| БрМЭЦМі: |
БОЦЊЮФеТжївЊНщЩмСЫ
HTTP ЫФжжБъЭЗЕФЛљБОИХФювдМАHTTP ЕФЛљБОЬиеїКЭЪЙгУЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ
БОЮФРДздгкCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЭЦМіЁЃ |
|
HTTP БъЭЗ
ЯШРДЛиЙЫвЛЯТ HTTP1.1 БъЭЗЖМгаФФМИжж
HTTP 1.1 ЕФБъЭЗжївЊЗжЮЊЫФжжЃЌЭЈгУБъЭЗЁЂЪЕЬхБъЭЗЁЂЧыЧѓБъЭЗЁЂЯьгІБъЭЗЃЌЯждкЮвУЧРДЖдетМИжжБъЭЗНјааНщЩм
ЭЈгУБъЭЗ
HTTP ЭЈгУБъЭЗжЎЫљвдетбљУќУћЃЌЪЧвђЮЊгыЦфЫћШ§ИіРрБ№ВЛЭЌЃЌЫќУЧВЛЪЧЯоЖЈгкЬиЖЈжжРрЕФЯћЯЂЛђепЯћЯЂзщМўЃЈЧыЧѓЃЌЯьгІЛђЯћЯЂЪЕЬхЃЉЕФЁЃHTTP
ЭЈгУБъЭЗжївЊгУгкДЋДягаЙиЯћЯЂБОЩэЕФаХЯЂЃЌЖјВЛЪЧЫќЫљаЏДјЕФФкШнЁЃЫќУЧЬсЙЉвЛАуаХЯЂВЂПижЦШчКЮДІРэКЭДІРэЯћЯЂЁЃ
ОЁЙмЭЈгУБъЭЗВЛЛсЯоЖЈгкЪЧЧыЧѓЛЙЪЧЯьгІБЈЮФЃЌЕЋЪЧФГаЉЭЈгУБъЭЗДѓВПЗжЛђШЋВПгУгквЛжжЬиЖЈРраЭЕФЧыЧѓжаЁЃвВОЭЪЧЫЕЃЌШчЙћФГИіЭЈгУБъЭЗГіЯждкЧыЧѓБЈЮФжаЃЌФЧУДДѓВПЗжЭЈгУБъЭЗЖМЛсЯдЪОдкИУЧыЧѓБЈЮФжаЁЃЯьгІБЈЮФвВЪЧвЛбљЕФЁЃ
ЯШСаГіРДвЛИіЧхЕЅЃЌНВУїЮвУЧЖМашвЊНщЩмФФаЉЭЈгУБъЭЗ
1.Cache-Control
2.Connection
3.Date
4.Pragma
5.Trailer
6.Transfer-Encoding
7.Upgrade
8.Via
9.Warning
Cache-Control
ЛКДцЃЈCacheЃЉЪЧМЦЫуЛњСьгђРяЕФвЛИіживЊИХФюЃЌЪЧгХЛЏЯЕЭГадФмЕФРћЦїЁЃВЛНіМЦЫуЛњжаЕФ CPU ЮЊСЫЬсИпжИСюжДаааЇТЪДгЖјбЁдёЪЙгУМФДцЦїзїЮЊИЈжњЃЌМЦЫуЛњЭјТчЭЌбљДцдкЛКДцЃЌЯТУцЮвУЧОЭРДНщЩмвЛЯТМЦЫуЛњЭјТчжаЕФЛКДцЁЃ
Cache-Control ЪЧЭЈгУБъЭЗЕФжИСюЃЌЫќФмЙЛЙмРэШчКЮЖд HTTP ЕФЧыЧѓЛђепЯьгІЪЙгУЛКДцЁЃ
вђЮЊМЦЫуЛњЭјТчжаЪЧПЩвдгаЕкШ§епГіЯжЕФЃЌвВОЭЪЧЛКДцЗўЮёЦїЃЌетИіжИСюЭЈЙ§гАЯьЧыЧѓ/ЯьгІжаЕФЛКДцЗўЮёЦїДгЖјДяЕНПижЦЛКДцЕФФПЕФЃЛВЛНігаЛКДцЗўЮёЦїЃЌЛЙгафЏРРЦїФкВПЛКДцвВЛсгАЯьСДТЗЕФЛКДцЁЃ
етИіБъЭЗжаПЩвдГіЯжаэЖрЕЅЖРЕФжИСюЃЌЦфЯъЯИаХЯЂПЩвддк RFC 2616
жаевЕНЃЌМДЪЙетЪЧГЃЙцБъЭЗЃЌФГаЉжИСювВжЛФмГіЯждкЧыЧѓЛђЯьгІжаЁЃЯТБэЬсЙЉСЫвЛИі Cache-Control
бЁЯюЕФзмНсВЂИцЫпФуШчКЮШЅЪЙгУ
ЧызЂвтЃЌдк Cache-Control БъЭЗжажЛФмГіЯжвЛИіжИСюЃЌЕЋЪЧдкЯћЯЂжаПЩвдГіЯжЖрИіетбљЕФБъЭЗЁЃ
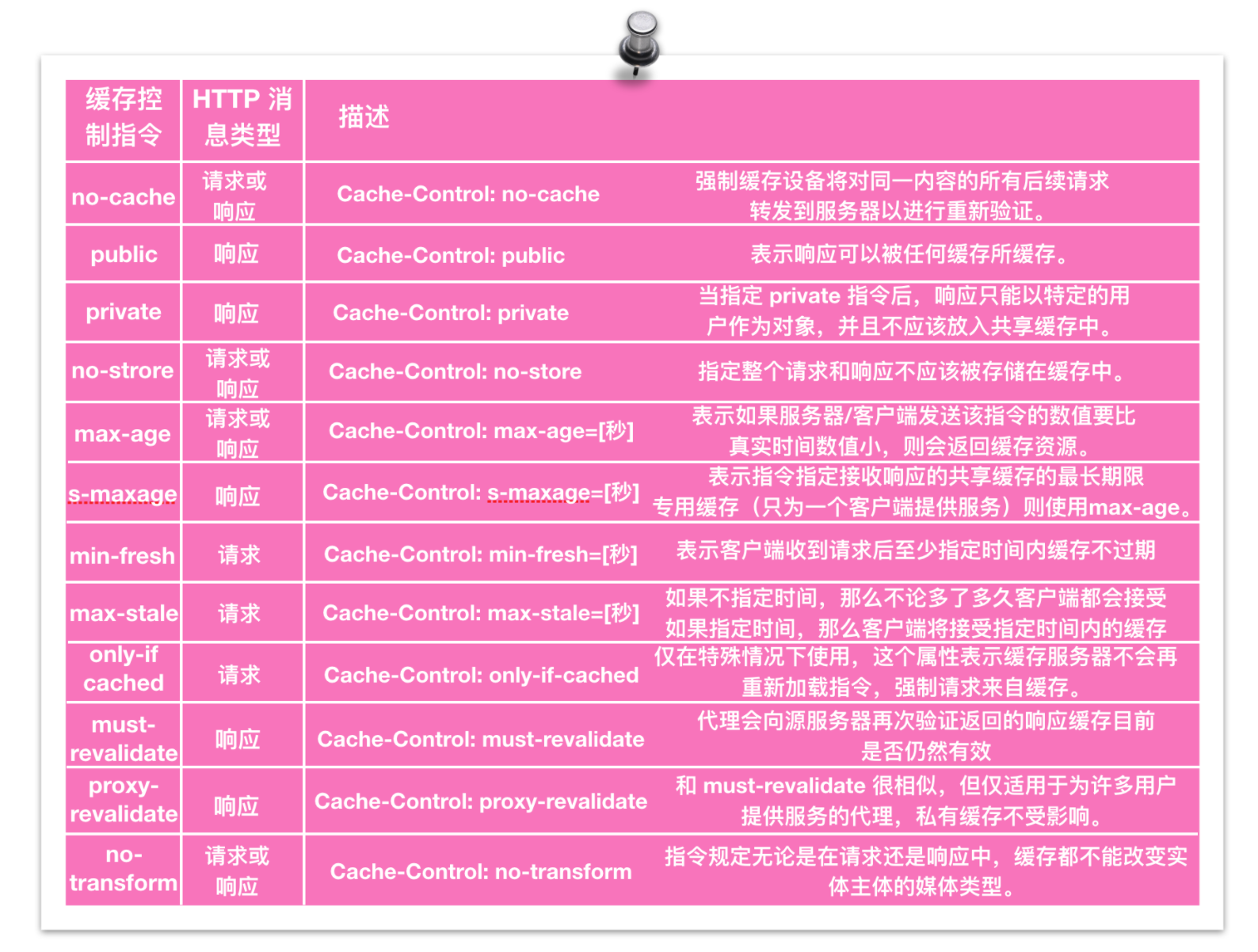
ЩЯУцетИіБэИёЦфЪЕЛсгаЫФжжЗжРр
ПЩЛКДцадЃК ЫќУЧЗжБ№ЪЧ no-cacheЁЂno-storeЁЂprivate КЭ public
ЛКДцгааЇадЪБМфЃК ЫќУЧЗжБ№ЪЧ max-ageЁЂs-maxageЁЂmax-staleЁЂmin-fresh
жиаТбщжЄВЂжиаТМгдиЃК ЫќУЧЗжБ№ЪЧ must-revalidate КЭ proxy-revalidate
ЦфЫћЃК ЫќУЧЗжБ№ЪЧ only-if-cached КЭ no-transform
ЗжБ№ЖдБэИёжаЕФФкШнНјаавЛЯТЯъЯИНщЩм
no-cache
no-cache КмШнвзКЭ no-store ЛьЯ§ЃЌвЛАуЖМЛсАб no-cache ШЯЮЊЪЧВЛЛКДцЃЌЦфЪЕВЛЪЧетбљЁЃ
ЪЙгУ no-cache жИСюЕФФПЕФЪЧЮЊСЫЗРжЙДгЛКДцжаЗЕЛиЙ§ЦкЕФзЪдДЃЌР§ШчЯТЭМЫљЪО

