| БрМЭЦМі: |
БОЮФРДздгк51ctoЃЌБОЮФжМдкЮЊДѓМвЬсЙЉгагУЕФИХРРвдМАЭјТчЗўЮёФЃаЭЕФБШНЯЃЌвдНвПЊЩшМЦКЭЪЕЯжИпадФмЭјТчМмЙЙЕФЩёУиУцЩДЁЃ |
|
ЗўЮёЖЫДІРэЭјТчЧыЧѓ
ЪзЯШПДПДЗўЮёЖЫДІРэЭјТчЧыЧѓЕФЕфаЭЙ§ГЬЃК
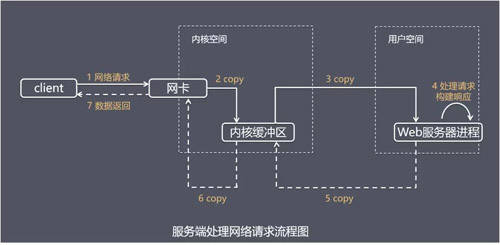
гЩЩЯЭМПЩвдПДЕНЃЌжївЊДІРэВНжшАќРЈЃК
1.ЛёШЁЧыЧѓЪ§ОнЃЌПЭЛЇЖЫгыЗўЮёЦїНЈСЂСЌНгЗЂГіЧыЧѓЃЌЗўЮёЦїНгЪмЧыЧѓЃЈ1-3ЃЉЁЃ
2.ЙЙНЈЯьгІЃЌЕБЗўЮёЦїНгЪеЭъЧыЧѓЃЌВЂдкгУЛЇПеМфДІРэПЭЛЇЖЫЕФЧыЧѓЃЌжБЕНЙЙНЈЯьгІЭъГЩЃЈ4ЃЉЁЃ
3.ЗЕЛиЪ§ОнЃЌЗўЮёЦїНЋвбЙЙНЈКУЕФЯьгІдйЭЈЙ§ФкКЫПеМфЕФЭјТч I/O
ЗЂЛЙИјПЭЛЇЖЫЃЈ5-7ЃЉЁЃ
ЩшМЦЗўЮёЖЫВЂЗЂФЃаЭЪБЃЌжївЊгаШчЯТСНИіЙиМќЕуЃК
1.ЗўЮёЦїШчКЮЙмРэСЌНгЃЌЛёШЁЪфШыЪ§ОнЁЃ
2.ЗўЮёЦїШчКЮДІРэЧыЧѓЁЃ
вдЩЯСНИіЙиМќЕузюжеЖМгыВйзїЯЕЭГЕФ I/O ФЃаЭвдМАЯпГЬ(НјГЬ)ФЃаЭЯрЙиЃЌЯТУцЯъЯИНщЩметСНИіФЃаЭЁЃ
I/O ФЃаЭ
НщЩмВйзїЯЕЭГЕФ I/O ФЃаЭжЎЧАЃЌЯШСЫНтвЛЯТМИИіИХФюЃК
1.зшШћЕїгУгыЗЧзшШћЕїгУЁЃ
2.зшШћЕїгУЪЧжИЕїгУНсЙћЗЕЛижЎЧАЃЌЕБЧАЯпГЬЛсБЛЙвЦ№ЁЃЕїгУЯпГЬжЛгадкЕУЕННсЙћжЎКѓВХЛсЗЕЛиЁЃ
3.ЗЧзшШћЕїгУжИдкВЛФмСЂПЬЕУЕННсЙћжЎЧАЃЌИУЕїгУВЛЛсзшШћЕБЧАЯпГЬЁЃ
СНепЕФзюДѓЧјБ№дкгкБЛЕїгУЗНдкЪеЕНЧыЧѓЕНЗЕЛиНсЙћжЎЧАЕФетЖЮЪБМфФкЃЌЕїгУЗНЪЧЗёвЛжБдкЕШД§ЁЃ
зшШћЪЧжИЕїгУЗНвЛжБдкЕШД§ЖјЧвБ№ЕФЪТЧщЪВУДЖМВЛзіЃЛЗЧзшШћЪЧжИЕїгУЗНЯШШЅУІБ№ЕФЪТЧщЁЃ
ЭЌВНДІРэгывьВНДІРэ
ЭЌВНДІРэЪЧжИБЛЕїгУЗНЕУЕНзюжеНсЙћжЎКѓВХЗЕЛиИјЕїгУЗНЃЛвьВНДІРэЪЧжИБЛЕїгУЗНЯШЗЕЛигІД№ЃЌШЛКѓдйМЦЫуЕїгУНсЙћЃЌМЦЫуЭъзюжеНсЙћКѓдйЭЈжЊВЂЗЕЛиИјЕїгУЗНЁЃ
зшШћЁЂЗЧзшШћКЭЭЌВНЁЂвьВНЕФЧјБ№
зшШћЁЂЗЧзшШћКЭЭЌВНЁЂвьВНЦфЪЕеыЖдЕФЖдЯѓЪЧВЛвЛбљЕФЃК
1.зшШћЁЂЗЧзшШћЕФЬжТлЖдЯѓЪЧЕїгУепЁЃ
2.ЭЌВНЁЂвьВНЕФЬжТлЖдЯѓЪЧБЛЕїгУепЁЃ
recvfrom КЏЪ§
recvfrom КЏЪ§(О Socket НгЪеЪ§Он)ЃЌетРяАбЫќЪгЮЊЯЕЭГЕїгУЁЃ
вЛИіЪфШыВйзїЭЈГЃАќРЈСНИіВЛЭЌЕФНзЖЮЃК
ЕШД§Ъ§ОнзМБИКУ
