| 编辑推荐: |
本文首先介绍了什么是边缘计算,其次介绍基于Kubernetes构建边缘计算平台
以及计算项目,最后对KubeEdge进行详解。
本文来自于csdn,由火龙果软件Alice编辑推荐。 |
|
什么是边缘计算
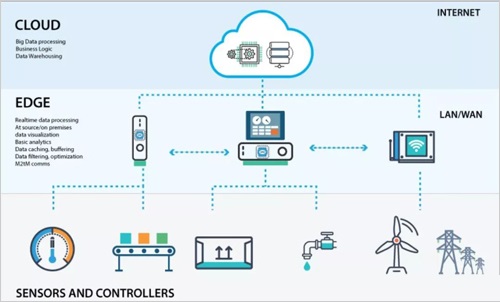
边缘计算
边缘计算(Edge computing)是一种在物理上靠近数据源头的网络边缘侧来融合网络、计算、存储、应用核心能力的开放平台。为终端用户提供实时、动态和智能的服务计算,边缘计算会将计算推向更接近用户的实际现场,这与需要在云端进行计算的传统云计算有着本质的区别,而这些区别主要表现在带宽负载、资源浪费、安全隐私保护以及异构多源数据处理上。

章鱼
这里有一个非常典型的例子, 就是章鱼,章鱼在捕猎时它们动作非常灵巧迅速,腕足之间高度配合,从来不会缠绕和打结。这是因为章鱼的神经元的分布是40%集中在他的头部,60%的神经元分布在他的触角上,是“多个小脑+一个大脑”的构造,类似于分布式计算。而边缘计算也是一种分布式计算,这种分布的好处呢,就是大部分重复的,低级的操作,都有触角来完成,是减轻了中央章鱼大脑的功耗,而让中央大脑只处理一些核心的数据。
随着5G,万物互联时代的到来,整个网络设备接入的数量,以及靠近设备端产生的数据会爆发式增长。这就遇到一个问题,如果所有数据处理都放到集中式数据中心,带宽,实时性,能耗,隐私等等都会面临很大的挑战。但采用边缘计算,就可以就近处理海量数据,大量设备可以实现高效协同工作,诸多问题迎刃而解。
边缘的价值
因此边缘计算有着它独特的价值:
连接的广泛性, 因为他高度分散,能够覆盖到用户的实际现场各个终端。
是数据带宽的优化,可以将部分业务下沉到数据的产生源头,这样大部分的数据并没有经过骨干网,这对于整体网络的带宽是一个极大的优化,通过本地数据预处理,可以极大减少传输带宽的需求,这里面最典型的例子就是CDN,通过就近拉取视频流,这样骨干网络只有中心站点到CDN站点几份的数据传输。但是每个CDN站点的访客可能数以万计或者百万计。
是边缘的自治性,整个业务下沉到边缘,高度分散之后,边缘跟中心云的网络不能很好的保障,这就需要在骨干网络质量不能保证的情况下,需要边缘具备一定的自治性。这样才能更好的服务终端业务的请求。
从端到端的体验来说,主要体现的是业务的实时性,因为大部分的业务请求都在边缘处理, 整体的业务请求可以缩小到10ms以内。
最后一点, 因为实施边缘计算以后,可以减少大量不必要的敏感数据的跨网传输,可以在边缘做数据的预处理或者匿名化处理,把最敏感的数据处理放在边缘,这样可以大大的增强数据的安全性和隐私保护。
推动边缘计算的四大主要因素
其实边缘计算这个概念已经出现了很长时间, 那么为什么近几年会快速发展呢,其中一方面是因为网络技术的快速发展,以及5G时代的到来,万物互联,一切连接皆有可能。从关键因素上来来,主要是4大点:
低时延,很多新兴的业务快速发展,包括自动驾驶,AI,VR等等,这些都对时延有非常苛刻的要求。
是随着接入到网络的设备数量大量增多, 导致数据爆发式增长, 这也是对边缘计算的一个很大的推动力。
是隐私安全,像现在人工智能, 以及对应的人脸,指纹识别等,但是这些最原始的指纹或者人脸的隐私信息,
我们不希望在公网传输被被人去盗取或者篡改数据,如果用边缘计算呢, 我们可以避免这种问题。
最后一点呢, 就是边缘的业务要具备自治能力,如果跟云端的网络请求断开,或者网络质量不高的情况下,
边缘业务要在出现故障时候,自我恢复。
这是推动边缘计算的四大主要因素。
基于Kubernetes构建边缘计算平台
