃЈVNIDЃЉЃЌВЛЭЌVNIDЕФСїСПБЛopenvswitchздЖЏИєРыЁЃЫљвдВЛЭЌЯюФПжЎМфЕФЗўЮёдкЭјТчВуВЛФмЛЅЭЈЁЃ
3. RouterИєРыЁЃRouterЪЧOCPЦНЬЈвЛИіживЊШэМўзЪдДЃЌЫќЬсЙЉСЫЭтВПЧыЧѓЕМШыOCPМЏШКФкВПЕФФмСІЁЃOCPЬсЙЉСЫRouterЗжзщЕФЙІФмЃЌВЛЭЌЕФprojectПЩвдЪЙгУЖРСЂЕФRouterЃЌВЛЛЅЯрИЩШХЃЌетбљОЭБмУтСЫгЩгкФГаЉгІгУСїСПЙ§ДѓЪБЖдЦфЫћгІгУдьГЩИЩШХЁЃ
ЮяРэзЪдДГиИєРыЁЃдкЖрзтЛЇЕФЛЗОГжаЃЌЮЊСЫЬсИпзЪдДЕФРћгУТЪвЛАуЧщПіЯТЮяРэзЪдДГиЪЧЙВЯэЕФЃЌЕЋЪЧгааЉгУЛЇвВЛсЬсЙЉЖРеМзЪдДГиЕФашЧѓЁЃеыЖдетжжРраЭЕФашЧѓЃЌOCPЦНЬЈРћгУnodeSelectorЕФЙІФмПЩвдНЋЛљДЁЩшЪЉзЪдДГиЛЎЗжИјЬиЖЈЕФprojectЖРЯэЃЌЪЕЯжДгЮяРэВуУцЕФИєРыЁЃ
openshiftРяУцЖдЖрзтЛЇЮЪЬтгаБШНЯКУЕФНтОіЗНАИЃЌopenshiftФЌШЯЪЙгУOVSРДЪЕЯжSDNЃЌИпМЖАВзАРяУцФЌШЯЪЙгУovs-subnet
SDNВхМўЃЌЭјТчЪЕЯжРрЫЦгкflatЭјТчЃЌвђДЫвЊЪЕЯжЖрзтЛЇПЩвддкАВзАЙ§ГЬжаЩшжУВЮЪ§ЃК
os_sdn_network_plugin_name='redhat/openshift-ovs-multitenant'
етбљopenshiftНЋЪЙгУovs-multitenantЖрзтЛЇВхМўЃЌЪЕЯжзтЛЇжЎМфЕФАВШЋИєРыЃЌСэЭтЃЌдкopenshiftЕФЖрзтЛЇКЭШнЦїжааФЛЏШежОЪЕЯжжаЃЌУПИізтЛЇЖМжЛФмВщПДЪєгкздМКЯюФПЕФШежОЃЌетИіШЗЪЕгаССЕуЕФЃЁ
Г§СЫOVSВхМўЃЌopenshiftЪЧЭъШЋжЇГжCNIБъзМЕФЃЌвђДЫЃЌЪЧвЊЪЧЗћКЯCNIБъзМЕФШ§ЗНSDNВхМўЃЌЖМЪЧПЩвддкopenshiftжаЪЙгУЕФЃЌФПЧАжЇГжЕФSDNВхМўгаЃК
1ЁЂCisco ContivЃЛ
2ЁЂJuniper ContrailЃЛ
3ЁЂNokia NuageЃЛ
4ЁЂTigera Calico ЃЛ
5ЁЂVMware NSX-T ЃЛ
СэЭтЃЌopenshiftЪЧжЇГжВПЪ№дкЮяРэЛњЁЂащФтЛњЁЂЙЋгадЦКЭЫНгадЦЩЯЕФЃЌПЩФмгааЉгУЛЇЛсРћгУвбгаЕФЙЋгадЦЛђЫНгадЦРДВПЪ№ЁЃетИіЪБКђЃЌШчЙћЪЙгУOVSВхМўЃЌФуOpenShiftжаЕФSDNПЩФмГіЯжoverlay
on overlayЕФЧщПіЃЌДЫНшжњШ§ЗНSDNВхМўЪЧИіВЛДэЕФбЁдёЃЌБШШчflannel+hostgwдкадФмЩЯПЯЖЈОЭгХгкФЌШЯЕФovs-multitenantЁЃ
Q6: elasticsearchдкK8SжаВПЪ№ЃП
A6
ВЛТлЪЧIaaSЛЙЪЧPaaSЃЌЪжЙЄВПЪ№ELKЖМЪЧВЛЭЦМіЕФЃЌЭЈЙ§ansibleПЩвдздЖЏЪЕЯжЃЌжСгкШчКЮЪЕЯжЃЌПЩвдВЮПМredhatЮФЕЕЃК
https://docs.openshift.org/3.9/install_config
/aggregate_logging.html
жСгкЫЕЗжВМЪНДцДЂЁЂБОЕиДцДЂЛЙЪЧМЏжаДцДЂЃЌетИіУЛгаМШЖЈД№АИЃЌЖМЪЧПЩвдВЮПМаавЕЪЕЯжЃЌБШШчRedhatОЭЪЧВЮПМЖдЯѓ
ВЛНЈвщelasticsearchВЩгУЗжВМЪНДцДЂЃЌШежОССДѓЧщПіЯТШчЙћЪЧЗжВМЪНДцДЂesаДЛсЪЧЦПОБЁЃ
ИљОнФуЕФУшЪіЃЌгІИУЪЧгаСНИіЗНУцЕФЮЪЬтЃК
1ЃЉesЕФКѓЖЫДцДЂЕФбЁдё
2ЃЉPodЕФДДНЈ
ЮЪЬтвЛЃК
ЗжВМЪНЃЌБОЕиЃЌМЏжаДцДЂВЛЙмЪЧдкДЋЭГЛЗОГЃЌЛЙЪЧдкШнЦїЕФЛЗОГжаЃЌЖМгаЪЙгУЁЃФПЧАЖдгкЪ§ОнПтгІгУЃЌЮвУЧПДЕНЛЙЪЧДЋЭГДцДЂ-МЏжаДцДЂЃЌеМСЫОјДѓЖрЪ§ЕФЪаГЁЁЃ
ЗжВМЪНДцДЂЃЌЫцзХдЦМЦЫуЕФаЫЦ№ЃЌЕЎЩњЕФвЛжжДцДЂМмЙЙЁЃЫќЕФгХЪЦКмУїЯдЃЌЮожааФНкЕуЃЌЕЏадЩьЫѕЃЌЪЪКЯдЦгІгУЃЌЕШЕШЁЃДЋЭГЕФГЇЩЬЃЌnetappЃЌemcЃЌibmЃЌhpЖМгаЗжВМЪНДцДЂЃЌЖМЪЧЛљгкЦфДЋЭГЕФММЪѕЃЛаТаЫЕФПЊдДЗжВМЪНДцДЂcephЃЌвбОГЩЮЊЗжВМЪНДцДЂЕФСьОќММЪѕЃЌгаredhatЃЌsuseЃЌxskyЃЌСЊЯыЃЌЛЊШ§ЕШЁЃ
ЗжВМЪНДцДЂЕФСгЪЦжївЊЪЧЃЌЛЙДІгкЗЂеЙНзЖЮЃЌММЪѕгаД§ГЩЪьЃЌгаД§ЪаГЁЕФНгЪмЁЃБОЕиДцДЂЃЌвЛАуЪЙгУЕФгІИУБШНЯЩйЁЃжївЊЪЧЪ§ОнИДжЦЭЌВНЗНУцЕФЮЪЬтЁЃ
МЏжаДцДЂЃЌФПЧАгУЕФзюЖрЕФЃЌВЛЙмЪЧFCSANЛЙЪЧIPSANЃЌЦфЮШЖЈадКЭАВШЋадЖМЪЧФмЙЛТњзувЊЧѓЕФЁЃЕЋЪЧЃЌдкадМлБШЃЌПЩРЉеЙадЗНУцЖМДцдкКмДѓЕФЮЪЬтЁЃ
ЮЪЬтЖўЃК
K8SЕФЫљгаЕФСїГЬЖМВЛЪЧЪжЖЏЭъГЩЕФЃЌЖМЪЧЛљгкздЖЏЛЏЭъГЩЁЃПЩвдЪЙгУchef/ansible/pupptЕШЙЄОпЭъГЩЁЃ