ДгФкКЫЯђНјГЬИДжЦЪ§Он
ЖдгквЛИіЬзНгзжЩЯЕФЪфШыВйзїЃЌЕквЛВНЭЈГЃЩцМАЕШД§Ъ§ОнДгЭјТчжаЕНДяЁЃЕБЫљЕШД§ЗжзщЕНДяЪБЃЌЫќБЛИДжЦЕНФкКЫжаЕФФГИіЛКГхЧјЁЃЕкЖўВНОЭЪЧАбЪ§ОнДгФкКЫЛКГхЧјИДжЦЕНгІгУНјГЬЛКГхЧјЁЃ
ЪЕМЪгІгУГЬађдкЯЕЭГЕїгУЭъГЩЩЯУцЕФ 2 ВНВйзїЪБЃЌЕїгУЗНЪНЕФзшШћЁЂЗЧзшШћЃЌВйзїЯЕЭГдкДІРэгІгУГЬађЧыЧѓЪБЃЌДІРэЗНЪНЕФЭЌВНЁЂвьВНДІРэЕФВЛЭЌЃЌПЩвдЗжЮЊ
5 жж I/O ФЃаЭЁЃЃЈВЮПМЁЖUNIXЭјТчБрГЬОэ1ЁЗЃЉ
зшШћЪН I/O ФЃаЭ(blocking I/OЃЉ
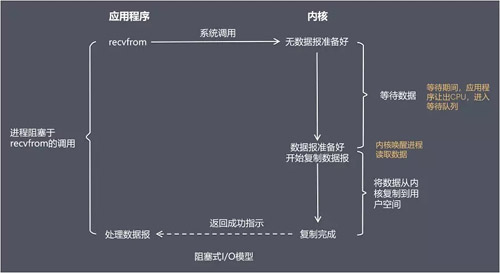
дкзшШћЪН I/O ФЃаЭжаЃЌгІгУГЬађдкДгЕїгУ recvfrom ПЊЪМЕНЫќЗЕЛигаЪ§ОнБЈзМБИКУетЖЮЪБМфЪЧзшШћЕФЃЌrecvfrom
ЗЕЛиГЩЙІКѓЃЌгІгУНјГЬПЊЪМДІРэЪ§ОнБЈЁЃ
БШгїЃКвЛИіШЫдкЕігуЃЌЕБУЛгуЩЯЙГЪБЃЌОЭзјдкАЖБпвЛжБЕШЁЃ
гХЕуЃКГЬађМђЕЅЃЌдкзшШћЕШД§Ъ§ОнЦкМфНјГЬ/ЯпГЬЙвЦ№ЃЌЛљБОВЛЛсеМгУ CPU зЪдДЁЃ
ШБЕуЃКУПИіСЌНгашвЊЖРСЂЕФНјГЬ/ЯпГЬЕЅЖРДІРэЃЌЕБВЂЗЂЧыЧѓСПДѓЪБЮЊСЫЮЌЛЄГЬађЃЌФкДцЁЂЯпГЬЧаЛЛПЊЯњНЯДѓЃЌетжжФЃаЭдкЪЕМЪЩњВњжаКмЩйЪЙгУЁЃ
ЗЧзшШћЪН I/O ФЃаЭ(non-blocking I/OЃЉ
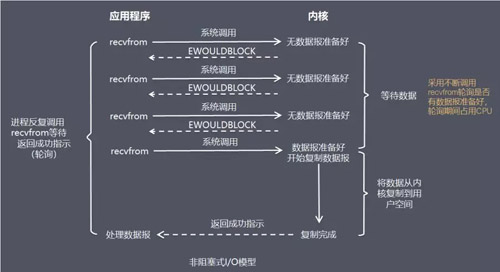
дкЗЧзшШћЪН I/O ФЃаЭжаЃЌгІгУГЬађАбвЛИіЬзНгПкЩшжУЮЊЗЧзшШћЃЌОЭЪЧИцЫпФкКЫЃЌЕБЫљЧыЧѓЕФ I/O ВйзїЮоЗЈЭъГЩЪБЃЌВЛвЊНЋНјГЬЫЏУпЁЃ
ЖјЪЧЗЕЛивЛИіДэЮѓЃЌгІгУГЬађЛљгк I/O ВйзїКЏЪ§НЋВЛЖЯЕФТжбЏЪ§ОнЪЧЗёвбОзМБИКУЃЌШчЙћУЛгазМБИКУЃЌМЬајТжбЏЃЌжБЕНЪ§ОнзМБИКУЮЊжЙЁЃ
БШгїЃКБпЕігуБпЭцЪжЛњЃЌИєЛсдйПДПДгаУЛгагуЩЯЙГЃЌгаЕФЛАОЭбИЫйРИЫЁЃ
гХЕуЃКВЛЛсзшШћдкФкКЫЕФЕШД§Ъ§ОнЙ§ГЬЃЌУПДЮЗЂЦ№ЕФ I/O ЧыЧѓПЩвдСЂМДЗЕЛиЃЌВЛгУзшШћЕШД§ЃЌЪЕЪБадНЯКУЁЃ
ШБЕуЃКТжбЏНЋЛсВЛЖЯЕибЏЮЪФкКЫЃЌетНЋеМгУДѓСПЕФ CPU ЪБМфЃЌЯЕЭГзЪдДРћгУТЪНЯЕЭЃЌЫљвдвЛАу Web
ЗўЮёЦїВЛЪЙгУетжж I/O ФЃаЭЁЃ
I/O ИДгУФЃаЭ(I/O multiplexingЃЉ
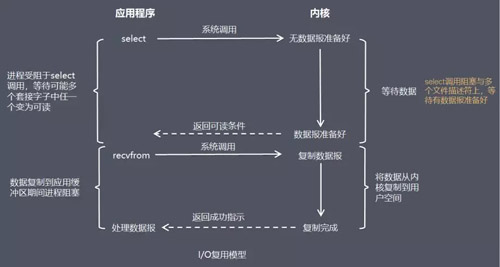
