| 编辑推荐: |
本文主要通过实验深入了解 TCP 数据的发送和接收。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者 ,由火龙果软件Linda编辑推荐。 |
|
阿里妹导读
本系列文章是组内写给新人和实习生的 TCP入门系列教程,结合了理论和实践,本篇为第二篇,建议先读上篇《通过实验深入了解TCP
连接的建立和关闭》。
写在前面
TCP 数据的发送与接收是个很大的话题,拖了很久也想不到好的切入点。这部分可以简单分为 「超时重传」、「窗口管理」
以及 「拥塞控制」 三个主要部分。掉书袋的话恐怕会让这篇文章被束之高阁(每写一道数学公式就会失去一半读者),所以这篇文档对具体算法只谈思想不谈公式,然后佐以代码或命令来验证实现细节。
TCP 超时重传
理解 TCP,就是理解如何在一个会出现信息丢失、重复、乱序的底层通信媒介上,设计一组交互协议来可靠保序地传递信息,同时还要兼顾传输的性能和稳定性。上篇提到
TCP 是基于自动重复请求的机制(Automnatic Repeat Request, ARQ)来设计的。简单说就是对待发送的数据(Payload)进行字节级别的编号(Sequence
Number)。在 TCP 完成三次握手建立了连接后(在不携带数据的包里,握手的 SYN 包和挥手的
FIN 也要占用编号),发送的数据均带有相应的位置序号。接收端可以根据序号对数据进行重排序来解决传输过载中存在的乱序送达的情况,并回复
ACK 包给发送端以告知数据送达(不需要请求回复一对一,只需要 ACK 最大的位置即可)。基于这个朴素的数据编号的想法,TCP
完成了发送和接收数据的基本逻辑。
再次回顾下 TCP 协议头的定义:
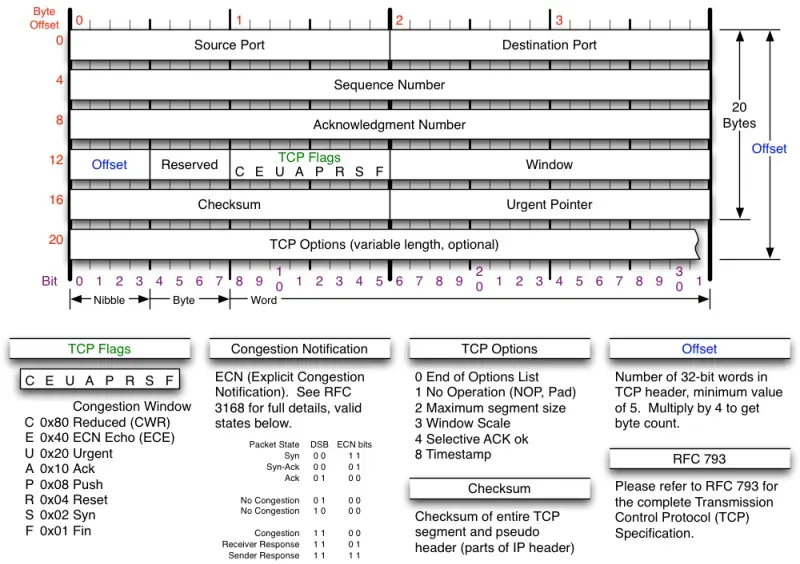
Sequence Number 是当前包携带的 Payload 数据的起始序号,Acknowledgment
Number 是接收到另一端的数据序号+1(期望的下一个数据的开始序号)。TCP flags 的 ACK
为 1 的话,ACK 字段就有效。因为 TCP 是全双工的,所以协议中经常会有发送数据的同时顺带 ACK
对端数据序号的包出现。
如果 TCP 包出现了丢失,发送端如何知晓?自然是接收端回复的 ACK 序号小于已发送的序号,那么这就要求发送端在发送数据之后启动一个定时器,在指定的时间未收到接收端的
ACK 时就要主动的重传尚未被确认的数据。那么这个超时时间设置多大合适?
TCP 基于时间的重传
在 vm-1 上开启 tcpdump 抓包:
# vm-1
# 如果只输出到控制台而不需要保存包到文件的话,将 -w tcp.pcap --print
参数删除即可
$ sudo tcpdump -s0 -X -nn "tcp port 9527"
-w tcp.pcap --print
# 上面命令的 --print 参数在 tcpdump v4.99.0 版本才引入,用于
-w 写文件的同时在控制台也输出详情。如果实验环境的 tcpdump 版本过低,可以从源码编译安装,或者使用下面低版本
tcpdump 等效命令:
$ sudo tcpdump -s0 "tcp port 9527"
-w - -U | tee tcp.pcap | tcpdump -r - -X -nn
|
在 vm-1 上使用 nc 监听 TCP 9527 端口:
# vm-1
$ nc -k -l 10.0.0.3 9527
|
在 vm-1 上再开个窗口循环打印连接状态:
# vm-1
$ while true; do sudo netstat
-anpo | grep 9527 | grep -v LISTEN; sleep
1; done
|
在 vm-2 上打开一个终端,使用 nc 连接服务端:
# vm-2
$ nc 10.0.0.3 9527
|
连接建立好后在 vm-2 上拦截所有 vm-1 发来的包:
# 直接拦截端口
$ sudo iptables -A INPUT -p tcp --sport 9527
-j DROP
|
然后在 vm-1 上的 nc 提示符下输入 abc 并回车,观察 tcpdump 的输出如下(重传包数据长度
4 是因为 nc 在发送的数据 abc 后面加入了 \n,所以是 4 字节):
# vm-1
$ sudo tcpdump -s0 -nn "tcp port 9527"
-w tcp.pcap --print
tcpdump: listening on enp0s5, link-type EN10MB
(Ethernet), snapshot length 262144 bytes
# 三次握手包
18:23:26.292107 IP 10.0.0.4.58290 > 10.0.0.3.9527:
Flags [S], seq 3350238918, win 64240, options
[mss 1460,sackOK,TS val 100736976 ecr 0,nop,wscale
7], length 0
18:23:26.292204 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [S.], seq 956527722, ack 3350238919, win
65160, options [mss 1460,sackOK,TS val 4067628109
ecr 100736976,nop,wscale 7], length 0
18:23:26.292497 IP 10.0.0.4.58290 > 10.0.0.3.9527:
Flags [.], ack 1, win 502, options [nop,nop,TS
val 100736977 ecr 4067628109], length 0
# 发送数据包
18:23:52.634568 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067654452 ecr 100736977], length
4
# 第 1 次重传
18:23:52.840375 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067654657 ecr 100736977], length
4
18:23:53.043925 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067654861 ecr 100736977], length
4
18:23:53.447031 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067655264 ecr 100736977], length
4
18:23:54.281683 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067656099 ecr 100736977], length
4
18:23:55.911371 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067657728 ecr 100736977], length
4
18:23:59.210005 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067661027 ecr 100736977], length
4
18:24:05.863329 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067667680 ecr 100736977], length
4
18:24:18.921724 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067680739 ecr 100736977], length
4
18:24:46.055221 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067707872 ecr 100736977], length
4
18:25:39.303611 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067761120 ecr 100736977], length
4
18:27:23.753849 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067865571 ecr 100736977], length
4
18:29:24.584549 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4067986401 ecr 100736977], length
4
18:31:25.418558 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4068107235 ecr 100736977], length
4
18:33:26.246973 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4068228064 ecr 100736977], length
4
18:35:27.081681 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4068348898 ecr 100736977], length
4
18:37:27.915367 IP 10.0.0.3.9527 > 10.0.0.4.58290:
Flags [P.], seq 1:5, ack 1, win 510, options
[nop,nop,TS val 4068469732 ecr 100736977], length
4
|
这里包的序号是 1:5(左闭右开区间)是因为 tcpdump 默认启用了相对序号的特性。想让 tcpdump
显示原始数据序号范围的话,命令行参数里加上 -S 就行。
vm-1 上的 netstat 的输出如下:
# vm-1
$ while true; do sudo netstat
-anpo | grep 9527 | grep -v LISTEN; sleep
1; done
tcp 0 0 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc off (0.00/0/0)
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (0.72/2/0)
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (1.32/3/0)
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (0.30/3/0)
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (2.50/4/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (5.91/5/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (11.79/6/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (25.30/7/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (50.30/8/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (102.28/9/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.51/10/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.04/11/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.34/12/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.79/13/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.29/14/0)
...
tcp 0 4 10.0.0.3:9527 10.0.0.4:58290
ESTABLISHED 87178/nc on (119.79/15/0)
|
vm-1 发出的数据包在没有回应之后开始了重传,总的重传次数由 net.ipv4.tcp_retries2
参数决定:
# vm-1
$ sysctl net.ipv4.tcp_retries2
net.ipv4.tcp_retries2 = 15
|
从 tcpdump 的抓包结果可以看出,从第一次重传到最后一次经历了大约 15 分钟。从 netstat
的定时器信息可以看出再次超时后定时器数值放大了约 2 倍,最后放大到约 120s 之后不再放大。每次重传时间间隔加倍称之为二进制指数退避(Binary
Exponential Backoff)。
这里需要引入 RTT 和 RTO 的概念:RTT(Round Trip Time) 指一个数据包从发出去到回来的时间,RTO(Retransmission
TimeOut) 指的是重传超时的时间。很显然,只有比较精确地评估出来对端接收到数据包并 ACK 回包的时间,才能准确地评估
RTO 的初始值。
RTO 评估的过大会导致通信效率降低,RTO 评估的过小会导致没有必要的重发加剧拥塞。RTT/RTO
的计算方法从 RFC793 的加权移动平均算法,到 1897 年《Improving Round-Trip
Time Estimates in Reliable Transport Protocols》这篇论文提出的
Karn's Algorithm,再到 RFC6298 的 Jacobson/Karels 算法。本文不介绍具体算法的公式和细节,Linux
内核计算 RTO 的代码可以在这里[1]围观。上篇里介绍过 net.ipv4.tcp_timestamps
这个选项。在时间戳启用时(高版本内核都默认打开了),就可以根据每个包携带的时间戳很好的计算时差了,从而有效地避免重传包对往返时间计算的干扰。
不知道你有没有注意到上面的参数 tcp_retries2 为什么后面有个 2?难不成还有个 tcp_retries1
么?还真有:
# vm-1
$ sysctl net.ipv4.tcp_retries1
net.ipv4.tcp_retries2
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
|
内核文档[2]里面对这两个参数的描述有些晦涩难懂。尤其是 tcp_retries1,什么叫“reports
this suspicion to the network layer”,report 了什么 suspicion?从代码[3]上看,重传次数超过
tcp_retries1 时,调用了tcp_mtu_probing(...)函数,这个函数作用是开始
MTU 探测。有一种丢包的可能性是路由发生了变化,新路径经过的某个设备 MTU 比之前小导致之前能正常通信的包被丢弃了。看来这个参数主要是配合
MTU 探测机制工作的。
而 tcp_retries2 的文档说的是,如果初始 RTO 是 TCP_RTO_MIN[4](200ms)的话,按照默认的
15 次,最大时间就是 924.6 秒(((2<<9)-1)*0.2 + (15-9)*120)。这个参数才是实际控制重传时间的。但是注意这个参数不是直接控制次数的,而是根据这个次数结合
TCP_RTO_MIN 计算出等待时间。但是具体的重传次数会根据结合的 RTO 时间来看。比如值是
15,实际的 RTO 很大有 120s ,等待时间也不会是 120*15=1800s 那么久,也会控制在
924.6 左右(相应的重传次数就小于 15 了)。一般情况下,RTO 大都是 200ms 以内,所以实验所得的重传次数也差不多符合这个配置值。
在连接存在时,可以使用 ss 命令查看连接的当前 RTT 和 RTO 值:
# vm-1
$ sudo ss -tip | grep -A
1 9527
ESTAB 0 0 10.0.0.3:9527 10.0.0.4:49308
users:(("nc",pid=116608,fd=4))
cubic wscale:7,7 rto:204
rtt:0.338/0.169 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:10 segs_in:2 send 343Mbps
lastsnd:295488 lastrcv:295488 lastack:295488
pacing_rate 685Mbps delivered:1 rcv_space:14600
rcv_ssthresh:64076 minrtt:0.338 snd_wnd:64256
|
先忽略别的信息,主要关注这里 rto:204 rtt:0.338/0.169 的部分。RTO 当前是
204 毫秒,RTT 是 0.338 毫秒(平均偏差 0.169ms)。上文也提到 Linux 内核的
TCP_RTO_MIN 是 200ms,明明 RTT 这么小,TCP_RTO_MIN 为什么要这么大?这是因为
RTO 要给 Delayed ACK(ACK 确认延迟) 兜底。在一个全双工通信的 TCP 连接中,当一端接收到数据后,何时发送
ACK 给对端呢?最理想的情况是接收端恰好也有数据要发送,所以让 ACK 顺便「搭车」是效率最优的。如果接收端没有数据要发送呢?大部分的
TCP 实现都会稍微等待一会,尽可能的让 ACK「搭车」发送以提升整体的网络利用效率(协议头可不小,网络上都是小包的话整体传输效率低)。因为
Delayed ACK 的存在,TCP_RTO_MIN 太小的话就会导致很多没有必要的重传产生了。
RFC1122 指出 TCP 实现 ACK 延迟应小于 500 毫秒。实践中各种 TCP 的实现一般最大取
200 毫秒。所以 RTO MIN 的宏定义是 200 毫秒就不意外了(哪怕 Linux 自己小于
200 毫秒也得考虑其他设备)。具体实现上 Linux 采用了一种动态调节算法,可以在每个报文返回
ACK(Quick ACK,快速确认)和传统延时 ACK (Delayed ACK)之间切换。逻辑上连接建立初期适合快速确认以帮助拥塞窗口快速增长,而连接建立后可以使用延时确认来整体提升网络传输效率。Linux
内核里延迟确认默认有 40 毫秒(RedHat 导出了相关配置[5],但是社区内核还是个宏定义[6])。
所以你看,RTT 的算法费这么大劲优化算法去公平计算各种情况下的往返时间,结果被 Delayed ACK
摆了一道。
TCP Fast Retransmit(快速重传)
因为 TCP_RTO_MIN 的存在,仅依赖 RTO 做重传的效率还是很低的,所以TCP 开始「打补丁」来优化重传。RFC5681
定义了一种 Fast Retransmit(快速重传)的机制。这个算法不考虑时间,而以接收到的数据驱动重传。简单说就是如果收到的包是乱序的,就重发之前最后一个
ACK 包。假设每个包一个字节,接收方之前已经 ACK 到 2 了。接下来没收到 2 反而收到了 3
4 5 的话,接收方就会重发 ACK 2 来提醒发送方。如果发送方连续收到 3 次相同的 ACK(Duplicate
ACK),就重传这个包。好处很明显,发送方不必等待 RTO 超时就可以快速重传可能丢失的包。但是缺点也存在,在发送方的视角里,自己发送了
2 3 4 5,收到了三个 ACK 2 的回应。那么应该重传 2 呢,还是 2 3 4 5 都重传?此时发送方无法确定是
2 丢失了还是 2 后面全部丢失了。纸上得来终觉浅,接下来实验验证下。
在上一篇文章中,基本上都是利用现成的 Linux 命令和机制去研究 TCP 协议栈的。但是数据和发送需要构造场景来研究数据重传等机制,所以需要对发送和接收的包做一些定制。发送和接收特定的底层协议包可以使用
raw socket 来进行。但是用 C 代码编写的话相对来说费时费力。故本文采用 scapy[7]
这个 python 开源库来构造发送和接收底层 TCP 数据包。
这里先看一个使用 scapy 进行三次握手的例子:
import time
from scapy.all import *
from scapy.layers.inet import
*
def main():
ip = IP(dst="10.0.0.3")
tcp = TCP(sport=9528, dport=9527,
flags='S', seq=1)
print("send SYN, seq=0")
resp = sr1(ip/tcp, timeout=2)
if not resp:
print("recv timeout")
return
resp_tcp = resp[TCP]
if 'SA' in str(resp_tcp.flags):
recv_seq = resp_tcp.seq
recv_ack = resp_tcp.ack
print(f"received SYN,
seq={recv_seq}, ACK={recv_ack}")
send_ack = recv_seq + 1
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=2, ack=send_ack)
print(f"send ACK={send_ack}")
send(ip/tcp)
elif 'R' in str(resp_tcp.flags):
print(f"received RST")
else:
print("received different
TCP flags")
time.sleep(100)
if __name__ == "__main__":
main()
|