Q7: K8SМЏШКжаЕФИїЪмЙмНкЕувдМАЦфжаЕФШнЦїШчКЮзіМрПиЃП
A7:
kubernetesвбГЩЮЊИїДѓЙЋЫОЧзэљЕФШнЦїБрХХЙЄОпЃЌИїжжЫНгадЦЙЋгадЦЦНЬЈЛљгкЫќЙЙНЈЃЌЦфМрПиНтОіЗНАИФПЧАгаШ§жжЃК
ЃЈ1ЃЉheapster+influxDB
ЃЈ2ЃЉheapster+hawkular
ЃЈ3ЃЉprometheus
prometheusзїЮЊвЛИіЪБМфађСаЪ§ОнЪеМЏЃЌДІРэЃЌДцДЂЕФЗўЮёЃЌФмЙЛМрПиЕФЖдЯѓБиаыжБНгЛђМфНгЬсЙЉprometheusШЯПЩЕФЪ§ОнФЃаЭЃЌЭЈЙ§http
apiЕФаЮЪНЗЂГіРДЁЃЮвУЧжЊЕРcAdvisorжЇГжprometheus,ЭЌбљЃЌАќКЌСЫcAdivisorЕФkubeletвВжЇГжprometheusЁЃУПИіНкЕуЖМЬсЙЉСЫЙЉprometheusЕїгУЕФapiЁЃ
prometheusжЇГжk8s
prometheusЛёШЁМрПиЖЫЕуЕФЗНЪНгаКмЖрЃЌЦфжаОЭАќРЈk8sЃЌprometheuЛсЭЈЙ§ЕїгУmasterЕФapiserverЛёШЁЕННкЕуаХЯЂЃЌШЛКѓШЅЕїШЁУПИіНкЕуЕФЪ§ОнЁЃ
k8sНкЕуЕФkubeletЗўЮёздДјcadvisorгУРДЪеМЏИїНкЕуШнЦїЯрЙиМрПиаХЯЂЃЌШЛКѓЭЈЙ§heapsterЪеМЏЃЌетбљдкdashboardЩЯПЩвдПДЕНШнЦїЪЙгУCPUКЭMemoryЁЃ
ЮЊСЫГЄЦкМрПиЃЌПЩвдВЩгУprometheusМрПиЗНАИnodeExporterЪеМЏжїЛњМрПиаХЯЂcadvisorЪеМЏШнЦїМрПиаХЯЂ
k8sжаашвЊИјkubeletХфКЯkube-reservedКЭsystem-reservedЯрЙиВЮЪ§ИјЯЕЭГдЄСєФкДц
МрПиСьгђЃЌЮоЗЧОЭЪЧE*KЃЌheapsterЁЂinfluxDBЁЂheapsterЁЂhawkularЁЂprometheusЁЂgrafanaетаЉЖЋЮїСЫЃЌОЭФПЧАРДПДЃЌprometheusгІИУЪЧзюОпЧАОАЕФМрПиЙЄОпЃЌдкopenshift
3.12РяУцЃЌheapsterНЋгЩprometheusЬцЛЛЃЌЮДРДгІИУЪЧprometheusЕФЬьЯТАЩЃЁ
ЖўЁЂЮЂЗўЮёВПЪ№piapian
Q1: ЮЂЗўЮёМмЙЙАДееЪВУДЯИСЃЖШВ№ЗжЃП
A1ЃК
МШШЛРэНтЮЂЗўЮёЪЧгУРДжиЙЙвЕЮёгІгУЕФЃЌетИіЮЪЬтОЭКмМђЕЅЃЌвдвЕЮёгІгУЮЊКЫаФЃЌЙЙНЈвЕЮёЗўЮёЁЃЭќЕєЃЌжиЙЙЃЁ
вЕЮёЗўЮёашвЊЪ§ОнЗўЮёЁЂМЦЫуЗўЮёЁЂЫбЫїЗўЮёЁЂЫуЗЈЗўЮёЁЁвдМАЛљБОЕФШежОЁЂМрПиЁЂХфжУЁЂзЂВсЗЂЯжЁЂЭјЙиЁЂШЮЮёЕїЖШЕШзщМўЁЃ
жСгкЪ§ОнЗўЮёдѕУДЪЕЯжЃЌПДФуЭХЖгФмСІЁЃетВХЩцМАЪ§ОнЗжВ№ЃЌФЃаЭжиЙЙЁЃ
ЗўЮёЭЈаХПЩвдПМТЧЪТМўЧ§ЖЏЛњжЦЃЌвВЪЧКѓЦквЕЮёЪ§ОнДІРэЃЌЬЌЪЦИажЊЃЌжЧФмЗчПиЃЌжЧФмгЊЯњЃЌжЧФмдЫЮЌЕШЕФЛљДЁЁЃ
ИаОѕетЪЧИіУЛгаБъзМД№АИЕФЮЪЬтЃЌШчКЮВ№ЃПАДЪВУДЬзТЗРДВ№ЃПЮЪД№етСНИіЮЪЬтЕФЛљДЁвЛЖЈвЊЪЎЗжЪьЯЄФуЕФвЕЮёТпМВХааЁЃЮЂЗўЮёетЖЋЮїЃЌгШЦфЪЧФЧжжвбОдЫааЖрФъЕФРЯЯЕЭГЃЌвЛВЛаЁаФОЭФмВ№ГіЮЪЬтЁЃ
ШчЙћЖддЦМЦЫуЃЌЖдOpenStackгаСЫНтЃЌНЈвщвдOpenStackжаЕФKollaЯюФПЮЊЮЂЗўЮёШыУХбЇЯАЖдЯѓЃЌKollaИЩЕФЪТЧщОЭЪЧАбOpenStackЗўЮёВ№ЗжГЩЮЂЗўЮёЕФаЮЪНХмдкШнЦїжаЃЌOpenStackКХГЦШЋЧђзюДѓПЊдДPythonЯюФПЃЌгЩМИЪЎИіПЊдДзгЯюФПзщГЩЃЌШчЙћФмАбетбљИДдгЕФМЏШКЯюФПЖМВ№ЗжГЩЮЂЗўЮёЃЌФЧУДвЛЖЈЛсЕУЕНКмЖрБ№ШЫИјВЛСЫЕФаФЕУЬхЛсЁЃ
етРявдOpenStackЮЊР§ЃЌKollaетИіЯюФПЖдOpenStackЕФВ№ЗжЃЌДѓИХШчЯТЃК
1ЁЂЯШАДЗўЮёЙІФмЛЎЗжЃЌЕУЕНДжСЃЖШЃЌШчМЦЫуЗўЮёЁЂЭјТчЗўЮёЁЂДцДЂЗўЮёЃЌетаЉзтСЃЖШФЃПщЭЈГЃЛсЙВЯэЭЌвЛИіbaseОЕЯёЃЌетИіbaseОЕЯёжадЄжУСЫЗўЮёФЃПщЕФЙВадвРРЕЃЛ
2ЁЂЛљгкЗўЮёФЃПщЕФЁАдзгадЁБВ№ЗжЃЌШчАбМЦЫуЗўЮёNovaВ№ЗжЮЊnoav-apiЁЂnova-schedulerЁЂnova-compouteЁЂnova-libvirtЕШЕШЃЌЫљЮНдзгадВ№ЗжЃЌОЭЪЧВ№ЗжЕНВЛФмдйЭљЯТВ№ЮЊжЙЃЌдзгВ№ЗжКѓЭЈГЃОЭЪЧБЫДЫЖРСЂЕФЕЅНјГЬСЫЃЌвВПЩвдАбЫћУЧГЦЮЊЪЧвЖзгНкЕуСЫЃЌЫћУЧЕФОЕЯёЖМЪЧеыЖдздМКвРРЕЕФЁАИіШЫЁБОЕЯёЃЌВЛФмБЛЦфЫћНјГЬЙВЯэСЫЁЃ
ШчЙћДгОЕЯёЕФНЧЖШРДПДЃЌДѓИХЪЧетбљЃК
ИИОЕЯёЃКcentos-base
вЛМЖзгОЕЯёЃКcentos-openstack-base
ЖўМЖзгОЕЯёЃКcentos-nova-base
вЖзгНкЕуОЕЯёЃКcentos-nova-api
