| UML软件工程组织 | |||
| |
|||
|
|||
可自管理的分布式工作流引擎的设计与实现
来源:soft6.com
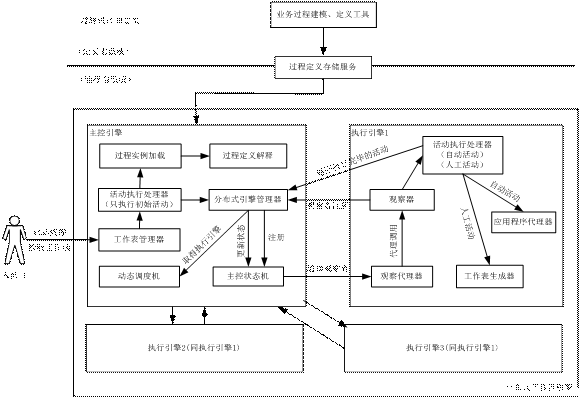
| 引言 工作流技术是实现企业业务过程建模、业务过程仿真分析、业务过程优化、业务过程管理与集成,从而最终实现业务过程自动化的核心技术[1]。早期的工作流应用系统都是集中式的,即由一个工作流引擎去完成整个流程实例的执行。随着计算机和网络技术的发展更加迅速和成熟,特别是Internet 应用日益普及的情况下,现代企业和政府的信息资源越来越表现出一种异构、分布、松散耦合的特点,信息共享、资源整合、协同办公已成为当前众多企业和政府的共同需求,而随着EJB、RMI、Web Service等分布式技术的日益成熟,分布式工作流的研究已成为当前众多组织和厂商的共同方向。 1.1 分布式工作流引擎概述 “分布式工作流引擎”的概念是相对于早期的集中式工作流引擎而言的,即整个工作流管理系统只有一个核心引擎,这个核心引擎负责解析工作流的流程定义,将工作流定义加载为运行时定义,然后调度和监控流程中每个活动的执行。对于人工活动结点,负责为参与者生成相关的工作项,对于自动活动结点,负责调用外部的具体应用(如企业中的HR、CRM等应用,或者是执行某项操作的一个JavaBean)[2],这种集中式的工作流管理系统由于主要的负荷全集中在一个工作流引擎上,因此在可扩展性、健壮性以及吞吐量等方面都不能满足企业执行大规模复杂应用的需求,尤其是当基于此集中式的工作流引擎的应用同时被大量用户访问时,将有可能导致工作流服务器的过载而瘫痪[3]。 所谓分布式工作流引擎是指采用一组分布在不同节点上的工作流引擎来共同协作完成整个工作流实例的执行。每个工作流引擎负责完成其中一部分活动实例的执行,不同的工作流引擎之间通过可靠的通信机制实现协作[4]。通过分布在不同网络节点上的多个工作流引擎的协作来运行工作流流程,可以明显改善集中式工作流引擎的性能瓶颈问题。 1.2 研究现状 在分布式工作流的研究领域,以IBM公司的基于“持久消息队列”、瑞士苏黎士大学的基于“事件驱动”和美国达特茅斯大学的基于“可移动代理”的分布式工作流系统较具典型性和可行性[1]。 基于“持久消息队列”的分布式工作流―Exotica/FMQM(FlowMark on Message Queue Manager),以“消息传送”为实现机制。执行节点接收到消息后,执行当前活动,执行完当前活动后,根据当前活动的输出连接弧向其它节点发送消息,从而推动整个过程实例的进程。 基于“事件驱动”的分布式工作流―EVE(Event Engine-事件引擎),主要由事件引擎服务器和Broker(代理)组成。事件引擎服务器负责接收来自本地代理及远程事件引擎服务器的事件,并根据ECA(Event Condition Action)规则定义,把事件发送给“感兴趣”的代理,当代理接到相应的事件后,就开始执行一个工作流实例的某一个活动,在这期间,代理还会产生新的事件。这些事件被通知到事件引擎服务器后,服务器将继续以事件的方式推动整个过程实例的进程。 基于“可移动代理”的分布式工作流―DartFlow,由可移动的代理将代码与数据传递到另外的网络节点上去执行,从而实现工作流过程的分布式执行。 Yan等人采用Petri网来对分布式工作流系统进行建模,进而提出标准的工作流结构和工作流块的概念, 以此支持复杂的分布式工作流管理系统的实现[5],Alonso等人考虑了分布式工作流引擎中的数据管理问题[6],Pallec等人采用MOF(Meta-Object Facility)来达到工作流管理系统中的互操作性[7]。这些方法或多或少都能达到分布式工作流管理系统的目的,但在系统的自管理性、可扩展性方面并不令人满意。本文针对当前企业和政府对分布式工作流管理系统应用的这种需求趋势,提出了一种分布式工作流引擎的实现方案,即使用JMX(Java Management Extensions)-Java管理扩展框架和Observer(观察者)模式,实现可高效自管理的分布式工作流引擎,同时利用观察者模式所具有的异步调用的特点,实现了整个工作流引擎的高效性和低耦合性。 2 可自管理的分布式工作流引擎(SMDWE--Self-Management Distributed Workflow Engine)的设计 2.1 SMDWE设计原理 SMDWE的设计分为二个部分,即数据存储的设计和逻辑控制的设计。 2.1.1 数据存储的设计 基于关系数据库的多表结构,以EJB的CMP(Container-Managed Persistence容器管理的持久性)作为持久化策略统一以实体Bean的形式存储工作流模型定义的相关数据及运行实例数据。