| БрМЭЦМі: |
БОЮФжївЊЗжЯэдкАЂРяАЭАЭФкВПЪЙгУ PostgreSQL ЕФвЛаЉГЁОАвдМАШчКЮНтОіетаЉЮЪЬтЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкИпаЇдЫЮЌЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд PostgreSQL етМИФъЕФЗЂеЙЗЧГЃбИУЭЃЌдкЙњФкЯЦЦ№СЫвЛВЈ
PostgreSQL ЕФШШГБЃЌЕЋдЫЮЌШЫВХЛЙЪЧБШНЯНєШБЃЌЫљвддквЛаЉЙЋЫОУЛгаДѓУцЛ§ЦЬПЊЃЌВЛЙ§ВЛгУЕЃаФЃЌКмЖрдЦГЇЩЬЖМЬсЙЉСЫ
PostgreSQL ЕФЪ§ОнПтЗўЮёЁЃ
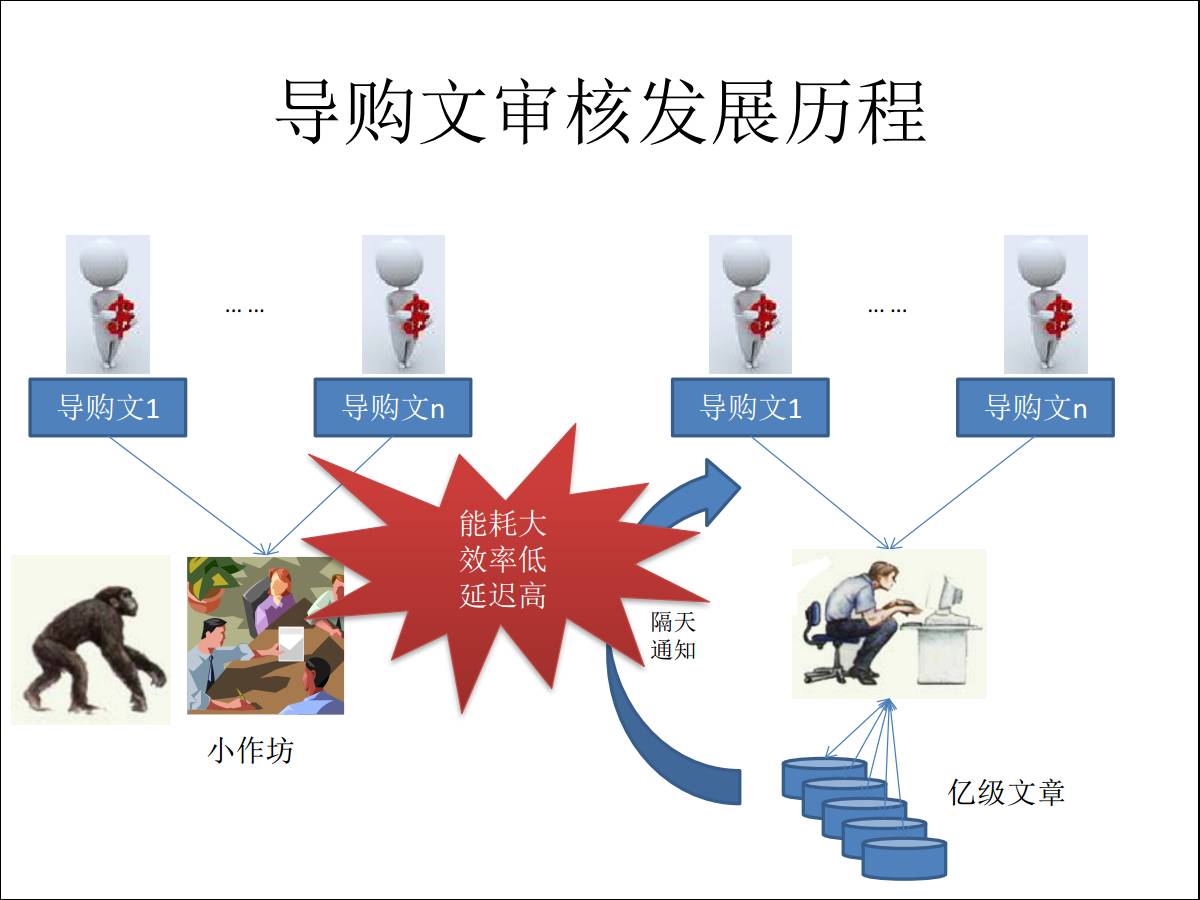
АЂРядЦЕФ RDS PostgreSQL Г§СЫЬсЙЉЙЋгадЦЗўЮёЃЌЭЌЪБвВЖдАЂРяАЭАЭМЏЭХЬсЙЉФкВПЕФЗўЮёЁЃНгЯТРДЮвЛсЗжЯэМИИідкАЂРяАЭАЭФкВПЪЙгУ
PostgreSQL ЕФвЛаЉГЁОАЁЃДѓМвПЩвдЯыЯыЫМПМвЛЯТЃЌШчЙћгУЦфЫћЪ§ОнПтКЭММЪѕЪжЖЮдѕУДНтОіетаЉЮЪЬтЁЃ
1.КЃСПЕМЙКЮФЪЕЪБШЅжи
2.ОЋзМЙуИцЭЖЗХ
3.TOB ЪЕЪБЛЯё
4.ШЮвтзжЖЮзщКЯ
5.ШЮвтзжЖЮФЃК§ЦЅХф
1. КЃСПЕМЙКЮФЪЕЪБШЅжи
1.1 ЕМЙКвЕЮёНщЩм
ЪзЯШЪЧКЃСПЕМЙКЮФЪЕЪБШЅжиЁЃдкШеГЃЩњЛюжаЬиБ№ЪЧУУзгКмЯВЛЖПДЕМЙКЕФЭЦЫЭЯћЯЂЃЈБШШчУПШеАзВЫМлЃЉЃЛЬиБ№ЪЧМвЭЅжїИОЃЌдкМвРяУЛЪТОЭфЏРРАзВЫМлЃЌШчЙћМвРягааЁКЂЕФЃЌаЁКЂВХвЛСНИідТЃЌвбОТђЕНЪЎМИЫъЕФвТЗўСЫЃЌетКЭЕМЙКЭЦЫЭгаУмЧаЙиЯЕЁЃ

етУДЖрЕФЕМЙКЮФеТЃЌУПвЛЦЊЮФеТЖМЛсЭЦКмЖрЕФЩЬЦЗЃЌШчЙћФуЪЧвЛИігУЛЇУПЬьЗПДетаЉЮФеТЖМЪЧвЛбљЕФЩЬЦЗЃЌЪЧКмСюШЫЬжбсЕФЁЃ
БШШчЫЕУПШеАзВЫОЋбЁЕФЮФеТРяПЩФмЛсЩцМАЕНМИЪЎИіЩЬЦЗЃЌећИіЕМЙКЦНЬЈПЩФмЛсГСЛ§ЩЯвкЕФЮФеТЃЌШчЙћЦНОљЮхЪЎИіЩЬЦЗЕФЛАЃЌОЭЛсгаЮхЪЎвкИіЩЬЦЗЁЃЕБШЛРяУцгажиЕўЃЌвЛЦЊЮФеТРяИњСэЭтвЛЦЊЮФеТПЩФмгавЛСНИіжиЕўЃЌетЪЧУЛгаЙиЯЕЕФЃЌЕЋЪЧФуВЛФм80%вдЩЯЖМжиЕўЃЌетИіжиЕўБШР§ЪЧашвЊПЩвдЩшЖЈЕФЁЃ
1.2 ЕМЙКЮФЩѓКЫЗЂеЙРњГЬ
вђЮЊЕъМвЛсШЅзіЭЦЙуЃЌОЭЛсгагЖН№ЃЌЭјТчаДЪжЛсЮЊСЫгЖН№ШЅаДЕМЙКЮФеТЁЃЕЋЪЧЮЊСЫЗРжЙГіЯжЕСЮФЯжЯѓЃЌОЭашвЊЩѓКЫЕМЙКЮФеТЃЌзюдЪМЕФзіЗЈЪЧЪВУДбљЕФЃПБШШчЮвИеаТНЈСЫетбљвЛИіЕМЙКЦНЬЈЃЌгУЛЇЪ§вВВЛЪЧЬиБ№ЖрЃЌетЪБКђЧывЛаЉНЯЮЊСЎМлЕФРЭЖЏСІРДАяФуНтОіЩѓКЫЕФЮЪЬтЃЌзюдчЦкЕФЮЊРЭЖЏСІУмМЏаЭЁЃ
ЗЂеЙЕНЕкЖўДњЃЌгУМЦЫуЛњАяФузіетИіЪТЧщЃЌаТЬсНЛвЛИіЮФеТЕФЪБКђЃЌвЊдкЩЯвкЕФЮФеТРяШЅБцБ№ИњЮвИеИеЬсНЛЕФЩЬЦЗЕФжиИДТЪЪЧЪВУДбљЕФЃЌЩцМАЕФдЫЫуСПЗЧГЃДѓЃЌвђДЫВЂВЛФмзіЕНЪЕЪБЕФЩѓКЫЃЌЭЈГЃЪЧИєЬьЕФЁЃ
ЖдгкЕМЙКЮФеТЕФБрМРДЫЕЃЌетИіаЇТЪЪЧЕЭЯТЕФЃЌЭјТчаДЪжЬсНЛЮФеТКѓЃЌЕкЖўЬьВХФмИцжЊгаУЛгаЭЈЙ§ЃЌВХФмЗЂЕНЭјеОЩЯУцЃЌетбљПЩФмОЭДэЙ§СЫЩЬМвЕФгЊЯњЪБЛњЁЃ
1.2.1 Ъ§ОнНсЙЙЮЪЬт

