| 编辑推荐: |
本文将详细剖析 FreeWheel Biz-UI 团队从 0 到 1 构建和改进全链路分布式追踪系统的过程。
本文来自于infoq,由火龙果软件Anna编辑、推荐。 |
|
Biz-UI 团队在核心业务系统的开发过程中,将具有共性的功能模块抽象出来,逐渐完成了中台的构建,为业务逻辑提供了强有力的基础组件支撑。其中分布式追踪系统作为一个重要的组成部分,为监控服务之间的调用、定位和调试线上问题,提供了有力的支撑。
微服务-捉虫记
小志所在的技术部门刚刚对臃肿的单体应用完成了拆解,推行微服务理念,将之前杂糅得不可开交的代码按业务模块拆分成一个一个的微服务。随着项目的推动,大家确实感受到微服务带来的收益,拆解完以后对单个微服务维护起来也更加方便。但与此同时也带来了一些之前未曾遇到的问题......
一阵急促的手机铃声打断了小志的思绪,看着熟悉的来电号码,小志心想真是怕什么来什么,新上的服务凌晨又出问题了。
“喂,小志啊,线上报警了,挺紧急的,你赶紧看一下吧,一会线上聊。”
熟练地翻开报警邮件,处理这类问题对小志来说已经轻车熟路。详细分析了一下报警内容,小志断定是下游服务出问题导致的报警。
“老李,我是小志,我们这边刚刚出来一个报警,挺严重的,刚看了一下系统日志,是在调你们订单服务的时候出错了,你帮看一下吧,我一会把日志发你钉钉。”
老李经过排查,发现是上游服务的问题,于是抓紧联系老钱。“老钱啊,还没睡呢吧?刚刚小志那边出问题,影响了不少客户。查日志发现是订单这边报错了,我看了一下订单服务的日志,是你们那边的库存服务报了不少
500,你赶紧起来看一下吧。”
屏幕前小志、老李、老钱正在热火朝天地捉虫找 bug.
微服务,作为一个近几年非常火热的话题,切切实实解决了很多单体应用的痛点,但与此同时也带来了一些新的痛点。
FreeWheel 核心业务部门结合自身的实际情况,以微服务的方式对之前的单一应用做了拆分。同时,为了避免上面故事里的情况发生,我们引入了分布式追踪系统用来解决【如何在微服务系统中快速定位问题?】、【如何观察复杂的调用链、分析调用的网络结构?】等等问题。
分布式追踪系统
分布式追踪系统(Distributed Tracing System)可以用来解决微服务系统中的常问题定位、bug
追踪、网络结构分析等问题。该系统的数据模型最早由Google’s Dapper 论文提出,主要包含如下几个部分:
Trace: 用来描述分布式系统中一个完整的调用链,每一个 Trace 会有一个独有的 Trace
ID。
Span: 分布式系统中的一个小的调用单元,可以是一个微服务中的 service, 也可以是一次方法调用,甚至一个简单的代码块调用。Span
可以包含起始时间戳、log 等信息。每一个 Span 会有一个独有的 Span ID.
Span Context: 包含额外 Trace 信息的数据结构,span context 可以包含
Trace ID、Span ID, 以及其他任何需要向下游 service 传递的 trace 信息。
在这基础上,社区为了实现各个编程语言和各种框架的接口统一,发展出了OpenTracing Specification
以及 OpenTracing API。后来业界也相继推出了几款比较成熟的产品,如 Zipkin、Jaeger、LightStep、DataDog
等。
分布式追踪系统是如何解决跨服务调用时的问题定位的呢?对于一次客户调用,分布式追踪系统会在请求的入口处生成一个
TraceID,用这个 TraceID 把客户请求进入每个微服务中的调用日志串联起来,形成一个时序图。如下图所示,假设
A 的两端表示一次客户调用的开始和结束,中间会经过类似 B、 C、D、 E 等后端服务。此时如果 E
出问题,就可以很快速地定位到,而不用同时让 A、B、C、D 都参与进来查问题。
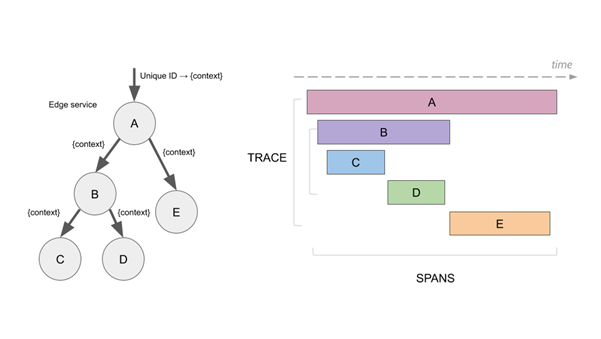
(图片来源:www.jaegertracing.io)
Biz-UI 分布式追踪系统实践
技术选型
在 FreeWheel 核心业务系统微服务搭建过程中,我们深度调研了现有的分布式追踪系统解决方案,针对其中几个比较重要的选型指标做了深度的讨论。
| 指标
|
描述 |
| 是否支持Go Client?