运行时采用一组实体Bean将静态定义加载为运行时定义。同时,该CMP也就是运行时实例。将运行时工作流的定义划分为小的对象,即如下的核心实例:流程(InstProcess)、活动(InstActivity)、工作项(Workitem)、转移(InstTransition)、其它相关数据。将运行时工作流的定义划分为小的对象,减少了资源冲突的可能,既提高了效率,又保证了线程安全性。同时可以将这些对象序列化之后方便地在执行引擎之间进行传递。 2.1.2 逻辑控制的设计 Observer(观察者)模式,是一种典型的设计模式,我们通常采用它来减少互相通信的组件之间的耦合从而实现异步调用。传统的观察者设计模式有两个主要的参与者:一个 subject(目标)和一个 observer(观察者),其中观察者关注目标的状态改变。 JMX是具有高度可伸缩性的管理框架,是 Java 应用程序的管理规范,目前已成为新的J2EE规范中一部分。JMX可以实现应用程序组件的热插拔、热配置和热管理。另外,JMX 的功能不仅仅是对组件进行管理,对那些基于组件进行开发的应用程序,JMX也提供了一个统一的、可配置的管理框架[8]。JMX管理框架中的MBean通知模型类似于Java中的事件监听器模型。MBean或管理应用程序可以作为MBean事件的监听器注册。在本实现中,我们将实现了NotificationListener接口的主控状态机(MainEngineObservable)作为MBean事件的监听器注册到MBeanServer上,用来接收由JMX框架提供的时间服务Timer所循环发出的通知。 SMDWE由一个主控引擎和分布在网络中的多个执行引擎构成。执行引擎作为观察者注册到主控引擎上,主控引擎和执行引擎分别作为目标对象和观察者。主控引擎由一个分布式引擎管理器充当具体的目标对象与执行引擎的观察代理器进行通信。主控引擎负责执行流程的初始活动和动态调度执行引擎去执行流程中的其它后续活动。当初始活动执行完毕时,目标对象(主控引擎)的状态发生改变,然后主控引擎调用动态调度机根据动态调度算法决定后续活动的执行者,同时观察者(执行引擎)得到一个状态变更通知(此通知中包括当前活动及其转移的相关数据和执行此活动的执行引擎的名称),然后目标对象(主控引擎)回调每个执行引擎的观察代理器的update()方法,如果执行引擎的名称与通知中的名称一致,则此执行引擎的观察代理器调用活动处理器执行相关的动作(执行流程的第二个活动),依次类推,此执行引擎在执行完自己的任务后,将回调主控引擎的addNotification()方法重新设置主控引擎的状态,此时其他的观察者(执行引擎)再次得到主控引擎的状态变更通知,然后符合条件的观察者(执行引擎)继续执行自己的动作,从而推动整个工作流流程的前进。 3 系统结构 根据对SMDWE的设计原理的分析,下面给出其整体结构图:
图1 SMDWE系统结构图 定义态系统主要包括可视化的过程建模定义工具,用户根据实际的业务流程进行建模,然后建模定义调用过程定义存储服务将业务模型存入数据库。 运行态系统是由部署在网络上的一个主控引擎和多个执行引擎共同组成。主控引擎和执行引擎之间通过EJB远程调用进行通信。SMDWE由工作表管理器、活动执行处理器(主控引擎、执行引擎)、过程实例加载器、过程定义解释器、分布式引擎管理器、动态调度机、主控状态机、观察代理器、观察器、应用程序代理器、工作表生成器等组成。下面对各部分做简单的说明: 工作表管理器:负责与流程参与者交互,为其生成相关的工作项,供办理人拾取、提交工作项; 活动执行处理器(主控引擎、执行引擎):负责执行具体的活动,对于人工活动负责生成相关的工作项,对于自动活动负责调用外部的具体应用(主控工作流引擎只负责执行初始活动); 过程实例加载器:主要负责接收用户的流程启动请求,然后对静态的流程定义进行加载; 过程定义解释器:负责将xml形式的流程定义与流程对象进行互相转换; 分布式引擎管理器:负责维护网络上所有的执行引擎的URL(Uniform Resource Locator统一资源定位符)及它们各自观察代理器的JNDI(Java Naming and Directory Interface - Java命名和目录接口),网络上所有的执行引擎都首先要注册到此管理器上,然后再由其注册到主控状态机上。流程执行时负责接收执行引擎发送的已执行活动的信息,取得其后继活动,调用JMX的时间服务向主控状态机发送状态变更通知。此管理器用EJB实现,由执行引擎的观察代理器远程调用; 动态调度机:主要根据负载均衡原理,利用轮转法,动态调度各个执行引擎; 主控状态机:作为目标对象维护执行引擎的观察者列表,负责记录每个流程实例中执行活动实例的状态,同时负责监听分布式引擎管理器发出的状态变更通知。