运行这个脚本:
# vm-1 开启服务端
$ nc -k -l 10.0.0.3 9527
# vm-2 先拦截掉自己给远端发送的 RST 包
# 因为 scapy 在这里是冒充协议栈给 vm-1
发包的,当 vm-1 的回包进入 vm-2 的协议栈后,vm-2 发现这个包不在合法流程里就回
RST 了
$ sudo iptables -A OUTPUT
-p tcp --tcp-flags RST RST --dport 9527 -j
DROP
$ sudo python3 ./tcp_conn.py
|
在 vm-1 上用 netstat 看到了这样的结果:
# vm-1
$ sudo netstat -anpo | grep
-E "Recv-Q|9527"
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 0 0 10.0.0.3:9527 0.0.0.0:*
LISTEN 28331/nc off (0.00/0/0)
tcp 0 0 10.0.0.3:9527 10.0.0.4:9528
ESTABLISHED 28331/nc off (0.00/0/0)
|
vm-1 上的抓包记录如下(因为方便对照验证 TCP 的真实 Sequence,后续 tcpdump
抓包时都加 -S 参数显示真实的 TCP Sequence):
# vm-1
$ sudo tcpdump -S -s0 -nn "tcp port 9527"
-w tcp.pcap --print
tcpdump: listening on enp0s5, link-type EN10MB
(Ethernet), snapshot length 262144 bytes
11:24:38.626133 IP 10.0.0.4.9528 > 10.0.0.3.9527:
Flags [S], seq 1, win 8192, length 0
11:24:38.626170 IP 10.0.0.3.9527 > 10.0.0.4.9528:
Flags [S.], seq 2987883333, ack 2, win 64240,
options [mss 1460], length 0
11:24:38.658416 IP 10.0.0.4.9528 > 10.0.0.3.9527:
Flags [.], ack 2987883334, win 8192, length
0
|
那在 vm-2 上用 netstat 能看到吗?当然看不到,因为这是我们“绕过” vm-2 的协议栈在直接和
vm-1 通信(其实不能叫绕过,只是使用了 raw socket 机制,没走标准的 TCP socket
通信而已)。
先在 vm-1 上写个监听 9527 端口并且对新连接发送数据的脚本(因为要多次发送数据,用 nc
「拼手速」不现实):
import socket
import time
def start_server(host, port,
backlog):
server = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
client.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, 1) # 禁用 Nagle 算法
client.sendall(b"a"
* 1460)
time.sleep(0.01) # 避免协议栈合并包的方式,不严谨但是凑合能工作
client.sendall(b"b"
* 1460)
time.sleep(0.01)
client.sendall(b"c"
* 1460)
time.sleep(0.01)
client.sendall(b"d"
* 1460)
time.sleep(0.01)
client.sendall(b"e"
* 1460)
time.sleep(0.01)
client.sendall(b"f"
* 1460)
time.sleep(0.01)
client.sendall(b"g"
* 1460)
time.sleep(10000)
if __name__ == '__main__':
start_server('10.0.0.3',
9527, 8)
|
接下来在 vm-2 扩展之前的 scapy 脚本:
import threading
import time
from scapy.all import *
from scapy.layers.inet import
*
class ACKDataThread(threading.Thread):
def __init__(self):
super().__init__()
self.first_data_ack_seq =
0
def run(self):
def packet_callback(packet):
ip = IP(dst="10.0.0.3")
resp_tcp = packet[TCP]
# 收到第二次握手包
if 'SA' in str(resp_tcp.flags):
recv_seq = resp_tcp.seq
recv_ack = resp_tcp.ack
print(f"received SYN,
seq={recv_seq}, ACK={recv_ack}")
send_ack = recv_seq + 1
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=2, ack=send_ack)
print(f"send ACK={send_ack}")
# 第三次握手
send(ip/tcp)
return
# 收到数据包
elif resp_tcp.payload:
print("-" * 50)
print(f"Received TCP
packet")
print(f"Flags: {resp_tcp.flags}")
print(f"Sequence: {resp_tcp.seq}")
print(f"ACK: {resp_tcp.ack}")
print(f"Payload: {resp_tcp.load}")
# send_ack = resp_tcp.seq
+ len(resp_tcp.load)
if self.first_data_ack_seq
== 0:
self.first_data_ack_seq =
resp_tcp.seq + len(resp_tcp.load)
send_ack = self.first_data_ack_seq
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=2, ack=send_ack)
print(f"send ACK={send_ack}")
send(ip/tcp)
send(ip/tcp)
send(ip/tcp)
send(ip/tcp)
interface = "enp0s5"
# 根据实际络接口名称更改
sniff(iface=interface, prn=packet_callback,
filter="tcp and port 9527", store=0)
def main():
thread = ACKDataThread()
thread.start()
time.sleep(1)
ip = IP(dst="10.0.0.3")
tcp = TCP(sport=9528, dport=9527,
flags='S', seq=1, options=[('MSS', 1460)])
# 第一次握手
print("send SYN, seq=0")
send(ip/tcp)
thread.join()
if __name__ == "__main__":
main()
|
分别在 vm-1 和 vm-2 上运行这两个脚本:
# vm-1
$ python3 ./tcp_server.py
# vm-2
# 确认下禁止协议栈往 vm-1 发 RST
$ sudo iptables -A OUTPUT
-p tcp --tcp-flags RST RST --dport 9527 -j
DROP
$ sudo python3 ./tcp_dup_ack.py
|
vm-1 上的 tcpdump 输出如下:
# vm-1
$ sudo tcpdump -S -s0 -nn
"tcp port 9527" -w tcp.pcap --print
tcpdump: listening on enp0s5,
link-type EN10MB (Ethernet), snapshot length
262144 bytes
13:51:35.318314 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [S], seq 1, win
8192, options [mss 1460], length 0
13:51:35.318585 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [S.], seq 3309748530,
ack 2, win 64240, options [mss 1460], length
0
13:51:35.352255 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309748531,
win 8192, length 0
13:51:35.352899 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309748531:3309749991,