|
FreeWheel核心业务系统大量用到Go作为开发语言,这就使得我们更倾向于提供便利的Go
客户端的解决方案。 |
是否支持gRPC?
|
各个业务模块之间主要通过gRPC进行通讯,是否能支持gRPC协议是一个重要的评价指标。 |
Trace数据如何存储?
|
业务代码接入Trace以后必然会产生大量的数据,这些Trace数据如何存储?如何分析?如何简洁清晰地将Trace信息展示给开发人员?这也是选型过程中需要考虑的一个重要指标。 |
| 扩展性 |
随着基础架构的升级改造,不断有新的组件被引入。评估解决方案是否支持诸如Istio等组件也将是需要考虑的问题。 |
基于上面几个指标,我们对市面上主流的开源项目进行筛选,包括 Jeager、Zipkin
等,考虑到市场占有率、项目成熟度、项目契合度,我们最终选择了同为 Golang 开发的 Jaeger。Jeager
Tracing 框架下主要包含三大模块:TracingAgent, Tracing Collector
和 Tracing Query。
| 服务
|
描述 |
| Agent |
作为宿主机上的一个daemon进程用来监听从服务端发出的trace数据包,然后批量地发往Collector。Agent会被部署到所有的宿主机上,同时也实现了对于Collector的路由和负载均衡等功能,以免所有请求都发到同一个Collector
实体上。 |
Collecto
|
Collector用来收集从Agent发来的trace数据包,并进行一系列处理,包括trace数据包校验、index、格式转换等,最终存储到对应的数据仓库。Collector可以对接像Cassandra、ElasticSearch这类的存储服务。在Jaeger后续的版本里也加入了对Kafka的支持,同时提供了一个Injester(也就是一个Kafka
consumer)用来消费Kafka中的数据。 |
| Query UI |
Query UI提供可视化的查询服务,从数据仓库中检索查询对应的Trace
ID,并进行可视化的加工展示。 |
| Spark Job |
Query UI不仅可以展示单个trace中各个Span的从属关系与时序关系,还能提供了展示各微服务之间调用关系的功能。Spark
Job从ElasticSearch读取原始的数据,并以离线的方式进行流处理,分析出服务之间的调用关系,调用次数等,生成的调用关系数据可以由Quey
UI进行展示。 |
| 客户端 |
用来与业务代码进行集成。 |
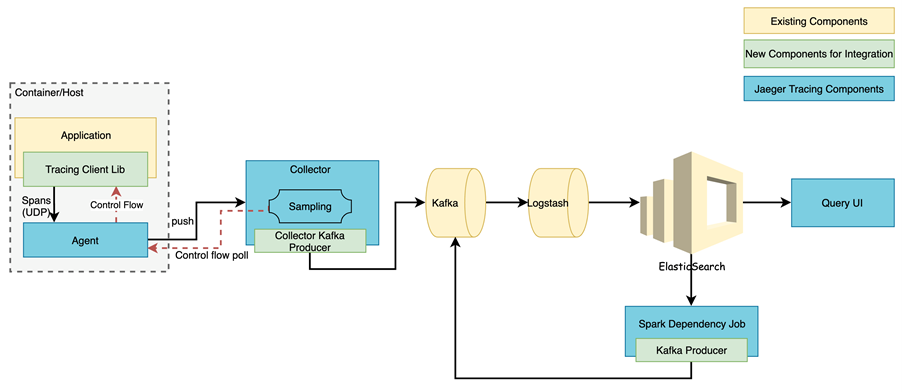
整体的架构如下图所示:

(图片来源:www.jaegertracing.io)
落地实践与优化改造
新系统实施的第一步往往是分析现有技术环境,目的是尽可能地复用已有的功能、模块,运维环境等。这样能大大减少后续的维护、运维等成本。
FreeWheel 核心业务平台现有的基础环境包括如下几点:
首先是现有微服务对外提供的接口协议多种多样,例如 gRPC、HTTP(基于 gRPC-Gateway)、HTTP(裸
HTTP) 等。
FreeWheel 现有一套 ELK+Kafka 集群用来收集和分析系统日志。
微服务的基础运行环境基于 Kubernetes+Istio,除了少许的特殊服务运行在物理机上以外,绝大部分业务服务都运行在
K8s 集群(AWS EKS)中,也就是说每个服务的实例都作为集群中的一个 pod 在运行。
基于以上背景,我们设计了 Tracing 系统实施方案,并对部分模块进行了升级改造。
首先,由于各个微服务对外提供的接口也不尽统一,现有的接口包括 gRPC、gRPC-Gateway、HTTP,甚至
WebSocket。我们在 Jeager-client 基础上做了一层封装,实现了一个 Tracing
client Lib,该 lib 可以针对不同的通讯协议对流量进行劫持,并将 Trace 信息注入到请求中。还扩展性地加入了过滤器(过滤给定特征的流量)、
TraceID 生成、TraceID 提取,与 Zipkin Header 兼容等功能。这部分会随着平台的不断扩展和改造进行持续的更新和维护。