状态变更时,负责向观察者(执行引擎)发送通知。最后调用动态调度机,决定下一个活动的执行者; 观察代理器:是执行工作流引擎负责观察目标对象的观察器的远程代理,由EJB实现; 观察器:执行引擎的本地观察者,启动时负责调用分布式引擎管理器将自身注册到主控引擎上,执行 流程时负责观察主控工作流引擎的状态,并提供update()回调方法; 应用程序代理器:负责代理执行外部的应用程序,如JavaBean、EJB、特定应用程序等; 工作表生成器:在执行引擎中只负责生成工作项; 4 系统实现方案 4.1 主控引擎的Observable组件模型
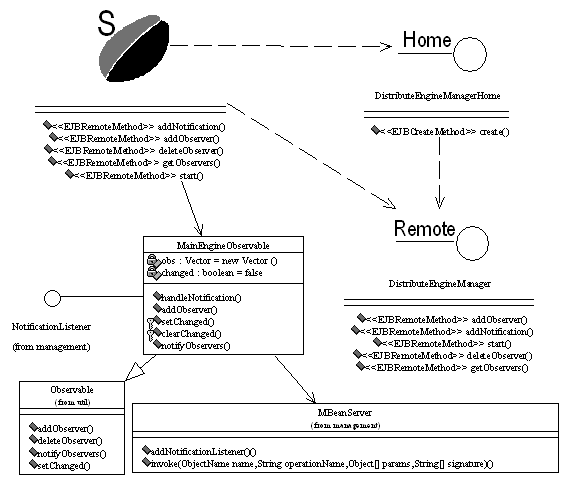
图2 主控引擎的Observable组件模型图 主控引擎的Observable组件模型如图2所示,其中MainEngineObservable类继承java.util.Observable类,作为主控引擎的流程状态机,其作用如下: 1) 实现目标对象(Subject)的身份,负责维护所有观察者(执行引擎观察器)的一个列表; 2) 实现javax.management.NotificationListener接口,负责监听分布式引擎管理器发出的状态变更通知; 3) 接到通知后,先调用父类Observable的setChanged()方法改变自身状态,然后调用notifyObservers()方法通知所有的观察者主控状态机的状态发生改变; 4) notifyObservers()方法分别调用注册表中的每个观察器的update()方法; DistributeEngineManagerBean分布式引擎管理器类实际上是MainEngineObservable的一个远程代理,由SessionBean实现,远程观察者(执行引擎)通过EJB远程调用分布式引擎管理器的方法,将自己注册到目标对象MainEngineObservable上。DistributeEngineManagerBean主要完成以下功能: 1) 保存远程观察者的URL; 2) 接受远程观察者的注册; 3) 调用MainEngineObservable类的addObserver()方法进行真正的注册; 4) 提供addNotification()方法接收已执行活动的信息,供主控引擎和执行引擎的活动处理器调用; 5) 提供triggerNotification()方法,给主控状态机发送真正的状态变更通知; 4.2 执行引擎的Observer组件模型
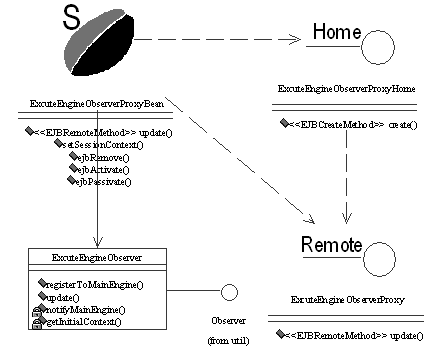
图3 执行引擎的Observer组件模型图 执行引擎的Observable组件模型如图3所示,其中ExcuteEngineObserver类充当执行引擎对主控引擎的观察者身份,实现了java.util.Observer接口类,提供一个update()回调方法,供主控引擎调用。在update()方法中实现对活动执行处理器的调用,从而完成工作流活动的执行。 ExcuteEngineObserverProxyBean类是ExcuteEngineObserver类的一个远程代理,实现了EJB 2.0的Home接口和Remote接口。主控引擎通过对此代理的远程调用,然后再由此代理通过本地调用ExcuteEngineObserver类的update()方法,间接实现对执行引擎的活动处理器的执行调用。 4.3 SMDWE的调度算法 为实现负载均衡,对执行工作流引擎采用轮转法进行调度,其调度算法如下: (1) 执行引擎注册:执行引擎启动时,通过EJB远程调用主控引擎的分布式引擎管理器,将自身注册到主控引擎的主控状态机上; (2) 过程实例加载:当主控引擎收到客户启动流程的请求后,引擎调用过程实例加载器,将需要启动的流程定义加载到运行库;然后过程实例加载器调用过程定义解释器,将xml流程定义转化为Process流程定义对象; (3) 初始活动执行:主控引擎调用活动执行处理器执行流程的第一个初始活动; (4)发送状态变更通知:活动执行处理器执行完毕后将此活动作为参数调用分布式引擎管理器的addNotification()方法发送已执行的通知; (5)取得后继活动:分布式引擎管理器根据已执行活动取得其后继活动及工作流相关数据; (6) 动态调度执行引擎:分布式引擎管理器取得执行引擎的观察器列表,调用动态调度机采用轮转法确定执行引擎的URL,然后将此URL、(5)中的后继活动作为参数调用自身的triggerNotification()方法给主控状态机发送消息; (7) 主控状态机给执行引擎发送通知:主控状态机监听到消息后,调用setChanged()方法改变自身状态,调用NotifyObservers()方法通知所有注册的执行引擎的观察器,回调每个执行引擎的观察器的update()方法; (8) 执行引擎执行活动:如果执行引擎的URL与参数中的URL一致,则执行引擎的观察器调用自身的活动处理器,执行当前活动。