етМИИіОЕЯёЕФМЬГаЙиЯЕЪЧетбљЕФЃКcentos-base->centos-openstack-base->centos-nova-base->centos-nova-api
вдЩЯжЛЪЧОйИіР§згЙЉВЮПМЃЌНЈвщЩюШыСЫНтЯТKollaетИіЯюФПЃЌЖдгкЮЂЗўЮёЕФВ№ЗжОЭЛсИќгаЕзЦјаЉЃЁ
ЯШНЋЯЕЭГФЃПщЛЏ НтёюЃЌБ№ЕФЮЂЗўЮёЛЙЪЧвЛЬхЖМжЛЪЧВПЪ№ЕФЮЪЬтЁЃ ГЃМћЕФёюКЯЗНЪНга ТпМёюКЯ ЙІФмёюКЯ
ЪБМфёюКЯЕШЃЌ ИаОѕДгТыХЉЕФНЧЖШРДЗжЮіНтОіёюКЯЪЧЛљгкЮЂЗўЮёЛЙЪЧsoaЛЏЕФзюДѓЧјБ№ЁЃ soaЛЏЕФЯЕЭГИќЖрЕФЪЧвЕЮёЯЕЭГЃЌСьгђФЃаЭМЖБ№ЕФЁЃ
дкЗжВМЪНЯЕЭГжадЖдЖВЛЙЛашвЊПМТЧадФмЃЌАВШЋЃЌЪТЮёЕШЃЌзюЦ№ТыЕФcapддђЛЙЪЧвЊАбПиЕФЁЃ ТыХЉНтёюЕФНЧЖШга
НгПкЛЏЃЌЖЏОВЗжРыЃЈВщбЏКЭаоИФЕШЃЉЃЌдЊЪ§ОнГщШЁЕШЕШЃЌИќЖрЕФЪЧДњТыЩЯЃЌЩшМЦФЃЪНЩЯЕФецЙІЗђ ЁЃ КмЖрМмЙЙЕФЙРМЦУЛетИіЫЎЦНЃЌ
жЛПДДѓЯѓВЛПДДѓЭШЁЃашвЊУїШЗЃК
1ЁЂГфЗжЗжЮіВ№ЗжЕФФПЕФЪЧЪВУДЃЌашвЊНтОіЪВУДЮЪЬтЁЃ
2ЁЂЪЧЗёОпБИЮЂЗўЮёММЪѕФмСІЃЌЪЧЗёвббЁаЭКУЯргІЕФММЪѕПђМмЃЌММЪѕБфЛЏЖдЦѓвЕгаЪВУДгАЯьЁЃ
3ЁЂЪЧЗёгаЭъЩЦЕФдЫЮЌЩшЪЉБЃеЯЃЌБШШчПьЫйХфжУЁЂЛљДЁМрПиЁЂПьЫйВПЪ№ЕШФмСІЁЃ
Q2: svnЛЗОГЯТЪЕЯжCI/CDЃП
A2ЃК
svnПЩвдЪЙгУhook(post commit)ЕФЗНЪНРДЪЕЯжЃЌЕЋЪЧашвЊБраДhookНХБОЃЌСщЛюЖШДцдкЮЪЬтЃЛ
етдкsvn-repoЕФСЃЖШНЯЯИЕФЧщПіЯТЛЙПЩааЃЌШчКЮвЛИіДѓЕФrepoЃЌЙмРэЦ№РДНЯИДдгЃЌВЛНЈвщЪЙгУЃЛ
НЈвщЪЙгУjenkins ТжбЏscmЕФЗНЪНДЅЗЂpipeline/job
ФмВЛФмЪЕЯжCI/CDгыSVNЮоЙиЃЌЙиМќЪЧФуШчКЮЙЙНЈpipelineЃЌЮЂЗўЮёРэФюЯТДѓжТетбљЃК
gitlab/svn->Jenkins->build images->
push images->docker-registry->pull images->containers
Q3: K8S DNSЗўЮёХфжУШчКЮЪЕЯжЮЂЗўЮёЕФЗЂВМЃП
A3ЃК
ХфжУk8s dns
DNS (domain name system),ЬсЙЉгђУћНтЮіЗўЮёЃЌНтОіСЫФбгкМЧвфЕФIPЕижЗЮЪЬтЃЌвдИќШЫадПЩЖСПЩМЧвфПЩБъЪЖЕФЗНЪНгГЩфЖдгІIPЕижЗЁЃ
Cluster DNSРЉеЙВхМўгУгкжЇГжk8sМЏШКЯЕЭГжаИїЗўЮёжЎМфЗЂЯжгыЕїгУЁЃ
зщМўЃК
SkyDNS ЬсЙЉDNSНтЮіЗўЮё
Etcd ДцДЂDNSаХЯЂ
Kube2sky МрЬ§kubernetesЃЌЕБгаServiceДДНЈЪБЃЌЩњГЩЯргІЕФМЧТМЕНSkyDNSЁЃ
ШчЗУЮЪЭтВПDNSЃЌПЩвдЩшжУexternal_dns ЕНconfigmapЪЕЯж
Q4: ЧыЮЪдкK8SжаВПЪ№Ъ§ОнПтЯждкгаКУЕФНтОіЗНАИСЫУДЃП
A4ЃК
вјСЊИуСЫвЛИіЛљгкШнЦїЕФDBaaSЃЌЪЧЙЉгІЩЬзіЕФЃЌетРяЪЧpptПЩвдВЮПМЃЌжївЊЕу:SAN КЭ SR-IOV
Q5: K8SФПЧАЪЧЗёгаПЩЪгЛЏЕФЗўЮёБрХХзщМў
A5ЃК
K8SФПЧАзюДѓЕФБзЖЫЃЌгаЕуРрЫЦOpenStackЕФдчЦкЃЌЪЙгУЦ№РДЬЋИДдгСЫЃЌвЛПюКУЕФВњЦЗШчЙћНіЪЧЙІФмЧПДѓЃЌЕЋЪЧВЛБугкЪЙгУЃЌЖдгУЛЇЖјбдЃЌЫћОЭВЛЪЧеце§втвхЩЯЕФКУВњЦЗЁЃФПЧАЃЌK8SжаКУЯёвВУЛЪВУДПЩЪгЛЏБрХХзщМўЃЌТњЪРНчЕФYAMLШУШЫблЛЈчдТвЁЃЮвЕФРэНтЃЌЕЅДПЕФK8SЪЙгУЪЧКмФбЙЙНЈвЛЬзЦНЬЈГіРДЕФЃЌвЊЙЙНЈвЛЬзздЖЏЛЏБрХХЦНЬЈЃЌгІИУЪЧвдK8SЮЊkernelЃЌМЏГЩЭтЮЇжюЖрЩњЬЌШІШэМўЃЌетбљВХФмЪЕЯжТњзужеЖЫгУЛЇвЊЧѓЕФздЖЏЛЏЕїЖШЁЂБрХХЁЂCI/CDЦНЬЈЁЃетОЭКУБШЕЅДПЪЙгУLinuxФкКЫРДздМКЙЙНЈЯЕЭГЕФЃЌЖМЪЧМЋЮЊЪьЯЄФкКЫЕФДѓХЃвЛбљЃЌШчЙћФкКЫЭтУцУЛгаКмЖрtoolsЁЂutilitiesЙЉФуЪЙгУЃЌЦеЭЈгУЛЇЪЧУЛЗЈЪЙгУLinuxЯЕЭГЕФЁЃДгетИіНЧЖШРДПДЃЌOpenshiftОЭЪЧШнЦїЮЂЗўЮёЪБДњЕФЁАLinuxЁБЁЃK8SПЩвдШЅбаОПЃЌЕЋЪЧШчЙћЪЧФУРДЪЙгУЕФЛАЃЌЛЙЪЧOpenShiftАЩЃЁ
ПЩвдИљОнгІгУРраЭжИЖЈЖдгІЕФyamlФЃАхЃЌЭЈЙ§жЦзїЧАЖЫвГУцЕїгУk8s apiЖЏЬЌИќаТзЪдДУшЪіВЂЪЙЦфЩњаЇЃЌжСгкЭЯзЇзщКЯЙІФмдкЧАЖЫзіЩшМЦ(еазЈвЕЧАЖЫАЁ)ЖдгІЕНКѓЖЫашвЊЕїгУФФаЉapi