ОйИіР§згФуОЭУїАзСЫЃЌNo-Cache ОЭЯрЕБгкЪЧГдзХЭыРяЕФЃЌеМзХЙјРяЕФЃЌШчЙћЙјРяЛЙгааТЕФШтЦЌЃЌОЭЯШГдЙјРяЕФЃЌШчЙћЙјРяУЛгааТЕФЃЌдйГдздМКЕФЃЌетРяЙјРяЕФОЭЯрЕБгкЪЧдДЗўЮёЦїВњЩњЕФЃЌЭыРяЕФОЭЯрЕБгкЪЧЛКДцЕФЁЃ
no-store
no-store ВХЪЧеце§втвхЩЯЕФВЛЛКДцЃЌУПДЮЗўЮёЦїНгЪмЕНПЭЛЇЖЫЕФЧыЧѓКѓЃЌЖМЛсЗЕЛизюаТЕФзЪдДИјПЭЛЇЖЫЁЃ
max-age
max-age ПЩвдгУдкЧыЧѓЛђепЯьгІжаЃЌЕБПЭЛЇЖЫЗЂЫЭДјга max-age ЕФжИСюЪБЃЌЛКДцЗўЮёЦїЛсХаЖЯздМКЛКДцЪБМфЕФЪ§жЕКЭ
max-age ЕФДѓаЁЃЌШчЙћБШ max-age аЁЃЌФЧУДЛКДцгааЇЃЌПЩвдМЬајИјПЭЛЇЖЫЗЕЛиЛКДцЕФЪ§ОнЃЌШчЙћБШ
max-age ДѓЃЌФЧУДЛКДцЗўЮёЦїНЋВЛФмЗЕЛиИјПЭЛЇЖЫЛКДцЕФЪ§ОнЁЃ
| Cache-Control:
max-age=60 |
ШчЙћ max-age = 0ЃЌФЧУДЛКДцЗўЮёЦїНЋЛсжБНгАбЧыЧѓзЊЗЂЕНЗўЮёЦї
зЂвтЃКетИі max-age ЕФжЕЪЧЯрЖдгкЧыЧѓЪБМфЕФ
must-revalidate
БэЪОвЛЕЉзЪдДЙ§ЦкЃЌЛКДцОЭБиаыдкдЪМЗўЮёЦїЩЯУЛгаГЩЙІбщжЄЕФЧщПіЯТВХЪЙгУЦфЙ§ЦкЕФЪ§ОнЁЃ
| Cache-Control:
must-revalidate |
no-store ЁЂno_cache ЁЂ must-revalidate
КЭ max-age ПЩвдвЛЦ№ПДЃЌЯТУцЪЧвЛИіетЫФИіБъЭЗЕФСїГЬЭМ

public
public ЪєаджЛГіЯждкПЭЛЇЖЫЯьгІжаЃЌБэЪОЯьгІПЩвдБЛШЮКЮЛКДцЫљЛКДцЁЃдкМЦЫуЛњЭјТчжаЃЌЗжЮЊСНжжЛКДцЃЌЙВЯэЛКДцКЭЫНгаЛКДцЃЌШчЯТЫљЪО

1private
ЕБжИЖЈ private жИСюКѓЃЌЯьгІжЛвдЬиЖЈЕФгУЛЇзїЮЊЖдЯѓЃЌетгы public ЕФгУЗЈЯрЗДЃЌЛКДцЗўЮёЦїжЛЖдЬиЖЈЕФПЭЛЇЖЫНјааЛКДцЃЌЦфЫћПЭЛЇЖЫЗЂЫЭЙ§РДЕФЧыЧѓЃЌЛКДцЗўЮёЦїдђВЛЛсЗЕЛиЛКДцЁЃ

1s-maxage
s-maxage жИСюЕФЙІФмКЭ max-age жИСюЕФЙІФмЯрЭЌЃЌВЛЭЌЕужЎДІдкгк s-maxage ВЛФмгУгкЫНгаЛКДцЃЌжЛФмгУгкЖргУЛЇЪЙгУЕФЙЋЙВЗўЮёЦїЃЌЖдгкЭЌвЛгУЛЇЕФжиИДЧыЧѓКЭЯьгІРДЫЕЃЌетИіжИСюУЛгаШЮКЮзїгУЁЃ
| Cache-Control:
s-maxage=60 |
min-fresh
min-freshжЛФмГіЯждкЧыЧѓжаЃЌmin-fresh вЊЧѓЛКДцЗўЮёЦїЗЕЛи min-fresh ЪБМфФкЕФЛКДцЪ§ОнЁЃР§Шч
Cache-Control:min-fresh=60ЃЌетОЭвЊЧѓЛКДцЗўЮёЦїЗЂЫЭ60УыФкЕФЪ§ОнЁЃ
| Cache-Control:
min-fresh=60 |
max-stable
max-stable жЛФмГіЯждкЧыЧѓжаЃЌБэЪОПЭЛЇЖЫЛсНгЪмЛКДцЪ§ОнЃЌМДЪЙЙ§ЦквВееГЃНгЪеЁЃ
| Cache-Control:
max-stable=60 |
only-if-cached
етИіБъЭЗжЛФмГіЯждкЧыЧѓжаЃЌЪЙгУ only-if-cached жИСюБэЪОПЭЛЇЖЫНідкЛКДцЗўЮёЦїБОЕиЛКДцФПБъзЪдДЕФЧщПіЯТВХЛсвЊЧѓЦфЗЕЛиЁЃ
| Cache-Control:
only-if-cached |
proxy-revalidate
proxy-revalidate жИСювЊЧѓЫљгаЕФЛКДцЗўЮёЦїдкНгЪеЕНПЭЛЇЖЫДјгаИУжИСюЕФЧыЧѓЗЕЛиЯьгІжЎЧАЃЌБиаыдйДЮбщжЄЛКДцЕФгааЇадЁЃ
| Cache-Control:
proxy-revalidate |
no-transform
ЪЙгУ no-transform жИСюЙцЖЈЮоТлЪЧдкЧыЧѓЛЙЪЧЯьгІжаЃЌЛКДцЖМВЛФмИФБфЪЕЬхжїЬхЕФУНЬхРраЭЁЃ
| Cache-Control:
no-transform |
Connection
HTTP авщЪЙгУ TCP РДЙмРэСЌНгЗНЪНЃЌжївЊгаСНжжСЌНгЗНЪНЃЌГжОУадСЌНг КЭ ЗЧГжОУадСЌНгЁЃ
ГжОУадСЌНг
ГжОУадСЌНгжИЕФЪЧвЛДЮЛсЛАЭъГЩКѓЃЌTCP СЌНгВЂЮДЙиБеЃЌЕкЖўДЮдйДЮЗЂЫЭЧыЧѓКѓЃЌОЭВЛдйашвЊНЈСЂ TCP
СЌНгЃЌЖјЪЧПЩвджБНгНјааЧыЧѓКЭЯьгІЁЃЫќЕФвЛАуБэЪОаЮЪНШчЯТ
Дг HTTP 1.1 ПЊЪМЃЌФЌШЯЪЙгУГжОУадСЌНгЁЃ
keep-alive вВЪЧвЛИіЭЈгУБъЭЗЃЌвЛАу Connection ЖМЛсКЭ keep-alive вЛЦ№ЪЙгУЃЌkeep-alive
гаСНИіВЮЪ§ЃЌвЛИіЪЧ timeoutЃЛСэвЛИіЪЧ maxЃЌЫќУЧЕФжївЊБэЯжаЮЪНШчЯТ
Connection:
Keep-Alive
Keep-Alive: timeout=5, max=1000 |
timeout: жИЕФЪЧПеЯаСЌНгБиаыДђПЊЕФзюЖЬЪБМфЃЌвВОЭЪЧЫЕетДЮЧыЧѓЕФСЌНгЪБМфВЛФмЩйгк5УыЃЌ
max: жИЕФЪЧдкСЌНгЙиБежЎЧАЗўЮёЦїЫљФмЙЛЪеЕНЕФзюДѓЧыЧѓЪ§ЁЃ
ЗЧГжОУадСЌНг
ЗЧГжОУадСЌНгБэЪОвЛДЮЛсЛАЧыЧѓ/ЯьгІКѓЙиБеСЌНгЕФЗНЪНЁЃHTTP 1.1 жЎЧАЪЙгУЕФСЌНгЖМЪЧЗЧГжОУСЌНгЃЌвВОЭЪЧ
Date
Date ЪЧвЛИіЭЈгУБъЭЗЃЌЫќПЩвдГіЯждкЧыЧѓБъЭЗКЭЯьгІБъЭЗжаЃЌЫќЕФЛљБОБэЪОШчЯТ
| Date: Wed, 21
Oct 2015 07:28:00 GMT |
БэЪОЕФЪЧИёСжЭўжЮБъзМЪБМфЃЌетИіЪБМфвЊБШББОЉЪБМфТ§АЫИіаЁЪБ

