| 编辑推荐: |
本文结合了理论和实践去写,旨在通过一系列实验帮助读者深入理解 TCP 连接的建立过程。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者 ,由火龙果软件Linda编辑推荐。 |
|
阿里妹导读
TCP/IP 这个主题很多文章比较陈旧,且以讹传讹的东西太多,所以本文作者结合了理论和实践去写,旨在通过一系列实验帮助读者深入理解
TCP 连接的建立过程。
写在前面
通信媒介可能会丢失或者改变被传递的消息,在这类有损通信信道上提供可靠通信协议的问题已经被研究了很多年。处理差错的两种主要方法是纠错码和数据重传。后者又称之为自动重复请求(Automatic
Repeat Request, ARQ),TCP 协议基于此方法设计。
本文不会完全阐述 TCP 协议的概念细节,更多的是以实验的方式揭示 TCP 在 Linux 内核协议栈上的实现细节。所以实践本文前需要先行阅读计算机网络基础以及
TCP/IP 协议相关的理论书籍。TCP 的原始规范是 RFC793[1],其中的一些错误在 RFC1122
[2]中被修正。拥塞控制(RFC5681、RFC3782、RFC3517、RFC3390、RFC3168)、重传超时(RFC6298、RFC5682、RFC4015)、连接管理(RFC5482)等特性在后续一系列的
RFC 文档中也进行了补充设计。
本文在阐述一些具体的行为和特性时也会提示相关的 RFC 文档。但是需要注意,具体系统的协议实现并非完全照搬
RFC 的每一句话,实践中在一些特定的场景下也会选择更有利于解决具体问题的方案。
实验环境
机器信息
两台虚拟机,IP 地址分别是 10.0.0.3(vm-1)和 10.0.0.4(vm-2):
$ uname -a
Linux workspace-1 5.10.134-16.3.an8.aarch64
#1 SMP Tue Mar
26 18:49:57 CST 2024 aarch64
aarch64 aarch64 GNU/Linux
$ ip -4 addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
qdisc noqueue
state UNKNOWN group default qlen
1000
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp0s5: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500
qdisc fq_codel state UP group default
qlen 1000
inet 10.0.0.3/24 brd 10.0.0.255 scope global
dynamic noprefixroute enp0s5
valid_lft 1746sec preferred_lft 1746sec
|
$ uname -a
Linux workspace-2 5.10.134-16.3.an8.aarch64
#1 SMP Tue Mar 26 18:49:57 CST 2024 aarch64
aarch64 aarch64 GNU/Linux
$ ip -4 addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
qdisc noqueue state UNKNOWN group default qlen
1000
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp0s5: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc fq_codel state UP group default
qlen 1000
inet 10.0.0.4/24 brd 10.0.0.255 scope global
dynamic noprefixroute enp0s5
valid_lft 1784sec preferred_lft 1784sec
|
TCP 连接的建立
开启抓包
在 vm-1 上开启 tcpdump 抓包:
# vm-1
# 如果只输出到控制台而不需要保存包到文件的话,将 -w tcp.pcap --print
参数删除即可
$ sudo tcpdump -s0 -X -nn "tcp port 9527"
-w tcp.pcap --print
# 上面命令的 --print 参数在 tcpdump v4.99.0 版本才引入,用于
-w 写文件的同时在控制台也输出详情。如果实验环境的 tcpdump 版本过低,可以从源码编译安装,或者使用下面低版本
tcpdump 等效命令:
$ sudo tcpdump -s0 "tcp port 9527"
-w - -U | tee tcp.pcap | tcpdump -r - -X -nn
|
创建连接
在 vm-1 上使用 nc 监听 TCP 9527 端口:
# vm-1
$ nc -k -l 10.0.0.3 9527
|
这时候可以在另一个终端使用 netstat 命令查看这个监听套接字的情况:
# vm-1
$ sudo netstat -anpo | grep Recv-Q; sudo netstat
-anpo | grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address
State PID/Program name Timer
tcp 0 0 10.0.0.3:9527 0.0.0.0:* LISTEN 1704/nc
off (0.00/0/0)
|
在 vm-2 上打开一个终端,使用 nc 连接服务端:
# vm-2
$ nc 10.0.0.3 9527
|
分别在 vm-1 和 vm-2 上执行 netstat 命令,可以看见服务端和客户端的连接信息:
# vm-1
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address
State PID/Program name Timer
tcp 0 0 10.0.0.3:9527 0.0.0.0:* LISTEN 1704/nc
off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:52336 ESTABLISHED
1704/nc off (0.00/0/0)
# vm-2
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign
Address State PID/Program name Timer
tcp 0 0 10.0.0.4:52336 10.0.0.3:9527 ESTABLISHED
4678/nc off (0.00/0/0)
|
此时 tcpdump 也输出了三次握手包的详情:
#
vm-1
$ sudo tcpdump -s0 -X -nn "tcp port 9527"
-w tcp.pcap --print
tcpdump: listening on enp0s5, link-type EN10MB
(Ethernet), snapshot length 262144 bytes
13:15:40.768222 IP 10.0.0.4.33408 > 10.0.0.3.9527:
Flags [S], seq 2741304532, win 64240, options
[mss 1460,sackOK,TS val 3003747107 ecr 0,nop,wscale
7], length 0
0x0000: 4500 003c d3a4 4000 4006 5311 0a00 0004
E..<..@.@.S.....
0x0010: 0a00 0003 8280 2537 a364 fcd4 0000 0000
......%7.d......
0x0020: a002 faf0 b2ea 0000 0204 05b4 0402 080a
................
0x0030: b309 8b23 0000 0000 0103 0307 ...#........
13:15:40.768304 IP 10.0.0.3.9527 > 10.0.0.4.33408:
Flags [S.], seq 1187094817, ack 2741304533,
win 65160, options [mss 1460,sackOK,TS val 2489161299
ecr 3003747107,nop,wscale 7], length 0
0x0000: 4500 003c 0000 4000 4006 26b6 0a00 0003
E..<..@.@.&.....
0x0010: 0a00 0004 2537 8280 46c1 a121 a364 fcd5
....%7..F..!.d..
0x0020: a012 fe88 1435 0000 0204 05b4 0402 080a
.....5..........
0x0030: 945d 9653 b309 8b23 0103 0307 .].S...#....
13:15:40.768647 IP 10.0.0.4.33408 > 10.0.0.3.9527:
Flags [.], ack 1, win 502, options [nop,nop,TS
val 3003747108 ecr 2489161299], length 0
0x0000: 4500 0034 d3a5 4000 4006 5318 0a00 0004
E..4..@.@.S.....
0x0010: 0a00 0003 8280 2537 a364 fcd5 46c1 a122
......%7.d..F.."
0x0020: 8010 01f6 c80b 0000 0101 080a b309 8b24
...............$
0x0030: 945d 9653 .].S |
执行 tcpdump 的目录下也生成了 tcp.pacp 文件,可以用 wireshark 打开分析:
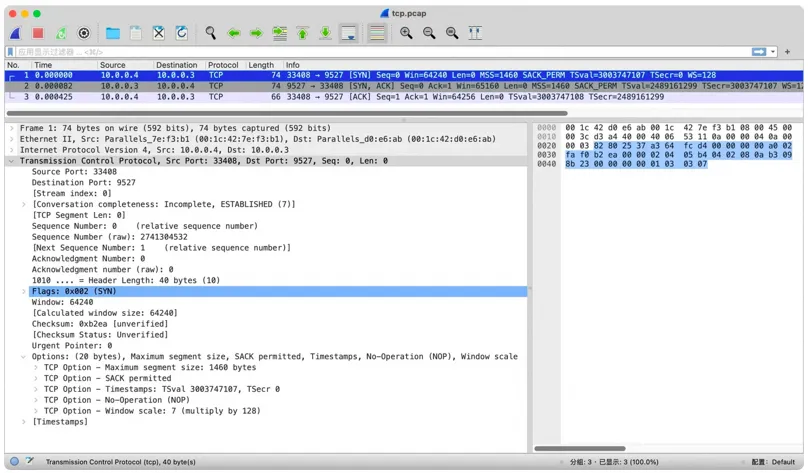
TCP 协议头解析
三次握手的过程(SYN -> SYN+ACK -> ACK)不再赘述,这里主要介绍下
options 字段,先回顾下 TCP 协议头的定义:
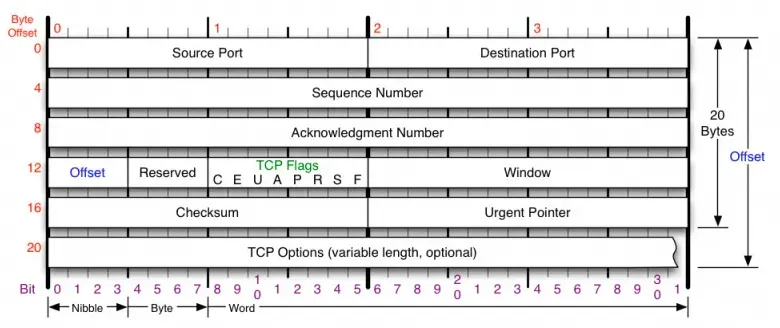
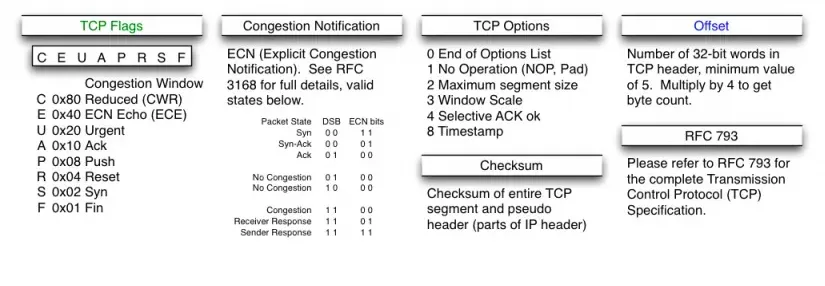
最小的 TCP 头是 20 字节,上面第一个握手包还包含了 20 字节的 options 字段,所以是
40 字节。大小从 offset 的值(十六进制 0xa0 等于 十进制 10,单位是 4 字节,10
* 4 = 40 字节)也能看出来。
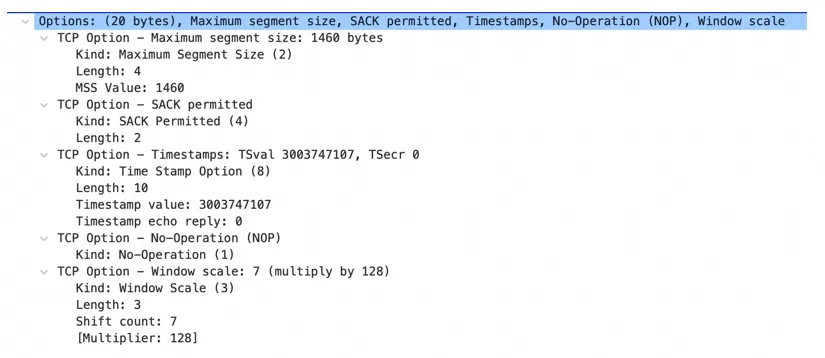
这个握手包恰好覆盖了 1、2、3、4、8 这五种常见的 options 字段:
第一个选项(2)是告知对端自己的 MSS 值(RFC6691[3]), MSS 选项传输的头是 MTU
减去 IP 基本头(v4 20 字节,v6 40 字节)和 TCP 基本头(20字节)的值,不考虑扩展头。从
ifconfig 的输出能看出来 MTU 是 1500,减去 IPv4 的 20 字节和 TCP 的
20 字节恰好是 1460 字节。
$ ifconfig
enp0s5: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
...
|
第二个选项(4)是:
SACK(Selective Acknowledgement)标记(RFC2018[4]/RFC2883[5])。这个选项这里先按下表,在后续的
TCP 发送和接收数据的章节再讨论。Linux 内核参数 net.ipv4.tcp_sack 可以控制这个特性的开关。
$ sysctl net.ipv4.tcp_sack
net.ipv4.tcp_sack = 1
|
第三个选项(8)是时间戳标记(RFC1323[6])。内核使用 TCP 时间戳来更好地估算 TCP
连接中的往返时间 (RTTM, Round Trip Time Measurement),可以更准确的进行
TCP 窗口和缓冲区的计算。同时在高速网络中,可以使用该值更好的判断 sequence 的回绕情况以避免协议错误(PAWS,Protect
Against Wrapped Sequences)。这个特性的开关可以用内核参数 net.ipv4.tcp_timestamps
控制:
$
sysctl net.ipv4.tcp_timestamps
net.ipv4.tcp_timestamps = 1 # 0 表示TCP 时间戳被禁用,1
表示 TCP 时间戳被启用(默认),2 表示 TCP 时间戳被启用,但没有随机偏移 |
第四个选项(1)NOP 一般是占位对齐用的。因为 TCP 包头 offset 字段的值是以 4 字节为单位的,所以
TCP 头的大小也只能是 4 的倍数。
第五个选项(3)表示 TCP 窗口缩放(RFC1323)。TCP 协议头的窗口大小由 2 字节表示(最大
65535 字节),但实际上内核默认的 TCP 缓存区大小比这个值大很多:
$ sysctl net.ipv4.tcp_rmem net.ipv4.tcp_wmem
net.ipv4.tcp_rmem = 4096 131072 6291456 # 分别是最小值、默认值、最大值,虽然名字是
ipv4,但是同时影响 ipv4 和 ipv6
net.ipv4.tcp_wmem = 4096 16384 4194304
|
所以 window 值需要一个“放大”倍数的选项来向通信的对端声明更大的 window 值,Window
Scale 这个 option 的值表示的是 shift count,即 2 的多少次方。这里是 7
次方,即 TCP 头里的 window 还要乘以 2^7 才是真正的窗口大小。这个机制由内核参数:
net.ipv4.tcp_window_scaling 控制开关。注意携带这个 option 之后的包才会放大,所以当前这个包
wireshark 输出的 Calculated window size 并没有乘以系数,后续的包才乘(这个
option 只在握手的时候交换信息,如果抓的包不包含握手包的话,是无法精确知道实际的 window
size 的)。
$ sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
|
顺便提一下,RFC1122 规定了不能被理解的 TCP option 会被简单的忽略掉,那么在私有的环境里完全可以定义私有的
TCP option 以完成一些特殊的需求,即使这个包发送到不支持的设备上也只是功能不生效而不会认为包异常。举个例子,某些
LB/NAT 服务希望透传原始的连接地址给后端服务,就可以将相关的原始请求地址和端口打包在一个私有的
TCP option 中发送给后端。后端支持的话就可以从 TCP option 中解析出来,不支持的话也会忽略这个
TCP option 而不报错。
三次握手的状态变化
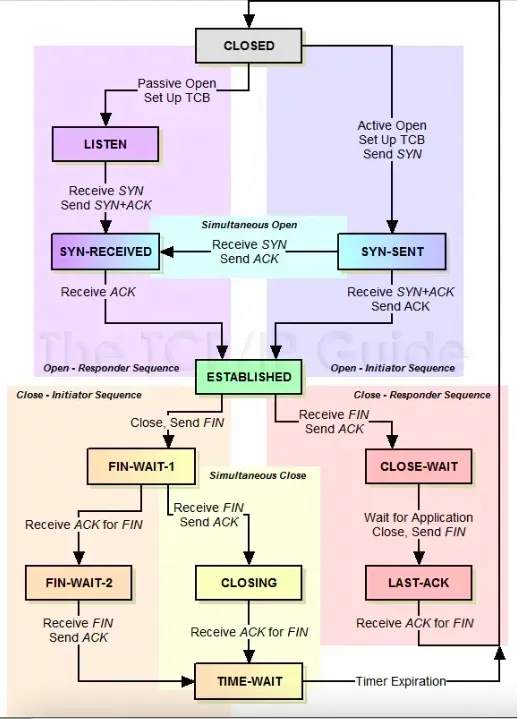
前文使用netstat命令看到了LISTEN和ESTABLISHED状态的socket,而 SYN-SENT
和 SYN-RECEIVED 状态在正常情况下是比较难看到的。下面用 iptables 拦截握手包来观察下协议的交互过程。
拦截 SYN 包
# vm-1
# 确认 iptables 运行中,否则要 sudo systemctl start iptables
# 新系统一般内置的是 firewalld,如果不想装 iptables 的话可以自行查阅
firewalld 的配置文档
$ sudo systemctl status iptables
# 清理掉所有规则,测试通信一切正常
$ sudo iptables -F
# 丢弃所有目标端口是 TCP 9527 端口的入包
$ sudo iptables -A INPUT -p tcp --dport 9527
-j DROP
|
配置完成规则后在 vm-2 上使用 nc 连接。
注意要调大默认的超时时间:
# vm-2
$ nc -w 3600s 10.0.0.3 9527 # 超时时间 3600 秒
|
此时能观察到 vm-2 的协议栈因为 TCP 超时开始重传 SYN 包:
# vm-2
$ sudo tcpdump -s0 -nn "tcp port 9527"
-w tcp.pcap --print
tcpdump: listening on enp0s5, link-type EN10MB
(Ethernet), snapshot length 262144 bytes
19:46:32.303016 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027198638 ecr 0,nop,wscale
7], length 0
19:46:33.305107 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027199640 ecr 0,nop,wscale
7], length 0
19:46:35.324485 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027201660 ecr 0,nop,wscale
7], length 0
19:46:39.578790 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027205914 ecr 0,nop,wscale
7], length 0
19:46:47.770402 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027214106 ecr 0,nop,wscale
7], length 0
19:47:03.896674 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027230232 ecr 0,nop,wscale
7], length 0