РрЫЦгкЪЧЯывЊвЛИіРрЫЦгкopenstack ЕФheatЙЄОпЃЌЛђепvmwareЕФblueprintЕФЙЄОпЁЃФПЧАЃЌЮЊСЫЪЪгІПьЫйЕФвЕЮёашЧѓЃЌЮЂЗўЮёМмЙЙвбОж№НЅГЩЮЊжїСїЃЌЮЂЗўЮёМмЙЙЕФгІгУашвЊгаЗЧГЃКУЕФЗўЮёБрХХжЇГжЃЌk8sжаЕФКЫаФвЊЫиServiceБуЬсЙЉСЫвЛЬзМђЛЏЕФЗўЮёДњРэКЭЗЂЯжЛњжЦЃЌЬьШЛЪЪгІЮЂЗўЮёМмЙЙЃЌШЮКЮгІгУЖМПЩвдЗЧГЃЧсвзЕидЫаадкk8sжаЖјЮоаыЖдМмЙЙНјааИФЖЏЃЛ
k8sЗжХфИјServiceвЛИіЙЬЖЈIPЃЌетЪЧвЛИіащФтIP(вВГЦЮЊClusterIP)ЃЌВЂВЛЪЧвЛИіецЪЕДцдкЕФIPЃЌЖјЪЧгЩk8sащФтГіРДЕФЁЃащФтIPЕФЗЖЮЇЭЈЙ§k8s
API ServerЕФЦєЖЏВЮЪ§ --service-cluster-ip-range=19.254.0.0/16ХфжУ;ащФтIPЪєгкk8sФкВПЕФащФтЭјТчЃЌЭтВПЪЧбАжЗВЛЕНЕФЁЃдкk8sЯЕЭГжаЃЌЪЕМЪЩЯЪЧгЩk8s
ProxyзщМўИКд№ЪЕЯжащФтIPТЗгЩКЭзЊЗЂЕФЃЌЫљвдk8s NodeжаЖМБиаыдЫааСЫk8s ProxyЃЌДгЖјдкШнЦїИВИЧЭјТчжЎЩЯгжЪЕЯжСЫk8sВуМЖЕФащФтзЊЗЂЭјТчЁЃ
ЗўЮёДњРэЃК
дкТпМВуУцЩЯЃЌServiceБЛШЯЮЊЪЧецЪЕгІгУЕФГщЯѓЃЌУПвЛИіServiceЙиСЊзХвЛЯЕСаЕФPodЁЃдкЮяРэВуУцЩЯЃЌServiceгаЪТецЪЕгІгУЕФДњРэЗўЮёЦїЃЌЖдЭтБэЯжЮЊвЛИіЕЅвЛЗУЮЪШыПкЃЌЭЈЙ§k8s
ProxyзЊЗЂЧыЧѓЕНServiceЙиСЊЕФPodЁЃ
ServiceЭЌбљЪЧИљОнLabel SelectorРДЫЂбЁPodНјааЙиСЊЕФЃЌЪЕМЪЩЯk8sдкServiceКЭPodжЎМфЭЈЙ§EndpointЯЮНгЃЌEndpointsЭЌServiceЙиСЊЕФPodЃЛЯрЖдгІЃЌПЩвдШЯЮЊЪЧServiceЕФЗўЮёДњРэКѓЖЫЃЌk8sЛсИљОнServiceЙиСЊЕНPodЕФPodIPаХЯЂзщКЯГЩвЛИіEndpointsЁЃ
ServiceВЛНіПЩвдДњРэPodЃЌЛЙПЩвдДњРэШЮвтЦфЫћКѓЖЫЃЌБШШчдЫаадкk8sЭтВПЕФЗўЮёЁЃМгЫйЯждквЊЪЙгУвЛИіServiceДњРэЭтВПMySQLЗўЮёЃЌВЛгУЩшжУServiceЕФLabel
SelectorЁЃ
ЮЂЗўЮёЛЏгІгУЕФУПвЛИізщМўЖМвдServiceНјааГщЯѓЃЌзщМўгызщМўжЎМфжЛашвЊЗУЮЪServiceМДПЩвдЛЅЯрЭЈаХЃЌЖјЮоаыИажЊзщМўЕФМЏШКБфЛЏЁЃетОЭЪЧЗўЮёЗЂЯжЃЛ
--serviceЗЂВМ
k8sЬсЙЉСЫNodePort ServiceЁЂ LoadBalancer ServiceКЭIngressПЩвдЗЂВМServiceЃЛ
NodePort Service
NodePort ServiceЪЧРраЭЮЊNodePortЕФServiceЃЌ k8sГ§СЫЛсЗжХфИјNodePort
ServiceвЛИіФкВПЕФащФтIPЃЌСэЭтЛсдкУПвЛИіNodeЩЯБЉТЖЖЫПкNodePortЃЌЭтВПЭјТчПЩвдЭЈЙ§[NodeIP]:[NodePort]ЗУЮЪЕНServiceЁЃ
LoadBalancer Service ЁЁЁЁ(ашвЊЕзВудЦЦНЬЈжЇГжДДНЈИКдиОљКтЦї,БШШчGCE)
LoadBalancer ServiceЪЧРраЭЮЊLoadBalancerЕФServiceЃЌЫќЪЧНЈСЂдкNodePort
ServiceМЏШКЛљДЁЩЯЕФЃЌk8sЛсЗжХфИјLoadBalancerЃЛServiceвЛИіФкВПЕФащФтIPЃЌВЂЧвБЉТЖNodePortЁЃГ§ДЫжЎЭтЃЌk8sЧыЧѓЕзВудЦЦНЬЈДДНЈвЛИіИКдиОљКтЦїЃЌНЋУПИіNodeзїЮЊКѓЖЫЃЌИКдиОљКтЦїНЋзЊЗЂЧыЧѓЕН[NodeIP]:[NodePort]ЁЃ
Q6: service meshКЭspring cloudЕФгХШБЕу
A6
2018ФъвдЧАЃЌПИЦ№ЮЂЗўЮёДѓЦьЕФЃЌПЩФмЪЧSpring CloudЁЃService MeshзїЮЊвЛжжЗЧЧжШыЪНAPIЕФПђМмЁЃБШЧжШыЪНЕФSpring
CloudЃЌЫфШЛЛЙдкДІгкГЩГЄЦкЃЌЕЋЪЧгІИУИќгаЧАОАЁЃ
Йигкservice meshЕФЖЈвхЃЌЭЈГЃвдBuoyant ЙЋЫОЕФ CEO Willian Morgan
дкЦфЮФеТ WHATЁЏS A SERVICE MESH AND WHY DO I NEED ONE
жаЖд Service MeshЕФЖЈвхЮЊВЮПМЃК
A service mesh is a dedicated infrastructure layer
for handling service-to-service communication. ItЁЏs
responsible for the reliable delivery of requests
through the complex topology of services that comprise
a modern, cloud native application. In practice, the
service mesh is typically implemented as an array
of lightweight network proxies that are deployed alongside
application code, without the application needing
to be aware.