Pragma
PragmaЪЧ http 1.1 жЎЧААцБОЕФРњЪЗвХСєзжЖЮЃЌНізїЮЊгы http ЕФЯђКѓМцШнЖјЖЈвхЁЃЫќЕФвЛАуаЮЪНШчЯТ
жЛгУгкПЭЛЇЖЫЗЂЫЭЕФЧыЧѓжаЁЃПЭЛЇЖЫЛсвЊЧѓЫљгаЕФжаМфЗўЮёЦїВЛЗЕЛиЛКДцЕФзЪдДЁЃ
ШчЙћЫљгаЕФжаМфЗўЮёЦїЖМвдЪЕЯж HTTP /1.1ЮЊБъзМЃЌФЧУДжБНгЪЙгУ Cache-Control:
no-cache МДПЩЃЌШчЙћВЛЪЧЕФЛАЃЌОЭвЊАќКЌСНИізжЖЮЃЌШчЯТ
Cache-Control:
no-cache
Pragma: no-cache |
Trailer
ЪзВПзжЖЮ Trailer ЛсЪТЯШЫЕУїдкБЈЮФжїЬхКѓМЧТМСЫФФаЉЪзВПзжЖЮЁЃИУЪзВПзжЖЮПЩгІгУдк HTTP/1.1
АцБОЗжПщДЋЪфБрТыЪБЁЃвЛАугУЗЈШчЯТ
Transfer-Encoding:
chunked
Trailer: Expires |
вдЩЯгУР§жаЃЌжИЖЈЪзВПзжЖЮ Trailer ЕФжЕЮЊ ExpiresЃЌдкБЈЮФжїЬхжЎКѓЃЈЗжПщГЄЖШ 0 жЎКѓЃЉГіЯжСЫЪзВПзжЖЮ
ExpiresЁЃ
Transfer-Encoding
Transfer-Encoding ЪєгкФкШнаЩЬЕФЗЖГыЃЌЯТУцЛсОпЬхНщЩмвЛЯТФкШнаЩЬЃЌЯждкЯШзіИідЄИцЃКTransfer-Encoding
ЙцЖЈСЫДЋЪфБЈЮФЫљВЩгУЕФБрТыЗНЪН
| Transfer-Encoding:
chunked |
зЂвтЃКHTTP 1.1 ЕФДЋЪфБрТыЗНЪННіЖдЗжПщДЋЪфгааЇЃЌЕЋЪЧ HTTP 2.0 ОЭВЛдйжЇГжЗжПщДЋЪфЃЌЖјЬсЙЉСЫздМКИќгааЇЕФЪ§ОнДЋЪфЛњжЦЁЃ
Transfer-Encoding вВЪєгк Hop-by-hopЃЈж№ЬјЃЉ ЪзВП ЃЌЯТУцРДЛиЙЫвЛЯТЃЌHTTP
БЈЮФБъЭЗГ§СЫПЩвдИљОнЪєадЫљдкЕФЮЛжУЗжЮЊ ЭЈгУБъЭЗЁЂЧыЧѓБъЭЗЁЂЯьгІБъЭЗ КЭ ЪЕЬхБъЭЗЃЛЛЙПЩвдАДееЪЧЗёБЛЛКДцЗжЮЊ
ЖЫЕНЖЫЪзВП(End-to-End) КЭ ж№ЬјЪзВП(Top-to-Top)ЁЃ
Г§СЫЯТУцАЫжжЪєгкж№ЬјЪзВПЭтЃЌЦфгрЖМЪєгкЖЫЕНЖЫЪзВП
Connection ЁЂKeep-Alive ЁЂProxy-Authenticate
ЁЂProxy-Authorization ЁЂTrailer ЁЂTE ЁЂTransfer-Encoding
ЁЂUpgrade
ЯТУцЛиЕНЬжТлжаРДЃЌTransfer-Encoding гУгкСНИіНкЕужЎМфДЋЪфЯћЯЂЃЌЖјВЛЪЧзЪдДБОЩэЁЃдкЖрИіНкЕуДЋЪфЯћЯЂЕФЙ§ГЬжаЃЌУПвЛЖЮЯћЯЂЕФДЋЪфЖМПЩвдЪЙгУВЛЭЌЕФ
Transfer-EncodingЁЃШчЭМЫљЪО

Transfer-Encoding жЇГжЮФМўбЙЫѕЃЌШчЙћФуЯывЊвдЮФМўбЙЫѕКѓЕФаЮЪНЗЂЫЭЕФЛАЁЃTransfer-Encoding
ЫљгаПЩбЁРраЭШчЯТ
chunkedЃК Ъ§ОнАДеевЛЯЕСаПщЗЂЫЭЃЌдкетжжЧщПіЯТЃЌНЋЪЁТд Content-Length БъЭЗЃЌВЂдкУПИіПщЕФПЊЭЗЃЌашвЊвдЪЎСљНјжЦЬюГфЕБЧАПщЕФГЄЖШЃЌКѓИњ
'\r\n'ЃЌШЛКѓЪЧПщБОЩэЃЌШЛКѓЪЧСэвЛИі'\r\n'ЁЃЕБНЋДѓСПЪ§ОнЗЂЫЭЕНПЭЛЇЖЫВЂЧвдкЧыЧѓвбБЛЭъШЋДІРэжЎЧАЃЌПЩФмЮоЗЈжЊЕРЯьгІЕФзмДѓаЁЪБЃЌЗжПщБрТыКмгагУЁЃ
Р§ШчЃЌдкЩњГЩгЩЪ§ОнПтВщбЏВњЩњЕФДѓаЭ HTML БэЪБЛђдкДЋЪфДѓаЭЭМЯёЪБЁЃ ЗжПщЕФЯьгІПДЦ№РДЯёетбљ
HTTP/1.1 200
OK
Content-Type: text/plain
Transfer-Encoding: chunked
7\r\n
Mozilla\r\n
9\r\n
Developer\r\n
7\r\n
Network\r\n
0\r\n
\r\n |
жежЙПщЭЈГЃЪЧ0ЁЃНєЫцTransfer-Encoding КѓУцЕФЪЧ Trailer БъЭЗЃЌ Trailer
ПЩФмЮЊПеЁЃ
compressЃК ЪЙгУ Lempel-Ziv-Welch(LZW) ЫуЗЈЕФИёЪНЁЃжЕУћГЦШЁзд UNIX
бЙЫѕГЬађЃЌИУГЬађЪЕЯжСЫИУЫуЗЈЁЃЯждкМИКѕУЛгафЏРРЦїЪЙгУетжжФкШнБрТыСЫЃЌвђЮЊетИізЈРћдк 2003 ФъОЭЭЃЕєСЫЁЃ
deflateЃКЪЙгУ zlib(дк RFC 1950 ЖЈвх) НсЙЙКЭ deflate бЙЫѕЫуЗЈ
gzipЃК ЪЙгУLempel-ZivБрТыЃЈLZ77ЃЉКЭ32ЮЛCRCЕФИёЪНЁЃетзюГѕЪЧ UNIX gzip
ГЬађЕФИёЪНЁЃHTTP / 1.1БъзМЛЙНЈвщГігкМцШнадФПЕФЃЌжЇГжДЫФкШнБрТыЕФЗўЮёЦїгІНЋ x-gzip
ЪЖБ№ЮЊБ№УћЁЃ
identityЃК ЪЙгУЩэЗнЙІФмЃЈМДЮобЙЫѕЛђаоИФЃЉЁЃ
вВПЩвдСаГіЖрИіжЕЃЌвдЖККХЗжИєЃЌРрЫЦвЛИіМЏКЯСаБэ
| Transfer-Encoding:
gzip, chunked |
Upgrade
ЪзВПзжЖЮ Upgrade гУгкМьВт HTTP авщМАЦфЫћавщЪЧЗёПЩЪЙгУИќИпЕФАцБОНјааЭЈаХЃЌЦфВЮЪ§жЕПЩвдгУРДжИЖЈвЛИіЭъШЋВЛЭЌЕФЭЈаХавщЁЃ

ЩЯЭМгУР§жаЃЌЪзВПзжЖЮ Upgrade жИЖЈЕФжЕЮЊ TLS/1.0ЁЃЧызЂвтДЫДІСНИізжЖЮЪзВПзжЖЮЕФЖдгІЙиЯЕЃЌConnection
ЕФжЕБЛжИЖЈЮЊ UpgradeЁЃ
Upgrade ЪзВПзжЖЮВњЩњзїгУЕФЖдЯѓНіЯогкПЭЛЇЖЫКЭСйНќЗўЮёЦїжЎМфЁЃвђДЫЃЌЪЙгУЪзВПзжЖЮ Upgrade
ЪБЃЌЛЙашвЊЖюЭтжИЖЈ Connection: UpgradeЁЃ
ЖдгкИНгаЪзВПзжЖЮ Upgrade ЕФЧыЧѓЃЌЗўЮёЦїПЩгУ 101 Switching Protocols
зДЬЌТызїЮЊЯьгІЗЕЛиЁЃ
Via
ЪЙгУ Via ЪЧЮЊСЫИњзйПЭЛЇЖЫКЭЗўЮёЦїжЎМфЕФЧыЧѓ/ЯьгІТЗОЖЃЌБмУтЧыЧѓбЛЗвдМАФмЙЛЪЖБ№ЧыЧѓ/ЯьгІСДжаЗЂЫЭепавщЕФЙІФмЁЃVia
зжЖЮгЩДњРэЗўЮёЦїЬэМгЃЌВЛТлЪЧе§ЯђДњРэЛЙЪЧЗДЯђДњРэЃЌВЂЧвПЩвдГіЯждкЧыЧѓБъЭЗКЭЯьгІБъЭЗжаЁЃЫќгУгкИњзйЯћЯЂзЊЗЂЁЃР§ШчЯТЭМЫљЪО