ЛиЕНдЪМЕФЪ§ОнШЅПДЃЌУПвЛЦЊЕМЙКЮФеТРяУцЩцМАЕН50ИіЩЬЦЗЃЌАДЦНОљЪ§РДЃЌЩЬЦЗЪЙгУвЛИіЪ§зщРДДцДЂЃЌетРяУцЕФУПИіЪ§жЕЖдгІЕФЖМЪЧЩЬЦЗЕФ
IDЃЌУПИіМЧТМЛсЩцМАЕНДѓИХ 50 ИіетбљЕФжЕЁЃ
ЕБгУЛЇЬсНЛвЛИіаТЕФЕМЙКЮФеТРДЕФЪБКђЃЌЮвУЧПДЕНгжгавЛЖбЕФжЕНјРДЃЌдѕУДзіФиЃП
ЮвУЧашвЊШЅБШЖдПтРяЕФУПвЛЬѕМЧТМЃЌПДЫћУЧжиЕўЕФдЊЫигаЖрЩйИіЃЌБШШчЫЕаТЩЯЕФЮФеТЭЦМіСЫЪЎИіЩЬЦЗЃЌгыРњЪЗЕМЙКЮФеТжаФГМЧТМжиЕўЕФгаАЫИіЩЬЦЗ
IDЃЌвтЮЖзХФуаТЩЯДЋЕФЮФеТга 80% ИњЦфжаЕФФГвЛЦЊЮФеТЕФЩЬЦЗЪЧжиЕўЕФЃЌЩѓКЫНсЙћЪЧОмОјЁЃ
1.2.2 PostgreSQL GINЫїв§гІгУ

дк PostgreSQL РяУцгавЛИіЪВУДММЪѕФмЙЛАяФуИпаЇЪЕЯжгІгУГЁОАФиЃПЮвУЧгУСЫ GIN Ыїв§ЃЌЫќОЭЪЧвЛИіЕЙХХЫїв§ЃЌдкФуЕФвЛЬѕМЧТМРяЃЌПЩвдЖдЪ§зщШЅНЈЫїв§ЃЌвЛИіЪ§зщга50ИіЩЬЦЗЃЌЕквЛСаЪЧвЛИіааКХЃЌНтПЊжЎКѓвЛИіааКХЖдгІетУДЖржЕЃЌЕЙзЊвЛЯТЛсБфГЩетИіжЕЖдгІЕФааКХЪЧЪВУДЃЌОЭЪЧАяФузіСЫЗзЊЁЃ
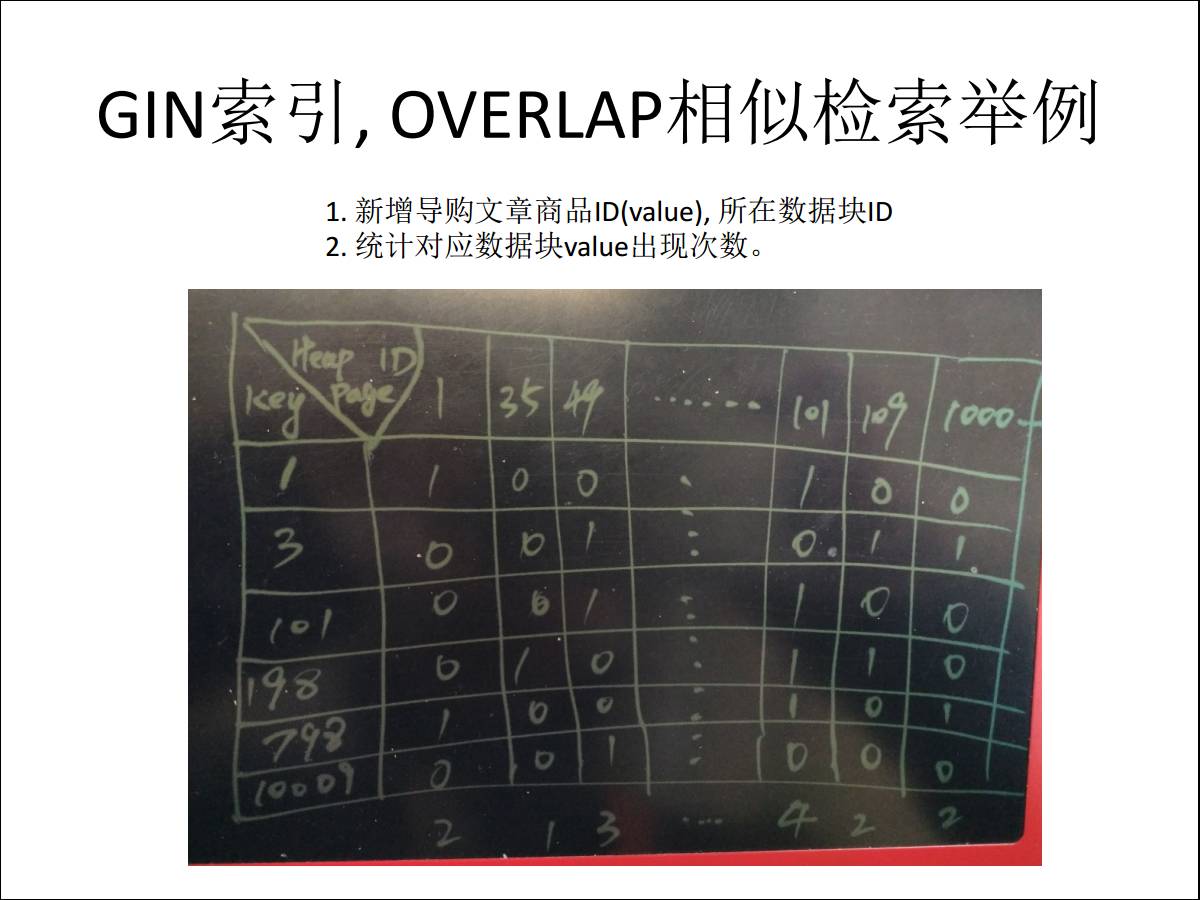
гаЪВУДгУФиЃПзіЭъСЫЗзЊЃЌгУЛЇЩЯДЋСЫвЛЦЊаТЕФЕМЙКЮФеТЃЌРяУцЩцМАЕНМйЩшЩЬЦЗЕФ IDЃЌЮвУЧПДзюзѓБпЕФвЛСаЃЌ1ЃЌ3ЃЌ101ЃЌ198ЃЌЩЯДЋетаЉЩЬЦЗ
ID ЩЯРДЃЌдкЫїв§ЩЯдѕУДЫбЫїЃЌБШШчЫЕЖд1етИі IDЃЌвђЮЊЫќгаааКХЃЌРяУцЖдгІЕФЪЧЪ§ОнПщЕФ ID МгЩЯетЬѕМЧТМдкЪ§ОнПщЕФЦЋвЦЃЌЖдгІЕФКХФУГіРДжЎКѓЃЌдкЕквЛИіЪ§ОнПщГіЯжЙ§ЃЌЭЈЙ§Ыїв§ЫбЫїГіРДЃЌдкЕк101ИіЪ§ОнПщРявВГіЯжЙ§ЃЌЪ§ОнПтЛсАяФуАбУПИіЪ§ОнПщРяЕФУќжаЩЬЦЗзмЪ§ИјМЧТМЯТРДЃЌОЭБфГЩСЫзюЯТУцЕФвЛааМЧТМЃЌ213
422ЃЌЪВУДвтЫМФиЃПДњБэЪЧдк101етИіЪ§ОнПщРягаУќжаЫФИіЩЬЦЗIDЁЃ
1.2.3 ЖржиЙ§ТЫЬсИпМьЫїаЇТЪ
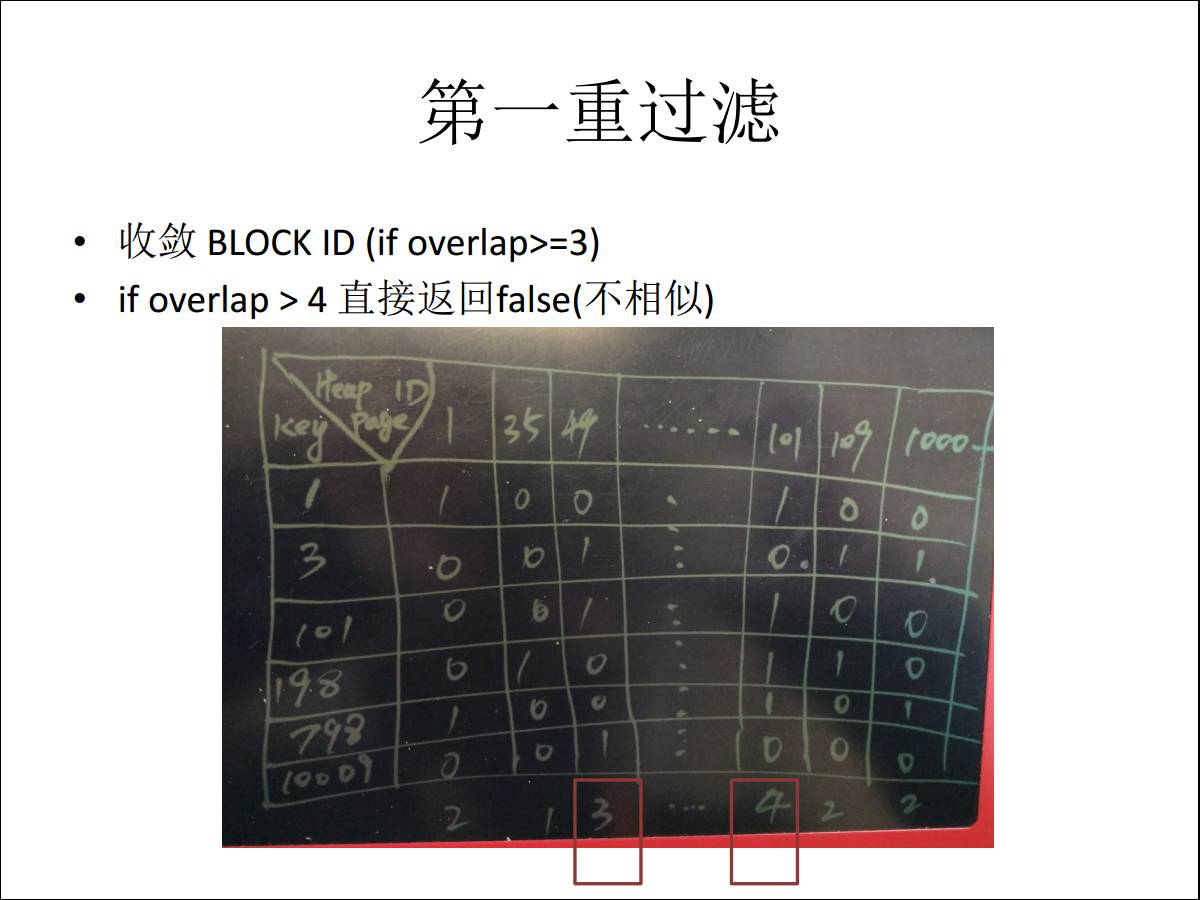
БШШчЩшжУСЫжиИДЪ§>4ЃЌЭЈЙ§Ыїв§ПЩвджБНгОмОјЗЂВМЁЃШчЙћЩшжУЮЊ>=3ФЧУДжЛвЊЬсШЁГіЕк49КХЪ§ОнПщКЭЕк101ЕФЪ§ОнПщЕФЪ§ОнЁЃНјШыЕкЖўЕРЙЄађЁЃ