ОЭаавЕЖјбдЃЌDockerКЭKubernetesНтОіЕФСЫЗўЮёВПЪ№ЕФЮЪЬтЃЌЕЋЪЧдЫааЪБЕФЮЪЬтЛЙЮДНтОіЃЌЖјете§ЪЧService
MeshЕФгУЮфжЎЕиЁЃService MeshЕФКЫаФЪЧЬсЙЉЭГвЛЕФЁЂШЋОжЕФЗНЗЈРДПижЦКЭВтСПгІгУГЬађЛђЗўЮёжЎМфЕФЫљгаЧыЧѓСїСП(гУЪ§ОнжааФЕФЛАЫЕЃЌОЭЪЧЁАeast-westЁБСїСП)ЁЃЖдгкВЩгУСЫЮЂЗўЮёЕФЙЋЫОРДЫЕЃЌетжжЧыЧѓСїСПдкдЫааЪБааЮЊжаАчбнзХЙиМќНЧЩЋЁЃвђЮЊЗўЮёЭЈЙ§ЯьгІДЋШыЧыЧѓКЭЗЂГіДЋГіЧыЧѓРДЙЄзїЃЌЫљвдЧыЧѓСїГЩЮЊгІгУГЬађдкдЫааЪБааЮЊЕФЙиМќОіЖЈвђЫиЁЃвђДЫЃЌБъзМЛЏСїСПЙмРэГЩЮЊБъзМЛЏгІгУГЬађдЫааЪБЕФЙЄОпЁЃ
ЭЈЙ§ЬсЙЉapiРДЗжЮіКЭВйзїДЫСїСПЃЌService MeshЮЊПчзщжЏЕФдЫааЪБВйзїЬсЙЉСЫБъзМЛЏЕФЛњжЦЁЊЁЊАќРЈШЗБЃПЩППадЁЂАВШЋадКЭПЩМћадЕФЗНЗЈЁЃгыШЮКЮКУЕФЛљДЁМмЙЙВувЛбљЃЌService
MeshВЩгУЕФЪЧЖРСЂгкЗўЮёЕФЙЙНЈЗНЪНЁЃ
ЧыВЮПМЃКhttps://developers.redhat.com/blog
/2016/12/09/spring-cloud-for-microservices-compared-to-kubernetes/
Q7: dubboЃЌzookeeperЛЗОГЯТЃЌK8SЕФЮЪЬтЃП
A7ЃК
гіЕНЙ§ЕФЮЪЬт
1.ШчЙћk8sЩЯЕФгІгУНіНіЪЧconsumerЃЌгІИУЪЧУЛЮЪЬтЕФЃЌВЛЙмproviderЪЧдкk8sМЏШКФкВПЛЙЪЧЭтВП
2.ШчЙћk8sЩЯЕФгІгУЪЧproviderЃЌзЂВсЕНzkЪБЪЧШнЦїЕижЗЃЌетЪБШчЙћconsumerШчЙћдкМЏШКФкВПШнЦїЗНЪНдЫааЪЧФмЗУЮЪЕНproviderЕФЃЌШчЙћconsumerдкМЏШКЭтВПЃЌФЧОЭЗУЮЪВЛЕНЃЌвВОЭЪЧФуЫЕЕФЧщПіАЩЁЃ
етИіЪБКђашвЊзівЛаЉТЗгЩВпТд: ЩшжУconsumerЫљдкЭјЖЮЕНk8sФкВПЭјЖЮЯТвЛЬјЮЊk8sМЏШКФкВПФГвЛИіНкЕуМДПЩЃЌЮвУЧдкЬкбЖдЦКЭАЂРядЦЩЯОЭЪЧетУДзіЕФЃЌVPCФкЗЧK8SНкЕувВПЩвджБЭЈK8SМЏШКФкВПoverlayЭјТчIPЕижЗ
ЭЈЙ§api gatewayРДБЉТЖашвЊЖдЭтЕФAPIЁЃgatewayВЛНіПЩвдДђЭЈЭјТчЃЌЛЙПЩвдвўВиФкВПapiЃЌЗНБуapiжЮРэ
Ш§ЁЂН№ШкаавЕШнЦїдЦЮЂЗўЮёЪЕМљЦЊ
Q1: Н№ШкаавЕЕФЮЂЗўЮёМмЙЙвЛАуЪЧдѕбљЕФЃЌАИР§гаФФаЉЃП
A1ЃК
-ЮЂЗўЮё(Microservices Architecture)ЪЧвЛжжМмЙЙЗчИёЃЌвЛИіДѓаЭИДдгШэМўгІгУгЩвЛИіЛђЖрИіЮЂЗўЮёзщГЩЁЃЯЕЭГжаЕФИїИіЮЂЗўЮёПЩБЛЖРСЂВПЪ№ЃЌИїИіЮЂЗўЮёжЎМфЪЧЫЩёюКЯЕФЁЃУПИіЮЂЗўЮёНіЙизЂгкЭъГЩвЛМўШЮЮёВЂКмКУЕиЭъГЩИУШЮЮёЁЃЮЂЗўЮёЪЧжИПЊЗЂвЛИіЕЅИі
аЁаЭЕФЕЋгавЕЮёЙІФмЕФЗўЮёЃЌУПИіЗўЮёЖМгаздМКЕФДІРэКЭЧсСПЭЈбЖЛњжЦЃЌПЩвдВПЪ№дкЕЅИіЛђЖрИіЗўЮёЦїЩЯЁЃЮЂЗўЮёвВжИвЛжжжжЫЩёюКЯЕФЁЂгавЛЖЈЕФгаНчЩЯЯТЮФЕФУцЯђЗўЮёМмЙЙЁЃвВОЭЪЧЫЕЃЌШчЙћУПИіЗўЮёЖМвЊЭЌЪБаоИФЃЌФЧУДЫќУЧОЭВЛЪЧЮЂЗўЮёЃЌвђЮЊЫќУЧНєёюКЯдквЛЦ№ЃЛШчЙћФуашвЊеЦЮевЛИіЗўЮёЬЋЖрЕФЩЯЯТЮФГЁОАЪЙгУЬѕМўЃЌФЧУДЫќОЭЪЧвЛИігаЩЯЯТЮФБпНчЕФЗўЮёЁЃ
-ЮЂЗўЮёМмЙЙЕФгХЕуЃК
УПИіЮЂЗўЮёЖМКмаЁЃЌетбљФмОлНЙвЛИіжИЖЈЕФвЕЮёЙІФмЛђвЕЮёашЧѓЁЃ
ЮЂЗўЮёФмЙЛБЛаЁЭХЖгЕЅЖРПЊЗЂЃЌетИіаЁЭХЖгЪЧ2ЕН5ШЫЕФПЊЗЂШЫдБзщГЩЁЃ