活动执行完毕,活动处理器再调用分布式引擎管理器的addNotification()方法再次循环执行(4)-(8)直到整个流程结束。 (9) 流程结束。整个流程执行完毕调用清除器清除相关的实例数据。 4.4 分布式工作流中的关键问题及解决方法 4.4.1 工作流相关数据和控制数据的处理 为保证分布式工作流相关数据的同步,本实现中将工作流的相关数据以实例变量的形式,采用实体Bean进行存贮;而在工作流的流程实例或活动实例中,对工作流的实例变量采用工作流命名空间二元组(WorkflowNameSpace variableList>)的形式进行封装,为此我们引入具有面向对象脚本语言特性的Java代码解释器BeanShell的NameSpace对工作流实例变量进行封装。然后将WorkflowNameSpace对象的实例序列化作为流程实例(InstProcess)或活动实例(InstActivity)的成员变量在执行引擎之间进行传递,从而实现了工作流相关数据传递的可靠传递。 工作流的控制数据主要包括工作流实例的一些数据,例如流程实例数据、活动实例数据、工作项数据。在分布式的工作流中主控引擎负责以实体Bean的形式持久化流程实例数据、活动实例数据和工作项数据,这样在应用层实现对工作流的监控时,就可以统一调度工作流的各种实例数据。执行引擎通过EJB远程调用的方式对实体Bean的数据进行维护,即各个执行引擎负责工作流活动实例数据和工作项数据的生成。对于人工型的活动,执行引擎的活动处理器先调用工作流表管理器为此活动生成工作项,如果成功则更改活动状态。对于自动型的活动,则调用应用程序代理器执行外部应用。 4.4.2 分布式事务的处理 工作流中的事务与仅仅满足ACID(Atomicity原子性、Consistency一致性、Isolation隔离性、Durability持久性)属性的经典事务模型是完全不同的:1)经典的事务模型主要是面向数据库的,而工作流中的事务主要是面向活动对象的,需要更复杂的逻辑控制;2)经典的事务模型活动时间很短,工作流中的事务活动时间很长,有可能是一天、一个月或更长;3)经典的事务模型要求一个事务如果不全部成功,就全部回滚,而工作流的事务不能因为一个活动的失败,就回滚整个流程实例(除非有极特殊的需求);4)经典的事务模型的恢复由数据库的事务控制,而工作流的恢复需要工作流数据和业务数据同时进行恢复,这时可能就会用到复杂的补偿操作。针对于工作流事务的以上特点,在本实现中只采取对某个工作流的活动进行事务控制,只有某一个活动完全执行成功后才去更改流程的状态,分布式执行引擎的活动处理器负责将当前的执行活动和状态两个参数传回给主控引擎的分布式引擎管理器,例如,当执行引擎的活动处理器执行工作流的活动时失败,活动处理器先调用已经根据实际的业务需求定义的一个补偿操作对业务数据进行恢复,然后调用分布式引擎管理器的addNotification()方法时,将当前执行的活动对象和错误标志传回主控引擎,分布式引擎管理器判断如果接收到的是一个错误标志,则调用动态调度机为此失败的活动重新分配一个执行引擎。 4.5 性能分析 4.5.1 可靠性 分布式工作流由于在引擎协作的过程中存在很多的远程数据传递,因此保证其数据传递的可靠性是分布式工作流首先要解决的问题。在本设计中传递的主要是实例数据,而这些实例数据以实体Bean的形式持久化到数据库,在数据传递失败时,从EJB容器的实例池中重新取得实体Bean的实例进行传递,因此有效地解决了数据远程传递失败时的恢复问题。第二种可能的问题是系统中的某个执行引擎在执行活动的过程中失败,此时则采用4.4.2一节中的方法进行恢复。第三种是数据的并发访问问题,为了在应用层实现工作流监控功能时对数据统一处理,所以在主控引擎中统一持久化实例数据。此时由于多个执行引擎通过会话Bean远程调用实体Bean来生成过程实例数据和工作项数据,因此由可能引起并发访问的冲突问题,解决办法是采用主控引擎的EJB容器提供的事务隔离策略控制实体Bean的访问,从而有效地解决了并发访问数据库的冲突问题。 4.5.2 可扩展性 可扩展性包括功能可扩展性和结构可扩展性。功能扩展性,由于本系统采用JMX作为整体的功能管理框架,JMX本身的对应用程序组件的热插拔、热配置、热管理的特性决定了本系统具有良好的功能扩展性。