ack 2, win 64240, length 1460
13:51:35.364258 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309749991:3309751451,
ack 2, win 64240, length 1460
13:51:35.374723 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309751451:3309752911,
ack 2, win 64240, length 1460
13:51:35.387491 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309752911:3309754371,
ack 2, win 64240, length 1460
13:51:35.400133 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309754371:3309755831,
ack 2, win 64240, length 1460
13:51:35.406093 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.410723 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309755831:3309757291,
ack 2, win 64240, length 1460
13:51:35.440428 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.478151 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.510656 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.510714 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [P.], seq 3309749991:3309751451,
ack 2, win 64240, length 1460
13:51:35.544376 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.601033 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.633382 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.665611 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.697836 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
13:51:35.731493 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3309749991,
win 8192, length 0
|
看起来不是很直观,直接用 Wireshark 打开抓到的包吧:
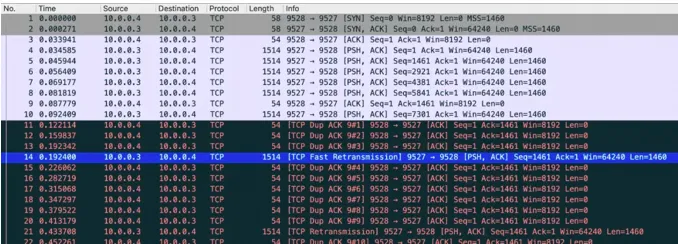
Wireshark 很贴心的标记了 [TCP Dup ACK] 以及 [TCP Fast Retransmission]
的字样。从左边的相对时间来计算,这个重传包距离早先的数据包发出来大约 160ms,还不到 RTO 的超时时间。而且从实际抓包的结果也能看到,Linux
仅重传了第一个包,而不是重传后面所有的包(其他的 TCP 实现立即重传后续所有的包也有可能)。至于后一次重传,就是
RTO 重传了,距离这个包差不多是 200ms 的样子。
在 Wireshark 菜单中打开「统计」->「TCP 流图形」->「序列号(tcptrace)」窗口,很容易识别出
Fast Retransmit 的:
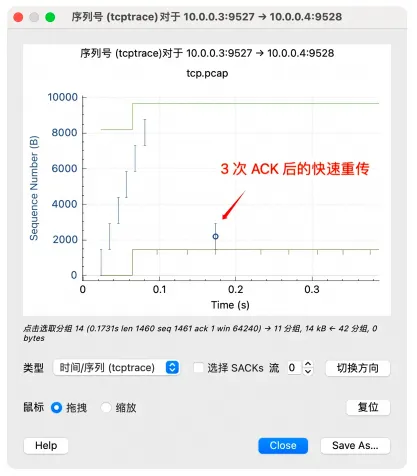
实际上在 Linux 上,这个 Duplicate ACK 触发重传的阈值是可以通过 net.ipv4.tcp_reordering
参数修改的:
# vm-1
$ sysctl net.ipv4.tcp_reordering
net.ipv4.tcp_reordering =
3
|
改成 1 后就重新抓包就能看到 1 次 [TCP Dup ACK] 就会触发重传包了:
# vm-1
$ sudo sysctl -w net.ipv4.tcp_reordering=1
net.ipv4.tcp_reordering =
1
|
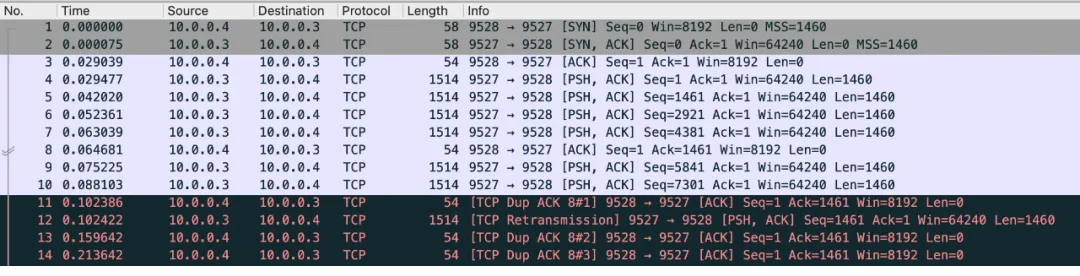
Wireshark 这次没标记 [TCP Fast Retransmission] 是因为 Wireshark
代码里标记 [TCP Fast Retransmission] 的算法是三次 Dup ACK 才会标记后面的重传。但是根据重传的时间也能看出来是小于
RTO 时间的。另外多说一句,Wireshark 的 Dup ACK 和 Linux 协议栈的识别逻辑也有一点区别。Wireshark
只判断 ACK 的点位相同就认为是 Dup ACK,但是如果 ACK 包的 SYN 发生了变化,Linux
协议栈不认为是 Dup ACK的。
试验完记得把参数改回去,正常的生产环境也请不要乱动这些参数。
TCP Selective Acknowledgment(SACK)
因为 ACK 只能表达最后一个收到的包。所以当收到了 0-10, 20-30, 40-50 的数据时,原始的
TCP 协议头实际上无法向对端表达 10-20, 30-40 这两个空洞没收到的(只能发送 ACK
11)。原始的协议头无法表达了,RFC2018 就建议用 TCP Option 来解决这个问题。这样发送端就可以根据这些提示信息更合理地发起重传了。在
Linux 上需要开启 net.ipv4.tcp_sack 参数启用这个功能(新内核都是默认开启的)。在三次握手的时候,就会携带
SACK 的 Option 互相声明自己的能力了。
# vm-1
$ sysctl net.ipv4.tcp_sack
net.ipv4.tcp_sack = 1
|
需要注意的是,接收方有权利丢弃(Reneging)通过 SACK 声明过的包。也就是说发送方不能认为接收方前一次
SACK 声明了某些区间时,就认为不用重传已经收到的包了。所以在 TCP 协议里,只有 ACK 过的点位才是明确收到的,所以发送方还是得老老实实地根据
ACK 维护好定时器,时刻准备着 RTO 重传。
这个实验服务端用 nc 就行:
# vm-1
$ nc -k -l 10.0.0.3 9527
|
客户端使用 scapy 故意发送带有空洞的数据包诱导服务端的协议栈发送 SACK 包(注意握手包这次要加
TCP Option 来声明支持 SACK):
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
from scapy.all import *
from scapy.layers.inet import
*
def main():
ip = IP(dst="10.0.0.3")
myself_seq = 1
tcp = TCP(sport=9528, dport=9527,
flags='S', seq=myself_seq, options=[("SAckOK",
'')])
print("send SYN, seq=0")
resp = sr1(ip/tcp, timeout=2)
if not resp:
print("recv timeout")
return
resp_tcp = resp[TCP]
if 'SA' in str(resp_tcp.flags):
recv_seq = resp_tcp.seq
recv_ack = resp_tcp.ack
print(f"received SYN,
seq={recv_seq}, ACK={recv_ack}")
myself_seq += 1
send_ack = recv_seq + 1
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=myself_seq, ack=send_ack)
print(f"send ACK={send_ack}")
send(ip/tcp)
# 特意注释掉,让发的数据有空洞
# send data
# payload = b"a"
* 10
# tcp = TCP(sport=9528, dport=9527,
flags='A', seq=myself_seq, ack=send_ack)
# send(ip/tcp/payload)
myself_seq += 10
payload = b"b"
* 10
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=myself_seq, ack=send_ack)
send(ip/tcp/payload)
myself_seq += 10
# 特意注释掉,让发的数据有空洞
# payload = b"c"
* 10
# tcp = TCP(sport=9528, dport=9527,
flags='A', seq=myself_seq, ack=send_ack)