ЮЂЗўЮёЪЧЫЩёюКЯЕФЃЌЪЧгаЙІФмвтвхЕФЗўЮёЃЌЮоТлЪЧдкПЊЗЂНзЖЮЛђВПЪ№НзЖЮЖМЪЧЖРСЂЕФЁЃ
ЮЂЗўЮёФмЪЙгУВЛЭЌЕФгябдПЊЗЂЁЃ
ЮЂЗўЮёвзгкБЛвЛИіПЊЗЂШЫдБРэНтЃЌаоИФКЭЮЌЛЄЃЌетбљаЁЭХЖгФмЙЛИќЙизЂздМКЕФЙЄзїГЩЙћЁЃЮоашЭЈЙ§КЯзїВХФмЬхЯжМлжЕЁЃ
ЮЂЗўЮёдЪаэФуРћгУШкКЯзюаТММЪѕЁЃ
ЮЂЗўЮёжЛЪЧвЕЮёТпМЕФДњТыЃЌВЛЛсКЭHTML,CSS ЛђЦфЫћНчУцзщМўЛьКЯЁЃ
-ЮЂЗўЮёМмЙЙЕФШБЕуЃК
ЮЂЗўЮёМмЙЙПЩФмДјРДЙ§ЖрЕФВйзїЁЃ
ашвЊDevOpsММЧЩЁЃ
ПЩФмЫЋБЖЕФХЌСІЁЃ
ЗжВМЪНЯЕЭГПЩФмИДдгФбвдЙмРэЁЃ
вђЮЊЗжВМВПЪ№ИњзйЮЪЬтФбЁЃ
ЕБЗўЮёЪ§СПдіМгЃЌЙмРэИДдгаддіМгЁЃ
-ЮЂЗўЮёЪЪКЯФФжжЧщПіЃК
ЕБашвЊжЇГжзРУцЃЌwebЃЌвЦЖЏжЧФмЕчЪгЃЌПЩДЉДїЪБЖМЪЧПЩвдЕФЁЃ
ЩѕжСНЋРДПЩФмВЛжЊЕРЕЋашвЊжЇГжЕФФГжжЛЗОГЁЃ
ЮДРДЕФЙцЛЎЃЌНЋвдВњвЕСДбгЩьЁЂПЭЛЇЕМЯђМАЛЅСЊЭј+ЮЊеНТдЗЂеЙЗНЯђЃЌашвЊBIЗжЮіЁЂвЕЮёЖЏЬЌРЉеЙЁЂвдМАУєНнЕФВњЦЗгыЗўЮёЖдНгКЭзАХфЕФФмСІжЇГХЃЌЛљгквдЩЯЕФММЪѕвЊЧѓЃЌгХЛЏНЈЩшжЇГХЦѓвЕвЕЮёМАгІгУдЫгЊЕФЛљДЁЩшЪЉЃЌНсКЯЛљДЁзЪдДЯжзДЃЌНЈСЂдЦМЦЫуММЪѕФмСІЃЌаЮГЩПьЫйЯьгІЃЌПЩГжајЗЂеЙЕФЯТвЛДњЪ§ОнжааФЁЃ
ЖдБШДЋЭГЗНАИЃЌШнЦїдЦЕФЗНАИЃЌНЋдкЖдЮЂЗўЮёМмЙЙЕФжЇГжЁЂвЕЮёЕЏадРЉШнЁЂздЖЏЛЏВПЪ№ЁЂВњЦЗПьЫйЩЯЯпЁЂУєНн/ЕќДњЁЂШЋУцЯЕЭГМрПиЕШЗНУцЖдITВПУХДјРДШЋЗНЮЛЕФЬсЩ§ЁЃ
ФПЧАН№ШкаавЕАИР§ЃК
вјааЃКжаЙњвјСЊЃЌЙЄЩЬвјааЃЌЦжЗЂвјааЁЂУЗжнПЭЩЬвјааЕШЃЛ
БЃЯеЃКЬЋЦНбѓБЃЯеЃЌЦНАВБЃЯеЁЂжаЙњШЫЪйЁЂДѓЕиБЃЯеЁЂжкАВБЃЯеЃЛ
жЄШЏЃККЃЭЈжЄШЏ
Q2: ВПЪ№дкK8SЩЯЕФЮЂЗўЮёЃЌШчКЮЪЕЯжгазДЬЌКЭЮозДЬЌЗўЮёЖдгкДцДЂЕФвЊЧѓЃП
A2ЃК
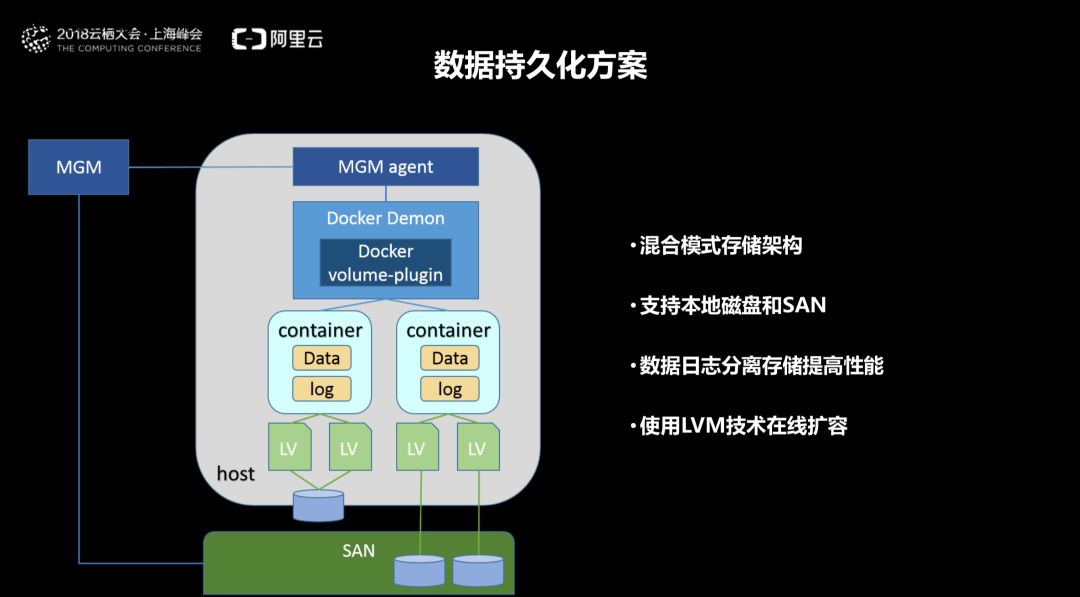
ШнЦїЕФЬиадОіЖЈСЫШнЦїБОЩэЪЧЗЧГжОУЛЏЕФЃЌШнЦїБЛЩОГ§ЃЌЦфЩЯЕФЪ§ОнвВвЛВЂЩОГ§ЁЃЖјЦфЩЯГадиЕФгІгУЗжЮЊгазДЬЌКЭЮозДЬЌЁЃШнЦїИќЧуЯђгкЮозДЬЌЛЏгІгУЃЌПЩЫЎЦНРЉеЙЕФЃЌЕЋВЂВЛвтЮЖЫљгаЕФгІгУЖМЪЧЮозДЬЌЕФЃЌЬиБ№ЪЧвјааЕФгІгУЃЌвЛаЉЗўЮёЕФзДЬЌашвЊБЃДцБШШчШежОЕШЯрЙиаХЯЂЃЌвђДЫашвЊГжОУЛЏДцДЂЁЃШнЦїДцДЂДѓжТгаШ§жжДцДЂЗНАИЃК
ЃЈ1ЃЉдЩњдЦДцДЂЗНАИЃКАДееДПДтЕФдЩњдЦЕФЩшМЦФЃЪНЃЌГжОУЛЏЪ§ОнВЂВЛЪЧДцДЂдкШнЦїжаЃЌЖјЪЧзїЮЊКѓЖЫЗўЮёЃЌР§ШчЖдЯѓДцДЂКЭЪ§ОнПтМДЗўЮёЁЃетИіЗНАИПЩвдШЗБЃШнЦїКЭЫќУЧЕФЪ§ОнГжОУЛЏжЇГжЗўЮёЫЩёюКЯЃЌЭЌЪБвВВЛашвЊФЧаЉЛсЯожЦРЉеЙЕФвРРЕЁЃ
ЃЈ2ЃЉАбШнЦїзїЮЊащФтЛњЃКРћгУШнЦїДјРДЕФБуаЏадЕФгХЕуЃЌвЛаЉгУЛЇНЋШнЦїзїЮЊЧсСПащФтЛњРДЪЙгУЁЃШчЙћБуаЏадЪЧЧЈвЦЕНШнЦїЕФдвђжЎвЛЃЌФЧУДВЩгУШнЦїЬцДњащФтЛњРДАВзАвХСєгІгУЪЧетжжБуаЏадЕФЗДФЃЪНЁЃгЩгкДѓОэжаДцДЂЪ§ОнЪЧНєёюКЯдкШнЦїЩЯЃЌБуаЏадФбвдЪЕЯжЁЃ
ЃЈ3ЃЉШнЦїГжОУЛЏЪ§ОнОэЃКдкШнЦїжадЫааЕФгІгУЃЌгІгУеце§ашвЊБЃДцЕФЪ§ОнЃЌПЩвдаДШыГжОУЛЏЕФVolumeЪ§ОнОэЁЃдкетИіЗНАИжаЃЌГжОУВуВњЩњМлжЕЃЌВЛЪЧЭЈЙ§ЕЏадЃЌЖјЪЧЭЈЙ§СщЛюПЩБрГЬЃЌР§ШчЭЈЙ§ЩшМЦЕФAPIРДРЉеЙДцДЂЁЃетИіЗНАИНсКЯСЫГжОУВуКЭЛђДПдЦдЩњЩшМЦФЃЪНЁЃ