дк I/O ИДгУФЃаЭжаЃЌЛсгУЕН Select Лђ Poll КЏЪ§Лђ Epoll КЏЪ§(Linux
2.6 вдКѓЕФФкКЫПЊЪМжЇГж)ЃЌетСНИіКЏЪ§вВЛсЪЙНјГЬзшШћЃЌЕЋЪЧКЭзшШћ I/O гаЫљВЛЭЌЁЃ
етСНИіКЏЪ§ПЩвдЭЌЪБзшШћЖрИі I/O ВйзїЃЌЖјЧвПЩвдЭЌЪБЖдЖрИіЖСВйзїЃЌЖрИіаДВйзїЕФ I/O КЏЪ§НјааМьВтЃЌжБЕНгаЪ§ОнПЩЖСЛђПЩаДЪБЃЌВХеце§ЕїгУ
I/O ВйзїКЏЪ§ЁЃ
БШгїЃКЗХСЫвЛЖбгуИЭЃЌдкАЖБпвЛжБЪизХетЖбгуИЭЃЌУЛгуЩЯЙГОЭЭцЪжЛњЁЃ
гХЕуЃКПЩвдЛљгквЛИізшШћЖдЯѓЃЌЭЌЪБдкЖрИіУшЪіЗћЩЯЕШД§ОЭаїЃЌЖјВЛЪЧЪЙгУЖрИіЯпГЬ(УПИіЮФМўУшЪіЗћвЛИіЯпГЬ)ЃЌетбљПЩвдДѓДѓНкЪЁЯЕЭГзЪдДЁЃ
ШБЕуЃКЕБСЌНгЪ§НЯЩйЪБаЇТЪЯрБШЖрЯпГЬ+зшШћ I/O ФЃаЭаЇТЪНЯЕЭЃЌПЩФмбгГйИќДѓЃЌвђЮЊЕЅИіСЌНгДІРэашвЊ
2 ДЮЯЕЭГЕїгУЃЌеМгУЪБМфЛсгадіМгЁЃ
аХКХЧ§ЖЏЪН I/O ФЃаЭЃЈsignal-driven I/O)
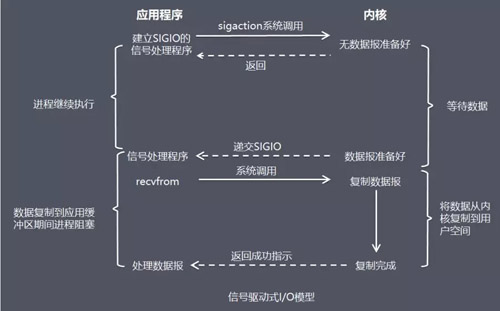
дкаХКХЧ§ЖЏЪН I/O ФЃаЭжаЃЌгІгУГЬађЪЙгУЬзНгПкНјаааХКХЧ§ЖЏ I/OЃЌВЂАВзАвЛИіаХКХДІРэКЏЪ§ЃЌНјГЬМЬајдЫааВЂВЛзшШћЁЃ
ЕБЪ§ОнзМБИКУЪБЃЌНјГЬЛсЪеЕНвЛИі SIGIO аХКХЃЌПЩвддкаХКХДІРэКЏЪ§жаЕїгУ I/O ВйзїКЏЪ§ДІРэЪ§ОнЁЃ
БШгїЃКгуИЭЩЯЯЕСЫИіСхюѕЃЌЕБСхюѕЯьЃЌОЭжЊЕРгуЩЯЙГЃЌШЛКѓПЩвдзЈаФЭцЪжЛњЁЃ
гХЕуЃКЯпГЬВЂУЛгадкЕШД§Ъ§ОнЪББЛзшШћЃЌПЩвдЬсИпзЪдДЕФРћгУТЪЁЃ
ШБЕуЃКаХКХ I/O дкДѓСП IO ВйзїЪБПЩФмЛсвђЮЊаХКХЖгСавчГіЕМжТУЛЗЈЭЈжЊЁЃ
аХКХЧ§ЖЏ I/O ОЁЙмЖдгкДІРэ UDP ЬзНгзжРДЫЕгагУЃЌМДетжжаХКХЭЈжЊвтЮЖзХЕНДявЛИіЪ§ОнБЈЃЌЛђепЗЕЛивЛИівьВНДэЮѓЁЃ
ЕЋЪЧЃЌЖдгк TCP ЖјбдЃЌаХКХЧ§ЖЏЕФ I/O ЗНЪННќКѕЮогУЃЌвђЮЊЕМжТетжжЭЈжЊЕФЬѕМўЮЊЪ§жкЖрЃЌУПвЛИіРДНјааХаБ№ЛсЯћКФКмДѓзЪдДЃЌгыЧАМИжжЗНЪНЯрБШгХЪЦОЁЪЇЁЃ
вьВН I/O ФЃаЭЃЈasynchronous I/OЃЉ
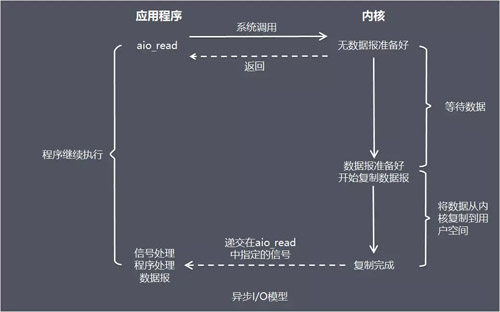
гЩ POSIX ЙцЗЖЖЈвхЃЌгІгУГЬађИцжЊФкКЫЦєЖЏФГИіВйзїЃЌВЂШУФкКЫдкећИіВйзїЃЈАќРЈНЋЪ§ОнДгФкКЫПНБДЕНгІгУГЬађЕФЛКГхЧјЃЉЭъГЩКѓЭЈжЊгІгУГЬађЁЃ