那么需要什么框架去构建边缘计算平台呢?我们可能首先想到的就是现在大火的Kubernetes。
对Kubernetes来说,它的核心功能基本上趋于成熟。现如今Kubernetes已经日益成为公有云/企业IT系统的基础设施,不仅大多数新兴的云原生负载是构建在Kubernetes上的,我们还将看到传统应用和负载也在以更快的速度向Kubernetes迁移,人们趋向于使用Kubernetes。而且Kubernetes
在朝着大规模,复杂场景的方向延伸,与AI、大数据、IoT、以及垂直行业等领域的结合越来越紧密。近来,越来越多围绕Kubernetes生态圈的创新,正在这些领域发生着。
与其他的新技术出世的情景类似,目前的边缘计算也是一片炙热的景象,多种技术形式出现,大家都在争夺这个领域。而且边缘计算的发展空间显然是无限的,实现的方式也是无限的,多种多样。这使得灵活性成为了非常重要的关键点。如果打算让下一代服务能够继续与传统IT进行交互操作,兼容传统IT,就要去边缘计算技术尽量能够在任何类型的架构(边缘、云或集中式硬件)中部署和扩展,去兼容异构的架构,而这更Kubernetes的设计理念有点类似。
Kubernetes项目源自于Google的borg项目,天生站在巨人的肩膀上,自2014年6月开源以来,Kubernetes在众多厂商和开源爱好者的共同努力下迅速崛起。现在已经基本成为容器编排的事实标准。而且越来越多的公司和组织加入CNCF,众多的开源爱好者参与Kubernetes社区开发,现在,Kubernetes已经成为容器编排领域的事实标准。超过80家厂商都已经提供了经过认证的标准的Kubernetes服务。除此之外,还有很多公司都在使用Kubernetes的服务。而且围绕Kubernetes的云原生版图也是越来越丰富。
边缘计算场景下:Kubernetes的优势
那么在边缘计算场景下使用Kubernetes ,具有哪些优势呢?
这里首先要从Kubernetes的架构说起。
了解Kubernetes的同学对Kubernetes已经很熟悉了,这里我再简单介绍一下:
从架构层面,Kubernetes是一种比较先进的松耦合的架构。控制层面有:API server,controller-manager,Scheduler,集群的状态都存在etcd中,数据面有:kubelet和kube-proxy安装在每个计算节点,用来管理Pod生命周期和网络的处理。
它所有的组件都是用过API server来进行访问的,这样可以保证数据访问的过程是可以被鉴权和认证的。同时所有组件之间,没有耦合关系,
他们都跟API server做交互,只依赖于API server,他的API是声明式设计的。同时在具体的应用声明周期的管理过程中呢,
他是通过多个API对象,彼此互不,和组合来实现解耦。
其次由于容器有轻量级、安全性、秒级启动等优秀的特性,容器天然的轻量化和可移植性,对应用进行容器化封装,使用容器本身的特性,充分使用build
once,run anywhere的优势,轻量化基础镜像,降低资源的占用,非常适合边缘计算的场景,这一点边缘计算的厂家和开发者们都心知肚明。而且鉴于Kubernetes已经成为云原生编排的事实标准,因此携手Kubernetes进入边缘将很有可能结束边缘计算当前混沌的状态,并定义云端和边缘统一的应用部署和管理的标准。
最后在边缘计算场景下,有着大量的异构设备,每种设备都有自己独特的特征属性,我们可以充分利用Kubernetes提供的扩展的API资源:CRD功能,对这些设备进行数据建模,数据抽象,从而进行统一管理。
边缘计算场景下:Kubernetes的挑战