# send(ip/tcp/payload)
myself_seq += 10
payload = b"d"
* 10
tcp = TCP(sport=9528, dport=9527,
flags='A', seq=myself_seq, ack=send_ack)
send(ip/tcp/payload)
elif 'R' in str(resp_tcp.flags):
print(f"received RST")
else:
print("received different
TCP flags")
time.sleep(100)
if __name__ == "__main__":
main()
|
在 vm-2 上运行这个脚本,vm-1 的 tcpdump 输出如下:
# vm-1
$ sudo tcpdump -S -s0 -nn
"tcp port 9527" -w tcp.pcap --print
tcpdump: listening on enp0s5,
link-type EN10MB (Ethernet), snapshot length
262144 bytes
14:53:08.394652 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [S], seq 1, win
8192, options [sackOK,eol], length 0
14:53:08.394674 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [S.], seq 884520693,
ack 2, win 64240, options [mss 1460,nop,nop,sackOK],
length 0
14:53:08.394849 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 3743896409,
win 502, options [nop,nop,TS val 138055818
ecr 4104949608], length 0
14:53:08.394855 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [R], seq 3743896409,
win 0, length 0
14:53:08.426952 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], ack 884520694,
win 8192, length 0
14:53:08.458978 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], seq 12:22,
ack 884520694, win 8192, length 10
14:53:08.458986 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [.], ack 2, win
64240, options [nop,nop,sack 1 {12:22}], length
0
14:53:08.491274 IP 10.0.0.4.9528
> 10.0.0.3.9527: Flags [.], seq 32:42,
ack 884520694, win 8192, length 10
14:53:08.491280 IP 10.0.0.3.9527
> 10.0.0.4.9528: Flags [.], ack 2, win
64240, options [nop,nop,sack 2 {32:42}{12:22}],
length 0
|
可以看到对面 ACK 了 12:22 和 32:42 这两个区间(左闭右开)以提示发送方重传空洞的数据。
在 Wireshark 中打开的话,也贴心的提示了我们有 [TCP Previous segment
not captured] 的情况(真实情况下抓的包也许只是没抓到,不一定是丢包了):
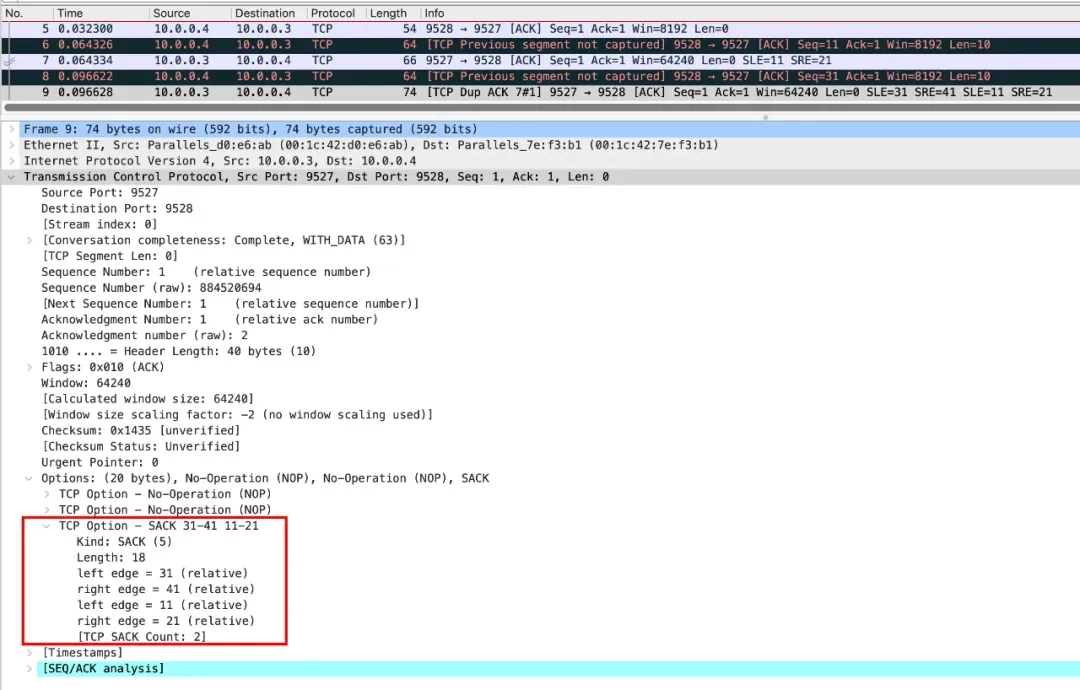
实际上 SACK 多个段的点位可能有交集,SACK 和 ACK 的点位也可能有交集,这种情况叫 Duplicate
SACK,缩写为 D-SACK. 用途是告诉发送方有哪些数据被重复接收了(RFC2883),其主要的目的是提示发送方收到的数据重复了。可以帮助发送方在了解是不是自己
RTO 太小了导致了没意义的重传之类的情况。这些提示信息能帮助 TCP 更好的进行流控。这里不展开讲了,这个特性由
net.ipv4.tcp_dsack 开关控制。
# vm-1
$ sysctl net.ipv4.tcp_dsack
net.ipv4.tcp_dsack = 1
|
当 SACK 开启的时候,快速重传的行为会有些区别。SACK 开启后的 Dup ACK 和没开启的
Dup ACK 的定义是不一样的。Linux 内核有个参数叫 net.ipv4.tcp_fack,用来控制
Forward Acknowledgement 开关。FACK 其实是用来做重传过程中的拥塞流控的。很多资料讲这个开关和
SACK 的关系然后教如何开启这个选项。事实上搜下内核代码就知道,这个选项早就是 obsolete
状态了。FACK 已经成为默认行为而不是需要开关控制的机制了。只是配置项还没删掉罢了。
这里不展开了,有兴趣的话可以翻翻最新的 Linux 内核协议栈代码。
TCP 窗口管理
先说窗口管理。TCP 连接的每一端都可以收发数据(全双工)。连接的收发数据量是通过一组窗口结构(window
structure)来维护的。每个 TCP 活动连接的两端都维护一个发送窗口结构(send window
structure)和接收窗口结构(receive window structure)。
发送窗口是这样的:
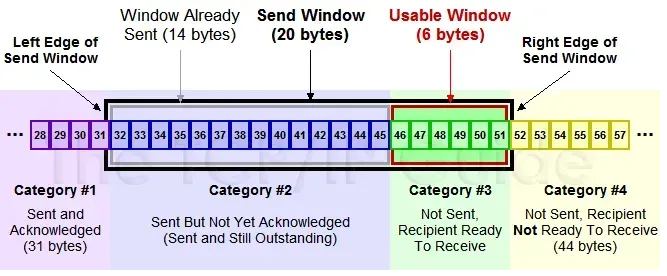
TCP 以字节为单位维护其窗口结构。这里 #1 是发送了且对端已经 ACK 确认过的,#2 是已经发送了但是尚未
ACK 过的,#3 是尚未发送的(接收方有空间可以发送),#4 是窗口大小以外的(接收方没空间了)。当接收方
ACK 了 32 后面的数据,这个窗口就可以往右边“滑动”了。所以又称之为滑动窗口(Sliding
Window)算法。
接收窗口比较简单(概念简单,实际的计算逻辑并不简单),单纯维护已经收到的字节即可。在应用程序收走数据之前,收到的数据要一直缓存在内核协议栈里。这里要注意
TCP 协议头里的 window 字段是连接的两端互相向对方声明自己的接收窗口的大小(发送窗口在协议交互上并无体现,而是连接的两端各自内部维护)。上一篇在三次握手的
TCP Option 中就有一个窗口的放大倍数(RFC1323),这个特性由内核参数 net.ipv4.tcp_window_scaling
控制。之前提到过,如果三次握手包没有抓到的话就不知道这个窗口的放大系数了,就无法正确地计算后续的通信窗口。实际上如果通信的连接尚在的话,ss
命令也可以查询内核中这个连接的窗口放大系数(输出里的 wscale 即为窗口放大系数,7 即 2^7
= 128 倍):
# vm-1
$ sudo ss -tip | grep -A
1 9527
ESTAB 0 0 10.0.0.3:9527 10.0.0.4:55652
users:(("nc",pid=219761,fd=4))
cubic wscale:7,7 rto:204
rtt:2.097/1.048 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:10 segs_in:2 send 55.2Mbps
lastsnd:54800 lastrcv:54800 lastack:54800
pacing_rate 110Mbps delivered:1 rcv_space:14600
rcv_ssthresh:64076 minrtt:2.097 snd_wnd:64256
# vm-2
$ sudo ss -tip | grep -A
1 9527
ESTAB 0 0 10.0.0.4:55652
10.0.0.3:9527 users:(("nc",pid=93231,fd=3))
cubic wscale:7,7 rto:204
rtt:3.064/1.532 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:10 bytes_acked:1 segs_out:2
segs_in:1 send 37.8Mbps lastsnd:56592 lastrcv:56592
lastack:56592 pacing_rate 75.6Mbps delivered:1
rcv_space:14480 rcv_ssthresh:64088 minrtt:3.064
snd_wnd:65160
|
下面用 Python 写个不读数据的服务端和循环发送的客户端来观察 TCP 窗口的变化情况:
import socket
import time
def start_server(host, port,
backlog):
server = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
time.sleep(10000)
if __name__ == '__main__':
start_server('10.0.0.3',
9527, 8)
|
import socket
import time