етжжФЃаЭгыаХКХЧ§ЖЏФЃаЭЕФжївЊЧјБ№дкгкЃКаХКХЧ§ЖЏ I/O ЪЧгЩФкКЫЭЈжЊгІгУГЬађКЮЪБЦєЖЏвЛИі I/O
ВйзїЃЌЖјвьВН I/O ФЃаЭЪЧгЩФкКЫЭЈжЊгІгУГЬађ I/O ВйзїКЮЪБЭъГЩЁЃ
гХЕуЃКвьВН I/O ФмЙЛГфЗжРћгУ DMA ЬиадЃЌШУ I/O ВйзїгыМЦЫужиЕўЁЃ
ШБЕуЃКвЊЪЕЯжеце§ЕФвьВН I/OЃЌВйзїЯЕЭГашвЊзіДѓСПЕФЙЄзїЁЃФПЧА Windows ЯТЭЈЙ§ IOCP
ЪЕЯжСЫеце§ЕФвьВН I/OЁЃ
Жјдк Linux ЯЕЭГЯТЃЌLinux 2.6ВХв§ШыЃЌФПЧА AIO ВЂВЛЭъЩЦЃЌвђДЫдк Linux ЯТЪЕЯжИпВЂЗЂЭјТчБрГЬЪБЖМЪЧвд
IO ИДгУФЃаЭФЃЪНЮЊжїЁЃ
5 жж I/O ФЃаЭзмНс
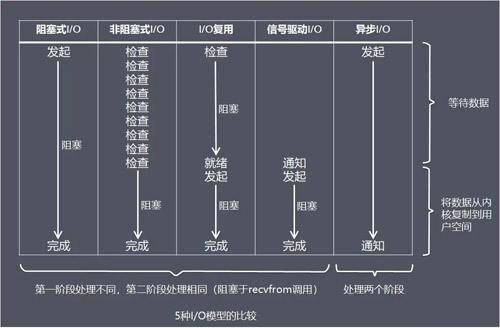
ДгЩЯЭМжаЮвУЧПЩвдПДГіЃЌдНЭљКѓЃЌзшШћдНЩйЃЌРэТлЩЯаЇТЪвВЪЧзюгХЁЃ
етЮхжж I/O ФЃаЭжаЃЌЧАЫФжжЪєгкЭЌВН I/OЃЌвђЮЊЦфжаеце§ЕФ I/O Вйзї(recvfrom)НЋзшШћНјГЬ/ЯпГЬЃЌжЛгавьВН
I/O ФЃаЭВХгы POSIX ЖЈвхЕФвьВН I/O ЯрЦЅХфЁЃ
ЯпГЬФЃаЭ
НщЩмЭъЗўЮёЦїШчКЮЛљгк I/O ФЃаЭЙмРэСЌНгЃЌЛёШЁЪфШыЪ§ОнЃЌЯТУцНщЩмЛљгкНјГЬ/ЯпГЬФЃаЭЃЌЗўЮёЦїШчКЮДІРэЧыЧѓЁЃ
жЕЕУЫЕУїЕФЪЧЃЌОпЬхбЁдёЯпГЬЛЙЪЧНјГЬЃЌИќЖрЪЧгыЦНЬЈМАБрГЬгябдЯрЙиЁЃ
Р§Шч C гябдЪЙгУЯпГЬКЭНјГЬЖМПЩвд(Р§Шч Nginx ЪЙгУНјГЬЃЌMemcached ЪЙгУЯпГЬ)ЃЌJava
гябдвЛАуЪЙгУЯпГЬ(Р§Шч Netty)ЃЌЮЊСЫУшЪіЗНБуЃЌЯТУцЖМЪЙгУЯпГЬРДНјааУшЪіЁЃ
ДЋЭГзшШћ I/O ЗўЮёФЃаЭ
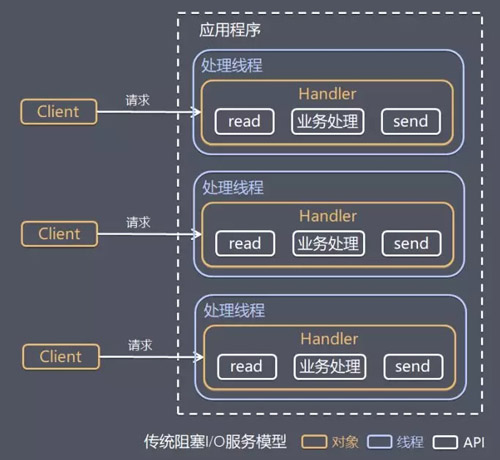
ЬиЕуЃК
ВЩгУзшШћЪН I/O ФЃаЭЛёШЁЪфШыЪ§ОнЁЃ
УПИіСЌНгЖМашвЊЖРСЂЕФЯпГЬЭъГЩЪ§ОнЪфШыЃЌвЕЮёДІРэЃЌЪ§ОнЗЕЛиЕФЭъећВйзїЁЃ
ДцдкЮЪЬтЃК
ЕБВЂЗЂЪ§НЯДѓЪБЃЌашвЊДДНЈДѓСПЯпГЬРДДІРэСЌНгЃЌЯЕЭГзЪдДеМгУНЯДѓЁЃ
СЌНгНЈСЂКѓЃЌШчЙћЕБЧАЯпГЬднЪБУЛгаЪ§ОнПЩЖСЃЌдђЯпГЬОЭзшШћдк Read ВйзїЩЯЃЌдьГЩЯпГЬзЪдДРЫЗбЁЃ
Reactor ФЃЪН
еыЖдДЋЭГзшШћ I/O ЗўЮёФЃаЭЕФ 2 ИіШБЕуЃЌБШНЯГЃМћЕФгаШчЯТНтОіЗНАИЃК
Лљгк I/O ИДгУФЃаЭЃЌЖрИіСЌНгЙВгУвЛИізшШћЖдЯѓЃЌгІгУГЬађжЛашвЊдквЛИізшШћЖдЯѓЩЯЕШД§ЃЌЮоашзшШћЕШД§ЫљгаСЌНгЁЃ