但是,Kubernetes不是天生为边缘计算而生的, 他是从集中式数据中心的场景里诞生出来的技术,因此在边缘计算场景下,Kubernetes也遇到了很多挑战:
为了减轻API server的访问压力以及集群状态的快速同步,Kubernetes优先使用事件监听(list-watch)方式而不是轮询方式来处理。这也是一个很大的亮点。这种情况比较适合于网络质量较好的数据中心去部署。但是反过来讲,这会对边缘计算场景带来挑战。Master和Node通信是通过list
watch机制,它没有办法在边缘场景这种受限的网络下很好的工作,本身list watch实现也是假设的是数据中心的网络,整体网络质量相对比较好的情况下。
另外Kubernetes节点是没有自治能力的,如何在网络质量不稳定的情况下,对边缘节点实现离线自治,这也是个问题。
Kubernetes各个组件其实是比较耗资源的,当然这种组件对资源的占用,相对于集中式数据中心的资源来说是微不足道的,但是在边缘,资源有限的场景下,Kubernetes是很难很好的工作的。一个kubelet启动大概就占用上百兆的内存,整个Kubernetes如果附上HA的能力,实际上会占用相当多的资源。如果你想你的应用跑在一些IOT网关或者设备上,他们可能只有几百兆的内存,或许一个原生kubelet都跑不起来。
还有就是,在边缘计算场景下,它有很多异构的边缘设备,支持的工业协议也不一样,那么这些边缘设备怎么管理,怎么让边缘应用通过比较解耦的方式与这些设备交互,这是Kubernetes本身没有提供的。我们只能充分利用Kubernetes
的CRD资源进行二次抽象。
还有一个问题是在边缘计算场景下,应用和节点的监控和报警问题,是在边端进行数据的监控报警,还是在云端统一进行收集,这也是一个很大的挑战,另一个问题,是在Kubernetes的架构选型上,我们到底采用哪种场景和架构。
边缘计算场景下:Kubernetes的架构选型
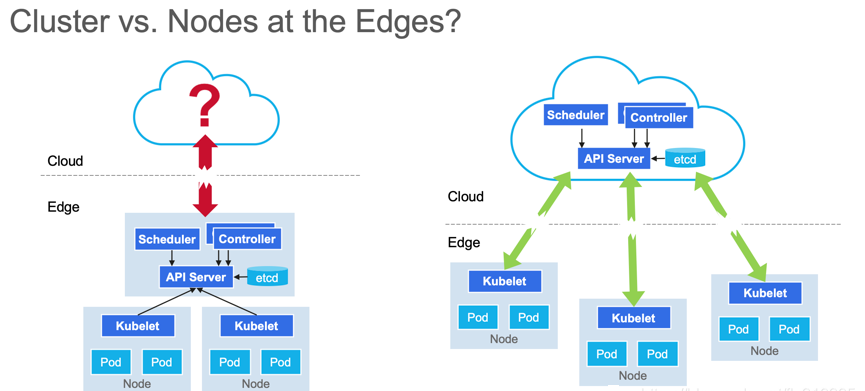
Kubernetes的架构选型
第一种是将整个Kubernetes集群跑在边缘,第二种是将Kubernetes的控制层面跑在云端,去管理边缘的计算节点。
这是很多在Kubernetes构建边缘计算平台时候,所面临的问题。
实际上在Kubernetes IOT EDGE这个working group调查中显示,两者比例是30%的人更倾向于把整个Kubernetes集群跑在边缘,这种场景更多的是一些近场的边缘,就是相对来说,靠近边缘的网络位置上的这种边缘计算,要求呢就是计算能力相对要高一点,首先要能够承载Kubernetes本身组件的运行。
还有70%更多的人,更倾向于这种现场的边缘计算,这种边缘是一种更轻量,更极致的边缘计算追求。在这种情况下,
没有太多的跨节点的调度,或者应用动态迁移的诉求,很多应用都会跟某个设备做绑定。
基于Kubernetes的开源边缘计算项目
其实现在基于Kubernetes平台的开源边缘计算项目已经有很多个了,这里列出来了三个:
K3s:https://github.com/rancher/k3s
Microk8s:https://github.com/ubuntu/microk8s
KubeEdge:https://github.com/kubeedge/kubeedge
当然还有其他的开源项目,有兴趣的大家可以自行查找。
K3s定位是在边缘端轻量化的Kubernetes集群。
删除了Kubernetes一些alpha的feature,专门针对ARM环境进行了发布,为了处理Node节点在内网的场景,专门增加tunnel
proxy的组件,来传递像exec 或者logs这些命令请求。对于Kubernetes的核心代码逻辑没有大的改动。
在资源占用上,已经比原生Kubernetes小了不少。Server在480M,Agent是120M。
由于Server和Agent主要还是通过List-watch来通信,还是很适合于纯边缘侧部署一整套Kubernetes集群,不适合云边协同的场景,只能运行在边缘侧。社区这块,有Rancher开发和管理。
Mincrok8s是轻量级的Kubernetes发行版
Mincrok8s和K3s在应用场景上差不多,比较适合纯边缘的环境,也是缺少云边协同的解决方案。支持ARM/Win10/macOS安装,Kubelet占用大约80M内存,Master占用大约600M内存,K3s对Kubernetes的部分核心代码做了修改,但是Mincrok8s并没有做修改。
KubeEdge由华为开源,2019年3月捐给CNCF基金会
同时也是Kubernetes IOT Edge working group的关键参考架构之一。
主要是针对边缘侧做了优化:包括边缘恻节点的离线状态自治,云边消息传输默认使用WebSocket。支持云边协同,同时支持云端集群和边缘端集群的管理。
在边缘侧节点Edgecore的内存暂用率大约是70M,同时兼容Kubernetes的核心API功能,现在大约有超过250个贡献者参与其中。
每个开源项目都有它的侧重点,各有优势,大家在技术选型时候可以根据自己的业务场景选择不同的开源项目。
在这里主要着重讲一下KubeEdge。
KubeEdge详解
KubeEdge三个核心理念
KubeEdge主打三个核心理念,首先是云边协同,边是云的延伸,用户的边可能位于私有网络,因此需要穿透私有网络,通过云来管理私有节点,KubeEdge默认采用WebSocket+消息封装来实现,这样只要边缘网络能访问外网情况下,就能实现双向通信,这就不需要边端需要一个公网的IP。同时呢,KubeEdge也优化了原生Kubernetes中不必要的一些请求,能够大幅减少通信压力,高时延状态下仍可以工作。
KubeEdge第二个核心理念是,做到节点级的元数据的持久化,比如Pod,ConfigMap等基础元数据,按照每个节点持久化在他的设备上,边缘的节点离线之后,它仍可以通过本地持久化的元数据来管理这些应用。熟悉Kubernetes的同学应该知道,当kubelet重启后,
它首先要向Master做一次list watch获取全量的数据,然后再进行应用管理工作,如果这时候边和云端的网络断开,是无法获得全量的基础元数据,也不能进行故障恢复。KubeEdge做了元数据的持久化后,可以直接从本地获得这些元数据,保障故障恢复的能力,保证服务的快速ready。
另外一个理念是极致的轻量化:在大多数边缘计算场景下,节点的资源是非常有限的,KubeEdge采用的方式是重组kubelet组件,移除了内置了面向于云厂商的驱动,通过CSI介入,去掉了static
Pod,同时支持CRI,支持多种container runtime。在空载时候,内存占用率很低。

KubeEdge整体架构
这是KubeEdge整体架构,KubeEdge对原生Kubernetes的架构侵入比较小,都是旁路设计。
云上:主要是通过旁路设计开发的CloudCore组件,边缘节点的同步和维护是通过CloudCore来维护,CloudCore通过list
watch来跟Kubernetes集群做信息同步。而CloudCore里面内置的CloudHub模块和边端内置的EdgeHub模块,构建了一个WebSocket消息通道,通过结构化的消息封装,来同步Kubernetes的基础元数据,比如Pod,ConfigMap等等。另外CloudCore里面还包含edgecontroler和devicecontroller模块,这两个模块分别用来管理Kubernetes的元数据以及跟Device相关的CRD资源。
边端:Edgecore,做到了持久化存储,edged相当于一个精简版的kubelet,支持CRI,底层可以对接多种container
runtime,deviceTwin和DEventBus主要是做设备的元数据管理以及MQTT协议的订阅和发布。主要是跟终端设备通信用。
在终端设备这里:现实场景里, 设备终端会有多种多样的访问协议,当然比较新兴的一些设备可能会直接支持MQTT协议,但是对于一些专用的设备或者工控的领域呢,会有他们专用的协议,KubeEdge呢采用了Mapper的设计,可以将这些专有的设备的协议转换成MQTT协议,来实现边缘的应用和云上的设备数据的同步和管理,当然KubeEdge最新版本还有SyncController,用来负责可靠性消息传输的同步问题,大家有兴趣的可以自行查看KubeEdge的源码。
云端的核心组件CloudCore
那么在云端的核心组件CloudCore,主要由下面几部分组成:

云端的核心组件CloudCore
Edge Controller:主要是来负责边缘节点元数据的同步和管理,主要是Pod,ConfigMap等应用相关的元数据。
Device Controller:是引入来管理边缘设备的模块,还有一套对应的CRD的定义,扩展的Kubernetes
API,用来管理边缘设备。
CloudHub模块:上文也简单讲过了,主要是管理与边缘端EdgeHub的websocket的连接,
下发云端发来的数据,和上传边缘发来数据跟云端同步。
CSI Driver:是为了实现标准的CSI方案而做的适配器。
Admission webhook:主要用来给扩展性API做一些合法性的校验。
KubeEdge边端的核心组件Edgecore
KubeEdge边端的核心组件Edgecore主要由下面几个模块组成:
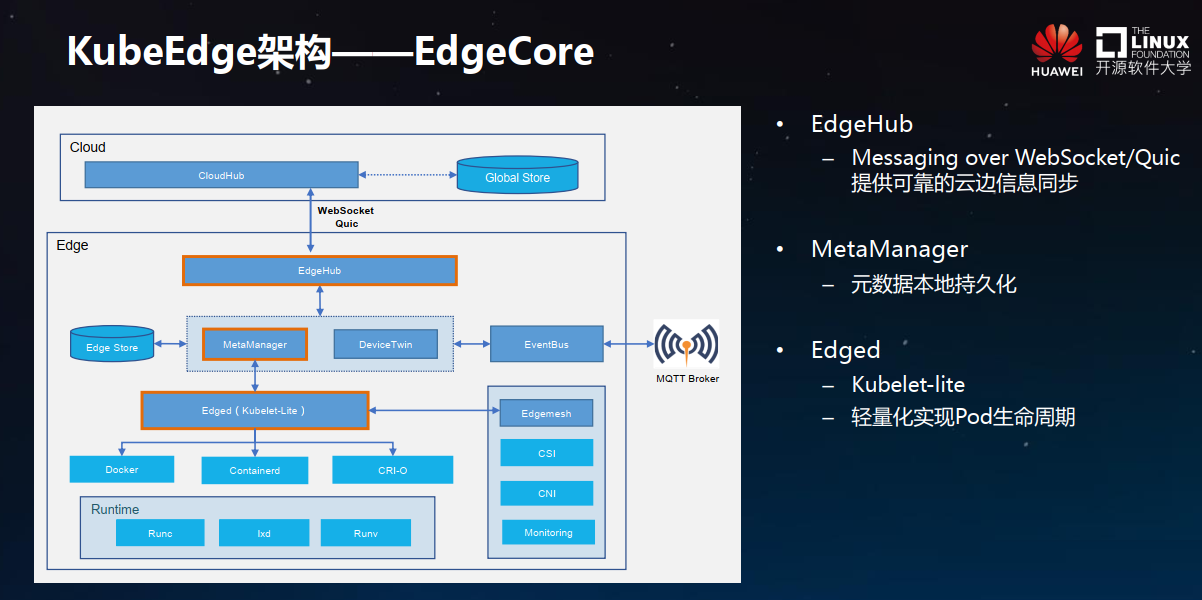
核心组件Edgecore
EdgeHub:主要是跟云端交互,它跟云端的CloudHub是对等的,首先由EdgeHub发起云端的WebSocket连接。
MetaManager:本地持久化数据管理,KubeEdge的离线自治的能力主要是由这个模块实现的,简单来说每个Node用到了哪些Pod,哪些ConfigMap,Secret,都会通过MetaManager写入边缘本地的持久化数据库中,现在当前用的SQLite。
DeviceTwin和EventBus:主要是设备管理,比如说设备状态的上报,以及设备控制指令的下发,而EventBus相当于MQTT的一个client。
Edged:是一个非常轻量化裁剪过的kubelet,使用了应用生命周期管理中最关键的几个模块,去掉了云存储的驱动。支持CRI接口,适配多个container
runtime。
整体KubeEdge比较适合于云边协同,边缘侧离线自治,通知对边缘侧资源要求比较苛刻的场景。如果您的场景需求跟这个比较类似,
建议尝试一下KubeEdge,来管理边缘集群。
同时呢,社区也有一些demo案例,
比如KubeEdge控制树莓派led,或者交通灯等等,可以让同学们能快速上手,对KubeEdge和边缘计算有个初步了解,有兴趣的同学可以研究一下。
Q&A
Q:边缘计算的边在哪里?网络的边缘到底是指什么,如何具象化?如何确定边的位置?边的位置和应用的关系?所谓的边与端的区别是什么?比如说摄像头算是边还是端?边缘网关算是边还是端?这个概念如何判断?
A:边缘计算的边具体在哪里,其实没有很明确的概念,一般主要看你的业务场景。网络边缘一般是指靠近客户现场一侧的网络边缘,在边缘计算场景下,应用是部署在边侧,就近计算,一般情况下摄像头我们可以是认为是端,但是如果摄像头自己有计算能力,有网络接入,能够部署应用,我们也可以理解是是边侧的计算节点。
Q:云边同步怎么做的?
A:KubeEdge云边同步主要通过EdgeHub和CloudHub这两个模块构建的WebSocket连接进行Kubernetes资源的同步的,连接请求首先由Edge端发起,一旦WebSocket建立后,云端就可以向边缘侧传递数据。
Q:如何保证云边状态的统一?Docker形式的边缘应用的优缺点有哪些?
A:KubeEdge最新版支持可靠性消息传输。云端的Kubernetes资源状态发生变化后,会默认通过WebSocket通道进行下发,如果这时候网络断开或者网络质量不高,会进行重传。但是这里为了防止资源状态数据的积压导致内存占用率过高,Kubeedge充分利用了Kubernetes的去重队列,对资源数据进行去重处理。
Q:Kubernetes Master,Kubernetes Node,KubeEdge Edge节点三者是什么关系?在Master上部署CloudCore去管理Edge节点,那Kubernetes
Node是否参与其中?是不是说Edge节点只需要跟Master节点上的CloudCore进行通信,不关心Node;Node也只在Kubernetes集群内通信,不关心Edge?
A:Kubernetes Node和KubeEdge Edge节点没有本质区别,Kubernetes的Node是由kubelet像API
server进行注册的,而KubeEdge Edge节点是KubeEdge通过云边协同机制通过CloudCore进行注册的。通过kubectl
get node看到都是Node,区别在于Edge Node会有专门的标签。
Q:在Kubernetes中,云和终端节点如何通讯的,全双工还是半双工的?实时还是轮询的?IPv6和5G是否应用其中?如何连接其中节点的?对于大量节点之间如何规划网域?是否存在安全问题?如何解决安全隔离问题?
A:Kubernetes中,Master和Node是用过list-watch机制进行通信的,Node上的kubelet启动后,会首先进行list获取全量的数据,之后进行watch,只watch变化的数据。对于Kubernetes的容器网络来说,社区都有比较成熟的CNI插件,Flannel,Calico等等,可以根据自己具体的业务需求来使用不同的网络插件。如果对于安全隔离要求很高,可以让Kubernetes跑在VM上,使用VM本身的隔离性。
===》再问:我说的安全问题是,因为考虑节点之间的自治势必存在节点互通情况,比如这种场景:我和我家邻居冰箱都用同一个Cloud服务,会不会出现对方通过节点之间的通讯,hack访问到我的冰箱。
===》A:这种我觉得应该是称作为SaaS服务会比较合适,虽然你和你家邻居的冰箱感觉是在边缘侧,但是这种应该不属于边缘计算场景,而且节点自治和节点互通也没啥关系。
Q:KubeEdge和EdgeX能结合使用吗?
A:我个人没有应用实践过。KubeEdge是Kubernetes在云端向边端的延伸。如果你如果曾经将Kubernetes和EdgeX结合使用过,理论上KubeEdge也是可以的。
Q:完全是KubEedge新手的话,该从哪里入手呢?
A:https://kubeedge.io/zh/,另外有什么问题可以在KubeEdge社区里提issue或者slack里提问。另外KubeEdge社区每两周周三下午会有社区例会,相关连接可以查看:https://github.com/kubeedge/kubeedge。
Q:KubeEdge当前应用于哪些商业场景?
A:最典型的是摄像头类场景,比如汽车保养门店,园区人脸识别入园,车牌识别等等。把AI计算类应用部署在客户现场一侧(比如汽车门店或者园区),直接就进图像识别。
Q:KubeEdge现在有支持哪些终端直接跑Node?除了前面提到的树莓派、交通灯。
A: 树莓派一般是用于开发测试场景。有兴趣的可以尝试一下华为的atlas开发者套件。一般ARM架构的服务器都可以。
Q:请问KubeEdge实际部署中遇到哪些问题?如何解决的? 现今面临的主要挑战是什么?
A:主要是边缘场景下,客户对云原生,Kubernetes的理解程度不一样,需要时间。这就跟最开始Kubernetes诞生以后,对传统观念是一个冲击。
Q:KubeEdge对关键功能是否有监控?监控方案是如何做的?报警规则分别有哪些?
A:KubEedge 1.3版本计划提供Metric功能,可以使用开源Prometheus去监控报警。
|