另外,为了充分利用公司现有的 ElasticSearch 集群,我们决定用 ElasticSearch
作为追踪系统的后端存储。由于使用场景为写多读少,为了保护 ElasticSerach,我们决定用 Kafka
作为缓冲,即对 Collecor 进行扩展,将数据进行处理并转换成 ElasticSearch 可读的
json 格式写入 Kafka, 再通过 logstash 消费写入 ElasticSearch 中。
此外,对于 Spark dependency Job,同样需要将数据转换为对应的 Json 格式写入
Kafka,最终存储到 ElasticSearch。这里对 Spark Dependency Job
的输出部分做了扩展,让其支持向 Kafka 中导入数据。最后,由于微服务系统内部部署环境的差异,我们提供了兼容
K8s sidecar, K8s Daemonset, On-perm daeom process
等部署方式。
新设计的架构如下图所示:
数据采集层
中间件
对于基于 Golang 开发的微服务,Trace 信息在服务内部传播主要依赖 context.Context。FreeWheel
核心业务系统中一般来讲支持两种通讯协议:HTTP and GRPC,其中 HTTP 接口主要依赖 GRPC-Gateway
自动生成。当然也有一部分服务不涉及 GRPC, 直接对外暴露 HTTP 接口。这里 HTTP 主要面向的调用方是
OpenAPI 或者前端 UI。同时,服务与服务之间一般采用 GRPC 方式通讯。对于这类场景,Tracinglib
提供了必要的组件供业务微服务使用。其传播过程如下图所示:
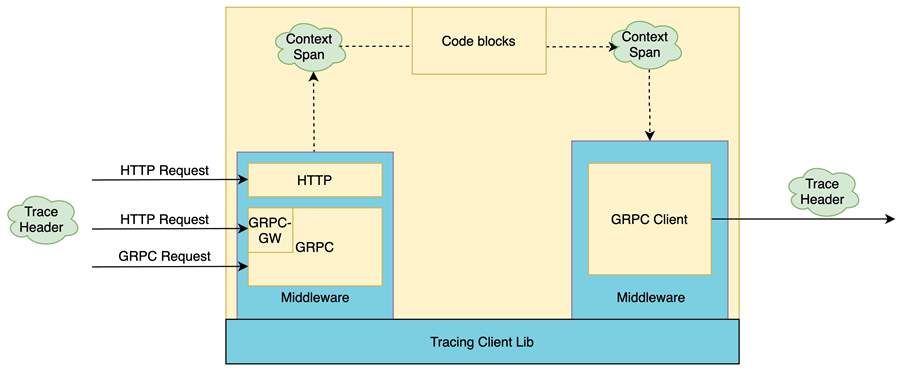
针对入口流量,Tracing Client Lib 封装了 HTTP 中间件、 GRPC 中间件,以及与
GRPC-Gateway 这一层的兼容。针对出口流量,Tracing Client Lib 封装了
GRPC-Client 中间件。这里的“封装”不单单指对 Jaeger client lib 提供方法的简单
wrapper,还包括诸如 Tracing 状态监测、请求过滤等功能。比较典型的像 "/check_alive",
"/metrics"这类没有必要 trace 的请求可以通过请求过滤的功能过滤掉从而不记录
Trace。
Istio 集成
了解 Istio 的同学应该知道,Istio 本身支持 Jaeger Tracing 集成。对于跨服务的请求,Istio
可以劫持诸如 GRPC/HTTP 等类型的流量,生成对应的 Trace 信息。因此如果能将业务代码中的
Trace 信息与 Istio 进行集成,就能够监控到整个调用网络与业务内部 Trace 的完整信息,方便查看
Istio sidecar 到服务这个调用过程的网络情况。
问题在于,Istio 集成 Tracing 时采取了 Zipkin B3 Header 标准,其格式如下:
X-B3-TraceId:
{TraceID}
X-B3-ParentSpanId: {ParentSpanID}
X-B3-SpanId: {SpanID}
X-B3-Sampled: {SampleFlag} |
而 FreeWheel 核心业务系统内部所采用的 TracerHeader 格式为:
| FW-Trace-ID:
{TraceID}:{SpanID}:{ParentSpanID}:{SampleFlag} |
并且 FW Trace Header 被广泛地应用在业务代码中,集成了诸如
log, change_history 等服务,一时间难以被完全替换。针对这个问题,我们重写了 Jaeger
Client 中的将 Injector 和 Extractor,其接口定义如下:
// Injector接口的主要作用是将Trace
Header数据按照既定的逻辑插入到上下文中。
type Injector interface {