Via КѓУцЕФЕФ 1.1, 1.0 БэЪОНгЪеЗўЮёЦїЩЯЕФ HTTP АцБОЃЌVia ЪзВПЪЧЮЊСЫИњзйТЗОЖЃЌОГЃКЭ
TRACE ЗНЗЈвЛЦ№ЪЙгУЁЃ
Warning
зЂвтЃКWarning зжЖЮМДНЋБЛЦњгУ
Warning ЭЈгУ HTTP БъЭЗЭЈГЃЛсИцжЊгУЛЇвЛаЉгыЛКДцЯрЙиЕФЮЪЬтЕФОЏИц
HTTP/1.1 жаЖЈвхСЫ 7 жжОЏИцЁЃЫќУЧЗжБ№ШчЯТ

ЧыЧѓБъЭЗ
ЧыЧѓБъЭЗгУгкПЭЛЇЖЫЗЂЫЭ HTTP ЧыЧѓЕНЗўЮёЦїжаЫљЪЙгУЕФзжЖЮЃЌЯТУцЮвУЧвЛЦ№РДПДвЛЯТ HTTP ЧыЧѓБъЭЗЖМАќКЌФФаЉзжЖЮЃЌЗжБ№ЪЧЪВУДвтЫМЁЃЯТУцЛсНщЩм
Accept
Accept-Charset
Accept-Encoding
Accept-Language
Authorization
Expect
From
Host
If-Match
If-Modified-Since
If-None-Match
If-Range
If-Unmodified-Since
Max-Forwards
Proxy-Authorization
RangeReferer
TE
User-Agent
ЯТУцЗжБ№РДНщЩмвЛЯТ
Accept
HTTP ЧыЧѓБъЭЗЛсИцжЊПЭЛЇЖЫФмЙЛНгЪеЕФ MIME РраЭЪЧЪВУД
ФЧУДЪВУДЪЧ MIME РраЭФиЃПдкЛиД№етИіЮЪЬтЧАФугІИУЯШСЫНтвЛЯТЪВУДЪЧ MIME
MIME: MIME (Multipurpose Internet Mail Extensions)
ЪЧУшЪіЯћЯЂФкШнРраЭЕФвђЬиЭјБъзМЁЃMIME ЯћЯЂФмАќКЌЮФБОЁЂЭМЯёЁЂвєЦЕЁЂЪгЦЕвдМАЦфЫћгІгУГЬађзЈгУЕФЪ§ОнЁЃ
вВОЭЪЧЫЕЃЌMIME РраЭЦфЪЕОЭЪЧвЛЯЕСаЯћЯЂФкШнРраЭЕФМЏКЯЁЃФЧУД MIME РраЭЖМгаФФаЉФиЃП
ЮФБОЮФМўЃК text/html ЁЂtext/plain ЁЂtext/css
ЁЂapplication/xhtml+xml ЁЂapplication/xml
ЭМЦЌЮФМўЃК image/jpegЁЂimage/gifЁЂimage/png
ЪгЦЕЮФМўЃК video/mpegЁЂvideo/quicktime
гІгУГЬађЖўНјжЦЮФМўЃК application/octet-streamЁЂapplication/zip
БШШчЃЌШчЙћфЏРРЦїВЛжЇГж PNG ЭМЦЌЕФЯдЪОЃЌФЧ Accept ОЭВЛжИЖЈimage/pngЃЌЖјжИЖЈПЩДІРэЕФ
image/gif КЭ image/jpeg ЕШЭМЦЌРраЭЁЃ
вЛАу MIME РраЭвВЛсКЭ q етИіЪєадвЛЦ№ЪЙгУЃЌq ЪЧЪВУДЃПq БэЪОЕФЪЧШЈжиЃЌРДПДвЛИіР§зг
| Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
етЪЧЪВУДвтЫМФиЃПШєЯывЊИјЯдЪОЕФУНЬхРраЭдіМггХЯШМЖЃЌдђЪЙгУ q= РДЖюЭтБэЪОШЈжижЕЃЌУЛгаЯдЪОШЈжиЕФЪБКђФЌШЯжЕЪЧ1.0
ЃЌЮвИјФуСаИіБэИёФуОЭУїАзСЫ

вВОЭЪЧЫЕЃЌетЪЧвЛИіЗХжУЫГађЃЌШЈжиИпЕФдкЧАЃЌЕЭЕФдкКѓЃЌapplication/xml;q=0.9 ЪЧВЛПЩЗжИюЕФећЬхЁЃ
Accept-Charset
Accept-Charset БэЪОПЭЛЇЖЫФмЙЛНгЪмЕФзжЗћБрТыЁЃAccept-Charset вВЪЧЪєгкФкШнаЩЬЕФвЛВПЗжЃЌЫќКЭ
Accept вЛбљЃЌвВПЩвдгУ q РДБэЪОзжЗћМЏЃЌгУЖККХНјааЗжИюЃЌР§Шч
Accept-Charset:
iso-8859-1
Accept-Charset: utf-8, iso-8859-1;q=0.5
Accept-Charset: utf-8, iso-8859-1;q=0.5, *;q=0.1 |
ЪТЪЕЩЯЃЌКмЖрвд Accept-* ПЊЭЗЕФБъЭЗЃЌЖМЪЧЪєгкФкШнаЩЬЕФЗЖГыЃЌЙигкФкШнаЩЬЮвУЧЯТУцЛсЫЕЁЃ
Accept-Encoding
БэЪО HTTP БъЭЗЛсБъУїПЭЛЇЖЫЯЃЭћЗўЮёЖЫЗЕЛиЕФФкШнБрТыЃЌетЭЈГЃЪЧвЛжжбЙЫѕЫуЗЈЁЃAccept-Encoding
вВЪЧЪєгкФкШнаЩЬ ЕФвЛВПЗжЃЌЪЙгУВЂЭЈЙ§ПЭЛЇЖЫбЁдё Content-Encoding ФкШнНјааЗЕЛиЁЃ
МДЪЙПЭЛЇЖЫКЭЗўЮёЦїЖМФмЙЛжЇГжЯрЭЌЕФбЙЫѕЫуЗЈЃЌЗўЮёЦївВПЩФмбЁдёВЛбЙЫѕВЂЗЕЛиЃЌетжжЧщПіПЩФмЪЧгЩгкетСНжжЧщПідьГЩЕФ:
вЊЗЂЫЭЕФЪ§ОнвбОБЛбЙЫѕСЫвЛДЮЃЌЕкЖўДЮбЙЫѕВЂВЛЛсЕМжТЗЂЫЭЕФЪ§ОнИќаЁ
ЗўЮёЦїЙ§диЃЌЮоЗЈГаЪмбЙЫѕДјРДЕФадФмПЊЯњЃЌЭЈГЃЃЌШчЙћЗўЮёЦїЪЙгУ CPU ГЌЙ§ 80% ЃЌMicrosoft
дђНЈвщВЛвЊЪЙгУбЙЫѕ
ЯТУцЪЧ Accept-Encoding ЕФЪЙгУЗНЪН
Accept-Encoding:
gzip
Accept-Encoding: compress
Accept-Encoding: deflate
Accept-Encoding: br
Accept-Encoding: identity
Accept-Encoding: *
Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5 |
ЩЯУцЕФМИжжБэЪіЗНЪНОЭвбОАб Accept-Encoding ЕФЪєадСаШЋСЫ
gzip: гЩЮФМўбЙЫѕГЬађ gzip ЩњГЩЕФБрТыИёЪНЃЌЪЙгУ Lempel-ZivБрТыЃЈLZ77ЃЉКЭ32ЮЛCRCЕФбЙЫѕИёЪНЃЌИааЫШЄЕФЭЌбЇПЩвдЖСвЛЯТ
ЃЈ https://en.wikipedia.org/wiki/LZ77_and_LZ78#LZ77
ЃЉ
compress: ЪЙгУ Lempel-Ziv-WelchЃЈLZWЃЉЫуЗЈЕФбЙЫѕИёЪНЃЌгааЫШЄЕФЭЌбЇПЩвдЖС
ЃЈhttps://en.wikipedia.org/wiki/LZWЃЉ
deflate: ЪЙгУ zlib НсЙЙКЭ deflate бЙЫѕЫуЗЈЕФбЙЫѕИёЪНЃЌВЮПМ
ЃЈhttps://en.wikipedia.org/wiki/Zlib ЃЉ КЭ ЃЈ https://en.wikipedia.org/wiki/DEFLATEЃЉ
br: ЪЙгУ Brotli ЫуЗЈЕФбЙЫѕИёЪНЃЌВЮПМ ЃЈ https://en.wikipedia.org/wiki/Brotli
ЃЉ
ВЛжДаабЙЫѕЛђВЛЛсБфЛЏЕФФЌШЯБрТыИёЪН
* : ЦЅХфБъЭЗжаЮДСаГіЕФШЮКЮФкШнБрТыЃЌШчЙћУЛгаСаГі Accept-Encoding ЃЌетОЭЪЧФЌШЯжЕЃЌВЂВЛвтЮЖзХжЇ
ГжШЮКЮЫуЗЈЃЌжЛЪЧБэЪОУЛгаЦЋКУ
;q= ВЩгУШЈжи q жЕРДБэЪОЯрЖдгХЯШМЖЃЌетЕугыЪзВПзжЖЮ Accept ЯрЭЌЁЃ
Accept-Language
Accept-Language ЧыЧѓБэЪОПЭЛЇЖЫашвЊЗўЮёЖЫЗЕЛиЕФгябдРраЭЃЌAccept-Language
вВЪєгкФкШнаЩЬЕФЗЖГыЁЃЗўЮёЖЫЭЈЙ§ Content-Language НјааЯьгІЃЌКЭ Accept ЪзВПзжЖЮвЛбљЃЌАДШЈжижЕ
qРДБэЪОЯрЖдгХЯШМЖЁЃР§Шч
Accept-Language:
de
Accept-Language: de-CH
Accept-Language: en-US,en;q=0.5 |
Authorization
HTTP Authorization ЧыЧѓЭЗгУгкЯђЗўЮёЦїШЯжЄгУЛЇДњРэЕФЦООнЃЌЭЈГЃгУдкЗўЮёЦївд401ЮДОЪкШЈзДЬЌКЭWWW-AuthenticateБъЭЗЯьгІжЎКѓЃЌЩЖвтЫМФиЃПФуВЛУїАзЕФЛАЮвЛеХЭМИјФуПД