在结构扩展性方面,大多数的分布式引擎不能满足企业的分布式需求,因为这些分布式引擎只是静态意义上的分布,即在流程定义期,将过程的活动定义与执行引擎所在的网络节点进行绑定(如基于消息的Exotica),这样导致了流程定义与执行引擎的紧偶合。而SMDWE是基于观察者模式实现,因此活动的执行是在运行期通过负载均衡算法动态决定的,所以是真正意义上的可动态柔性扩展的系统。在实现时编写一个可由容器自动启动的Servlet,每个执行引擎启动时,此Servlet自动执行,调用观察代理器,由观察代理器远程调用分布式引擎管理器的addObservers()方法将自身注册到主控引擎上。主控引擎的分布式引擎管理器将每个注册过的执行引擎的URL存入数据库,动态调度机动态调度执行引擎时首先调用分布式引擎管理器的getObservers()方法获得所有注册成功的执行引擎列表,然后根据轮转法进行调度。系统需要扩展时,在相应的网络节点上重新部署一个执行引擎,然后启动执行引擎,执行引擎按照上面的方法注册到主控引擎,实现了动态扩展。 4.5.3 容错性 当分布式环境中的某个分布式工作流引擎出现故障时,只有那些正在此分布式工作流引擎执行的过程实例会受到影响,不会使整个系统瘫痪。而当其他流程实例请求工作流引擎时将会绕过此工作流引擎。 5 应用实例 根据上面的设计与实现分析,下面给出一个应用实例来说明怎样应用本文中的方法实现SMDWE的可自管理性和可靠性,应用JMX的时间通知模型实现分布式引擎的异步性。 1) 执行引擎的自动扩展:执行引擎的动态扩展是通过分别调用主控引擎的分布式引擎管理器的注册 方法addObserver()和注销方法deleteObserver()实现的。其清单如下DistributeEngineManagerBean.java: public void addObserver(String excuteEngineURL,String observerJNDIName,String homeInterfaceName) throws WorkflowException { //向主控引擎注册一个观察者 observerList.add(excuteEngineURL+":"+observerJNDIName+":"+homeInterfaceName); } public void deleteObserver(String excuteEngineURL,String observerJNDIName,String homeInterfaceName) throws WorkflowException{ //删除一个指定URL的观察者 observerList.remove(excuteEngineURL+":"+observerJNDIName+":"+homeInterfaceName); } addObserver()和deleteObserver()方法是两个远程方法,执行引擎启动时由观察器(ExcuteEngineObserver.java)通过EJB远程调用addObserver()方法,将自身注册到主控引擎上。如果执行引擎关闭则调用deleteObserver()方法注销自己。当系统因为性能原因需要扩展时,就在网络上新部署一个执行引擎并启动,则这个新部署的引擎通过上面的方法注册到了主控引擎。这样系统就具备了高度的可自管理性,执行引擎可随时关闭或加入到系统中来。 2) 活动执行失败时的失败转发:执行引擎执行活动完毕后,不管成功与否都调用分布式引擎管理器 的addNotification()方法,将执行完毕的活动传回主控引擎,并返回一个是否成功的标志。清单如下: public synchronized void addNotification(InstActivity activity, boolean isSucess) throws WorkflowException { this.isSucess = isSucess; if (this.isSucess) { if (errorList.contains(activity)) { errorList.remove(activity); } List lstNextActivities = getNextActivities(activity); Iterator it = lstNextActivities.iterator(); while (it.hasNext()) { InstActivity nextActivity = (InstActivity) it.next(); nextActivity.setExcuteEngineURL(getDynamicExcuteEngineURL()); toDoList.add(nextActivity); } } else { errorList.add(activity); } } 从清单中可以看出,如果活动执行成功则取出其后继活动放入待办列表中,如果执行失败则放入失败列表errorList中,此时主控引擎可将此失败的活动继续分配给其它的执行引擎继续执行,因此结合本文中的其它提高可靠性的方法,到达了系统的可靠性要求。 