// Inject 将 `SpanContext` and 注入到 `carrier`中,这里carrier主要是指上下文Context
//
Inject(ctx SpanContext, carrier interface{}) error
}
// Extractor接口的主要作用是将上下文中的Trace数据抽取出来
type Extractor interface {
// Extract 将上下文作为carrier, 提取其header中的Trace信息,并返回一个SpanContext对象。
Extract(carrier interface{}) (SpanContext, error)
} |
新实现的 Injector 和 Extractor 同时兼容 B3
Header 和 Freewheel Trace Header。服务接收到请求时会优先查看有没有 B3
Header,在生成新 Span 的时候同时插入 FreeWheel Trace Header。即
FreeWheel Trace Header 继续在服务内部使用,跨服务之间的调用以 B3 Header
为主。
X-B3-TraceId:
{TraceID}
X-B3-ParentSpanId: {ParentSpanID}
X-B3-SpanId: {SpanID}
X-B3-Sampled: {SampleFlag}
FW-Trace-ID: {TraceID}:{SpanID}:{ParentSpanID}:{SampleFlag} |
数据缓冲与中转层
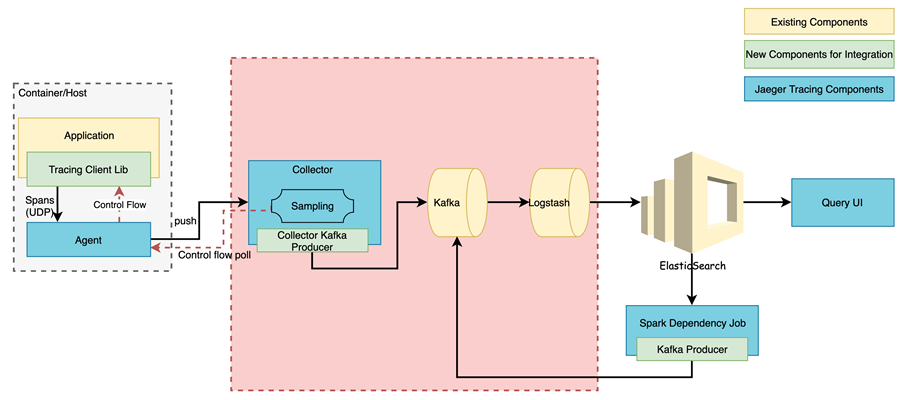
上文提到数据存储选用 ElasticSearch, 数据的采集与存储是一个典型的写多读少的业务场景。对这类场景,我们引入
Kafka 作为数据的缓冲与中转层。基于这个思路我们对 Collector 进行了改造,加入了 Collector
Kafka Producer 组件,在 Collector 上将 span 信息转为 json 发给
Kafka,然后由 Logstash 作为 Consumer 存储到 ElasticSearch。对于
Trace 信息,ElasticSearch 存储主要分为两大部分:服务/操作索引和 Span 索引。服务/操作索引主要用来为
query ui 提供快速检索服务(Service Name)和操作(Operation Name),
结构如下:
//索引结构
{
"serviceName": "v3_adaptor",
"operationName": "HTTP GET"
} |
Span 结构体由 Tracing 客户端生成,主要一下几大部分:
基础 trace 信息,如 traceID, spanID, parentID, operationName,duration。
Tags,这部分主要包含业务逻辑相关的信息如 request method, url, response
code 等。
References,主要用来表示 Span 的父子从属关系。
Process,服务的基本信息。
Logs,用于给业务代码扩展使用。
//Span body
{
"traceID": "5082be69746ed84a",
"spanID": "5082be69746ed84a",
"operationName": "HTTP GET",
"startTime": ...,
"duration":
616,
"references": [
{
"refType": "CHILD_OF",
"spanID": "14a9e000a96a2671",
"traceID": "259f404f8409a4d7"
}
],
"tags": [
{
"key": "http.url",
"type": "string",
"value":
"/services/v3/**.xml"
},
{
"key": "http.status_code",
"type": "int64",
"value":
"500"
},
//...