19:47:37.688850 IP 10.0.0.4.49728 > 10.0.0.3.9527:
Flags [S], seq 2027654690, win 64240, options
[mss 1460,sackOK,TS val 3027264024 ecr 0,nop,wscale
7], length 0
|
最后客户端报错:
# vm-2
$ nc -w 3600s 10.0.0.3 9527
Ncat: Connection timed out.
|
可以看到,截止连接超时,SYN 包一共重传了 6 次(7 个包),第一次间隔 1s,第二次 2s,第三次
4s,等待时间逐渐翻倍。SYN 重传最大次数由内核参数 net.ipv4.tcp_syn_retries
决定:
# vm-2
$ sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
|
在重传的过程中,可以在 vm-2 的 netstat 信息中看到处于 SYN_SENT 状态的套接字。
# vm-2
$ while true; do sudo netstat -anpo | grep 9527;
sleep 1; done
tcp 0 1 10.0.0.4:49728 10.0.0.3:9527 SYN_SENT
44754/python3 on (0.78/0/0)
tcp 0 1 10.0.0.4:49728 10.0.0.3:9527 SYN_SENT
44754/python3 on (1.74/1/0)
tcp 0 1 10.0.0.4:49728 10.0.0.3:9527 SYN_SENT
44754/python3 on (0.70/1/0)
tcp 0 1 10.0.0.4:49728 10.0.0.3:9527 SYN_SENT
44754/python3 on (3.68/2/0)
|
最后一列 Timer 的格式为 timer(a/b/c)
timer 的取值有 off/on/keepalive/timewait 四种,分别表示 无定时器/重传定时器/keepalive
定时器/timewait 定时器
(a/b/c) 的含义为 (定时器的值/已经发送的重传次数/已发送的保活探测次数)。
从 netstat 的结果很明显可以看出当前处于第几次重传,以及距离下次重传还有多久。因为 SYN
包被丢弃了,vm-1 并不知道 vm-2 的 49728 端口在尝试连接,在 vm-1 上 netstat
看不到任何信息。
拦截 SYN+ACK 包
在 vm-2 上配置 iptables 的拦截规则(也要清理掉之前 vm-1 的拦截规则):
# vm-2
# 清理掉所有规则,测试通信一切正常
$ sudo iptables -F
# 丢弃所有源端口是 TCP 9527 端口的入包(注意方向,vm-2 上要拦截
sport)
$ sudo iptables -A INPUT -p tcp --sport 9527
-j DROP
|
如果只使用 iptables 拦截第二次握手包的话,会导致源端协议栈 SYN 重传的,这样就没法测试
SYN+ACK 重传了。所以发送端在发完 SYN 包后不能有其他逻辑。nc 做不到只发送 SYN 包就退出,改用
nmap 来进行实验。
# vm-2
$ sudo nmap -sS 10.0.0.3 -p 9527
|
此时能观察到 vm-1 的协议栈因为 SYN+ACK 无响应而重传(如果不 DROP 掉 SYN+ACK
包的话,vm-2 的协议栈会回复 RST 重置连接的):
$ sudo tcpdump -s0 -nn "tcp port 9527"
-w tcp.pcap --print
tcpdump: listening on enp0s5, link-type EN10MB
(Ethernet), snapshot length 262144 bytes
20:33:14.312050 IP 10.0.0.4.61796 > 10.0.0.3.9527:
Flags [S], seq 329704385, win 1024, options
[mss 1460], length 0
20:33:14.312078 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
20:33:15.320577 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
20:33:17.334085 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
20:33:21.494471 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
20:33:29.687877 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
20:33:45.817673 IP 10.0.0.3.9527 > 10.0.0.4.61796:
Flags [S.], seq 3063951492, ack 329704386, win
64240, options [mss 1460], length 0
|
可以看到,截止连接超时,SYN+ACK 包一共重传了 5 次(共 7 个包,第 1 个是 SYN,后
6 个 SYN+ACK),等待时间也是从 1s 开始逐渐翻倍。SYN+ACK 重传最大次数由内核参数
net.ipv4.tcp_synack_retries 决定:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
|
在重传的过程中,可以在 vm-1 的 netstat 信息中看到处于 SYN_RECV 状态的套接字。
$ while true; do sudo netstat -anpo | grep SYN_RECV;
sleep 1; done
tcp 0 0 10.0.0.3:9527 10.0.0.4:61796 SYN_RECV
- on (0.05/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:61796 SYN_RECV
- on (1.01/1/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:61796 SYN_RECV
- on (3.99/2/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:61796 SYN_RECV
- on (2.95/2/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:61796 SYN_RECV
- on (1.91/2/0)
|
处于 SYN_RECV 状态的套接字在内核的 SYN Queue 里等待第三次握手包 ACK 到达,但如果不断有
SYN 包发送,但是服务端回复的 SYN+ACK 包石沉大海的话。大量 SYN_RECV 状态的连接会快速消耗服务端的资源,这就是所谓的
SYN Flood 攻击。当服务端收到第三次 ACK 握手包的话,连接会变成 ESTABLISHED
状态,并从 SYN Queue (以下称半连接队列) 里移动到 Accept Queue (以下称全连接队列)
里,等待应用程序调用 accept()获取后移除。
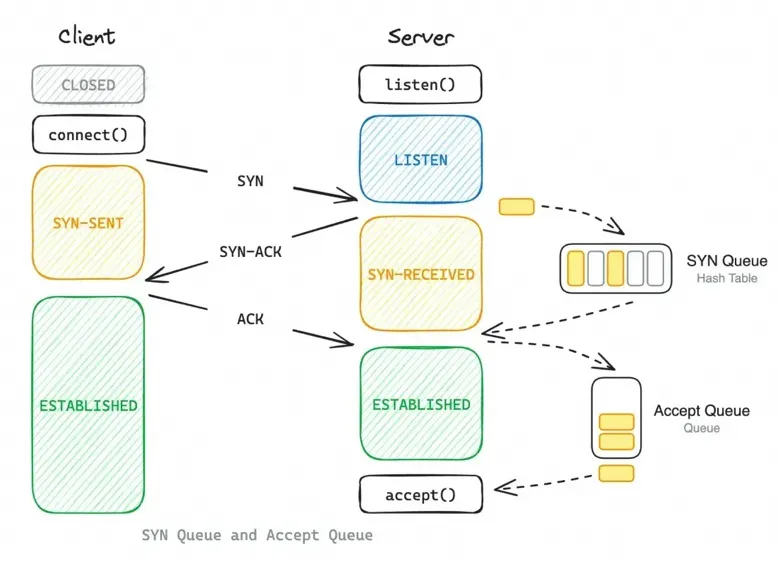
有多个内核参数与半连接队列/全连接队列有关:
net.ipv4.tcp_max_syn_backlog:控制收到 SYN 报文时,尚未完成三次握手因而还未建立的
TCP 连接请求可以被放到半连接队列中的最大数量(半连接队列长度)。
net.core.somaxconn: 已经完成三次握手,但是尚未被应用程序调用 accept()
获取的最大连接数量(全连接队列长度)。
net.ipv4.tcp_syncookies: SYN Cookie 机制,启用后当前连接收到 SYN
包后不进入半连接队列,而是根据时间戳,四元组信息计算出一个 Cookie 信息作为 ISN 返回给客户端,等收到了
ACK 包时从序号里反算出当时信息。配置为 0 时不启用;配置为 1 时当半连接队列满时启用;配置为
2 时无条件启用。
不同的内核版本对于半连接队列/全连接队列的长度计算有些许差异(尤其半连接队列的限制在历史上经过了很多次变化调整),vm-1/vm-2
使用的 5.10.134-16 版本的内核计算方法是:
# 半连接队列当前长度(backlog 是调用 listen() 时的 backlog
参数,下同)
min(backlog, net.core.somaxconn, net.ipv4.tcp_max_syn_backlog)
# 全连接队列最大长度
min(backlog, net.core.somaxconn)
|
很多资料里提到的早先那个 roundup_pow_of_two 的计算方法在 v4.4 开始的一个提交[7]中修改了。
说不准你在实验的时候,更高版本内核的某些行为就和这篇文章里的实验结果不太一致了。这也很正常,要学会研究方法而不是记住数字。
下面的实验可以快速验证下队列长度(保持上面 vm-2 的 iptables 设置,继续拦截 vm-1
的握手包):
# vm-1
$ sudo sysctl -w net.ipv4.tcp_syncookies=0 net.ipv4.tcp_max_syn_backlog=4
net.core.somaxconn=8
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_max_syn_backlog = 4
net.core.somaxconn = 8
# vm-2
$ while true; do sudo nmap -sS 10.0.0.3 -p 9527;
done
|
此时 vm-1 上看到的统计:
$ sudo netstat -anpo | grep SYN_RECV | wc -l
4
|
可见半连接队列的长度被限制住了,后续发送的 SYN 包被直接丢弃了。netstat -s 可以看到相关的
SYN 包被丢弃的统计(累积值):
$ sudo netstat -s | grep -E "LISTEN|overflowed"
378 SYNs to LISTEN sockets dropped
$ sudo netstat -s | grep -E "LISTEN|overflowed"
382 SYNs to LISTEN sockets dropped
$ sudo netstat -s | grep -E "LISTEN|overflowed"
384 SYNs to LISTEN sockets dropped
|
下面验证下全连接队列的限制,因为 nc -l 会默认去做 accept() 操作,所以这里用 python
写个脚本来创建一个只 listen 的监听套接字:
import socket
import time
def start_server(host, port, backlog):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
while True:
time.sleep(1)
if __name__ == '__main__':
start_server('10.0.0.3', 9527, 8)
|
在 vm-2 上写个循环建连的 python 脚本:
import socket
import time
def connect_and_hold(host, port, count):
cli_list = []
try:
for i in range(count):
cli = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
cli.connect((host, port))
cli_list.append(cli)
except Exception as e:
print(f"Failed to connect: {e}")
while True:
time.sleep(1)
if __name__ == '__main__':
connect_and_hold('10.0.0.3', 9527, 10)
|
在 vm-1 上启动服务端后,在 vm-2 上发起连接:
# 记得清掉 vm-2 的 iptables 规则
sudo iptables -F
# vm-1
python3 ./server.py
# vm-2
python3 ./conn.py
|
此时在 vm-1 上可以观测到相关的 drop 记录:
$ sudo netstat -s | grep -E "LISTEN|overflow"
1 times the listen queue of a socket overflowed
# 全连接队列 DROP
466 SYNs to LISTEN sockets dropped # 半连接队列 DROP
|
vm-1 和 vm-2 执行 netstat 的统计结果如下:
# vm-1
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address
State PID/Program name Timer
tcp 9 0 10.0.0.3:9527 0.0.0.0:* LISTEN 54108/python3
off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49568 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49580 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49588 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49566 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49586 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49594 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49626 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49598 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:49610 ESTABLISHED
- off (0.00/0/0)
# vm-2
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign
Address State PID/Program name Timer
tcp 0 0 10.0.0.4:49610 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 1 10.0.0.4:49628 10.0.0.3:9527 SYN_SENT
48261/python3 on (3.94/2/0)
tcp 0 0 10.0.0.4:49586 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49566 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49626 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49594 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49568 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49598 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49588 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
tcp 0 0 10.0.0.4:49580 10.0.0.3:9527 ESTABLISHED
48261/python3 off (0.00/0/0)
|
可以观察到 vm-2 上第 10 个连接处于 SYN_SENT 状态,定时器显示其在进行
SYN 包的重传。从这个结果可以看出来,当全连接队列满的时候,半连接队列也是拒绝连接的。如果全连接队列不满的时候呢?修改上面的
conn.py 脚本里的连接数为 6,重新运行服务端和客户端程序,然后在 vm-2 上拦截 vm-1
的握手包,单独发一个 SYN 包过去试试:
# vm-2
$ sudo iptables -A INPUT -p tcp --sport 9527