def start_client(host, port):
client = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
client.connect((host, port))
client.setblocking(False)
send_size = 0
data = b"a" * 100000
while True:
try:
size = client.send(data)
if size > 0:
send_size += size
print(f"send_size: {send_size}")
except BlockingIOError:
time.sleep(0.1)
pass
if __name__ == '__main__':
start_client('10.0.0.3',
9527)
|
分别在 vm-1 和 vm-2 上运行这个脚本:
# vm-1
$ python3 ./tcp_server.py
# vm-2
$ python3 tcp_client.py
send_size: 46336
send_size: 118128
send_size: 218128
send_size: 318128
send_size: 418128
send_size: 429280
|
在新窗口上用 netstat 输出 socket 信息:
# vm-1
$ sudo netstat -anpo | grep
-E "Recv-Q|9527" | grep -v LISTEN
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 110720 0 10.0.0.3:9527
10.0.0.4:34756 ESTABLISHED 220953/python3
off (0.00/0/0)
# vm-2
sudo netstat -anpo | grep
-E "Recv-Q|9527" | grep -v LISTEN
Proto Recv-Q Send-Q Local
Address Foreign Address State PID/Program
name Timer
tcp 0 318560 10.0.0.4:34756
10.0.0.3:9527 ESTABLISHED 94429/python3 probe
(13.13/0/0)
|
可以看到目前 vm-1(服务端)的 Recv-Q 和 vm-2 (客户端)Send-Q 都堆积了请求,此时客户端的
send 再也写不进去数据了。
用 Wireshark 打开抓的包:
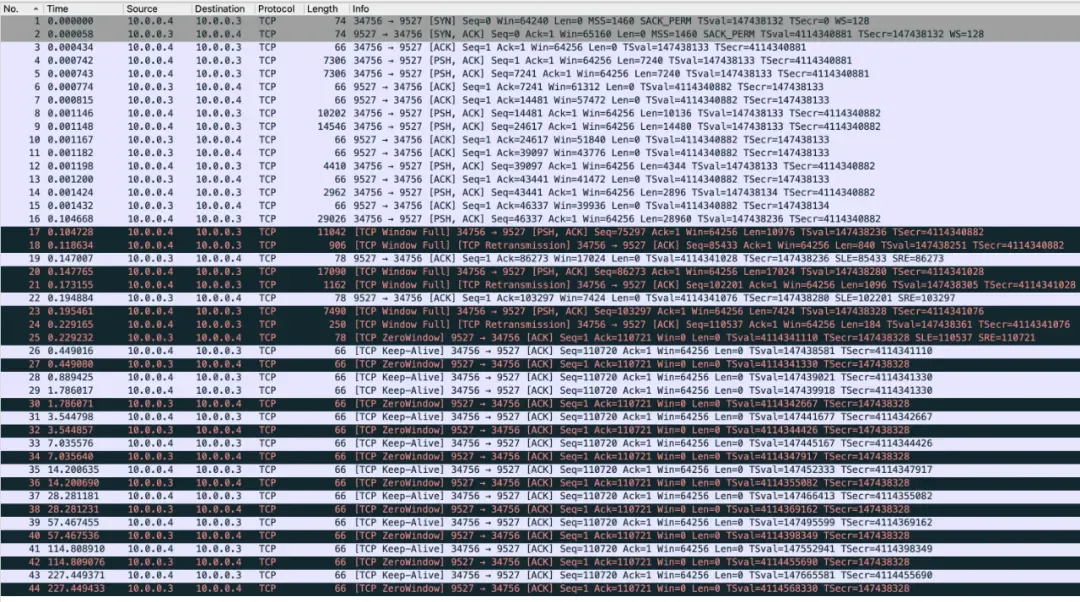
第一眼看到这个图的时候我有点懵,单个包的大小超过了 MTU 好多,出现了 Jumbo Frames(巨帧)。第一反应是
VM 软件的原因,查阅了 Parallels Desktop 后果然发现其支持 Jumbo Frames
选项。简单查了下官方文档,Apple M 系列芯片暂时不能更换默认的 Virtio 网络适配器。但是
ipconfig 看到的 MTU 就是 1500 并没有配置巨帧。有同事提醒我你的 VM 是不是默认开了网卡
GRO/GSO 特性。
# vm-1
$ sudo ethtool -k enp0s5
| grep -E "generic-segmentation-offload|generic-receive-offload"
generic-segmentation-offload:
on
generic-receive-offload:
on
# TSO 也开着
$ sudo ethtool -k enp0s5
| grep tcp-segmentation-offload
tcp-segmentation-offload:
on
|
嚯,都是开的。那还是关上吧(两个 VM 都关掉):
# vm-1 and vm-2
$ sudo ethtool -K enp0s5
gso off
$ sudo ethtool -K enp0s5
gro off
$ sudo ethtool -K enp0s5
tso off
$ sudo ethtool -k enp0s5 |
grep -E "generic-segmentation-offload|generic-receive-offload|tcp-segmentation-offload"
tcp-segmentation-offload:
off
generic-segmentation-offload:
off
generic-receive-offload:
off
|
重新抓包就可以抓包原始的包了:
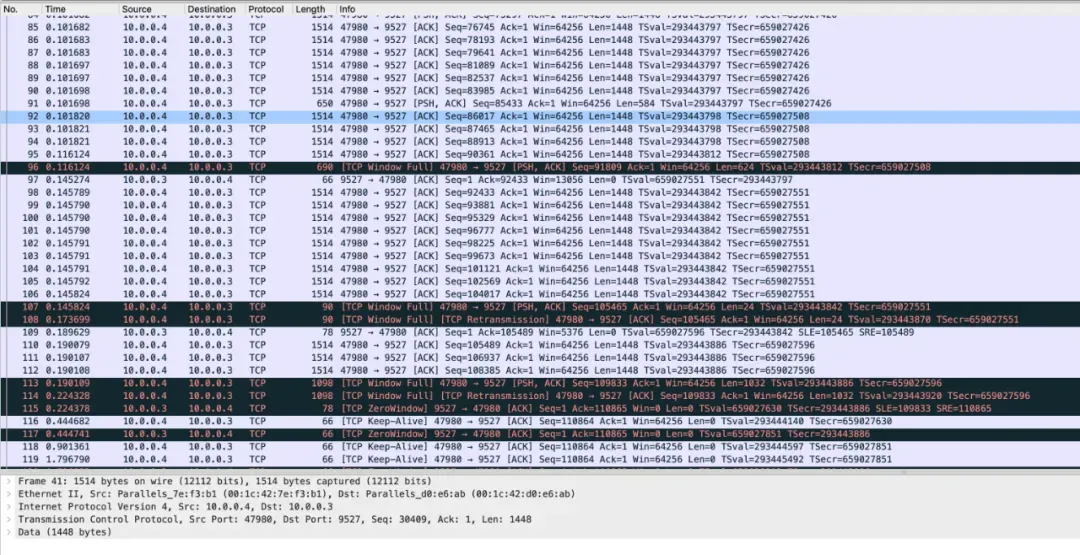
在窗口大小变成 0 后,发送方无法发送数据,此时发送方会触发零窗口探测(Zero Window Probe)。上面
netstat 的输出里也看到了 probe Timer 的存在。RFC1122 建议在一个 RTO
后即开始窗口探测,随后的探测时间类似重传一样会进行指数递增。
注意这里 Wireshark 识别到的 TCP Keep-Alive 包其实不是真的开了 Keep-Alive
的缘故(并没有打开)。而是零窗口探测包的回包因为窗口大小没变过,从而对端回复了 Last ACK 的包恰好和
Keep-Alive 的行为一样。
TCP 基于窗口的流量控制可能会导致一个名为糊涂窗口综合征(Silly Window Syndrome)的现象。通俗说就是每当接收方窗口释放出来一点点后,发送方即发送几个字节。这样会造成持续性的小包发送和接收,整个网络的利用率降低。接收方这边,RFC1122
规定在窗口恢复到至少一个发送方的 MSS 大小或者接收方缓存空间的一半(二者中小的那个值)前,不能通告比之前大的窗口值。发送方这边就是
Nagle 算法了,这是 RFC896里提到的用于减少拥塞的一种手段,该算法要求 TCP 只要有已发送但未确认的数据,新数据如果小于
SMSS 的长度就不能发送。其本质目的也是减少小包发送。一般情况下对延迟有较高要求的系统都会关闭 Nagle
算法,方法是设置 TCP_NODELAY 这个 socket 选项(上文的 Python 代码里设置过)。
上面的例子为了在静态情况下可以看到稳定的 Send-Q 和 Recv-Q 值。在正常的业务系统里,这两个值多采集几次都是在跳变的,且一般情况下会接近于
0 值。如果看到了 Send-Q 长时间不为 0 说明对面的协议栈没有接收数据,再结合 window
size 的情况就可以推断出是不是对端的业务程序没有及时的取走数据。Recv-Q 不为 0 说明本端的程序没有及时地从内核
recv 数据导致了堆积,要检查应用程序是不是繁忙。
稍微改下上面的服务端代码,由从来不读数据改成读一会停一会的循环:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import socket
import time
def start_server(host, port,
backlog):
server = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
client.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, 1) # 禁用 Nagle 算法
while True:
for i in range(5):
client.recv(4096)
time.sleep(1)
if __name__ == '__main__':
start_server('10.0.0.3',
9527, 8)
|
重新运行这 2 个脚本,用 Wireshark 打开抓包文件后,点击菜单「统计」->「TCP
流图形」->「窗口尺寸」:
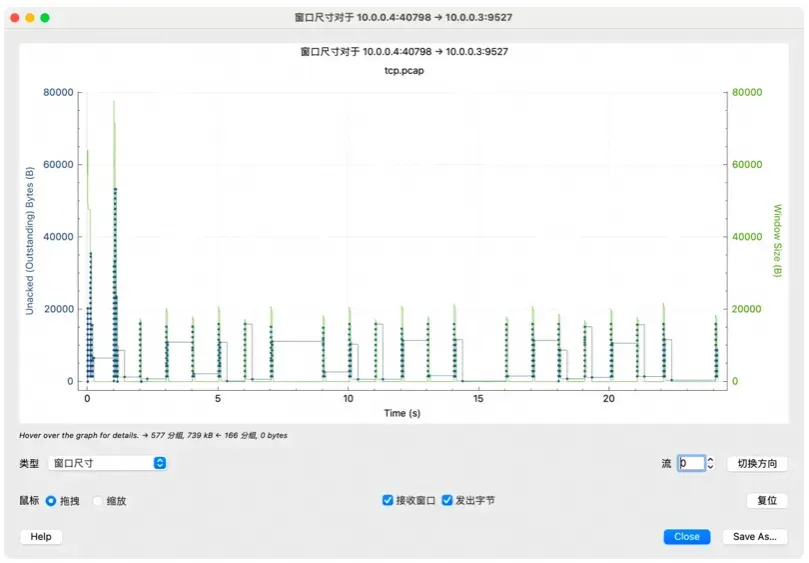
这样可以直观的看到窗口大小的变化情况(如果看到的是一个水平线,请点击右下角的「切换方向」)。可以看到窗口增大后立即就有数据包(蓝色点)发出,窗口变小乃至变成
0 后就不再有数据发送了。这样接收端就可以通过窗口大小这个数值来控制发送端的发送频率。
接着把左边类型切换到「时间/序列(tcptrace)」,可以看到整个发送阶段的窗口、ACK、以及发送的情况:
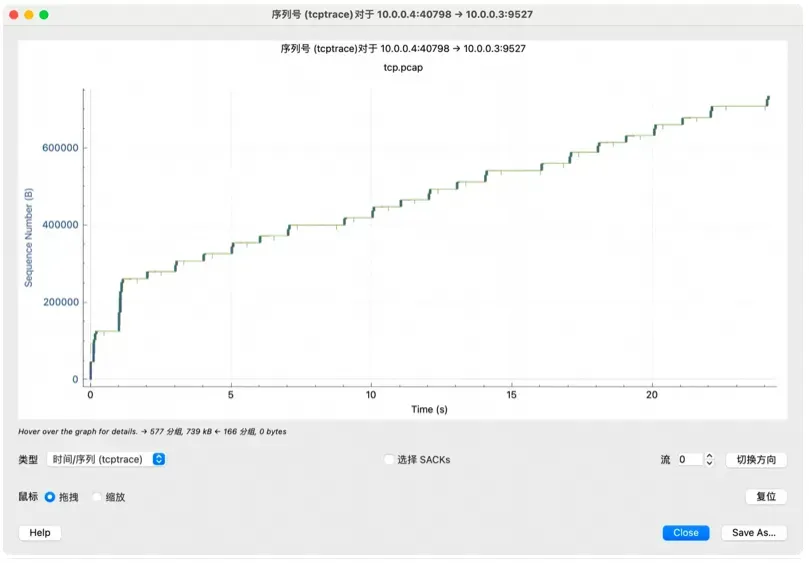
滚动鼠标放大一个局部:
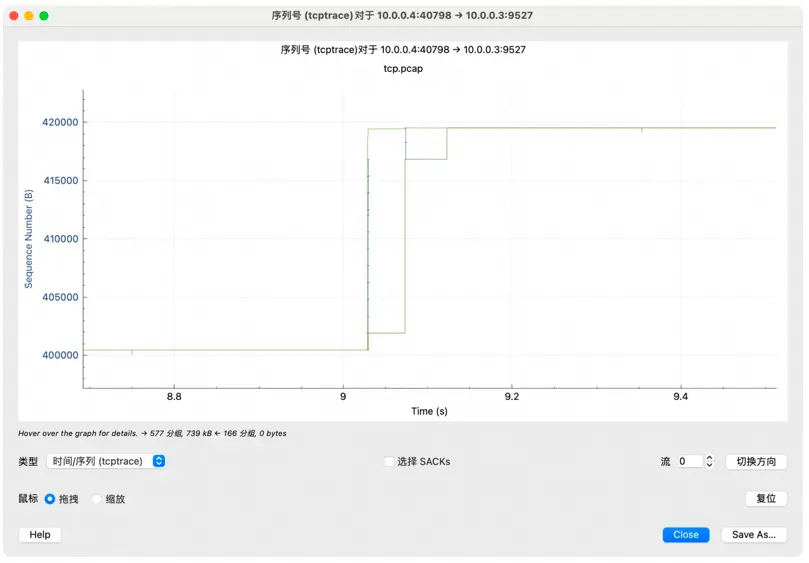
这里简单解释下这个图,X 轴是时间,Y 轴是 Sequence Number,绿色线是接收方的 window
size,蓝色线是发送的包(捕获到的包),黄色的线是 ACK 过的 Sequence Number
值。那么从图上就可以看出来,每当接收方的 window size 增大的时候,立即就有包发送出去了。当
window size 为 0(线平了)的时候,发送立即就停止了。所以这个图告诉我们这个传输是接收方的瓶颈,是接收方通过
window size 的关闭对发送端进行了限流。
TCP 拥塞控制
TCP 协议通过调整接收窗口的大小对发送端进行限流。这个设计解决了接收端和发送端速率不匹配的问题。但是仅仅这样是不够的。在
TCP 传输过程中,要经过很多的处理节点(分组交换的存储-转发模型)。任意一条通信线路的繁忙都会造成网络的拥塞从而影响通信。TCP
不是一个自私的协议,当 TCP 感觉到网络时延突然增加的时候、如果拥塞突然发生的时候,每个进行中的