ЧыЧѓБъЭЗ Authorization ЪЧгУРДИцжЊЗўЮёЦїЃЌгУЛЇЕФШЯжЄаХЯЂЃЌЗўЮёЦїдкжЛгаЪеЕНШЯжЄКѓВХЛсЗЕЛиИјПЭЛЇЖЫ
200 OK ЕФЯьгІЃЌШчЙћУЛгаШЯжЄаХЯЂЃЌдђЛсЗЕЛи 401 ВЂИцжЊПЭЛЇЖЫашвЊШЯжЄаХЯЂЁЃЯъЯИЙигк Authorization
ЕФаХЯЂЃЌКѓУцвВЛсЯъЯИНтЪЭ
Expect
Expect HTTP ЧыЧѓБъЭЗжИЪОЗўЮёЦїашвЊТњзуЕФЦкЭћВХФме§ШЗДІРэЧыЧѓЁЃШчЙћЗўЮёЦїУЛгаАьЗЈЭъГЩПЭЗўЖЫЫљЦкЭћЭъГЩЕФЪТЧщВЂЧвЗўЮёЖЫДцдкДэЮѓЕФЛАЃЌЛсЗЕЛи
417 Expectation Failed ЁЃHTTP 1.1 жЛЙцЖЈСЫ100-continue
ЁЃ
ШчЙћЗўЮёЦїФме§ГЃЭъГЩПЭЛЇЖЫЫљЦкЭћЕФЪТЧщЃЌЛсЗЕЛи 100
ШчЙћВЛФмТњзуЦкЭћЛђЗЕЛиШЮКЮЦфЫћ4xx ЕФзДЬЌТыЃЌЛсЗЕЛи 417
Р§Шч
PUT /somewhere/fun
HTTP/1.1
Host: origin.example.com
Content-Type: video/h264
Content-Length: 1234567890987
Expect: 100-continue |
From
From ЧыЧѓЭЗгУРДИцжЊЗўЮёЦїЪЙгУгУЛЇДњРэЕФЕчзггЪМўЕижЗЁЃЭЈГЃЧщПіЯТЃЌЦфЪЙгУФПЕФОЭЪЧЮЊСЫЯдЪОЫбЫїв§ЧцЕШгУЛЇДњРэЕФИКд№ШЫЕФЕчзггЪМўСЊЯЕЗНЪНЁЃЮвУЧдкЪЙгУДњРэЕФЧщПіЯТЃЌгІОЁПЩФмАќКЌ
From ЪзВПзжЖЮЁЃР§Шч
| From: webmaster@example.org |
ФуВЛгІИУНЋ From гУдкЗУЮЪПижЦЛђепЩэЗнбщжЄжа
Host
Host ЧыЧѓЭЗжИУїСЫЗўЮёЦїЕФгђУћЃЈЖдгкащФтжїЛњРДЫЕЃЉЃЌвдМАЃЈПЩбЁЕФЃЉЗўЮёЦїМрЬ§ЕФTCPЖЫПкКХЁЃШчЙћУЛгаИјЖЈЖЫПкКХЃЌЛсздЖЏЪЙгУБЛЧыЧѓЗўЮёЕФФЌШЯЖЫПкЃЈБШШчЧыЧѓвЛИі
HTTP ЕФ URL ЛсздЖЏЪЙгУ80зїЮЊЖЫПкЃЉЁЃ
| Host: developer.mozilla.org |
Host ЪзВПзжЖЮдк HTTP/1.1 ЙцЗЖФкЪЧЮЈвЛвЛИіБиаыБЛАќКЌдкЧыЧѓФкЕФЪзВПзжЖЮЁЃ
If-Match
If-Match КѓУцПЩвдИњвЛДѓЖбЪєадЃЌаЮЪНЯё If-Match етжжЕФЧыЧѓЭЗГЦЮЊЬѕМўЧыЧѓЃЌЗўЮёЦїНгЪеЕНЬѕМўЧыЧѓКѓЃЌашвЊХаЖЈЬѕМўЧыЧѓЪЧЗёТњзуЃЌжЛгаЬѕМўЧыЧѓЮЊецЃЌВХЛсжДааЬѕМўЧыЧѓ
РрЫЦЕФЛЙга If-MatchЁЂIf-Modified-Since
ЁЂIf-None-Match ЁЂIf-Range ЁЂIf-Unmodified-Since
Ждгк GET КЭ POST ЗНЗЈЃЌЗўЮёЦїНідкгыСаГіЕФ ETagЃЈЯьгІБъЭЗЃЉ жЎвЛЦЅХфЪБВХЗЕЛиЧыЧѓЕФзЪдДЁЃетРягжЖрСЫвЛИіаТДЪ
ETagЃЌЮвУЧЩдКѓдйЫЕ ETag ЕФгУЗЈЁЃЖдгкЯёЪЧ PUT КЭЦфЫћЗЧАВШЋЕФЗНЗЈЃЌдкетжжЧщПіЯТЃЌЫќНіНіНЋЩЯДЋзЪдДЁЃ
ЯТУцЪЧСНжжГЃМћЕФАИР§
Ждгк GET КЭ POST ЗНЗЈЃЌЛсНсКЯЪЙгУ Range БъЭЗЃЌЫќПЩвдШЗБЃаТЗЂЫЭЧыЧѓЕФЗЖЮЇгыЩЯвЛИіЧыЧѓЕФзЪдДЯрЭЌЃЌШчЙћВЛЦЅХфЕФЛАЃЌЛсЗЕЛи
416 ЯьгІЁЃ
ЖдгкЦфЫћЗНЗЈЃЌЬиБ№ЪЧ PUT ЗНЗЈЃЌIf-Match ПЩвдЗРжЙЖЊЪЇИќаТЃЌЗўЮёЦїЛсБШЖд If-Match
ЕФзжЖЮжЕКЭзЪдДЕФ ETag жЕЃЌНіЕБСНепвЛжТЪБЃЌВХЛсжДааЧыЧѓЁЃЗДжЎЃЌдђЗЕЛизДЬЌТы 412 Precondition
Failed ЕФЯьгІЁЃР§Шч
If-Match: "bfc13a64729c4290ef5b2c2730249c88ca92d82d"
If-Match: * |
If-Modified-Since
If-Modified-Since ЪЧ HTTP ЬѕМўЧыЧѓЕФвЛВПЗжЃЌжЛгадкИјЖЈШеЦкжЎКѓЃЌЗўЮёЖЫаоИФСЫЧыЧѓЫљашвЊЕФзЪдДЃЌВХЛсЗЕЛи
200 OK ЕФЯьгІЁЃШчЙћдкИјЖЈШеЦкжЎКѓЃЌЗўЮёЖЫУЛгааоИФФкШнЃЌЯьгІЛсЗЕЛи 304 ВЂЧвВЛДјШЮКЮЯьгІЬхЁЃIf-Modified-Since
жЛФмЪЙгУ GET КЭ HEAD ЧыЧѓЁЃ
If-Modified-Since гы If-None-Match НсКЯЪЙгУЪБЃЌЫќНЋБЛКіТдЃЌГ§ЗЧЗўЮёЦїВЛжЇГж
If-None-MatchЁЃвЛАуБэЪОШчЯТ
| If-Modified-Since:
Wed, 21 Oct 2015 07:28:00 GMT |
зЂвтЃКетЪЧИёСжЭўжЮБъзМЪБМфЁЃ HTTP ШеЦкЪМжевдИёСжФсжЮБъзМЪБМфБэЪОЃЌЖјВЛЪЧБОЕиЪБМфЁЃ
If-None-Match
ЬѕМўЧыЧѓЃЌЫќгы If-Match ЕФзїгУЯрЗДЃЌНіЕБ If-None-Match ЕФзжЖЮжЕгы ETag
жЕВЛвЛжТЪБЃЌПЩДІРэИУЧыЧѓЁЃЖдгкGET КЭ HEAD ЃЌНіЕБЗўЮёЦїУЛгагыИјЖЈзЪдДЦЅХфЕФ ETag ЪБЃЌЗўЮёЦїНЋЗЕЛи
200 зїЮЊЯьгІЁЃЖдгкЦфЫћЗНЗЈЃЌНіЕБзюжеЯжгазЪдДЕФ ETag гыСаГіЕФШЮКЮжЕЖМВЛЦЅХфЪБЃЌВХЛсДІРэЧыЧѓЁЃ
ЕБ GET КЭ POST ЗЂЫЭЕФ If-None-Matchгы ETag ЦЅХфЪБЃЌЗўЮёЦїЛсЗЕЛи 304ЁЃ
If-None-Match:
"bfc13a64729c4290ef5b2c2730249c88ca92d82d"
If-None-Match: W/"67ab43", "54ed21",
"7892dd"
If-None-Match: * |
гаЭЌбЇПЩФмЛсКУЦц W/ ЪЧЪВУДвтЫМЃЌетЦфЪЕЪЧ ETag ЕФШѕЦЅХфЃЌЙигк ETag ЮвУЧЛсдкЯьгІБъЭЗжаЯъЯИНВЪіЁЃ
If-Range
If-Range вВЪЧЬѕМўЧыЧѓЃЌШчЙћТњзуЬѕМўЃЈIf-Range ЕФжЕКЭ ETag жЕЛђепИќаТЕФШеЦкЪБМфвЛжТЃЉЃЌдђЛсЗЂГіЗЖЮЇЧыЧѓЃЌЗёдђНЋЛсЗЕЛиШЋВПзЪдДЁЃЫќЕФвЛАуБэЪОШчЯТ
| If-Range: Wed,
21 Oct 2015 07:28:00 GMT |
If-Unmodified-Since
If-Unmodified-Since HTTP ЧыЧѓБъЭЗвВЪЧвЛИіЬѕМўЧыЧѓЃЌЗўЮёЦїжЛгадкИјЖЈШеЦкжЎКѓУЛгаЖдЦфНјаааоИФЪБЃЌЗўЮёЦїВХЗЕЛиЧыЧѓзЪдДЁЃШчЙћдкжИЖЈШеЦкЪБМфКѓЗЂЩњСЫИќаТЃЌдђвдзДЬЌТы
412 Precondition Failed зїЮЊЯьгІЗЕЛиЁЃ
| If-Unmodified-Since:
Wed, 21 Oct 2015 07:28:00 GMT |
Max-Forwards
MDN АбетИіБъЭЗжУЛвСЫЃЌЫљвдЯТУцФкШнШЁздЁЖЭМНт HTTPЁЗ
Max-Forwards вЛАугУгк TRACE КЭ OPTION ЗНЗЈЃЌЗЂЫЭАќКЌ Max-Forwards
ЕФЪзВПзжЖЮЪБЃЌУПОЙ§вЛИіЗўЮёЦїЃЌMax-Forwards ЕФжЕОЭЛс -1ЃЌжБЕН Max-Forwards
ЮЊ0ЪБЗЕЛиЁЃMax-Forwards ЪЧвЛИіЪЎНјжЦЕФећЪ§жЕЁЃ
ПЩвдСщЛюЪЙгУЪзВПзжЖЮ Max-ForwardsЃЌеыЖдвдЩЯЮЪЬтВњЩњЕФдвђеЙПЊЕїВщЁЃгЩгкЕБ Max-Forwards
зжЖЮжЕЮЊ 0 ЪБЃЌЗўЮёЦїОЭЛсСЂМДЗЕЛиЯьгІЃЌгЩДЫЮвУЧжСЩйПЩвдЖдвдФЧЬЈЗўЮёЦїЮЊжеЕуЕФДЋЪфТЗОЖЕФЭЈаХзДПігаЫљАбЮеЁЃ
Proxy-Authorization
Proxy-Authorization ЪЧЪєгкЧыЧѓгыШЯжЄЕФЗЖГыЃЌЮвУЧдкЩЯУцЬсЕНвЛИіШЯжЄЕФ HTTP
БъЭЗЪЧ AuthorizationЃЌВЛЭЌгк Authorization ЗЂЩњдкПЭЛЇЖЫ - ЗўЮёЦїжЎМфЃЛProxy-Authorization
ЗЂЩњдкДњРэЗўЮёЦїКЭПЭЛЇЖЫжЎМфЁЃЫќБэЪОНгЪеЕНДгДњРэЗўЮёЦїЗЂРДЕФШЯжЄЪБЃЌПЭЛЇЖЫЛсЗЂЫЭАќКЌЪзВПзжЖЮ Proxy-Authorization
ЕФЧыЧѓЃЌвдИцжЊЗўЮёЦїШЯжЄЫљашвЊЕФаХЯЂЁЃ
| Proxy-Authorization:
Basic YWxhZGRpbjpvcGVuc2VzYW1l |
Range
Range HTTP ЧыЧѓБъЭЗжИЪОЗўЮёЦїгІЗЕЛиЮФЕЕжИЖЈВПЗжЕФзЪдДЃЌПЩвдвЛДЮЧыЧѓвЛИі Range РДЗЕЛиЖрИіВПЗжЃЌЗўЮёЦїЛсНЋетаЉзЪдДЗЕЛиИїИіЮФЕЕжаЁЃШчЙћЗўЮёЦїГЩЙІЗЕЛиЃЌФЧУДНЋЗЕЛи
206 ЯьгІЃЛШчЙћ Range ЗЖЮЇЮоаЇЃЌЗўЮёЦїЗЕЛи416 Range Not SatisfiableДэЮѓЃЛЗўЮёЦїЛЙПЩвдКіТд
Range БъЭЗЃЌВЂЧвЗЕЛи 200 зїЮЊЯьгІЁЃ
| Range: bytes=200-1000,
2000-6576, 19000- |
Referer
HTTP Referer ЪєадЪЧЧыЧѓБъЭЗЕФвЛВПЗжЃЌЕБфЏРРЦїЯђ web ЗўЮёЦїЗЂЫЭЧыЧѓЕФЪБКђЃЌвЛАуЛсДјЩЯ
RefererЃЌИцЫпЗўЮёЦїИУЭјвГЪЧДгФФИівГУцСДНгЙ§РДЕФЃЌЗўЮёЦївђДЫПЩвдЛёЕУвЛаЉаХЯЂгУгкДІРэЁЃ
| Referer: https://developer.mozilla.org/testpage.html |
TE
ЪзВПзжЖЮ TE ЛсИцжЊЗўЮёЦїПЭЛЇЖЫФмЙЛДІРэЯьгІЕФДЋЪфБрТыЗНЪНМАЯрЖдгХЯШМЖЁЃЫќКЭЪзВПзжЖЮ Accept-Encoding
ЕФЙІФмКмЯрЯёЃЌЕЋЪЧгУгкДЋЪфБрТыЁЃ
ЪзВПзжЖЮ TE Г§жИЖЈДЋЪфБрТыжЎЭтЃЌЛЙПЩвджИЖЈАщЫц trailer зжЖЮЕФЗжПщДЋЪфБрТыЕФЗНЪНЁЃгІгУКѓепЪБЃЌжЛашАб
trailers ИГжЕИјИУзжЖЮжЕЁЃ
| TE: trailers,
deflate;q=0.5 |
User-Agent
ЪзВПзжЖЮ User-Agent ЛсНЋДДНЈЧыЧѓЕФфЏРРЦїКЭгУЛЇДњРэУћГЦЕШаХЯЂДЋДяИјЗўЮёЦїЁЃ
Mozilla/5.0
(Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101
Firefox/47.0
|
ЯьгІБъЭЗ
ИеИеЮвУЧЕФзХжиЕувЛжБЗХдкПЭЛЇЖЫЧыЧѓЃЌЯждкЮвУЧАбЙизЂЕузЊЛЛвЛЯТЗХдкЗўЮёЦїЩЯЁЃЯьгІЪзВПзжЖЮЪЧгЩЗўЮёЦїЗЂЫЭИјПЭЛЇЖЫЯьгІжаЫљАќКЌЕФзжЖЮЃЌгУгкВЙГфЯргІаХЯЂЕШЃЌетВПЗжБъЭЗвВЪЧЗЧГЃЖрЃЌЮвУЧЯШвЛЦ№РДПДвЛЯТ
Accept-Ranges
Age
ETag
Location
Proxy-Authenticate
Retry-After
Server
Vary
www-Authenticate
Accept-Ranges
Accept-Ranges HTTP ЯьгІБъЭЗЃЌетИіБъЭЗгаСНИіжЕ
ЕБЗўЮёЦїФмЙЛДІРэПЭЛЇЖЫЗЂЫЭЙ§РДЕФЧыЧѓЪБЃЌЪЙгУbytes РДжИЖЈ
ЕБЗўЮёЦїВЛФмДІРэПЭЛЇЖЫЗЂРДЕФЧыЧѓЪБЃЌЪЙгУ none РДжИЖЈ
Accept-Ranges:
bytes
Accept-Ranges: none |
Age
Age HTTP ЯьгІБъЭЗИцЫпПЭЛЇЖЫдДЗўЮёЦїдкЖрОУжЎЧАДДНЈСЫЯьгІЃЌЫќЕФЕЅЮЛЮЊУыЃЌAge БъЭЗЭЈГЃНгНќгк0ЃЌШчЙћЪЧ0дђПЩФмЪЧДгдДЗўЮёЦїЛёШЁЕФЃЌШчЙћВЛЪЧБэЪОПЩФмЪЧгЩДњРэЗўЮёЦїДДНЈЃЌФЧУД
Age ЕФжЕБэЪОЕФЪЧЛКДцКѓЕФЯьгІдйДЮЗЂЦ№ШЯжЄЕНШЯжЄЭъГЩЕФЪБМфжЕЁЃДњРэДДНЈЯьгІЪББиаыМгЩЯЪзВПзжЖЮ AgeЁЃвЛАуБэЪОШчЯТ