-j DROP
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign
Address State
tcp 6 0 10.0.0.3:9527 0.0.0.0:* LISTEN 55439/python3
off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55484 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55520 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55504 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:53019 SYN_RECV
- on (3.18/2/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55514 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55488 ESTABLISHED
- off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:55482 ESTABLISHED
- off (0.00/0/0)
|
从这个结果中可以看到有一个 SYN_RECV 的连接,其成功进入了半连接队列。
综上,全连接队列满的时候,即使半连接队列不满也不会接受新的连接,会直接丢弃包(这个提交[8]开始的,v4.10
版本之后)。当全连接队列不满的时候,允许新连接进入半连接队列。那么当半连接队列里的连接要往全连接队列移动时发现全连接队列满了怎么办?协议栈要如何处理第三次握手的
ACK 包呢?直接丢弃还是给客户端回 RST 直接断开?不同的业务场景有不同的选择,所以内核给了个参数控制这个行为:
net.ipv4.tcp_abort_on_overflow: 此值为 0 表示握手到第三步时全连接队列满时则扔掉客户端发过来的
ACK 包。但是客户端那边因为握手包已经发出,已经自动进入 ESTABLISHED 状态准备传输数据了。服务端丢弃了
ACK 包后这个链接还是处于 SYN_RECV 状态的(如果此时客户端发数据,服务端会直接丢弃。客户端就开始重传,此时的重传次数受内核的
net.ipv4.tcp_retries2 参数控制);此值为 1 则直接给客户端发送 RST 包直接断开连接。这里强调下,这个参数只在半连接队列往全连接队列移动时才有效。而全连接队列已经满的情况下,内核的默认行为只是丢弃新的
SYN 包(而且目前没有参数可以控制这个行为),这会导致客户端 SYN 不断重传。
想想看为什么 Accept Queue 满了,客户端的第一次握手包只能直接丢弃而不能根据 tcp_abort_on_overflow
的配置决定行为?
其实很简单,当服务未启动的时候,端口未打开的情况下收到 SYN 包是要回复 RST 的,这表示端口不可达。如果
Accept Queue 满了也这么做的话,就无法区分这两种情况了。而服务端返回过 SYN+ACK,但是
Accept Queue 已经放不进去的时候选择静默丢弃或者直接回复 RST 断开不会造成协议通信上的歧义。
上述实验并未发送数据,但是我们注意到 LISTEN 状态的 socket 的 Recv-Q 统计有数值(恰好等于当前全连接队列长度),在
man netstat 搜 Recv-Q 和 Send-Q 可以看到这样的说明:
Recv-Q
Established: The count of bytes not copied by the
user program connected to this socket.
Listening: Since Kernel 2.6.18 this column contains
the current syn backlog.
Send-Q
Established: The count of bytes not acknowledged by
the remote host.
Listening: Since Kernel 2.6.18 this column contains
the maximum size of the syn backlog.
Listening 状态下, Recv-Q 就是目前全连接队列的当前值,但是 netstat 的 Send-Q
并没有像文档那样正常显示全连接队列的最大值。而 ss 命令是可以正常显示的(当前值 9 比最大值 8
大 1 是因为内核判断长度限制的时候用了 > 而不是 >=,所以其实比限制值多了一个,囧):
# vm-1
$ sudo ss -antl | grep -E "Recv-Q|9527"
State Recv-Q Send-Q Local Address:Port Peer
Address:PortProcess
LISTEN 9 8 10.0.0.3:9527 0.0.0.0:*
|
为什么 netstat 和 ss 结果有差异呢?翻下 netstat 的源码看看(其实以前就知道 ss
可以显示,netstat 不行,正好借写这篇文章的机会看下):
# 先用 strace 看看 netstat 怎么打印的
$ strace netstat -ntl
# 从输出结果看,这部分数据来自 /proc/net/tcp(省略无关行)
$ cat /proc/net/tcp
sl local_address rem_address st tx_queue rx_queue
tr tm->when retrnsmt uid timeout inode
1: 0300000A:2537 00000000:0000 0A 00000000:00000009
00:00000000 00000000 1000 0 310710 10 0000000000000000
100 0 0 10 0
# 看起来 /proc/net/tcp 里显示的 rx_queue 确实是 9,tx_queue
没有值
# netstat 源码翻了下没什么价值,就是在解读 /proc/net/tcp
并打印而已,tx_queue 输出是 0 就显示 0 了,就是数据源的问题
# 用 strace 跟踪下 ss 看看
$ strace ss -ntl
# 输出一大堆,原来走的是 netlink 机制从内核额外获取的信息
# 翻了下内核的相关代码,netlink 确实返回了 sk->sk_ack_backlog
和 sk->sk_max_ack_backlog,所以 ss 的显示是对的
|
顺便翻下 /proc/net/tcp 的生成代码,在 get_tcp4_sock() 函数里:
static void get_tcp4_sock(struct sock *sk, struct
seq_file *f, int i)
{
...
if (state == TCP_LISTEN)
rx_queue = READ_ONCE(sk->sk_ack_backlog);
else
/* Because we don't lock the socket,
* we might find a transient negative value.
*/
rx_queue = max_t(int, READ_ONCE(tp->rcv_nxt)
-
READ_ONCE(tp->copied_seq), 0);
...
}
|
当 state 是 TCP_LISTEN 时,仅对 rx_queue 返回了全连接队列的当前长度,并没有根据这个状态去改变
tx_queue 的默认值。所以 netstat 拿到的 LISTEN 套接字的队列长度就不符合文档所述。深挖了下,最早在内核
v2.6.18 发布前的这个提交[9]引入的当前队列长度,已经是2006 年的事情了。不过这个提交里tcp_diag_get_info()也没有返回总长度限制,继续翻
git 日志发现是 v2.6.24 发布前的这个提交[10]加进去了返回当前总长度,但是只改了 netlink
部分。至此get_tcp4_sock()成了被遗忘的角落(/proc/net/tcp 也被标记为过期特性)。至于
netstat 的文档错误,不知道是不是 netstat 的 man 文档编写的时候是不是和 ss
串台了。
我找了位小同学提交了一个 patch[11],但是社区的态度是 “I do not think it
is a fix, and I am not sure we want this patch anyway.
/proc interface is legacy, we do not change it.” 即使合到主线,大量旧内核的系统还是无法正常获取信息,所以平时还是用
ss 吧。
好了,到这里连接创建的实验结束,清理下 vm-1 和 vm-2 上所有运行的脚本,切记要清空掉 iptables
配置以免干扰后续实验(sudo iptables -F)。
TCP 连接的关闭
客户端按下 ctrl+c 退出 nc 命令,此时在 vm-1 和 vm-2 上多执行几次 netstat
命令,输出的结果如下:
# vm-1
$ sudo netstat -anpo | grep Recv-Q; sudo netstat
-anpo | grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address
State PID/Program name Timer
tcp 0 0 10.0.0.3:9527 0.0.0.0:* LISTEN 1704/nc
off (0.00/0/0)
# vm-2
$ sudo netstat -anpo | grep Recv-Q; sudo netstat
-anpo | grep 9527
Proto Recv-Q Send-Q Local Address Foreign
Address State PID/Program name Timer
tcp 0 0 10.0.0.4:52336 10.0.0.3:9527 TIME_WAIT
- timewait (57.31/0/0)
$ sudo netstat -anpo | grep Recv-Q; sudo
netstat -anpo | grep 9527
Proto Recv-Q Send-Q Local Address Foreign
Address State PID/Program name Timer
tcp 0 0 10.0.0.4:52336 10.0.0.3:9527 TIME_WAIT
- timewait (54.04/0/0)
$ sudo netstat -anpo | grep Recv-Q; sudo
netstat -anpo | grep 9527
Proto Recv-Q Send-Q Local Address Foreign
Address State PID/Program name Timer
tcp 0 0 10.0.0.4:52336 10.0.0.3:9527 TIME_WAIT
- timewait (52.92/0/0)
|
服务端上的连接已经消失,客户端(主动断连的一方)进入了 TIME_WAIT 状态,并且最后一列显示了
timewait 定时器的相关信息。
TIME_WAIT 下定时器的值会不断减少,最终完全关闭该连接(括号里后两个值无效) 。Linux
默认的 MSL(Maximum Segment Lifetime, 最大报文生存时间) 定义成 30s,所以默认的
TIME_WAIT 时间等于 2 * MSL 就是 60s. TIME_WAIT 有什么影响呢?显然在主动关闭的一方,默认情况下会使得同一个
IP 地址的连接之前用过的端口在 60s 内无法再次被使用(协议五元组一致)。
Linux 内核提供了以下参数来间接影响 TIME_WAIT 的状态:
1、net.ipv4.tcp_timestamps: TCP 时间戳机制。RFC1323 中实现了
TCP 拓展规范,以便保证网络繁忙的情况下的高可用。其定义了一个新的 TCP Option - 两个四字节的
timestamp 字段,第一个是 TCP 发送方的当前时钟时间戳,第二个是从远程主机接收到的最新时间戳(前文介绍过这个参数了)。但是要注意,这个选项突然关闭的时候,发送的新包突然不带时间戳了。如果目的端是低版本内核且开启
net.ipv4.tcp_tw_recycle 可能会导致一个 PAWS 周期内的新连接的 SYN
包被丢弃(社区内核 3.17 的 这个提交[12] 引入的,但是注意下红帽的 3.10 内核也包含这个修改,4.12
才删除的)。
2、net.ipv4.tcp_tw_recycle: 丢弃所有来自同一个远端发送的 timestamp
时间戳小于上次记录的时间戳的任何数据包。使用该选项必须保证数据包的时间戳是单调递增的。在 LB/NAT
的网络环境里,这是无法保证的(甚至原始的 timestamp 选项会在包转发时直接移除)。另外从内核
v4.10 版本开始 随机化了 TCP 时间戳[13](从 host 维度递增改成了只保证单个 conn
维度递增)。但是现状是很多存量设备的低版本内核还是启用了这个选项,所以 v4.11 还是把时间戳又改回了之前按照
host 维度递增 [14]的逻辑。否则运行新版本内核的设备和运行旧版本内核的设备通信时,会因为对方开启了
net.ipv4.tcp_tw_recycle 选项而丢弃正常的 TCP 包。
接着社区删除了per connection的 timestamp cahce[15],至此 tcp_tw_recycle
的核心逻辑基本上就被清除出了内核,所以后面 直接移除了这个选项[16]。至此内核 v4.12 版本开始没有这个选项了。如果还在用旧版本的内核,生产环境下任何情况都不建议开启这个选项,尤其是在各种
LB/NAT 设备遍布的今天,这个选项只会造成麻烦。
因为 net.ipv4.tcp_tw_recycle 的原因丢弃的包可以用 netstat -s 查看统计:
|
$ netstat -s | grep "passive connections
rejected because of time stamp"
136964 passive connections rejected because
of time stamp
|
3、net.ipv4.tcp_tw_reuse: 将处于 TIME_WAIT 状态的 socket
用于新的 TCP 连接,依赖 net.ipv4.tcp_timestamps 选项开启。原理是 connect()
调用时允许内核复用超过 1s 的 TIME_WAIT 状态的连接。(被动接受连接的服务开启这个选项没什么作用)。
4、net.ipv4.tcp_max_tw_buckets: 内核持有的状态为 TIME_WAIT
的最大连接数。如果超过这个数字,新的 TIME_WAIT 的连接会被立即销毁。
$
sysctl net.ipv4.tcp_timestamps net.ipv4.tcp_tw_reuse
net.ipv4.tcp_max_tw_buckets
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 2 # 0 - disable, 1 -
global enable, 2 - enable for loopback traffic
only
net.ipv4.tcp_max_tw_buckets = 8192 |
一般情况下,这个 2 * MSL 值是不建议修改的,官方内核并没有提供直接修改该定时值的配置项(有些分支比如阿里云的内核[17]导出了
net.ipv4.tcp_tw_timeout 来修改 TIME_WAIT 默认等待时间,但请谨慎修改)。
关于 TIME_WAIT 状态存在的目的以及上述参数的讨论,有篇文章讲的很好,可以参考阅读[18],本文不赘述了。
短连接和 TIME_WAIT 状态实验
这里简单验证下 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_max_tw_buckets
参数的效果:
# 先调大 net.ipv4.tcp_max_tw_buckets 的值
$ sudo sysctl -w net.ipv4.tcp_max_tw_buckets=1000000
net.ipv4.tcp_max_tw_buckets = 1000000
# 关闭 net.ipv4.tcp_tw_reuse
$ sudo sysctl -w net.ipv4.tcp_tw_reuse=0
net.ipv4.tcp_tw_reuse = 0
# 查看 net.ipv4.ip_local_port_range 配置
$ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 60999
|
写个 python 脚本循环建连并立即断开:
import socket
def connect_and_immediately_disconnect(host,
port, count):
try:
for i in range(count):
cli = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
cli.connect((host, port))
cli.close()
except Exception as e:
print(f"Failed to connect: {e}")
if __name__ == '__main__':
connect_and_immediately_disconnect('10.0.0.3',
9527, 70000)
|
可以使用下面的命令统计当前 TIME_WAIT 状态的 socket 数量:
$ sudo netstat -anpo | grep 9527 | grep timewait
| wc -l
28232
|
客户端端口占用完 32768~60999 后客户端报错「没有可用的地址」:
$ python3 ./conn.py
Failed to connect: [Errno 99] Cannot assign
requested address
|
方案一:打开 net.ipv4.tcp_tw_reuse 后,TIME_WAIT 的 socket
数量稳定在一万多个不再增多,客户端没有再报错,顺利执行完退出。
$
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_reuse = 1
$ sudo netstat -anpo | grep 9527 | grep timewait
| wc -l
14116
|
方案二:关闭 net.ipv4.tcp_tw_reuse(方案一),将 net.ipv4.tcp_max_tw_buckets
设置为 5000 重复上述实验,TIME_WAIT 的 socket 数量到 5000 便不再上涨:
$ sudo sysctl -w net.ipv4.tcp_tw_reuse=0
net.ipv4.tcp_tw_reuse = 0
$ sudo sysctl -w net.ipv4.tcp_max_tw_buckets=5000
net.ipv4.tcp_max_tw_buckets
= 5000
$ sudo netstat -anpo | grep
9527 | grep timewait | wc -l
5000
|
还有一个问题,很多过时资料说的超过阈值后 /var/log/messages 会打印 “TCP: time
wait bucket table overflow” 的报错。但其实在内核 v2.6.37 后就改成了统计值而不是打日志[19]。这个统计值可以用
netsta -s 查看:
# 因为 conn.py 连接了 70000 次,超过
5000 后开始递增 TCPTimeWaitOverflow 错误,恰好 65000
次
$ netstat -s | grep TCPTimeWaitOverflow
TCPTimeWaitOverflow: 65000
|
上述实验中,都是客户端主动关闭连接的。在一般的系统设计里这是推荐的做法,相对来说把 TIME_WAIT
状态留在客户端更好一些。如果留在服务端,一来耗费更多的服务器资源,二来可用措施相对少一点。当然,如果能用长连接的话更好,因为此类调参大都是在违反
TCP 协议本身,TIME_WAIT 需要等待 2 * MSL 是为了通信的可靠性(所以 Linux
内核回绝了该配置可修改的提议,不支持修改默认的 60s 等待)。
正常关闭的情况下,在 netstat 的输出结果里只能看到 TIME_WAIT 状态的 socket
信息,要想看到 FIN_WAIT_1、FIN_WAIT_2、CLOSE_WAIT、LAST_ACK
等状态也要用 iptables 拦截才能观察到。
拦截第一个 FIN 包
# vm-1
$ nc -k -l 10.0.0.3 9527
# vm-2
$ nc 10.0.0.3 9527
# 在 vm-1 上设置 iptables 丢弃 vm-2
的 FIN 包
$ sudo iptables -A INPUT
-p tcp --dport 9527 --tcp-flags FIN FIN -j
DROP
|
完成后退出 vm-2 的 nc(键盘按下 crtl+c 组合键),此时观察到 vm-2 上的连接进入了
FIN_WAIT_1 状态:
# vm-2
$ while true; do sudo netstat
-anpo | grep 9527; sleep 1; done
tcp 0 1 10.0.0.4:43602 10.0.0.3:9527
FIN_WAIT1 - on (1.86/0/0)
tcp 0 1 10.0.0.4:43602 10.0.0.3:9527
FIN_WAIT1 - on (0.75/0/0)
...
tcp 0 1 10.0.0.4:43602 10.0.0.3:9527
FIN_WAIT1 - on (37.48/2/0)
tcp 0 1 10.0.0.4:43602 10.0.0.3:9527
FIN_WAIT1 - on (36.46/2/0)
...
|
抓包的结果显示 FIN 重传了 9 次:
# vm-1
$ sudo tcpdump -s0 -nn "tcp
port 9527" -w tcp.pcap --print
tcpdump: listening on enp0s5,
link-type EN10MB (Ethernet), snapshot length
262144 bytes
20:36:01.807300 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 858866730,
ack 476455863, win 502, options [nop,nop,TS
val 3301094457 ecr 3783934485], length 0
20:36:02.014156 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301094663
ecr 3783934485], length 0
20:36:02.224638 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301094874
ecr 3783934485], length 0
20:36:02.646304 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301095295
ecr 3783934485], length 0
20:36:03.478598 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301096128
ecr 3783934485], length 0
20:36:05.142164 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301097791
ecr 3783934485], length 0
20:36:08.569241 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301101218
ecr 3783934485], length 0
20:36:15.222388 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301107871
ecr 3783934485], length 0
20:36:28.538659 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301121188
ecr 3783934485], length 0
20:36:55.159701 IP 10.0.0.4.46622
> 10.0.0.3.9527: Flags [F.], seq 0, ack
1, win 502, options [nop,nop,TS val 3301147809
ecr 3783934485], length 0
|
这个重传次数由内核参数 net.ipv4.tcp_orphan_retries 决定(连接关闭时所有的超时重传次数都受这个参数控制):
# vm-2
$ sudo sysctl net.ipv4.tcp_orphan_retries
net.ipv4.tcp_orphan_retries
= 0
|
# 内核 `tcp_orphan_retries()` 函数判断设置是 0 且当前 rto <
max_rto 的情况下会重置这个值为 8 次
这里还有另外一个配置项是: net.ipv4.tcp_max_orphans,当一个连接调用close()后就不再属于哪一个进程(孤儿
orphan 连接),孤儿连接超过阈值就不等 FIN ACK 走常规的关闭连接了,而是直接发 RST
重置连接。
# vm-2
$ sysctl net.ipv4.tcp_max_orphans
net.ipv4.tcp_max_orphans
= 8192
|
拦截第二个 FIN 包
# vm-1
$ nc -k -l 10.0.0.3 9527
# vm-2
$ nc 10.0.0.3 9527
# 在 vm-2 上设置 iptables 丢弃 vm-1
的 FIN 包
$ sudo iptables -A INPUT
-p tcp --sport 9527 --tcp-flags FIN FIN -j
DROP
|
完成后退出 vm-2 的 nc(键盘按下 crtl+c 组合键),此时观察到 vm-2 上的连接进入了
FIN_WAIT_2 状态,而 vm-1 上的连接进入了 LAST_ACK 状态:
# vm-2
$ while true; do sudo netstat
-anpo | grep 9527; sleep 1; done
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
ESTABLISHED 57486/nc off (0.00/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
ESTABLISHED 57486/nc off (0.00/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
ESTABLISHED 57486/nc off (0.00/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
ESTABLISHED 57486/nc off (0.00/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
FIN_WAIT2 - timewait (59.64/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
FIN_WAIT2 - timewait (58.62/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
FIN_WAIT2 - timewait (57.59/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
FIN_WAIT2 - timewait (56.56/0/0)
tcp 0 0 10.0.0.4:45954 10.0.0.3:9527
FIN_WAIT2 - timewait (55.53/0/0)
# vm-1
$ while true; do sudo netstat
-anpo | grep 9527 | grep -v LISTEN; sleep
1; done
tcp 0 0 10.0.0.3:9527 10.0.0.4:45954
ESTABLISHED 67885/nc off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:45954
ESTABLISHED 67885/nc off (0.00/0/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (0.26/1/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (0.05/2/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (0.67/3/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (2.94/4/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (1.91/4/0)
tcp 0 1 10.0.0.3:9527 10.0.0.4:45954
LAST_ACK - on (0.88/4/0)
|
FIN_WAIT2 状态下,超时时间由 net.ipv4.tcp_fin_timeout 这个内核参数决定,超过了就会强制结束状态(不会进入
TIME_WAIT 状态,默认 60s)。
# vm-1
$ sudo sysctl net.ipv4.tcp_fin_timeout
net.ipv4.tcp_fin_timeout
= 60
|
注意上面 netstat 的定时器信息显示的是 timewait 字样。在 Linux 内核里,这个状态的一些处理逻辑也是类似
TIME_WAIT 状态的。
顺带说一句,《TCP/IP 详解》第二版里将 net.ipv4.tcp_fin_timeout 参数称为
Linux 上定义的 2 * MSL 设置。这么说是说不对的。只有连接切换到 TIME_WAIT 状态后才是标准的等待
2 * MSL 的时间。前文也说了社区版本内核并没有直接导出这个参数来支持动态修改(目前内核里就是个宏定义,改了要重新编译内核)。而
FIN_WAIT2 状态的超时其实只是对异常状态的一种防御,避免主动关闭连接后对端不响应。正常情况下另一端也会关闭
socket 发送 FIN 包的,此时 socket 会正常的进入 TIME_WAIT 状态。
正常情况下,shutdown(2) 这个系统调用也可以构造出这个场景:
# vm-1 启动 python 的 server
$ python3 server.py
# vm-2
# 懒得改脚本了,直接 ipython 随手敲一下算了
$ ipython
Python 3.6.8 (default, Jan
29 2024, 15:29:06)
Type 'copyright', 'credits'
or 'license' for more information
IPython 7.16.3 -- An enhanced
Interactive Python. Type '?' for help.