TCP 通信都会觉得是自己的问题,然后尝试把路让出来(泪目)。这就依赖 TCP 里另外一个重要的部分——拥塞控制。这一块可以说是
TCP 里最复杂的一部分内容,涉及到的 RFC 和讨论多如牛毛。而且直到今天,新的拥塞控制算法还在不断的被提出和应用,以适应不断提速网络信道和场景不断变化的现实世界。
拥塞控制主要的算法是以下几个:(1) 慢启动,(2) 拥塞避免,(3) 拥塞发生,(4) 快速恢复。这几个算法不是一次就确定的,1988
年 TCP-Tahoe 提出了 1-3,1990 年 TCP Reno 在 Tahoe 的基础上增加了
4. 这里不展开这几个算法的介绍和描述了,随便一本介绍 TCP 的书里都有。最早的讨论论文应该是这篇[8]。
拥塞控制的经典算法有 Reno/New Reno、HSTCP、CUBIC,以及近些年研究活跃的 BBR
算法(论文在这里[9],知乎讨论[10]也有意思)。最新的 BBR 出到 v3 版本了,可以关注 Google
的 github bbr [11]项目。
Linux 内核在 2.6.19 后默认的拥塞控制是 CUBIC 算法。这是一种温和的拥塞算法,它使用三次函数作为其拥塞窗口的算法,并且使用函数拐点作为拥塞窗口的设置值。
net.ipv4.tcp_congestion_control
参数用于设置拥塞控制算法,而 net.ipv4.tcp_allowed_congestion_control
表示目前支持的算法:
# vm-1
$ sysctl -a | grep congestion
net.ipv4.tcp_allowed_congestion_control
= reno cubic
net.ipv4.tcp_available_congestion_control
= reno cubic
net.ipv4.tcp_congestion_control
= cubic
|
之前说的 TCP 协议头里的 window size 一直是 Receiver Window Size(rwnd)。拥塞控制还有自己的一个
window,叫 Congestion Window(cwmd)。这个窗口是当前网络的限制,发送端不会发送超过这个窗口的容量(没有
ACK 的包大小总数不会超过 cwnd 的大小)。rwnd 的值在 TCP 的通信过程中一直随着协议在更新,而
cwnd 只是发送方根据当前数据发送的情况实时计算的一个值,记录在协议栈内部。
cwnd 的值可以使用 ss 命令查看:
# vm-1
$ ss -tip | grep -A 1 9527
ESTAB 0 0 10.0.0.3:9527 10.0.0.4:60268
users:(("nc",pid=1727,fd=4))
cubic wscale:7,7 rto:204
rtt:0.327/0.163 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:10 segs_in:2 send 354Mbps
lastsnd:6620 lastrcv:6620 lastack:6620 pacing_rate
709Mbps delivered:1 rcv_space:14600 rcv_ssthresh:64076
minrtt:0.327 snd_wnd:64256
|
注意这里 cwnd 的值意为 MSS 的倍数,也就是这里的 1448 * 10 = 14480 字节。另外前面显示的
cubic 也提示了当前连接使用的拥塞控制算法是 cubic 算法。这里的 10 倍 RSS 意思是在
TCP 通信开始后,发送端在收到接收端第一个 ACK 之前,最多只允许发送这么多的未确认包。不断地收到
ACK 后 cwnd 会不断的调大,直到其超过对端的 rwnd 后就不会成为瓶颈了(此时发送窗口被对端
rwnd 限制)。
最早的时候 cwnd 的初始值一直是 1 倍 RSS 大小的,后来随着网络设备的整体提升,RFC2581更新为
4,RFC6928 更新到 10 .Linux 内核也调整初始值为 10 倍的 RSS 大小。
别想着改了,是个宏定义。有人提出能否给不同的 socket 设置这个参数都被骂的“狗血淋头”。维护者觉得开了这个口子只会被滥用继而影响全球互联网的稳定性。
在 BBR 以前,基本上拥塞控制算法都是以丢包为衡量网络质量的依据的。一旦遇到网络丢包的情况,发送端就开始对发送窗口进行回缩以尝试减少网络拥塞。但是很多情况下丢包不是因为拥塞造成的,比如某些设备异常或者交换机的
buffer 因为突增流量堆积了一下然后有了些延迟导致轻微超时等问题。在远距离公网传输中这并不是新鲜事。本身
TCP 协议就设计了重传机制来解决此类问题。单纯因为某些网络传输的固定丢包率就怀疑乃至 PUA 自己从而主动降低发送速率不一定就是对的。基于这个逻辑,BBR
的发送速率控制完全不在意丢包,自己会不断探测整个传输链路的带宽和时延,最终让发送数据稳定在带宽时延积。我没有详细阅读过
BBR 的论文,如果哪里说的不对还请指正。
接下来用 dd 制造一个 400M 的文件,然后用 nc 发送测试:
# vm-1
$ nc -l 10.0.0.3 9527 >
/dev/null
# vm-2
$ dd if=/dev/zero of=testfile
bs=1M count=400
$ nc 10.0.0.3 9527 < testfile
|
在 vm-1 上抓包后打开捕获的文件:
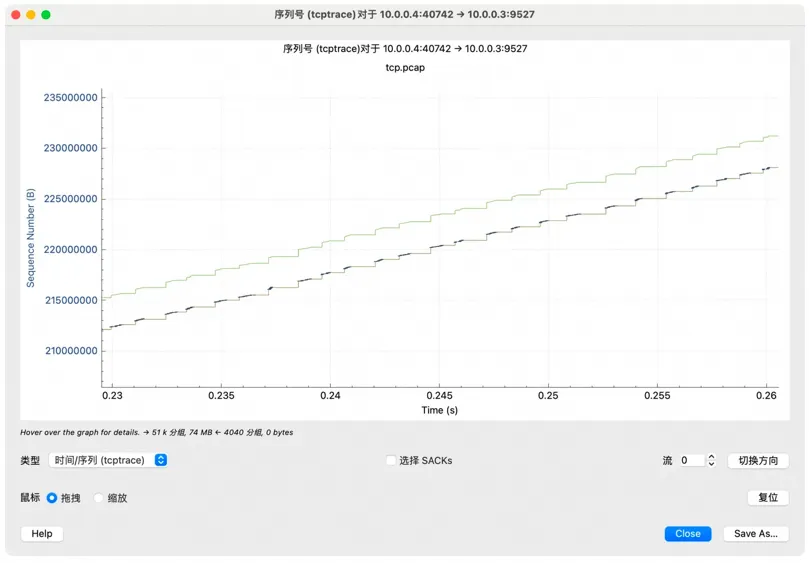
通过 Wireshark 的「统计」-> 「捕获文件属性」菜单可以看到 Wireshark
计算的带宽(文件太小了,TCP 刚飚起来就结束了,平均带宽不高):
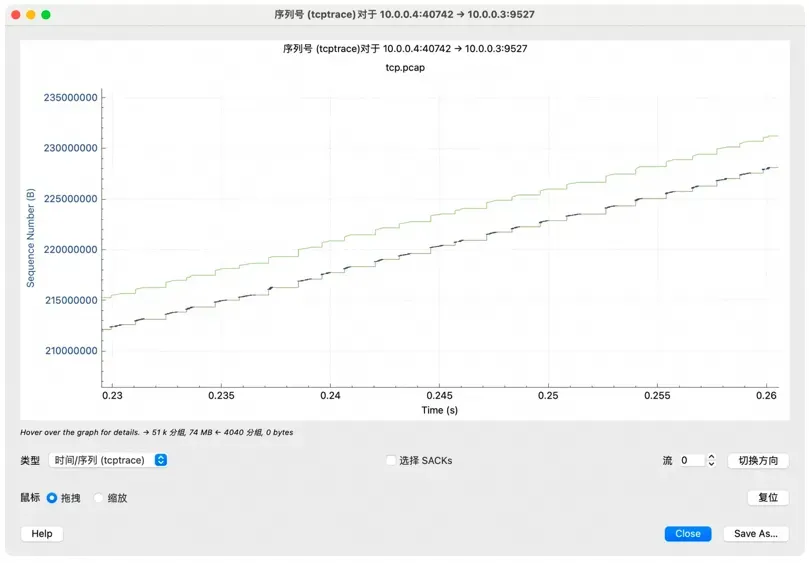
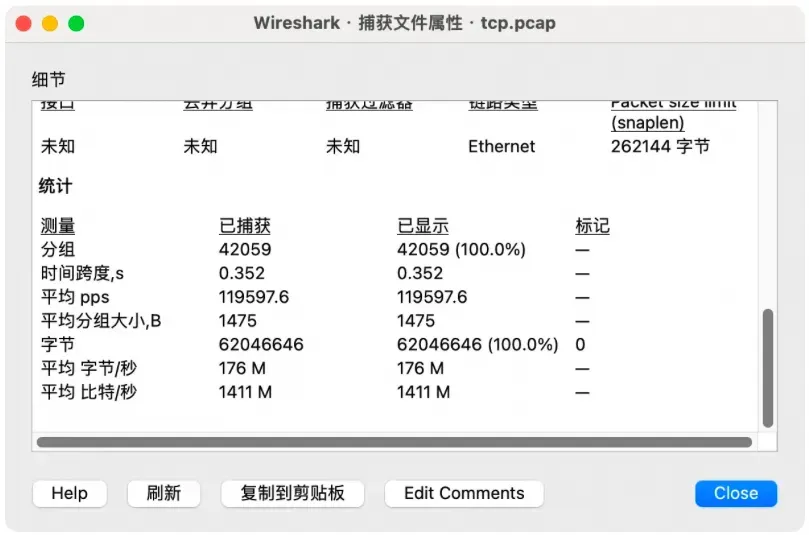
发送一个 4G 的文件,这次抓包计算的带宽才像样(tcptrace 图类似就不贴了):
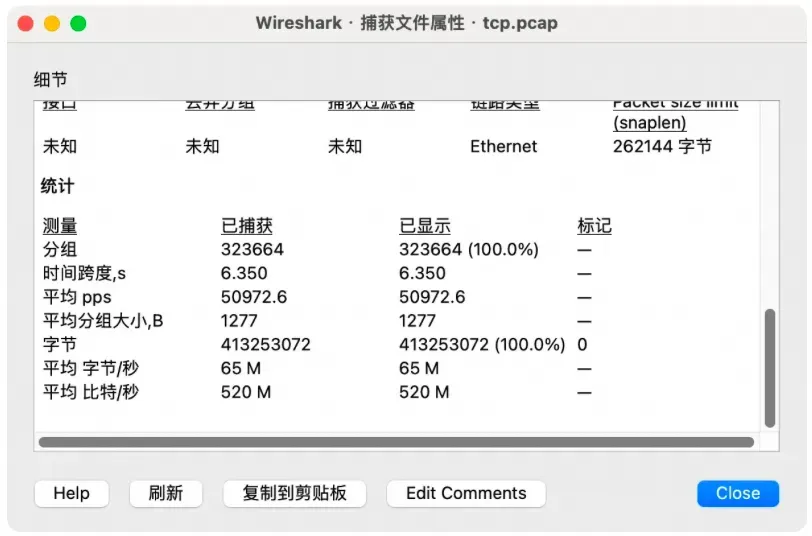
TCP 稳定传输后,图里的发送和接收端都不是瓶颈。接下来使点坏,用 tc 注入丢包然后重新抓包:
# vm-2
$ sudo yum install iproute-tc
# Anolis OS 8.9 默认没安装
$ sudo tc qdisc replace dev
enp0s5 root netem loss 5% # 注入 5% 的丢包
|
抓包的时候明显就感觉发送了很久很久,不等了直接结束发送,打开抓包文件:
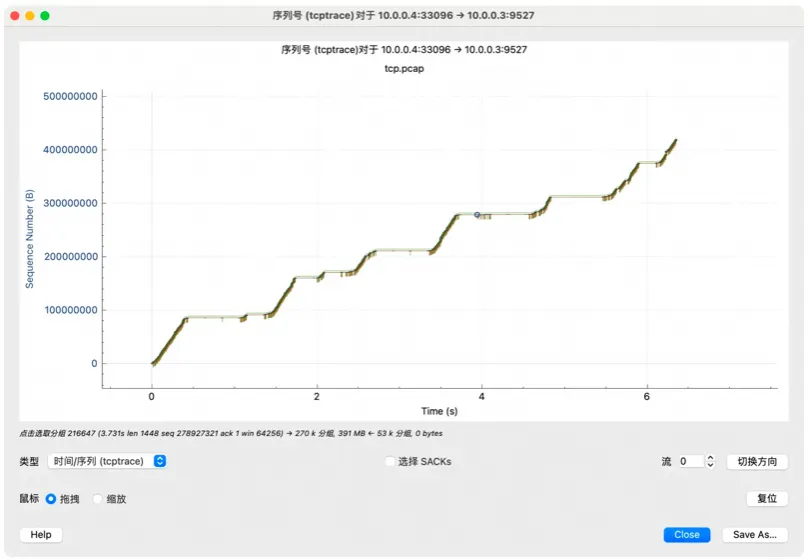
可以看到 TCP 在努力的发送数据,接收窗口也没成为瓶颈。但是因为丢包的缘故(放大可以看到红色的线),所以拥塞窗口不断的被惩罚。此时带宽仅有
65M 每秒左右了。这是本机测试的情况,因为往返的 RTT 很低,拥塞控制的快速恢复算法可以很快起到作用。有兴趣的话可以用
tc 注入丢包的同时给网路注入模拟的延迟,那么带宽就低得可怜了。
切到窗口尺寸图能看到接收窗口基本上稳定,但是发送窗口在不断变化:
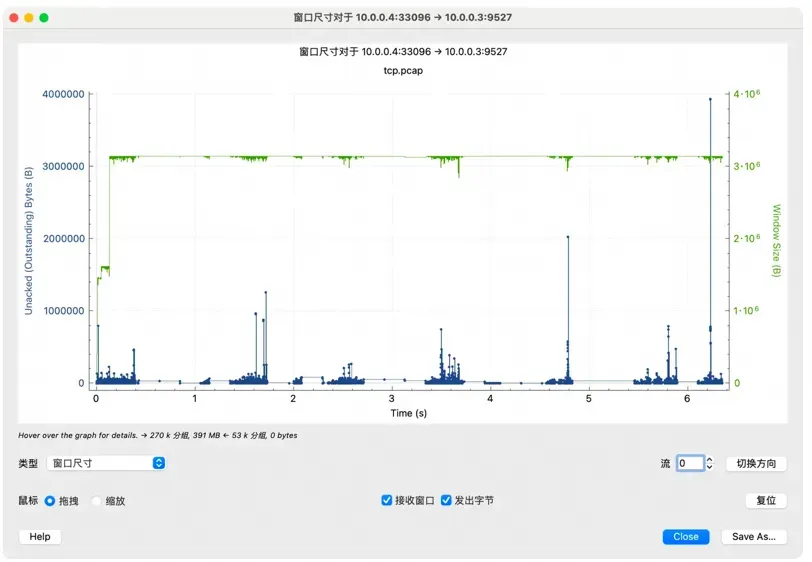
也可以在发送过程中用 ss 命令查看发送端的 cwnd 信息:
# vm-2
$ ss -i | grep -A 1 9527
tcp ESTAB 0 608544 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.229/0.241 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:2 ssthresh:26 bytes_sent:222031056
bytes_retrans:10521168 bytes_acked:211457761
segs_out:153345 segs_in:28180 data_segs_out:153343
send 101Mbps lastsnd:132 lastrcv:3052 lastack:132
pacing_rate 3.63Gbps delivery_rate 55kbps
delivered:146063 busy:3052ms unacked:36 retrans:2/7266
lost:17 sacked:19 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:556416 minrtt:0.042
snd_wnd:3141760
$ ss -i | grep -A 1 9527
tcp ESTAB 0 605024 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.466/0.327 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:14 ssthresh:13 bytes_sent:225927624
bytes_retrans:10800632 bytes_acked:215106721
segs_out:156036 segs_in:28840 data_segs_out:156034
send 348Mbps lastrcv:3420 pacing_rate 417Mbps
delivery_rate 797Mbps delivered:148564 busy:3420ms
unacked:14 retrans:0/7459 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:584752 minrtt:0.042
snd_wnd:3129216