ETag
ETag ЖдгкЬѕМўЧыЧѓРДЫЕецЪЧЬЋживЊСЫЁЃвђЮЊЬѕМўЧыЧѓОЭЪЧИљОн ETag ЕФжЕНјааЦЅХфЕФЃЌЯТУцЮвУЧОЭРДЯъЯИСЫНтвЛЯТЁЃ
ETag ЯьгІЭЗЪЧЬиЖЈАцБОЕФБъЪЖЃЌЫќФмЙЛЪЙЛКДцБфЕУИќИпаЇВЂФмЙЛНкЪЁДјПэЃЌвђЮЊШчЙћЛКДцФкШнЮДЗЂЩњБфИќЃЌWeb
ЗўЮёЦїдђВЛашвЊжиаТЗЂЫЭЭъећЕФЯьгІЁЃГ§ДЫжЎЭтЃЌETag ФмЙЛЗРжЙзЪдДЭЌЪБИќаТЛЅЯрИВИЧЁЃ
ШчЙћИјЖЈ URL ЩЯЕФзЪдДЗЂЩњБфИќЃЌБиаыЩњГЩвЛИіаТЕФ ETag жЕЃЌЭЈЙ§БШНЯЫќУЧПЩвдШЗЖЈзЪдДЕФСНИіБэЪОаЮЪНЪЧЗёЯрЭЌЁЃ
ETag жЕгаСНжжЃЌвЛжжЪЧЧП ETagЃЌвЛжжЪЧШѕ ETagЃЛ
ЧП ETag жЕЃЌЮоТлЪЕЬхЗЂЩњЖрУДЯИЮЂЕФБфЛЏЖМЛсИФБфЦфжЕЃЌвЛАуЕФБэЪОШчЯТ
| ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4" |
Шѕ ETag жЕЃЌШѕ ETag жЕжЛгУгкЬсЪОзЪдДЪЧЗёЯрЭЌЁЃжЛгазЪдДЗЂЩњСЫИљБОИФБфЃЌВњЩњВювьЪБВХЛсИФБф
ETag жЕЁЃетЪБЃЌЛсдкзжЖЮжЕзюПЊЪМДІИНМг W/ЁЃ
Location
Location ЯьгІБъЭЗБэЪО URL ашвЊжиЖЈЯђвГУцЃЌЫќНіНігы
3xx(жиЖЈЯђ) Лђ 201(вбДДНЈ) зДЬЌЯьгІвЛЦ№ЪЙгУЁЃЯТУцЪЧвЛИівГУцжиЖЈЯђЕФЙ§ГЬ

ЪЙгУЪзВПзжЖЮ Location ПЩвдНЋЯьгІНгЪмЗНв§ЕМжСФГИігыЧыЧѓ URI ЮЛжУВЛЭЌЕФзЪдДЁЃ
Location КЭ content-Location ЪЧВЛвЛбљЕФЃКLocation БэЪОФПБъЕФжиЖЈЯђЃЈЛђаТДДНЈзЪдДЕФ
URLЃЉЁЃШЛЖј Content-Location БэЪОЗЂЩњФкШнаЩЬЪБгУгкЗУЮЪзЪдДЕФжБНг URLЃЌЖјЮоаыНјвЛВНаЩЬЁЃLocation
ЪЧгыЯьгІЯрЙиСЊЕФБъЭЗЃЌЖј Content-Location гыЗЕЛиЕФЪЕЬхЯрЙиСЊЁЃ
Proxy-Authenticate
HTTP ЯьгІБъЭЗ Proxy-Authenticate ЛсЖЈвхШЯжЄЗНЗЈЃЌгІИУЪЙгУЩэЗнбщжЄЗНЗЈРДЗУЮЪДњРэЗўЮёЦїКѓУцЕФзЪдДМДПЭЛЇЖЫЁЃ
Ыќгы HTTP ПЭЛЇЖЫКЭЗўЮёЖЫжЎМфЕФЗУЮЪШЯжЄааЮЊЯрЫЦЃЌВЛЭЌжЎДІдкгк Proxy-Authenticate
ЕФШЯжЄЫЋЗНЪЧПЭЛЇЖЫгыДњРэжЎМфЁЃЫќЕФвЛАуБэЪОаЮЪНШчЯТ
Proxy-Authenticate:
Basic
Proxy-Authenticate: Basic realm="Access
to the internal site" |
Retry-After
HTTP ЯьгІБъЭЗ Retry-After ИцжЊПЭЛЇЖЫашвЊдкЖрОУжЎКѓжиаТЗЂЫЭЧыЧѓЃЌЪЙгУДЫБъЭЗжївЊгаШчЯТШ§жжЧщПі
ЕБЗЂЫЭ 503(ЗўЮёВЛПЩгУ)ЯьгІЪБЃЌетБэЪОИУЗўЮёдЄМЦЮоЗЈЪЙгУЖрГЄЪБМфЁЃ
ЕБЗЂЫЭ 429(ЬЋЖрЧыЧѓ)ЯьгІЪБЃЌетБэЪОЗЂГіаТЧыЧѓжЎЧАвЊЕШД§ЖрГЄЪБМфЁЃ
ЕБЗЂЫЭжиЖЈЯђЕФЯьгІЯёЪЧ 301(гРОУвЦЖЏ)ЃЌетБэЪОдкЗЂГіжиЖЈЯђЧыЧѓжЎЧАвЊЧѓгУЛЇПЭЛЇЖЫЕШД§ЕФзюЖЬЪБМфЁЃ
зжЖЮжЕПЩвджИЖЈЮЊОпЬхЕФШеЦкЪБМфЃЌвВПЩвдЪЧДДНЈЯьгІКѓЫљГжајЕФУыЪ§ЃЌР§Шч
Retry-After:
Wed, 21 Oct 2015 07:28:00 GMT
Retry-After: 120 |
Server
ЗўЮёЦїБъЭЗАќКЌгаЙидЪМЗўЮёЦїгУРДДІРэЧыЧѓЕФШэМўЕФаХЯЂЁЃ
гІИУБмУтЪЙгУЙ§гкШпГЄКЭЯъЯИЕФ Server жЕЃЌвђЮЊЫќУЧПЩФмЛсаЙТЖФкВПЪЕЪЉЯИНкЃЌетПЩФмЛсЪЙЙЅЛїепШнвзЕиЗЂЯжВЂРћгУвбжЊЕФАВШЋТЉЖДЁЃР§ШчЯТУцетжжаДЗЈ
| Server: Apache/2.4.1
(Unix) |
Vary
Vary HTTP ЯьгІБъЭЗШЗЖЈШчКЮЦЅХфЧыЧѓБъЭЗЃЌвдОіЖЈЪЧЗёПЩвдЪЙгУЛКДцЕФЯьгІЃЌЖјВЛЪЧДгдЪМЗўЮёЦїЧыЧѓвЛИіаТЕФЯьгІЁЃ
www-Authenticate
HTTP WWW-Authenticate ЯьгІБъЭЗЖЈвхСЫгІгУгкЛёЕУЖдзЪдДЕФЗУЮЪШЈЯоЕФЩэЗнбщжЄЗНЗЈЁЃWWW-AuthenticateБъЭЗгы401ЮДОЪкШЈЕФЯьгІвЛЦ№ЗЂЫЭЁЃЫќЕФвЛАуБэЪОаЮЪНШчЯТ
WWW-Authenticate:
Basic
WWW-Authenticate: Basic realm="Access to
the staging site", charset="UTF-8" |
Access-Control-Allow-Origin
вЛИіЗЕЛиЕФ HTTP БъЭЗПЩФмЛсОпга Access-Control-Allow-Origin ЃЌAccess-Control-Allow-Origin
жИЖЈвЛИіРДдДЃЌЫќИцЫпфЏРРЦїдЪаэИУРДдДНјаазЪдДЗУЮЪЁЃ Зёдђ-ЖдгкУЛгаЦООнЕФЧыЧѓ *ЭЈХфЗћЃЌИцЫпфЏРРЦїдЪаэШЮКЮдДЗУЮЪзЪдДЁЃР§ШчЃЌвЊдЪаэдД
https://mozilla.org ЕФДњТыЗУЮЪзЪдДЃЌПЩвджИЖЈЃК
Access-Control-Allow-Origin:
https://mozilla.org
Vary: Origin |
ШчЙћЗўЮёЦїжИЖЈЕЅИіРДдДЖјВЛЪЧ *ЭЈХфЗћЕФЛА ЃЌдђЗўЮёЦїЛЙгІдк Vary ЯьгІБъЭЗжаАќКЌ Origin
ЃЌвдЯђПЭЛЇЖЫжИЪО ЗўЮёЦїЯьгІНЋИљОндЪМЧыЧѓБъЭЗЕФжЕЖјгаЫљВЛЭЌЁЃ
ЪЕЬхБъЭЗ
ЪЕЬхБъЭЗгУгкHTTPЧыЧѓКЭЯьгІжаЃЌР§Шч Content-LengthЃЌContent-LanguageЃЌContent-Encoding
ЕФБъЭЗЪЧЪЕЬхБъЭЗЁЃЪЕЬхБъЭЗВЛОжЯогкЧыЧѓБъЭЗЛђепЯьгІБъЭЗЃЌЯТУцР§згжаЃЌContent-Length ЪЧвЛИіЪЕЬхБъЭЗЃЌЕЋЪЧШДГіЯждкСЫЧыЧѓБЈЮФжа
POST /myform.html
HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac
OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Content-Length: 128 |
ЯТУцОЭРДЫЕвЛЯТЪЕЬхБъЭЗЖМАќКЌФФаЉ
Allow
Content-Encoding
Content-Language
Content-Length
Content-Location
Content-MD5
Content-Range
Content-Type
Expires
Last-Modified
ЯТУцРДЗжПЊЫЕвЛЯТ
Allow
HTTP ЪЕЬхБъЭЗ Allow СаГіСЫзЪдДжЇГжЕФЗНЗЈМЏКЯЁЃШчЙћЗўЮёЦїЯьгІ405 Method Not
AllowedзДЬЌТывджИЪОПЩвдЪЙгУФФаЉЧыЧѓЗНЗЈЃЌдђБиаыЗЂЫЭДЫБъЭЗЁЃР§Шч
етЖЮДњТыБэЪОЗўЮёЦїдЪаэжЇГж GET ЁЂPOST КЭ HEAD ЗНЗЈЁЃЕБЗўЮёЦїНгЪеЕНВЛжЇГжЕФ HTTP
ЗНЗЈЪБЃЌЛсвдзДЬЌТы 405 Method Not Allowed зїЮЊЯьгІЗЕЛиЁЃ
Content-Encoding
ЮвУЧЩЯУцНВЙ§ Accept-Encoding ЪЧПЭЛЇЖЫЯЃЭћЗўЮёЖЫЗЕЛиЕФФкШнБрТыЃЌЕЋЪЧЪЕМЪЩЯЗўЮёЖЫЗЕЛиИјПЭЛЇЖЫЕФФкШнБрТыЪЕМЪЩЯЪЧЭЈЙ§
Content-Encoding ЗЕЛиЕФЁЃФкШнБрТыЪЧжИдкВЛЖЊЪЇЪЕЬхаХЯЂЕФЧАЬсЯТЫљНјааЕФбЙЫѕЁЃжївЊвВЪЧЫФжжЃЌКЭ
Accept-Encoding ЯрЭЌЃЌЫќУЧЪЧ gzipЁЂcompressЁЂdeflateЁЂidentityЁЃЯТУцЪЧвЛзщЧыЧѓ/ЯьгІФкШнбЙЫѕБрТы
Accept-Encoding:
gzip, deflate
Content-Encoding: gzip |
Content-Language
ЪзВПзжЖЮ Content-Language ЛсИцжЊПЭЛЇЖЫЃЌЗўЮёЦїЪЙгУЕФздШЛгябдЪЧЪВУДЃЌЫќгы Accept-Language
ЯрЖдЃЌЯТУцЪЧвЛзщЧыЧѓ/ЯьгІЪЙгУЕФгябдРраЭ
| Content-Language:
de-DE, en-CA |
Content-Length
Content-Length ЕФЪЕЬхБъЭЗжИЗўЮёЦїЗЂЫЭИјПЭЛЇЖЫЕФЪЕМЪжїЬхДѓаЁЃЌвдзжНкЮЊЕЅЮЛЁЃ
ШчЩЯЃЌЗўЮёЦїЗЕЛиИјПЭЛЇЖЫЕФжїЬхДѓаЁЪЧ 3000 зжНкЁЃ
Content-Location
Content-Location ПЩВЛЪЧЖдгІ Accept-LocationЃЌвђЮЊУЛгаетИіБъЭЗЙўЙўЙўЙўЁЃЪЕМЪЩЯ
Content-Location ЖдгІЕФЪЧ LocationЁЃ
Location КЭ Content-Location ЪЧВЛвЛбљЕФЃЌLocation БэЪОжиЖЈЯђЕФ
URLЃЌЖј Content-Location БэЪОгУгкЗУЮЪзЪдДЕФжБНг URLЃЌвдКѓЮоашНјааНјвЛВНЕФФкШнаЩЬЁЃLocation
ЪЧгыЯьгІЙиСЊЕФБъЭЗЃЌЖј Content-Location ЪЧгыЗЕЛиЕФЪ§ОнЯрЙиСЊЕФБъЭЗЃЌШчЙћФуВЛКУРэНтЃЌПДвЛЯТЯТУцЕФБэИё

ПЭЛЇЖЫЛсЖдНгЪеЕФБЈЮФжїЬхжДааЯрЭЌЕФ MD5 ЫуЗЈЃЌШЛКѓгыЪзВПзжЖЮ Content-MD5 ЕФзжЖЮНјааБШНЯЁЃ
| Content-MD5:
e10adc3949ba59abbe56e057f20f883e |
ЪзВПзжЖЮ Content-MD5 ЪЧвЛДЎгЩ MD5 ЫуЗЈЩњГЩЕФжЕЃЌЦфФПЕФдкгкМьВщБЈЮФжїЬхдкДЋЪфЙ§ГЬжаЪЧЗёБЃГжЭъећЃЌгаЮоБЛаоИФЕФЧщПіЃЌвдМАШЗШЯДЋЪфЕНДяЁЃ

Content-Range
HTTP ЕФ Content-Range ЯьгІБъЭЗЪЧеыЖдЗЖЮЇЧыЧѓЖјЩшЖЈЕФЃЌЗЕЛиЯьгІЪБЪЙгУЪзВПзжЖЮ Content-RangeЃЌФмЙЛИцжЊПЭЛЇЖЫЯьгІЪЕЬхЕФФФВПЗжЪЧЗћКЯПЭЛЇЖЫЧыЧѓЕФЃЌзжЖЮвдзжНкЮЊЕЅЮЛЁЃЫќЕФвЛАуБэЪОШчЯТ
| Content-Range:
bytes 200-1000/67589 |
ЩЯЖЮДњТыБэЪОДгЫљга 67589 ИізжНкжаЗЕЛи 200-1000 ИізжНкЕФФкШн
Content-Type
HTTP ЯьгІБъЭЗ Content-Type ЫЕУїСЫЪЕЬхФкЖдЯѓЕФУНЬхРраЭЃЌКЭЪзВПзжЖЮ Accept
вЛбљЪЙгУЃЌБэЪОЗўЮёЦїФмЙЛЯьгІЕФУНЬхРраЭЁЃ
Expires
HTTP Expires ЪЕЬхБъЭЗАќКЌ ШеЦк/ЪБМфЃЌдкИУШеЦк/ЪБМфжЎКѓЃЌЯьгІБЛШЯЮЊЙ§ЦкЃЛдкЯьгІЪБМфжЎФкБЛШЯЮЊгааЇЁЃЬиЪтЕФжЕБШШч0БэЪОЙ§ШЅЕФШеЦкЃЌБэЪОзЪдДвбЙ§ЦкЁЃ
| Expires: Wed,
21 Oct 2015 07:28:00 GMT |
дДЗўЮёЦїЛсНЋзЪдДЪЇаЇЕФШеЦкЛђЪБМфЗЂЫЭИјПЭЛЇЖЫЃЌЛКДцЗўЮёЦїдкНгЪмЕН Expires ЕФЯьгІКѓЃЌЛсХаЖЯЪЧЗёАбЛКДцЗЕЛиИјПЭЛЇЖЫЁЃ
дДЗўЮёЦїВЛЯЃЭћЛКДцЗўЮёЦїЖдзЪдДЛКДцЪБЃЌзюКУдк Expires зжЖЮФкаДШыгыЪзВПзжЖЮ Date ЯрЭЌЕФЪБМфжЕЁЃЕЋЪЧЃЌЕБЪзВПзжЖЮ
Cache-Control гажИЖЈ max-age жИСюЪБЃЌБШЦ№ЪзВПзжЖЮ ExpiresЃЌЛсгХЯШДІРэ
max-age жИСюЁЃ
Last-Modified
ЪЕЬхзжЖЮ Last-Modified жИУїзЪдДЕФзюКѓаоИФЪБМфЃЌЫќгУзїбщжЄЦїРДШЗЖЈНгЪеЛђДцДЂЕФзЪдДЪЧЗёЯрЭЌЁЃЫќЕФзїгУВЛШч
ETag ФЧУДзМШЗЃЌЫќПЩвдзїЮЊвЛжжКѓБИЛњжЦЃЌАќКЌ If-Modified-Since Лђ If-Unmodified-Since
БъЭЗЕФЬѕМўЧыЧѓНЋЪЙгУДЫзжЖЮЁЃЫќЕФвЛАуБэЪОШчЯТ
| Last-Modified:
Wed, 21 Oct 2015 07:28:00 GMT |
змНс
БОЦЊЮФеТжївЊНщЩмСЫ HTTP ЫФжжБъЭЗЕФЛљБОИХФюЃЌЕЋЪЧВЂУЛгаКИЧШЋВПЃЌБЯОЙ
HTTP БъЭЗФкШнШЗЪЕЬЋЖрСЫЃЌвдЩЯНщЩмЕФЛљБОЖМЪЧЦНГЃЙЄзїжаГЃгУЕФвЛаЉИХФюЁЃ |