DockerЗЂВМСЫШнЦїОэВхМўЙцЗЖЃЌдЪаэЕкШ§ЗНГЇЩЬЕФЪ§ОнОэдкDockerв§ЧцжаЬсЙЉЪ§ОнЗўЮёЁЃетжжЛњжЦвтЮЖзХЭтжУДцДЂПЩвдГЌЙ§ШнЦїЕФЩњУќжмЦкЖјЖРСЂДцдкЁЃЖјЧвИїжжДцДЂЩшБИжЛвЊТњзуНгПкAPIБъзМЃЌОЭПЩНгШыDockerШнЦїЕФдЫааЦНЬЈжаЁЃЯжгаЕФИїжжДцДЂПЩвдЭЈЙ§МђЕЅЕФЧ§ЖЏГЬађЗтзАЃЌДгЖјЪЕЯжКЭDockerШнЦїЕФЖдНгЁЃПЩвдЫЕЃЌЧ§ЖЏГЬађЪЕЯжСЫКЭШнЦїв§ЧцЕФББЯђНгПкЃЌЕзВудђЕїгУКѓЖЫДцДЂЕФЙІФмЭъГЩЪ§ОнДцШЁЕШШЮЮёЁЃФПЧАвбОЪЕЯжЕФDocker
Volume PluginжаЃЌКѓЖЫДцДЂАќРЈГЃМћЕФNFSЃЌGlusterFSКЭПщЩшБИЕШЁЃ
K8SжаЕФГжОУадДцДЂжївЊЛЙЪЧЭЈЙ§PVЁЂPVCКЭStorageClassРДЪЕЯжЁЃ
ЖдгкЮозДЬЌЗўЮёЃЌДцДЂПЩФмЪЧВЛБивЊЕФЃЌЕЋЪЧЖдгкгЩзДЬЌЗўЮёЃЌашвЊИїжжРраЭЕФДцДЂРДБЃГжзДЬЌЁЃдкK8SжаЃЌPVЬсЙЉДцДЂзЪдДЃЌPVCЪЙгУДцДЂзЪдДЃЌЖўепЪЧЙЉгІепКЭЯћЗбепЕФЙиЯЕЃЌФЧУДЗўЮёЪЧШчКЮАбЪ§ОнДцДЂЕНPVЩЯЕФФиЃП
ЮвУЧжЊЕРK8SжаЗўЮёдЫаадкPODжаЃЌвђДЫдкPODЕФYAMLЖЈвхЮФМўжаЃЌОЭашвЊЖЈвхPVCЃЌВЂжИЖЈвЊЙиСЊЕФPVCУћГЦЃЌШЛКѓPVCЛсИљОнздЩэЕФYAMLЮФМўЖЈвхАѓЖЈКЯЪЪЕФPVЃЌСїГЬОЭЪЧЃКPOD->PVC->PV,ЕБШЛЃЌетЪЧОВЬЌЙЉИјЗНЪНЃЌОВЬЌЙЉИјЕФЬиЖЈОЭЪЧЯШгаPVдйгаPVCЁЃ
ЖдгкЖЏЬЌЙЉИјЗНЪНЃЌОЭашвЊЖЈвхstorageclassЃЌВЂдкДцДЂРрЕФYAMLЮФМўжаЩљУїДцДЂОэЙЉгІепЃЌШчaws-ebsЁЂceph-rbdКЭcinderЕШЃЌЕБPODашвЊДцДЂЕФЪБКђЃЌдйЖЏЬЌДДНЈPVЃЌЦфЬиЕуОЭЪЧЯШPVCдйPVЃЛ
ЕБШЛЃЌДцДЂетПщБОЩэгаКмЖрашвЊПМТЧЕФЕиЗНЃЌзюМбД№АИЛЙЪЧЙйЭј
https://kubernetes.io/docs/concepts
/storage/persistent-volumes/
етРягаСНИіРЉдФЖСЃЌЙигкШнЦїдЩњДцДЂЃК
https://www.linuxfoundation.org/press-release
/opensds-aruba-release-unifies-sds-control-for-kubernetes-and-openstack/
https://github.com/openebs/openebs
Q3: kubernetsШчКЮDevopsЪЕЯжГжајВПЪ№ЗЂВМВтЪдШЋСїГЬЃП
A3ЃК
ЪЙгУдЩњkubernetsЪЕЯжCI/CDзюДѓЕФБзЖЫЃЌОЭЪЧФуашвЊздМКИуЖЈJenkinsЁЂRegistryЃЌвдМАЭтЮЇЕФELKМрПиЁЂgrafanaЕШЕШЖЋЮїЃЌЕЅЪЧВПЪ№етаЉЖМвЊЛЈЗбДѓСПЪБМфЁЃ
OpenshiftвбОМЏГЩJenkinsЃЌздДјФкВПregistryЃЌжЇГжpipelineЃЌгУЛЇашвЊзіЕФОЭЪЧДюНЈздМКЕФGitlabЛђепSVNгУвдДцЗХздМКЕФдДДњТыЃЌOpenshiftЩчЧјдкJenkinsжаЪЕЯжСЫКмЖрopenshiftВхМўЃЌЪЙЕУФудкJenkinsКЭopenshiftжЎМфПЩвдЪЕЯжЛЅЖЏЙиСЊВйзїЃЌЭЌЪБopenshiftЬсЙЉСЫЫНгаОЕЯёВжПтЃЌПЩвдНЋБрвыКѓЕФdockerОЕЯёДцДЂдкopenshiftФкВПregistryжаЃЌШЛКѓдкПЊЗЂЁЂВтЪдКЭЩњВњЛЗОГЖМПЩДгетИіregistryжазЅШЁОЕЯёВПЪ№ЃЌПЊЗЂЁЂВтЪдКЭЩњВњЛЗОГжЎМфдкJenkinsжаЭЈЙ§openshiftВхМўНјааДЅЗЂЃЌЭъУРНтОіЙЙНЈpipelineЪЕЯжCI/CDЁЃЫљвдЃЌЭъШЋУЛБ№вЊздМКИуk8s+JenkinsЃЌopenshiftвбОЬсЙЉСЫвЛеОЪННтОіЗНАИЁЃЛЙЪЧФЧОфЛАЃЌгыЦфУЦЭЗИуK8SЃЌВЛШчжБНгЩЯopenshiftЃЁ