],
"logs": [],
"process":
{
"serviceName": "your_service_name",
"tags": [
{
"key": "hostname",
"type": "string",
"value":
"xx-mac"
},
//...
]
}
} |
存储与计算层
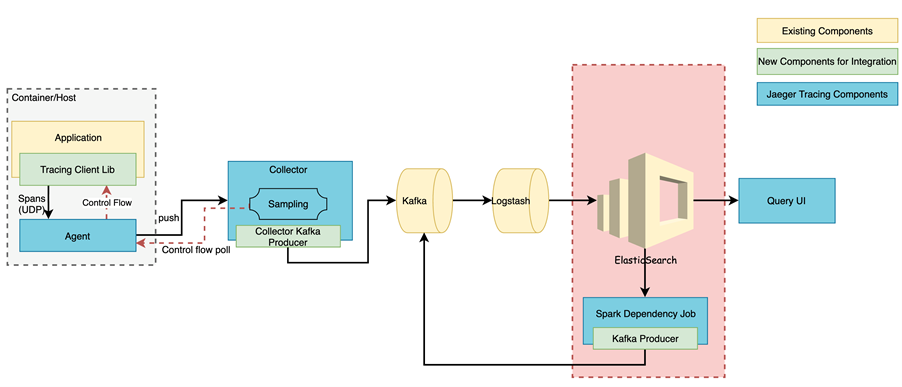
这一层主要用于对 Trace 数据进行持久化和离线分析。利用 ElasticSearch 会对数据进行分片,分
index 的存储,防止历史数据丢失,方便对历史问题进行回溯。不过既然提到持久化就难免要考虑数据规模的问题,持续大量的历史数据写入到
ElasticSeach 会不断增加其负担,而且对于过于久远的历史数据,被检索到的频率也相对较小。这里我们采取定期归档的策略,对于超过
30 天的数据进行归档,转存到 ES 之外以备不时之需。ElasticSearch 只对相对较“热”的数据提供检索服务。
离线分析主要用于对 EalsticSearch 中的 Span 数据进行分析,上文我们提到一个 Span
数据结构包含其自身的 TraceID 和它父节点的 TraceID,每一个节点都包含自身从属与哪个服务。
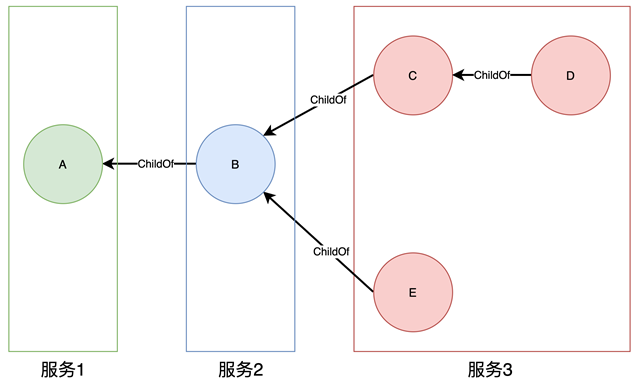
这里我们只关心跨服务之间的调用关系,例如上图,离线分析时只考虑 A, B, C, E 这几个节点,由于
D 节点与 C, E 节点都在服务 3 内部,所以将其忽略。分析出来的结果如图所示
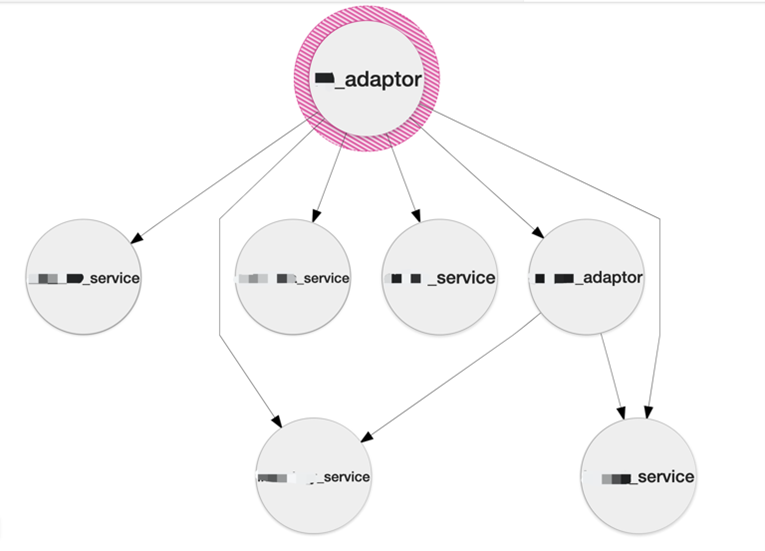
展示层
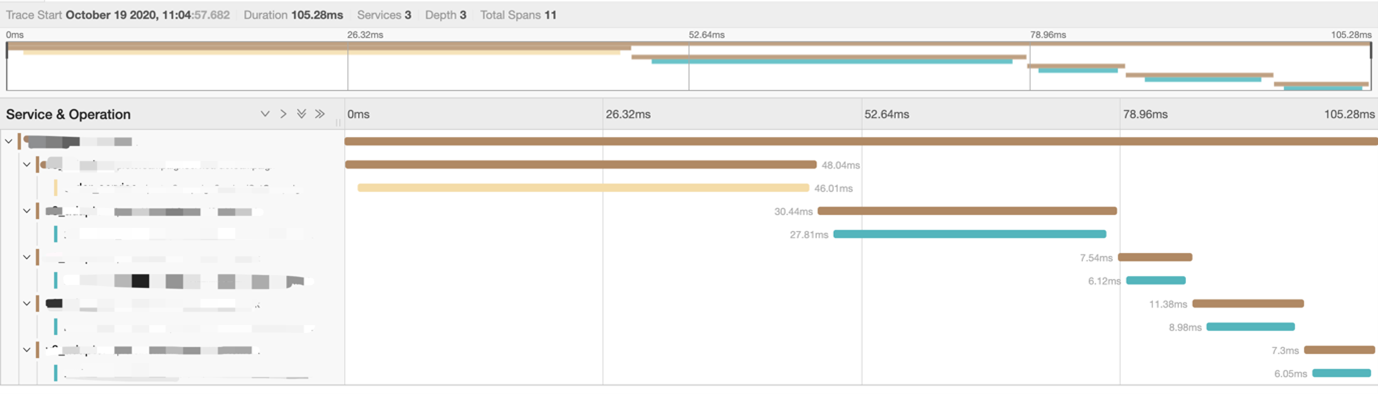
展示层主要指 Query-UI, 功能是从 ElacticSearch 中查询数据,对具有相同 TraceID
的数据进行聚合,并在前端进行渲染。从 QueryUI 中可以清晰的看到一条请求经历了几个不同的服务(以不同颜色标注),在每个服务中的到达时间和结束时间,整个请求总共经历的时间等。
未来展望
随着 FreeWheel 核心业务平台不断地扩充和演进,分布式追踪系统也需要进行不断升级改造以适配业务需求。例如部分业务代码正在尝试
Serverless 的方式,也就要求 Tracing 系统支持诸如 AWS Lambda 等使用场景。对于这种形式的需求,我们将紧跟业务,持续调研,以期服务更多的场景。此外,现有服务调用拓扑网络是基于离线数据生成的,我们也期望未来能找到一些在线处理的解决方案,如
Flink、Spark Streaming 等,做到实时的调用关系统计。
|