In [1]: import socket
In [2]: c = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
In [3]: c.connect(('10.0.0.3',
9527))
In [4]: c.shutdown(socket.SHUT_WR)
|
然后使用 netstat 就可以分别看到这 2 个状态的 socket 了:
# vm-1
$ sudo netstat -anpo | grep
-E "Recv-Q|9527"
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 1 0 10.0.0.3:9527 0.0.0.0:*
LISTEN 23797/python3 off (0.00/0/0)
tcp 1 0 10.0.0.3:9527 10.0.0.4:54788
CLOSE_WAIT - off (0.00/0/0)
# vm-2
$ sudo netstat -anpo | grep
-E "Recv-Q|9527"
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 0 0 10.0.0.4:54788 10.0.0.3:9527
FIN_WAIT2 7269/python3 off (0.00/0/0)
|
vm-2 是主动 FIN的发送方,转换到了FIN_WAIT_1状态后立即收到了 vm-1 的 ACK
就切换到了FIN_WAIT_2状态,而 vm-1 收到FIN并发出ACK后就进入了CLOSE_WAIT状态,这就是
TCP 的半关闭。shutdown()调用转换到FIN_WAIT2是豁免net.ipv4.tcp_fin_timeout超时的,所以上面netstat
看到的 Timer 是 off 状态。
连接保活
在一个空闲的 TCP 连接中并不会发送任何数据。前文在完成三次握手的连接后,多次添加了 iptables
规则去拦截数据包,这并不影响已经建立的连接。因为 TCP 的“连接”本身就是双方建立的一个逻辑上的通信状态机而已。甚至连接建立好后不发送数据,让中间的网络设备重启后再发送也不影响连接的有效性(特定情况下,假定没有使用
NAT 机制等)。特别地,默认情况下通信一方直接宕机或者拔掉网线,另一端一直没有数据交换的话会一直处于“连接”状态到永远。
TCP 的保活机制就是为了解决上述机制设计的,但这并不是标准 TCP 规范的一部分(大部分的实现都支持,比如
Linux 内核)。这是一个争议很多的特性,TCP 层的保活很多时候无法取代应用层自己的保活设计,所以很多时候并不会有意识的在应用代码里开启这个选项。这里只是简单地提一下这个特性以及相关的内核参数:
# vm-2
$ sysctl net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_probes net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_time
= 7200
net.ipv4.tcp_keepalive_probes
= 9
net.ipv4.tcp_keepalive_intvl
= 75
|
net.ipv4.tcp_keepalive_time:在 TCP 保活打开的情况下,最后一次数据交换到
TCP 发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为 7200s
net.ipv4.tcp_keepalive_probes:在首包之后,没有回应情况下最大允许发送保活探测包的次数,到达此次数后直接放弃尝试,并关闭连接,默认值为
9
net.ipv4.tcp_keepalive_intvl:在首包探测之后,如果依旧是没有 TCP 数据包的情况下,继续发送保活探测包的发送频率,默认值为
75s
关于 net.ipv4.tcp_keepalive_intvl,很多资料写的是探测没有确认后的下一次间隔探测时间。求求了,就是您不看内核文档去验证,起码自己做下实验吧。这个参数就是下一次的
keepalive 包的时间间隔而已。只要 2 边没发过数据,下一次探活的间隔还是这个时间。如果两边发送
TCP 数据了,下一次探活的时间就用 net.ipv4.tcp_keepalive_time 了。
# vm-2 修改下默认值
$ sudo sysctl -w net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_time
= 10
|
继续改一下上述实验客户端的代码,在connect()之前加入:
c.setsockopt(socket.SOL_SOCKET, socket.SO_KEEPALIVE,
1)即可打开 keepalive 机制(哪边打开哪边主动发,对端被动回应。2 边可以独立打开,各自受各自的上述内核参数控制),运行后查看
netstat 信息:
# vm-2 sudo netstat -anpo
| grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 0 0 10.0.0.4:50020 10.0.0.3:9527
ESTABLISHED 7417/python3 keepalive (9.56/0/0)
|
抓包的信息这里就不贴了,只需要知道 keepalive 包其实就是在 ack 之前已经 ack 过的
sequence 就行,有兴趣的话可以自己研究下。唯一需要注意的是一些 keepalive 机制“不生效”的情况,如果你完全依赖
keepalive 机制去保证网络异常情况下的异常连接断开的兜底时间的话,那你可能要失望了。因为这个过程中,大概率会有正常通信的
TCP 包没有收到而触发重传。一旦有重传包,那么 keepalive 就会认为是有数据发送的。此时重传的兜底时间和次数会干扰预设的
keepalive 兜底次数和时间,总的连接断开时间往往会超过预期。如果应用层协议无法做到心跳探活的话,RFC428
的 TCP USER_TIMEOUT 机制也许能帮到你,具体细节和一个生产环境的例子可以参考这篇文章《为什么
Lettuce 会带来更长的故障时间?》。
一般来说,应用层协议能自己设计心跳和探活的话尽量在应用层做。相关的讨论太多了,可以自行检索相关资料。
总结
RFC 关于 TCP 协议本身的描述以及后续为 TCP 打的各个补丁也只是规定了其外在的协议流程。但是很多不在
RFC 内容里的实现细节,在 Linux 内核协议栈的版本的演进中变化了很多次。所以工程上遇到了棘手的问题还是要先确认内核版本号,然后在这个版本号上去看当时的实现策略,否则很容易因为过时的记忆导致问题分析走到岔路去。协议栈参数含义和优化的文章很多,但是很多都是互相抄袭甚至以讹传讹,很多时候要是要自己扒下内核协议栈源码再验证下才能确定。 |