ЕБФГЬѕСЌНггааТЕФЪ§ОнПЩвдДІРэЪБЃЌВйзїЯЕЭГЭЈжЊгІгУГЬађЃЌЯпГЬДгзшШћзДЬЌЗЕЛиЃЌПЊЪМНјаавЕЮёДІРэЁЃ
ЛљгкЯпГЬГиИДгУЯпГЬзЪдДЃЌВЛБидйЮЊУПИіСЌНгДДНЈЯпГЬЃЌНЋСЌНгЭъГЩКѓЕФвЕЮёДІРэШЮЮёЗжХфИјЯпГЬНјааДІРэЃЌвЛИіЯпГЬПЩвдДІРэЖрИіСЌНгЕФвЕЮёЁЃ
I/O ИДгУНсКЯЯпГЬГиЃЌетОЭЪЧ Reactor ФЃЪНЛљБОЩшМЦЫМЯыЃЌШчЯТЭМЃК
Reactor ФЃЪНЃЌЪЧжИЭЈЙ§вЛИіЛђЖрИіЪфШыЭЌЪБДЋЕнИјЗўЮёДІРэЦїЕФЗўЮёЧыЧѓЕФЪТМўЧ§ЖЏДІРэФЃЪНЁЃ
ЗўЮёЖЫГЬађДІРэДЋШыЖрТЗЧыЧѓЃЌВЂНЋЫќУЧЭЌВНЗжХЩИјЧыЧѓЖдгІЕФДІРэЯпГЬЃЌReactor ФЃЪНвВНа Dispatcher
ФЃЪНЁЃ
МД I/O ЖрСЫИДгУЭГвЛМрЬ§ЪТМўЃЌЪеЕНЪТМўКѓЗжЗЂ(Dispatch ИјФГНјГЬ)ЃЌЪЧБраДИпадФмЭјТчЗўЮёЦїЕФБиБИММЪѕжЎвЛЁЃ
Reactor ФЃЪНжага 2 ИіЙиМќзщГЩЃК
ReactorЃЌReactor дквЛИіЕЅЖРЕФЯпГЬжадЫааЃЌИКд№МрЬ§КЭЗжЗЂЪТМўЃЌЗжЗЂИјЪЪЕБЕФДІРэГЬађРДЖд
IO ЪТМўзіГіЗДгІЁЃ ЫќОЭЯёЙЋЫОЕФЕчЛАНгЯпдБЃЌЫќНгЬ§РДздПЭЛЇЕФЕчЛАВЂНЋЯпТЗзЊвЦЕНЪЪЕБЕФСЊЯЕШЫЁЃ
HandlersЃЌДІРэГЬађжДаа I/O ЪТМўвЊЭъГЩЕФЪЕМЪЪТМўЃЌРрЫЦгкПЭЛЇЯывЊгыжЎНЛЬИЕФЙЋЫОжаЕФЪЕМЪЙйдБЁЃReactor
ЭЈЙ§ЕїЖШЪЪЕБЕФДІРэГЬађРДЯьгІ I/O ЪТМўЃЌДІРэГЬађжДааЗЧзшШћВйзїЁЃ
ИљОн Reactor ЕФЪ§СПКЭДІРэзЪдДГиЯпГЬЕФЪ§СПВЛЭЌЃЌга 3 жжЕфаЭЕФЪЕЯжЃК
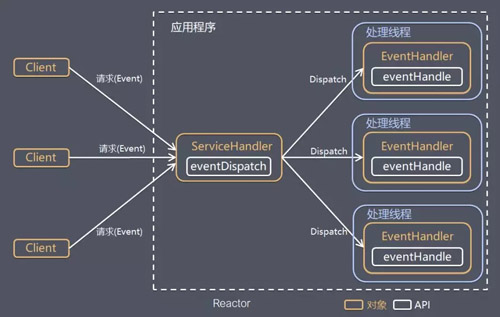
ЕЅ Reactor ЕЅЯпГЬ
ЕЅ Reactor ЖрЯпГЬ
жїДг Reactor ЖрЯпГЬ
ЯТУцЯъЯИНщЩмет 3 жжЪЕЯжЗНЪНЁЃ
ЕЅ Reactor ЕЅЯпГЬ

ЦфжаЃЌSelect ЪЧЧАУц I/O ИДгУФЃаЭНщЩмЕФБъзМЭјТчБрГЬ APIЃЌПЩвдЪЕЯжгІгУГЬађЭЈЙ§вЛИізшШћЖдЯѓМрЬ§ЖрТЗСЌНгЧыЧѓЃЌЦфЫћЗНАИЪОвтЭМРрЫЦЁЃ
ЗНАИЫЕУїЃК
Reactor ЖдЯѓЭЈЙ§ Select МрПиПЭЛЇЖЫЧыЧѓЪТМўЃЌЪеЕНЪТМўКѓЭЈЙ§ Dispatch НјааЗжЗЂЁЃ
ШчЙћЪЧНЈСЂСЌНгЧыЧѓЪТМўЃЌдђгЩ Acceptor ЭЈЙ§ Accept ДІРэСЌНгЧыЧѓЃЌШЛКѓДДНЈвЛИі Handler
ЖдЯѓДІРэСЌНгЭъГЩКѓЕФКѓајвЕЮёДІРэЁЃ
ШчЙћВЛЪЧНЈСЂСЌНгЪТМўЃЌдђ Reactor ЛсЗжЗЂЕїгУСЌНгЖдгІЕФ Handler РДЯьгІЁЃ