6 总结 目前分布式工作流管理系统正朝着自管理的方向发展,本文提出了一种基于JMX框架和观察者模式实现高效自管理的分布式工作流引擎的设计与实现方法。执行引擎可以随时加入到自管理的分布式工作流管理系统中,加入时只需在网络上新部署一个工作流引擎即可,真正地实现了分布式工作流引擎的自管理和自扩展,每当新增一个执行引擎时,系统便自动扩展,同时具有了更好的处理能力。 参考文献 [1] FAN Yu-shun, LUO Hai-bin, LIN Hui-ping, et al. Fundamentals of Workflow Management Technology[M]. Beijing: Tsinghua University Press, 2001. p.211-220. (in Chinese) [范玉顺,罗海滨,林慧萍,等.工作流管理技术基础[M]. 北京:清华大学出版社,2001: 211-220] [2] Workflow Management Coalition. WFMC-TC-1003. The Workflow Reference Model, Document Status - Issue 1.1, http://www.wfmc.org/standards/docs/tc003v11.pdf [3] Thomas Bauer, Peter Dadam University of Ulm, Dept. of Databases and Information Systems, Efficient Distributed Workflow Management Based on Variable Server Assignments. http://www.informatik.uni-ulm.de/dbis/01/dbis/downloads/BaDa00.pdf [4] Workflow Management Coalition. WFMC-TC-1023. Workflow Standard –Interoperability Wf-XML Binding - Issue 1.1, http://www.wfmc.org/standards/docs/Wf-XML-11.pdf [5] Yan Y, Bejan, A. Modeling workflow within distributed systems[C]. in: The Sixth International Conference on Computer Supported Cooperative Work in Design. July 2001 :433 – 439 [6] Alonso G, et al. Distributed data management in workflow environments[C]. in: Proceedings of Seventh International Workshop on Research Issues in Data Engineering, April 1997: 82 - 90 [7] Le Pallec X, Vantroys T. A cooperative workflow management system with the Meta-Object Facility[C]. in: Proceedings of Fifth IEEE International Enterprise Distributed Object Computing Conference (EDOC '01). Sept. 2001: 273 – 280 [8] Java? Management Extensions Instrumentation and Agent Specification, v1.2 http://jcp.org/aboutJava/communityprocess/final/jsr003/index3.html |
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |