| ±ύΦ≠ΆΤΦω: |
±ΨΈΡΫΪΫι…ή±Ώ‘ΒΦΤΥψ≥ΓΨΑ»γΚΈΙΙΫ®Α≤»Ϊ‘Υ–– ±ΦΦ θΜυΉυΘ§“‘ΦΑΑ≤»Ϊ»ίΤς‘ΎΦήΙΙΓΔΆχ¬γΓΔΦύΩΊΓΔ»’÷ΨΓΔ¥φ¥ΔΓΔ“‘ΦΑ
K8s API Φφ»ίΒ»ΖΫΟφΒΡ”ωΒΫΒΡάßΡ―Χτ’ΫΚΆΉνΦ― ΒΦυΓΘ
±ΨΈΡά¥Ή‘”ΎΑΔάο‘ΤΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΆΤΦωΓΘ |
|
’ΐΈΡΘΚ
±ΨΈΡ÷ς“ΣΖ÷ΈΣΥΡΗω≤ΩΖ÷Θ§ Ήœ»«ΑΝΫΗω≤ΩΖ÷ΜαΖ÷±πΫι…ή“Μœ¬ACKΑ≤»Ϊ…≥œδ»ίΤςΚΆ±Ώ‘Β»ίΤςΘ®Edge KubernetesΘ©Θ§’βΝΫΗωΖΫœρΡΎ»ίΡΩ«Α¥σ≤ΩΖ÷»ΥΫ”¥Ξ≤Δ≤Μ «ΚήΕύΓΘΒΎ»ΐ≤ΩΉ≈÷ΊΖ÷œμΑ≤»Ϊ…≥œδ»ίΤς‘Ύ±Ώ‘Β’β±ΏΒΡΫβΨωΖΫΑΗ”κ ΒΦυΨ≠―ιΘ§ΉνΚσΜαΫι…ή“Μœ¬Έ“Ο«‘ΎΑ≤»Ϊ»ίΤςΖΫœρ–¬ΒΡΧΫΥςΚΆ ΒΦυ-Ω…–≈/ΜζΟήΦΤΥψΓΘ
Α≤»Ϊ»ίΤς‘Υ–– ±
Ψί Gartner ‘Λ≤βΘ§2019 Ρξ“ΜΑκ“‘…œΒΡΤσ“ΒΜα‘ΎΤδΩΣΖΔΚΆ…ζ≤ζΜΖΨ≥÷– Ι”Ο»ίΤς≤Ω π”Π”ΟΘ§»ίΤςΦΦ θ»’«ς≥… λΈ»Ε®Θ§»ΜΕχ‘ΎΈ¥»ίΤςΜ·ΒΡΤσ“ΒΜρ”ΟΜß÷–Θ§42%
“‘…œΒΡ ήΖΟ’Ώ±μ Ψ»ίΤςΑ≤»Ϊ≥…ΈΣΤδ»ίΤςΜ·ΒΡΉν¥σ’œΑ≠÷°“ΜΘ§÷ς“ΣΑϋά®»ίΤς‘Υ–– ±Α≤»ΪΓΔΨΒœώΑ≤»ΪΚΆ ΐΨίΑ≤»ΪΦ”ΟήΒ»ΓΘ
ΕΥΒΫΕΥΒΡ‘Τ‘≠…ζΑ≤»ΪΦήΙΙ

‘ΎΫ≤Α≤»Ϊ…≥œδ»ίΤς÷°«ΑΦρΒΞΫι…ήœ¬ΕΥΒΫΕΥ‘Τ‘≠…ζΑ≤»ΪΦήΙΙΘ§÷ς“ΣΖ÷ΈΣ»ΐ≤ΩΖ÷ΘΚ
1.Μυ¥ΓΦήΙΙΑ≤»Ϊ
Μυ¥ΓΦήΙΙΑ≤»Ϊ“άάΒ”Ύ‘Τ≥ß…ΧΜρ’Ώ «Ή®”–‘Τ“Μ–©Μυ¥Γ…η ©Α≤»ΪΡήΝΠΘ§“≤Αϋά® RAM»œ÷ΛΘ§œΗΝΘΕ»RAM Ύ»®Θ§÷ß≥÷…σΦΤΡήΝΠ»»ΓΘ
2.Α≤»Ϊ»μΦΰΙ©”ΠΝ¥
’β≤ΩΖ÷Αϋά®ΨΒœώ«©ΟϊΘ§ΨΒœώ…®ΟηΘ§Α≤»ΪΚœΙφ»»ȧ…θ÷ΝΑϋά®”–“Μ–©Ψ≤Χ§Φ”ΟήBYOKΘ§DevSecOpsΘ§Α≤»ΪΖ÷ΖΔΒ»ΓΘ
3.»ίΤς‘Υ–– ±ΒΡΑ≤»Ϊ
’β≤ΩΖ÷Αϋά®Α≤»Ϊ…≥œδΗτάκΘ§ΜΙΑϋά®ΝΥ»ίΤς‘Υ–– ±ΤδΥϋΖΫΟφ“Μ–©Α≤»ΪΜζ÷ΤΘ§»γKMSΘ®ΟΊ‘ΩΙήάμΖΰΈώΘ©Φ·≥…ΓΔΕύΉβΜßΒΡΙήάμΚΆΗτάκ»»ΓΘ
Α≤»Ϊ»ίΤς‘Υ–– ±Ε‘±» 
Ϋ”œ¬ά¥Ζ÷œμœ¬“ΒΫγ‘ΎΑ≤»Ϊ»ίΤς‘Υ–– ±ΒΡ“Μ–©ΖΫΑΗΕ‘±»Θ§“ΒΫγΑ≤»Ϊ»ίΤς‘Υ–– ±Ζ÷ΈΣΥΡ¥σάύΘΚ
OS»ίΤς+Α≤»ΪΜζ÷Τ
÷ς“Σ‘≠άμ «‘Ύ¥ΪΆ≥ OS »ίΤς÷°…œ‘ωΦ”“Μ–©Η®÷ζΑ≤»ΪΗ®÷ζ ÷ΕΈά¥‘ωΦ”Α≤»Ϊ–‘Θ§»γSELinuxΓΔAppArmorΓΔSeccompΒ»Θ§ΜΙ”–docker
19.03+Ω…“‘»ΟDocker‘Υ––‘Ύ Rootless ΒΡΡΘ Ϋ÷°œ¬Θ§Τδ Β’β–©ΕΦ «Ά®ΙΐΗ®÷ζΒΡΙΛΨΏ ÷ΕΈά¥‘ω«ΩOS»ίΤςΒΡΑ≤»Ϊ–‘Θ§ΒΪ“ά»ΜΟΜ”–ΫβΨω»ίΤς”κHostΙ≤œμΡΎΚΥάϊ”ΟΡΎΚΥ¬©Ε¥Χ”“ί¥χά¥ΒΡΑ≤»Ϊ“ΰΜΦΈ ΧβΘΜΕχ«“’β–©Α≤»ΪΖΟΈ ΩΊ÷ΤΙΛΨΏΕ‘Ιήάμ‘±»œ÷ΣΚΆΦΦΡή“Σ«σ±»ΫœΗΏΘ§Α≤»Ϊ–‘“≤œύΕ‘Ήν≤νΓΘ
”ΟΜßΧ§ΡΎΚΥ
¥ΥάύΒδ–Ά¥ζ±μ « Google ΒΡ gVisorΘ§Ά®Ιΐ Βœ÷ΕάΝΔΒΡ”ΟΜßΧ§ΡΎΚΥ»Ξ≤ΙΜώΚΆ¥ζάμ”Π”ΟΒΡΥυ”–œΒΆ≥Βς”ΟΘ§ΗτάκΖ«Α≤»ΪΒΡœΒΆ≥Βς”ΟΘ§ΦδΫ”–‘¥οΒΫΑ≤»ΪΡΩΒΡΘ§Υϋ «“Μ÷÷Ϋχ≥Χ–ιΡβΜ·‘ω«ΩΓΘΒΪœΒΆ≥Βς”ΟΒΡ¥ζάμΚΆΙΐ¬ΥΒΡ’β÷÷Μζ÷ΤΘ§ΒΦ÷¬ΥϋΒΡ”Π”ΟΦφ»ί–‘“‘ΦΑœΒΆ≥Βς”ΟΖΫΟφ–‘ΡήœύΕ‘¥ΪΆ≥OS»ίΤςΫœ≤νΓΘ”…”Ύ≤Δ≤Μ÷ß≥÷
virt-io Β»–ιΡβΩρΦήΘ§ά©’Ι–‘Ϋœ≤νΘ§≤Μ÷ß≥÷…η±Η»»≤εΑΈΓΘ
Library OS
Μυ”Ύ LibOS ΦΦ θΒΡ’β÷÷Α≤»Ϊ»ίΤς‘Υ–– ±Θ§±»Ϋœ”–¥ζ±μ UniKernelΓΔNabla-ContainersΘ§LibOSΦΦ θ±Ψ÷ «’κΕ‘”Π”ΟΕ‘ΡΎΚΥΒΡ“ΜΗω…νΕ»≤ΟΦτΚΆΕ®÷ΤΘ§–η“ΣΑ―
LibOS ”κ”Π”Ο±ύ“κ¥ρΑϋ‘Ύ“ΜΤπΓΘ“ρΈΣ–η“Σ¥ρΑϋΤ¥‘Ύ“ΜΤπΘ§±Ψ…μΦφ»ί–‘±»Ϋœ≤νΘ§”Π”ΟΚΆ LibOS ΒΡάΠΑσ±ύ“κΚΆ≤Ω πΈΣ¥ΪΆ≥ΒΡ
DevOPS ¥χά¥Χτ’ΫΓΘ
MicroVM
Έ“Ο«÷ΣΒά“ΒΫγ–ιΡβΜ·(Μζ)±Ψ…μ“―Ψ≠Ζ«≥ΘΒΡ≥… λΘ§MicroVM«αΝΩ–ιΡβΜ·ΦΦ θ «Ε‘¥ΪΆ≥–ιΡβΜ·ΒΡ≤ΟΦτΚΆΘ§±»Ϋœ”–¥ζ±μ–‘ΒΡΨΆ «
Kata-ContainersΓΔFirecrackerΘ§ά©’ΙΡήΝΠΖ«≥Θ”≈–ψΓΘVM GuestOS Αϋά®ΡΎΚΥΨυΩ…Ή‘”…Ε®÷ΤΘ§”…”ΎΨΏ±ΗΆξ’ϊΒΡOSΚΆΡΎΚΥΥϋΒΡ”Π”ΟΦφ»ί–‘ΦΑΤδ”≈–ψΘΜΕάΝΔΡΎΚΥΒΡΚΟ¥Π «Φ¥±ψ≥ωœ÷Α≤»Ϊ¬©Ε¥Έ Χβ“≤ΜαΑ―Α≤»Ϊ”ΑœλΖΕΈßœό÷ΤΒΫ“ΜΗω
VM άοΟφΘ§Β±»ΜΥϋ“≤”–Ή‘ΦΚΒΡ»±ΒψΘ§Overhead Ω…ΡήΜᬑ¥σ“ΜΒψΘ§ΤτΕ·ΥΌΕ»œύΕ‘Ϋœ¬ΐ“ΜΒψΓΘ
Άξ»ΪΕ≈ΨχΑ≤»ΪΈ ΧβΒΡΖΔ…ζ-≤ΜΩ…ΡήΘΓ
Linus Torvalds ‘χ‘Ύ 2015ΡξΒΡ LinuxCon …œΥΒΙΐ "The only
real solution to security is to admit that bugs happen,
and then mitigate them by having multiple layers.Γ±
Θ§Έ“Ο«ΈόΖ®Ε≈ΨχΑ≤»ΪΈ ΧβΘ§»μΦΰΉήΜα”– BugΓΔKernel ΉήΜα”–¬©Ε¥Θ§Έ“Ο«–η“Σ»ΞΟφΕ‘’β–©œ÷ ΒΈ ΧβΘ§Φ»»ΜΈόΖ®Ε≈ΨχΡ«Έ“Ο«–η“ΣΨΆΗχΥϋΘ®”Π”ΟΘ©Φ”…œΗτάκ≤ψΘ®…≥œδΘ©ΓΘ
Α≤»Ϊ»ίΤς‘Υ–– ±―Γ‘ώ
”ΟΜß―Γ‘ώΑ≤»Ϊ»ίΤς‘Υ–– ±–η“ΣΩΦ¬«»ΐΖΫΟφΘΚΑ≤»ΪΗτάκΓΔΆ®”Ο–‘“‘ΦΑΉ ‘¥–߬ ΓΘ
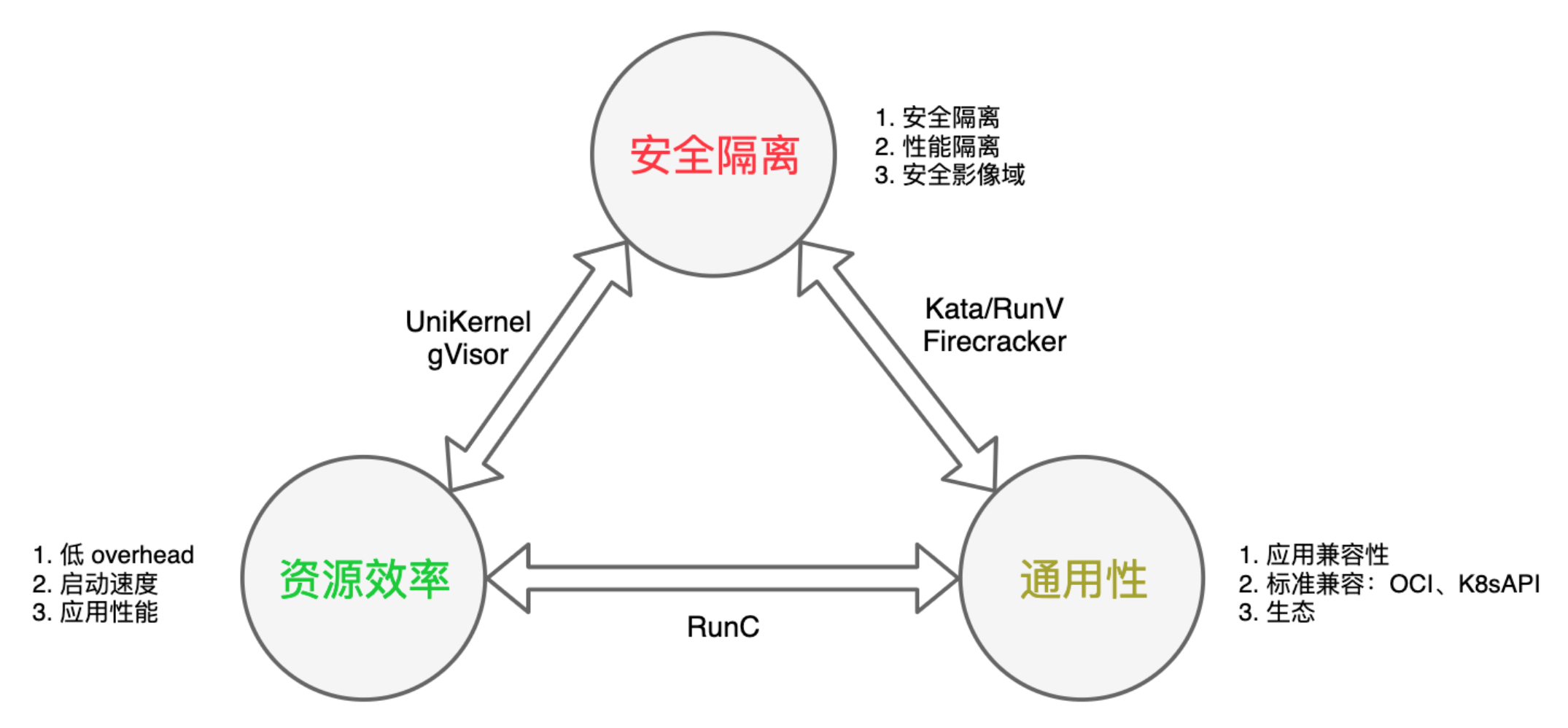
Α≤»ΪΗτάκ
÷ς“ΣΑϋά®Α≤»ΪΗτάκΚΆ–‘ΡήΗτάκΓΘΑ≤»ΪΗτάκ÷ς“Σ «Α≤»ΪΈ Χβ”ΑœλΒΡΖΕΈßΘ§–‘ΡήΗτάκ÷ς“Σ «ΫΒΒΆ»ίΤςΦδΒΡœύΜΞΗ…»≈ΚΆ”ΑœλΓΘ
Ά®”Ο–‘
Ά®”Ο–‘Θ§ Ήœ» «”Π”ΟΦφ»ί–‘Θ§”Π”Ο «ΖώΩ…“‘‘Ύ≤Μ–όΗΡΜρ’Ώ–ΓΝΩ–όΗΡΒΡ«ΑΧαœ¬‘Υ––‘Ύ…œΟφΘΜΤδ¥Έ «±ξΉΦ–‘Φφ»ίΘ§Αϋά®
OCI Φφ»ίΓΔK8sAPI Φφ»ίΒ»ΘΜΉνΚσΓΑ…ζΧ§Γ±±Θ÷ΛΥϋΩ…≥÷–χ–‘ΚΆΫΓΉ≥–‘ΓΘ
Ή ‘¥–߬
Ή ‘¥–߬ Ϋ≤ΨΩΗϋΒΆ OverheadΘ§ΗϋΩλΒΡΤτΕ·ΥΌΕ»Θ§ΗϋΚΟΒΡ”Π”Ο–‘ΡήΓΘ
ΉήΫα
Τδ ΒΡΩ«ΑΟΜ”–»ΈΚΈ“Μ÷÷»ίΤς‘Υ–– ±ΦΦ θΩ…“‘Ά§ ±¬ζΉψ“‘…œ»ΐΒψΘ§ΕχΈ“Ο«–η“ΣΉωΒΡΨΆ «ΗυΨίΨΏΧεΒΡ≥ΓΨΑΚΆ“ΒΈώ–η«σΚœάμ―Γ‘ώ ΚœΉ‘ΦΚΒΡ»ίΤς‘Υ–– ±ΓΘ
‘ΎΓΗΉ ‘¥–߬ ΓΙΚΆΓΗΆ®”Ο–‘ΓΙΉωΒΡ±»ΫœΚΟΒΡ «¥ΪΆ≥ΒΡOS»ίΤςΓΔrunCΒ»Θ§ΒΪΑ≤»Ϊ–‘Ήν≤νΘΜ‘ΎΓΗΉ ‘¥–߬ ΓΙΚΆΓΗΑ≤»ΪΗτάκΓΙΉωΒΡ±»ΫœΚΟΒΡ «
UniKernelΓΔgVisor Β»Θ§ΒΪ”Π”ΟΦφ»ίΚΆΆ®”Ο–‘Ϋœ≤νΘΜ‘ΎΓΗΑ≤»ΪΗτάκΓΙΚΆΓΗΆ®”Ο–‘ΓΙΖΫΟφΉωΒΡ±»ΫœΒΡ «
Kata-containersΓΔFirecrackerΒ»Θ§ΒΪ overhead ΩΣœζ…‘¥σΤτΕ·ΥΌΕ»…‘¬ΐΘ§”Π”Ο–‘Ρή“≤œύΕ‘¥ΪΆ≥OS»ίΤςΫœ≤νΓΘ
ACKΑ≤»Ϊ…≥œδ»ίΤς
Έ“Ο«ΑΔάο‘Τ»ίΤςΖΰΈώ ACK ≤ζΤΖΜυ”Ύ Alibaba Cloud Sandbox ΦΦ θ‘Ύ 2019
Ρξ 09 ‘¬ΖίΆΤ≥ωΝΥΑ≤»Ϊ…≥œδ»ίΤς‘Υ–– ±ΒΡ÷ß≥÷Θ§Υϋ «‘Ύ‘≠”–Docker»ίΤς÷°ΆβΧαΙ©ΒΡ“Μ÷÷»Ϊ–¬ΒΡ»ίΤς‘Υ–– ±―ΓœνΘ§ΥϋΩ…“‘»Ο”Π”Ο‘Υ––‘Ύ“ΜΗω«αΝΩ–ιΡβΜζ…≥œδΜΖΨ≥÷–Θ§”Β”–ΕάΝΔΒΡΡΎΚΥΘ§ΨΏ±ΗΗϋΚΟΒΡΑ≤»ΪΗτάκΡήΝΠΘ§ΧΊ±π Κœ”ΎΕύΉβΜßΦδΗΚ‘ΊΗτάκΓΔΕ‘≤ΜΩ…–≈”Π”ΟΗτάκΒ»≥ΓΨΑΓΘΥϋ‘ΎΧα…ΐΑ≤»Ϊ–‘ΒΡΆ§ ±Θ§Ε‘–‘Ρή”ΑœλΖ«≥Θ–ΓΘ§≤Δ«“ΨΏ±Η”κDocker»ίΤς“Μ―υΒΡ”ΟΜßΧε―ιΘ§»γ»’÷ΨΓΔΦύΩΊΓΔΒ·–‘Β»ΓΘ

Ε‘”ΎΈ“Ο«≥ΓΨΑά¥ΥΒΘ§ΓΗΑ≤»Ϊ–‘ΓΙΚΆΓΗΆ®”Ο–‘ΓΙ «Έό“…Ήν÷Ί“ΣΒΡΘ§Β±»Μ–‘ΡήΚΆ–߬ Έ“Ο«“≤ΉωΝΥ¥σΝΩΒΡ”≈Μ·ΘΚ
«αΝΩ–ιΡβΜζ…≥œδΘΜ
ΕάΝΔ kernelΘ§«ΩΗτάκΘ§Α≤»ΪΙ ’œ”ρ”ΑœλΉν–ΓΘΜ
Φφ»ί OCI ±ξΉΦΘ§ΦΗΚθΦφ»ίΥυ”– K8s APIΘΜ
‘Φ 25 MB ΒΡΦΪΒΆ Overhead ΩΣœζΘΜ
500ms ΦΪΥΌΤτΕ·Θ§”Β”–‘≠…ζ¥ΪΆ≥OS»ίΤς‘Φ 90% ΒΡ”≈–ψ–‘ΡήΘΜ
ΚœΕύΉβΗΚ‘ΊΗτάκΓΔ≤ΜΩ…–≈»ΐΖΫ”Π”ΟΗτάκΓΔΕύΖΫΦΤΥψΓΔServerless Β»≥ΓΨΑΓΘ
ACK±Ώ‘Β»ίΤςΘ®ACK@EdgeΘ©
ΥφΉ≈ΆρΈοΜΞΝΣ ±¥ζΒΡΒΫά¥Θ§÷«Μέ≥« –ΓΔ÷«Ρή÷Τ‘λΓΔ÷«ΡήΫΜΆ®ΓΔ÷«ΡήΦ“Ψ”Θ§5G ±¥ζΓΔΩμ¥χΧαΥΌΓΔIPv6ΒΡ≤ΜΕœΤ’ΦΑΘ§ΒΦ÷¬ ΐΑΌ“ΎΒΡ…η±ΗΫ”»κΆχ¬γΘ§‘ΎΆχ¬γ±Ώ‘Β≤ζ…ζZBΦΕ ΐΨίΘ§¥ΪΆ≥‘ΤΦΤΥψΡ―“‘¬ζΉψΈοΝΣΆχ ±¥ζ¥σ¥χΩμΓΔΒΆ ±―”ΓΔ¥σΝ§Ϋ”ΒΡΥΏ«σΘ§±Ώ‘Β‘ΤΦΤΥψ±ψ”Π‘ΥΕχ…ζΓΘ
±Ώ‘ΒΦΤΥψ…η ©ΖΰΈώ‘Ϋά¥‘ΫΡ―“‘¬ζΉψ±ΏΕΥ»’“φ≈ρ’ΆΒΡΥΏ«σΘ§“ρΕχ‘Τ…œΖΰΈώœ¬≥ΝΘ§±Ώ‘Β ServerlessΓΔ±Ώ‘Β≤ύΗτάκ≤ΜΩ…–≈ΗΚ‘ΊΒ»»’«ς«ΩΝ“...
Υυ“‘Θ§ΈΣΝΥ¬ζΉψΈ“Ο«±Ώ‘Β‘ΤΦΤΥψ≥ΓΨΑ–η«σΘ§Έ“Ο« ACK ΆΤ≥ωΝΥ Kubernetes ±Ώ‘ΒΑφΓΘ

œ»ά¥Ω¥œ¬Βδ–ΆΒΡ±Ώ‘Β‘ΤΡΘ–ΆΘ§Υϋ”…‘ΤΘ®≤ύΘ©ΓΔ±ΏΘ®≤ύΘ©ΓΔΕΥΘ®≤ύΘ©»ΐ≤ΩΖ÷Ι≤Ά§Ήι≥…Θ§»ΐ’ΏœύΜΞ–≠Ά§Θ§≤ΔΧαΙ©Ά≥“ΜΒΡΫΜΗΕΓΔ‘ΥΈ§ΚΆΙήΩΊ±ξΉΦΓΘ‘Τ≤ύΆ≥“ΜΙήΩΊΘ§ «’ϊΗωΡΘ–ΆΒΡ÷– ύ¥σΡ‘ΘΜ±Ώ≤ύ”…“ΜΕ®ΦΤΥψ/¥φ¥ΔΡήΝΠΒΡΫΎΒψΉι≥…Θ§ «Ψύάκ…η±ΗΚΆ”ΟΜßΉνΫϋΒΡΦΤΥψ/¥φ¥ΔΉ ‘¥ΘΜ“ΎΆρΕΥ≤ύ…η±ΗΨΆΫϋΦΤ»κΓΑ±Ώ‘ΒΫΎΒψΓ±ΓΘ
ΓΑ±ΏΓ±”÷Ζ÷ΈΣΝΫ¥σάύΘΜ“ΜΗω «ΙΛ“ΒΦΕΒΡ±ΏΘ§’βάύ±»ΫœΒδ–Ά¥ζ±μ «‘Τ≥ß…ΧΧαΙ©ΒΡ CDN ΫΎΒψΦΤΥψΉ ‘¥ΓΔΖΰΈώΜρ’Ώ
Serverless Β»Θ§ΙΛ“ΒΦΕΒΡ±Ώ“≤Ω…ΧαΙ© AI ‘Λ≤βΓΔ Β ±ΦΤΥψΓΔΉΣ¬κΒ»ΖΰΈώΡήΝΠΘ§Α―‘Τ…œΒΡΖΰΈώœ¬≥ΝΒΫ±Ώ≤ύΓΘΒΎΕΰάύ «”ΟΜßΜρ’ΏΙΛ≥ßΓΔ‘Α«χΓΔ¬Ξ”νΓΔΜζ≥ΓΒ»Ή‘ΦΚΧαΙ©ΦΤΥψΉ ‘¥ΖΰΈώΤςΜρ’ΏΆχΙΊΖΰΈώΤςΘ§»γ“ΜΗωΦ“ΆΞΆχΙΊΩ…“‘ΉςΈΣ±Ώ‘ΒΫΎΒψΫ”»κΒΫΦ·»Κ÷–¥”ΕχΩ…“‘Ρ…ΙήΩΊ÷ΤΦ“ΆΞ÷–ΒΡ÷«ΡήΒγΤς…η±ΗΓΘ
Ρ«±Ώ‘Β Serverless »γΚΈΫβΨωΕύΉβΜßΗΚ‘ΊΗτάκΘΩΙΛ≥Χ»γΚΈ‘ΎΉ‘ΦΚΒΡΡΎΆχΜΖΨ≥Α≤»Ϊ‘Υ––»ΐΖΫΧαΙ©ΒΡ”Π”ΟΖΰΈώΚΆΗΚ‘ΊΘΩ’β“≤ΨΆ «Έ“Ο«‘Ύ±Ώ‘Β≤ύ“ΐ»κΑ≤»Ϊ…≥œδ»ίΤςΒΡΗυ±Ψ‘≠“ρΓΘ
ΫβΨωΖΫΑΗ
’ϊΧεΖΫΑΗ 
œ»Ω¥œ¬’ϊΧεΫβΨωΖΫΑΗΘ§…œΟφΦήΙΙΆξ»ΪΤθΚœΝΥΓΑ‘Τ-±Ώ-ΕΥΓ±ΡΘ–ΆΘ§Έ“Ο«’ϊΗωΦήΙΙ «Μυ”Ύ Kubernetes
ά¥ΩΣΖΔΒΡΓΘ
ΓΑ‘Τ≤ύΓ±Θ§Φ»ΓΑΙήΩΊΕΥΓ±Θ§ΧαΙ©ΝΥ’ϊΗω K8s Φ·»ΚΒΡΆ≥“ΜΙήΩΊΘ§Ά–ΙήΝΥ K8s Φ·»ΚΓΑΥΡ¥σΦΰ(masterΉιΦΰ)Γ±ΘΚkube-apiserverΓΔkube-controller-managerΓΔkube-scheduler“‘ΦΑ
cloud-controller-managerΘ§Ά§ ±Έ“Ο«‘ΎΓΑ‘Τ≤ύΈΣΓ±‘ωΦ”ΝΥ AdminNode ΫΎΒψ”ΟΜß≤Ω π
Addons ΉιΦΰΘ§»γ metrics-serverΓΔlog-controller Β»Ζ«ΚΥ–ΡΙΠΡήΉιΦΰΘΜΒ±»ΜΘ§ΓΑ‘Τ≤ύΓ±“≤Μα ≈δ‘Τ…œΒΡΗςάύΖΰΈώΈΣΉ‘ΦΚΗΫΡήΘ§»γΦύΩΊΖΰΈώΓΔ»’÷ΨΖΰΈώΓΔ¥φ¥ΔΖΰΈώ»»ΓΘ
ΓΑ±Ώ≤ύΓ±Θ§Φ»±Ώ‘ΒNodeΫΎΒψΘ§Έ“Ο«÷ΣΒάΓΑ‘Τ≤ύΓ±ΒΫΓΑ±Ώ≤ύΓ±ΒΡ»θΆχΜαΒΦ÷¬±Ώ‘ΒNode ßΝΣΘ§ ßΝΣ ±ΦδΙΐ≥ΛΜαΒΦ÷¬
Master Ε‘ΫΎΒψ…œΒΡ Pod ΖΔ≥ω«ΐ÷π÷ΗΝνΘ§ΜΙ”–ΕœΆχΤΎΦδΓΑ±Ώ‘ΒΫΎΒψΓ±÷ςΜζ÷ΊΤτΚσ”Π”Ο»γΚΈΜ÷Η¥ΚΆΉ‘÷ΈΘ§’β–©ΕΦ «
Edge Kubernetes ΟφΝΌΒΡΉν¥σΧτ’Ϋ÷°“ΜΘΜΒ±‘Ύ K8s “ΐ»κΑ≤»Ϊ…≥œδ»ίΤς‘Υ–– ±Θ§ΜαΖΔœ÷ K8s
Api ≤ΜΦφ»ίΓΔ≤ΩΖ÷ΦύΩΊ“λ≥ΘΓΔ»’÷ΨΈόΖ®’ΐ≥Θ≤…Φ·ΓΔ¥φ¥Δ–‘ΡήΦΪ≤νΒ»÷νΕύΈ ΧβΘ§ΕΦΗχΈ“Ο«¥χά¥ΝΥΦΪ¥σΒΡΧτ’ΫΓΘ
‘ΎΖ÷œμΫβΨω“‘…œΈ Χβ«ΑΘ§Έ“Ο«œ»Ω¥œ¬‘Τ≤ύΑ≤»Ϊ…≥œδ»ίΤςΖΫΑΗΓΘ
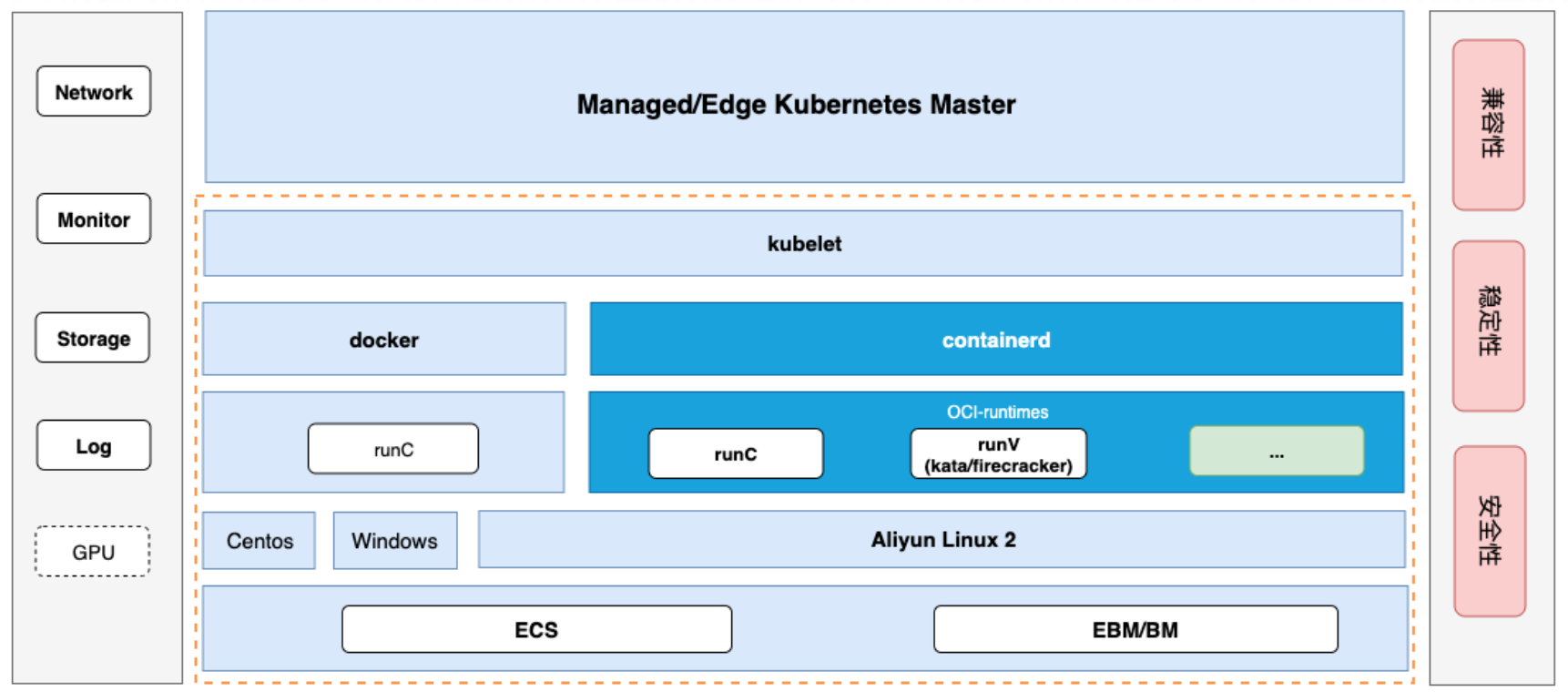
…œΆΦ≥»…Ϊ–ιΩρΡΎ «ΫΎΒψ‘Υ–– ±ΒΡΉιΦΰΖ÷≤ψΫαΙΙΘ§…œΟφ « kubeletΘ§CRI-Runtime ”– Docker
ΚΆ Containerd ΝΫάύΘ§Τδ÷–Α≤»Ϊ…≥œδ»ίΤς‘Υ–– ±ΖΫΑΗΘ®…νάΕ…Ϊ±≥ΨΑ≤ΩΖ÷Θ©÷–Έ“Ο«―Γ‘ώΝΥ Containerd
ΉςΈΣ CRI-RuntimeΘ§÷ς“ΣΩΦ¬«ΒΫ Containerd ΒΡΫαΙΙΦρΫύΘ§Βς”ΟΝ¥ΗϋΕΧΘ§Ή ‘¥ΩΣœζΗϋ–ΓΘ§Εχ«“ΥϋΨΏ”–ΦΑΤδΝιΜνΒΡΕύ
Runtimes ÷ß≥÷Θ§ά©’ΙΡήΝΠ“≤Ηϋ”≈ΓΘ
Έ“Ο«‘Ύ“ΜΗωΓΑΑ≤»Ϊ…≥œδΫΎΒψΓ±…œΆ§ ±ΧαΙ©ΝΥ RunC ΚΆ RunV ΝΫ÷÷‘Υ–– ±ΒΡ÷ß≥÷Θ§Ά§ ±‘Ύ K8s
Φ·»Κ÷–Ε‘”ΠΒΡΉΔ»κΝΥΝΫΗω RuntimeClassΘ® runc ΚΆ runv Θ©“‘±ψ«αΥ…«α“ΉΑ¥–ηΒςΕ»ΚΆ―Γ‘ώΘ§ΓΑΆ§ ±ΧαΙ©
RunC ÷ß≥÷Γ± “≤ «ΩΦ¬«ΒΫ÷ν»γ kube-proxy Β» Addon ΉιΦΰΟΜ±Ί“Σ‘Υ––‘ΎΑ≤»Ϊ…≥œδ÷–ΓΘ
OS Έ“Ο«―Γ‘ώΝΥΑΔάο‘ΤΒΡΖΔ––Αφ OSΘΚAliyun LinuxΘ§4.19+ ΒΡ Kernel Ε‘»ίΤςΒΡΦφ»ί–‘Ηϋ”≈ΓΔΈ»Ε®–‘ΗϋΚΟΘ§Ά§ ±Έ“Ο«Ε‘ΤδΫχ––ΝΥΦΪ…ΌΒΡΕ®÷ΤΘ§“‘±ψ÷ß≥÷”≤Φΰ–ιΡβΜ·ΓΘ
Ήνœ¬Οφ‘Υ––ΨΆ «Έ“Ο«ΒΡ¬ψΫπ τΖΰΈώΤςΘ§‘Ύ‘Τ…œΈ“Ο«ΧαΙ©ΝΥ…ώΝζΘ§‘Ύ±Ώ‘Β≤ύ»ΈΚΈ÷ß≥÷”≤Φΰ–ιΡβΜ·ΒΡ¬ψΫπ τΖΰΈώΤςΨυΩ…ΓΘ
±Ώ‘ΒΫ”ΫΎΒψ÷Έάμ
Έ Χβ
K8s ΙήΩΊΕΥ”κ±Ώ‘ΒΫΎΒψΕœΆχΈ§ΜΛΘ§»γΙΛ≥ßΖβΆχΡΎ≤Ω…η±ΗΈ§ΜΛΒ»Θ§≥§Ιΐ Pod »ί»Χ ±ΦδΘ®Ρ§»œ300sΘ©ΚσΜαΒΦ÷¬ΙήΩΊΕΥΖΔ≥ωΓΑ«ΐ÷π ßΝΣΫΎΒψ…œΥυ”–
PodsΓ±÷ΗΝνΘ§‘ΎΈ§ΜΛΫα χΆχ¬γΜ÷Η¥ΚσΘ§±Ώ‘ΒΫΎΒψ ’ΒΫ«ΐ÷π÷ΗΝν…Ψ≥ΐΥυ”–”Π”Ο PodΘ§’βΕ‘”Ύ“ΜΗωΙΛ≥ßά¥ΥΒ «‘÷Ρ―–‘ΒΡΓΘ
‘ΎΖβΘ®ΕœΘ©ΆχΤΎΦδ±Ώ‘ΒΫΎΒψ”≤Φΰ÷ΊΤτΘ§ΨΆΜαΒΦ÷¬ΫΎΒψ…œ“άάΒΙήΩΊΕΥΘ®»γ kube-apiserverΘ©ΒΡ≤ΩΖ÷ΉιΦΰΜρ ΐΨίΈόΖ®’ΐ≥ΘΤτΕ·Μρ‘Ί»κΓΘ
≥ΘΦϊ…γ«χΖΫΑΗ
…γ«χΖΫΑΗ“ΜΘΚ

÷ς“Σ‘≠άμ «Μυ”Ύ kubelet checkpoint Μζ÷ΤΑ―“Μ–©Ή ‘¥Ε‘œσΜΚ≥εΒΫ±ΨΒΊΈΡΦΰΘ§ΒΪ kubelet
checkpoint ΡήΝΠΫœ»θΘ§ΫωΩ…“‘Μξ¥ε pod Β»Ηω±πάύ–ΆΕ‘œσΒΫ±ΨΒΊΈΡΦΰΘ§œώ≥Θ”ΟΒΡ ConfigMap/Secret/PV/PVC
Β»‘ί≤Μ÷ß≥÷ΓΘΒ±»Μ“≤Ω…“‘Ε®÷Τ–όΗΡ kubeletΘ§ΒΪΚσΤΎΜα¥χά¥ΒΡ¥σΝΩΒΡ…ΐΦΕΚΆΈ§ΜΛ≥…±ΨΓΘ
…γ«χΖΫΑΗΕΰΘΚ

άϊ”ΟΦ·»ΚΝΣΑνΘ§Α―’ϊΗω K8s Φ·»Κœ¬≥ΝΒΫ±Ώ‘Β≤ύΘ§»γΟΩΗω EdgeUnit ¥φ‘Ύ“ΜΗωΜρΕύΗω K8s
Φ·»ΚΘ§Ά®Ιΐ‘Τ≤ύΒΡ K8s Federation Ϋχ––ΕύΦ·»Κ/ΗΚ‘ΊΙήάμΓΘΒΪ“ρΈΣ EdgeUnit Ζ÷…Δ–‘«“ΙφΡΘΫœ¥σ≈”¥σΘ§ΜαΒΦ÷¬Φ·»ΚΙφΡΘ ΐ±Ε‘ωΦ”Θ§≤ζ…ζ¥σΝΩΒΡ
Overhead ≥…±ΨΘ§ΚήΕύ EdgeUnit ΡΎΆ®≥ΘΫω”–ΦΗΧ®ΜζΤςΓΘΕχ«“’β÷÷ΦήΙΙ“≤±»ΫœΗ¥‘”Θ§Ρ―“‘‘ΥΈ§Θ§Ά§ ±Θ§±Ώ‘ΒK8sΦ·»Κ“≤ΚήΡ―Η¥”Ο‘Τ…œ≥… λΖΰΈώΘ§»γΦύΩΊΓΔ»’÷ΨΒ»ΓΘ
Έ“Ο«ΒΡΖΫΑΗ 
»γ…œΆΦΘ§‘ΎΈ“Ο«ΒΡ±Ώ‘Β÷ΈάμΖΫΑΗ÷–Θ§Έ“Ο«‘ωΦ”ΝΥΝΫΗωΖ«≥Θ÷Ί“ΣΒΡΉιΦΰΘΚ
ECM(edge-controller-manager)ΘΚΫΎΒψΉ‘÷ΈΙήάμΘ§Κω¬‘Ή‘÷ΈΡΘ ΫΫΎΒψ…œΒΡ Pod
«ΐ÷πΒ»ΓΘ
Μυ”Ύ node-lifecycle-controllerΘΜ
Ά®Ιΐ Annotation ≈δ÷ΟΩΣΙΊΘ§±μ ΨΫΎΒψ «ΖώΩΣΤτΉ‘÷ΈΡΘ ΫΘΜ
Ε‘”ΎΉ‘÷ΈΡΘ ΫΒΡΫΎΒψΘ§Β±ΫΎΒψ ßΝΣΘ®NotReadyΒ»Θ© ±Κω¬‘Ε‘ΫΎΒψ…œ»ί»Χ≥§ ±ΒΡ Pod «ΐ÷πΓΘ
EdgeHubΘΚ±Ώ‘ΒΫΎΒψ¥ζάμ
ΉςΈΣ kubelet ΚΆ apiserver ÷°ΦδΒΡΜΚ¥φΚΆ¥ζάμ;
‘ΎΆχ¬γ’ΐ≥Θ«ιΩωœ¬Θ§EdgeHub÷±Ϋ”¥ζάμΉΣΖΔ Kubelet «κ«σΒΫ apiserverΘ§≤ΔΜΚ¥φΫαΙϊΒΫ±ΨΒΊ;
‘ΎΫΎΒψΕœΆχΒΡ«ιΩωœ¬Θ§EdgeHub άϊ”Ο±ΨΒΊΜΚ¥φ≥δΒ± apiserverΘ§ΒΪ EdgeHub≤ΔΈ¥’φ’ΐΒΡ
apiserverΘ§Υυ“‘–κΚω¬‘Υυ”–Ιΐά¥ΒΡ–¥≤ΌΉς«κ«σΓΘ
ΦύΩΊΖΫΑΗ 
…œΆΦΈΣ’ϊΗωΦύΩΊΒΡ‘≠άμΆΦΘ§Νς≥Χ «ΘΚ
metrics-server Ε®ΤΎ÷ςΕ·œρΥυ”–ΫΎΒψ kubelet «κ«σΦύΩΊ ΐΨίΘΜ
kubelet Ά®Ιΐ CRI Ϋ”ΩΎœρ containerd «κ«σΦύΩΊ ΐΨίΘΜ
containerd Ά®Ιΐ Shim API œρΥυ”–»ίΤς shim «κ«σ»ίΤςΒΡΦύΩΊ ΐΨίΘΜ
Shim API ΡΩ«Α”–ΝΫΗωΑφ±Ψ v1 ΚΆ v2ΓΘ
containerd-shim-kata-v2 Ά®Ιΐ–ιΡβ¥°ΩΎœρ VM GuestOSΘ®PODΘ© ΡΎΒΡ
kata-agent «κ«σΦύΩΊ ΐΨίΘ§kata-agent ≤…Φ· GuestOS ΡΎΒΡ»ίΤςΦύΩΊ ΐΨί≤Δœλ”ΠΓΘ
Έ“Ο« runC shim ”ΟΒΡ « containerd-shimΘ§’βΗωΑφ±ΨΥδ»Μ±»ΫœάœΘ§ΒΪΈ»Ε®–‘Ζ«≥ΘΚΟΘ§Ψ≠Ιΐ¥σΝΩΒΡ…ζ≤ζ―ι÷ΛΓΘ
metrics-server Α―ΦύΩΊ ΐΨί≥ΐΝΥ Sink ΒΫ‘ΤΦύΩΊ…œΆβΘ§Ή‘ΦΚΡΎ¥φ÷–ΜΙ¥φΖ≈ΝΥΉνΫϋ“ΜΕΈ ±ΦδΒΡΦύΩΊ ΐΨίΘ§”Ο”ΎΧαΙ©Ηχ
K8s Metrics APIΘ§’β–© ΐΨίΩ…”Ο”Ύ HPA Β»ΓΘ
Έ“Ο«”ωΒΫΒΡΈ Χβ « CRI ContainerStats Ϋ”ΩΎΧαΙ©ΒΡΦύΩΊ÷Η±ξΖ«≥Θ…ΌΘ§»± ßΝΥ
NetworkΓΔBlock IOΒ»Ζ«≥Θ÷Ί“ΣΒΡAPIΘ§≤Δ«““―”–ΒΡ CPU ΚΆ Memory ΒΡ ΐΨίœν“≤ΦΑΤδ…ΌΓΘ
// ContainerStats
provides the resource usage statistics for a container.
message ContainerStats {
// Information of the container.
ContainerAttributes attributes = 1;
// CPU usage gathered from the container.
CpuUsage cpu = 2;
// Memory usage gathered from the container.
MemoryUsage memory = 3;
// Usage of the writeable layer.
FilesystemUsage writable_layer = 4;
}
// CpuUsage provides the CPU usage information.
message CpuUsage {
// Timestamp in nanoseconds at which the information
were collected. Must be > 0.
int64 timestamp = 1;
// Cumulative CPU usage (sum across all cores)
since object creation.
UInt64Value usage_core_nano_seconds = 2;
}
// MemoryUsage provides the memory usage information.
message MemoryUsage {
// Timestamp in nanoseconds at which the information
were collected. Must be > 0.
int64 timestamp = 1;
// The amount of working set memory in bytes.
UInt64Value working_set_bytes = 2;
} |
Ρ«»γΚΈ≤ΙΤκΦύΩΊAPIΘΩ”…”ΎΈ“Ο«”–Ή≈≈”¥σΒΡ¥φΝΩΦ·»ΚΘ§Έ“Ο«ΒΡΗΡΕ·Φ»≤ΜΡή”Αœλ“―”–ΒΡ”ΟΜßΦύΩΊΘ§“≤≤ΜΡήΕ‘’ϊΗωΦύΩΊ…η ©ΖΫΑΗΉω¥σΒΡΗΡΕ·Θ§Υυ“‘ΗΡΕ·ΨΓΝΩ‘ΎΩΩΫϋΒΉ≤ψΒΡΒΊΖΫΉω ≈δΚΆ–όΗΡΘ§Έ“Ο«Ήν÷’ΨωΕ®Ε®÷Τ
kubeletΘ§’β―υ’ϊΗωΦύΩΊΜυ¥Γ…η ©≤Μ–η“ΣΉω»ΈΚΈ±δΗϋΓΘ
œ¬Οφ « kubelet ΨΏΧε–όΗΡΒΡ‘≠άμΆΦΘΚ

kubelet ΒΡΦύΩΊΫ”ΩΎΖ÷ΈΣ»ΐ¥σάύΘΚ
1.summary άύΘ§…γ«χΚσΟφ÷ςΆΤΫ”ΩΎΘ§”–Pod”ο“εΘ§Φ»Ω…“‘ ≈δ
CRI Runtime “≤Ω…“‘Φφ»ί DockerΓΘ
/stats/summaryΓΘ
2.default άύΘ§ΫœάœΒΡΫ”ΩΎΘ§ΈόPod”ο“εΘ§…γ«χΜα÷πΫΞΖœΤζ¥ΥάύΫ”ΩΎΓΘ
/stats
/stats/container
/stats/{podName}/{containerName}
/stats/{namespace}/ {podName}/ {uid}/{containerName}
3.prometheusάύΘ§prometheusΗώ ΫΒΡΫ”ΩΎΘ§ ΒΦ …œΚσΕΥ Βœ÷Η¥”ΟΝΥ
default άύΒΡΖΫΖ®ΓΘ
/metrics
/metrics/cadvisor
ΈΣΝΥΗϋΚΟΒΡΦφ»ίΘ§Έ“Ο«Ε‘»ΐάύΫ”ΩΎΨυΫχ––ΝΥ ≈δΓΘ…œΆΦΚλ…Ϊ≤ΩΖ÷ΈΣ–¬‘ωΘ§ΜΤ…Ϊ–ιΩρ≤ΩΖ÷ΈΣ–όΗΡΓΘ
1.summary άύ
–¬‘ωΈΣ containerd Ή®Ο≈ Βœ÷ΝΥΫ”ΩΎ containerStatsProvider ΘΚcontainerdStatsProviderΘ§“ρ
kubelet Ά®Ιΐ CRI Ν§Ϋ” containerdΘ§Ι containerdStatsProvider
‘Ύ Βœ÷…œΗ¥”ΟΝΥ criStatsProviderΘ§ Ά§ ±‘ωΦ”ΝΥ NetworkΓΔBlock IO Β»ΓΘ
1.default άύΚΆ prometheus άύ
‘Ύ»κΩΎ¥Π‘ωΦ”≈–ΕœΖ÷÷ßΘ§»τΈΣ containerd ‘ρ÷±Ϋ”Ά®Ιΐ contaienrdStatsProvider
ΡΟ ΐΨίΓΘ
ΒΦ …œΘ§÷Μ–όΗΡ kubelet ΜΙ≤ΜΙΜΘ§Έ“Ο«ΖΔœ÷ containerd ΚσΕΥΖΒΜΊΒΡΦύΩΊ ΐΨί“≤ΟΜ”–
NetworkΓΔBlock IOΒ»Θ§Υυ“‘Έ“Ο«ΆΤΕ·ΝΥ…γ«χ‘Ύ containerd/cgroups ά©’Ι≤ΙΤκΝΥAPIΓΘ
»’÷ΨΖΫΑΗ 
…œΆΦ «Έ“Ο«ΒΡ»’÷ΨΖΫΑΗΘ§Έ“Ο«–η“ΣΆ®ΙΐΑΔάο‘Τ»’÷Ψ≤…Φ· Agent Logtail ≤…Φ·»ίΤς»’÷ΨΘ§÷ς“Σ”–»ΐ÷÷ Ι”ΟΖΫ ΫΘΚ
DaemonSet ≤Ω πΒΡ Logtail
≤…Φ·ΫΎΒψ…œΥυ”–»ίΤςΒΡ±ξΉΦ δ≥ωΓΘ
Ά®Ιΐ»ίΤςΜΖΨ≥±δΝΩ≈δ÷ΟΒΡ»ίΤςΡΎΒΡ≤…Φ·»’÷Ψ¬ΖΨΕΘ§‘ΎΥό÷ςΜζ…œΤ¥Ϋ”»ίΤςΒΡ rootfs ¬ΖΨΕΘ§Ω…‘ΎΥό÷ςΜζ…œ÷±≤…»ίΤςΡΎ»’÷ΨΈΡΦΰΓΘ
Sidecar ≤Ω πΒΡ Logtail
÷Μ≤…Φ·Ά§ Pod ΡΎΒΡΤδΥϊ”Π”Ο»ίΤς»’÷ΨΈΡΦΰΓΘ
Έ“Ο«‘Ύcontainerd/Α≤»Ϊ…≥œδ»ίΤς”ωΒΫΒΡΈ ΧβΘΚ
Logtail –η“ΣΝ§Ϋ”»ίΤς“ΐ«φΜώ»Γ÷ςΜζ…œΒΡΥυ”–»ίΤς–≈œΔΘ§ΒΪ÷Μ÷ß≥÷dockerΘ§≤Μ÷ß≥÷ containerdΓΘ
Υυ”– runC ΚΆ runV »ίΤς±ξΉΦ δ≥ωΈόΖ®≤…Φ·ΓΘ
Logtail DaemonSet ΡΘ ΫΈόΖ®÷±≤… runC ΚΆ runV ΡΎΓΘ
ΫβΖ®ΘΚ
÷ß≥÷ containerdΘ§Ά§ ±ΩΦ¬«ΒΫΆ®”Ο–‘Θ§Έ“Ο«‘Ύ Βœ÷…œΆ®Ιΐ CRI Ϋ”ΩΎΕχΖ« containerd
SDK ÷±Ϋ”Ν§Ϋ” containerdΘ§’β―υΦ¥±ψ“‘ΚσΜΜΝΥΤδΥϊ CRI-RuntimeΘ§Έ“Ο« Logtail
Ω…“‘«α“Ή÷±Ϋ”÷ß≥÷ΓΘ
Ά®Ιΐ Container Spec Μώ»Γ»ίΤς±ξΉΦ δ≥ω»’÷Ψ¬ΖΨΕΘ§”…”Ύ»γ¬έ runC ΜΙ « runV »ίΤςΒΡ±ξΉΦ δ≥ωΈΡΦΰΨυ‘Ύ
Host …œΘ§Υυ“‘÷Μ“Σ’“ΒΫ’βΗω¬ΖΨΕΩ…“‘÷±Ϋ”≤…Φ·ΓΘ
‘Ύ runC ΒΡ»’÷ΨΈΡΦΰ¬ΖΨΕ≤ι’“…œΘ§Έ“Ο«ΉωΝΥΗω”≈Μ·ΘΚ”≈œ»≥Δ ‘≤ι’“ Upper DirΘ§Ζώ‘ρ≤ι’“ devicemapper
ΉνΦ―ΤΞ≈δ¬ΖΨΕΘ§”…”Ύ runV ”–ΕάΝΔ kernel ΈόΖ®‘Ύ Host ≤ύ÷±≤…»ίΤςΡΎ»’÷ΨΈΡΦΰΓΘ”…”Ύ runV
»ίΤςΚΆ Host ΡΎΚΥ≤Μ‘ΌΙ≤œμΘ§ΒΦ÷¬ΈόΖ®‘Ύ Host …œ÷±Ϋ”≤…Φ· runV »ίΤςΡΎΒΡ»’÷ΨΈΡΦΰΓΘ
¥φ¥ΔΖΫΑΗ
Α≤»Ϊ…≥œδ»ίΤς¥φ¥ΔΖΫΑΗ…φΦΑΒΫΝΫΖΫΟφΘ§Ζ÷±π « RootFS ΚΆ VolumeΓΘ
RootFS Ω…“‘ΦρΒΞΒΡάμΫβΈΣ»ίΤςΒΡΓΑœΒΆ≥≈ΧΓ±Θ§ΟΩ“ΜΗω»ίΤςΨυ”–”–“ΜΗω RootFSΘ§ΡΩ«Α÷ςΝςΒΡ RootFS
”– Overlay2ΓΔDevicemapper Β»ΘΜ
Volume Ω…“‘ΦρΒΞΒΡάμΫβΈΣ»ίΤςΒΡΓΑ ΐΨί≈ΧΓ±Θ§Ω…“‘ΈΣ»ίΤς”Οά¥ΉςΈΣ ΐΨί¥φ¥Δά©’ΙΓΘ
RootFS 
Ε‘”ΎΑ≤»Ϊ…≥œδ»ίΤς≥ΓΨΑ÷–»ίΤς RootFS Έ“Ο«≤ΔΟΜ”–≤…”ΟΡ§»œΒΡ overlayfsΘ§÷ς“Σ «“ρΈΣ overlayfs
τ”ΎΈΡΦΰΡΩ¬ΦάύΘ§‘Ύ runC Α― rootfs ΡΩ¬Φ mount bind ΒΫ»ίΤςΡΎΟΜ”–»ΈΚΈΈ ΧβΘ§ΒΪ‘Ύ
Α≤»Ϊ…≥œδ»ίΤς kata …œ÷±Ϋ” mount bind ΒΫ»ίΤςΡΎΜαΨ≠Ιΐ kata ΒΡ 9pfsΘ§ΜαΒΦ÷¬
block io –‘Ρήœ¬ΫΒ ΐ °±ΕΘ§Υυ“‘ Έ“Ο«≤…? devicemapper ΙΙΫ®ΝΥ?ΥΌΓΔΈ»Ε®ΒΡ»ίΤς
Graph DriverΘ§”…”Ύ devicemapper ΒΡΒΉ≤ψΜυ”Ύ LVMΘ§ΈΣΟΩΗω»ίΤςΖ÷≈δΒΡ dm
ΨυΈΣ“ΜΗω block deviceΘ§Α―’βΗω…η±ΗΖ≈»κ»ίΤςΡΎΨΆΩ…“‘±ήΟβΝΥ kata 9pfs ΒΡ–‘Ρή”ΑœλΘ§’β―υΨΆΩ…“‘ Βœ÷“ΜΗωΙΠΡήΓΔ–‘Ρή÷Η±ξ»Ϊ?Ε‘?
runC ≥ΓΨΑΒΡ RootFSΓΘ
”≈Βψ/ΧΊΒψΘΚ
≤…”Ο devicemapper snapshot Μζ÷ΤΘ§ Βœ÷ΨΒœώΖ÷≤ψ¥φ¥ΔΘΜ
IOPSΓΔBandwidth ”κ RunC overlayfs + ext4 Μυ±Ψ≥÷ΤΫΘΜ
Μυ”Ύ snapshot ‘ω«ΩΩΣΖΔΘ§ Βœ÷»ίΤςΨΒœώΦΤΥψΚΆ¥φ¥ΔΒΡΖ÷άκΓΘ
Volume 
‘Ύ»ίΤςΒΡ¥φ¥Δ…œΘ§Έ“Ο«≤…”ΟΝΥ±ξΉΦΒΡ…γ«χ¥φ¥Δ≤εΦΰ FlexVolume ΚΆ CSI PluginΘ§‘Ύ‘Τ…œ÷ß≥÷‘Τ≈ΧΓΔNAS
“‘ΦΑ OSSΘ§‘Ύ±Ώ‘ΒΈ“Ο«÷ß≥÷ΝΥ LocalStorageΓΘ
FlexVolume ΚΆ CSI Plugin ‘Ύ Βœ÷…œΘ§Ρ§»œΨυΜαΫΪ‘Τ≈ΧΓΔNAS Β»œ»Ι“‘ΊΒΫ±ΨΒΊΡΩ¬ΦΘ§»ΜΚσ
mount bind ΒΫ»ίΤςΡΎΘ§’β‘Ύ runC »ίΤς…œ≤ΔΟΜ”–»ΈΚΈΈ ΧβΘ§ΒΪ‘ΎΑ≤»Ϊ…≥œδ»ίΤς÷–Θ§”…”ΎΙΐ 9PFS
Υυ“‘“ά»Μ―œ÷Ί”Αœλ–‘ΡήΓΘ
’κΕ‘…œΟφΒΡ–‘ΡήΈ ΧβΘ§Έ“Ο«ΉωΝΥΦΗΖΫΟφΒΡ”≈Μ·ΘΚ
‘Τ…œ
NAS
”≈Μ· FlexVolume ΚΆ CSI PluginΘ§’κΕ‘…≥œδ(runV) PodΘ§Α― mount
bind ΒΡΕ·Ήςœ¬≥ΝΒΫ…≥œδ GuestOS ΡΎΘ§¥”Εχ±ήΩΣΝΥ 9PFSΘΜΕχΕ‘ runC Pod ±Θ≥÷‘≠”–Ρ§»œΒΡ––ΈΣΓΘ
‘Τ≈ΧΜρ±ΨΒΊ≈Χ
‘Τ≈ΧΜρ±ΨΒΊ≈ΧΜα‘Ύ±ΨΒΊ“ά»ΜΗώ ΫΜ·Θ§ΒΪ≤ΜΜα mount ΒΫ±ΨΒΊΡΩ¬ΦΘ§Εχ «÷±Ϋ”Α― block device
÷±Ά®ΒΫ…≥œδ÷–Θ§”……≥œδ÷–ΒΡ agent ÷¥––Ι“‘ΊΕ·ΉςΓΘ
±Ώ‘Β
‘Ύ±Ώ‘Β≤ύΘ§Έ“Ο«≤…”ΟΝΥ Virtio-fs ±ήΩΣ 9PFS ΒΡΈ ΧβΘ§’β÷÷ΖΫ ΫΗϋΆ®”ΟΘ§Έ§ΜΛΤπά¥“≤Ηϋ«α±ψΘ§‘Ύ–‘Ρή…œΜυ±ΨΩ…“‘¬ζΉψ±Ώ‘Β≤ύΒΡ–η«σΘ§Β±»ΜΈόΖ®ΚΆΓΑ‘Τ…œ÷±Ά®Γ±”≈Μ·ΒΡ–‘ΡήΚΟΓΘ
Άχ¬γΖΫΑΗ 
‘ΎΆχ¬γΖΫΑΗ÷–Θ§Έ“Ο«Ά§―υΦ»–η“ΣΩΦ¬«ΓΑ‘Τ…œΓ±ΚΆΓΑ±Ώ‘ΒΓ±Θ§“≤–η“ΣΩΦ¬«ΒΫΓΑΆ®”Ο–‘Γ±ΚΆΓΑ–‘ΡήΓ±Θ§‘Ύ K8s
÷–ΜΙ–η“ΣΩΦ¬«ΒΫΆχ¬γΖΫΑΗΕ‘ ΓΑ»ίΤςΆχ¬γΓ± ΚΆ ΓΑService Άχ¬γΓ± ΒΡΦφ»ί–‘ΓΘ
»γ…œΆΦΘ§Έ“Ο«ΒΡΆχ¬γΖΫΑΗ÷–Υδ»Μ”–»ΐ÷÷ΖΫΑΗΓΘ
Bridge «≈Ϋ”ΡΘ Ϋ
ΆχΩ®÷±Ά®ΡΘ Ϋ
IPVlan ΡΘ Ϋ
Birdge«≈Ϋ”ΡΘ Ϋ
«≈Ϋ”ΡΘ Ϋ τ”Ύ±»ΫœάœΒΡ“≤±»Ϋœ≥… λΒΡ“Μ÷÷Άχ¬γΖΫΑΗΘ§ΥϋΒΡ”≈ΒψΨΆ «Ά®”Ο–‘±»ΫœΚΟΘ§ΦήΙΙΖ«≥ΘΈ»Ε®ΚΆ≥… λΘ§»±Βψ «–‘ΡήΫœ≤νΘ§ΧΊΒψ «ΟΩΗω
Pod ΕΦ–η“ΣΖ÷≈δ Veth PairΘ§Τδ÷–“ΜΕΥ‘Ύ Host ≤βΘ§“ΜΕΥ‘Ύ»ίΤςΡΎΘ§’β―υΥυ”–»ίΤςΡΎΒΡΫχ≥ωΝςΝΩΕΦΜαΆ®Ιΐ
Veth Pair ΜΊΒΫ HostΘ§Έό–η–όΗΡΦ¥Ω…Ά§ ±ΆξΟάΦφ»ί K8s ΒΡ»ίΤςΆχ¬γΚΆ Service
Άχ¬γΓΘΡΩ«Α’β÷÷ΖΫΑΗ÷ς“Σ”Π”Ο”Ύ‘Τ…œΒΡΫΎΒψΓΘ
ΆχΩ®÷±Ά®ΡΘ Ϋ
ΙΥΟϊΥΦ“εΘ§ΨΆ «÷±Ϋ”Α―ΆχΩ®…η±Η÷±Ά®ΒΫ»ίΤςΡΎΓΘ‘Ύ‘Τ…œΚΆ±Ώ‘Β”…”ΎΜυ¥ΓΆχ¬γ…η ©ΖΫΑΗ≤ΜΆ®Θ§‘Ύ÷±Ά®ΖΫΟφ¬‘”–≤ΜΆ§Θ§ΒΪ‘≠άμ «œύΆ§ΒΡΓΘ
‘Τ…œΘ§÷ς“Σ”Οά¥÷±Ά® ENI Β·–‘ΆχΩ®ΒΫΟΩΗω Pod ΡΎΓΘ
±Ώ‘ΒΘ§±Ώ‘ΒΆχ¬γΖΫΑΗΜυ”Ύ SR-IOVΘ§Υυ“‘÷ς“Σ”Οά¥÷±Ά® VF …η±ΗΓΘ
÷±Ά®ΖΫΑΗΒΡ”≈Βψ «Θ§Ήν”≈ΒΡΆχ¬γ–‘ΡήΘ§ΒΪ ήœό”ΎΫΎΒψ ENI ΆχΩ® Μρ VF …η±Η ΐΝΩΒΡœό÷ΤΘ§“ΜΑψ“ΜΧ®¬ψΫπ τΖΰΈώ…Χ÷ΜΡή÷±Ά®
Εΰ»ΐ °Ηω PodΘ§PodΟήΕ»ΫœΒΆΒΦ÷¬ΫΎΒψΉ ‘¥άΥΖ―ΓΘ
IPVlanΡΘ Ϋ
IPVlan «Έ“Ο«œ¬“Μ¥ζΆχ¬γΖΫΑΗΘ§’ϊΧε–‘ΡήΗΏ”Ύ Bridge «≈Ϋ”ΡΘ ΫΘ§Ϋ®“ιΡΎΚΥΑφ±Ψ 4.9+Θ§»±Βψ «Ε‘
K8s Service Άχ¬γ÷ß≥÷Ϋœ≤νΘ§Υυ“‘Έ“Ο«‘ΎΡΎΚΥΓΔruntime “‘ΦΑΆχ¬γ≤εΦΰ…œΉωΝΥ¥σΝΩΒΡ”≈Μ·ΚΆ–όΗ¥ΓΘΡΩ«Α
IPVlan Άχ¬γΡΘ Ϋ“―‘ΎΜ“Ε»÷–Θ§Φ¥ΫΪ»Ϊ”ρΩΣΖ≈ΙΪ≤βΓΘ
Άχ¬γ–‘ΡήΕ‘±»
œ¬ΆΦ «ΗςΗωΖΫΑΗΆχ¬γ–‘ΡήΕ‘±»ΘΚ

ΉήΫα
¥” Ping ±―”ΓΔ≤ΜΆ§¥χΩμΓΔTCP_RR ΚΆ UDP_RR ΕύΗωΖΫΟφΆ§ ±Ε‘±»ΝΥ’βΦΗ÷÷Άχ¬γΖΫΑΗΘ§HostΉςΈΣΜυΉΦΓΘΩ…“‘Ω¥≥ωΘ§÷±Ά®ΆχΩ®ΒΡ–‘ΡήΩ…“‘ΉωΒΫΫ”ΫϋhostΒΡ–‘ΡήΘ§ipvlanΚΆbridge”κ÷±Ά®ΆχΩ®ΖΫ Ϋ”–“ΜΕ®≤νΨύΘ§ΒΪ«ΑΝΫ’ΏΆ®”Ο–‘ΗϋΚΟΘΜΉήΧεά¥ΥΒ
ipvlan ±» bridge –‘ΡήΤ’±ιΗϋΚΟΓΘ
ΝμΆβΘ§±μ÷– Ping ±―”ΒΡœύΕ‘ΑΌΖ÷±»Ϋœ¥σΘ§ΒΪ ΒΦ …œ¥” ΐ÷Β≤νΨύά¥ΥΒ÷Μ”–ΝψΒψΝψΦΗΚΝΟκ≤νΨύΓΘ
ΉΔΘΚ“‘…œΈΣΡΎ≤Ω ΐΨί≤β ‘ΫαΙϊΘ§ΫωΙ©≤ΈΩΦΓΘ
Εύ‘Υ–– ±(RuntimeClass)ΒςΕ»
Kubernetes ¥” 1.14.0 Αφ±ΨΩΣ Φ“ΐ»κΝΥ RuntimeClass APIΘ§Ά®ΙΐΕ®“ε
RuntimeClass Ε‘œσΘ§Ω…“‘ΚήΖΫ±ψΒΡΆ®Ιΐ pod.Spec.runtimeClassName
Α― pod ‘Υ––‘Ύ÷ΗΕ®ΒΡ runtime ÷°…œΘ§»γ runcΓΔrunvΓΔrunhcsΒ»Θ§ΒΪ «’κΕ‘Κσ–χ≤ΜΆ§ΒΡ
K8s Αφ±ΨΘ§Ε‘ RuntimeClass ΒςΕ»÷ß≥÷≤ΜΆ§Θ§÷ς“ΣΖ÷ΈΣΝΫ¥σΫΉΕΈΓΘ
1.14.0 <= Kubernetes Version < 1.16.0 
apiVersion:
node.k8s.io/v1beta1
handler: runv
kind: RuntimeClass
metadata:
name: runv
---
apiVersion: v1
kind: Pod
metadata:
name: my-runv-pod
spec:
runtimeClassName: runv
nodeSelector:
runtime: runv
# ... |
ΒΆ”Ύ 1.16.0 Αφ±ΨΒΡ K8s ΒςΕ»Τς≤Μ÷ß≥÷ RuntimeClassΘ§–η“Σœ»ΗχΫΎΒψ¥ρ…œ‘Υ–– ±œύΙΊΒΡ
LabelΘ§»ΜΚσ‘ΌΆ®Ιΐ runtimeClassName ≈δΚœ NodeSelector Μρ Affinity
Άξ≥…ΓΘ
Kubernetes Version >= 1.16.0
¥” K8s 1.16.0 Αφ±ΨΩΣ ΦΘ§Ε‘ RuntimeClass ΒςΕ»ΒΡ÷ß≥÷ΒΟ“‘ΗΡ…ΤΘ§ΒΪ¥” Βœ÷…œΘ§≤Δ≤Μ «‘Ύ
kube-scheduler ΒΡ–¬‘ωΕ‘ RuntimeClass ÷ß≥÷ΒΡΥψΖ®Θ§Εχ «‘Ύ RuntimeClass
API …œ–¬‘ωΝΥ nodeSlector ΚΆ tolerationsΘ§¥Υ ±”ΟΜßΒΡ pod …œ÷Μ–η“Σ÷ΗΕ®
runtimeClassName ΕχΈό–η÷ΗΕ® nodeSelector Μρ affinityΘ§ kube-apiserver
ΒΡ Admission WebHook –¬‘ωΝΥ RuntimeClass ΒΡ MutatingΘ§Ω…“‘Ή‘Ε·ΈΣ
pod ΉΔ»κ pod.spec.runtimeClassName ΥυΙΊΝΣΒΡ RuntimeClass
Ε‘œσάο≈δ÷ΟΒΡ nodeSelector ΚΆ tolerations Θ§¥”ΕχΦδΫ”ΒΊ÷ß≥÷ΒςΕ»ΓΘ

Ά§ ±Θ§”…”ΎΚήΕύ–¬ΒΡ‘Υ–– ±Θ®»γ Α≤»Ϊ…≥œδΘ©Ή‘…μ”– overheadΘ§Μα’Φ”Ο“ΜΕ®ΒΡΡΎ¥φΚΆCPUΘ§Υυ“‘
RuntimeClass API …œ–¬‘ωΝΥ overhead ”Ο”Ύ÷ß≥÷¥Υάύ≥ΓΨΑΘ§’β≤ΩΖ÷Ή ‘¥‘Ύ Pod
ΒΡΒςΕ»…œ“≤Μα±Μ kube-scheduler ΦΤΥψΓΘ
≤ΈΩΦΘΚ
runtimeclass issue
runtimeclass
kep
pod-overhead
–¬ΧΫΥς-Ω…–≈/ΜζΟήΦΤΥψ 
ΚήΕύ”ΟΜßΩΦ¬«ΒΫ≥…±ΨΓΔ‘ΥΈ§ΓΔΈ»Ε®–‘Β»“ρΥΊ»Ξ…œ‘ΤΘ§ΒΪΆυΆυ“ρΈΣΕ‘ΙΪ”–‘ΤΤΫΧ®Α≤»ΪΦΦ θΒΘ”«“‘ΦΑ–≈»ΈΘ§ΚήΕύ“ΰΥΫ ΐΨίΓΔΟτΗ– ΐΨίΕ‘‘ΤΓΑΆϊΕχ»¥≤ΫΓ±ΘΜΆυΆυœ÷”–ΒΡΑ≤»ΪΦΦ θΩ…“‘ΑοΈ“Ο«ΫβΨω¥φ¥ΔΦ”ΟήΓΔ¥Ϊ δΙΐ≥Χ÷–ΒΡΦ”ΟήΘ§ΒΪΈόΖ®ΉωΒΫ”Π”Ο‘Υ––Ιΐ≥ΧΒΡΦ”ΟήΘ§’β–© ΐΨί‘ΎΡΎ¥φ÷– «ΟςΈΡΒΡΘ§»κ«÷’ΏΜρ’Ώ‘Τ≥ß…Χ”–ΡήΝΠ¥”ΡΎ¥φΩζΧΫ ΐΨίΓΘΨΆ «‘Ύ’β÷÷±≥ΨΑœ¬Θ§Ω…–≈/ΜζΟήΦΤΥψ”Π‘ΥΕχ…ζΘ§Υϋ «Μυ”Ύ»μ”≤ΦΰΦΦ θΘ§ΈΣΟτΗ–”Π”Ο/ ΐΨί‘ΎΡΎ¥φ÷–¥¥Ϋ®“ΜΩι
EncalveΘ®Ζ…ΒΊΘ©Θ§Υϋ «“ΜΩι”≤ΦΰΦ”ΟήΒΡΡΎ¥φΘ§»ΈΚΈΤδΥϊΒΡ”Π”Ο≥Χ–ρΓΔOSΓΔBIOSΓΔΤδΥϊ”≤Φΰ…θ÷Ν‘Τ≥ß…ΧΨυΈόΖ®ΫβΟή’β≤ΩΖ÷ΡΎ¥φ ΐΨίΓΘ

‘Ύ¥Υ±≥ΨΑœ¬Θ§Έ“Ο«ΝΣΚœΝΥΕύΗωΆ≈Ε”Θ§‘Ύ ACK …œ―–ΖΔΝΥΜυ”Ύ Intel SGX ”≤ΦΰΦ”ΟήΒΡ TEE
‘Υ–– ±Θ§Ω…»Ο”ΟΜßΒΡ”Π”ΟΒΡ≈ή‘Ύ“ΜΗωΗϋΦ”Α≤»ΪΓΔΩ…–≈ΒΡ‘Υ–– ±ΜΖΨ≥÷–Θ§Αο÷ζΗϋΕύΒΡ”ΟΜßΤΤ≥ΐ…œ‘ΤΒΡΑ≤»Ϊ’œΑ≠Θ§Έ“Ο«“≤ΫΪ‘Ύ
2020ΡξQ1Ϋχ––ΙΪ≤βΓΘ |