Handler ЛсЭъГЩ ReadЁњвЕЮёДІРэЁњSend ЕФЭъећвЕЮёСїГЬЁЃ
гХЕуЃКФЃаЭМђЕЅЃЌУЛгаЖрЯпГЬЁЂНјГЬЭЈаХЁЂОКељЕФЮЪЬтЃЌШЋВПЖМдквЛИіЯпГЬжаЭъГЩЁЃ
ШБЕуЃКадФмЮЪЬтЃЌжЛгавЛИіЯпГЬЃЌЮоЗЈЭъШЋЗЂЛгЖрКЫ CPU ЕФадФмЁЃHandler дкДІРэФГИіСЌНгЩЯЕФвЕЮёЪБЃЌећИіНјГЬЮоЗЈДІРэЦфЫћСЌНгЪТМўЃЌКмШнвзЕМжТадФмЦПОБЁЃ
ПЩППадЮЪЬтЃЌЯпГЬвтЭтХмЗЩЃЌЛђепНјШыЫРбЛЗЃЌЛсЕМжТећИіЯЕЭГЭЈаХФЃПщВЛПЩгУЃЌВЛФмНгЪеКЭДІРэЭтВПЯћЯЂЃЌдьГЩНкЕуЙЪеЯЁЃ
ЪЙгУГЁОАЃКПЭЛЇЖЫЕФЪ§СПгаЯоЃЌвЕЮёДІРэЗЧГЃПьЫйЃЌБШШч RedisЃЌвЕЮёДІРэЕФЪБМфИДдгЖШ O(1)ЁЃ
ЕЅ Reactor ЖрЯпГЬ
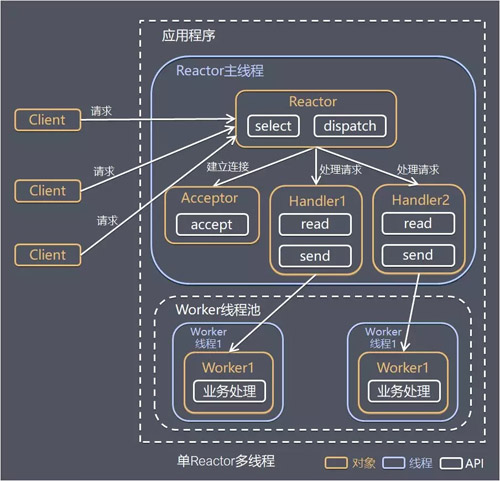
ЗНАИЫЕУїЃК
Reactor ЖдЯѓЭЈЙ§ Select МрПиПЭЛЇЖЫЧыЧѓЪТМўЃЌЪеЕНЪТМўКѓЭЈЙ§ Dispatch НјааЗжЗЂЁЃ
ШчЙћЪЧНЈСЂСЌНгЧыЧѓЪТМўЃЌдђгЩ Acceptor ЭЈЙ§ Accept ДІРэСЌНгЧыЧѓЃЌШЛКѓДДНЈвЛИі Handler
ЖдЯѓДІРэСЌНгЭъГЩКѓајЕФИїжжЪТМўЁЃ
ШчЙћВЛЪЧНЈСЂСЌНгЪТМўЃЌдђ Reactor ЛсЗжЗЂЕїгУСЌНгЖдгІЕФ Handler РДЯьгІЁЃ
Handler жЛИКд№ЯьгІЪТМўЃЌВЛзіОпЬхвЕЮёДІРэЃЌЭЈЙ§ Read ЖСШЁЪ§ОнКѓЃЌЛсЗжЗЂИјКѓУцЕФ Worker
ЯпГЬГиНјаавЕЮёДІРэЁЃ
Worker ЯпГЬГиЛсЗжХфЖРСЂЕФЯпГЬЭъГЩеце§ЕФвЕЮёДІРэЃЌШчКЮНЋЯьгІНсЙћЗЂИј Handler НјааДІРэЁЃ
Handler ЪеЕНЯьгІНсЙћКѓЭЈЙ§ Send НЋЯьгІНсЙћЗЕЛиИј ClientЁЃ
гХЕуЃКПЩвдГфЗжРћгУЖрКЫ CPU ЕФДІРэФмСІЁЃ
ШБЕуЃКЖрЯпГЬЪ§ОнЙВЯэКЭЗУЮЪБШНЯИДдгЃЛReactor ГаЕЃЫљгаЪТМўЕФМрЬ§КЭЯьгІЃЌдкЕЅЯпГЬжадЫааЃЌИпВЂЗЂГЁОАЯТШнвзГЩЮЊадФмЦПОБЁЃ
жїДг Reactor ЖрЯпГЬ
еыЖдЕЅ Reactor ЖрЯпГЬФЃаЭжаЃЌReactor дкЕЅЯпГЬжадЫааЃЌИпВЂЗЂГЁОАЯТШнвзГЩЮЊадФмЦПОБЃЌПЩвдШУ
Reactor дкЖрЯпГЬжадЫааЁЃ
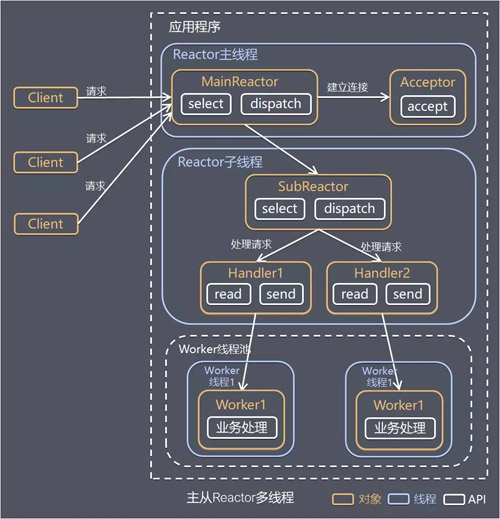
ЗНАИЫЕУїЃК
Reactor жїЯпГЬ MainReactor ЖдЯѓЭЈЙ§ Select МрПиНЈСЂСЌНгЪТМўЃЌЪеЕНЪТМўКѓЭЈЙ§
Acceptor НгЪеЃЌДІРэНЈСЂСЌНгЪТМўЁЃ