kubernetesашвЊећКЯJenkinsЁЂHarborЁЂGitlabЛЙгаШежОЙмРэЁЂМрПиЙмРэЕШЕШЕФЦфЫћзщМўЃЌПДашвЊЃЌРДЪЕЯжГжајВПЪ№ГжајЗЂВМЕФШЋСїГЬЁЃ
GitLabжївЊИКд№ПЊЗЂДњТыЕФДцЗХЙмРэЁЃ
JenkinsЪЧвЛИіГжајМЏГЩГжајЗЂВМв§ЧцЃЌЪЙгУjenkinsИаОѕЫќЬЋжиСЫЃЌВЛЬЋЪЪКЯШнЦїЃЌЕБШЛвВПЩвдбЁдёЦфЫћЕФЁЃ
HarborОЭЪЧЫНгаОЕЯёВжПтСЫЃЌаТАцHarborЬсЙЉСЫОЕЯёАВШЋЩЈУшЕШЙІФмЃЌЕБШЛвВПЩвдЪЙгУЦфЫћЕФЃЌШчregistryЁЃ
ЭъГЩDevOpsЕФЛАашвЊећКЯетаЉНјаавЛаЉЦНЬЈЛЏЕФПЊЗЂЃЌетбљВХЛсгаБШНЯКУЕФНЛЛЅЬхбщЁЃвВПЩвджБНгЪЙгУJenkins
Q4:ЮЂЗўЮёЕФБрХХK8SЬсЙЉСЫКмЖрyamlЮФМўЃЌЕЋетЦфЪЕгУЛЇЬхбщВЂВЛКУЃЌгаЪВУДЭМаЮБрХХЕФНтОіЫМТЗУДЃПвдМАдѕбљгУЮЂЗўЮёЕФРэФюДђдьЦѓвЕжаЬЈЃЈSOAЃЉЃП
A4ЃК
SOAУцЯђЗўЮёМмЙЙЃЌЫќПЩвдИљОнашЧѓЭЈЙ§ЭјТчЖдЫЩЩЂёюКЯЕФДжСЃЖШгІгУзщМўНјааЗжВМЪНВПЪ№ЁЂзщКЯКЭЪЙгУЁЃЗўЮёВуЪЧSOAЕФЛљДЁЃЌПЩвджБНгБЛгІгУЕїгУЃЌДгЖјгааЇПижЦЯЕЭГжагыШэМўДњРэНЛЛЅЕФШЫЮЊвРРЕадЁЃ
ДѓЖрЪ§ГѕДЮНгДЅYAMLЕФШЫЖМЛсОѕЕУетРрЮФЕЕФЃАхЬхбщМЋВюЃЌИаОѕЬЋЗДШЫРрСЫЃЌИїжжЖдЦыЁЂИёЪНЃЌвЛВЛаЁаФОЭгяЗЈБЈДэЃЌЭЈГЃгжВЛФмзМШЗЖЈЮЛДэЮѓЕуЃЌЖдаТЪжРДЫЕЃЌетжжYAMLЮФБОШЗЪЕКмЭЗЬлЃЌЕЋЪЧгжУЛЗЈЃЌK8SРяУцОЁЪЧYAMLЃЌФЮКЮЃПЃПЃПЃП
МДЪЙецгаЭМаЮБрХХНтОіЫМТЗЃЌИаОѕвВЪЧЛЛЬРВЛЛЛвЉЁЃ
НтОіЮЪЬтЕФИљБОАьЗЈЃЌЭЈГЃОЭЪЧИЊЕзГщаНЁЃФПЧАЃЌвбгаДѓХЃЗЂЦ№noYAMLдЫЖЏЃЌЫфШЛЛЙЮДГЩЦјКђЃЌЕЋЪЧжСЩйЫЕУїШЗЪЕгаКмЖрШЫВЛЯВЛЖYAMLЃЌЖјЧвдкЪЙгУЪЕМЪааЖЏРДВЛЯВЛЖЁЃ
ЯИЪ§YAMLЁАЪЎзкзяЁБЃК
https://arp242.net/weblog/ yaml_probably_not_so_great_after_all.html
https://news.ycombinator.com/item?id=17358103
ШчЙћЯЃЭћдкK8SЩЯдЫааЮЂЗўЮёЃЌФЧУДгаБивЊСЫНтвЛаЉдЦдЩњБрГЬгябдЃЌШчЃК
PulumiЃЈhttps://www.pulumi.com/ЃЉ
BallerinaЃЈhttps://ballerina.io/ЃЉ
ЖдгкжеЖЫгУЛЇЖјбдЃЌЛђаэЦНЬЈВХЪЧФузюжеашвЊЕФЁЃЩшЯыФугавЛИіЦНЬЈв§ЧцЃЌетИіЦНЬЈв§ЧцМЏГЩСЫDockerМАЦфЕїЖШв§ЧцK8SЃЌШЛКѓФужЛашвЊБраДвЕЮёТпМДњТыЃЌШЛКѓОЕЯёЗтзАЁЂШнЦїВПЪ№ЕїЖШШЋВПНЛгЩЦНЬЈДІРэЃЌЕБШЛетИіЙ§ГЬжаИїжжYAMLЮФМўвВгЩЦНЬЈздЖЏЩњГЩЃЌКЮРжЖјВЛЮЊЃП
ФЧЮЪЬтОЭЪЧЃКгаУЛгаетбљЕФЦНЬЈЃП
вдЧАОЭгаЃЌЕЋЪЧШЗЪЕВЛдѕУДКУгУЃЌЕЋЪЧOpenShift V3ГіРДжЎКѓЃЌИіШЫШЯЮЊЫќОЭЪЧЮвУЧвЊевЕФЦНЬЈЁЃзїЮЊжеЖЫгУЛЇЃЌЮвИіШЫВЂВЛНЈвщжБНгИуK8SЃЌЖдK8SгааЉИХФюЪѕгяЩЯЕФРэНтЃЌОЭПЩжБНгЩЯOpenShift
V3ЁЃK8sКЭDockerНіЪЧOpenshiftЕФkernelЃЌГ§ДЫжЎЭтЃЌOpenShiftЛЙМЏГЩСЫКмЖргІгУГЬађБрвыЁЂВПЪ№ЁЂНЛИЖКЭЩњУќжмЦкЙмРэЕФЩњЬЌШІШэМўЃЌвђДЫЃЌБШЦ№гВЩЯK8SЃЌOpenShiftвВаэВХЪЧКмЖрШЫашвЊбАевЕФЖЋЮїЃЁ |