ИеВХНВЕФЪЧзіЕФЕквЛВуЙ§ТЫЃЌЕкЖўВуЙ§ТЫЪЧАяФуЖЈЮЛЕНСНИіЪ§ОнПщСЫЃЌШЛКѓФуШЅУПвЛЬѕМьВщЃЌвђЮЊУПИіЪ§ОнПщЩцМАЕФМЧТМвВОЭЪЧМИАйЬѕЃЌећИіЯТРДаЇТЪОЭЗЧГЃИпЁЃ
1.2.4 ЗТецЪ§ОнВтЪдНсЙћ
ИљОнецЪЕЪ§ОнЕФЬиеїЃЌЙЙНЈвЛХњЗТецЪ§ОнЁЃ
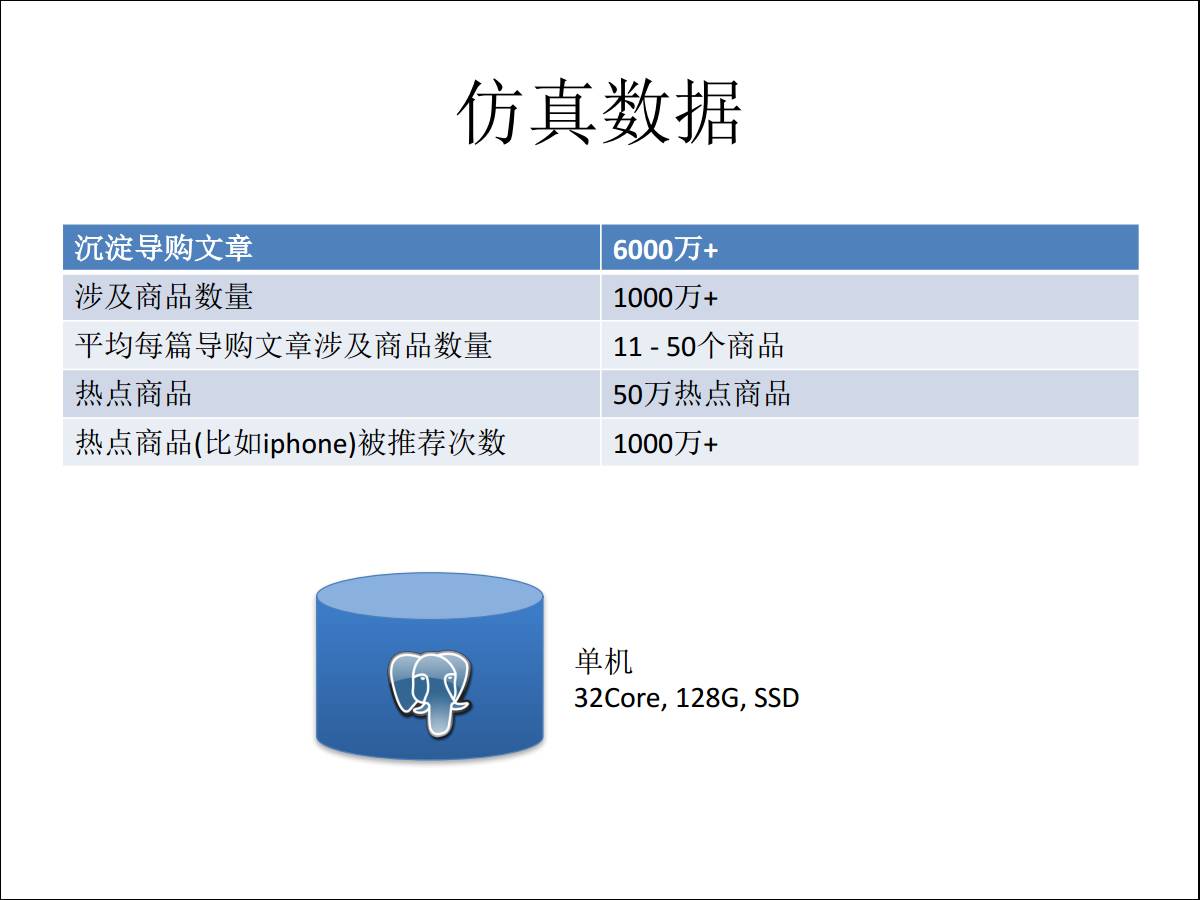
БЛЭЦМіЕФЩЬЦЗЪ§змСПЃКГЌЙ§1ЧЇЭђЃЌУПвЛЦЊЕМЙКЮФеТЦНОљЯТРДЩцМАЕФЩЬЦЗЃЌДгРњЪЗЪ§ОнРДПДЪЧ11ЕН50ИіЩЬЦЗЃЌвЛЦЊЮФеТЛсЭЦ11ЕН50ИіЩЬЦЗИјФуЁЃ
ШШЕуЩЬЦЗЃКЪЧЫЕЗЧГЃДѓЕФЕъЦЬИјЕФгЖН№ЗЧГЃИпЃЌКмЖрШЫдИвтШЅаДЮФеТЭЦМіетжжЩЬЦЗЃЌетЪЧШШЕуЩЬЦЗЁЃ
1.2.5 PostgreSQLгХЛЏЪБаЇВтЪд
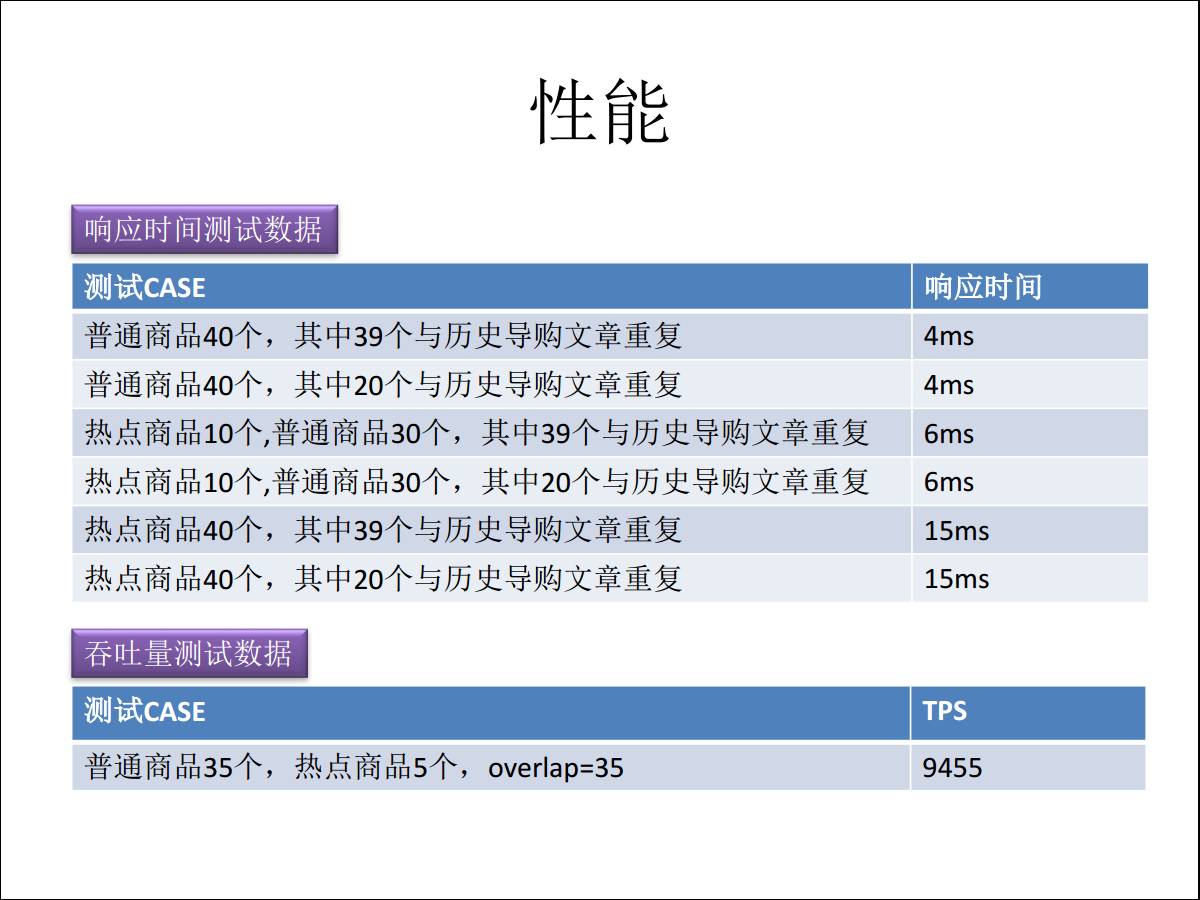
етаЉВтЪдЖдгІЕФОЭЪЧЪЕМЪЕФгІгУГЁОАЃЌвЛЦЊаТЕФЮФеТЩЯРДжЎКѓЃЌЖрПьЕФЪБМфФмЙЛИцЫпФугаУЛгаШЫИњФужиЕўЃЌШчЙћФуЪЧЦеЭЈЩЬЦЗЕФЛАЃЌЙ§ТЫ39ИіИњФужиИДЕФЃЌЮвОЭАбЮФеТЬцЕєЃЌВЛШУФуЗЂВМСЫЁЃ
ШчЙћвЛЦЊЮФеТРяЭЦЕФЖМЪЧШШЕуЩЬЦЗЃЌвђЮЊБЛЭЦМіЕФДЮЪ§ЖрЃЌМЧТМЫљЩцМАЕФЪ§ОнПщИќЖрЃЌвђДЫвЛМЖЙ§ТЫГіРДЕФЪ§ОнПщБШНЯЖрЃЌЖўМЖЙ§ТЫзіЕФОЭБШНЯЖрЃЌЕЋЪЧвВФмЙЛДяЕН15ИіКСУыЁЃ
ЭЬЭТСПДяЕН1ЭђЃЌЯрБШвдЭљИєЬьвЊИцЫпФуФмЙЛЩѓКЫЭЈЙ§ЃЌЯждкПЩвдзіЕНЪЕЪБЯьгІЁЃ
етЪЧ PostgreSQL дкАЂРяЕФЕМЙКЦНЬЈЕФгІгУЃЌвђЮЊЪЙгУЦфЫћЕФММЪѕИљБОУЛЗЈНтОіетИіЮЪЬтЃЌвђЮЊЮвУЧдкАЂРягавЛИі
ATA ЕФММЪѕТлЬГЗЂЬћзгЃЌИеКУЫћУЧПДЕНетИіММЪѕЃЌевЕНЮвУЧЭХЖгЃЌШЅИјЫћУЧзіСЫетИіЗНАИВЂЩЯЯпЁЃ
2ЁЂОЋзМЙуИцЭЖЗХ
ЕкЖўИігІгУГЁОАЪЧОЋзМЕФЙуИцЭЖЗХЃЌетИіЖдгІЕФЪЧЙуИцгЊЯњЕФВњЦЗЃЌЪ§СПМЖвВЪЧХгДѓЕФЁЃЮвУЧПДетИіГЁОАЕФНщЩмЃЌдкФуЪЙгУВњЦЗЕФЪБКђвЛаЉфЏРРааЮЊЃЌБШШчФуфЏРРСЫФФаЉЕъЦЬЁЂЙКТђСЫФФаЉЩЬЦЗЃЌетаЉдкЪ§ОнЦНЬЈРяЖМЪЧгаИњзйМЧТМЕФЃЌБШШчЫЕУПИіШЫфЏРРСЫФФаЉЕъЦЬЃЌфЏРРСЫЖрЩйДЮЃЌфЏРРСЫФФаЉЩЬЦЗЃЌетаЉЪ§ОнОЭПЩвдгУРДзіОЋзМЕФЙуИцЭЖЗХЁЃ
2.1 вЕЮёНщЩм

ЪВУДвтЫМФиЃПБШШчЫЕзюНќОГЃфЏРРЛЏзБЦЗЛђепЫљЙизЂЕФЩЬЦЗЃЌФудкЙКТђЧАПЩФмЛсвЛжБфЏРРЃЌИљОнетаЉааЮЊЃЌПЩвдШІГівЛаЉзюНќЖМдкЙизЂЛЏзБЦЗЕФШЫШКЃЌТєЛЏзБЦЗЕФЩЬМвОЭПЩвдЖЈЯђЭЦЫЭдЫгЊЕФЛюЖЏЃЌАбЯћЯЂИцЫпетаЉШЫЃЌвђЮЊетаЉШЫПЩФмзюНќОЭвЊТђСЫЁЃ
ЖдгквЛИігЊЯњЯЕЭГРДЫЕЃЌЫќЕФЗЧГЃживЊЕФжИБъЃЌвЛИіЪЧОЋзМадЃЌСэЭтЪЧЪЕЪБадЃЌШчЙћФуНёЬьфЏРРЭъжЎКѓПЩФмЯТЕЅСЫЃЌЕкЖўЬьдйИцЫпФуУЛгаШЮКЮвтвхЃЌОЭВЛЛсдйИјФужиИДЭЦМіСЫЁЃвђДЫетСНИіживЊЕФвђЫивЛНсКЯЃЌЮвУЧПДPostgreSQLдкРяУцдѕУДАяжњЦНЬЈДяЕНаЇЙћЁЃ
ЪзЯШПДЪ§ОнНсЙЙЃЌвЛИіЪЧгУЛЇIDЃЌШЛКѓЪЧЕъЦЬЙьМЃЃЌФуфЏРРетИіЕъЦЬЖрЩйДЮЃЌфЏРРетИіЩЬЦЗЖрЩйДЮЃЌзюКѓФуТђСЫетИіЩЬЦЗЖрЩйЪ§СПЃЌЛсгавЛаЉетбљЕФЙьМЃЃЌШЛКѓЛсгаЕиРэЮЛжУЃЌЛљгкЕиРэЮЛжУЕФЭЦМіЃЌвВЛсДцЮЛжУаХЯЂЁЃИљОнетаЉЃЌЮвУЧПЩвдИљОнЪБМфЧјМфЁЂЮЛжУЁЂфЏРРЕФЕъЦЬЁЂфЏРРЕФЩЬЦЗЕШЬѕМўЃЌШІбЁШЫШКЁЃ
дйПДЪ§ОнСПЃЌећИіСПМЖЪЧАйвкМЖБ№ЃЌЩЬЦЬЪЧвкМЖБ№ЃЌЕЅИігУЛЇЙьМЃЦНОљфЏРРвЛЧЇИігУЛЇЃЌЛЙгафЏРРЕФЩЬЦЗСПМЖвдМАЙКТђЕФЩЬЦЗСПМЖЃЌЛљБОЩЯЪЧдкЧЇетИіМЖБ№ЃЌЕБШЛетИіМЖБ№ЙРЕУБШНЯИпЃЌЩшМЦЪБашвЊПМТЧЮДРДЕФЬхСПЁЃ
2.2 НзЬнЛЏОйР§
вЕЮёашЧѓИеВХвбОНВЙ§ЃЌИљОнФГИіЩЬЦЗЃЌБШШчфЏРРФГИіЩЬЦЗГЌЙ§ЖрЩйДЮЕФШЫШКЃЌФГИіЧјгђфЏРРФГаЉЩЬЦЗГЌЙ§ЖрЩйДЮЕФШЫШКЃЌЯрЕБгкЪЧОЋзМШІШЫЕФвтЫМЁЃЮвУЧдѕУДЖдетИіГЁОАзіЩшМЦЃП
ЪзЯШЪЧЪ§зжЃЌфЏРРСЫЖрЩйДЮЩЬЦЗЃЌЪЧИіОЋзМЕФЪ§зжЃЌШчЙћЫЕетаЉЭъЭъШЋШЋОЋзМЕФДцдкРяУцЕФЛАЃЌВЛРћгкКѓЦкЕФгХЛЏЁЃ
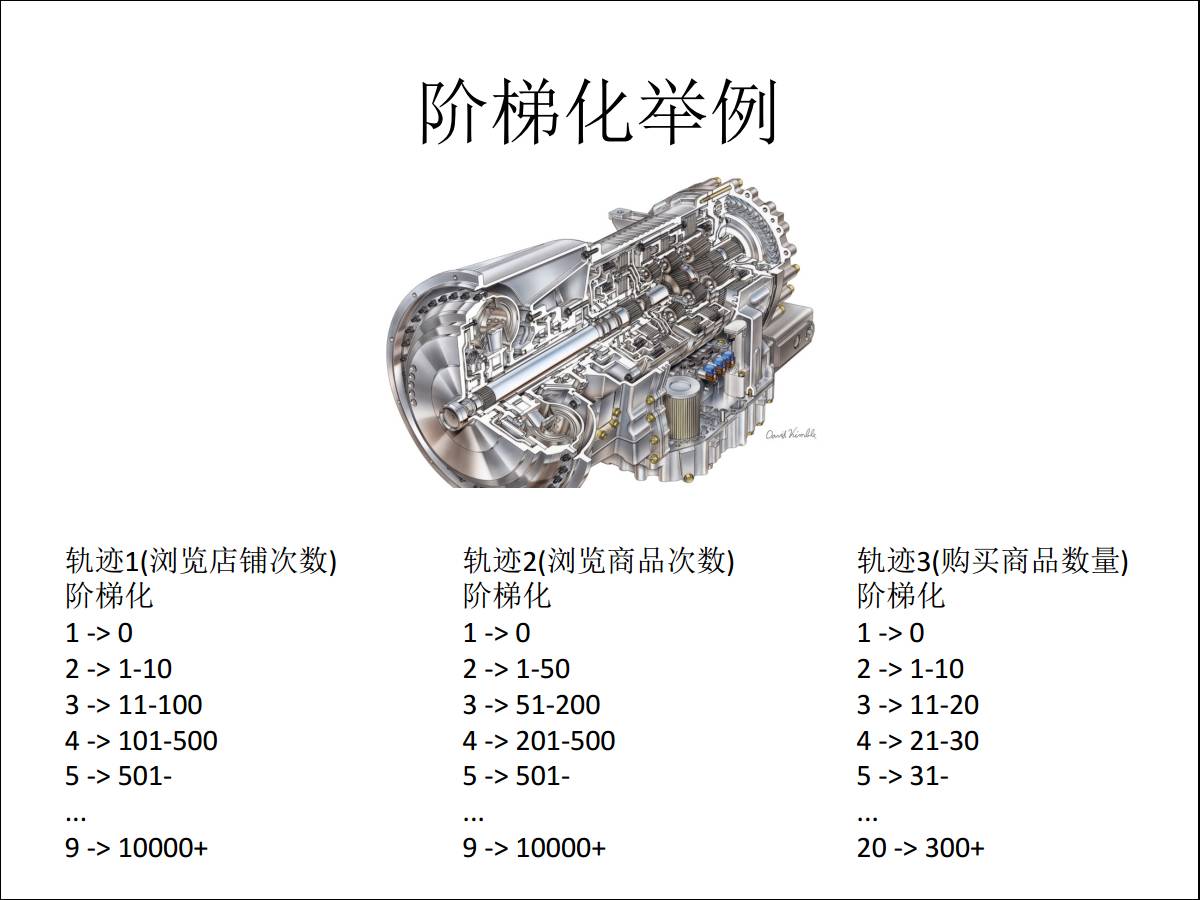
ЫљвдЮвУЧЪзЯШЛсзівЛИіНзЬнЛЏЃЌетЪЧЦћГЕЕФБфЫйЯфЃЌБШШчЫЕ10ATЕФЦћГЕЃЌЖдгкОЋзМгЊЯњРДЫЕПЩФмЪЎЕЕВЛЙЛЃЌвЊзіЕУОЋзМЃЌЮвОЭвЊЭЖЗХГЌЙ§фЏРРДЮЪ§100ДЮЕФЁЃ
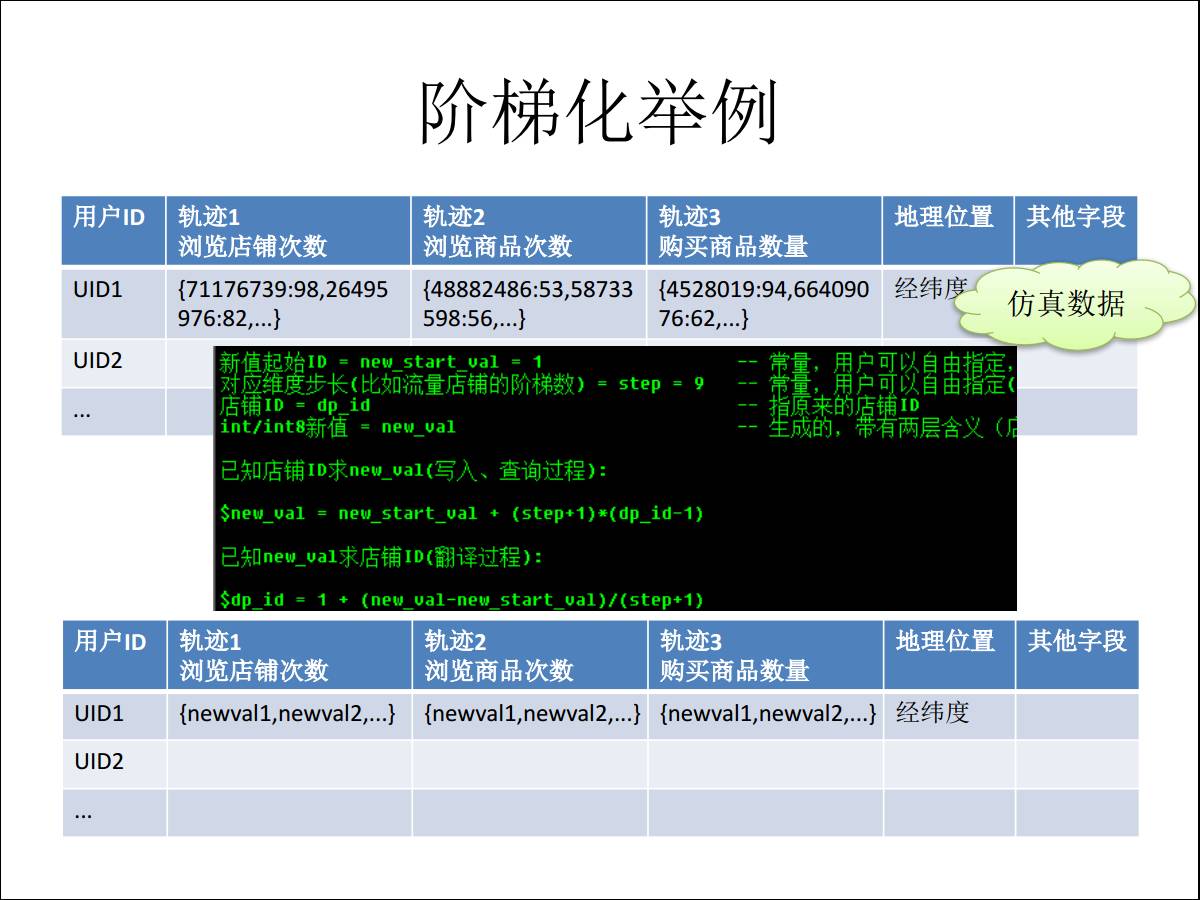
етЪЧЕЕЮЛНзЬнЛЏЃЌЖдааЮЊЙьМЃОЋзМДЮЪ§зіЗЖЮЇЃЌИљОнВЛЭЌЗЖЮЇЖЈНзЬнЃЌЖЈЭъНзЬнЃЌЮвЕФУПИігУЛЇ ID МгЩЯЖдгІЕФЙьМЃЃЌЯрЕБгкЪЧЮвИјФуВІвЛИіЕЕЮЛвЛбљЃЌБШШчСљЕЕЃЌЫЕУїФуетИігУЛЇЪЧТфдкСљЕЕетИіЗЖЮЇЃЌетбљзіжЎКѓОЭПЩвдАбзѓЩЯНЧЕФетИіжЕЃЌетЪЧдРДЕФжЕЃЌДњБэетИігУЛЇфЏРРСЫетИігУЛЇ98ДЮЃЌЮвАбЫќНзЬнЛЏжЎКѓОЭБфГЩ
711 767 740ЃЌБэЪОЫќЪЧ1ЕЕЃЌЦДГЩвЛИіжЕЃЌАбетИіЖЋЮїМгЩЯШЅЁЃ
ЭМжаЫљЪОЙЋЪНЮЊзЊЛЛЙЋЪНЃЌдѕУДАбРЯЕФжЕзЊГЩаТЕФжЕЃЌдРДЮвгУСНИіаТЕФдЊЫиБэЪОЕФЪ§зжЃЌБфГЩвЛИіЪ§зжРДБэЪОЁЃШЛКѓЮвОЭПЩвдЖдЙьМЃНЈЕЙХХЫїв§ЃЌетИіЫїв§НЈЭъжЎКѓЃЌОЭПЩвдЪЕЯжЖЈЯђШІШЫЁЃБШШчЫЕфЏРРЕФЩЬЦЗАќКЌЪВУДЃЌБШШчАќКЌФГвЛИіЩЬЦЗЕФ
ID МгЕЕЮЛЪ§ЃЌетЪЧЖдЪ§зщЕФВйзїЁЃ
фЏРРСЫЪЎИіЕъМвШЮвтвЛМвГЌЙ§ЖрЩйДЮЕФЃЌЮвОЭгУ overlap ЕФзіЗЈзіЁЃ
2.3 ЪЕЯжЖЈЯђШІШЫ
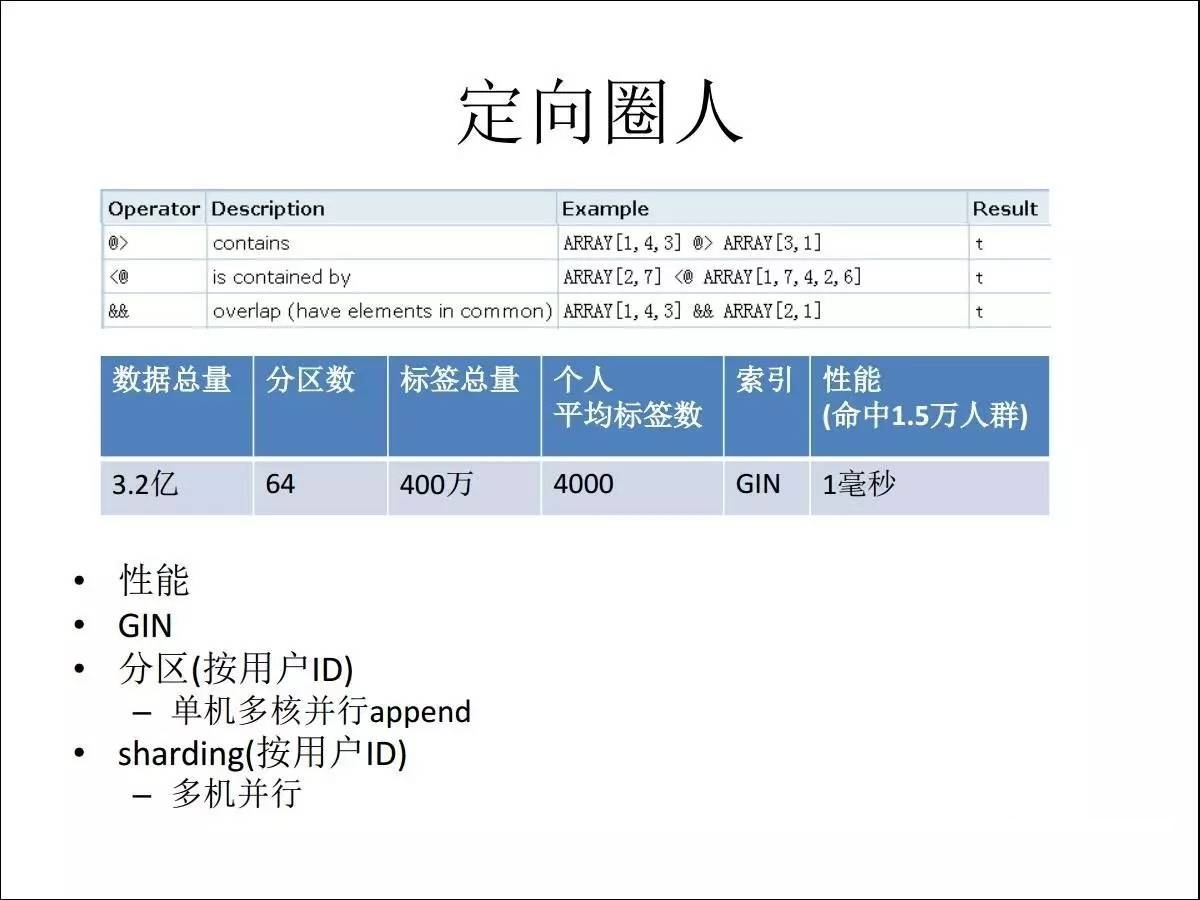
ЕБгУЛЇСПЪЧ 3.2 вкМгЩЯ 64 ИіЗжЧјЪ§ЃЌБъЧЉзмСПЪЧ 400 ЭђЃЌИіШЫЦНОљБъЧЉЪ§ЪЧ4ЧЇИіЃЌдквЛКСУыОЭПЩвдЭкГівЛЭђЖрЕФШЫШКГіРДЃЌЪЕЯжСЫОЋзМЕФЪЕЪБгЊЯњЁЃДгСПМЖРДЫуЃЌШчЙћВЛгУЪ§зщРраЭЕФЛАвЊДцЖрЩйЬѕМЧТМЃП
УПИіШЫЖМгаЫФЧЇИіБъЧЉЃЌШчЙћВЛгУЪ§зщЕФЛАЃЌУПвЛИіОЭЪЧвЛЬѕМЧТМЃЌетбљГЫ3.2вкЃЌЯрЕБгкЪЧ1.2ЭђвкЕФЪ§зжЃЌЖјЪЙгУвЛЬЈжїЛњОЭПЩвдНтОіЁЃЪЙгУ
PostgreSQL ЕФЪ§зщКЭGINЫїв§ЃЌЧЩУюЕФНтОіСЫвЕЮёЕФЮЪЬтЁЃ
3ЁЂTOB ЪЕЪБЛЯё
ЮвУЧдйПД TOB ЪЕЪБЛЯёЃЌетЪЧАЂРядЦЖдЭтЕФвЛИіЯюФПЃЌTOB ЕФЪЕЪБЛЯёЕФвЕЮёЁЃ
3.1вЕЮёНщЩм

ИњЧАУцвЛИіР§згЯюФПЗЧГЃРрЫЦЃЌВюБ№ОЭдкгк TAG Ъ§ВЛвЛбљЁЃЧАУцНВЕФР§згTAGЪ§га400ЭђИіЃЌдкетИіЯЕЭГРяУцЪЧ1ЭђИі
TAG РДУшЪі TOB ЕФгУЛЇЃЌОЭКУЯёЮвИјФуПДЯрвЛбљЃЌЬљвЛЭђИі TAGЃЌЛљБОЩЯАбЬиеїУшЪіЕУЧхГўСЫЁЃ

ЕБГѕЩшМЦ1ЭђИі TAGЃЌЛљБОЩЯвЛЧЇЖрИіСавбОЪЧМЋЯоСЫЃЌвђЮЊвЛЬѕМЧТМЪЧВЛФмПчЪ§ОнПщЕФЃЌЫљвдЖдгкетжжГЌЙ§СНЧЇИізжЖЮЕФБэЃЌвЊУДОЭЪЧВ№БэЃЌИљОнIDШЅСЊКЯЦ№РДЁЃ
вђДЫвЛеХБэПЯЖЈЪЧИуВЛЖЈЕФЃЌЫбЫїЕФЬѕМўЪЧАДееАќКЌФФаЉ TAG ВЂЧвВЛАќКЌФФаЉ TAGЃЌетжжБШНЯРрЫЦгкЭкОђаЭЕФВйзїЃЌдРДЪЙгУСЫ8ЬЈЮяРэЛњЃЌ1вкИігУЛЇЃЌ1ЭђЬЈ
TAG ШЅНтОіетИіЮЪЬтЁЃ
3.2 ШІШЫ-вЕЮёжИБъ

ЫМПМвЛЯТНЋРДЕФЩшМЦЃЌетИігУЛЇШчЙћжЛЪЧЛЛвЛИіЦНЬЈПЩФмУЛЪВУДаЫШЄЃЌЫћЪЧЫЕНЋРДвЊгУЛЇСПМЖдйеЧвЛБЖЃЌЭЌЪБЯЃЭћбЙЫѕГЩБОЃЌвђЮЊгУСЫКмЖрГЩБОЁЃ
TAG Ъ§га1ЭђЃЌУПИі TAG вЛСаЃЌШчЙћДцвЛеХБэПЯЖЈЪЧИуВЛЖЈЕФЃЌгУЛЇЙцФЃМг TAG ЪЧвЛЭђвк user
tagsЃЌЬљБъЧЉЁЂЩОГ§БъЧЉЁЂИќаТБъЧЉЖМвЊЧѓЗжжгМЖЕФбгГйЁЃ

гЩгкЪЧ TOB ЕФЯЕЭГЃЌВщбЏЕФВЂЗЂвЊЧѓ200ЕН300ЃЌгУЛЇИљОн TAG зжЖЮВщГіАќКЌЁЂВЛАќКЌЁЂЛђепЖрИізжЖЮЕФзщКЯЁЃзюКѓОЭЪЧЯьгІЪБМфЕФвЊЧѓЃЌетжжВщбЏЯьгІЪБМфвЊКСУыМЖЁЃ
3.3 ЗНАИНщЩм

ЮвУЧРДЯыдѕУДЩшМЦетИіБэНсЙЙЃЌвђЮЊвЛеХБэЪЧДцВЛЯТвЛЭђИізжЖЮЕФЃЌШчЙћУПИі TAG вЛИізжЖЮЕФЛАЃЌФувЊаДКмЖрЕФ
and Ињ orЃЌЛљБОЩЯзіВЛЕНКСУыЃЌ80ЬЈЛњЦївВзіВЛЕНЃЌетОЭЪЧЮЪЬтЁЃЪЧВЛЪЧУПИізжЖЮЖМвЊНЈЫїв§ЃЌЕкЖўЪЧГЌПэБэдѕУДНтОіЃЌетЖМЪЧГЁОАвЊУцСйЕФЮЪЬтЁЃ

ЮвУЧРДПДНтОіЗНАИЕФгХШБЕуЁЃЪзЯШЪЧгУЪ§зщДцЃЌвЛИіЪ§зщзюДѓГЄЖШЪЧ1ИіGЃЌШчЙћЮвгУ int4 зіБъЧЉЕФЛАПЩвдДц
2.6 вкИі TAGЃЌШЛКѓЛЙПЩвдНјааЗжЧјЁЃ
query ЕФаДЗЈвВМђЕЅЃЌдРДвЊАќКЌФГвЛаЉ TAG ЕФЪ§зщГіРДЃЌАќКЌСНИіЕФОЭПЩвдЁЃжИЖЈ TAG жЎвЛЕФЛАОЭЪЧПДгаУЛгаЯрНЛЃЌзюКѓЪЧВЛАќКЌЃЌЪЧУЛгаАьЗЈжЇГжЫїв§ЕФЃЌетЪЧЗНАИвЛЁЃ

дйПДЗНАИЖўЃЌАб TAG БфГЩ BTIЃЌЕЋЪЧгаИіЮЪЬтЪЧЮвВЛФмЖдУПИі BTI НЈЫїв§ЃЌБШШчЫЕвЊЧѓЕк10Иі
BTI ЕШгк1ЕФЃЌАбФуетИігУЛЇРЬГіРДЃЌзюДѓЕФШБЕуОЭЪЧУЛЗЈНЈЫїв§ЃЌЕЋЪЧЪ§ОнСПЯТНЕКмЖрЃЌвђЮЊвЛИі BTI
КЭвЛИіЪ§зщзжНкВюСЫМИЪЎБЖЁЃетИіЗНАИвЊУДЭЈЙ§ CPU ЖрКЫВЂааВтЫуЃЌвЛИі32КЫЕФЛњЦїдкет11ЬѕМЧТМРяЫбвЛБщвВвЊЛЈЪЎМИУыЁЃ

ЗНАИШ§ЪЙгУСЫАЂРядЦ RDS PostgreSQL ЬсЙЉЕФ varbitx РЉеЙЁЃеыЖдЗНАИ2зівЛДЮЗзЊЃЌвЛИі
TAG вЛЬѕМЧТМЃЌУПИігУЛЇвЛИі BTIЃЌЫќЕФПеМфИњЕкЖўЗНАИЪЧвЛбљЕФЃЌБШЕквЛИіЫѕаЁВюВЛЖр80БЖЕФбљзгЁЃ
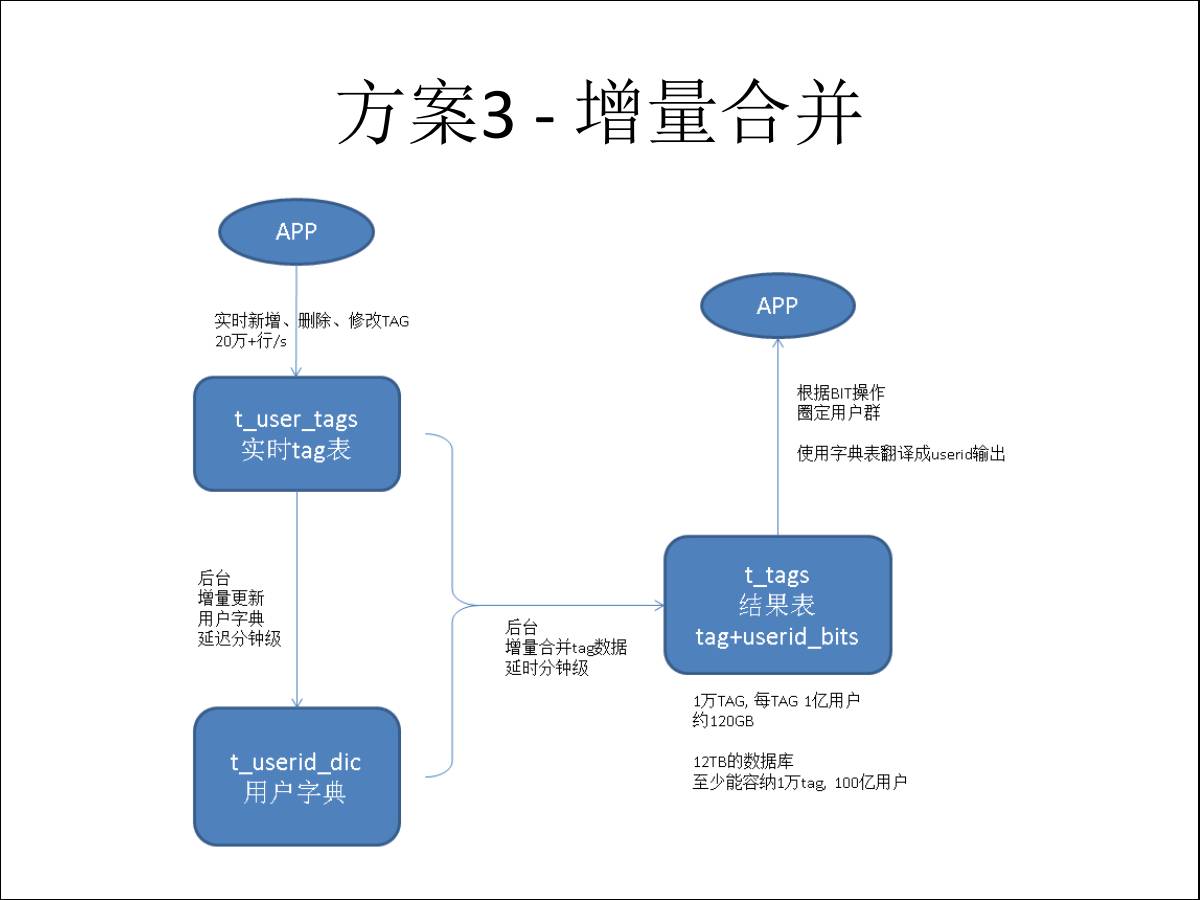
ЮвУЧдкЪЙгУетИіЗНАИжЎКѓвЊШЅРЬвЛХњгУЛЇГіРДЃЌЪЧМЧТМгыМЧТМжЎМфЕФдЫЫуЃЌвђЮЊЮвжЛга1ЭђЬѕМЧТМЃЌЕБШЛНЈЫїв§ЪЧзюКУЕФЃЌФужЛвЊдк1ЭђЬѕМЧТМЩЯНЈЫїв§ЁЃ

зюжеЮвУЧЕФЗНАИЪЧбЁдёСЫЗНАИШ§ЃЌетЪЧЮвУЧИјЫћУЧЩшМЦЕФЪ§ОнКЯВЂЙ§ГЬЃЌзюжежЇГжСЫЫћЕФгІгУГЁОАЃЌЭЈЙ§вЛЬЈЛњЦїОЭНтОіСЫдРДАЫЬЈЛњЦїЮоЗЈНтОіЕФЮЪЬтЁЃ
3.4 ЗНАИПеМфЦРЙР

етЪЧЗНАИЕФЖдБШЃЌЪзЯШЪЧПеМфЩЯЕФЖдБШЁЃШчЙћЪЙгУЗНАИ1ЃЌашвЊ8ИіTЕФПеМфЃЌШчЙћЪЧЗНАИ2Лђеп3жЛвЊ100ИіGПеМфОЭПЩвдЁЃ

Г§СЫЖдБШПеМфЛЙвЊЖдБШВщбЏаЇТЪЃЌЕквЛИіЗНАИЖдПеМфвЊЧѓКмЖрЃЌЕЋЪЧВњЩњЕФаЇТЪвВВЛЕЭЃЌАќРЈВхШыИќаТЁЂВщбЏЯьгІЖМЪЧТњзуПЭЛЇашЧѓЕФЃЌжЛЪЧеМгУПеМфБШНЯЖрЁЃ

ЖдгкЗНАИ2ЃЌЮвЕУгУ BIT дЫааЁЃ

ЗНАИ3ЃЌУПИіжИБъЖМЪЧТњзуашЧѓЃЌАќРЈЪ§ОнЕФКЯВЂаДШыЃЌВщбЏВЂЗЂЪЧГЌЙ§СЫгУЛЇзюГѕдЄМЦЕФвЊЧѓЁЃ
3.5 ЪЕЪЉЧАКѓЖдБШ
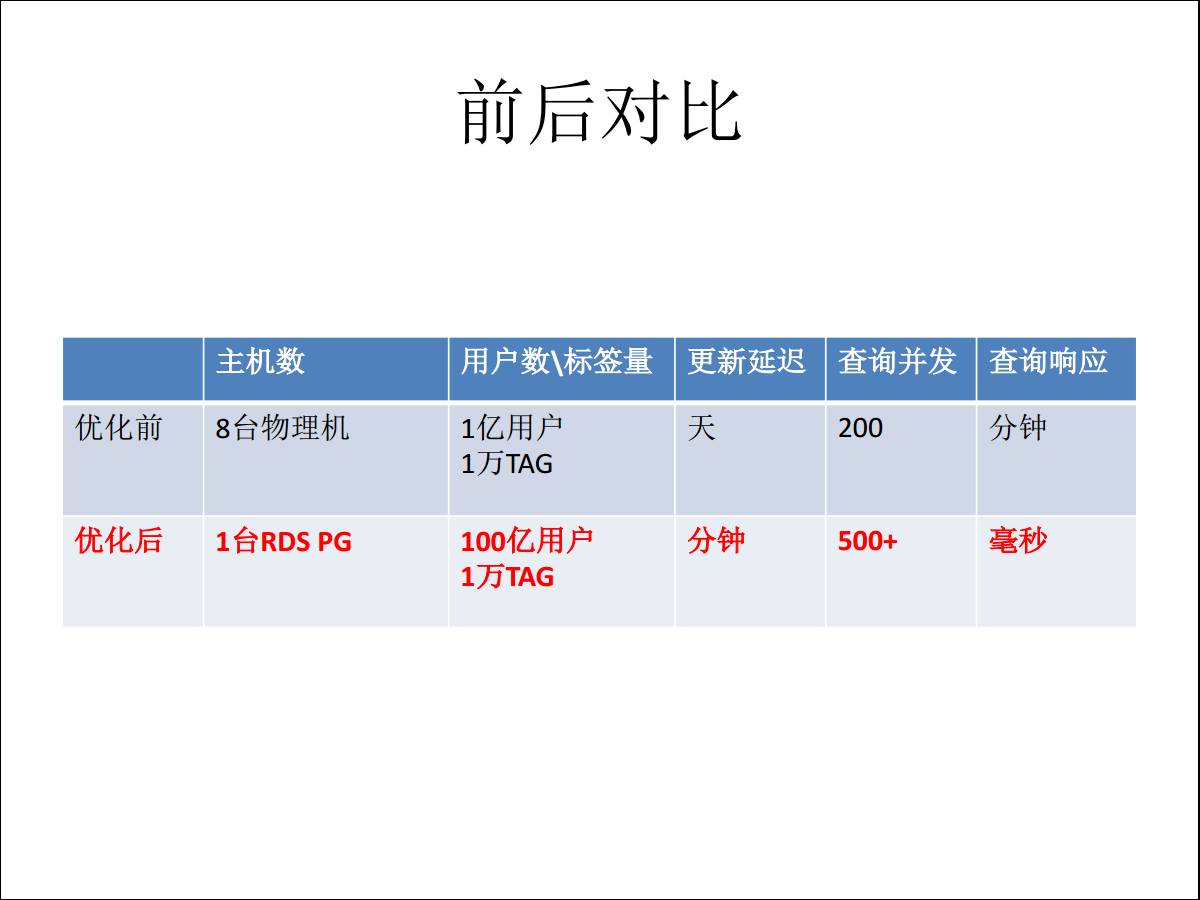
гХЛЏЧАгУСЫ8ЬЈЮяРэЛњЃЌгУЛЇЬхСПЗСЫвЛИіСПМЖжЎКѓЃЌдРДЕФИќаТЪЧЬьМЖБ№ЃЌЯждкЪЧЗжжгМЖБ№ЁЃВщбЏВЂЗЂвВЪЧЗСЫвЛБЖЃЌЯьгІвВДгдРДЕФЗжжгМЖНЕЕНКСУыМЖЁЃ

ЮДРДдкФкКЫВуЕФгХЛЏЃЌШчЙћжЛИќаТСЫвЛаЉгУЛЇЕФ TAGЃЌНЋРДИќаТФГвЛаЁПщЪ§ОнЕФЪБКђЃЌВЛгУИќаТЯждкећИіДѓЕФвЛИі
BITЃЌНЋРДЪЧПЩвдзіЕНПьНнИќаТЁЃ
4ЁЂШЮвтзжЖЮзщКЯ
дйЗжЯэСНИіГЁОАЃЌвЛИіЪЧШЮвтзжЖЮЕФзщКЯВщбЏЃЌвВЪЧвЛИіБШНЯГЃМћЕФГЁОАЁЃ
4.1 вЕЮёНщЩм
дкфЏРРвЛаЉвГУцЕФЪБКђгаКмЖрбЁЯюЃЌФуПЩвдЙДЪЧВЛЪЧдљЫЭЭЫЛѕдЫЗбЯеЛђепвВПЩвдЙДбЁЪЧЗёвЊЖўЪжЛђепЬьУЈЃЌЖдгУЛЇЪЧгаКмЖрбЁдёЕФЃЌЖјЖдгкЩшМЦШЫдБРДЫЕОЭЕУПМТЧЃЌФуЕФУПвЛИібЁдёЖдгІЪ§ОнПтРяЖМЪЧвЛИізжЖЮЃЌЪЧВЛЪЧУПИізжЖЮЖМвЊНЈЫїв§ЃЌШчЙћЮвИјгУЛЇ60ИібЁдёЃЌЪЧВЛЪЧЖМвЊНЈЫїв§ЁЃ

УПИізжЖЮЖМНЈЫїв§ЛсДјРДвЛЖЈЕФгАЯьЃЌдкИќаТЁЂВхШыЕФЪБКђЃЌЫїв§ЕФБфИќЛсв§Шы RTЃЌБШШчУПИќаТвЛДЮЫїв§ЃЌдіМг
0.1 КСУыЕФ RTЃЌНЈЪЎИіЫїв§ЕФЪБКђОЭБфГЩвЛИіКСУыЃЌетЪЧЗЧГЃбЯжиЕФЮЪЬтЁЃЕЋЪЧвЕЮёгжвЊЧѓУПИізжЖЮЖМвЊЙДбЁЃЌдѕУДПьЫйЯьгІИјгУЛЇЃЌетИіЮЪЬтЪЧКмУЌЖмЕФЁЃ
НтОіЗНАИЃКGINзщКЯЫїв§-ШЮвтзщКЯВщбЏ
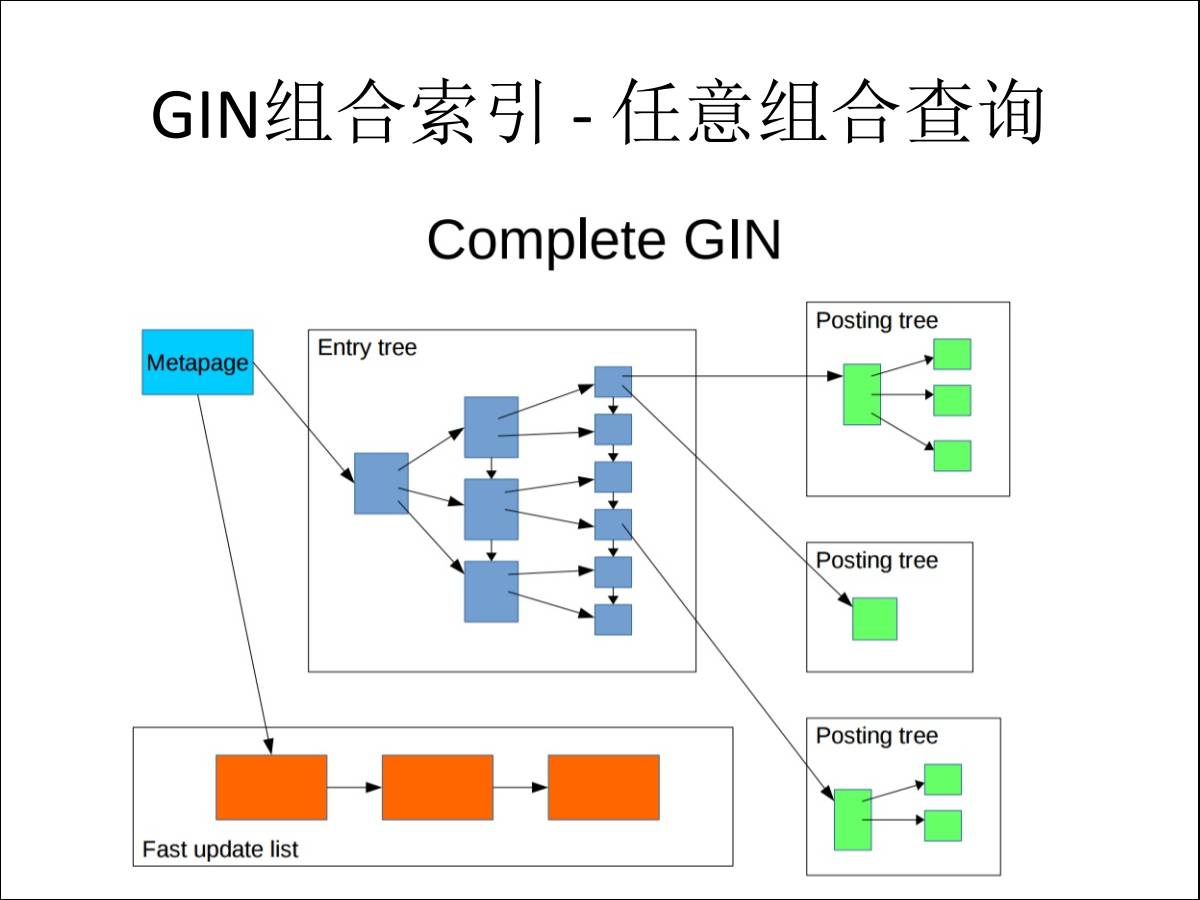
ИУдкФФИізжЖЮНЈЫїв§ЃЌЛЙЪЧгУЕЙХХЫїв§ЃЌГ§СЫЕЙХХзїгУЃЌЛЙПЩвдЮЊУПИізжЖЮЩЯУцЖМНЈЗћКЯЕЙХХЫїв§ЃЌДяЕНЪВУДаЇЙћФиЃПБШШчЫЕга6ИіСаЪЧИјгУЛЇПЩвдбЁдёЕФЃЌЮвдРДПЩФмвЊНЈ6ИізжЖЮЃЌвЛИіНзВуЕФШЮвтзщКЯЕФЫїв§ВХФмДяЕНаЇЙћЁЃ
4.2 ЪЕЪЉКѓЕФадФмжИБъ
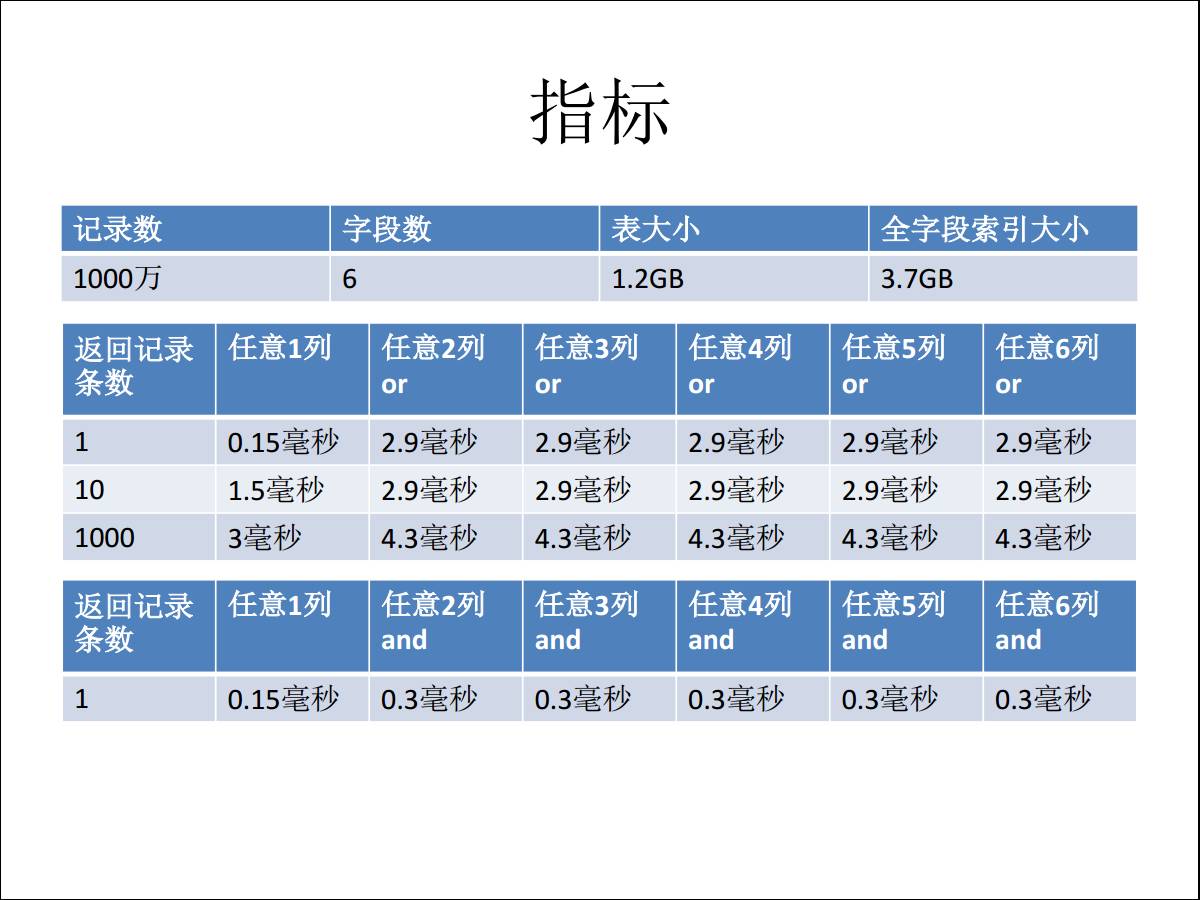
ЕЋЪЧЯждкНЈвЛИіЫїв§ЃЌПДШЮвтСљИіСаЃЌШЮвтСазі OR Лђеп AND ЕФВщбЏДяЕНЪВУДаЇЙћЃППЩвдПДЯьгІЪБМфЃЌШЮвт
AND ЖМПЩвдДяЕНСуЕуМИИіКСУыЃЌвВОЭЪЧдкетбљЕФГЁОАЯТЃЌПЩвдЭЈЙ§вЛИіетбљЕФЫїв§НтОіФудРДИљБООЭВЛжЊЕРНЈЖрЩйИіЫїв§ВХФмНтОіЕФЮЪЬтЁЃШчЙћДѓМвЯыСЫНтGINЫїв§ЕФФкВПдРэЃЌПЩвдВЮПМЮвЕФ
GITHUB (https://github.com/digoal/blog/blob/master/README.md)ЁЃЁЃ
5ЁЂШЮвтзжЖЮФЃК§ЦЅХф
5.1 вЕЮёНщЩм
дйв§ШыЯТУцвЛИігІгУГЁОАЃЌЪЧЮвУЧЕФПЭЛЇЙиЯЕЯЕЭГЃЌЮвУЧдкетИіЯЕЭГРяЪЧЮЊгУЛЇЬсЙЉСЫРрЫЦгкФуОѕЕУЫбЫїв§ЧцдкФмИЩЕФЪТЧщЁЃ

БШШчгУЛЇЬсЙЉвЛаЉЙиМќзжРДЫбЫїЃЌЖјЧвЪЧШЮвтНзЖЮЕФЃЌжЛвЊЦЅХфетИіЙиМќзжОЭЗДРЁИјФуЃЌдРДЮвИљБОВЛжЊЕРдѕУДНЈЫїв§ЁЃБШШчЪЧ
URL ЕижЗЃЌШчЙћНЈШЋЮФМьЫїИљБООЭУЛгУЃЌвђЮЊШЋЮФМьЫїРяУцЪЧЕУЗжДЪЕФЃЌЕУгазжЕфЃЌЖјURLЪЧУЛгаЪВУДвтвхЕФЃЌПЩФмШЁЕФУћзжИљБОУЛЗЈЗжДЪЗжГіРДЃЌЫљвдМьЫїНтОіВЛСЫЁЃ
ЛЙгавЛаЉЙЋЫОУћГЦЃЌЙЋЫОЕФУћГЦПЩФмВЛЪЧвЛИіГЃМћДЪЃЌЭљЭљШЋЮФМьЫїДЪПтжаУЛгаЃЌУЛЗЈНјааЗжДЪЁЃвђДЫШЋЮФМьЫїЮоЗЈНтОіФЃК§ВщбЏЕФЮЪЬтЁЃЫбЫїв§ЧцФмВЛФметИіЮЪЬтФиЃП
ПЩвдНтОіЃЌЕЋЪЧЫќЕУИњЫбЫїв§ЧцЭЌВНЪ§ОнЃЌЛЙгаПМТЧЪ§ОнПтКЭЫбЫїв§Ц№ЕФвЛжТадЮЪЬтЁЃЖюЭтЕФВњЩњЕФЗбгУЛЙгаЮЌЛЄГЩБОЕФЮЪЬтЃЌвђЮЊФуЛЙЕУЮЌЛЄвЛИіЫбЫїв§ЧцЃЌАќРЈЪ§ОнЕФЭЌВНЃЌЛЙгаИќаТЃЌАќРЈЪ§ОнЕФЙ§ЦкЕШЕШЁЃ
5.2 pg_trgm НтОіЗНАИ

МШШЛетСНИіЖМНтОіВЛСЫЃЌгаЪВУДЗНЗЈФмНтОіетИіЮЪЬтЃПдк PostgreSQL РяУцгавЛИіНазі PGTRGM
ЕФаЁзщМўЃЌПЩвдАяФуЕФДЪВ№ГЩСЌајвЛИівЛИіЕФзжЖЮЃЌШЅзіЦЅХфЃЌПЩвдДяЕНЗЧГЃИпЕФВщбЏаЇТЪЁЃзюжеДяЕНЕФаЇЙћЃЌЪ§ОнСПЪЧвкМЖБ№ЃЌгУЛЇШЮвтЕФФЃК§ЫбЫїЪЧПЩвдДяЕНКСУыМЖБ№ЕФЯьгІЁЃ |