Acceptor ДІРэНЈСЂСЌНгЪТМўКѓЃЌMainReactor НЋСЌНгЗжХф Reactor згЯпГЬИј
SubReactor НјааДІРэЁЃ
SubReactor НЋСЌНгМгШыСЌНгЖгСаНјааМрЬ§ЃЌВЂДДНЈвЛИі Handler гУгкДІРэИїжжСЌНгЪТМўЁЃ
ЕБгааТЕФЪТМўЗЂЩњЪБЃЌSubReactor ЛсЕїгУСЌНгЖдгІЕФ Handler НјааЯьгІЁЃ
Handler ЭЈЙ§ Read ЖСШЁЪ§ОнКѓЃЌЛсЗжЗЂИјКѓУцЕФ Worker ЯпГЬГиНјаавЕЮёДІРэЁЃ
Worker ЯпГЬГиЛсЗжХфЖРСЂЕФЯпГЬЭъГЩеце§ЕФвЕЮёДІРэЃЌШчКЮНЋЯьгІНсЙћЗЂИј Handler НјааДІРэЁЃ
Handler ЪеЕНЯьгІНсЙћКѓЭЈЙ§ Send НЋЯьгІНсЙћЗЕЛиИј ClientЁЃ
гХЕуЃКИИЯпГЬгызгЯпГЬЕФЪ§ОнНЛЛЅМђЕЅжАд№УїШЗЃЌИИЯпГЬжЛашвЊНгЪеаТСЌНгЃЌзгЯпГЬЭъГЩКѓајЕФвЕЮёДІРэЁЃ
ИИЯпГЬгызгЯпГЬЕФЪ§ОнНЛЛЅМђЕЅЃЌReactor жїЯпГЬжЛашвЊАбаТСЌНгДЋИјзгЯпГЬЃЌзгЯпГЬЮоашЗЕЛиЪ§ОнЁЃ
етжжФЃаЭдкаэЖрЯюФПжаЙуЗКЪЙгУЃЌАќРЈ Nginx жїДг Reactor ЖрНјГЬФЃаЭЃЌMemcached
жїДгЖрЯпГЬЃЌNetty жїДгЖрЯпГЬФЃаЭЕФжЇГжЁЃ
3 жжФЃЪНПЩвдгУИіБШгїРДРэНтЃКВЭЬќГЃГЃЙЭгЖНгД§дБИКд№гНгЙЫПЭЃЌЕБЙЫПЭШызјКѓЃЌЪЬгІЩњзЈУХЮЊетеХзРзгЗўЮёЁЃ
ЕЅ Reactor ЕЅЯпГЬЃЌНгД§дБКЭЪЬгІЩњЪЧЭЌвЛИіШЫЃЌШЋГЬЮЊЙЫПЭЗўЮёЁЃ
ЕЅ Reactor ЖрЯпГЬЃЌ1 ИіНгД§дБЃЌЖрИіЪЬгІЩњЃЌНгД§дБжЛИКд№НгД§ЁЃ
жїДг Reactor ЖрЯпГЬЃЌЖрИіНгД§дБЃЌЖрИіЪЬгІЩњЁЃ
Reactor ФЃЪНОпгаШчЯТЕФгХЕуЃК
ЯьгІПьЃЌВЛБиЮЊЕЅИіЭЌВНЪБМфЫљзшШћЃЌЫфШЛ Reactor БОЩэвРШЛЪЧЭЌВНЕФЁЃ
БрГЬЯрЖдМђЕЅЃЌПЩвдзюДѓГЬЖШЕФБмУтИДдгЕФЖрЯпГЬМАЭЌВНЮЪЬтЃЌВЂЧвБмУтСЫЖрЯпГЬ/НјГЬЕФЧаЛЛПЊЯњЁЃ
ПЩРЉеЙадЃЌПЩвдЗНБуЕФЭЈЙ§діМг Reactor ЪЕР§ИіЪ§РДГфЗжРћгУ CPU зЪдДЁЃ
ПЩИДгУадЃЌReactor ФЃаЭБОЩэгыОпЬхЪТМўДІРэТпМЮоЙиЃЌОпгаКмИпЕФИДгУадЁЃ
Proactor ФЃаЭ
дк Reactor ФЃЪНжаЃЌReactor ЕШД§ФГИіЪТМўЛђепПЩгІгУЛђепВйзїЕФзДЬЌЗЂЩњЃЈБШШчЮФМўУшЪіЗћПЩЖСаДЃЌЛђепЪЧ
Socket ПЩЖСаДЃЉЁЃ
ШЛКѓАбетИіЪТМўДЋИјЪТЯШзЂВсЕФ HandlerЃЈЪТМўДІРэКЏЪ§ЛђепЛиЕїКЏЪ§ЃЉЃЌгЩКѓепРДзіЪЕМЪЕФЖСаДВйзїЁЃ