$ ss -i | grep -A 1 9527
tcp ESTAB 0 844416 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.421/0.264 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:2 ssthresh:11 bytes_sent:293110480
bytes_retrans:14158544 bytes_acked:278928769
segs_out:202433 segs_in:36387 data_segs_out:202431
send 55Mbps lastsnd:64 lastrcv:3796 lastack:64
pacing_rate 879Mbps delivery_rate 64Mbps delivered:192641
busy:3796ms unacked:16 retrans:2/9778 lost:15
sacked:1 dsack_dups:2 rcv_space:14480 rcv_ssthresh:64088
notsent:821248 minrtt:0.042 snd_wnd:3143424
$ ss -i | grep -A 1 9527
tcp ESTAB 0 851312 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.205/0.149 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:1 ssthresh:2 bytes_sent:293647688
bytes_retrans:14213568 bytes_acked:279429777
segs_out:202804 segs_in:36593 data_segs_out:202802
send 56.5Mbps lastsnd:100 lastrcv:4200 lastack:100
pacing_rate 203Mbps delivery_rate 106Mbps
delivered:192988 busy:4200ms unacked:3 retrans:1/9816
lost:1 sacked:2 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:846968 minrtt:0.042
snd_wnd:3144576
$ ss -i | grep -A 1 9527
tcp ESTAB 0 850696 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.98/0.51 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:3 ssthresh:2 bytes_sent:293736016
bytes_retrans:14219360 bytes_acked:279512313
segs_out:202865 segs_in:36625 data_segs_out:202863
send 35.5Mbps lastrcv:4576 pacing_rate 42.5Mbps
delivery_rate 90.5Mbps delivered:193043 busy:4576ms
unacked:3 retrans:0/9820 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:846352 minrtt:0.042
snd_wnd:3144576
$ ss -i | grep -A 1 9527
tcp ESTAB 0 1707576 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.102/0.03 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:11 ssthresh:18 bytes_sent:327989160
bytes_retrans:16014880 bytes_acked:311939529
segs_out:226523 segs_in:40560 data_segs_out:226521
send 1.25Gbps lastsnd:124 lastrcv:4952 lastack:124
pacing_rate 3.25Gbps delivery_rate 1.45Gbps
delivered:215452 busy:4952ms unacked:24 retrans:11/11060
lost:12 sacked:12 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:1672824 minrtt:0.042
snd_wnd:3143168
$ ss -i | grep -A 1 9527
tcp ESTAB 0 1707576 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:408
backoff:1 rtt:0.102/0.03 mss:1448 pmtu:1500
rcvmss:536 advmss:1448 cwnd:1 ssthresh:18
bytes_sent:327990608 bytes_retrans:16016328
bytes_acked:311939529 segs_out:226524 segs_in:40560
data_segs_out:226522 send 114Mbps lastsnd:288
lastrcv:5324 lastack:496 pacing_rate 3.25Gbps
delivery_rate 1.45Gbps delivered:215452 busy:5324ms
unacked:24 retrans:1/11061 lost:12 sacked:12
dsack_dups:2 rcv_space:14480 rcv_ssthresh:64088
notsent:1672824 minrtt:0.042 snd_wnd:3143168
$ ss -i | grep -A 1 9527
tcp ESTAB 0 1501208 10.0.0.4:33096
10.0.0.3:9527
cubic wscale:7,7 rto:204
rtt:0.109/0.024 mss:1448 pmtu:1500 rcvmss:536
advmss:1448 cwnd:24 ssthresh:7 bytes_sent:348547864
bytes_retrans:17222512 bytes_acked:331290601
segs_out:240721 segs_in:43740 data_segs_out:240719
send 2.55Gbps lastrcv:5676 pacing_rate 3.05Gbps
delivery_rate 1.98Gbps delivered:228804 busy:5676ms
unacked:24 retrans:0/11894 dsack_dups:2 rcv_space:14480
rcv_ssthresh:64088 notsent:1466456 minrtt:0.042
snd_wnd:3136128
|
可以看到 cwnd 好不容量变大后又回缩,这位就是限制了当前发送的「罪魁祸首」。
本来想贴下 bbr 的对比实验,可惜我这两个 vm 不支持 bbr 算法。欢迎评论区贴出来实验结果,一定比上面
cubic 的结果好很多。
我有台国外的服务器,网络丢包比较严重的。之前用的 cubic 算法时传输带宽很糟糕,换成 bbr 后有百倍的提升。如果你也有一台这样的服务器,也可以改成
bbr 算法试试,也许有惊喜。
写在后面
作为入门文章,介绍到这里就该结束了。工作和实践中你的场景可能是编写使用 TCP 的网络程序或者抓包发现
TCP 的异常或者定位性能问题。讨论这些的文章都比较吃经验(尤其是问题定位)。相信有了这两篇文章的铺垫,能帮你阅读和理解其他高屋建瓴的文章了,那我的目的也就达到了。
附录
文章里列举了一些 TCP 相关的 RPC 文档作为佐证,如果想了解 TCP 协议的标准化这是第一手的权威资料。不过我没检索到这些
RFC 的关系图,索性自己整理了一个:
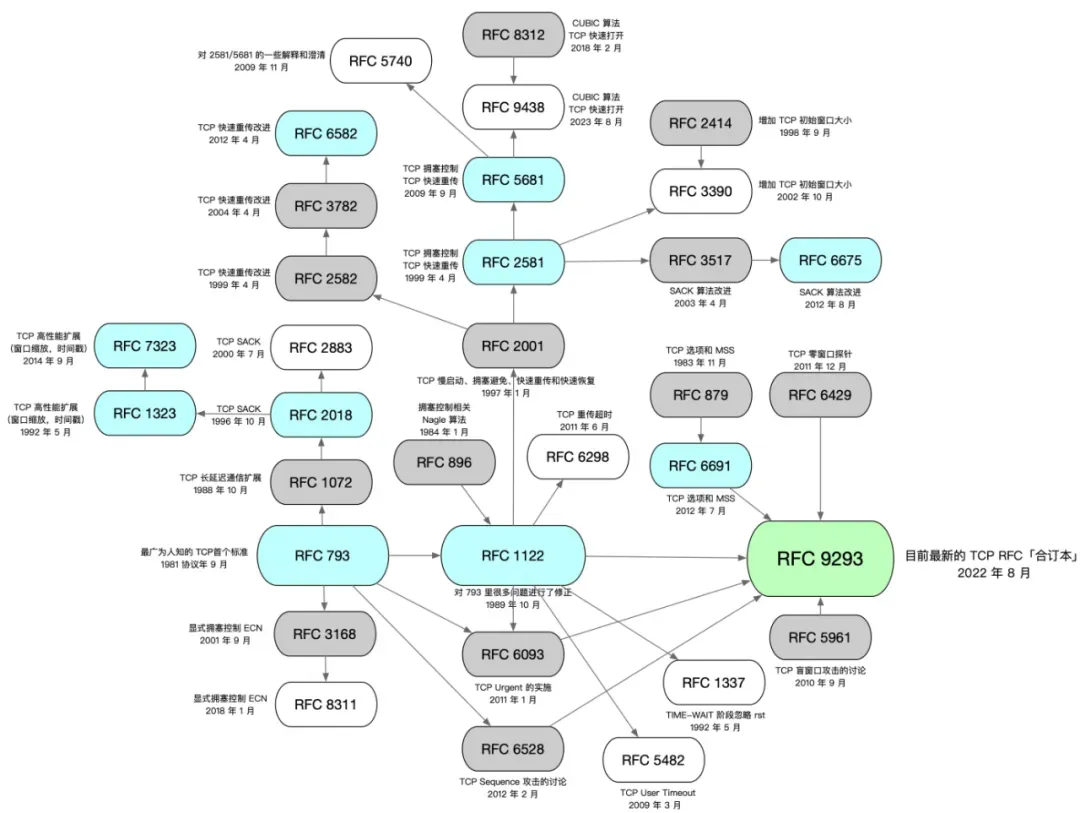
图里本来不想画已经被标记为「Historic」的废弃文档(比如 793 的前面其实还有 761 初稿)。但是有些
RFC 起到了至关重要的承上启下的作用,而且经常被一些资料提及,所以也在图里(底色标记为灰色)。蓝色底色的是一些关键的
RFC 和节点,绿色的就是迄今为止最大的合订本了,这里有篇中文翻译[12]可以参考。
如果想阅读 TCP 的 RFC 的话,就不用从 793 开始阅读了,直接读 9293 更好一些。虽然
9293 也没囊括当前 TCP 协议的所有边边角角,但是绝大多数细节都在里面了。其实 9293 不包括所有细节的目的是想把
TCP 协议的 RFC 分为主体和扩展算法两部分。即实现 TCP 协议的话,需要实现「强制」的主体功能部分与一些可选的算法(尤其是拥塞控制那一堆算法)。
使用 GPU 共享推理一键部署
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。支持快速创建Kubernetes集群,白屏配置任务数据共享存储和下载,并通过命令行工具Arena快速提交模型训练任务、部署推理服务。
|