ЦфжаЕФЖСаДВйзїЖМашвЊгІгУГЬађЭЌВНВйзїЃЌЫљвд Reactor ЪЧЗЧзшШћЭЌВНЭјТчФЃаЭЁЃ
ШчЙћАб I/O ВйзїИФЮЊвьВНЃЌМДНЛИјВйзїЯЕЭГРДЭъГЩОЭФмНјвЛВНЬсЩ§адФмЃЌетОЭЪЧвьВНЭјТчФЃаЭ ProactorЁЃ
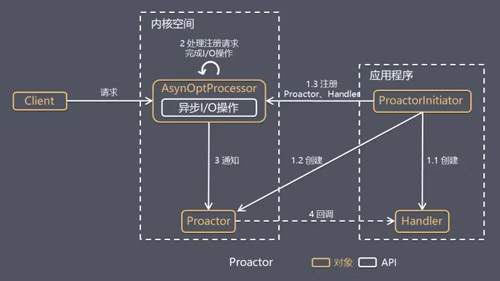
Proactor ЪЧКЭвьВН I/O ЯрЙиЕФЃЌЯъЯИЗНАИШчЯТЃК
1.Proactor Initiator ДДНЈ Proactor КЭ
Handler ЖдЯѓЃЌВЂНЋ Proactor КЭ Handler ЖМЭЈЙ§ AsyOptProcessorЃЈAsynchronous
Operation ProcessorЃЉзЂВсЕНФкКЫЁЃ
2.AsyOptProcessor ДІРэзЂВсЧыЧѓЃЌВЂДІРэ I/O
ВйзїЁЃ
3.AsyOptProcessor ЭъГЩ I/O ВйзїКѓЭЈжЊ ProactorЁЃ
4.Proactor ИљОнВЛЭЌЕФЪТМўРраЭЛиЕїВЛЭЌЕФ Handler
НјаавЕЮёДІРэЁЃ
5.Handler ЭъГЩвЕЮёДІРэЁЃ
ПЩвдПДГі Proactor КЭ Reactor ЕФЧјБ№ЃК
1.Reactor ЪЧдкЪТМўЗЂЩњЪБОЭЭЈжЊЪТЯШзЂВсЕФЪТМўЃЈЖСаДдкгІгУГЬађЯпГЬжаДІРэЭъГЩЃЉЁЃ
2.Proactor ЪЧдкЪТМўЗЂЩњЪБЛљгквьВН I/O ЭъГЩЖСаДВйзїЃЈгЩФкКЫЭъГЩЃЉЃЌД§
I/O ВйзїЭъГЩКѓВХЛиЕїгІгУГЬађЕФДІРэЦїРДНјаавЕЮёДІРэЁЃ
3.РэТлЩЯ Proactor БШ Reactor аЇТЪИќИпЃЌвьВН
I/O ИќМгГфЗжЗЂЛг DMA(Direct Memory AccessЃЌжБНгФкДцДцШЁ)ЕФгХЪЦЃЌЕЋЪЧгаШчЯТШБЕуЃК
4.БрГЬИДдгадЃЌгЩгквьВНВйзїСїГЬЕФЪТМўЕФГѕЪМЛЏКЭЪТМўЭъГЩдкЪБМфКЭПеМфЩЯЖМЪЧЯрЛЅЗжРыЕФЃЌвђДЫПЊЗЂвьВНгІгУГЬађИќМгИДдгЁЃгІгУГЬађЛЙПЩФмвђЮЊЗДЯђЕФСїПиЖјБфЕУИќМгФбвд
DebugЁЃ
5.ФкДцЪЙгУЃЌЛКГхЧјдкЖСЛђаДВйзїЕФЪБМфЖЮФкБиаыБЃГжзЁЃЌПЩФмдьГЩГжајЕФВЛШЗЖЈадЃЌВЂЧвУПИіВЂЗЂВйзїЖМвЊЧѓгаЖРСЂЕФЛКДцЃЌЯрБШ
Reactor ФЃЪНЃЌдк Socket вбОзМБИКУЖСЛђаДЧАЃЌЪЧВЛвЊЧѓПЊБйЛКДцЕФЁЃ
6.ВйзїЯЕЭГжЇГжЃЌWindows ЯТЭЈЙ§ IOCP ЪЕЯжСЫеце§ЕФвьВН
I/OЃЌЖјдк Linux ЯЕЭГЯТЃЌLinux 2.6 ВХв§ШыЃЌФПЧАвьВН I/O ЛЙВЛЭъЩЦЁЃ
вђДЫдк Linux ЯТЪЕЯжИпВЂЗЂЭјТчБрГЬЖМЪЧвд Reactor ФЃаЭЮЊжїЁЃ |








